
Abstract
Assessment and evaluation at all levels of educational systems have become policy priorities for many countries. Two common reasons for this are student learning expectations and accountability. Although much effort has been put into the creation and refinement of content standards, standardized tests, and methods for using testing results, there has been less attention paid to the development of performance standards (proficiency levels) that greatly affect policy decision making. The present study investigates the Objective Standard Setting Model (OSS) as an improved criterion-referenced method for setting multilevel performance standards. To demonstrate how OSS can be employed for performance standard setting, our study used data from preservice teachers completing an assessment literacy test in a pre- and posttest environment. Using OSS, performance standard levels of proficient and excellent were established with clear content-related descriptions of growth in student content mastery.
Globally, assessment and evaluation of students, teachers, schools, and school leaders have become prominent policy features in many educational systems (Holloway, 2003; OECD, 2013). Although the reasons assessment and evaluation have taken such firm root in school systems internationally vary widely, two purposes commonly identified include meeting student learning objectives and increasing systems for accountability of teachers in demonstrating student success (OECD, 2013). To address either of these related goals, the first step requires the development of educational content standards, which provide a blueprint about classroom instructional focus, and describe student learning throughout the learning process (Moore, Toth, & Marazano, 2017; Schmoker & Marzano, 1999). Many countries have successfully created and implemented such instructional standards (OECD, 2013). Integral to such a process, are assessments. Both teacher developed classroom assessments and required standardized tests must be deliberately aligned with content standards and classroom instruction to ensure valid and reliable measures of student learning if we are to infer with any degree of confidence that student learning goals have or have not been achieved for low- or high-stakes accountability purposes (Martone & Sireci, 2009; Moore et al., 2017; Schmoker & Marzano, 1999).
Although policy makers, curriculum, and assessment developers have paid great attention to both creating content standards and aligning standardized tests to those content standards (Bhola, Impara, & Buckendahl, 2005), the process by which performance standards (proficiency levels) are set generally receives less critical analysis by practitioners and those responsible for establishing educational policy. Perhaps this is in part due to the nature of setting performance standards. Typically, psychometricians (educational assessment experts), lead the process of performance standard setting, and this is generally realized through some form of high-level statistical or measurement methodology not commonly understood by most in the education field (Zieky & Perie, 2006). Determining performance cut scores for standardized test proficiency levels (e.g., below proficient, proficient, above proficient) is a critically important piece of the assessment and evaluation policy puzzle as they may directly affect decision making about an entire educational system: students (e.g., grade-level promotion, graduation, tracking, admittance), teachers (e.g., evaluations and merit pay), schools (e.g., using areas of strength and weakness for resource allocation, effectiveness accountability), and school leaders (e.g., accountability to community and government). If a goal is to use standardized test results to evaluate student learning and/or content growth as well as meaningfully direct policy (Darling-Hammond, 2002; OECD, 2013), then cut scores need to be purposefully aligned with content standards (criterion referenced—comparing students to content mastered) so the judgments are related to content allowing for educationally meaningful decisions to be made. However, most methods of establishing cut scores on standardized educational assessments are instead either norm referenced (comparing student performance to other students; FairTest: The National Center for Fair and Open Testing, 2007; National Center for Education Statistics, 2016; Oescher, Kirby, & Paradise, 2014) or connected only indirectly to content (Collins, 2014; McCaffrey, Koretz, Lockwood, & Hamilton, 2003).
With this in mind, the purpose of our study is to examine the establishment of a criterion referenced, multilevel performance standard, and its use in meaningfully measuring growth in preservice teacher achievement. Our study uses data from preservice teacher assessment literacy pre- and posttests as a demonstration of this process in an educational context. Specifically, our research questions are as follows:
Standard Setting Methods
Establishing performance standards for end of academic year standardized tests, which classify students into achievement levels (e.g., below proficient, proficient, above proficient) is a frequent and long-standing occurrence internationally (OECD, 2013). With the more recent introduction of teacher evaluation systems in many countries (e.g., Finland, Netherlands, Singapore, the United States; Stewart, 2013), standards used to evaluate student growth have also been created and used to infer teacher impact on student learning from the beginning to the end of an academic year. When available, externally developed standardized tests are commonly used to assess teacher impact on student learning (or value added). However, many teachers teach noncore areas where appropriately aligned externally developed standardized tests have not been created, and instead use teacher-made assessments to assess their students’ learning growth (Prince et al., 2009). The notion of teachers using self-developed and implemented assessments as a growth standard measure, for making potentially high-stakes decisions about their own teaching impact is a multifaceted dilemma too large to fall within the scope of this article. Instead, in the sections that follow, we will focus on the common methods psychometricians and policy makers utilize when establishing performance standards (achievement and/or growth) for externally developed standardized tests.
