
Abstract
The Open Data Commons (ODC) for Traumatic Brain Injury (ODC-TBI) and Spinal Cord Injury (ODC-SCI) are secure online platforms for members of the neurotrauma community to access curated, publicly available domain-specific data, and manage, share, and publish datasets with a citable DOI. Currently, preparing and uploading a dataset and its corresponding data dictionary involve multiple rounds of manual revisions to meet ODC guidelines. Here, we present the ODC Minimum Data Standards (MDS) and the ODC Data Quality App (ODCdqa), an open-source web-based tool that simplifies the revision and curation workflow. The ODCdqa allows users to automate initial data quality checks and provides immediate feedback on whether the dataset meets ODC data specifications or requires edits. All publicly available datasets on the ODC-SCI and ODC-TBI websites were passed into the ODCdqa for analysis. Exclusion criteria were: (1) did not have a data dictionary, and (2) the dataset and/or data dictionary had different headers. The aggregated results were then used to identify common areas of difficulty and inform the future directions of ODC tool development and platform. Out of the 124 publicly available ODC datasets uploaded between 2018 and September 2025, 119 were used (84 from ODC-SCI, 35 from ODC-TBI). Both ODC-SCI and ODC-TBI had a trend of reducing the number of failed checks as the platform matured over the years, and the MDS and ODCdqa were used regularly by curators and users. In summary, the ODCdqa is an automated tool that allows any user to perform initial checks to determine whether a dataset and its corresponding data dictionary are ready for upload to the ODC platform. As the ODC platform evolves, more checks and features will be added to the ODCdqa.
Introduction
In the last decade, data management and sharing have become a global concern in biomedical research, with the aim of better addressing the reproducibility crisis, reducing waste, and increasing value.1–6 Although principles of rigorous data collection, curation, and analysis are not new to research, 7 especially in data-intensive fields (e.g., imaging), the recent global movements toward open science and data sharing are creating challenges for fields that have historically been developed around small datasets. One of the reasons for these challenges may be the unrecognized need to develop and adopt field-wide data standards and practices. 5 Adopting consistent approaches to data collection, organization, and metadata annotation enables comparison and interoperability across independently collected datasets and can foster innovation. With the advent of high-throughput technologies and increasing requirements for data sharing from funding agencies (e.g., the National Institutes of Health and the U.S. National Science Foundation), knowledge across all aspects of data management and sharing is becoming essential. Funding agencies are increasingly establishing policies and mandates for data sharing, following guidelines such as the FAIR (Findable, Accessible, Interoperable, and Reusable) principles, 8 which provide guidance for implementing and promoting data sharing and reuse in a rigorous and reproducible manner. For instance, the National Institute of Health’s (NIH) Data Management and Sharing Policy mandates that data from NIH-funded or conducted research studies must be managed using best practices and shared with the general public (National Institutes of Health).
The Open Data Commons (ODC) for Traumatic Brain Injury (ODC-TBI, odc-tbi.org) and Spinal Cord Injury (ODC-SCI, odc-sci.org) are two community-driven, domain-specific data-sharing platforms that follow the FAIR data principles.9–14 As of the last quarter of 2025, the ODC-TBI represents the only open NIH-supported specialist data-sharing repository for the field of pre-clinical TBI, and the ODC-SCI represents the only one for SCI research (https://sharing.nih.gov/data-management-and-sharing-policy/sharing-scientific-data/repositories-for-sharing-scientific-data). The ODCs allow for both private and public data spaces and enable researchers to publish citable datasets accessible to the general public through the generation of Digital Object Identifiers (DOIs). To ensure the quality and usability of publicly shared data, the ODC community has established Minimum Data Standards (MDS)10,11 for uploading and publishing data. Every dataset submitted for publication undergoes quality review by members of the ODC Data Team to ensure compliance with the ODC MDS. While setting minimum requirements for data structure, format, and content ensures shared data is FAIR, the process of preparing and uploading a dataset (and associated data dictionary) for publication can often be held up by multiple rounds of manual revisions if the initial submission does not conform to the ODC MDS.
Curating and preparing data for sharing can be time-consuming efforts that often require a combination of domain knowledge and data expertise (e.g., research data management), which may not be available to every research group—especially those with limited resources. However, the development of domain-specific repositories, data standards, and open-source tools that facilitate data curation can greatly democratize data sharing and lessen the technical expertise required to make data shareable. These data curation hurdles can be addressed if data producers and curators have access to tools that streamline the quality-check process (e.g., through automation) and provide immediate feedback on whether the data conform to a specific standard.
Here, we present the ODC MDS, its components that facilitate FAIR data, and a set of quality checks for MDS compliance. We also introduce the ODC Data Quality App (ODCdqa), an open-source data tool we developed to guide both the ODC Data Team (curators) and users through data formatting compliance, quality checks, and initial data exploration (tool provided via code and a web-based graphical user interface [GUI]). To assess the impact of MDS implementation in the ODCs, we performed a retrospective analysis of data quality over time and demonstrate that a minimal set of easy-to-follow standards improves data quality and compliance in neurotrauma data sharing.
Methods
Development and implementation of the ODC MDS
Datasets shared on the ODC are initially uploaded to a virtual private space (Personal Space), from which the user can choose to share their dataset with other members of their laboratory (share to Lab Space) or publish their data via DOI request (share to Public Space).11,12 To confirm that publicly shared data is compliant with FAIR data principles, the DOI request initiates a Quality Control Check by the ODC Data Team followed by editorial review. We refer the reader to the ODC documentation and publications11,12 for further information on the ODC data spaces and functionalities.
