
Abstract
A thorough understanding of monosyllabic-word-recognition processes, in contrast with multisyllabic-word processing, has accumulated over the past decades. One fundamental challenge regarding multisyllabic words concerns their parsing into smaller units and the nature of the cues determining the parsing. We propose that the organization of consonant and vowel letters provides powerful cues for parsing, and we present data from a new task showing that a word’s orthographic structure, as determined by the number of vowel-letter clusters, influences estimations of its length. Words were briefly presented on a computer screen, and participants had to estimate word length by drawing a line on the screen with the mouse. In three experiments, participants estimated words comprising fewer orthographic units as shorter than words comprising more units even though the words matched for number of letters. Further results demonstrated that the length bias was driven by orthographic information and not by phonological structure.
Keywords
Despite attempts to increase attention to multisyllabic-word processing (e.g., Jared & Seidenberg, 1990; Spoehr & Smith, 1973; Yap & Balota, 2009), understanding of visual word recognition is still largely based on monosyllabic stimuli. Yet the identification of multisyllabic words entails specific challenges.
One such issue concerns the parsing of letter strings into smaller units. Most theories presuppose that words are parsed into units that approximately correspond to spoken syllables, but neither the precise delimitation of the units nor the nature of parsing cues have been established. Thus, one of the first implemented models of multisyllabic-word reading (Ans, Carbonnel, & Valdois, 1998) assumes the existence of orthographic syllables. In contrast, in another influent model (Perry, Ziegler, & Zorzi, 2010), letter strings are parsed into graphemes that are assigned to onset, nucleus, and coda constituent slots, so that orthographic syllables are aligned with phonology.
We have proposed a different scheme based on the idea that the arrangement of consonants and vowels in the string provides powerful parsing cues (Chetail & Content, 2012, 2013). Alphabetically printed words are composed of recurring visual marks, the letters, which readers learn to ascribe to two categories, consonants and vowels. We hypothesized that the consonant-vowel (CV) pattern—the representation of the letter string in terms of these two categories—affords robust, invariant cues that guide parsing. One operationalization of this theoretical principle is that each series of contiguous vowel letters constitutes an orthographic-unit core element, to which adjacent consonants aggregate.
The differential role of consonants and vowels in visual word recognition has been supported by a large body of behavioral, neuropsychological, and neuroimaging studies (e.g., Berent & Perfetti, 1995; Buchwald & Rapp, 2006; Carreiras & Price, 2008; Lee, Rayner, & Pollatsek, 2001, 2002; Miceli, Capasso, Benvegnu, & Caramazza, 2004; New, Araújo, & Nazzi, 2008), which have indicated that consonants provide stronger constraints on lexical selection than do vowels (e.g., Duñabeitia & Carreiras, 2011). In the research reported here, we explored a related but distinct issue, namely, the role of the arrangement of consonant and vowel letters in parsing, rather than their differential contribution to lexical access.
Most often, CV parsing would delimit units that are isomorphic with spoken syllables and facilitate their alignment with phonological constituents. However, this is not always true. Hiatus words are one case in point because they comprise fewer orthographic units than syllables. In phonology, a hiatus is a sequence of two full vowels determining two syllabic nuclei (e.g., ao in chaotic, /keɪ.ɑ.tɪk/). Yet as long as the corresponding orthographic cluster includes no consonant, we hypothesize that it would be handled as a unitary group and would hence produce a mismatch between orthographic and phonological structure (Fig. 1). In support of this view, results from a previous study we conducted showed that readers underestimate the number of syllables in hiatus words (Chetail & Content, 2012). In the same study, the presence of an orthographic hiatus slowed down access to pronunciation, which supports the idea that the parsing causes a misalignment in later graphemic analysis. Interestingly, there is little graphemic-segmentation ambiguity in French, so it is unlikely that the effects in these studies—conducted with French-speaking participants—stemmed from graphemic misparsing. Whereas in English, many pairs of vowels can be segmented as one or two graphemes (e.g., ea in creation vs. appear), each vowel sequence in French corresponds either to a single grapheme (e.g., au, /o/) or to two graphemes (e.g., ao, /ao/).