Norm-Referenced Standard Setting
There are four popular norm-referenced growth models used in the United States for determining how much student learning over the course of an academic year is enough to be considered adequate growth: trajectory, transition tables, student growth percentiles (SGPs), and projection (Carey & Manwaring, 2011). The most common growth model strategy is the trajectory model, which requires a state to identify the gap between a student’s current achievement level and the state-established proficiency level. Over the next 3 or 4 years, the state then determines if the student is likely to reach proficient given his or her historical growth. If the student closes one third or one fourth of his or her achievement gap each year, the student is deemed to have reached adequate yearly growth (Carey & Manwaring, 2011). This degree of growth is largely arbitrary and not defined by a criterion or the academic content a student should be mastering at their grade level as defined by content standards.
Transition tables, the second most common growth model strategy implemented, places students in one of the three subcategories when they perform below proficient (i.e., weak, low marginal, or high marginal). Students are expected to move up at least one category each year to make their annual growth target (Carey & Manwaring, 2011). Categories below proficient speak to the performance of students when compared with averages of other students (normative) rather than mastery of content (criterion referenced). When a student is said to have grown, we have no way of understanding their learning growth in terms of content mastery. All we can really say is that in the normative (bell curve) “race,” the student has propelled himself of herself into area wherein the majority exists.
The third growth model strategy, SGPs, is a method that employs norms across years. SGPs compare scores of similar groups of students across years to determine whether more or less growth for the current classes are demonstrated. Percentiles are calculated and possible growth trajectories are constructed based on previous performance of students. It is expected that students will reach “learning targets” within 3 years (Carey & Manwaring, 2011; New York State Department of Education, 2014). However, there are no clear content-defined learning targets established within SGP standards (norms) to ensure mastery has occurred, only the hope and aspiration that greater growth in terms of raw normative scores will likely correlate with increased content mastery.
A final and quite complex growth model strategy is called the projection model. The projection model includes two parts. First, performance standards (or a series of achievement levels) are established. This process is a mixture of normative and criterion-referenced methods. In Ohio, for example, standard setting begins by establishing a content-based criterion. Yet, it progresses into a norm-driven task as panelists review information from other states, and other tests, and based on this “contextual information” adjust their own standards to largely remain in concordance with norms (American Institutes for Research [AIR], 2016a). These standards are thus never clearly based in content, but instead muddled by referencing of norms. Second, the projection model does as its name suggests, and attempts to predict reasonable student learning growth based on past growth. It employs advanced statistics (hierarchical linear modeling) to compare current students with large cohorts of similar students from previous years, and from other states to predict future success of reaching proficiency. This model primarily looks backward to predict future performance. Students are suggested to have met their learning growth targets if their current year’s score meets or exceeds predictions based on their earlier year’s performance and the performance levels established (Carey & Manwaring, 2011). Part of the difficulty in explaining the operation of such models is that many are kept in theoretical black boxes, and explained in nonpsychometric terms in the most general of ways (AIR, 2016b).
Ultimately, whether performance or growth standards are firmly based in normative groups, without reference to specific content, or use normative data to massage results into a politically acceptable reality, they are not criterion referenced. Results of such learning growth and achievement standard setting processes that are not clearly tied to academic content can lead to last-minute cut-score changes in response to political outcry, largely because an explanation of growth or achievement meaning (i.e., what a child specifically has or has not mastered) is impossible to determine and defend. In June 2016, Ohio was forced to lower performance standards, stating only that they now possessed “actual Ohio data” and that the norms used to define those original growth standards were not useful for the actual Ohio cohort (Candisky, 2016). Such arbitrary and norm-referenced standard setting conditions are unaccepz and inconceivable in the world of high-stakes testing where decisions need to be legally defensible and mastery of specific content is required (Silber & Foshay, 2010). As such, most social science fields where high-stakes testing is implemented (e.g., medicine, law) have adopted criterion referencing methods for standard setting.
Criterion-Referenced Standard Setting: Traditional
Although there are a myriad of traditional options for criterion-referenced standard setting, these may be largely divided in two groups: test-taker performance and definition of content. The test-taker performance approach might be deemed an assessment of content via hypothetical test-taker performance. This approach is typified in the popularized Angoff (1971) model, but is also seen in other models including those offered by Nedelsky (1954), Jaeger (1982), and Ebel (1979). A fundamental requirement of these models is that expert standard-setting judges evaluate the content presented in items on an assessment and make “predictions of success.” Specifically, experts are asked to predict what number (or proportion) of hypothetical, minimally competent test-takers will answer each item correctly. An average or sum of the product of these predictions serves as the standard, usually after a series of iterative sessions wherein experts are asked to discuss and come to consensus (normative decisions) about predictions. Today in fields where criterion standard setting is utilized routinely (e.g., high-stakes testing), the Angoff model has become the most popularized of performance standard models. When use of the Angoff model was challenged by the National Academy of Education (National Academy of Education; 1993), Cizek (1993) noted that he considered the Angoff model to be “reasonable, useful, acceptable, and—in many circumstances—preferable” to other models. His conclusion was based, however, on the notion that many other models were based in relative terms (e.g., normative approaches wherein students were compared with one another) while Angoff and similar criterion approaches tended to relate more toward content. Although this is clear, reliance on predictions of success is certainly a justifiable weakness substantiated in the NAE report because predictions of success are notoriously poor and they are only tangentially related to content, including other confounding ideas such as difficulty.