The ODC MDSs were developed as an integral part of the ODCs through a series of community workshops, community board meetings, and user feedback. Noting that the Personal and Lab Spaces are frequently used for private and/or intermediary data storage, the minimum requirements for hosting a dataset on ODC depend on the intended data storage location. As such, the ODC MDS has established a minimal set of data formatting standards for all data uploads, and an expanded set of requirements for publishing with a DOI (i.e., required for data stored in the Public Space; strongly recommended for all data uploads).9,11 Although the core components are the same across odc-sci.org and odc-tbi.org, each community has established a different set of minimally required variables for public data release. The elements and main components of the MDS are described in Results section.
Development of the ODC Data Quality App
The detailed development and implementation of the ODC data quality R package and the associated app are described in the documentation for the tool (see Table 1). In brief, the backend of the application was developed in R, 15 implemented as an R package, and the GUI is implemented in RShiny. 16 The ODCdqa research resource identifier is RRID:SCR_027889.
All Links to Code and Resources

Retrospective analysis of ODC public data
To show the utility of the ODCdqa for analysis of datasets for MDS compliance, we performed a retrospective analysis of data quality. Data were obtained from the Public Spaces of both odc-tbi.org and odc-sci.org platforms between the first public release (2018 for odc-sci.org and 2020 for odc-tbi.org) and September 2025 (Supplementary Tables S1 and S2). These datasets were passed to the ODCdqa for data quality checks via an R script that directly called the quality-checking functions. A total of 124 datasets were available for extraction (89 on odc-sci.org and 35 on odc-tbi.org). Of those, 5 datasets from odc-sci.org were excluded from analysis (2 datasets were retracted by authors, and 3 did not include a data dictionary in a format suitable for automated data checks), leaving a total of 119 datasets eligible for analysis. Because of minor differences in the number of checks performed across the two communities, the datasets and data dictionaries for each community were imported, and checks for each community were run separately. To preserve anonymity, each dataset was assigned a codename based on the following format: Dataset_[number], where [number] is a randomly generated number between 1 and 119 (the total number of datasets included for Historical Checks).
Resource availability
The tool and resources used in this work, including a copy of the script used along with details on each step of the retrospective analysis, can be found on the ODC public GitHub repository (Table 1).
Results
The ODC minimum data standards
The ODC MDS specifies four components: a minimal data formatting specification, a minimum set of variables, a minimal data dictionary structure, and minimal metadata information (Table 2). The data formatting specification ensures structural interoperability across all datasets in the ODCs. That is, all datasets are structured and formatted in the same way to facilitate machine-based operations (e.g., joining two datasets). To facilitate interoperability and open sharing, the ODC uses comma-separated values (.csv) files as the format for uploading tabular data. Data contained in uploaded .csv files must be arranged in tidy data format,11,17 which specifies how to organize data in tabular structures (e.g., spreadsheets) to facilitate sharing and data reuse. An extensive treatment and example of the tidy data format for biomedical research have been provided elsewhere.17,18 In brief, the tidy format assumes that each column of a table or spreadsheet represents a unique variable, the first row contains the variable names (also known as headers), and each subsequent row contains a unique observation. The required set of variables ensures that a minimum amount of information is present across datasets, and their standardization ensures semantic interoperability at the variable level. Each community has established a specific set of required variables to be included in published data; for ODC-SCI, these are referred to as Community Data Elements (CoDEs), 19 whereas ODC-TBI uses the term Common Data Elements (CDEs), as the variables have been established and vetted through the NIH CDE development process. The data dictionary structure facilitates reusability by providing metadata and contextual information for each dataset variable. The data dictionary also facilitates interoperability and the performance of automatic quality checks. Finally, the minimal metadata information provides further contextual information on the shared data, including a structured abstract narrative that summarizes the content and reasons for the data, as well as author and institutional information, and links to other publications, documents, and resources related to the shared data.
Main Components of the ODC Minimal Data Standard

MDS, Minimum Data Standards; ODC, Open Data Commons.
The minimum requirements for a dataset to be hosted on the ODC depend on where it resides on the ODC. Datasets uploaded to the Personal or Lab Spaces are recommended to meet the minimal specification (Box 1). To facilitate data interoperability and reuse, all data publications (i.e., datasets that will be shared in the public domain [Public Space] with a citable DOI) must comply with the full MDS for the dataset and data dictionary. To confirm MDS compliance, all datasets that request a DOI undergo (1) an editorial review 20 to determine whether the dataset falls within the scope of ODC-SCI or ODC-TBI and enough metadata is provided to facilitate data reuse and (2) additional quality control checks performed by the ODC Data Team (Box 2).
Box 1.
Minimal recommended data formatting specifications for upload to the ODCs
The variable names are required to:
Be shorter than 64 characters. Long variable names often cause formatting issues. Variable names must start with a letter.
In addition, the ODC requires that:
Variable names be intuitive (e.g., use “Date_Birth” instead of “DB”). Precludes spaces in variable names. Use underscore (“_”) instead. This can be easily accomplished with “find and replace” functionalities in most spreadsheet software. Does not allow special characters except underscores (“_”) and periods (“.”).
Box 2.
