
Abstract
Verbal rating scale polarity and verbalizations of the middle category that do not match the polarity in agreement rating scales were investigated. Two randomized web survey experiments were conducted using a probability panel of German Internet users. The classical bipolar “disagree/agree” verbalization was compared with the unipolar “do not agree/agree” alternative. In both experiments, attitudes on gender roles were measured using a different number of rating scale categories (seven vs. five) in each. After controlling for variables related to satisficing, biases were lowest with the unipolar “do not agree/agree” rating scale in which the verbalization of the middle category was also unipolar. Reliability decreased when the verbalization of the middle category did not suit the rating scale polarity. Researchers should pay attention to the polarity of rating scales and use verbalization of the middle category consistent with the rating scale polarity.
Keywords
Introduction
Rating scales are widely used in social science online surveys. A rating scale represents a continuum with individual response options that extend from one extreme to the other, for example, from “strongly disagree” to “strongly agree”, The cognitive response process for questionnaires is conceptualized by Tourangeau, Rips, and Rasinski (2009) as consisting of four cognitive tasks: (i) comprehension of the question, (ii) retrieval of relevant information, (iii) usage of this information to generate the response, and (iv) mapping the response on the response options, that is, rating scales. The dual process model of cognitive process is widely accepted in the literature, according to which it is seldom possible to activate responses about attitudes or behaviors automatically; instead, respondents have to go through all processes described by Tourangeau, Rips, and Rasinski (2009) to generate their responses. The complexity, depth, and accuracy of this cognitive work can vary according to three factors: (i) task difficulty, (ii) respondent ability, and (iii) respondent motivation (Krosnick & Presser, 2009). In the case of high task difficulty, low ability and low motivation, subtle or dramatic shortcuts, referred to as satisficing behavior, are possible (Krosnick, 1991).
Different rating scales may be associated with different degrees of satisficing due to difficulties in understanding the meaning of categories. Such difficulties may result in decreased respondent motivation and differences in the interpretation of individual rating scale categories (Krosnick & Presser, 2009). Well-researched issues are the number of categories or whether to verbally label or not label each category (Maitland, 2009a, 2009b). Five to seven categories as well as verbal labeling of each category have been found to be associated with a high measurement quality (Alwin & Krosnick, 1991; Menold, 2017; Menold, Kaczmirek, Lenzner, & Neusar, 2014; Weng, 2004). However, there is no clarity in the research on how to verbalize rating scales.
With respect to verbalization, the mapping process may be influenced by two interrelated features: (i) scale polarity and (ii) verbalization of the middle category. Scale polarity refers to the choice between bipolar and unipolar rating scales (Schaeffer & Presser, 2003). Bipolar rating scales include two opposite rating spectrums in one scale, such as disagreement and agreement, disliking and liking, and difficulty and ease. Unlike bipolar rating scales, unipolar rating scales consist of one single rating spectrum, for example, agreement, application, or liking. A popular bipolar “disagree/agree” rating scale graduates disagreement as one and agreement as the other continuum (Krebs, 2012), whereas its unipolar “do not agree/agree” version only graduates degrees of agreement. The verbalization of the middle category relates to the scale polarity because its meaning is different in bipolar and unipolar rating scales (Krosnick & Fabrigar, 1997; Schaeffer & Presser, 2003). In a bipolar rating scale, the middle can express either indifference or ambivalence (Kaplan, 1972), whereas the meaning of the middle point in a unipolar rating scale is less clear and refers to a moderate degree of ratings (Krosnick & Fabrigar, 1997).
Comparing unipolar and bipolar verbalizations of agreement rating scales is of relevance because markedly different bipolar “disagree/agree” and unipolar “do not agree/agree” verbalizations have been used interchangeably. In international surveys, translations of agreement rating scales from the source English language into other languages often capture other polarities than the source; in addition, the middle category is verbalized inconsistently. The International Social Survey Program (ISSP, 2014; https://www.gesis.org/issp/home/) illustrates this. The English source questionnaire of the ISSP uses bipolar agreement rating scales such as “strongly agree,” “agree,” “neither agree/nor disagree,” “disagree,” and “strongly disagree” for the items on gender roles. In contrast, the rating scale in Germany is unipolar and uses the following labels: “strongly agree,” “rather agree,” “neither–nor,” “rather do not agree,” and “do not agree at all.”
One objective of this article is therefore to investigate response behavior and measurement quality associated with unipolar and bipolar verbalizations of agreement ratings when the meaning of the middle category is varied. The other objective is to evaluate some moderating influences, relevant to respondents’ satisficing behavior, such as the influence of Attitude Strength (Krosnick & Presser, 2009), Need for Cognition (NFC; Cacioppo & Petty, 1982), and Conscientiousness (e.g., Costa & McCrae, 1992).
Previous research on the polarity of rating scales used face-to-face interviews (O’Muircheartaigh, Gaskell, & Wright, 1995; Schwarz, Knäuper, Hippler, Noelle-Neumann, & Clark, 1991) or self-administered paper questionnaires (Krebs, 2012; Schwarz & Hippler, 1994) rather than online data collection. The research presented in this article is therefore conducted with the additional aim of providing insights for online survey research. The theoretical background and empirical evidence with respect to rating scale polarity, verbalization of the middle category, and moderating factors are described and research hypotheses are presented in the following.
Rating Scale Polarity
A bipolar rating scale graduates a continuum from a high (or the highest) degree of one spectrum (e.g., disagreement) to its lowest degree, continuing with a neutral or zero middle point followed by the lowest degree of the other spectrum (agreement) and ends up with a high (or the highest) degree of this spectrum. Numeric bipolar scales, for example, use numeric labels ranging from a negative to a positive number, for example −3 through the middle 0 to +3. Unipolar rating scales graduate from an absence of a property (or the lowest degree) at the one pole, continue with the low, the moderate, the high degree, and finally end up with the highest degree at the other pole. In numeric unipolar rating scales, positive numbers, for example, from 1 to 7 are used.
