
Abstract
Recent evidence has suggested that reward modulates bottom-up and top-down attentional selection and that this effect persists within the same task even when reward is no longer offered. It remains unclear whether reward effects transfer across tasks, especially those engaging different modes of attention. We directly investigated whether reward-based contingency learned in a bottom-up search task was transferred to a subsequent top-down search task, and probed the nature of the transfer mechanism. Results showed that a reward-related benefit established in a pop-out-search task was transferred to a conjunction-search task, increasing participants’ efficiency at searching for targets previously associated with a higher level of reward. Reward history influenced search efficiency by enhancing both target salience and distractor filtering, depending on whether the target and distractors shared a critical feature. These results provide evidence for reward-based transfer between different modes of attention and strongly suggest that an integrated priority map based on reward information guides both top-down and bottom-up attention.
Keywords
Efficiently allocating attentional resources to a subset of relevant information is crucial for increasing the fitness of an observer. Research has demonstrated that the allocation of attention is controlled by two partially segregated networks of brain areas. The top-down attention system, which recruits parts of the intraparietal and superior frontal cortices, is specialized for selecting stimuli on the basis of cognitive factors, such as current goals and expectations. The bottom-up attention system, by contrast, recruits the temporoparietal and inferior frontal cortices, and is involved in processing stimuli on the basis of stimulus-driven factors, such as physical salience and novelty (Corbetta & Shulman, 2002; Kastner & Ungerleider, 2000; Shomstein, Lee, & Behrmann, 2010).
Another important contributor to increasing fitness is evaluating reward contingencies and adjusting one’s behaviors accordingly. Recent evidence has indicated that reward is a powerful determinant of attentional deployment. Studies have shown that top-down attentional priority is given to stimuli associated with a higher probability or greater amount of reward (Della Libera & Chelazzi, 2006; Lee & Shomstein, 2013; Navalpakkam, Koch, Rangel, & Perona, 2010; Shomstein & Johnson, 2013). Reward-based modulation is also applied to bottom-up attention, as evidenced by studies showing that even the most efficient pop-out search is modulated by reward schedules (Kiss, Driver, & Eimer, 2009; Kristjansson, Sigurjonsdottir, & Driver, 2010). Interestingly, the effects of reward persist when the reward contingency is no longer relevant, even several days after training (Anderson, Laurent, & Yantis, 2011b; Della Libera & Chelazzi, 2009).
Although it is well established that attention is strongly modulated by reward and that the effects of reward persist within the same type of task, it remains unclear whether the effect of reward contingency learned within one type of task is transferred to a different type of task, specifically when the two tasks engage different attentional orienting systems, top-down and bottom-up. If effects of reward transfer across different attentional systems, then this would suggest that an integrated priority map, based on reward contingencies, guides attentional selection. Alternatively, if the transfer does not occur, this would suggest that reward-based priority maps are derived separately for top-down and bottom-up selection.
Considering that in real-world environments, reward-associated stimuli appear in dynamic contexts in combination with various features, it is critical to understand how a rewarded feature is integrated with other features and whether the effects of reward are generalized across different attentional settings. Most previous studies, however, have focused exclusively on the effect of reward within a single attentional domain (i.e., top-down or bottom-up), investigating the lingering effects of reward contingency in a similar type of task with no reward schedule (Della Libera & Chelazzi, 2009) or the effect of reversing reward schedules within the same task (Kristjansson et al., 2010). One exception is a recent study by Anderson, Laurent, and Yantis (2011a) that demonstrated a value-based transfer from top-down to bottom-up tasks in which attentional capture by a distractor was modulated by its prior reward association. However, while important, the results are not sufficient to be interpreted as direct evidence for an integrated reward-based priority map. First, the same reward-associated stimuli (e.g., a red circle) were used in both top-down and bottom-up tasks, which did not allow for examining integration of a rewarded feature with other features. Second, the target feature associated with reward in the training phase was used as a distractor feature in the test phase, which makes it unclear whether the observed transfer was due to a lingering target template or to the effect of prior reward associations. Third, the results provided evidence only for a unidirectional transfer (from top-down to bottom-up), such that the effect could have been due to lingering conscious valuation developed in the top-down phase. Therefore, for conclusive evidence for an integrated reward-based priority map, it is necessary to demonstrate a transfer effect in the opposite direction—that is, from bottom-up to top-down.
In the research reported here, we trained reward contingency in a pop-out-search task using a biased reward schedule and tested whether the effects of reward were transferred to a subsequent conjunction-search task with no biased reward schedule. This way, we could demonstrate how a rewarded feature is integrated with other features and whether the effects of reward are generalized across different attentional settings. Additionally, we examined whether the salience in the priority map is determined by enhancing target features previously associated with reward, by suppressing distractor features, or both.
Method
Participants
Different groups of undergraduate students ranging in age from 18 to 22 years participated in a 1-hr session—Experiment 1: N = 22 (14 female, 8 male); Experiment 2: N = 19 (11 female, 8 male); Experiment 3: N = 25 (14 female, 11 male). All participants had normal or corrected-to-normal vision and gave informed consent. All of the experimental procedures were approved by the institutional review board of George Washington University.