Criterion-Referenced Standard Setting: Modern
Historically, standard setting protocols in education have employed traditional statistics (e.g., norm-referenced) principally because they are more widely taught in higher education programs (E. V. Smith, Conrad, Chang, & Piazza, 2002). Conversely, higher stakes modern assessment programs often make use of more advanced item response theory (IRT)-based (e.g., Rasch) models, which offer greater conceptual understanding and the ability to track criterion-based growth. Modern approaches emerged in response to the overwhelming practical and philosophical problems associated with the Angoff and other traditional approaches (e.g., Ebel, 1979; Jaeger, 1982; Nedelsky, 1954). Traditional models suffer from several problems. First, expert predictions are rarely accurate (Plake, Melican, & Mills, 1991), making standards set using these performance models less reliable. Such a discrepancy has been evident for decades yet few choose to address it short of postnorming of the results after they are determined to be less than useful. In fact, this acknowledgment is possibly the substantive rationale for “iteration,” or the presentation of impact data, now enshrined in the Standards for Educational and Psychological Testing (AERA/APA/NCME, 2014). Second, expert judges rarely agree, and because agreement is required in the traditional models, it becomes a problem. The need for expert agreement has itself also led to the institutionalization of several rounds of iterative decision-making sessions during which time experts are provided with actual item difficulties along with other data, and offered an opportunity to then adjust their predictions in light of the provided real data (AERA/APA/NCME, 2014). Such practices ultimately amount to a norming of the predictions and subsequently defeats the purpose of the multiple judgments sought from diverse expert panels (Stone, 2001). Third, if the goal is to define content, and presumably a criterion-referenced performance standard is content based, then defining content only indirectly through hypothetical test-taker performance is wholly insufficient (Stone, 1996, 2009; Stone, Koskey, & Sondergeld, 2011) because content is only tangentially related to the defined test-taker performance and is not the basis for its definition. In an attempt to address these fundamental challenges to the validity of traditional performance standard setting models, newer approaches for the establishment of criterion-referenced standards were developed, including the Bookmark Approach (Lewis, Mitzel, & Green, 1996) and the OSS model (Stone, 1996). For the purpose of this article, we will focus on the OSS model.
OSS seeks to define standards directly through content, not predictions of success (Stone, 2001). Similar to traditional methods of performance standard setting, expert judges are used in the process. However, in OSS, expert judges are asked to review the content of items on an assessment and determine whether or not the content as presented in the item should be considered essential for the successful test-taker to have mastered—not to predict the likely percentage of successful test-takers. Although all content on an assessment should be relatively important and reasonable, not all content is essential (i.e., critical, core, highly central). For example, in medical testing, it is often critical for test-takers to have mastered concepts relative to performing cardiopulmonary resuscitation. Items that assess knowledge of finger placement, breath, and similar application concepts might be considered essential. Conversely, items that assessed a test-taker’s understanding of the physiological changes that occur in a body during the performance of this protocol may not be considered essential. Similar essential/not essential decisions on essay tests in an educational setting were reported in a recent study (Stone et al., 2011). Expert judges use assessments that have been previously analyzed using the Rasch measurement model (Rasch, 1960/1980), thus each item has an associated item difficulty measure. The average item difficulty of the pool of items selected by each judge as essential becomes the basis for the performance standard, and best represents the content selected.
OSS is made possible only because of the Rasch model, and the use of the Rasch model for developing and maintaining the assessment instrument is essential. The Rasch model is a method for transforming raw, deterministic scores (i.e., ordinal test scores) onto a linear, probabilistic scale similar to a ruler with units of measurement called logits (log-odds-units). This transformation preserves and enhances the meaning of the content inherent in the assessment while creating true interval-level measures. Raw test scores (e.g., 75 out of 100 correct) fail to address either the inherent connections between an item and its content, or an item with its difficulty. For example, the score of 75 may represent any 75 items, the easiest, the hardest, or some combination thereof which all sum to the same 75% correct raw score when using traditional methods. The Rasch model addresses this concern through a logarithmically developed construct ruler that arranges items and persons along a single less to more ruler. Items are presented on one side of the ruler with easier items on the bottom and more difficult items on the top. People are placed on the other side of the same ruler with less able people on the bottom and more able people on the top.
