
Abstract
The role of visual representations during language processing remains unclear: They could be activated as a necessary part of the comprehension process, or they could be less crucial and influence performance in a task-dependent manner. In the present experiments, participants read sentences about an object. The sentences implied that the object had a specific shape or orientation. They then either named a picture of that object (Experiments 1 and 3) or decided whether the object had been mentioned in the sentence (Experiment 2). Orientation information did not reliably influence performance in any of the experiments. Shape representations influenced performance most strongly when participants were asked to compare a sentence with a picture or when they were explicitly asked to use mental imagery while reading the sentences. Thus, in contrast to previous claims, implied visual information often does not contribute substantially to the comprehension process during normal reading.
Keywords
Much research has suggested that listeners and readers activate visual and motor representations of objects that are referred to in spoken or written form (for a review, see Zwaan, 2004). Since the publication of Barsalou’s (1999) seminal article, many of these findings have been interpreted in terms of embodied cognition, which is the view that high-level cognitive processes such as language, memory, and thought involve reenactment or simulation of perception and action states. This idea contrasts sharply with amodal theories of knowledge (e.g., Kintsch, 2008), in which the format of high-level cognitive processes is dissociated from perceptual processes. However, amodal propositions or features can in principle also be used to capture perceptual representations, and theories of embodied cognition assume that “a simulator produces simulations that are always partial and sketchy, never complete” (Barsalou, 1999, p. 586). It is therefore uncertain whether any experimental evidence could falsify either theory with regard to representational format (see Mahon & Caramazza, 2008; for an analogous debate in mental imagery, see Kosslyn, 1994; Pylyshyn, 1981).
Regardless of the modal or amodal format of conceptual representations, the evidence for the activation of visual representations during language processing remains intriguing. Do perceptual representations deserve a more explicit role in models of language processing than is currently the case? To answer this question, the conditions under which such representations become activated must be determined.
One hypothesis is that the activation of visual representations is a crucial component of language processing: Whenever one processes a word that refers to an object (e.g., tomato), one activates a visual representation that specifies its shape (e.g., round), and this representation forms a necessary part of the situation model assembled during comprehension. Thus, visual representations may routinely be activated during language processing (e.g., Wassenburg & Zwaan, 2010).
This claim is supported by studies showing that visual representations were activated even though they were presumably not needed for the task. For instance, in a sentence-picture verification study, Zwaan, Stanfield, and Yaxley (2002) presented participants with sentences about objects that implied that the objects had a particular shape (e.g., “The ranger saw the eagle in the sky” or “The ranger saw the eagle in the nest,” which implies that the eagle had its wings spread or tucked in, respectively). Participants more quickly decided that a subsequently viewed object (e.g., an eagle) had been mentioned in the sentence when its shape corresponded to that implied in the sentence than when these shapes mismatched. This suggests that visual representations of shape were activated. The same pattern was seen when the verification task was replaced by picture naming.
Similarly, for spatial orientation, Stanfield and Zwaan (2001) found that participants were faster to indicate that an object (e.g., a vertically oriented nail) had been mentioned in a preceding sentence when its orientation matched that implied in the sentence (e.g., “The carpenter hammered the nail into the floor”) than when these orientations mismatched (e.g., “The carpenter hammered the nail into the wall”). Recently, Zwaan and Pecher (2012) replicated the orientation and shape effects in an online study that used the sentence-picture verification task. Pecher, van Dantzig, Zwaan, and Zeelenberg (2009) observed the same effects in a memory task, in which participants read a set of sentences and then judged whether subsequently presented images had been mentioned in those sentences. Findings showed that participants’ judgments were influenced by the orientation and shape implied in sentences read 45 min earlier. This suggests that representations of shape and orientation were activated during sentence reading and retained over time.
An alternative hypothesis is that visual representations are not crucial for language comprehension. Visual representations become activated during language processing, but this may be a by-product of the way information cascades through the cognitive system (Mahon & Caramazza, 2008). Moreover, whether or to what extent visual representations are activated may depend on the particular situation in which a concept is instantiated. According to this hypothesis, the activation of visual representations can be limited to certain task situations.
