
Abstract
Speakers of all languages gesture, but there are differences in the gestures that they produce. Do speakers learn language-specific gestures by watching others gesture or by learning to speak a particular language? We examined this question by studying the speech and gestures produced by 40 congenitally blind adult native speakers of English and Turkish (n = 20/language), and comparing them with the speech and gestures of 40 sighted adult speakers in each language (20 wearing blindfolds, 20 not wearing blindfolds). We focused on speakers’ descriptions of physical motion, which display strong cross-linguistic differences in patterns of speech and gesture use. Congenitally blind speakers of English and Turkish produced speech that resembled the speech produced by sighted speakers of their native language. More important, blind speakers of each language used gestures that resembled the gestures of sighted speakers of that language. Our results suggest that hearing a particular language is sufficient to gesture like a native speaker of that language.
Speakers of all languages gesture when they talk (Feyereisen & de Lannoy, 1991; Goldin-Meadow, 2003; Kendon, 1980; McNeill, 1992), but there are systematic differences in the gestures that speakers of different languages produce (Gullberg, Hendricks, & Hickmann, 2008; Kita & Özyürek, 2003). Where do these cross-linguistic differences in gesture come from? One possibility is that children learn to gesture in language-specific ways by watching other speakers gesture. An alternative possibility is that children learn language-specific gestures simply by learning to speak a particular language. We turned to congenitally blind speakers to answer this question.
Iverson and Goldin-Meadow (1998) found that congenitally blind English speakers gesture even when talking to other blind individuals, and that the gestures they produce are similar in type and number to the gestures produced by sighted English speakers. However, this study used a reasoning task not known to elicit gesture that varies cross-linguistically. Thus, although it is known that blind speakers gesture, it is not known whether blind speakers of different languages gesture like sighted speakers of those languages (and thus display language-specific differences in their gestures), or whether all blind speakers gesture in the same generic way. This question can be answered only by studying a domain in which gesture accompanying speech is known to differ across languages, and by studying blind and sighted individuals who could potentially display those differences.
The gestures children see can influence the breadth of their gestural repertoires. Italian children, who live in a gesture-rich world (Kendon, 1995, 2004), use a greater variety of iconic gestures than do American children, whose gestural environments are less varied (Iverson, Capirci, Volterra, & Goldin-Meadow, 2008; see also Furman, Küntay, & Özyürek, 2014). Thus, some aspects of gesture may be learned from seeing other individuals gesture. If seeing gesture is necessary to gesture like a native speaker, congenitally blind speakers of different languages should all gesture alike, because, according to this hypothesis, they lack the input that would create differences in their gestures. If, on the other hand, individuals become native gesturers by becoming native speakers, congenitally blind speakers of a given language should produce gestures similar to the gestures produced by sighted speakers of the same language. 1
We tested these hypotheses by studying the gestures speakers produce when describing events in a domain characterized by strong cross-linguistic variability: motion across space (Talmy, 2000). Speakers of Turkish and English produce distinctively different gestures when describing manner (e.g., running) and path (e.g., entering) components of motion (Kita & Özyürek, 2003; Özçalışkan, 2015a). English speakers typically conflate manner and path components into a single gesture, whereas Turkish speakers produce separate gestures for manner and path and tend to produce more path-only than manner-only gestures (cf. the Turkish and English speakers in the top row of Fig. 1b); these gesture patterns mirror patterns found in spoken English and Turkish (Choi & Bowerman, 1991; Özçalışkan & Slobin, 1999; Slobin, 1996). Although these cross-linguistic patterns in gesture are robust, little is known about their source. We turned to gestures produced by individuals who have been blind from birth and who speak different languages to explore the etiology of this variation.

Example stimulus scene (a) and its description in gesture (b) by speakers of Turkish (left) and English (right). The still shots and arrows in (b) illustrate the gestures produced by sighted speakers without blindfolds (top row), sighted speakers with blindfolds (middle row), and blind speakers (bottom row). The straight arrows represent separated gestures showing path only (moving across space), and the zigzag arrows represent conflated gestures combining path with manner (running fingers across space).
Method
Participants
Participants included 40 congenitally blind adults (20 native English speakers and 20 native Turkish speakers). We compared these blind speakers with 80 sighted adult speakers, 40 in each language (20 who wore blindfolds, 20 who did not wear blindfolds), as they described scenes involving physical motion (e.g., a girl running into a house, as in Fig. 1a). 2 The selection criteria for the blind speakers were that they have an ophthalmologic diagnosis of congenital blindness, with light perception at best, and no other documented physical, neurological, or mental deficits. 3 We had half of the sighted adults in each language perform the task with their vision unimpeded and half perform the task while wearing a blindfold to make sure that preventing sighted individuals from seeing the stimuli would not affect their patterns of speech or gesture. Within each language group, the sighted adults with and without blindfolds were comparable to the blind adults with respect to age; there were more females than males in each of the English-speaking groups, but not in the Turkish-speaking groups (see Table 1).
