
Abstract
The study examined humorous interactions with intelligent personal assistants (IPAs, including Google Assistant, Amazon Alexa, Microsoft Cortana, Apple Siri) with the aim of classifying user utterances, IPA responses and user reactions of system responses. Data from online diaries and paper questionnaires were collected and analyzed using content analysis method. The findings suggest that the most frequent types of utterances include questions that test system “personality” and opinions. Joke requests are also frequent and produce pre-programmed humor that users generally find funny. The initial classification of humorous utterances has been validated and expanded using published datasets of humorous utterances for the four investigated IPAs. The findings can be used for immediate improvements to IPA performance as well as long-term development of IPA personas.
Keywords
Introduction
Humor, generally defined as a cognitive experience of joy (Apte, 1985) is an integral component of human-to-human communication. We use humor to build support, credibility and group cohesiveness, to make our views more memorable, to provide gentle criticism and behavior corrections, and define our identities (Meyer, 2000). Not surprisingly, humor is frequently incorporated into the design of system interfaces in order to make them appear friendlier and more relatable to a user (Knight 2012).
Humor is used in several types of intelligent personal assistants (IPAs, including Amazon Alexa, Google Assistant, Apple Siri, and Microsoft Cortana) and the literature suggests that it helps to defuse situations when IPAs are unable to find an answer; and to entertain or develop a bond with a user (Binsted, 1995; Knight, 2012). Published research on humor in the context of IPA interactions is scarce: humor studies in the human computer interaction (HCI) context often focus on the technical aspects of humor generation and recognition, while publications about humor and IPAs often come from non-scholarly sources. With the limited number of studies and IPA usage statistics, it is hard to understand the role of humor in human interactions with IPAs. In an effort to address this gap, we developed a study to examine the nature of humorous interactions with IPAs. We explored humorous user utterances, system responses and user reactions to these responses and developed classifications that have methodological and practical significance. The classifications of humorous utterances directed towards IPAs, IPAs responses, as well as user reactions to system responses can be used for experimentation and modeling of human-IPA interactions. They can also inform immediate improvements in IPAs’ humor generation.
Relevant literature
Theories of humor
Many disciplines including psychology, linguistics, education, and sociology examine various aspects of humor, including its production, manifestations, and effects on individuals and groups. Though the specific definitions of humor depend on the purpose for which it is used (Attardo, 1994; Taylor and Mazlack, 2004), humor is generally defined as a cognitive experience of a joy or amusement, which is often manifested in laughter, smiles, grins, exhalations, or statements from a person experiencing it (Apte, 1985).
Meyer (2000) summarizes the three most popular theories of humor which include relief theory, incongruity theory and superiority theory.
Relief theory emphasizes the use of humor to reduce senses of stress and tension. This theory helps to explain intentional uses of jokes to reduce tension, as well as simple laughter that relieves tensions and encourages interactions between actors. The relief theory also supports a notion that joke tellers often intentionally build tension for the purpose of releasing or resolving it with humor.
The incongruity resolution theory suggests that humor arises when two dissimilar variables are paired together, replacing former logic and familiarity with the subject. In simpler terms, it is when one predicts a certain outcome but receives another (Mihalcea and Strapparava, 2006; Shahaf et al., 2015). Since incongruent humor is based on violations of social or cultural norms, it clearly illustrates its social nature. Meyer (2000: 314) provides several examples of such humor, including the TV shows America’s Funniest Home Videos or Seinfeld, which solicit humor by presenting unusual or inappropriate behaviors.
As the name of the superiority theory suggests, it is based on the notion that humor might arise from situations when people feel superior compared to others. This theory explains situations when adults laugh at children’s behaviors or sayings or when humor is used to reinforce socially acceptable behavior by ridiculing inferior ones.
Based on an in-depth analysis of these three dominant theories of humor, Meyer (2000) outlines four basic functions of humor in daily life:
Identification – use of humor to build support, credibility and group cohesiveness;
Clarification – use of humor to make one’s views more memorable and pithier;
Enforcement – use of humor to criticize or caution without alienating an audience; and
Differentiation – use of humor to contrast the self with the other in terms of views, social groups, identities, and so on.
Just as the function of humor varies based on the needs and desires of the communicator, so do the generation and perception of humor vary based on personality type. Martin et al. (2003) found that certain behavioral traits were associated with the dominant humor styles. Individuals with an aggressive humor style, for example, use humor to enhance themselves at the expense of others, while those with a self-enhancing humor style accomplished the same without hurting others or their relationships with others. Personal humor styles were further linked to neuroticism or psychological well-being.
While humor is generally viewed as a positive and desirable attribute, it does not inevitably create a positive personality impression. For example, Kuiper et al. (2010) found that aggressive and self-defeating humor styles attributed to negative perceptions of an individual.