Minimal requirements for public data publication in the ODCs with a DOI
The minimal metadata required for publication includes:
ODC MDS quality checks
The ODCs have established a set of quality checks, adapted from the Frictionless data framework (https://framework.frictionlessdata.io/), to guide the initial upload process and assist the ODC Data Team in assessing dataset compliance with the ODC MDS during the publication process. Some quality checks are performed during dataset upload, ensuring a minimal quality to all private and public datasets in the ODC. The check during the upload process is automatic and requires no human oversight, as data upload is handled privately within the data owner’s account. When the data owner requests a DOI for publication, the ODC Data Team (curators) conducts further quality checks, divided into three domains: source, structure, and schema (Table 3). In addition, datasets seeking approval for publication and issuance of a DOI undergo editorial review where the metadata is checked for completeness and relevance (see ODC documentation).
Data Quality Checks Are Performed by the ODCs During Upload and Before Acceptance for Data Publication

The automatic ones performed during upload are marked.
ODC, Open Data Commons; ODCdqa, ODC Data Quality App; SCI, spinal cord injury; TBI, traumatic brain injury.
A tool for aiding MDS compliance and data curation
Performing the ODC MDS quality checks manually is time-consuming, can lead to unintentional errors, and cannot be easily reproduced. Additionally, it is challenging for a single person or a group of individuals to thoroughly review large datasets to confirm the absence of duplicated entries (i.e., entire rows or columns of data) or other anomalies. To overcome these challenges, we have implemented the MDS quality checks in an open-source R package and web application called ODCdqa (ODC Data Quality App), available as free open-source software under the MIT license for public use. Designed with users (i.e., data uploaders) and curators (i.e., the ODC Data Team) in mind, the ODCdqa was created to streamline the workflow of data preparation, curation, and assessment for compliance with the ODC MDS. The ODCdqa offers two main functionalities: (1) an auto-filled data dictionary template and (2) a reproducible, automated quality control process for assessing compliance with ODC MDS. The workflows of these functions are discussed in greater detail below, but in brief, users upload a data file, which automatically generates a data dictionary template structured in accepted ODC format. The data dictionary can be downloaded as a CSV file and customized by the user to meet metadata requirements. Once a data dictionary is complete, the user then uploads both the data file and data dictionary file and runs the quality control check process, which generates a customized report of compliance with the ODC MDS. For data uploaders, the ODCdqa tool is most effective when used prior to dataset upload as it reduces the amount of time needed to create a data dictionary, allows users to troubleshoot and resolve errors that may arise during the upload process, and identifies ODC MDS compliance issues that may need resolving before the ODC Data Team can approve the dataset for publication and issue a DOI. Examples of different views of the user interface and functionalities are shown in Figures 1–3.
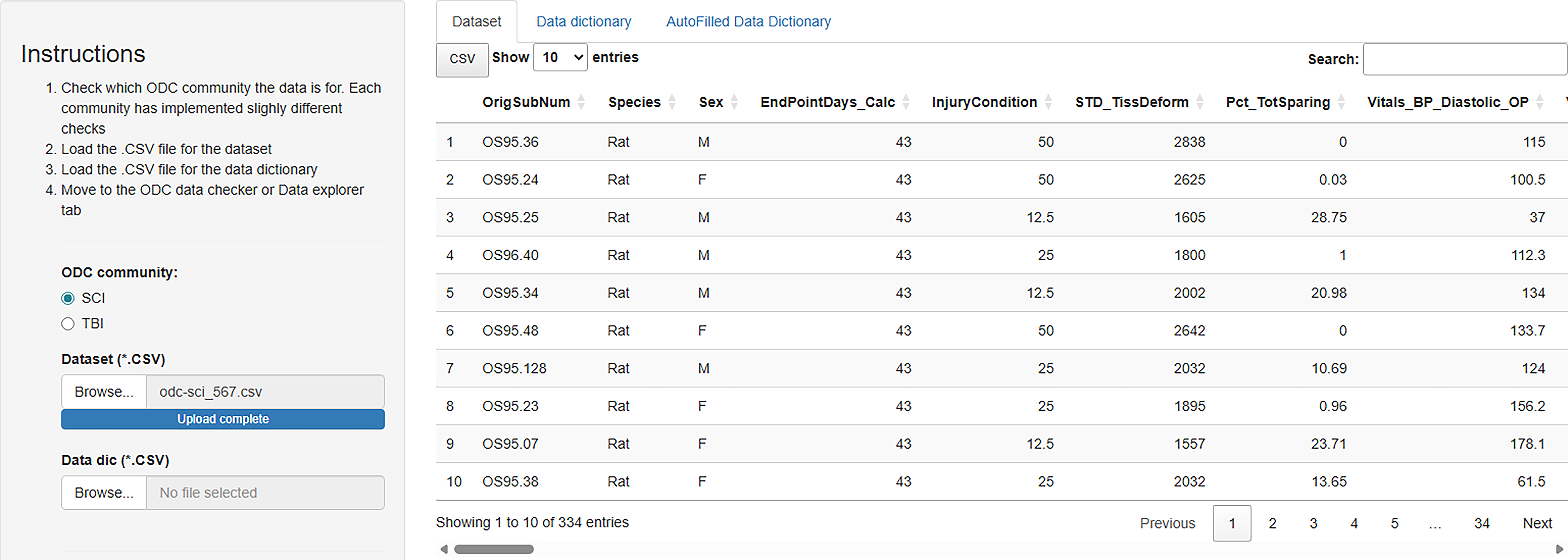
ODCdqa user interface for the interactive dataset preview. The figure shows the initial page after the user uploads a CSV-format dataset. The user is able to filter and search for specific entries in this interactive view. For example, a user might want to filter by Treatment to focus the view, or search for the text “day post-injury (DPI)” to return all time points containing that text. These functionalities enable quick exploration of the dataset. By default, ODCdqa displays an interactive preview of the entire dataset and/or the data dictionary upon upload.