Characteristics of the Sample
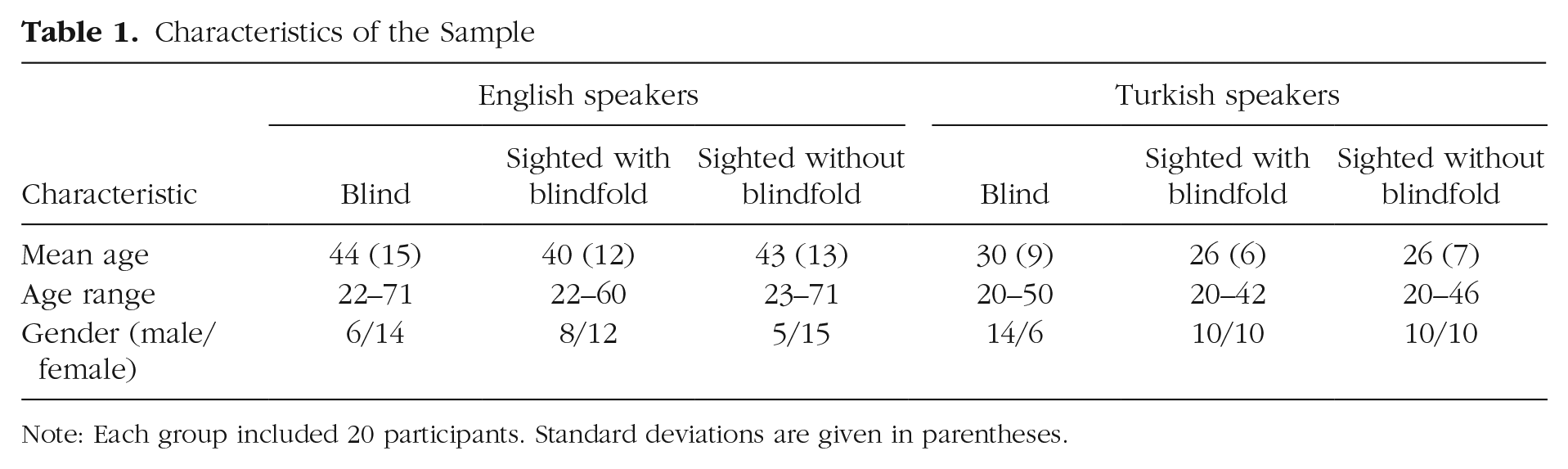
Note: Each group included 20 participants. Standard deviations are given in parentheses.
Procedure
Participants were videotaped while describing 12 three-dimensional scenes displaying motion along three different types of paths—4 paths to a landmark (e.g., running into a house), 4 paths over a landmark (e.g., flipping over a beam), and 4 paths from a landmark (e.g., running away from a motorcycle). The scenes displayed various manners of motion (e.g., running, flipping, crawling). For each type of path, 3 scenes depicted movement across a spatial boundary (movement into, over, or out of a landmark), and 1 depicted movement that did not cross a boundary (movement toward, along, or away from a landmark). Table 2 lists the manners and paths used in the 12 scenes.
List of Motion Events Used in the Study
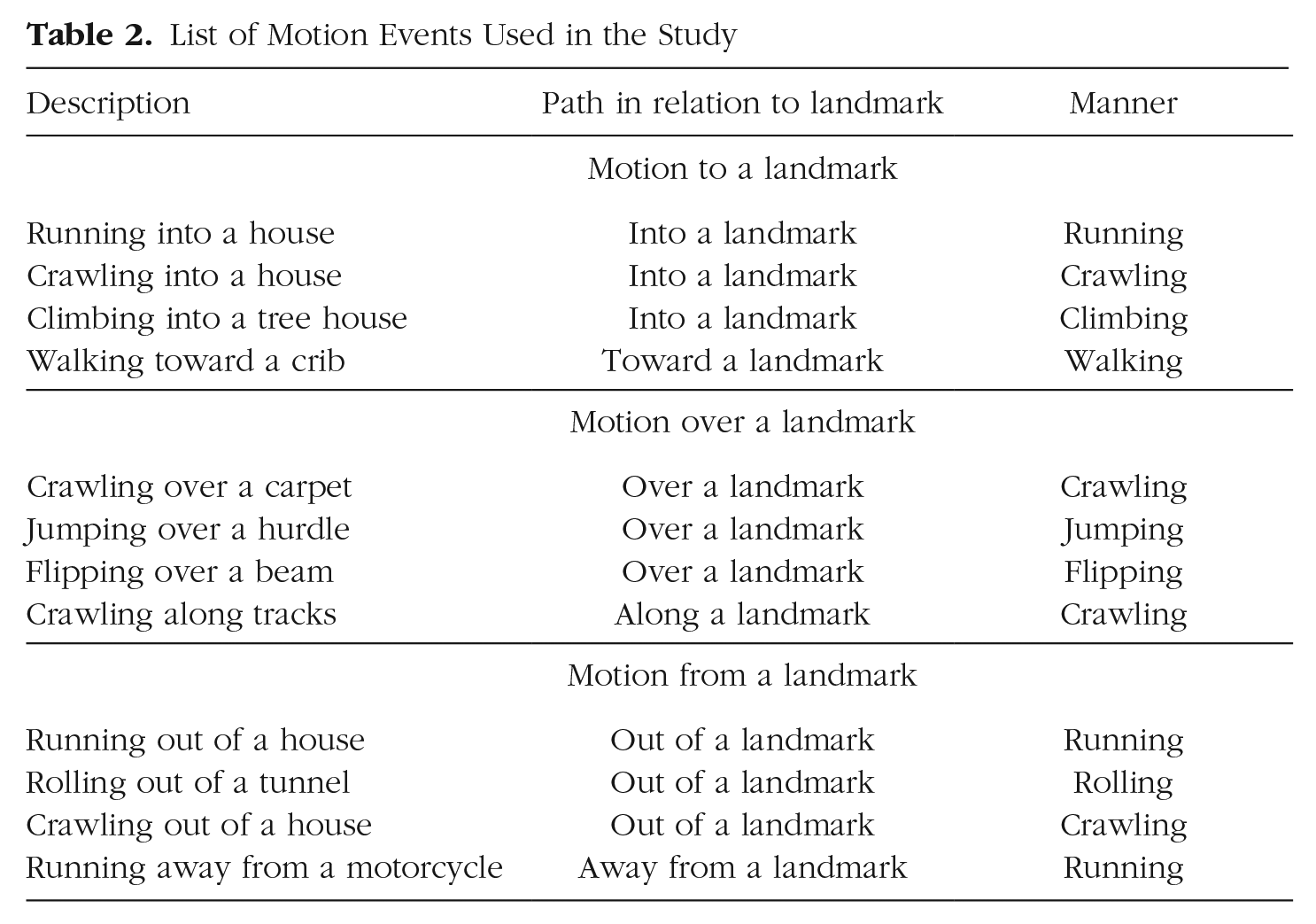
Each scene was preconstructed on a 5- × 15-in. white foam board and contained a landmark and three identical stationary dolls (named Eve in English and Oya in Turkish) in varying postures intended to capture three snapshots of a continuous motion with manner and path (see Fig. 1a). The landmark and dolls were glued to the foam board so that presentation of the materials would be uniform across groups. The blind individuals and sighted individuals who wore blindfolds explored the stimuli haptically with their hands, without any visual exposure; the sighted individuals who did not wear blindfolds explored the stimuli visually, without any haptic exposure. Participants were told that Eve/Oya appeared three times in each scene, but that they should think of her movement as a single continuous motion and describe it as such.
In pilot work, we found lower rates of spontaneous gesturing in blind speakers than in sighted speakers. To maximize the chances that equal numbers of blind and sighted participants would gesture, we told participants to use their hands as naturally as possible as they described each scene. In a few cases, participants did not gesture when describing a scene; we then asked them to describe the scene again, but using their hands. 4 To familiarize participants with the task, we asked them to complete two practice trials before the test scenes. Presentation order of the test scenes was counterbalanced across participants within each group. Counterbalancing was done in three blocks, each containing four items, one of each of the three different path types with boundary crossing (into, out of, or over) and one non-boundary-crossing event.
Coding
