
Abstract
Recently, semi-supervised learning has demonstrated significant potential in the field of medical image segmentation. However, the majority of the methods fail to establish connections among diverse sample data. Moreover, segmentation networks that utilize fixed parameters can impede model training and even amplify the risk of overfitting. To address these challenges, this paper proposes an adversarial consistency-based semi-supervised segmentation method, leveraging a dual multiscale mean teacher model. First, by designing a discriminator network with adaptive feature selection and training it alternately with the segmentation network, the method enhances the segmentation network's ability to transfer knowledge from the limited labeled data to the unlabeled data. The discriminator evaluates the quality of the segmentation network's results for both labeled and unlabeled data, while simultaneously guiding the network to learn consistency in segmentation performance throughout the training process. Second, we design a Triple-attention dynamic convolutional (TADC) module, which allows the convolution kernel parameters to be adjusted flexibly according to different input data. This improves the feature representation capability of the network model and helps reduce the risk of overfitting. Finally, we propose a novel feature selection and fusion module (FSFM) within the segmentation network, which dynamically selects and integrates important features to enhance the saliency of key information, improving the overall performance of the model. The proposed adversarial consistency-based semi-supervised segmentation method is applied to the MosMedData dataset. The results demonstrate that the segmentation network outperforms the baseline model, achieving improvements of 3.83%, 3.97%, 3.14% in terms of Dice, Jaccard, and NSD scores, respectively, for the segmentation of pneumonia lesions. The proposed segmentation method outperforms state-of-the-art segmentation networks and demonstrates superior potential for segmenting pneumonia lesions, as evidenced by extensive experiments conducted on the MosMedData and COVID-19-P20 datasets.
Keywords
Introduction
Lung diseases pose a grave threat to human life and health. A diverse array of lung diseases prevails, including pulmonary nodules,1–3 pneumonia, 4 and pulmonary embolisms. 5 Computer - aided diagnostic techniques, however, have emerged as a powerful tool in this regard. These techniques are capable of detecting even the most subtle foci, thereby significantly enhancing the diagnostic efficiency.6–8 Recently, medical image segmentation technology has made remarkable progress in the detection and analysis of lung diseases, and accurate and reliable image segmentation is very important for early diagnosis and treatment of pneumonia as a serious lung infection disease. In recent years, supervised deep learning methods9–11 such as U-Net networks 12 and networks improved on this basis have been applied to a large number of medical fields, and these network models have gained good results in the field of medical image processing by virtue of their unique encoder-decoder structure, however, the shortcomings of supervised segmentation methods are also obvious. First, these supervised segmentation methods rely on large-scale labeled datasets for training; however, medical images are more complex, such as lung CT images with irregular variations in the texture, size, and location of the infected region, as well as fuzzy boundaries of the lesions as well as low contrast, 13 making it expensive and difficult to construct high-quality labeled datasets through manual labeling methods. To solve this problem, semi-supervised learning-based methods are gradually applied to the field of medical image segmentation. Semi-supervised learning methods combine a small amount of labeled data and a large amount of unlabeled data for training, and this emerging technology not only reduces the dependence on experts, but also effectively mitigates the problem of data scarcity and overfitting faced by supervised methods, which greatly promotes the development and application of image segmentation technology for pneumonia. Semi-supervised learning has significant advantages over traditional supervised learning methods and has shown excellent performance in different medical image domains. Specifically, semi-supervised segmentation methods based on Mean Teacher 14 have been widely applied to medical image segmentation tasks by performing coherent learning under perturbation. A large amount of current research focuses on improving the reliability of generating pseudo-labels during training to enhance model performance, but the problems of insufficient feature mining of unlabeled data by the model as well as inefficient feature learning and weak generalization of its features remain challenging. And by playing on the role of a priori relationships between unlabeled and labeled data and applying the knowledge learned from the limited labeled data to the unlabeled data, the segmentation network can be motivated to generate high-quality prediction results for the unlabeled data through this method. Yu et al. 15 used the MC-Dropout method during training to generate predictions and compute the prediction uncertainty through multiple forward propagation so that the segmentation network fits a relatively reliable target region. In order to better distinguish the reliability and unreliability of generating predictions on unlabeled data, Xia et al. 16 generated multiple views with view differences by spatially varying the 3D data, and subsequently, the MC-dropout mechanism was introduced in the model architecture in order to estimate the uncertainty of each view. Xiang et al. 17 used four classifiers with different loss functions at the decoder side of the network in order to address the problem of cognitive uncertainty, through multiple different classifiers in order to generate diverse predictions, where certain regions are considered to have a high level of confidence if they exhibit similar segmentation results across all four predictions. Lu et al. 18 combined pseudo-labels and consistency regularization to improve the reliability of pseudo-labels by calculating the KL variance between the pseudo-labels generated by the teacher model and the predictions of the student model and treating it as an estimate of uncertainty to guide consistency loss. The MC-dropout method used by Yu 15 and Xia 16 et al. requires multiple inference, which is computationally expensive. The uncertainty approach proposed by Xiang et al. 17 and Lu et al. 18 improves the reliability of pseudo-labels to some extent, but does not establish a link between unlabeled and labeled data. In order to better improve the learning efficiency of the model on the features of unlabeled data, this paper, from the perspective of adversarial consistency learning, proposes a discriminator network with adaptive feature selection and makes it involved in segmentation training, which improves the prediction quality of unlabeled data by judging the prediction quality of different sample data as well as the consistency learning in the training process through the mutual game with the segmentation network and thus improves the prediction quality of unlabeled data. At the same time, the generalization performance of the model is improved.
In supervised image segmentation tasks, due to the limited diversity of training samples, the parameters of the segmentation network such as weights and biases are fixed, which means that once the model is trained, these parameters do not change with different input samples. However, the segmentation network in semi-supervised learning will be adversely affected by using fixed model parameters for different types of sample data, e.g., when dealing with different sample data. The fixed model parameters on the one hand limit the model's ability to adapt on different data distributions. On the other hand, it may lead to a situation where the model is not able to fully utilize this data for learning, resulting in poor quality of generated pseudo-labels as well as overfitting. Chen et al. 19 proposed dynamic convolution in order to improve the representation of the network, which selects or weights multiple convolution kernels by analyzing the features of each input to extract features more efficiently. Jiang et al. 20 designed a new dynamic convolutional block and replaced the normal convolutional fast in 3D U-Net, which greatly improves the ability of the segmentation network to extract information and to perform segmentation accurately and quickly. Wang et al. 21 proposed that the network enhances the extraction of image features by using multi-dimensional dynamic convolution combined with four different attention mechanisms to fully capture the rich contextual information in the image and improve the performance of the model. While the above methods dynamically aggregate weights from multiple convolutional kernels through flexible convolutional operations and bring some performance gains, they also give rise to a significant increase in the number of parameters and do not take into account the modeling of image dependencies between the spatial and channel dimensions, which leads to limited feature expressiveness as well as insufficient feature fusion and transfer. Aiming at the above mentioned problems, we put forward a triple-attention dynamic convolution (TADC) module based on the characteristics of semi-supervised training samples. This module is capable of dynamically selecting parameters in accordance with different samples and establishing interdependencies among different feature dimensions, thereby enhancing the overall representation of the model with respect to data features.
In order to solve the above problems, a discriminator network with adaptive feature selection is designed on the basis of a dual multiscale mean teacher model. The network consists of a novel triple - attention dynamic convolution (TADC). The alternate training of the segmentation network and the discriminator network motivates the segmentation network to improve its ability to transfer the knowledge learned at the labeled data to the unlabeled data, thus generating reliable segmentation results. In addition, feature selection and fusion modules were designed to enhance the feature representation in the channel and spatial dimensions. Thus, the contributions of this paper are as follows:
