
Abstract
Using a lifting and balancing task, we contrasted two alternative views of planning joint actions: one postulating that joint action involves distinct predictions for self and other, the other postulating that joint action involves coordinated plans between the coactors and reuse of bimanual models. We compared compensatory movements required to keep a tray balanced when 2 participants lifted glasses from each other’s trays at the same time (simultaneous joint action) and when they took turns lifting (sequential joint action). Compared with sequential joint action, simultaneous joint action made it easier to keep the tray balanced. Thus, in keeping with the view that bimanual models are reused for joint action, predicting the timing of their own lifting action helped participants compensate for another person’s lifting action. These results raise the possibility that simultaneous joint actions do not necessarily require distinguishing between one’s own and the coactor’s contributions to the action plan and may afford an agent-neutral stance.
Joint actions require that two or more people coordinate their actions in space and time (Sebanz, Bekkering, & Knoblich, 2006; Sebanz & Knoblich, 2009). Examples include exchanging money at a sales counter (Clark, 1996), holding the door open for another person (Santamaria & Rosenbaum, 2011), lifting objects together (Bosga & Meulenbroek, 2007), or picking up a glass of champagne from a waiter’s tray at a reception. The latter action provides a challenge for the waiter because he or she quickly needs to compensate for the change in weight (i.e., generate an upward movement) in order to keep the tray balanced. In the terms of predictive-control theory, the waiter will use a forward model (i.e., an internal model that permits prediction of actions’ consequences) to predict how to best compensate (Friston, 2011; Miall & Wolpert, 1996; Pezzulo & Cisek, 2016; Shadmehr, Smith, & Krakauer, 2010; Wolpert, Doya, & Kawato, 2003).
Use of predictive control implies that compensation will be easier if the waiter lifts the glass him- or herself. In such a bimanual action, action plans are coordinated in space and time (Kelso, Southard, & Goodman, 1979a, 1979b; Schöner, 1990), and the agent has access to the state of the lifting hand—information that will help in predicting the timing and extent of the perturbation. We refer to this as the bimanual condition. Predicting the perturbation caused by another person’s lifting action is harder, because internal information about the perturbation is missing. There is one exception to this: When two waiters simultaneously lift glasses off each other’s trays, they could use information about their own lifting to predict the timing of the other’s lifting action. We refer to the case in which coactors take turns lifting glasses from each other’s trays as the sequential joint condition and the case in which they lift the glasses simultaneously as the simultaneous joint condition.
Comparing compensatory movements across these three conditions (bimanual, sequential joint, and simultaneous joint) allowed us to test two alternative views of how prediction supports joint action. In principle, coactors may combine two sets of forward models (one for the self and one for the other) to predict joint outcomes (Sebanz & Knoblich, 2009). In this case, predicting the timing and extent of one’s own lifting action should not help in compensating for another person’s lifting action. Alternatively, coactors may reuse a bimanual model for the joint lifting action. That is, they may coordinate the action plans of the self and other in the same way that they coordinate the plans for their left and right hands when they lift a glass from their own tray, so that the movements of their right hand, for example, are reused to predict the other person’s right-hand movement. In this case, predicting the timing and extent of one’s own lifting action should help in compensating for another person’s lifting action. Thus, if a bimanual model is reused, it should be easier to compensate for the weight change in the simultaneous joint condition than in the sequential joint condition.
Method
Twenty right-handed participants (ages 21–32 years) with normal vision were tested in dyads. The 2 participants forming a dyad faced each other at a comfortable interpersonal distance (Fig. 1a). Their dominant hand was free to move, and their nondominant hand balanced a tray at an elbow angle of 90°. A “glass” (cylindrical object with a diameter of 4 cm and a height of 12 cm) was positioned on each tray. Participants’ hand movements were measured using TrakSTAR (Ascension Technology, www.ascension-tech.com) sensors attached to the back of their hands.

