
Abstract
Objective
This study aims to enhance cybersecurity by implementing a robust biometric-based authentication approach. A Multimodal Biometric System (MBS) is proposed, utilizing feature-level fusion of human facial (physiological) and speech (behavioral) features to improve security, accuracy, and user convenience. The system addresses the limitations of traditional authentication methods, including unimodal biometrics and password-based security.
Background
In the modern digital landscape, human-computer interaction and digital platforms play a crucial role in daily life. With billions of users engaging in social media, financial transactions, and e-commerce, the demand for secure authentication mechanisms has intensified. However, the increasing sophistication of cyber threats poses significant risks, undermining trust, security, and confidence in digital systems.
Results
The system's performance was evaluated using two publicly available Voxceleb1 and VidTIMIT datasets, achieving accuracy rates of 98.23% and 97.92%, with Equal Error Rates (EERs) of 3.23% and 3.62%, respectively.
Conclusion
The proposed approach outperforms conventional optimization techniques and existing state-of-the-art MBS. As a contactless and non-intrusive authentication system, it enables seamless data acquisition through devices equipped with cameras and microphones, such as smartphones, ensuring real-time processing of biometric modalities.
Keywords
Introduction
The digital world has brought with it a plethora of interactive gadgets, ranging from smartphones to smart appliances, all of which offer vital services to their customers. These gadgets are capable of communicating with one another via the internet, resulting in the Internet of Things (IoT) network.1,2 The personal information acquired by these devices are very confidential, thus protecting them from intruders is a top priority without compromising the user experience. The use of biometric based authentication system2–4 is a promising strategy for both improving individualization in service delivery and bolstering the safety of sensitive information.
With the proliferation of Multimodal Biometric Systems (MBS), 5 it is now possible to achieve the most demanding security criteria without resorting to passwords or Unimodal Biometric System (UBS). 5 Moreover, the Corona pandemic outbreak has accelerated the shift towards contactless biometric systems as opposed to those that rely on the sense of touch. Further, major advantages of contactless MBS are high precision, speedy matching, adaptability and effortless communication with systems in the medical sector, law enforcement, educational institutions, and border and aviation security. 5 In order to create a reliable MBS and lessen the chance of corona transmission, the choice of speech (behavioral) and face (physiological) modalities evolved as viable options. The major benefit of the face modality over others is that the data acquisition can be done without the user's cooperation or awareness, as in airports or other public places in mass. Similarly, compared to other modalities which require greater user cooperation and certain proximity to the device; speech-based recognition, especially for disabled, kids or elderly people, is convenient and reliable considering the ease of accessing a speech-receiving device and its contactless nature. Also, to construct a robust MBS the selection of biometric cues or modalities should be such that one's flaw can be compensated by the other thereby improving the performance of such system. In nutshell, the data acquisition process for the aforesaid system under adverse conditions, such as low illumination and noisy environment are independent of each other i.e., does not hamper one another w.r.t. quality, data acquisition, etc. As a corollary, face and speech modalities together pair up to be the most reliable and user convenient one.
The extracted biometric characteristics are an abundant source of information. Combining features enables classes to be highly distinguishable, thereby enhancing the effectiveness and precision of the MBS. The selection of a suitable fusion strategy is becoming more crucial for the development of a successful multimodal biometric based authentication system. There are five different types of fusion strategies that are frequently used: feature level, rank level, sensor level, match score level and decision level fusion. 6 Among these, the advantage of feature-level fusion (pre-classification) is the melding of associated features derived from multiple biometric algorithms into single robust template, which enables the identification of prominent feature sets to expedite the recognition accuracy. By integrating diverse biometric characteristics via feature level fusion strategy, 6 the MBS can greatly decrease the overlap within the feature spaces of individuals (interclass similarities). Likewise, the unified feature vectors yield an exceedingly resilient and trustworthy human recognition system that is challenging to fabricate or imitate. Hence, the fused feature of aforesaid modalities will yield an efficient and robust MBS.
The research work structure is: Section 2 describes the related works regarding MBS followed by the problem formulation for this research. The proposed OEMBAS model is discussed in details in Section 3 including feature extraction, feature-level fusion and classification. Section 4 describes the experimental setup, datasets and performance metrics including the validation part of OEMBAS with other methodologies based on different 60-70-80-90 percentage of training data, five traditional optimization approaches and different machine learning (Random Forest (RF), Gaussian Mixture Model (GMM), Support Vector Machines (SVM)) and DL (LSTM, Bi-LSTM, Bi-GRU, DCNN, Bi-LSTM-DCNN) based classifiers in terms of ten performance metrics 3 such as: positive measures (accuracy, sensitivity, precision and specificity), 3 negative measures (False Negative Rate (FNR), False Positive Rate (FPR) and Equal Error Rate (EER)) and other measures (F-measure, Mathew's Correlation Co-efficient (MCC) and Negative Predictive Value (NPV)) 3 along with cost function and statistical measures. Also, the comparison of the OEMBAS with a few similar state-of-the-art MBS is carried out. Section 5 is the conclusion of this work.