Adaptive Feature Aggregation Discriminator Network: We proposed a novel discriminator network based on adversarial training with adaptive feature selection. This network empowers the segmentation network to transfer knowledge from labeled data to unlabeled data more effectively, guaranteeing that the segmentation quality for both labeled and unlabeled data is highly consistent, thereby improving the model's generalization ability. Triple - Attention Dynamic Convolution (TADC) Module: Developed the TADC module, which has the ability to adaptively adjust convolution kernel parameters based on different sample data. This mechanism enables flexible adjustment of model parameters according to diverse samples in the network, effectively mitigating the risk of model overfitting. 3D Triple Attention Module: Introduced a 3D triple attention module at the front - end of dynamic convolution. It promotes feature expressiveness and fusion via cross - dimensional interactions between channels and spatial dimensions, providing a more robust feature representation for subsequent processing. Feature Selection and Fusion Module: Constructed a feature selection and fusion module. This module extracts information from the feature channel layer, preserves the valuable part, and then combines it with the extracted spatial information. Subsequently, the fused features are processed through a series of convolution operations to further boost their spatial - dimensional feature representation.
Related work
Semi-supervised learning has made significant advancements in the field of medical image segmentation compared to traditional supervised learning methods. The most common approaches in this domain include pseudo-labeling and consistency regularization. In practice, pseudo-labeling methods are widely employed in tasks such as image and semantic segmentation. These methods help alleviate the model's dependence on large amounts of labeled data by using the model's predictions on unlabeled data as pseudo-labels, which are then used in conjunction with labeled data for training. 22 However, this method faces several challenges, such as the potential for noisy pseudo-labels, which can degrade the model's performance. In addition, the choice of confidence threshold plays a crucial role in the selection of pseudo-labels. An inappropriate threshold can either ignore useful pseudo-labels or introduce noise. Therefore, generating reliable pseudo-labels is essential for improving model performance. 23 In addition, a growing body of research in recent years has explored effective methods based on consistency regularization, which encourages prediction consistency by applying different perturbations to the same inputs or models. For example, the Mean Teacher model,14,24 a widely used semi-supervised learning approach designed to enhance model performance with limited labeled data, introduces a self-ensembling technique. It combines a student model and a teacher model, where the weights of the teacher model are updated using the Exponential Moving Average (EMA) of the student model's weights. While simple and efficient, this approach inevitably faces some challenges. For instance, Lu et al. 7 proposed addressing the reliability issue of pseudo-labels by incorporating uncertainty estimation to correct noisy pseudo-labels. Specifically, they used the Kullback–Leibler (KL) variance predicted by the teacher-student model as an uncertainty estimate, guiding the consistency loss to mitigate the impact of noisy pseudo-labels during training. Xu et al. 25 proposed the Ambiguity-Consensus Mean-Teacher (AC-MT) model to extract useful information from unlabeled data. This model is grounded in the concepts of entropy, model uncertainty, and self-identification of label noise. It improves performance by applying consistency learning in regions that are fuzzy yet still valuable for the model. Adiga et al. 26 proposed efficient segmentation methods with low computational complexity to enhance the performance of segmentation networks. These methods improve model effectiveness by learning anatomically-aware representations from labeled data through pre-training and by leveraging global information from segmentation masks to address uncertainty in segmentation tasks. Wang et al. 27 introduced entropy minimization and virtual adversarial strategies based on the Mean Teacher (MT) model to enhance network segmentation quality while smoothing decision boundaries. Xiao et al. 28 employed two teacher networks based on CNN and Transformer to regularize and guide the student network. Additionally, they focused on global information and enabled the teacher networks to supervise each other alongside the student network. Li et al. 29 proposed a semi-supervised learning framework that involves two student networks, where the teacher model parameters are alternately updated by the student networks. This approach reduces the similarity between the teacher and student model weights, thereby minimizing error accumulation.
Although consistency-based regularization has become the dominant method for semi-supervised learning in image segmentation, many segmentation approaches for unlabeled data struggle with slow progress in feature learning and are inefficient in this regard. Meanwhile, the use of Generative Adversarial Networks (GANs) is increasingly gaining traction in medical image segmentation tasks. Zhang et al. 30 proposed an enhanced Dense GAN network, which trains a deep learning model to improve performance by generating high-quality image augmentation data. Jiang et al. 31 proposed a synthesis method that generates realistic COVID-19 CT images using conditional GANs. This approach effectively addresses the challenge of limited data availability. Xu et al. 32 proposed GASNet, which incorporates generative adversarial training to enhance the segmentation performance of the network. This is achieved by using a binary classification discriminator to determine whether the healthy volume is generated and synthesized by the generator. Li et al. 33 proposed the Generative Adversarial Semi-Supervised Network (GASNet) to address the challenge of limited access to pixel-level labels in medical images. In this framework, the segmentation network acts as a generator, producing pseudo-labels that are evaluated for reliability by an uncertainty discriminator. The credibility of these pseudo-labels is further ensured through the use of a feature mapping loss. Wu et al. 34 proposed an adversarial training method called Auxiliary Adversarial Learning (AAL), which enhances the segmentation quality of unlabeled images. This is achieved by assigning distinct labels to the segmentation results of labeled and unlabeled images, thereby improving the overall segmentation performance. Zhang et al. 35 proposed a deep adversarial network that optimizes image segmentation quality by iteratively applying the adversarial training process, improving the segmentation of both unlabeled and labeled images.
Since the fixed-parameter segmentation network used as the backbone in a semi-supervised learning framework is prone to overfitting and requires significant memory overhead, it presents several challenges. Due to the diversity of sample data, there is a significant performance variation across different data types. Furthermore, the use of fixed-parameter segmentation networks in the training process for both labeled and unlabeled data introduces notable limitations. In recent years, increasing researches have focused on exploring how to leverage flexible convolutional operations and adaptively adjust the convolutional kernel parameters based on different inputs. Yin et al. 36 proposed a segmentation algorithm with low computational complexity and high performance. By using a dynamic filter, the algorithm can adjust the filter parameters in real-time based on different sample inputs, thereby enhancing its ability to capture and represent features. Hu et al. 37 proposed Dynamic Convolution-based Domain and Content Adaptive Convolution (DCAC) to address the limitations of static convolution. This method adapts to different image sources and features by flexibly adjusting the convolution operation. The model's convolution parameters are dynamically generated based on the domain code of each input image or its global feature conditions, enabling better adaptation to varying data. Su et al. 38 proposed a method that combines domain-adaptive and dynamic convolution to address the diversity and complexity of clinical data. This approach enables the model to leverage domain-specific knowledge and dynamically adjust its internal mechanisms when handling a wide range of data, thereby enhancing overall performance.
Semi-supervised segmentation framework design
In this paper, we propose a novel pneumonia infection segmentation method using dual multiscale mean teacher model 39 and adversarial consistency learning in chest CTs. Additionally, we design an adversarial discriminator network that incorporates proposed the 3D TADC module for improved pneumonia infection segmentation. The proposed segmentation framework consists of both a student model and a teacher model, with each model comprising the same encoder-decoder architecture. The semi-supervised framework for pneumonia infection segmentation with dual multiscale and adversarial consistency learning is shown in Figure 1(a). Additionally, we introduce a novel adversarial consistency learning-based discriminator with adaptive feature selection, and its structure is illustrated in Figure 1(b). This network incorporates adaptive feature selection module, the proposed 3D TADC, and average pooling. The discriminator takes both the original image and the concatenation of the segmentation results as input to evaluate the quality of the segmentation outputs generated by the network. It assesses the segmentation results on both labeled and unlabeled data, ensuring that the two segmentation outputs are as consistent as possible. This approach effectively enhances the segmentation network's ability to transfer knowledge learned from labeled data to unlabeled data. Furthermore, the discriminator network incorporates novel dynamic convolutional layers, which are designed to mitigate the risk of model overfitting while enhancing the model's ability to extract and interpret features.