Speech was transcribed and segmented into spoken sentence units. The minimum sentence unit in speech contained one verb and associated arguments (e.g., Eve runs into the house; Oya eve koşuyor, “Oya house-to runs”); some sentence units in speech contained a subordinate clause as well (e.g., Eve enters the house running; Oya eve girer koşarak, “Oya house-into enter running”). We also transcribed all gestures that accompanied each spoken sentence unit. Gesture was defined as communicative hand movement that had an identifiable beginning and end; in our analysis, we included only gestures that conveyed characteristic actions or features associated with the stimulus scenes. A spoken sentence unit could be accompanied by one or more gestures (e.g., a manner gesture alone or a manner gesture followed by a path gesture); we treated all gestures that accompanied a given spoken sentence unit as a gesture sentence unit.
Sentence units in speech and gesture were further coded for packaging of different types of motion elements: A sentence unit in speech was coded as conflated if it conveyed both manner and path within a single spoken clause (e.g., Eve runs into the house; Oya eve koşuyor, “Oya house-to runs”); it was coded as separated if it conveyed only manner (e.g., she is running; koşuyor, “running”), only path (e.g., she enters the house; eve girer, “house-to enters”), or manner and path in two separate clauses, with path in the verb of the main clause and manner in a subordinate clause (Eve enters the house running; Oya giriyor eve koşarak, “Oya house-to enters running”). This construction appeared only six times in English, but was frequent in Turkish. Turkish speakers occasionally used a third strategy in speech, combining a neutral verb that does not convey path (e.g., go, “move”) with path in a satellite and manner in a subordinate second clause (e.g., Oya koşarak eve gitti, “Oya went to the house running”). These instances were classified as separated (i.e., manner and path in two clauses). Agreement between coders was 100% for coding motion elements in speech.
Sentence units in gesture were also coded for packaging of different types of motion elements. A sentence unit in gesture was coded as conflated if it conveyed manner and path simultaneously within a single gesture (e.g., fingers wiggled as the hand moved across space, as illustrated on the right in Fig. 1b); it was coded as separated if it conveyed manner only (e.g., fingers wiggled in place in an upside-down V) or path only (e.g., hand moved across space, as illustrated on the left in Fig. 1b). A sentence unit in gesture that consisted of a gesture conveying manner followed by a gesture conveying path (e.g., fingers wiggled in place and then a finger moved across space), or vice versa, was also coded as separated. Participants in all groups also produced conflated gestures followed by separated gestures within a single sentence unit. Mixed responses of this sort accounted for approximately 4% of the data in each group and were excluded from the analyses. Agreement between coders was 93% for identifying gestures; 96% for describing gesture form (i.e., iconic, deictic, or beat); and 90% for coding motion elements in gesture.