Related works
DL 6 has achieved significant success, especially with ensemble classifiers, in the fields of pattern recognition and classification. 6 The utilization of meta-heuristic algorithms for training classifiers offers a powerful optimization approach that can efficiently navigate complex search spaces. By leveraging meta-heuristic techniques, classifiers can adapt and evolve over iterations, leading to improved accuracy and robustness in various machine learning tasks, even in the presence of noisy or high-dimensional data. Moreover, the flexibility and scalability of meta-heuristic algorithms make them well-suited for addressing challenging optimization problems encountered in classifier training across diverse domains, from pattern recognition to financial forecasting. Many researchers have made efforts to construct such DL based MBS 6 that show promising performance, as documented in the literature. Among these efforts, Vekariya et al., 7 proposed a technique for multi-biometric authentication that involves feature-level fusion too. The proposed method utilizes a Binary Chimp Optimized Adaptive Kernel Support Vector Machine (BCO-AKSVM) to determine the most effective features. The method's experimental results demonstrate a high level of accuracy of 97%. Purohit et al., 8 introduced an MBS that utilizes fingerprint, ear, and palm biometric data. The researchers introduced a novel approach utilizing grey wolf optimization to achieve feature-level fusion, specifically for the purpose of picking the most optimal features. Wu et al., 9 developed LVID, a smartphone biometric authentication method that uses both voice and lip motions. For precise authentication, LVID uses a combination of two biometrics, a fine-grained estimate of lip movements and a pure speech sample obtained from the recorded signal. With 104 subjects tested, LVID was able to recognize 93.47% of threats and authenticate users with 95% accuracy. The assessment is limited to a small group of students. Increasing the number of participants and broadening their age range will aid in gaining a better understanding of the system's performance. Mustafa et al., 10 introduced a decision level fusion technique that combines fingerprint and iris biometrics utilizing the Gray Level Co-occurrence Matrix (GLCM) with KNN classifier for feature extraction. The final decision is made using an AND gate. Based on the results, the fusion strategy described in this study clearly outperformed UBS. The method achieved a 95% efficiency level in reaching the final outcome, for 20 users.
Singh et al., 11 introduced an MBS that utilizes feature-level fusion of facial and fingerprint information. The PCA approach was employed for facial feature extraction, while the Raymond Thai algorithm was utilized for minutiae extraction as a fingerprint feature. This proposed approach using SVM classifier, significantly enhances efficiency and has a stated accuracy rate of 95.38%. Nainan et al., 12 introduced a speaker recognition system incorporating dynamic voice features with static features. This inclusion of important speaker information leads to a significant enhancement in the accuracy of automatic speaker recognition (ASR). The Fisher score approach was utilized to identify the most influential characteristics using a 1D-CNN, leading to a notable enhancement in the accuracy of ASR to 94.77%. The multi-kernel SVM technique is employed for recognition. Abinaya et al., 13 devised MBS that combines multiple modes of behavior, including keystroke (typing timings) and audio (speech) features. This system employs pretrained DL models to identify the individual. The features from the two modalities were merged using a weighted linear approach of feature-level fusion. These merged features were then trained by a DL convolutional neural network (CNN) classifier model. Similarly, Abdulbaqi et al., 14 have created a prototype system that verifies users by analysing the distinctiveness of their ECG signal in conjunction with their facial features, utilizing Awica Wavelet Transform algorithms. However, only 94% of classification accuracy was achieved. Recently, A. El_Rahman et al., 15 has presented a technique for fusing fingerprints and ECG at the feature level, utilizing CNN as the classifier. Based on the results of the experiments, the proposed approach has an accuracy of 94.5%.
Problem formulation
The reliability of biometric systems shifts depending on the specific biometric modalities, features, classifier and optimization techniques being employed. The UBS is susceptible to spoofing attacks and has interclass variability. In order to build a trustworthy MBS employing facial and vocal features, a thorough literature analysis was conducted. From the perspective of modality choice, it has been discovered that the amount of study on MBS utilizing both face and voice is low in comparison to the amount of research into either modality alone. From the perspective of fusion level, it was discovered that in MBS, sensor modifications during score fusion, feature incompatibility during feature fusion, score normalization due to variation during score fusion, serial versus parallel design process during rank fusion, and a lack of data during decision fusion all pose challenges. Developing protective methods that satisfy operational requirements, enhancing public trust in biometric technology and preserving personal data are essential for achieving a higher user acceptability point.
Therefore, to tackle the above problems, this paper proposes an MBS with following contributions:
For robust feature extraction – The three state-of-the-art speech feature extraction techniques: Power Normalized Cepstral Coefficient (PNCC), Constant Q Cepstral Co-efficient (CQCC) and Spectral Flux (SF) is suggested and implemented. Also, for face modality the state-of-the-art Eye Aspect Ratio (EAR) technique along with Improved-Active Shape Model (I-ASM) is proposed and implemented. Fusion of face with speech feature - The feature level fusion melds feature for better classification and reduce data dimensionality. Moreover, melding image-audio features culminate into a more potent and resilient recognition system. Thus, an improved mutual information-based feature level fusion though concatenation is proposed. Classifier - The state-of-the-art Bi-LSTM with DCNN (weighted) as ensemble classifier is proposed. Optimization - For optimal weight tunning and to minimize the inaccuracy of the suggested classifier, the state-of-the-art MRFO technique with improvement as SI-MRFO is proposed and implemented. Ultimately, the goal of this research is to improve and deliver a reliable authentication solution for cyber security application like an IoT setting by leveraging a high-quality face and speech feature set for optimal trained ensemble model-based MBS.
Proposed scheme
In MBS, it is extremely challenging to spoof or forge numerous biometric features simultaneously for an authenticated user. As a consequence, it offers greater precision and more resilience to illegal access by an adversary than a UBS. Moreover, the MBS provides user data confidentiality and improves security. In this paper, we have proposed an Optimal trained Ensemble classifier based Multimodal Biometric Authentication System (OEMBAS) model for user authentication (verification) as given in Figure 1.