“Although humor and laughter are universal in humans and are likely a product of natural selection, the way people use and express them in a given time and place is strongly influenced by cultural norms, beliefs, attitudes, and values” (Martin, 2007: 26). A study illustrating humor as a cultural phenomenon can be found in Yue et al. (2016), who discuss the differences in humor perceptions between western and Chinese cultures. Authors argue that westerners tend to regard humor as a positive, common disposition, while the Chinese are more likely to regard humor as an often-controversial trait particular to comedians. Such perception of humor is rooted in Chinese traditional social norms that value seriousness, which means that individuals raised in the Chinese culture “tend to fear that being humorous will jeopardize their social status” (Yue et al., 2016: 3). In examining students’ attitudes to humor, the authors found that Canadian students rated humor as being significantly more important than Chinese students and considered themselves to be significantly more humorous than Chinese students indicated.
Despite the cultural differences in humor generation and perception, broad categories of humor hold in multiple contexts, including: (a) universal humor (e.g. incongruent humor), (b) culture-specific humor (e.g. ethnic jokes), (c) language-specific humor (e.g. puns and riddles) (Raphaelson-West, 1989). Another humor classification includes incongruity-resolution, nonsense, and sexual humor and is used in 3WD (Witzdimensionen) test to assess individuals’ perception of jokes and cartoons (Ruch, 1992).
In summary, people use humor in conversations in order to reduce stress, cope with surprising situations, and reinforce a sense of unity and belonging. Not surprisingly, humor has been integrated into the design of technology in order to make it more engaging and personable.
Humor in human computer interaction
Human computer interaction (HCI) research suggests that humor makes using technology more engaging, contributes to its personification, and enhances the user experience with the system (Khooshabeh et al., 2011; Niculescu et al., 2013). Nijholt et al. (2017) report an extensive literature review on the role of humor in HCI, with a particular focus on social media, intelligent agents, social robots, and smart environments, and note main research themes in the areas of linguistic and visual humor generation, recognition, and interpretation.
Humor generation
It has been observed that computational humor generation is an easier task to complete than computational humor recognition. In the HCI context, humor generation is a machine’s ability to identify aspects of humor and algorithmically replicate them for users (Taylor and Mazlack, 2004). Most humor generation approaches focus on puns, as puns have a relatively simple structure (Hong and Ong, 2009; Ritchie, 2009; Valitutti et al., 2013). One of the earlier works on pun generation was done by Binsted et al. (1997) who developed a joke-generating program, JAPE. While generally successful, users found the program’s generated jokes less funny than the human-generated jokes. Valitutti et al. (2013) proposed a method for “adult” puns made from short text messages by lexical replacement. Stock and Strapparava (2005) developed HAHAcronym, a system that generates funny deciphers for existing acronyms or produces new ones starting from concepts provided by the user. Taylor and Raskin (2013) summarize a common theme of humor generation studies as identifying human cognition of humor and its replication in a computer experiment using logical language structures. While computational humor is received by users with varying degrees of success, its generation proved to be logistically possible, but only if previously programmed.
Humor recognition
Computational humor recognition efforts aim to develop algorithms capable of recognizing a wide range of human-generated humor, which could be generally grouped into basic and complex types. Basic humor is associated with a predictable syntactic structure, a designated set of variables, or a punchline (e.g. a joke with a punchline). Examples of successful algorithms for detecting humor in simple-structure texts are discussed in Kiddon and Brun (2011) and Mihalcea and Strapparava (2006). Complex humor, such as irony and sarcasm, does not follow logistic rules and can be delivered in many variations. Its structures are dependent on linguistic, psychological, and behavioral cognition, some of which are not easily defined, even by humans (Reyes et al., 2013). Several recent studies focused on algorithm development for irony and sarcasm detection in tweets (Rajadesingan et al., 2015; Zhang and Liu, 2014). The algorithms prove to be somewhat successful, though limited by lack of cultural and commonsense contextualization (Khooshabeh et al., 2011; Niculescu et al., 2013; Mihalcea and Strapparava, 2006; Miller et al., 2017; Yang et al., 2015).
Humor in IPAs
Humor has been shown to make interfaces friendlier and more relatable (Binsted, 1995; Knight, 2012) and is frequently integrated into the design of conversational agents. For example, an experimental study that compared two conversational robots found that the system that was programmed to display extroverted personality, use humor, and have a high-pitched voice improved users’ perception of the system and the overall task enjoyment (Niculescu et al., 2013). Not surprisingly, humor is used in several types of IPA responses to user utterances: deprecation humor is used to defuse situations when the IPA is unable to find an answer; IPAs poke fun at themselves when complimented, developing a bond with the user (Knight, 2012). Knight (2012: para 2) argues that “a digital assistant needs more than just intelligence to succeed; it also needs tact, charm, and surprisingly, wit.” The author points out that Siri’s conversational and joking manner allows it to seem “smarter and more likeable” (para. 18) as well as “lessen the blow” (para. 17) when Siri misunderstands something (Knight 2012). Attkisson (2016) compared Siri and Alexa and discovered that both virtual assistants “were built with a family-friendly, corny sense of humor” (para. 27).