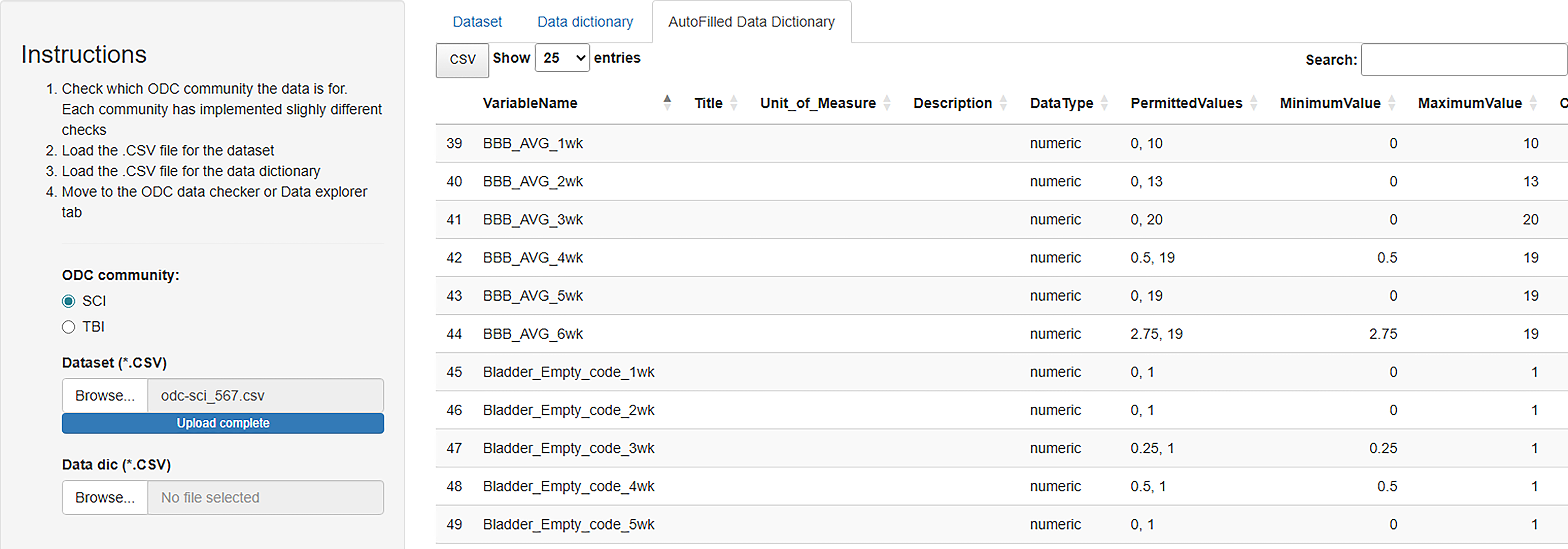
ODCdqa user interface for AutoFilled Data Dictionary. Users who wish to utilize the data dictionary template generation feature will be able to download a copy of the template under the “AutoFilled Data Dictionary” tab. Note that the template uses the available information from the uploaded dataset. Information such as Titles, Units, and Descriptions not present in the uploaded dataset are left empty for the user to fill in themselves. Future versions of the app could incorporate extracting that information from preset standards such as CoDEs or CDEs. CDEs, Common Data Elements; CoDEs, Community Data Elements.
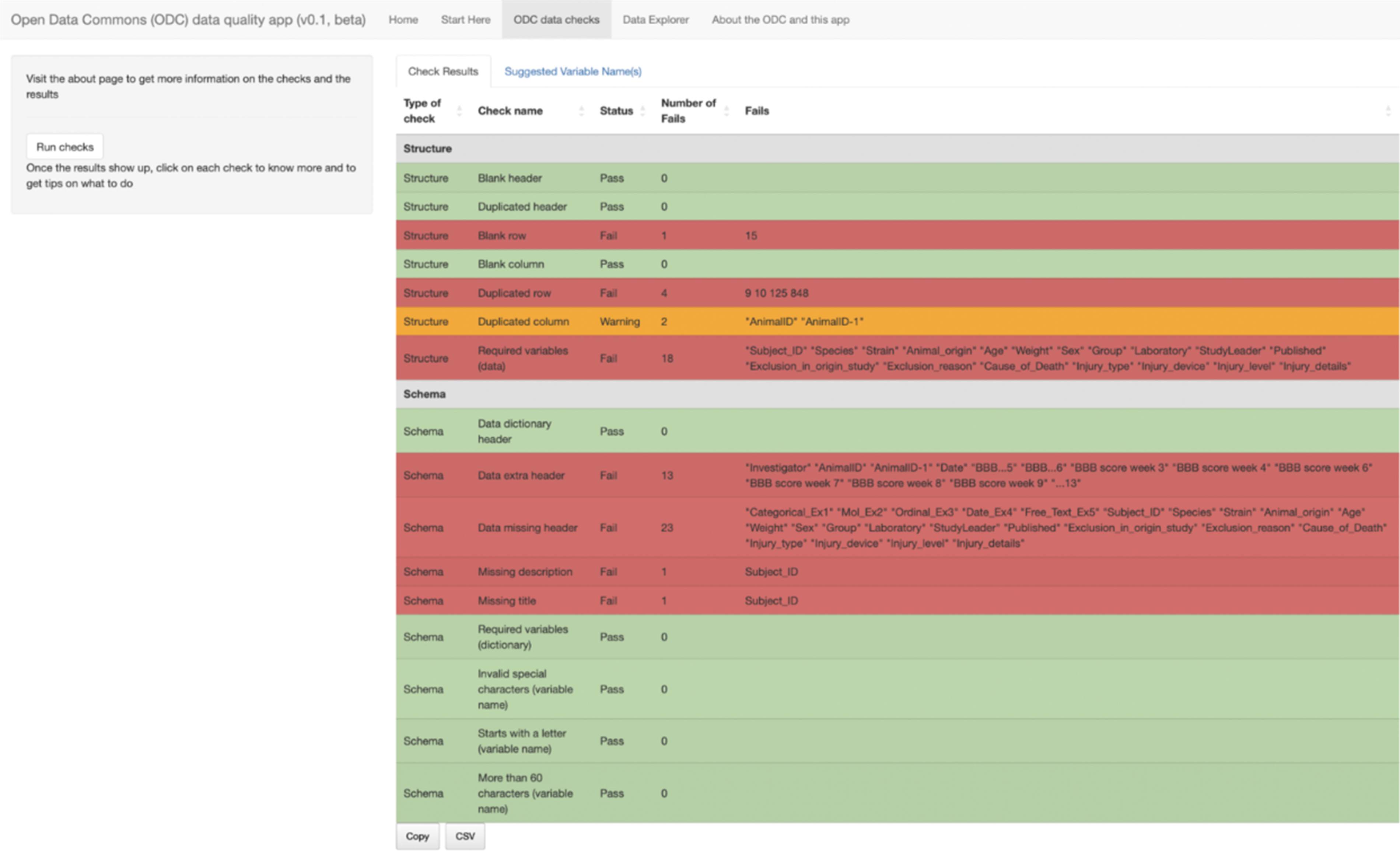
ODCdqa user interface for results of ODC data quality checks. The figure shows the results of the data quality checks on a sample dataset. Each check is color-coded according to its status. Pass, Fail, and Warning are color-coded as green, red, and orange, respectively. Checks with the Fail or Warning status will show the number of fails and where it failed (i.e., line number or variable name). Note that most checks are Pass/Fail only. The CSV button at the bottom of the page enables users to download a copy as a CSV file. ODC, Open Data Commons.
Auto data dictionary template generation
An automatically generated data dictionary template with variable names, variable type (numeric or character), permitted values, minimum, and maximum will be created if no data dictionary is uploaded (Figs. 1 and 2). The values for this template are taken from the uploaded dataset (Fig. 1). As such, the user needs to