
Abstract
Background
The development of automatic methods for vertebral segmentation provides the objective analysis of each vertebra in the spine image, which is important for the diagnosis of various spinal diseases. However, vertebrae have inter-class similarity and intra-class variability, and some adjacent vertebrae exhibit adhesion.
Objective
To solve the adhesion problem of adjacent vertebrae and ensure that the boundary between adjacent vertebrae can be accurately demarcated, we propose an image segmentation method based on deep learning and marker controlled watershed.
Methods
This method consists of a dual-path model of localization path and segmentation path to achieve automatic vertebral segmentation. For the vertebral localization path, a high-resolution network (HRNet) is used to locate vertebral center. Moreover, based on spine posture, a new bone direction loss (BD-Loss) is designed to constrain HRNet. For the vertebral segmentation path, we proposed a VU-Net network to achieve vertebral preliminary segmentation. Additionally, a position information perception module (PIPM) is introduced to realize the guidance of HRNet to VU-Net. Finally, we novelly use the outputs of HR-Net and VU-Net deep learning networks to initialize the marker controlled watershed algorithm to suppress the adhesion of adjacent vertebrae and achieve vertebral fine segmentation.
Results
The proposed method was evaluated on two spine X-ray datasets using four metrics. The first dataset contains sagittal images of the cervical spine, while the second dataset contains coronal images of the whole spine, both with different health conditions. Our method achieved Recall of 96.82% and 94.38%, Precision of 97.24% and 98.14%, Dice coefficient of 97.03% and 96.22%, Intersection over Union of 94.24% and 92.72% on the cervical spine and whole spine datasets respectively, outperforming current state-of-the-art techniques.
Keywords
Introduction
The spine plays a vital role in the human body, providing support and stability for daily activities. Unfortunately, sedentary behavior, poor posture, and other lifestyle changes have slowly led to spinal diseases becoming one of the primary health concerns for individuals of all ages. 1 X-ray imaging is the preferred method for the diagnosis of spinal diseases due to its simple operation and low cost. Currently, doctors often manually segment vertebrae and perform parameter estimation based on medical guidelines, which is not only time-consuming but also susceptible to subjective factors. 2 Automatic segmentation of vertebrae greatly reduces the effort required for marking and guarantees consistent diagnosis. 3 Therefore, it is of great significance to explore an automatic vertebral segmentation method to assist doctors in diagnosis. However, the process of automatic vertebral segmentation in X-ray images faces challenging problems such as the similarity between adjacent vertebrae, the variability of the same vertebra in different images and the adhesion of adjacent vertebrae.
Vertebral segmentation is the task of classifying vertebrae into regions of interest at the pixel level.4,5 In recent years, deep learning has been developed rapidly and used widely in various fields due to its strong learning ability and excellent mobility. 6 In particular, in the field of vertebral segmentation task, deep learning shows encouraging potential. At present, there are two main methods for vertebral segmentation based on deep learning: single-task segmentation and multi-task segmentation. For the single-task segmentation, it only focuses on segmenting vertebrae in the image into regions of interest. Lessmann et al. 7 proposed a single fully convolution network that iteratively regresses vertebral labels, independent of the number of visible vertebrae in spine CT and MR images. To accommodate highly variable vertebral shapes, Rehman et al. 8 integrated a parametric level set algorithm in a deep learning network. The probability map from the pre-trained network is used to initialize the level set to improve the robustness to noise. Additionally, Rak et al. 9 proposed a novel graph cut formulation that makes full use of the anatomical information of vertebral shapes in spine MR images. In order to obtain vertebral semantic feature, Han et al. 10 proposed a long short-term memory network, which increases the long-range spatial correlation between pixels and realizes pixel-level segmentation. Payer et al. 11 proposed to segment each vertebra from coarse to fine by employing a spatial configuration network to determine vertebral coordinates and performing refined binary segmentation on each identified vertebra in spine X-ray images. Pang et al. 12 proposed a new two-stage framework that connects a 3D graph convolutional network for 3D coarse segmentation with a 2D residual U-Net for 2D fine segmentation, which solves the problems of vertebral intra-class variability and inter-class similarity. Besides, Al Arif et al. proposed to combine the three processes of global localization, center localization and vertebrae segmentation in a single thread to realize the segmentation of spine X-ray images.
For the multi-task segmentation, it includes not only segmenting each vertebra but also simultaneously performing other tasks such as vertebral localization and recognition. 13 Pang et al. 14 proposed a dual-path network that simultaneously locates and segments vertebrae. Zhang et al. 15 introduced a co-attention module to learn the correlation information between vertebral localization, recognition and segmentation tasks during the network propagation. Then, Li et al. 16 proposed a multi-channel cross attention for fusing features from vertebral localization and segmentation networks to generate a comprehensive description of the spine.