Although it has often been claimed that perceptual or motor representations become activated automatically or routinely (e.g., Pulvermüller, 2005; Wassenburg & Zwaan, 2010), some proponents of the embodied cognition hypothesis have also suggested that the activation of perceptual representations in linguistic or conceptual tasks may depend on context (e.g., van Dam, van Dijk, Bekkering, & Rueschemeyer, 2012). For instance, Pecher, Zeelenberg, and Barsalou (2003) observed that property verification on a given trial (e.g., APPLE-green) was faster and more accurate after a trial that involved the same sensory modality (e.g., DIAMOND-sparkle) than after a trial that involved a different modality (e.g., AIRPLANE-noisy). Furthermore, Solomon and Barsalou (2004) found that performance in property verification depended on perceptual variables only when thorough processing was encouraged through the presence of associatively related fillers. Moreover, studies of priming between shape-related word pairs have yielded inconsistent results. In a lexical decision task, Schreuder, Flores d’Arcais, and Glazenborg (1984) observed perceptual priming (e.g., ball-apple; both are round objects), but Pecher, Zeelenberg, and Raaijmakers (1998) failed to replicate the priming effect, except when visual representations had been emphasized by shape-decision tasks before the experiment. Recall that our aim was not to evaluate theories of embodied and disembodied cognition but to investigate the orthogonal issue of whether visual representations routinely influence performance.
Other support for context dependence comes from eye-tracking studies using the visual-world paradigm, in which participants listen to spoken sentences while viewing arrays of objects. In these studies, on hearing or anticipating a spoken word (e.g., snake), participants rapidly shifted their gaze to visually similar objects (e.g., a cable; Dahan & Tanenhaus, 2005; Huettig & Altmann, 2007; Rommers, Meyer, Praamstra, & Huettig, 2013). However, this did not happen when the objects were replaced with printed words (Huettig & McQueen, 2011). Regarding color representations, Connell and Lynott (2009) observed that naming colors of colored words was easier when the color of the typeface was congruent with that of the object described (e.g., bear in a brown typeface) than when it was not. However, Connell (2007) found that responses to picture probes were faster when the colors did not match than when they did match. Both facilitation (Zwaan et al., 2002) and interference (Richardson, Spivey, Barsalou, & McRae, 2003) have also been reported for orientation. Finally, Kang, Yap, Tse, and Kurby (2011) failed to replicate an effect of object size reported by Sereno, O’Donnell, and Sereno (2009).
In the present experiments, we investigated whether information about the shape and orientation of objects mentioned in written sentences routinely influences performance. The studies discussed previously differed in many ways, including the materials used, the timing of the stimuli, and the tasks. We used the same materials in all of the present experiments but varied the task. Participants read sentences and named pictures (Experiment 1), explicitly compared sentences with pictures (Experiment 2), or used imagery before naming pictures (Experiment 3). If the activation of visual representations is an inherent part of the comprehension process, it should influence performance across a range of processing tasks. If visual representations influence performance in a task-dependent manner, larger effects might be observed in Experiments 2 and 3 than in Experiment 1.
Experiment 1
Participants
Fifty-two native speakers of Dutch (45 women, 7 men) with an average age of 20 years (range = 17–26 years) were paid for their participation. All had normal or corrected-to-normal vision and reported no language impairments.
Stimuli and design
The stimuli consisted of the 92 black-and-white picture-sentence quadruplets used in Pecher, van Dantzig, Zwaan, and Zeelenberg (2009). Each quadruplet consisted of two sentences and two black-and-white pictures, with each picture matching one sentence. In 52 of the quadruplets, the orientation of the objects (horizontal or vertical) was manipulated such that they either matched or mismatched the orientation implied in the sentences. In the remaining 40 quadruplets, the shapes of the objects were manipulated to either match or mismatch the shapes implied in the sentences, as in the studies discussed previously. Each participant saw one of four lists, in which one sentence-picture combination from each quadruplet occurred. In addition, each list included 92 filler items in which the sentence did not imply a particular shape or orientation and did not mention the picture (fillers were the same across all lists). The pictures varied in size (width range = 63–720 pixels, height range = 63–540 pixels). The items occurred in random order, and the same condition (match, mismatch, and filler) did not occur more than three times in succession.
