
Abstract
Background
Industrial weld defect detection is challenged by the minimal grayscale contrast between defects and the background, as well as by blurred defect edges, which together hinder the performance of detection algorithms. Moreover, practical industrial environments require high detection accuracy, fast inference speed, and flexible deployment.
Objective
To address these challenges, this study proposes an improved YOLOv8n defect detection method that enables more accurate, faster, and lightweight automated weld defect detection.
Methods
The key improvements are as follows. First, in the backbone, the original C2f module is replaced by the C2f_OREPA feature extraction module, constructed with the Online Convolution Parameterization Approach (OREPA), which reduces computational complexity and enhances feature representation. Second, a downsampling module, DCDConv, is introduced to replace the conventional convolution after the first standard convolution layer, allowing better preservation of fine defect features and improving the detection of subtle defects. Additionally, in the neck, a cross-scale feature fusion module (CCFM) is incorporated to improve detection performance across defects of different scales.
Results
Experiments on our self-constructed dataset comprising eight weld defect categories show that the improved model achieves a mean average precision (mAP) of 87.6%, a 4.5% increase over the original YOLOv8n. Meanwhile, the model reduces the number of parameters by 26.9%, decreases computational cost by 35.7%, and achieves an inference speed of 103 frames per second (FPS). On the public NEU-DET dataset, the improved model obtains an mAP of 82.8%, outperforming the original YOLOv8n by 6.7%. Overall, the proposed model surpasses mainstream object detection frameworks, including YOLOv8n, YOLOv12n, Faster R-CNN, and RetinaNet.
Conclusion
In summary, the proposed method provides an accurate, efficient, and deployment-friendly solution for weld defect detection in industrial applications, demonstrating substantial practical value.
Introduction
Welding, as a fundamental process in modern industry, plays an essential role in critical sectors such as aerospace, automotive manufacturing, mechanical engineering, and shipbuilding. 1 The quality of welded joints directly influences the performance, safety, and service life of industrial components.Therefore, regular and reliable weld inspection is crucial for ensuring the overall quality of industrial products. 2
At present, industrial weld defect detection still relies heavily on manual visual inspection. 3 However, this approach suffers from several notable limitations. First, inspection results are highly dependent on the inspector's experience, leading to subjective variations in interpreting evaluation criteria and consequently resulting in poor consistency. Second, during prolonged and high-volume inspection tasks, manual inspection often induces visual fatigue, increasing the likelihood of missed defects and misjudgments, thereby making it difficult to maintain consistent inspection quality. Consequently, the development of automated weld defect detection systems to eliminate subjective human factors and improve detection efficiency and reliability has become an urgent and important research focus in industrial quality inspection. 4
In recent years, the rapid advancement of artificial intelligence has provided new opportunities for addressing these challenges. Deep learning–based object detection methods, particularly those employing convolutional neural networks (CNNs), have been widely adopted in weld defect detection owing to their strong feature-learning capabilities. These methods can be broadly divided into two categories. The first category comprises two-stage detection algorithms, represented by Faster R-CNN, 5 which first generate candidate regions and subsequently perform classification and bounding-box regression. This approach provides high detection accuracy but suffers from relatively slow inference speed. The second category consists of single-stage detection algorithms, such as SSD 6 and the YOLO (You Only Look Once) series,7,8 which formulate object detection as a unified regression problem.These algorithms substantially improve detection speed while maintaining high accuracy, making them well suited for real-time industrial applications.
Despite progress in welding defect detection research, practical industrial applications still face several critical challenges: (1)
To overcome the above challenges, this study proposes an improved detection algorithm based on YOLOv8n. The main contributions are as follows:
To mitigate the difficulty of extracting features from weld defects with grayscale values similar to the background and to overcome the limited feature extraction capability of the traditional C2f module, the proposed approach replaces the original C2f module in the backbone with the C2f_OREPA module. This module integrates the online convolutional parameterization method OREPA,
9
reducing computational complexity while improving the model's ability to extract subtle defect features. To alleviate the loss of detail caused by conventional downsampling and to better handle the blurred edges of weld defects, a downsampling module, DCDConv, is designed to replace the convolutional operation following the first standard convolutional layer in the backbone. DCDConv adopts a “pooling + channel segmentation” strategy to preserve key features of small defects (e.g., porosity) and mitigates the limitations of single-dimensional information extraction in traditional convolutions. This design improves detection accuracy for blurred edges and minute defects. To accommodate the large scale variation of weld defects and to overcome the insufficient cross-scale feature fusion of traditional FPN structures, a lightweight cross-scale feature fusion module (CCFM)
10
is incorporated into the Neck, forming the C-Neck architecture. CCFM efficiently integrates multi-scale features, improving the model's adaptability to defects of different sizes—particularly enhancing small-target detection—while reducing parameter complexity and increasing suitability for industrial deployment.
The remainder of this paper is organized as follows. Section 2 reviews related work and discusses the limitations of existing methods. Section 3 presents the design principles of the three proposed modules. Section 4 evaluates the model's performance through dataset descriptions, comparative experiments, and ablation studies. Section 5 discusses the strengths and limitations of the model, outlines future research directions, and concludes the paper.
Related work
In the field of X-ray weld defect detection, research efforts worldwide can broadly be divided into two main directions: traditional image processing methods and deep learning–based approaches. Traditional methods typically involve four key steps—image preprocessing, defect region segmentation, feature extraction, and defect classification—to progressively achieve defect identification. However, these methods suffer from cumbersome workflows, dependence on handcrafted feature design, and limited generalization capability. Consequently, deep learning–based weld defect detection has become the mainstream research direction. Based on their technical characteristics, deep learning–based methods can be divided into two categories: two-stage detection algorithms and single-stage detection algorithms.
Two-stage detection algorithm for weld defect detection
Two-stage detection algorithms typically first generate candidate regions and then perform classification and bounding-box refinement. These methods generally offer superior detection accuracy. Chen et al. 11 proposed an end-to-end X-ray weld defect detection method based on an improved R-CNN, which enhances detection performance by strengthening feature extraction capabilities. However, the method requires tens of thousands of annotated samples, rendering data collection costly in real industrial environments. Chen et al. 12 integrated Faster R-CNN with an enhanced ResNet-50 architecture that incorporates deformable convolutions and a Feature Pyramid Network (FPN). This approach substantially improved detection performance for multi-scale defects, particularly small targets, achieving a 4.8% increase in mean Average Precision (mAP) over the original Faster R-CNN. Nevertheless, it still fails to meet real-time detection requirements in industrial applications. Ajmi et al. 13 developed a Faster R-CNN-based detection model that demonstrated robust performance and high localization accuracy on low-quality, small-scale X-ray datasets. The model outperformed YOLO and DCNN; however, its advantages were mainly observed for specific defect types, indicating limited generalization capability. Wang et al. 14 proposed a ResNet-based ZIOT method that reduces background interference through an object-magnification network, thereby improving detection accuracy but reducing detection efficiency. Dai Zheng et al. 15 incorporated a merged convolutional layer into R-CNN to enhance feature extraction, but the method still inherits the limitations of traditional FPN in multi-scale feature fusion. Sang-jin Oh 16 applied Faster R-CNN for automated detection of welding defects in radiographic images and achieved high accuracy. However, its complex architecture, large number of parameters, and slow inference speed hinder real-time deployment. Wang et al. 17 investigated deep learning–based binary classification of welding defects and improved performance through data augmentation and learning-rate optimization. However, this approach cannot distinguish specific defect types, limiting its practical applicability.
Single-stage detection algorithms for weld defect detection
Single-stage detection algorithms directly predict object categories and locations, providing notable speed advantages that make them well suited for real-time industrial applications. Numerous studies have been conducted to further improve detection speed. Liu et al. 18 proposed the LF-YOLO model, incorporating a Reinforced Multi-Scale Feature (RMF) module and an Efficient Feature Extraction (EFE) module to address the multi-scale characteristics of weld defects, thereby improving both detection accuracy and speed. However, its performance on minute weld defects (e.g., cracks, lack of fusion) remains inadequate. Yang et al. 19 developed a deep learning-based method for detecting defects in steel-pipe welds. They placed considerable emphasis on data preprocessing, combining traditional augmentation techniques with YOLOv5's Mosaic method to effectively reduce overfitting during training. However, the preprocessing workflow remains insufficiently automated. Wu et al. 20 introduced the SimAM attention mechanism into a YOLOv8-based framework and replaced standard convolutions with Focus modules to enhance small-object detection. However, these modifications increased the network depth and computational load, resulting in slower inference. Kwon et al. 21 integrated context-aware modules and multi-scale fusion mechanisms into YOLOv5, improving accuracy but also increasing model size and hardware resource requirements. Pan et al. 22 proposed the WD-YOLO model, which integrates a GCE image-enhancement module, a NeXt backbone, and a dual attention mechanism. This framework effectively addresses challenges such as low image contrast and large variations in defect size. However, its inference speed remains lower than that of some ultra-lightweight models, and its generalization capability is limited by the diversity of defect types in the training dataset. Wang Hejia et al. 23 enhanced the YOLOv8 backbone using the MCLA hybrid local-channel attention mechanism, but complex textures still lead to frequent misclassifications. Li et al. 24 investigated RetinaNet and Transformer architectures, achieving improved detection performance but at the cost of real-time capability due to substantial computational demands. Song Kun et al. 25 proposed GMVG-Net, a lightweight multi-scale feature-fusion network built upon YOLOv5. Through the introduction of the MSFEF module for multi-level feature extraction, the integration of Ghost Bottleneck into the backbone, and the deployment of the lightweight VoVGSCSP module in the neck while replacing C3 with GSConv, they reduced model complexity and achieved an 11.1% improvement over the original YOLOv5. However, its generalization capability in complex industrial scenarios remains unverified, and its practical deployment performance has yet to be demonstrated. Bai et al. 26 proposed CBI-YOLO, a lightweight detection model based on YOLOv8n that integrates Cross-Stage Partial Path Convolution (CSPPC), a Bidirectional Feature Pyramid Network (BiFPN), and Inner Intersection over Union (InnerIoU). However, it did not achieve a significant accuracy improvement, making it unsuitable for industrial scenarios that require high detection precision.