Proposed segmentation algorithm. (a) Semi-supervised framework for segmentation of pneumonia infections with dual multiscale and adversarial consistency learning; (b) Structure of the discriminator network.
Additionally, the segmentation network and the discriminator network are trained alternately during the training process. Notably, the discriminator network is not required during the inference phase, this leads to a reduction in unnecessary computational costs. In the supervised training phase, labeled data is fed into the student network, which generates segmentation results at four different scales from various layers of the decoder. The multiscale supervised loss is then calculated by comparing these four segmentation results with the ground truth. In the unsupervised training phase, unlabeled data is fed into both the student and teacher networks. The consistency loss between the segmentation results of the teacher and student networks at different scales is then computed.
FSFMT-Net structure design
We designed Feature Selection and Fusion Mean Teacher Network (FSFMT-Net) as the backbone network, which is shown in Figure 2, the network is an improvement on the Dual Multi-scale Mean Teacher Network (DM2TNet) network. 39 The segmentation network is divided into two parts, the encoder and the decoder. At the encoder side, the original 3D image undergoes two down-sampling operations with two different spatial dimensions to obtain two auxiliary 3D images. Subsequently, the three 3D images with three different spatial dimensions will be subjected to four convolutions and max-pooling operations and will then obtain the feature maps of the four groups, each of which contains three features with different spatial resolutions. In addition, the three different spatial resolution features of each group are aggregated by the attention module, which is shown in Figure 3. At the decoder side, by up-sampling the aggregated features and merging them with neighboring features, the input image and its multidimensional perceptual multi-scale representation can be fused for better segmentation of lung infection, and ultimately, multiple segmentation results at different scales are generated at the decoder layer. Finally, we incorporated a feature selection and fusion module into the final output layer of the network. This module enables better utilization of the feature information within the input data. It allows the network to focus more on significant features while suppressing less important ones. By fusing global channel information and global spatial information, the performance of the entire network is enhanced.
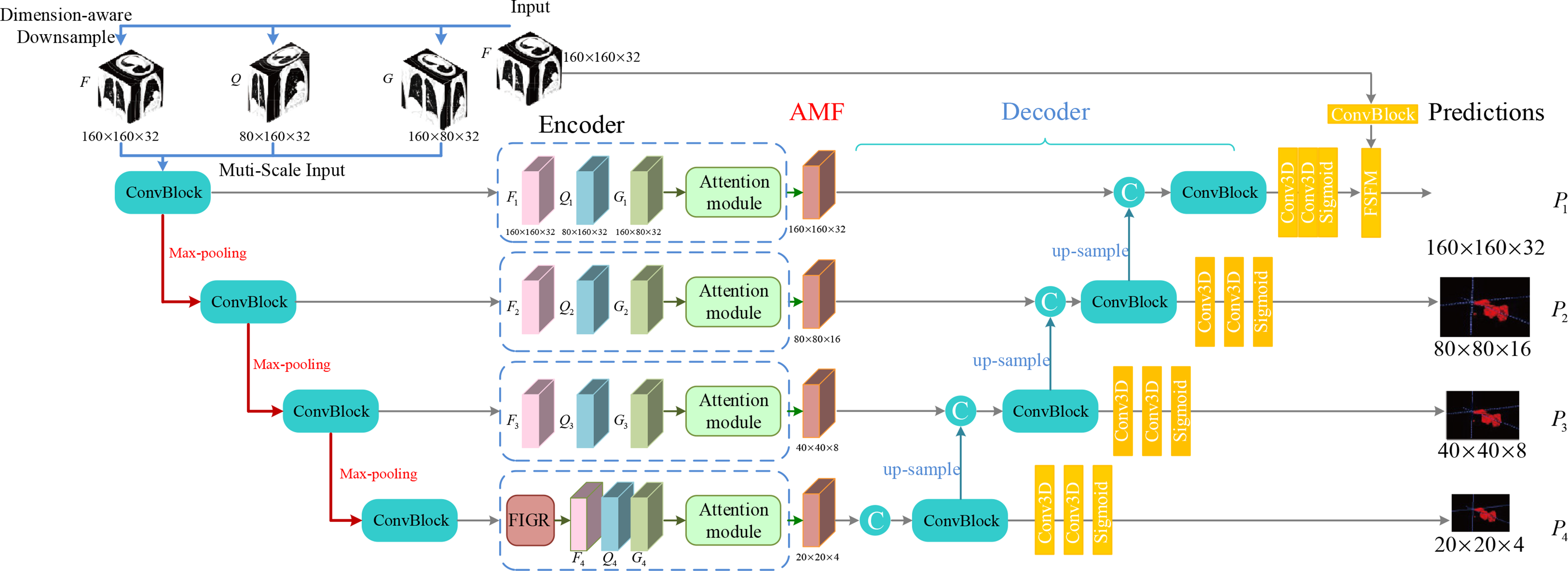
Structure of the teacher-student network model.
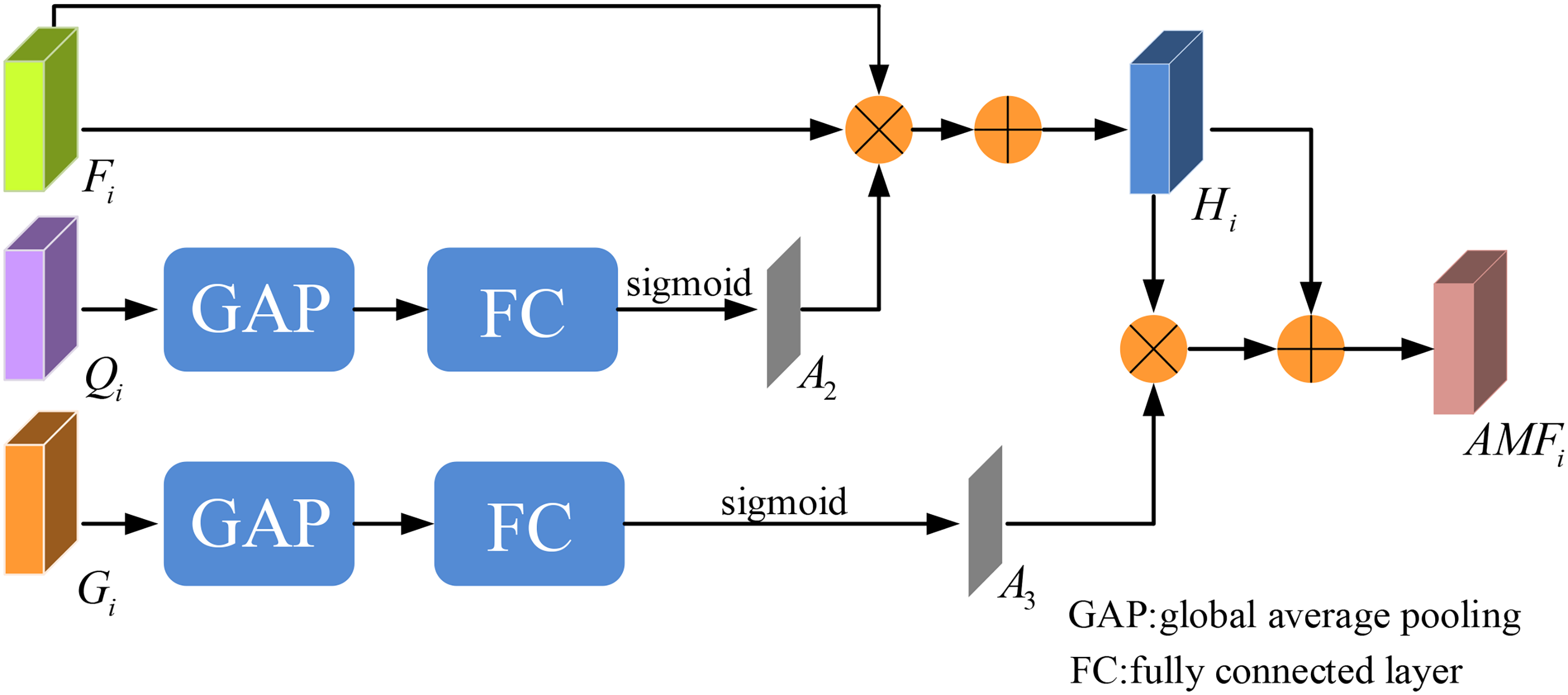
Structure of attention modules in networks.
Discriminator networks with adaptive feature selection based on adversarial consistency learning
Although Mean Teacher-based semi-supervised learning methods have shown promise in medical image processing by calculating consistency loss through data perturbation, they often overlook the a priori relationship between labeled and unlabeled data. This oversight can hinder the model's ability to effectively leverage the information from unlabeled data, ultimately reducing both prediction accuracy and generalization ability. In this paper, we extended the discriminator proposed by Lei et al. 40 into a novel discriminator network with adaptive feature selection. This approach enables the model to more effectively transfer knowledge from the limited labeled data to the unlabeled data, while simultaneously reducing the reliance on large amounts of labeled data. It achieves this by learning the a prior relationship between labeled and unlabeled data.
First, the original image is passed through the adaptive feature selection module. The resulting image, processed by the adaptive feature selection module, is then concatenated with the predictions generated by the student network for the image data. The concatenated data will then pass through dynamic convolution and global average pooling, ultimately outputting a value of 0 or 1. The discriminator network primarily assesses the quality of the segmentation result, outputting either 0 (poor) or 1 (good). During the training process, the discriminator network encourages the student network to generate the highest-quality predictions possible for the unlabeled data, aiming for an output of 1 from the discriminator network. The objective function for optimizing both the student network and the discriminator network is as follows:
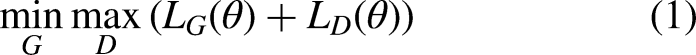
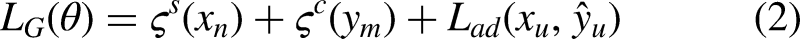
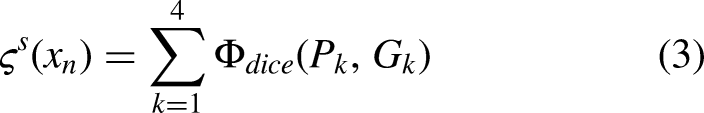
As the network is trained, the segmentation predictions improve progressively, generating reliable pseudo-labels for the unlabeled data. Subsequently, the discriminator network evaluates the quality of the segmentation results, aiming for the best possible judgment. The objective function
To enhance the model's ability to represent important features, we embed an adaptive feature selection module
41
at the front end of the discriminator network. The structure of the module is shown in Figure 4. This module adjusts the channel weights of the input feature maps by calculating inter-channel attentional weights. Specifically, the input feature maps are first processed using three convolutional layers to generate three feature maps