In comparison with unipolar numeric rating scales, bipolar numeric rating scales have been found to be associated with a positivity bias (O’Muircheartaigh et al., 1995; Schwartz & Hippler, 1994; Schwarz et al., 1991). This means that with the bipolar numeric rating scales respondents tend to avoid the negative numbers, overuse the other parts of the rating scale, and produce more positive results than with unipolar numeric rating scales. As a consequence, researchers seem to avoid bipolar numeric rating scales, while the bipolar verbal “disagree/agree” scales are very popular. In verbal rating scales, numeric labels are not used, and only verbal labels are employed for each category. Many studies (see, e.g., Krosnick & Presser, 2009) have found higher levels of acquiescence in “disagree/agree” scales than with other formats and verbalizations. Acquiescence means agreeing to a statement regardless of its content (Paulhus, 1991). The use of an item-specific format has been suggested as a way of reducing acquiescence as a biased reaction in disagree/agree rating scales. Respondents then do not evaluate whether they disagree or agree with a statement (“I am happy”) but graduate the item content directly, for example, their happiness on the scale “not happy at all” to “very happy” when responding to the question “How happy are you?” (e.g., Saris, Revilla, Krosnick, & Schaeffer, 2010). Compared to the disagree/agree format, which can be universally used in grids with different statements, the disadvantage of the item-specific format is that statements (or items) cannot be used in a grid with the same rating scale and an individual rating scale must be presented with each item. Research on the positivity bias in numeric rating scales shows that an alternative solution would effectively reduce acquiescence. If higher acquiescence on the disagree/agree scale might be due to its bipolar nature, it may be the case that respondents tend to avoid the disagree-part in the same way that they avoid negative numbers (e.g., the numbers −3, −2, −1). The positivity bias or acquiescence may be reduced by the unipolar “do not agree/agree” version. The first research hypothesis addresses this issue.
Unlike the item-specific format, the unipolar “do not agree/agree” format can be used universally with different statements and therefore presents a handier alternative to disagree/agree formats than the item-specific format.
Very little research has been undertaken on comparing unipolar “do not agree/agree” and bipolar disagree/agree rating scales. The research that does exist has investigated reliability and generated mixed results. Krebs (2012) found a higher Cronbach’s α coefficient in the bipolar than in the unipolar scales, irrespective of whether numeric or verbal labels are used. Using a reliability estimation method within the frame of the popular latent variable modeling (LVM) approach (Raykov & Marcoulides, 2011), Menold and Raykov (2015) found a higher reliability for the unipolar application than for the bipolar agreement rating scale. Bearing in mind the paucity of empirical evidence available and the mixed results of research to date, the present research addresses differences in reliability between unipolar and bipolar agreement rating scales as follows:
The focus lies on reliability because this is directly relevant to the precision of the measurement with a rating scale and is also a necessary prerequisite of validity (e.g., Raykov & Marcoulides, 2011).
Verbalization of the Middle Category in Unipolar and Bipolar Rating Scales
It is widely accepted in the literature that the graduations of a rating scale should be exhaustive and it has been suggested that an explicit middle category should be provided for this reason (e.g., Krosnick & Presser, 2009; Sturgis, Roberts, & Smith, 2014). However, no clarity exists on how to verbalize the middle category (Sturgis et al., 2014), while the rating scale polarity should be considered due to the different meaning of the middle point in bipolar and unipolar rating scales (Krosnick & Fabrigar, 1997). The middle category of a bipolar rating scale expresses either indifference or ambivalence (Kaplan, 1972). Indifference means having a neutral position as well as the absence of a position or preference either toward one or other direction that is stable over different situations. Indifference is expressed by neither positive nor negative attitudes (feelings) and is verbally specified by the term neither–nor (Krosnick & Fabrigar, 1997). Another meaning of the middle category in a bipolar rating scale would be that respondents are ambivalent, and the direction of the opinion depends on the situation. In the case of ambivalence, respondents sometimes have positive and sometimes negative feelings, which prevent them from having a clearly positive or negative attitude (e.g., Yoo, 2010; Zaller & Feldman, 1992). Ambivalence is expressed by “partly disagree/partly agree” (e.g., Ferstl, Sinz, Eckert, & Isselhorst, 2005; Ruël, Bondarouk, & van der Velde, 2007). In German, a simplification “partly/partly” (“teils-teils”) has usually been used. Unlike the meaning of indifference or ambivalence in bipolar rating scales, the middle category of a unipolar rating scale is associated with a moderate position or degree that can be articulated by the verbal labels “moderate,” “fair,” “middle,” “in the middle” (Rohrmann, 1978), “to some extent” (Krebs, 2012), or “about a half” (Saris et al., 2010).
The different meaning of the middle category in the unipolar and bipolar verbal rating scales has been mainly disregarded in surveys because the bipolar middle category has often been used in unipolar rating scales and vice versa. If verbalization of the conceptual midpoint does not suit the polarity of the rating scale, it is referred to as a “mismatched” verbalization. In the ISSP example presented, the unipolar German “do not agree/agree” scale faces mismatched verbalization as it contains the middle neither–nor with the typical bipolar indifferent meaning. In German, mismatched verbalization with “partly agree/partly disagree” (or simply partly/partly: teils-teils) can also easily be found either in inventories or in textbooks (Henkel & Neuß, 2015; Rattinger & Kraemer, 1995; Stegmann et al., 2010).
Previous research has not addressed mismatched verbalizations of the middle category but investigated its provision as compared with a situation without the middle category (see, e.g., Krosnick & Fabrigar, 1997; Menold & Bogner, 2014, for overviews). The main finding is that provision of the middle category results in it being selected more often. This result has been interpreted as respondents preferring to endorse the middle category (“middle responding” as a response bias). This enables them to avoid thinking about their attitudes and enables them to comfortably use the middle category due to satisficing (e.g., Krosnick & Fabrigar, 1997). There is therefore an unresolved dilemma in the literature between this finding and the suggestion that a middle category is used to provide an exhaustive continuum (see the first paragraph of this section). A possible solution would be to change perspectives and to ask how the middle category could be verbalized to reduce middle responding. If verbalization of the middle category mismatches the remaining scale polarity, it may appear to be outside of the continuum and therefore attract respondents. In addition, respondents may have difficulties in understanding the rating scale meaning with mismatched verbalizations, which might lower their motivation and foster satisficing in the form of middle responding. It can also be assumed that an explicit middle category which matches the polarity is avoided to the advantage of either positive or negative ratings, resulting in lower middle responding. Potential effects such as these are described by Hypothesis 3:
Similarly, we expect an increase in error variance when mismatched verbalization of the middle category is used.
Moderators of Biased Effects of the Verbalization of Rating Scales
The biased effects of the features of the question, including rating scales, are stronger if the attitudes under investigation are weak (Schuman & Presser, 1981; see Bassili & Krosnick, 2000, for an overview). Whereas strong attitudes are easily available in memory, are highly pronounced, and have significant impacts on cognition and behavior, weak attitudes are not (Bassili & Krosnick, 2000). This characteristic of attitudes is referred to as Attitude Strength. Respondents with weak attitudes have to spend greater effort generating their responses and this is associated with higher complexity and difficulty of the cognitive response process (Tourangeau, Rips, & Rasinski, 2009). Attitude Strength, particularly the aspect of certainty in the provided response, moderates middle responding, which is lower in the case of higher certainty (Bassili & Krosnick, 2000; Bishop, 1990; Krosnick & Schuman, 1988). Likewise, Attitude Strength may reduce acquiescence.
