
Abstract
Does the perceptual system for looking at the world overlap with the conceptual system for thinking about it? We conducted two experiments (N = 403) to investigate this question. Experiment 1 showed that when people make simple semantic judgments on words, interference from a concurrent visual task scales in proportion to how much visual experience they have with the things the words refer to. Experiment 2 showed that when people make the same judgments on the very same words, interference from a concurrent manual task scales in proportion to how much manual (but critically, not visual) experience people have with those same things. These results suggest that the meanings of frequently visually experienced things are represented (in part) in the visual system used for actually seeing them, that this visually represented information is a functional part of conceptual knowledge, and that the extent of these visual representations is influenced by visual experience.
As you search through your fridge for a bottle of salad dressing, a voice calls, “Wasn’t last night’s sunset amazing?” It takes you a moment to consider, and before you can respond, your partner expresses disappointment in your inability to recall a memorable evening. Although your attention was certainly absorbed by your search for that elusive bottle of dressing, viewing the items in the fridge might have made it especially challenging to think about a sunset. Why? According to sensorimotor-based models of cognition, conceptual knowledge is grounded in the same sensorimotor systems used while experiencing the world (e.g., Allport, 1985; Barsalou, 1999). So if your visual system is engaged when you are trying to think about something predominantly experienced visually, such as a sunset, some of the resources that normally help you consider (or simulate) the sunset will be unavailable. If your partner had instead asked about something experienced more in other modalities, such as an ocean breeze, responding might have been easier.
Evidence supporting sensorimotor-based models has been mounting. Brain areas involved in sensing, perceiving, and acting are also active when we read or hear language related to sensation, perception, and action (for reviews, see Barsalou, 2016; Meteyard, Cuadrado, Bahrami, & Vigliocco, 2012), suggesting that these brain areas support conceptual processing. However, sensorimotor activation during conceptual processing does not necessarily show that activity in sensorimotor systems forms a functional part of conceptual representations.
Rather, sensorimotor activation may be simply associated with (or peripheral to) conceptual processing (Mahon & Caramazza, 2008). That is, visual system activation when people think about sunsets may be a consequence, rather than a functional part, of conceptualizing sunsets. A complementary argument has been made in response to demonstrations that priming the sensory modality associated with a concept can partially activate that concept (e.g., Connell, Lynott, & Dreyer, 2012; Helbig, Steinwender, Graf, & Kiefer, 2010; Vermeulen, Mermillod, Godefroid, & Corneille, 2009). That is, sensory information could, in principle, elicit a cascade of activation, which in turn activates an abstract concept representation (Mahon & Caramazza, 2008). Each of these arguments—that sensorimotor activation is a consequence of, and that such activation leads to, abstract concept processing—would suggest that this activation is not part of our concept representations.
To demonstrate unequivocally that activity in the visual system (or any sensory system) is part of a conceptual representation requires showing that when that system is disrupted (e.g., via brain damage, stimulation, or an interfering task that relies on that system), processing that concept is also disrupted. Yet despite the theoretical importance of such evidence, surprisingly little exists. Most comes from the neuropsychological literature. Patients with difficulty accessing concepts that are thought to primarily rely on a particular sensorimotor system (e.g., the ventral/visual-processing stream for animals and dorsal/object-related action stream for tools) tend to have brain damage affecting that system (for reviews, see Gainotti, 2000, 2015). Some studies have examined effects of interference on conceptual processing (primarily for actions or action-associated objects) in unimpaired individuals. These studies have generally found that interfering with (e.g., via a concurrent interfering task) sensorimotor activity thought to be associated with an action or object makes conceiving of it more difficult (e.g., Ostarek & Huettig, 2017, Experiment 1; Pobric, Jefferies, & Lambon Ralph, 2010; Shebani & Pulvermüller, 2013; Vukovic, Feurra, Shpektor, Myachykov, & Shtyrov, 2017; Witt, Kemmerer, Linkenauger, & Culham, 2010; Yee, Chrysikou, Hoffman, & Thompson-Schill, 2013; but cf. Matheson, White, & McMullen, 2014).
However, most studies compare interference between categories of concepts (e.g., living/nonliving, concrete/abstract). Thus, it remains possible that some categorical property (e.g., concreteness; Ostarek & Huettig, 2017)—not sensorimotor experience—is responsible for the interference. Distinguishing among these possibilities is critical—a fundamental prediction of sensorimotor-based models is that sensorimotor experience with things determines the extent to which sensorimotor information is part of their representations. So, for example, although concreteness is correlated with sensorimotor experience, it is sensorimotor experience that should account for the conceptual-processing difficulty produced by sensorimotor interference.
