
Abstract
Research on Nicaraguan Sign Language, created by deaf children, has suggested that young children use gestures to segment the semantic elements of events and linearize them in ways similar to those used in signed and spoken languages. However, it is unclear whether this is due to children’s learning processes or to a more general effect of iterative learning. We investigated whether typically developing children, without iterative learning, segment and linearize information. Gestures produced in the absence of speech to express a motion event were examined in 4-year-olds, 12-year-olds, and adults (all native English speakers). We compared the proportions of gestural expressions that segmented semantic elements into linear sequences and that encoded them simultaneously. Compared with adolescents and adults, children reshaped the holistic stimuli by segmenting and recombining their semantic features into linearized sequences. A control task on recognition memory ruled out the possibility that this was due to different event perception or memory. Young children spontaneously bring fundamental properties of language into their communication system.
All natural human languages share a number of universal organizing properties, or “design features” (Hockett, 1987), which are robust across cultures and conditions (Feldman, Goldin-Meadow, & Gleitman, 1978). For instance, in all languages, holistically presented information is broken down into discrete segments and recombined into linear sequences. For example, a motion event that simultaneously includes both the manner (e.g., rolling) and path (e.g., descending) of a shape is linguistically expressed as a linear sequence of words expressing different aspects of the event (e.g., “ball rolling down the hill”). The present study investigated whether children show stronger tendencies to segment and linearize information in their communication systems than adolescents and adults do. That is, we investigated whether children spontaneously bring the design features of language into their communication system.
The critical role played by children in language creation is particularly apparent in cases such as those involving deaf children who are raised in a hearing family without exposure to a sign language. These children have been shown to spontaneously invent their own gestural communication systems, known as home signs (Fant, 1972; Feldman et al., 1978; Goldin-Meadow, 2003; Goldin-Meadow & Feldman, 1977). These home signs show core linguistic properties not observed in their parents’ gesturing, including systematic ordering of semantic elements and syntactically conditioned omission of semantic elements that are inferable from the context (Goldin-Meadow, 2003). These structures in home signs have been shown to be common across deaf children (Goldin-Meadow & Mylander, 1983) and even across cultures (e.g., United States and Taiwan; Goldin-Meadow & Mylander, 1998; Goldin-Meadow, Özyürek, Sancar, & Mylander, 2009).
By definition, a home-sign system is used only by a deaf child, and the system does not develop into a full-blown language. In contrast, when a group of deaf children form a community and the communication system is passed onto younger generations of deaf children, the system becomes a full-blown language relatively quickly. Nicaraguan Sign Language (NSL) is such a case (e.g., Kegl, Senghas, & Coppola, 1999; Senghas & Coppola, 2001; Senghas, Kita, & Özyürek, 2004; cf. a similar case of a new sign language, Al-Sayyid Bedouin Sign Language, reported by Sandler, Meir, Padden, & Aronoff, 2005; see also Senghas, 2005). Until the first special-education school in Nicaragua was established in 1977, deaf Nicaraguan children were largely isolated from each other. The language of instruction at their special-education school was Spanish, and teachers did not use any sign language. However, when the school created an opportunity for deaf children to communicate with each other gesturally, their gestural communication system soon developed into a full-blown language. Every year, a new group of children joined the school, and they learned this language from the older children in the school. Rather than just learning the sign language, the children also changed the language in a profound way.
In its initial 10 to 15 years, NSL users developed an increasingly strong tendency to segment complex information into elements and express them in a linear fashion (Senghas et al., 2004). Senghas et al. (2004) investigated how NSL signs and Spanish speakers’ gestures expressed a complex motion event, in which a shape’s manner and path of motion are shown simultaneously. They compared signs produced by successive cohorts of deaf NSL signers, who entered the special-education school as young children (age 6 or younger) at different periods in the history of NSL, with speech-accompanying gestures produced by native Spanish-speaking adults. The first cohort of signers, who entered the school before 1983, were the first to develop the home signs into a language-like system. Like adult Spanish speakers, they frequently expressed both the manner and path of motion in a single sign (gesture); in contrast, the second and third cohorts, who joined the community in 1984 through 1993 and after 1993, respectively, showed stronger tendencies to segment manner and path in two separate signs and linearly ordered the two elements.
