
Abstract
This research introduces a Multistage-Vision Transformer (Multistage-ViT) model for precisely classifying various lung diseases using chest radiographic (CXR) images. The dataset in the proposed method includes four classes: Normal, COVID-19, Viral Pneumonia and Lung Opacity. This model demonstrates its efficacy on imbalanced and balanced datasets by enhancing classifier accuracy through deep feature extraction. It integrates backbone models with the ViT architecture, creating rigorously hybrid configurations compared to their standalone counterparts. These hybrid models utilize optimized features for classification, significantly improving their performance. Notably, the multistage-ViT model achieved accuracies of 99.93% on an imbalanced dataset and 99.97% on a balanced dataset using the InceptionV3 combined with the ViT model. These findings highlight the superior accuracy and robustness of multistage-ViT models, underscoring their potential to enhance lung disease classification through advanced feature extraction and model integration techniques. The proposed model effectively demonstrates the benefits of employing ViT for deep feature extraction from CXR images.
Introduction
Lung diseases, which include COVID-19, pneumonia and lung opacities, pose a significant global health challenge due to their widespread prevalence and potential for severe health impacts. COVID-19, resulting from the SARS-CoV-2 virus, primarily targets the respiratory system, causing symptoms that range from mild cough to severe acute respiratory distress syndrome (ARDS). 1 Pneumonia is a condition where an infection causes the air sacs in one or both lungs to become inflamed. It can result from bacteria, viruses, or fungi, leading to symptoms such as chest pain, fever and breathing difficulties. Lung opacities, seen as areas of increased density on radiographic images, can indicate various conditions including infections, inflammations or tumors. Early and accurate detection of these conditions through imaging techniques such as chest X-rays (CXR) and computer tomography (CT) scans are essential for effective treatment and management, underscoring the importance of advancements in medical imaging and diagnostic technologies.2,3 Expert evaluation of these images remains crucial, with fluctuations in density indicative of disease severity.
The rapid advancements in artificial intelligence (AI) and deep learning have revolutionized the field of medical image analysis. The accurate and timely diagnosis of lung diseases such as COVID-19, viral pneumonia and lung opacity is critical for effective treatment and patient management. Traditional convolutional neural networks (CNN) have demonstrated significant success in various image classification tasks. 4 The recent development of Vision Transformers has introduced new possibilities for enhancing the accuracy and reliability of medical image analysis.5,6
The Vision Transformer (ViT) 7 utilizes self-attention mechanisms and significantly outperforms CNN.8–10 ViT has demonstrated significant potential in the field of medical imaging, particularly in the detection and diagnosis of lung diseases using CXR and CT images. Leveraging the transformer architecture's self-attention mechanisms, ViT models can effectively capture global contextual information from medical images, which is crucial for identifying subtle anomalies and complex patterns associated with lung conditions.11,12 ViT has been utilized for the automated detection of tuberculosis from CXR, showcasing superior performance over traditional CNN in terms of accuracy and robustness. 13 Additionally, in the context of COVID-19, ViT models have been employed to analyze chest CT scans, providing accurate segmentation and classification of infected regions, thereby aiding in rapid and reliable diagnosis. 14
Furthermore, the application of ViT in lung disease diagnosis extends to enhancing image quality and generating high-resolution images from low-quality scans. 15 This capability is particularly beneficial in resource-limited settings where high-quality imaging equipment may not be available. ViT models have been used to enhance CT images, improving the visibility of fine details and supporting better diagnosis and treatment planning. 16 Moreover, ViT has been applied to segment lung tissues and nodules from CT images, facilitating early detection and classification of lung cancer. 17 Integrated ViT with advanced image processing techniques, researchers are continually pushing the boundaries of medical imaging, making significant strides in the early detection and management of lung diseases. 18
This work offers the following significant contributions:
Propose a Multistage-Vision Transformer (Multistage-ViT) model to accurately classify various lung diseases using chest X-ray (CXR) images, ensuring suitability for both imbalanced and balanced datasets. Improve classifier accuracy by leveraging deep feature extraction from CXR images through a combination of backbone models and the ViT model. Conduct experiments with four different combinations of backbone models (VGG19, VGG16, InceptionV3 and ResNet50) integrated with the ViT model. Perform extensive comparisons between these hybrid models and standalone backbone models, utilizing optimized features extracted from the hybrid models for classification.
Related work
The integration of AI and deep learning technologies in medical diagnostics has significantly advanced the accuracy and efficiency of identifying lung diseases. Vision Transformers (ViTs) have developed as a powerful alternative to traditional CNNs, offering superior capabilities in capturing long-term dependencies and extracting detailed semantic information. 19 ViTs captures long-range dependencies, providing a more comprehensive analysis of chest X-ray (CXR) images. Tang et al. 2021 demonstrated that ViTs surpassed traditional models such as ResNet and VGG in terms of accuracy, sensitivity and specificity, highlighting their potential in medical image analysis. 20
ViTs have shown consistent performance across various datasets, including those with diverse image qualities and patient demographics. This robustness is essential for real-world applications, where data heterogeneity is common. Wang et al. 2023 found that ViTs maintain high diagnostic accuracy regardless of variations in the dataset, making them particularly valuable for clinical decision support systems. 21 These systems can be seamlessly integrated into hospital information systems, providing real-time diagnostic assistance and streamlining clinical workflows, as described by. 22
ViTs have been highly effective in pneumonia detection, particularly when combined with CNN backbones like VGG16 and ResNet50. 23 Gao et al. 2021 demonstrated that hybrid models enhance classification accuracy and reduce false positives compared to standalone CNNs. 24 Lin et al. 2022 highlighted the effectiveness of ViT in detecting lung opacities, particularly in the early stages of conditions like ARDS. Their study showed that ViTs handle imbalanced datasets with remarkable precision and recall, making them a reliable tool for accurate clinical diagnostics. 25
The combination of ViTs with pre-trained CNNs, has led to higher accuracy and faster convergence, suitable for real-time critical care settings. This synergy exemplifies AI's future in medical imaging, offering tools for timely and accurate diagnoses, including COVID-19, pneumonia and lung opacity. 26 Recent developments include CAD systems using both CNN and ViT models for COVID-19 and other lung diseases. Models like VGG-16 and ViT achieved notable accuracies on balanced dataset. Ukwuoma et al. 2022 developed a deep learning model addressing blurriness and low contrast, using an ensemble technique and global second-order pooling with ViTs for detailed analysis. 27
Optimizing ViT models with different optimizers, including Adam, AdamW and RAdam, has significantly improved the accuracy of lung disease classification. RAdam showed the best performance on a balanced dataset, while FastViT with NAdam excelled on an imbalanced dataset. 28 This demonstrates the importance of choosing the right optimization strategy for enhancing model accuracy and robustness in handling diverse data distributions.
The exploration of EfficientNet, multiscale vision transformers (MViT) and other architectures has advanced COVID-19 diagnosis, though challenges like overfitting, especially in multiscale models, have been noted. 29 Fine-tuned ViT models have shown superior accuracy and robustness, enhancing clinical interpretation. Studies combining Convolutional Vision Transformers and CNNs have demonstrated high sensitivity and low false negative rates, proving effective in distinguishing various lung conditions. 30 ViT architecture has also achieved impressive results in pneumonia detection, confirming its efficacy in accuracy, sensitivity and specificity. 31
The continuous integration and development of ViTs alongside existing technologies have enhanced their clinical applicability and reliability. The literature emphasizes the importance of ViTs in accurately classifying lung diseases, particularly through self-attention mechanisms. 32 The combination of ViTs with CNNs, data augmentation and optimization techniques has significantly improved diagnostic accuracy. 33 This research focuses on refining these models, addressing overfitting and expanding their use across a broader spectrum of diseases.
Methodology
The proposed deep learning models outlined in this section follow standard procedures, including collecting CXR data, pre-processing images, splitting data, training, testing and analyzing performance. Figure 1 provides a block diagram of the proposed model which includes dataset distribution, feature extraction: primary and advanced deep features and classification.
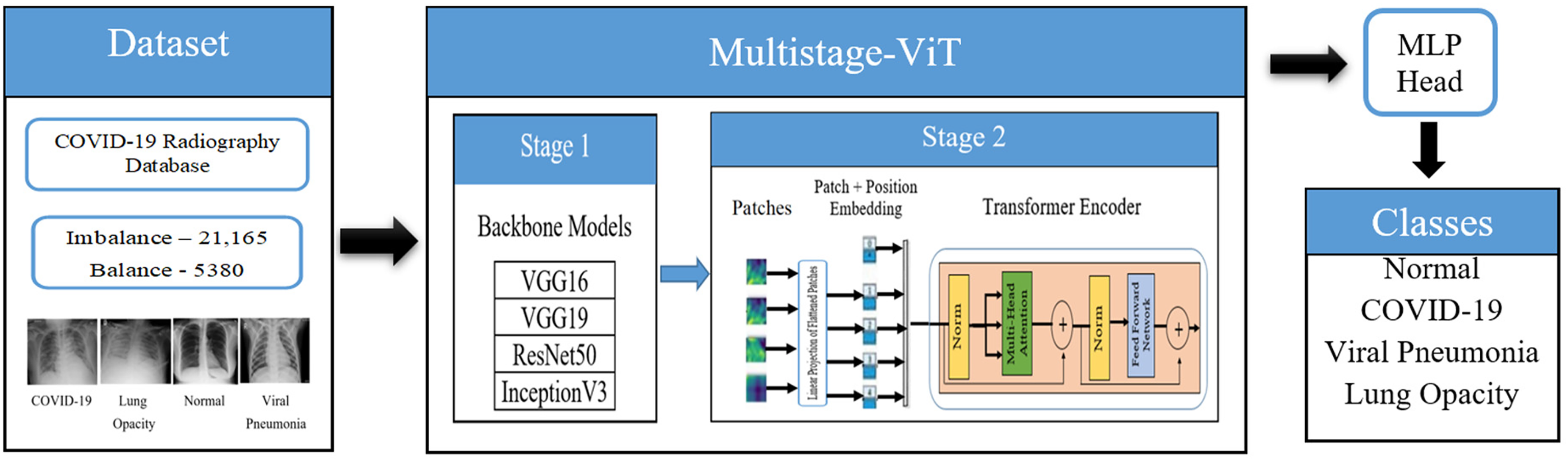
Block diagram for the proposed model.
Dataset
The dataset for this study is constructed using the COVID-19 Radiography database from Kaggle. 34 It comprises chest X-rays depicting normal, COVID-19, viral pneumonia and lung opacity (non-Covid lung infection) images as shown in Figure 2. The dataset includes X-ray images and their corresponding masks. Table 1 outlines the class distributions in two datasets, imbalance and balance, for training and testing a machine learning model in medical image classification. Imbalance dataset, which mimics real-world class distributions, has 16,930 training cases (2892 COVID-19, 4809 Lung Opacity, 8153 Normal and 1076 Viral Pneumonia) and 4235 testing cases (724 COVID-19, 1203 Lung Opacity, 2039 Normal and 269 Viral Pneumonia). Conversely, the balanced dataset ensures equal representation with 4304 training cases and 1076 testing cases, uniformly divided across all classes (1076 each for training and 269 each for testing). This configuration helps in assessing model performance in both realistic and controlled, balanced conditions. These CXR images are in PNG (Portable Network Graphics) format and have a resolution of 299 * 299 pixels.
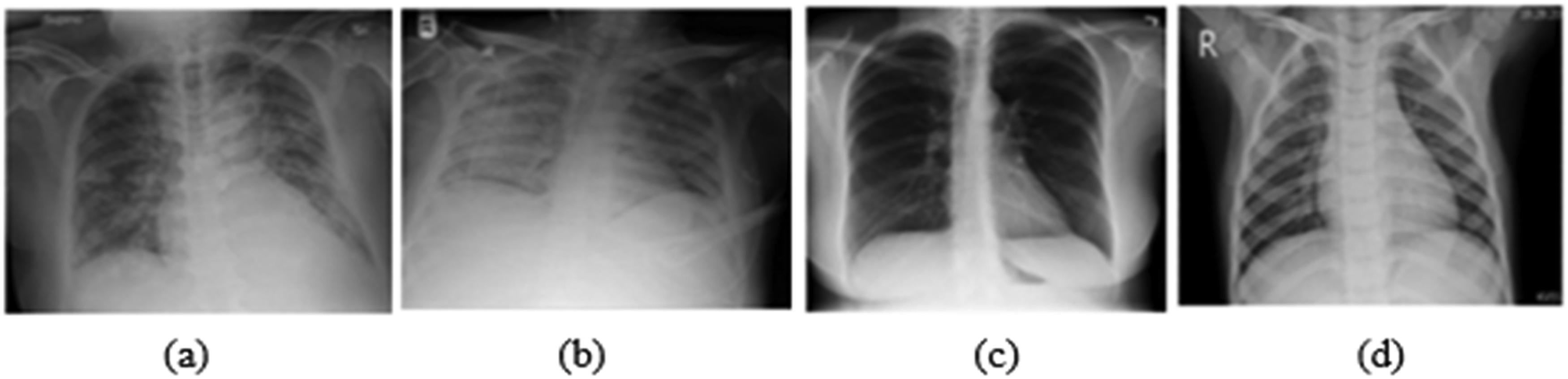
Sample CXR images of (a) COVID-19, (b) Lung opacity, (c) Normal and (d) Viral pneumonia.
Dataset distribution of the proposed method.

