
Abstract
As secondary data become increasingly integrated into research and coursework across a widening variety of fields and disciplines, data reference is gaining traction as a major area of library research support. To examine the current landscape of data reference, we distributed a survey via regional and international library listservs asking librarians about their experiences and opinions related to their data reference work. For this paper, the full collected dataset was limited to only academic librarians who answer at least one data reference question per month in order to identify the unique needs of respondents doing reference work in academic institutions, with the ultimate goal of improving our own work as academic librarians at our institution. We used a grounded theory approach to analyze the qualitative survey response data, and supplemented this analysis with descriptive statistics and chi-square tests for the quantitative responses. Through this analysis, we identify a theoretical framework consisting of three themes relating to limitations to success where librarians must advocate for change in order to maintain and improve high-quality data reference work in the academic sphere: (1) technology and resource limitations, such as substandard database interfaces; (2) institutional limitations, such as insufficient staff time or resources dedicated to data reference; and (3) personal limitations, such as a lack of data skills. While librarians have varying levels of influence over each of these three areas, identifying and targeting these categories can help librarians and other data professionals focus resources and build cases for additional support from their library and campus administrators.
Keywords
Introduction
Data reference work has been an increasingly important part of librarianship as more fields and disciplines become interested in finding and using secondary data. This area of growth has given rise to the phenomenon of the “accidental data librarian” as well as interest in the library world in training and professional development around data librarianship. In order to gain a broad picture of the current landscape of data reference, we surveyed librarians and library staff from a variety of library types about their experiences providing secondary data reference services. Throughout this paper—for expediency and brevity—we use the term “data librarian” to encompass all library staff that do this type of data reference work, from those that answer one data-related question per month to data specialists that are immersed in data reference on a daily basis. Our scope does not specifically include other areas of data support such as data management, curation, and large-scale data analysis.
Building off our previous research, this paper examines structural limitations that librarians at academic institutions encounter when trying to support data reference needs. In previous work with our survey results, we honed in on sources of frustration for librarians answering data questions, regardless of the librarians’ depth of knowledge and experience: the field is constantly changing, the needs of users continue to evolve over time, and there are some aspects of data librarianship that we cannot control and prepare for in terms of training (Kubas and McBurney, 2019). We also investigated challenges that stem from users’ limited data literacy skills and offered potential strategies for librarians to deal with these issues (McBurney and Kubas, 2019). Through our iterative analysis of the qualitative results of this survey, themes around structural and systemic limitations that academic data librarians encounter when seeking to offer and improve their data reference services began to emerge, prompting further investigation into this area and resulting in this paper.
This study identifies three themes that constitute a theoretical framework of structural limitations to success that academic data librarians face—technological, institutional, and personal—and discuss how these areas reflect and expand upon what has previously been discussed in the literature. Through identifying these broad areas and examining the existing literature alongside survey responses from current academic data librarians, we assess the level of control and influence the librarian has over specific categories of limitations or barriers, and then discuss recommendations and next steps for addressing these structural barriers impeding data reference services in academic libraries.
Literature review
Throughout the data librarian literature, there are examples and discussion around the factors that can limit the success of data librarians in their interactions and support of patrons. The largest overarching limit is that no one library or service can provide for all potential data questions that arise. Geraci et al. (2012) note that “[a]n attempt to offer a complete service for all conceivable kinds of users and data would almost certainly over-commit any organization” (p. 10.1).