Furthermore, if sensorimotor-based information is truly part of conceptual knowledge, this crucial relationship between sensorimotor experience and interference may be detectable not only during deliberate verification or retrieval of a concept’s features (as shown, e.g., by Amsel, Urbach, & Kutas, 2014; Edmiston & Lupyan, 2017; and Ostarek & Huettig, 2017, for visual features and by Chrysikou, Casasanto, & Thompson-Schill, 2017, for manipulation information) but also when the conceptual task does not require accessing sensorimotor properties. Yet very few studies have obtained evidence that the relationship between experience and interference holds when the task does not require explicit retrieval of sensorimotor information (auditory: Bonner & Grossman, 2012; Trumpp, Kliese, Hoenig, Haarmeier, & Kiefer, 2013; manipulation: Wolk et al., 2005; Yee et al., 2013). And in the visual modality, this issue is almost entirely unexplored (but see Rey, Riou, Vallet, & Versace, 2017, discussed below).
Why might vision be different? One reason could be the importance of visual search. If representations of visually experienced things share resources with the visual system, then what you are currently looking at could interfere with your ability to think about the very thing you are searching for. Animals that rely heavily on vision may therefore have developed a method of storing conceptual information that originated via visual experience in a format (one that is presumably more abstract; see Ungerleider & Mishkin, 1982) that is not susceptible to interference from the current visual percept. Indeed, some studies have failed to find evidence that concept-related visual shape information is stored in certain visual-perception regions (e.g., Yee, Drucker, & Thompson-Schill, 2010; see also Ostarek, Joosen, Ishag, de Nijs, & Huettig, 2019).
Here, we directly tested whether conceptual representations of visually experienced things share resources with the visual system. There is some evidence that they may. A tone associated with a complex visual mask delayed semantic judgments (relative to a tone associated with a blank square) on words as a function of visual experience with their referents (Rey et al., 2017). However, because an interference control was lacking (e.g., a tone associated with a complex nonvisual stimulus), this study leaves open the possibility that the visually experienced stimuli may have been particularly susceptible to interference generally. Here, we examined whether interference from a concurrent visual task (see Fig. 1a) when people make simple semantic judgments on heard words scales in proportion to how much visual experience people have with the things the words refer to (Experiment 1). We also included a control interference task previously used to demonstrate the role of motor information in object representations (Yee et al., 2013). This control allowed us to test whether visually experienced things are simply unusually susceptible to interference generally (Experiment 2). Furthermore, we included several other important controls: Critical words all referred to nonliving things, the semantic judgment was orthogonal to the amount of visual experience, and our analyses controlled for concreteness. These controls enabled testing of a fundamental prediction of sensorimotor-based models: Conceptual representations are grounded in sensorimotor experience.
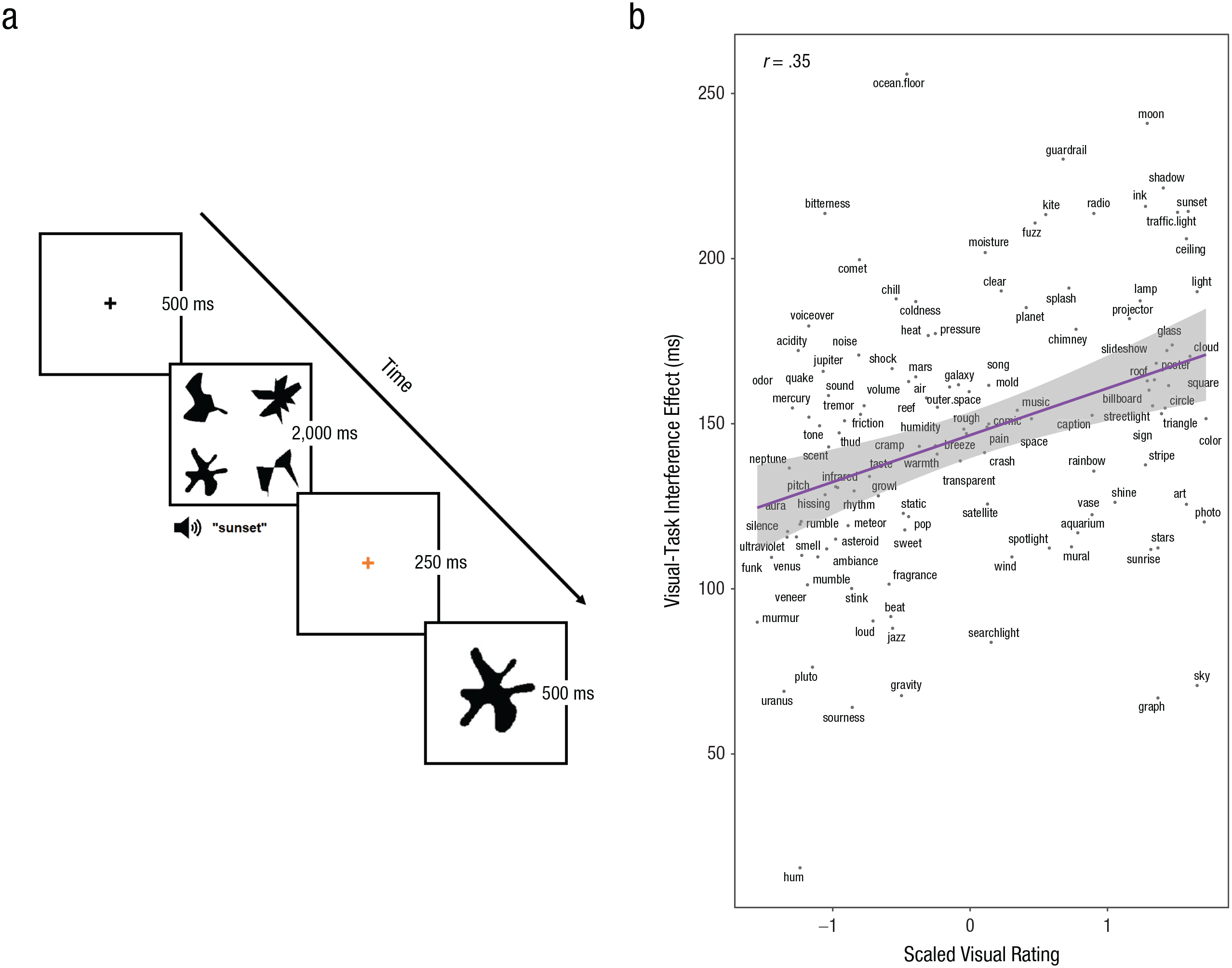
Example trial sequence and results from the visual-interference condition of Experiment 1. In each trial (a), participants saw an array of four geometric nonsense shapes, followed 500 ms later by an auditorily presented word, on which they performed a semantic judgment. Two seconds after the shapes appeared, they were replaced by a fixation cross for 250 ms. Then a single shape appeared, and participants indicated whether it had been present in the prior array. The scatterplot (b) shows the correlation between scaled visual-experience ratings and the visual-task interference effect (response time on word judgments in the interference condition – response time on word judgments in the no-interference condition). Word ratings are scaled (mean-centered) for figure interpretability across experiments, individual points reflect the actual data points (word labels are displaced for visibility), the solid line indicates the best-fitting regression, and the error band shows the 95% confidence interval. The bivariate Pearson’s correlation (r) is also shown.