Feature extraction
The proposed model employs a two-stage approach for efficient feature extraction. In the first stage, a backbone model is utilized to extract features from CXR images and reduce their dimensionality, thereby decreasing the processing time required for the subsequent stage. In the second stage, the Vision Transformer (ViT) model is applied to these initial features for a more detailed and comprehensive feature extraction.
Stage 1: primary features
In the first stage, various backbone models are used to extract primary features from the input CXR images. To assess the model's effectiveness, different backbone models such as ResNet50, VGG16, VGG19 and InceptionV3 are evaluated. These models are initialized with weights from the ImageNet dataset and then applied to extract features from both imbalanced and balanced datasets. 35
VGG models
VGG16 and VGG19 are deep CNNs that excel in feature extraction, characterized by their structured architecture and small convolutional filters. 36 In this study, the CXR image size in the dataset is 299*299*3 pixels, resized to 256*256*3 with three color channels (RGB) to ensure standardized input for consistent feature extraction. The process begins with a series of convolutional layers using 3*3 filters, designed to extract various features such as edges and textures from the images. These layers produce feature maps that capture different aspects of the input images. After the convolutional layers, max-pooling layers are employed to downsample the spatial dimensions of the feature maps by half at each stage, thus progressively shrinking the feature map sizes to 128*128, 64*64, 32*32, 16*16 and finally 8*8 after the fifth pooling layer. The output from the last convolutional layer consists of feature maps sized 8*8*512 as shown in Table 2.
VGG16 and VGG19 model architectures: layer-wise architecture and parameters.
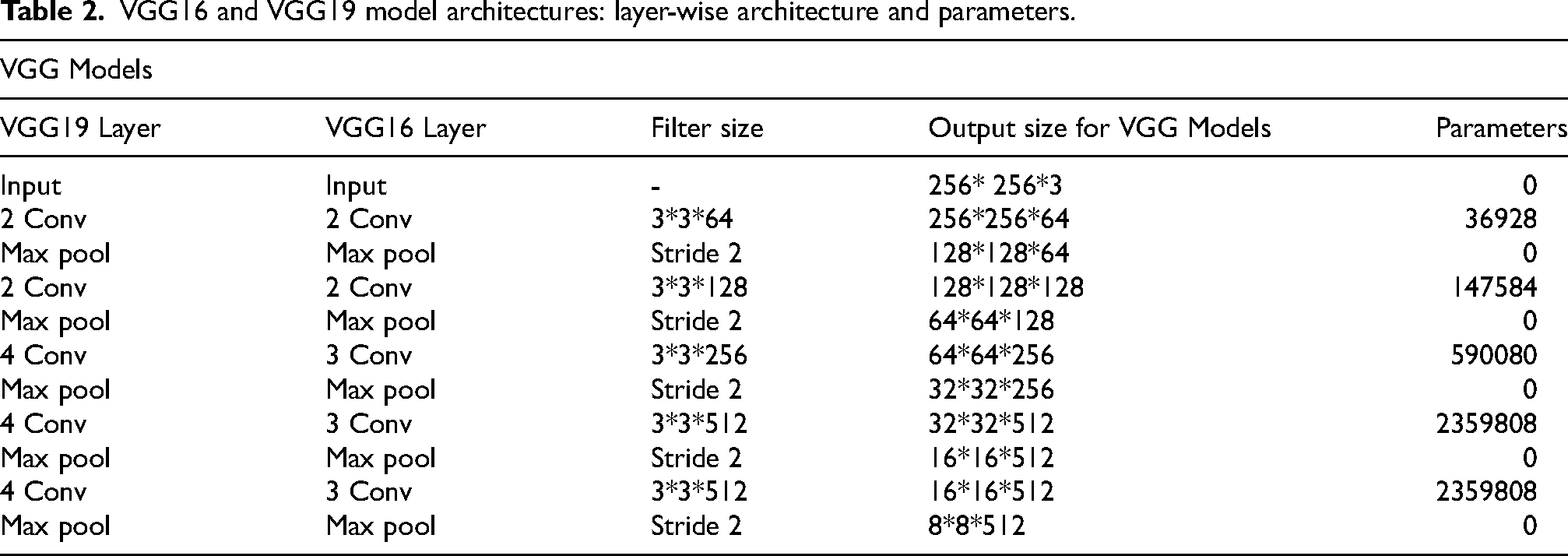
In the context of feature extraction, the fully connected layers typically present in the complete VGG16 and VGG19 architectures are not utilized. Instead, the feature set from the final convolutional layer serves as the extracted features. These models are pre-trained on the ImageNet dataset, which provides a robust foundation of learned features, enhancing their ability to extract relevant features from test CXR images. The primary features extracted by VGG16 and VGG19 are then used to extract deeper features, leveraging their detailed representation of the input images. The selection between VGG16 and VGG19 depends on the application specific requirements. VGG19, with its deeper architecture, provides more detailed feature extraction and increased processing capabilities.
ResNet50
ResNet50 is a deep learning model with 50 layers, designed to mitigate the vanishing gradient problem. It uses residual blocks with skip connections, allowing input to bypass intermediate layers and connect directly to the output. 37 Initially, the input images are 299*299*3 and then resized to 256*256*3 for compatibility with ResNet50. The network starts with an input layer for these resized images. The initial Conv1 layer uses 64 filters of 7*7, producing an output of 128*128*64, followed by a max pooling layer that reduces the size to 64*64*64, capturing basic features like edges and textures. The network progresses through four main stages of residual blocks: Conv2 (blocks 1–3), Conv3 (blocks 1–4), Conv4 (blocks 1–6) and Conv5 (blocks 1–3).
Each block uses a bottleneck design with 1*1, 3*3 and 1*1 convolutions, with skip connections facilitating easier gradient flow and deeper network training. The final output from the Conv5 stage, specifically block 3, is an 8*8*2048 output feature map as shown in Table 3. ResNet50 captures detailed features at various levels, from basic edges to complex patterns, making it highly effective for image analysis tasks. Its ability to learn comprehensive feature representations allow it to accurately and efficiently process diverse visual data. These extracted primary features are then passed into stage 2 for further deep feature extraction.
ResNet50: layer-wise architecture and parameters.

