
Abstract

Because speech perception is vitally important, the visual system may possess exceptional sensitivity to track speech-related signals conveyed by lip movements even when the observer is unaware of the speaking face. We tested this possibility using continuous flash suppression (CFS; e.g., Tsuchiya & Koch, 2005), in which a critical stimulus, a speaking face, was presented to one eye while a strong dynamic mask presented to the other eye rendered the speaking face invisible. We determined whether the visual system could still encode spatiotemporal patterns of lip movements when observers were aware of only the randomly flashing mask display.
In two experiments, we demonstrated visual encoding of invisible lip movements by way of cross-modal facilitation of spoken-word categorization (e.g., Sumby & Pollack, 1954; see the Supplemental Material available online for additional methodology). In Experiment 1, half of the trials (masked-face trials) consisted of a CFS display in which the dynamic mask (updated at 10 Hz) comprised a random array of contrast-enhanced features taken from the face that was presented to the other eye (Fig. 1a). After the face faded in (across 1,000 ms), participants heard a word spoken (duration = 1,000–1,650 ms) and determined whether it was a target word (a tool name) or a nontarget word (a name of a nontool object) as quickly and accurately as possible. The face concurrently articulated either the spoken word (congruent condition) or a different word (incongruent condition).
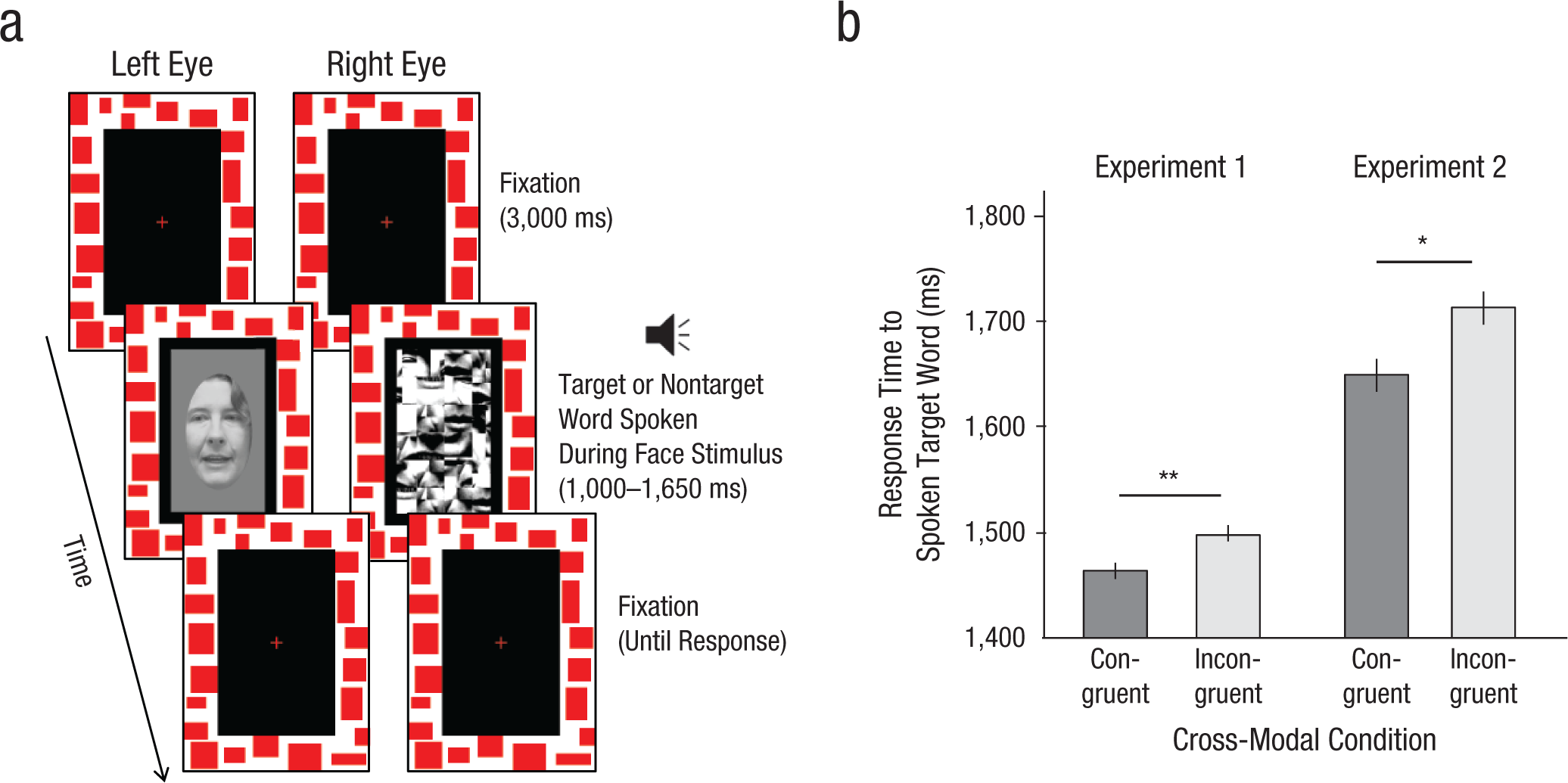
Example trial sequence and results from masked-face trials in Experiments 1 and 2. In each masked-face trial (a), a face was presented to one eye (fading in over the course of 1,000 ms) while a dynamic mask was presented to the other. Participants then heard a target word or a nontarget word while the face articulated either the spoken word (congruent condition) or a different word (incongruent condition). Participants indicated whether they had heard a target or nontarget word. In Experiment 1, participants then indicated whether the face had been visible, and if it had, they indicated the location of a probe that had appeared near the mouth; in Experiment 2, participants indicated the color of an ellipse that had covered the mouth region whether or not they had seen the face. Average response times to spoken target words (b) are shown for the congruent and incongruent conditions, separately for Experiments 1 and 2. Error bars represent ±1 SEM adjusted for within-participants comparisons. Asterisks indicate a significant difference between conditions (*p < .05, **p < .01).