Adaptive feature selection module structure.
3D triple-attention dynamic convolution
When different samples use the same model parameters in a parameter-invariant network, there is a risk of overfitting the segmentation network, leading to unreliable pseudo-labels. To address this issue, Lei et al. 40 proposed a dynamic convolution-based bidirectional attention component. Inspired by this, this paper designs a novel 3D TADC module from another perspective, as shown in Figure 5. Specifically, dynamic convolution allows the convolution kernel parameters to be adaptively adjusted based on different input data, enabling the model to handle diverse samples more effectively. This reduces the risk of overfitting while enhancing the model's ability to extract and understand features. Additionally, a 3D triple-attention module is integrated before the dynamic convolution in the network to address the issue of limited feature expressivity.
3D Triple-attention dynamic convolutional module.
The TADC module is shown in Figure 5. The input feature map
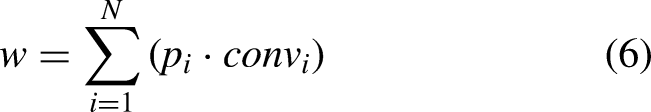

Designed 3D triple-attention module structure.
The dependencies between the spatial and channel dimensions are not effectively captured since the channel and spatial dimensions are processed separately, with features computed independently in each dimension. Inspired by the 2D triadic attention module, 42 we propose a novel 3D cross-dimensional triple attention mechanism to enhance the correlation between different locations within the same layer of feature maps in the spatial dimension. This is achieved by capturing the cross-dimensional interactions between the spatial and channel dimensions. The structure of the 3D triadic attention module is illustrated in Figure 6.
Spatial attention and channel attention are modeled on the input tensor through three branches, specifically, to achieve cross-dimensional interaction features between the aggregated channel C and the spatial dimensions W and H, as well as spatial dimensions to interact with information in the direction of the image height and width. Finally, the attention weights obtained on the three branches are averaged to aggregate the fine tensor generated in each branch. In addition, a Z-Pool is applied to each branch. It compresses the original multi-channel into two channels by means of a maximum pooling and average pooling operation. This reduces the computational effort while preserving the rich representation of the tensor. Z-Pool can be expressed in Equation (7).
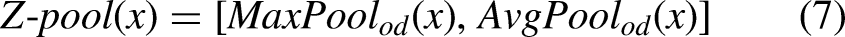
For a given input feature x, the operation
The feature vector goes through a convolutional layer with kernel size
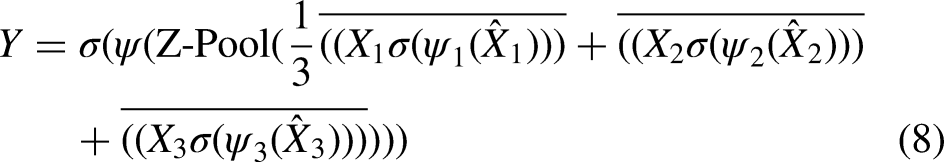
Where
Feature selection and fusion module
In order to filter out features with important information, reduce redundant information, and improve the expressiveness of features, the work of Yang et al. 43 and Xing et al. 44 provides new ideas and directions for this paper. We designed a feature selection and fusion module (FSFM), as shown in Figure 7, which enables feature fusion by dynamically selecting important features both across channels and spatial dimensions. In the feature selection process, the channel dynamic selection mechanism selectively retains the most task-relevant feature channels based on the information in the feature map, thereby enhancing the prominence of important features. Alternatively, the spatial dynamic selection mechanism does not treat the entire feature map equally; instead, it focuses on key regions. Finally, integration of important features selected in channels and spatial, spatial convolution is performed on the fused features to enhance their representation in the spatial dimension.