In summary, although current detection methods are relatively advanced, they still face challenges such as high computational cost, poor performance on small or elongated defects, limited generalization capability, and difficulties in deployment. To address these limitations, this paper proposes a lightweight and enhanced network based on YOLOv8n. By enhancing edge perception and multi-scale feature fusion, the proposed model achieves a better balance among accuracy, speed, and model size, thereby providing greater value for industrial applications.
Method
YOLOv8n algorithm
YOLOv8 is a family of object detection algorithms released by Ultralytics in January 2023. It comprises five progressively scaled models—n, s, m, l, and x—each providing incremental improvements in detection accuracy. The architecture supports a wide range of visual tasks, including object detection, instance segmentation, pose estimation, object tracking, and image classification. Through the integration of multiple new features and architectural optimizations, YOLOv8 has emerged as one of the leading architectures in contemporary object detection. Compared with existing models such as Faster R-CNN, RetinaNet, and YOLOv7, YOLOv8 introduces notable enhancements in backbone design, neck feature-fusion mechanisms, positive/negative sample assignment strategies, loss function design, and deployment efficiency. It is particularly well suited for industrial inspection scenarios that require stringent real-time performance.
This study adopts YOLOv8n as the base model for refinement. Its architecture primarily consists of three components: the backbone, the neck, and the detection head. The backbone extracts multi-scale feature maps from the input images. The neck fuses shallow detail features with deep semantic features from the backbone, drawing inspiration from Feature Pyramid Networks (FPN) and Path Aggregation Networks (PANet). It achieves cross-scale feature fusion through upsampling and concatenation, thereby enhancing the model's multi-scale representation capability. The detection head performs object classification and bounding-box regression on the fused feature maps, generating the final detection results.
Improved YOLOv8n algorithm
This study adopts YOLOv8n as the baseline model and improves it through three key modifications. First, within the backbone, the Online Convolution Parameterization (OREPA) mechanism is integrated into the C2f module to create a novel feature-extraction unit, C2f_OREPA, which enhances computational efficiency and substantially reduces training cost. Second, the lightweight downsampling module DCDConv replaces the conventional convolutions following the first standard convolution layer in the backbone. This modification aims to minimize information loss during early-stage downsampling of weld-defect features while preventing feature discontinuities caused by batch operations. Finally, the lightweight cross-scale feature-fusion module CCFM is incorporated into the neck to construct the C-Neck architecture. This design enhances the model's adaptability to defects across different scales, particularly improving detection performance for small targets. Figure 1 illustrates the architecture of the improved YOLOv8n model.
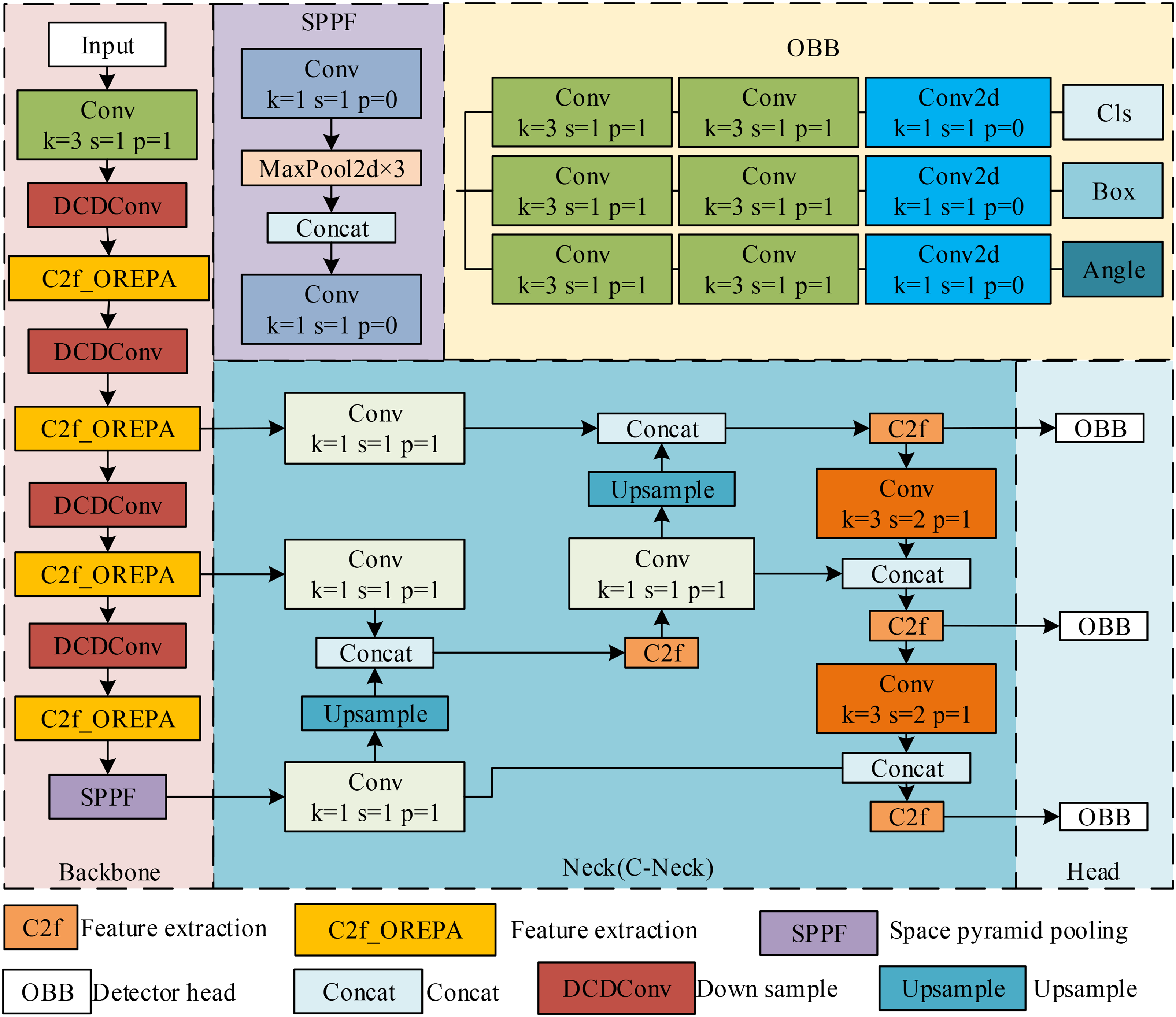
Improved YOLOv8n algorithm.
C2f_OREPA module
To meet the dual requirements of high inference efficiency and detection accuracy in industrial weld inspection, this study proposes replacing the original C2f structure in the backbone with the C2f_OREPA module. This modification addresses the high computational cost and limited sensitivity to low-contrast defects inherent in the original YOLOv8n C2f module. The C2f_OREPA module integrates the Online Convolutional Re-parameterization (OREPA) mechanism, which substantially reduces computational complexity and resource consumption during model training while preserving strong feature-extraction capability. The architecture of the C2f_OREPA module is shown in Figure 2.