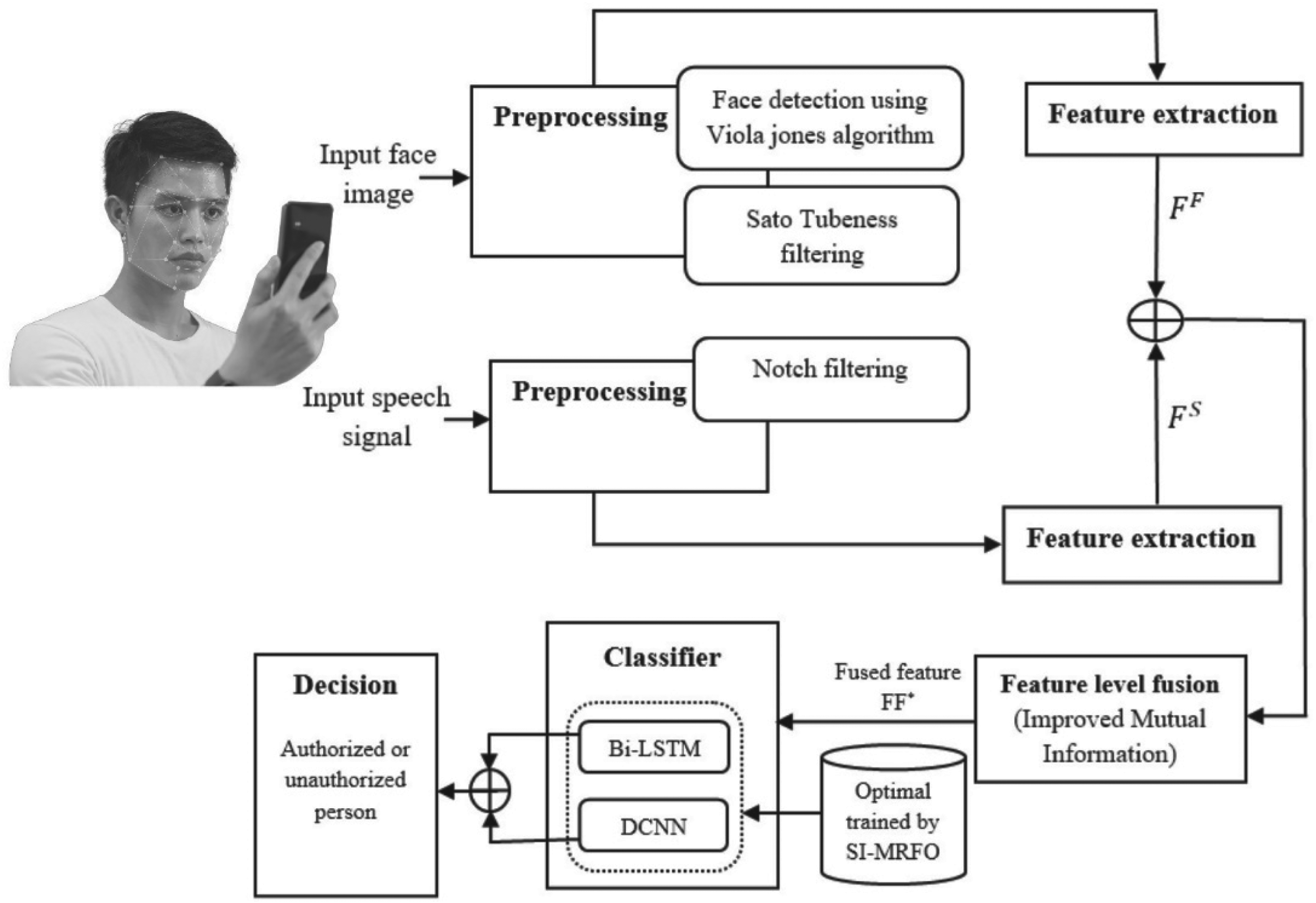
Overall layout of proposed OEMBAS model.
For user authentication process, every MBS must go through two phases, training and testing.3,4,16 In case of training phase, the user takes the initiative to sign up. A brief video is acquired by a smart sensor camera. The audio/speech signal is preprocessed from the recorded video in order to obtain reliable speech attributes. The facial image frame is derived from the same video for effective feature extraction. The resulting feature vectors are concatenated in order to achieve feature-level fusion. Classifier is used to train these fused feature templates of individual speaker models, which are then saved in a database for later usage (testing). Testing is carried out in a manner analogous to training, except that the claimed user's fused biometric template is compared to the trained reference N models already recorded in the database. The claimed user's fused template is compared one-to-one with all registered templates in the database to determine whether or not the user is legitimate. The final decision is made according to how closely the query matches the reference data based on performance metrics. The OEMBAS has four processes, which are explained in detail below:
For efficient user authentication,4,16 preprocessing 16 is the initial step, where the input face image and the input speech signal is preprocessed. For input face image preprocessing, 17 face detection is performed by using the Viola Jones algorithm. 18 After the completion of face detection process, Sato tubeness 19 filtering process is used to filter the input face image. Similarly, for input speech signal preprocessing, a notch filtering 20 process is carried out. It is a band-stop filter 20 which reduces frequencies within a small band of frequencies while transmitting all the other frequencies unmodified. It is suitable for use in audio systems to remove disruptive frequencies like powerline hum.