Designed feature selection and fusion module.
Specifically, for the input feature maps

Subsequently, the fused features are optimally selected using global channel information. This information is first used to assess the importance of each feature channel, guiding the processing and refinement of the features. Next, a
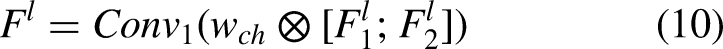
In the spatial information extraction section of the feature,
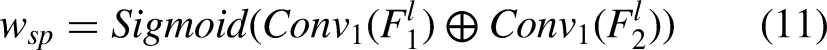

Finally, the fused features are fed into two convolutional blocks with convolutional kernels
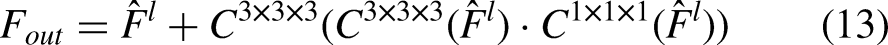
Results and analysis
Dataset
This study uses the MosmedData dataset, 45 provided by the Moscow City-owned Hospital in Russia. The dataset comprises five subsets (CT-0 to CT-4) with 1110 lung CT images of anonymous healthy individuals and COVID-19 patients, including males (42%), females (56%), and 2% of samples with missing gender annotation. Patient ages range from 18–97 years. CT-0 (254 samples): Normal lung CT images without COVID-19 infection. CT-1 to CT-4 (856 samples): Lung CT images with varying COVID-19 infection severity (increasing with subset numbering), including 50 expert-annotated samples converted into ground truth binary masks (infected areas = 1, non-infected = 0). For the semi-supervised segmentation task, data from CT-1 to CT-4 were used. Of the 50 annotated samples, 32 were allocated to training, 8 to validation, and 10 to testing (via random stratified sampling). Additionally, 806 unlabeled samples were incorporated into training to expand the dataset for semi-supervised learning.
Evaluating metrics
In the experiment, multiple metrics are used to evaluate segmentation results from different perspectives. The selected metrics include Dice, Jaccard, Normalized Surface Distance (NSD), and Average Boundary Distance (ABD). Dice and Jaccard metrics measure set similarity, with values ranging from 0 to 1. A value closer to 1 indicates higher similarity between predictions and ground truth, reflecting better segmentation performance. The mathematical formulas for the Dice and Jaccard coefficients are shown in Equations 14 and 15:
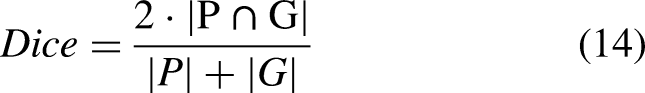

The NSD metric is used to measure the proximity between the segmentation result and the ground truth in terms of boundaries. The mathematical formula for NSD is shown in Equation 16:
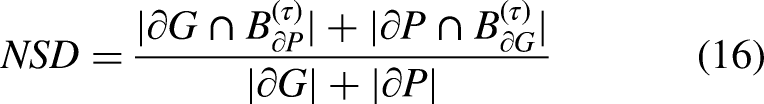
ADB metric is used to evaluate the average distance between the boundary of the segmentation result and that of the ground truth. The lower its value is, the higher the fit of the two boundaries and the more ideal the segmentation effect is. The mathematical formula of ADB is shown in Equations 17–19:



