
Abstract
The HadCRUT4 time series of 166 annual values of global average temperature was analysed both deterministically and stochastically and the results compared. The deterministic model comprised the sum of a linear trend and a multi-decadal oscillation fitted by ordinary least squares regression. The stochastic model was an ARMA(1,2) model with a drift term included. The deterministic model showed a linear trend of 0.5℃ per century while the stochastic model showed no significant drift. In both cases, the residuals were tested for self-correlation using standard statistical tests. The residuals from the deterministic model were significantly self-correlated whereas those from the stochastic model were not. We conclude that the stochastic model was a much better fit to the data and that the apparent linear trend of the deterministic model was spurious and a consequence of performing a regression in which time was the explanatory variable.
Keywords
Introduction
In recent decades, energy policy, both nationally and internationally, has been primarily concerned with the reduction in carbon emissions from the combustion of fossil fuels. This has arisen from a proliferation of theories of climate, encapsulated in complex numerical models, which purport to relate global surface air temperature to the concentration of carbon dioxide in the atmosphere. All this activity is based on a single empirical observation, viz. that there has been a significant increase in global average temperature over the last century and a half. Here we show that this observation is false and is based on an overly-simplistic interpretation of the data.
Discussion
In physics, there are a number of important dichotomies. These include the dichotomy between relativistic and Newtonian mechanics, between quantum and classical field theories and between linear and non-linear systems. There is a further dichotomy, equally important, the dichotomy between deterministic and stochastic processes. It might be argued that this is mere sophistry with little practical consequence but that is not so. Indeed, the conclusion of this article that ‘the stochastic model was a much better fit to the [global average temperature] data’ indicates that systems which are as fundamentally stochastic as fluid dynamic systems must be treated statistically lest spurious alarms and costly false positives result.
A deterministic process is a process for which, once initial conditions are known, all future states of a system can be predicted. A stochastic process is a process for which, given the initial conditions, futures states are not completely predetermined but are governed by the laws of probability.
Any system describable in terms of analytic functions or differential equations alone is deterministic. The interaction of solid objects with force fields and with one another are well described by deterministic models. Celestial mechanics is an example.
Fluid dynamical systems are commonly dealt with deterministically using the Navier–Stokes equations or variations thereof. In order to do this, it is commonly assumed that the fluid involved is a ‘continuum’, i.e. it is everywhere continuous and differentiable and so is deterministic, as when the Navier–Stokes equations are converted to the discrete form of finite difference equations for the purpose of numerical modelling of fluids. Here Taylor’s theorem is commonly used to make the transition to the discrete case, the continuum assumption being implicit in this use of Taylor’s theorem.
It has been well known for more than a century that no real fluid is a true continuum. This is demonstrated by the Brownian motion. The velocity field in any real fluid varies rapidly and discontinuously in both time and space. It is not differentiable. Hence the use of Taylor’s theorem in defining the finite difference equations of numerical models is not justified. Instead, there is a probabilistic relationship between the state of a fluid and the preceding state. Real fluids are stochastic not deterministic. Observed fluid dynamic phenomena such as turbulence, vortex shedding and wave breaking are testament to the stochastic nature of real fluids. Even at laboratory scales, the Navier–Stokes equations cannot adequately describe the behaviour of fluids in high Reynold’s number regimes. Aspects of these regimes which can be quantified are dependent on other methods such as dimensional arguments, self-similarity and physical intuition. Kolmogorov’s turbulence spectrum is an example.
If a system is deterministic, then its variables are all single-valued functions of time. Experimental observations of dynamical variables are commonly displayed as functions of time and a ‘line of best fit’ or regression line fitted to the observations to display the trend or rate of change with time. This is commonplace, something most researchers learned at school.
However, there can be serious problems with this methodology when the system under investigation is stochastic. Nelson and Kang 1 demonstrated that, for certain stochastic processes such as a ‘random walk’, the use of time as the explanatory variable can lead to the appearance of a trend even though none was present in the original data. They report for a random walk process: Regression of a random walk on time by least squares will produce R2 values of around .44 regardless of sample size when the variable has, in fact, no dependence whatever on time (zero drift). It follows that an observed trend obtained by regressing a physical quantity on the time may or may not be real, depending on the deterministic or stochastic nature of the system under investigation. Although not widely known outside the field of Econometrics, the implications of this article cannot be overestimated. It seems to be little known in the physical sciences.
Attempts to model global climate have hitherto depended on coupled ocean-atmosphere general circulation models. Such models are deterministic because the Navier–Stokes equations of fluid dynamics on which they are based are, themselves, deterministic.
Hasselmann 2 proposed a stochastic model of climate variability wherein slow changes in climate are explained as the integral response to continuous random excitation by short period ‘weather’ disturbances. Thus, intrinsic quantities such as temperature are the outcome of the integration by natural processes of quasi-random, extrinsic quantities such as heat. As a consequence, such measurements can be regarded as the outcome of a stochastic process and can be expected to exhibit a power law spectrum with negative exponent due to such integrating effects. The best known and simplest example of such a process is the ‘random walk’ obtained when white noise is integrated or summed. It has a power law spectrum with an index of −2.
Pelletier
3
has shown that variance spectrum of atmospheric temperature exhibits a variety of power law relationships over a wide range of time scales from 2 years to 100,000 years, i.e. over a given frequency scale:

