
Abstract
There has been a sustained need to quantify past climate changes from proxy records to better understand the driving mechanisms and thus to improve the prediction of the future. Transfer function is an intuitive and frequently used method in this regard. However, this method is unable to provide interpretive and predictive results from proxy records, because physical processes are not included. The inverse proxy modelling method opened up a new avenue for quantitative palaeoclimate reconstructions through the integration of proxy records with deterministic models. It is fundamentally different from the statistical approach, representing a conceptual advance in quantitative palaeoclimatology. Here we demonstrate the potential of this method by placing a mechanistic model and a 6000 year long peat cellulose δ18O record obtained from the high-cold and monsoonal eastern Tibetan Plateau (c. 3500 m a.s.l.) in a Bayesian paradigm. In this worked example, the marginal posterior probability distributions of palaeoclimate variables such as the δ18O of soil water, temperature, and relative humidity were inferred jointly through the solution to an ill-posed inverse problem using the Markov chain-Monte Carlo method. Our results indicate that the observed variation of the peat cellulose δ18O record in this monsoonal area essentially reflects the changes in the oxygen isotopic composition of soil water, which is closely linked to that of rainfall. Compared with hydrology, temperature and humidity have little influence on the oxygen isotope fractionation of leaf water.
Keywords
Introduction
Quantitative palaeoclimate information obtained from various proxies may not only deepen our insight into the mechanisms of past climate changes, but also constitute a primary knowledge base for predicting the future. A commonly followed approach to quantifying past climate changes from proxy records is the transfer function method (Birks, 1995; Bryson and Kutzbach, 1974; Huntley and Prentice, 1988; Imbrie and Kipp, 1971). The essence of this method is first to establish an empirical relationship between proxy data and climate variables based on modern observations, and then use this to translate fossil proxy records to quantitative palaeoclimate data. However, as criticized by Guiot et al. (2000), this method has several inherent drawbacks. First, the empirical relationship established under modern boundary conditions may not hold for the past. The best example in this regard is the pollen–climate transfer function. All these kinds of regression equations do not take into account the time-varying atmospheric CO2 level, which is a crucial limiting factor for vegetation growth (Cowling and Sykes, 1999). Second, the reference modern proxy data used to constrain the transfer function may have been disturbed by human activity, leading to a biased statistical relationship that is inapplicable to render the proxy records in climatic terms. The final caveat is that the statistical relationship based on spatially distributed modern data may be incomplete because of lack of adequate analogs for the past (Jackson and Williams, 2004).
Many attempts have been made to overcome the aforementioned limitations (Bhattacharya, 2006; Guiot, 1990; Haslett et al., 2006; Korhola et al., 2002; Kühl et al., 2002; Mosbrugger and Utescher, 1997; Robertson et al., 1999; Toivonen et al., 2001; Vasko et al., 2000; Wolfe, 1995). However, none of these methods considers the underlying physical processes that control the formation of the proxies, and thus still unable to yield interpretive results of the proxies. Assimilations of proxy data in process-based deterministic models have shown great potential in palaeoclimatological studies (Gebbie and Huybers, 2006; Gebka et al., 1999; Hargreaves and Annan, 2002; Heinze and Hasselmann, 1993; Hopcroft et al., 2009; Huybers et al., 2007; LeGrand and Wunsch, 1995; McKeague et al., 2005; Rajver et al., 1998; Widmann et al., 2010; Wunsch, 2003). This concept was first introduced to the area of quantitative palaeoclimatology by Guiot et al. (2000), who also gave it the name ‘Inverse Proxy Modeling’ (Guiot et al., 2009). Although this method has been extensively used to quantify past climate changes from pollen records in conjunction with mechanistic vegetation models within the framework of Bayesian statistical inference over the past decade (Garreta et al., 2010; Guiot et al., 2000; Hatté and Guiot, 2005; Hatté et al., 2009; Rousseau et al., 2006; Wu et al., 2007a, b), its utility for inversion of past climate from other abiotic proxy records has never been tested. Here we conduct a Bayesian inversion of climate changes on the eastern Tibetan Plateau during the last 6000 years through integrating a peat cellulose δ18O record with a simplistic yet mechanistic model of oxygen isotope fractionation in plant cellulose. Our results show that this proxy data-model fusion technique is a promising way to quantify the climate information of the past mechanistically.
