
Abstract
A brain tumor (BT) is considered one of the most crucial and deadly diseases in the world, as it affects the central nervous system and its main functions. Headaches, nausea, and balance problems are caused by tumors pressing on nearby brain tissue and affecting its function. The existing techniques are challenging to analyze diseased brain images since abnormal brain tissues lead to distorted or biased results during image processing, like tissue segmentation and non-rigid registration. To overcome these issues, proposed a DS-GAN model for inpainting brain MRI images. Initially, the input MRI images are segmented using a Gated shape convolution neural network (GS-CNN). In the first GAN, grayscale pixel intensities and the remaining image edges are utilized to create edge generators or edge reconstruction Generative Adversarial Networks (EGAN), which are capable of creating false edges in areas that are missing. The results of the experimental results demonstrated that the Jaccard Index (JI) was 0.82, while the Dice Index (DI) was 0.86. The proposed DS-GAN in terms of L1 loss, PSNR, SSIM, and MSE obtained was 2.18, 0.972, 32.04, and 26.42. As compared to existing techniques, the proposed DS-GAN model achieves an overall accuracy of 99.18%.
Introduction
BT segmentation is a hard venture due to their numerous behavior each in phrases of shape and function. 1 MRI is the over different imaging modality for the analysis and preparation of mind tumors due to its non-invasive assets without the publicity to ionizing radiations and superior image contrast in soft tissues.2,3 Various tissue contrast image types are employed by MRI modalities. These images enable the extraction of structural information that is valuable for the diagnosis and treatment of tumors and their sub-regions. 4 The function of image inpainting is to provide visually realistic and semantically cohesive material to an image's blank regions.5,6 The public benefits from image inpainting in many real-world situations, such as when images require to be edited, distracting aspects removed, or facial defects corrected.7,8 All these techniques need the definition of the inpainting zones. Segmentation-based techniques are greatly influenced by the effectiveness of segmentation. 9
Inpainting models can suffer from sudden color distortions despite the substantial improvements in image inpainting, especially when there are large missing portions.10,11 Generative models, such as GANs, utilize probability distributions to produce artificial data. 12 A discriminator that utilizes the produced data as input for generating real data and a generator that generates synthetic data in response to random inputs make up GAN two major fundamental components. 13 GANs are extensively employed in healthcare technology due to their strong performance and durability.14,15 In addition, the limited dataset has encouraged the usage of GANs to supply the necessary quantity of images to support training processes, which is crucial to achieving results with increased accuracy. 16 For general computer vision applications, GAN-based data augmentation has shown excellent results. It demonstrates the excellent generalization capabilities of GAN by comparing the generated noise variable distribution to the real one using a sharp value function. 17 GANs may create high-fidelity, high-resolution images in the medical image processing domain without supervision. By produced T1-weighted brain MRI images are equally accurate as real images. 18
GANs can supply more variant instances by using a min-max two-player game to transform the separate distribution of confined training models into a continuous distribution.
19
By combining the genuine and false data generated by GANs, it enhances the performance of the model. However, a significant portion of these works are confined to 2D images.
20
Moreover, segmenting brain MR with conditional GAN generators allows training the Cycle GAN model to accurately recognize geometric violations in growing MR and generates more training data for BT segmentation.
21
The main contribution of the paper is summarized as,
In this research, a novel DS-GAN model has been proposed for inpainting multi-modality brain MRI images. Initially, the input images are semantic segmentation utilizing a Gated Shape Convolution Neural Network (GS-CNN). In the first GAN, grayscale pixel intensities and the remaining image edges are utilized to create edge generators, or EGAN, which are capable of creating false edges in areas that are missing. The second GAN uses the RGAN approach to fill in the gaps by combining edge information from the absent regions with color and texture information from the nearby regions. The overall evaluation of the proposed DS-GAN model was estimated by some parameters such as specificity, recall, accuracy, precision, JI, and DI, respectively.
The rest of the papers have five sections were separated as follows. Section 2 defines literature reviews. The suggested DS-GAN model is discussed in Section 3. The results and discussion are described in Section 4. The conclusion is described in Section 5.
The proposed DS-GAN model raises the following research questions: SQ1: How can brain MRI images with missing or distorted regions be accurately inpainted? SQ2: How does the proposed DS-GAN model compare to existing GAN-based techniques in terms of image inpainting performance? SQ3: What improvements does the Gated Shape Convolutional Neural Network (GS-CNN) bring to brain MRI image segmentation?
Literature survey
Researchers have recently published a number of strategies and techniques, mostly for the effective inpainting of MRI brain images. This section provides an overview of a few of those semantic segmentation, edge detection, and area identification methods.
In 2020 Armanious et al. 22 proposed an ipA-MedGAN for inpainting medical images. A novel structure for the localized distortion inpainting of medical modalities. It makes it possible to inpaint regions of any shape without needing to know where the pixels are located within the regions of interest. By combining two discriminator networks with distinct receptive fields, a pre-trained feature extractor network, and a cascading MultiRes-UNets generator.