Task
In the pop-out-search task (Fig. 1a), each trial comprised a sequence of fixation, search display, and feedback. The fixation display consisted of a white fixation cross (0.5° × 0.5°) presented in the center of a black background for 700 ms. A search display, composed of white line segments (1.13° in length), remained visible until the participant made a response. The set size on each trial varied randomly among 9, 16, and 25, and the line segments were arranged in a 3 × 3, 4 × 4, or 5 × 5 matrix, respectively, with all segments separated from one another by 1.5°. The target was defined by a unique orientation, either horizontal or vertical, randomly positioned among 45°-oriented distractors. Participants were asked to press the “1” key on a keyboard for horizontal targets and to press the “2” key for vertical targets. Each response was followed by reward feedback presented for 800 ms. One of the target orientations (horizontal or vertical) was more highly rewarded than the other (counterbalanced across participants). High-reward targets were followed by high-reward feedback (10 points) on 80% of trials and by low-reward feedback (1 point) on the remaining 20% of trials; low-reward targets were followed by low-reward feedback on 80% of trials and by high-reward feedback on the remaining 20% of trials. Five points were deducted for each incorrect response.
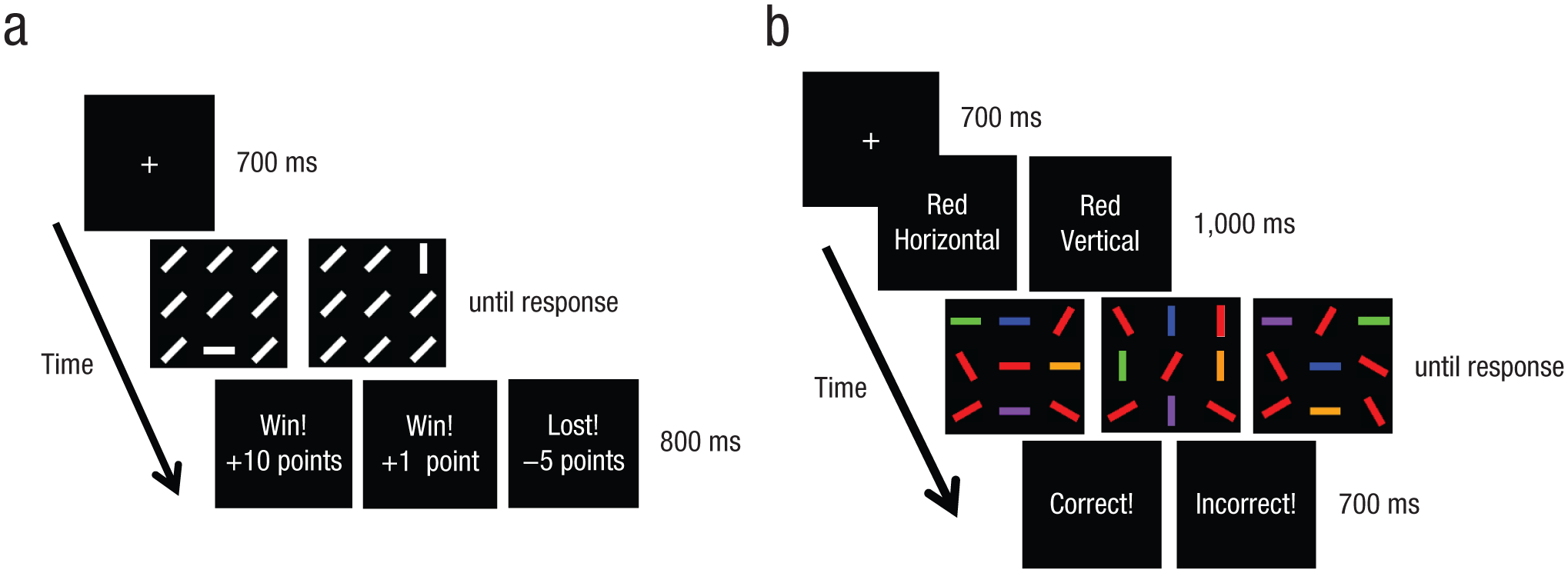
Schematic diagram showing the time course for a trial in (a) the pop-out-search task and (b) the conjunction-search task. See the text for details.
For the conjunction-search task (Fig. 1b), Experiments 2 and 3 were slightly different from Experiment 1 (explained in the corresponding sections). In Experiment 1, a white fixation cross (0.5° × 0.5°) was presented for 700 ms, followed by a target prime in which the words “Red horizontal” or “Red vertical” were presented in the center of the screen in white type (font size 18) for 1,000 ms. A search display consisted of line segments (1.13° in length) of various colors and orientations, and remained visible until the participant made a response. The arrangement of line segments and set size followed the same restrictions as in the pop-out-search task. The target was defined by a combination of color and orientation (red horizontal vs. red vertical) and was embedded in distractors that had combinations of four different colors (blue, green, orange, purple) and orientations (30°, 60°, 120°, 150°). Half of the distractors shared a color feature with the target, and the other half shared an orientation feature with the target. Seventy percent of trials were target-present trials. Participants were asked to press the “c” key for target-present trials and the “m” key for target-absent trials. After each response, a 700-ms feedback display indicated whether the response was correct or incorrect, but no reward feedback was displayed, which nullified the reward associations learned in the pop-out-search task.