The logit (log-odd unit or logarithmically transformed raw score) item measures represent the quantification of the construct, and offer a meaningful way to qualitatively express it. Using the measures, items are arranged from easiest to hardest along a construct ruler. The construct ruler represents an operationalization of the construct using the content expressed in the items. Ruler arrangement may be seen as developmental as well, such that students progress from easier content to harder content as they proceed along the ruler. Because as suggested, the Rasch analysis arranges the items (in this definitional manner) on the same ruler as the persons (arranged from less mastery to greater mastery), it is possible to directly describe the content a person has mastered by viewing their positioning on the ruler. This item/person placement is defined as a conjoint measurement system, and allows for immediate comparison in a manner not unlike measuring a person’s height. When the height of a person is measured at 60 in., it may be said that the person has “mastered” 60 in., but is still challenged by the 61st in. Likewise a student placed along this ruler may be said to have mastered the content (items) below his or her measure, but have not yet mastered content (items) that lie above their measure. By extension then, any standard or standards (measure[s]) defined along this ruler may be simultaneously described as a quantity and a quality. The quality is, therefore, a true criterion, defined by content. Classical raw score models, which simply arrange the items in order of performance values of single, nongeneralizable samples, using nonequal intervals, fail to achieve this more generalizable goal.
Based on these improvements, the OSS model has been successfully and consistently used to establish performance standards on written dichotomous and performance examinations (e.g., oral rated examinations; MacDougall & Stone, 2015). In all instances, however, a single standard was established (passing vs. failing). Because the Rasch model ruler is used in applying the standard, and a construct is created within OSS, it should be theoretically possible to create a multilevel standard using the same approach. For example, it should be possible to establish two performance levels (e.g., proficient and advanced) within an exercise, and apply those standards to the same construct ruler. As developing multiple performance standards using the OSS model has not been attempted, our study will be expanding the field in the area of performance standard setting.
Method
Instrumentation
The Assessment Literacy Inventory (ALI; Mertler & Campbell, 2005) was developed as a 35-item scenario-based objective test. Five scenarios are presented with seven multiple-choice questions per scenario. Multiple-choice items were created specifically to align with the Standards for Teacher Competence in Educational Assessment of Students (AFT, NCME, & NEA, 1990) such that one item in each scenario aligns with one of the following competency topics: (a) choosing assessments; (b) developing assessments; (c) administering, scoring, and interpreting assessment results; (d) using assessment results for decision making; (e) developing grading procedures; (f) communicating assessment results; and (g) recognizing inappropriate assessment practices. The ALI was shown to be appropriate for use with practicing and preservice teachers and had high internal consistency across the overall assessment (KR20 = 0.74; Mertler & Campbell, 2005).
For our study, all 35 multiple-choice items were administered to preservice teachers and item performance was assessed using Rasch methods. With the exception of two items, all others performed within acceptable psychometric ranges. Rasch infit and outfit statistics were appropriate for all items when looking at standardized fit statistics (ZSTD between −2.0 and 2.0 and mean squares between 0.5 and 1.5 logits), and only two items possessed a negative point-biserial statistic. A negative point-biserial is an excellent indicator that an item does not relate well with the overall construct being investigated. The two items with negative point-biserial statistics were removed from final analysis as they appeared to not align well with the construct of assessment literacy. To explain further, one of the removed items was a “not” item, and it is common for negatively worded items to perform poorly on assessments as reverse thinking can cause confusion for test-takers (Colosi, 2005). The second item removed focused on a specific testing policy that was not taught in the course preservice teachers completing the assessment were taking, and it appeared preservice teachers were simply guessing at the answer. All remaining items (33 in total) performed well and were included in the standard setting task and final analyses.
Sample and Data Collection Procedures
Standard setting exercise
To conduct a standard setting exercise, 6 to 12 experts in the content being tested are required to act as item judges. Nine experts in the field of testing and assessment agreed to complete the standard setting exercise in our study. All of our judges are considered experts in the field of testing and assessment because they teach university-level courses covering the same content on the ALI, and all hold either a doctorate or master’s degree in a related field. More females participated (n = 6, 66.7%) than males (n = 3, 33.3%). Furthermore, participant’s U.S. university affiliation was broad—three Midwestern, one southern, and one southwestern.
On agreement to participate in the 30- to 45-min standard setting exercise, expert judges were sent a copy of the ALI and asked to first read through all items to familiarize themselves with the assessment. Next, expert judges were asked to reread the items and classify them as either (a) necessary to demonstrate minimal proficiency in classroom assessment practices, (b) necessary to demonstrate advanced competency in classroom assessment practices, or (c) not necessary to demonstrate classroom assessment competency. Definitions of minimal proficiency and advanced competency were provided to expert judges. Minimal proficiency was defined as a preservice teacher minimally prepared to handle classroom assessment tasks they would likely encounter on a daily basis. Advanced competency was defined as a preservice teacher prepared to meet both minimal proficiency levels (described earlier) and advanced proficiency, (i.e., skills they would likely only learn from higher level classroom assessment courses).
