
Abstract
Intraoperative cone beam computed tomography (CBCT) is critical for pedicle screw planning; however, image quality is frequently compromised by artifacts and low contrast, potentially leading to adverse clinical outcomes. To address these limitations, we propose the Spatiotemporal Adaptive Warm-Start Diffusion Model (STADW-M), a novel framework aimed to generate high-quality synthetic CT (sCT) images from CBCT data, thereby enhancing surgical precision. The STADW-M integrates an Artifact-Aware Adaptive Diffusion Module to mitigate localized artifact distributions and a Dually-Guided Structural Consistency Module to preserve anatomical integrity. Furthermore, we employ a CBCT Warm-Start strategy alongside composite loss functions to optimize textural fidelity and accelerate model convergence. Quantitative experiments demonstrated significant improvements over original CBCT images: with RMSE decreased from 890.1 to 152.9 HU, MAE decreasing from 859.7 to 102.6 HU, and PSNR increased from 13.6 to 27.9 dB. Crucially, the generated sCTs maintained high anatomical consistency with reference CTs. In clinical validation, automated screw planning based on sCTs achieved a 100% Grade A standard, with 94.7% of screws placed without cortical breach and 5.3% exhibiting only minor (<2 mm) erosion. The proposed method effectively synthesizes high-quality CT images, preserving vertebral anatomy and significantly improving the accuracy and safety of intraoperative pedicle screw planning.
Keywords
Introduction
Different imaging modality can capture distinct information about tissues, thereby enabling a comprehensive evaluation of anatomical structures and functions in the human body. It, in turn, can help improve the accuracy and precision of subsequent diagnostic and therapeutic tasks. 1 Consequently, multi-modal imaging is well employed in therapeutic tasks to enhance diagnostic accuracy and treatment decisions, such as image-guided surgery and radiation therapy. 2 Cone-beam computed tomography (CBCT) is instrumental in image-guided diagnostic and therapeutic systems in clinical practice, owing to its capacity for on-site and high-resolution volumetric imaging for patients undergoing therapy. 2 A primary application of CT and CBCT image-guided treatments lies in robot-assisted spinal surgery. Numerous studies indicate that the surgery, guided by CT or CBCT images, enhances screw placement accuracy and diminishes radiation exposure time.3–8 CBCT is typically a necessary imaging tool for image-guided or robot-assisted spinal surgeries, with screw paths typically planned by surgeons directly on intraoperative CBCT or by registering preoperative CT images to intraoperative CBCT images. Nonetheless, the physical imaging properties of CBCT frequently lead to a high degree of image artifacts, inadequate contrast, and compromised image quality.9–12 Quality-reduced CBCT images may lead to increased uncertainty in screw planning, potentially causing improper screw placement and serious complications. Consequently, obtaining high-quality intraoperative CBCT images is crucial for high quality and reliable image-guided or robot-assisted spinal surgeries.
Recently, numerous model-based methods have been developed and studied to improve the image quality of CBCT.13–17 Alongside these conventional model-based methods for enhancing image quality, techniques employing Convolutional Neural Networks (CNN) have also been widely used to augment CBCT image quality and to convert CBCT into CT. UNET is an easily implemented, stable generative network for synthesizing CT from CBCT. Kida, Chen, Thummerer, and Yuan et al.12,18–20 utilized a UNET-based network model and trained it with paired data to generate two-dimensional synthesized CT images of various anatomical regions. Recently, Generative Adversarial Networks (GAN) models have been extensively employed in image generation tasks. Owing to the adversarial loss, GAN network models and Cycle GAN network models exhibit remarkable realism in image synthesis, while eliminating the need for strictly paired data.21–23 Using GAN networks trained with paired data, Barateau, Zhang, and Dahiya et al.24–26 successfully generated synthesized CT images for the head, neck, pelvis, and other anatomical locations, thereby significantly enhancing the quality of CBCT images. Kida, Kurz, Lei, Liu, Gao, Xue, and Lemus et al.27–33 improved upon the Cycle GAN network model and created synthesized CT images for various regions, such as the pelvis, abdomen, brain, chest, and nasopharynx, from CBCT images. Their methods substantially increased the realism and observability of the synthesized CT images. Despite the promising experimental results achieved by these methods, they still possess limitations. The UNET-based generative model, while easy to implement, necessitates strict paired data and suffers from anatomical misalignment issues, which negatively impact model accuracy and image authenticity. The GAN generative model exhibits unstable convergence, slow training, and weak retention of anatomical structures for unpaired data. In a similar vein, the Cycle GAN model also struggles with convergence, slow training, and challenges in deployment and implementation.
Serving as a recent alternative to the aforementioned methods, deep diffusion models have gained extensive attention in generative modeling within the field of computer vision.34,35 Initiating with pure noise samples, diffusion models create image samples from the target distribution through iterative denoising. This denoising is executed via trained neural network architectures, aiming to maximize data correlation. Owing to the incremental random sampling process and explicit likelihood features, diffusion models can offer enhanced sample quality and diversity. Recognizing this potential, diffusion-based approaches have lately been employed in tasks such as single-modal image generation36–40 and unconditional image generation. 41 Since diffusion models commence with pure noise samples and produce image samples through successive noise removal, it becomes apparent that distinct images are generated for various noise initializations. Different structures and pixel intensities in CT images possess explicit physiological significance, and random initialization noise may lead to alterations in generated CT structures, thereby introducing erroneous information.
In this study, we propose a novel method for synthesizing CT images from CBCT data, referred to as STADW-M. This model employs a multitask framework that integrates modules for deformable image registration, dually-guided structural consistency, and artifact-aware adaptive diffusion to generate high-quality synthetic CT images. By incorporating efficient attention mechanisms and a Warm-Start initialization, STADW-M improves both the accuracy and computational efficiency of the image generation process. Moreover, the model effectively mitigates artifacts and preserves anatomical consistency.
Materials and method
Materials
Dataset 1 (utilized for training the STADW-M network): We obtained intraoperative CBCT and preoperative CT images for 44 patients undergoing lumbar pedicle screw implantation from Beijing Jishuitan Hospital. The CBCT images have a pixel size of 0.5 mm
Dataset 2 (assessing the utility of STADW-M): We obtained intraoperative CBCT images for 36 patients from Beijing Jishuitan Hospital. The CBCT images have a pixel size of 0.5 mm
Denoising diffusion probabilistic models
Denoising Diffusion Probabilistic Models (DDPM) are a type of generative model that utilizes a Markov diffusion process with T time steps to establish a mutual mapping between real images and pure noise. In the forward direction, small amounts of Gaussian noise are repeatedly added to the real image
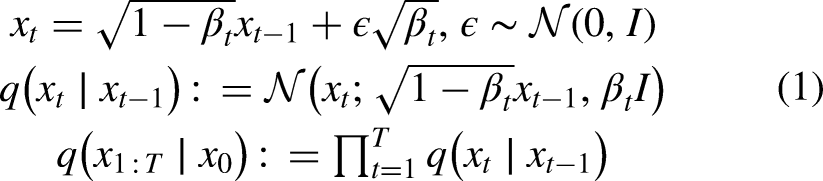
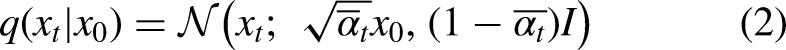
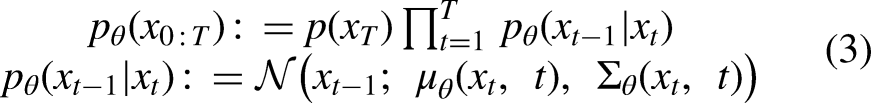
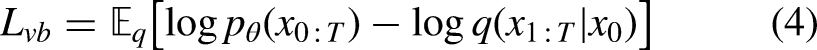

Here, KL refers to Kullback-Leibler divergence. Ho et al.