We had participants complete an initial set of 200 trials of the conjunction-search task to obtain their baseline levels of performance before they were exposed to biased-reward training. Then, a block of 50 trials of the pop-out-search task was alternated with a block of 50 trials of the conjunction-search task five times. To motivate participants, we told them that they would receive $2 in addition to course credit for accumulating more than 95% of the total possible points. In fact, on completion of the experiment, all participants received $2 in addition to the course credit, and were fully debriefed.
Results
Experiment 1
We tested whether the effects of reward established in the context of bottom-up search were transferred to a different context in which top-down search was required, even when the reward contingency was no longer relevant. To rule out the possibility that the reward-based carry-over effect was due to motor enhancement rather than sensory enhancement, we had participants respond to different aspects of the target (orientation for pop-out search and presence for conjunction search) with different key mappings.
For the pop-out-search task (Fig. 2a), a repeated measures analysis of variance (ANOVA) with reward (high, low) and set size (9, 16, 25) as within-subjects factors and reaction times (RTs) as the dependent measure revealed a significant main effect of reward, F(1, 21) = 40.14, p < .001, with faster mean RTs for high-reward targets (648 ms) than for low-reward targets (692 ms). This confirmed that the reward manipulation elicited a significant modulation effect in favor of the target orientation associated with higher reward. There was also a significant effect of set size, F(2, 42) = 4.16, p < .05, with faster mean RTs for a set size of 16 (662 ms) than for a set size of 25 (676 ms), F(1, 21) = 7.83, p < .05. Although the set-size effect was unexpected considering previous results showing that RTs for pop-out search mostly stay flat across set sizes (Treisman & Gelade, 1980; Wolfe, 1994), it can be explained by an effect of grouping whereby diagonal distractors were easily grouped together in the set size of 16, making search more efficient (Humphreys, Quinlan, & Riddoch, 1989; Nothdurft, 1993). The reward-by-set-size interaction was not significant. The mean accuracy rate was 97%, with no significant main effects or interaction.
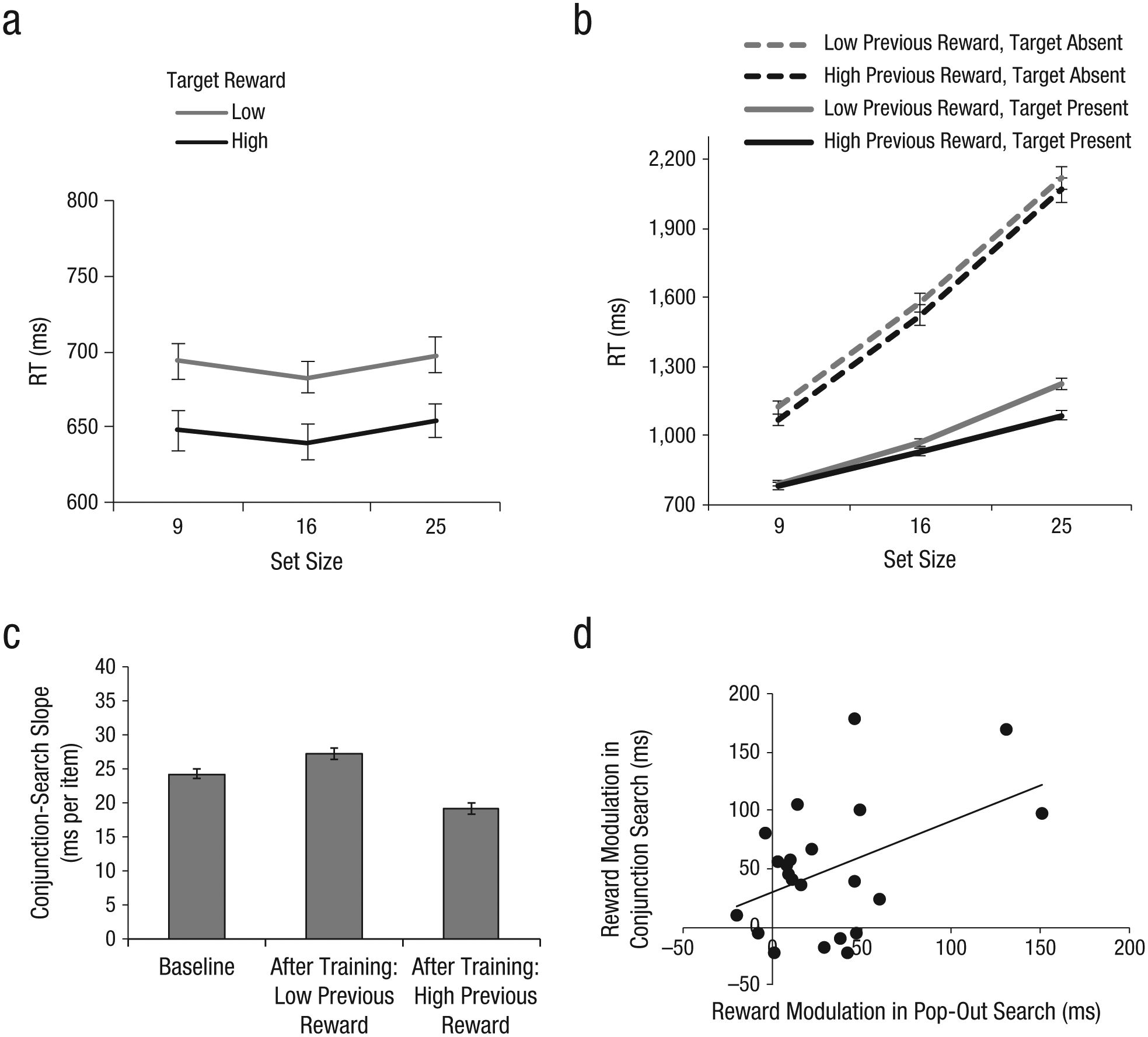
Results from Experiment 1. Panel (a) shows mean reaction times (RTs) in the pop-out-search task as a function of set size and target reward level. Panel (b) shows mean RTs in the conjunction-search task as a function of set size and conditions (previous reward level: high vs. low; target: present vs. absent). Panel (c) shows mean conjunction-search slopes obtained before reward training (baseline) and after reward training for previously high-reward and low-reward targets. Panel (d) shows a scatter plot (with best-fitting regression line) illustrating the relationship between the magnitude of reward effects in the pop-out-search task and in the conjunction-search task. For graphs in (a) through (c), error bars represent standard errors of the mean.