In the single-task segmentation methods, the methods7–9 using vertebral prior knowledge effectively realized vertebral segmentation, while Pang
12
and Al Arif
17
realized vertebral segmentation from coarse to fine through the multi-stage network. However, these single-task methods lack generalization and depend on the quality of the dataset. In the multi-task segmentation methods,14–16 the relationship between tasks is used to segment vertebrae, which effectively deals with the diversity and complexity of vertebrae images. However, due to the integration of multiple tasks, the network structure becomes complex and is prone to the overfitting problem. Additionally, it is difficult to accurately identify vertebral edge information, and adhesion is prone to occur when predicting adjacent vertebrae. To solve the above problems, we propose a two-stage method which accomplishes automatic segmentation of vertebrae by fusing the vertebral prior knowledge, the relationship between vertebral localization and segmentation networks, and the marker controlled watershed algorithm. The challenges associated with vertebral under-segmentation and over-segmentation, particularly the vertebral adhesion, are effectively addressed. Our main contributions are summarized as follows:
A position information perception module (PIPM) is proposed to convert the localization features of the vertebral localization network into a guidance matrix, directing the vertebral segmentation network to focus on vertebral related regions. The vertebral localization network uses a high-resolution network (HRNet) to locate vertebral center. To solve the problem of information loss caused by direct upsample of HRNet, an atrous unit is proposed. Additionally, a bone orientation loss (BD-Loss) is proposed to constrain HRNet by taking spine posture as a prior knowledge for vertebral precise localization. A VU-Net, based on the encoder and decoder structure of U-Net, is used as the vertebral segmentation network for vertebral preliminary segmentation. The encoder of VU-Net adopts VGG16 to extract vertebral edge information and introduces dropout layers to address the limited generalization capability during training on small-scale spine datasets. To achieve cross-layer sharing and reuse of features, dense units are introduced in the decoder of VU-Net. Additionally, guidance units are introduced in the decoder allows for the fusion of HRNet and VU-Net features, thereby enabling HRNet to guide VU-Net. The marker controlled watershed algorithm, combined with deep learning, is employed for vertebral fine segmentation. Utilizing the outputs of the HRNet localization network and the VU-Net segmentation network, the watershed algorithm is initialized to detect vertebral edge by simulating the separation of water flow and dike, enabling the automatic and accurate segmentation of adjacent vertebrae.
The structure of this paper is organized as follows. Section 2 describes the proposed method in detail. Section 3 describes the experimental conditions and evaluation metrics. Section 4 analyzes the experimental results. The final conclusions section is contained in Section 5.
Methods
The framework of the proposed method is shown in Figure 1. As the localization network, the improved HRNet locates vertebral center. The proposed VU-Net constituting the segmentation network achieves vertebral preliminary segmentation under the guidance of the proposed PIPM, which introduce the output of HRNet into VU-Net. Then, based on the outputs of these two networks the marker controlled watershed algorithm accomplishes vertebral fine segmentation in spine X-ray images which is the ultimate aim in this paper.

The framework of the proposed method, which includes a localization network (HRNet) for vertebral center localization, a segmentation network (VU-Net) for vertebral preliminary segmentation, and a marker controlled watershed algorithm for vertebral fine segmentation.
Vertebral localization and segmentation
Localization network
To extract a set of highly representative vertebral localization features, the HRNet 18 is improved as the localization network, retaining its advantage of being robust to coordinate perturbations. HRNet always maintains high-resolution branches to keep the features of the target edge and other details. And information is iteratively exchanged between parallel high-resolution and low-resolution branches to capture long-range features. However, HRNet adopts direct upsample to fuse feature maps of different resolutions after the final fusion stage, neglecting the global information of the feature maps. To solve this problem, we propose an atrous unit that contains a series of convolution operations with different convolution kernels and dilation rates. With the assistance of the atrous unit, the improved HRNet can capture features of different scales and receptive fields.
The improved HRNet is shown in Figure 2. The main body consists of four fusion stages and three transition stages. Each fusion stage is responsible for the interaction between different branches. The third and fourth fusion stages are stacked four times and two times, respectively. The transition stage generates a branch downsampled by a factor of 2. Before entering the main body, the input image is first downsampled by a factor of 4. After a series of fusion and transition, four features with different resolutions are obtained, denoted as C1, C2, C3, and C4, which correspond to 1/4, 1/8, 1/16, and 1/32 of the input image, respectively. Then, the P1 and P2 feature maps are obtained by the direct upsample and the atrous unit, respectively. As shown in Figure 2, the atrous unit consists of 1 × 1 convolutions that reduce the parameters of HRNet, 3 × 3 convolutions that capture vertebral internal features, and dilated convolutions with different rates that capture broader contextual information of the feature maps. Based on the resolution of the feature maps, ratios of 5, 3 and 1 are used for the C1, C2, and C3 feature maps, respectively. The result of vertebral center localization is obtained by upscaling the fusion of the P1 and P2 feature maps by a factor of 4.
