
Abstract
Nonarbitrary mappings between sound and shape (i.e., the bouba-kiki effect) have been shown across different cultures and early in development; however, the level of processing at which this effect arises remains unclear. Here we show that the mapping occurs prior to conscious awareness of the visual stimuli. Under continuous flash suppression, congruent stimuli (e.g., “kiki” inside an angular shape) broke through to conscious awareness faster than incongruent stimuli. This was true even when we trained people to pair unfamiliar letters with auditory word forms, a result showing that the effect was driven by the phonology, not the visual features, of the letters. Furthermore, visibility thresholds of the shapes decreased when they were preceded by a congruent auditory word form in a masking paradigm. Taken together, our results suggest that sound-shape mapping can occur automatically prior to conscious awareness of visual shapes, and that sensory congruence facilitates conscious awareness of a stimulus being present.
The bouba-kiki effect refers to the tendency for people to preferentially match particular linguistic sounds with particular shapes, even when the sounds carry no concrete meaning and the shapes are entirely abstract: For example, a curved shape is more often matched up with a soft-sounding word form like “bouba,” and an angular shape with a sharp-sounding word form like “kiki” (Ramachandran & Hubbard, 2001). This effect was first documented by Köhler (1929) and has been replicated in numerous studies since then (for recent reviews, see Imai & Kita, 2014; Lockwood & Dingemanse, 2015). The bouba-kiki effect has been observed across different languages (Bremner et al., 2013; Ramachandran & Hubbard, 2001), which suggests that the effect is not limited to individual languages, cultures, or writing systems. Similarly, the effect is seen in children under the age of 3 (Maurer, Pathman, & Mondloch, 2006), so it does not rely on adult levels of linguistic proficiency. Furthermore, studies conducted with infants as young as 4 months of age have shown that they attend differentially to multimodal stimuli according to whether the mappings between linguistic sounds and shapes are congruent or incongruent (Ozturk, Krehm, & Vouloumanos, 2013; Peña, Mehler, & Nespor, 2011), an indication that the effect has its origins in properties of the early sensory system.
Many researchers have taken the pervasiveness of these findings to suggest that sound symbolism is universal (e.g., Imai & Kita, 2014) and represents an innate property of the human sensory systems (e.g., Maurer, 1993; Mondloch & Maurer, 2004; Ramachandran & Hubbard, 2001) or shared sensory experience of the world (e.g., Spence, 2011). Current lines of research are investigating which classes of sounds best match particular visual features (D’Onofrio, 2014; Nielsen & Rendall, 2011, 2013) and are unpacking the neural correlates of these effects (Asano et al., 2015; Kovič, Plunkett, & Westermann, 2010; Revill, Namy, DeFife, & Nygaard, 2014; Sučević, Savić, Popović, Styles, & Ković, 2015).
After nearly a century of investigations into the bouba-kiki effect, there has been little discussion about the cognitive processes or the level of processing it requires. With the exception of a handful of studies involving young infants (Ozturk et al., 2013; Peña et al., 2011), almost all studies in this field have been confounded by the possibility of strategic response biases or conscious evaluations of how well stimuli “go together” (e.g., Westbury, 2005). It therefore remains unclear what level of processing gives rise to the sense of an audiovisual match: Such mappings could rely on (a) introspective processes about perceptual goodness of fit, (b) an association matrix linking conscious experiences of sensory perception across modalities, or (c) automatic sensory processes that are active prior to the conscious perception of a sensory stimulus or conscious awareness of a match. In the experiments reported here, we asked whether sound-shape mapping is an automatic sensory process, by investigating whether the bouba-kiki effect can arise before, or in the absence of, conscious awareness.
To test whether sound-shape mapping occurs automatically for stimuli that have not yet been consciously perceived, we used two methods to probe thresholds at which invisible stimuli became visible: continuous flash suppression (CFS; Experiments 1 and 2) and visual masking (Experiment 3). In a typical breaking-CFS paradigm, a series of dynamically changing images (Mondrian stimuli) is presented to the dominant eye, and a static target image is presented to the nondominant eye (Tsuchiya & Koch, 2005). The intensity of the target stimulus is gradually ramped up to determine the first moment at which it “breaks through” the suppression caused by the flashing Mondrian stimuli. We used this paradigm to examine whether the congruence of a written word with the shape it appears inside can influence the threshold at which the compound visual image reaches conscious awareness. In Experiment 1, we presented a written nonword inside a novel shape that was either congruent or incongruent with the word’s phonology (“kiki” inside an angular shape and “bubu” inside a rounded shape, or vice versa). We tested whether the congruence of these stimuli affected the time taken to perceive them under CFS. In Experiment 2, we tested whether the congruence effect depended on the phonology of the written word or on the shape of its written letters, by training participants to “read” word forms constructed out of unfamiliar letters with no systematic sound symbolism.
Furthermore, to investigate whether the effect occurs in paradigms that allow binary measurement of visual awareness, to avoid the prolonged duration of breaking through, we used a visual masking paradigm in Experiment 3. In this paradigm, a target is presented very briefly between forward and backward visual masks, and the intensity of the target is adaptively varied in order to determine the threshold at which it becomes visible. We presented the visual shapes from Experiments 1 and 2 briefly (i.e., 33 ms) between forward and backward masks while presenting the word forms auditorily, to test whether congruence of the auditory word forms influenced the threshold at which the briefly presented visual stimuli became visible. We predicted that the time participants took to see the composite word-shape stimuli in Experiments 1 and 2 and the visibility threshold for the visual stimuli in Experiment 3 would depend on the auditory representations of the word forms (their phonology), whether extracted directly from audio or from writing, rather than on the visual shape of the letters.
Participants
Across the three experiments, 96 participants were recruited (age range: 18–35 years). All participants were proficient in English, were unfamiliar with the bouba-kiki effect, and reported normal or corrected-to-normal vision. They gave informed consent prior to the experiment and were reimbursed $10 for participating in a session lasting 60 min. This study was approved by the institutional review board of the National University of Singapore. Sixteen participants were removed from analyses and replaced because of low accuracy on the location task (see Experiment 1, Stimuli and Procedure; Experiment 1: n = 4; Experiment 2a: n = 2; Experiment 2b: n = 1; Experiment 3: n = 9). Our final sample for each experiment consisted of 20 participants (our target number). 1
Experiment 1
Stimuli and procedure
Each of the four target stimuli comprised a pseudoword (“bubu” or “kiki”), presented in black text inside a white shape (rounded or angular). Thus, two stimuli were congruent, and two were incongruent. These reduplicated pseudowords (following Maurer et al., 2006; Ozturk et al., 2013) did not have discrete lexical meanings in the local community. The rounded and angular shapes (see Fig. 1, top row) were created from the same basic oval by adding radial, symmetrical protrusions; for a given shape, all protrusions were of equal length. In the rounded shape, curved projections were created from circles with centers aligned to the outer edge of the oval, and in the angular shape, spikes were added to the oval where the centers and overlaps of the protrusions were located in the rounded shape; thus, there were twice as many spikes in the angular shape as curves in the rounded shape. These forms were designed to capture some of the most salient contrasts in bouba-kiki stimuli used across a variety of studies. Each target stimulus was presented 40 times, for a total of 160 trials, half congruent and half incongruent.