In recent times, much has been made of the apparent rising trend in global average temperature commonly attributed to rising greenhouse gas concentrations in the atmosphere. At issue is whether this trend is a real, deterministic trend or whether the observed variations are merely the random outcome of a stochastic process.
The data
Two time series were downloaded for analysis. They were:
The HadCRUT4 series of 1666 annual values from 1850 to 2015 inclusive were downloaded from http://www.metoffice.gov.uk/hadobs/hadcrut4/data/current/time_series/ on 12 April 2016.
4
There are a number of such global temperature data sets available, e.g. those from GISS, NOAA and BEST. Statistically, they are almost identical. HadCRUT4 was chosen because it was longer. A data set of proxy temperatures from isotope ratios in Greenland ice cores, the GISP2 Ice Core Temperature and Accumulation Data. These were downloaded from ftp://ftp.ncdc.noaa.gov/pub/data/paleo/icecore/greenland/summit/gisp2/isotopes/gisp2_temp_accum_alley2000.txt on 20 April 2016.5,6 Like most ice core records, the data values were sampled at unequal intervals of time. In order to convert them to a form suitable for processing, the record was divided into 50-year intervals and the data averaged in each interval to form a time series. Only the most recent 10,000 years of ice core data were used, i.e. the data were all from the Holocene Epoch.
A deterministic model
A deterministic model typically comprises a linear function of one or more functions of the explanatory variable plus a random element. In this case, the explanatory variable is the time. The parameters are estimated by minimizing the sum of squares of the differences between an estimate and the true values of the sample, the residuals. This is the ordinary least squares (OLS) method. It is based on the assumption that a deterministic relationship with the explanatory variable does exist and that the random elements at different times have zero mean and are independent of one another. The random element can be thought of as ‘measurement error’.
The model
The HadCRUT4 time series values were fitted with a straight line by the OLS method of linear regression, i.e. the model

was fitted to the data and is shown as the straight line in Figure 1(a).
The deterministic method: (a) The HadCRUT time series. The straight solid line shows the linear trend of temperature vs. time. The dashed line shows the multiple regression fit of a linear trend plus a sinusoid. (b) Residuals from the time series of the linear trend plus sinusoid. (c) The autocorrelation function of the residuals, φ.
There is also the appearance of a ‘multi-decadal oscillation’ present so a regression model of the form

Coefficient estimates for the deterministic model of equation (3).

Standard error, t-value, p-value and 95% confidence intervals are shown for each.
Standard error, t-value, p-value and 95% confidence intervals are shown for each.
The fitted function (dashed curve) described by (2) is shown superimposed on the data in Figure 1(a). The linear trend in temperature, if it is real, is given by coefficient estimate,
Testing the fit of the deterministic model
The fitting of a function by OLS regression requires that the sequence of residuals
Testing the residuals of regression model of equation (3) for self-correlation.