Importantly, the visual task used nonsense shapes unrelated to the appearance of the words’ referents—that is, the shapes were intended to interfere with, not prime, the stimulus concepts. If the visual system supports representation of visually experienced things, then occupying it with unrelated shapes should interfere more with thinking about visually experienced things (e.g., sunset) than infrequently visually experienced things (e.g., breeze).
Experiment 1
Method
Participants
We conducted a power analysis in G*Power (Version 3.1; Faul, Erdfelder, Lang, Buchner, 2007) based on pilot data and determined that to detect an estimated small effect size at a power (β) of .80, we would need 199 participants in our within-participants design. To account for potential experimenter and participant error, we recruited 205 undergraduate students from the University of Connecticut. Ultimately, all participants were included in the analyses (N = 205). Participants were compensated with course credit, and the study was approved by the University of Connecticut Institutional Review Board.
Word stimuli
Words were rated for degree of visual experience in an online norming study. Norming participants (N = 58) did not participate in Experiment 1 but were drawn from the same undergraduate participation pool. For each word, they rated the question, “How much visual experience have you had with this?” on a scale from 1 (very little) to 7 (very much). Ratings were Winsorized at the 5th and 95th percentiles to minimize the influence of extreme responses. The mean visual rating was 4.48 (SD = 1.33, range = 2.41–6.76). We calculated word frequency and concreteness following Brysbaert, Warriner, & Kuperman’s (2014) norms. All of the stimuli and associated ratings can be found in the Supplemental Material available online. Correlations among stimulus characteristics are shown in Table 1.
Pearson’s Correlations Among Stimulus Characteristics

Manual ratings were collected in Experiment 2.
p < .05. **p < .001.
Procedure
Participants underwent a two-phase (interference and no interference) experiment. In the interference task, participants saw an array of 4 geometric nonsense shapes randomly sampled from a set of 32 possible shapes (for examples, see Fig. 1a). The shapes were intended to be unrelated to the concepts being elicited (i.e., the shapes were selected so as to not resemble real-world things). Then, 500 ms after the shapes appeared and while they were still on screen, participants heard a word (e.g., sunset, breeze), on which they performed a semantic judgment (“Is this an animal or not?”). Two seconds after the shapes appeared, they were replaced with a red cross for 250 ms. Then, a single shape appeared and participants indicated whether that shape had been present in the prior array. Figure 1a shows a schematic of the task. Half of the participants were given feedback (i.e., a beep) when they answered incorrectly on the shape-array interference task. 1 In the no-interference condition, no shapes were presented: Participants simply performed the word judgment, a blank screen was shown instead of the array of shapes, and then participants were to click a button when a fixation cross appeared. Phase order was counterbalanced across participants. Two hundred forty words were presented (120 nonliving things that varied with respect to visual experience and 120 animals—the animals were unanalyzed foils, included so that half of the trials would elicit a “yes” response; we did not collect visual-experience ratings on these). Importantly, the answer to the critical word-judgment task was the same (“no”) for all of our experimental items; that is, the word judgment was orthogonal to the amount of visual experience. The word lists presented in the interference and no-interference conditions were counterbalanced across participants. Critically, the exact same words were used (between participants) in the interference and no-interference conditions, so that any interference effects would not be due to properties of the words themselves.
