
Abstract
This article presents a new and freely available tool for performing analyses according to the Rasch model (RM) and the latent class analysis (LCA). The software allows for the estimation of the model parameters and offers several measures of model fit. A graphical user interface (GUI) provides access to numerous options regarding data, models, and output. For educational purposes, an optional annotate feature allows to augment the output with brief explanations and citations regarding the procedures. Based on published data, the features of GANZ RASCH are briefly illustrated in two worked examples. The program intends to combine ease of use while allowing for performing a full-fledged analysis, thus targeting a wide range of users.
Introduction
The Rasch model (RM; Rasch, 1960, 1966) is a probability model for a dichotomous random variable Xvi
involving the two real-valued latent parameters θ
v
(v = 1 … n) and β
i
(i = 1 … k). It is a member of the exponential family and the probability of a keyed (positive) response (usually coded with one) is

Numerous parameter estimation methods have been developed, differing with respect to their assumptions: One can apply the unconditional (or Joint) maximum likelihood method (UML or JML; cf. Baker & Kim, 2004; Molenaar, 1995), where item and person parameters are alternately updated. Unfortunately, this method suffers from the so-called incidental parameter problem (Neyman & Scott, 1948). In short and applied to the present case, it means that the item parameters β i (which are structural parameters) cannot be estimated consistently in the presence of the person parameters θ v (which are incidental or nuisance parameters). One way to circumvent this problem is to apply marginal maximum likelihood estimation (MML, cf. Baker & Kim, 2004; Molenaar, 1995), in which a proper distribution of the incidental parameters has to be assumed and only the hyperparameters of this distribution (which are now likewise structural parameters) are estimated. However, this approach will not be further pursued in the present context.
One estimation method, fully taking advantage of the existence of sufficient statistics, is the conditional maximum likelihood estimation method (CML), originally proposed by Rasch (1960) and further elaborated by Andersen (1970). To put it in a nutshell, the item difficulty parameters are estimated by conditioning on the sufficient statistics of the person parameters. This fact entirely liberates us from making any distributional assumptions, yet delivers unbiased and consistent item parameter estimates. The person parameters are estimated separately by means of a maximum likelihood estimation, using the item parameter estimates obtained before. It is intrinsic to this approach that estimates for respondents with perfect or zero scores approach plus or minus infinity. Nevertheless, estimates for such cases can be obtained by means of a modified procedure of Warm (1989), which attenuates the unbound growth of the estimates.
The three methods considered so far are iterative by nature. In contrast, a closed form estimation method is at our disposal as well, namely, the pairwise method (cf. Fischer, 1974, p. 268; Molenaar, 1995, p. 49). It excellently suits didactical purposes, as it can be accomplished with a pocket calculator. However, this procedure is limited by requirements likely to fail in small data sets or when item difficulties vary largely (see below).
Numerous methods for assessing the model fit have been proposed, a conclusive overview of which can be found in Glas and Verhelst (1995). One method, which is directly derived from specific objectivity, is the conditional likelihood ratio test (LRT) according to Andersen (1973). This test assesses the subgroup invariance of item parameter estimates (which is a consequence of specific objectivity) by means of splitting the sample into g subgroups (horizontal split). Originally, Andersen proposed splitting along the proficiency scale θ, that is, according to the score, but any other criterion of substantive interest can be taken as well. In the case of a two group split (e.g., using the score median as split criterion), the subgroup item parameter scatterplot can be used for a rough appraisal of model adequacy: Points scattering closely around the 45° line substantiate model fit. In a similar manner, the Martin-Löf-Test (MLT, cf. Glas & Verhelst, 1995) assesses the unidimensionality assumption by splitting the item set into two groups (vertical split).
