
Abstract
Purpose
Artificial intelligence (AI) shows considerable potential for sports injury prediction, yet a comprehensive methodological review of its empirical applications remains limited. This study aimed to systematically review the empirical literature on the use of AI and machine learning (ML) for sports injury prediction.
Methods
Following the PRISMA 2020 guidelines, a systematic search was conducted across PubMed, IEEE Xplore, SPORTDiscus, Web of Science, and Scopus for literature published between January 2015 and March 2026. In addition to the structured database search, a small number of database-recommended articles identified through platform recommendation functions were also screened for eligibility. After a multi-stage screening process, 18 empirical studies were included in the final qualitative synthesis.
Results
Risk of bias assessment using PROBAST indicated that only one study (5.6%) had a low overall risk of bias, whereas most studies were judged to be high risk, primarily because of weaknesses in the analysis domain and reliance on internal validation. Across the included studies, AI-based models demonstrated potential for handling multidimensional training load, physiological, biomechanical, and psychological data; however, most prediction models relied exclusively on internal validation, limiting confidence in their generalizability.
Conclusion
AI demonstrates clear promise for sports injury prediction, but the current evidence base remains constrained by limited external validation, inconsistent reporting practices, and the continued overrepresentation of male cohorts. Future research should prioritize methodological rigor, broader geographic and demographic representation, standardized reporting, and explainable AI (XAI) approaches to enhance the trustworthiness and practical utility of these models for coaches and clinicians.
Introduction
Sports injuries are a prevalent challenge inherent to athletic training and competition. They can cause physical pain and functional limitations for athletes but may also lead to long-term psychological consequences. Furthermore, injuries can disrupt participation, necessitate tactical adjustments, and reduce a team's competitive advantage. Beyond their performance-related impact, sports injuries also impose substantial economic and resource burdens. Goodlin et al. reported that annual medical expenditures for sports injuries in the United States amount to at least $160 billion, and between 2008 and 2013, Major League Baseball lost approximately $1.6 billion in salaries due to player injuries. 1 Edouard et al. further found that approximately two-thirds of track and field athletes sustain at least one injury per season, and that around 100 injuries occur per 1000 registered athletes during international championships. 2 These findings underscore that sports injuries remain a significant and persistent challenge in competitive sports.
Recent research suggests that the relationship between psychological state and sports injury may be bidirectional. Not only can injuries negatively affect mental health, but an athlete's psychological state—such as stress, anxiety, mood fluctuations, and sleep quality—may also contribute to injury risk. These psychological factors may indirectly influence concentration, decision-making, and neuromuscular control, thereby increasing the likelihood of injury occurrence.
Accordingly, recent studies have begun to incorporate subjective psychological indicators into AI-based prediction models, integrating these variables with objective physiological and training-load data to establish more comprehensive injury risk prediction systems. For instance, Bergeron et al. incorporated psychological variables such as sleep quality and academic stress as key features in a machine learning model for injury risk prediction, highlighting the potential value of integrating psychological data into sports injury forecasting. 3 Sports injuries are widely regarded as a key factor hindering sustained training and performance development 4 ; therefore, effective prevention has become a major focus in sports medicine and sports science.
Despite the growing emphasis on injury prevention, traditional prediction and assessment methods face substantial practical challenges. Sports injuries are often sudden and multifactorial, with etiologies involving complex interactions among intrinsic characteristics, extrinsic exposures, and inciting events, making accurate assessment based on single variables difficult. Furthermore, coaches often rely on intuition and experience, while athletes may overestimate or underestimate their physical condition during self-assessment, leading to subjective data bias. 5 Traditional statistical models, such as linear regression, may be less effective in capturing the multifactorial, non-linear, and dynamic mechanisms of injury risk, and may struggle to adequately model the complex interactions among workload, recovery, biomechanics, and psychological status. For example, factors such as the acute:chronic workload ratio, sleep quality, and psychological stress are highly interrelated and may influence injury risk in ways that are difficult for linear models to fully capture.6,7,8 Van Eetvelde et al. similarly noted that injury prediction requires the integration of intrinsic and extrinsic risk factors with inciting events to build more explanatory risk models. 9 In the sports injury literature, and particularly in football-related research, recent methodological reviews have further emphasized that current injury prediction studies remain highly heterogeneous in terms of variable selection, data imbalance handling, validation approaches, and performance reporting, thereby complicating interpretation and limiting robust comparison across studies.
Against this background, AI has demonstrated significant potential in sports medicine by offering new opportunities for sports injury prediction. Through high-performance computing and machine learning techniques, AI can learn risk patterns from large historical datasets and model non-linear relationships that are difficult to detect using conventional approaches. 10 Common algorithms, such as Random Forest and Support Vector Machine, are capable of handling multidimensional and highly interdependent variables to build predictive risk models that may support medical teams and coaches in making timely intervention decisions. Bahr and Krosshaug emphasized the need for a multifactorial approach that integrates risk factors and inciting mechanisms, and this complexity supports the application of advanced computational methods in injury prediction. 11 In parallel, recent biomechanics research has highlighted the increasing importance of objective movement analysis, wearable technologies, and neuromuscular assessment for enhancing sports performance, mitigating injury risks, and optimizing rehabilitation, further supporting the integration of biomechanical and physiological data into AI-based injury prediction frameworks.