Data analysis
Data were analyzed in the R programming environment (Version 3.5.1; R Core Team, 2018) using the lme4 package (Bates, Mächler, Bolker, & Walker, 2015). The raw data and analysis scripts are available in the Supplemental Material. Models were constructed with visual experience with a given item (measured as a continuous variable) and interference condition (interference vs. no interference) as the primary fixed effects and with random slopes for both participant (1 + exp_cond|participant) and word (1 + exp_cond|word) as a function of interference condition, where exp_cond refers to interference condition. Word length (i.e., duration of the sound file), word frequency (log-transformed SUBTLEX frequency; Brysbaert et al., 2014), and concreteness were included in the models as control factors. The critical effect of interest was the interaction between visual experience and visual interference. This interaction, in which the effect of interference increases as a function of visual experience, can be interpreted as showing an overlap in systems for performing the visual task and representing visual knowledge about a concept. Although we also initially included random slopes for visual experience, concreteness, and their respective interactions (Barr, Levy, Scheepers, & Tily, 2013), these models did not converge. Accordingly, we removed random effects until convergence was achieved, starting with the random slopes for the interactions, then for the continuous word-level variables, and finally the random intercepts for participant and word. We were able to retain the interference-condition random slopes crossed with word and participant, which were most theoretically important to retain because of participant- and word-level variability in response to interference (see Matuschek, Kliegl, Vasishth, Baayen, & Bates, 2017). The primary dependent measures were response time (RT, assessed using linear mixed-effects models) and accuracy (assessed using logistic mixed-effects models) on the word-judgment task. Because RTs were measured from the onsets of the auditory words, RTs shorter than 150 ms were unlikely to reflect processing of the auditory words and were removed.
The models were constructed in three steps: (a) a control main-effects model with interference condition, each of the control variables (duration, frequency, concreteness), and visual experience; (b) a control model testing the Concreteness × Visual Interference interaction; and (c) the critical Visual Experience × Visual Interference interaction model, which tested whether visual experience accounted for visual interference over and above any effects of concreteness. Within a given model, we report effects as the model estimates (or for logistic models, odds ratios, or ORs). When the OR is less than 1, we report the inverse odds for interpretability (1/OR). For linear and logistic models, respectively, |t| and |z| values greater than 2 were considered statistically significant. Likelihood-ratio tests were used to evaluate the statistical significance of each successive model, and here, p values less than .05 were considered statistically significant.
Results
Word-judgment task
On the word-judgment task, participants were faster and more accurate in the no-interference condition than in the interference condition (RT: M = 925 ms, SD = 222 and M = 1,072 ms, SD = 265, respectively; accuracy (proportion of correct responses): M = .988, SD = .108 and M = .981, SD = .183, respectively). The models assessed effects on these word judgments. The control main-effects model showed significant effects of interference condition; RTs were estimated to be about 161 ms slower under visual interference (95% confidence interval, or CI = [140, 182]), β = 0.63, SE = 0.04, t(203) = 15.17, p < .001. 2 There was also an effect of word duration—for each 100 ms of increased duration, RTs were about 26 ms slower (95% CI = [18, 34]), β = 0.11, SE = 0.02, t(112) = 6.48, p < .001—and an effect of concreteness—greater concreteness (in units of concreteness on a scale from 1 to 7) was associated with RTs that were about 20 ms slower per unit (95% CI = [4, 35]), β = 0.05, SE = 0.02, t(113) = 2.48, p = .015. 3 The control model testing for an interaction between concreteness and visual interference did show an interaction; the response-slowing effect of visual interference increased with concreteness by about 12 ms per unit (95% CI = [3, 21]), β = 0.03, SE = 0.01, t(108) = 2.57, p = .012. A likelihood-ratio test comparing the concreteness model with the model with only the main effects showed that this concreteness model was more predictive than the main-effects model, χ2(1) = 6.41, p = .011.
The model testing our critical prediction—that visual experience with things influences the extent to which they are represented in the visual system—showed an interaction between visual experience and visual interference, in which the response-slowing effect of visual interference increased as the amount of visual experience (in units visual experience, on a scale from 1 to 7) increased, by about 8 ms per unit (95% CI = [2, 14]), β = 0.04, SE = 0.02, t(115) = 2.80, p = .006. Importantly, this model was significantly more predictive than the model with the concreteness interaction alone, χ2(1) = 7.67, p = .006. 4 To show the effect of visual experience, we used the raw data to plot, for each item, the size of the interference effect (RT in the interference condition – RT in the no-interference condition) against the visual-experience rating for that word (see Fig. 1b).