35
recommend predicting the cumulative noise
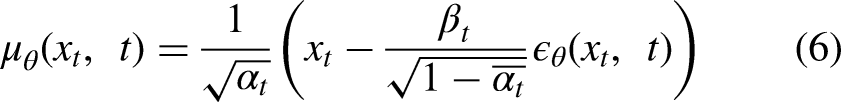

For all experiments, the diffusion process uses
Generating sCT from CBCT utilize spatiotemporal adaptive warm-start diffusion models
Model structure
The Spatiotemporal Adaptive Warm-Start Diffusion Models (STADW-M) constitutes a multitask model, comprising some modules for different tasks: The Deformable Image Registration (REG) module, the Dually-Guided Structural Consistency Module (DGSC), and the Artifact-Aware Adaptive Diffusion Module (ADM). The REG module mitigates the impact of misalignment on the results. The DGSC module combines a dual-domain guidance mechanism, incorporating spatial and Fourier domain regularization, to provide precise anatomical structure constraints. This ensures global structural integrity and low-frequency information consistency in the generated images, effectively mitigating registration errors. Meanwhile, the ADM module employs an artifact-aware adaptive diffusion process that dynamically adjusts the trajectories of forward noising and reverse denoising based on the spatial variation characteristics of artifacts in CBCT images, thereby focusing the model’s attention on the regions most in need of restoration.
In STADW-M, we adopt the U-Net
46
+ Self-Attention(SA)
47
network architecture. This structure comprises four down sampling modules as the encoder and four UpSampling modules as the decoder. Each down sampling module includes a 3D convolution module, a MaxPooling module, and a SA module, while each UpSampling module is composed of a 3D convolution module, an UpSampling module, and a SA module. For an input image with size N, the computational complexity of self-attention is approximately
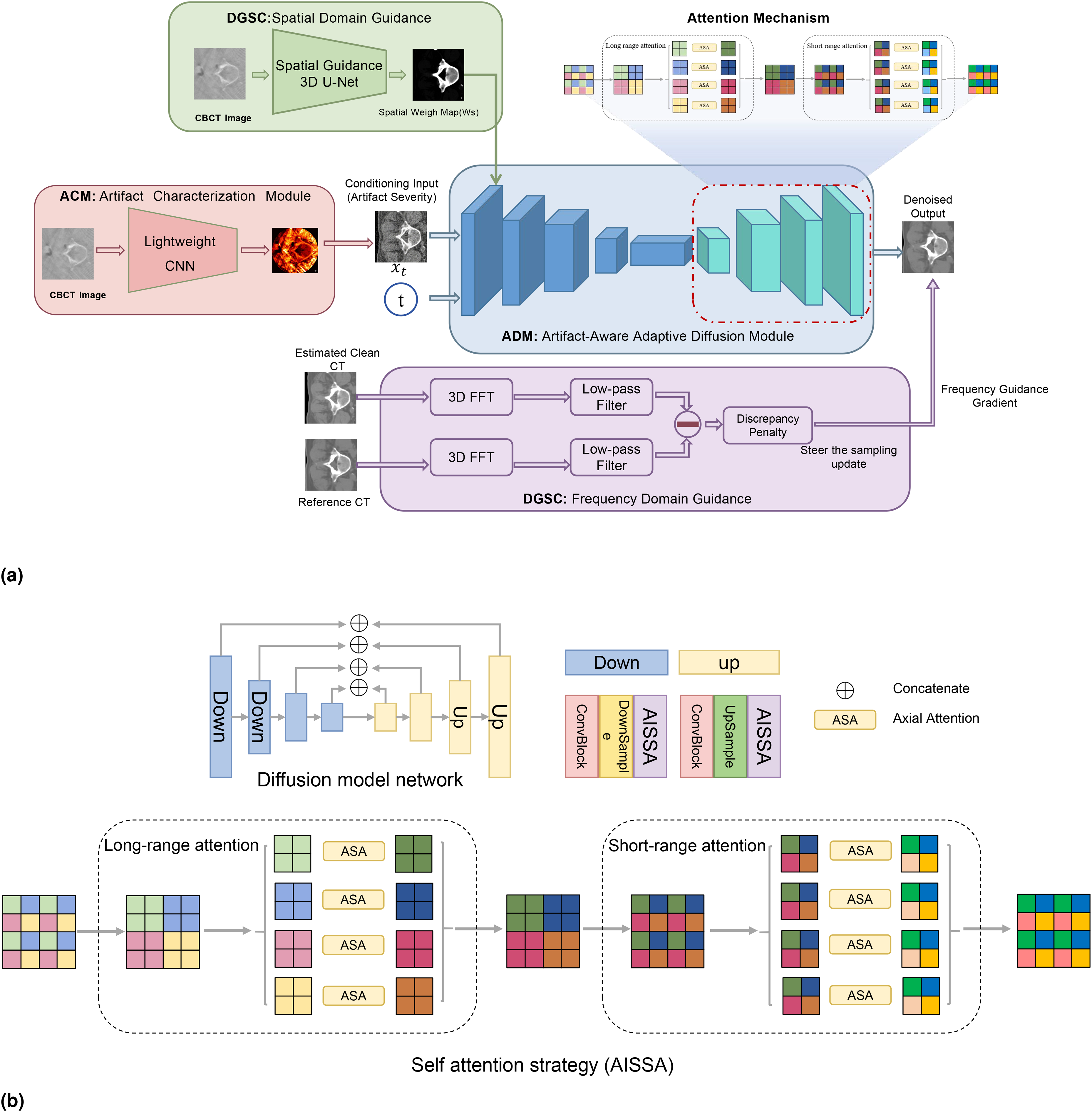
The overall algorithm flow, (a) the model framework with an artifact characterization module (ACM) for estimating artifact severity, a dually guided structural consistency module (DGSC) for providing spatial and frequency-domain guidance, and an artifact-Aware Adaptive Diffusion Module (ADM) for progressive denoising and sCT generation, and (b) the self-attention structure, which combines interlaced Sparse Self-Attention (ISSA) and axial attention (ASA) to reduce computational complexity.