In order to anticipate the skills needed to support data services, some library and information science (LIS) programs currently prepare students for data librarianship. However, most data librarians today are not formally trained in data services through their LIS program (Kellam and Peter, 2011: 3) and instead are part of the widely acknowledged phenomenon of the “accidental data librarian” (Kellam and Peter, 2011: 151). In 2015, McCaffrey and Giesbrecht (2016) conducted a comprehensive scan of course calendars of 59 American Library Association accredited schools to determine how many courses across LIS programs included data reference or data librarianship skills. They found that courses with a data librarianship component tended to focus on “big data” and research data management (RDM), and typically did not include any exploration of data reference (McCaffrey and Giesbrecht (2016: 356). Furthermore, they point to a lack of recent articles at the time focused on data reference work in libraries as evidence of limited resources for LIS students interested in data librarianship (McCaffrey and Giesbrecht, 2016: 357). In response, some LIS programs, like the one at the Toronto iSchool where McCaffrey teaches, have developed single data librarianship courses that have been well-received by students, but McCaffrey and Giesbrecht still note that one course is not adequate preparation (McCaffrey and Giesbrecht, 2016: 368–369). Along similar lines, Swygart-Hobaugh explains that her Data Services in Libraries course at San José State University includes a unit on data reference, but she also emphasizes that much of what a data librarian does is informed by learning on the job (2017). One other possible avenue for LIS students is the creation of a “major” that focuses on various aspects of data librarianship (McCaffrey and Giesbrecht, 2016: 369). Experts in the field recommend that LIS students look for a program with a data curation emphasis, or an intern experience where they can learn data skills, and emphasize taking a social science research methods class to learn methodology and gain a basic understanding of statistical software, file transfers, and storage media (Geraci et al., 2012: 11.3; Kellam and Peter, 2011: 157).
Professional development training for established library staff is discussed as well. Due to the many factors in data services that are beyond the control of the librarian, “[p]rofessional development, continuing education, training, and just keeping current are essential responsibilities of the data librarian” (Geraci et al., 2012: 20.1). In addition to the typical strategies of attending conferences and keeping up on trends in the literature, data librarians will also need to continually learn new skills as the field changes and develops, and current skills will “go out of date or need augmenting” (Rice and Southall, 2016: 51). Many experts also suggest getting support from colleagues in order to develop new skills: Hoffman (2015) describes how their library implemented division cross-training on recommended resources and weekly learning groups for statistical analysis software (p. 15), while Kellam and Peter (2011) recommend team teaching as a way to increase data use in research and classrooms, with a subject liaison co-teaching alongside a data librarian. They note that “[t]his approach takes the pressure off librarians who are not as comfortable with data sources” (p. 82). In our own previous work compiling suggested strategies for answering data questions, we found that survey respondents had a wide range of strategies that involved consulting others, including internal colleagues, but also noting that external sources such as vendors and government agencies can also be helpful (McBurney and Kubas, 2019: 500). One highly cited option among our respondents was to join listservs such as IASSIST or BUSLIB, both for “lurking” and learning, and for asking questions of the group at large (p. 500). Others in the literature also noted the advantage of looking to other colleagues both internal and external to the institution as well as data providers on all levels of publishing and data dissemination (Bordelon, 2016; Kellam and Peter, 2011; Rice and Southall, 2016).
Data skills are becoming increasingly necessary for subject specialists as secondary data become more easily available to researchers and more frequently utilized across disciplines. While this may seem daunting to the subject liaison, Bordelon (2016) asserts that librarians who fail to gain an understanding of the methodology and major data resources in their subject areas will not be able to provide adequate support for their patrons (p. 36). On the other hand, when discussing data librarians who do not have subject expertise, Rice and Southall (2016) acknowledge that “[d]ata-related queries tend to be more difficult, more time consuming, and sometimes even bewildering to the non-subject expert trying to provide assistance to the experienced researcher” (p. 40). However, data librarians can still provide secondary data reference support without being an expert in the field by becoming familiar with commonly used datasets in that field and collaborating with researchers to pinpoint data needs (p. 38). Data reference work builds on traditional searching and reference interview skills (Bordelon, 2016; Geraci et al., 2012), and while this work can feel intimidating to subject specialists or “accidental” data librarians, it is increasingly seen as a natural progression of our traditional work. As Smith et al. (2016) note, with the growth in secondary data needs at academic institutions, reference services overall would benefit from a focus on data reference and incorporating the skillsets of both subject specialists and data librarians (p. 26).