Basic concepts and theoretical framework of the inverse proxy modeling method
In this section, we explain the philosophy of the inverse proxy modeling method. Instead of presenting a comprehensive discussion, here we only introduce the main elements and outline the general theoretical framework. For a full account of this method, readers are referred to Guiot et al. (2009). The conceptual difference between the transfer function and the inverse proxy modeling methods is illustrated in Figure 1. The transfer function method intuitively expresses climate variables as a function of proxy data using empirical constraints through regression analyses (Figure 1A):
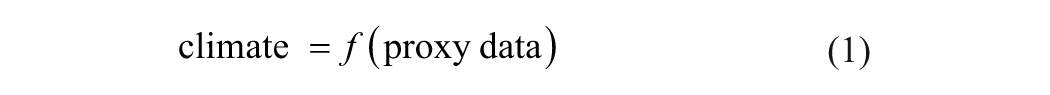
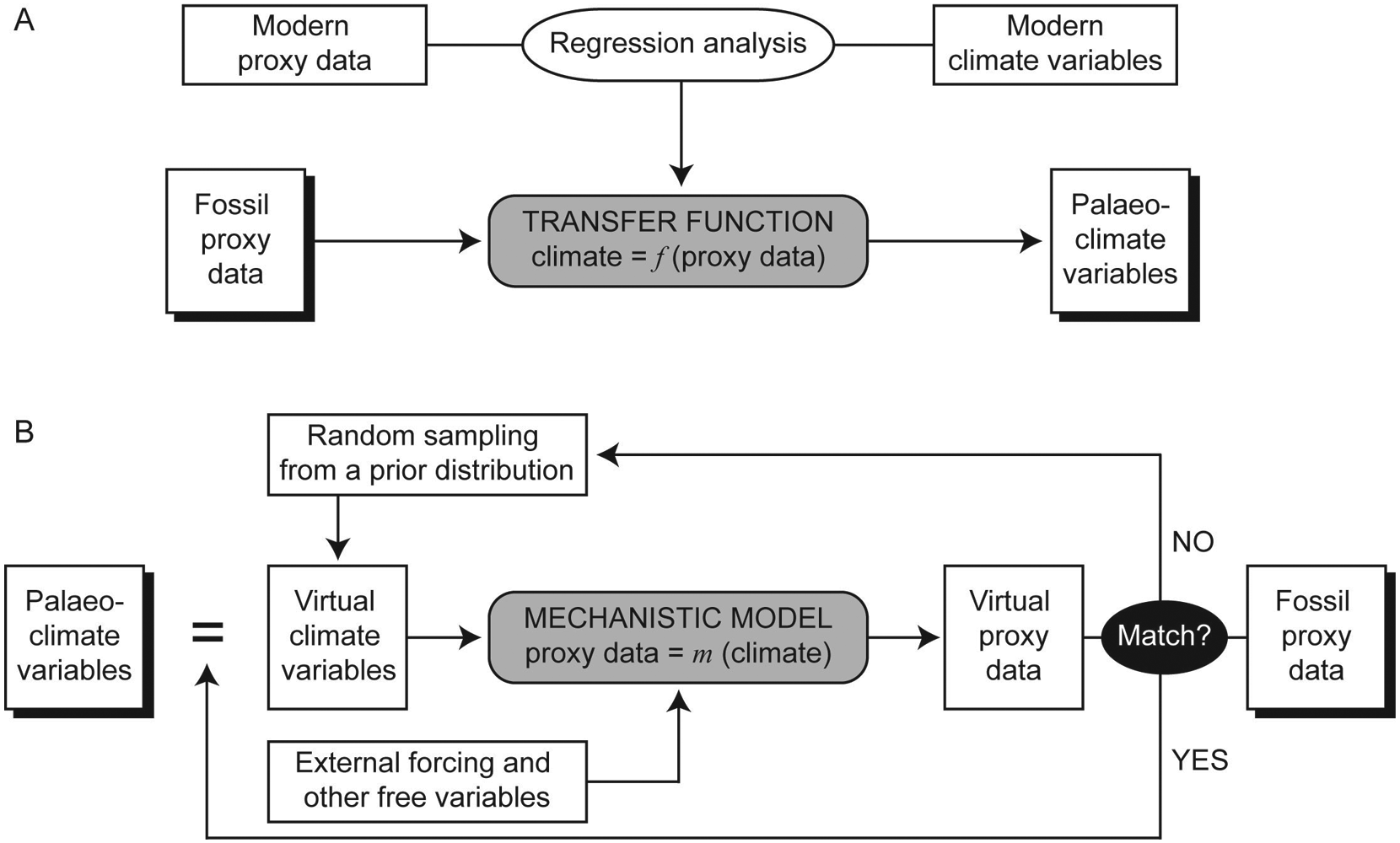
Diagrams illustrating the difference in concept between the traditional transfer function method (A) and the inverse proxy modeling method (B)
Conversely, the inverse proxy modeling method treats climate variable as the parameters of mechanistic models that describe the formation of proxy data (Figure 1B):
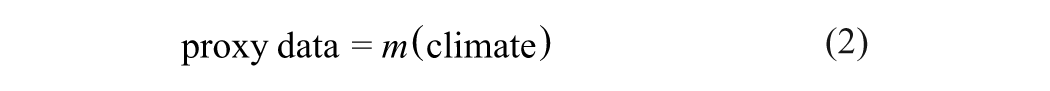
Specifically, if the physics behind the climate proxies is known, then we can put forward a deterministic model, say m(θ), with parameters θ being some major climate variables. Unlike the forward modeling, which is aimed at providing mechanistic interpretations of the proxy data, the inverse modeling is to find an optimal estimate of model parameters from proxy data. Through solving this problem, quantitative palaeoclimate information may be obtained.
The inverse proxy modeling method yields quantitative palaeoclimate information not as straightforward as the transfer function method does. It first randomly generates a candidate set of the climate variables, which is then input to the mechanistic models along with other forcing factors and complementary environmental variables to generate a simulated proxy record that is to be compared with the fossil proxy record (Figure 1B). If both data sets match to some degree, keep this candidate; otherwise, reject and repeat the above procedure until acceptable values are obtained. Perturb these values iteratively in their parameter space and repeat the whole procedure for a thousand times or even more to build frequency histograms, which mimic the probability distributions of the palaeoclimate variables.