It can be argued, for two reasons, that preadolescent children drove NSL’s transition into a more segmented and linear system. First, the signing by the first cohort was similar to the hearing speakers’ gestural model. The first-cohort signers, who reached adolescence by the mid 1980s, did not pick up the second cohorts’ innovations. Second, another grammatical innovation of the second-cohort signers was driven by preadolescent children. Many sign languages use locations in signing space to keep track of referents, and hand movements for verbs are inflected toward locations with relevant referents to indicate who or what the subject and the object are (e.g., Klima & Bellugi, 1979). The frequency of such inflection of verbs increased significantly in the second-cohort signers, compared with the first-cohort signers; however, this effect occurred among second-cohort signers who entered the school when they were 10 years old or younger but not among those who entered when they were older than age 10 (Senghas & Coppola, 2001). Together, these findings indicate that preadolescent children were the primary driving force of structural change in NSL.
Although Senghas et al.’s (2004) result may be explained by children’s natural tendency to segment and linearize communicative information, a more recent study on the cumulative cultural evolution of language has since provided an alternative explanation (Kirby, Cornish, & Smith, 2008), namely that the process of transmission of language from one learner to the next can also shape language into more segmented and linear forms. In Kirby et al.’s study, adult participants learned an artificial language that contained labels for motion stimuli that had three simultaneous aspects: object shape, object color, and movement trajectory. In the seed language, given to the first participant in the transmission chain, the labels were arbitrary and holistic, that is, the labels could not be broken down into parts that separately encoded the three aspects of the stimuli. The artificial language was transmitted from one language learner to another; in other words, the output from one learner was used as the input for the next learner. When participants were prevented from simplifying the language by not distinguishing certain aspects, the language became more segmented and linear through transmission: For example, the initial, middle, and final parts of the label encoded color, shape, and trajectory, respectively. Computational and mathematical models have similarly indicated that the iterative learning processes themselves can explain various aspects of the structure of language (e.g., Brighton, 2002; Christiansen & Chater, 2008; Kirby, Dowman, & Griffiths, 2007; Kirby, Smith, & Brighton, 2004; Scott-Phillips & Kirby, 2010; Smith, Brighton, & Kirby, 2003).
Given these insights from iterative learning studies, it is possible that the shift of NSL into a system with a more segmented and linear organization (Senghas et al., 2004) may simply exemplify a general effect of transmitting a language across cohorts. Thus, the results reported by Senghas et al. may not constitute clear evidence that young children have age-specific biases to organize their communication system into a more segmented and linear form. The present study therefore examined whether typically developing English-speaking children showed a stronger tendency to segment and linearize information than adolescents and adults in a communication task that did not involve iterative learning. We presented video stimuli of motion events in which a shape’s manner and path varied and asked the participants to depict the scenes with pantomimes, that is, gestures without speaking.
Previous work has shown that hearing adults, without knowledge of sign language, introduce language-like structure in some situations but not in others. In some studies, adults placed semantic elements in a consistent order when pantomiming an event with multiple components (Gershkoff-Stowe & Goldin-Meadow, 2002; Goldin-Meadow, McNeill, & Singleton, 1996). Furthermore, their pantomime order remained the same irrespective of the canonical word order in the participants’ native languages (Goldin-Meadow, So, Özyürek, & Mylander, 2008), which indicates that adults can introduce language-like structure in pantomime communication. Hearing adults, however, did not segment and linearize information when pantomiming motion events containing manner and path, unlike deaf children using home signs (Goldin-Meadow, Namboodiripad, Mylander, Özyürek, & Sancar, in press; Özyürek, Furman, & Goldin-Meadow, 2014). No previous studies have directly compared pantomime representations between hearing children and hearing adults; thus, it is not yet known whether hearing children are more likely than hearing adults to introduce language-like structure—in particular, segmented and linear organization—in pantomiming.
We compared three age groups of hearing participants: 4-year-olds, 12-year-olds, and adults. Four-year-olds were selected for three reasons. First, children at this age are still thought to be within the sensitive period for language acquisition (Lenneberg, 1967; Newport, 1988). Second, deaf children who were first exposed to NSL before age 6 showed the strongest tendencies for grammatical innovation (Senghas & Coppola, 2001). Third, the mean age for first exposure to NSL in Senghas et al. (2004) was 4 years. We chose 12-year-olds as the adolescent group because studies have highlighted a decline in children’s sensitivity to the structural patterns of language from around age 12 (e.g., Johnson & Newport, 1989; Newport, 1988) and because the NSL signers who were first exposed to NSL at age 10 or older did not show grammatical innovation (Senghas & Coppola, 2001).