The accuracy data were analyzed in the same way as the RT data. 5 There was a significant main effect of visual interference; participants were 1.69 times less likely to respond accurately under interference (OR = 0.59, 95% CI = [0.47, 0.74]; z = −4.52, p < .001). There were also main effects of duration and concreteness; participants were 1.37 times more likely to respond accurately for every 100-ms increase in duration (OR = 1.37, 95% CI = [3.25, 175.08]; z = 3.15, p = .002) and 1.92 times less likely to respond accurately with each unit increase in concreteness (OR = 0.52, 95% CI = [0.34, 0.77]; z = −3.25, p = .001). However, there were no interactions with visual interference (zs < 1, n.s.); thus, the accuracy data are reported here for completeness but will not be discussed further.
Visual-shape-judgment task
The interfering visual-shape-judgment task was quite difficult, as reflected by low accuracy (M = .656, SD = .475). Models analogous to those described above revealed that neither accuracy nor RT (M = 830 ms, SD = 480) on the task was predicted by visual ratings, nor were there any effects of duration, frequency, or concreteness.
Discussion
Overall, Experiment 1 showed that visual interference slowed semantic judgments on words as a function of the degree of visual experience with the words’ referents. This effect was attributable to visual experience, over and above the effect of concreteness.
Experiment 2
Experiment 1 suggests that visual experience drives the extent to which concepts for visually experienced things are grounded in the visual system. However, it remains possible that among the tested items, those involving more visual experience were, for some unanticipated reason, especially susceptible to interference generally (rather than particularly susceptible to visual interference). To investigate this possibility, in Experiment 2, we employed a manual-interference task on the same stimuli. Including this condition also allowed us to test, for the same words, the predictions of sensorimotor-based models in a different modality. That is, the processing difficulty elicited by manual interference should be accounted for by manual experience (as in Yee et al., 2013).
Method
Participants
Participants were 198 undergraduate students from the University of Connecticut who had not participated in Experiment 1. Again, all participants were included in the analyses (N = 198). They were compensated with course credit.
Word stimuli
Words were the same as those used in Experiment 1. Because Experiment 2 used a manual-interference task, we collected manual-interference ratings to explore whether manual- rather than visual-experience ratings might explain any interference effects observed in Experiment 2. Norming participants (N = 60) did not participate in Experiment 2 but were drawn from the same undergraduate participant pool. They rated each word for manual experience: “How much experience have you had touching this with your hands?” Manual ratings were collected and treated in the same way as the visual ratings collected alongside Experiment 1. The mean manual rating was 2.94 (SD = 1.43, range = 1.00–6.22).
Procedure
In the interference condition, participants performed a concurrent manual task from the study by Yee et al. (2013) throughout the experiment (see Fig. 2a) while making the word judgment with their feet on a button box placed on the floor. In this task, participants repeatedly moved their hands through a series of three simple motions performed on a table. The motions were selected by Yee et al. to be unlikely to be associated with any objects, particularly when performed as a continuous sequence, and the task has been shown to disrupt processing of concepts experienced predominantly in the manual modality (e.g., hammer; Yee et al., 2013). While participants performed the hand movements at their own pace, they were encouraged to speed up if they did not complete at least one cycle of the three hand movements per word. Otherwise, the procedure was identical to that used in Experiment 1, except that in the no-interference condition, as in the manual-interference condition, participants used their feet to respond.

Example trial sequence and results from the manual-interference condition of Experiment 2. In each trial (a), participants repeatedly moved their hands through a series of three simple motions performed on a table (task adapted from the study by Yee, Chrysikou, Hoffman, & Thompson-Schill, 2013). Participants also heard an auditorily presented word, on which they performed a semantic judgment. The scatterplot in (b) shows the relation between scaled visual-experience ratings and the manual-task interference effect (response time to word judgments in the interference condition – response time to word judgments in the no-interference condition). The scatterplot in (c) shows the relation between scaled manual-experience ratings and the manual-task interference effect. In (b) and (c), word ratings are scaled (mean-centered) for figure interpretability across experiments, individual points show the actual data points (word labels are displaced for visibility), the solid line indicates the best-fitting regression, and the error band reflects the 95% confidence interval. The bivariate Pearson’s correlation (r) is also shown for each plot.
Data analysis
Data were analyzed in the same way as in Experiment 1.
Results
In Experiment 2, participants again responded more quickly and accurately on the word-judgment task in the no-interference condition than in the interference condition (RT: M = 955 ms, SD = 227 and M = 1,021 ms, SD = 284, respectively; accuracy: M = .973, SD = .164 and M = .949, SD = .219, respectively).
In the main-effects model, interference condition, duration, and concreteness had statistically significant effects on RTs. Responses were estimated to be about 77 ms slower in the interference condition (95% CI = [59, 94]), β = 0.30, SE = 0.03, t(205) = 8.70, p < .001, and were also slower with increasing duration by about 15 ms per 100 ms of duration (95% CI = [79, 231]), β = 0.07, SE = 0.02, t(112) = 4.24, p < .001, and with increasing concreteness by about 14 ms per unit of concreteness (95% CI = [0, 29]), β = 0.04, SE = 0.02, t(112) = 2.01, p = .047, the same pattern as observed in Experiment 1. The control model testing for an interaction between interference and concreteness, β = 0.002, SE = 0.01, t(113) = .11, p = .912, was no more predictive than the main-effects model, χ2(1) = 0.01, p = .911.