For the conjunction-search task, trials were classified as containing a previously high- or low-reward target solely on the basis of the reward contingencies in the pop-out-search task. Central to the study was the performance in target-present trials. A repeated measures ANOVA revealed a significant effect of reward, F(1, 21) = 20.57, p < .001, with faster mean RTs for previously high-reward targets (934 ms) than for previously low-reward targets (997 ms; see Fig. 2b). There was also a significant effect of set size, F(2, 42) = 144.12, p < .001, with RTs linearly increasing as the set size increased, which confirmed that the task involved attentionally demanding top-down search. Most importantly, the reward-by-set-size interaction was significant, F(2, 42) = 15.78, p < .001, which indicates that the search efficiency for targets differed depending on targets’ prior associations with reward. To compare search efficiency, we calculated search slopes for each condition by dividing RT differences by set-size differences. Search for targets previously associated with the higher reward was more efficient, as evidenced by a shallower search slope for previously high-reward targets (19 ms per item) than for previously low-reward targets (27 ms per item). The pattern of accuracy rates was consistent with that observed in the RT data, with no speed-accuracy trade-offs (see the Supplemental Material available online).
These results are important for two reasons. First, they corroborate previous findings showing that even the most efficient bottom-up search is modulated by the reward value of targets (Kiss et al., 2009; Kristjansson et al., 2010). Second, and more importantly, they demonstrate a novel finding—that the effects of reward established within a bottom-up search task are transferred to a subsequent top-down search task, even when the reward contingency is no longer relevant and the previously rewarded feature is integrated with other features.
To examine how conjunction-search performance was affected by reward-based transfer effects, we compared baseline conjunction-search performance before reward training with that after reward training, investigating whether search became more efficient for previously high-reward targets, less efficient for previously low-reward targets, or both. Because there was no significant difference (F < 1) in baseline conjunction-search performance for to-be-high-reward and to-be-low-reward targets, baseline data were collapsed across that factor.
For target-present trials, a repeated measures ANOVA was conducted with session (baseline, postreward training) and set size (9, 16, 25) as within-subjects factors and RTs as the dependent measure, with previously high- and low-reward targets analyzed separately. An effect of session was observed for both previously high-reward targets, F(1, 21) = 54.76, p < .001, and previously low-reward targets, F(1, 21) = 20.92, p < .001, with faster mean RTs for postreward training (934 ms for previously high-reward targets, 997 ms for previously low-reward targets) relative to baseline (1,091 ms), a result that may have reflected practice effects. The effect of set size was also significant for both previously high-reward targets, F(2, 42) = 212.98, p < .001, and previously low-reward targets, F(1, 21) = 287.21, p < .001, with linearly increasing RTs across set sizes. More importantly, for previously high-reward targets, the session-by-set-size interaction was significant, F(2, 42) = 4.70, p < .05. Search for previously high-reward targets became more efficient after reward training (M = 19 ms per item) relative to baseline (M = 24ms per item; see Fig. 2c), whereas search efficiency for previously low-reward targets remained unchanged relative to baseline. These results demonstrate that reward-based transfer occurs exclusively for previously high-reward targets and not for previously low-reward targets.