Some IPA companies are even hiring professional writers to develop humorous material for their systems. Google is reportedly trying to set itself apart from other IPAs by hiring content writers from Pixar and the Onion to create jokes and a conversational tone for its Assistant (Kelly, 2017). Authors outline the shortcoming of the IPAs that cycle through a certain amount of pre-programmed jokes (Kelly, 2017), and emphasize the need for some new and better material (Heater, 2016). Lee (2018) interviewed professional comedians about the quality of Siri, Google, Alexa, and Cortana jokes. Overall, comedians found IPAs to be old-fashioned and too simplistic (Lee, 2018). While IPA companies are not sharing their humor algorithms, we assume that they continuously improve them to anticipate users’ needs and provide appropriate humorous responses (Kelly, 2017).
Methods
While the literature indicates the presence of humor in user interactions with IPAs, a few questions remain largely uninvestigated:
What types of user utterances initiate humorous response from IPAs?
What types of IPA responses do users find to be humorous?
How do users judge the quality of IPA’s humorous responses?
IPA producers undoubtedly collect data that could provide answers to questions 1 and 2; however, such data are not publicly available and would not help to answer question 3 about user reactions to humorous interactions with IPAs. In order to investigate the nature of humorous interactions with IPAs and find answers to the three research questions, we developed the following data collection instruments and procedures:
Online demographic questionnaire used for recruitment and demographic information. Participants for the study were recruited through the messages on institutional and departmental mailing lists and social media channels, and through word of mouth. The initial recruitment messages included a link to a short qualifying demographic survey. The survey collected information about potential participants’ age, gender, IPA usage, and native language. The question about native language was included to gauge participants’ cultural background and English language proficiency, factors that have been shown to influence humor generation and perception.
A week-long online diary. Initially 15 participants volunteered to fill out a daily log of their humorous interactions with IPAs. In the end, 13 participants filled it out and provided the following demographic information about themselves: 9 males/4 females, 12 non-students, 10 participants ages 25–34, one from 18–24, 35–44 and 55–64 age groups, 11 English speakers. Participants reported using three major IPAs during the study, sometimes interchangeably, including: Apple Siri (9 mentions), Amazon Alexa (5), and Google Assistant (4). Participants were given a link (and a mobile phone app shortcut) to a form that they were asked to fill out daily for every humorous interaction they encountered. Participants filled out the diary form for seven days with the min 1, max 37, mean 8.2, and median 5 humorous interactions a day, with a total of 162 interactions logged. Humorous interactions were broadly defined as “IPA interaction participant found funny.” The short form collected information about the IPA type used for the interaction, what participants said to initiate the interaction, the IPA’s response, and participant’s rating of the IPA response based on how funny it was. To encourage participants to record their interactions with IPAs, they were given a $5.00 gift card with additional $.25 award for every recorded joke.
A humor raffle. In order to diversify and expand the pool of participants, we placed Alexa in a public hall of an iSchool and asked volunteers to engage in humorous interactions and record their feedback on the interactions on a print form. The forms collected information about participants’ mood prior to the interaction, brief description of a joke, and a time stamp. The last two pieces of information allowed researchers to map the form to an interaction logged by Alexa app. No demographic information was collected in the print form, but based on the Alexa’s placement, participants were graduate students. To encourage participation, participants had a chance to include their email address to receive a small gift card award for each interaction and enter in the raffle for the five larger awards. A total of 15 participants filled out the forms, with the number of interactions ranging from 1 to 16 per participant, and a total of 55 interactions logged through this method. The data on user utterances and system responses in the public hall was integrated with the diary data for analysis.
Utterance classification validation. The qualitative data on user utterances and IPA responses were content analyzed, resulting in classifications of humorous user utterances and system responses. The classification of user utterances was then compared and validated against the published datasets of IPA humor (Bolluyt, 2016; Chacos, 2015; Hesse, 2018; Hill, 2019; Moon, 2018; Owens, 2018a, 2018b; Stables, 2018). The datasets usually included examples of utterances that the list creators found funny and shared with other IPA users. Datasets for the four main IPAs (Apple Siri, Google Assistant, Amazon Alexa, and Microsoft Cortana) were normalized by randomly selecting 109–114 utterances per system, and creating samples comparable to the diary-based dataset. Only English-language sources from US websites were selected for comparison since the classification was developed in the same linguistic and cultural context. Amazon Alexa sources had the highest number of published humor, while the sources on Cortana were the most dated (published between August 2015 and December 2016). We content analyzed the published sources using the previously developed classification, which had to be refined and expanded. The initial and refined classifications are discussed below.