Apparatus and procedure
Participants were tested individually in a sound-damped booth, seated in front of a 17-in. iiyama HM703UT monitor (Iiyama, Japan), a custom-built button box, and a Sennheiser microphone (Wedemark, Germany). Presentation software (Version 14.1; Neurobehavioral Systems, Albany, CA) was used to display the images on the monitor. Each trial started with a 200-ms black screen. Then a sentence appeared in the center of the screen in white, 15-point Arial font. After participants pressed a button to indicate that they had read the sentence, a white fixation cross appeared on the screen for 250 ms, followed by a picture of an object for 3 s. Participants named the object in the picture, and their speech was recorded. After every eight trials, there was an optional break. Participants were instructed to read each sentence carefully and to name each picture as quickly and accurately as possible.
Analysis
A speech-waveform editor was used to manually measure naming latencies. Responses different from the object name mentioned in the sentence were discarded. One of the orientation items had to be excluded because of an error in the construction of the materials. The data analysis followed that of Zwaan et al. (2002). For both the orientation and the shape items, the response latencies were aggregated to medians for each participant and entered in a 2 (condition: match, mismatch) × 2 (picture version: e.g., horizontal, vertical) × 4 (list: 1–4) repeated measures analysis of variance (ANOVA), with list as a between-subjects variable (because of the counterbalanced design, no item analyses are reported; see Raaijmakers, Schrijnemakers, & Gremmen, 1999).
Because Experiments 1 to 3 yielded null effects that are surprising given previous findings, we further examined the effects seen in each experiment in two ways. First, because traditional p values never allow one to accept the null hypothesis, we computed an approximation to Bayesian information criterion (BIC) posterior probabilities (pBIC) from the ANOVA following Wagenmakers (2007) and Masson (2011). In the case of a null effect, we report the evidence for the null hypothesis, pBIC(H0|D). In the case of a significant effect, we report the evidence for the alternative hypothesis, pBIC(H1|D), but note that these two probabilities sum to 1. Second, we conducted a more powerful analysis using linear mixed-effects regression models (Baayen, Davidson, & Bates, 2008). The responses were log-transformed to reduce skewness and analyzed with a model that included the fixed factor condition (match, mismatch) and random intercepts and slopes by participant, picture, and sentence. We used the R (Version 10.2.1; R Development Core Team, 2009) libraries lme4 (Version 0.999375-34) and languageR (Version 1.0). The match condition was mapped onto the intercept. We used a likelihood-ratio test to compare this model and a model without the fixed effect of condition but with the same random-effects structure. Error rates were low (see Table S1 in the Supplemental Material available online).
Results and discussion
Separate analyses were carried out for the orientation and shape items. For the orientation items, we discarded 128 incorrect responses and two trials because of a technical error (5% of all trials). The 9-ms difference in reaction times between the match and mismatch conditions (see Fig. 1) was not significant, F(1, 48) = 0.999, p = .323, η p 2 = .020. There was a Condition × List interaction, F(3, 48) = 3.920, p = .014, η p 2 = .197, and a three-way Condition × Picture Version × List interaction, F(3, 48) = 2.781, p = .051, η p 2 = .148. The pBIC(H0|D) for the main effect of condition was .808; according to Raftery’s (1995) classification, this value constitutes positive evidence that there was no effect of orientation. The mixed-effects model also did not indicate an effect of condition, β = 0.0084 (back-transforming the beta to a time yielded a value of 8 ms), χ2(1) = 1.480, p = .224.

Average reaction time (based on by-participant medians) in Experiments 1, 2, and 3 as a function of whether pictures matched or mismatched the descriptions given in sentences. Results are shown separately for orientation items (top) and shape items (bottom). Error bars indicate standard errors.