Next, we further hypothesized that if the change in search efficiency in the conjunction-search task was a direct result of reward-based transfer from the pop-out-search task, then participants with greater reward effects in the pop-out-search task should exhibit greater reward-based transfer in the conjunction-search task. The direct relationship was examined by correlating the magnitude of reward effects in the pop-out-search task with that in the conjunction-search task. The magnitude of reward effects was calculated for each participant by averaging RT differences between high- and low-reward targets for each set size. There was a significant positive correlation between the magnitude of reward effects in the two tasks, r = .45, p < .05 (Fig. 2d), which indicates that the degree of reward-based benefit in bottom-up search predicted the extent of reward-based carryover in the subsequent top-down search. This result provides direct evidence that the effects of reward contingency learned in the context of bottom-up search are transferred to a different context in which reward contingency is irrelevant and top-down search is required.
Experiment 2
In Experiment 1, we examined whether search efficiency is modulated by a target feature previously associated with reward. In Experiment 2, we focused on how search efficiency is modulated by the presence of a distractor feature previously associated with reward. Namely, we asked whether distractors previously associated with reward enhance search efficiency via increased distractor filtering or hinder search by capturing attention. To determine this, we included distractors that contained a feature previously associated with reward in the conjunction-search display. Half of the target-colored (red) distractors had an orientation that had previously been associated with reward (vertical for a red horizontal target, horizontal for a red vertical target), and the other half of the red distractors had neutral orientations (30°, 60°, 120°, or 150°; see Fig. 3a). By comparing conjunction-search performance in Experiment 2 (which included a mix of “loaded” and neutral distractors) with that in Experiment 1 (which included only neutral distractors), we were able to test whether adding previously rewarded distractors enhanced or hindered search performance. If loaded distractors are filtered out more efficiently, then search efficiency should be greater in Experiment 2 than in Experiment 1. By contrast, if loaded distractors capture attention, search should be less efficient in Experiment 2 than in Experiment 1.
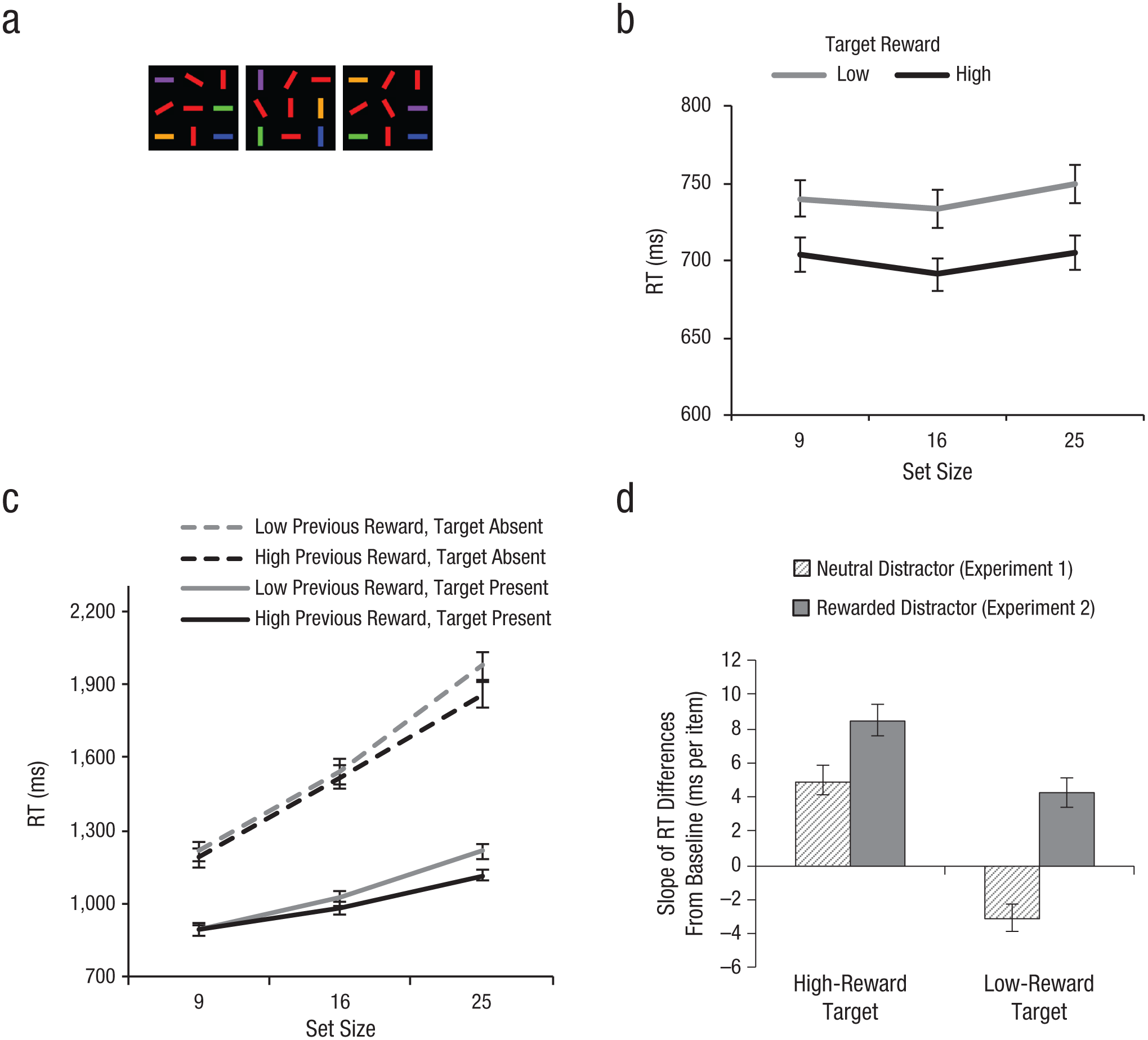
Example stimuli and results from Experiment 2. Panel (a) shows examples of conjunction-search displays (from left to right, displays for a target-present trial with a red horizontal target, target-present trial with a red vertical target, and a target-absent trial preceded by a “red horizontal” target prime). Panel (b) shows mean reaction times (RTs) in the pop-out-search task as a function of set size and target reward level. Panel (c) shows mean RTs in the conjunction-search task as a function of set size and condition (previous reward level: high vs. low; target: present vs. absent). Panel (d) shows the mean slopes of differences from baseline levels as a function of target reward level and type of distractors (neutral, Experiment 1, vs. previously rewarded, Experiment 2). For graphs in (b) through (d), error bars represent standard errors of the mean.