In practice, the key issue is how to define and evaluate the matching. Techniques diverge at this step. The least-squares inversion method minimizes the sum of squares of the model residuals to solve for parameters θ:
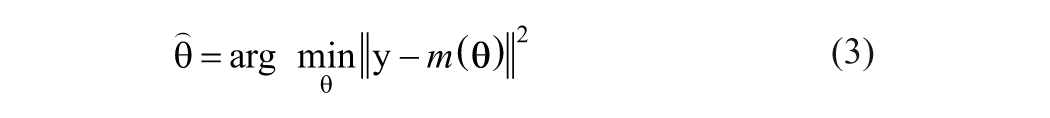
where y is the proxy record, θ the climate variables, m(θ) the modeled proxy record, and
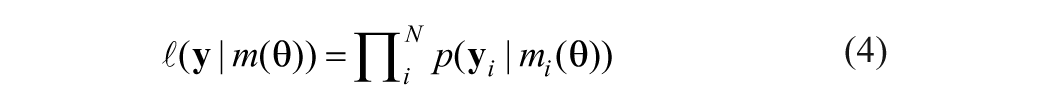
where N is the length of the observational data set. An optimal estimate for parameters θ may be obtained by maximizing this likelihood function. Because the inverse problem usually is ill-posed, particularly when the model is nonlinear, the solution may not exist in the strict sense or may not be unique (Blaauw et al., 2010).
Bayesian inference appears to be a powerful and increasingly popular method for solving complex inverse problems in a conceptually simple and theoretically unified way (Gilks et al., 1996). It is a probabilistic approach in which all sorts of uncertainty are expressed in terms of probability density functions. The implementation generally consists of three steps. First, we need to formulate a statistical model (i.e. the likelihood function) that could adequately describe the relationship between our beliefs about m(θ) and the proxy record y. Then we propose an initial belief (i.e. the prior probability) about parameters θ. Finally, we apply Bayes’ rule to obtain an updated belief (i.e. the posterior probability) of these parameters:
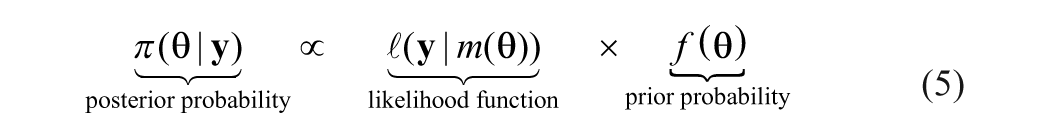
The posterior probability distribution usually cannot be given analytically because of its mathematical complexity, but it can be simulated using the Markov chain-Monte Carlo (MCMC) method. From such a probabilistic expression, we can easily calculate some statistical moments such as the mean, median, and variance of parameters θ so as to address the uncertainty of the solution.
Model, data, and algorithm
It has long been known that the enrichment of the heavy oxygen isotope in plant vascular tissue reflects the average growing conditions of the plant as a function of temperature, humidity, and water availability (Burk and Stuiver, 1981; Epstein and Yapp, 1977; Gray and Thompson, 1976). Therefore, measuring the oxygen isotopic composition of plant remains such as tree-ring (Raffalli-Delerce et al., 2004) and peat cellulose (Helliker and Ehleringer, 2002) may reveal past climate conditions. However, most of these attempts were made in a qualitative way (Brenninkmeijer et al., 1982; Hong B.et al., 2009; Hong Y.T. et al., 2000; Ménot-Combes et al., 2002; Xu et al., 2006). In this section, we provide an example to illustrate how quantitative palaeoclimate information can be retrieved by assimilating a peat cellulose δ18O record in a simplistic yet mechanistic model of oxygen isotope fractionation in plant cellulose using Bayesian inference.
Model of oxygen isotope fractionation in plant cellulose
The model of oxygen isotope fractionation in plant cellulose was established by Roden et al. (2000). It is composed of two major components: one describes the biophysical processes that lead to the enrichment of the heavy oxygen isotope in leaf water, and the other accounts for the biochemical processes governing the oxygen isotope exchange between different organic components during cellulose synthesis. In this model, the oxygen isotope ratio is normalized to the standard mean ocean water (SMOW) in parts per thousand using the delta notation:
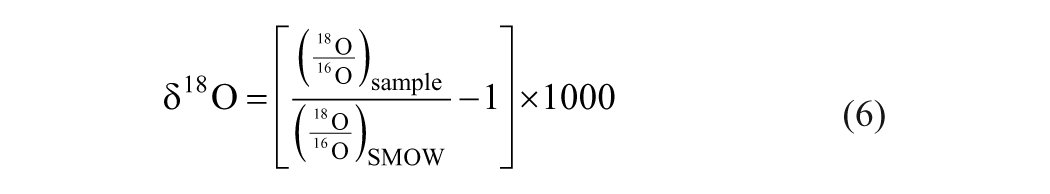
The essential biophysical process linking the oxygen isotopic composition of leaf water with climate is evapotranspiration, which leads to a progressive enrichment of the heavy oxygen isotope in leaf water with respective to that in soil water. This process was first modeled by Dongmann et al. (1974) based on the equation for oxygen isotope fractionation in an open water body during the phase change from liquid to vapor and during molecular diffusion (Craig and Gordon, 1965). The oxygen isotopic composition of leaf water can be expressed as:
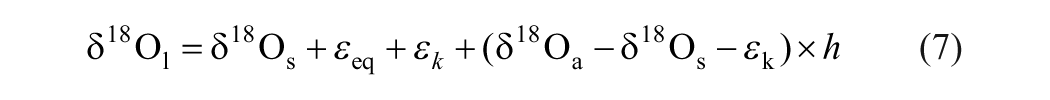
where subscripts l, s and a refer to leaf water, soil water, and the atmospheric water vapor, respectively, h is the relative humidity, εk the kinetic separation parameter, which is set to 16‰ according to the relative rate of molecular diffusion of 16O and 18O in the turbulent boundary layer (Dongmann et al., 1974), and εeq the equilibrium separation parameter, which can be expressed as a function of absolute temperature (T) in degrees Kelvin (Majoube, 1971):