Examples of the experimental stimuli. The top row shows the congruent stimuli in Experiment 1. The middle row shows two of the test stimuli in Experiment 2; they were either congruent or incongruent depending on which novel word form the participant was trained to read as “kiki” and which the participant was trained to read as “bubu.” The bottom row shows the visual stimuli used for training in Experiments 2a and 2b and as visual targets in Experiment 3.
The experimental procedure is illustrated in Figure 2. Each trial began with a fixation period of random duration (0–1 s). After the fixation period, a high-contrast dynamic pattern mask (a series of colorful Mondrian stimuli), flashing at 10 Hz, was presented to the dominant eye, simultaneously to the left and to the right of the fixation point, which remained on-screen. At the same time, a target stimulus was presented to the nondominant eye, either to the left or to the right side of the fixation point. The contrast (alpha value) of the target stimulus gradually increased from 0% to 75% over 10 s. The target stimulus was therefore initially invisible and gradually faded in, while the visual percept from the nondominant eye was suppressed by binocular rivalry from the flashing Mondrian stimuli presented to the dominant eye. In this manner, conscious awareness of the gradually emerging target was delayed.
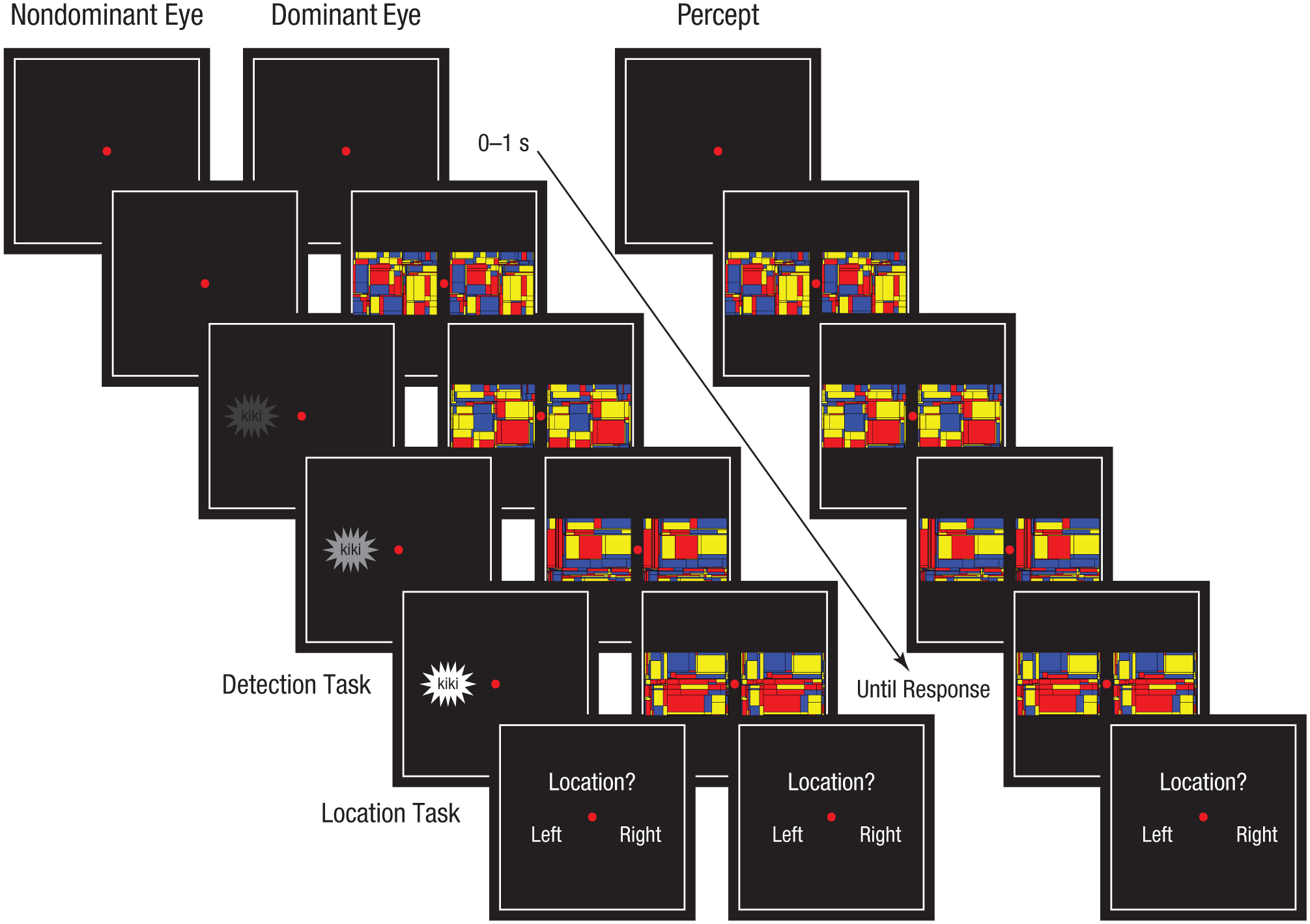
Illustration of the procedure (left) and percepts (right) in Experiment 1. After an initial fixation period, a series of colored Mondrian stimuli, flashing at 10 Hz, were presented to the dominant eye, simultaneously to the left and right of the fixation point. At the same time, the target stimulus was presented to the nondominant eye, either to the left or to the right of the fixation point. The contrast of the target increased from 0% to 75% over 10 s. Participants pressed a button when the target first became visible (detection task) and then reported whether the target had appeared on the left or right (location task).
Participants were asked to press the space bar when any part of the target stimulus became visible (detection task). Next, they indicated whether it appeared at the left or the right side of the fixation point, using the left and right arrow keys on the computer keyboard (location task). The location task was used to identify false alarms so they could be excluded from analysis. Participants with accuracy 3 SD or more below the group mean for the location task were removed and replaced prior to analysis. The Mondrian series was presented for up to 10 s or 500 ms after participants reported seeing the target, to prevent them from seeing an afterimage of the target. If a participant did not report seeing the target, it remained at the final contrast (i.e., 75%) for 500 ms after the Mondrian series was turned off, which ensured that the target stimulus became visible. Note that participants were not asked to report the identity of the written word or the shape of the target stimulus.