In 2024 Zhao et al. 23 designed TBI-GAN, a unique generative adversarial network, to improve brain area segmentation data in TBI MR images. The proposed TBI-GAN is appropriate for augmentation of traumatic brain segmentation since it can inpaint both the MRI image and brain area label maps based on templates of a normal brain. The greatest results in 2D and 3D brain region segmentation in TBI MRI images are improved by the segmentation network.
In 2021 Wang et al. 24 suggested a medical image inpainting model based on edge and structural information (ESMII). Moreover, the features are from the image at three scales using multi-scale residual blocks in order to get around the deep network's degradation issue. The network is generating more substantial structural textures because of the multi-level loss. On the datasets for abdominal CT, abdominal MRI, and COVID CT, it performs optimally and numerically.
In 2022 Tang et al. 25 proposed 3D Tensor-Wise Brain-Aware Gate network (TW-BAG) for distorted DTI inpainting. The suggested approach has been tailored to the situation by making use of several tensor-wise decoders and a dynamic gate mechanism. The Human Connectome Project (HCP) dataset, which is accessible to the public, uses scalar DTI measurements and mutual image similarity metrics that result from the projected tensors. Fractional anisotropy (FA) errors in the gathered region are decreased by 0.1561 and 0.0087, respectively.
In 2024 Pitchai et al. 26 developed a fuzzy K-Means clustering segmentation system for brain tumors using deep learning. First, the wiener filter is used to denoise the MRI images to remove noise. To classify the images as abnormal or normal, an ANN is utilized. Lastly, the tumor region has been segmented using the fuzzy K means technique on the aberrant images. With a maxi accuracy of 94%, the proposed semantic segmentation technique produces better segmentation results.
In 2020 Jia et al. 27 suggested a brain tumor semantic segmentation called fully automatic heterogeneous segmentation utilizing support vector machines (FAHS-SVM). Integrates relaxed metrics, morphology, and structural information into the cerebrovenous system's MRI imaging. A high degree of homogeneity between the neighboring brain tissue and anatomy characterizes the segmenting function. The experimental findings demonstrated that the suggested technique could identify diseased and normal tissues in MRI images with 98.51% accuracy.
In 2024 Haque et al. 28 designed a deep neural NeuroNet-19 network architecture to detect brain tumors. The iPPM ensures the retrieval of multi-scale feature maps for both local and global image conditions. Four classes of meningioma, BTs glioma, pituitary tumors, and no tumor, are used to train NeuroNet 19. It finds that, at 99.3%, NeuroNet19 obtains the maximum accuracy.
In 2021 Chong et al. 29 created a 3D MRI image volume of the human brain with T1-contrast, utilizing a GAN approach trained on 11 × 12 MRI images. The texture network is used to precisely restrict contrast patterns in image sections and to understand the 3D shape modifications in BT. The shape network creates a 3D voxel-wise deformation map that is used to twist brain images from the Montreal Neurological Institute (MNI). The texture network is then used to style axially aligned slices.
In 2021 Abu-Srhan et al. 30 developed a paired-unpaired Unsupervised Attention-guided GAN model called uagGAN to convert MRI data to CT images. After initializing on a paired dataset, the uagGAN model undergoes a cascade process to retrain on an unpaired dataset. It generates fine structure images by combining non-adversarial losses with the Wasserstein GAN adversarial loss function. It's used to produce attention masks, which enhance image quality and accuracy.
In 2020 Sun et al. 31 proposed an MRI segmentation and augmentation based on generative adversarial networks, 3D MRI images without disturbing against the disease. A large quantity of labeled data when using segmentation networks. A set of analyses conducted on the BRATS17 dataset validates the efficiency of MM-GAN in improving and anonymizing data. It improves the tumor core's and the entire tumor's dice scores by 0.16 and 0.17, respectively.
From these literature surveys use overly deep layers, causing essential low-level features to disappear before reaching higher layers, which reduces model efficiency. Compared to other existing models, the proposed method for brain image inpainting offers significant advancements in the field of medical image processing. While existing techniques primarily focus on inpainting general or medical images, often lack specialization for the unique challenges presented by brain images. These methods may not fully address the intricacies of brain structures, leading to inaccurate reconstructions or loss of critical information. In contrast, the proposed brain image inpainting method is specifically designed to handle the complex patterns and textures of brain tissues. It provides a more precise and reliable reconstruction by incorporating specialized algorithms that better preserve anatomical details. This method not only improves the quality of inpainted brain images but also enhances diagnostic accuracy, making it a valuable contribution to medical imaging, particularly in scenarios where image defects or data loss hinder effective diagnosis. Likewise, generators are needed to detect edges and regions. To solve this issue, the DS-GAN model is presented, which inpaints brain MRI images to increase their accuracy.