Artifact-aware adaptive diffusion module
To focus the model’s attention on the regions most in need of restoration, we propose an Artifact Characterization Module (ACM) in ADM module. This module employs a lightweight CNN network
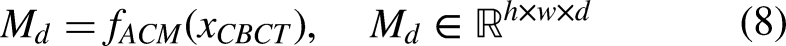
We then employ this approach
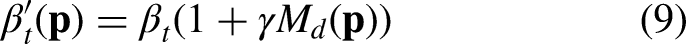
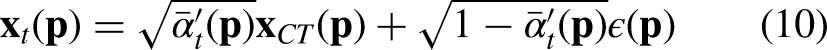
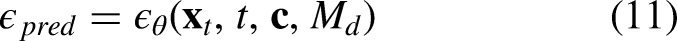
Dually-guided structural consistency module
To ensure the generated sCT maintains anatomical consistency with the patient, we introduce a dual-domain guidance mechanism spanning both the spatial domain and the frequency domain. First we employ a 3D U-Net architecture (
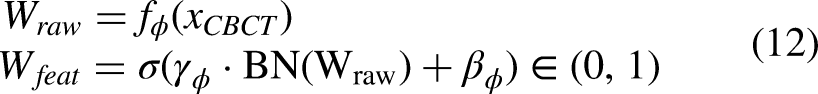
To mitigate minor misregistration between the reference CT and the CBCT, we introduce a frequency-domain guidance term. In the Fourier domain, low-frequency components encode the global, macro-structural content of an image. At each sampling step
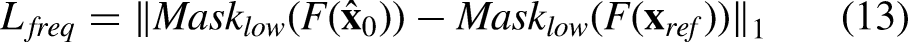
Loss function
We optimize sCT synthesis with a composite objective:
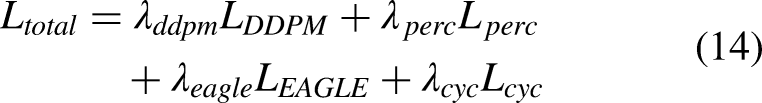
Here,
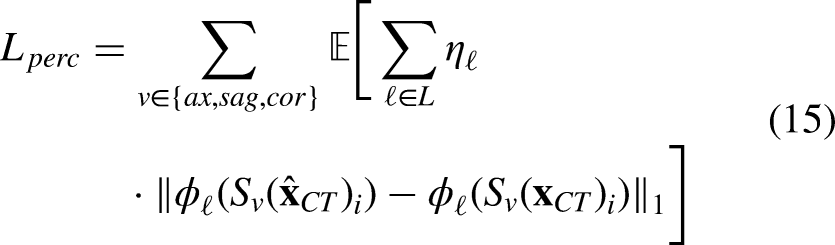
To enhance edge fidelity, we introduce the edge-aware gradient-spectrum loss
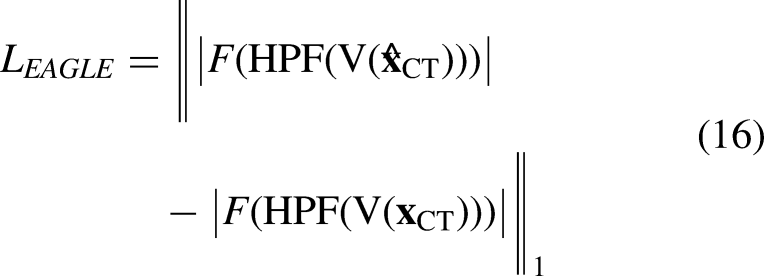
Finally, To ensure the robustness of the mapping between the CBCT and CT domains, we incorporate a cycle consistency constraint. The CBCT
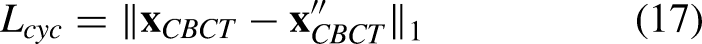
Together, these terms complement the diffusion objective by aligning high-level appearance across orthogonal views, sharpening structural boundaries in the frequency domain of gradient statistics, and regularizing the bidirectional mapping between CBCT and CT domains.
Generation of sCT from CBCT via warm-star
DDPM usually starts with a sample from

To quantify the benefit of the Warm-Start, let the true terminal random variable be:
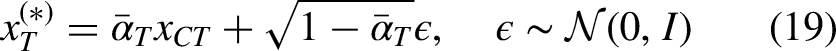
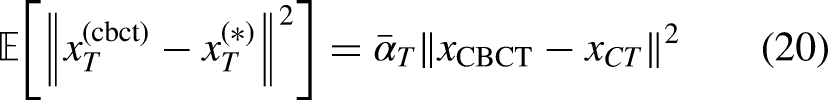
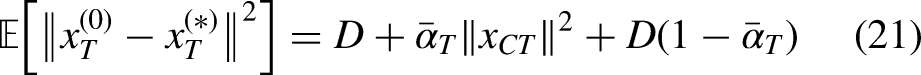
In clinically reasonable preprocessing, where pre-processing steps like image registration typically ensure that the misalignment error
An equivalent perspective is given by Gaussian KL divergences. Denote the true terminal law by
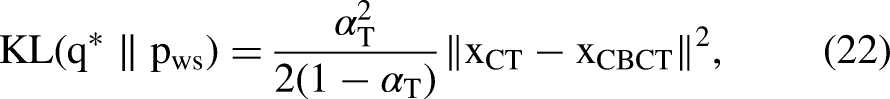
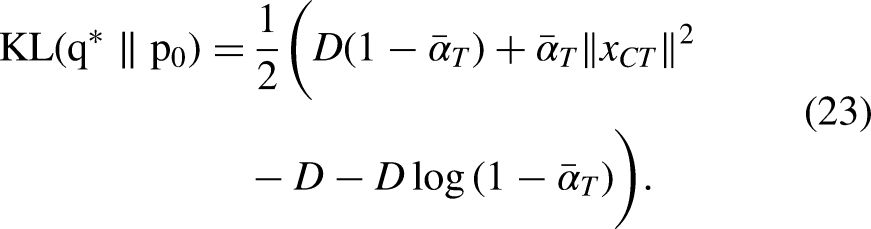
Similarly,
Evaluation criteria
In order to evaluate the performance of different synthetic image generation models in terms of pixel-level Hounsfield Units (HU) accuracy, noise level, and structural similarity, we utilize four evaluation metrics, namely Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM). Given three images,
MAE:
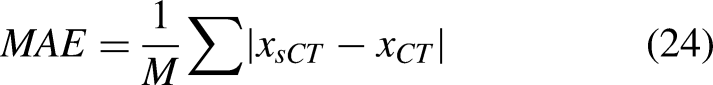
RMSE:
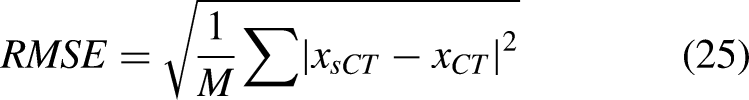
PSNR:
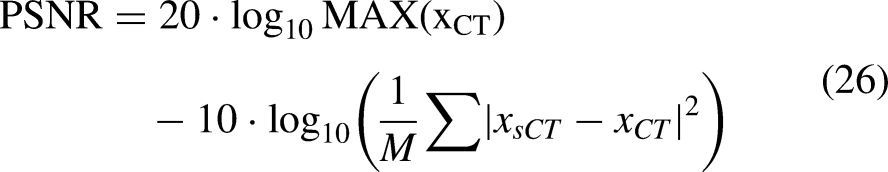
SSIM:
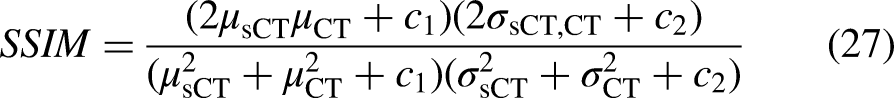
The
Implementation details
During the experimental phase, the proposed model was trained on dataset 1 using 80% of the data for training, 10% for testing, and the remaining 10% for validation. The Adam optimization algorithm was used for training all networks with a learning rate of
We established various algorithmic combinations to evaluate the impact of individual components on the resultant outputs: (1) DDPM+ADM+DGSC+WS (STADW-M); (2) DDPM+DGSC+WS (STDW-M); (3) DDPM+ADM+WS (STAW-M); (4) DDPM+ADM+DGSC (STAD-M).