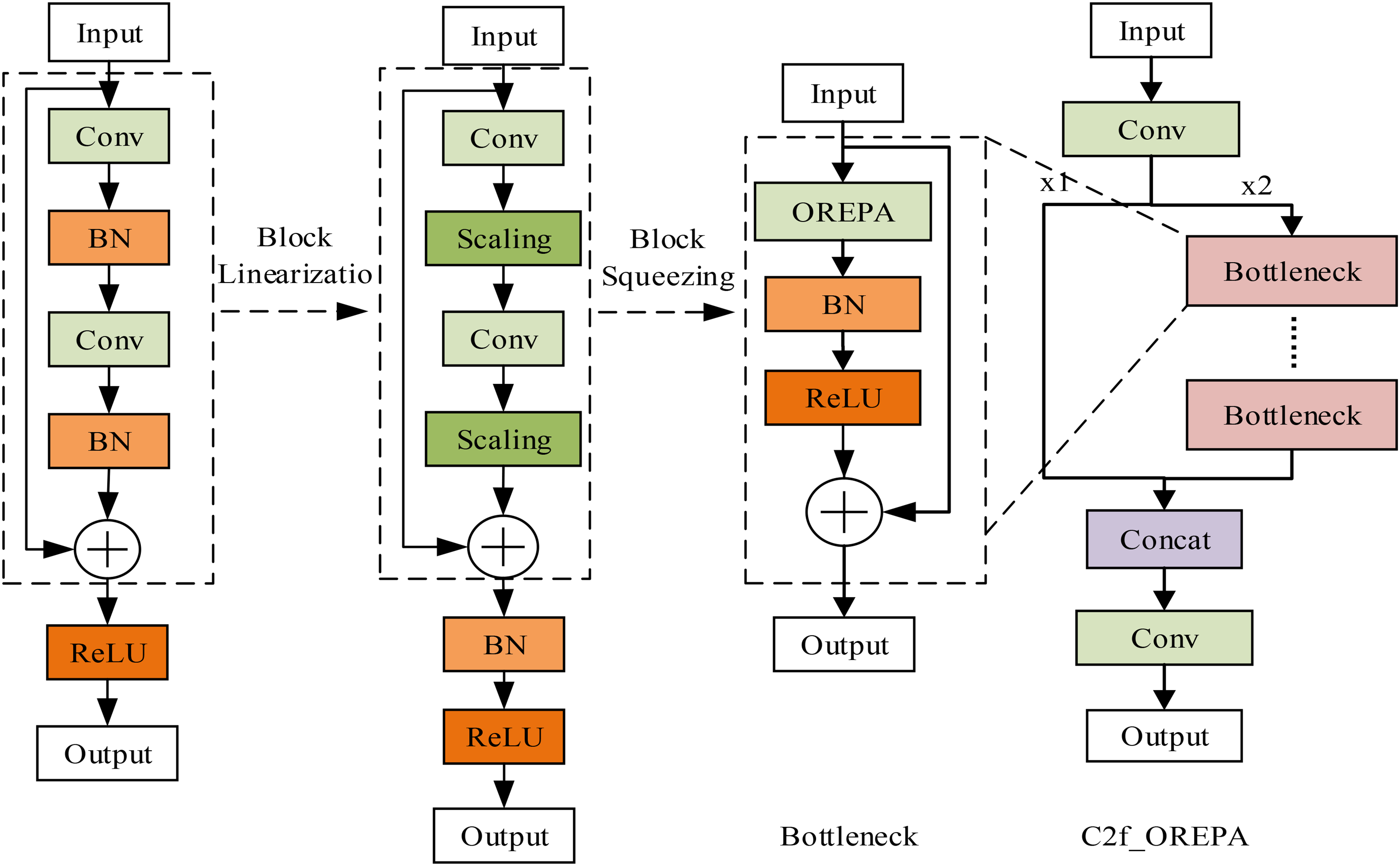
C2f_OREPA structure.
The core of the OREPA method is to enhance training efficiency through two stages: (1) using linear scaling layers to improve the training performance of online modules, and (2) compressing multiple complex convolutional layers across training stages into a single convolutional operation, thereby greatly reducing training overhead. The detailed implementation process of the OREPA module is presented in Figure 3.
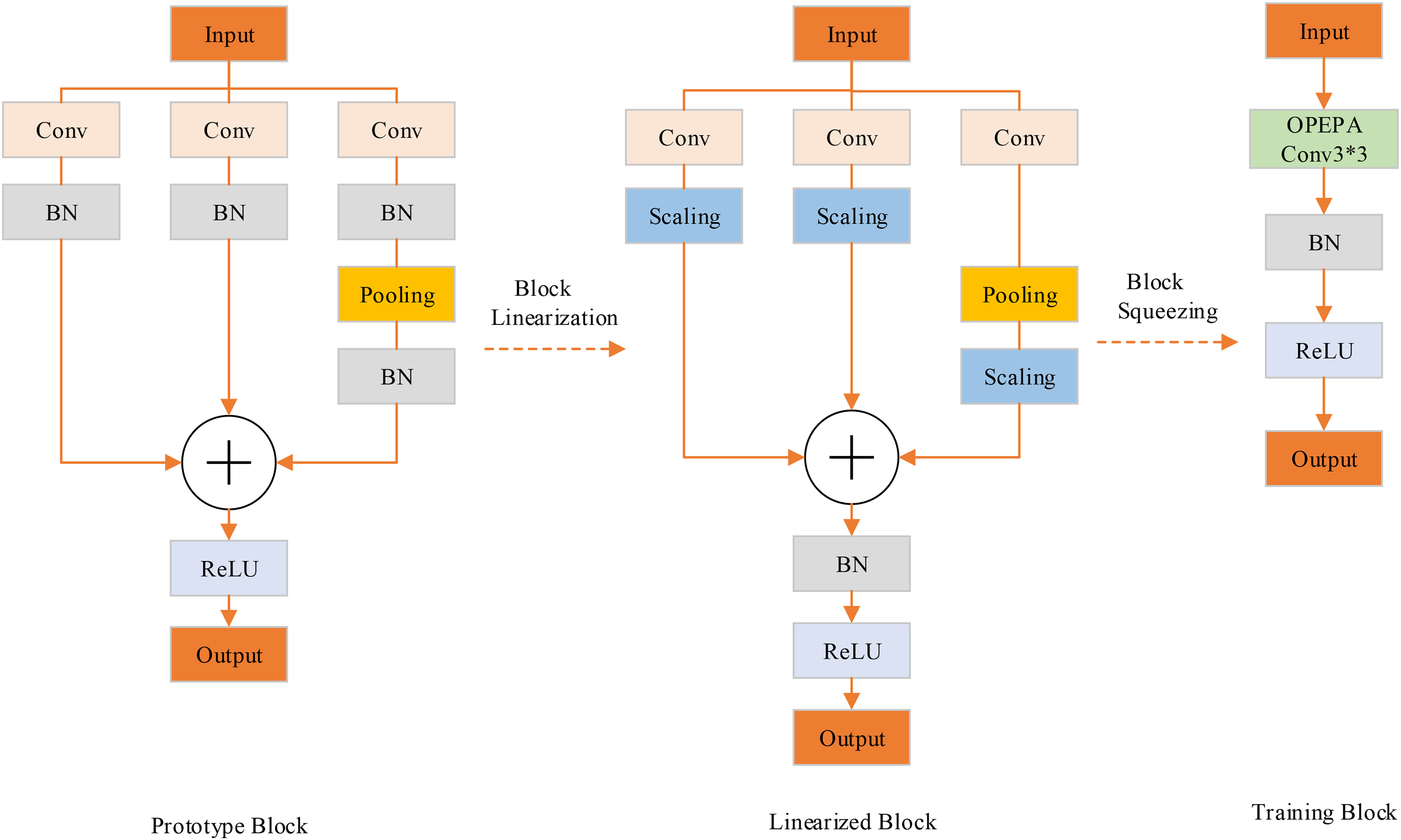
OREPA structure.
Block linearization
The linearization phase of the module consists of the following 3 steps:
Removal: First, remove all the training-time non-linear normalization layers in the reparameterization block. Add Scaling: Second, add a linear scaling layer at the end of each branch to diversify the optimization directions. Add Normalization: Finally, add a post-normalization layer right after each block to stabilize training.
Block squeezing
Block squeezing primarily aims to reduce the computational burden and storage requirements imposed by intermediate layers in neural networks. This process transforms linear blocks into a single convolutional kernel, enabling operations originally performed on intermediate feature maps to be executed more efficiently on the kernel itself. This structural simplification reduces both computational cost and memory consumption. The concept of block squeezing is illustrated in Figure 4, where Figure 4(a) shows the simplified sequential structure and Figure 4(b) visualizes the simplified parallel structure.