The visual stimuli were generated with MATLAB (The MathWorks, Inc., Natick, MA) and PsychToolbox (Brainard, 1997; Pelli, 1997). Participants viewed the dichoptic images through a mirror stereoscope mounted on a chin rest, from a distance of 57 cm. The stimuli were presented against a black background on a 22-in. Samsung 2233RZ LCD monitor with a resolution of 1,680 × 1,050 pixels and a refresh rate of 120 Hz. Throughout the experiment, a white frame (subtending 3.9° × 3.9°) remained on-screen to facilitate proper fusion.
Results
Excluded from analysis were individual trials on which the answer to the location task was incorrect and trials with suppression times more than 3 SD above or below the participant’s mean for each condition. On average, 93.4% of trials were valid; the percentage of excluded trials ranged from 0.6% to 26.9%.
Congruent stimuli (e.g., “kiki” in an angular shape) broke suppression faster than incongruent stimuli (e.g., “kiki” in a rounded shape), paired-samples t(19) = −2.12, p = .047, Cohen’s d = 0.10, 95% confidence interval (CI) = [0.00, 0.20], as is evident in Figure 3 (also see Fig. 4 for individual-level data from Experiment 1). Accuracy on the location task was 97.4% and did not differ significantly between the two conditions, paired-samples t(19) = 1.30, p = .21. Given that the target stimuli broke through suppression earlier when the word and the shape were congruent, our findings suggest that congruence between the word and the shape was processed before either had been consciously perceived.
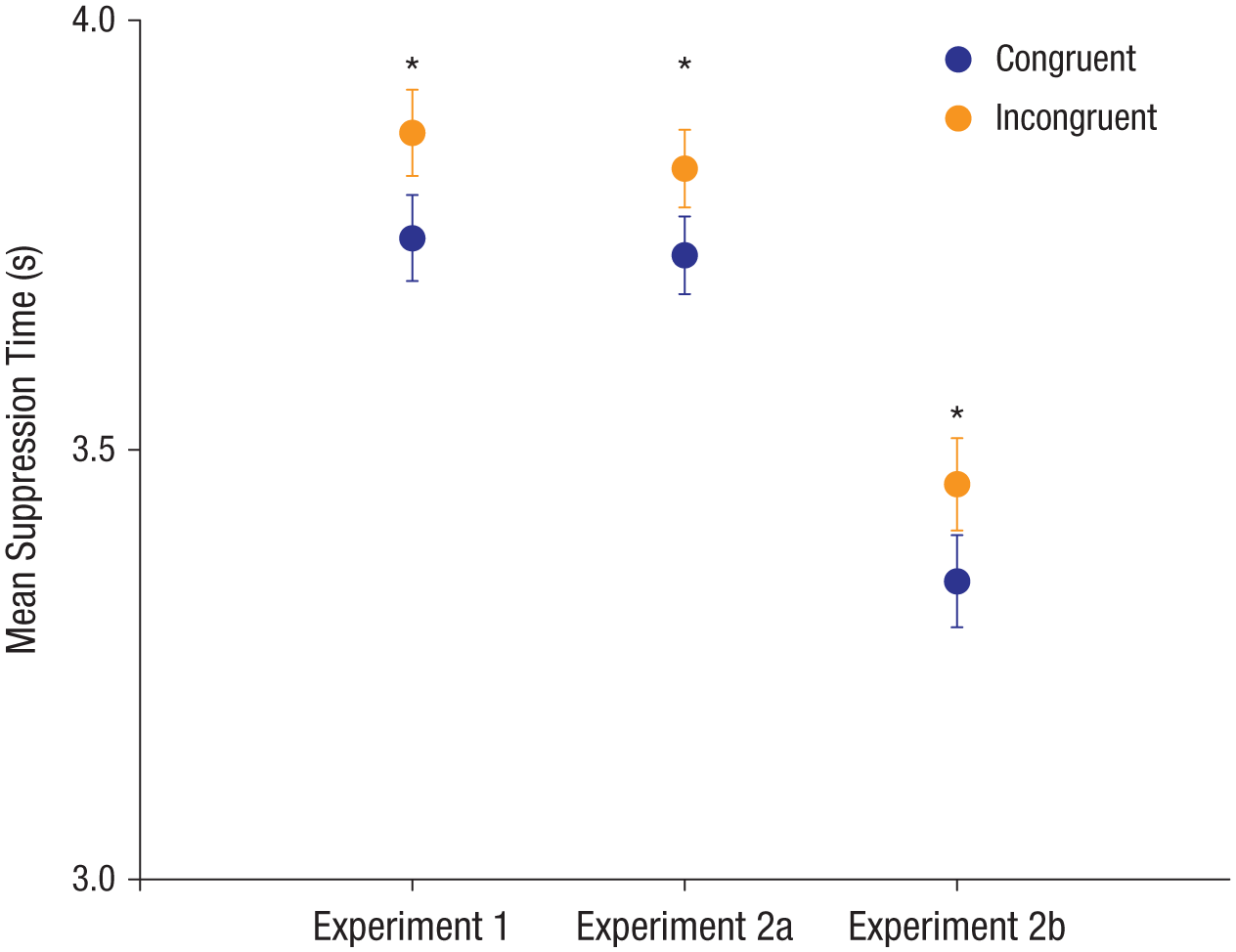
Mean suppression time in the two conditions (congruent, incongruent) in Experiments 1, 2a, and 2b. Error bars represent ±1 SEM. Asterisks indicate significant differences between conditions (p < .05).