Minimum and maximum values of the Breusch–Godfrey and Ljung–Box test statistics and their corresponding probabilities for a maximum lag of 40.
The probabilities listed in Table 2 are so small that we can reject the null hypothesis that the non-zero ACF values are purely random and that equation (3) is a good fit to the data. It can be rejected at a very high level of significance.
The stochastic model
A stochastic model is based in the assumption that the value at any given time is deterministically related to the value or values at p previous times plus an additional random element. When the random elements are independently distributed the model is known as an ‘autoregressive’ (AR) model of order p.
The random element may itself be a linear function of q independent random variables each with zero mean in which case the model is said to have a ‘moving average’ (MA) component of order q. Combining the two gives an autoregressive moving average model of order (p, q), an ARMA(p, q) model.
The random components are not regarded as measurement errors but as properties inherent in the system itself.
The model
An ARMA(1,2) model was fitted to the HadCRUT4 time series using the Python statistical package: statsmodels.tsa.arima-model.ARMA. The package’s css-mle option was selected whereby the conditional sum of squares likelihood was maximized and its values used as starting values for the computation of the exact likelihood via a Kalman filter.
The fitted model was thus

Note that the parameter c is similar to the coefficient a1 in (2) and (3). Setting a1 = 1 and the other coefficients in (4) to zero for the moment, gives

Coefficient estimates for the stochastic model of equation (4).

Standard error, z-value, p-value and confidence limits are shown for each.
The most important feature of Table 3 is the small value and large confidence interval of the drift term estimate,
Also of interest is the autoregressive coefficient,
Testing the fit of the stochastic model
The sequence of residuals is shown in Figure 2(b) and its autocorrelation function in Figure 2(c). The ACF values at non-zero lags appear to be randomly distributed on either side of zero. As before the Breusch–Godfrey test and Ljung–Box tests were used to see if the null hypothesis that the residual are unselfcorrelated can be rejected. The results are shown in Table 4. None of the probabilities listed in Table 4 lie below the critical value of 0.05 and so there is no reason to reject the null hypothesis that the non-zero value of the ACF are due entirely to chance. The ARMA(1,2) model is a very good fit to the HadCRUT4 time series.
The stochastic method: (a) The HadCRUT time series. (b) Residuals from fitting an ARMA(1,2) model, (c) The autocorrelation function of the residuals, φ. Testing the residuals of the ARMA(1,2) model for self-correlation. Minimum and maximum values of the Breusch–Godfrey and Ljung–Box test statistics and their corresponding probabilities for a maximum lag of 40.

The frequency domain
Whereas a deterministic model such as (3) can be displayed in the time domain, as in Figure 1(a), it is usually more useful to display stochastic models in the frequency domain as variance density spectra. The ARMA parameters allow the population variance spectral density, Sf, of the time series to be estimated as a continuous function of the frequency, e.g. for the ARMA(1,2) process discussed here:


The HadCRUT4 time series
Figure 3 shows the ARMA(1,2) spectral estimate of the HadCRUT4 time series plotted using logarithmic scales (thick line). Also shown is the periodogram of the sample (thin line).
The variance density spectral estimate, 
As a consequence of the above-discussed whiteness tests confirming the absence of self-correlation of the residuals, this spectral estimate is optimal. There can be no peak, trough or trend in the spectrum other than those depicted in Figure 2, because this would require further poles and/or zeros in the z-plane, which are not included in the ARMA model. Such extra poles or zeros, if unaccounted for, would inevitably lead to self-correlation of the residuals, which would then have failed the Ljung–Box and Breusch–Godfrey tests.
For 
The
Of course, this does not imply that a unit pole exists, only that its existence cannot be rejected. In the field of Econometrics, such a result would sound an alarm and the researcher would be tempted to abandon the ARMA model for an ARIMA model appropriate to a non-stationary time series.
However, examination of Figure 3 shows that the 3 dB cutoff frequency is much smaller than the smallest frequency in the periodogram, i.e. the cutoff period of 1400 years is much longer than the sample length of 166 years. By using the ADF test to determine whether the time series is non-stationary, we are attempting to predict behaviour of the spectrum for periods which are an order of magnitude greater than the sample length. Common sense would suggest that this is unreliable.
The GISP2 time series
Casting further light on this issue requires a much longer time series. Although the length of contemporary time series was limited by the short period during which accurate temperature measurements were made, subsidiary data are available in the form of proxy temperature time series derived from stable isotope ratios of atmospheric gases trapped in ice-cores. There is a trade-off between length of such proxy records and their time resolution. At longer time scales, events such as ice-age terminations suggest an underlying quasi-deterministic process which depends on astronomical quantities 10 and which cannot be assumed to be stationary. It is therefore desirable to use data from the relatively recent past, the Holocene epoch of the last 10,000 years following the last Ice Age Termination.
The GISP2 proxy-temperature time series fom Central Greenland ice cores was such a data set with a time resolution of 50 years over the last 10,000 years. A time series of equally spaced values was constructed from the GISP2 data by averaging the value in each 50-year interval. It is displayed in Figure 4(a).
(a) Time series of the GISP2 Central Greenland ice-core proxy temperature anomaly for the last 10,000 years. (b) The population spectrum of the fitted ARMA(1,3) process (thick line) and periodogram (thin line) of this time series shown in (a). The vertical-dashed line shows 
Statistics of the GISP2 time series.