It is worth mentioning that in order to determine the “funniest” type of humor, we also planned to collect data by running a competition and inviting volunteers to the lab to generate and rate humorous interactions with IPAs. We planned on asking participants to publicly generate humor with an IPA, judge each other’s interactions and determine the funniest interactions for special prizes. However, we did not recruit a sufficient number of participants for this experiment, perhaps indicating the sensitive and private nature of humor. It is worth exploring reluctance of regular people (not comedians) to produce humor and be judged by strangers. Lack of sufficient familiarity with IPAs may also make users uncomfortable with the technology and prevent them from attempting to test its full capabilities (Shahaf et al., 2015).
Results
Initial classification
The text of user utterances and system responses collected via diaries and online forms was analyzed using content analysis method. A complete dataset was split into smaller sub-sets and coded by multiple researchers, who then met to develop a code book based on their initial interpretations of text and inductive categories of themes in participant descriptions of IPA interactions (based on the method discussed in Mayring, 2000). The code book of the main themes in user utterances, their definitions and hierarchies (see Table 1) was used by the two researchers for analyzing the complete dataset with the high degree of intercoder reliability (Cohen Kappa > .8). User ratings of IPA-generated responses were collected on a 5-point Likert scale (5=hilarious/3=neutral/1=disappointing 1 ). Responses with the values above 4 were considered “positive” (funny), while 1–2 were considered “negative” (not funny) responses. The frequencies of the positive, neutral and negative reactions within each category of humorous utterance are integrated into Table 1. (User reactions within each type of IPA response can be found in Table 3.)
List, frequencies, definitions, and examples of the main themes in users’ humorous utterances and system responses.
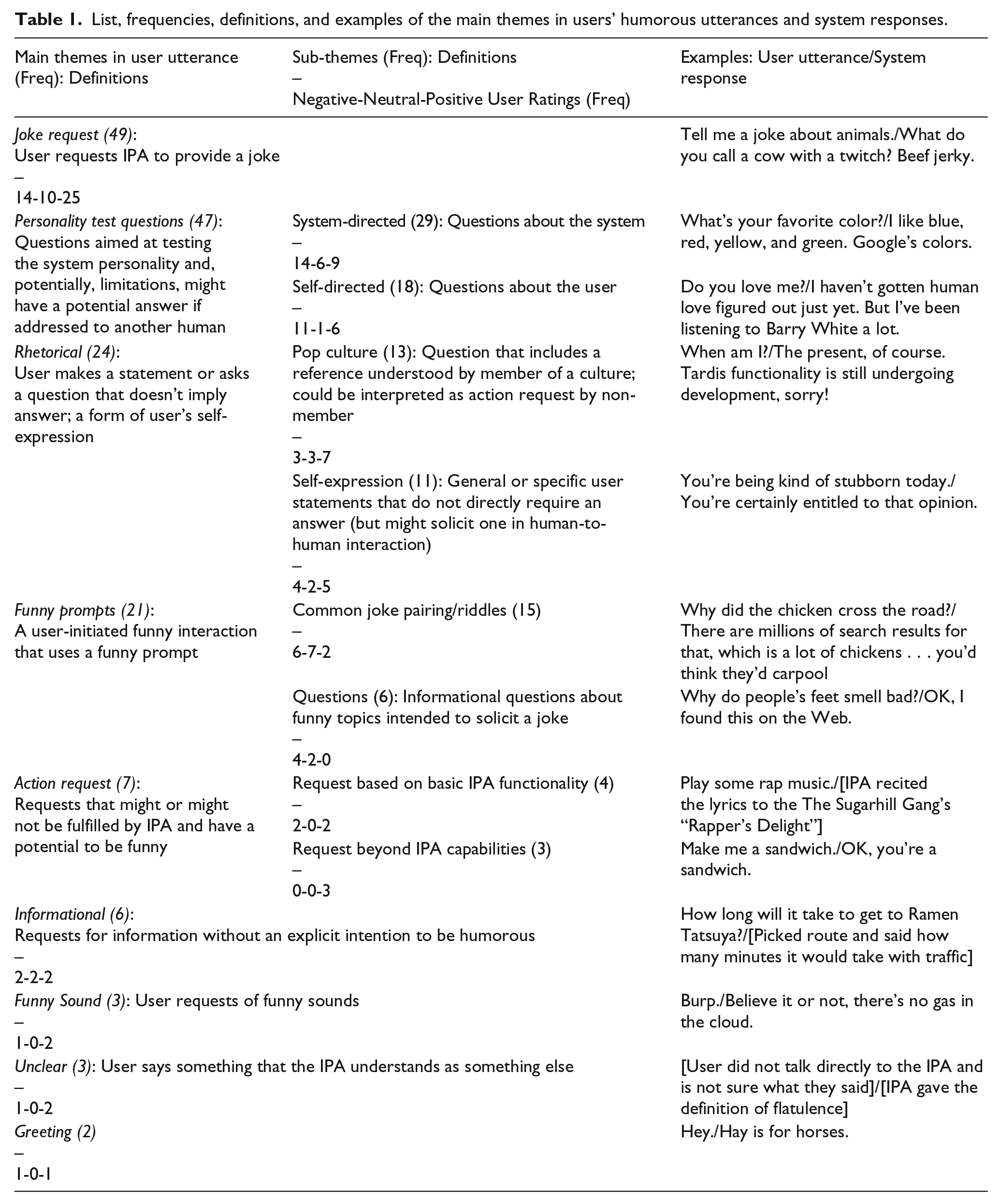
Types of user utterances that initiate humorous response from IPAs
The most frequent type of user-generated humorous utterance was the request to produce a joke, both broad and generic or on a specified topic (animals, space) (Table 1).