confirm and edit this template if necessary. For minor single edits, this can be done inside the application by double-clicking on the appropriate field and editing or entering text in the textbox; for more comprehensive edits (e.g., editing or adding multiple variable titles or descriptions), we recommend downloading the template as a CSV and making edits in another spreadsheet software, such as Excel or similar.
Reproducible ODC data quality checks
The ODCdqa incorporates automatic MDS checks (Figs. 3 and 4). While the current web-based tool allows anyone to run automatic checks for a single dataset at a time, users with programming expertise can access and utilize portions of the underlying code to automate checks for multiple datasets simultaneously. See the ODCdqa documentation for an example of how to do this.
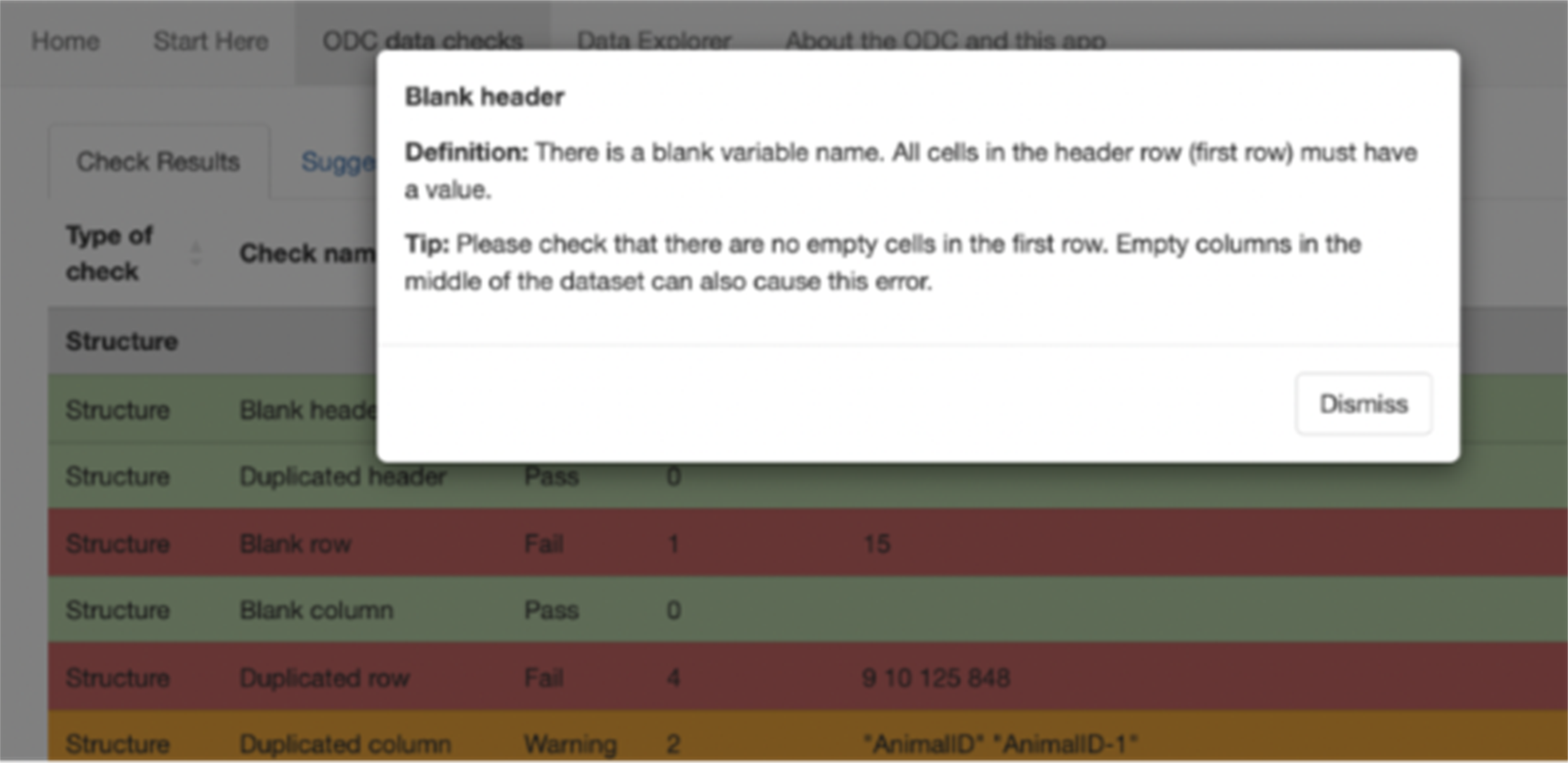
Pop-up for More Information. Clicking the name of a Check (e.g., blank header) under the “Check name” column allows users to view a pop-up with a definition of the Check performed and a tip on how to resolve a failed Check.
Quality checks on historical ODC public data
We demonstrate the utility of the MDS and the application of the quality check tool by retrospectively analyzing publicly available datasets on the ODC. Since the introduction of ODC MDS has been implemented over time, it provides a natural experiment on the consequences of policy implementation of the data quality checks and the use of the tool by the data team.