Feature extraction
Subsequent to the face detection and signal denoising, distinctive features are extracted from each modality. The key features are chosen and improved for each modality based feature extraction techniques. 21 The details of each feature extraction techniques are mentioned below:
Face: improved-active shape model with eye aspect ratio (I-ASM with EAR)
The feature extraction techniques EAR
22
along with improved ASM is proposed and considered as the state-of-the-art algorithms. Since, the effect of these features on recognizing the facial feature points from the face image is high with enhanced accuracy. Moreover, the six scalar values of EAR
22
technique extract the information based on eyes (open and closed states of eyes i.e., for liveliness detection) and combined framewise for each sample. In order to discover the best match between the model as well as the data inside a new image, ASM
23
uses a prior model to determine what is anticipated in the image. A shape could be described by a 2n-D element vector X = (x1, y1, …., yn)T made up of n points, (Xi, Yi). The statistic shape is created using the same coordinates as the training shape S(S = Xi). The Generalized Procrustes Analysis (GPA) technique
24
aligns the training set S. All alignment shapes’ average shape vector is represented by average shape


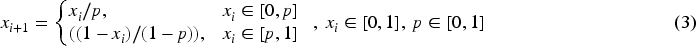
Also, PCA
25
is applied to the covariance matrix J conventionally computed in Equation (4) and as per the proposed logic; improved computational formula for covariance matrix is calculated in Equation (5), where W depicts normalized data.


The shape variance given by the associated eigenvector is equal to the Eigen value of J2. The form of variation, or how the landmark points shift together as their shape changes, is provided by the eigenvectors.
To recognize a speaker3,16 we have extracted distinct and robust speech features, the state-of-the-art techniques PNCC, CQCC and SF are chosen and concatenated framewise for each sample. As higher the number of features enhances the distinguishing ability of the classifier and efficiency of the MBS. The PNCC,3,16,21 is a cepstral domain feature that is considered as a state-of-the-art method for extracting noise robust acoustic features. The formulation of PNCC was motivated by the fact that its feature set is more resistant to acoustical variations, performs well even when the speech signal is undistorted and has computational complexity comparable to that of Mel-Frequency Cepstral Coefficient (MFCC)3,25 and Perceptual Linear Prediction (PLP). 21 For the simulation of PNCC, we have used sampling rate of 16 kHz, FFT size 512, length of window is 25 ms, overlap window size is 10 ms, number of filters in the filter bank is 128 and number of extracted features are 13. The second feature is CQCC 26 extraction utilizes a hybrid of the constant Q transform and cepstral analysis. In contrast to the majority of automatic speaker verification system frontends, CQCC represents the spectro-temporal resolution which accurately records the tampering objects. It denotes the characteristic of spoofing attacks, thereby increasing the system's accuracy. we have extracted 19 CQCC features. At last, the third feature is Spectral Flux, 27 is used to create a decision rule that aims to reduce the frequency of decision errors. As a result, this attribute is used to enhance the speech verification decision-making. These three speech features are used as features for speech modality.
Feature level fusion of face and speech modalities
The above features, from the face (I-ASM with EAR) and speech (PNCC, CQCC and SF) modalities are combined at feature level6,9,25,26 through concatenation as feature set. To extract the efficient components from their corresponding features set, we determine the ratio of inter-class as well as intra-class variance in order for each dimension of the speech and face features. The standard feature level fusion FF is carried out as Equation (6). Also, the standard feature level fusion produces a spatial distortion in feature fusion due to the lack of considering the class or label. Thus, the drawbacks have been conquered in this research work by including the Mutual Information (MI)
28
between the features and the labels. This improved feature level fusion calculation is done using Equations (6)-(8).


Where, mi is the mean feature vector of user i, mall is the global mean across all users. High inter class variance ensures better separation between different users.

Where, mj,i is the feature vector of sample j for user i, mi is the mean feature vector for that user, n is the number of samples per user. Low intra class ensures that features of the same user remain consistent.
Since, the standard mutual information lacks the information about the interaction between the features and the classifier, therefore the proposed logic for improved feature fusion is evaluated as Equation (9):

Where IMI is the Improved MI i.e., normalized MI defined in Equation (11) and conventional MI calculation is done in Equation (10) as:
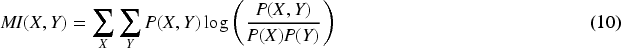
Where P(X,Y) is the joint probability distribution of features X and labels Y, P(X) and P(Y) are the marginal distributions. Higher MI means better feature-label correlation, leading to improved classification. Since IMI normalizes MI, it accounts for variations in data distribution, making the authentication system more stable.

Where, H(X) and H(Y) are the entropies of features and labels, W is a weight factor. IMI ensures the MI value is scale-invariant, making it more effective for fusion.
Where
For user authentication process, we employ an ensemble classification algorithm to obtain the final classified output (authorized or unauthorized person) by giving the fused feature
Proposed Self Improved-Manta Ray Foraging Optimization (SI-MRFO) Algorithm for optimal tuning of the BiLSTM-DCNN as ensemble classifier
The Manta ray foraging optimization (MRFO) 29 algorithm is a state-of-the-art bio-inspired optimization technique for dealing with global optimization problems. It is useful in feature selection for efficient classification, hyperparameter tuning and optimizing deep learning models for high performance of the system. The major objective of optimization technique 30 is to minimize the error. In this work, in order to find the optimum solution in the search space, proposed SI-MRFO simulates the foraging habits of manta rays (sea creature) in the wild. SI-MRFO employs three foraging techniques: (proposed) chain foraging, (proposed) cyclone foraging, and somersault foraging. Chain foraging: enhance local search ability and guides feature selection towards the best-performing feature subsets. Cyclone foraging: enhance global search ability and ensures exploration by searching different feature combinations. Somersault foraging: enhance local search ability and raises the convergence rate. The exploitation search is mostly aided by chain foraging and somersault foraging behaviors, whereas the exploration search is primarily aided by cyclone foraging. The three foraging behaviors are used in combination with the following update processes to solve optimization problems using SI-MRFO.
In this phase, first, the weight function of the Bi-LSTM (∂) and DCNN (τ) classifier i.e.,
Key hyperparameters tuned include:
Learning rate and batch size Number of LSTM units and convolution filters Dropout rate, fusion vector dimensions Number of epochs and optimizer selection
This hyperparameter tuning strategy ensured global exploration and local exploitation, resulting in a well-generalized model with improved accuracy and stability.