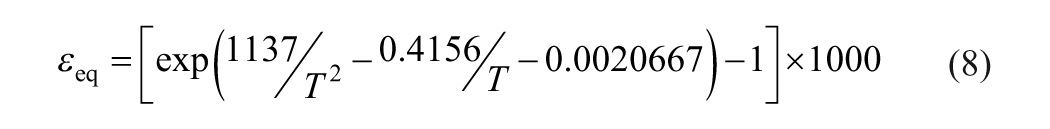
Assuming that the meteoric water is predominantly from the well-mixed regional air mass that is in equilibrium with soil water, the δ18O shift of atmospheric water vapor relative to soil water, denoted by δ18Oa−δ18Os, is governed by the equilibrium fractionation, i.e. δ18Oa−δ18Os = −εeq. Therefore, Eq. (7) can be further simplified as:
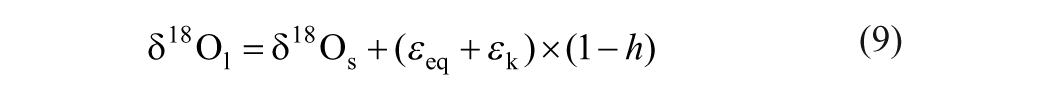
The photosynthesis generally can increase the δ18O value by about 27‰ in leaf cellulose during the interaction between carbonyl and soil water (Yakir and DeNiro, 1990). In addition, a secondary fractionation may occur, if there is a partial equilibrium exchange between the synthesized carbohydrate and soil water. Taken together, the isotopic composition of plant cellulose can be expressed as:
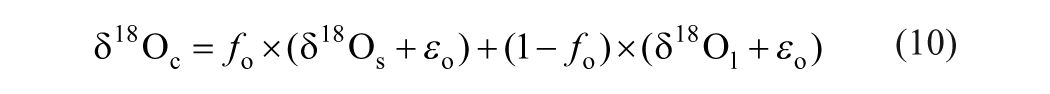
where ϵo = 27‰ is a biochemical fractionation factor (Yakir and DeNiro, 1990), and f o = 0.42 is the proportion of the carbon-bound oxygen undergoing exchange with soil water (Roden et al., 2000).
The δ18O value of plant cellulose now is reduced to a function of parameter vector θ = [δ18Os,T,h], which will be inferred herewith.
Description of the peat cellulose δ18O record
The δ18O record of bulk peat α-cellulose is derived from the Hongyuan Peatland (32°46′N, 102°30′E). Situated on the northeastern edge of the Tibetan Plateau (Figure 2A), it is the world’s highest (c. 3500 m a.s.l.) wetland ecosystem dominated by Carex mulieensis. The climate condition in Hongyuan ranges from cool to cold with a sharp seasonal shift, reflecting the influence of the Indian Monsoon (Xu et al., 2006). Mean annual relative humidity is about 0.7, and mean annual precipitation is 650 mm. Modulated by the South Asian monsoon, most of the precipitation occurs in summer months. The interannual variation of both relative humidity and mean annual precipitation is mild, while mean annual temperature shows a remarkable fluctuation, varying between 0.5 and 4.0°C. Given this climate setting, the 6000 year long δ18O record (Figure 1B), supported by seven AMS radiocarbon ages (Xu et al., 2006), primarily reveals orbital-scale changes in the Indian summer monsoon driven by summer insolation (Berger and Loutre, 1991). Superimposed on this long-term trend are small-scale fluctuations, which have been interpreted as changes in temperatures presumably modulated by variable solar activity (Xu et al., 2006).

(A) Shaded relief map showing the topographical feature of the Tibetan Plateau. Solid dot indicates the location of the Hongyuan Peatland from where the peat cellulose δ18O record was derived (Xu et al., 2006). AAM, Arctic air mass; WJS, westerly jet stream; EAM, East Asian monsoon; SAM, South Asian monsoon. (B) Changes in the peat cellulose δ18O values during the last 6000 years (reversed scale) and comparison with summer insolation at 30°N
The Hasting-within-Gibbs algorithm
The relationship between data and model can be expressed as:

Here we consider addictive white noise sequence, ε, as independent and identically distributed Gaussian with mean vector µ = 0 L and unknown positive definite covariance matrix Σ = σ2IL×L, where 0L is a vector made of L zeros, IL×L an identity matrix with dimension of L×L, and L the length of the data set. Accordingly, the likelihood function is defined as:
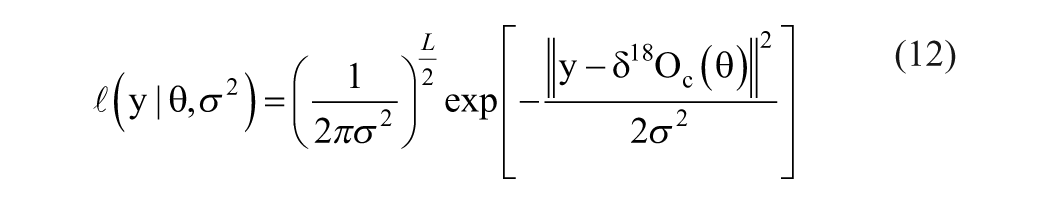
With the definition of their prior probability distributions (Appendix 1), a straightforward use of the Bayesian theorem yields the posterior probability distributions of the parameters:
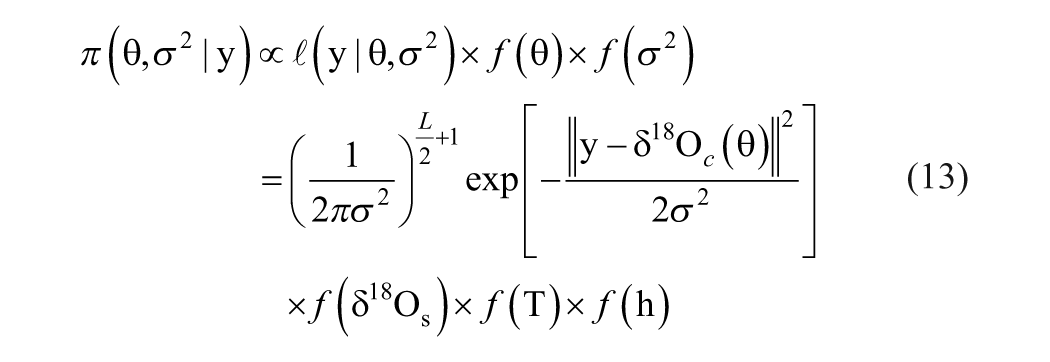
We estimate parameter θ and σ2 using the Hasting-within-Gibbs method, which is outlined in Algorithm 1. The MCMC method is used to simulate the marginal posterior probability distribution of parameters T and h. In addition to the Hasting-type move, a scheme of reversible jump is followed to accelerate the mixing of the Markov chains (Appendix 2). If the move of the chains for these two parameters is acceptable, then δ18Os and σ2 were updated sequentially using a Gibbs sampler (Appendix 3).