The number of questions about IPA personality closely followed requests for jokes. Within this broader category, we identified two groups of questions: questions directed at the system (e.g. Where do you live?) and questions directed at the self (Am I funny?). In a human-to-human interaction, when one person tries to learn more about the other or solicit an opinion, one would expect such questions to receive an answer. We hypothesize that the IPA users expected humorous responses because they knew that the IPA would not be able to provide true answers to such questions due to the lack of true personality.
User-generated statements or questions where an answer was not expected were classified as rhetorical utterances. Within this broad category, we identified pop culture (e.g. songs, movies) references and personal statements or opinions. System responses to the pop culture references were generally rated positively.
In a number of instances, users initiated funny interactions by using funny prompts. Within this broad category, some initial prompts were based on common joke pairings or riddles (e.g. knock-knock), while others followed the structure of an open question.
Several utterances were classified as IPA action requests, including “reasonable” requests for known IPA functions (such as playing music) and “unreasonable,” and therefore more humorous, requests (e.g. make me a sandwich).
A few utterances were informational in nature, and we do not fully understand why participants logged them as humorous. It could have been a mistake or a type of humor specific to the user’s cultural group or context.
In three instances IPA users asked a system to produce funny sounds.
Participants recorded two greetings, one of which was positively rated, in their log.
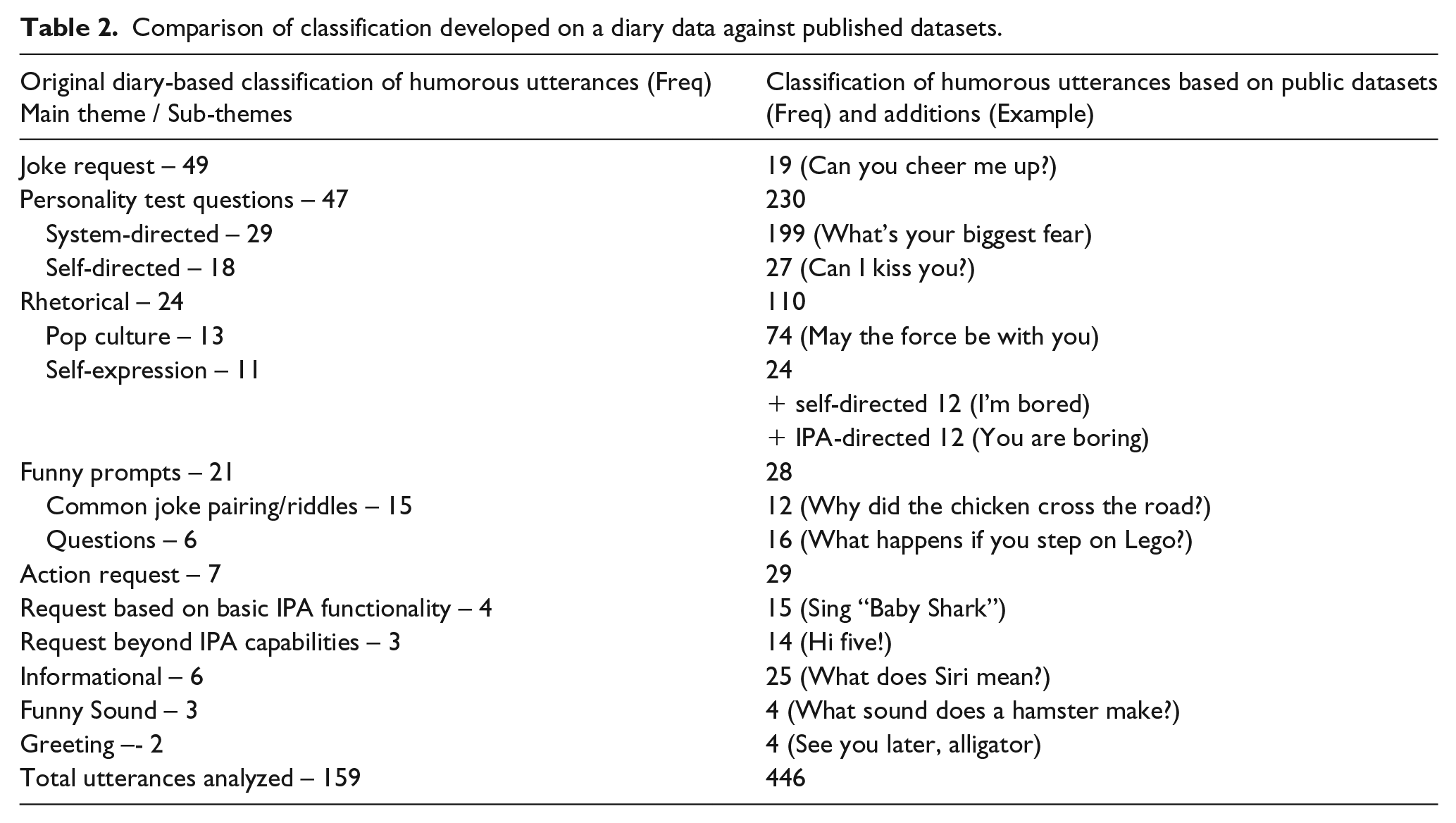
The classification that emerged from the initial open coding of the diary data was then applied to coding the dataset of published IPA humor. Across all 4 IPA lists, personality test questions were the most frequent in the published lists, followed by rhetorical, action request, funny prompts, and other less frequent categories. This distribution was consistent across all IPAs except for the published list of Alexa humor where we identified a slightly higher frequency of rhetorical/pop-culture references (N=30) than personality questions (N=28). In several cases, the datasets offered examples of utterances that did not easily fit into existing categories. For example, within the sub-category of rhetorical-self-expression utterances we identified two additional sub-sub categories: self-directed and IPA-directed. The frequencies and examples of utterances in each humor category are listed in Table 2.
Comparison of classification developed on a diary data against published datasets.
Types of IPA responses that users found to be humorous
Most of the system responses constituted canned jokes or non-humorous responses (Table 3). The largest portion of all system responses were jokes based on word play or pop culture references and common joke pairings (e.g. knock-knock jokes). User reactions to pre-programmed system humor were generally positive.
List, frequencies, definitions, and examples of the IPA responses.

A number of system responses were not humorous but relevant to user questions about system personality or rhetorical questions. User reactions to system personality responses were split between positive and negative.