Analysis
Using R (R Core Team, 2013) and the glmer() function in the lme4 library (Bates, Maechler, Bolker, & Walker, 2014), we analyzed the count data by fitting generalized linear mixed-effects models with a Poisson distribution function. Language (English, Turkish) and group (blind, sighted without blindfold, sighted with blindfold) were between-subjects and within-items factors, respectively. Packaging (separated, conflated) and output channel (speech, gesture) were within-subjects and within-items factors, respectively. Path type (to, over, from) was a within-subjects and between-items factor. All factors were treatment coded (see Table 3 for a list of all factors used in the analyses and the reference level for each factor). We treated subject (N = 120) and scene (N = 12) as random effects, including random intercepts for both in all analyses. 5 To control for effects of type of path, we included path type as a fixed effect in all models. Our procedure was the same for all statistical tests. If a statistical test involved a subset of the data, we first excluded all irrelevant data. For example, to test for a difference between blind English and Turkish speakers in frequency of conflated gesture packaging, we selected only the data for the relevant levels of the factors: language (English, Turkish), group (blind), packaging (conflated), and output channel (gesture). We then fit a model that included the term we wanted to test (in this case, language). Next, we fit a reduced model that excluded the term we wanted to test but was otherwise the same. Finally, we compared the models using a likelihood ratio test via the anova() command. This procedure compared the relative fits (expressed as log likelihoods) of the two models to test the statistical significance of the term removed in the reduced model (in this case, language). We report the chi-square statistics, degrees of freedom, and p values for these tests.
Factors Used in the Analyses
Predictions
If speakers learn language-specific gestures by watching others gesture, then blind speakers of English should not display the gesture patterns unique to sighted English speakers, nor should blind speakers of Turkish display the gesture patterns unique to sighted Turkish speakers. We would thus expect sighted speakers, but not blind speakers, to display language-specific gesture patterns, and we would expect an interaction of group, language, and packaging. The fact that children growing up in gesture-rich environments such as Italy or Turkey have larger gestural repertoires than children growing up in less gesture-rich environments (Furman et al., 2014; Iverson et al., 2008) suggests that the gestures individuals see others produce can have an impact on their own gestures, lending weight to this first hypothesis.
In contrast, if speakers learn language-specific gestures by learning to speak their language, then blind speakers of English should gesture like sighted speakers of English, and blind speakers of Turkish should gesture like sighted speakers of Turkish. In this case, we would expect differences between English and Turkish speakers (i.e., a significant interaction between language and packaging), but no differences between blind and sighted speakers within each language (i.e., no effect of group). The fact that gesture and speech form a single integrated system under most circumstances (Goldin-Meadow, 2003; McNeill, 1992; but see note 1) suggests that gesture should go hand in hand with speech, and that speakers (blind or sighted) of the same language should gesture alike, and differently from speakers (blind or sighted) of a different language.
Results
The tables in the appendix present the mean number of separated and conflated motion elements produced in speech and gesture for each scene by speakers of each language in each group. Here, we summarize the results of our regression analyses. (The details on the regression models and outputs are provided in the Supplemental Material available online.)
Packaging motion elements in speech
Both sighted and blind speakers showed the expected cross-linguistic differences in speech (Fig. 2, top panels). We found a Language × Packaging interaction in speech for each group—sighted without blindfold (Model 1): b = 2.20, χ2(1) = 19.49, p < .001; sighted with blindfold (Model 2): b = 2.34, χ2(1) = 24.82, p < .001; blind (Model 3): b = 2.12, χ2(1) = 22.74, p < .001. We then tested for a three-way Language × Packaging × Group interaction to see if the two-way interaction varied by group, and found that it did not (Model 4)—sighted with blindfold relative to blind: b = 0.09; sighted without blindfold relative to blind: b = −0.08, χ2(2) = 0.48, p = .785. 6 English and Turkish speakers thus differed in their packaging of motion elements in speech whether they were sighted or blind and, if sighted, whether or not they wore a blindfold.