Building on this rationale, numerous recent studies have attempted to apply AI and ML techniques to sports injury risk prediction and have shown considerable potential. Previous reviews have examined the broader application of AI and ML in sports medicine or injury-related research; however, many have combined heterogeneous tasks such as injury diagnosis, image-based classification, rehabilitation assessment, and risk prediction. This makes it difficult to isolate the methodological strengths and limitations of AI-based models specifically intended for prospective sports injury prediction. The existing literature also faces several limitations, including constrained application scenarios, inconsistent metric definitions, limited external validation, and a lack of comprehensive synthesis. In addition, the current evidence base appears to be geographically concentrated, with some football regions and populations remaining underrepresented in AI-based injury prediction research, which may restrict the global generalizability of currently available models. Accordingly, the present review differs from previous reviews by focusing exclusively on empirical studies that used AI or ML for prospective or prognostic sports injury prediction, while excluding diagnostic imaging and purely classification-based studies. This review also updates the evidence through March 2026, synthesizes model types, predictor domains, validation strategies, and performance metrics, and evaluates the methodological quality of included prediction models using PROBAST. By doing so, this review seeks to provide a focused and systematic assessment of both the predictive potential and the current methodological limitations of AI-based injury prediction models in sports settings, while helping practitioners better understand the applied boundaries of AI in sports medicine.
Methods
This study was conducted as a systematic review to identify, evaluate, and synthesize empirical research on the application of AI and ML in sports injury prediction. A structured review approach was used to improve the transparency, reproducibility, and consistency of study identification, screening, and synthesis.
Search strategy
The literature search strategy for this study was adapted from keywords used in previous high-quality systematic reviews,12,13 with modifications based on the current research question. The final search terms were developed through team discussion and expert consultation to ensure both breadth and specificity.
The search strategy was designed to retrieve studies specifically focused on sports injury prediction using artificial intelligence (AI) or machine learning (ML). To improve search sensitivity and precision, Medical Subject Headings (MeSH) were used in PubMed, and equivalent controlled vocabulary terms were applied where appropriate in other indexed databases. The search terms were structured around three conceptual domains:
To improve specificity and maintain a focus on predictive models rather than diagnostic classification, negative filters (NOT logic) were applied to exclude diagnostic imaging and purely clinical identification studies, such as MRI-, CT-, or fracture-classification-based studies. Full database-specific search strategies are provided in Supplementary Table S1.
The search strategy was systematically applied across PubMed, IEEE Xplore, Web of Science, Scopus, and SPORTDiscus. The search period covered January 2015 to March 2026 in order to capture recent developments in AI-based sports injury prediction. In addition to the structured database search, a small number of database-recommended articles identified through platform recommendation functions were screened for eligibility.
Inclusion criteria
Studies were included if they met the following criteria: (1) they were peer-reviewed journal articles with full text available; (2) they were published in English; (3) they explicitly applied AI or ML methods; (4) they focused on sports injury prediction, including prospective or prognostic prediction of injury occurrence or related outcomes; and (5) the study participants were human athletes or comparable structured physically trained populations. Studies based on animal models or simulated data were not included.
Exclusion criteria
To enhance the relevance and quality of the included literature, studies were excluded if they met any of the following criteria: (1) publication types such as reviews, editorials, book chapters, dissertations, or theses; (2) non-English publications; (3) studies that did not explicitly apply AI or ML methods, or were not directly related to sports injury prediction as a prospective or prognostic task; (4) studies involving animal models or simulated data rather than human participants; and (5) articles for which the full text was unavailable for screening and quality assessment.
Selection of sources of evidence
The literature screening process was conducted independently by two researchers. First, all retrieved records were screened by title and abstract based on the predefined inclusion and exclusion criteria. Full-text articles that passed the initial screening were then reviewed by both researchers to confirm their eligibility. Any disagreements during the screening process were resolved through review and arbitration by a senior expert in the field to reach a final consensus.
The conduct and reporting of this systematic review followed the PRISMA 2020 statement. 14
Data extraction
During the data extraction phase, key study characteristics were recorded, including injury type, primary study aim, sample size, participant demographics, sport type, data source, AI/ML model type, study design, country of origin, and publication year. Performance metrics such as accuracy, precision, recall, sensitivity, specificity, and area under the curve (AUC) were also extracted where available. When multiple metrics or time points were reported, those identified by the original authors as primary or most relevant to the study aim were prioritized. Missing or unclear data were recorded as “not reported,” and no assumptions were made to infer unavailable values.