Results replicated those of Experiment 1, such that pop-out search was modulated by reward (Fig. 3b) and the modulation effect was transferred to the subsequent conjunction search (Fig. 3c; see the Supplemental Material). Next, we examined the effect of the presence of previously rewarded distractors on conjunction-search efficiency. Because the relationship between target and distractor orientations differed across Experiments 1 and 2, we normalized the RT data for each experiment by subtracting the mean RT in the postreward training blocks from the mean RT in the baseline blocks for each participant, reward condition, and set size. The resulting RT differences from baseline reflect the pure effect of reward independent of target-distractor contexts, given that the physical stimuli were exactly the same between the baseline and postreward-training blocks. Next, we calculated the slope of the RT differences to quantify the effect of reward on conjunction-search efficiency (Fig. 3d). A greater slope of the RT differences indicated greater effects of reward on conjunction-search efficiency relative to baseline.
For target-present trials, a mixed ANOVA was conducted with experiment (Experiment 1, Experiment 2) as a between-subjects factor, reward (high, low) as a within-subjects factor, and the slope of the RT differences from baseline as the dependent measure (Fig. 3d). There was a significant effect of reward, F(1, 39) = 30.54, p < .001, with greater mean slope differences for previously high-reward targets (6.7 ms per item) than for previously low-reward targets (0.6 ms per item). Most importantly, the main effect of experiment was significant, F(1, 39) = 6.53, p < .05, with greater mean slope differences in Experiment 2 (6.4 ms per item) than in Experiment 1 (1.0 ms per item). The reward-by-experiment interaction was not significant, which indicates that the presence of previously rewarded distractors enhanced search efficiency regardless of reward levels. This result provides strong evidence that search becomes more efficient when targets are embedded among distractors previously associated with reward, which suggests that the benefit of reward-based transfer is not confined to target features but also extends to distractor features, making search more efficient via increased distractor filtering.
Experiment 3
Experiment 2 demonstrated that the presence of a previously rewarded feature improves search efficiency by increasing distractor filtering. This result is somewhat counterintuitive, given that previous studies have demonstrated that a distractor previously associated with reward hinders search by capturing attention (Anderson et al., 2011a, 2011b). One of the possible explanations for the contrasting findings is that previously rewarded distractors in Experiment 2 were filtered out more efficiently because they shared a critical feature (color) with the target. The target in the conjunction-search task was either a red horizontal or a red vertical line, which made the color red a critical feature in setting a target template (Folk, Remington, & Johnston, 1992). Also, a target prime presented in each trial could have helped set a target template in advance, thereby selectively enhancing the target orientation and suppressing the distractor orientation. To address this possibility, in Experiment 3, a target prime was not presented in order to eliminate an advance setup of a target template. Also, previously rewarded distractors shared an orientation feature, rather than a color feature, with the target. Nontarget-colored distractors had either an orientation previously associated with reward (high, low) or a neutral orientation (135°). The reward levels of the target (high, low) and distractors (high, low, neutral) were fully crossed, and trial types were randomly intermixed.