Proposed DS-GAN model
The DS-GAN model for inpainting brain MRI images has been proposed in this research. In the first GAN, grayscale pixel intensities and the remaining image edges are utilized to create EGAN, which is capable of creating false edges in areas that are missing. An overall diagram of the Proposed model is shown in Figure 1.
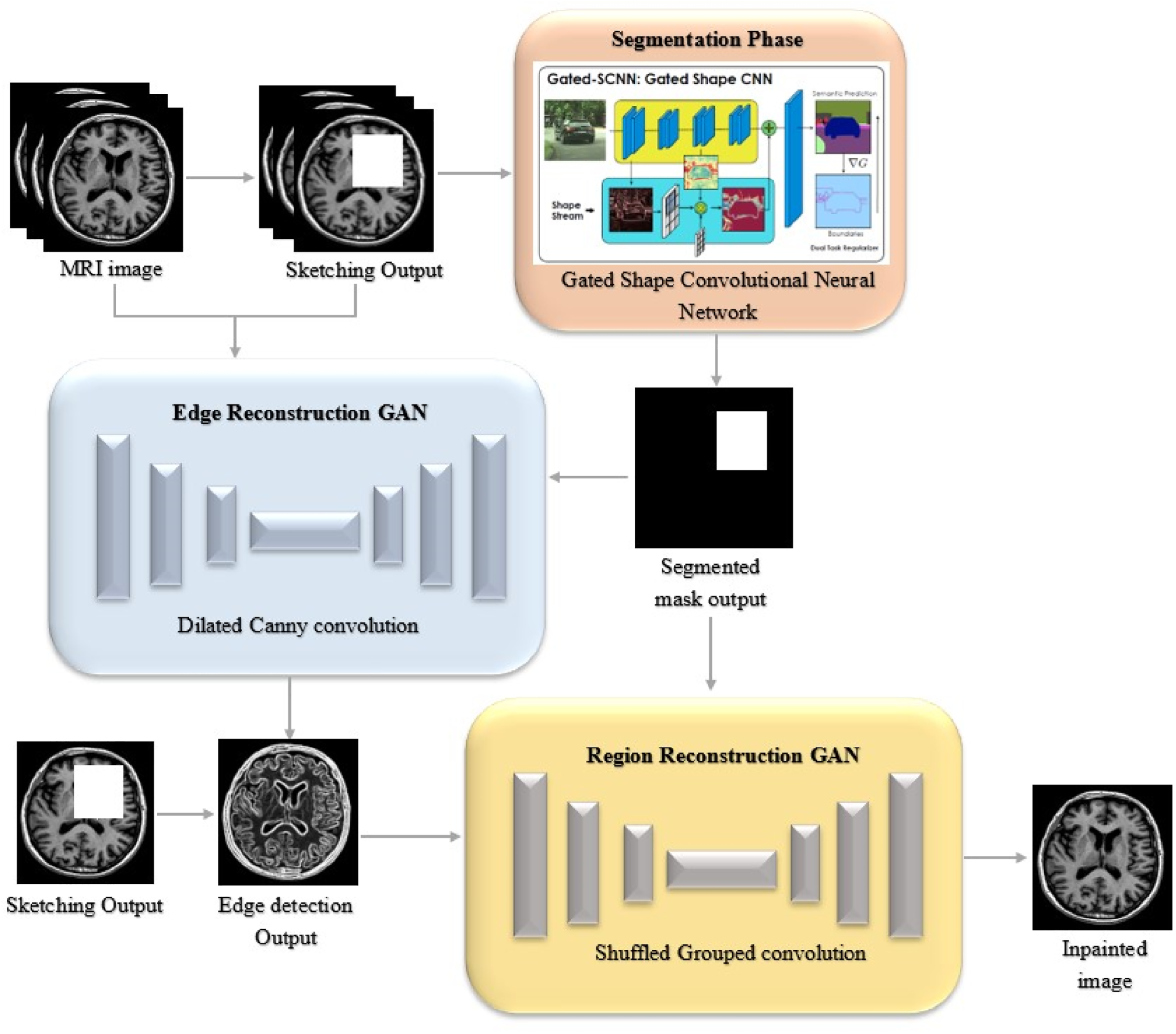
The overall workflow of the proposed DS-GAN methodology.

GS-CNN architecture.
In the proposed method, a brain MRI image dataset containing 2D images is used. This dataset has a 256 × 256 resolution. It considers a total of 70 images; 45 images are abnormal and they are affected by different kinds of diseases. For every disease, only 15 images are used. The remaining 25 images are normal, and they are not affected by any kind of injury. This method used a split of 65% for training and 35% for the testing process.