Quality assessment
The risk of bias and applicability of the included prediction models were assessed using the Prediction model Risk Of Bias ASsessment Tool (PROBAST). 15 PROBAST was specifically developed to assess the risk of bias and applicability of studies that develop, validate, or update multivariable prediction models.15,16 The tool is organized into four key domains: (1) participants, (2) predictors, (3) outcome, and (4) analysis. 15 These domains comprise 20 signaling questions that guide structured and transparent judgments of risk of bias. 16 Following PROBAST guidance, each domain was rated as ‘low’, ‘high’, or ‘unclear’ risk of bias, and an overall high risk of bias was assigned if at least one domain was judged to be at high risk.15,16
Results
Based on the aforementioned literature screening process, a total of 18 eligible empirical studies were included in this review. The following sections provide a comprehensive analysis of their study characteristics, applied AI/ML technologies, model predictive performance, and identified physiological and biomechanical risk factors associated with sports injuries.
Study selection
The systematic search was finalized in March 2026, covering literature published between January 2015 and March 2026. A total of 955 potentially relevant records were retrieved from PubMed (n = 645), IEEE Xplore (n = 122), Web of Science (n = 51), Scopus (n = 76), SPORTDiscus (n = 55), and other methods (database-recommended articles; n = 6). After an initial screening of titles and abstracts, 924 articles were excluded. The remaining 31 articles underwent a full-text review, of which 13 were excluded based on predefined criteria (e.g., methodological guidelines or commentaries, qualitative surveys/perceptions, and imaging-based or non-sports dataset studies). Ultimately, 18 empirical studies were included in the final analysis (Figure 1).
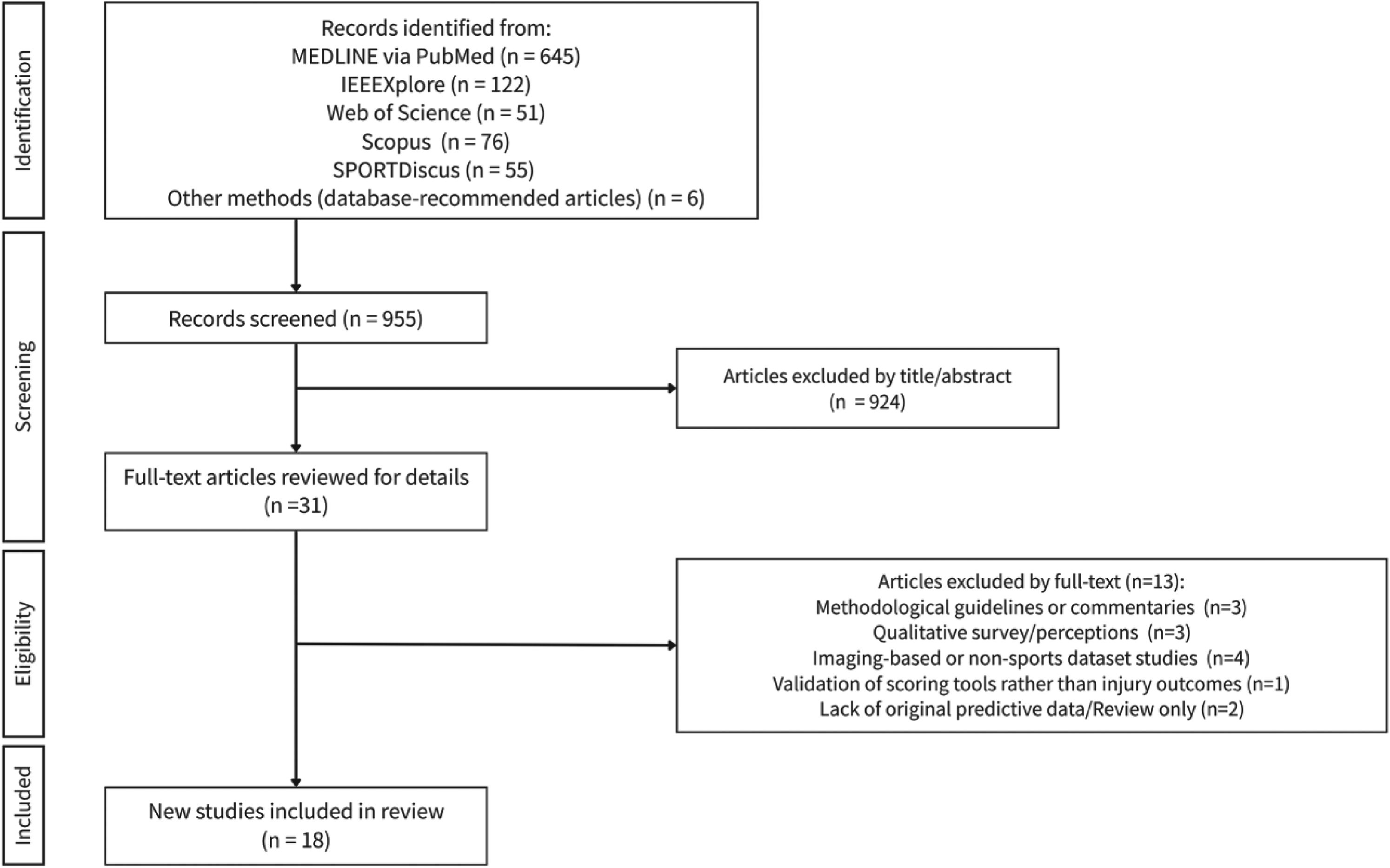
PRISMA flow diagram.