Experimental setup and results. The top-down views of the setup (a) show the participants’ posture at the beginning of each trial (dark shading) and their posture at the end of each trial (light shading) in the bimanual condition (top) and the two joint conditions (bottom). In the simultaneous joint condition, participants were instructed to lift the glasses from their trays as simultaneously as possible. In the sequential joint condition, participants were asked to take turns in lifting the glasses from each other’s trays. The sample raw data in (b) illustrate the time course of the vertical movements of the hand holding the tray across six experimental trials (delimited by vertical lines). The purple dots show the movements that compensated for the weight change caused by the glass being lifted. The inset shows the integral (in yellow) used as the measure of compensatory movements. The bar graph (c) shows the average of the total compensatory movement performed in each of the five experimental conditions. Error bars represent ±1 SEM. Asterisks indicate significant differences (p < .001). The line graph (d) shows the average time course of vertical movement of the hand holding the tray in each of the conditions. On the y-axis, 0 refers to the height of the hand at the beginning of each trial. The bands around the plotted lines in (d) represent ±1 SEM.
Participants were instructed to keep the tray at a constant position. In the bimanual condition, they simultaneously lifted the glasses from their own trays. In the simultaneous-joint condition, participants simultaneously lifted the glasses from each other’s trays. In the sequential-joint condition, they took turns in lifting the glasses from each other’s trays. We also included two control conditions. In the first control condition, participants did not lift the glasses but held in their free hands a glass that weighed the same as the glass that was lifted from their tray (by another participant). This condition controlled for the possibility that any difference in compensatory movement between the simultaneous joint and sequential joint conditions might be due to the fact that information about the weight of the glass was available throughout the compensatory phase in the former but not the latter condition. In the second control condition, each participant lifted a glass from a table while the glass on his or her tray was simultaneously lifted off the tray by another participant. This condition controlled for the possibility that any difference in compensatory movement between the simultaneous joint and sequential joint conditions might be due to the mere execution of a simultaneous lifting task (which might, e.g., activate coherent action-perception loops or improve balance control) rather than to a bidirectional and symmetric interaction between the coactors.
Each participant performed 20 trials in each condition. After each trial, participants themselves repositioned the glass they had lifted to its original position. The order of the three experimental conditions and the two control conditions was counterbalanced.
Results
Our measure of the compensatory movements of the hand holding the tray was the integral of the movement curve on the vertical axis (Fig. 1b) from the start of the perturbation (i.e., 0 ms) until 300 ms after the perturbation. The integral merges compensatory hand movements in the up and down directions. A one-way analysis of variance revealed a significant effect of condition, F(4, 95) = 19.3211, p < .001, Cohen’s f = 0.9. Post hoc analyses (Tukey’s test) revealed that participants’ compensatory movements in the simultaneous joint condition were significantly reduced compared with their compensatory movements in the sequential joint condition (p < .001) and the two control conditions (both ps < .001) but still larger than their compensatory movements in the bimanual condition (p < .001; see Figs. 1c and 1d). Furthermore, compensatory movements in the sequential joint condition were significantly different from those in the first control condition (p < .05). Compensatory movements in the second control condition were not significantly different from compensatory movements in the sequential joint or the first control condition. We performed the same analysis for the period of time preceding the perturbation (from −300 ms to 0 ms) but found no significant differences between conditions (all ps > .05).
Discussion
Participants’ compensatory tray-balancing movements were reduced when they lifted one another’s glasses simultaneously compared with when they lifted one another’s glasses sequentially. This result indicates that predicting and having access to the timing and outcomes of their own lifting actions helped participants to compensate for the effects of another person’s lifting action.