Segmentation
In this Proposed method, the Gated Shape-CNN network for segmentation. This network is made up of two network streams and a fusion module. Two streams comprise the network: a shape stream that analyzes semantic boundaries as shape information, and a normal stream that is a standard segmentation CNN. Through the use of local supervision and our thoughtfully crafted Gated Convolution Layer (GCL), we are able to compel the shape stream to analyze only boundary-connected data. Next, combine boundary features from the semantic region and form stream characteristics from the regular stream to generate a more precise semantic segmentation result, particularly in the area of boundaries. Figure 2 illustrates the GS-CNN, which integrates a shape stream and a regular stream for segmentation. ASPP applies geometric features in the shape stream, while the regular stream focuses on context and spatial features.
There are two types of streams: regular and shaped. An arbitrary backbone architecture can be the normal stream. As shapes are processed, supervision, Gated Convolutional Layers (GCL), and residual blocks are used. A fusion part uses an Atrous Spatial Pyramid Pooling module (ASPP) to merge the data from the two streams at multiple scales. An effective dual-task regularizer is used to guarantee high-quality boundaries on semantic segmentation masks.
Regular steam
This technique, designated as
Shape stream
The output of this stream, denoted as
Fusion module
This module, designated as
Gated convolution layer
The GCL layer, which connects the semantic segmentation and semantic boundaries, makes it easier for data from the normal to shape stream. GCL is a fundamental part of the design that assists in filtering out unnecessary information so that the shape stream processes only pertinent data. The form stream differs from the ordinary stream in that it does not include characteristics from it. Instead, it makes use of GCL to deactivate its activations that aren't considered pertinent by the higher-level data that is part of the regular stream. As a result, the shape stream can process the image at a very large resolution by implementing an efficient, shallow architecture.
GCL is in a few different places between the two streams. Let t ∈ 0, 1, · · ·, n be an index, and let n be the quantity of locations. The average illustrations of the matching shape and regular streams are processed by a GCL are represented by


Figure 3 shows the edge reconstruction and region reconstruction stages of the image inpainting network in our proposed DS-GAN model. Each stage has a generator and a discriminator, and both stages use an adversarial model. Let

Architecture of the proposed DS-GAN model.
A canny edge detector is used to compute the edge maps. It is a basic method for creating edge maps. Their grayscale and edge map will be represented as
Input the masked grayscale image

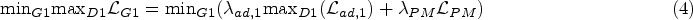
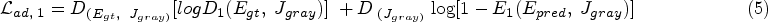

Shuffled Grouped Convolution is the term for the method of using group convolution to obtain information. In convolutional neural networks, shuffled channel shuffle is an operation that aids in combinatorically determining the information flow between feature channels. Different learning segments result from the application of grouped convolution. These distinct segments each include unique learned kernel-based information that can be merged in different ways with higher layers. There are two convolutions in the stacked group. The term “group convolution” is GConv. To start, two convolution layers are stacked and have an equal number of groups. After that, the only input channels that each output channel is related to are those in the group. Second, once GConv1 has finished processing data from various groups, the input and output channels are fully related. And lastly, a channel-shuffle-based equivalent of GConv2.
Results and discussion
A Matlab-2019b result analysis is used to gauge the effectiveness of the proposed DS-GAN model. A further processing step involves dividing MRI images from publicly available datasets into edges. Based on the test sample analysis, precision (PR), recall (RE), accuracy (AC), Specificity (SP) DI, and JI are evaluated. Additionally, the DS-GAN model's efficiency is discussed and examined, along with the overall accuracy rate.
Figure 4 illustrates the experimental results from the proposed DS-GAN model using MRI images. Column (Clm) 1 shows the input images, and Clm 2 shows the output results. The segmented mask images are presented in Clm 3. The edge detection images are shown in Clm 4. Clm 5 shows the brain MRI images painted using the DS-GAN discovered images.