Student achievement growth testing
The ALI was administered to 96 preservice teachers taking a mandatory undergraduate assessment and testing course at one Midwest university. Preservice teachers were given the assessment as an assignment that received credit for completion during the first week of class (pre-assessment) and again in the last week of class (postassessment), thus a 100% response rate was attained. Preservice teachers independently completed the ALI online for both testing times. Submissions were anonymous and preservice teachers created four-digit code that was used to link pre- and postdata.
Among the 96 preservice teachers completing both the pre- and postassessment, all were enrolled in their assessment and testing course in a fall term, were at a senior-level standing, and were in the process of completing a methods teaching field placement in the same term. Gender was unevenly distributed with more females (n = 62, 64.5%) than males (n = 34, 35.4%) in the sample. Most preservice teachers were studying to be secondary educators (Grades 7-12 certification; n = 81, 84.4%) with fewer studying to become middle-grades educators (Grades 4-9; n = 15, 15.6%). Preservice teacher content area specialization was broad covering social studies (n = 24, 25.0%), math (n = 17, 17.7%), language arts (n = 17, 17.7%), world languages (n = 11, 11.5%), science (n = 6, 6.3%), and business education (n = 2, 2.1%). Approximately 20% (n = 19) did not report a content area. More than three quarters of the preservice teachers (n = 75, 78.1%) indicated they had completed prior courses that discussed assessment in some manner, but nearly all (n = 92, 95.8%) reported they had never taken a course focused specifically on assessment prior to this class. No other demographic data were collected from preservice teachers to protect participant identities.
Data Analysis
OSS Standard Setting
The OSS framework consists of three principle components: the establishment of the fundamental criterion, a refinement of the criterion, and an accounting for error. Step 1 requires expert standard setting judges to first review a content-balanced assessment. A “content balanced assessment” is an assessment that follows the predefined examination content blueprint for coverage and emphasis. Judges select items, which they believe meet the criteria of “essential” for content mastery. Items that meet this criteria are considered the most important core content, and are central to for test-takers to understand to demonstrate mastery of the curriculum associated with the assessment. Expert judges complete this exercise individually, after a series of training exercises, and after a discussion takes place regarding the nature of minimal competency. Step 1 requires the use of a previously Rasch-calibrated assessment, because item difficulties (in logits) are used to quantify the sets of selected essential items. The mean item difficulty associated with each expert judge’s selected set of essential items becomes the quantified criterion (cut measure/score) for that judge. An overall mean across expert judges becomes the final quantified criterion.
Because the quantified criterion is a mean, a gross representation of items across an assessment, it is often wise to refine the criterion when making high-stakes decisions. A second step in the process adds a process to better refine the criterion. A content-balanced sample of 10 items above and 10 items below the criterion point, within two standard errors of the measure, are selected to create a refining Rasch construct ruler. Expert judges are then presented with the ruler and asked, individually, to review the 20-item ruler and determine at what point the items shift in content from essential to nonessential. This break between item difficulties becomes the refined criterion point for each expert judge. An average break point across all judges becomes the final refined criterion measure. Those familiar with the Bookmark method will recognize that this refinement shares similar goals. Yet, it differs in its status as a refinement and not a gross establishment process.
Finally, because no measurement process is free from error, OSS accounts for error associated with the model by introducing the standard error of the person measure as Step 3. Traditional models ignore measurement error altogether. There are three ways in which measurement error may be handled. Error may be used to reduce the standard (in which case the “innocent” test-taker is never held accountable for measurement error and persons are passed if there is doubt). Error may be used to increase the standard (in which case the “public” is protected by not passing a person in whom we have doubt). We might also use a balanced approach in which case measurement error is held constant.
For the purposes of the present study, Step 2 was omitted because of the exploratory nature of the project. In addition, measurement error in Step 3 was used to increase the standard and ensure that higher confidence in performance standards was maintained.
Achievement Growth
Prior to assessing preservice teacher achievement growth, pretest scores were equated to posttest scores through a process known as common item equating (Wright & Stone, 1979), which places both sets of scores on the same ruler, making them immediately comparable. To accomplish this, posttest item measures were first derived from a Rasch dichotomous analysis using Winsteps version 3.74.0 (Linacre, 2012). To ensure reasonable equating, all posttest item measures were checked to see if they were suitable anchors. Anchor items are used to connect one test to the other (hence the term common item equating). Anchors must be reasonably stable, demonstrating excellent performance statistics. Stability is assessed through displacement statistics. Items with less than –.40 or greater than +.40 displacement are considered to be too variable for the purposes of equating, meaning, their difficulty changed too much from Time 1 to Time 2. Of the 33 ALI items, 14 (42.4%) were used as pretest anchor items because their displacement measure from pre- and postassessment was between –.40 and .40 logits (Kenyon, MacGregor, Ryu, Cho, & Louguit, 2006). It is common to equate with only three to four common items on small examinations (Pibal & Cesnik, 2011), thus, being able to use 14 items was highly beneficial in helping to maintain fidelity of measures between the pre- and posttests.