A total of 119 public datasets (84 on ODC-SCI and 35 on ODC-TBI) uploaded between 2018 and 2025 were analyzed for MDS quality checks (Fig. 5A). Overall, some checks are consistently passed in both ODC communities, while others have a high failure rate. A summary across all analyzed datasets (Fig. 5B) shows that for both ODC communities, all datasets are compliant with the schema check on the data dictionary headers. On the other hand, missing at least one variable in the minimal set with the recommended name is the most prevalent failed check across all datasets. Over time, the average fails per dataset in the ODC-SCI reduces (from an average of above 5 in 2020 to less than 3 in 2025), while it stays low in the ODC-TBI with an average around 3 or lower (Fig. 5C). It is important to note that the Required variables check is not fully implemented in the ODCdqa because of the challenges of integrating an automatic semantic similarity check between a variable and its reference in the minimal variable set. Thus, the ODCdqa only checks whether an exact match to each community’s set of required variables is present. The ODC Data Team manually checks for semantic relatives to missing required variables during the publication review process, and it is possible we are overestimating the failure rate in this analysis. Indeed, we have previously shown that oftentimes ODC datasets that fail the “required variables” check do contain all variables in the minimal set but use variable names different from the recommendations. 19 When focusing on the number of missing variable names from the recommended minimal set, there is a clear reduction of those over time in both ODCs from >10 in 2020 to <3 in 2025 (Fig. 5D).