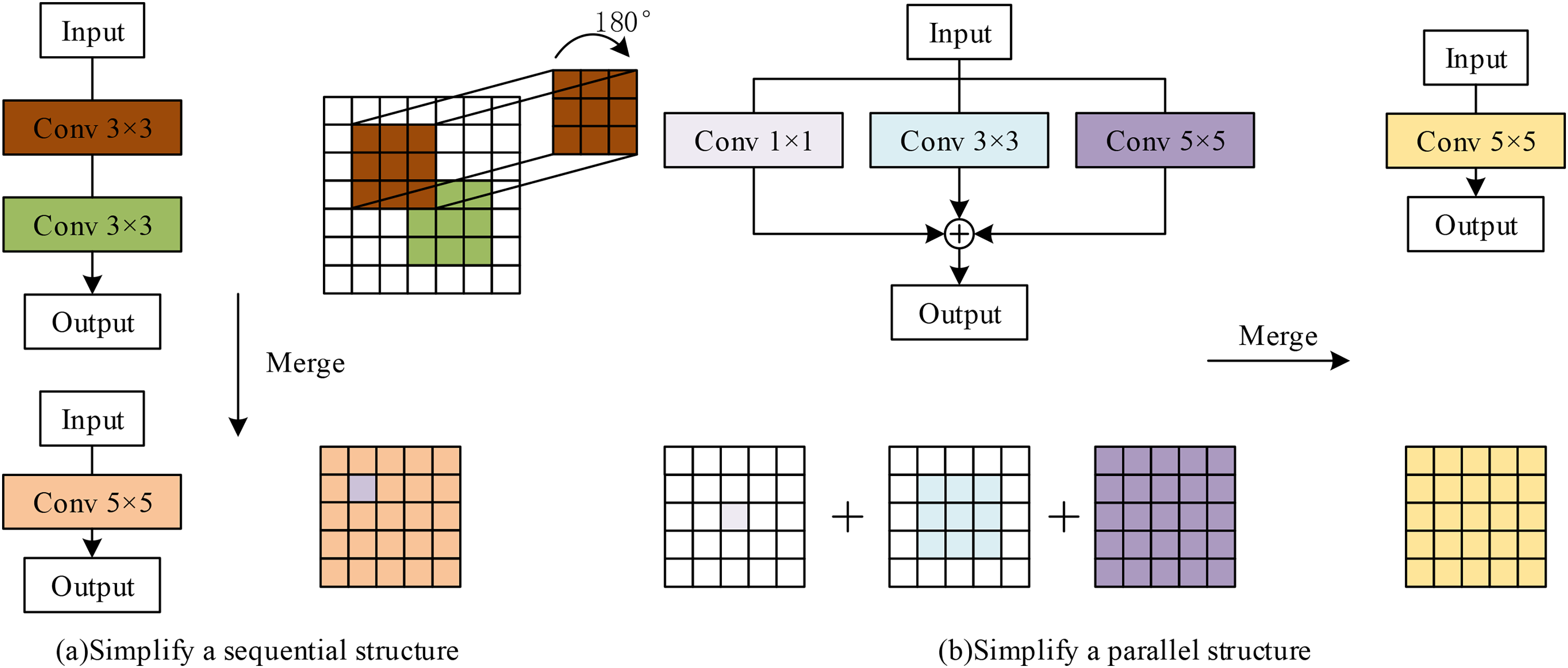
Block squeezing. (a) simplify a sequential structure, (b) simplify a parallel structure.
In the following sections, we demonstrate the simplification of sequential structures (Figure 4(a)) and parallel structures (Figure 4(b)), beginning with the definition of convolutional notation. Let X and Y denote the input and output tensors, respectively, and let W represent the convolutional weights. Omitting the bias term, which is common practice, the convolution operation can be expressed as: Simplifying Sequential Structure

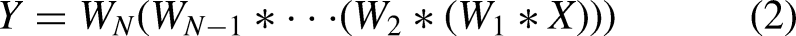
Based on the associative property, these layers can be compressed into a single layer as shown in Equation (3): Simplifying Parallel Structure
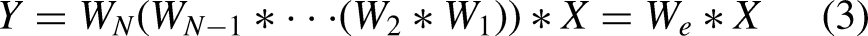
Leveraging the linearity of convolutions, parallel structures can merge multiple branches into one according to Equation (4):
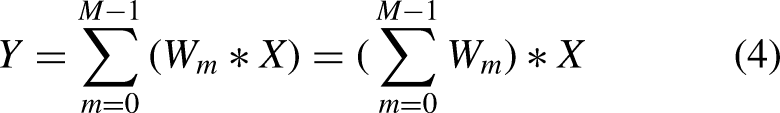
Based on these two simplification rules, a single convolution operation during training is sufficient to obtain unified end-to-end mapping weights. The core idea of the OREPA method is to transform operations—such as convolution and element-wise addition—that were originally performed on intermediate feature maps into direct manipulations of convolutional kernels. This strategy not only streamlines the model architecture but also improves training efficiency and offers a novel implementation pathway for constructing high-performance detection models.
Given OREPA's capability to substantially reduce computational overhead while maintaining model accuracy, this study incorporates it into the C2f module of YOLOv8. In particular, the convolutional layer in the original Bottleneck structure is replaced to optimize the module. By reparameterizing the original complex structure into a single convolutional layer, the approach significantly reduces computational cost and training time while preserving the richness of feature representations and maintaining diversity in optimization directions. This modification also accelerates the convergence of the model.
DCDConv module
To address typical characteristics of industrial weld defects—such as blurred edges and low contrast—and to overcome the limitations of the original convolutional (Conv) modules in YOLOv8n, which extract information in a single manner and exhibit limited representation capability, this study proposes the DCDConv module with enhanced feature extraction capacity. The proposed module replaces most Conv layers in the backbone, except for the initial layer. This design improves the model's sensitivity to subtle defects while retaining the initial convolutional layer to avoid excessive loss of the original weld information. As a result, the model maintains high detection accuracy while achieving better suitability for lightweight network architectures.
As illustrated in Figure 5(b), the DCDConv module first performs preliminary downsampling using AvgPool2d and then splits the feature map along the channel dimension. One branch is processed using Focus convolution, whereas the other passes sequentially through MaxPool2d, a convolution layer, and a SiLU activation function. This architecture effectively preserves edge information of small defects while reducing the spatial dimensions of the feature map, thereby improving the model's ability to detect small targets. Focus convolution performs downsampling through slicing operations, transforming high-resolution inputs into low-resolution feature maps with expanded channel dimensions. This operation reduces computational cost and reorganizes spatial information into the channel dimension. The subsequent convolution, batch normalization (BN), and SiLU activation further enhance feature extraction, improving the capture of critical information while minimizing detail loss.
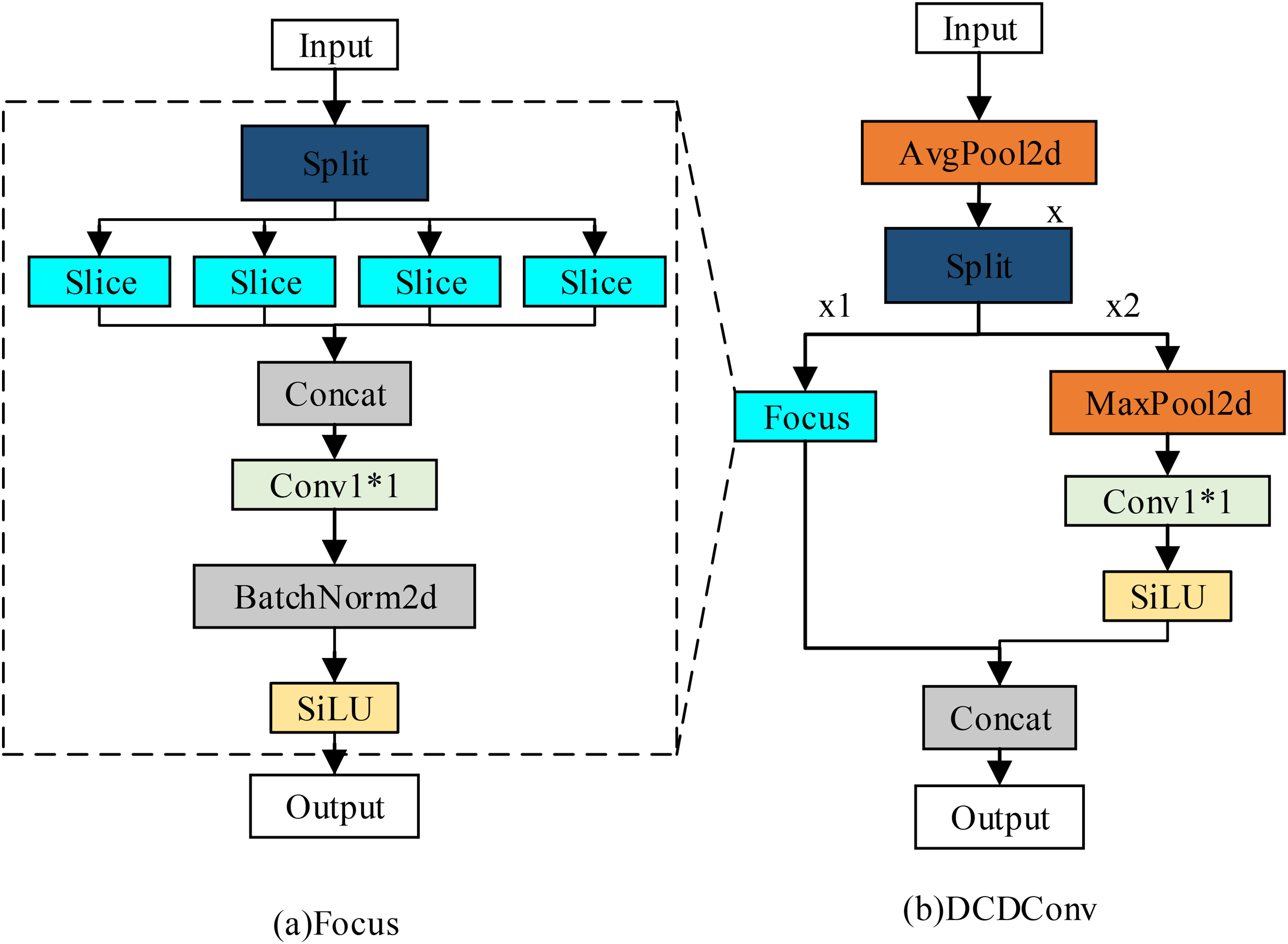
DCDConv structure. (a) Focus, (b) DCDConv.