Once pre–post scores were on a similar scale, preservice teacher achievement growth was assessed traditionally with a paired sampled t test of person measures (logits) to see if there were statistically significant increases in scores from pre- and posttest. Preservice teacher achievement growth was also looked at descriptively in terms of ability level to determine the number of preservice teachers who fell into each ability level (i.e., below standard, proficient, advanced) at each assessment point. Finally, a graphical comparison of preservice teacher achievement growth measures was conducted to see how preservice teachers compared over time with the performance standards as well as the content. This was done by using a Rasch variable map, which places person ability on one side of the map and item difficulty on the other side of the same measurement scale. From bottom to top, items are ordered easiest to more challenging and people are ordered less able to more able to form this hierarchical conjoint measurement system with logits as the unit of comparison.
Results
OSS Standard Setting Findings
Table 1 presents results from the expert judges empaneled to establish standards on the examination. Two standards, Proficient and Advanced were established. The Proficient standard (0.13) was 0.16 logits lower than the Advanced standard (0.29), or precisely two standard errors of measure different, and thus represented a statistically different achievement mark. Although there were some discrepancies in individual expert judge ratings between Proficient and Advanced, six of the expert judges established standards that represented a clear distinction between Proficient and Advanced. Some unexpected patterns were noted as well. Two judges established standards in which Proficient and Advanced were statistically equivalent and two judges established standards that were directly opposite to that anticipated (such that Proficient was actually higher than Advanced). The nature of the experts (all university professors who taught the assessment course), the homogeneous nature of the test and test subjects, and the very small number of items on the test may have played a role in some of these pattern.
Judge Standards (in Logits).

Note. Final standard = Raw standard + 2 (person measure standard error of measurement (SEM)).
Achievement Growth Findings
Statistically significant growth in preservice teacher assessment literacy knowledge (as assessed by ALI measures) was found over time with posttest scores (M = 0.84, SD = 0.81) being significantly higher than pretest scores (M = 0.30, SD = 0.60); t(95) = 6.98, p < .001, two tailed. In terms of pre–post standard level growth, while a marginal number of preservice teachers fell within the same standard level from pre- and postassessment (n = 9, 9.4%), overall there were more preservice teachers in the Advanced and Proficient levels combined at posttest (n = 85, 88,5%) compared with pretest (n = 64, 66.6%). The biggest increase was in the Advanced category with 78.1% (n = 75) postpreservice teachers in this category compared with 58.3% (n = 56) at the pretest. See Table 2 for these complete results. In addition, Figure 1 graphically depicts this shift on the Rasch variable map. As can be seen on the variable map, the distribution of preservice teachers appears to shift upward at posttest in comparison with the distribution of preservice teachers at pretest. This indicates these preservice teachers are able to answer more difficult items at the posttest than at the pretest.
ALI Pre–Post Student Comparison by Standard Level.
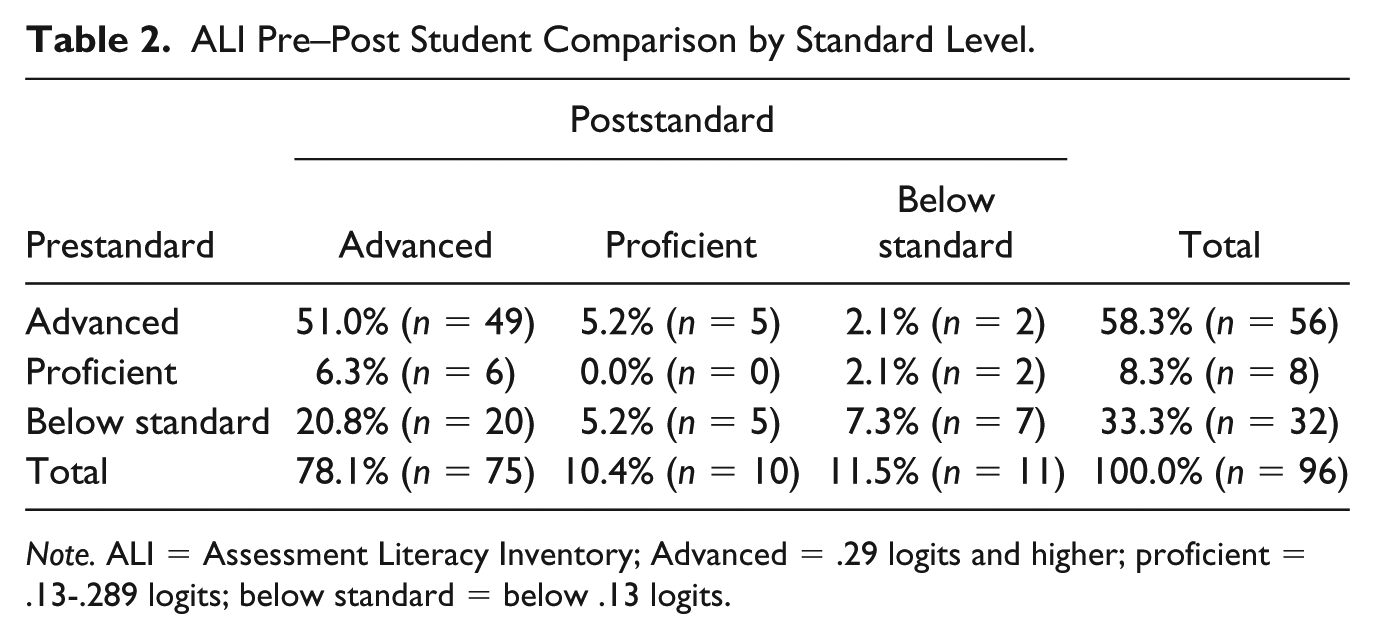
Note. ALI = Assessment Literacy Inventory; Advanced = .29 logits and higher; proficient = .13-.289 logits; below standard = below .13 logits.