InceptionV3
InceptionV3 is a deep CNN designed to efficiently extract rich feature representations from images. It begins with an input layer for images of size 299*299*3, followed by a series of convolutional layers that progressively increase in filter depth to capture various levels of feature abstraction. The early layers focus on detecting edges and textures, while the deeper layers identify more complex patterns. 38 The architecture includes several distinctive Inception modules (labeled A, B, C, D and E), which are tailored to extract multi-scale features concurrently. These modules combine 1*1, 3*3, 5*5 and sometimes 7*7 convolutions with pooling operations to capture a wide range of spatial patterns as shown in Table 4. This design enhances computational efficiency and effectiveness in recognizing features across different scales and complexities. Additionally, the model incorporates max pooling layers to reduce the spatial dimensions of feature maps, minimizing computational load while retaining essential information. The final layers aggregate these primary features, which are then used in the subsequent stage of the proposed work.
InceptionV3: layer-wise architecture and parameters.

Stage 2: advanced feature extraction using ViT
During this stage, ViT model is utilized to enhance the extraction of deep features from the primary features of CXR images. Initially, these features are derived from backbone models like VGG16, VGG19, ResNet50 and InceptionV3, resulting in feature maps with dimensions 8∗8∗512 for VGG models and 8∗8∗2048 for ResNet50 and InceptionV3. The ViT processes these maps to capture intricate patterns and long-range dependencies, 39 as detailed in Figure 1.
The process is initiated by reducing the dimensions of these feature maps to make them suitable for the ViT architecture. An average pooling layer is employed to halve the spatial dimensions, resulting in reduced feature maps such as (B, 512, 4, 4) for the VGG models and (B, 2048, 4, 4) for ResNet50 and InceptionV3, where B denotes the batch size. These reduced feature maps are divided into patches, with each patch representing a portion of the spatial region of the feature map. Each patch with dimensions (4 *4*C) (where C is the number of channels) is converted into flattened vector as shown in Eq. (1)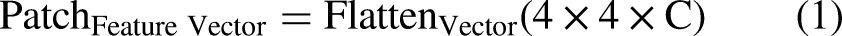