Related to this ever-present need to expand personal data skills is the need to define the level of assistance a librarian can provide for the whole research process. As a baseline, Geraci et al. (2012) suggest that the first level of data reference support should include general and advanced information searching, reference interview skills, general familiarity with data resources and key studies, and familiarity with common jargon and acronyms (pp. 12.2–3). Beyond this baseline, there is uncertainty around what level of data support librarians should provide. Data librarians can struggle with whether or not they should also be able to provide patrons with assistance in areas such as statistical software, cleaning datasets, research methodology, or data management (Hoffman, 2015: 14–15). Ideally, librarians would be able to provide basic support for common statistical packages, while passing on more in-depth questions to software experts (Bordelon, 2016: 36). In addition, technology services provided by the library—such as computer equipment, access to software and data, or specialized computing support—as well as the librarian’s ability to advocate for change and accommodate future trends in how data are made available, will impact researchers’ success (Geraci et al., 2012: 10.8).
Secondary data are becoming increasingly complex to locate in an Internet world where there are many possible avenues for data discovery, and data librarians often must employ “Nancy Drew-like tenacity” in their search down these avenues to determine if data exist (Kellam and Peter, 2011: 90). Now that data are increasingly available online via a plethora of websites and resources, knowledgeable intermediaries like data librarians are becoming more and more vital as a touchpoint in data reference service and support (Geraci et al., 2012: 7.11). In the quest to determine if a dataset exists or not, data librarians employ a variety of strategies and skills including a search of articles and literature around the data topic to see if others have already confirmed that the data are not available (Bauder, 2014: 148). Sometimes after exhausting all possible search strategies, data librarians must conclude with some certainty that the data likely does not exist, which is often difficult for the user to accept, even when the data question posed is “wildly unrealistic” as Kellam and Peter (2011) note. As one interviewee in Kellam and Peter’s interviews with data librarians says, “[t]he intensity of desire for data does not correspond to its availability” (Kellam and Peter: 157). Data librarians must continually balance the expectation of users and the complex landscape of data sources and availability.
In this balancing act of trying to find data, data librarians also battle against difficult database interfaces, nontraditional access points, and a world very different from books and journal articles (Bauder, 2014: 11). Bauder sums this up well: There is no single WorldCat-like portal for data; there is no data-specific set of standard subject headings; and the standards for citing data in publications are weak to nonexistent, making it challenging to track down a specific data set from a secondary source. (p. 11)
Within this context, users often must make trade-offs when the ideal dataset cannot be found, especially when “the researcher is starting with an original research question rather than a known study or dataset” (Rice and Southall, 2016: 41). These tradeoffs can occur because of a variety of reasons that may be in the power of the researcher but may also stem from how access is mediated at the database or resource level. Some datasets contain more sensitive data or data that is personally identifiable where users need to jump through extra hoops to obtain access (Rice and Southall, 2016: 41). In these situations, data librarians need to manage all of these factors and educate and communicate with the user about their best options under the circumstances.
For data that require purchase, access to some resources become more complex if libraries opt to license the content rather than purchase direct access to data outright. In some of these cases, libraries are limited by the resource vendor or owner—even if the resource is free—in how much can be downloaded at once and what the data output looks like when downloaded (Geraci et al., 2012: 8.4). These functionality issues can be a barrier in how well the data fit the needs of the user and how easily it can be used for analysis. Another issue noted by Geraci et al. (2012) is that when the library licenses access rather than storing data locally, the database access “can be interrupted without notice for short or long periods” of time (p. 8.5). The convenience of not having to determine how to host data is offset with how much control the library has over access to the content. Long-term access is particularly precarious in this situation when many “governments and some commercial vendors often favor the most recent data and delete older, historical data” that users often want and that data librarians find tough to find (Geraci et al., 2012: 8.6). Furthermore, a vendor may “go out of business, change its missions, or [be] bought by another company that no longer supports a particular data product,” all of which can impact access to particular resources and data (Geraci et al., 2012: 8.6). Similar issues can also impact data availability from government entities. The continued popularity of proprietary software such as SPSS, Stata, and Minitab—even with many quality open source software options available—means that data vendors and distributors still often integrate their data with software that not everyone can access (Geraci et al., 2012: 13.1–2).