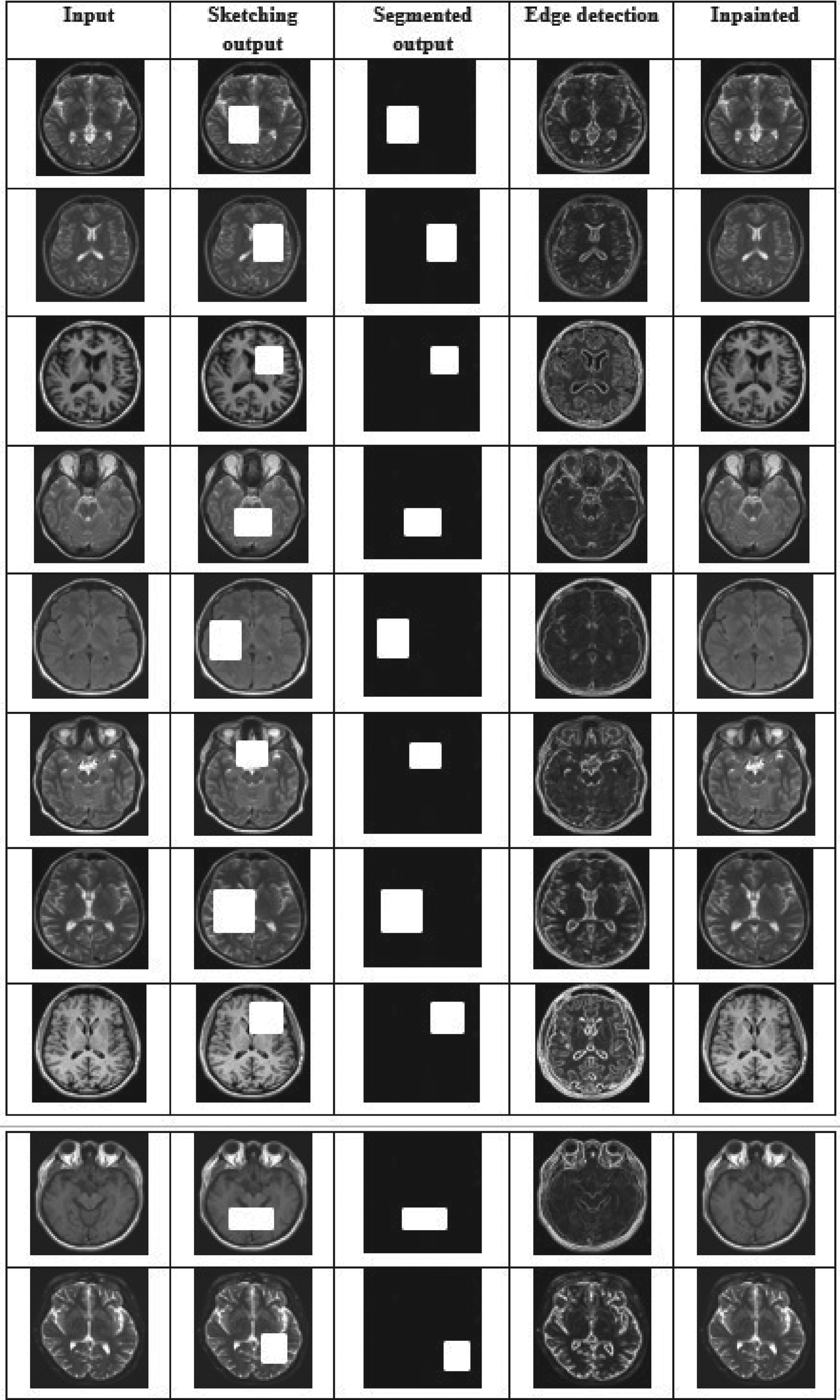
The experimental results of the proposed DS-GAN model.
Recall, precision, and accuracy were the particular measuring methods utilized to assess the overall performance of the proposed DS-GAN model.
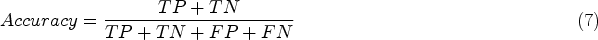


The dice index (DI) involves the use of an index of the three-dimensional edge of the image occlusions in addition to a reproducibility validation parameter. To find the precise ratio of the real region to pixels, DI is computed. Equation (10) computes the anticipated pixels and background pixels. By separating connection sizes by union sizes, the JI calculates how similar two finite samples are to one another. The JI, or similarity index, between anticipated and actual pixels is calculated in equation (11).


The overall Performance analysis of the proposed DS-GAN model.