Examples of English and French words with matching (left) and mismatching (right) consonant-vowel (CV) orthographic structure and syllable structure. Given that a detailed analysis of orthographic consonant attachment is beyond the scope of the present study, in this figure, intervocalic consonants in the orthographic structure are associated with vowel nodes on the basis of the maximal onset principle (e.g., Pulgram, 1970).
Previous evidence for CV parsing has come from tasks requiring full-stimulus identification, making it difficult to disentangle orthographic from phonological factors. In the present study, we used a new technique based on length estimation to assess whether orthographic structure influences the perception of an elementary visual dimension. Earlier studies suggested that the appraisal of physical dimensions can be affected by linguistic information. For example, determining the center of written words is influenced by their graphemic composition (Fischer, 2004), and perceiving the color of a letter within a word partly depends on the word’s syllabic structure (Prinzmetal, Treiman, & Rho, 1986). The length-estimation task was devised because it provides an indirect measure of structural effects without directing participants’ attention toward word structure or constituents. Furthermore, because the task does not require identification or access to phonology, it may isolate phenomena related to the earliest stages of orthographic processing. If hiatus words comprise fewer orthographic units, we expect them to be estimated as shorter than control words matched on number of letters.
In Experiment 1, the duration of stimulus presentation was sufficient to enable full identification, whereas a shorter duration was employed in Experiment 2. Experiment 3 showed that the length-estimation bias is due to the organization of letters and not phonemes.
Experiment 1
Method
Participants
Sixteen native French speakers participated in this experiment.
Stimuli
A set of 168 French words was selected from Lexique (New, Pallier, Brysbaert, & Ferrand, 2004) on the basis of the orthogonal combination of two factors: number of syllables and word type (for a full list of stimuli and characteristics of the words used, see the Stimuli and Items’ Characteristics sections of the Supplemental Material). Pairs of words matched for number of letters, number of phonemes, lexical frequency, and summed bigram frequency were selected; in each pair, one word included a hiatus (e.g., création, /kʀe.a.sjɔ̃/), whereas the other did not (e.g., délivrer, /de.li.vʀe/). Half of the words were bisyllabic, and half were trisyllabic. Eighty-four filler words that were either three or nine letters long were added, for a total of 252 words.
Procedure
Presentation and response recording were programmed with the Psychophysics Toolbox (Brainard, 1997). Items were displayed on a Philips 107S monitor (1280- × 960-pixel resolution). To ensure that hiatus and control words occupied the same amount of space, we presented stimuli in lowercase type in a fixed-width font. On each trial, a fixation cross appeared for 500 ms, followed by a 33-ms mask. The stimulus was then presented for 100 ms, followed by the 33-ms mask. After that, the mouse cursor appeared on the screen, and participants had to draw a line representing the physical length of the word. They used the mouse to lengthen or shorten the line and clicked to enter their response (Fig. 2). Participants performed nine practice trials with feedback before completing the 252 trials in random order.

Example trial sequence. The fixation cross was followed by a mask (a row of 21 hash marks). The stimulus was then presented, followed by the same mask. Stimuli were centered horizontally in the upper part of the screen (1/3 of the screen height from the top of the screen). The mouse cursor appeared in the lower part of the screen (1/3 of the screen height from the bottom of the screen). Its horizontal position varied randomly among six coordinates (extending from 3/12 to 8/12 of the width of the screen, measured from the left edge).
Results
Extreme length-estimate values deviating from the real length of words by 90% or more were discarded from analyses (1.19%). We fitted linear mixed-effect regression models including word type (hiatus, control) and number of syllables as fixed factors and random intercepts for participants and items. Because bisyllabic and trisyllabic words differed in their number of letters and graphemes, these variables were added as covariates. Finally, because readers are generally exposed to proportional fonts and might thus rely on a memory representation incorporating letter-size variations, we included a proportionality correction as a further covariate.
Overall, the estimated length of words was close to their real length (mean word length = 6.02 characters, mean estimated length = 6.46 characters), although slightly overestimated (Fig. 3a). In spite of the precision of the estimates, hiatus words were estimated as shorter than control words, t = −3.38, p < .0001, 1 and bisyllabic words were estimated as shorter than trisyllabic words, t = −3.30, p < .0004. Additionally, the number of letters, t = 22.84, p < .0001, and the proportionality correction, t = 6.30, p < .0001, significantly contributed to predict performance. There was no significant effect of the number of graphemes, t = 0.65, p = .49. The only significant interaction was between number of letters and number of syllables, t = −3.46, p < .0004, with trisyllabic words producing a slightly flatter slope than bisyllabic words (see the Statistical Analyses and Additional Controls and Analyses sections of the Supplemental Material).