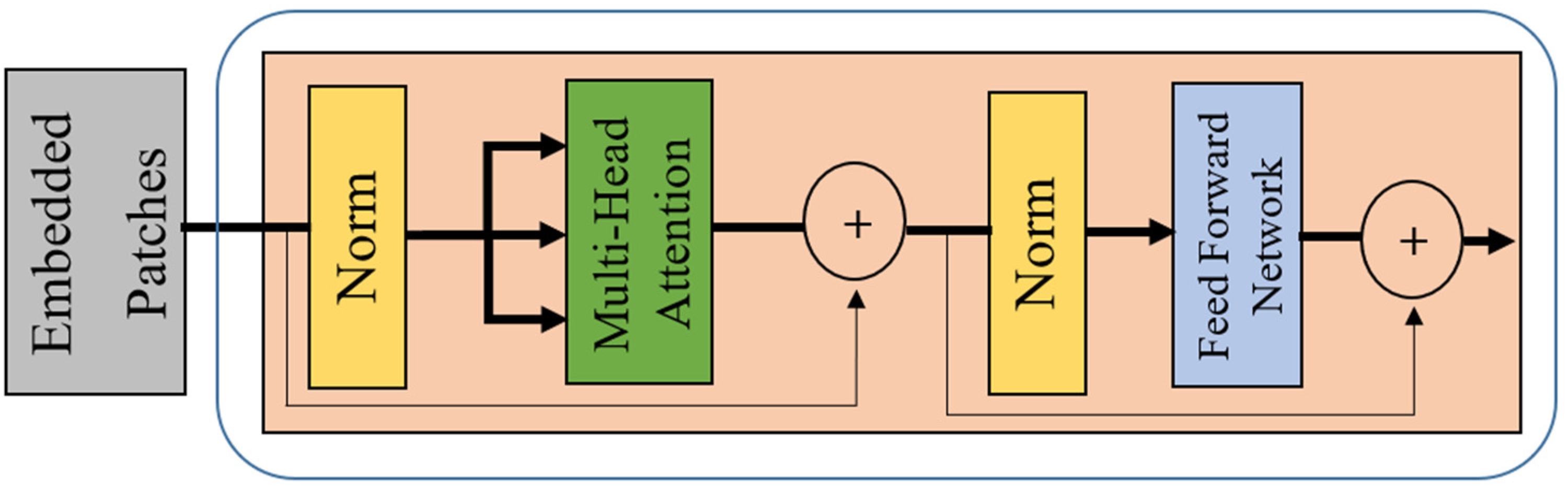
Transformer encoder.
The output of the transformer encoder is given by Eq. (4).

In the final step, a Multi-Layer Perceptron (MLP) head is used for classifying the lung CXR images. The deep feature vectors from the last transformer encoder block are passed into the MLP classifier, which includes two hidden layers followed by an output layer. The operations within the MLP classifier are described by Eq`s. (5, 6 & 7).

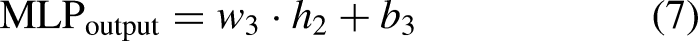
Results
The proposed model, which integrates a backbone model with the ViT, is assessed using metrics such as accuracy, loss, precision, F1-score and recall. To evaluate the multistage-ViT model's effectiveness, four different backbone models are tested. Initially, the CNN model's weights are set using pre-trained weights from a transfer learning model trained on the ImageNet dataset. This approach bypasses the need for extensive training during the primary feature extraction stage, addressing the challenge of long processing times typically associated with training complex models from scratch, especially with a dataset exceeding 20,000 CXR images.
The backbone models serve two crucial functions: (1) Extracting primary features from the input CXR images while significantly reducing the number of trainable parameters in the first stage, and (2) Decreasing the dimensionality of the input CXR images to optimize the ViT's performance in the subsequent stage, enabling it to concentrate on the most essential features. Following this, the ViT model is trained to extract deep features and classify lung diseases using the training sets from both the imbalanced and balanced datasets. Finally, the overall model's performance is evaluated on the testing sets.
Experimental setup
All experiments in this work were conducted on Windows 11 PCs version 21H2, featuring a 64-bit operating system, an Intel(R) Xeon(R) 3.31 GHz processor and 32 GB of RAM. CUDA version 11.7 was utilized on an NVIDIA Quadro P4000 GPU. The experiments were programed in Python 3.11.5 and executed using Jupyter Notebook, with various libraries such as Keras and TensorFlow. The dataset was split into 80% for training and 20% for validating and testing, providing approximately 4235 images for testing the model. A consistent epoch count of 50 was chosen to maintain fairness in the comparison of all experiments. Given the dataset's multi-class classification requirements, categorical cross-entropy was employed as the loss function to accurately measure the difference between the predicted and true probability distributions. The Adam optimizer was selected for its efficiency and minimal need for parameter adjustments. The backbone models produced primary feature dimensions of 8*8*C, leading to the choice of a patch size of four in the ViT model, corresponding to half of the original feature size. The remaining parameters were fine-tuned based on the specific demands of the experiments as shown in Table 5.
Experimental Hyperparameters and Settings.