Experimental setting
The network model for this experiment is implemented using the PyTorch deep learning framework. The experiments were conducted on a computer running the Windows 10 operating system, equipped with a GeForce RTX 3090 graphics card (24GB) and an Intel Core i9-11900 K processor. The Adam optimizer is used for model training with a learning rate set to 0.0008. Due to the limitations of the device's GPU memory, the batch size is set to 1, and the training is conducted over 200 epochs. Additionally, an early-stopping strategy is employed during training to prevent overfitting.
Ablation studies
In the ablation studies, we use MDA-CNN as the benchmark model and conduct four sets of experiments to assess the impact of each designed module on segmentation performance. The experimental setups are as follows: (1) using MDA-CNN as the baseline network; (2) adding only the feature selection and fusion module (FSFM) on top of the baseline network; (3) Adding a discriminator network consisting of adaptive feature selection and TADC module to the baseline network; and (4) adding the FSFM to the setup in (3), which is then used as the final model in this paper.
From Table 1, it can be observed that when the FSFM is added to the benchmark model MDA-CNN, the segmentation network shows improved scores on the four segmentation metrics—Dice, Jaccard, NSD, and ADB. This indicates that the segmentation performance is enhanced compared to the benchmark model without the FSFM. When a discriminator network with adaptive feature selection and TADC was added to the baseline model and trained alternately with the segmentation network, the segmentation network's performance improved by 2.83%, 3.1%, 3.24%, and 0.89% on the four segmentation metrics, respectively. Finally, the method proposed in this paper achieves improvements of 3.83%, 3.97%, and 3.14% on the four evaluation metrics, namely Dice, Jaccard, and NSD, compared to the baseline model.
Ablation study with semi-supervised segmentation algorithm (mean ± standard deviation).

Comparative experiments
Comparison experiment of adding Gaussian noise at different locations
To evaluate the algorithm's generalization ability in noisy environments, Gaussian noise, as a common type of interference, can effectively test the algorithm's capability to suppress random noise. However, if too much noise is introduced, it can interfere with model training and degrade segmentation performance. This is especially problematic in tasks involving the generation of reliable pseudo-labels for unlabeled data in semi-supervised training, as excessive noise can negatively impact the accuracy of the segmentation results. The segmentation performance in the experiment was compared across four scenarios: (1) adding Gaussian noise only to the labeled image data input of the student model, (2) adding Gaussian noise only to the unlabeled image data input of the teacher model, (3) adding Gaussian noise to the unlabeled image data input of both the student and teacher models, and (4) not adding any Gaussian noise to the unlabeled image data of either the student or teacher models. The results are summarized in Table 2.
Comparative experiments for different locations of noise (mean ± standard deviation).

Comparison of the effect of replacing normal convolution with dynamic convolution.

Comparative experiments with varying numbers dynamic convolutional layers
In this paper, we fixed the hyperparameter K = 4 as a prerequisite while varying the number of TADC layers in the discriminator, and experimentally validated the replacement of standard convolution layers with the TADC module in the discriminator network. Specifically, in the experiment, we replace one, two, three, and four convolutional layers with TADC module in the discriminator network. The results for each configuration are presented in Table 3. The performance of the segmentation network improves progressively as more ordinary convolution layers are replaced with TADC module in the discriminator network. The reason is that the network becomes capable of extracting more complex and abstract features with each additional layer, enabling the discriminator to more effectively assess the quality of different samples. Thus, two factors can be elaborated. On one hand, the triple-attention module enables the modeling of dependencies between the feature space and the channel dimensions, enhancing the network's representational power and its ability to capture more subtle differences in the data. On the other hand, dynamic convolution allows the convolution kernel parameters to be adjusted dynamically based on different samples. As a result, the TADC module, with its multiple layers, can progressively enhance the performance of the discriminator. it enables the network to learn from simple, low-level features to more complex, high-level features, thereby improving its discriminative power.
Comparative experiments with different temperature adjustment strategies
The discriminator's first four layers use TADC modules with a dynamic temperature (

Comparison of the effects of different temperature adjustment strategies.
Comparative experiments with different values of K
The size of the parameter K in dynamic convolution determines the scale of the weight parameters, which in turn affects the number of weights to be learned and the complexity of weight updates during the model's training process. A larger K value can increase the number of weight parameters, leading to higher computational and memory demands. On the other hand, varying values of K result in dynamic convolution weights with different structures and numerical distributions. This, in turn, impacts the effectiveness of the subsequent 3D convolution operation on the input feature maps. Different dynamic convolution weights lead to varying levels of attention and combinations of the input features during the convolution process, thereby influencing the overall performance. Therefore, in this experiment, we compare the segmentation performance for different K values, with the results presented in Table 4. We fixed the first four layers of the discriminator as TADC modules as a prerequisite while adjusting the hyperparameter K, the performance of the model with different values of K is compared. The results show that when K is set to 4, the performance of all performance metrics of the model is superior. Specifically, compared with the cases where K is set to other values, each performance indicator of the model performs better. At this time, the diagnostic effect of the model is the best.
Comparison of the effect of hyperparameter K at different values.

Verify the impact of FSFM on the overall effect at different layers of the network
The Feature Selection and Fusion Module (FSFM) proposed in this paper mainly focuses on extracting global channel and global spatial information. It filters out features containing important information by extracting global channel information and global spatial information respectively. Meanwhile, it fuses the input information from different feature maps to enhance network performance. In this paper, the FSFM is incorporated into various layers of the segmentation network. This is done to examine the influence of the module's placement on the overall network performance. The corresponding results are presented in Figure 9. The FSFM exhibits superior performance when positioned within a shallow network. In contrast, its effectiveness diminishes when placed in a deep network. This could be attributed to the nature of shallow networks, where the feature maps encompass a greater abundance of low - level features like edges and textures. The FSFM is adept at effectively filtering and fusing these low - level features, which are characterized by a higher degree of diversity. In contrast, within deep networks, the features have become highly abstract. As a result, the FSFM struggles to glean valid information from these abstract features. In fact, it might even introduce noise when attempting to process such highly - abstracted characteristics. Therefore, placing the FSFM at different locations in the network has a large impact on the overall performance.

Comparison of the impacts of FSFM at various positions within the network.
Validity verification of the proposed module
To validate the effectiveness and generalization of the proposed TADC module and feature selection and fusion module (FSFM) module, comparative experiments are conducted on both the 3D U-Net 46 and DM2TNet 39 networks. The overall performance of both networks improves after integrating the triple attention dynamic convolution, with significant increases in the Dice similarity coefficient and Jaccard coefficient compared to the original networks. The improved 3D U-Net shows a 1.01% increase in the Dice similarity coefficient and a 1.53% increase in the Jaccard index, as shown in Figure 10(a). Similarly, the enhanced DM2TNet demonstrates a 0.96% improvement in the Dice similarity coefficient and a 1.37% increase in the Jaccard index, as shown in figure Figure 11(a). This demonstrates the enhanced quality and expressiveness of the processed features.

Validation of module validity based on 3D UNet.