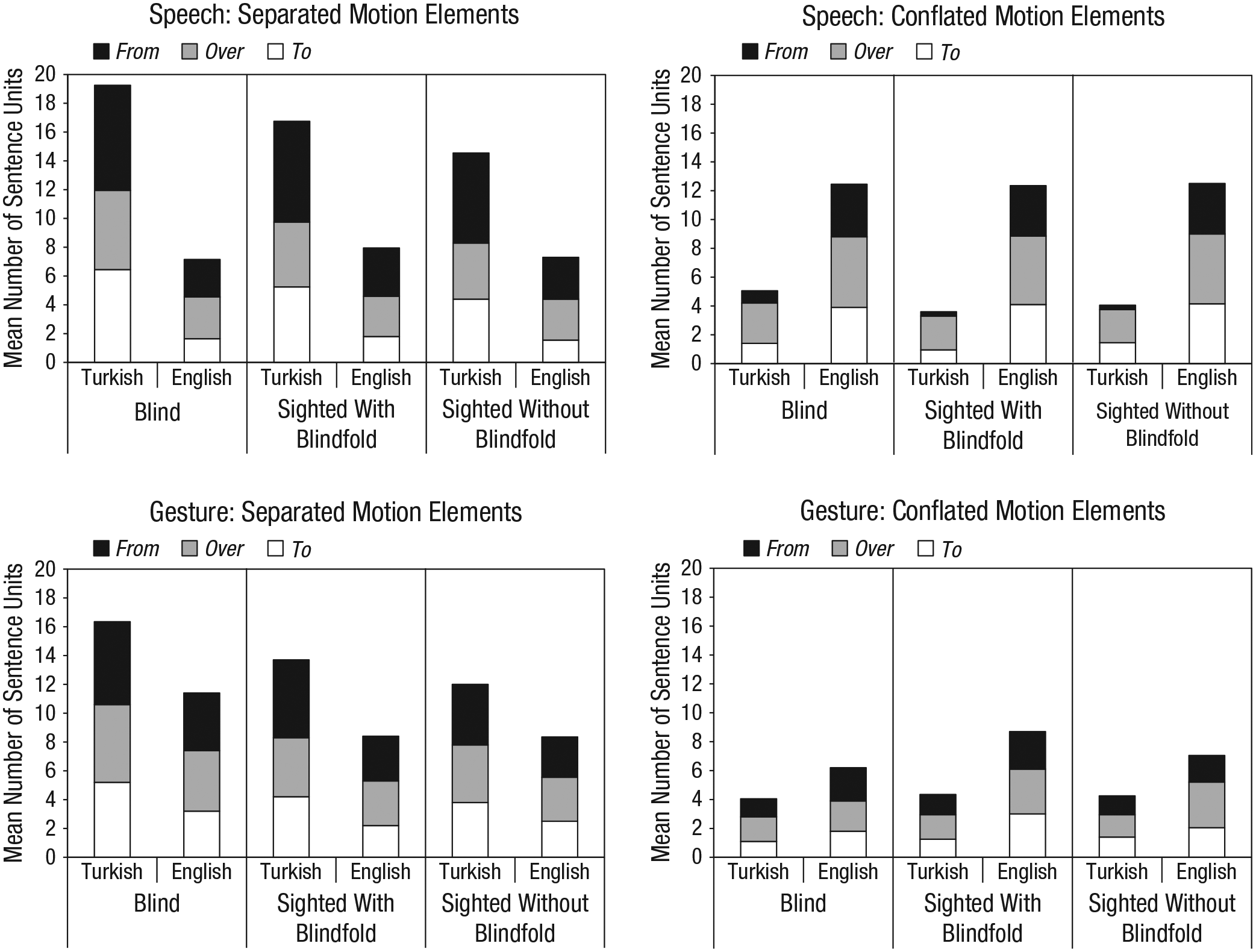
Mean number of sentence units with separated and conflated packaging of motion elements. The top row presents results for speech, and the bottom row presents results for gesture. Means across all three path types are shown separately for Turkish and English speakers in each of the three groups, and means for each of the three path types (to, over, and from) are indicated by the shading.
We explored these interactions by contrasting packaging of motion elements in speech between the two languages within each group (see Table 4 for a detailed summary of the frequency of the various types of sentence units in speech, including a breakdown of types of responses within the separated category). As expected, within every group, Turkish speakers produced more separated sentence units in speech than English speakers did—sighted without blindfold (Model 5): b = 1.01, χ2(1) = 14.95, p < .001; sighted with blindfold (Model 6): b = 0.91, χ2(1) = 16.71, p < .001; blind (Model 7): b = 1.13, χ2(1) = 23.39, p < .001. In contrast, and again as expected, English speakers in each group produced more conflated sentence units than Turkish speakers in the same group—sighted without blindfold (Model 8): b = −1.42, χ2(1) = 18.12, p < .001; sighted with blindfold (Model 9): b = −1.57, χ2(1) = 19.69, p < .001; blind (Model 10): b = −1.07, χ2(1) = 17.42, p < .001.