The critical model with the Visual Experience × Manual Interference interaction, β = 0.03, SE = 0.02, t(113) = 1.56, p = .121, was, as expected, no more predictive than the concreteness interaction model, χ2(1) = 2.42, p = .120. This, together with follow-up analyses (described below), suggests that the results of Experiment 1 did not simply reflect items involving more visual experience being especially susceptible to interference in general, rather than visual interference in particular. When analogous models were tested using errors, the same main effects were observed for accuracy; participants were 2.04 times less likely to respond accurately under interference (OR = 0.49, 95% CI = [0.42, 0.57]; z = −9.30, p < .001), 1.16 times more likely to respond accurately per 100-ms duration (OR = 1.16, 95% CI = [1.01, 1.31]; z = 2.52, p = .012), and 1.45 times less likely to respond accurately per unit concreteness (OR = 0.69, 95% CI = [0.54, 0.88]; z = −3.10, p = .002). As in Experiment 1, in accuracy, there were no interactions between interference (here, manual) and concreteness, visual experience, or the manual-experience measure described below; thus, the accuracy data are reported here for completeness but not discussed further.
Returning to RTs, we tested a further interaction model with a Manual Experience × Manual Interference interaction to learn whether, in line with Yee et al.’s (2013) findings, manual experience could explain the effect of manual interference. Consistent with the results of this prior study, this interaction was significant; the response slowing induced by manual interference increased as a function of manual experience (in units of manual experience on a scale from 1 to 7) by about 8 ms per unit (95% CI = [1.92, 13.82]), β = 0.04, SE = 0.02, t(113) = 2.61, p = .010. Furthermore, including this manual-experience interaction made the model significantly more predictive than the model with only the concreteness and visual-experience interactions, χ2(1) = 6.63, p = .010, and importantly, when manual experience was included, the effect of visual experience was reduced from marginal (p = .121) to nonexistent, β = 0.005, SE = 0.02, t(114) = 0.24, p = .81, suggesting that the marginal effect of visual experience was due to shared variance between manual- and visual-experience ratings rather than visual experience per se. Figure S2 in the Supplemental Material shows the relation between manual interference and manual experience after the latter has been residualized on visual experience. (Fig. S1 in the Supplemental Material shows the relation between visual interference and visual experience after the latter has been residualized on manual experience).
Thus, items involving more visual experience were not as susceptible to interference in a different modality (i.e., manual; see Fig. 2b) as they were to visual interference, and the nonsignificant positive relationship between visual experience and manual interference was entirely accounted for by manual experience. We also conceptually replicated 6 Yee et al.’s (2013) findings by showing that interference induced by a manual task increases as a function of the degree of manual experience associated with a concept (see Fig. 2c).
For completeness, we also conducted an exploratory analysis using the manual ratings that we collected in Experiment 2 to test whether the effect of visual interference observed in Experiment 1 could be predicted by manual experience—our account predicts that the effect of visual interference should be better explained by experience in the same (i.e., visual) modality than by experience in a different modality. As expected, the effect of manual experience on visual interference was not significant (i.e., a response-slowing effect of about 4 ms; 95% CI = [–0.69, 8.81]), β = 0.02, SE = 0.01, t(110) = 1.69, p = .093. Further, when we used a likelihood-ratio model to compare the model that included only the Visual Experience × Visual Interference interaction (described in Experiment 1) with the model that included both a visual-experience interaction and a Manual Experience × Visual Interference interaction, the inclusion of the manual-experience interaction did not significantly increase the model’s fit to the data, χ2(1) = 2.83, p = .093.
Evaluating the evidence for modality specificity in the effects of experience on interference
Although the effect of manual experience on visual interference was nonsignificant, it approached significance, raising an important question: How strong is the evidence that interference from a visual task is better predicted by visual than by manual experience? 7 To assess this, we were inspired by Ostarek et al. (2019) to conduct follow-up Bayesian analyses using the brms package in R, which allows one to use identical fixed and random-effects structures to those implemented in lme4 (Bürkner, 2017). Briefly, we used the higher-order models from Experiments 1 and 2, including both the visual- and manual-experience interactions in each to directly compare the visual- and manual-experience interactions. Because Bayesian models are less susceptible to convergence issues than linear mixed-effects models, we were able to include by-participant random slopes for the interactions between our item-level variables (visual experience, manual experience, and concreteness) and interference condition. Priors for the interactions among concreteness, manual experience and interference, and visual experience and interference were set on the basis of similar previous research (e.g., Edmiston & Lupyan, 2017; Ostarek & Huettig, 2017; Ostarek et al., 2019; Yee et al., 2013). Importantly, to be conservative, we set the prior for the secondary experience variable (e.g., manual experience in the visual-interference experiment) to be positive (it was the same as that for the concreteness interaction). 8 Following Wagenmakers, Lodewyckx, Kuriyal, & Grasman, (2010), we used the Savage-Dickey method to generate estimates and 95% credible intervals (CrIs) for each fixed effect and then computed Bayes factors (BFs) to describe the evidence in favor of both the null (BF01) and directional (BFdir) hypotheses. In both cases, BFs larger than 1 indicate evidence in favor of the hypothesis (i.e., in favor of the null or directional hypothesis, respectively), whereas BFs less than 1 indicate evidence against the hypothesis. Greater distance from 1 reflects stronger evidence; for example, a BF01 of 2 reflects 2 times as much evidence for the null compared with the alternative hypothesis, and a BF01 of 0.25 reflects 4 times (1/0.25 = 4) as much evidence for the alternative compared with the null hypothesis (Wagenmakers et al., 2010).