Proposed chain foraging: The Manta rays’ chain foraging method is written as Equation (12):
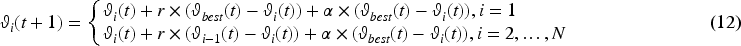
Here,

Proposed cyclone foraging: The Manta rays’ cyclone foraging is written as Equation (14):
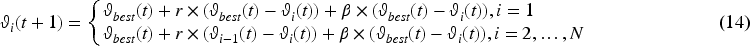
Here,
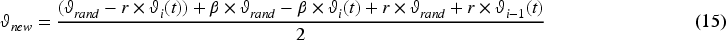
At last, the Manta rays’ somersaulting foraging with S somersault factor is written as Equation (16):
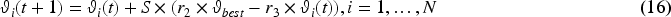

In this section, the proposed OEMBAS is implemented using Python programming language to examine its performance and comparison with the conventional approaches. The aforementioned MBSs are trained and tested for two standard video and speech-face dataset, VoxCeleb1 31 and VidTIMIT, 25 with learning data percentage i.e., training dataset from 60-70-80-90 percentage and 40-30-20-10 percentage for testing respectively. However, from computational perspective, we are considering the result based on 80 percent for training data and remaining 20 percent for testing data. The OEMBAS is compared with five state-of-the-art optimization techniques 29 such as Henry Gas Solubility Optimization (HGSO), 32 COOT Optimization, 33 Bald Eagle Search (BES), 34 Blue Monkey Optimization (BMO) and MRFO 29 in terms of positive measures (accuracy, precision, sensitivity and specificity), 35 negative measures 35 (FPR, FNR and EER) and other measures 35 (F-measure, MCC and NPV) 35 along with cost function and statistical analysis.
Comparison of OEMBAS (proposed approach) with different classifier based MBS
The ablation assessment on OEMBAS model for 80% of training data and 20% of testing data, with similar MBSs (using speech and face modality) based on different classifiers such as Random Forest (RF), Support Vector Machine (SVM), Bi-directional Gate Recurrent Unit (Bi-GRU), GMM, 12 Long Short-Term Memory (LSTM), 21 BiLSTM, 21 DCNN and Bi-LSTM-DCNN are assessed using distinctive performance measures illustrated in Table 1. From computational perspective, the proposed OEMBAS model using optimal tuned hybrid Bi-LSTM-DCNN classifier was found superior over other MBSs. This advancement for the proposed MBS i.e., OEMBAS is because of the distinctive feature extraction, improved mutual information based feature level fusion of speech and face modality as well as ensemble classifier Bi-LSTM-DCNN being optimized using proposed bio-inspired SI-MRFO technique.
Assessment of proposed approach (in %) with various classifier based MBSs for both datasets.

Assessment of proposed approach (in %) with various classifier based MBSs for both datasets.
Figure 2 shows the comparison of convergence evaluation i.e., cost function of proposed SI-MRFO over different technique based MBS such as HGSO, COOT, BES, BMO and MRFO, while changing the optimization iteration from 0 to 50. It was observed that the proposed SI-MRFO and the conventional methods obtained higher error rate during the initial (0th) iteration. However, it was observed that as the iteration progressed, the error rate declined. Using dataset1, the proposed SI-MRFO attained an error rate of 1.045 in the 15th iteration, while reaching to the 50th iteration it acquired the (lowest) error rate of 1.016 as indicated in Figure 2, whilst the COOT is 1.06, BMO is 1.041, HGSO is 1.020 and MRFO is 1.019, respectively. The overall results using both datasets, affirmed that the proposed SI-MRFO is considerably more efficient in identifying and verifying the MBS with a low error value than the conventional methodologies.

Convergence analysis of proposed SI-MRFO with conventional optimization techniques.
The statistical estimation of OEMBAS over the HGSO, COOT, BES, BMO and MRFO based different MBSs under different statistical measures is summarized in Table 2. For the better MBS the model should attained lesser error rate. Similarly, the OEMBAS scored the lowest error value in almost all the statistical measures for both datasets. For Dataset1, the OEMBAS acquired error rate for the median statistical measure is 1.021, whereas for the HGSO is 1.026, COOT is 1.062, BES is 1.053, BMO is 1.041 and MRFO is 1.025. Simultaneously, for the maximum statistical measure, the HGSO, COOT, BES, BMO and MRFO maintained the greatest error value of 1.128, 1.099, 1.227, 1.124 and 1.133, though the OEMBAS generated the lowest error value of 1.098. Similarly, for Dataset2 the OEMBAS attained superior result compared to other techniques. Hence, it can be inferred that the OEMBAS has provided excellent performance than the other five conventional optimization technique. This clearly indicates that due to improved MRFO (SI-MRFO) the proposed OEMBAS can be regarded as more accurate and trustworthy authentication system.
Statistical assessment of OEMBAS model with traditional optimization approaches.

Statistical assessment of OEMBAS model with traditional optimization approaches.