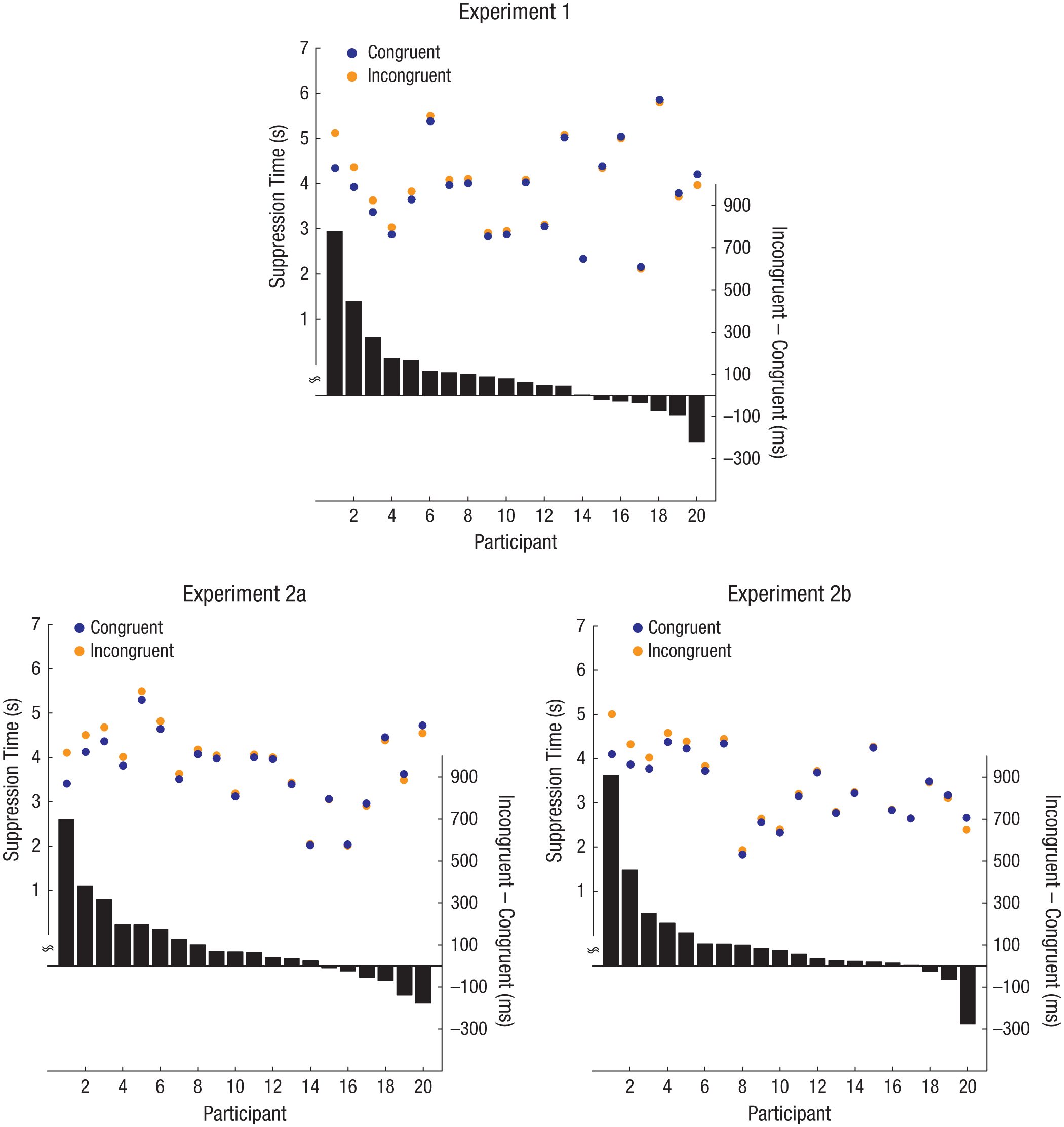
Individual participants’ suppression times (circles, left y-axis) in the two conditions (congruent, incongruent) of Experiments 1, 2a, and 2b. From left to right, the participants are ordered according to the strength of the effect. The bars in the lower part of each graph show the difference in suppression time (right y-axis) between the conditions. (See the Supplemental Material for enlarged versions of these graphs with error bars showing standard errors of the mean.)
Experiment 2
Given the physical attributes of the Latin letters used in the target stimuli in Experiment 1, it is possible that perceptual features of the letter shapes were involved in the observed effect. That is, the letters in “kiki” contain more acute angles, straight lines, and small elements than the letters in “bubu,” so the effect might have been based on a mapping between the visual features of the letters and the visual features of the surrounding shapes (angles vs. curves, high vs. low spatial frequency) that was independent of the written words’ phonology. To address this confound of visual similarity between the letter shapes and their surrounding context, in Experiment 2 we introduced written words created from two unfamiliar letters that did not have these visual dissimilarities.
In Experiment 2, we tested whether the congruence effect observed prior to conscious awareness depended on sound-shape congruence or was simply a result of the visual similarity between certain Latin letters and certain nonletter shapes. We controlled the visual similarity between the words and shapes using word forms composed of unfamiliar letters that were experimentally controlled for their sound-symbolic properties. We trained two groups of people to “read” the same set of letters in different ways, to see whether the phonology of a written word was sufficient to produce the preconscious bouba-kiki effect regardless of what the letters looked like. We hypothesized that the effect is driven by a written word’s phonology and therefore predicted that we would observe the same result as in Experiment 1.
Stimuli and procedure
Auditory stimuli
A Singaporean bilingual speaker of English and Mandarin spoke each word form (i.e., “bubu,” “kiki”) three times with a slight upward pitch inflection. These audio stimuli were recorded in a sound-proof recording booth using a RØDE NT55 (Silverwater, Sydney, New South Wales, Australia) microphone sampling 16 bits at 48 kHz. Volume was adjusted, and the tokens were trimmed to remove head and tail clicks using GoldWave Version 5.70 (GoldWave Inc., 2015). The token of “kiki” and the token of “bubu” that were best matched in pitch, rhythm, and inflection were selected as exemplars for training.
Visual stimuli
A pair of unfamiliar letters from the West African Vai script were selected from a database of 56 letter pairs from ancient and unfamiliar scripts, previously tested for their sound-symbolic properties. The selected letters have neutral sound symbolism for canonical linguistic contrasts (Turoman & Styles, 2016), and they are well matched in their visual properties: Each contains both curves and acute angles and both horizontal and vertical components, and they share small visual features. Each novel visual word forms consisted of two instances of one of these letters, so that the word forms had reduplicated structure. Each word form was presented in black text on a white background during the training period and on a white shape during the test (see Fig. 1, middle row).
Training
Each testing block was preceded by a training block, during which participants learned to read the two novel word forms as “kiki” and “bubu.” In each training trial, a single word was presented auditorily, followed by a visual presentation (for up to 3 s) of one of the novel word forms. Participants were asked to report whether the sound and the shape matched. They began by guessing which visual word form represented which auditory word form, and trial-by-trial feedback (i.e., “correct” or “wrong”) allowed them to infer the correct phonology for each visual word form. Training ended when a participant responded correctly on 20 consecutive trials. Half of the participants learned one pairing of the unfamiliar Vai letters to the auditory word forms (Experiment 2a), and the other half learned the opposite mapping (Experiment 2b).