The DCDConv module adopts a “pooling + convolution” core architecture, replacing the traditional stacked convolutional layers. This design substantially reduces the number of parameters and lowers memory consumption. The overall structure of the DCDConv module is presented in Figure 5.
The specific calculation formula for DCDConv is:
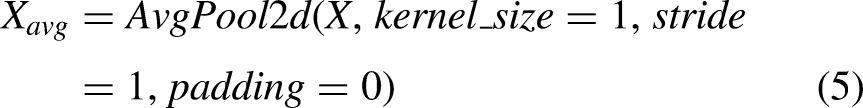
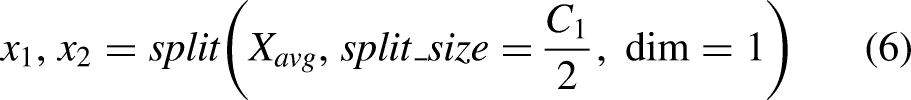

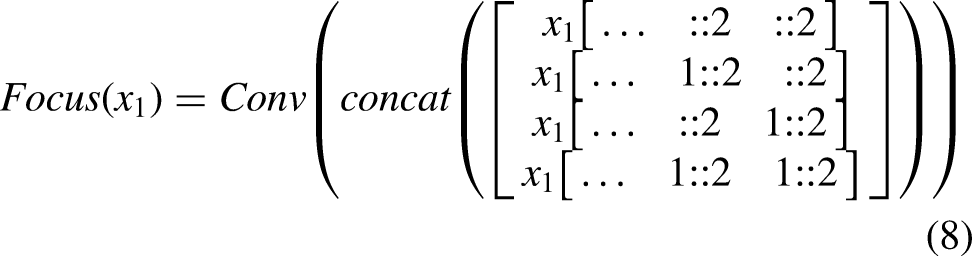
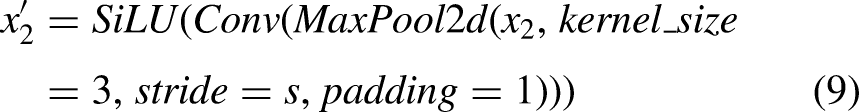
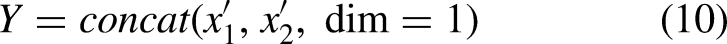
C-Neck module
To address the challenges posed by the variability in weld defect sizes, the high similarity among different defect categories, and the limited ability of traditional methods to integrate cross-scale information and capture multi-class defect features, this study introduces a Cross-Scale Feature Merging Module (CCFM) to enhance the neck portion of the original network. The proposed module effectively integrates multi-level features, improving the model's adaptability to scale variations and enhancing its detection performance for small-scale defects. By combining fine-grained features with contextual semantic information, the CCFM substantially improves the model's overall performance in complex weld defect scenarios.
Specifically, a 1 × 1 convolution is first applied to the feature maps generated by the backbone. This operation reduces the number of channels while preserving the spatial resolution of the feature maps, thereby decreasing the parameter count and facilitating cross-channel information exchange to enhance feature representation. The improved neck structure, referred to as C-Neck, is illustrated in the Neck section of Figure 1. The detailed architecture of the CCFM module is presented in Figure 6.
CCFM module structure.
The fusion block integrates two adjacent-scale features into a new feature representation, as illustrated in Figure 6 (Fusion). It comprises two 1 × 1 convolutional layers for channel adjustment, followed by N RepBlocks—each consisting of sequential RepConv layers—for progressive feature fusion. The outputs from the two branches are merged using element-wise addition. The computation for this process is formulated as follows: Training Phase Inference phase:
Where X is the input and
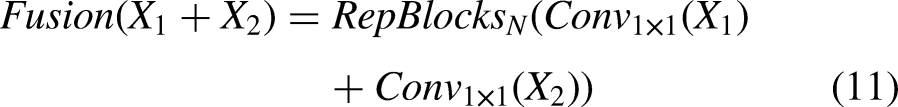
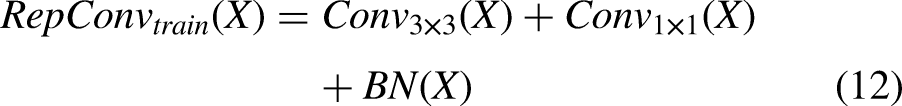
Merge convolutions with
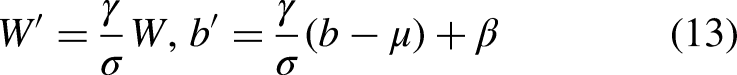
Merging multiple branches: A 1 × 1 convolution kernel can be transformed into a 3 × 3 convolution kernel through zero-padding. An identity mapping can be considered as a 1 × 1 convolution with a unit matrix kernel, which can likewise be converted into a 3 × 3 convolution kernel. Finally, the three transformed 3 × 3 convolution kernels are summed together, along with their respective biases, resulting in a final, functionally equivalent 3 × 3 convolutional layer
Therefore, during inference, the computation within a RepConv block simplifies to:
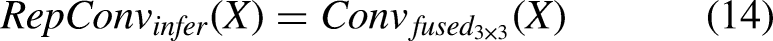
Complexity analysis
To evaluate the efficiency of the proposed model and its suitability for deployment in resource-constrained environments, this section provides a comprehensive analysis of its theoretical time and space complexity.
Theoretical complexity analysis offers hardware-independent efficiency metrics, primarily including the number of parameters (Params) and floating-point operations (FLOPs). In this study, floating-point operations (FLOPs) are used as the primary quantitative metric. By comparing the original YOLOv8n modules—C2f, Conv, and Neck—with the enhanced modules proposed in this work—C2f_OREPA, DCDConv, and C-Neck—and aligning the results with the GFLOPs reported in the experimental section, this study verifies the lightweight advantages of the proposed model.
Two widely used metrics are adopted in this study.
Parameters: The total number of learnable weights and biases in the model. Parameters determine the model's size and serve as a key indicator of spatial complexity, typically measured in millions (M). Floating-Point Operations (FLOPs): The total number of floating-point calculations required for a single forward pass. FLOPs are the primary measure of temporal complexity and reflect the computational burden of the model, typically expressed in billions (G).
For parameter estimation, the total number of learnable weights across all layers—including convolutional and fully connected layers—was calculated. For FLOPs computation, only convolutional layers were considered, as they contribute to the majority of the computational cost. The FLOPs for a convolutional layer are computed as follows:
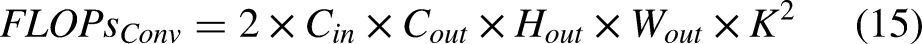
Analysis of the data in Table 1 indicates that the proposed C2f_OREPA module increases the number of parameters by 83.1% (+0.59 M) compared with the original C2f module, while simultaneously reducing computational complexity by 53.8% (−0.7 GFLOPs). The increase in parameters mainly stems from the additional trainable weights introduced by the OREPA architecture, which is designed to improve the model's representational capacity during training. However, the principal advantage of this module is its ability to equivalently transform complex multi-branch structures into a single convolutional layer during inference. This transformation eliminates redundant computational paths, achieving substantial computational compression. Compared with standard convolutional downsampling, the proposed DCDConv module reduces parameters and computational load by 85.3% (−0.29 M) and 31.6% (−0.6 GFLOPs), respectively, thereby significantly improving both parameter efficiency and computational efficiency. These improvements make the module particularly suitable for edge deployment scenarios, where model size and computational resources are severely constrained. The improved C-Neck module reduces the number of parameters and computational load by 82.6% (−1.09 M) and 34.1% (−1.5 GFLOPs), respectively. By streamlining intermediate channel dimensions and eliminating redundant computations, it enables more efficient multi-scale feature interaction while largely preserving the original feature fusion capability. These improvements significantly reduce the complexity and computational burden of the neck network.
Complexity analysis of original and improved modules.

Experimental results and analysis
Dataset introduction
This study employs a self-constructed weld defect dataset for experimental evaluation. The dataset contains eight common types of weld defects: lack of penetration, crack, undercut, indentation, pit, broken arc, circular defect, and barred defect. It consists of 490 original images with a resolution of 1920 × 1536 pixels. To address the limited dataset size, image augmentation techniques, including rotation, were applied, increasing the total number of images to 923. After annotation, these images formed the final experimental dataset. To ensure balanced data distribution, the dataset was divided into training, validation, and test sets in an 8:1:1 ratio. Stratified sampling was adopted to maintain consistent proportions of each defect type across subsets, thereby preventing classification bias from affecting model evaluation. Additionally, transfer learning was incorporated using the COCO2017 dataset as the source domain for pre-training. Despite substantial differences between the source and target domains, this approach effectively accelerates model convergence, alleviates feature redundancy issues associated with training from scratch, and ultimately improves performance on the self-constructed weld seam dataset. After pre-training, the model parameters were transferred to the weld defect detection task for fine-tuning. By combining data augmentation with transfer learning, the study achieved effective defect detection performance despite the limited amount of labeled data.