Results
The marginal posterior probability distributions of parameter θ and σ2 were simulated using Markov chains of 50000 iterations (Figures 3 and 4). Samples were drawn from the chains once they reached a stationary state after the burin-in period (about the first 5000 iterations). To reduce the storage requirement and to remove the autocorrelation of the samples, we thin out the chains by keeping only every tenth values during the run, which are used to calculate the statistical moments such as the mean and standard deviation of parameter θ and to generate frequency histogram of σ2 that mimic its posterior probability distribution.
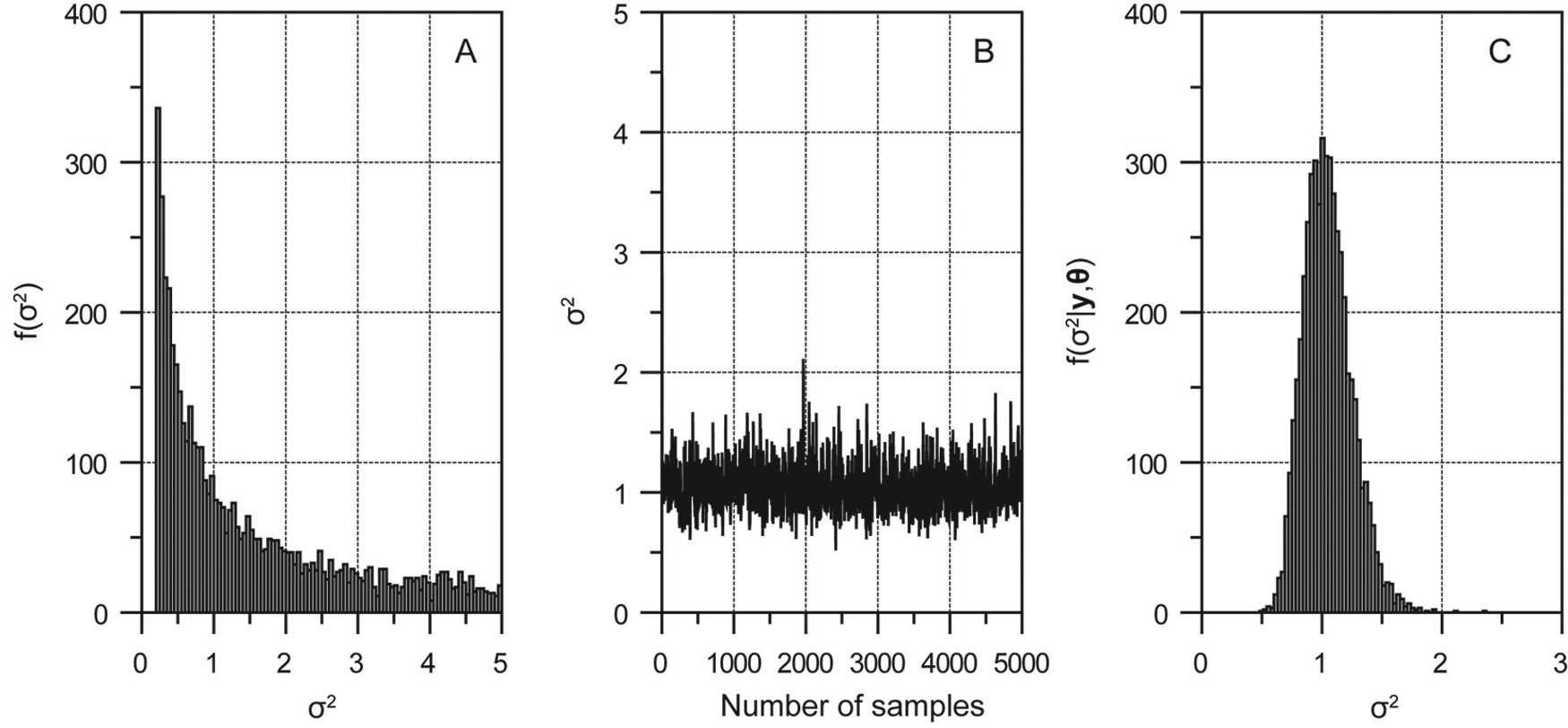
(A) Prior probability distribution of covariance σ2, which is assumed to follow a weakly informative Jeffreys’ distribution. (B) Markov chain of σ2 thinned out by keeping only every tenth values after the burn-in period. (C) Histogram showing the simulated marginal posterior probability distribution of σ2 using the Markov chain
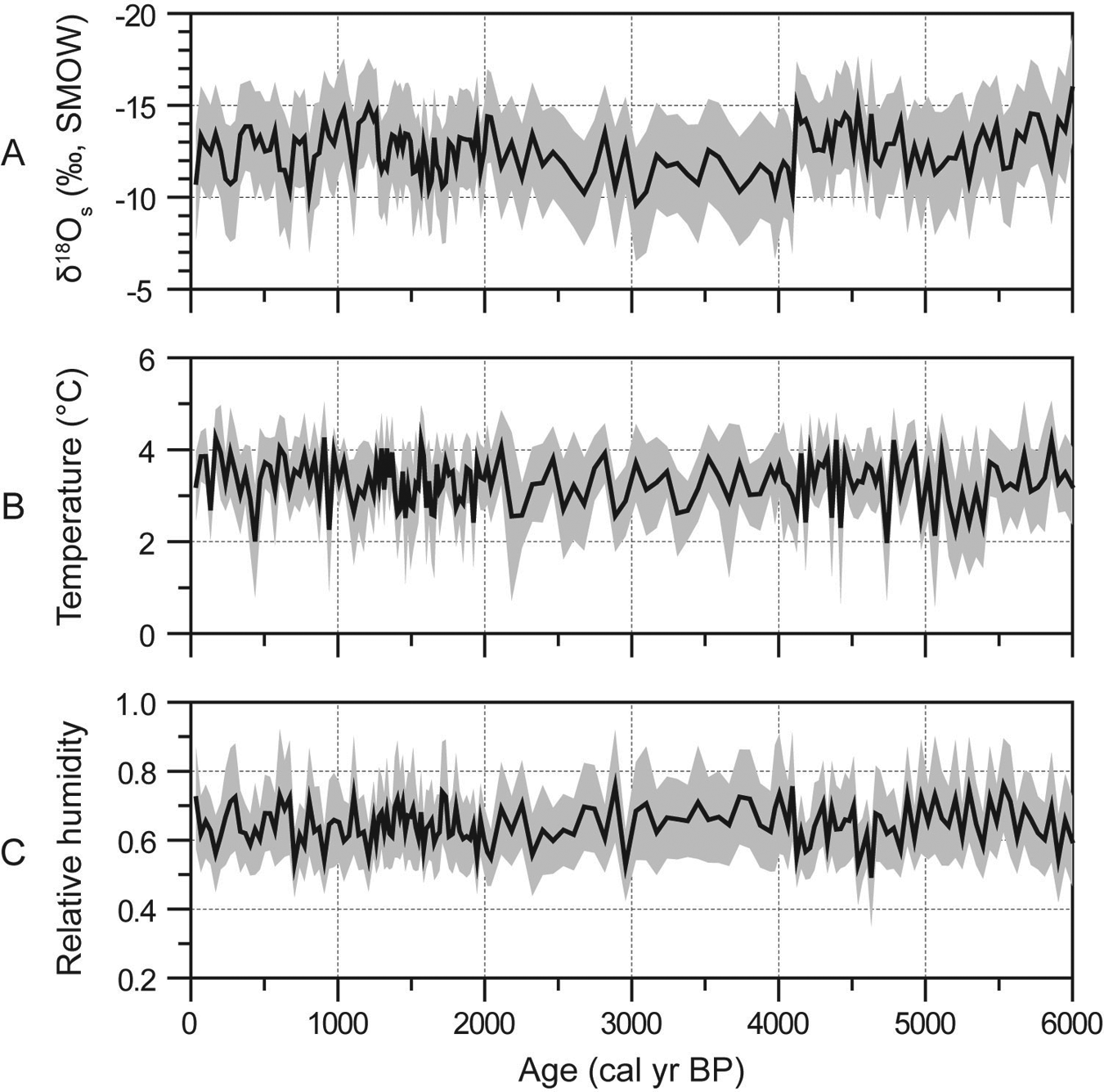
Quantitative palaeoclimate information inferred from the Hongyuan peat cellulose δ18O record. (A) δ18O values of soil water. Note vertical axis in reverse order. (B) Annual mean air temperature. (C) Relative humidity. The posterior probability distributions of these variables are summarized using the mean and the standard deviation as denoted by the solid lines and the lightly shaded envelopes, respectively