Mean Number of Separated and Conflated Sentence Units Produced in Speech and in Gesture by Each Group
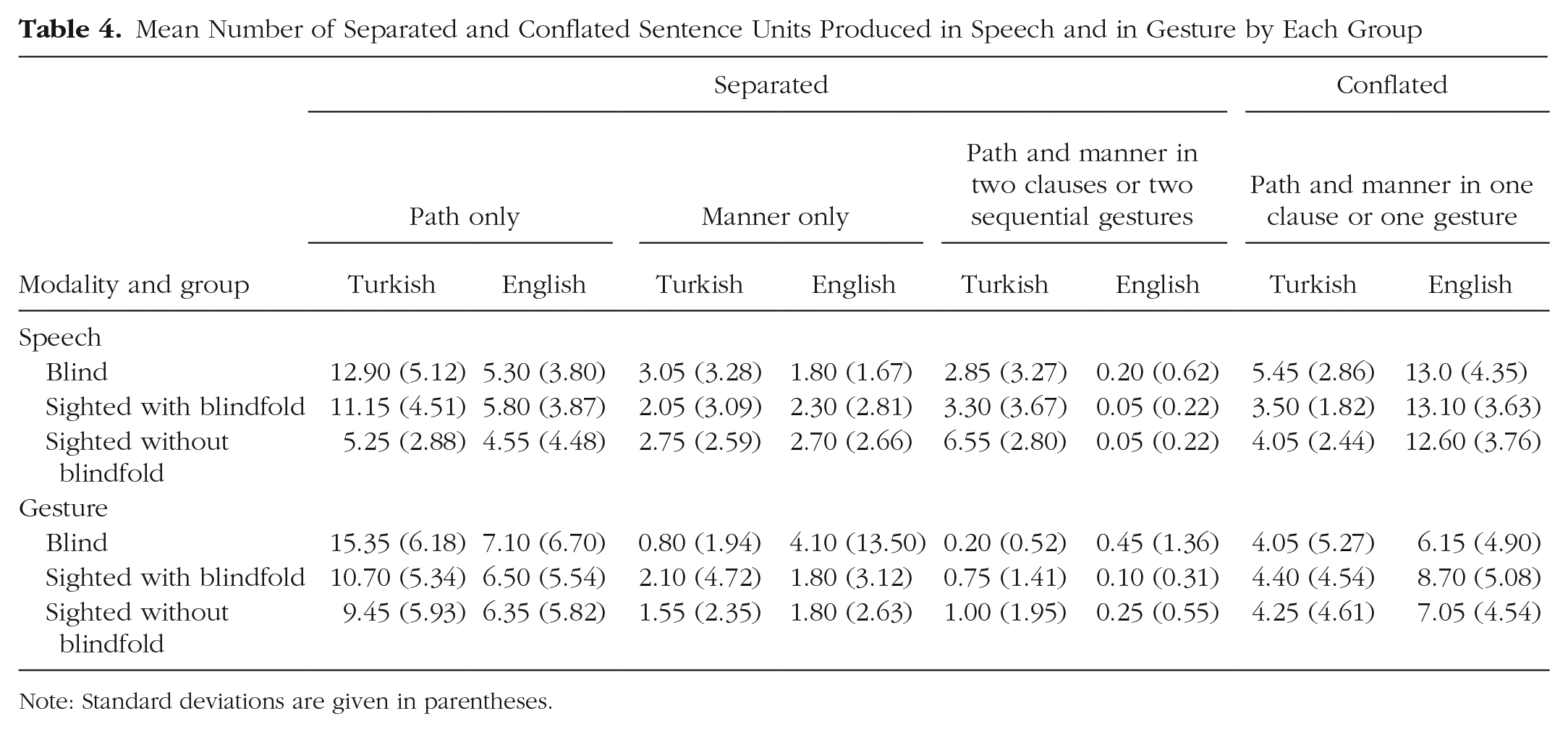
Note: Standard deviations are given in parentheses.
To determine whether these cross-linguistic differences varied by path type, we tested whether there was a significant Language × Packaging × Path Type interaction for each group. This higher-order interaction was significant for all three groups—sighted without blindfold (Model 11): b = −1.03 for over relative to to paths, b = 1.13 for from relative to to paths, χ2(2) = 22.42, p < .001; sighted with blindfold (Model 12): b = −1.35 for over relative to to paths, b = 0.66 for from relative to to paths, χ2(2) = 22.55, p < .001; blind (Model 13): b = −1.19 for over relative to to paths, b = 0.10 for from relative to to paths, χ2(2) = 15.32, p < .001. Thus, the cross-linguistic effect did vary by path type. However, the two-way Language × Packaging interaction was also significant at every level of path type and at every level of group (Models 14–22: p < .05 for all nine tests); that is, for each of the three path types produced by each of the three groups, Turkish speakers produced more separated sentence units than English speakers, and English speakers produced more conflated sentence units than Turkish speakers (Fig. 2, top panels).
Packaging motion elements in gesture
On the basis of previous studies (Gullberg et al., 2008; Kita & Özyürek, 2003), we expected the cross-linguistic patterns found in speech to also appear in gesture in sighted participants. Our question was whether these patterns would appear in blind participants as well. We found that they did. Figure 2 (bottom panels) presents the data. As in the speech analyses, we found a Language × Packaging interaction in gesture for each group—sighted without blindfold (Model 23): b = 0.85, χ2(1) = 16.62, p < .001; sighted with blindfold (Model 24): b = 1.26, χ2(1) = 18.44, p < .001; blind (Model 25): b = 0.80, χ2(1) = 16.64, p < .001. We then tested for a three-way Language × Packaging × Group interaction to see if the two-way interaction varied by group, and found that it did not (Model 26)—sighted with blindfold relative to blind: b = 0.40; sighted without blindfold relative to blind: b = 0.08; χ2(2) = 3.22, p = .200. English and Turkish speakers thus differed in their packaging of motion elements in gesture whether they were sighted or blind and, if sighted, whether or not they wore a blindfold.
We explored these interactions by contrasting packaging of motion elements in gesture between the two languages within each group (see Table 4 for a detailed summary of the frequency of the various types of gestures, including a breakdown of types of responses within the separated category). As in their speech, Turkish speakers in each group produced more separated gestures than English speakers in the same group—sighted without blindfold (Model 27): b = 0.48, χ2(1) = 6.93, p = .008; sighted with blindfold (Model 28): b = 0.49, χ2(1) = 6.72, p = .010; blind (Model 29): b = 0.75, χ2(1) = 7.74, p = .005. In contrast, in every group, English speakers produced more conflated gestures than Turkish speakers did—sighted without blindfold (Model 30): b = −0.78, χ2(1) = 5.73, p = .016; sighted with blindfold (Model 31): b = −0.96, χ2(1) = 11.80, p < .001; blind (Model 32): b = −0.97, χ2(1) = 5.23, p = .022.