Another model of equal importance for social sciences is the latent class analysis (LCA; Dayton, 1998; Formann, 1984; Lazarsfeld, 1950). In contrast to the RM, the LCA assumes the latent variable to be categorical, which complies with the assumption of mutually exclusive and exhaustive subpopulations (the “latent classes”). Each of the latent classes exhibits a constant probability for its members to respond positively to a manifest dichotomous item. The LCA allows for the estimation of both the conditional item probabilities (given the latent class) and the class sizes. It belongs to the mixture models, as the latent classes appear “mixed” in the data, which resulted in using the term “unobserved heterogeneity” as well. This approach might be preferable if a latent classification (or typology) is assumed or is to be achieved. For dichotomous items, the model equation is
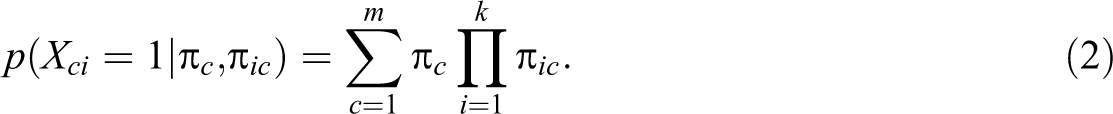
Based on the response pattern frequencies, maximum likelihood estimates of the model parameters
The overall goodness of fit can be assessed by means of the family of power divergence statistics (Read & Cressie, 1988), which covers several procedures to compare the observed and the expected response pattern frequencies. Probably the most prominent member of this family is the Pearson test statistic (cf. Dayton, 1998; Formann, 2003); however, Read and Cressie (1988) argue that a certain modification of this method is preferable for theoretical reasons (p. 96). The Freeman–Tukey test (Freeman & Tukey, 1950) and the Wilks’s likelihood ratio statistic (Wilks, 1938) are also members of the power divergence family of statistics. Formann (2003) provides an excellent overview of these methods.
Several other goodness-of-fit measures have been proposed as well. In this context, the information-based indices (Akaike’s Information Criterion [AIC], Akaike, 1973; Sakamoto, Ishiguro, & Kitagawa, 1986; Bayesian information criterion [BIC], Schwarz, 1978; consistent AIC [CAIC], Bozdogan, 1987; AIC, Hurvich & Tsai, 1989) play a crucial role. These indices allow for comparing different latent class analyses for the same data, covering a varying number of latent classes. Basically (at the risk of oversimplification), these indices rely on the sum of minus two times the log likelihood of the final estimation step and the (weighted) number of parameters used in the model. This results in a small index if the model describes the data well while pursuing the desideratum of parsimony. Therefore, the model with the lowest index among several candidate models is chosen. A very indicative introduction to information indices is provided by Anderson and Burnham (2002).
GANZ RASCH 1 : A New Program
This article presents a new software, allowing for the estimation of the parameters of the RM and the LCA and for the assessment of fit of either model. It employs a graphical user interface (GUI) with tabs resembling the workflow of a typical analysis: The three main steps of an analysis (load data, choose model, and view output) form the top level tabs containing subsections (Level-2 tabs) for purposes associated with the respective step. A permanently visible Quick Navigation bar on the left-hand side of the program window allows for directly accessing all Level-1 and Level-2 tabs with one mouse click.
The program has been developed under the MS-Windows® operating system and was successfully tested under both the Linux and the Mac operating systems, using an emulator.
2
All models default to essential options covering parameter estimation and model fit, hence standard analyses can be performed with just a few mouse clicks. The RUN button is always visible, yet disabled if required input is missing. For users less acquainted with the models, the program output might appear enigmatic. In trying to provide some relief, an ANNOTATE OUTPUT option allows for augmenting the listing with notes concerning the methods applied and hints for further reading. Of course, such a feature can never substitute a thorough study of the relevant literature—but it might provide easier access to the topic and direct users toward useful resources. Furthermore, some plots allow for a quick visualization of crucial results.