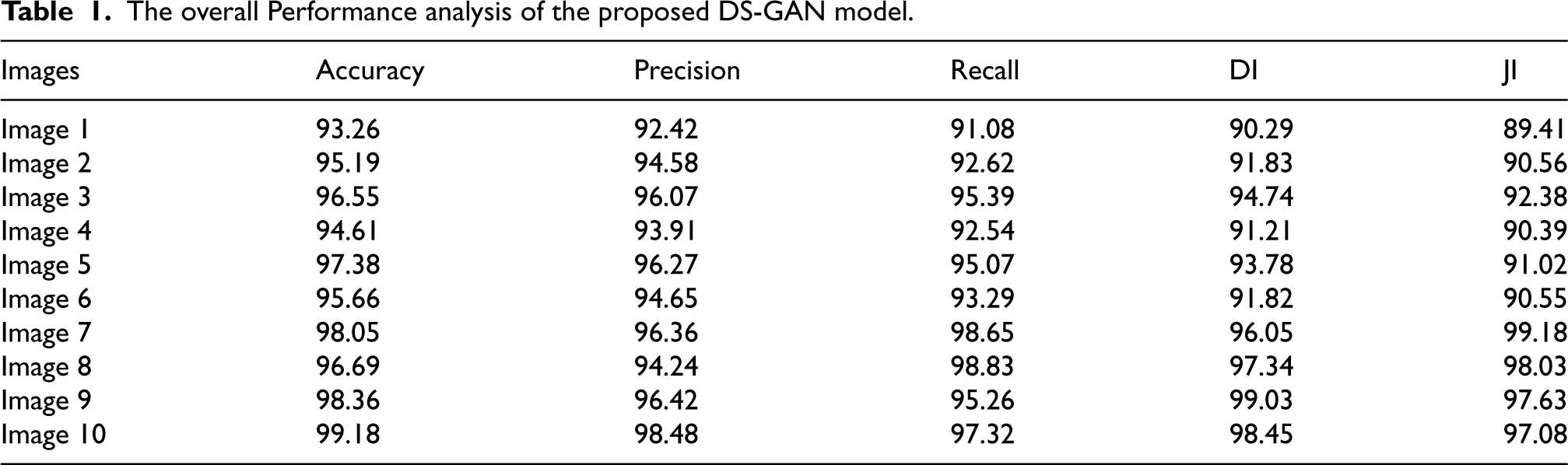
The PSNR and MSE were also used to evaluate capability. One often-used statistic to assess the output, ground truth, and image quality of a proposed network is the PSNR. An extensive comparison is made between the modified and reference photos. The original and inked image error ratio is measured by the mean squared error (MSE). Models with lower error rates are thought to be more effective when their MSE values are used to measure their efficacy. Table 2 shows the performance as determined by those requirements.
The analysis of the DS-GAN model based on PSNR, and MSE.
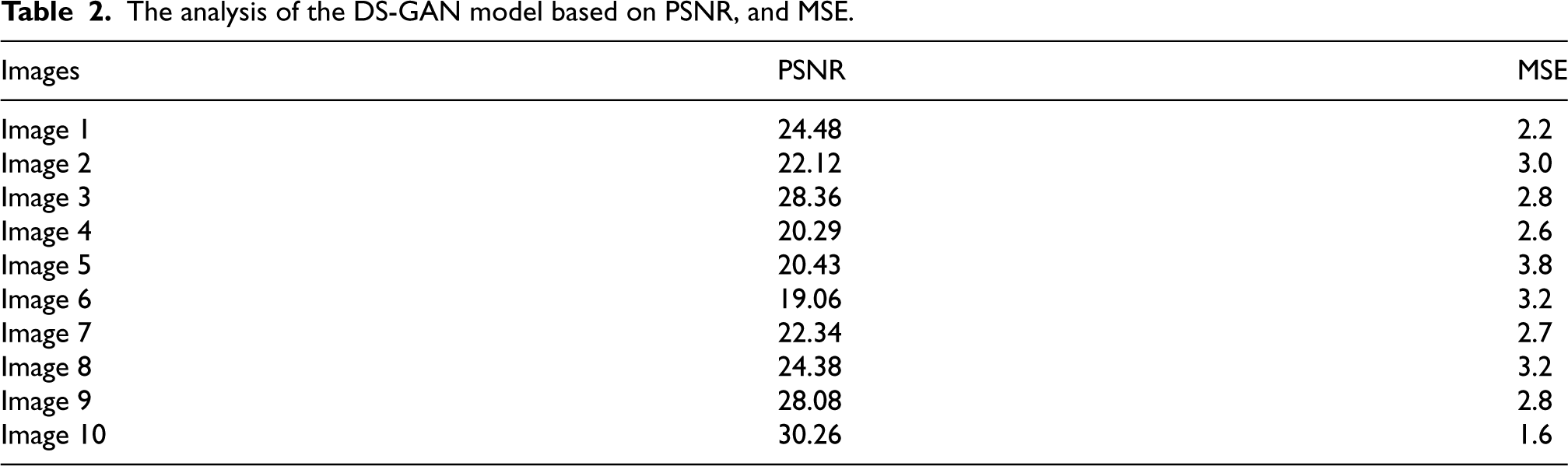
The efficiency of the proposed DS-GAN model inpaints MRI images. The segmentation and inpainting performance are estimated in terms of PR, RE, AC, JI, and DI. The overall accuracy for the publicly accessible dataset achieved by the proposed DS-GAN model is 99.18%. Additionally, the Proposed DS-GAN model attains a total precision of 98.48% and a recall of 97.32%. Based on Table 2, the DS-GAN model is the best performing, indicating accuracy at a high level. The training and testing AC and loss curves are shown in Figures 5 and 6.

The AC curve of the DS-GAN model.