To determine whether these cross-linguistic differences in gesture varied by path type, we tested whether there was a significant Language × Packaging × Path Type interaction for each group. We found no evidence of a three-way interaction in any of the three groups—sighted without blindfold (Model 33): b = 0.18 for over relative to to paths, b = −0.04 for from relative to to paths, χ2(2) = 0.34, p = .846; sighted with blindfold (Model 34): b = −0.64 for over relative to to paths, b = −0.35 for from relative to to paths, χ2(2) = 2.51, p = .285; blind (Model 35): b = −0.52 for over relative to to paths, b = −0.01 for from relative to to paths, χ2(2) = 2.20, p = .334. That is, for each of the three path types produced by each of the three groups, Turkish speakers produced more separated gestures than English speakers, and English speakers produced more conflated gestures than Turkish speakers (Fig. 2, bottom panels), just as they did in speech. Blind individuals show the same cross-linguistic differences in gesture that sighted individuals do, despite not being able to observe others gesturing.
Discussion
This study replicates previous work showing that sighted speakers of Turkish package manner and path gestures differently from sighted speakers of English (Gullberg et al., 2008; Kita & Özyürek, 2003). But we took this work one important step further by showing that blind speakers of these two languages package manner and path gestures in precisely the same ways as sighted speakers of these languages. Our findings thus underscore the tight link between speech and gesture, and identify speech as the source of the cross-linguistic variation observed in gesture. Blind speakers learn language-specific gestures by learning to speak the language, not by watching others move.
However, gesture and speech can be out of sync at various points in development. For example, children learning Turkish and those learning English display language-specific speech by age 3 (separated packaging in Turkish, conflated packaging in English) but use the same gestures until age 9 (separated packaging; Özyürek et al., 2008). Between the ages of 3 and 9, English learners thus produce separated gesture along with conflated speech, which suggests that language-specific gesture takes time to develop. Does seeing the gestures that other individuals produce influence when language-specific gestures first emerge? If so, blind children’s gestures and sighted children’s gestures ought to follow different developmental trajectories. Studies of congenitally blind children at different points in language learning will show whether the onset of language-specific patterns in gesture is affected by seeing other people gesture. Whatever the developmental trajectories, our findings make it clear that the final state does not depend on seeing gesture—language-specific gesture can be learned just by learning the language.
Footnotes
Appendix
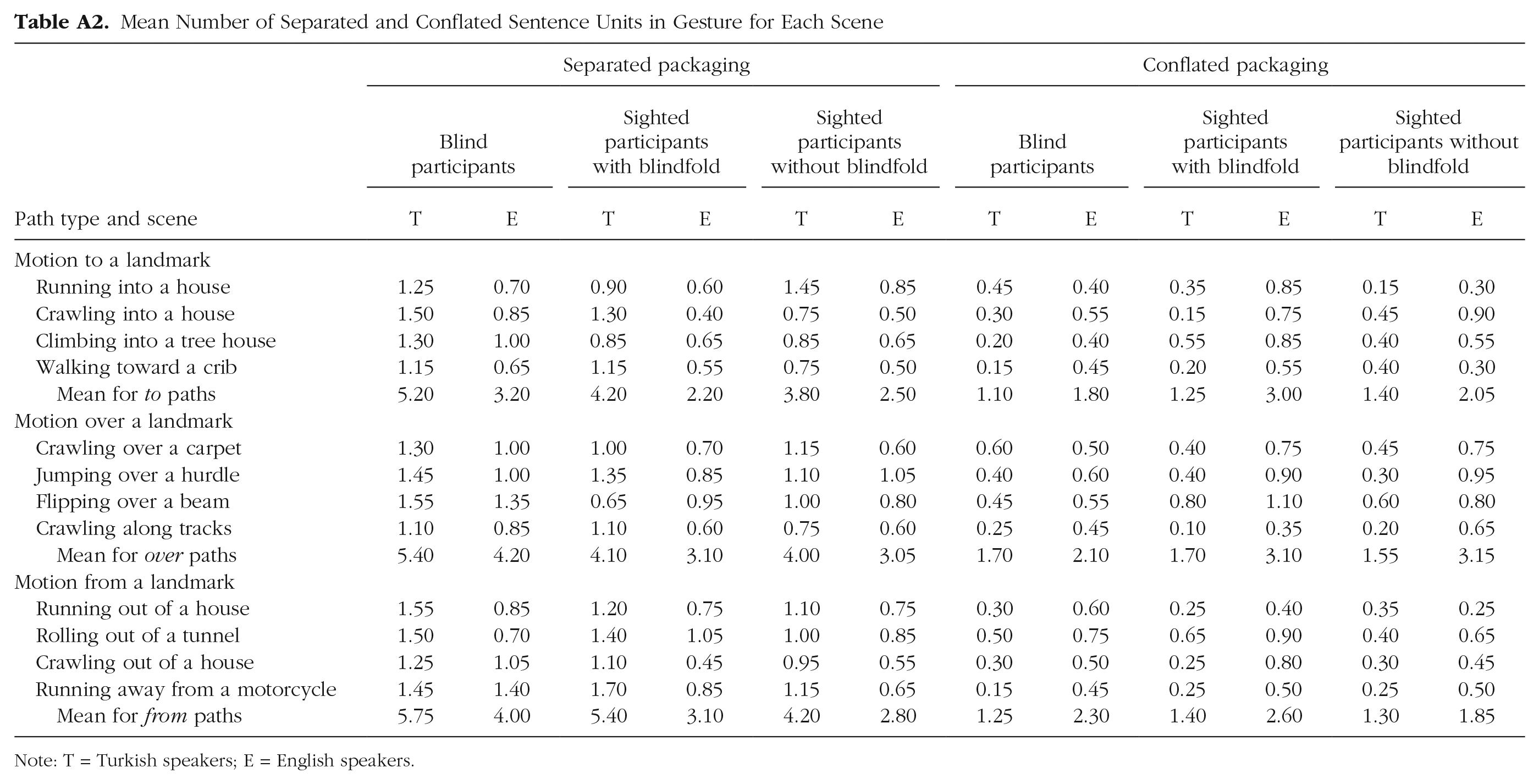