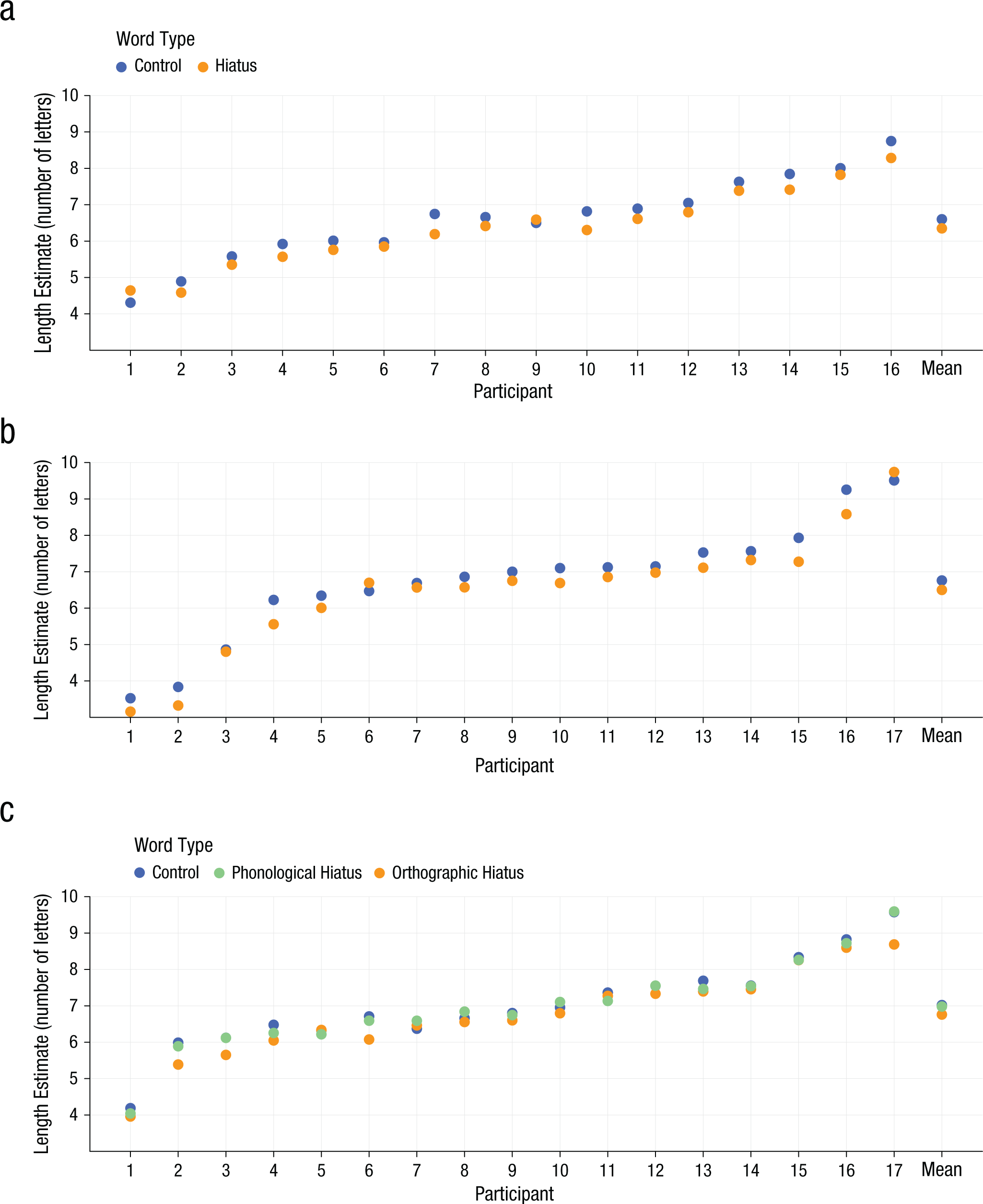
Word-length estimates (in number of letters) as a function of word type for each participant. Results are shown separately for (a) Experiment 1, (b) Experiment 2, and (c) Experiment 3. Control and hiatus words were matched on their number of letters. Average word length was 6.02 letters in Experiments 1 and 2 and 6.89 letters in Experiment 3.