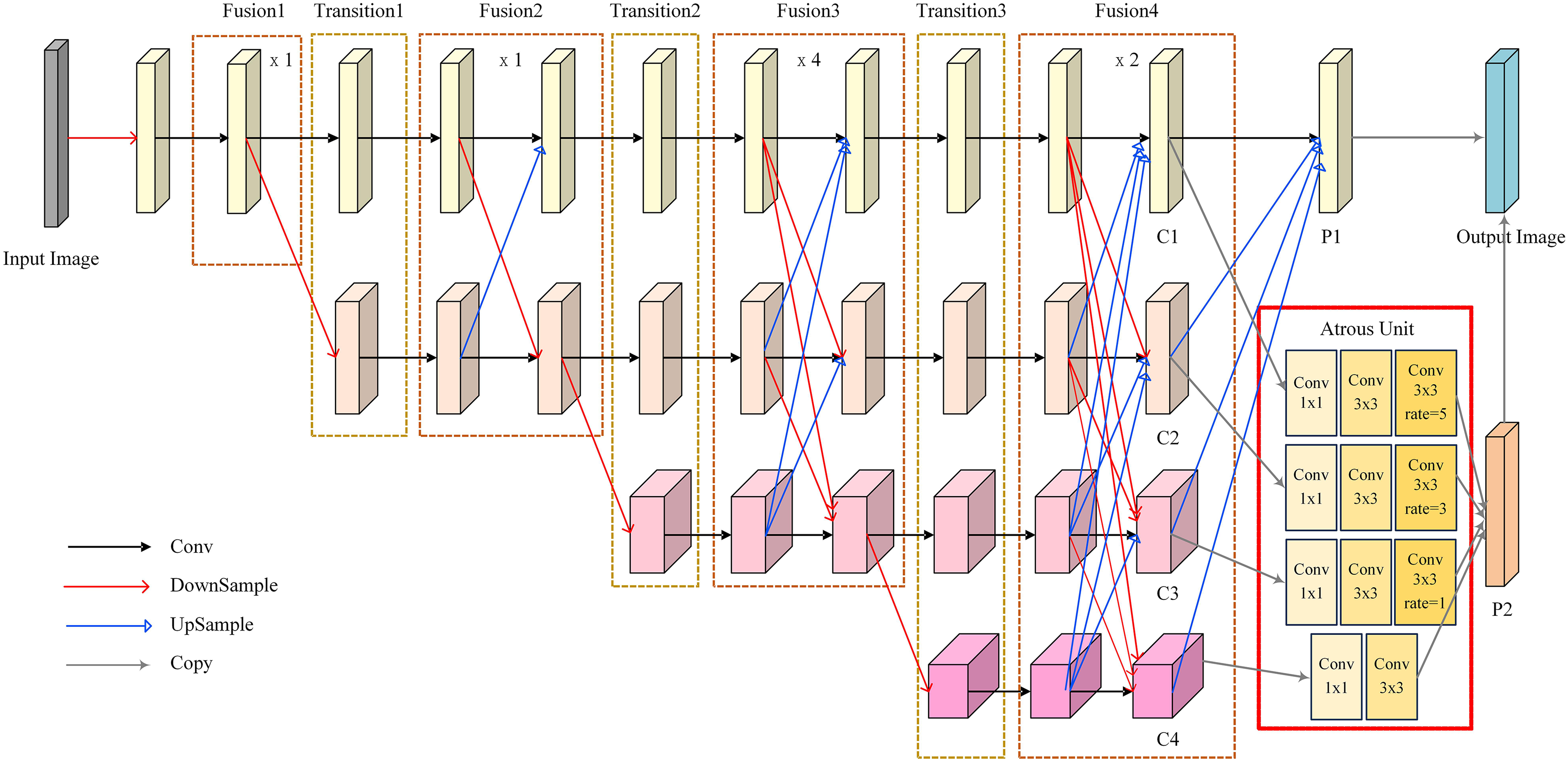
The architecture of the improved HRNet. P1 is obtained by the direct upsample. P2 is obtained by the atrous unit.
Position information perception module
In order to enhance the ability of the vertebral segmentation network to identify vertebrae in spine X-ray images, a position information perception module (PIPM) is proposed to convert the localization features of HRNet into a guidance matrix M, enabling HRNet to guide the segmentation network effectively.
As shown in Figure 3, the guidance matrix M consists of two sets of weight coefficients, denoted as M1 and M2. The M1 weight coefficient implies all features in the spine image. Some convolution layers are first performed on the localization features to generate different feature maps fa, fb, and fc. The fa and fb feature maps are learned to obtain features that distinguish vertebral intra-class variability and inter-class similarity, respectively. Then the matrix multiplication of fa and fb feature maps is performed, and the Softmax activation function is used to normalize the feature maps into probability distribution maps. Finally, the M1 weight coefficient is obtained by multiplying the probability distribution maps and fc feature map, which constructs the dependencies between pixels. The M2 weight coefficient focuses attention on the related regions of vertebral localization. Max pooling and average pooling are used to capture the spatial information of high-level and low-level features, respectively. Max pooling extracts vertebral salient features while maintaining invariance, and average pooling aggregates the overall information of the image. Finally, the M2 weight coefficient is obtained through the Sigmoid layer. After obtaining the MI and M2 weight coefficients, we fuse their channels to obtain the guidance matrix M. The higher the pixel values in the M guidance matrix, the greater the probability they represent vertebral localization.