Models and Algorithms
In essence,
The Andersen and the Martin-Löf tests allow for an inferential check of assumptions specific to the RM, providing several options allowing for a very flexible use of these tests. The graphical model check described above is provided as well. In order to detect conspicuous items,
The LCA is supported for up to 12 latent classes and employs the EM algorithm. Again, several methods of assessing model fit are provided, including, for example, four information-based criteria and four power divergence statistics. Two plots seem noteworthy: First, a line diagram of the item probabilities per class (the
Although the main focus of the program is on probabilistic models, some basic classical psychometric indices—like the item-total correlation (uncorrected and corrected) and the lower bound of reliability according to Cronbach (coefficient alpha; Cronbach, 1951)—are displayed as well. The covariance and the correlation matrices can be requested, an option that might prove useful for further use, for example, with a structural equation modeling software.
Selected Features Specific to GANZ RASCH
This section highlights some technical features possibly distinguishing
RM: Parameter estimation with the CML method
Wright and Douglas (1977) appreciate the “theoretically ideal” (p. 573) CML method, but they consider it computationally too costly for practical application, because a complex combinatorial task has to be performed (involving the elementary symmetric function, γ
r
, cf. Baker & Harwell, 1996; Fischer, 1974). However, this function can now be evaluated in a split second (cf. Molenaar, 1995, p. 46).
RM: Parameter estimation with the pairwise method
The pairwise method is of interest, for it delivers virtually the same estimates as the CML method while it is at the same time computationally extremely simple and fast. However, this method has one limitation, possibly narrowing down its applicability: For each pair of items, both response patterns 0–1 and 1–0 have to be observed at least once. This is not much of a problem when samples are large and items are of similar difficulty. However, the combination of easy and difficult items is likely to violate this requirement, unless the sample is sizable. However, the program optionally provides a corrective procedure, which is experimental, yet promising: Unobserved combinations are given a frequency of one. While this correction (demonstrably) does not affect other item’s estimates, it retains the method applicable. Note that this correction is similar to the Bayesian approach of assigning priors to the likelihood function (which would in this case be the Dirichlet distribution). But while in a Bayesian framework, one would add a value of one to each pattern frequency (i.e., without scanning the data),
RM: Goodness of fit with the Andersen test
The program supports several split methods with great flexibility: (a) When deciding for the score median split, one can choose with a mouse click whether to put respondents realizing exactly the median value into the lower or into the upper score group. (b) If the median was either beyond a value of two or above k−2, one group would vanish and the procedure would fail. In that case, an (optional) adaption allows for automatically increasing or decreasing the cutoff value, until both groups contain observations. This feature is useful for heavily skewed score distributions. (c)
RM: Goodness of fit with the Martin-Löf test
The
RM: Alpha inflation when applying multiple goodness-of-fit tests
Each test introduces a risk α of committing a Type I error of falsely rejecting the null hypothesis of model fit. When m > 1 tests are applied, the overall (familywise) risk of falsely deciding at least once increases considerably. For that reason, a modified value
Worked Examples
A historical example will be used for demonstrating the usage of
Example 1: The RM
After reading the data from SPSS, the default options (CML estimation, Andersen test applying the median split, and the graphical model check) were retained and three additional random splits were selected. The part of the program output containing the parameter estimates is depicted in Figure 1 . The item parameter estimates are perfectly in line with those reported by Andersen (1980, p. 290), and the person parameter estimates perfectly fit those presented by Formann (1995, p. 247).