Differences in cognitive or attentional load cannot explain the present findings. Such differences would predict the opposite pattern: In the simultaneous joint condition, participants were required to process their own and their partner’s movements at the same time, whereas in the sequential joint condition, they could fully devote their resources to predicting the outcomes of their partner’s observed action. The results obtained in the two control conditions rule out the possibilities that the reduced compensation during simultaneous joint action was due to access to weight information throughout the compensatory-movement phase (i.e., compensation was smaller in the simultaneous joint condition than in the first control condition) or due to the mere simultaneous execution of a lifting action (i.e., compensation was smaller in the simultaneous joint condition than in the second control condition). A substantial reduction in compensatory movement occurred only when coactors performed simultaneous and reciprocal joint actions.
The pattern of results implies that coactors do not always combine two sets of forward models (one for the self and one for the other) to predict joint-action outcomes. Rather, the results can be readily explained by the assumption that participants reused a bimanual model while performing simultaneous joint action. Figure 2a illustrates how a bimanual model from optimal-control theory (Diedrichsen, Shadmehr, & Ivry, 2010; Scott, 2012; Shadmehr et al., 2010; Todorov, 2004) might describe the situation of an agent lifting a glass off a tray with the right hand while keeping the tray at a constant height with the left hand. XC represents the estimated state of the tray’s height; Xl and Xr represent the estimated states (e.g., posture and velocity) of the left and right hands, respectively; and ul and ur represent the motor commands sent to the left and right hands, respectively (or, alternatively, expected proprioception in active-inference schemes; Adams, Shipp, & Friston, 2013; Pezzulo, Rigoli, & Friston, 2015). Estimation of tray height and hand states (XC, Xl, Xr ) depends on current sensations as well as predictions generated by internal models. If the estimate for