Next respondents’ characteristics can influence their motivation to conduct the cognitive work thoroughly and therefore the depth of the cognitive process as well as the shortcuts related to satisficing. This is the extent to which respondents enjoy thinking about issues and like cognitive demands, which is referred to as the Need for Cognition (NFC, Cacioppo & Petty, 1982). According to Krosnick and Presser (2009), NFC can be expected to moderate the effect of the features of rating scales on response behavior and data quality and it can therefore be expected that acquiescence, the positivity bias or middle responding might be higher pronounced when respondents’ NFC is low.
Finally, stable personality traits may serve as moderating factors when exploring the effects of rating scales on the biases in response. Respondents’ conscientiousness might be directly relevant to their response behavior. It is a personality trait conceptualized by the Big-Five personality approach and describes accuracy and thoroughness as stable personal characteristics that influence corresponding behavior in different situations (e.g., Costa & McCrae, 1992). It is possible that more conscientious respondents might respond more thoroughly and more accurately to the survey questions and would therefore produce lower satisficing and fewer biased reactions. Biased reactions may therefore be expected to decrease as Conscientiousness increases. Unlike Attitude Strength, the empirical evidence for the moderating effects of NFC and Conscientiousness as factors influencing satisficing behavior is deficient. The hypothesis with respect to the moderating factors is as follows:
Method
Study Design
Two online experiments were conducted in Germany. The first experiment used seven categories in a rating scale and the second experiment five categories. The particular number of categories was chosen because rating scales with five to seven fully verbalized categories have been found to be associated with higher reliability than rating scales with other numbers of categories (e.g., Krosnick & Fabrigar, 1997; Maitland, 2009b).
In both experiments, four rating scale forms were realized and presented to randomly divided groups of respondents. The first group (BIPOLAR MATCHED) used a verbal bipolar rating scale with a suitable bipolar meaning for the middle category. In the first experiment, with seven categories, the labels were “fully disagree,” disagree,” “rather disagree,” partly disagree/partly agree, rather agree, agree, and “fully agree” (German: “lehne völlig ab,” “lehne ab,” “lehne eher ab,” “teils/teils,” “stimme eher zu,” “stimme zu,” “stimme voll und ganz zu”). The labels in the second experiment with five categories were “fully disagree”, “rather disagree”, “partly disagree/partly agree”, “rather agree”, and “fully agree” (“lehne voellig ab”, “lehne eher ab”, “teils/teils”, “stimme eher zu”, “stimme voll und ganz zu”). The middle category partly disagree/partly agree expressed ambivalence (German wording teils/teils compare usual realizations in, e.g., German Longitudinal Election Study [GLES], longtime panel, 2013–2017; Rattinger & Kraemer, 1995; Stegmann et al., 2010). The author decided to use partly/partly because it is very popular in Germany and has also often been used as mismatched verbalization in unipolar “do not agree/agree” rating scales. In addition, expressing ambivalence depicts the two factorial structure of attitude (Yoo, 2010; Zaller & Feldman, 1992). The widely used neither-nor expresses indifference and might overlap with “do not know,” which is conceptually placed outside of the rating scale continuum. In addition, respondents express ambivalence regarding their choice of the middle category more often than indifference (Klopfer & Madden, 1980). The verbal labels in the bipolar rating scales for the remaining categories were derived from existing surveys (compare, e.g., GLES, longtime panel, 2013–2017), so that typically used bipolar rating scales were implemented.
The second experimental group used a UNIPOLAR MATCHED agreement rating scale with the labels “do not agree at all”, “do not agree”, “slightly agree,” “moderately agree,” “agree,” “agree almost fully,” “fully agree” (seven categories: German “stimmt überhaupt nicht”, “stimmt nicht,” “stimmt wenig”, “stimmt mittelmäßig”, “stimmt”, “stimmt ziemlich”, “stimmt voll und ganz”) as well as do not agree at all, slightly agree, moderately agree, “agree to great extent,” fully agree (five categories: German: “stimme überhaupt nicht zu,” “stimme wenig zu,” “stimme mittelmäßig zu,” “stimme ziemlich zu,” “stimme voll und ganz zu”). This labeling parallels the definition of the unipolar rating scales (e.g., Schuman & Presser, 1981) and was introduced by Rohrmann (1978) who has emprically developed approximately equidistant verbal unipolar labels for the German language. Such labels are also commonly used in German surveys for unipolar verbalizations (e.g., GLES, 2013–2017 or ESS, 2016, see, e.g., political interest for the latter). Therefore, consistent unipolar rating scales were implemented in this group.
The unipolar and bipolar rating scales cannot be exactly parallel, as disagreement and agreement are graduated in the bipolar rating scale but only agreement is graduated in a unipolar rating scale. A comparison between unipolar and bipolar verbalization is nevertheless sensible because not agreement is often used interchangeably with disagreement (e.g., in international surveys, see, e.g., for the ISSP in the Introduction section) and gathering empirical evidence on their comparability is essential for such a use. The unipolar and bipolar rating scales were realized in the tradition of the corresponding previous research (Krebs, 2012; Schwarz et al., 1991), which was important for the comparison of the results.
The respondents in the third experimental group (BIPOLAR MISMATCHED) used the same bipolar scales as the first group. However, the label for the middle category was replaced with the moderately from the UNIPOLAR MATCHED group. Finally, the fourth group (UNIPOLAR MISMATCHED) used the same unipolar verbal labels as described for the UNIPOLAR MATCHED group, except for the middle option that was labeled with a bipolar middle partly/partly.
This implemented a full factorial 2 × 2 design that allows for the estimation of the main effects of “POLARITY,” which is a comparison between unipolar and bipolar rating scales, and “MATCHING,” which is a comparison between suitable and mismatched verbalization of the middle category. In addition, the interaction between the two factors (the effects of polarity and the verbalization of the middle category), that is the differences between the four described groups, can be investigated.
The various rating scales were used to measure gender role attitudes (see Appendix) from the German General Social Survey (ALLBUS, 2008; http://www.gesis.org/allbus) in both experiments. Gender role attitudes consist of two subconcepts: consequences for parenting and general gender ideologies (Braun, 2006), 3 items each. For further information on the construct, see Braun (2006). The author’s own confirmatory factor analysis (CFA) of the ALLBUS (2008) data showed that the items represent two factors, interpreted as parenting and gender ideologies, χ2(df = 8) = 56.52, p < .001; Root Mean Square Error of Approximation (RMSEA) = .04; Comparative Fit Index (CFI) = .99, r (between the two factors) = −.81; standardized loadings of items ranged from λ = .54 to λ = .88.