In this section, the OEMBAS is compared to similar MBSs with different optimization techniques such as HGSO, COOT, BES, BMO and MRFO. The assessment is done based on positive measures such as accuracy, sensitivity, precision and specificity; negative measures such as FNR, FPR and EER and other measures such as F-measure, MCC and NPV, as illustrated in Figures 3 and 4 using Dataset1 and Dataset2 respectively. The investigation on OEMBAS was carried out for varied percentage of data ranging between 60–90 of training and 40-10 of testing, respectively. In particular, for Dataset1, at the 80% of training data and 20% of testing data, the OEMBAS recorded the positive metric such as the value of accuracy is 98.23%, Specificity is 94.00%, Precision is 99.10% and Sensitivity is 99.20%, whilst the HGSO, COOT, BES, BMO and MRFO generated lesser positive metric values. Similarly, for Dataset2, at the 80% of training data and 20% of testing data, the OEMBAS recorded the positive metric such as the value of accuracy is 97.92%, Specificity is 93.00%, Precision is 97.90% and Sensitivity is 98.10%, whilst the HGSO, COOT, BES, BMO and MRFO generated lesser positive metric values. In addition, the objective of the OEMBAS is minimizing the negative and maximizing the positive measure values. Similarly, as the training data percentage is increased the negative metric value get reduced for the OEMBAS approach. The results of the aforementioned ablations demonstrate that each component meaningfully contributes to the observed performance and that the fusion-based, optimized ensemble achieves the best results (accuracy: 98.23%, EER: 3.23%).
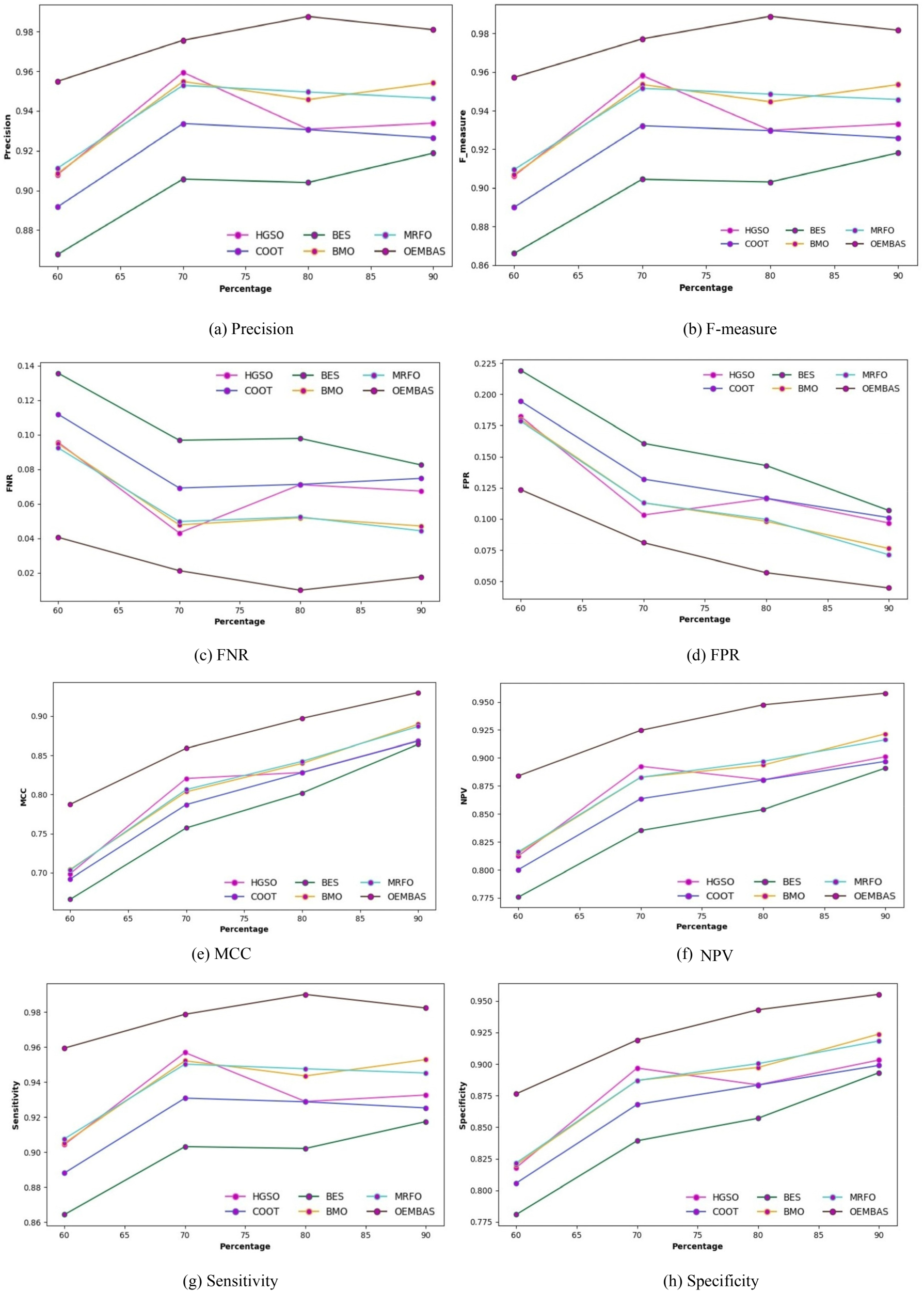
Performance analysis of OEMBAS with conventional optimization techniques using Dataset1.