Validation of module validity based on DM2TNet.
In addition, the 3D U-Net and DM2TNet integrated with the feature selection and fusion module (FSFM) show improvements of 1.96% and 2.04% in the Dice similarity coefficient, respectively, with slight improvements observed across all other metrics, as shown in Figure 10(b) and Figure 11(b)
This fully demonstrates the effectiveness of the proposed TADC and feature selection and fusion module (FSFM).
Validity verification of the proposed module
In this study, the DM2TNet employs a multiscale supervised loss in the supervised training phase and a multiscale consistency loss in the unsupervised training phase. The student model is optimized by computing the combined loss, which is the sum of both these losses, throughout the training process. In this paper, we compare the model's segmentation performance under two different scenarios: single-scale output and multi-scale output. The results are presented in Figure 12. The results show that the method with multi-scale consistency constraints improves the Dice and Jaccard metrics by 0.94% and 0.86%, respectively, compared to the single-scale output. Multi-scale approaches are better suited for scenarios involving complex or multi-focal data, as the network can extract both low-level and high-level features by processing data at different scales. This is particularly important for segmentation tasks that require decision-making across varying contexts and backgrounds. Therefore, this method allows the segmentation network to better adapt to targets of varying scales, thereby enhancing the accuracy of recognition and prediction.
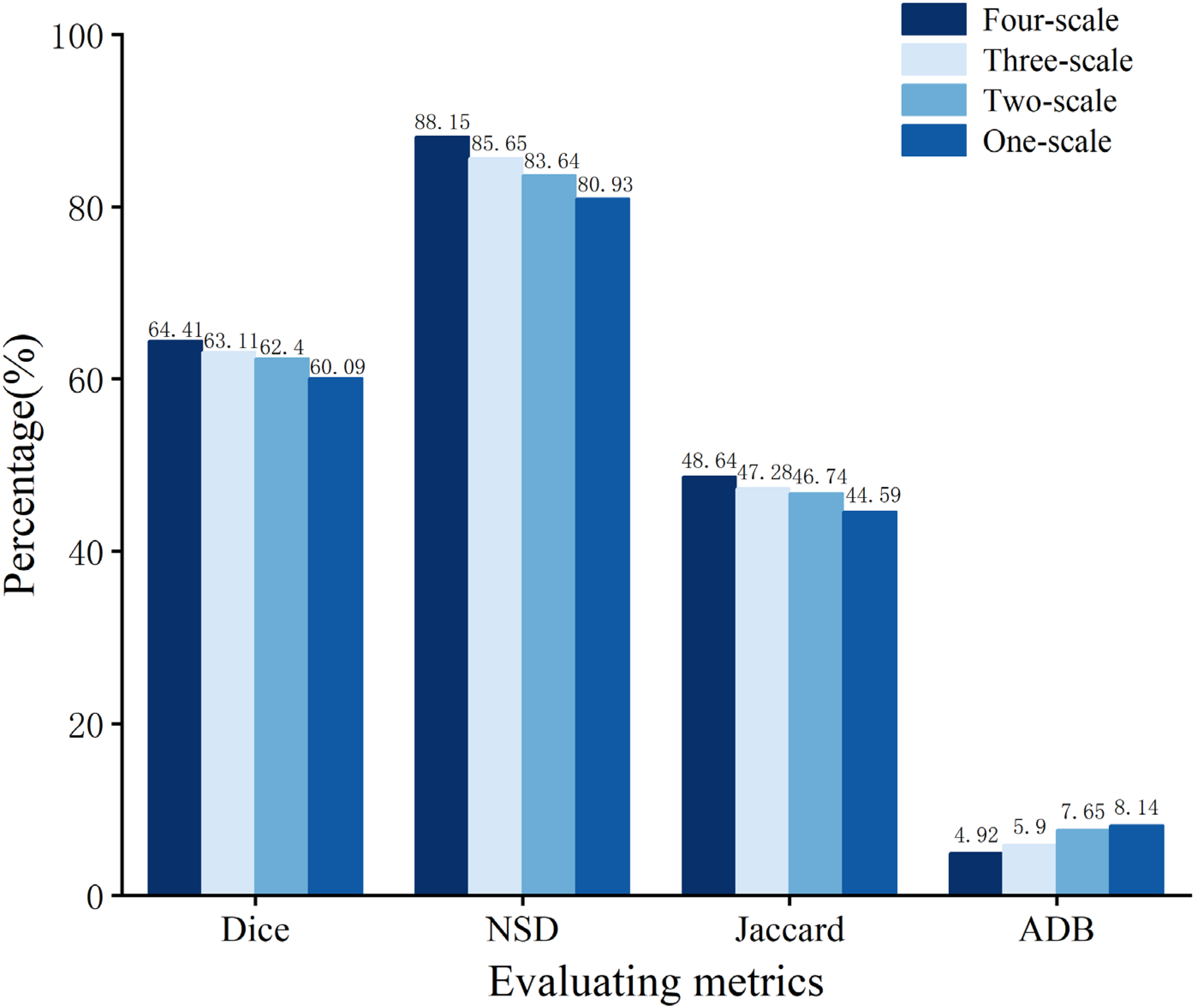
Comparative experiments at different scales.
Visualization of segmentation results
In this study, to thoroughly analyze and evaluate the segmentation performance, we randomly picked the visualization outcomes of tissue segmentation regarding lung infections, Figure 13(a) visualizes the segmentation results of smaller lesions, and Figure 13(b) visualizes those of larger lesions. By comparing the segmentation results predicted by the model with the ground truth and the original image, we can clearly observe the alignment between the segmented regions and the lesions in the original image, as well as the discrepancies with the ground truth. The model was able to accurately detect even some of the smaller lesion areas in the lung images, without any omissions. At the same time, by comparing the segmentation results with those manually labeled by the experts, it is evident that although small lesions are challenging to distinguish due to factors such as imaging quality, the model still manages to recognize them accurately. This results in a high degree of similarity between the segmentation outcomes and the ground truth. On the other hand, notwithstanding that certain infected tissues display fuzzy boundaries and delicate grayscale distinctions when contrasted with the adjacent normal tissues, the proposed segmentation algorithm remains capable of precisely identifying the crucial characteristics of the lesions and attaining accurate segmentation of the infected areas within the lungs. Overall, the proposed method demonstrates exceptional performance in segmenting small and ambiguous lesions, highlighting its significant clinical application potential.