As data librarians work with users to find secondary data and traverse the various access issues that go along with data resources, they develop a better understanding of the issues to keep in mind when making collection and acquisition decisions. The skills and understanding that data librarians need when determining what types of resources and access is acceptable boil down to working knowledge of how users employ “statistical software and how data files and digital documentation are managed” (Geraci et al., 2012: 11.4). Furthermore, when reviewing data resources, additional knowledge is needed of “quantitative research methodologies and data collection, preparation, and distribution practices” of data (Geraci et al., 2012: 11.5). For Geraci et al. (2012), these skills are essential in the work of data acquisition and deciding which resources to highlight and recommend to users and include in research guides.
The cost of secondary data resources and how budget lines and funds are meted out and organized within an institution can create significant difficulties for data librarians. Some libraries may allocate funds to a specific data resource budget while others may require that data resources are purchased through larger department-level funds. Complicating the funding model is the fact that data resources are usually interdisciplinary so it is difficult to decide how purchasing decisions are made (Kellam and Peter, 2011: 36). Yet another funding model is to have one single fund for “all online resources from article databases to numeric data products,” which Kellam and Peter (2011) also find problematic because the use cases and costs are so different (p. 36). Journal article packages can be astronomical in cost but many data and statistics resources can also be very expensive, especially company and business intelligence databases, “even with concessionary pricing for academic use” as Rice and Southall (2016) note (p. 54). Libraries are acknowledging a need for funds to support data reference and discovery, but there are still hurdles to navigate at various levels of the organization.
In addition to providing funding support for collections, many authors note the importance of administrative support for data services more broadly and argue that in order to successfully support data services, the library as a whole must be willing to commit adequate staff time and funding to the endeavor (Geraci et al., 2012: 12.2–3; Kellam and Peter, 2011: 35). Geraci et al. (2012) compare it to “any other specialised collection or archive” (pp. 12.2–3) and note that depending on the level of service to which the library decides to commit, each additional level of support will require further staff training and allocation of time (Geraci et al., 2012: 12.1). Kellam and Peter (2011) note that data support is expensive, and they advise that librarians working to establish or expand their data services need to make sure that their administration supports their plans for the level of service they will provide as well as the future directions of the service (p. 156). Because time and funding are so essential to data services, administrative support is vital to the success of the service.
Methods
Our survey captured responses from librarians and library staff who answer data reference questions. We used Qualtrics to administer the survey, which we sent to a number of local, national, and international library listservs, listed in Supplemental Appendix A. It was open from 27 November to –22 December 2017, and we sent reminder emails to the listservs halfway through the open period. The survey was further shared by colleagues on Twitter. Our institution’s institutional review board (IRB) determined this project did not fall under human subject research rules.
The survey received a total of 360 responses. Because we are librarians at academic institutions, we decided we were most interested in examining the responses from other academic librarians, in order to use our results to improve our own work. Librarians at academic and research institutions have unique needs and roles compared to librarians at other types of institutions, and we wanted to identify and learn from the specific structural and systemic limitations that academic data librarians encounter. In addition, we wanted to focus on respondents who answer data reference questions on a fairly regular basis, so we chose to limit our results to academic librarians who answer at least one data question per month. These choices resulted in a final dataset of 236 responses.