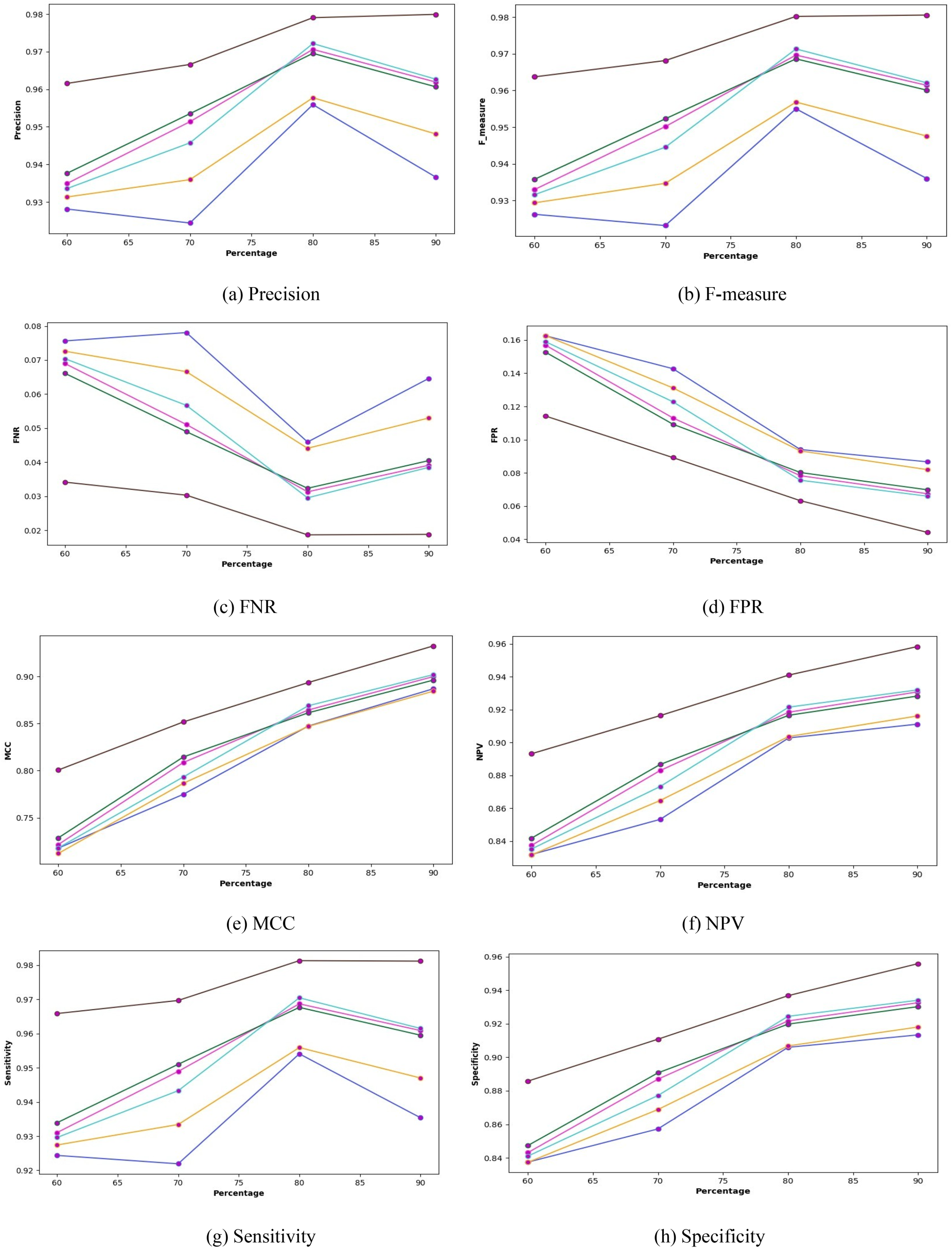
Performance analysis of OEMBAS with conventional optimization techniques using Dataset2.
The proposed SI-MRFO algorithm introduces significant enhancements over the conventional MRFO framework, specifically tailored for optimizing complex deep learning-based MBS architectures. Its novelty lies in the integration of a self-adaptive inertia weight mechanism, which dynamically adjusts the balance between exploration and exploitation during the optimization process. This mechanism mitigates premature convergence and stagnation in local optima, which are common limitations of classical MRFO, especially when tuning deep models (Bi-LSTM-DCNN) in a high-dimensional fused feature space.
Moreover, SI-MRFO incorporates a feedback-driven mutation operator, inspired by differential evolution strategies, to increase diversity in candidate solutions, thus improving the robustness and convergence speed of the optimization. These innovations contribute to superior performance in selecting optimal hyperparameters for the ensemble classifier and fine-tuning the feature-level fusion strategy. The mathematical formulation, algorithmic flow and theoretical convergence characteristics have been rigorously discussed and benchmarked against the original MRFO and other optimizers (e.g., COOT, BMO, etc.) to substantiate its superiority both algorithmically and empirically.
Comparison with a few state-of-the-art methodologies
This study demonstrates innovative strides within the MBS domain, notably by investigating the integrated utilization of face and speech for user authentication. Existing literature predominantly emphasizes face paired with modalities other than speech or vice versa.9–11 For centuries, individuals have relied on recognizing others through facial or verbal cues, rather than through attributes like ear, hand, signature, finger/fingerprints, etc. While previous studies offer valuable groundwork for MBS applications,36,37 research into combining face with speech interaction remains relatively unexplored, highlighting the novelty and significance of this study's contribution. The performance comparison of the proposed OEMBAS with a few state-of-the-art MBSs in terms of accuracy of classifier and EER 38 is presented in Table 3. Moreover, to facilitate better understanding, Table 4 presents a summary of the ablation study conducted on both databases, reporting performance metrics in terms of accuracy and EER. Based on the findings, we can infer that the OEMBAS is significantly more efficacious at user authentication.
Performance comparison of the proposed work with state-of-the-art methods.