Figure 3 demonstrates how the prior belief of σ2 can be updated using the proxy record and a given likelihood function. A weakly informative Jeffreys’ prior was used to address the non-negativity of σ2 (Figure 3A). By taking advantage of the hybrid Metropolis-Hasting-Gibbs algorithm, the Markov chain for σ2 converges rapidly (Figure 3B). The frequency histogram of samples drawn from this chain is presented in Figure 3C. As proved in Appendix 3, the marginal posterior probability of σ2 follows an inverse Gamma distribution with a mode close to 1 (Figure 3C).
Instead of using a histogram as for σ2, the marginal posterior probability distributions of the palaeoclimate variables are visualized using the mean and the standard deviation, which are presented in Figure 4. The δ18O of soil water exhibits large variability between −15 and −10‰ (Figure 4A), dominating the variance of the peat cellulose δ18O record. Also, the average value of our reconstructed δ18O of soil water is very close to that of present-day precipitation, i.e. −12‰ (Zhang et al., 2001), suggesting that the δ18O of soil water strongly depends on that of precipitation. In contrast, the annual mean temperature shows subtle fluctuations between 2 and 4°C (Figure 4B). The reconstructed relative humidity was stabilized at about 0.6 (Figure 4C), revealing the dominance of monsoonal climate in this area throughout the last 6000 years.