Test
The materials and method for the test were as described for Experiment 1, with the exception that the novel visual word forms were used. Congruence of a stimulus depended on the training received: A stimulus with a rounded shape was congruent if the participant had been trained that the Vai word form inside the shape was “bubu,” and a stimulus with an angular shape was congruent if the participant had been trained that the Vai word form inside the shape was “kiki”—regardless of which visual letters were used. Thus, for example, the stimulus shown on the right in the middle row of Figure 1 was congruent in Experiment 2a and incongruent in Experiment 2b. Four blocks of testing under CFS were completed by each participant, and each block contained 20 congruent and 20 incongruent trials. In total, 160 trials were completed.
Results
Participants and trials were excluded as in Experiment 1. In Experiment 2a, 95.8% of trials, on average, were valid, and the percentage of trials excluded ranged from 0.6% to 8.7%. In Experiment 2b, 96.4% of trials, on average, were valid, and the percentage of trials excluded ranged from 0.6% to 19.4%.
For each experiment, Figure 4 shows individual participants’ suppression time in each condition, as well as the difference between suppression times in the two conditions (also see Fig. 3 for mean suppression times in Experiments 2a and 2b). We replicated the preconscious bouba-kiki effect observed in Experiment 1: Whichever letters were read as “kiki” broke suppression faster when they appeared inside the angular shape than when they appeared inside the rounded shape, and the reverse was found for the letters that were read as “bubu.” As is evident in Figure 3, the congruence effect was observed for both groups of participants, who were trained on opposite letter-to-phonology mappings—Experiment 2a: paired-samples t(19) = −2.29, p = .03, Cohen’s d = 0.12, 95% CI = [0.01, 0.19]; Experiment 2b: paired-samples t(19) = −2.16, p = .04, Cohen’s d = 0.14, 95% CI = [0.00, 0.22]. This result suggests that the congruence effect was due to a sensory alliance between the visual shapes and the phonology represented by the newly learned letters. A direct comparison of the suppression times of the groups trained with the different mappings yielded no significant difference, independent-samples t(38) = 0.17, p = .86. The accuracy rates for the location task in Experiments 2a and 2b were 98.2% and 99.3%, respectively, and there was no significant difference in accuracy between the two conditions in either Experiment 2a, paired-samples t(19) = 0.44, p = .67, or Experiment 2b, paired-samples t(19) = 0.57, p = .58.
Experiment 2 replicated the effect observed in Experiment 1, with novel word forms controlled for their visual properties. Given that congruence was manipulated by the auditory training, the fact that both Experiment 2a and Experiment 2b showed faster breakthrough times for visual word forms that were congruent with their outline shapes clearly demonstrates that the congruence effect is due to the congruence of the sounds represented by the written forms (i.e., the phonology), not by the shapes of the letters themselves.
Experiment 3
Two questions remained unanswered after Experiments 1 and 2. First, in the breaking-CFS paradigm, it was important that the word and the shape were combined to create a single visual stimulus, which necessitated the use of written representations of the words. This meant that access to the phonology of the words required some degree of decoding and was therefore mediated by reading or word-recognition processes. Because of this limitation, it remained unclear whether visibility thresholds would be affected in a similar way if the word forms were presented auditorily, albeit using a different paradigm to measure thresholds.
Second, the breaking-CFS paradigm relies on a single reaction time per trial, so it is not possible to untangle time to perceive from time to respond. As there has been some debate over whether this paradigm reflects the duration of preconscious processing or the duration (depth) of access to consciousness (e.g., Gayet, Van der Stigchel, & Paffen, 2014; Yang, Brascamp, Kang, & Blake, 2014), we investigated whether we would obtain supporting evidence using another method known to tap into the threshold between invisibility and conscious awareness of a visual stimulus. Specifically, we presented the word forms auditorily in a visual masking paradigm.
Thus, Experiment 3 was designed to investigate whether auditory word forms would generate threshold-lowering effects on congruent visual stimuli, as was observed with written word forms in Experiments 1 and 2. We used the visual masking paradigm to measure detection sensitivity for the visual shapes while congruent and incongruent auditory word forms were presented. Given our findings in Experiments 1 and 2, we predicted that a congruent sound would lower the visibility threshold of the corresponding shape, by priming a visual form with particular edge characteristics (spiky, curvy). We predicted that this would be possible only when a sufficient amount of auditory processing had occurred prior to the brief appearance of the visual stimulus (i.e., with stimulus onset asynchronies, SOAs, at which the audio preceded the onset of the faint visual stimulus).
Stimuli and procedure
The visual shapes from the previous experiments (spiky, curved) were used, along with the auditory stimuli used for training in Experiments 2a and 2b (i.e., “bubu” and “kiki”). The visual stimuli subtended 3° × 3° and were presented against a black background on a 21.5-in. iMAC LCD monitor with a resolution of 1,920 × 1,080 pixels and a refresh rate of 60 Hz. Participants viewed the stimuli while resting on a chin rest at a distance of 44 cm. The auditory stimuli were delivered via ATH-M20 headphones (Audio-Technica, Machida, Tokyo, Japan).
Participants were asked to maintain fixation on a red central fixation dot throughout the experiment. The experimental procedure is shown in Figure 5. Each trial began with a 500-ms blank screen, followed by the 33-ms presentation of the visual target on the left or right side of the fixation dot, sandwiched between a forward and a backward mask. Each 200-ms mask consisted of two 6 × 8 arrays of random symbols (subtending 3.9° × 4.7°), one to the left and one to the right of the fixation dot. These masks effectively hide faint visual stimuli from conscious perception. In order to determine the contrast at which each person was reliably able to detect the presence of a visual stimulus (i.e., the lowest level at which a stimulus was still visible), we varied the contrast of the visual targets according to a 2-up/1-down procedure (i.e., the Bruceton test; Dixon & Mood, 1948): The contrast decreased by 3% immediately in the next trial when the shape was detected and increased by 3% when the shape was undetected two trials in a row. One staircase from the bottom (i.e., 15% contrast) and one staircase from the top (i.e., 45% contrast) were implemented for each combination of three SOAs and two shapes, for a total of 12 staircases. Each staircase contained 30 trials. The top and bottom contrasts were chosen on the basis of the results of a pilot test with 3 participants, to ensure that the bottom contrast was invisible and the top contrast was visible.