We additionally compared the performance of medical image generation approaches based on CycleGAN improved by Dong et al., 50 Conditional diffusion model, 51 EGDiff, 52 and our proposed method in the task of generating sCT from CBCT.
It is important to note that the CBCT volumes in this study are acquired and reconstructed using a vertebra-centered small-FOV protocol. Consequently, the native reconstructed CBCT field of view (FOV) inherently covers only the anatomical region around the vertebrae and contains no background air voxels. Therefore, evaluation on the native CBCT FOV is effectively equivalent to evaluation within an anatomical/body mask, and does not rely on any post-hoc truncation or ROI selection that could bias the quantitative metrics. For clarity, all metrics reported in this work are computed over the entire native CBCT FOV, i.e., the complete valid reconstructed anatomical volume. All images were visualized using the same CT window width (WW)
Results
Results of CT-CBCT registration
To achieve more accurate alignment between CT and CBCT, we adopted an unsupervised deformable fine-registration approach to mitigate the adverse impact of residual misregistration on downstream results. According to the quantitative evaluation, the mean surface distance (MSD) of the finely registered CT (rCT) in the sagittal, coronal, and axial planes was 1.61, 1.27, and 1.19 mm, respectively, while the average surface distance (ASD) was reduced to 0.75, 0.43, and 0.69 mm, respectively. In addition, the Dice similarity coefficient (DSC) was 0.93, 0.93, and 0.95, and the Jaccard similarity coefficient (JSC) was 0.87, 0.87, and 0.90 for the three planes, respectively (Table 1). Collectively, these objective metrics demonstrate that the proposed unsupervised deformable fine-registration method achieves high-precision registration. As shown in Figure 2, after unsupervised deformable fine registration, rCT and CBCT exhibit improved fine-scale correspondence, and the structural discrepancies between the two modalities are further reduced.

Results of CT-CBCT registration. The columns show CT, CBCT, and registered CT (rCT) while the rows are the cross-sections at different axial levels. Following fine registration, rCT exhibits improved correspondence with CBCT with reduced local structural discrepancy.
Registration results for deformable CT-CBCT alignment.
Evaluation of sCT image quality with objective metrics
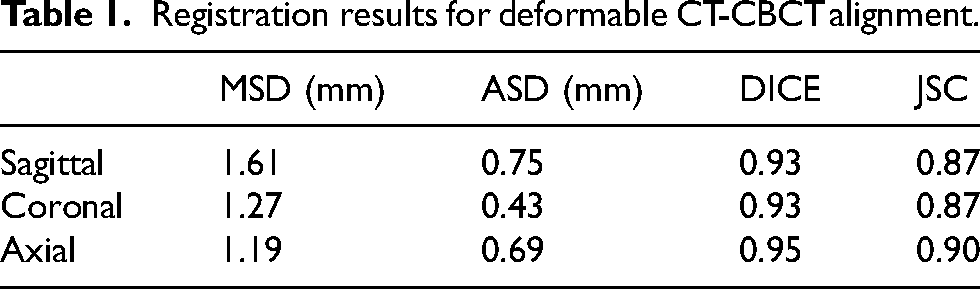
As depicted in Figure 3, both the image quality and spatial uniformity of sCT have experienced significant improvements in comparison to CBCT, while preserving the anatomical structure. Generally, the image quality of sCT is markedly superior to that of CBCT. Due to registration errors, the anatomical structures between CBCT and CT may differ; however, sCT’s anatomical structure aligns with CBCT, indicating that sCT effectively retains the anatomical information of CBCT, specifically the structure of the vertebrae. This approach can infer missing components based on the known vertebral information in the CBCT image (Figure 3, third row). sCT not only reduces artifacts and restores fine image structures but also reestablishes the CT values of CBCT. Figure 3 demonstrates that noise and artifacts throughout the image have been efficiently eliminated, with the discrepancy between sCT and CT being considerably smaller than that between CT and CBCT.