The architecture of the PIPM. M is the guidance matrix. M1 and M2 are the weight coefficient.
Segmentation network
For the vertebral segmentation network, a VU-Net network is proposed to separate the vertebrae from the background, based on the U-Net. 19 When dealing diverse spine images, the simplicity of the U-Net structure often results in inaccurate segmentation of vertebrae. In this paper, we improved the U-Net structure in several aspects, as shown in Figure 4. In the VU-Net encoder stage, the simple and efficient VGG16 network with smaller 3 × 3 convolution kernels is used to capture richer vertebral edge information. In addition, dropout layers are added to prevent the overfitting problem in processing small-scale spine datasets, thereby achieving regularization of VU-Net. In the VU-Net decoder stage, dense units are added to allow each layer to directly obtain the gradient information of the previous layer. These dense units serve to enhance feature representation capabilities, enable deeper image analysis, and alleviate the problem of gradient disappearance. In addition, guidance units are added to fuse the features of HRNet and VU-Net to minimize the interference from extraneous information during the segmentation process. These guidance units enable VU-Net to achieve vertebral preliminary segmentation under the guidance of HRNet.
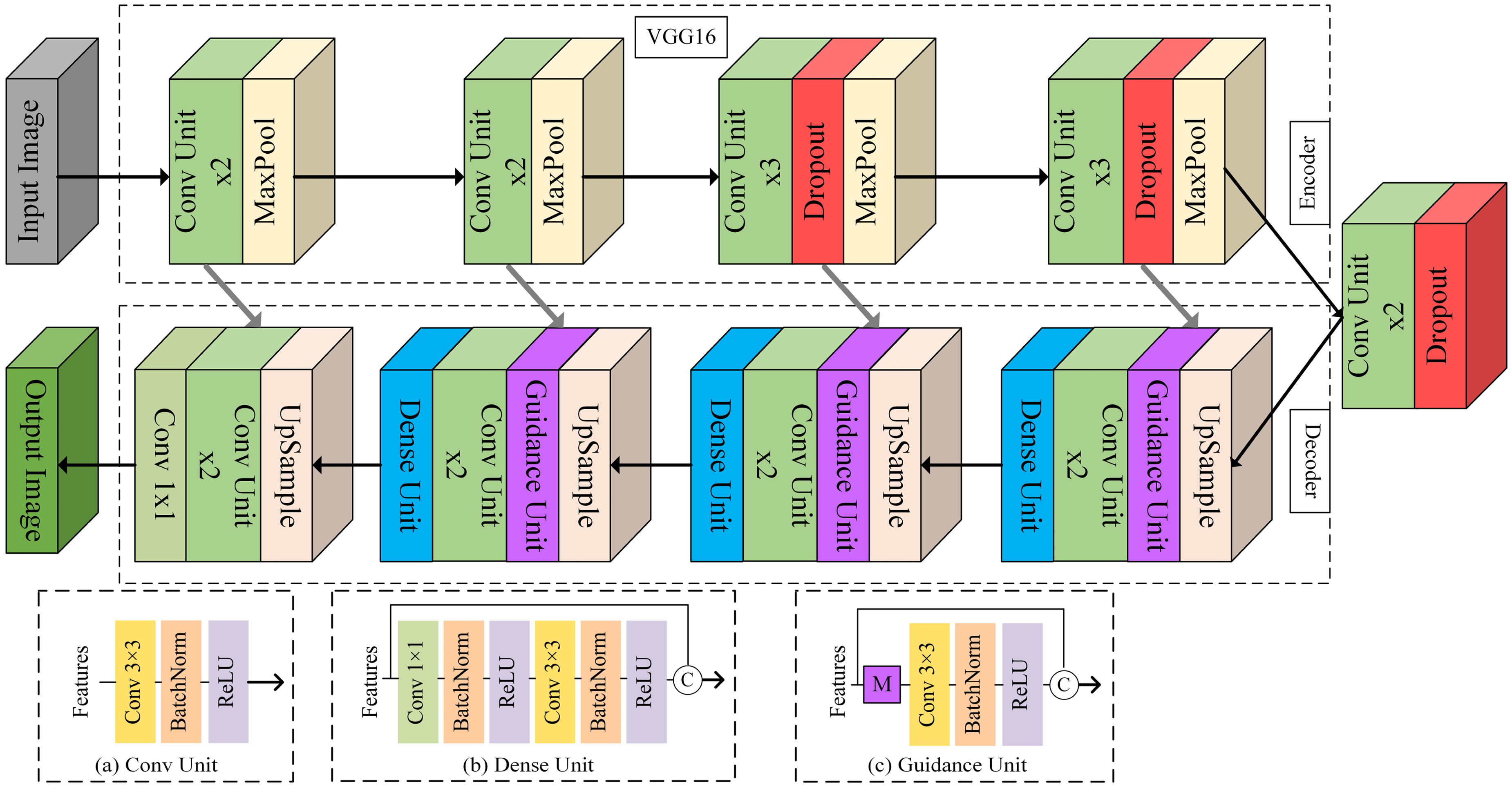
The architecture of the vu-net. M is the guidance matrix generated by the PIPM.