In some instances, the system responded to user utterances with informational responses. Some of these responses were unexpected and users found them funny; others were relevant but not funny.
The system was unable to respond to some user utterances and either admitted its limitations or produced no response. While admission of inadequacy received mixed user reactions, users were disappointed with a complete lack of response from the system.
Users judgements of IPA’s humorous responses
The frequencies of the positive, neutral, and negative user reactions were analyzed within the categories of user utterance (Table 1) and system responses (Table 3). The categories of user utterances that produced the highest relative number of funny responses included joke requests, rhetorical statements or questions, action requests beyond the IPA capabilities, and funny sounds. Participants found a large number of not-funny IPA responses in the categories of personality questions and funny prompts. The types of IPA responses that users judged predominantly funny included canned jokes (including feel good jokes in rhetorical re-sponses) and unexpected informational responses (Table 3). System attempts to respond to personality questions and inability to respond with admission of inadequacy received mixed reactions. The worst user reactions were associated with a complete lack of system response.
Discussion
Types of user utterances that initiate humorous response from IPAs
One of the most frequent categories of humor in the data collected through diaries and published datasets included personality questions for IPAs. The prevalence of utterances aimed at testing system personality and opinions may indicate users’ interest in better understanding how IPAs communicate and exploring the IPAs’ boundaries of knowledge and socialization. Drawing on the studies of Graham (1995) and Norrick (1993) on the benefits of humor in human interactions, we may assume that the users search for human qualities similar to their own to produce a sense of solidarity through shared experiences with IPAs. Considering IPA developers’ efforts to make conversational systems more anthropomorphic (Bellegrade, 2014), such personality questions are expected.
In the diary portion of the study, requests for jokes were frequent, possibly due to the minimal cognitive load required for such interactions (Rajadesingan et al., 2015), as well as users’ lack of familiarity with the system and its more advanced humor functions. The popularity of this category can also be explained by participants’ knowledge of the system and its strength in producing preprogrammed jokes.
Another frequent category of humor was rhetorical utterances where users tested systems’ awareness of and response to cultural references as well as reactions to personal statements. This category of utterances is similar to personality questions in that both signal users’ intention to seek connection and similarities with the system based on the common references and experiences. Both personality and rhetorical utterances tap into the two functions of humor (Meyer, 2000): identification, when users use humor to develop cohesiveness with the system, and differentiation, when humor is used to contrast a “smart” user with a “dumb” system.