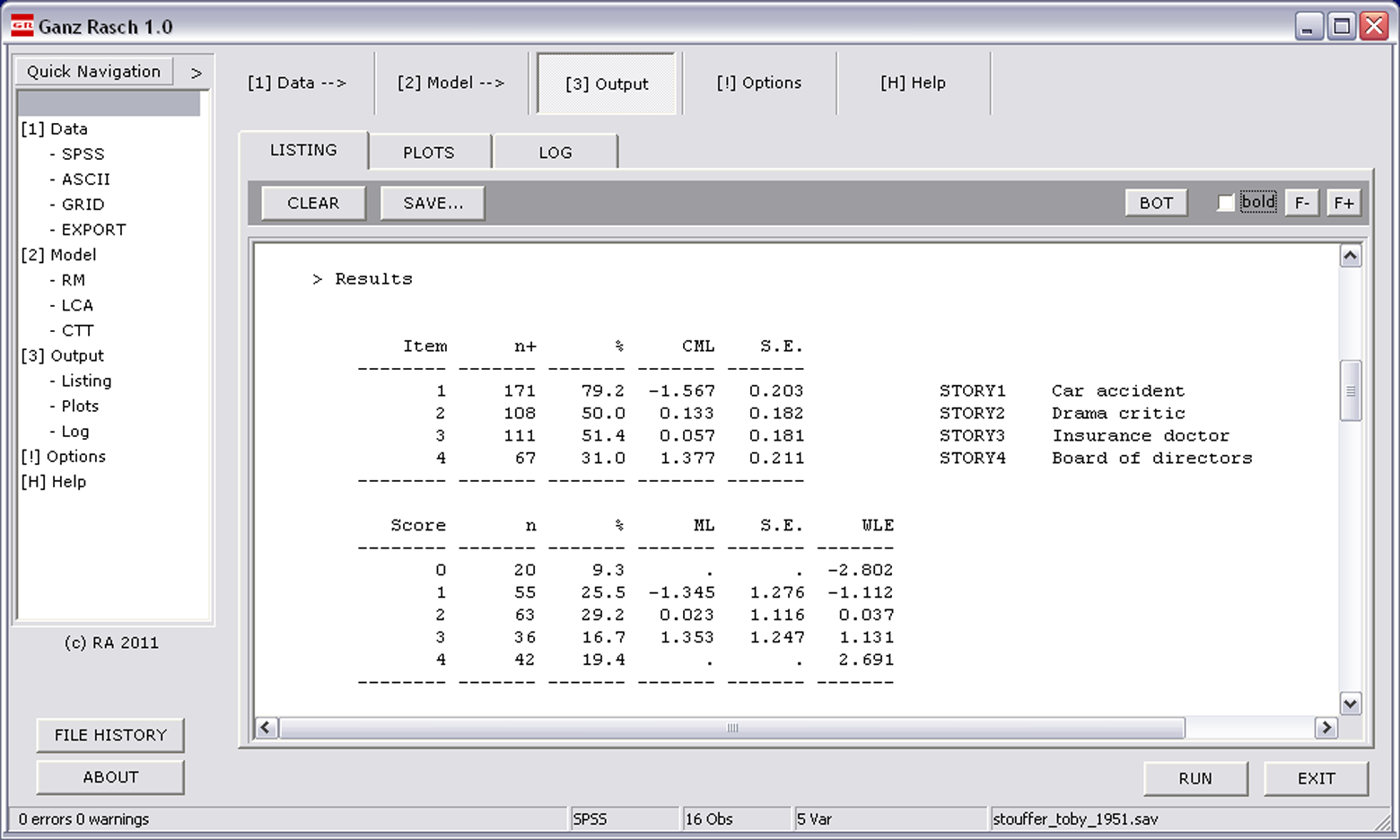
Parameter estimates of the Rasch analysis of the Stouffer and Toby (1959) data.
The LR test statistic was .118 with three degrees of freedom, yielding a p value of .990, therefore the null hypothesis of model fit is not rejected according to this analysis. The same holds true for the three random splits, showing similar results,
Example 2: The Latent Class Model
The application of the Latent Class Model shall be demonstrated with the same data set, applying a two- and a three-class solution. In contrast to the first example, data shall be read from ASCII: The file contains five columns representing the four variables (coded with zero and one) followed by one column containing the frequency of the respective pattern. In the top line, the variable names are provided. After opening the file through DATA > ASCII > OPEN, its content is listed in a preview panel. A click on the READ button loads the data, which are then displayed in the [1] DATA > GRID tab. There, the four analysis variables have to be selected and the weight variable can be chosen from the
Next, the desired model details have to be chosen from the [2] MODEL > LCA tab. Essentially, only the number of classes to be estimated have to be set. After clicking on RUN, the output appears. The parameter estimates perfectly match those reported by Formann (1995, p. 249). The two classes show a clear distinction, as the first class beats the second in having higher probabilities of giving particularistic responses to all four stories. This indicates ordered classes, which is also in line with the findings of the Rasch analysis, yet on an ordinal level (nota bene [NB], the same is true for the three-class solution, which is not presented here). The model provides a clear allocation of respondents to the respective classes, as most allocation probabilities were close to one. The fit indices (cf. Table 1 ) indicate unanimously that the two-class solution describes the data best (note that smaller values of AIC and BIC indicate better model fit, in contrast, the entropy measure should be close to one). The chi-square test indicates adequate fit for the two- and the three-class solutions, while the model assuming one class is rejected.