Study Participants
The data were collected from a probability online access panel of German-speaking persons living in the Federal Republic of Germany and aged 18 years or older. This panel included Internet users. The panelists were recruited by a telephone survey using a dual frame (cell phone and land line numbers) design between February and August 2011. As result, 1,665 panel participants with a Recruitment Rate of 9% were obtained. Struminskaya, Kaczmirek, Schaurer, and Bandilla (2014) describe additional details on the recruitment in the panel.
The data for the first experiment were collected in July and August 2012, with the panel in which 644 of the panelists were invited to participate in the survey (the difference to 1,665 is due to the panel attrition). Of these, 544 responded (completion rate [COMR] = 84%). (All deviations from this number reported in the article are due to missing data.) The participants were 54% male and the average age of participants was 42.9 years (SD = 14.87 years). Of these participants, 22% did not have a school leaving certificate or had only basic education, 14.3% had a medium level of education, and 63.8% had higher education (university entree). The experimental groups did not differ with respect to gender, χ2 (3, N = 542) = 6.02; p >.10; age, F (3, 539) = 0.57; p >.10; or education, χ2 (6, N = 515) = 1.73; p > .10.
The data for the second experiment were collected from the same panel in March 2013. An invitation to participate in the survey was given to 600 participants from which 482 responded (COMR = 80%; all deviations from this number reported in the article are due to missing data). This means that most of the participants of the first experiment participated in the second experiment as well, which is typical for panel studies. However, the randomization in the second experiment was conducted independently from the first experiment. The samples are treated as independent experiments due to this fact and due to a considerable time span between the waves. The sample composition did not differ markedly from that of the first experiment with respect to gender (53% male), age (M = 43.42, SD = 15.02), and education (61% with university entree degree). Likewise, as in the first experiment, the experimental groups did not differ either with respect to gender, χ2 (3, N = 466) = 1.12; p >.10; age, F (3, 462) = 1.23; p >.10; or education, χ2 (6, N = 444) = 9.31; p > .10.
Data Analysis
Different scores were used as dependent variables. The first score was the amount of the positivity bias. The positivity bias in a bipolar rating scale means that respondents avoid the negative part or disagreement, whereas in a unipolar rating scale, it means avoiding not agreeing or little agreement (Schwarz et al., 1991). To operationalize the positivity bias, in accordance to Schwarz et al. (1991), the sum of choices on the left-hand side of a rating scale was calculated throughout 6 items. The higher the frequency of endorsement, the lower was the positivity bias. The second score was referred to as “acquiescence” and described how often the agreement part in the bipolar scale and corresponding degree of agreement in the unipolar rating scale was used. In addition, the frequency in the choice of the middle category was calculated to describe middle responding. Mean differences in these scores between the experimental groups were compared by means of two-factor multivariate analysis of variance (MANOVA) and multivariate analysis of covariance (MANCOVA; which is an appropriate analysis strategy for the 2 × 2 factorial design described above). With the MANOVA, the effects of the experimentally varied factors and their interactions were evaluated. With a separate MANCOVA, the additional effect of moderators was investigated. Within each of the multivariate analyses, univariate analyses of variances (ANOVAs) and of covariances (ANCOVAs) for each of dependent variables were conducted.
To measure Attitude Strength, respondents evaluated how certain they were when responding to the items about gender roles (compare Bassili & Krosnick, 2000, for a similar operationalization). This question was placed immediately after the questions concerning gender roles and was rated on a five-category verbal rating scale, ranging from “not certain at all” to “very certain”. NFC was measured on a 16-item German NFC scale (Bless, Bohner, Fellhauer, & Schwarz, 1991) and conscientiousness was assessed using a subscale of the German short Big Five Inventory [BFI-K] (Rammstedt & John, 2005).
The reliability of multicomponent measures can be accessed through cross-sectional reliability metrics. In previous research on rating scales, Cronbach’s α has been predominantly used (e.g., Weng, 2004). However, α can only be interpreted in terms of reliability if the items measure a latent dimension with equal loadings and if there are no covaried error variances between the items (τ-equivalent measures). Otherwise, α may not only underestimate but also overestimate reliability (e.g., Raykov & Marcoulides, 2011), which might result in biased comparisons between the experimental groups. Because the assumption of τ-equivalence is often violated in the social science measurement, less restrictive reliability assessment methods have been recommended (e.g., Raykov & Marcoulides, 2011; Schweizer, 2011). Here, the composite reliability (Raykov & Marcoulides, 2011) was obtained, which is a CFA-based estimation of reliability conducted within the frame of LVM. This reliability method relies only on the assumption that items represent a measure of a latent dimension and relaxes other assumptions of τ-equivalence (congeneric CTT model). The reliability (ρ) was measured as follows (Raykov & Marcoulides, 2011, p. 161):

where b 1,…, bp were the factor loadings of the p items and θ1,…,θ p were the error variances. Reliability differences between the experimental conditions were assessed with the help of multigroup confirmatory factor analysis (MGCFA), see for example, Menold and Raykov (2015), for details.
The MGCFA analysis was conducted using the maximum likelihood estimation with robust standard errors (MLR), an estimator robust to nonnormality of data because none of the gender role items in every group was normally distributed (assessed with the Kolmogorow–Smirnow test). MLR has also been suggested when the ordinal variable has five or more values (e.g., Muthén & Muthén, 2014), which corresponds to the rating scales with five or seven categories.
Results
Response Bias
For the first experiment, with seven categories on rating scales, the descriptive results along the values of F statistics obtained from the ANOVAs, which tested the corresponding differences for significance, are displayed in Table 1. There were neither noteworthy nor significant differences for the mean frequencies of the choices on the left-hand side of the rating scale (positivity bias), right-hand side (acquiescence), and middle category (middle responding) between the unipolar and bipolar rating scales, so that the main effect of the experimental variation in the factor POLARITY was not significant. Hypothesis 1, which anticipated a higher positivity bias or higher acquiescence in the bipolar than in the unipolar rating scales, must therefore be rejected.
Experiment 1: Descriptive Statistics (Mean, SD) for Response Behavior and Regression Coefficients for Covariates by Experimental Groups With Results of ANOVAs and ANCOVAs.