Decision on backbone models
Figure 4 showcases the classification performance of backbone models like VGG16, VGG19, ResNet50 and InceptionV3 on an imbalanced dataset under two different learning rates. Key performance metrics such as accuracy, precision, recall and F1-score are illustrated for each model. A series of experiments were conducted with various learning rates, and 0.001 and 0.0001 were observed to deliver optimal performance, as shown in the Figure 4. In Figure 4 (a), with a learning rate of 0.001, VGG16 shows strong performance with 0.92 accuracy, 0.90 precision, 0.91 recall and 0.92 F1-score, indicating stability across all metrics. VGG19 follows closely VGG16, suggesting marginally reduced effectiveness. ResNet50 and InceptionV3 both display good, consistent performance, with scores around 0.89 for accuracy and slight variations in precision, recall and F1-score. In Figure 4 (b), with a learning rate of 0.0001, VGG16 achieves the highest scores across all metrics, with 0.94 accuracy, 0.92 precision, 0.92 recall and 0.94 F1-score. VGG19 also performs well, with scores slightly lower than VGG16. ResNet50 and InceptionV3 both show consistent results, with 0.91 accuracy and balanced performance in other metrics. Overall, VGG16 exhibits the most notable improvement at the lower learning rate, while all models benefit from the more conservative learning rate, demonstrating strong and balanced performance. The backbone models showed superior performance when Adam optimizers was used with a learning rate of 0.0001, compared to a learning rate of 0.001.
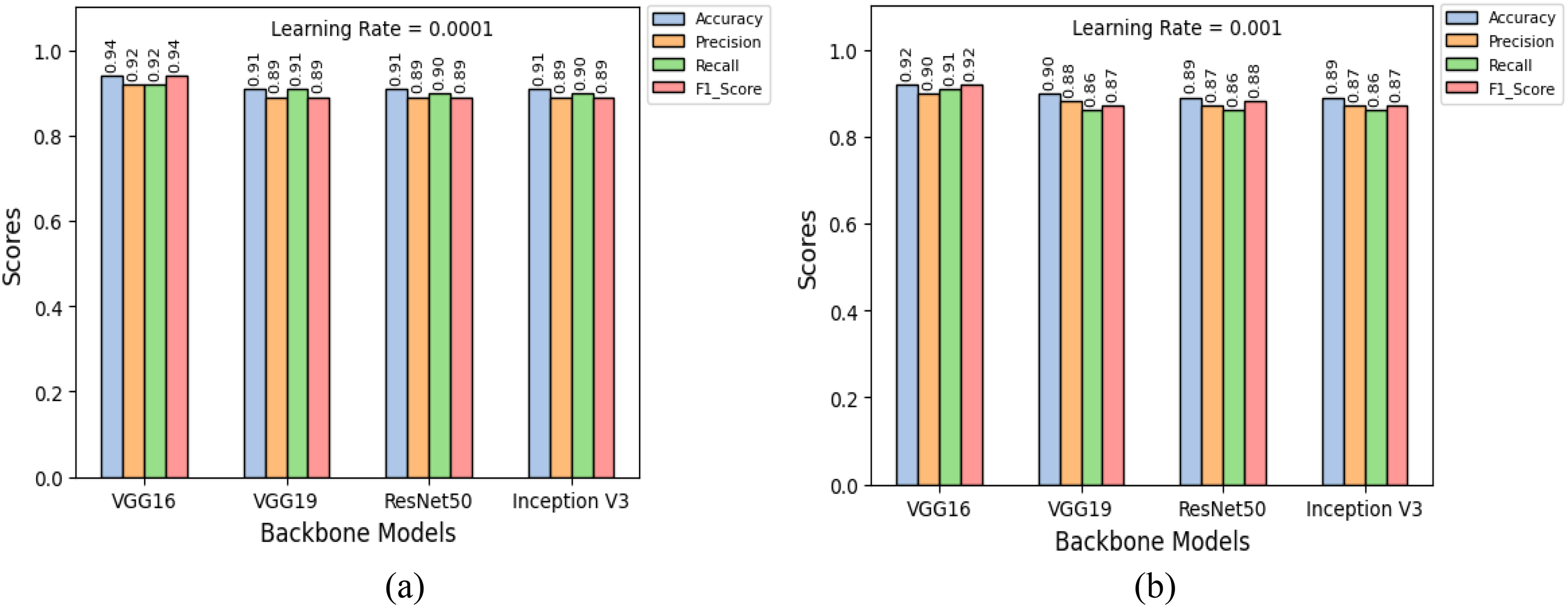
Classification performance result of the backbone models using imbalance dataset for (a) Learning rate =0.001 and (b) Learning rate =0.0001.
Classification outcomes for the imbalanced dataset
Table 6 compares the performance of backbone models and multistage-ViT on an imbalanced dataset, focusing on training and validation accuracy as well as loss. Backbone models VGG16, VGG19, ResNet50 and InceptionV3 show varying results. VGG16 achieved 93.35% training and 90.18% validation accuracy, with loss of 0.1890 and 0.2782 for training and validation. VGG19 performed better, with 97.91% training and 95.72% validation accuracy and loss of 0.0757 and 0.1337. ResNet50 presented 96.75% training and 95.17% validation accuracy, with loss of 0.1009 and 0.1408. InceptionV3 led among the backbone models, with 97.56% training and 94.52% validation accuracy and the lowest loss at 0.0792 and 0.1482. Multistage-ViT model significantly improved performance across all models. VGG16 with ViT, reached 99.56% training and 95.07% validation accuracy, with a much lower loss of 0.0165 and 0.1800. VGG19 with ViT achieved 99.40% training and 94.89% validation accuracy, with loss of 0.0198 and 0.1911. ResNet50, under this approach, had 98.12% training and 94.33% validation accuracy, with loss of 0.0481 and 0.1954. InceptionV3 with ViT topped the charts, with 99.93% training and 96.88% validation accuracy and the lowest loss of 0.0028 and 0.1528. Multistage-ViT approach significantly enhances the performance of all backbone models, particularly in handling imbalanced datasets, leading to superior classification results with better generalization, which is illustrated in Figure 5.

The performance of Multistage-ViT models using an imbalance dataset. Loss and Accuracy of (a) VGG16 + ViT (b) VGG19 + ViT (c) ResNet50 + ViT and (d) InceptionV3 + ViT.
Performance comparison of backbone models and multistage-ViT on an imbalanced dataset: evaluating training and validation accuracy and loss.
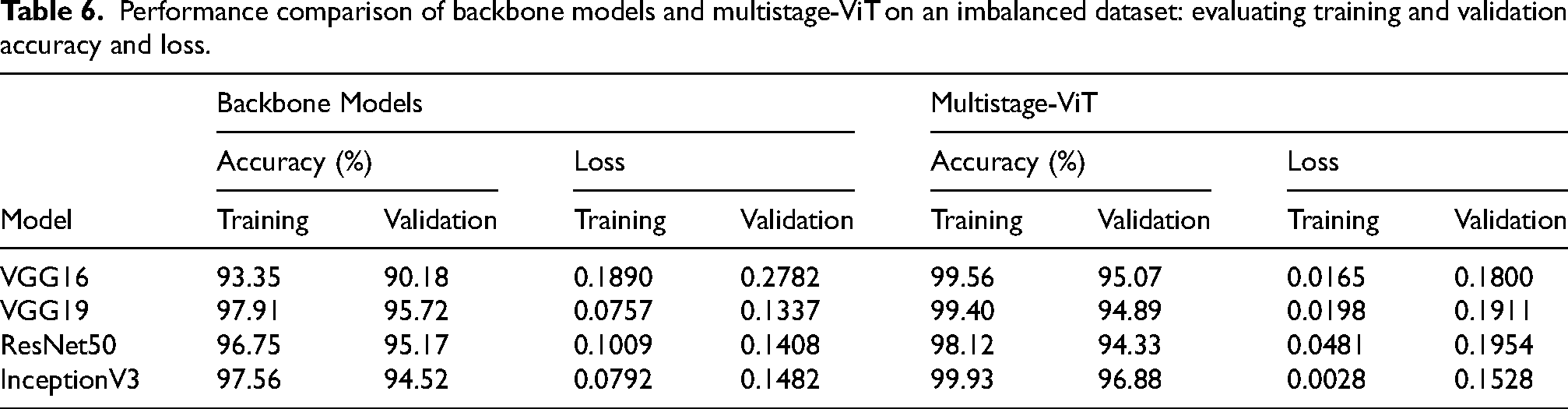
Furthermore, the results from the four experiments show that the InceptionV3 + ViT model excels in the training phase, achieving an accuracy of 99.93% with a loss of 0.0028. The model also performs strongly during validation, registering an accuracy of 96.88% and a loss value of 0.1528.
Figure 6 shows the model performance rankings on an imbalanced dataset across four metrics: train accuracy, validation accuracy, train loss and validation loss. The chart compares the rankings of various models, including VGG16, VGG19, ResNet50, InceptionV3 and their respective versions with ViT integration. In Table 7, the Multistage-ViT model consistently outperforms the backbone models in precision, recall, and F1-score, with the InceptionV3 + ViT combination delivering the highest performance. This highlights the superior capability of the Multistage-ViT approach in effectively managing imbalanced datasets for accurate lung disease classification. Figure 7 displays the confusion matrices for the proposed model, tested with VGG16, VGG19, ResNet50 and InceptionV3, each combined with a ViT-based model.

Comparison of model performance rankings on imbalanced dataset.

The confusion matrix for the imbalanced dataset for the models (a) VGG16 + ViT (b) VGG19 + ViT (c) ResNet50 + ViT and (d) InceptionV3 + ViT.
Comparative performance metrics of backbone models and multistage-ViT on imbalanced datasets: F1-score, precision and recall.