Discussion
The oxygen isotope-based palaeoclimate reconstructions heavily rely on a statistical relationship that links the oxygen isotopic composition of precipitation to temperature (Dansgaard, 1964). This is true at a global scale. However, in the monsoonal areas, the δ18O of precipitation does not show any correlation with temperature; rather, it is negatively correlated to precipitation known as the ‘amount effect’ (Araguás-Araguás et al., 1998). The climatic conditions in our study area are dominated by the Indian Monsoon. Our reconstructed relative humidity implies that the monsoonal climate might have prevailed during the last 6000 years. Therefore, the large variations in our reconstructed δ18O of soil water cannot be solely explained by changes in temperature. Instead, they essentially reveal the changes in precipitation amount. Also, our reconstructed δ18O of soil water shows a long-term trend of shift toward the present-day value, which in turn reveals a weakening summer monsoon following the decreases in summer insolation during the second half of the Holocene (Berger and Loutre, 1991). This is in accordance with that revealed by the Dongge Cave speleothem δ18O record in monsoonal areas elsewhere (Wang et al., 2005). Superimposed on this long-term trend, our reconstructed δ18O of soil water also exhibits millennial-scale fluctuations, revealing the instability of the Indian Monsoon at this timescale (Gupta et al., 2003).
In contrast to the large variability in the oxygen isotopic composition of soil water, our reconstructed annual mean temperature shows centennial-scale changes throughout the second half of the Holocene, presumably induced by solar activity (Xu et al., 2006). However, these subtle changes may have resulted from the internal oxygen isotope fractionation processes in leaf prior to cellulose synthesis. For example, experimental studies (Helliker and Ehleringer, 2002) revealed that the heavy oxygen isotope of water tends to be enriched progressively from the base toward the tip of a leaf referred to as the Péclet effect. Therefore, for peat cellulose δ18O records, the small-scale variations may reveal the intra-plant variability of the oxygen isotopic composition of leaf water rather than the changes in climate and environment variables, because different parts of sedge leaves might inevitably have been sampled and measured. The Péclet effect can be properly modeled (Farquhar and Gan, 2003), and this process can be easily incorporated in the mechanistic model to tackle the intra-plant variability of the oxygen isotopic composition of leaf water. But in practice, it is unable to identify which part of the sedge leaves the samples come from.
We choose uniform prior probability distributions to address the complete lack of information about these climate variables for the past. Using other different types of prior would not affect the results so much, because the posterior is mainly determined by the likelihood and the observational data. This is the major advantage of Bayesian inference, which allows us to use the observational data to update the existing information that is often incomplete and inconclusive. Nevertheless, we still assign a relatively large yet reasonable range for these parameters to vary, so that optimal estimates may be obtained using the MCMC method. The ranges are determined based on modern observations or by their definition. For example, following a latitudinal gradient, the δ18O of precipitation varies between −20 and −5‰ (Zhang et al., 2002), and the mean annual temperature changes from 0 to 6°C across the Tibetan Plateau. By definition, the relative humanity can take only values that lie in between 0 and 1. Therefore, compared with the δ18O of soil water, the small-scale changes in our reconstructed temperature and humidity appear not to be suppressed by the narrow parameter spaces assigned in their prior probability distribution; rather, they imply that these variables only play a minor role in oxygen isotopic fractionation in leaf water and the observed fluctuations in the δ18O of plant cellulose mainly reflect the variations in that of soil water.
The modeled peat cellulose δ18O data using the posterior mean of these parameters are plotted against the observational data in Figure 5. These data points align themselves well along the 1:1 line. Recalling that the modal value of σ2 is very close to 1 (Figure 3C), the model residuals tend to be a white noise process as assumed at the beginning, which implies that our solution is optimal mathematically. However, this does not necessarily guarantee that the solution is physically meaningful and geologically sound. This is an important caveat common to the ill-posed inverse problems. If the degrees of freedom of parameters in the model can be reduced, or multiple proxy records are used in the inversion (Guiot et al., 2009), a much more robust constraint of the climate variables may be obtained. Also, the performance of the classical Metropolis-Hasting algorithm depends on the choice of an appropriate step size for the move of the Markov chains. Choosing a small step size can yield a relatively high acceptance probability and thus an efficient mixing of the chains, but expensive computation time is required to allow the parameter space being fully browsed.