The risk of bias assessment for the 18 included studies is summarized in Table 1. Based on the PROBAST criteria, only one study (5.6%) was classified as having a low overall risk of bias. 17 Most studies (94.4%) were classified as high risk, mainly associated with limitations in the Analysis domain.
PROBAST risk of bias assessment.
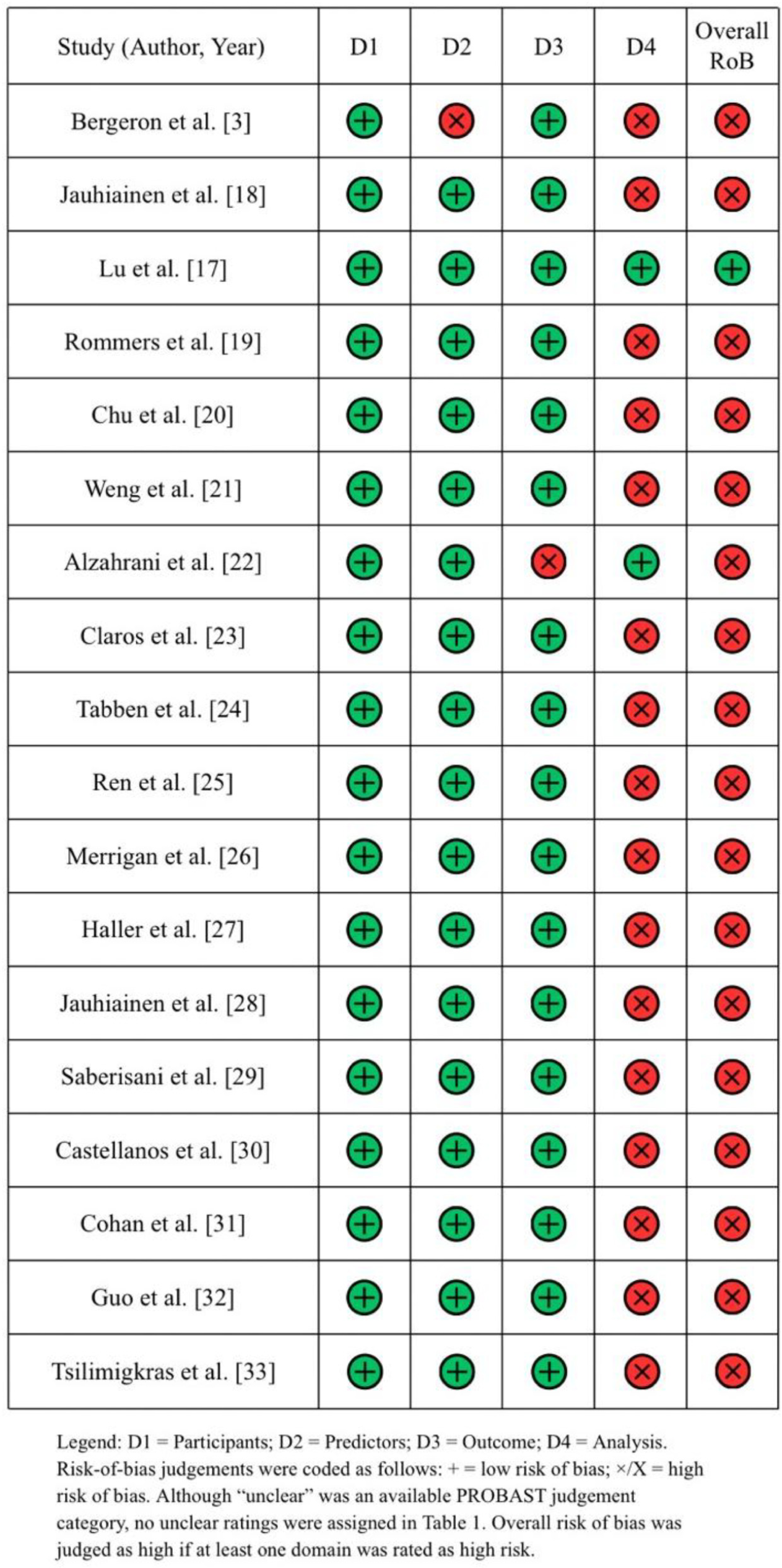
PROBAST risk of bias assessment.
Specifically, most risk prediction models relied exclusively on internal validation (e.g., k-fold cross-validation) without testing on an external, independent dataset, which often leads to optimistic performance estimates. Furthermore, a significant methodological concern was the lack of detail regarding data splitting techniques; many studies failed to report whether stratification was used or how temporal leakage was prevented in longitudinal training-load datasets. Additionally, the reporting quality was generally low, with only one study 17 providing 95% confidence intervals (CIs) for performance metrics, limiting the assessment of model precision.
The characteristics and performance of the 18 included studies are presented in Table 2. Following the refined scope of this review, all included studies focused exclusively on prospective or prognostic injury prediction models, aiming to forecast the probability of injury occurrence.