For the shape items, we discarded 228 incorrect responses and 24 trials because of a technical error (11.6% of all trials). The 16-ms difference in reaction time between the match and mismatch conditions (Fig. 1) was not significant, F(1, 48) = 0.759, p = .388, η p 2 = .016, and there was positive evidence for the null hypothesis, pBIC(H0|D) = .827. There was a trend for a Condition × List interaction, F(3, 48) = 2.511, p = .070, η p 2 = .136, and a Condition × Picture Version × List interaction, F(3, 48) = 4.352, p = .009, η p 2 = .214. Only the mixed-effects model showed an effect of condition, β = 0.02418 (back-transformed: 19 ms), χ2(1) = 5.540, p = .019. A joint analysis of the orientation and shape medians in a 2 (item type: orientation, shape) × 2 (condition: match, mismatch) ANOVA yielded no Item Type × Condition interaction, F < 1, which suggests that the effects were comparably small.
In sum, using the same analyses (ANOVAs on medians) and sample size that Zwaan et al. (2002) used, we found that neither the orientation nor the shape manipulation had a significant effect on naming latencies. This is surprising, given the congruency effects found for both manipulations by Pecher, van Dantzig, Zwaan, and Zeelenberg (2009), who used the same materials in a memory task, and the findings by Zwaan et al. (2002, Experiment 2), who used materials similar to our shape items in a naming task and found a 33-ms difference between responses for matching and mismatching items. However, in the mixed-effects model, a small effect appeared for shape. In the next experiment, we examined whether stronger effects would be obtained with the same materials in a sentence-picture verification task, in which participants were explicitly required to relate the sentences to the pictures (following Stanfield & Zwaan, 2001, and Zwaan et al., 2002, Experiment 1).
Experiment 2
Participants
Forty-four native speakers of Dutch (38 women, 8 men) with an average age of 21 years (range = 18–26 years) were paid for their participation. All had normal or corrected-to-normal vision and reported no language impairments. None had taken part in Experiment 1.
Stimuli
The stimuli from Experiment 1 were used.
Procedure
Experiment 1 was the same as Experiment 2 except for the task. Participants were asked to indicate as quickly and accurately as possible whether the depicted object had been mentioned in the preceding sentence by pressing a button on a button box. A green button on the left indicated yes and a red button on the right indicated no. When the participant pressed one of the buttons, the picture disappeared from the screen.
Results and discussion
The analysis was the same as for Experiment 1. For the orientation items, 54 incorrect trials were discarded (2.4% of all trials). The ANOVAs on median reaction times showed that the mean difference of 1 ms between the match and mismatch conditions (see Fig. 1) was not significant, F(1, 40) = 0.627, p = .433, η p 2 = .015, and there was positive evidence for the null hypothesis, pBIC(H0|D) = .825. There was a trend toward a Condition × Picture Version × List interaction, F(3, 40) = 2.624, p = .064, η p 2 = .164. In the mixed-effects model, the effect of condition also did not reach significance, β = 0.02263 (back-transformed: 14 ms), χ2(1) = 3.224, p = .073.
For the shape items, 63 incorrect trials (3.5% of all trials) were discarded. On average, participants were 50 ms slower in the mismatch condition than in the match condition (Fig. 1), F(1, 40) = 33.455, p < .001, η p 2 = .455, with very strong evidence for the alternative hypothesis, pBIC(H1|D) = .999. Condition further interacted with list, F(3, 40) = 4.300, p = .010, η p 2 = .244, and with picture version, F(1, 40) = 11.443, p = .002, η p 2 = .222. There was a Condition × Picture Version × List interaction, F(3, 40) = 13.420, p < .001, η p 2 = .502. In the mixed-effects model, there was also a significant effect of condition; β = 0.06724 (back-transformed: 44 ms), χ2(1) = 3.224, p < .001. A joint analysis of the orientation and shape medians yielded a Type × Condition interaction, F(1, 43) = 11.964, p = .001, η p 2 = .218, indicating that the shape effect was larger than the orientation effect.