tray height (XC ) deviates from the desired state because of an expected weight reduction (e.g., a weight reduction generated by the same agent), the system can generate predictions of the appropriate motor commands (ul) that would keep the tray at the desired height in the face of the perturbation—and hence, exert accurate control. It is important to note that in this bimanual model, the same variable (XC ) influences the motor commands for both hands (see the arrows from XC to both ul and ur). In other words, tray height is controlled through coordinated actions of the two hands, which implies that the hand lifting the glass contributes to keeping the tray stable.
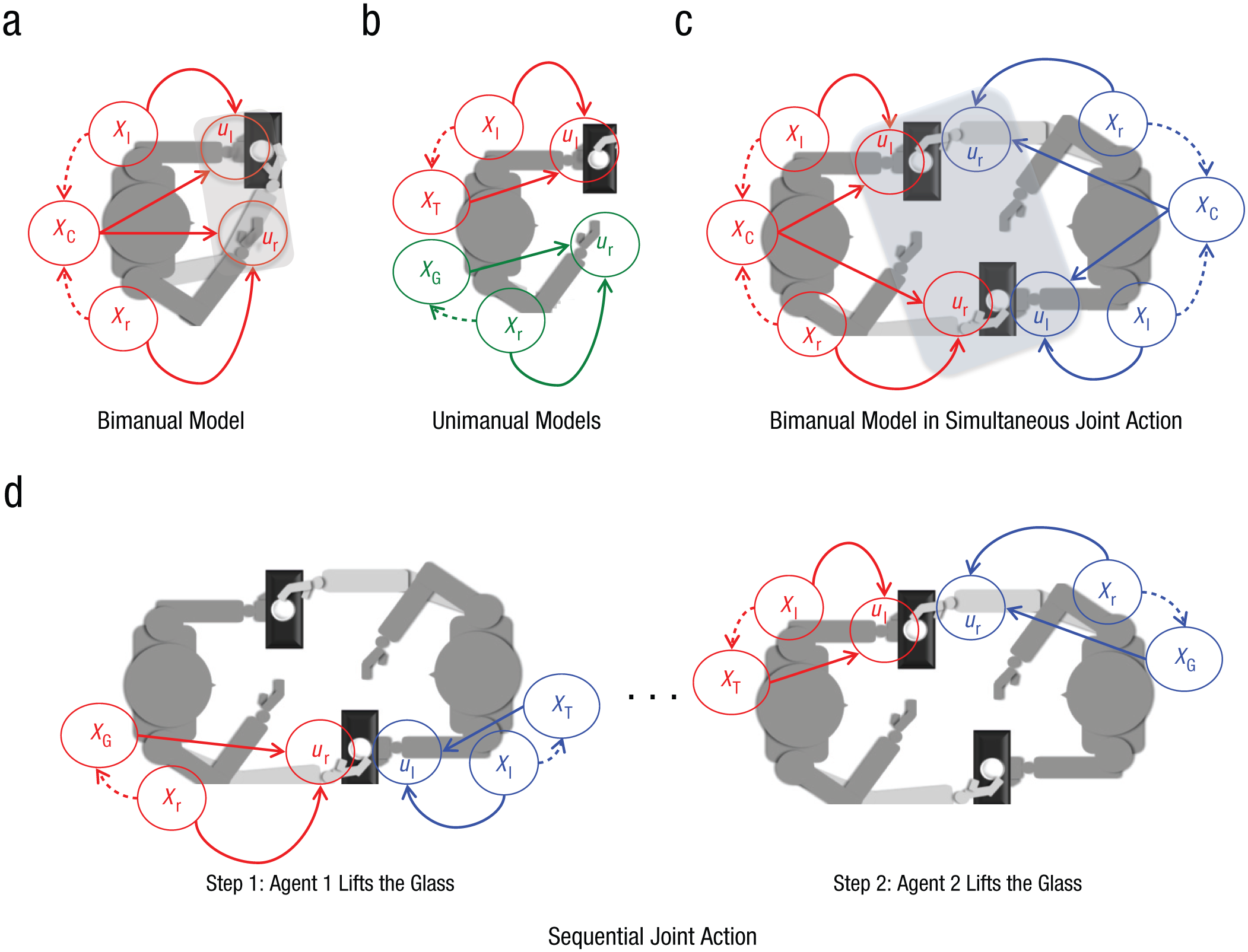
Optimal-control models for the three experimental conditions. In a bimanual model for the bimanual condition (i.e., lifting a glass from a tray one is holding), the control of the left hand and the control of the right hand are interdependent (a); that is, the motor commands for both hands (ul and ur) depend on the estimations of hand states (Xl, Xr), as well as a shared variable (XC) representing the estimated state of the tray’s height (see the solid lines between variables). Furthermore, it is possible to estimate (XC) on the basis of both Xl and Xr (see the dashed lines). This situation promotes a coordinated unfolding of motor plans for the two hands (see the shaded rectangle). If the same situation were hypothetically cast in terms of two unimanual models, then the control of the left hand would be independent of the control of the right hand (b); that is, the control of the left and right hands would depend on two separate sets of internal variables—XT and Xl for the left hand and XG and Xr for the right hand—and this would prevent the unfolding of coordinated motor programs that is a hallmark of bimanual control. A bimanual model could be reused (i.e., applied to two agents rather than two arms) in the simultaneous joint condition (c). Performance in the sequential joint condition is better described in terms of a separate unimanual model for each agent (d). See the main text for additional explanation. For the sake of simplicity, we have omitted temporal indices from the models.