Characteristics and performance of included studies on ai-based sports injury prediction.
Characteristics and performance of included studies on ai-based sports injury prediction.
The study populations demonstrated an increasing trend toward demographic and geographic diversity. While earlier research predominantly featured professional male athletes, more recent studies have expanded to include female and other non-traditional cohorts. For example, Jauhiainen et al. developed an ACL injury prediction model using data from female elite handball and soccer players, whereas Merrigan et al. examined noncontact lower-body injury predictability in female NCAA Division I athletes using countermovement jump force-time metrics.26,28 In addition, the geographic scope of recent studies has broadened beyond traditionally dominant North American and European settings. For instance, Saberisani et al. investigated football injury prediction in Iranian professional players, Tabben et al. analyzed subsequent injury patterns in professional football players from the Qatar Stars League, and Guo et al. examined ACL injury prediction in male collegiate basketball players in an Asian context.24,29,32 Furthermore, the demographic scope has expanded beyond elite professionals to include collegiate athletes and more diverse competitive contexts, providing broader insight beyond traditional male professional cohorts. Overall, these developments suggest a gradual move toward greater contextual diversity, although male athletes remain overrepresented in the current literature.
Methodological quality and validation strategies
A significant validation gap persists within the field of injury prediction. Notably, most included studies relied solely on internal validation strategies, such as k-fold cross-validation or random data splitting, rather than external validation in independent cohorts. For example, Jauhiainen et al. explicitly reported repeated cross-validation procedures and emphasized the instability of prediction estimates across repetitions, ultimately concluding that statistical predictive ability did not necessarily translate into clinical usefulness. 28 Only a small minority of studies reported more rigorous testing procedures or uncertainty estimates. Castellanos et al., for instance, evaluated concussion prediction using a held-out test set and reported AUROC with 95% confidence intervals, while the study by Lu et al. was one of the few studies in the review to provide confidence intervals for model performance metrics.17,30 Additionally, reporting quality was often limited, with many studies failing to clearly describe stratification procedures, temporal separation strategies, or safeguards against data leakage in longitudinal datasets. Collectively, these issues suggest that many reported performance metrics may be optimistic and may not fully reflect real-world model generalizability.
Technical frameworks and predictors
To provide a more structured synthesis of the heterogeneous evidence, the included studies can be broadly grouped according to model type, predictor domain, and sport context. In terms of model type, tree-based ensemble methods, including Random Forest, XGBoost, and CatBoost, were commonly used for handling non-linear injury risk factors in tabular datasets involving workload, injury history, clinical, and biomechanical variables. For example, Guo et al. reported that Random Forest achieved the highest predictive performance for ACL injury risk among male basketball players, 32 while Weng et al. identified CatBoost as the best-performing model in baseball-related upper extremity injury prediction. 21 Support Vector Machine and logistic-regression-based approaches were also frequently applied, particularly in smaller datasets or studies emphasizing interpretable classification. Emerging research has also begun to apply deep learning and temporal modeling approaches. Cohan et al., for instance, used a deep learning framework to forecast injuries in NBA basketball based on longitudinal injury and game-related data. 31
In terms of predictor domains, the included studies generally drew on four overlapping categories: workload and exposure variables, previous injury and clinical history, biomechanical or neuromuscular measures, and subjective or contextual indicators such as sleep quality, academic stress, or questionnaire-based measures. Previous injury history and training load metrics remained among the most frequently reported and consistent predictors across studies. Tsilimigkras et al. further extended this line of work by incorporating both external load and internal load variables, including heart-rate-related measures, into a soccer injury risk model, highlighting the importance of physiological overload alongside mechanical demand. 33 Meanwhile, more complex models increasingly incorporated biomechanical and neuromuscular indicators. Guo et al. integrated sport-specific side-cutting biomechanics and electromyography, 32 while Bergeron et al. demonstrated the added value of subjective psychological indicators such as sleep quality and academic stress. 3
Finally, sport contexts varied across the included evidence, with football/soccer, basketball, baseball, rugby, and collegiate multi-sport cohorts represented. This structured grouping suggests that model choice was often shaped by data structure and sport context, but the lack of standardized predictor definitions and validation procedures limits direct comparison across studies. Together, these findings suggest an increasing emphasis on holistic and multimodal injury prediction frameworks.
Model performance metrics
Reported model performance was variable, with AUC values in many studies falling approximately between 0.65 and 0.85, suggesting modest to moderate discriminative ability in most cases. For example, Jauhiainen et al. reported a mean AUC-ROC of 0.63 for ACL injury prediction in female elite athletes, emphasizing that statistically significant prediction above chance may remain insufficient for clinical implementation. 28 By contrast, Claros et al. reported an AUC of 0.82 for predicting post-concussion musculoskeletal injury risk in collegiate athletes, suggesting that more comprehensive and clinically structured variable sets may improve predictive discrimination. 23
However, performance metrics should be interpreted cautiously. Merrigan et al. reported a high overall model accuracy of 85.6% but a low AUC of 0.659 and a recall of 0.0%, indicating that no injuries in the testing dataset were correctly classified. 26 Similarly, Haller et al. observed apparently high classification accuracy in a holistic monitoring framework, yet also acknowledged low precision and a considerable number of false positives. 27 These examples highlight that accuracy alone is insufficient for evaluating injury prediction models, particularly in imbalanced datasets, and that clinically meaningful interpretation requires consideration of recall, precision, AUC, and generalizability.