In detail, compared to the standard U-Net, the VU-Net encoder stage consists of 12 conv units, 4 max pooling layers, and 3 dropout layers. Each conv unit uses a 3 × 3 convolution with the ReLU activation function to preserve vertebral edge information. Max pooling layers are introduced in the first, second, third, and fourth downsample layers, which have a window of 2 and a step size of 2. By stacking conv units and max pooling layers, VU-Net progressively extracts features and diminishes feature size. Dropout layers are introduced in the third, fourth, and fifth downsample layers to minimize the overfitting. The VU-Net decoder stage consists of 8 conv units, 3 dense units, 3 guidance units and a 1 × 1 convolution. Dense units and guidance units are introduced in the first, second, and third upsample layers. Stacking multiple dense units at a relatively low computational cost creates a large receptive field with fewer parameters. Guidance units utilize the guidance matrix M generated by the PIPM, multiplied element-wise with the segmentation features, facilitating the fusion of HRNet and VU-Net features. Finally, in the last layer of VU-Net, a 1 × 1 convolution generates the probability map of the input image, achieving vertebral preliminary segmentation.
Loss function
For the two deep learning networks HRNet and VU-Net, we use different loss functions. The overall loss function is designed as follows:
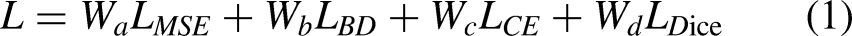
The label for HRNet is the heatmap generated by the vertebral center, which is manually labeled. In this paper,

In the VU-Net deep learning network, we denote
Marker controlled watershed
In order to solve the problem of blurred or adherent vertebral boundaries caused by factors such as spinal diseases or surgical implants, as indicated by the red arrow in Figure 5(b). We use the marker controlled watershed algorithm as a post-processing step, incorporating the deep learning to separate the adherent vertebrae and generate continuous boundaries with a single pixel width. The watershed algorithm is a graph-based technique originally proposed by Vincent et al., 20 which relies on the gray gradient information and regards the pixels as the height on the terrain. However, the gradient information of the ribs and other parts in the spine image is similar to vertebrae, which easily leads to the mis-segmentation of vertebrae. The predefined markers specify the region of interest. However, currently methods rely on manually labeled markers, resulting in limitations such as high requirements for expert knowledge, subjectivity, and constrained generalization ability in the segmentation process. In this paper, we used the heatmap generated by HRNet as the marker, which reflects the topographic surface of the watershed. The heatmap exhibits the max response at the vertebral center, with pixel values decreasing as they approach the edge of the vertebra, as shown in Figure 5(c). It is worth noting that the pixel values between adjacent vertebrae are close to negative one, as indicated by the red arrow in Figure 5(c), which determines the position of the watershed line between them. In addition, the vertebral preliminary segmentation result of VU-Net is employed as the image to be fined segmented by the watershed algorithm, which has eliminated substantial background regions, as shown in Figure 5(b). By integrating the outputs of the above two deep learning networks, HRNet and VU-Net, as input to the watershed algorithm, we implement vertebral fine segmentation by simulating the geographic flooding process, where the neighboring vertebrae are separated and the vertebral edges are accurately determined, as shown in Figure 5(d).
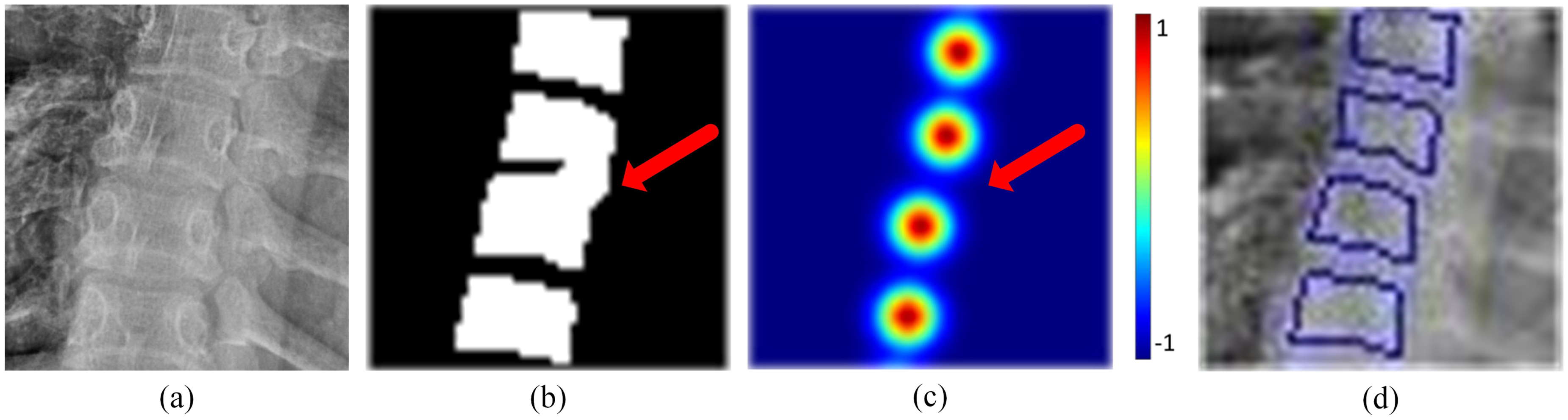
The post processing. (a) is a section of the whole spine input image. (b) is the result of VU-Net. (c) is the result of HRNet. (d) is the result of the marker controlled watershed. Red arrow highlights the boundaries of adjacent vertebrae.