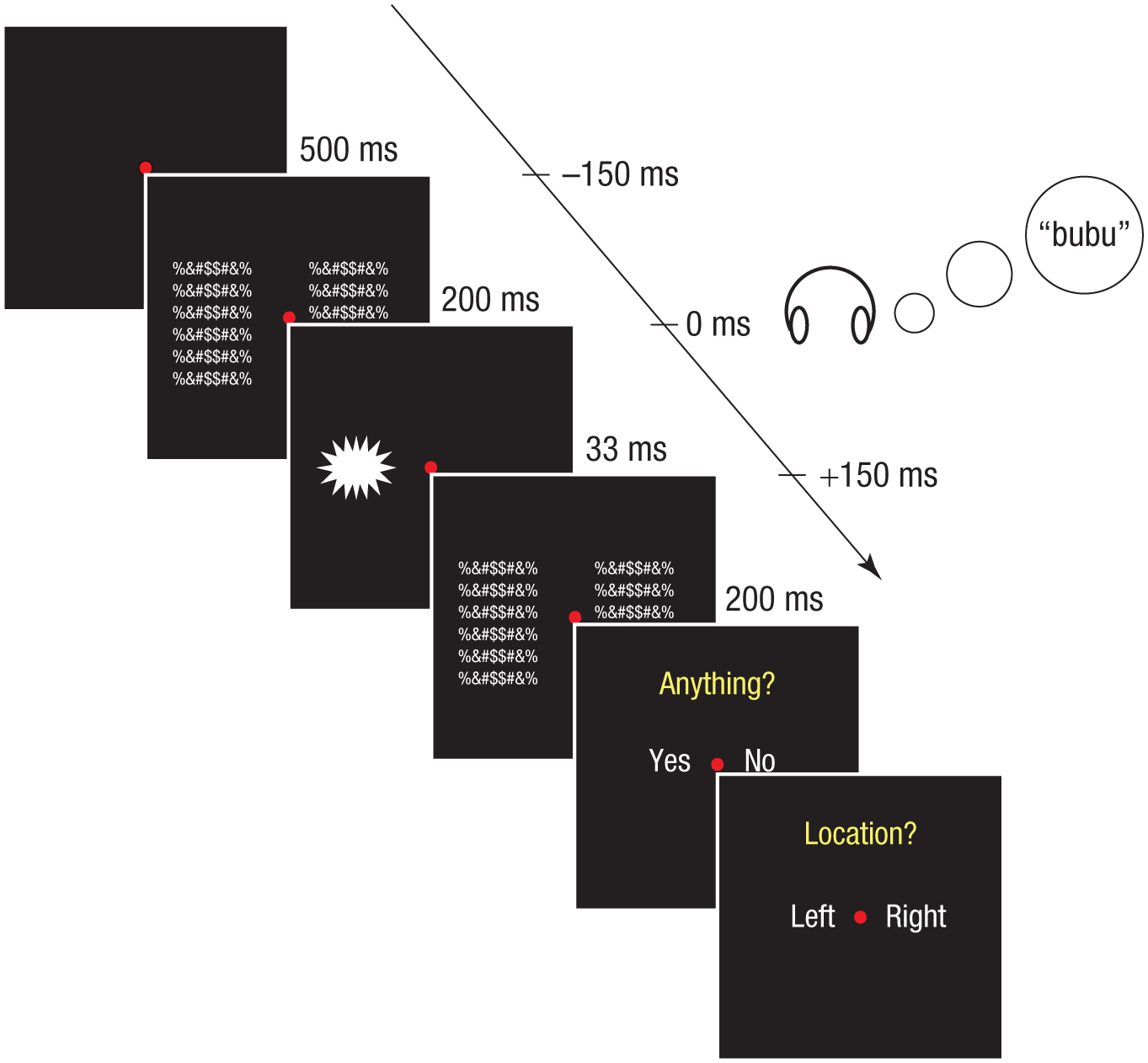
Illustration of the procedure in Experiment 3. Each trial began with a 500-ms blank screen, followed by a 200-ms forward mask, the 33-ms visual target, and a 200-ms backward mask. The auditory target (e.g., “bubu”) was delivered 150 ms before, 150 ms after, or concurrently with the visual target. Participants’ task was to indicate first the visibility and then the location (left or right) of the shape.
In order to evaluate whether the congruence of an auditory word form influenced the threshold at which the stimulus became visible, we presented the word forms at three different SOAs: 150 ms before the target (–150 ms), simultaneously with the target (0 ms), and 150 ms after the target (+150 ms). The three SOAs were chosen on the basis of a recent event-related potential study demonstrating that a frontal component differentiated processing of sound-shape congruence versus incongruence as early as 100 to 160 ms after stimulus onset (Sučević et al., 2015), suggesting that audiovisual integration may require more than 100 ms from the onset of the audio or visual stimulus before an effect can be observed. After the stimulus presentation, participants were required to report whether or not they had seen a visual target and then to specify its location (left or right of the fixation point). Participants were instructed to indicate the location as accurately as possible regardless of whether or not they had reported the target to be visible. The purpose of this location task was to identify false alarms.
Every participant completed a congruent block, in which the sounds and the shapes matched (i.e., “bubu” with the rounded shape, “kiki” with the angular shape), and an incongruent block, in which the pairings were reversed. Each block contained 360 trials, for a total of 720 trials. The order of the two blocks was counterbalanced across participants. Criteria for excluding participants and trials were the same as in Experiment 1. Trials on which participants reported that the target was visible yet failed to correctly indicate its location were excluded (3.5% and 2.9% of trials in the congruent and incongruent blocks, respectively).
Results
Accuracy on the location task did not differ between the incongruent and congruent blocks either when the visual shapes were reported to be visible, paired-samples t(19) = 1.40, p = .19, or when they were reported to be invisible, paired-samples t(19) = 0.31, p = .76 (Fig. 6). In short, participants reported the visibility of the stimulus with the same degree of accuracy in the two conditions.