Given the previous NSL results (Senghas & Coppola, 2001; Senghas et al., 2004) and the home-sign results (Özyürek et al., 2014), we predicted that 4-year-olds would show stronger tendencies than adolescents or adults to reorganize holistically presented stimulus events into segmented and linear encoding in pantomime. We ran a control task on recognition memory for events to rule out the possibility that any difference in pantomimed gestures could be attributed to limited event perception and memory.
Method
Participants
Native English speakers in the United Kingdom participated: 37 four-year-olds (mean age = 4.5 years), 28 adolescents (mean age = 12.4 years), and 35 adults (mean age = 21.5 years). The number of participants was determined by the submission deadline for the first and second authors’ undergraduate honors theses. The original target was 30 per group.
Materials
Pantomime task
The stimuli for the pantomime task were eight animation clips depicting a smiling square or circle traversing a green “hill” against a blue “sky” (a still frame from one clip is shown in Fig. 1; for full clips of all eight animations, see Videos S1–S8 in the Supplemental Material available online). The path and the manner of the motion event were presented simultaneously, with the shape either ascending or descending the slope, while performing either 11 bounces or 11 rotations. The eight clips represented all combinations of the two shapes (square or circle), two motions (rolling or bouncing), and two paths (up or down the slope).

Screenshot from one of the animation clips used in the pantomime task. On each trial, a smiling shape (a circle, as shown here, or a square) bounced or rolled up or down a slope. For the full clips, see Videos S1 through S8 in the Supplemental Material.
Recognition task
Each of the eight animation clips used in the pantomime task was coupled with another clip that was identical except that the manner and path of the moving shapes were presented sequentially. For example, the square bounced at the bottom of the hill and then slid up the hill in a constant position (manner-then-path event). In each clip, the shape bounced or rotated 11 times. The duration of the clips showing manner and path sequentially matched that of the animation clips showing manner and path simultaneously (for full clips, see Videos S9–S25 in the Supplemental Material).
Procedure
Each participant was tested individually while seated at a table next to an experimenter and facing a laptop computer. Another experimenter sat opposite, approximately 1.5 m away, to film the session. All participants performed the pantomime task before the recognition task.
The pantomime task began with two warm-up trials. In each experimental trial, the participant watched an animation clip and then was asked to use either hand to show the experimenter, without speaking, what the shape (animated circle or a square) had done. This procedure was followed for each of the eight animation clips.
In the recognition task, participants watched pairs of consecutively presented video clips. They were instructed to indicate whether the clips in each pair were the same or different, in terms of the way that the shape moved, and to explain what differed if they said the second clip differed from the first one. The first clip always showed manner and path simultaneously; the second clip was the same as the first clip half of the time, and it showed manner and path sequentially the other half of the time. The participant watched a total of eight clip pairs. Correct identification of a difference between the clips was indicated by verbal or gestural explanation of the presence of two phases, either temporal segmentation or separation of manner and path (e.g., expressions “and then” or “at the end”). Misidentification of differences (e.g., detection of irrelevant differences) and inconclusive explanations (not clearly indicating an understanding of the presence of two phases in the sequential stimulus) were coded as incorrect responses.
Variables
All dependent variables or measures that were analyzed for the target research question, as well as all independent variables or manipulations, whether successful or failed, are reported in the Results section. No analyses were carried out before the data collection was completed.
Coding
Gestures were segmented into movement phases following the procedure in Kita, van Gijn, and van der Hulst (1998). The stroke phase, the meaning-carrying movement phase (Kita et al., 1998), of each gesture was coded as showing (a) manner segmentation (if the gesture expressed at least one complete cycle of a rotation in the case of a roll, or an upward or downward sweep in the case of a bounce), (b) path segmentation (if the gesture expressed a straight trajectory), or (c) manner and path simultaneously, or was coded (d) as unclear.
On the basis of the gestures coded for each trial, trials were classified into the following four mutually exclusive response types. First, simultaneous-expression-only responses included only gestures that expressed manner and path simultaneously within a single movement. Second, manner-and-path-segmentation responses included gestures expressing both manner and path as separate elements. Third, manner-segmentation-only responses included a segmented manner but not path gesture. Fourth, path-segmentation-only responses included a segmented path but not manner gesture. The responses of manner segmentation only, path segmentation only, or both manner and path segmentation could also include additional simultaneous manner-and-path gestures. Unclear gestural responses were not taken into account. Fourteen trials (out of 799) that included only unclear gestures were excluded from the analysis because they were not informative about the hypothesis tested. (See Methodological Details in the Supplemental Material for additional details on participants, materials, procedure, and coding.)