To validate the model's generalization capability, comparative experiments were further conducted using the public NEU-DET dataset. The results demonstrate that the improved model achieves stable and superior detection performance across diverse data environments.
Experimental environment
For this study, the CPU configuration consisted of an Intel® Core™ i5-9400F processor running at 2.90 GHz, while the GPU configuration utilized an NVIDIA GeForce GT 1060 with 6 GB of memory. The deep learning framework employed was PyTorch version 1.12, with CUDA version 11.6 and Python version 3.9. Model parameter settings are detailed in Table 2.
Parameter settings of the model.
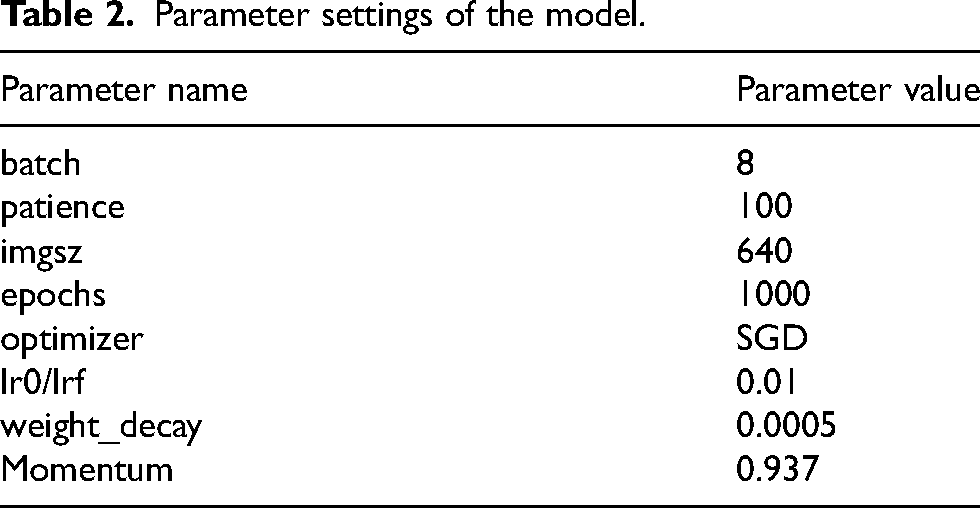
All models were trained using 640 × 640 input images and identical training parameters for up to 1000 epochs under consistent experimental conditions. An early stopping mechanism was applied to terminate training if no performance improvement was observed during the last 100 epochs. All models were trained according to the settings listed in Table 2.
Evaluation metrics
Model performance was evaluated using precision (P), recall (R), mean Average Precision (mAP), number of parameters (Params), computational complexity (GFLOPs), and inference speed (FPS). Specifically, the number of parameters (Params) reflects the model size, with larger parameter counts requiring more memory. Computational complexity (GFLOPs) quantifies the model's computational workload in gigaflops per second. Inference speed (FPS) represents the number of frames processed per second, where higher FPS values indicate faster inference. The Average Precision (AP) for a single class denotes the area under the precision–recall curve. The mAP represents the mean Average Precision across all classes at an Intersection over Union (IoU) threshold of 0.5. Higher mAP values indicate better detection performance. The formula for calculating mAP is as follows:

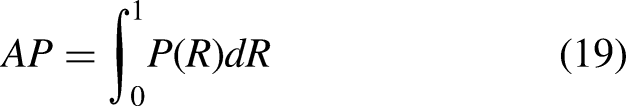
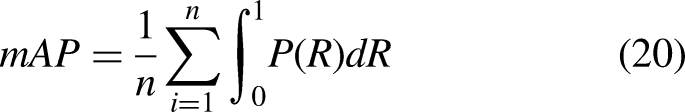

Comparative experiments on different positions of the downsampling DCDConv module
To evaluate how different placements of the DCDConv module affect detection performance, four comparative experiments were conducted. The results are summarized in Table 3. The experimental configurations are as follows: Group 1 uses the original YOLOv8n model; Group 2 replaces all standard convolutions in both the backbone and neck with DCDConv; Group 3 replaces only the backbone convolutions; and Group 4 replaces only the neck convolutions.
Effect of different locations of DCDConv on model performance.

As shown in Table 3, applying DCDConv exclusively to the backbone (Group 3) yields a 3.7% increase in mAP, a 9% reduction in parameters, a 0.6 GFLOPs decrease in computational cost, and nearly identical inference speed. Considering accuracy, computational complexity, and efficiency, this study adopts replacing standard backbone convolutions with DCDConv as the final model optimization strategy.
Feature extraction module comparison experiment
To validate the effectiveness of the improved algorithm in constructing the C2f_OREPA feature extraction module for weld defect detection, four alternative feature extraction modules were selected to replace the original C2f for comparison. The selected modules include C2f_DUAL, 27 C2f_DCNv3, 28 C2f_ODConv, 29 and C2f_OREPA. Performance comparison experiments were conducted on a self-constructed dataset using these four feature extraction modules under consistent experimental conditions and parameter settings. The comparison results are summarized in Table 4.
Comparison results of four feature extraction modules.
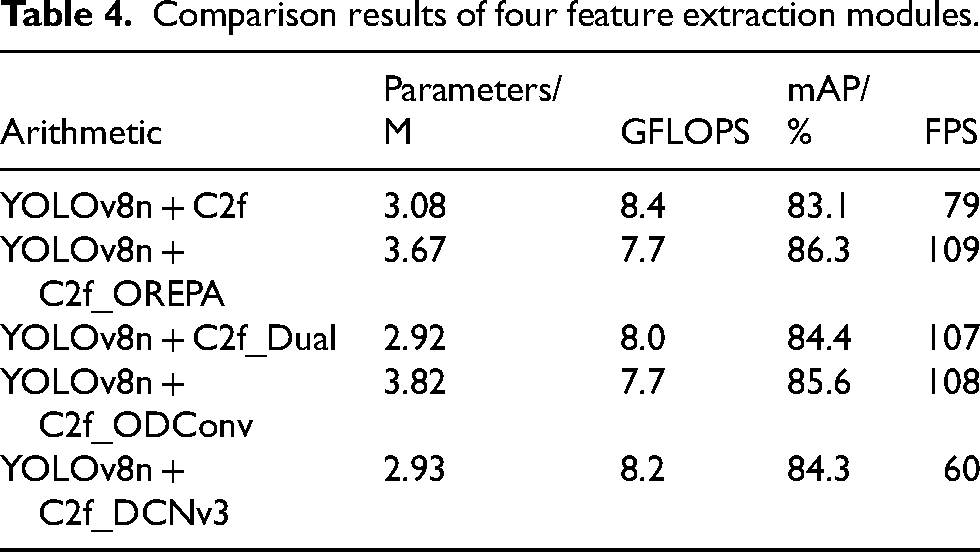
As shown in Table 4, incorporating the C2f_OREPA feature extraction module increases mAP by 3.2%, incurs only a minor increase in parameters, reduces computational cost by 0.7 GFLOPs, and substantially improves detection speed. Therefore, this study adopts the C2f_OREPA feature extraction module to replace the original C2f module as the proposed network improvement.
Ablation studies
Building on the preliminary experiments, this section presents ablation studies using the YOLOv8n model as the baseline. The three proposed improvement modules from Section 3—C-Neck (A), C2f_OREPA (B), and DCDConv (C)—are introduced sequentially to evaluate their individual contributions. The results are summarized in Table 5.
Results of ablation experiments.
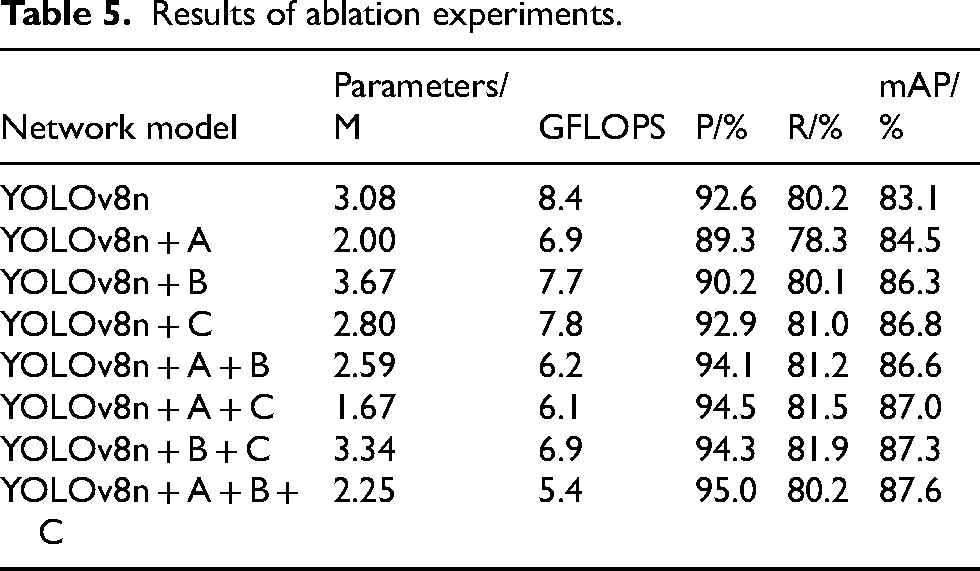
As shown in Table 5, the comprehensive improvement scheme proposed in this study reduces the number of parameters by 26.9%, decreases computational complexity by 35.7%, and increases mAP by 4.5% compared with the original YOLOv8n model. These results indicate that the synergistic effect of the three modules effectively enhances model performance, demonstrating the strong potential of the proposed method for weld defect detection.