The shape-congruency effect was larger in the verification task (Experiment 2; 50 ms) than in the naming task (Experiment 1; 16 ms). In a joint analysis of the median reaction times from Experiments 1 and 2, this was confirmed by a Condition × Experiment interaction, F(1, 94) = 6.977, p = .010, η p 2 = .069. This finding supports task dependence, because the participants apparently activated and used visual representations of shape more systematically in the verification task than in the naming task. In the verification task, the participants had to compare the content of the sentences with the depicted objects; this can be done by using visual representations. We hypothesized that if task relevance does explain the greater influence of visual representations in sentence-picture verification compared with naming, one would expect to see a shape-congruency effect and possibly an orientation-congruency effect in a naming task in which readers were explicitly instructed to recruit visual representations.
Experiment 3
Participants
Eighty-eight native speakers of Dutch (74 women, 14 men) with an average age of 20 years (range = 18–28 years) were paid for their participation. All had normal or corrected-to-normal vision and reported no language impairments. None had participated in Experiments 1 or 2.
Stimuli
The stimuli from Experiments 1 and 2 were used.
Procedure
The procedure was the same as in Experiment 1, except that participants were asked to create a visual image of the situation described in each sentence during reading, before they pressed the button to continue. To remind participants of this instruction, we replaced every other break screen with an imagery rating screen on which participants were asked to indicate how well they had been able to create visual images, using a scale from 1 (very badly; my images were vague, dark, or even absent) to 10 (very well; my images were as bright and lively as normal visual perception).
Results and discussion
The analysis was the same as for Experiment 1. For the orientation items, we discarded 193 incorrect responses (4.3% of all trials). The 7-ms advantage for the match condition (Fig. 1) was not significant, F(1, 84) = 1.632, p = .205, η p 2 = .019, with positive evidence for the null hypothesis, pBIC(H0|D) = .825. There was a Condition × List interaction, F(3, 84) = 3.476, p = .020, η p 2 = .110, and a Condition × Picture Version × List interaction, F(3, 84) = 5.659, p = .001, η p 2 = .168. The mixed-effects model did not indicate an effect of condition, β = 0.006347 (back-transformed: 5 ms), χ2(1) = 0.995, p = .318.
For the shape items, we discarded 330 incorrect responses (9.4% of all trials). On average, participants were slower by 20 ms to name the pictures in the mismatch condition than in the match condition (Fig. 1), which yielded a main effect of condition, F(1, 84) = 10.108, p = .002, η p 2 = .107, with positive evidence for the alternative hypothesis, pBIC(H1|D) = .941. There was a Condition × List interaction, F(3, 84) = 3.721, p = .014, η p 2 = .117, and a Condition × Picture Version × List interaction, F(3, 84) = 7.261, p < .001, η p 2 = .206. The mixed-effects model also indicated an effect of condition, β = 0.029034 (back-transformed: 23 ms), χ2(1) = 9.100, p = .003. Thus, in contrast to Experiment 1, Experiment 3 showed a clear effect of implied shape in an object-naming task, though in joint analyses it was not significantly larger than the orientation effect—Type × Condition interaction: F(1, 87) = 1.460, p = .230, η p 2 = .017, or larger than the shape effect in Experiment 1—Condition × Experiment interaction: F(1, 138) = 0.006, p = .937, η p 2 = .000. This result is suggestive of the idea that recruiting mental imagery during sentence reading facilitated picture recognition, thereby shortening naming latencies. 1
Experiment 4
In the previous experiments, object-shape information influenced performance in a task-dependent manner, but orientation representations barely influenced performance at all. Does this reflect an inherently smaller influence of orientation representations relative to shape representations on response latencies? In Experiment 4, a rating study, we examined whether the two item sets differed in how well the visual representations implied by the sentences corresponded to the pictures on the screen.
Participants
Forty native speakers of Dutch (33 women, 7 men) with an average age of 20 years (range = 17–23 years) were recruited from the same participant pool as the previous participants and paid for their participation. None of them had participated in Experiments 1, 2, or 3.