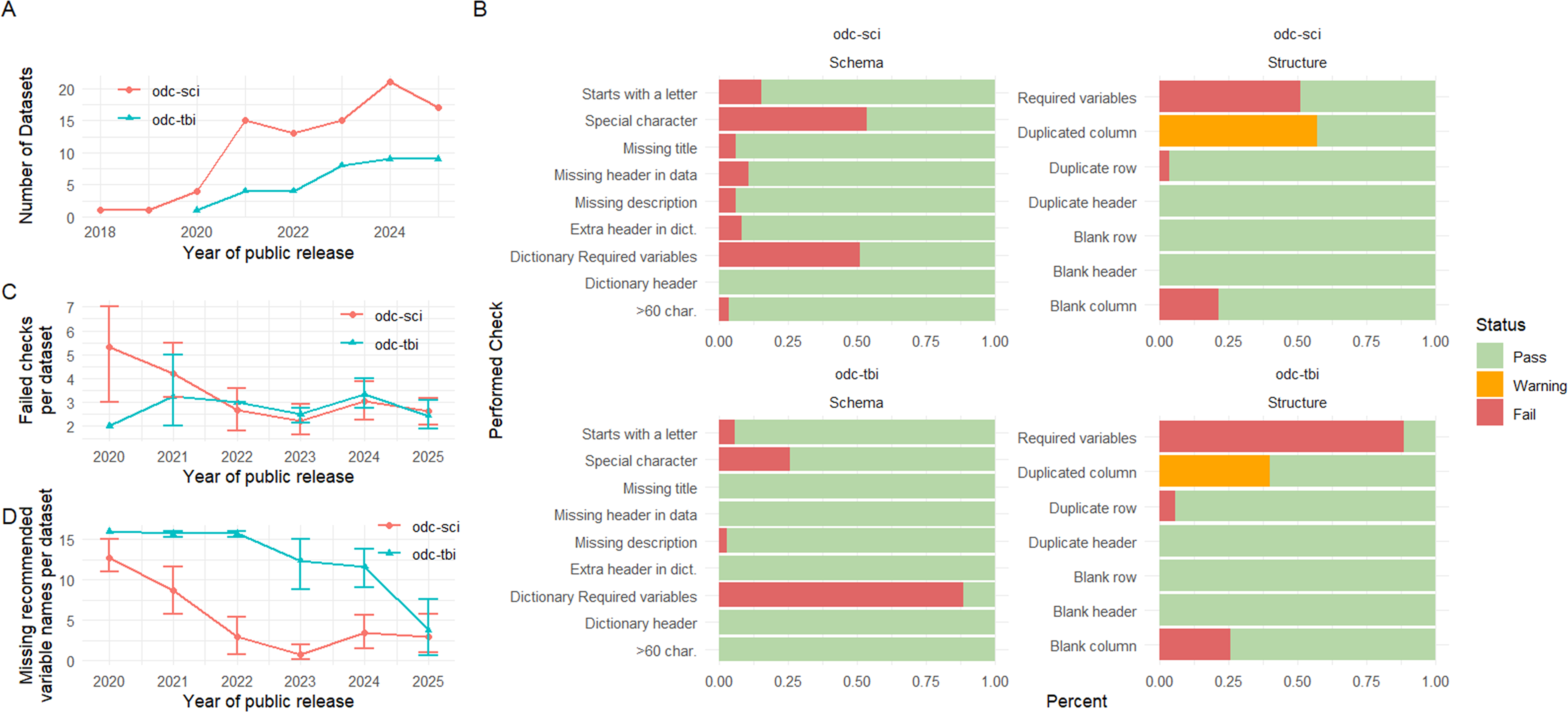
Retrospective analysis of MDS checks for both ODCs.
Discussion
The implementation of MDS and automated quality assurance tools within neurotrauma research represents a critical advancement toward improving open data integrity, interoperability, and reproducibility. Our retrospective analysis of datasets hosted on the ODCs demonstrates that structured data governance policies, combined with technological solutions, can significantly enhance compliance with FAIR principles that are increasingly expected by funders and journals.8,21 In line with the broader open-science literature documenting cultural and technical barriers to sharing,1,22–24 we observe that structure and schema compliance with MDS increases when guidance is concrete, and tooling is embedded directly into submission workflows. We provide tools and code to facilitate adoption and accelerate innovation in open data-sharing governance in neurotrauma and, more broadly, in biomedical research.
Impact of minimal data standards on data quality
Since the ODC MDS was introduced and iteratively refined through community workshops, governance, and user feedback, we have seen a longitudinal improvement in compliance. Specifically, the reduction in failed checks for structural and schema compliance in ODC-SCI suggests that community-driven standards are effective when consistently applied. In the ODC-TBI, compliance with ODC MDS was already high in datasets at the beginning of publishing (2020) and maintained over all the analyzed years. This might be explained by a spillover effect from the ODC-SCI, as both communities have a shared governance structure, data curation team, and rely on the same platform. Indeed, members of the data curation team at ODC used their experience in ODC-SCI to guide users in ODC-TBI, even before the MDS were officially enforced. In addition, there is a considerable overlap between members of both communities. Thus, it is possible that the lessons learned in ODC-SCI, which started publishing datasets 2 years earlier, had an influence on the data preparation and quality checking in ODC-TBI by users and the curation team. Nonetheless, our results also indicate an improvement in ODC-TBI over time in the reduction of the number of minimal variables missing the variable name as recommended by the ODC-TBI governance team. We note the important role of the data curation teams in both ODC-TBI and ODC-SCI, which actively work with data submitters to prepare their data for MDS compliance. These trends underscore the importance of clear and easy-to-follow standards for data formatting, variable naming, and metadata completeness.7,11 Our observations are consistent with the community’s prior reports that Community-driven Data Elements (CoDEs) improve reporting quality and semantic interoperability in SCI datasets, 19 while the broader SCI clinical/pre-clinical community is converging on interoperable data standards to drive translation from research to practice. 25
Role of automation in data curation and data quality checks
Manual curation of large, heterogeneous pre-clinical datasets is time-consuming and error-prone. The ODCdqa application addresses this by providing (1) an auto-generated data dictionary template and (2) reproducible automatic MDS checks. These features not only streamline the data preparation process but also democratize access to best practices in data management for research groups with limited to no informatics expertise. By reducing the technical burden, ODCdqa facilitates broader participation in open science initiatives, which should accelerate the publication of datasets. However, automation is not perfect. Certain checks, such as verifying the scientific relevance of metadata or ensuring adherence to community-specific variable sets, still require human oversight. While increasing automation reduces burden, we emphasize a hybrid model: automated checks handle routine and scalable validation, whereas ODC Data Team review ensures scientific relevance, adequate metadata narrative, and appropriate handling of community-specific required variables. This approach aligns with best-practice recommendations across open science.8,24
Despite the observed improvements, the most persistent challenge we observed was semantic interoperability (e.g., required elements present but named differently than recommended terms). For example, the most frequent failure involved missing recommended variable names from the minimal set, even when equivalent variables are present under different names.19,20,26 This is well recognized across biomedicine: standards adoption typically lags structural conformance, and semantic mapping remains hard to automate at scale.19,27–29 This highlights the limitations of automated checks in resolving semantic discrepancies and suggests that future iterations of the ODCdqa should incorporate natural language processing or ontology-based mapping to improve variable presence recognition,30–32 ideally linked to CDE registries (PRECISE-TBI 33 ; NINDS TBI CDEs; NINDS Pre-clinical CDEs).