The results indicate that when introduced individually, DCDConv provided the most significant improvement in mAP (+3.7%), confirming its effectiveness in preserving fine-grained features. C2f_OREPA increased mAP by 3.5%, demonstrating its effectiveness in enhancing feature extraction capabilities. C-Neck contributed a 1.4% increase in mAP, underscoring the crucial role of cross-scale feature fusion. When all three modules were integrated synergistically, mAP further increased by 4.5%, indicating strong complementarity among the modules. The enhanced network outperformed the original model in precision, recall, and mAP, demonstrating improved task adaptability and stronger generalization capability.
To visually assess the detection performance of the improved network, this study compares the training results of the original model with those obtained after introducing each individual module. During training, the maximum number of iterations was set to 1,000, and an early stopping mechanism was applied, terminating training if validation performance failed to improve for 100 consecutive iterations. Key performance metrics were recorded every 10 iterations, and the corresponding performance curves are shown in Figure 7.
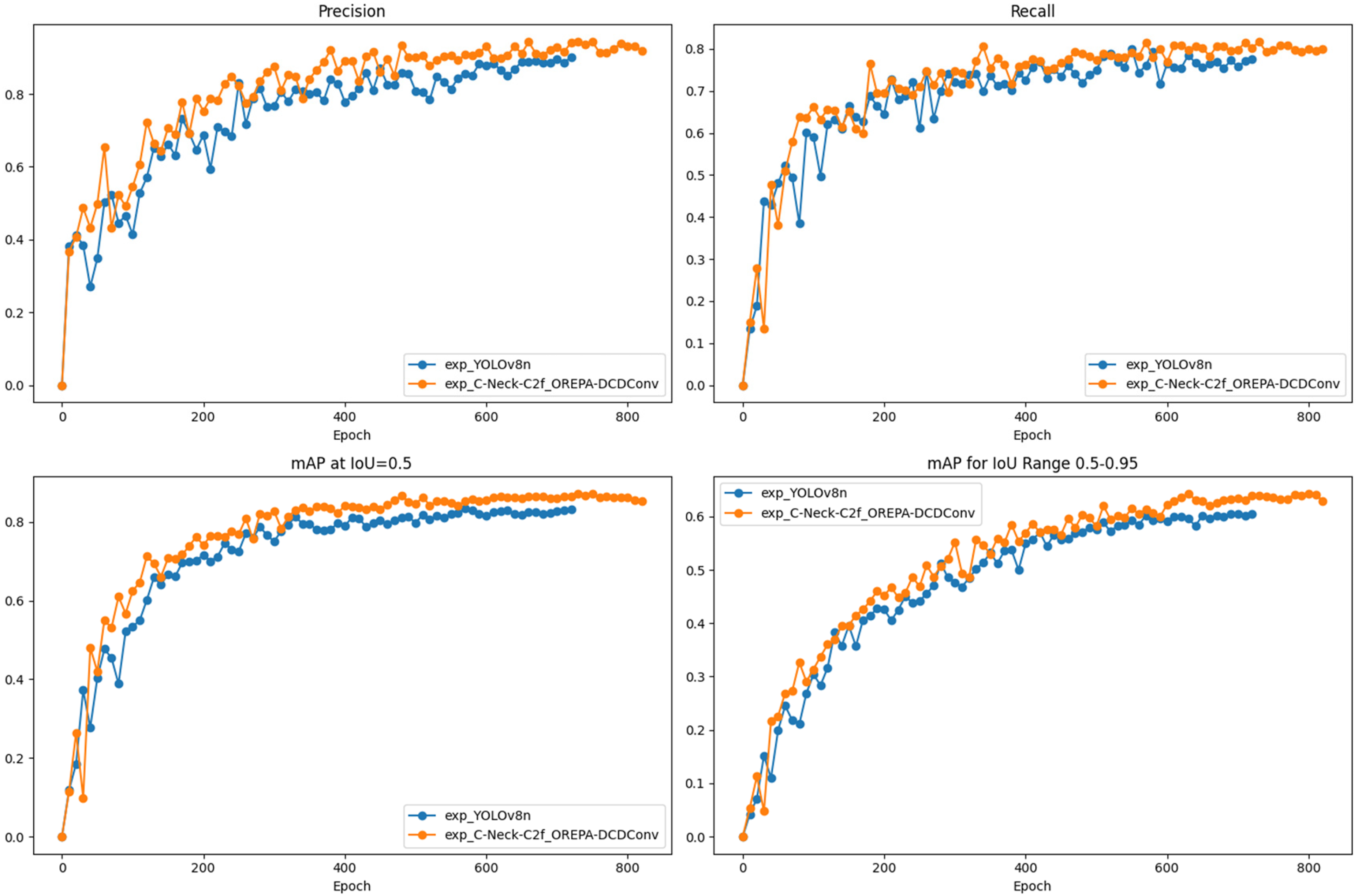
Comparison of evaluation indexes of ablation experiments.
Comparative experiments with other algorithms
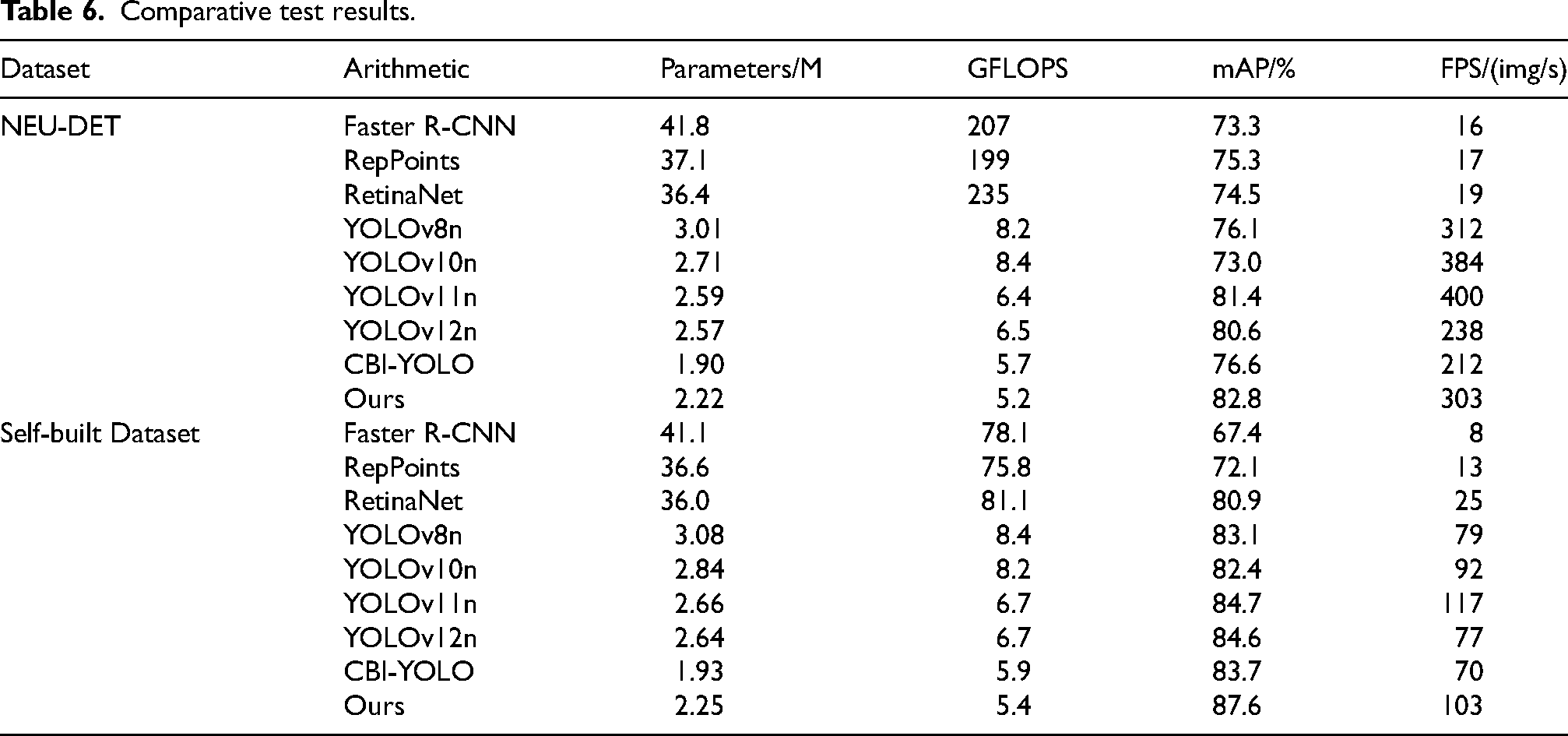
To comprehensively evaluate the effectiveness of the proposed algorithm, the improved model was compared with several mainstream detection models, including Faster R-CNN, RepPoints, RetinaNet, YOLOv8n, YOLOv10n, YOLOv11n, YOLOv12n, and CBI-YOLO. The evaluation was conducted across four dimensions: detection accuracy (mAP), number of parameters, computational complexity (GFLOPs), and inference speed (FPS). Additionally, to assess the model's generalization capability, all models were uniformly evaluated on the public NEU-DET dataset. The results are summarized in Table 6. As shown in Table 6, on the NEU-DET dataset, the proposed algorithm achieves an mAP of 82.8%, outperforming all comparison models. This corresponds to a 6.7% improvement over the original YOLOv8n and a 1.4% increase over the best-performing comparison model, YOLOv11n. On the self-constructed dataset, the proposed algorithm achieves an mAP of 87.6%, the highest among all models, representing a 4.5% improvement over YOLOv8n and demonstrating consistently high-precision detection performance. Across both datasets, the proposed algorithm exhibits the lowest computational complexity among all comparison models, with parameter count only slightly higher values than CBI-YOLO. Compared with YOLOv8n, it reduces the parameter count by approximately 26% and the computational complexity by about 35%, demonstrating excellent lightweight characteristics. Overall, the results demonstrate that the proposed improved model achieves an effective balance between accuracy and efficiency, exhibiting superior overall performance.