Prior research suggests that spatial attention influences unaware as well as aware visual processing (e.g., Cohen, Cavanagh, Chun, & Nakayama, 2012) and that attention to the mouth region is necessary for lip movements to facilitate spoken-word perception (e.g., Alsius, Navarra, Campbell, & Soto-Faraco, 2005; Driver & Spence, 1994). To help direct attention to the mouth region, on the other half of the trials, we presented the face without the dynamic mask (i.e., the face was presented to both eyes) and instructed participants to localize a small circular probe briefly presented in one of six locations near the mouth (see Fig. S1 in the Supplemental Material). These attention-enforcement trials were randomly intermixed with the critical masked-face trials. To further enforce attention to the mouth region on the masked-face trials, we also presented the probe (continuously, in this case) in one of the same six locations on the masked face.
On both types of trial, after categorizing the spoken word, participants reported whether the face was visible, and if it had been, they also reported the location of the probe. Participants reported seeing the face on 5% of the masked-face trials, and the data from those trials were removed from the analyses. If the visual system automatically extracts lip movements even when they are suppressed from awareness, we expected spoken-word categorization to be facilitated by lip movements that were congruent (relative to incongruent) with the spoken word, even when the face was invisible on the masked-face trials.
Indeed, response times to the spoken target words on the masked-face trials were significantly faster when the lip movements were congruent with the target words than when they were incongruent, t(45) = 2.66, p < .01 (Fig. 1b). The accuracy of target-word classification was 92%, with no evidence of a speed/accuracy trade-off. This congruency effect was absent for response times on the attention-enforcement trials (congruent condition: M = 1,558 ms; incongruent condition: M = 1,568 ms), t(45) = 1.15, n.s., likely because having to localize a briefly flashed probe interfered with the processing of lip movements.