In sum, length estimates were biased by both the number of syllables and the number of orthographic units. Results from a word-identification test with the same materials administered to fresh participants showed that 96% of the words were identified with a 100-ms display duration but only 38% with a 50-ms display duration. Hence, to test whether the CV pattern influences perceptual structure at an early stage of processing, we replicated Experiment 1 with a 50-ms display duration.
Experiment 2
Method
Participants
Seventeen new French speakers participated in this experiment.
Stimuli and procedure
The stimuli and the procedure were the same as in Experiment 1 except that words were presented for 50 ms rather than 100 ms.
Results
Extreme length-estimate values deviating from the real length of words by 90% or more were discarded from analyses (7.89%). We ran a mixed-model analysis similar to that used in Experiment 1.
Despite the reduction in the words’ visibility, word type still had a significant independent contribution to length estimates, t = −3.88, p < .0002, whereas the syllable-length effect decreased by half and failed to reach significance, t = −1.34, p = .16 (Fig. 3b). The number of letters, t = 15.17, p < .0001, and the proportionality correction, t = 3.52, p < .0001, as well as the interaction between number of letters and number of syllables, t = −2.08, p = .03, significantly contributed to predict performance. There was no effect of the number of graphemes, t = 0.05, p = .95 (see the Statistical Analyses section of the Supplemental Material).
Although the probability of word identification was strongly reduced, length estimation was influenced by orthographic structure, which suggests that limited orthographic information is sufficient to induce the length-estimation bias. The dissociation between the effect of number of syllables and the effect of word type lends further support to the idea that the latter phenomenon is caused by orthographic encoding processes and emerges even when the full phonological form is not available.
To directly demonstrate that the word-type effect is driven by the arrangement of vowel and consonant letters and not by the presence of two adjacent vowel phonemes in words’ spoken form, we conducted a third experiment with an additional condition using hiatus words in which the two adjacent vowel phonemes mapped onto two vowels separated by a silent consonant (e.g., bahut, /ba.y/). Despite the presence of a phonological hiatus, such items had the same number of vowel clusters as did the control words and should not have led to underestimation if such underestimation is caused by words’ orthographic CV pattern.
Experiment 3
Method
Participants
Seventeen new French speakers participated in this experiment.
Stimuli
The stimuli were 45 triplets of French words that were matched for number of letters, number of phonemes, number of syllables, and lexical and bigram frequencies. Two words in each triplet exhibited a phonological hiatus. In one of them (the orthographic-hiatus word), the two adjacent vowels coincided with two contiguous vowel graphemes (e.g., chaos, /ka.o/), as did the hiatus words used in Experiments 1 and 2. The hiatus was thus present both in the written and the spoken form of the word. In the other hiatus word (the phonological-hiatus word), the two vowels producing the hiatus pattern were separated by one or two mute consonant letters (e.g., bahut, /ba.y/, in which the h is silent). In that case, the hiatus was present only phonologically, because orthographically, the two vowel graphemes were separated by at least one consonant letter. Twenty-nine triplets included trisyllabic words, and 16 included bisyllabic ones. The same fillers used in Experiments 1 and 2 were added.
Procedure
The procedure was the same as in Experiment 1.
Results
Extreme length-estimate values deviating from the real length of words by at least 90% were discarded from analyses (0.67% of the data). For 1 participant, data for eight trials were missing because of a technical problem. We ran mixed-model analyses similar to those used in Experiment 1. The only difference was that word type was coded with two parameters, one contrasting the phonological-hiatus and control sets and one contrasting the orthographic-hiatus and control sets.
Orthographic-hiatus words were estimated to be shorter than control words, t = −4.72, p < .0001, whereas there was no significant difference between phonological-hiatus and control words, t = −0.72, p = .48 (Fig. 3c). In addition, bisyllabic words were estimated to be shorter than trisyllabic words, t = −3.50, p = .001. The number of letters, t = 11.35, p < .0001, and the proportionality correction, t = 3.93, p < .0006, significantly contributed to the model, whereas neither the effect of number of graphemes, t = −0.10, p = .92, nor any of the interactions reached significance (see the Statistical Analyses section of the Supplemental Material).