Comparative test results.
Detection effect comparison
To systematically evaluate the performance of various object detection models across different weld defect detection tasks, this study compares the detection accuracy (AP) and mean Average Precision (mAP) for eight defect categories: lack of penetration (la), crack (cr), undercut (un), indentation (in), pit (pi), broken arc (br), circular defect (ci), and barred defect (ba). The results are summarized in Table 7.
Comparison of weld defect detection accuracy Among different models.
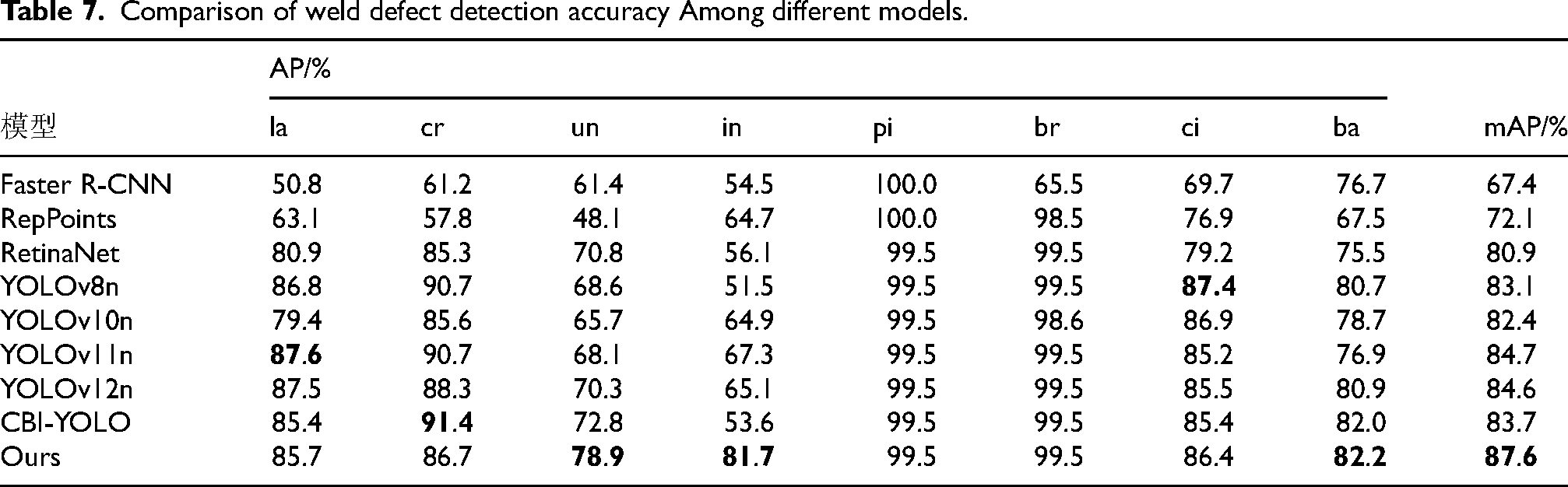
In terms of detection accuracy (AP) for each defect type, the proposed algorithm demonstrates superior performance across multiple categories. Specifically, for undercut (un) and indentation (in) defects, the algorithm achieves AP values of 78.9% and 81.7%, respectively, significantly outperforming all comparison models. For critical defect types such as crack (cr) and lack of penetration (la), the proposed algorithm attains AP values of 86.7% and 85.7%, respectively. Although these values are slightly lower than the peak performance of YOLOv8n and YOLOv11n in individual categories, they still represent a high level of accuracy. For relatively easier-to-detect defects, such as pits (pi) and broken arcs (br), the proposed algorithm achieves near-saturated performance of 99.5%, comparable to that of multiple mainstream models. In terms of overall detection performance (mAP), the proposed algorithm ranks first with 87.6%, outperforming YOLOv11n (84.7%), YOLOv12n (84.6%), and the original YOLOv8n (83.1%), while substantially surpassing two-stage detectors such as Faster R-CNN (67.4%). These results demonstrate that, while maintaining strong detection capability for highly visible defects, the proposed algorithm substantially enhances its ability to detect challenging defects, exhibiting a more balanced and robust overall detection performance.
To visually compare the detection performance of the improved YOLOv8n model with other mainstream detectors, Figure 8 displays representative examples from eight weld defect categories. The results show that models such as Faster R-CNN, RepPoints, RetinaNet, YOLOv8n, YOLOv10n, YOLOv11n, YOLOv12n, and CBI-YOLO exhibit varying levels of missed detections or false positives in specific defect categories. Specifically: (1) undercut defects: Faster R-CNN, RepPoints, YOLOv8n, and CBI-YOLO exhibited missed detections. (2) circular defect: RetinaNet exhibited missed detections. (3) barred defect: Faster R-CNN, RepPoints, and YOLOv10n showed missed detections. (4) lack of penetration defects: RepPoints and YOLOv12n showed missed detections. (5) indentation: YOLOv11n generated false positives.
Comparison of detection effect of 8 types of defects.
In contrast, the improved model proposed in this study demonstrates more stable detection performance and higher localization accuracy across all defect categories, effectively reducing both false negatives and false positives. These findings confirm that the enhanced YOLOv8n model offers superior robustness and practical utility for weld defect detection, making it well-suited for high-precision inspection in complex industrial environments.
Discussion and conclusions
To address the challenges of high false negative and false positive rates, complex computational structures, and excessive parameter counts in weld defect detection, this study proposes a detection model built upon an improved YOLOv8n architecture. By integrating three modules—C-Neck, DCDConv, and C2f_OREPA—the model achieves notable improvements in detection performance while preserving a lightweight design. Experimental results show that the improved model achieves a mean average precision (mAP) of 87.6%, corresponding to a 4.5% improvement over the original YOLOv8n. It reduces the parameter count by 26.9%, lowers computational complexity by 35.7%, and achieves an inference speed of 103 frames per second (FPS), thereby striking a favorable balance between detection accuracy and efficiency. Although the parameter count of our model slightly exceeds that of CBI-YOLO, it surpasses mainstream detectors such as YOLOv11n and YOLOv12n by reducing parameters by more than 14.8% while increasing mAP by over 2.9%. These results demonstrate a clear comprehensive advantage in both accuracy and efficiency, confirming its potential for deployment in resource-constrained industrial environments.
Although the proposed approach demonstrates strong accuracy and a lightweight architecture, its generalization capability in extremely small-sample scenarios remains limited. The current model relies on data augmentation and transfer learning to alleviate the scarcity of labeled data. Future research could explore small-sample learning strategies—such as Generative Adversarial Networks (GAN) and meta-learning—to generate high-quality synthetic samples or develop cross-domain adaptation mechanisms. Such approaches could reduce dependence on large-scale labeled datasets and enhance the model's adaptability in data-scarce scenarios.
Footnotes
Acknowledgments
We would like to thank the editors and reviewers for their review, who improved the paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Natural Science Foundation of Shanxi Province under Grant 202303021211148 and 202203021222038 and the National Natural Science Foundation of China under Grant 62401517.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.