Importantly, using Bayesian analyses, we can directly compare two fixed effects and evaluate the evidence that one is greater than the other. For Experiment 1, this analysis (based on 100,000 samples from the posterior distribution for each of four model chains) produced an estimate of the visual-experience interaction (9.34, SE = 1.95, 95% CrI = [6.11, 12.57], BF01 < 0.01, BFdir > 2,000) that was larger than that of the manual-experience interaction (3.16, SE = 1.90, 95% CrI = [–0.03, 6.14], BF01 = 1.36, BFdir = 18.42). Most critically, the 95% CrI for the difference between the visual- and manual-experience interactions did not contain zero (estimate of difference = 6.18, SE = 3.16, 95% CrI = [1.13, 11.54], BF01 = 1.99, BFdir = 34.71), providing considerable evidence that interference from a visual task is better predicted by visual than by manual experience.
Similar results (in the opposite direction) were observed for Experiment 2. The estimate of the manual-experience interaction (8.91, SE = 2.10, 95% CrI = [5.58, 12.44], BF01 < 0.01, BFdir > 2,000) was larger than the estimate of the visual-experience interaction (–2.58, SE = 2.01, 95% CrI = [–5.97, 0.66], BF01 = 2.34, BFdir = 0.10; note that there was evidence against the directional visual-experience interaction). Most importantly, the 95% CrI for the difference between the manual- and visual-experience interactions did not contain zero (estimate of difference = 11.48, SE = 3.34, 95% CrI = [6.31, 17.05], BF01 = 0.09, BFdir = 1999), providing strong evidence that interference from a manual task was better predicted by manual than by visual experience.
A final test of whether concepts predominantly experienced through vision are particularly susceptible to visual interference should compare across experiments to evaluate whether visual experience predicts visual better than manual interference. To do this, we compiled the data from Experiments 1 and 2 into one data set and computed an interference effect (RT in the interference condition – RT in the no-interference condition; see Figs. 1b, 2b, and 2c) for each item in each experiment (averaged over participants). The model was constructed with interference effect as the dependent measure and experiment (visual, manual), duration, frequency, concreteness, visual experience, manual experience, and the interactions among concreteness, visual experience, manual experience, and experiment as the predictors. Priors for the control variables were set to 0 (SE = 1) because we did not expect them to predict interference. The prior for the concreteness interaction was also set to 0 (SE = 1) because it should equally predict visual and manual interference. Priors for the visual- and manual-experience interactions were equal to the difference between the priors used in the Bayesian analyses described above for Experiments 1 and 2 (e.g., prior for Visual Experience × Visual Interference interaction – prior for Visual Experience × Manual Interference interaction), as this difference should reflect the Experience × Experiment interaction. There was substantial evidence that visual experience better predicted visual than manual interference (estimate = 10.17, SE = 2.25, 95% CrI = [6.57, 13.98], BF01 = 0, BFdir > 2,000) and substantial evidence that manual experience better predicted manual than visual interference (estimate = −8.05, SE = 2.33, 95% CrI = [–12.80, –3.25], BF01 = 0.8, BFdir = 665.67).
Thus, Bayesian follow-up analyses provide support for the conclusion that more visually experienced things are particularly susceptible to interference in the visual modality and more manually experienced things are particularly susceptible to interference in the manual modality.
General Discussion
Performing a concurrent visual task slowed concept processing as a function of the amount of visual experience that people have with a word’s referent. Returning to our opening scene, if your visual system is occupied by the complex array of items in the fridge, it will be more difficult to think about something with which you have substantial visual experience, such as a sunset, than something less visually experienced, such as a breeze.
In contrast, for the same judgments on the very same words, a concurrent manual task produced a different pattern: Conceptual processing slowed more as a function of manual experience. Thus, the relationship between visual interference and visual experience in Experiment 1 was not simply an effect of interference broadly. If you had been rolling out dough when asked to think about the sunset, you would have been no slower to think about it than the ocean breeze, as the motor system resources used for rolling out dough do not overlap with the visual resources required to think about sunsets. You might, however, be slower to think about a shovel you had used to build a sandcastle, as the motor resources for rolling out dough overlap with those that represent the meaning of shovel.