The bulk of our data reported here is qualitative. The qualitative data are drawn from responses to two open-ended questions (“What other frustrations or roadblocks do you experience when answering data questions?” and “What tips, tricks, or strategies for answering tough data questions do you have to share with other library staff?”) as well as the free text answers to the “Other” option in the question “What are your strategies for answering these data questions? [check all that apply].” Of the full dataset of 236 responses, 132 people (56%) answered at least one of these three free response questions, resulting in a 6,980-word corpus for us to analyze. The authors used the constant comparative analysis method of grounded theory to analyze the qualitative data (Glaser and Strauss, 1967; Strauss and Corbin, 1998). Open coding was used to find similarities and differences between individual participant responses, and codes were developed by consensus between the authors. Then, codes were grouped into related categories through axial coding by examining the context and conditions in which librarians support data reference and how that context shapes librarian experience. The final stage of this analysis is reaching theoretical saturation where large overarching themes emerge between categories. In our analysis, some themes coalesced around users, while others gathered around librarians’ experiences. For this paper, we focus on our finding of a new theoretical framework of structural limitations in data reference support. This theoretical framework is built on three key themes, discussed below in the Findings section.
Quantitative responses were exported from Qualtrics as a CSV file, and data cleanup was done in Google Sheets. Questions with a free response “Other” option were examined and answers that fit into existing categories were recoded as such. We analyzed the quantitative data in SPSS using chi-square tests as all of our dependent variables were nominal/categorical dichotomous variables and our independent variables were ordinal with more than two levels. The p-value of statistical significance was set at less than 0.05.
Respondent demographics
Overall, our survey respondents were mainly North American data librarians. Respondents were from a total of 7 countries, with 203 (86%) of the 236 respondents from the United States. Twenty respondents were from Canada, three from South Africa, and one each from Slovenia, Switzerland, the United Kingdom, and Zimbabwe. Six did not answer. Respondents from the US were spread out across all regions, but were most concentrated in the Midwest census region at 44%, while 23% were from the South, 20% were from the Northeast, and 13% were from the West.
Findings
Three themes emerged from the qualitative data to construct our theoretical framework of structural limitations in data reference support: Technology and Resource Limitations, Institutional Limitations, and Personal Limitations. Quantitative data results are also included to further illustrate these themes.
Technology and resource limitations
In the free-response answers, one theme that emerged was that secondary data resources can be difficult to access due to technological limitations or limitations with the resources themselves. Respondents noted that a resource might have a poor search functionality or clunky interface that makes it hard for patrons and librarians alike to use. One respondent stated, “Data sources are all organized differently, so navigation is very difficult and it can be hard to know what you’re looking at even when you find the right data!” Respondents also said that some databases have export limitations related to file size or type, or their metadata and documentation may be insufficient. In addition, resources that are in an unfamiliar language can be hard for patrons to utilize, and tools like Google Translate are often not accurate enough. Translation problems can also occur depending on the technology used; for example, one respondent listed Adobe Flash as a barrier for access and translation. From our own experience, we know that the language of the database interface is important to researchers who are comparing data across multiple countries which can often require combining data from various country-specific data resources. If the translation is not accurate or intelligible, the researcher does not have enough information to accurately create their custom dataset.
It is unclear whether survey respondents’ comments about poor resource functionality are referring to free or paid resources, but we do know that many free online data resources are not curated like we might expect in a typical database, and often the user or librarian has to do additional work to get the data into a usable format. Often, paid resources are simply repackaging other freely available datasets, and the costs are mainly for the better interface that makes the data more findable and accessible, such as with well-known tools like Data Planet or Statista. While a paid resource may do a better job in areas such as download options or translations, paid resources can sometimes introduce new issues, such as only exporting data in proprietary formats, which can cause additional accessibility and compatibility problems as noted in the literature review (Geraci et al., 2012). Paid resources can also have access issues when it comes to download limitations, as researchers increasingly are interested in studies that require bulk downloads of large datasets. Another major downside to paid resources where free resources often excel is in the realm of findability via Internet browsers and other online search tools. A library or institution may subscribe to or purchase content from a database of secondary data, but a user must go through the library’s website and proxy to access the data, which creates a certain barrier to discoverability and findability.
Access issues can take many forms, including restrictions on who can access a database or dataset. Some respondents noted that a typical problem included lack of public access to sensitive or private data (see also Rice and Southall, 2016). Other survey respondents mentioned issues around restricted access due to consortial agreements to which their own institution did not belong. In our own experience, we have helped patrons who were limited in their access to Inter-university Consortium for Political and Social Research (ICPSR) datasets because the license agreement required the researcher to be the principal investigator (PI) of a project, or a PhD student or higher. Related to restricted access, one respondent said that “business data is often proprietary—can get summaries but not raw data.”