Experiments
Dataset and pre-processing
The experiments are conducted on two spine X-ray datasets for training and validation. The first dataset includes 295 sagittal images of the cervical spine annotated with six vertebrae from the Second Hospital of Shanxi Medical University. Images range in size from 700 to 3000 pixels, with a variety of spine orientations, patient poses, and cropping styles. This dataset includes images of vertebral fractures, degenerative changes, and surgical bone implants. Some of the images had jewelry, clothing and other extraneous items. Each vertebra in the image was labeled by orthopedic experts. The second dataset is the contains 90 coronal images of the whole spine annotated with 18 vertebrae from the public dataset AASCE 2019. 21 The two datasets contain different conditions such as spinal diseases, surgical implants, and poor image quality, truly reflecting the diversities and challenges of the spine image. In the following part, two datasets denoted as Dataset-CS and Dataset-WS respectively. To prevent the network overfitting problem, we augment the two dataset using data augmentation techniques such as translation, mirroring, and rotation, resulting in 3984 cervical spine images and 1962 whole spine images. The two datasets are divided into training and validation sets with a ratio of 9:1. To ensure that all experiments use the same augmented dataset, the same random state is applied during data augmentation. Before being input into the model, the images of the two datasets are resized to 256 × 256 and 256 × 512 pixels respectively, without distortion compression by adding gray bars on both sides. They are then normalized by subtracting the mean pixel value and dividing by the standard deviation of the pixel values.
The two datasets consist strongly supervised labels of manually labeled vertebral masks and weakly supervised labels of vertebral center coordinates. For HRNet, weakly supervised labels are converted into heatmaps that can be learned as a regression task. Knowing the coordinates

Training and evaluation metrics
The experiments were conducted on an NVIDIA GeForce RTX 3080. During the training process, we adopted a batch size of 2 setting and used the Adam optimizer with an initial learning rate of 0.01. At the same time, we monitor the loss of training and validation images, and evaluate the performance of the model every 5 epochs. When the training loss keeps decreasing and the validation loss no longer improves or starts increasing, we stop the training process. Four evaluation metrics including Recall, Precision, Dice coefficient, and Intersection over Union (IoU) are used to evaluate our model. Recall measures the ability of the model to recognize vertebrae. Precision gauges the ability of the model to predict how many of the predicted vertebrae belong to the labeled vertebrae. Both Dice and IoU measure the overlap between the predicted vertebrae and the labeled vertebrae, with Dice assigning more weight to true positives in its calculation.
Results and discussion
Results and discussion of the ablation experiment
We conducted an ablation experiment based on the U-Net, successively adding the proposed VU-Net, atrous, PIPM, BD-Loss and marker-controlled watershed modules, which was used to evaluate the performance gains from each module and the impact of their combination improvements on the model. The experimental results are shown in Table 1 and Figure 6. The best results are shown in bold in the table, and the differences between the experimental results are indicated in box form. The final model achieves values of 96.82%, 97.24%, 97.03%, and 94.24% of the four metrics on Dataset-CS, and values of 94.60%, 98.13%, 96.33%, and 92.92% of the four metrics on Dataset-WS. The highest Precision, Dice and IoU are achieved on the two datasets, and vertebrae can be distinguished with clear edges.

Results of the ablation study on Dataset-CS and Dataset-WS. Rows 1 and 2 are images from Dataset-CS,and rows 3 and 4 are images from Dataset-WS. (a) Ground Truth. (b) U-Net. (c) VU-Net. (d) VU-Net + HRNet + PIPM. (e) VU-Net + HRNet-atrous + PIPM. (f) VU-Net + HRNet-atrous + PIPM +
The results of the ablation study on Dataset-CS and Dataset-WS in terms of Recall (%), Precision (%), Dice (%), and IoU (%) metrics.