Classification outcomes for the balanced dataset
Table 8 presents a detailed performance comparison between backbone models and multistage-ViT models on a balanced dataset, focusing on training and validation metrics. The VGG16 backbone model reached a success rate of 94.35% during training and 91.15% during validation, accompanied by an error rate of 0.0603 in training and 0.2300 in validation. VGG19 showed slightly lower effectiveness, with a training phase success rate of 92.78% and a validation phase rate of 89.04%, and corresponding error metrics of 0.1901 and 0.3124. ResNet50 recorded a training phase accuracy of 92.74% and a validation set accuracy of 89.47%, with higher training and validation phase errors of 0.2017 and 0.3773, respectively. InceptionV3 performed better, achieving a training phase success rate of 94.65%, a validation success rate of 90.64%, and the lowest error during training among the backbone models at 0.0238, though with a slightly higher validation error of 0.2998.
Performance comparison of backbone models and multistage-ViT on a balanced dataset: evaluating training and validation accuracy and loss.
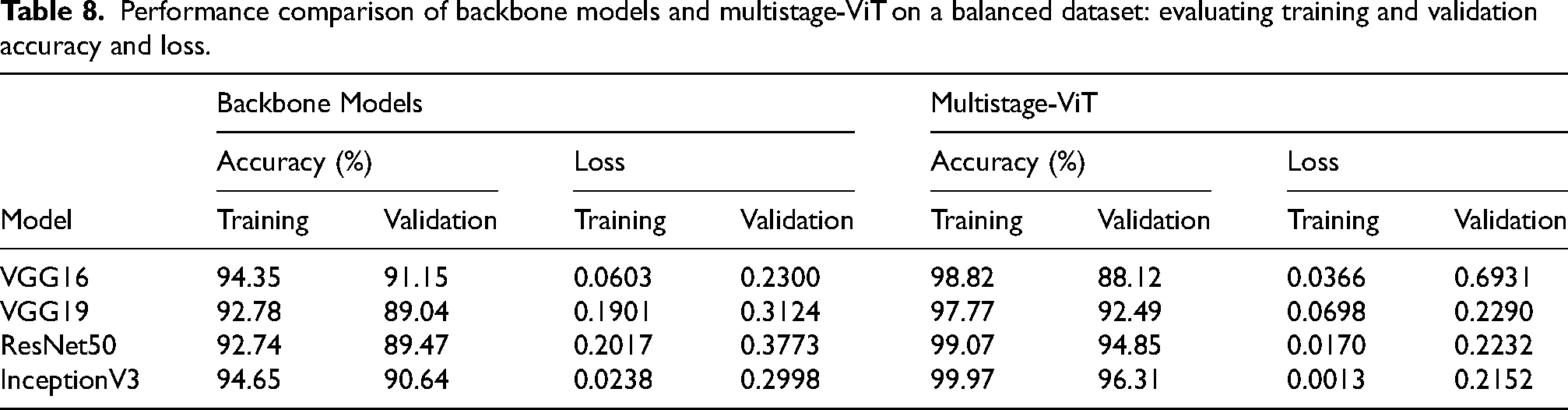
The multistage-ViT models demonstrated significant improvements across all metrics. The VGG16 + ViT configuration reached a success rate of 98.82% during training and 88.12% during validation, with a training phase error of 0.0366 and a validation phase error of 0.6931. The VGG19 + ViT model showed further improvement, achieving a training phase accuracy of 97.77% and a validation success rate of 92.49%, with reduced error metrics of 0.0698 and 0.2290. ResNet50 + ViT delivered strong results, with a training success rate of 99.07% and a validation phase accuracy of 94.85%, paired with minimal error rates of 0.0170 and 0.2232. The InceptionV3 + ViT model stood out, reaching the highest training phase accuracy of 99.97% and a validation phase rate of 96.31%, with the lowest error in training at 0.0013 and a validation error of 0.2152. This comparison underscores the superior performance and effectiveness of the multistage-ViT models over the standalone backbone models in handling the balanced dataset, resulting in better generalization with reduced loss and these are illustrated by the corresponding loss and accuracy curves for the multistage-ViT models for balanced dataset in Figure 8. Figure 8 highlights the effectiveness of the Multistage-ViT model in lung disease classification on a balanced dataset. The results show a significant improvement in accuracy and reduction in loss across all tested backbone configurations, including VGG16, VGG19, ResNet50, and InceptionV3. Among these, the InceptionV3 + ViT combination stands out with the highest performance, achieving a training accuracy of 99.97% and a validation accuracy of 96.31%, along with minimal loss. This demonstrates the ability of the proposed model to effectively leverage both primary and advanced feature extraction stages, ensuring robust classification and reduced overfitting in balanced dataset conditions.
The performance of Multistage-ViT models using balanced dataset. Loss and Accuracy of (a) VGG16 + ViT (b) VGG19 + ViT (c) ResNet50 + ViT and (d) InceptionV3 + ViT.
Moreover, the four experiments show that the InceptionV3 + ViT model delivers excellent performance during the training phase, achieving an accuracy of 99.97% and a low loss of 0.0013. The model also performs impressively in the validation phase, with an accuracy of 96.31% and a loss of 0.2152.
Figure 9 illustrates the performance rankings of various backbone models and their corresponding Multistage-ViT integrations on a balanced dataset, evaluated across training accuracy, validation accuracy, training loss, and validation loss. The Multistage-ViT models consistently outperform their standalone backbone counterparts, with significantly higher accuracy and lower loss metrics. Among the configurations, the InceptionV3 + ViT model achieves the best performance across all criteria, demonstrating its exceptional capability to extract relevant features and generalize well. This underscores the superior robustness and reliability of the Multistage-ViT approach in accurately classifying lung diseases from chest X-rays.

Comparison of model performance rankings on balanced dataset.
In Table 9, the Multistage-ViT model consistently outperforms the backbone models in precision, recall and F1-score on balanced datasets, with particularly strong results for VGG16 and InceptionV3 + ViT. This highlights the superior accuracy and reliability of the Multistage-ViT approach in lung disease classification, even with balanced data.
Comparative performance metrics of backbone models and multistage-ViT on balanced datasets: F1-score, precision and recall.

Figure 10 presents confusion matrices for the Multistage-ViT models combined with different backbone architectures (VGG16, VGG19, ResNet50, and InceptionV3) on a balanced dataset. The results highlight the strong classification performance of all configurations, with high precision and recall across all classes (Normal, COVID-19, Viral Pneumonia, and Lung Opacity). Among the models, InceptionV3 + ViT demonstrates the most accurate predictions, with minimal misclassification errors across classes. This indicates the proposed model's ability to handle complex feature relationships effectively and achieve reliable performance in lung disease classification.