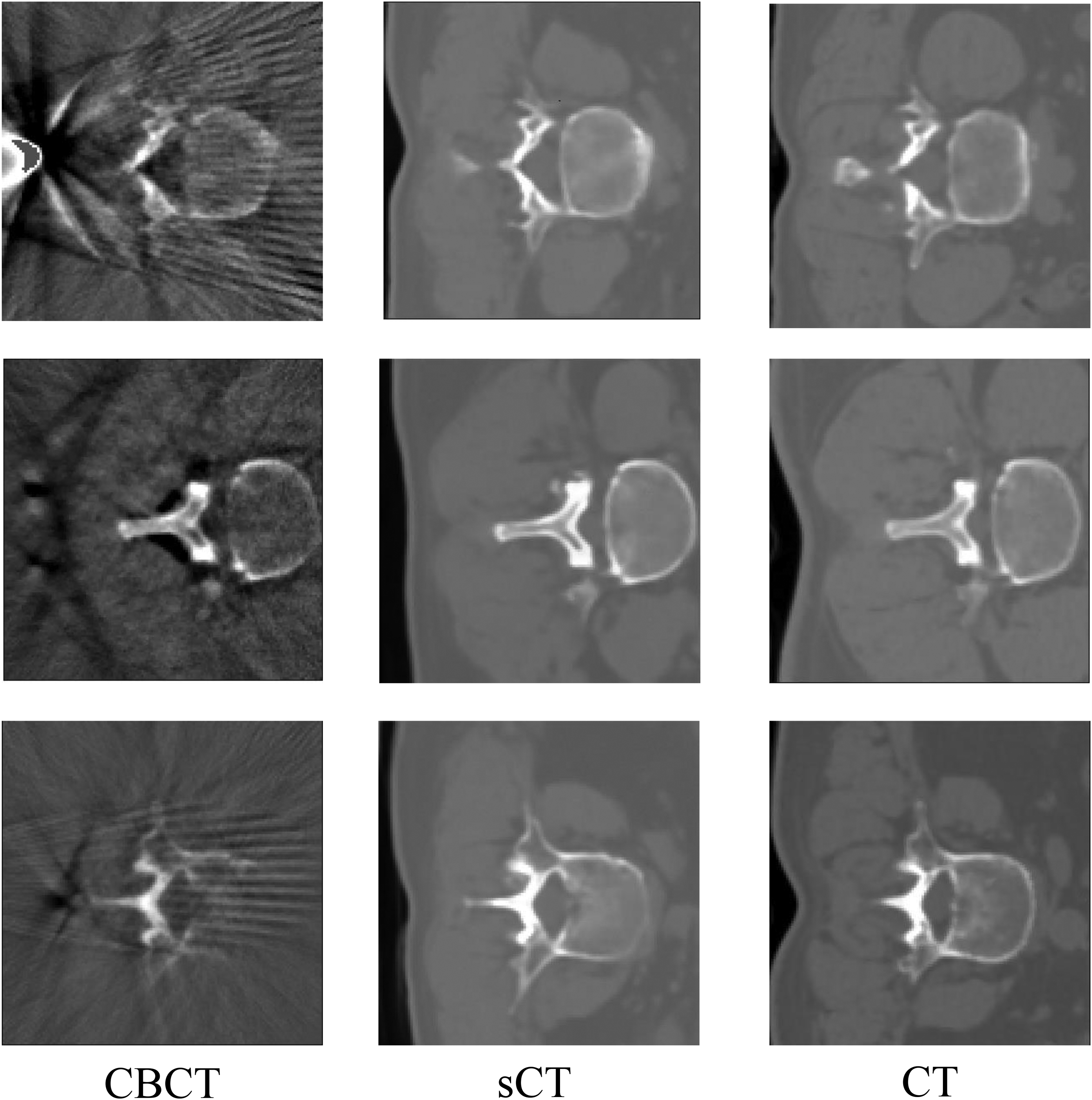
Compares the image quality among CBCT, sCT, and CT. The left, middle, and right columns are the CBCT, sCT, and CT, respectively while the upper, middle, and bottom rows correspond to the slices at different axial levels. Compared with CBCT, sCT demonstrates superior image quality and enhanced spatial uniformity.
Table 2 presents the quantitative results for all test cases, illustrating the differences between CBCT and CT, as well as between sCT and CT. In comparison with CBCT and CT, the RMSE and MAE of sCT and CT have decreased to 152.9
The mean and standard deviation of the objective evaluation results of CBCT-CT and sCT-CT for all test data.

Evaluation of sCT image quality with CT values
Regarding CT value enhancement, the overall CT value distribution of sCT closely aligns with that of CT. Figure 4 illustrates the CT value distribution along two red line paths, assessing the improvement in CT values. Line 64 crosses soft tissue and bone tissue regions; with the exception of the red arrow position, sCT’s CT values at other locations remain highly consistent with CT’s values, demonstrating a significant difference compared to the relationship between CBCT and CT values. At the red arrow location, the original CBCT image is devoid of the anatomical structure of the CT image; thus, this structure is not reconstructed in sCT but preserves the anatomical information of the CBCT image. This inconsistency between sCT and CT emphasizes the superiority of the developed algorithm in preserving CBCT anatomical structures. The path (profiles) of line 32 solely passes through the soft tissue region, and as depicted in the figure, sCT’s CT values are not only corrected to align with CT’s values, but the corrected CT values also display smoothness comparable to CT’s values.
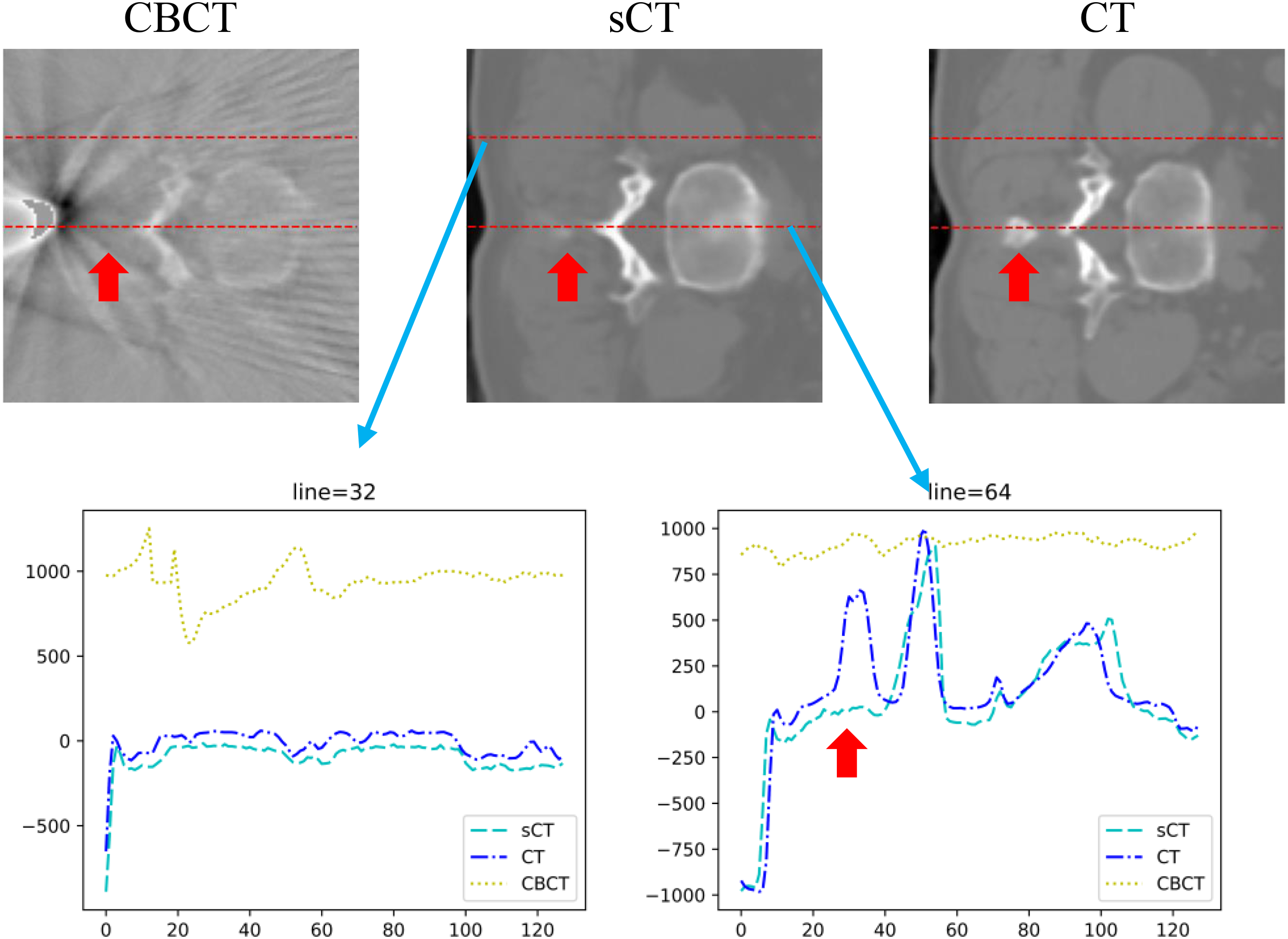
HU profiles on the selected lines. The upper images show the axial slices from CBCT, sCT, and CT with two selected lines (line 32 and line 64). The lower figures show the corresponding HU profiles along the lines. Overall, sCT exhibits a CT-value distribution closer to that of CT than CBCT, in both soft-tissue and bone-containing regions, while remaining anatomically consistent with CBCT.