For the pop-out-search task (see Fig. 4a), the same pattern of results was replicated (see the Supplemental Material). For the conjunction-search task (see Fig. 4b and the Supplemental Material), the search slope for each condition was calculated from RTs and submitted to a repeated measures ANOVA with target reward (high, low) and distractor reward (high, low, neutral) as within-subjects factors and search slopes as the dependent measure (Fig. 4c). There was a significant effect of target reward, F(1, 24) = 30.42, p < .001, with shallower mean search slopes for previously high-reward targets (20 ms per item) than for previously low-reward targets (28 ms per item). The distractor reward effect was also significant, F(2, 48) = 6.89, p < .005, with shallower mean search slopes for neutral distractors (20 ms per item) than for either previously high-reward distractors (26 ms per item) or previously low-reward distractors (25 ms per item), which suggests that previously rewarded distractors interfered with search, compared with neutral distractors. More importantly, the target-reward-by-distractor-reward interaction was significant, F(2. 48) = 7.22, p < .005, which indicates that search efficiency changed on the basis of the target and distractor’s previous reward associations. For previously high-reward targets, search among previously high-reward distractors (M = 18 ms per item) was as efficient as search among neutral distractors (M = 18 ms per item), with previously low-reward distractors significantly interfering with search (M = 23 ms per item). For previously low-reward targets, by contrast, both previously high- and low-reward distractors interfered with search relative to neutral distractors (M = 21 ms per item), with greater interference from previously high-reward distractors (M = 35 ms per item) than low-reward distractors (M = 28 ms per item). These results suggest that the extent of distractor interference is dependent on the current target template: When searching for a previously high-reward target, it is easier to selectively suppress previously high-reward distractors; when searching for a previously low-reward target, by contrast, it is hard to suppress distractor features, especially those that were previously associated with high reward.
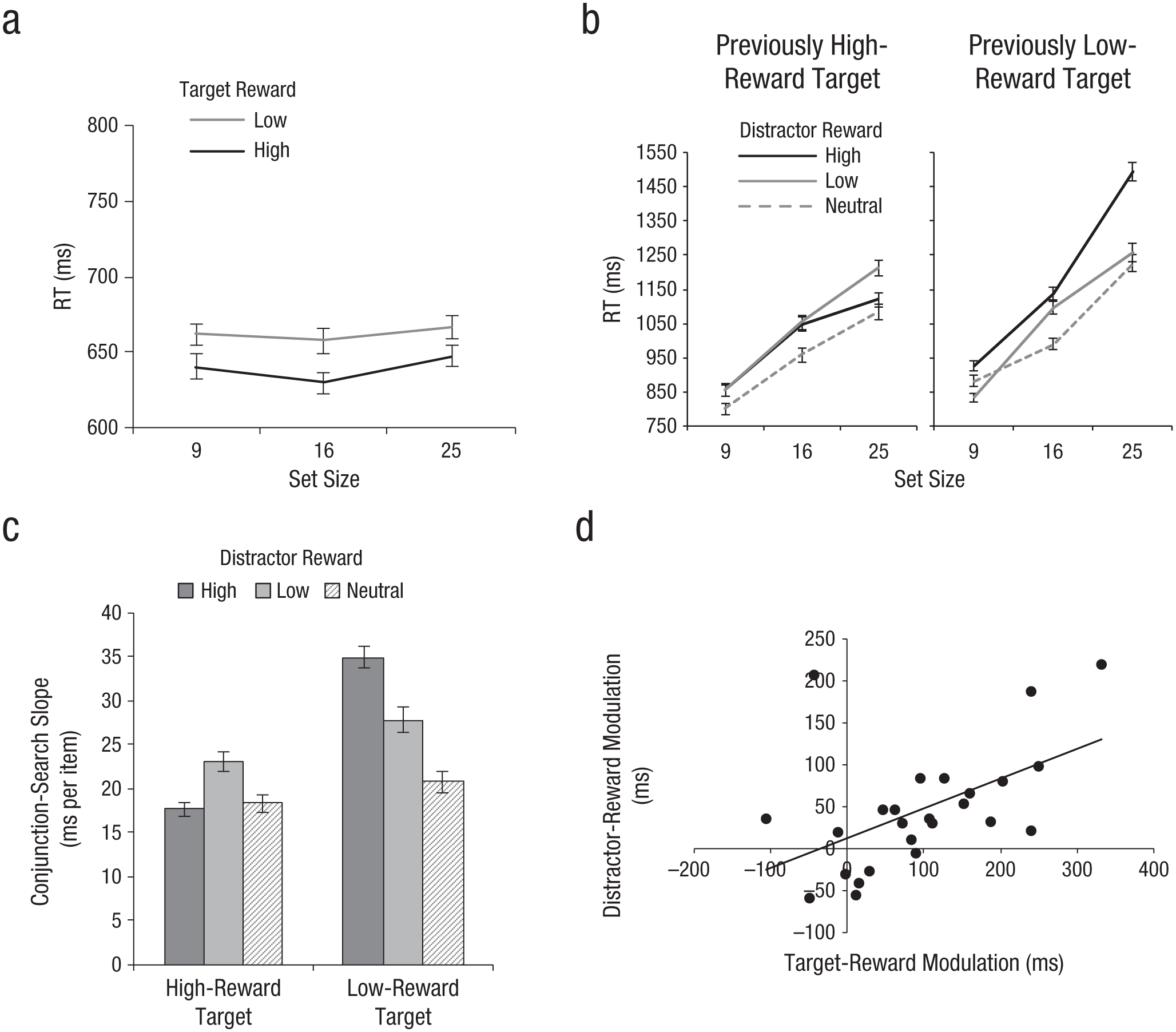
Results from Experiment 3. Panel (a) shows mean reaction times (RTs) in the pop-out-search task as a function of set size and target reward level. Panel (b) shows mean RTs in the conjunction-search task as a function of set size and distractor reward level; results are shown separately for previously high-reward targets and previously low-reward targets. Panel (c) shows mean search slopes as a function of target reward level and distractor reward level. Panel (d) shows a scatter plot (with best-fitting regression line) illustrating the relationship between the magnitude of reward effects in target enhancement (high-reward targets vs. low-reward targets) and in distractor interference (low-reward distractors vs. high-reward distractors). For graphs in (a) through (c), error bars represent standard errors of the mean.