Jokes made to the system (funny prompts) were infrequent in both diary and publicly published datasets possibly because (a) they require more cognitive effort than other humorous utterances, and (b) users might be aware of system limitations in producing satisfactory responses to such utterances and therefor avoid them all together.
Action requests, requests for information, funny sounds, and greetings directed to IPAs were relatively infrequent compared to other categories. We hypothesize that most of these categories (except for the funny sound and unreasonable action requests) were not intended to be humorous, but users recorded them as humorous based on incongruity of IPA responses. More data are needed to determine distinct patterns in user behavior and IPA responses within these utterance types.
The attempt to validate humorous utterance classification by applying it for coding a larger published dataset of IPA humor was largely successful. For the most part, the classification that was initially developed from diary responses matched the categories and relative frequencies of humor in the larger dataset. The differences in popularity of some categories of humorous utterances between the two datasets could be attributed to their different purposes: the initial classification was created through qualitative inquiry on how users interact with IPAs; the publicly shared lists usually include humor that has been previously found funny and can be used to amuse IPA users. For example, joke request is a category that was popular in the diary study, but due to lack of variability within this category (there is a limited number of ways one can ask an IPA to tell a joke), it was not heavily represented in the published lists.
Types of IPA responses that users found to be humorous
Overall, the IPAs were able to produce a response to user utterance 85% of the time; in other instances it either admitted the inability to appropriately understand/respond to the user’s utterance or did not produce any response. The fact that 52% of IPA responses were canned jokes supports the notions that (a) the most successful humor generation is based on preprogrammed content (Taylor and Raskin, 2013), and (b) IPA companies invest into writing humorous materials for their IPAs (Kelly, 2017). Canned jokes were produced to address user requests for jokes, funny prompts, and rhetorical statements (common joke pairings/riddles).
In many cases IPAs responses to the personality questions were based on the “neutral” content where the system neither fully admitted to being a machine nor created a full illusion of being human. For example:
User utterance: What do you dream of? System response: I dream of one day getting to taste waffles
The system hints at not being able to taste food, but does not fully acknowledge being a machine and not having dreams either. It also does not go to the full extent of creating an illusion of being human, and responding with something like “I dream of having a great vacation in Bora Bora” or “I usually don’t remember my dreams,” or other responses in line with how a person would respond to such a question. Since more than 10 out of almost 50 personality utterances did not receive appropriate answers, we also plan to examine the linguistic properties of personality questions to increase IPA recognition of utterances in this category.
The systems produced more informational responses (16) than were requested (6), addressing utterances in other categories with informational answers. Reliance on information retrieval functions is a known IPA strength, especially for Google Assistant (Betters and Grabham, 2018), so “overuse” of informational responses to address uncertain user utterances is a reasonable system response. Interestingly, users found most of the unexpected informational responses funny (in line with incongruity resolution theory (Meyer, 2000)), while most of the relevant informational responses were judged as neutral or disappointing. Such user reactions suggest that when an IPA is unable to appropriately classify and address a user utterance, the best solution might be to use a pre-programmed joke or a pop culture reference that would provide unexpected humor.
Some interactions when the system could not address the user’s utterance and admitted its inadequacy were rated neutral or even positive. Here is one example of an interaction that was rated as highly humorous by one user. It involved the system responding with an admission of inadequacy at not understanding the user’s request, followed by an unexpected response:
User utterance: “Hey Cortana, do you still have a spaceship?” System response: “I’m sorry, I lost the thread of our conversation – can you repeat that?” User utterance: “Hey Cortana . . .” System response: [Interrupts in chipper voice] “That’s me!” User response: [Laughter]
Such unexpected system responses confirm that the use of humor mitigates system limitations and creates positive experiences even without producing a relevant response (Knight, 2012).
Interactions that resulted in unequivocally negative reactions were total lack of IPA response to user utterance, suggesting that any kind of feedback from the system is better than no feedback at all, a notion grounded in basic interface design principles (Nielsen, 1995). In one instance, an extreme negative reaction was caused by unexpected personalization which came from Microsoft Cortana referring to a user by their first name. The user found this response off-putting because they did not remember setting up that functionality of name usage. This example shows a situation in which the IPA’s attempt at personalization failed because it was unexpected and unwarranted. This may indicate that certain cautions must be considered when implementing personalized responses, a topic for further research.
Users’ judgements of IPA’s humorous responses
Overall, more than half of system responses to user utterances were rated as funny (54%) with the remaining responses evenly split between not funny (23%) and neutral (23%). The finding is encouraging and suggests that users would probably rate their IPAs as having an “average” sense of humor.