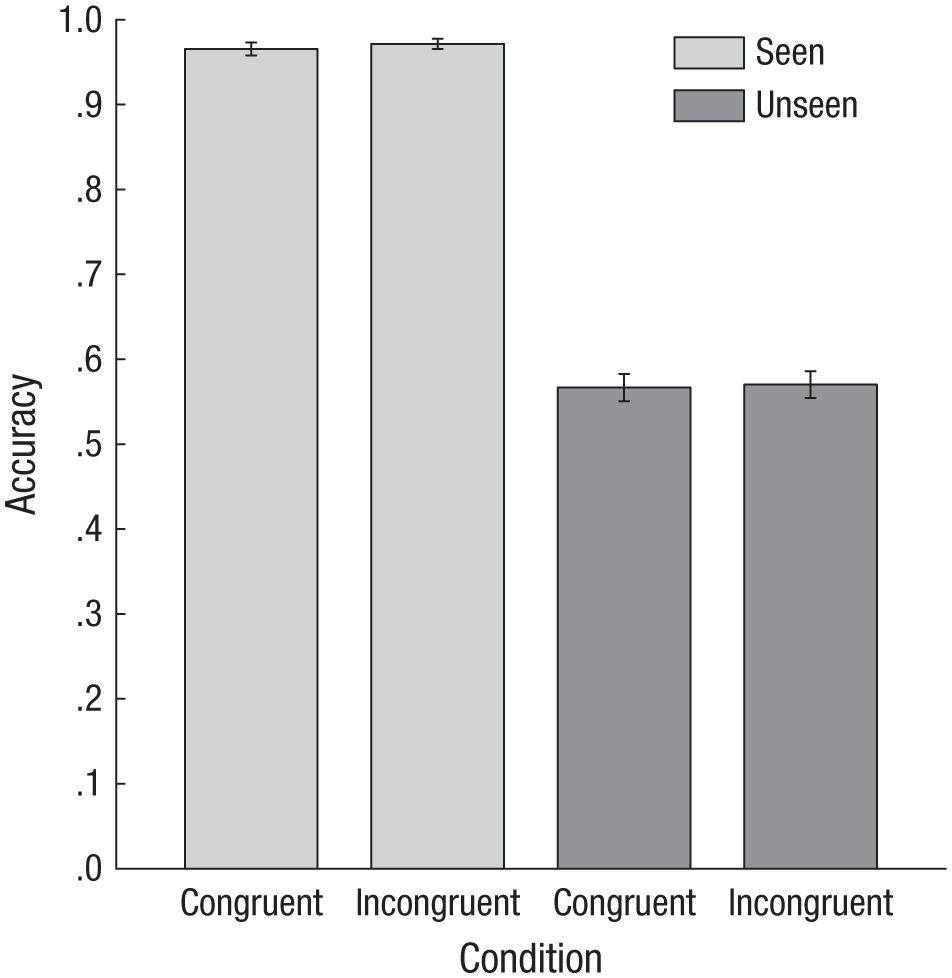
Accuracy on the location task in Experiment 3 when the target was seen and when it was not seen, separately for congruent and incongruent trials. Error bars represent ±1 SEM.
For each individual, all the turning points in the upward and downward staircases (invisible-to-visible, visible-to-invisible) were recorded separately for each stimulus combination, in each block of the study, and these values were averaged to calculate the visibility threshold for each staircase. The mean of the upward- and downward-staircase values within a given condition were taken as the participant’s sensitivity for visual targets in that condition. This method has been used to reliably evaluate the lowest level of intensity at which a participant can typically detect the presentation of a faint stimulus briefly presented between visual masks (e.g., Dixon & Mood, 1948).
A two-way (Congruence × SOA) repeated measures analysis of variance was performed on the stimulus visibility values. The main effects of congruence, F(1, 19) = 3.89, p = .06, η p 2 = .17, and SOA, F(1, 19) = 2.87, p = .07, η p 2 = .13, were both close to the alpha level for statistical significance, and these marginal effects were moderated by a significant two-way interaction, F(2, 38) = 4.86, p = .01, η p 2 = .20, indicating that congruence had different effects depending on SOA. Specifically, post hoc t tests for the three SOAs yielded a significant difference between the congruent and incongruent conditions only when the sound was presented 150 ms before the shape, paired-samples t(19) = 2.65, p = .016 (significant after Bonferroni correction; Fig. 7).

Visibility threshold in Experiment 3 as a function of stimulus onset asynchrony, separately for the congruent and incongruent conditions. The asterisk indicates a significant difference between conditions (p < .05).
We found that when the auditory word form was congruent with the shape (e.g., “kiki” with an angular shape), the threshold for detecting the shape was significantly lower if the audio stimulus was presented before the visual stimulus appeared. Note that this effect was not a generalized cuing effect (in which the presence of an early audio stimulus enhanced awareness of any upcoming visual stimulus), but was selective to those combinations of audio word form and visual shape that exhibited canonical sound-shape congruence (“kiki”-spiky, “bubu”-curved). Thus, in this experiment, the congruence of an auditory word form with a subsequently presented faint shape sandwiched between two visual masks enhanced the masked shape’s visibility. This finding provides a conceptual replication of the results reported in Experiments 1 and 2, which also showed that the conscious awareness of shapes was enhanced when they contained written words whose phonology was congruent with the shapes. Here we have shown that the prior auditory presentation of congruent phonology has the same effect—reducing the threshold at which a faint visual stimulus is detected. Furthermore, our results using the visual masking paradigm support the claim that the sounds of the word forms are involved in the mapping process, as sharp-sounding word forms were mapped to the sharp visual features of shapes prior to conscious awareness.
General Discussion
We investigated the automaticity of the bouba-kiki effect using two paradigms: first, using written words and shapes rendered invisible by a form of interocular suppression and, second, using auditory word forms with visual shapes hidden from conscious awareness by visual masks. We found that the congruence of a word form (the phonology of written words in Experiments 1 and 2 and auditory words in Experiment 3) with a visual shape could be processed even before the shape reached conscious awareness: A word can sound like a shape before the shape has been seen. Experiment 1 showed that a congruent stimulus (e.g., pseudoword “kiki” inside an angular shape) broke CFS faster than an incongruent stimulus. More important, this effect was replicated in Experiment 2 when the visual properties of the words were controlled by training people to read pseudowords constructed from an unfamiliar script. Crucially, Experiment 3 provided converging evidence in a visual masking paradigm: When the sound and shape were congruent, awareness of the shape was enhanced, as reflected by a significantly lower visibility threshold. Taken together, Experiments 1 and 2 show that visual shape can be automatically mapped to the linguistic content (i.e., phonology) represented by a written form, and that this process occurs before either the shape or the letters have been consciously perceived. Furthermore, Experiment 3 shows that the enhancement due to sound-shape correspondence can occur when a congruent auditory word form precedes a shape presented below the level of conscious perception.