Interobserver reliability
A second coder independently coded 82% of the trials. For a given trial, there was 92.3% agreement for the presence of manner gestures (Cohen’s κ = .748, p < .001), 96.3% agreement for the presence of path gestures (Cohen’s κ = .683, p < .001), and 96.8% agreement for the presence of simultaneous manner-path gestures (Cohen’s κ = .815, p < .001).
Results
Pantomime task
We compared the proportion of response types across age groups. There was a significant effect of age on the proportion of all four response types (Fig. 2): those with both manner and path segmentation, Kruskal-Wallis χ2(2) = 24.32, p < .001 (all analyses are two-tailed); those with manner segmentation only, χ2(2) = 44.22, p < .001; those with path segmentation only, χ2(2) = 13.08, p < .001; and those with simultaneous expression only, χ2(2) = 66.96, p < .001. Only children produced responses in which gestures sequentially expressed both manner and path segmentation. Post hoc Mann-Whitney tests (with Bonferroni correction) revealed that children produced significantly more manner-segmentation-only responses and more path-segmentation-only responses than adolescents (manner segmentation only: p < .001; path segmentation only: p = .015) or adults (manner segmentation only: p < .001; path segmentation only: p = .012). Children produced significantly fewer responses with simultaneous expression only, compared with adolescents (p < .001) or adults (p < .001). There were no significant differences at all between adolescents and adults.
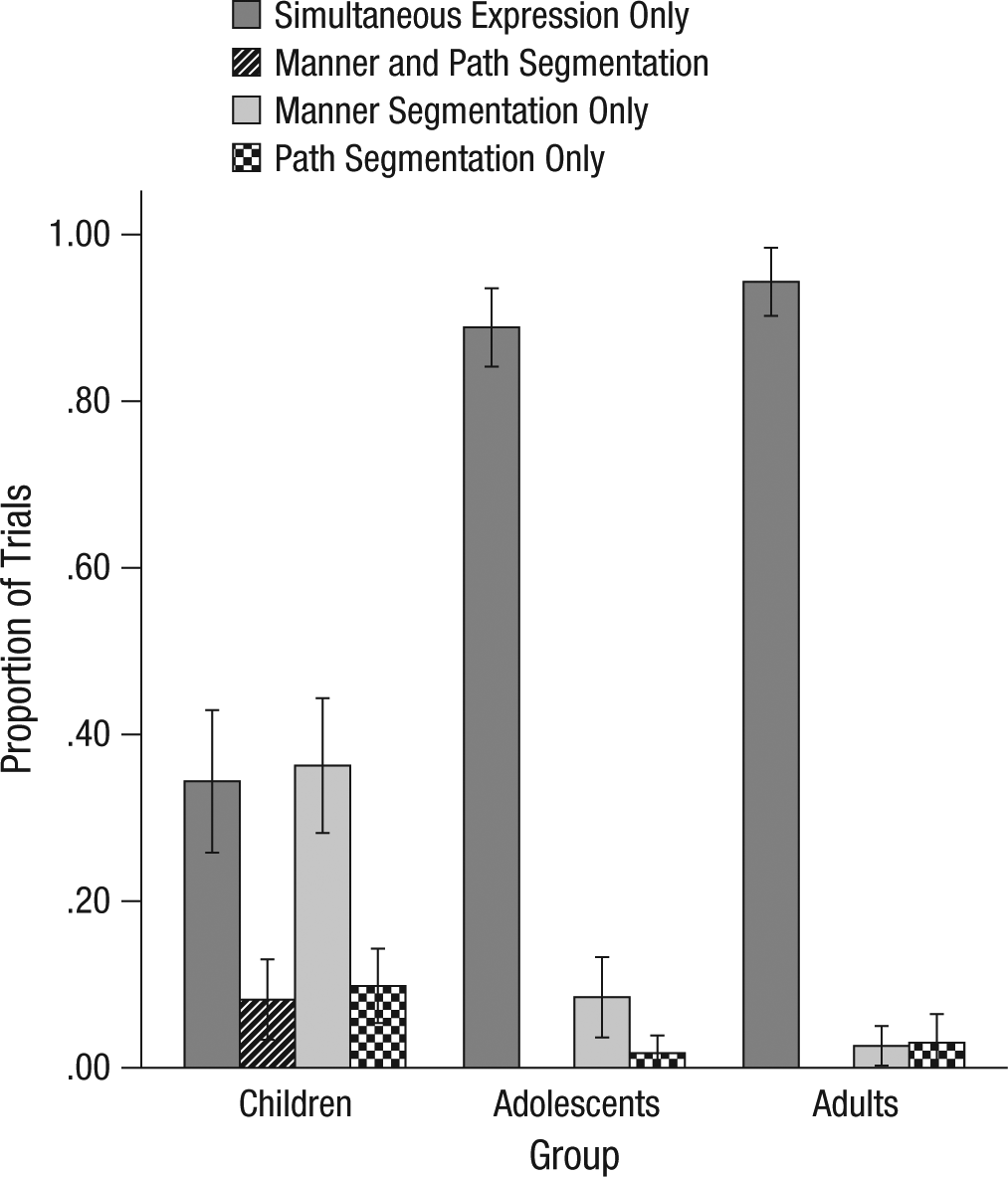
Results for the pantomime task: mean proportion of trials containing each of the four types of responses produced by children, adolescents, and adults. Error bars show standard errors.