In sum, the length-estimation bias was replicated. Critically, the comparison of phonological- and orthographic-hiatus words enabled us to disentangle the influence of orthographic and phonological structure. The fact that only orthographic-hiatus words were estimated to be shorter than control words demonstrates that the effect is not due to the presence of a phonological hiatus but rather to the orthographic structure of the letter string.
General Discussion
Participants combined several sources of information to estimate the spatial extent of the stimuli, and the most salient cue was the words’ actual length on the display. As reflected by the beta parameter for the number of letters, an increase of one character in length produces a change of approximately one character in the estimates. In contrast, the size of the effects of number of orthographic units and of number of syllables is much smaller. Thus, the difference between hiatus and control words—one orthographic unit—led to a difference of roughly 0.25 characters in estimations of length (from 0.06 to 0.89 of one character across participants, corresponding to 1%–13% of word length). If the only source of information used was the number of orthographic units, the word-type effect should have been larger. However, as with many perceptual illusions, participants relied on physical information so that the discrepancy between perception and reality was attenuated and the veridicality of phenomenal experience was preserved. For example, in word bisection, the average graphemic bias is about four pixels (Fischer, 2004). Similarly, the rate of illusory conjunctions due to syllabic structure ranges between only 5% and 20% (Prinzmetal et al., 1986). Thus, even if hiatus words encompass one orthographic unit fewer than matched controls (Chetail & Content, 2012), one should not expect a massive bias, given that this structural cue is combined with the spatial-extent information. Nevertheless, regardless of its small size, the effect is systematic and reliable. Forty-four participants out of 50 showed an effect across the three experiments (sign test, p < 5.0 × 10–8).
One of our goals in the present study was to use a task that demanded neither word identification nor access to phonology to assess whether the effect of hiatus was related to orthographic or to phonological information. Direct evidence in favor of an orthographic locus stems from the observation of a length bias when the hiatus pattern was present in the printed form but not when it was present in the phonological form only (Experiment 3). Furthermore, the dissociation between the orthographic effect and the effect of number of syllables indicates that partial letter information is sufficient to organize strings into perceptual units in the absence of full phonological information. With 100-ms exposure times (Experiments 1 and 3), participants’ estimates were influenced by the number of syllables after the number of letters was partialled out. However, this phonological bias was contingent on word identification, whereas the orthographic bias was unaffected by exposure duration, given that only the former decreased and fell short of significance when presentation duration was reduced to 50 ms (Experiment 2). How is it possible for the perceptual system to extract structure when the identification of the stimuli is impaired? The fact that participants had trouble identifying the stimuli does not exclude the possibility that partial information from the letter string impinged on the perceptual system. In a framework in which information gradually flows from lower-level orthographic units (e.g., letters) to higher-level orthographic units, partial sensory information may suffice to trigger activity in the system, causing the structure to emerge.
As pointed out in the introduction, it is often assumed that letter strings are parsed into graphemic constituents (e.g., Perry et al., 2010). However, when we included the number of graphemes in the statistical models, there was no influence of the number of graphemes whatsoever. First, the hiatus effect was still significant when the number of graphemes was partialled out, and second, the number of graphemes had no independent contribution to the estimation of word length. Hence, we found no evidence in favor of an early graphemic parsing. Although our study was not designed to examine the role of graphemes, the findings are in line with Lupker, Acha, Davis, and Perea’s (2012) conclusion that graphemes do not constitute basic perceptual units. It remains possible, however, that graphemic parsing occurs at a later stage of processing that was not captured by the present task.
To conclude, the present findings illustrate that the perception of a physical property of letter strings can be influenced by their linguistic structure—namely, their CV pattern. This length-estimation bias suggests that the CV pattern, that is, the organization of consonants and vowels in letter strings, provides a powerful perceptual organization principle and that elementary processes, such as size estimation, can be permeated by higher-level information.
Footnotes
Acknowledgements
The authors thank S. Lupker, J. A. Duñabeitia, and an anonymous reviewer for very helpful comments on a previous draft of this manuscript.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
The work reported here has been supported in part by the Interuniversity Attraction Poles Program of the Belgian Science Policy Office (Project P7/33). F. Chetail is a postdoctoral researcher for the National Fund for Scientific Research (F.R.S.-FNRS).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.