Fit Indices of the Three Latent Class Models Considered for the Stouffer and Toby Data
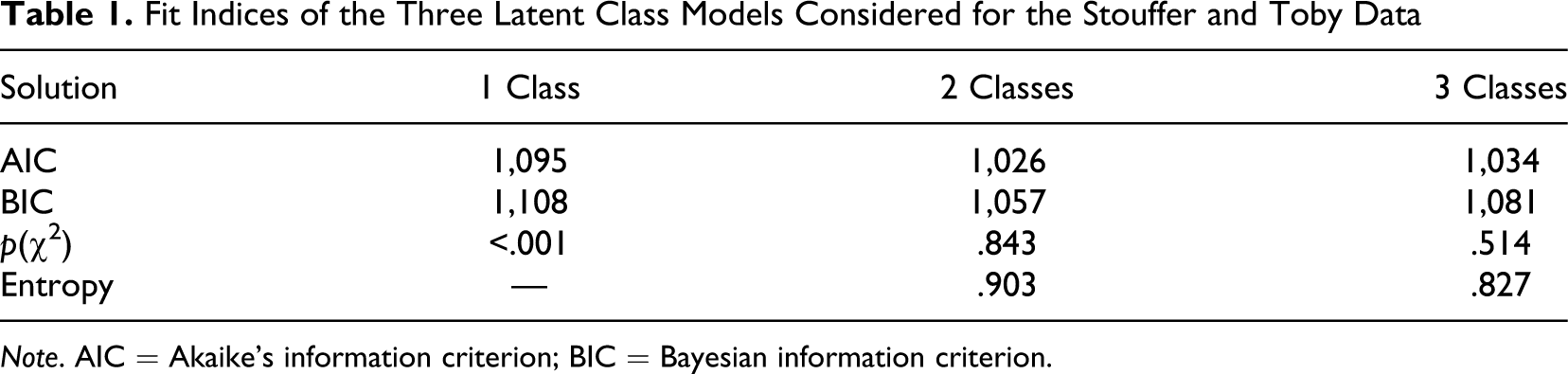
Note. AIC = Akaike’s information criterion; BIC = Bayesian information criterion.
Both results support the conclusion of Stouffer and Toby (1951), that “this fusion of variables in our situations does seem to generate a unidimensional scale, the dimension involved being the degree of strength of a latent tendency to be loyal to a friend even at the cost of other principles” (p. 400).
Summary and Outlook
The current article presents a free software,
The fit of both models can be judged by several criteria, each being sensitive to other kinds of model violation. Concerning the RM, special attention was paid to methods related to specific objectivity, because they are pivotal for the Rasch family of models. Item fit indices are provided as well, so many different users might find options he or she considers meaningful.
Of course, point-and-click software might entice users to apply methods they have not fully understood. Such an attitude shall not be befriended at all; therefore, clues and suggestions are integrated into the output annotations. They serve as teasers, providing incentives for exploring and dealing with the underlying theories.
Note that the program is continuously developed further, with new features emerging. Depending on the users’ comments and requests, specific features might be added in future versions. For keeping up with the newest development, the website www.ganzrasch.at will be maintained.
Footnotes
Acknowledgments
The author is indebted to Ingrid Koller for extensive program testing and invaluable debugging assistance under Windows, Marco J. Maier for testing the program under Linux, and Markus Schaer for testing the program under the MacOS.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.