Many survey respondents noted the difficulty determining whether or not the data requested even exists. Many respondents also said that patrons often request granular microdata that cannot be found, and explained that they have to work with patrons to find alternative data or adjust their research question to fit what is available. Numerous responses shared some variation on the comment that it is “[d]ifficult to know when to stop looking, that is, [a]m I just not finding something, or does it not exist?” Since it can be hard to verify the lack of a certain type of data, a few respondents suggested finding similar examples in the literature: “Pearl growing through literature—so much easier to find data that you know exists instead of that you hope exists.” These survey comments further illustrate the discussion by experts in the field around the issue of determining whether or not a dataset exists (Bauder, 2014; Kellam and Peter, 2011). Additional concerns noted in the literature were around websites that remove old data when new data are added, which makes historical or time-series datasets more challenging to find (Geraci et al., 2012). In order to deal with limitations like this, we as data librarians need to manage patron expectations and help educate users throughout the data discovery process on why these limits are in place and what options they have for their research.
While data librarians do not have much control or influence over these types of limitations, our main avenues of influence for paid resources are through which resources we purchase, what kinds of access improvements we can buy, and if we become a big enough customer, we might be able to influence the vendor with our feedback. Free resources on the other hand usually have fewer options for direct influence or change since the data providers are not looking for ways to improve their profit. However, some free resources do provide the option for users to leave feedback or suggestions for improvement and many free resource providers do strive to improve their tools outside of any profit-driven model.
All of these concerns and examples show that we need to be mediators in the discovery process and proactively work to bring feedback from users to the vendors whenever possible. Since we are working closely with researchers, we hear a wide variety of types of questions and are the most informed on what resources they need. We also need to be able to educate ourselves on these topics in order to make the case for spending collection money on vendors that repackage data when the freely available versions of those datasets are not complete or accessible, or for spending more money on more powerful access to database content, such as API capabilities or bulk-download access. We can also work on developing our own skills so that the technological limitations of these resources matter less in our day-to-day work.
Beyond working with vendors, we could also find ways to surmount these technological limitations through collaborating with our colleagues. Since we are most familiar with researcher’s needs, we are uniquely positioned to combine our knowledge to develop more open source tools for data discovery and access.
Institutional limitations
Another theme emerging from respondents’ free-response comments pertained to institutional limitations to success when answering secondary data reference questions. A number of respondents indicated that their job duties and responsibilities beyond data reference made it difficult to devote time to these questions. This was also indicated in the survey by the high number of respondents who listed numerous duties and responsibilities that they held (Figure 1). As noted in the literature, data skills have become increasingly important for subject liaisons, and this is further illustrated by the fact that 78% of our respondents are also subject specialists. Most people who answer data reference questions have a variety of duties beyond that role, which means that their time can be split or stretched thin.

Data librarian duties.
In regards to the average number of data questions per month that data librarians received, we found that 66% of respondents answer 5 or fewer questions per month (Figure 2), which is not surprising given that so many data librarians listed many other duties and responsibilities as part of their work (Figure 1). However, we were surprised by the 22% of respondents who said that they answer 10 or more data questions per month. We did not anticipate such a high number of people in that category and therefore did not offer a broad enough scale to capture responses higher than 10.