The same bimanual model can be applied to the simultaneous joint condition (Fig. 2c). In this case, the control commands of Agent 1 affect the state of the hands of Agent 2 by operating on Agent 2’s tray. Similarly, the control commands of Agent 2 affect the state of the hands of Agent 1 by operating on Agent 1’s tray. This promotes coordination of both the two agents’ actions (coordination analogous to the coordination of the left and right hands in bimanual control, shown in Fig. 2a) and the two agents’ internal variables. As in the bimanual case, each actor can use the state of both his or her left hand (Xl) and his or her right hand (Xr ) to estimate the tray’s height (XC ); each actor can also use the prediction (or corollary discharge; von Holst & Mittelstaedt, 1950) of his or her own lifting action to compensate for the other actor’s lifting action. Because the effect of Agent 1’s own hand movement on the height of Agent 2’s tray is synchronous with and very similar to the effect of Agent 2’s hand movement on Agent 1’s own tray, Agent 1 can use the state of his or her hand (Xr) vicariously to estimate the timing and impact of Agent 2’s hand movement on Agent 1’s own tray—and in turn, to produce precise compensatory movements. And, of course, the same reasoning applies to Agent 2’s control of his or her own tray. Furthermore, as in single-agent bimanual control, the lifting movement of each agent can effectively contribute to keeping the other agent’s tray stable. In sum, using a bimanual model in the simultaneous joint condition, the coactors can effectively engage in an interpersonal feedback loop. For Agent 1, Agent 2’s movements are treated as if they were performed by Agent 1’s own limbs, and for Agent 2, Agent 1’s movements are treated as if they were performed by Agent 2’s own limbs.
Joint action in the sequential joint condition (Fig. 2d) is better understood in terms of two unimanual actions (lift and then hold or vice versa) of the two actors. Unimanual models of hand movement assume that the control of the left hand and control of the right hand are independent. For example, Figure 2b shows (hypothetical) unimanual models for an actor performing two actions in parallel: lifting with the right hand and holding a tray in the left hand. In a unimanual model for the sequential joint condition, estimates of tray height depend only on the state of the hand holding the tray (Xl), and an actor cannot compensate for the other actor’s lifting (see Fig. 2d) by using the state of his or her other hand (Xr ) to estimate the motor commands needed to keep the tray at a stable height. Although there is a theoretical possibility that actors could apply their bimanual models to sequential joint action as well, our results show that reuse of bimanual models is effective only for actions that are very close together in time (synchronous). Even if the actor holding the tray used the state of his or her right hand (Xr ) to estimate the tray’s height (XC ), that estimate would be imprecise given the large differences (e.g., time lag) between the two lifting actions. Thus, the bimanual model would be ineffective.
Although participants could have used a bimanual model in the second control condition, they would have received no benefit from using it because the internal control variables and action plans used by the two coactors overlapped less than in the simultaneous joint condition. This is because the joint action was not reciprocal in the second control condition, and the motor commands of the agent who lifted the glass from the table did not affect the state of the agent who lifted the glass from the tray (i.e., the loop between the two coactors was not closed). This, in turn, prevented the alignment of internal control variables and the resulting coordinated unfolding of action plans that is a hallmark of bimanual models. Whereas the agent who lifted the glass from the table could use the sensed weight perturbations to adjust his or her internal variables (and lifting actions) to be closer to the other agent’s internal variables (and lifting actions), the agent who lifted the glass from the tray could not do the same, as he or she lacked equivalent (proprioceptive) error signals—hence, the overlap between the two agents’ internal variables was poorer than in the simultaneous joint condition. The agent who lifted the glass from the table could not use the state of his or her hand to estimate the perturbations produced by the other agent and compensate for them; nor could the latter agent’s actions be considered as part of a coordinated program to keep his coactor’s tray balanced, as was the case in the simultaneous joint condition. The absence of a benefit from reusing a bimanual model in the second control condition suggests that the bimanual scheme is effective only when the coactors are reciprocally coupled and their plans and predictions can unfold coherently in time (Noy, Dekel, & Alon, 2011).
To sum up, our findings can be interpreted in terms of a reuse of bimanual models in simultaneous joint actions. Using a bimanual model was more effective in compensating for another person’s lifting action (simultaneous joint condition) than was predicting the other person’s action (e.g., the timing and amplitude of the perturbation) from observing his or her movement (sequential joint condition), but using a bimanual model to compensate for another person’s lifting action was less effective than compensating for one’s own lifting action (bimanual condition). The latter result was expected because using one’s own model to specify motor commands will be more accurate for one’s own actions than for another person’s actions (Keller, Knoblich, & Repp, 2007).