Discussion
Summary of principal findings
This systematic review synthesized 18 empirical studies that applied artificial intelligence and machine learning techniques to sports injury prediction. Overall, the findings suggest that this field has expanded rapidly in recent years, with increasing diversity in study populations, sports contexts, and data sources. Across the included studies, tree-based ensemble methods such as Random Forest, XGBoost, and CatBoost were the most frequently used algorithms, although deep learning approaches have also begun to emerge in more complex or longitudinal datasets.
A central finding of this review is that, despite promising performance in some individual studies, most AI-based sports injury prediction models remain methodologically underdeveloped. Based on the PROBAST assessment, only one study demonstrated a low overall risk of bias, with most judged to be high risk primarily because of weaknesses in the analysis domain, particularly the reliance on internal validation alone. These findings suggest that much of the current literature remains at a proof-of-concept stage rather than being ready for routine clinical or field deployment.
In addition, this review reaffirmed that previous injury history and training load remain the most frequently reported and consistent predictors across sports and settings. At the same time, more recent work has begun to integrate broader predictor domains, including biomechanical variables, wearable sensor outputs, electromyography, and subjective psychological indicators such as sleep or stress. These developments suggest that the field is gradually moving from single-domain screening toward more holistic and multimodal injury prediction frameworks.
Interpretation and comparison with existing literature
Methodological quality and validation gap
A major finding of this review is the persistence of a clear validation gap. Most included studies used internal validation strategies such as random train-test splits, k-fold cross-validation, or bootstrap-based resampling, whereas external validation across independent cohorts was uncommon. This is important because internally validated models may perform well within the development dataset yet fail to generalize when applied to new teams, seasons, institutions, or athlete populations. Jauhiainen et al., for example, explicitly demonstrated that although prediction performance was statistically better than chance, the resulting ACL injury model still lacked sufficient clinical utility. 28
This concern is consistent with the broader methodological literature. Majumdar et al. noted that football injury prediction studies are characterized by substantial heterogeneity in variable selection, data treatment, balancing procedures, and validation approaches, making unified interpretation difficult and limiting practical translation. 34 They further emphasized that further progress in the field will require not only better-performing algorithms but also multiple seasons of data, careful handling of class imbalance, and more interpretable analytical pipelines.
The validation gap also affects how high reported performance values should be interpreted. Some studies reported strong accuracy or discrimination metrics, but these estimates were often derived from small samples, event-sparse datasets, or single-center cohorts. Under such conditions, even apparently strong model performance may partly reflect overfitting, optimistic sampling, or hidden leakage rather than robust predictive ability. Accordingly, future studies should treat external validation as a core design requirement rather than an optional enhancement.
Reporting quality and interpretation of performance metrics
A second important issue concerns reporting quality. Across the included studies, model reporting was inconsistent, particularly with respect to uncertainty estimates, calibration, data preprocessing steps, and the handling of missing values. Only a very limited number of studies reported confidence intervals for key performance metrics. This omission substantially limits the ability to judge the precision, stability, and reproducibility of reported models.
Equally important, this review highlights that model performance cannot be interpreted on the basis of accuracy alone. In injury prediction, class imbalance is often substantial because injury events are much less frequent than non-injury observations. Under these conditions, a model may achieve high overall accuracy while still performing poorly in identifying injured athletes. The study by Merrigan et al. provides a clear example: despite relatively high accuracy, the model's AUC was modest and recall was 0.0%, meaning that no injuries in the testing dataset were correctly classified. 26 Haller et al. likewise reported apparently strong classification results but also acknowledged low precision and a notable false-positive burden. 27
This interpretation aligns closely with the concerns raised by both Cohan et al. and Majumdar et al., who emphasized that sports injury datasets are typically imbalanced and that inappropriate evaluation metrics can overstate practical usefulness.31,34 Therefore, future research should routinely report a broader range of metrics, including AUC, recall/sensitivity, specificity, precision, F1-score, and calibration-related information, ideally with confidence intervals.
Predictor domains: From foundational variables to multimodal frameworks
Although algorithmic diversity has increased, the main predictor domains used in injury prediction models have remained relatively consistent. Previous injury history and workload-related measures continue to emerge as foundational predictors across multiple studies and sports. This pattern is biologically plausible and practically meaningful: prior injury likely reflects residual impairment, incomplete recovery, or persistent vulnerability, whereas workload variables capture cumulative and acute mechanical and physiological stress.