Rasch variable map for ALI scores over time.
More importantly, because this performance standard setting process is firmly rooted in defining content-based criteria, the performance standards defined through the proposed OSS process are both quantitatively and qualitatively meaningful. Although the standard reflects a number of items (quantity) the student should have mastered, and a level of difficulty associated with that group of items (quantity), it is also expressible and explainable in terms of the content necessary (quality). In essence, a strength of the Rasch measurement process is the definition of the construct in terms of the items used. Figure 1 presents the content (item) defined construct in item difficulty order. The presentation of items in this manner describes the development of knowledge, skills, and abilities (KSAs) within assessment. Applied to this described content are the two standards (Proficient and Advanced). Based on a content analysis, the KSAs for Proficiency cover fundamental content relative to teachers creating classroom assessments and are very practical in nature. Differentially, the KSAs distinguishing the Advanced level, describe advanced applications, which reflect issues that concern data to improve instruction, standardization, and higher level classroom applications. Finally, the items that exceed Advanced reflect content, that is, far more theoretical in nature, and concern test philosophy, ethics, and statistics.
Discussion
The idea of performance standards both in terms of psychometrics and as policy are intertwined inexplicably with the notion of validity (are we measuring what we really intend to measure). Validity of the performance standards must be seen broadly, or in the words of Borsboom (2005) both ontologically (process) and epistemologically (product). For example, standard setting exercises consist of two elements: the manner in which judges set the standard (process) and the standard itself (product). Previous traditional validity studies in standard setting have focused primarily on the product and not the process (Kane, 1994). Although more modern OSS validation studies have effectively met both validation considerations in establishing single-level performance standards on various types of assessments (Stone et al., 2011), until this study, the definition of multilevel performance standards (e.g., Proficient and Advanced) had never been attempted. Although there were some unusual patterns acknowledge in the standards established by the experts, the outcome of this study more generally demonstrated that using OSS produced positive results for these two fundamental expressions of validity (process and product) when developing performance standards for an assessment. It is expected that with more attention paid to judge selection and a longer, more reliable assessment, the problems encountered may be overcome.
Process validity evidence was established in our study as expert standard setting judges were able to fully engage in the process, making two decisions simultaneously, regarding the Proficient and Advanced nature of content. This was an important and indeed critical distinction for judges to make. In fact, it required judges to sort items into three groups: not essential for any preservice teacher, essential for proficient and advanced preservice teachers, and essential only for advanced preservice teachers. Such an achievement is critical for establishing process validity and is not at all easy to achieve. Numerous scholars (e.g., Dauphinee, Blackmore, Smee, Rothman, & Reznick, 1997; Plake, Melican, & Mills, 1991) have reported the deficiencies of performance standards that arise from expert panels who do not fully engage effectively and with a keen understanding of the process. Although defining a single performance is complicated, defining two or three becomes exponentially so. As Wilkerson and Lang (2007) described, “we need to start with a plan that reduces the confusion [of judges] introduced by item difficulty, while also controlling for judge effects. That means [using] Rasch” (p. 301). The process applied in our Rasch-based model addresses the confusion frequently felt by judges through a nearly exclusive focus on academic content rather than prediction of the success. Standard setters are typically content experts, and not psychometric fortune tellers. Concentrating on the definition of content is, thus, almost de facto easier for judges than attempting to make predictions of success.