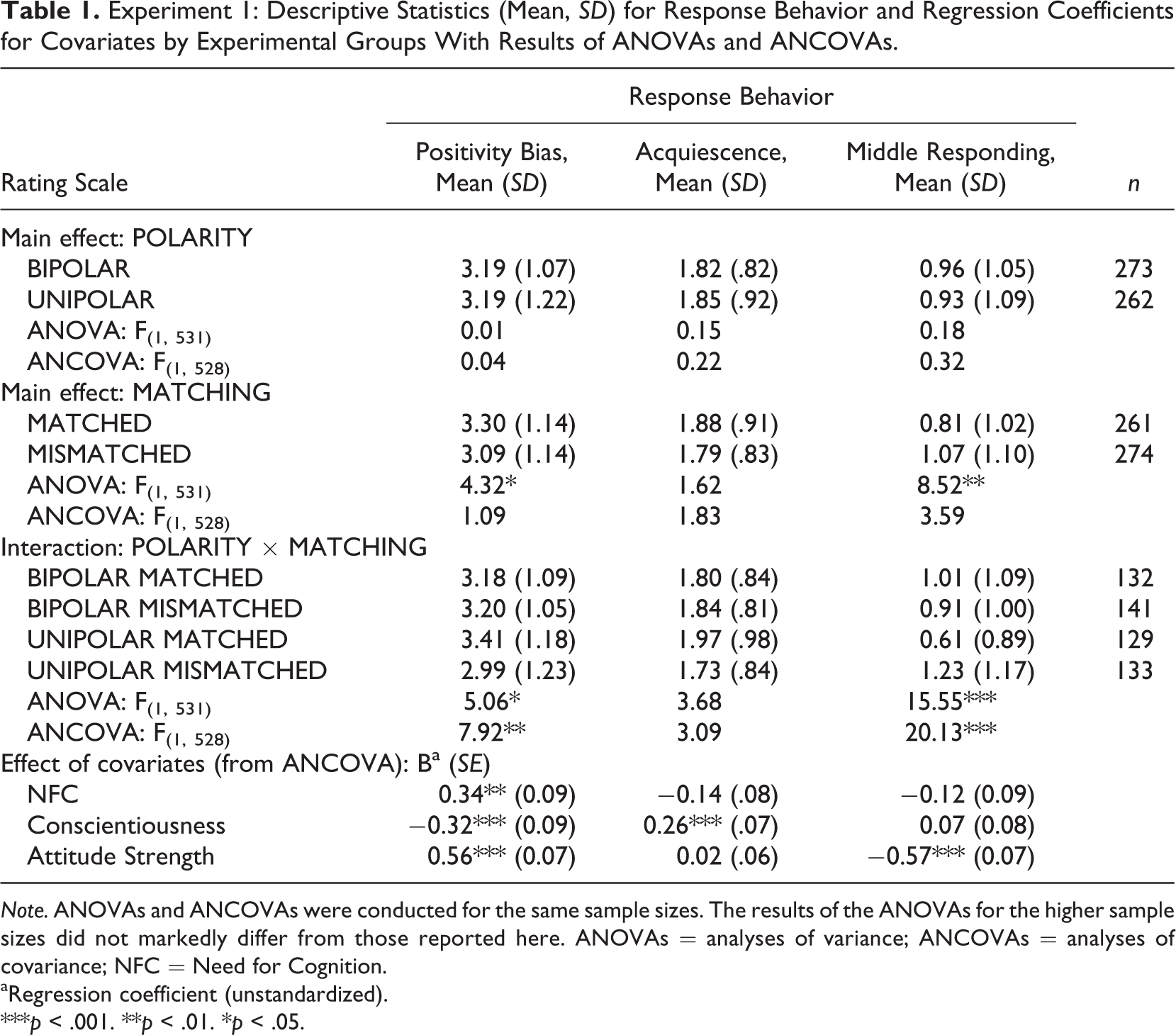
Note. ANOVAs and ANCOVAs were conducted for the same sample sizes. The results of the ANOVAs for the higher sample sizes did not markedly differ from those reported here. ANOVAs = analyses of variance; ANCOVAs = analyses of covariance; NFC = Need for Cognition.
aRegression coefficient (unstandardized).
***p < .001. **p < .01. *p < .05.
Hypothesis 3 anticipated higher middle responding with mismatched than with matched middle category. This is supported by the results, since the corresponding difference between the MATCHED and MISMATCHED verbalization (main effect of MATCHING; Table 1) was significant. An interesting result was that the matching of the middle category influenced positivity bias, which was significantly lower (higher frequencies in the choices of the left-hand part) if the verbalization of the middle category matched the polarity.
The results with respect to the interaction between POLARITY and MATCHING show pronounced and significant differences between the four experimental groups with regard to the positivity bias and middle responding (Table 1). The positivity bias was the lowest (with the highest mean frequency in the choice of the left-hand part of the rating scale) for the UNIPOLAR MATCHED and the highest for the UNIPOLAR MISMATCHED verbalization. In addition, the positivity bias was higher for both bipolar rating scales (BIPOLAR MATCHED and BIPOLAR MISMATCHED) than for the UNIPOLAR MATCHED form, whereas there was no notable difference between both bipolar forms. This led to a modified decision with respect to Hypothesis 1: The positivity bias was lower for the unipolar (“do not agree/agree”) format than for the bipolar disagree/agree scales, but only if the verbalization of the middle category for the unipolar scale matched the polarity (i.e., if moderately was used in the “do not agree/agree” continuum). Similarly, middle responding was highest for the unipolar “do not agree/agree” scale with the mismatched partly/partly verbalization and lowest for this unipolar scale with the suitable verbalization moderately. There was no noteworthy difference between both bipolar disagree/agree scales in middle responding (Table 1). The conclusion with respect to Hypothesis 3 should therefore be modified as well because it applied to the unipolar rating scales only. This means that respondents tended to use the mismatched middle partly/partly more frequent if it was implemented in the unipolar agreement continuum.
In the next data analysis step, the explanatory covariate variables Attitude Strength, NFC, and Conscientiousness were added to the previous MANOVA analysis to evaluate how this alters the effects of the experimental variations (Hypothesis 5). As a result, the addition of these variables to the analysis eliminated the effect of mismatched verbalization on the positivity bias and the middle responding. However, the interaction term between the variation in polarity and verbalization of the middle category remained significant. This refers to the highest middle responding and positivity bias in the UNIPOLAR MISMATCHED group (partly/partly in “do not agree/agree” continuum) and to the lowest middle responding and lowest positivity bias in the UNIPOLAR MATCHED group (moderately for “do not agree/agree” continuum), this also compared with the both bipolar rating scales.