Figure 5 illustrates the HU distribution in the red rectangular area for CBCT, sCT, and CT. In comparison with CT and CBCT, the CT value difference between CT and sCT is extremely small. Within the ROI region, the CT value distribution of sCT resembles that of CT, demonstrating that the generated sCT and CT’s CT values exhibit high consistency.

HU distribution within the ROI indicated by the red box for CBCT, sCT, and CT. The upper images show the selected ROIs, and the lower figures present the corresponding HU distributions. Compared with CBCT, the HU distribution of sCT is closer to that of CT.
Ablation experiment
We conducted a series of ablation studies to systematically evaluate the importance of the main elements in our algorithm. By comparing the results in Table 3, we found that the STADW-M method generates the highest quality sCT images. Since the diffusion model starts with pure noise samples and generates image samples through iterative denoising, the random initialization of noise may cause the CT values of the generated sCT to be biased, so the CT values of the sCT generated by the STAD-M method have some inaccuracies. The CBCT images used in this study have a lower quality, with significant noise in the CT values, and soft tissues and some cancellous bones are not clearly distinguished, resulting in errors between the CT values of sCT generated by the STA-M method and the actual CT values. Compared with STD-M and STA-M, the objective evaluation values of the sCT generated by the STAD-Mmethod with the incorporated ADM and DGSC module show a significant improvement, indicating that the those modules can enhance the performance of the model. Overall, compared to CBCT, the sCT image quality and visibility generated by our method have significantly improved, and the vertebrae and soft tissues can be clearly distinguished (as shown in Figure 6). Through a series of ablation studies, we have proven the impact of different elements in our algorithm on the sCT generation performance and chose the optimal settings to achieve the best sCT image quality and visibility.

Comparison of ablation experiment results. Compared with the other ablation settings, the full STADW-M model produces sCT with clearer vertebral and soft-tissue depiction, reduced artifacts, and a visual appearance closer to CT.
Comparison of ablation test results.

Comparison of results of different methods for generating sCT.

Comparison with state-of-the-art techniques
The aim of this study is to convert CBCT images into high-quality images resembling standard-dose CT (sCT) images to enhance the clinical diagnostic and therapeutic applications of CBCT. To this end, we compared the performance of three network models, namely CycleGAN, 50 Conditional DDPM, 51 and EGDiff, 52 for CBCT-to-CT conversion and then compared them with our proposed method. Moreover, motivated by the SynthRAD2023 CBCT-to-CT challenge report 53 and to ensure a fair reference to a strong challenge-derived baseline, we additionally reproduced the champion method SMU-MedVision on our dataset and included it in the comparison. The experimental results indicate that the sCT images generated by our method demonstrate significantly superior quality compared to those produced by the other three approaches, as shown in Table 4. Specifically, these methods experience issues such as soft tissue contrast noise, image blurring, and excessive image smoothing in the generated sCT images (including the champion SMU-MedVision, Figure 7). In contrast, the sCT images synthesized by our proposed method display lower noise and artifacts, higher authenticity, and better preservation of anatomical structures, particularly bone tissue. In summary, our proposed method demonstrates excellent performance in medical image conversion tasks, providing an effective conversion technique for low-dose CBCT images in clinical applications and offering practical value for medical image diagnosis and treatment, especially image-guided spinal surgery.
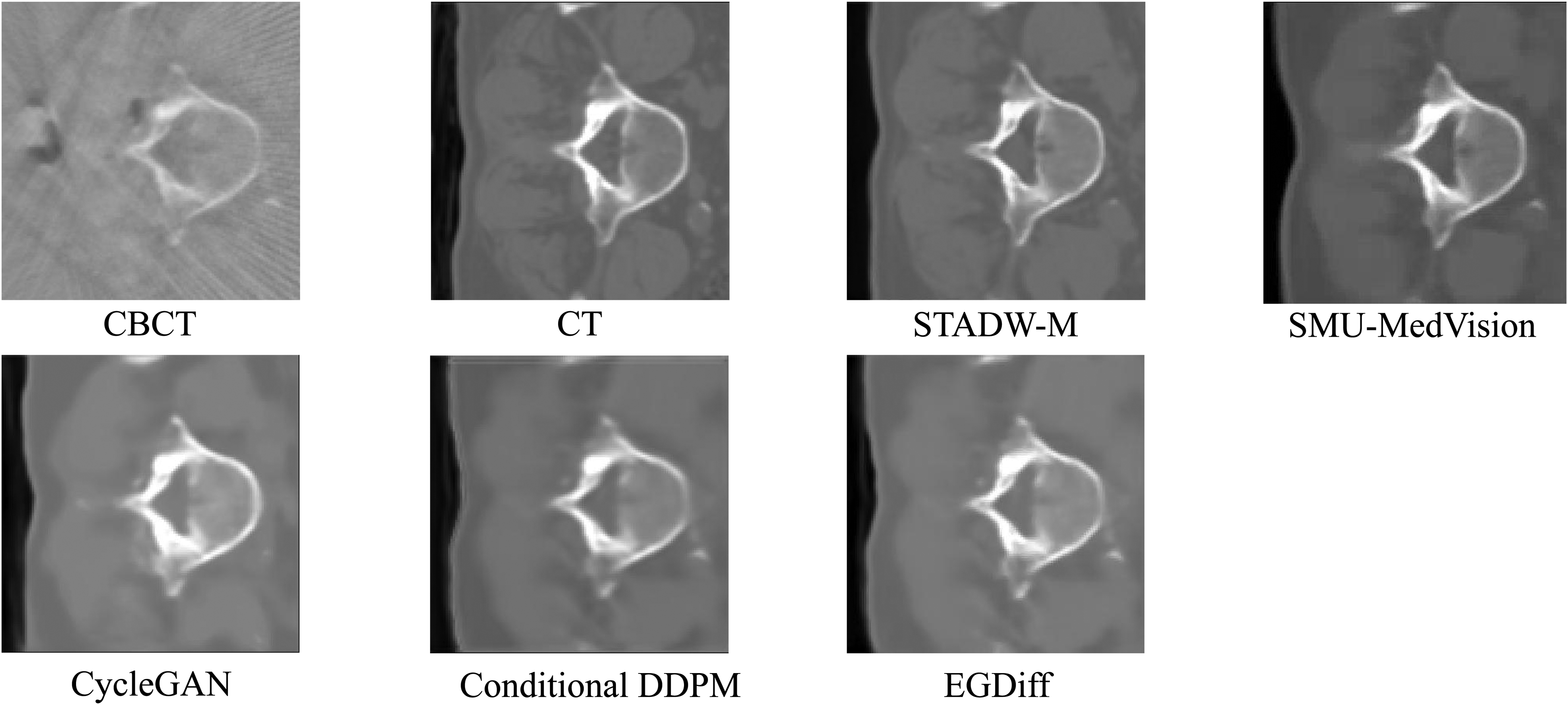
Comparison of results from different methods for generating sCT.