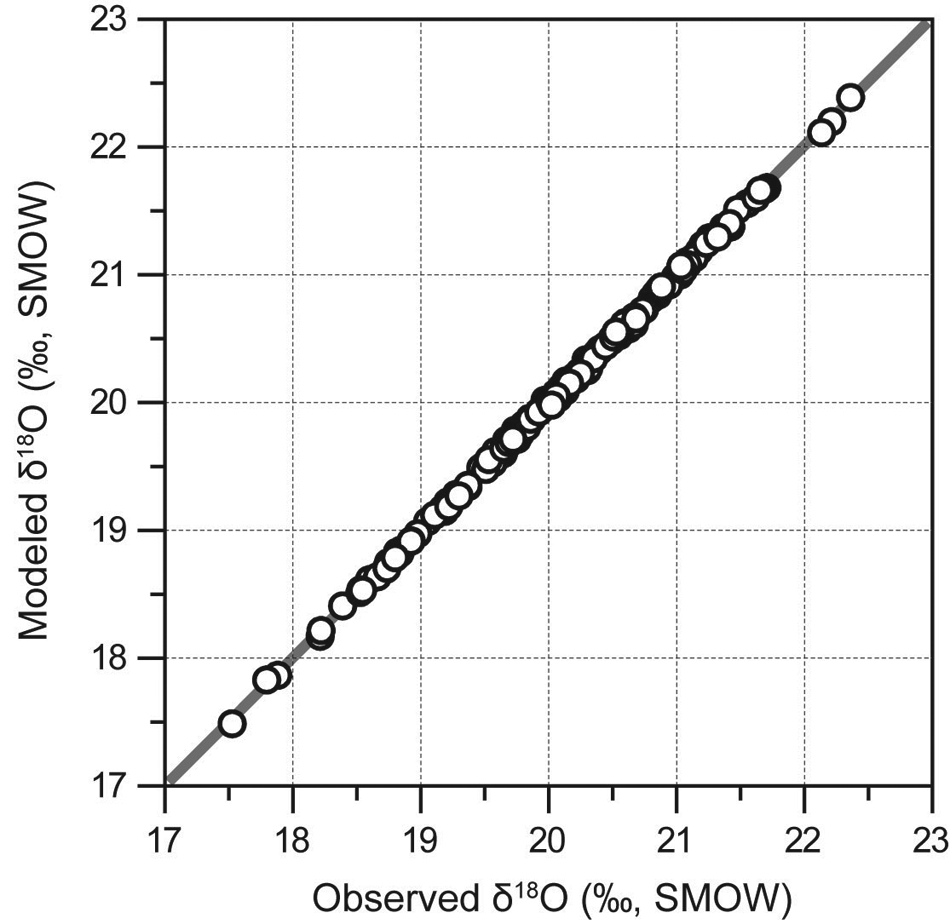
Scatter plot of the observed versus predicted peat cellulose δ18O data. Solid line shows the 1:1 relationship
The reliable reconstructions of climate for the past rely on an appropriate understanding of the relationship between climate and the proxies. This relationship should be formulated using a complex deterministic model instead of a simplistic statistical equation. The advantage of involving process-based models in palaeoclimate reconstruction is significant in several aspects. First, it could ensure a better understanding of the proxies mechanistically. Second, it is able to account for the complications that may be intractable using the transfer function method. Finally and most importantly, human disturbance may bias the statistical relationship between proxy and climate variables in terms of transfer function, but it could not alter the underlying physics that governs the formation of the fossil proxy records. However, there are only very a few kinds of palaeoclimate proxy that can be characterized using process-based models to date, and these models may be incomplete with some processes not being well understood and properly parameterized. Therefore, one of the major research targets in the future is to improve the understanding of the underlying physical processes so as to develop mechanistic models for most of the proxies. Another important caveat with this method is the dilemma between model complexity and computation cost. Mechanistic models covering the full spectrum of the processes involved in generating the proxies are preferable for the inverse proxy modeling. However, increasing the complexity of the models would inevitably increase the computational time. If a tremendously complicated model is incorporated, the inversion could turn out to be computationally intractable.
Concluding remarks
Within the Bayesian paradigm, we are able to reconstruct climate changes on the eastern Tibetan Plateau during the last 6000 years quantitatively by integrating a peat cellulose δ18O record with a process-based model of oxygen isotope fractionation in plant cellulose. Our results indicate that, to a large extent, the observed variation of the δ18O record reflects the changes in the oxygen isotopic composition of soil water, which appears to be a function of precipitation amount. Compared with hydrology, temperature and humidity have little influence on the oxygen isotopic fractionation of leaf water. This conforms the prevailing notion that the δ18O records in monsoonal areas should be primarily interpreted in terms of the ‘amount effect’.
The forefront of palaeoclimatological studies requires the development of not only reliable proxies of climate variables, but also powerful methods that can be used to integrate these proxy records across broad spectra. The inverse proxy modeling stands out as an excellent method for quantitative palaeoclimate reconstruction, because deterministic models and proxy records are integrated in a unified framework. This model–data fusion technique fundamentally differs from the traditional transfer function approach, and it represents a conceptual innovation in palaeoclimatological studies. This worked example also shows the promise of Bayesian statistics in quantitative palaeoclimatology. It not only offers a mathematical feasibility to solve the ill-posed inverse problems, but also provides an effective approach to quantifying the uncertainty of the inferred palaeoclimate data.
Footnotes
Appendix 1. Prior probability distribution of parameters
We choose a weakly informative prior probability distribution for parameter vector θ, given that their values are completely unknown for the past. The prior probability distributions of δ18Os, T, and h are set to be uniform (UNIF) supported on a specific interval:
The prior of σ2 follows Jeffreys’ distribution:
Appendix 2. Reversible jump and the acceptance probability
Draw a random number λ from the proposal distribution
Therefore, the acceptance probability for this reversible jump move becomes:
where J is the Jacobian of the transformation, which is defined as:
Appendix 3. Marginal posterior probability distribution of δ 18 O s,and σ 2
Equation (13) is rearranged to solve for δ18Os yielding a truncated multivariate normal (MVN) distribution:
where: E = y − (1−f0)×(εeq+εk)×(1−h)−ε0 is the mean vector; Θ = σ2IL×L is the positive definite covariance matrix; I(δ18Os) is an indicator function defined as:
A straightforward use of the Bayesian theorem yields an inverse Gamma (IG) distribution for the marginal posterior of σ2:
Acknowledgements
We are grateful to Dr X. Hai for providing us with the Hongyuan peat oxygen isotope data. Our gratitude is also extended to the two anonymous reviewers for their constructive comments and suggestions.
S.-Y. Yu would like to thank the 100-Talents Program and the Strategic Priority Research Program (Grant No. XDA05120401) of the Chinese Academy of Sciences as well as the National Science Foundation of China (grant no. 41023006) for funding this work.