Stimuli and design
The stimuli from the previous experiments were used. The 40 participants were divided into four groups of 10, and each group was randomly assigned to one of the four lists. These lists contained the same items as the lists in the previous experiments but without the fillers. The shape and orientation items were now presented in separate test blocks because they required different judgments. Block order was counterbalanced among participants.
Procedure
We used the online experiment package WebExp to perform the experiment (Keller, Gunasekharan, Mayo, & Corley, 2009). On each trial, a sentence was presented above a picture. Participants were asked to look carefully at each sentence and picture and to rate the fit between the sentence and the picture in terms of object shape or orientation (depending on the block) using a scale from 1 (poorest fit) to 10 (best fit).
Results and discussion
ANOVAs were performed on by-participant mean ratings (Fig. 2). For the orientation items, the average rating was 4.6 points higher in the match condition than in the mismatch condition, F(1, 36) = 247.044, p < .001, η p 2 = .873. For the shape items, ratings were 3.3 points higher in the match condition than in the mismatch condition, F(1, 36) = 173.664, p < .001, η p 2 = .828. A joint analysis showed that the rating difference between the match and mismatch conditions was larger for the orientation items than for the shape items—Type × Condition interaction: F(1, 36) = 29.796, p < .001, η p 2 = .453. This means that the pattern of results—shape-congruency effects but no reliable orientation-congruency effects—cannot be ascribed to poorer quality of the orientation items compared with the shape items.
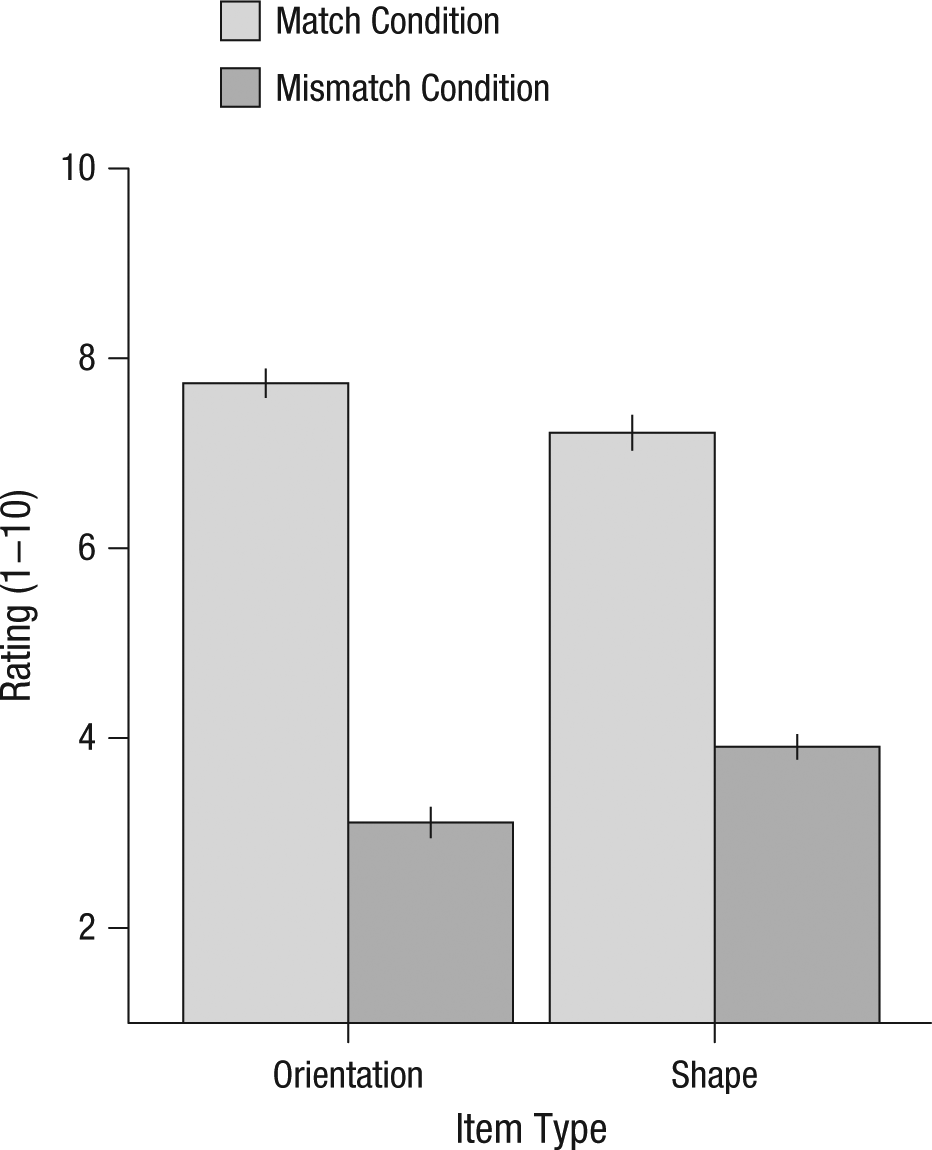
Mean rating as a function of item type and condition in Experiment 4. Error bars indicate standard errors of the mean.