Effect of sampling steps on performance and runtime
Fast inference is critical for intraoperative applications. For diffusion-based CBCT-to-CT synthesis, inference latency is largely determined by the number of sampling steps. Accordingly, we analyzed the speed–quality trade-off by varying the sampling steps
As shown in Table 5, increasing the number of sampling steps consistently improves image quality, as evidenced by lower RMSE/MAE and higher SSIM/PSNR. Specifically, MAE decreases from
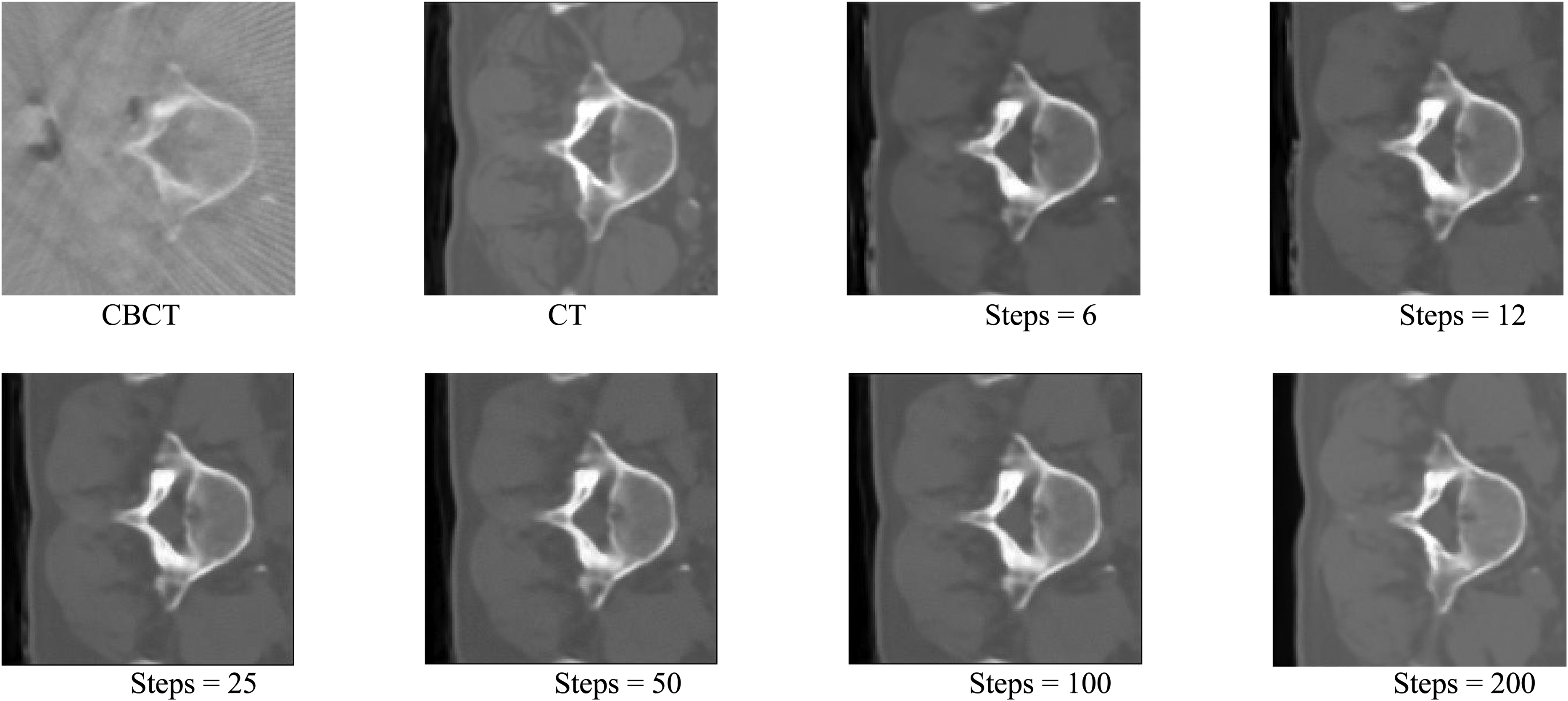
Qualitative comparison of CBCT-to-CT synthesis with different sampling steps.
Effect of sampling steps on CBCT-to-CT synthesis performance and runtime (mean
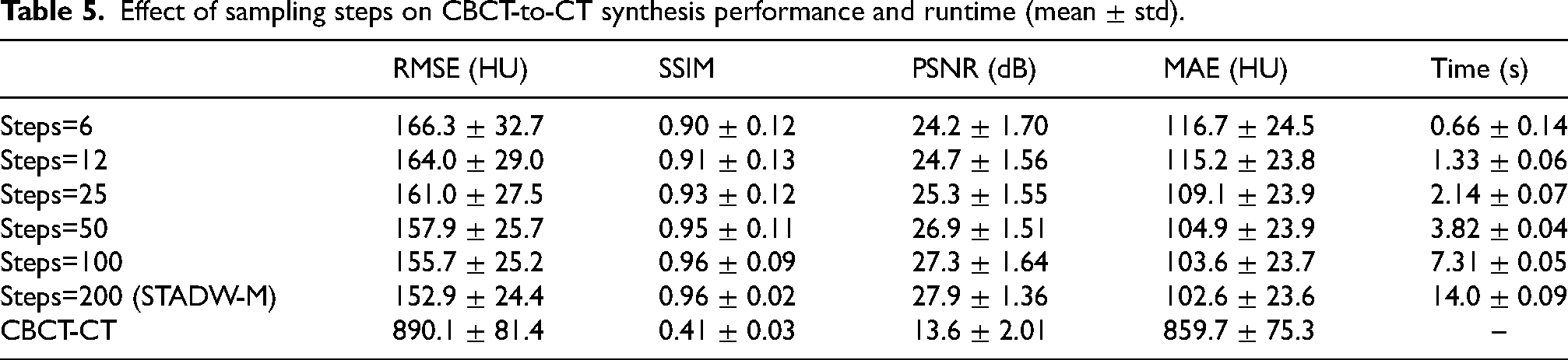
In contrast, runtime grows approximately linearly with
Screw trajectory planning based on sCT
This study also performed screw trajectory planning tests to evaluate the practical application value of the algorithm. Trajectories were generated using a geometry-driven planning framework adapted from (Zhang et al., Phys. Med. Biol., 2023 54 ). Briefly, a binary vertebral mask is obtained to delineate anatomical and avoidance boundaries. Trajectory planning is then cast as a max-min clearance optimization, selecting the screw axis that maximizes the minimum distance to the avoidance boundary. The axis is estimated from orthogonal axial and sagittal projections: in each plane, boundaries are identified via contour detection, and the optimal line is solved using a maximum-margin (SVM-based) formulation. The final 3D trajectory is reconstructed by jointly enforcing the two orthogonal projection constraints.