The congruency effect was also absent for response times to the spoken nontarget words on both the masked-face trials (congruent condition: M = 1,590 ms; incongruent condition: M = 1,589 ms), t(45) = 0.13, n.s., and the attention-enforcement trials (congruent condition: M = 1,647 ms; incongruent condition: M = 1,651 ms), t(45) = 0.07, n.s. The lack of congruency effects on nontarget trials may reflect the fact that processes beyond word identification are necessary to decide that the target information is absent; consistent with this possibility, results showed that response times to nontargets were significantly slower than those to targets, t(45) = 19.11, p < 10–11.
To control for the possibility that participants might have failed to report face visibility on some of the masked-face trials, we conducted a second experiment with new participants. Masked-face and attention-enforcement trials were conducted as in Experiment 1, except that we now incorporated a more stringent indicator of face visibility. A tinted translucent ellipse was placed over the mouth region of the face. On each trial, after responding to the spoken word, participants reported the color of the ellipse (red, blue, green, or yellow); critically, they were required to guess the color even if they had not seen the face. All masked-face trials on which participants correctly reported the color (30%) were removed from analysis.
The same pattern of results was obtained as in Experiment 1. On the masked-face trials, response times to the spoken target words were significantly faster when the lip movements were congruent with the target word than when they were incongruent, t(23) = 2.12, p < .05 (Fig. 1b), with a mean accuracy of 92% and no evidence of a speed/accuracy trade-off. Consistent with the first experiment, results showed no congruency effect for target response times on the attention-enforcement trials (congruent condition: M = 1,619 ms; incongruent condition: M = 1,639 ms), t(23) = 0.80, n.s., or for nontarget response times on either the masked-face trials (congruent condition: M = 1,777 ms; incongruent condition: M = 1,743 ms), t(23) = 1.06, n.s., or the attention-enforcement trials (congruent condition: M = 1,708 ms; incongruent condition: M = 1,779 ms), t(23) = 1.97, n.s. Also consistent with the first experiment, results showed that response times to nontargets were significantly slower than those to targets, t(23) = 5.45, p < 10–4.
These results demonstrate that even when a speaking face is rendered invisible by a dynamic mask with strong motion signals, the visual system accurately encodes invisible lip movements to facilitate auditory perception of the corresponding spoken words. This cross-modal effect is likely to occur at the level of encoding words; it has been shown that invisible lip movements do not generate a McGurk effect (Palmer & Ramsey, 2012), which suggests that invisible lip movements do not influence auditory perception at the level of encoding syllables.
Dorsal motion-processing mechanisms (e.g., V3a, V5) would have predominantly responded to the strong and visible flashing mask (e.g., Moutoussis, Keliris, Kourtzi, & Logothetis, 2005). The invisible lip movements would thus likely have been processed through the ventral visual pathway, including the superior temporal sulcus (STS), an area that selectively responds to biological motion and movements of facial features (e.g., Allison, Puce, & McCarthy, 2000; Calvert & Campbell, 2003; Grossman et al., 2000), and might then have facilitated spoken-word perception via multimodal portions of the STS (e.g., Calvert, Campbell, & Brammer, 2000).
Previous research has demonstrated sophisticated unconscious processing of static images such as words, faces, the sex of human bodies, and contextual congruence (e.g., Jiang, Costello, Fang, Huang, & He, 2006; Jiang, Costello, & He, 2007; Mudrik, Breska, Lamy, & Deouell, 2011; Yang, Zald, & Blake, 2007). Our results extend these prior findings to the processing of dynamic information. Static information can theoretically be extricated from a dynamic mask by temporal averaging. However, unconscious extrication of the subtle dynamics of lip movements from the overwhelming random dynamics of the mask requires sophisticated tuning of the ventral visual system to the behaviorally relevant dynamics.
Footnotes
Acknowledgements
The first and second authors made equal contributions to this research. This work is in memory of E. Guzman-Martinez.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
This study was supported by National Institutes of Health Grants R01EY021184 and R01EY018197 and by National Science Foundation Grant BCS 0643191.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.