To examine the direct relationship between the effects of reward in target enhancement and in distractor interference, we correlated the magnitude of reward-based target enhancement (high-reward targets vs. low-reward targets) and distractor interference (low-reward distractors vs. high-reward distractors). The magnitude of the reward effect was calculated for each participant by averaging the RT differences between high- and low-reward targets (or distractors) in each set size. There was a significant positive correlation between the two factors, r = .52, p < .001 (Fig. 4d), which indicates that the degree of reward-based target enhancement predicted the extent of reward-based distractor interference. The observed direct relationship suggests that a reward-based priority map is influenced by values associated with both targets and distractors.
Discussion
In this research, we demonstrated that the effect of reward contingency trained in a bottom-up search task is transferred to a subsequent top-down search task, even though the reward contingency is no longer relevant. It was observed that the salience of the target in a top-down search task was selectively enhanced when it contained a feature that had been associated with a high amount of reward in the previous bottom-up search task. Importantly, the transfer of the reward effect across different modes of attention cannot be ascribed to participants’ persistent intentional strategy. First, participants were not given explicit instructions as to the reward contingency and had to learn it implicitly through bottom-up search trials with ambiguous probabilistic reward schedules. Second, to engage top-down attention, we used a conjunction-search task in which a feature previously associated with reward had to be integrated with a new feature. Therefore, even if participants were aware of the contingencies of a single feature, that alone cannot fully explain their more efficient search for conjunction targets in different contexts. Third, our use of various set sizes enabled measuring of not only absolute RTs but also the slopes of the RTs, and participants had shallower search slopes as well as faster absolute RTs for previously high-reward targets. Absolute RT differences might be explained by lingering deliberate strategy, but the search-slope differences cannot be explained by this factor.
Our study provides two important, novel findings that elucidate how a reward-based priority map is constructed. First, reward-based transfer influences search efficiency not only by enhancing target salience but also by changing distractor filtering. The presence of previously rewarded distractors either enhanced or interfered with search efficiency, depending on whether the distractors shared a critical feature with the target and whether a target template could be set in advance. This result dovetails nicely with findings from previous research (Anderson et al., 2011a, 2011b) demonstrating that a single previously rewarded distractor captures attention and thereby hinders search performance, and complements such work with a novel finding that previously rewarded distractors, under certain circumstances, enhance search efficiency via increased distractor filtering. The top-down nature of the conjunction-search task and the target prime presented before each search display helped participants selectively enhance the target feature and suppress the distractor feature. Also, the presence of multiple (instead of single) rewarded distractors could have enabled easier grouping and filtering. Second, when distractors previously associated with reward capture attention, the extent of interference is dependent on the current target template. Previously high-reward distractors did interfere with search performance when participants searched for previously low-reward targets, but they did not interfere when participants searched for previously high-reward targets. These results indicate that not only the reward associations of a target and distractors but also the relationship between the two is considered when one constructs a reward-based priority map.
In conclusion, our results strongly suggest that top-down and bottom-up attentional selections are both guided by a common priority map based on reward information, rather than by two separate priority maps. Many computational and neurobiological models of attention have provided evidence for the existence of a priority map—a topographic map that represents salience of the sensory input (Fecteau & Munoz, 2006; Goldberg, Bisley, Powell, & Gottlieb, 2006; Itti & Koch, 2001). It is proposed that the multiple maps of different features are combined into a single map, such that the most conspicuous locations in the scene are processed rapidly and efficiently. Although such a priority map was originally thought to reflect bottom-up salience, many follow-up studies have demonstrated that top-down influences such as context and goal are also incorporated (Gottlieb, 2007; Mazer & Gallant, 2003; Thompson & Bichot, 2005). Within the reward domain, recent studies have similarly provided evidence for the existence of a topographic map that encodes reward- and decision-related information (Platt & Glimcher, 1999; Serences, 2008; Sugrue, Corrado, & Newsome, 2004). Our findings suggesting that the reward-based priority map is commonly used for both bottom-up and top-down attentional guidance add critical evidence to a recently growing body of work showing that reward- and attention-based selections are integrated (Awh, Belopolsky, & Theeuwes, 2012; Gottlieb & Balan, 2010; Lee & Shomstein, 2013; Shomstein & Johnson, 2013).
Footnotes
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
This work was supported by National Science Foundation Grant BCS-1059523 and National Institutes of Health Grant R21-EY021644 to S. Shomstein.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.