These findings have several implications. First, they provide strong evidence for a fundamental prediction of sensorimotor-based models (e.g., Allport, 1985; Barsalou, 1999)—conceptual representations are grounded in sensorimotor experience. Second, aspects of the representations of visually experienced things share resources with the visual system. Finally—and critically—these aspects are a functional part of representations. Although earlier neuroimaging work suggested that the visual system is active when the meaning of visually experienced things is being processed (for a review, see Meteyard et al., 2012), the present findings show that this activity plays a functional role in understanding their meaning.
Our results converge with evidence that when one makes explicit judgments about visual properties of things (e.g., judging whether “Does it have stripes?” applies to tiger), viewing a visual noise pattern is more disruptive than when making judgments about encyclopedic properties (Edmiston & Lupyan, 2017). They are also consistent with evidence that visual noise can disrupt concreteness judgments for concrete concepts more than abstract ones (Ostarek & Huettig, 2017, Experiment 1), presumably because concrete—but not abstract—things can be experienced visually. These studies, however, required judgments explicitly related to the featural dimension of interest (i.e., explicit judgments about visual properties or concreteness judgments wherein all concrete items were highly visually imageable), whereas we show that visual experience can affect conceptual processing even when the task is orthogonal to that experience. 9 Relatedly, we show that (as also suggested by Rey et al., 2017) it is the amount of visual experience, not concreteness, that determines the visual system’s involvement in conceptualization.
Interestingly, in exploratory analyses, we observed a trend whereby manual experience with things may be associated with slowed processing under visual interference. Whereas Bayesian analyses provided substantial evidence that visual interference was better predicted by visual than manual experience, the trend still merits consideration. In particular, it is important to consider which components of the visual system may have been engaged by the visual-interference task. Given that visual information is processed in both a ventral (“what”) and a dorsal (“how”) stream (Goodale & Milner, 1992), one possibility is that our visual task also, to some degree, occupied the “how” stream, which supports processing of object manipulability (e.g., Almeida, Mahon, & Caramazza, 2010; Chao & Martin, 2000), and interference of this dorsal stream may have driven the (trend toward) interference from our visual task on processing frequently manually experienced things. In fact, there is functional MRI evidence that a shape task very similar to ours engages not only the lateral occipital complex, a higher-level region of the ventral stream involved in encoding object shape, but also the superior parietal lobe, which is part of the dorsal stream (Song & Jiang, 2006). Future work should investigate whether the effects observed here persist with lower-level visual interference. They may not—during sentence comprehension, perceptual simulation is not affected by interference targeting low-level visual processing, although progressively modifying the interference task to target higher levels of the visual system appears to gradually increase its effect on perceptual simulation (Ostarek et al., 2019).
Conclusion
As predicted by sensorimotor-based models of cognition (e.g., Allport, 1985; Barsalou, 1999), the more something is experienced visually, the more its conceptual representation shares resources with those involved in visual processing. This has the perhaps counterintuitive implication that when you are looking for something, having to scan through unrelated things could interfere with your ability to think about the very thing you are searching for. That is, we do not represent the target concept using only abstract information divorced from the visual substrates used to concurrently process visual input—rather, we rely on those substrates for its conceptual representation, in proportion to the amount of visual experience that contributed to that representation. Perhaps this contributes to why it can be so hard to keep what you wanted in mind once you open the refrigerator door and look inside.
Supplemental Material
Davis_Fig_S1 – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Davis_Fig_S1 for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
Davis_Fig_S2 – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Davis_Fig_S2 for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
Davis_OpenPracticesDisclosure_rev – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Davis_OpenPracticesDisclosure_rev for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
Exp1_raw_data – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Exp1_raw_data for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
Exp2_raw_data – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Exp2_raw_data for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
Fig_S1_and_S2_captions – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Fig_S1_and_S2_captions for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
Main_analysis_script – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, Main_analysis_script for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Supplemental Material
ratings – Supplemental material for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference
Supplemental material, ratings for Making It Harder to “See” Meaning: The More You See Something, the More Its Conceptual Representation Is Susceptible to Visual Interference by Charles P. Davis, Gitte H. Joergensen, Peter Boddy, Caitlin Dowling and Eiling Yee in Psychological Science
Footnotes
Acknowledgements
We thank Roisin Healy, Jon Serino, Jenna Lee, Carol-Ann Sharo, Conor Hylton, Khalil Badley, and Emma Dzialo for their extensive help with data collection and Gerry Altmann, Zachary Ekves, Kyra Krass, Aitou Lu, Hannah Morrow, Yanina Prystauka, and Katherine White for helpful comments on earlier versions of the manuscript. We also thank Louise Connell for helpful advice and Marcus Johnson for assistance with experimental setup.
Transparency
Action Editor: Philippe G. Schyns
Editor: D. Stephen Lindsay
Author Contributions
P. Boddy and E. Yee developed the original study concept. All the authors designed the study. C. P. Davis analyzed the data. C. P. Davis and E. Yee wrote the manuscript. P. Boddy, G. H. Joergensen, and C. Dowling revised the manuscript. All the authors approved the final manuscript for submission.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.