Next, we compared the proportions of the four response types within each age group to see which was most dominant. There were significant differences in the proportion of each response type produced by children, Friedman χ2(3) = 35.90, p < .001; adolescents, χ2(3) = 71.36, p < .001; and adults, χ2(3) = 87.81, p < .001. Post hoc Mann-Whitney tests (with Bonferroni correction) revealed that responses with manner segmentation only and those with simultaneous expression only significantly dominated children’s responses, compared with responses containing both manner and path segmentation or those with path segmentation only (all ps < .001). Although adolescents produced more responses with manner segmentation only than with both manner and path segmentation (p < .001), responses with simultaneous expression only dominated all other responses (all ps < .001). In adults, responses with simultaneous expression only completely dominated all other responses (all ps < .001).
Finally, following the analysis in Özyürek et al. (2014), we compared the proportions of trials with mixed gestural responses (manner gestures or path gestures, combined with simultaneous gestures) across all age groups. The age groups differed significantly from each other—children: M = .400, SE = .040; adolescents: M = .098, SE = .023; adults: M = .043, SE = .018; Kruskal-Wallis χ2(2) = 47.37, p < .001; post hoc Mann-Whitney tests (with Bonferroni correction) indicated that children produced significantly more mixed responses than did either adolescent or adults.
Recognition task
All three age groups showed a high degree of competence in the recognition task. The mean proportion of correct responses was .95 (SD = .11) for children, 1.00 (SD = .004) for adolescents, and .99 (SD = .005) for adults. Although there was a significant effect of age on the proportion of correct responses, Kruskal-Wallis χ2(2) = 8.838, p = .012, post hoc analysis failed to determine the locus of the effect.
Descriptive analysis of children’s verbal explanations for differences they observed provided further support that event perception and event memory did not underlie their segmented and linearized gestures in the pantomime task. When children correctly responded “different,” they provided accompanying explanations that correctly expressed their understanding of the difference between simultaneous and sequential motion events. In the few cases when children incorrectly responded “different,” their subsequent explanations were inconclusive, in the sense that they did not refer to the simultaneity or sequentiality of manner and path. This suggests that the few incorrect responses did not reflect an inability to distinguish between simultaneous and sequential events.
To further verify that children’s performance on the recognition task could not explain patterns of gesture responses in the pantomime task, we ran Spearman correlations to compare the proportions of the gesture types produced in the pantomime task (reported in Fig. 2) with the proportion of correct responses in the recognition task. No significant correlations were found—both manner and path segmentation: rs = − .031; manner segmentation only: rs = .111; path segmentation only: rs = −.113; simultaneous expression only: rs = .077.
Discussion
We compared how young children (4-year-olds), adolescents (12-year-olds), and adults depicted the manner and path of a motion event using pantomimes (gestures without speaking). Compared with adolescents and adults, young children showed the strongest tendencies to segment and linearize the manner and path of a motion event that had been represented to them simultaneously. Moreover, the difference in the pantomime performance between the three age groups cannot be attributed to young children’s poor event perception or memory because the children performed very well in the event-recognition task and because the children’s performances in the pantomime task and the recognition task did not correlate. The results indicate that young children, but not adolescents and adults, have a bias to segment and linearize information in communication.