At the same time, the literature is increasingly moving beyond these core variables. Tsilimigkras et al. incorporated both external and internal load, including heart-rate-derived variables, suggesting that physiological overload may add predictive value beyond purely mechanical training metrics. 33 Guo et al. integrated sport-specific biomechanics and EMG during unanticipated side-cutting, illustrating the value of capturing movement patterns at biomechanically critical phases. 32 Claros et al. combined demographic, injury-specific, and concussion-assessment variables to model subsequent musculoskeletal injury after concussion, while Bergeron et al. highlighted the importance of psychological and contextual variables such as sleep quality and academic stress.3,23
These developments are consistent with a broader shift in sports biomechanics and athlete monitoring. Dhahbi emphasized that biomechanical analysis, wearable technologies, and neuromuscular monitoring are increasingly central not only to performance optimization but also to injury mitigation and rehabilitation planning. 35 In this sense, the growing move toward multimodal models is theoretically coherent. However, the inclusion of more variables does not automatically guarantee better real-world performance. Larger and more heterogeneous datasets also create new challenges related to missingness, feature redundancy, dimensionality, and transportability. Thus, the field should pursue multimodal integration cautiously and with strong methodological discipline.
Gender imbalance and population generalizability
Another important observation is the continued overrepresentation of male athletes. Although more recent studies have begun to include female elite athletes and NCAA women's sport cohorts, the literature remains predominantly male-centered. This imbalance matters because female athletes may differ from male athletes in hormonal milieu, neuromuscular control, biomechanics, exposure patterns, and injury mechanisms. Models derived primarily from male cohorts may therefore not generalize well to female populations without dedicated validation.
This issue extends beyond sex to broader questions of generalizability. The geographical profile of the literature has become more diverse, with recent studies from Iran, Qatar, Greece, and broader Asian contexts, yet representation remains uneven. Gaddour et al. argued that AI-driven football injury prediction research remains geographically incomplete, particularly in underrepresented regions such as Africa, where contextual, infrastructural, and athlete-specific factors may differ substantially from those of Europe or North America. 36 This point is relevant more broadly: the external validity of injury prediction models likely depends not only on sport type but also on local training culture, competition structure, environmental conditions, and resource availability. This concern also extends to structured physically demanding populations outside elite sport. For example, Dhahbi et al. reported a retrospective cohort of 979 newly recruited male police cadets during an initial training phase, showing that musculoskeletal injury profiling in tactical cohorts is both feasible and clinically relevant, with nearly half of recruits sustaining at least one injury and most injuries occurring between Weeks 2 and 5. 37 Taken together, these observations suggest that future research should prioritize more inclusive and context-sensitive datasets rather than assuming that models developed in one setting will be universally portable.
Clinical translation, explainability, and implementation challenges
From a practical standpoint, the current evidence suggests that AI models should be viewed as decision-support tools rather than replacements for clinician or practitioner judgment. This is particularly true for injury prediction, where model outputs must be interpreted in context and where false positives and false negatives may carry meaningful consequences for both athlete welfare and performance planning. The implementation challenge is therefore not simply to maximize discrimination, but to develop models that are interpretable, operationally usable, and trustworthy.
Explainability is especially important here. Some recent studies have already begun to incorporate explainable AI techniques, such as SHAP-based model interpretation, to clarify which variables contribute most strongly to risk classification. This approach is valuable not only for building user trust, but also for generating clinically meaningful hypotheses and identifying modifiable intervention targets. Weng et al., for instance, used SHAP to interpret model predictions in baseball-related injury forecasting, illustrating how explainability can bridge predictive analytics and individualized prevention. 21
In addition, the increasing use of wearable devices, computer vision, force plates, and other sensor-based platforms introduces a separate but related challenge: technological standardization. This concern has been emphasized in recent methodological commentary on AI and sport technologies. In “The Algorithmic Athlete,” Dhahbi and Chamari argued that AI-driven and sensor-based systems require more rigorous and standardized evaluation extending beyond model performance alone to include assessment of the underlying measurement technologies, including verification, analytical validation, and practical or clinical validation. 38 This point is highly relevant to sports injury prediction. Even a theoretically strong model may be difficult to interpret or reproduce if the underlying measurement system lacks standardization, validity, or consistent reporting. Accordingly, progress in injury prediction will depend not only on better algorithms, but also on better measurement infrastructure and stronger reporting standards.
Strengths and limitations of this review
This review has several strengths. First, the search strategy was intentionally interdisciplinary, covering both medical and engineering-oriented databases. This increased the likelihood of capturing studies across sports medicine, biomechanics, data science, and wearable technology domains. Second, the review process followed PRISMA principles, improving transparency in study selection and reporting. Third, and most importantly, the review prioritized methodological appraisal through PROBAST rather than relying solely on descriptive summaries of model performance. This allowed critical methodological weaknesses—especially those related to analysis, validation, and reporting—to be identified systematically rather than being obscured by performance metrics alone.
Nevertheless, several limitations should be acknowledged. First, although the final set of 18 studies allowed for qualitative synthesis, the evidence base remains relatively small and heterogeneous. Second, the restriction to English-language publications introduces potential language bias. Third, because of substantial heterogeneity in injury definitions, study populations, predictor sets, model architectures, and evaluation metrics, a formal meta-analysis was not appropriate. Finally, as with any systematic review in a rapidly evolving field, some newer studies may reflect emerging methodological norms that differ from older ones, making direct comparison imperfect.