With respect to the effect of covariates, Table 1 shows that the higher NFC was, the lower was the positivity bias, as NFC was positively related with the high means of the choices of low agreement or disagreement. In contrast, the higher Conscientiousness was, the lower was the mean frequency of the usage of the “negative/low” part of a rating scale (higher positivity bias) and the higher was acquiescence. With the higher Attitude Strength, the middle responding and the positivity bias were lower. Although the effect of Conscientiousness was not in line with the satisficing explanation, consideration of this variable along with NFC and Attitude Strength altered the experimental effect of matched verbalization, which is in line with Hypothesis 5. The expectation in this hypothesis was that the experimental effects depend on the covariate variables under investigation. However, the finding of the lowest positivity bias and lowest middle responding for the “do not agree/agree” unipolar rating scale with matched middle moderately (UNIPOLAR MATCHED) remained unaffected by the covariate variables (Table 1).
Table 2 shows the results of Experiment 2 in which the items were identical to Experiment 1 but which used a five-category rating scale instead. Unlike the first experiment, the polarity of a rating scale was shown to have a clear and significant effect on the positivity bias and acquiescence in the expected directions. The positivity bias was higher (lower use of the left-hand part) in the bipolar “disagree/agree” than in the unipolar “do not agree/agree” rating scales; the acquiescence was also more pronounced in the bipolar than in the unipolar rating scales. Hypothesis 1 was therefore clearly corroborated.
Experiment 2: Descriptive Statistics (Mean, SD) for Response Behavior and Regression Coefficients for Covariates by Experimental Groups With Results of ANOVAs and ANCOVAs.
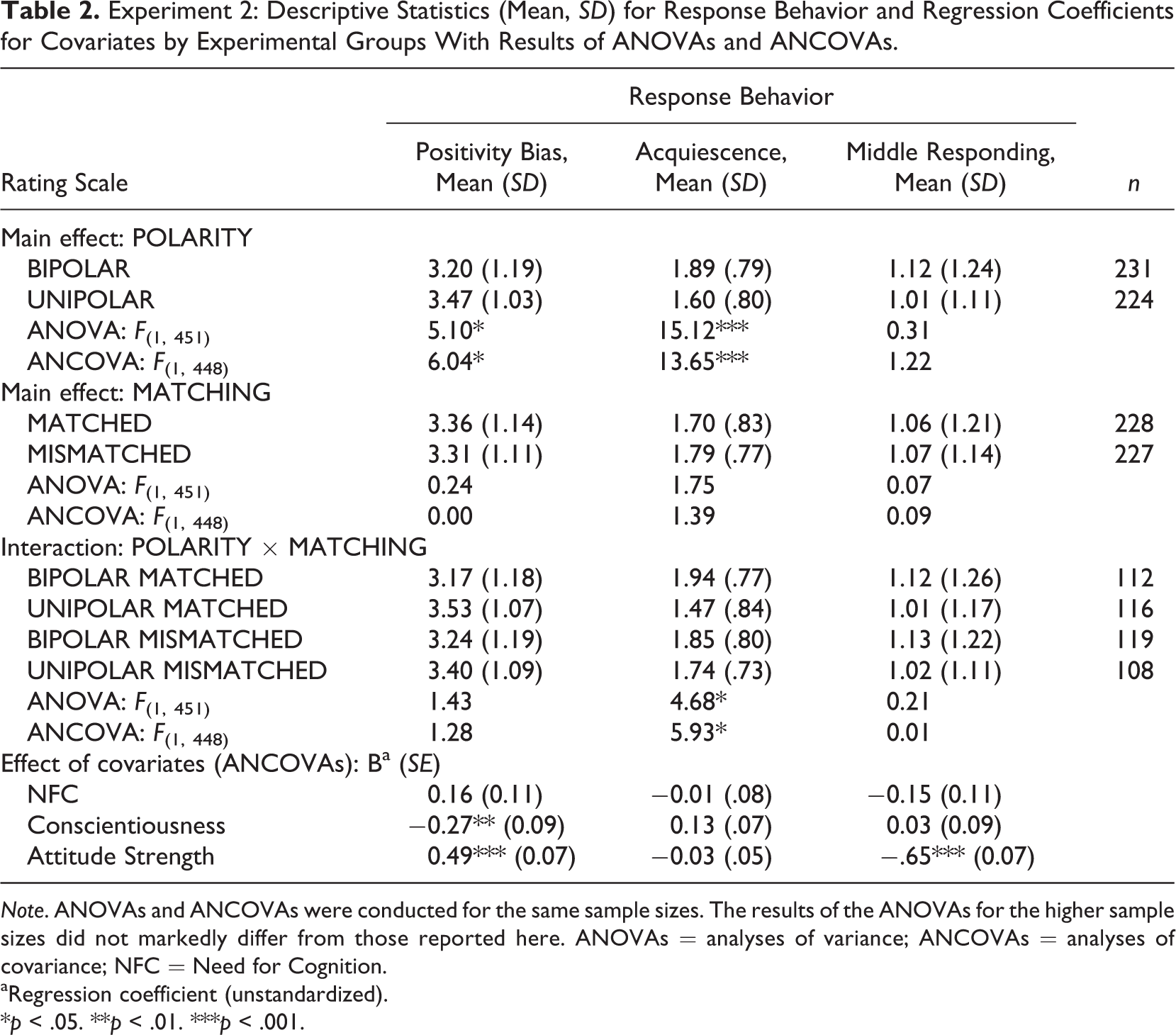
Note. ANOVAs and ANCOVAs were conducted for the same sample sizes. The results of the ANOVAs for the higher sample sizes did not markedly differ from those reported here. ANOVAs = analyses of variance; ANCOVAs = analyses of covariance; NFC = Need for Cognition.
aRegression coefficient (unstandardized).
*p < .05. **p < .01. ***p < .001.
Unlike Experiment 1, for the middle responding, no significant influence by experimental variations was obtained, and there were no pronounced differences between matched and mismatched verbalizations. Thus, Hypothesis 3 with the assumption of a higher tendency to the middle responding with mismatched than with suitable verbalization of the middle category had to be rejected. Significant interaction between polarity and matching was obtained for acquiescence. This refers to the lowest frequency of acquiescence in the case of the UNIPOLAR MATCHED group (“do not agree/agree” with “moderately”), compared to other experimental groups. This result is also in line with Hypothesis 1; hence, it can be added that the acquiescence in the unipolar rating scales can be further reduced by incorporation of the appropriate verbalization of the middle category.