Our findings in Experiments 1 and 2 are novel for a number of reasons. In Westbury’s (2005) experiment, participants made a lexical decision without paying attention to the relationship between the word and its background shape, but we went further, showing that sound-shape congruence can exert an effect even when the composite stimulus is invisible. Also, although CFS has previously been used to investigate a wide range of cognitive-perceptual processing, including processing involved in facial expression recognition (e.g., priming of facial expressions by suppressed upright faces: Almeida, Pajtas, Mahon, Nakayama, & Caramazza, 2013; facial attractiveness: Hung, Nieh, & Hsieh, 2016; saliency: Hsieh, Colas, & Kanwisher, 2011; Hsieh & Colas, 2012), syntactic processing (Hung & Hsieh, 2015), semantic and orthographic priming (Costello, Jiang, Baartman, McGlennen, & He, 2009), and audiovisual priming (Lupyan & Ward, 2013), this is the first report that congruence between a visual word form and the visual properties of a shape can influence behavior when neither the word nor the object has been seen. Furthermore, we showed that the phonological representation of a recently learned visual word form can interact with visual features of shapes during emergence from suppression. These CFS experiments demonstrate that the effects are driven by the phonology associated with written word forms, not by the visual shape of the letters.
In Experiment 3, we obtained a similar effect: Congruence between auditory and visual stimuli influenced the perceptual threshold of visual stimuli presented below the level of conscious awareness, but only when the auditory stimulus was presented first. This finding suggests that activation arising from the auditory pseudoword primes the detection of visual shape features to enhance the perception of visual targets below the threshold of consciousness. Our finding is novel for two reasons. First, the type of congruence we tapped into is a different kind of sensory alliance that has not been reported in the literature on thresholds of visual awareness—an unlearned sensory match that arises spontaneously during stimulus presentation. Second, although some researchers have argued that the time taken to break suppression is not a good measure of unconscious processing (see the Supplemental Material for further discussion), we demonstrated that the effect was not specific to the liminal zone of CFS, but reflected a more general sound-shape mapping without awareness: In Experiment 3, results obtained with a masking paradigm demonstrated that interaction between the visual and auditory domains can occur within a short time window (i.e., 150 ms) when the visual stimulus is presented extremely briefly (for only 33 ms), such that stimuli just below the threshold of visual perception can be “rescued” into visibility by a congruent audio prime. Note that in this case we refer only to consciousness in the visual domain, as in Experiment 3 the audio was always presented at a conscious level. So rather than claiming that the sound-shape mapping can occur entirely unconsciously, we argue that an audible sound, when presented slightly earlier, can prompt a congruent visual shape to be seen, an effect that suggests there is an interaction between conscious and unconscious perception.
Experiment 3 provided three advantages in examining linguistic sound symbolism (i.e., the bouba-kiki effect) at the limits of visual perception: First, the extremely brief visual presentation (i.e., 33 ms) prevented the partial awareness that may occur in the typical breaking-interocular-suppression design, in which invisibility may be confounded with participants’ uncertainty about whether they perceived the stimulus clearly (e.g., Gayet et al., 2014). Second, participants reported simply whether they were able to see a stimulus or not, and the measured threshold was lower when the visual stimulus had been presented after a congruent, rather than incongruent, auditory prime. This means that hearing a congruent word form effectively rescued some stimuli that were too faint to be perceived otherwise. This effect could have arisen only if the interaction between the phonology of the word form and visual features occurred prior to conscious awareness. Finally, in the poststudy debriefing session, participants reported that they did not perceive the visual shape consciously in most of the trials, which means that the masking was effective, and when the shapes and sounds were presented at a conscious level, participants reported that they were unaware of any relationships between them, which means that participants were not biased by preexisting notions of sound-symbolic congruence. This lack of conscious expectations about the mapping between words and images reduces the likelihood that the effects arose out of strategic response biases.
Taken together, all three experiments showed that congruence between a word form (spoken or written) and a visual shape enhances conscious awareness of the shape when it has been rendered invisible by interocular suppression or by brief, faint, masked presentation. The experiments demonstrated that this effect is driven by phonology, not orthography, and it was similar whether the word form was presented visually or auditorily. Furthermore, the finding that cross-modal matching decreases the threshold required to consciously perceive a visual shape demonstrates that the effect occurs before conscious awareness of the images that are matched up with the sounds.
One other study has investigated the level of processing required by effects like the bouba-kiki effect. Parise and Spence (2012) explored sound-symbolic mappings in a series of Implicit Association Tests (IATs) designed to compare different kinds of cross-modal congruence in a high-speed reaction time task. The cross-modal IAT involves pressing keys in response to four different stimuli. There are only two response keys; one is assigned to two different stimuli, and the other is assigned to the remaining two stimuli. For example, participants may be told to press the left key in response to a high pitch or a small dot and the right key in response to a low pitch or a large dot. Only one stimulus (audio or visual) is presented per trial, and the pairings of stimuli assigned to the same key are changed between blocks. Responses are faster when the stimuli assigned to the same key have a pervasive implicit association (e.g., high-small) than when there is some level of conflict or incongruence in the mapping (e.g., high-large; Greenwald, McGhee, & Schwartz, 1998). Parise and Spence observed implicit associations between pitch and size, pitch and angularity, and auditory smoothness (sine or square wave) and angularity. In addition, their data supported two canonical sound-symbolism mappings: Sapir’s (1929) mapping of “mil” with small dots and “mal” with large dots, and Köhler’s (1929) mapping of “maluma” with curvy line drawing and “takete” with angular line drawings. All five effects were of the same magnitude, which suggests that linguistic sound symbolism, like cross-modal processing for well-known sensory correspondences (e.g., between pitch and height), can occur without evaluating the quality of a match between stimuli. The authors argued that their results reflect an automatic level of cross-modal processing, as the interference when incongruent stimuli were assigned to the same response key was not under voluntary control.
The experiments we have reported here went one step further, demonstrating that sound symbolism not only can influence the speed of postperceptual decisions about which key to press in a high-speed response paradigm, but also can influence the threshold at which a difficult-to-see stimulus becomes visible. We therefore argue that our results reflect cross-modality in automatic perceptual processing, and that this is the first demonstration that the influence of linguistic sound symbolism begins at preconscious stages of processing.
Supplemental Material
HungSupplementalMaterial – Supplemental material for Can a Word Sound Like a Shape Before You Have Seen It? Sound-Shape Mapping Prior to Conscious Awareness
Supplemental material, HungSupplementalMaterial for Can a Word Sound Like a Shape Before You Have Seen It? Sound-Shape Mapping Prior to Conscious Awareness by Shao-Min Hung, Suzy J. Styles and Po-Jang Hsieh in Psychological Science
Footnotes
Acknowledgements
We would like to thank PerMagnus Lindborg for loaning audio recording equipment and Ng Kend Tuck for recording and processing the audio stimuli.
Action Editor
Edward S. Awh served as action editor for this article.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
This study was supported by a Nanyang Assistant Professorship Grant to S. J. Styles for “The Shape of Sounds in Singapore.”
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.