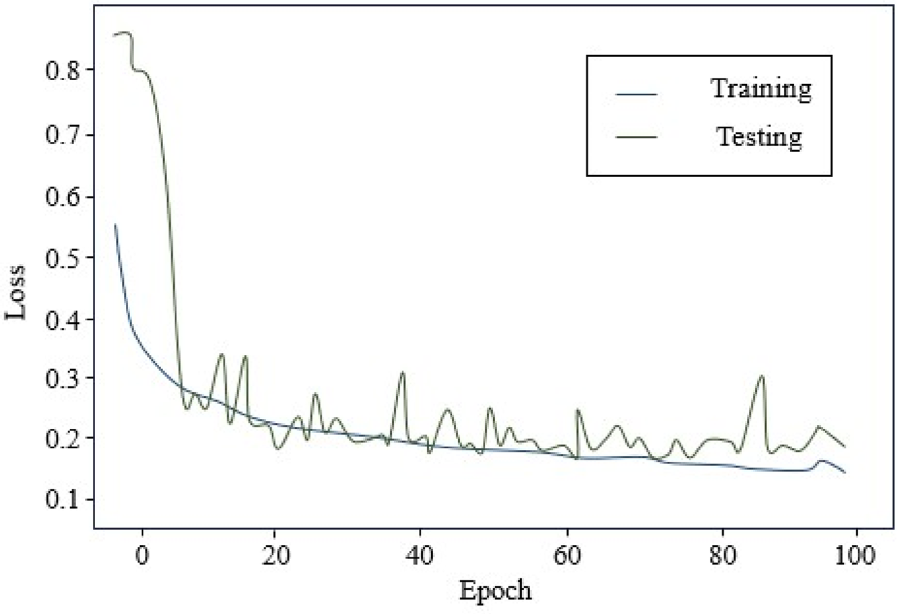
The loss curve of the DS-GAN model.
In Figure 5, the accuracy graphs of the transfer learning models are estimated with the number of epochs and accuracy range. The AC of the pre-trained network advances with the no. of epochs. Figure 6 displays the epochs and loss graphs range, demonstrating the loss of the trained network reduces when the epochs are increased. DS-GAN model is proposed that accurately inpaints brain MRI images. The proposed DS-GAN model has an accuracy of 99.18% based on its performance throughout the training phase.
In this section, the DS-GAN model was related to different GAN structures based on various inpainting performance parameters. The capability of existing GAN contexts was analyzed to demonstrate that the outcomes of the proposed DS-GAN are more effective in the process of brain MRI image inpainting. Initially, the proportional estimation was accomplished between previous segmentation networks as demonstrated in Table 3.
A comparative analysis of semantic segmentation networks using JI and DI.

A comparative analysis of semantic segmentation networks using JI and DI.
Using Table 3, the proper proportions of the dice and Jaccard coefficients were obtained, and then several segmentation networks were compared in terms of performance measures. In terms of comparison, the Gated Shape CNN outperformed the segmentation networks. The Gated Shape CNN increases the overall Jaccard index by 0.34, 0.08, 0.18, and 0.1 better than Attention U-net, Mask RCNN, SegNet, and Attention V-net respectively. The Gated Shape CNN increases the overall Dice index by 0.22, 0.04, 0.3, and 0.08 is better than Attention U-net, Mask RCNN, SegNet, and Attention V-net respectively. The proposed DS-GAN model is calculated and built on the segmentation networks in the Jaccard and dice coefficients, as illustrated in Figure 7.
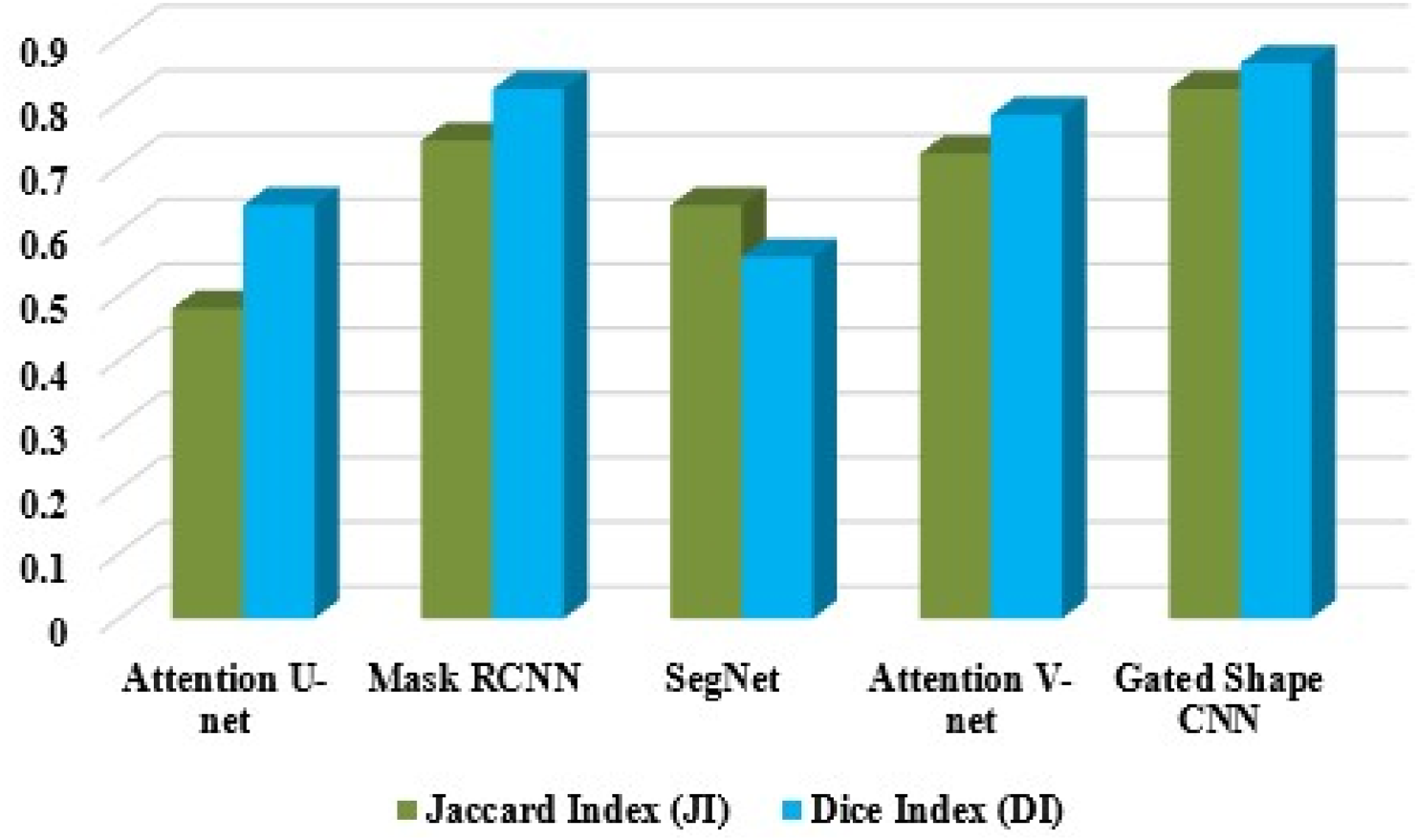
Comparison of existing and proposed model.
This Gated Shape CNN achieves defined results with an accuracy of 98.46%, outperforming other models. The outcome of the inpainting reveals that the incorporation of the GAN allows the suggested DS-GAN model to operate more quickly and achieve optimal outcomes. According to the above comparison, the proposed DS-GAN performs better in terms of accuracy conditions than the most advanced methods. Table 4 presents a comparison analysis of the proposed DS-GAN and each advanced approach based on loss, similarity index, and noise ratio.