Mean Number of Separated and Conflated Sentence Units in Gesture for Each Scene
| Separated packaging |
Conflated packaging |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Blind participants |
Sighted participants with blindfold |
Sighted participants without blindfold |
Blind participants |
Sighted participants with blindfold |
Sighted participants without blindfold |
|||||||
| Path type and scene | T | E | T | E | T | E | T | E | T | E | T | E |
| Motion to a landmark | ||||||||||||
| Running into a house | 1.25 | 0.70 | 0.90 | 0.60 | 1.45 | 0.85 | 0.45 | 0.40 | 0.35 | 0.85 | 0.15 | 0.30 |
| Crawling into a house | 1.50 | 0.85 | 1.30 | 0.40 | 0.75 | 0.50 | 0.30 | 0.55 | 0.15 | 0.75 | 0.45 | 0.90 |
| Climbing into a tree house | 1.30 | 1.00 | 0.85 | 0.65 | 0.85 | 0.65 | 0.20 | 0.40 | 0.55 | 0.85 | 0.40 | 0.55 |
| Walking toward a crib | 1.15 | 0.65 | 1.15 | 0.55 | 0.75 | 0.50 | 0.15 | 0.45 | 0.20 | 0.55 | 0.40 | 0.30 |
| Mean for to paths | 5.20 | 3.20 | 4.20 | 2.20 | 3.80 | 2.50 | 1.10 | 1.80 | 1.25 | 3.00 | 1.40 | 2.05 |
| Motion over a landmark | ||||||||||||
| Crawling over a carpet | 1.30 | 1.00 | 1.00 | 0.70 | 1.15 | 0.60 | 0.60 | 0.50 | 0.40 | 0.75 | 0.45 | 0.75 |
| Jumping over a hurdle | 1.45 | 1.00 | 1.35 | 0.85 | 1.10 | 1.05 | 0.40 | 0.60 | 0.40 | 0.90 | 0.30 | 0.95 |
| Flipping over a beam | 1.55 | 1.35 | 0.65 | 0.95 | 1.00 | 0.80 | 0.45 | 0.55 | 0.80 | 1.10 | 0.60 | 0.80 |
| Crawling along tracks | 1.10 | 0.85 | 1.10 | 0.60 | 0.75 | 0.60 | 0.25 | 0.45 | 0.10 | 0.35 | 0.20 | 0.65 |
| Mean for over paths | 5.40 | 4.20 | 4.10 | 3.10 | 4.00 | 3.05 | 1.70 | 2.10 | 1.70 | 3.10 | 1.55 | 3.15 |
| Motion from a landmark | ||||||||||||
| Running out of a house | 1.55 | 0.85 | 1.20 | 0.75 | 1.10 | 0.75 | 0.30 | 0.60 | 0.25 | 0.40 | 0.35 | 0.25 |
| Rolling out of a tunnel | 1.50 | 0.70 | 1.40 | 1.05 | 1.00 | 0.85 | 0.50 | 0.75 | 0.65 | 0.90 | 0.40 | 0.65 |
| Crawling out of a house | 1.25 | 1.05 | 1.10 | 0.45 | 0.95 | 0.55 | 0.30 | 0.50 | 0.25 | 0.80 | 0.30 | 0.45 |
| Running away from a motorcycle | 1.45 | 1.40 | 1.70 | 0.85 | 1.15 | 0.65 | 0.15 | 0.45 | 0.25 | 0.50 | 0.25 | 0.50 |
| Mean for from paths | 5.75 | 4.00 | 5.40 | 3.10 | 4.20 | 2.80 | 1.25 | 2.30 | 1.40 | 2.60 | 1.30 | 1.85 |
Note: T = Turkish speakers; E = English speakers.
Acknowledgements
We thank C. Ramdeen, B. Sancar, A. Pollard, and V. Reyes for their help with data collection, transcription, and coding. We also thank A. Correira at the Center for the Visually Impaired, E. Yılmaz at Bogaziçi University Center for the Visually Challenged, and M. Demirok at Altınokta Center for the Blind for their help in recruitment and data collection.
Action Editor
Matthew A. Goldrick served as action editor for this article.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
This work was supported by Grant 12-FY08-160 from the March of Dimes Foundation to Ş. Özçalışkan and S. Goldin-Meadow.
Open Practices
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.