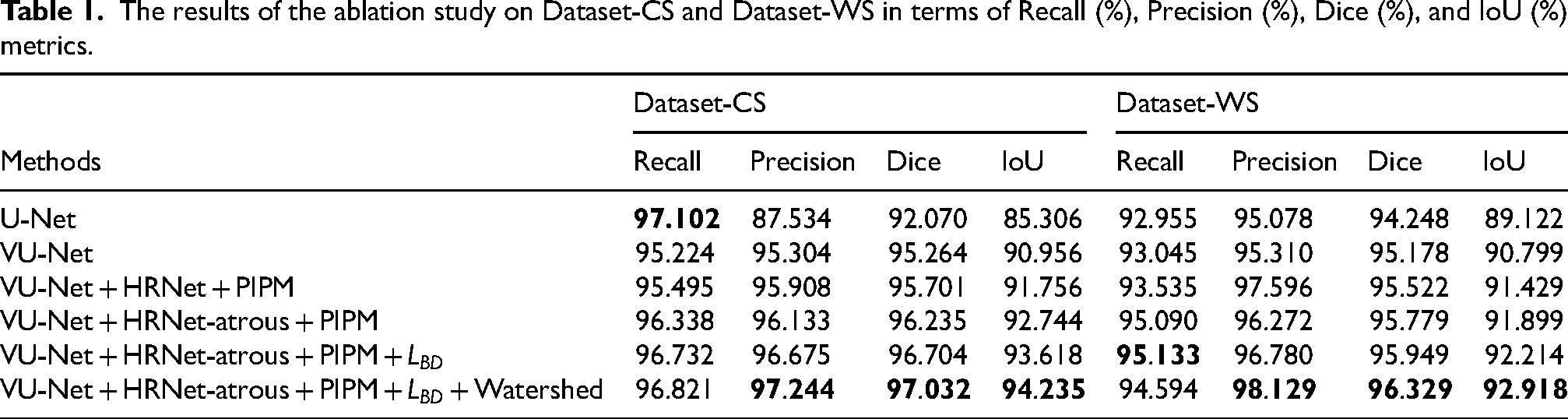
In the baseline experiment based on the U-Net, Dataset-CS exhibits the highest Recall, indicating that the U-Net can effectively identify vertebral regions. But the two datasets show the lowest Precision, meaning that there is mis-segmentation. As seen in Figure 6(b), regions such as the pelvis, surgical implants, jaw, and teeth are mislabeled as vertebrae. The introduction of the VU-Net increases Precision values on the two datasets compared to the U-Net, with a notable 7.77% increase on Dataset-CS. As seen in Figure 6(c), the mis-segmentation regions of the two datasets are significantly reduced, indicating that the VU-Net improves the ability to capture global information and reduces false positives. However, there are still some erroneous segmentation regions with low overlap with the ground truth, reflected in the lower IoU. Then, we replaced the localization network with the HRNet and introduced the PIPM, which converts the features of the HRNet into a guidance matrix integrated into the VU-Net. This allows the HRNet to guide the VU-Net to focus on vertebral related regions. The results show that the four metrics are increased on the two datasets, and the vertebral regions are accurately segmented, as shown in Figure 6(d). Nonetheless, issues of over-segmentation and under-segmentation persist, especially around vertebrae with nearby surgical implants. To address this, we introduce an atrous unit to help the HRNet identify more vertebral pixels. This improves the Recall, Dice, and IoU metrics on the two datasets. However, there is a decrease in Precision on Dataset-WS, indicating that while the atrous unit enhancing the ability of the model to obtain more global information, it also focuses the model on noise. In addition, Figure 6(e) shows adhesion of adjacent vertebrae in the two datasets and inaccurate localization of adjacent vertebrae on Dataset-WS. To achieve precise vertebral localization, we design the BD-Loss to constrain the HRNet based on spine posture. This improves all metrics on the two datasets, with the highest Recall achieved on Dataset-WS. As shown in Figure 6(f), each vertebra can be accurately localized regardless of the spine posture changes. However, distinguishing some adjacent vertebrae remains challenging, particularly on Dataset-WS where adjacent vertebrae are close and boundaries unclear. Therefore, we introduce the marker controlled watershed. Experiments show that the Dice metric of the final model reaches 97.03% on Dataset-CS and 96.33% on Dataset-WS, which means that the under-segmentation and over-segmentation problems are effectively balanced. Compared to the U-Net, the final model improves Precision, Dice and IoU metrics on Dataset-CS by 9.71%, 4.96%, and 8.93%, respectively. On Dataset-WS, the final model improves the four metrics by 1.64%, 3.05%, 2.08%, and 3.80%, respectively. Figure 6(e) shows no adhesion of adjacent vertebrae on the two dataset, and vertebrae edges are clearly visible.
Results and discussion of the comparative experiment
Additionally, we conducted a comparative experiment with the current state-of-the-art models, including U2-Net, 22 DGMSNet, 14 and GCN. 23 The experimental results, shown in Table 2 and Figure 7. Our model outperforms these latest models in the Recall, Precision, Dice, and IoU metrics on the two datasets. Although all models are capable of detecting vertebral relevant regions, our model stands out in terms of detail retention and effectively mitigates issues including under-segmentation, mis-segmentation, and vertebral adhesion.