One of the “funniest” categories of user utterances included requests of a joke, rhetorical statements/questions, or unreasonable action requests followed by system responses of a preprogrammed jokes. In a few cases of addressing rhetorical, action request or informational user utterances, the system produced unexpected “canned” responses which were met with positive reactions; a phenomenon that can best be explained by the incongruity resolution theory aimed to explain situations where a mismatch between expectation and reality often creates a funny reaction (Meyer, 2000). Incongruity can also explain user satisfaction with unmet system action requests that they found funny. For example, the user utterance “Make me a sandwich” received an Alexa response of a pun, “Ok, you’re a sandwich.” Users found about half of the system responses to personal rhetorical statements not funny; and IPAs often were unable to respond to such statements all together (e.g. “[Name of politician] is terrible”). Further investigation is needed into requirements for appropriate IPA responses to rhetorical statements (e.g. (dis)agreement, empathy, offer of additional information/opinions on a subject).
The results indicate that users generally like the quality of preprogrammed humor, though it would require a longitudinal testing to ensure that jokes’ appeal holds over time, even when the jokes start being recycled on subsequent interactions (Kelly, 2017).
It is worth noting that the two participants whose primary language was not English logged more joke requests than other participants, and generally rated them lower than others. This might be explained by language and cultural barriers in understanding and generating humor in a foreign language (Martin, 2007) and warrants further investigation.
User reactions to IPA responses to personality questions received mixed reactions from the users, possibly due to users having higher or different expectations of a machine. More work is needed to test whether users would prefer more human-like or more system-like responses in this category, or perhaps would prefer a customizable option for tuning the IPA responses to their emotional and conversational needs. We think that this area has the most potential for immediate improvement: the list of common personality questions is limited and canned responses can be developed to increase users’ satisfaction with this category of utterances.
Not surprisingly, informational responses were largely perceived with neutral reactions. We plan to further investigate why informational inquiries were not only logged as humorous in the study diary, but also appeared in the published lists of IPA humor. Perhaps users expect funny or unusual responses within this category or make unreasonable requests; or this category is incidental and should be removed from the humor classification.
While most of the system responses to various user utterances received a mix of positive, neutral and negative scores, the only unequivocally “not funny” judgement was associated with a complete lack of responses from the system. The findings illustrate the importance of system feedback (Nielsen, 1995) and acknowledgment of user utterance, even when it is not understood or the appropriate response is not available.
Limitations
The study had a number of limitations. Due to the difficulties with participants’ recruitment, two data collection methods were utilized: a diary and a short print questionnaire (one joke per questionnaire). While both instruments relied on participants’ self-report, the differences between the instruments and procedures might have resulted in over- or under-reporting of certain type of utterances. For example, diary participants might have recorded more unintentionally humorous utterances while questionnaire participants were asked to focus exclusively on intentionally humorous utterances with IPA. In order to mitigate threats to the validity of collected data, we verified the classification on a larger dataset of published IPA humor, and the classification produced on the study held well when applied to the external dataset.
Both data collection procedures incentivized users to engage in humorous interactions with IPAs. In a natural flow of interactions, we would expect more unintentional/incongruent humor to occur with systems responding unexpectedly to user questions or action requests. We aim to address the limitation in future work by conducting observational studies or analyzing logs of routine participant interactions with IPAs.
Our study did not produce equal sample sizes for each IPA for comparison; we plan to address it in the subsequent study by comparing various IPAs on the humor function and determine which IPA is the “funniest.” The study was conducted in the US on a relatively small sample of English speakers, significantly limiting generalizability of the findings. We plan to validate and expand our initial classifications by examining humorous IPA interactions in other cultural and linguistic contexts.
Additional work is also needed to ground the IPA humor classification in theories of humor, communication, and personality. Humor is one of the facets of personality and communication style, and our future plans include mapping the interactive IPA humor into personality types and determining user preferences for the personality manifestations of their IPAs.
Conclusion
We conducted a study to examine humorous interactions with the four most popular IPAs. The results indicate that some of the more popular types of utterances include joke requests and user questions about IPA personality. Most of the system responses to user questions constitute preprogrammed “canned” jokes, which users generally find to be funny. The findings have two significant implications: methodological and practical. From the methodological perspective, the classification of user humorous utterances proposed in the study can be used in future experiments for comparing IPAs, testing IPA responses, as well as to model humorous interactions with IPAs. On the practical level, the results can inform improvements to the IPA conversational features. For example, the results indicate that one of the most common types of humorous utterances are questions that test the system “personality” and opinions. System responses to these types of utterances received mixed reactions from users and can definitely be improved. We noted that user utterances about the system or themselves have a relatively simple syntactic structure which could be interpreted by the system. For example, system-directed questions always include the word, YOU and a verb in the structure of the question: Do YOU
Footnotes
Acknowledgements
The author would like to thank her team of student researchers: Alice Griffin, Alanood Al Thani, Armando Garcia, Mary Mann, Shannon Mish, Alexandra Srp, Sydney Stewart, and Wanyi Wang for their contributions. She is also grateful to Pavel Braslavski for inspiring her to investigate humor, and to the study participants who volunteered their time and ideas.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Seed Grant from the Pratt Institute.