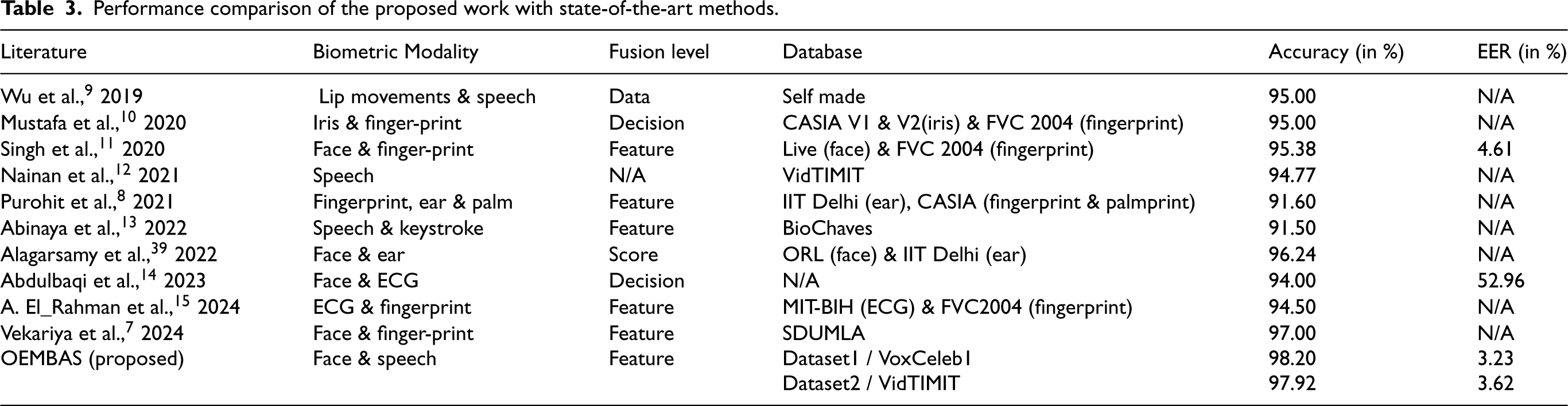
Performance comparison of the proposed work with state-of-the-art methods.
Summary of the above ablation study results.

In real-world settings, deploying a robust MBS entails addressing practical challenges beyond algorithmic performance.
Latency and Computational Efficiency: The proposed system has been profiled for training and inference times across multiple platforms, including CPU and GPU configurations. On an NVIDIA RTX 3080 GPU, the average inference time is 0.34 s per instance, making it feasible for near real-time applications. User Acceptability and Usability: The system relies on non-intrusive, contactless modalities (face and speech), enhancing user comfort and hygiene—particularly relevant in post-pandemic authentication scenarios. A user study is planned for future work to assess user experience, satisfaction and interaction latency under varying acoustic and lighting conditions. Environmental Variability: No real-user field testing has been conducted to date and this remains a limitation. While extensive evaluation was performed on benchmark datasets (VoxCeleb1 and VidTIMIT), future work aims to include in-situ validation through longitudinal data collection under real deployment conditions (e.g., surveillance, access control). Security and Privacy Concerns: Adversarial robustness remains an area for future exploration.
Conclusion
In this work, we have proposed a novel MBS named as an OEMBAS model for user authentication using face and speech combined at feature level. The optimal training of the ensemble classifier is done using improved and advanced MRFO algorithm. In particular, the OEMBAS recorded the maximal positive metric, less negative metric and cost function (on both datasets) than all other conventional optimization techniques and different classifiers on two open-source datasets such as Voxceleb1 and VidTIMIT. In particular, for dataset1 / Voxceleb1, at the 80% of training data, the OEMBAS attained the following metrics: Accuracy of 98.23%, Specificity of 94.00%, Precision of 99.10% and Sensitivity of 99.20%. Moreover, for Dataset2 / VidTIMIT at the 80% of training data, the OEMBAS attained the following metrics: Accuracy of 97.92%, Specificity of 93.00%, Precision of 97.90% and Sensitivity of 98.10%. The EER value of the OEMBAS for both Datasets are 3.23% and 3.62% respectively, which is the lowest compared to other similar work and approaches (HGSO, COOT, BES, BMO and MRFO) denoting high performance of the model. In nutshell, this advancement is because of the selection of robust state-of-the-art and improved feature extraction techniques for face and speech modality, improved mutual information based feature level fusion of both modalities as well as ensemble classifier BiLSTM-DCNN being optimized using improved metaheuristic MRFO technique. Hence, the proposed approach for user authentication utilizing contactless MBS can be deemed as an efficient, reliable and hygienic security solution. The future research may incorporate transformer based architecture using cross-domain generalization with multi-accent and multi-ethnic datasets for better performance.
This study proposes a novel Optimally Trained Ensemble Multimodal Biometric Authentication System (OEMBAS), integrating proposed human facial (physiological) and speech (behavioral) features at the feature level. The system enhances authentication performance using an advanced proposed SI-MRFO algorithm for hyperparameter tuning and optimal training of the BiLSTM-DCNN ensemble classifier. Experimental results on Voxceleb1 and VidTIMIT datasets demonstrate superior performance compared to conventional optimization techniques. At 80% training data, the system achieved 98.23% accuracy, 99.10% precision, and 99.20% sensitivity on Voxceleb1, and 97.92% accuracy, 97.90% precision, and 98.10% sensitivity on VidTIMIT. The Equal Error Rates (EERs) of 3.23% and 3.62%, respectively, are the lowest among existing approaches. The superior performance of OEMBAS is attributed to robust proposed feature extraction techniques, improved mutual information-based feature-level fusion and ensemble classification optimization using an enhanced metaheuristic SI-MRFO technique. The proposed contactless multimodal biometric system ensures high security, reliability, and hygiene, making it an effective and scalable solution for user authentication in cybersecurity applications.
Footnotes
Ethical considerations
Author contributions
The authors confirm contribution to the paper as follows: Study conception, design, analysis and interpretation of results and draft manuscript preparation: K. Jha, supervision: A. Jain and S. Srivastava. All authors reviewed the results and approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.