In this test, we collected CBCT and CT data from 36 patients and 94 screws, comprising 6 screws from L1, 14 screws from L2, 16 screws from L3, 28 screws from L4, and 30 screws from L5. This study first converted CBCT images to sCT, and then conducted screw trajectory planning on CT, CBCT, and sCT. This paper evaluated the quality of the planned pedicle screw trajectory using the distance from the screw surface to the pedicle cortex (DSOS), with MGM representing DSOS > 0 mm, CAE representing

Distribution of DSOS for calculated screw trajectories. (a) Screw path planning on CBCT. (b) Screw path planning on CT. (c) Screw path planning on sCT.
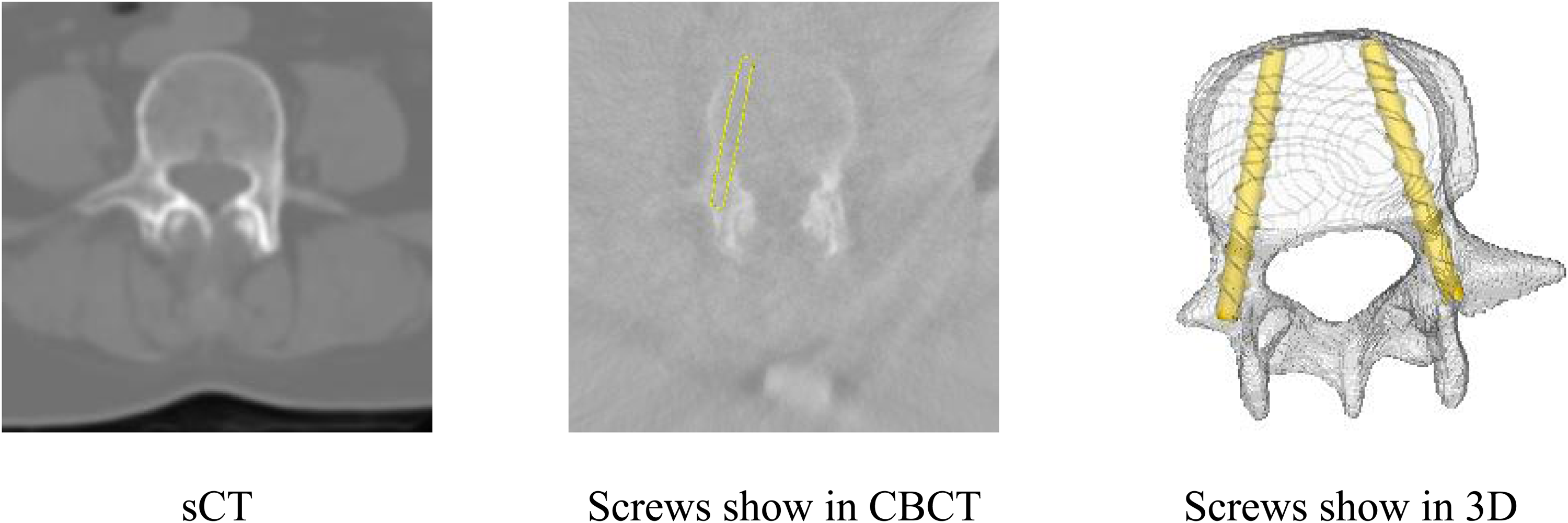
Screw trajectory planning based on sCT.
The MGM, CAE and non-acceptable for screw trajectory planning on sCT, CT and CBCT.

Discussion and conclusion
In this study, we proposed the Spatiotemporal Adaptive Warm-Start Diffusion Model (STADW-M), which integrates a registration module, dual-domain structural guidance, and an artifact-aware mechanism to synthesize high-quality sCT from intraoperative CBCT. Quantitative evaluations and screw trajectory planning assessments indicated that our method outperformed state-of-the-art techniques in both image quality and anatomical fidelity, achieving clinical utility approaching that of diagnostic CT.
Compared with traditional generative methods, the proposed STADW-M addresses limitations inherent in CBCT-to-CT synthesis. Whereas GAN-based approaches frequently exhibit training instability and structural hallucinations, and standard DDPM-based encounter challenges with random initialization resulting in anatomical inconsistencies, our method incorporates targeted innovations. Specifically, the Artifact-Aware Adaptive Diffusion Module and Dually-Guided Structural Consistency Module leverage prior feature maps to distinguish between anatomical structures and noise, effectively suppressing the inherent artifacts of CBCT while preserving bone cortex details. Crucially, to mitigate the stochastic deformation caused by pure Gaussian noise initialization in the reverse diffusion process, we implemented a Warm-Start strategy. By replacing the standard prior
Although the algorithm proposed in this paper can generate high-quality sCT images, it has limitations. First, the DDPM requires paired CT and CBCT images, but such ideal CBCT-CT pairs are not easily obtained because they are not acquired simultaneously. To address this issue, we incorporated the Reg module into the algorithm to fully align CT and CBCT. However, due to the difficulty in completely aligning CT and CBCT resulting from registration errors, the generated sCT might exhibit slight deformations. Furthermore, CBCT has considerable errors in CT values and cannot differentiate between soft tissue regions and those obscured by noise, leading to disputes regarding the accuracy of soft tissue structures in the generated sCT.
Although the accuracy of the soft tissue regions in the generated sCT may be disputed due to the quality of CBCT images, the anatomical structure of the vertebrae is preserved completely and clearly. For pedicle screw implantation, a complete and accurate vertebral anatomical structure is more critical, and the results of screw trajectory planning demonstrate the clinical value of this method. In summary, the method proposed in this paper performs well in medical image transformation tasks, providing an effective conversion method for CBCT images in clinical applications, and has practical application value for robot-assisted spinal surgery.
Footnotes
Ethics statement
The study was ethically approved by the Ethical Committee of Capital Medical University, Beijing, China (No. Z2024SY064). Written consent from the participants was waived due to the retrospective design of the study.The experimental design abided by the principles of the Helsinki Declaration.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Beijing Natural Science Foundation, Grant Nos. 1S24093 and L241029; Beijing Municipal Health Commission, Grant No. 2024-2-2076; National Natural Science Foundation of China, Grant No. 61827809.
Declaration of competing interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.