Consideration of Attitude Strength, NFC, and Conscientiousness did not change the experimental effects (Table 2), and Hypothesis 5 was not therefore corroborated in the second experiment. NFC did not correlate with response behavior, while the findings of the first experiment with respect to the relation of Conscientiousness to the positivity bias and those of the Attitude Strength with the positivity bias and middle responding were reassembled.
In summary, a higher positivity bias and a higher acquiescence were found for the bipolar “disagree/agree” than for the unipolar “do not agree/agree” rating scales and clear support for Hypothesis 1 was determined in the second experiment with the five-category rating scales. With seven categories and a unipolar “do not agree/agree” continuum (in Experiment 1), this effect was dependent on the verbalization of the middle category, as the positivity bias was higher in the bipolar “disagree/agree” rating scales than in the unipolar “do not agree/agree” scale, in that the middle category moderately matched the unipolarity. Likewise, a higher middle responding with the mismatched middle category was observed in the first experiment with seven categories, but not in the second experiment, with five categories. Hypothesis 3, which predicted higher middle responding in the case of mismatched verbalization, is therefore only corroborated if seven categories are used in a rating scale. Although there were comparable results with respect to the effect of Attitude Strength and Conscientiousness in both experiments, their consideration was relevant for the results in the first experiment only. NFC played a role in the first experiment only as well. Hypothesis 5 consequently applied to the seven category rating scales (first experiment), but not to the five-category rating scales (second experiment). In both experiments, therefore, the unipolar “do not agree/agree” rating scale with the suitable middle “moderately” lead either to the lowest positivity bias accompanied with the lowest middle responding or to the lowest acquiescence, as compared with the bipolar “disagree/agree” rating scales and with the unipolar “do not agree/agree” scales, where the middle “partly/partly” did not match the polarity.
Reliability
The reliability coefficients and their differences with standard errors (SEs) as well as the corresponding 95% confidence intervals (CIs) are shown in Table 3. The analyses were based on the one-factor MGCFA models for the parenting and gender ideologies, respectively. With each model, reasonable goodness of fit was reached (χ2 was not significant, RMSEA ≤ .07, CFI ≥ .99). In each model, all items had significant loadings on the corresponding factors.
Composite Reliability (ρ) and their Pairwise Differences (D) With Confidence Intervals (CIs) by Concept and by Rating Scale Group in Two Experiments.
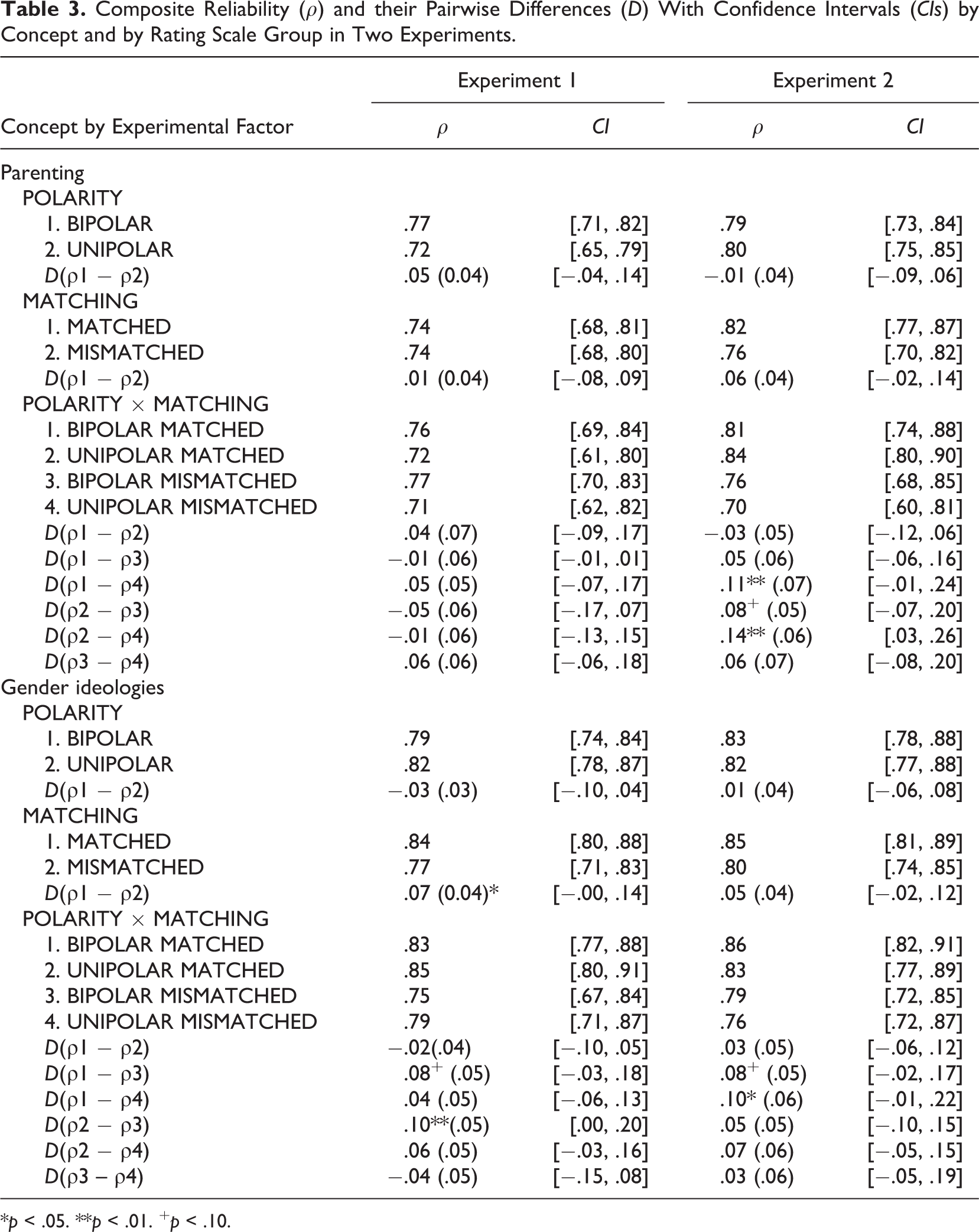
*p < .05. **p < .01. + p < .10.
Reliability was compared along the 2 × 2 factor design for (i) the differences between unipolar and bipolar rating scales, (ii) matched and mismatched verbalization, and (iii) four groups displaying interaction between the two factors. For the parenting items, there were no significant differences between the unipolar and bipolar rating scales (POLARITY; Table 3) as well as mismatched and matched verbalization (MATCHING) in both experiments. There were no significant differences between the four experimental groups in Experiment 1 either (POLARITY × MATCHING; Table 3). However, in Experiment 2, reliability was markedly and significantly higher for the bipolar and unipolar scales with matched verbalization than for the unipolar group with mismatched verbalization (“partly/partly”). The 95% CIs were thereby mainly not overlapping and the corresponding differences, D(ρ1 − ρ4) and D(ρ2 − ρ4), were high and significant.