Directions for future research and practical implications
To move the field from proof-of-concept toward robust real-world application, several priorities should guide future work. First, external validation must become routine. Models should be tested across independent cohorts, institutions, teams, seasons, and preferably across different geographical settings. Where feasible, temporal validation using later seasons or prospective validation in newly recruited cohorts should be prioritized over random split-sample validation alone, particularly for longitudinal training-load and injury surveillance datasets. Without this step, claims of predictive utility remain provisional. Second, reporting practices should become more standardized. Future AI-based prediction studies should align more closely with the updated TRIPOD + AI guidance for prediction model reporting. 39 In particular, studies should clearly report the intended use of the model, target population, predictor and outcome definitions, missing-data handling, model development procedures, and validation strategy. Greater standardization of datasets is also needed, including harmonized definitions of injury outcomes, exposure time, training-load variables, biomechanical indicators, and return-to-play status. In addition, performance reporting should include uncertainty estimates, such as 95% confidence intervals for discrimination, calibration, and classification metrics. Greater methodological transparency may enhance reproducibility and allow more credible comparison across studies. Third, explainability should be incorporated more systematically. As models become more complex, black-box predictions alone are unlikely to gain sustained practitioner trust. XAI techniques such as SHAP or LIME can help clarify individualized risk patterns and support the translation of model output into practical prevention strategies. Fourth, future research should prioritize more representative datasets. This includes female athletes, underrepresented regions, youth cohorts, and non-traditional but physically comparable cohorts where injury burden is high. Broader representation will improve both scientific fairness and real-world generalizability.
For practitioners, the present evidence suggests cautious optimism. In real-world sports team settings, AI-based injury prediction models could be integrated into athlete-monitoring systems that combine workload data, injury history, wellness questionnaires, wearable sensor outputs, and biomechanical assessments. For example, a model could flag athletes showing elevated risk patterns, prompting coaches, athletic trainers, or clinicians to review training load, recovery status, and consider individualized prevention strategies. In rehabilitation environments, prediction models could support return-to-play decision-making by tracking recovery trajectories and identifying athletes who may require additional assessment. In clinical workflows, these tools may help prioritize follow-up evaluation or guide shared decision-making when combined with professional assessment. However, successful implementation depends on high-quality data, interoperable infrastructure, appropriate privacy safeguards, clinician and coach training, and user trust in model outputs. Given the present limitations in validation and reporting, these tools should support—not replace—clinical reasoning, coach expertise, and individualized athlete management.
Conclusion
This systematic review synthesized 18 empirical studies on AI- and ML-based sports injury prediction, with particular attention to methodological quality. Overall, the field shows considerable promise, but current evidence remains constrained by a widespread reliance on internal validation, inconsistent reporting practices, and a generally high risk of bias. As a result, many published models should still be viewed as preliminary rather than clinically established.
Across the included studies, previous injury history and training load were the most frequently reported and consistent predictor domains, while newer approaches increasingly incorporated biomechanics, wearable-derived signals, neuromuscular variables, and psychological indicators. These developments suggest a meaningful shift toward more holistic and multimodal injury prediction. However, stronger predictive frameworks will require not only richer data, but also better study design, clearer reporting, and more rigorous external validation.
The review also identified persistent structural issues in the literature, including male-dominated study populations, uneven geographical representation, variable injury definitions, and insufficient attention to uncertainty and calibration. Future progress should therefore prioritize methodological rigor over algorithmic novelty alone. Standardized reporting, independent validation, explainable AI, and better evaluation of underlying sensor and monitoring technologies will be essential if AI-based injury prediction is to become trustworthy, interpretable, and clinically actionable.
In summary, AI has clear potential to enhance sports injury prevention, but the field has not yet reached a level of evidence sufficient for routine deployment. Advancing toward personalized, equitable, and practically useful injury prevention systems will depend on combining computational sophistication with transparent methods, representative datasets, and strong validation in real-world contexts.
Supplemental Material
sj-docx-1-thc-10.1177_09287329261455797 - Supplemental material for From data to prevention: A systematic review of artificial intelligence applications in sports injury prediction
Supplemental material, sj-docx-1-thc-10.1177_09287329261455797 for From data to prevention: A systematic review of artificial intelligence applications in sports injury prediction by Chu-Hsuan Lee, Ming-Hui Chang and Zheng-Hao Li in Technology and Health Care
Footnotes
Abbreviations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Credit statement / author contributions
C.-H.L.: Conceptualization, methodology, investigation, funding acquisition, writing – original draft, and writing – review and editing.
M.-H.C.: Conceptualization, methodology support, and writing – review and editing.
Z.-H.L.: Data extraction, data curation, investigation, formal analysis, and writing – original draft.
All authors read and approved the final version of the manuscript.
Funding
The author is grateful to the National Science and Technology Council, R.O.C for supporting this research under grant 115-2420-H-239-002-.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.