General Discussion
We compared the activation of two types of visual representations, shape and orientation, across three different task settings. Our research was motivated by the question of whether the striking demonstrations of the activation of visual representations during language tasks (e.g., Stanfield & Zwaan, 2001; Zwaan et al., 2002) reflect routine or task-dependent processes. There were two major findings.
First, effects of implied orientation seem to be very difficult to obtain. We cannot resolve this discrepancy between earlier studies, which found significant effects, and our experiments, which failed to find orientation effects. In the present experiments, effects of orientation were absent not only in naming tasks (in which this factor had not been tested before) but also in sentence-picture verification, in which we did observe a clear effect of shape. The ratings obtained in Experiment 4 confirmed that the items in the orientation set were well chosen. The larger effects for shape than for orientation therefore cannot be attributed to a difference in item quality; instead, they are likely to depend on cognitive factors, such as the importance of shape in object recognition (Biederman & Cooper, 1991). Orientation is more dependent on viewpoint and is thus less characteristic of objects. Although our results do not exclude the possibility that orientation representations could be routinely activated (Wassenburg & Zwaan, 2010), they do cast doubt on claims that orientation representations routinely influence performance.
Second, the results advance our understanding of the role of visual representations in language processing by showing that the influence of shape representations depends on the task. Shape influences were weaker during naming (Experiment 1) than during sentence-picture verification (Experiment 2) and when participants were instructed to use imagery (Experiment 3). The influence of implied shape representations seems to occur on demand rather than being an inherent consequence of the reading process.
Because the imagery instructions were the only difference between Experiments 1 and 3, our data suggest that the use of imagery can be a mediating factor between language processing and the activation of visual representations. In conceptual-processing research, this idea has previously been rejected because of the absence of correlations between the size of the modality-switch effect discussed in our introduction (Pecher et al., 2003) and visual-imagery measures (Pecher, van Dantzig, & Schifferstein, 2009). In the present study, we took an experimental approach, and our results support the involvement of imagery. It is noteworthy that in a joint analysis of Experiments 1 and 3, we observed no Experiment × Condition interaction. One interpretation of this pattern of results is that some participants in Experiment 1 spontaneously used imagery without explicit instruction to do so. Stanfield and Zwaan (2001, p. 156) mentioned that in a related unpublished study (Stanfield, 2000), 25% of the participants reported trying to actively generate images, which is consistent with the use of spontaneous imagery. Thus, the relationship between imagery and the activation of visual representations is clearly worth further investigation.
In sum, our findings paint a different picture of the role of visual representations than did previous studies. They suggest that orientation representations play only a minor role during language comprehension and that the influence of shape representations is mediated by task demands and probably by the use of imagery. During everyday reading tasks, implied visual information often does not contribute substantially to the comprehension process.
Footnotes
Acknowledgements
We thank Ronald Fisher and John Nagengast for technical support, and we thank the research assistants of our lab for testing some of the participants and measuring speech onsets. We are grateful to Diane Pecher for providing the experimental materials and suggesting the Bayesian analyses, and we thank her and an anonymous reviewer for their comments.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.