It is possible that participants used preparatory strategies (e.g., tensing the arm holding the tray) as part of their tray-balancing control. However, the use of such strategies cannot fully explain our findings, as these strategies could be applied in all the conditions (e.g., even if one cannot exactly predict the timing of perturbation, one can maintain an isometric contraction of the arm for a sufficiently long period). The lack of significant differences between conditions in arm movements preceding the perturbation supports this interpretation.
Also, participants may have used reflexive reactions in addition to (or instead of) the more sophisticated control schemes discussed here; for example, they may have exclusively used feedback information (not predictions) to compensate for the change in weight (such reactions would be analogous to reactive postural adjustments; Alexandrov, Frolov, Horak, Carlson-Kuhta, & Park, 2005). However, the use of reactive strategies based only on feedback cannot fully explain our findings. Given that the change in weight was the same in all conditions, it is unclear why reactive strategies to proprioceptive feedback would have produced differential adjustments in our experimental conditions. And compensatory adjustments based on visual feedback should have been better, not worse, in the sequential joint condition than in the simultaneous joint condition, as in the former condition participants could devote their full attention to the coactor’s movements and therefore should have had better visual-feedback information.
Another possibility is that participants used a more nuanced scheme based on corollary discharges of their own actions (Crapse & Sommer, 2008). That is, they could have used these corollary discharges to directly cancel out the perturbations created by their coactors’ movements when these signals were comparable (i.e., in the simultaneous joint and second control conditions). This explanation would not be incompatible with what we are proposing here; rather, it can be considered a special case of (optimal) motor control that uses only corollary discharges instead of full state estimation (which can also incorporate, e.g., visual information) to derive a control policy that keeps the tray balanced.
The current results imply that learning coordination within the self can help with learning how to coordinate with other people, particularly when one is performing the same actions synchronously with another person (Candidi, Curioni, Donnarumma, Sacheli, & Pezzulo, 2015; Friston & Frith, 2015; Kelso, 1995; Marsh, Richardson, & Schmidt, 2009; Pezzulo, 2011; Pezzulo & Dindo, 2011; Pezzulo, Donnarumma, & Dindo, 2013; Richardson, Marsh, Isenhower, Goodman, & Schmidt, 2007). Performing identical actions at the same time is frequent—in singing, ensemble music (Keller, Novembre, & Hove, 2014), and dance (McNeill, 1997); in sport activities, such as joint juggling and gymnastics; in performance theater and improvisation, such as the mirror game, in which two actors attempt to spontaneously perform the same movements at the same time (Noy et al., 2011); and in cultural rituals, such as military marching or church singing (Wiltermuth & Heath, 2009). Furthermore, many mundane joint actions, such as lifting or transporting objects together, resemble the task we studied in that they require two agents to coordinate their actions on a very fine-grained time scale to balance objects together. An interesting case that has been studied in detail is joint improvisation in the mirror game (Noy et al., 2011); in this game, performing the same action synchronously might be an intentional strategy used to dissolve the boundary between self and other (Sebanz et al., 2006). Finally, the current findings suggest that during simultaneous joint action, coactors form a joint plan that does not necessarily separate each actor’s contributions (Pezzulo, 2013; Pezzulo, Iodice, Ferraina, & Kessler, 2013; Vesper, Butterfill, Knoblich, & Sebanz, 2010). From a computational perspective, this can be achieved when two interacting agents who share the same generative (forward) models align their actions and predictions during an interaction (Friston & Frith, 2015). Our results raise the possibility that simultaneous joint actions may afford an agent-neutral stance, whereas sequential joint actions may afford a stance that distinguishes between self and other.
Footnotes
Action Editor
Marc J. Buehner served as action editor for this article.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
G. Knoblich was supported by the European Research Council (ERC) under the European Union’s Seventh Framework Program (FP7/2007-2013)/ERC Grant 609819, SOMICS (Construction of Social Minds: Coordination, Communication, and Cultural Transmission).