The comparison of the existing GAN model with the proposed DS-GAN model.

The comparison of different GAN designs according to the particular performance indicators for image inpainting is shown in Table 4. The L1 loss is the only loss function present in these GAN architectures. 33 The L1 loss, frequently referred to as the perceptual loss, is used to quantify differences between the actual and the predicted. The suggested DS-GAN outperforms the other GAN architectures in terms of L1 loss, SSIM, PSNR, and MSE. The proposed approach outperforms the ipA-MedGAN, 22 TBI-GAN, 23 TW-BAG, 25 and uagGAN 32 in terms of PSNR value while achieving a low degree of loss.
From Table 5, the comparison of several GAN architectures based on their accuracy in painting the images. The Proposed DS-GAN model achieves total accuracy of 0.09%, 9.22%, 3.87%, and 2.17% better than ES-GAN, 32 Patch-GAN, 34 CDA-GAN, 35 and RTGAN 36 respectively. It is obvious from Table 5 that our innovative network outperforms the current methods. As a result, the suggested DS-GAN model's calculated fallouts may be used to accurately inpaint brain MRI images.
Comparison of the existing and the proposed models.

This paper presented a novel DS-GAN model for inpainting brain MRI images. In the first GAN, grayscale pixel intensities and the remaining image edges are utilized to create edge generators, or EGAN, which are capable of creating false edges in areas that are missing. A second GAN is used to fill in the missing regions using edge information from the missing regions combined with color and texture information from surrounding regions. Experiment analysis showed JI and DI to be 0.82 and 0.86, respectively. The proposed DS-GAN in terms of L1 loss, PSNR, SSIM, and MSE obtained was 2.18, 0.972, 32.04, and 26.42. The proposed DS-GAN model has a total accuracy of 99.18%, which is relatively better than the existing methods. In the future, utilizing 3D brain MRI datasets will significantly enhance the accuracy of segmentation results. The 3D data allows for a more comprehensive analysis of brain structures, capturing finer details and spatial relationships that are often missed in 2D images. This improvement will lead to more precise and reliable outcomes, particularly in clinical applications such as diagnosis and treatment planning.
Footnotes
Acknowledgements
The author would like to express his heartfelt gratitude to the supervisor for his guidance and unwavering support during this research for his guidance and support.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.