A striking difference from the HadCRUT spectrum is the existence of a strong trough with a minimum at .0045 year−1 (period = 223 years). While spectral peaks display the presence of deterministic cycles or resonant phenomena, a trough such as this one implies a convoluting or averaging process. A possible explanation lies in the diffusion of atmospheric gases between layers during the firn stage of ice formation, an unavoidable artefact of the ice core proxy-temperature methodology.
A summary of the statistics is shown in Table 5. Once again the drift term is not significant, but this time, the ADF test indicates that we can dismiss the null-hypothesis that the time series has a unit pole with a high degree of confidence. This time the low pass cut-off is at
This evidence from proxy data suggests that the contemporary HadCRUT4 time-series may well be stationary and not a true random-walk.
Demonstrating false correlation with a synthetic time series
If the HadCRUT4 time series of global average temperature is not a true random walk, it is important to determine whether Nelson and Kang’s conclusions still applies: is a false correlation with time possible when the series is stationary? For that purpose, a number of simulations were run for time series generated artificially using the parameters listed in Table 3 and with the drift term, c, set to zero. Each synthetic time series was 166-long and generated by the process:
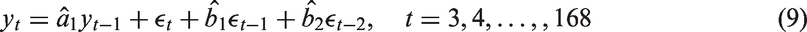
For each sample, r, the correlation coefficient of yt on t was calculated and the number of values in each percentage binned to give the frequency distribution, f. The outcome is plotted in Figure 5. The distribution is bi-modal with peaks near The frequency, f, of r, the sample correlation coefficient holding between value and time for one million 166-long samples generated by equation (9).
The reason for this behaviour is demonstrated graphically in Figure 6. A single 10,000-long time series was also generated using equation (9) and is shown in Figure 6(a). Thus, Figures 4(a) and 6(a) are directly comparable. The former looks smoother because of the spectral trough at .0045 year−1 attributable to firn processes. Figure 6(a) shows the time series we would expect to see if we had 10,000 years of global average temperature data rather than only 166 years.
(a) A 10,000 long-time series of ‘annual temperatures’ generated artificially using the coefficients of the ARMA(1,2) model of Figure 2 and filtered and decimated in the same manner as the GISP2 data shown in Figure 4(a). (b) A 166-long segment showing the detail between the vertical lines in (a).
The two dashed vertical lines in Figure 6(a) designate an arbitrarily located 166-year long interval. The detail of the interval, expanded in time, is displayed in Figure 6(b). It exhibits an upward ‘trend’ remarkably similar to that of the HadCRUT4 data. There are many other 166-long intervals in Figure 6(a), which would have given a similar result and many others which would have shown an apparent downward trend.
It is clear from Figure 6 that such spurious upward and downward trends occur in a short sample of a time series when there is a large concentration of variance at periods longer than sample length, i.e. when the time series has a ‘red’ spectrum. This is still true even when the spectrum is flattened at low frequencies providing the 3 dB cut-off period is much longer than the sample length, i.e. when

Note also that a ‘multi-decadal oscillation’ appears in Figure 6(b). It is as spurious as the rising trend since no oscillatory behaviour is implied by the generating equation (10).
Conclusion
The process which gives rise to a red spectrum flattened below a cut-off frequency is widely found in engineering and in nature. In electronics, it occurs when electronic noise is fed through an RC integrator as with the bass control of an audio amplifier. In the natural world, it occurs when energy is randomly stored. It is a particular sort of Markov process termed a ‘centrally biased random walk’ and known colloquially as ‘red noise’. Using the techniques described above other ‘oscillations’ such as the Pacific Decade Oscillation can also be shown to be centrally biased random walks specified by a small number of ARMA parameters. This is not surprising since the PDO is derived from a large subset of the global average temperature data used here.
The small increase in global average temperature observed over the last 166 years is the random variation of a centrally biased random walk. It is a red noise fluctuation. It is not significant, it is not a trend and it is not likely to continue.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.