For the second concept (gender ideologies), there were neither markedly pronounced nor significant differences between unipolar and bipolar rating scales, which applied to both experiments again. The reliabilities for both experiments were lower for mismatched verbalization of the middle category than those with the suitable verbalization, while in the first experiment this difference was significant. Next, in the first experiment, the lowest reliability was obtained with the bipolar mismatched, whereas in the second experiment, the unipolar mismatched rating scale exhibited the lowest reliability.
Accordingly, the results do not corroborate Hypothesis 2, which predicted higher reliability for the unipolar than the bipolar rating scales. By way of contrast, reliability was often lower when mismatched verbalization of the middle category was used, as compared to suitable verbalization, which supported Hypothesis 4. Depending on occasion, either unipolar mismatched or bipolar mismatched verbalizations of the middle category (“moderately for disagree/agree and partly/partly for do not agree/agree”) resulted in the lowest reliability.
Discussion
Two randomized experiments were performed to analyze how verbal rating scale polarity affects (i) response behavior with regard to the positivity bias, acquiescence, and middle responding and (ii) measurement quality in terms of reliability. The effects of the NFC, Attitude Strength, and Conscientiousness were also investigated.
A robust finding, which is generalizable among two experiments and which was not affected by satisficing or personality factors, was that either the positivity bias or the acquiescence, or both, were lowest in the case of the unipolar “do not agree/agree” rating scales with the suitable verbalization of the middle category (moderately). Compared to these forms, the positivity bias or acquiescence was higher in bipolar rating scales. The inappropriate, mismatched bipolar verbalization of the middle category (partly/partly) in the unipolar “do not agree/agree” rating scale led either to the highest positivity bias in combination with the highest middle responding or to the highest acquiescence. Both experiments therefore show that the approach popularly adopted in German language surveys, that is the popular unipolar “do not agree/agree” (“stimme nicht zu”/”stimme zu” vs. “stimmt nicht”/“stimmt”) rating scale with “partly/partly” (teils-teils) as the scale middle, can lead to biased results compared to the use of the suitable middle “moderately”.
The study also showed that the effects of mismatched verbalization of the middle category were affected by the NFC, Attitude Strength, and Conscientiousness, but only in the case of higher task difficulty, which is the case with seven, but not with five categories. This mirrors the theoretical assumption of a higher response bias effect of rating scale formats in the case of a higher satisficing (e.g., Krosnick & Fabrigar, 1997). Also, the respondents’ Conscientiousness exhibited a mediating effect, although the positivity bias and acquiescence were higher when Conscientiousness increased. This effect seems not to be related to the satisficing behavior and Conscientiousness consequently appears to have an independent effect on response biases, which is also known from other studies (Mõttus et al., 2012). Therefore, this variable along with the NFC should be taken into account when analyzing response behavior. However, it was a stable result that positivity bias and the middle responding were minimized if the unipolar agreement rating scale (“do not agree/agree”) with the suitable verbalization of the middle category “moderately” was used. This result was unaffected, if additional explanatory variables were included in the analysis.
Reliability did not differ between unipolar and bipolar rating scales but was lower if the verbalization of the middle category did not match the polarity of the rating scale. Mismatched verbalization of the middle category can obviously lead to irritations and difficulties on the part of respondents. A particular advantage of the present reliability analysis is that a more precise reliability assessment method within the framework of LVM was used as compared with previous studies.
The results concerning a lower positivity bias in the case of the verbal unipolar rating scales than in the case of the verbal bipolar rating scales correspond to previous results on numeric polarity (Schaeffer & Presser, 2003; Schwarz et al., 1991) and those which compare “disagree–agree” with the item-specific formats (Saris et al., 2010). The present article contributes to the literature because it shows that the positivity bias or acquiescence can be caused by verbal bipolarity as well. In addition, it shows that acquiescent response bias in “disagree/agree” rating scales can be reduced, if the unipolar “do not agree/agree” alternatives are used.
A frequent finding in the literature has been that the provision of the middle category fosters middle responding (e.g., Kalton, Roberts & Holt, 1980; Krosnick & Fabrigar, 1997). However, the results of the presented studies illustrate that maintaining the middle category with an optimal verbalization may decrease middle responding. Hence, this effect might be more pronounced for longer (with seven categories) than for introduce after (with five catgories) rating scales (Kieruj & Moors, 2010).
The results of the experiments conducted online provide insights for the online mode of data collection. However, it is important to take into account that people with lower education were underrepresented in the present online samples and the effects could be higher if more such people participated in the study. The differences found between both experiments could be plausibly explained by higher task difficulty as the use of seven categories implies a more demanding situation than use of five categories. Hence, alternative explanations are possible, as two experiments with different number of categories also present two measurement occasions and were not subjected to random variation. In the future, the results should be replicated by the use of the number of categories as a third random variation. Further restrictions relate to the fact that two strongly related attitudes were measured. Likewise, the results should be replicated with measures of other attitudes and also with other rating scale dimensions such as importance, probability, frequency, or application. The bipolar middle category “partly/partly” that expresses ambivalence was used in the present research. “Neither-nor”, which does not suit the theoretical conceptualization of attitudes and is difficult to differentiate from “do not know”, has been also found to foster middle responding (Sturgis et al., 2014). Further research should therefore investigate whether the effects of “neither-nor” are comparable to those of “partly/partly”, if it is inappropriately used in unipolar rating scales.
In conclusion, bipolar verbal “disagree/agree” scales and mismatched verbalization of the middle category can lead to biased data. Reliability can also be reduced if the verbalization of the middle category does not match the rating scale polarity. The unipolar “do not agree/agree” rating scales with the middle “moderately” can be used instead of the bipolar “disagree/agree” scale to reduce acquiescence and may be a reasonable alternative to the item-specific format. However, more research is needed to compare those verbalizations with the item-specific format to strengthen this conclusion. Inappropriate bipolar verbalization of the middle category (partly/partly) in the unipolar “do not agree/agree” rating scales seems to be particularly problematic. Therefore, using “partly agree/partly disagree” (German “teils-teils”) should be avoided, if the agreement scale is unipolar.
Footnotes
Appendix
Authors Note
Data are available from the author on request. SPSS 23 and Mplus 7.31 were used for the analyses.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.