Product validity evidence was established through the use of the Rasch-based OSS model as well. The outcome (i.e., the performance standards or in validity terms, the “product”) was the establishment of two, statistically independent performance standards (Proficient and Advanced) that may be described quantitatively and more importantly through qualitative description. A Proficient performance standard represented a lower performance level than the Advanced performance standard both in terms of qualitative content and in terms of quantitative representation, which was the clear, desired outcome. Criterion-referenced performance standards must, by definition, include the elaboration of a linear variable that expresses the continuum of understanding from less to more. Classical (or true score) performance standard setting models have largely been shown to be ineffective for this purpose, for a variety of reasons including their failure to directly define content-based criteria and their use of iterative adjustment practices, which reduce the veracity of the standards using normative information. (Stone, 1995; Beltyukova, Stone, & Fox, 2004). Development of a Rasch-based continuum makes the understanding of one performance standard useful, and the establishment of multiple levels of performance standards even moreso. The Advanced and Proficient standards are describable in terms of content mastery and performance. Our two-level standard (Advanced and Proficient) demonstrated clear, distinguishable content differences where Proficiency indicates mastery of fundamental practical classroom assessment KSAs (e.g., creating classroom assessments); Advanced means mastery of higher level classroom application KSAs (e.g., using data to improve instruction, standardization); and Exceeds Advanced shows understanding of theoretical assessment KSAs (e.g., test philosophy, ethics, statistics). The ability to describe in detail the content participants are required to have mastered at each performance level represents a significant leap within standard setting, where the emphasis has been on quantities without direct connect to content, despite their description as criterion referenced.
Simple and direct comparisons of performance seem an essential requirement for the establishment of product validity relative to any performance standard and helps us answer related questions. What does it mean to be proficient in terms of content? How does this differ from being considered Advanced or Below Proficient? What content should we focus on next to move student learning forward in an efficient manner? Rasch-based cut-scores on linear continua represent a great step forward in both understanding performance and translating that performance into useful information for teachers and policy makers to thereby use for decision making. OSS offers the strength of a construct-driven, item-mapped Rasch ruler that carefully operationalizes and expresses the content in ways that traditional models or random assignment simply cannot (Stone, 1995; Stone, 2004), because performance standards are placed on a meaningful content (construct) ruler (Figures 1 and 2). Differences in the performance standards are not simply numeric, as they would be for any performance standard, even the traditional Angoff standards, but they are content based. For example, the items that fall between the two standards Proficient and Advanced represent the type of content that is expected of Advanced preservice teachers but not of Proficient preservice teachers. It is descriptive. It is elaborative. It is content-based and not strictly quantitative. Unlike most reports from standardized tests, it provides instructors with an understanding of what the test-takers have mastered and what they have or may have not (FairTest: The National Center for Fair and Open Testing, 2012). In 1978, Gene Glass criticized traditional standard setting as answering a question quantitatively that was not prepared for quantitative expression. The OSS model blends quantitative translation with qualitative expression to address Glass’s important criticism.

Rasch construct–described content standards.
Limitations and Future Study
For this study, the sample of test-takers were all college-level seniors who had completed the pre- and post-ALI assessments online and unproctored. Although preservice teachers were instructed to complete these assessments without the use of additional resources, and informed that the results were being used for formative information rather than a grade, some preservice teachers may have looked up answers in textbooks or online resulting in them demonstrating higher than anticipated performance levels. This could explain the small number of preservice teachers who had high prescores only to appear as less able at posttest. However, on average, preservice teachers performed significantly better when completing the posttest as we would have expected after finishing one full semester of a college-level assessment course, and thus the results from this study are effective for demonstration purposes.
Judges may have been a limitation in this study because they were all college-level assessment instructors, and frequently believe that all assessment content is very important. It is possible that different (probably lower) performance standards would have been set if perhaps practitioners or administrators had been used as the judges, or in addition to the expert panel of college-level instructor judges. Thoughtful considerations should be made when choosing experts for performance standard setting exercises as their expertise and beliefs are essentially what create the cut-scores, and different experiences lead to different performance standards (Stone, 1996).
Final Thoughts
We can no longer afford to measure academic mastery or growth by simply comparing the performance of test-takers to one other. This norm-referenced method is neither appropriate nor fair for measuring individual learning. Instead, we must establish meaningful criterion-referenced benchmarks across the content being assessed, such that test-taker performance may be measured against this content. Applying the OSS model, demonstrated in our work more broadly and in higher stakes situations in the field of education, seems appropriate. In the medical field, efforts to ensure standards are precisely defined by experts and in comparison with content allows for more reliable and defensible interpretations of candidate results (MacDougall & Stone, 2015). Ensuring standards are appropriate and set using truly meaningful measurement protocols that meet a more modern conceptualization of validity, which includes both product and process, should be seen as critical. In the field of education, when results of student test performance affect teacher careers (e.g., evaluation systems), student grade level advancement, or district and school resource distribution, performance standard setting becomes both a psychometric and educational policy concern. To use the term du jour within the education policy-maker community, it is hard to imagine anything more valuable in the process of “adding value” than to correctly define criterion-referenced cut-scores that are meaningful and legitimately based in the performance of KSAs of our students.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.