The children often combined segmented expressions with simultaneous expressions within a single response (gestures expressing manner or path segmentation, combined with gestures simultaneously expressing both manner and path). They produced such mixed responses more often than adolescents and adults. Mixed expressions were common in home signs (Özyürek et al., 2014) and in the first cohort that signed in NSL (Senghas, Özyürek, & Goldin-Meadow, 2010). Such expressions may be important stepping-stones toward more fully segmented and linear forms of communication (Özyürek et al., 2014; Senghas et al., 2010).
Young children were more likely to segment the manner of motion than the path of motion. This may be because the children found manner to be more noteworthy, similar to the suggestion that speech-accompanying gestures are more likely to be produced when communicating noteworthy information (McNeill, 1992). Speech-accompanying gestures encoded the path of motion more often when the change of location was a prerequisite for the next event in the story, making the motion path more noteworthy (Kita & Özyürek, 2003).
The children’s bias toward segmented and linear organization of communication dovetails with the finding that iterative learning gradually makes language more segmented and linear (Kirby et al., 2008). As all languages are learned by children and transmitted iteratively from generation to generation, these two biases may explain why human language universally has segmented and linear organization, in general.
Languages are, of course, not completely segmented and linear, and they have synthetic expressions, in which a single linguistic form simultaneously encodes multiple semantic elements. Segmented forms may be more common in labels for events than for objects because event representation may include more semantic elements. Synthetic expressions may also arise because of demands on efficiency in encoding, The current status of languages may reflect equilibrium points for various competing forces that shape language.
The notion that properties of language might be a product of children’s natural tendencies to shape their communication system is also compatible with findings from children’s home signs. Despite lack of access to conventional language input, deaf children spontaneously create home signs that exhibit various features of language (Feldman et al., 1978; Goldin-Meadow, 2003; Goldin-Meadow & Mylander, 1983, 1998; Özyürek et al., 2014).
The tendency for segmented and linear organization in pantomime gestures was observed only in young children. This is compatible with the findings that preadolescent children were the driving force behind grammatical innovation in NSL (Senghas & Coppola, 2001; Senghas et al., 2004) and that exposure to a second language in preadolescence is important for acquisition of morphosyntax (Johnson & Newport, 1989).
Why do young children have a bias to segment and linearize information in communication? One possibility is that this tendency may be due to their limited processing capacity. Compared with adults, children may be less able to process two semantic elements simultaneously within a conceptual planning unit for communication. They may need to conceptually plan one semantic element at a time. There is some evidence that young children have a smaller capacity for speech production than adults. For example, English-speaking children often omit the subject noun phrase, even when it is not grammatical to do so. Children are more likely to do so when the sentence is more complex (e.g., sentences with negation—L. Bloom, 1970; sentences with more morphemes—P. Bloom, 1990; Freudenthal, Pine, & Gobet, 2007). Similar capacity limitation for conceptual planning for communication may have caused children to express one semantic element at a time.
The participants in the current study spoke English, and the segmentation and linearization tendency observed may be a consequence of learning this particular language or any language. This explanation, however, is not very plausible because adults, who had the most experience in using the English language, showed very little tendency for segmentation and linearization. Cross-linguistic comparison of children’s pantomime will be an important area for future research, to further probe the possible effect of spoken languages.
One limitation of the current study is that pantomimes were not compared with gestures that accompanied speech. A previous study on speech-accompanying gesture (Özyürek et al., 2008) showed that, among English speakers, young children segmented manner and path information more often than adults did (but this was not true for Turkish speakers). It is unlikely, however, that the English-speaking children in the current study simply transferred their representations in speech-accompanying gestures into pantomimes for two reasons. First, the age difference was far greater in the current study than in the study on speech-accompanying gestures (Özyürek et al., 2008). 1 Second, at least for adults, the nature of representation in pantomimes qualitatively differs from that in speech-accompanying gestures (Goldin-Meadow et al., 1996; Özyürek et al., 2014). An important future research topic is to compare representations in children’s pantomimes with those in children’s speech-accompanying gestures.
To summarize, the present study provided evidence that typically developing young children spontaneously organize their gestural communication systems into more segmented and linear forms. In all human languages, complex information may be segmented and semantic elements may be expressed linearly because all languages are learned, and therefore shaped, by young children.
Footnotes
Acknowledgements
We thank Christ Church CE Primary School; Hotwells Primary School, Bristol; and Oundle & Kings Cliffe Middle School, Peterborough, for their collaboration. We also thank Norman Freeman and tutors at the University of Bristol Psychology-Zoology Honors Program for facilitating this study.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.