Visualization of segmentation result.
Disscusion
Experimental comparison
This study compares the proposed method with other state-of-the-art models that have also been evaluated on the MosmedData dataset, as presented in Table 5. Based on the data presented in the table, it is evident that the proposed method outperforms others in several key metrics. Furthermore, the proposed 3D TCDA and adaptive feature selection discriminator network allow the segmentation model to more accurately capture and model the spatial information in the data, as well as effectively interpret the complex three-dimensional structures. This results in superior performance compared to other methods, including both 2D and 3D approaches. Specifically, our method achieves a Dice similarity coefficient value of 64.41, which significantly outperforms the Dice scores of Mean Teacher, DM2T-Net, and U-Net++. This highlights the substantial advantage of the proposed method over most existing models in terms of prediction accuracy and error reduction. The proposed method achieves a Jaccard value of 48.64, which is the highest in the table and significantly outperforms all other models. As a result, the proposed method leads in both the DICE coefficient and Jaccard index. Furthermore, our method also demonstrates advantages in performance on NSD and ADB compared to other approaches. In summary, the proposed algorithm performs exceptionally well and outperforms existing methods across several key evaluation metrics. This demonstrates that the design of the network architecture, along with the optimization of the training algorithm, effectively enhances the model's overall performance.
Comparison of results with other models and algorithms (

Figure 14 horizontally shows segmentation results of 3D U-Net, 46 VNet, 51 MDA-CNN 39 combined with VIT (Vision Transformer 52 ), our method (Ours), and the ground truth. Specifically, U-Net's results contain discrete, irregular regions with blurry boundaries, missing fine structures and struggling to capture small lesions or complex edges. VNet's segments are more compact but still lack details (e.g., incomplete small lesions), outperforming U-Net yet requiring further improvement. MDA-CNN + VIT's outputs are closer to ground truth but exhibit local edge inaccuracies (e.g., in magnified boxes) and poor complex-background feature discrimination. Our method's contours closely align with ground truth, enabling better restoration of small lesions and fine boundaries, and more precise capture of local details while maintaining overall structures.

Visual comparison of segmentation results yielded by distinct methods on the MosmedData dataset.
Discusses the performance of GRMA-Net
To assess the model's generalization ability and reliability, we tested it on the COVID-19-P20 dataset using the best weights obtained from training on the MosMedData dataset. The COVID-19-P20 dataset 53 and the MosMedData dataset exhibited substantial disparities in both the magnitude of the infected area and imaging characteristics. This validation approach helps evaluate the model's ability to adapt to diverse data characteristics and assess its performance across different datasets. Additionally, we compare the generalization performance of the proposed algorithm with that of other network models, and the results are presented in Table 6. The algorithm proposed in this paper demonstrates a higher value in the Dice coefficient. Additionally, we visualized the segmentation results for a randomly selected sample from the COVID-19-P20 dataset, as shown in Figure 15. In the figure, we zoomed in to highlight the infected tissue region in the original image and compared the model's prediction with the ground truth. From the figure, it is evident that the model is still able to make accurate predictions, even in the presence of complex or irregularly shaped infected regions. Therefore, the model is validated across different datasets, demonstrating strong generalization ability and robustness.

Visualization of segmentation results for verifying generalization performance.
Comparison of results with other models and algorithms.

Conclusion
In this study, we designed a novel pneumonia infection segmentation method using dual multiscale mean teacher model and adversarial consistency learning in chest CTs. The method is designed with a discriminator network with spatial attention, and the quality of prediction on unlabeled data is continuously improved during training while the discriminator network and the segmentation network are in an adversarial relationship with each other. Specifically, the discriminator determines the prediction quality of the input labeled and unlabeled data and the original image respectively, and the discriminator continuously motivates the segmentation network to generate higher-quality segmentation results during the training process. At the same time, an adaptive feature selection module is embedded in the discriminator, which adjusts the channel weights of the feature map to improve the feature expression ability of the network. In addition, the use of fixed model parameters for different sample data may lead to overfitting risk. And it is not applicable to use the same model parameters for two different types of data, labeled data and unlabeled data, in semi-supervised training. Therefore, we use dynamic convolution in the semi-supervised framework to solve this problem. By proposing TADC kernel and dynamically adjusting the operation of convolution kernel, the features of different data can be better adapted. Meanwhile, the designed TADC also enhances the model feature representation capability. Finally, we designed an innovative feature selection and fusion module (FSFM) that enables the segmentation network to focus on important regions, thereby enhancing the prominence of key features. In conclusion, the proposed adversarial consistency semi-supervised segmentation method for pneumonia infection holds significant value and meaning. In the future, we will attempt to introduce multimodal data fusion techniques and specialized data augmentation methods targeting the sophisticated morphological characteristics of pneumonia into our research, striving to achieve more breakthrough progress in follow-up work.
Footnotes
Ethics approval
This study utilized a public database of chest CT scans, from which the personal information of patients was removed. Therefore, this article does not contain any studies involving human participants or animals.
Consent to participate
This work utilized a public medical image dataset. Therefore, human subjects were not involved in this study.
Consent to publish
This doesn't apply to our research because our analysis and framework are built upon publicly accessible benchmark datasets.
Authors' note
Yu Gu is also affiliated with the Information Engineering College, Hebei University of Architecture, Zhangjiakou, Hebei 075000, China.
Author contributions
The first draft of the manuscript was written by Jianning Zang and Yu Gu. The review and editing of the manuscript were completed by Yu Gu, Xiaoqi Lu and Lidong Yang. The methodology of the study was completed by Jianning Zang, Baohua Zhang and Dahua Yu. The software in the study was completed by Jing Wang, Ying Zhao and Siyuan Tang. The validation of the study was completed by Jianjun Li, Xin Liu and Qun He.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The National Natural Science Foundation of China (grant numbers: 62001255, 62161040, 62262048, 62441212, and 61841204); The Central Government Guides Local Science and Technology Development Fund Project of China (grant numbers: 2025ZY0007, 2021ZY0004, and 2022ZY0024); Hebei Natural Science Foundation (grant number: F2025404013); Program for Young Talents of Science and Technology in Universities of Inner Mongolia Autonomous Region (grant numbers: NJYT23057, NJYT22074, and NJYT23106); the Fundamental Research Funds for Inner Mongolia University of Science & Technology (grant numbers: 042, 019, and 101); Inner Mongolia Autonomous Region Natural Science Foundation (grant numbers: 2024MS06008, 2024LHMS06006, 2019MS06003, 2022MS06017, 2022MS06009, and 2015MS0604); Inner Mongolia Health Technology Program Project (grant number: 202201395); Baotou Health Science and Technology Program (grant number: wsjkkj2022120); Inner Mongolia College Science and Technology Research Project (grant number: NJZY145); Chunhui Program of the Ministry of Education of the People's Republic of China (Research on CAD for Lung Cancers with Big Image Data based on Hessian Dot Filter and PSO–SVM) (grant numbers: [2019]1383); 2024 Inner Mongolia Archives Technology Project (2024–47); Inner Mongolia Autonomous Region college students innovation and entrepreneurship training projects (grant numbers:202310130004, s202410130004).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data that support the findings of this study are openly available in MosMedData dataset at https://doi.org/10.48550/arXiv.2005.06465.