The confusion matrix for the balanced dataset for the models (a) VGG16 + ViT (b) VGG19 + ViT (c) ResNet50 + ViT and (d) InceptionV3 + ViT.
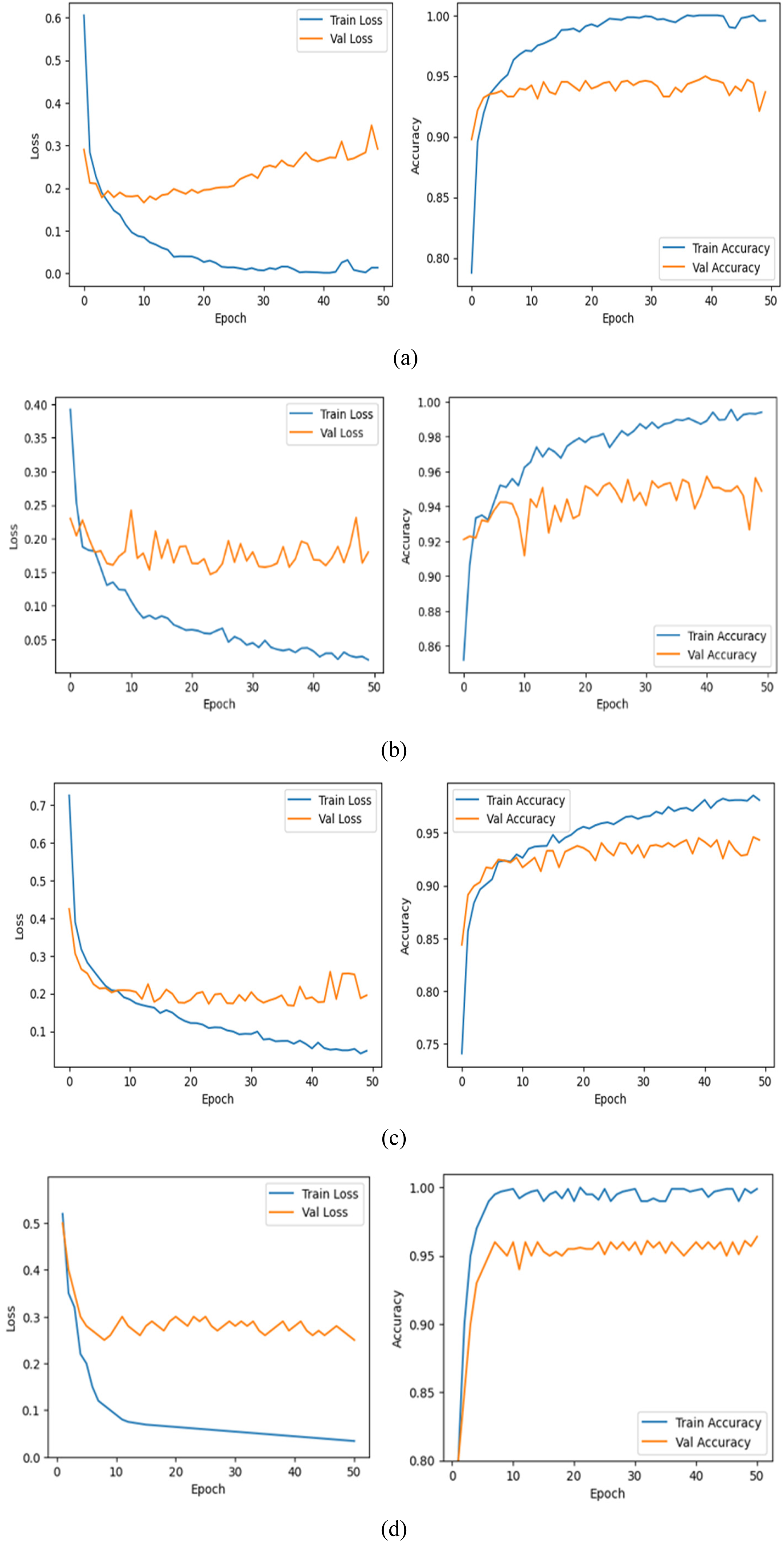
Figure 11 illustrates the ROC curves for the Multistage-ViT model (InceptionV3 + ViT configuration) on both imbalanced and balanced datasets, showing classification performance across four classes (COVID-19, Lung Opacity, Normal, and Viral Pneumonia). The high AUC values across all classes and the micro-average curve indicate excellent discriminative ability of the model. The model performs consistently better in both data scenarios, with slightly higher AUC values for the balanced dataset. This highlights the model's robustness and its effectiveness in handling diverse class distributions while maintaining strong classification accuracy.
ROC curves showing classification performance: (a) Imbalanced dataset and (b) Balanced dataset.
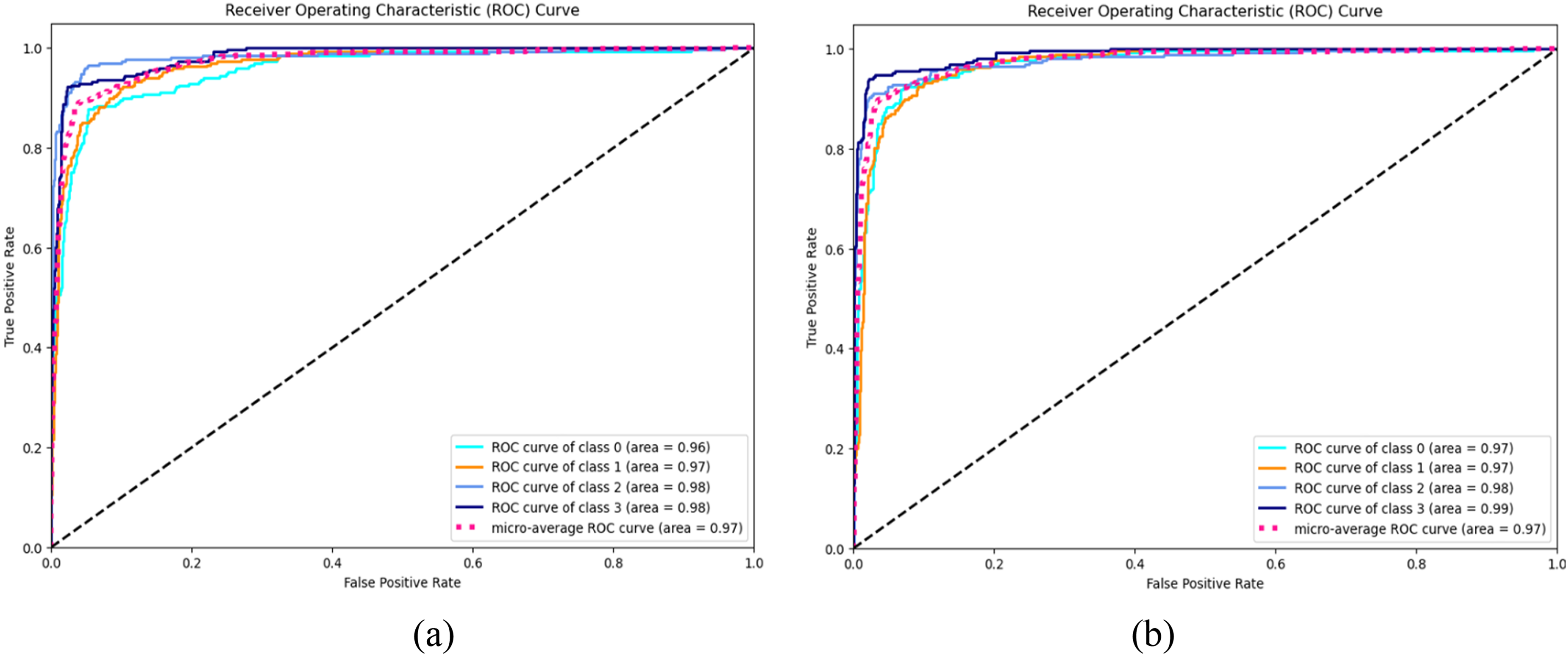
Figure 12 presents Grad-CAM visualizations comparing the feature representations of InceptionV3 and InceptionV3 + ViT models on chest X-ray images. The input CXR images are shown in Figure 12(a), followed by Grad-CAM outputs from the InceptionV3 model in Figure 12(b) and the InceptionV3 + ViT model in Figure 12(c). The InceptionV3 + ViT model generates more precise and focused feature maps, effectively highlighting critical lung regions associated with the classification of COVID-19, lung opacity, and viral pneumonia. This enhanced visualization demonstrates the model's ability to capture subtle and complex features, offering superior localization of disease-related areas compared to InceptionV3 alone. The results highlight the strength of the Multistage-ViT model in accurately identifying pathological regions with greater precision.
Grad-CAM analysis of the backbone and multistage-ViT Model on a balanced dataset: (a) Input CXR images (b) Inception V3 and (c) Inception V3 + ViT.
Discussion
The analysis of both imbalanced and balanced datasets reveals substantial improvements in both accuracy and loss metrics when comparing backbone models to multistage-ViT models. The integration of Vision Transformer (ViT) significantly enhances the performance of the models. In the imbalanced dataset, notable enhancements are observed. The VGG16 model training accuracy rises from 93.35% to 99.56% and its training loss drops from 0.1890 to 0.0165. Similar improvements are noted across other models, demonstrating the advanced feature extraction capabilities of ViT, which effectively enhance the learning process, even with imbalanced data. Additionally, validation accuracy generally improves, showcasing the models’ robustness and ability to maintain strong performance on unseen data. In the case of the balanced dataset, the multistage-ViT models exhibit even more impressive gains. InceptionV3 training accuracy is increased from 94.65% to 99.97%, with a significant reduction in training loss from 0.0238 to 0.0013. These results highlight the superior capability of the ViT-enhanced models to extract and utilize relevant features, ensuring higher accuracy and lower loss. The consistent improvements in validation accuracy further indicate the model's ability to generalize well. Overall, the analysis shows that the multistage-ViT models perform exceptionally well on the balanced dataset, achieving consistently higher training and validation accuracy and a significant loss reduction. This suggests that the balanced dataset is more favorable for evaluating the proposed models, as it better supports their ability to generalize and achieve consistent, superior performance across all metrics.
It is also observed that multistage-ViT models consistently outperform standalone backbone models across both imbalanced and balanced datasets, as indicated by higher precision, recall and F1-scores. The improvements are more pronounced in the imbalanced dataset, where the addition of ViT significantly enhances the model's ability to handle class imbalances and improve classification accuracy. On the balanced dataset, both sets of models perform well, but the multistage-ViT configurations still show slight enhancements, ensuring robust performance across all classes. Finally, the InceptionV3 + ViT model demonstrates the highest metrics overall, highlighting its greater capability in feature extraction and classification. These findings underscore the efficacy of integrating ViT with backbone models, particularly in complex medical image classification tasks.
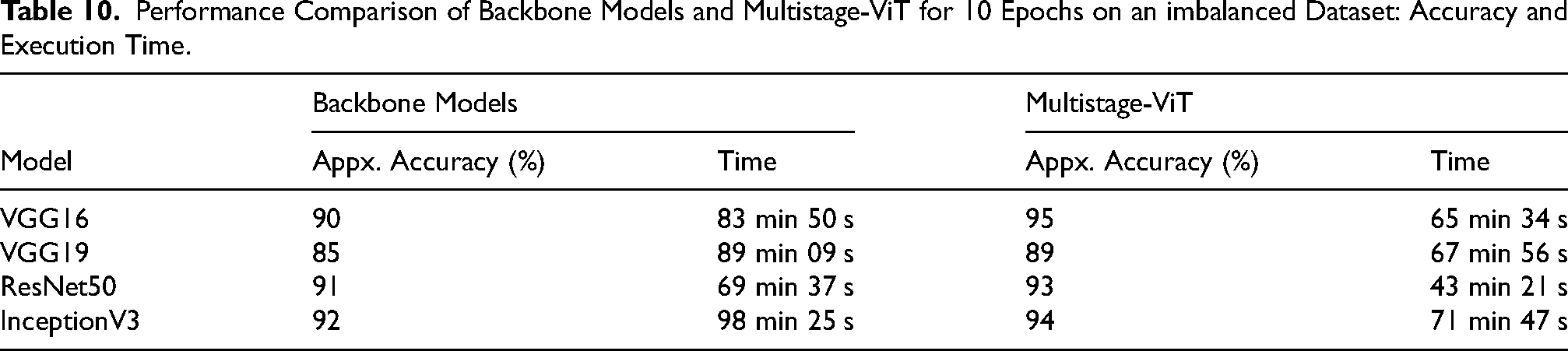
Table 10 and Table 11 compare the accuracy and execution time required by the backbone models and the Multistage-ViT for both imbalanced and balanced datasets over 10 epochs. On the imbalanced dataset in Table 10, InceptionV3 as a backbone model achieved 92% accuracy in 98 min 25 s, whereas the proposed Multistage-ViT with InceptionV3 reached 94% accuracy in 71 min 47 s Similarly, VGG16 as a backbone model achieved 90% accuracy in 83 min 50 s, while the Multistage-ViT using VGG16 improved accuracy to 95% in 65 min 34 s On the balanced dataset in Table 11, the reduction in execution time is even more pronounced. ResNet50 as a backbone model achieved 87% accuracy in 15 min 40 s, whereas the Multistage-ViT with ResNet50 achieved 93% accuracy in just 11 min 27 s Similarly, VGG19 took 26 min 32 s to achieve 89% accuracy as a backbone model, while the Multistage-ViT using VGG19 reached 91% accuracy in 22 min 59 s These results demonstrate that the Multistage-ViT not only achieves higher accuracy but also requires fewer epochs and less execution time compared to backbone models, making it more efficient and effective for both imbalanced and balanced datasets.
Performance Comparison of Backbone Models and Multistage-ViT for 10 Epochs on an imbalanced Dataset: Accuracy and Execution Time.
Performance Comparison of Backbone Models and Multistage-ViT for 10 Epochs on a balanced Dataset: Accuracy and Execution Time.