Implications for FAIR data sharing and policy compliance
Our results align with a broader policy landscape that now expects robust data management and sharing. The NIH Data Management and Sharing Policy 21 requires DMS Plans for all NIH-funded research generating scientific data and encourages the use of domain-appropriate repositories. 21 ODC-SCI and ODC-TBI exemplify this model as NIH-recommended, domain-specific repositories with built-in quality control, DOIs for citation, and minimal standards for metadata documentation. For TBI, the PRECISE-TBI initiative and NINDS CDEs provide detailed pre-clinical/clinical elements and guidance that can be operationalized in tools like ODCdqa to accelerate harmonization and reuse 34 (PRECISE-TBI CDE 33 ; NINDS CDEs). For SCI, ongoing work on community-driven CDEs and translational infrastructure complements the ODC approach and reinforces the need for machine-actionable standards.19,25 By operationalizing FAIR principles through domain-specific standards and tools, ODC platforms exemplify how community-driven infrastructures can support compliance with these policies while fostering reproducibility and transparency in pre-clinical research. Looking ahead, expanding ODCdqa’s functionality to include semantic validation, integration with CDE repositories, and machine-readable metadata will further enhance interoperability and reuse. Additionally, embedding these tools into repositories’ data submission workflows could standardize quality assurance across biomedical domains, reducing variability and improving trust in shared datasets.
Limitations and future directions
First, our automated “Required variables” check may overestimate failures because it cannot yet fully infer semantic equivalence (e.g., AgeAtInjury vs. Age_Injury). This mirrors well-documented community challenges in variable-level harmonization and the broader reproducibility literature.1,19,35,36 Second, our retrospective design cannot disentangle policy, training, and community learning effects from the effect of MDS and ODCdqa implementation due to confounding. Prospective studies should evaluate the incremental impact of ODCdqa adoption on error reduction, curation time, and time-to-publication across labs, and make use of causal inference designs to estimate the effect of policy changes implementation. Finally, to address persistent semantic drift, future versions should integrate ontology mapping, template-driven metadata entry linked to CDE registries, and active learning to flag likely synonyms and features that can be prototyped by connecting ODCdqa to PRECISE-TBI/NINDS catalogs and broader NIH repository finders (PRECISE-TBI; NINDS Pre-clinical CDEs; NIH Data Repository Finder).
Conclusion
This article introduces a tool for researchers in the neurotrauma community to ease the transition to the recently introduced data-sharing policies and mandates put forth by funding agencies. The combination of minimal data standards and automated quality assurance tools represents a scalable strategy for improving data quality in neurotrauma research. These efforts not only advance FAIR data sharing but also set a precedent for other biomedical domains seeking to enhance reproducibility and transparency through open science practices.
Transparency, Rigor, and Reproducibility Summary
The datasets used for analysis are openly available under the CC-BY license on odc-sci.org and odc-tbi.org; links and reference numbers are provided in Supplementary Tables S1 and S2, respectively. Table 1 provides all links to the open-source code for the tool’s backend and GUI, as well as the code reproducing the analysis presented in this work.
Authors’ Contributions
K.A.F., H.R., and A.T.-E. contributed to the conception, design, and code of the study. K.A.F. and A.T.E. developed software and performed statistical analysis. K.A.F. and A.T.E. wrote the first draft of the article. All authors are part of the ODC development and governance team and actively participated in the development and implementation of MDS, quality checks, and ODCdqa. All authors contributed to article revision, read, and approved the submitted version.
Authors Declaration
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
Acknowledgments
The authors would like to thank all members of the ODC-TBI and ODC-SCI communities for their time, effort, and contributions to promoting and advancing data sharing and open science.
The PRECISE-TBI Investigators (in alphabetic order): Axtman, P.J.; Bandrowski, Anita; Davis, Lex Maliga; Dixon, C. Edward; Ferguson, Adam R.; Floyd, Candace L.; Grethe, Jefferey S.; Gu, Zezong; Gurkoff, Gene; Harris, Neil G.; Huie, J. Russell; Johnson, Catherine E.; LaPlaca, Michelle; Martone, Maryann E.; Radabaugh, Hannah L.; Surles-Zeigler, Monique; Torres-Espin, Abel; Van de Vord, Pamela J.
Funding Information
K.A.F.: Wings for Life, Craig H. Neilsen Foundation, Christopher and Dana Reeve Foundation. This work was supported by grants from the National Institutes of Health (NIH: U24NS122732; UH3NS106899 R01NS122888 to A.R.F.), U.S. Department of Veterans Affairs (VA: I50BX005878; I01RX002245, I01RX002787 to A.R.F.), Wings for Life Spinal Cord Research Foundation and Craig H. Neilsen Foundation (to A.R.F.), and Canadian Institute of Health Research (CIHR to A.T.E.).
Supplemental Material
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.