Results of the comparison study on Dataset-CS and Dataset-WS. Rows 1 and 2 are images from Dataset-CS,and rows 3 and 4 are images from Dataset-WS. (a) Ground Truth. (b) U2-Net. (c) DGMSNet. (d) GCN. (e) Ours.
The results of the comparison study on Dataset-CS and Dataset-WS in terms of Recall (%), Precision (%), Dice (%), and IoU (%) metrics.
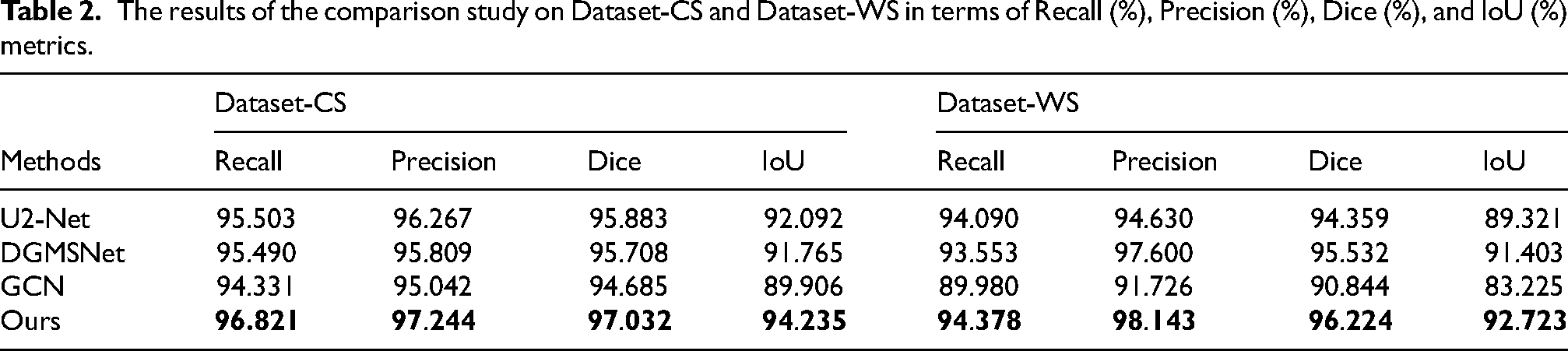
U2-Net performs well in all metrics on Dataset-CS, with Recall, Precision and Dice all exceeding 95%, but IoU is slightly lower and there is adhesion phenomenon. On Dataset-WS, although the performance is slightly lower than Dataset-CS, Recall, Precision and Dice remained above 94%. However, under-segmentation is evident, with weak overlap between prediction and true segmentation, which is reflected in the low IoU value. DGMSNet performs slightly worse than U2-Net, but still delivers good results. On Dataset-CS, Recall, Precision and Dice are also above 95%, despite a lower IoU and under-segmentation. On Dataset-WS, the Precision is 97.6%, indicating robust segmentation accuracy. However, Dataset-WS contains more vertebrae and interference areas, and mis-segmentation occurs in segmentation. GCN extends the convolution operation to the image domain and can better locate each vertebra. However, GCN is not as effective as other models in detecting vertebral pixels, and there are serious adhesion and under-segmentation problems on both datasets, with all metrics being the lowest in the comparison methods. Compared to other models, the proposed model achieves the highest in the four metrics on the two datasets and performs well in capturing details.
Conclusions
This paper introduces an automatic vertebral segmentation method in spine X-ray images based on deep learning and marker controlled watershed algorithm, which solves the problems of mis-segmentation and vertebral adhesion by utilizing the prior knowledge of vertebrae, the correlation between tasks, and the marker controlled watershed algorithm. Specifically, we propose a BD-Loss based on spine posture, which enhances spatial constraints on HRNet and improves its robustness. Then, we designed a PIPM to integrate HRNet features into a proposed VU-Net network, allowing VU-Net to focus on vertebral related regions while ignoring distant background regions, thus achieving vertebral preliminary segmentation. Finally, the outputs of HRNet and VU-Net are used to initialize the watershed algorithm to achieve vertebral fine segmentation. Extensive experiments on two spine X-ray datasets demonstrate the excellent performance of the proposed model. There is no adhesion between adjacent vertebrae, and each vertebra is segmented with distinct edge. The vertebral segmentation results obtained by our method can efficiently calculate a variety of clinical indicators, which enables the identification and diagnosis of a variety of spinal diseases, including scoliosis, kyphosis, and vertebral fractures, thereby assisting physicians in achieving rapid and reliable diagnosis. However, there exists an underfitting phenomena, particularly in the regions of the vertebral edge, primarily due to insufficient consideration of the specificity of local vertebral deformations. In the future, we will explore more precise methods to accommodate various vertebral variations.
Footnotes
Acknowledgment
We would like to thank the editors and reviewers for improving the content of this article. This work was supported in part by the Basic Research Program of Shanxi Province (202103021224204).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.