Conclusion
This study presents a multistage-ViT model specifically designed for lung disease classification, leveraging the impact of a backbone model followed by a vision transformer. The dataset includes both imbalanced and balanced datasets, with the Imbalance set consisting of 16,930 training images and 4235 testing images, while the balance set standardizes to 1076 images per category for both training and testing phases. The proposed model follows a two-stage feature extraction process: first, primary features are extracted using a backbone model fine-tuned on the ImageNet dataset, followed by the extraction of deep features using the Vision Transformer. The classification of CXR images into Normal, COVID-19, Viral Pneumonia and Lung Opacity is then finalized using an MLP head classifier.
The performance of the multistage-ViT model was rigorously tested across four different backbone models and evaluated on metrics such as accuracy, loss, precision, F1-score and recall. The findings demonstrate the model's exceptional accuracy in lung disease classification, particularly in configurations involving InceptionV3 + ViT model, demonstrated exceptional training accuracy, reaching 99.93% on the imbalanced dataset and 99.97% on the balanced dataset, with corresponding validation losses of 0.0028 and 0.0013, respectively. Furthermore, the two-stage feature extraction approach improves accuracy and significantly reduces computational time by minimizing redundant parameters during the primary feature extraction stage. This performance underscores the efficacy of using a vision transformer for deep feature extraction, as evidenced by the optimal results compared to standalone backbone models. The study highlights the potential of the multistage-ViT approach in significantly enhancing the accuracy and reliability of lung disease classification, suggesting a promising direction for future research and application in this field.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.