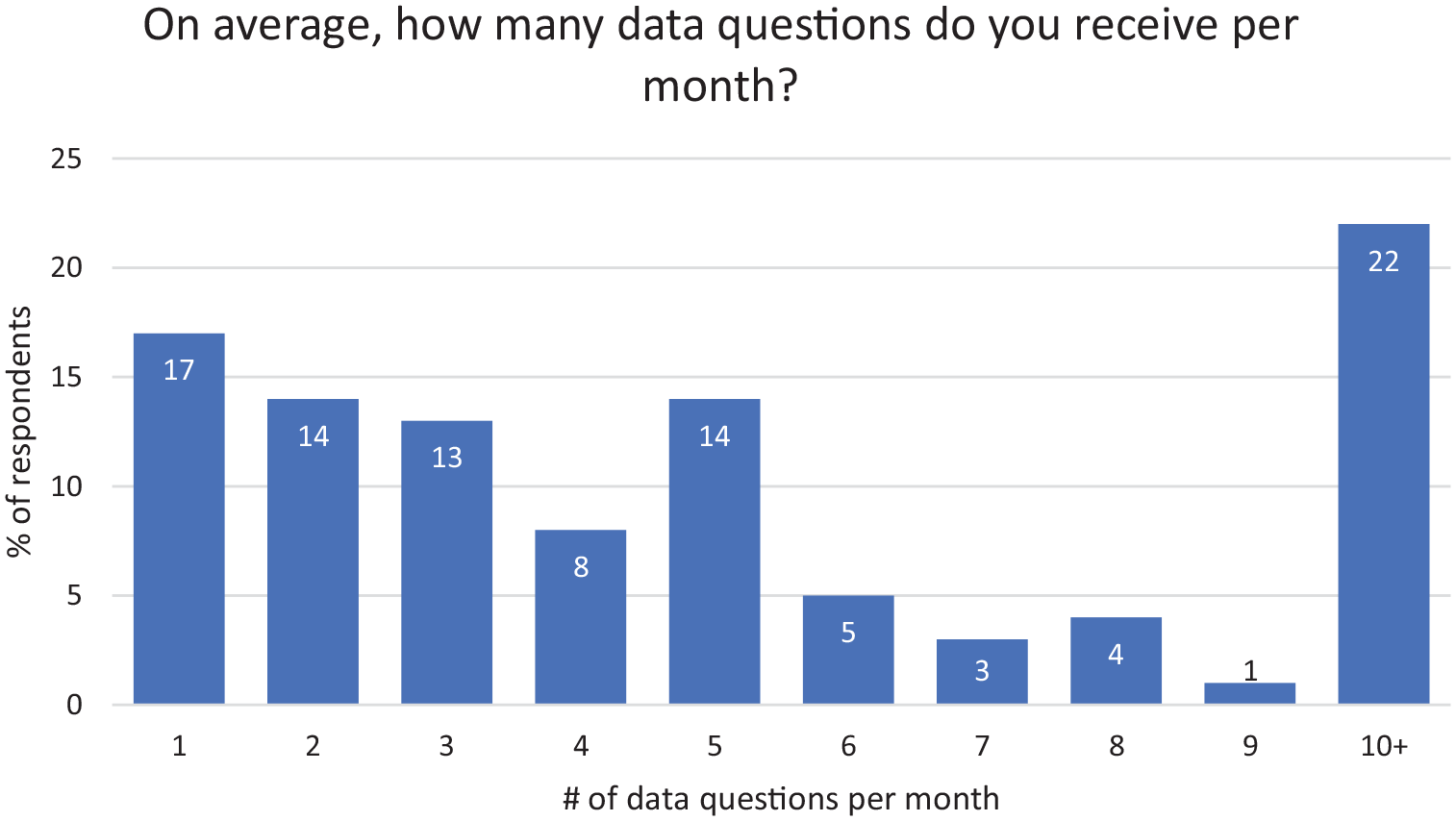
Frequency of data questions.
In their free-response answers, survey respondents expressed a lack of support from supervisors and administrators who may not understand the complexity of data questions. Respondents also explained that their supervisors as well as other colleagues had misperceptions about the workload that answering data questions can entail, with one respondent noting that “[c]olleagues and admin have no clue one ‘simple’ request can take hours I don’t have.” These types of comments are also supported by quantitative data from our survey. Respondents reported spending a significant amount of time on each data reference question; over 75% said that on average they spend more than half an hour on each question. As many authors in the literature have noted, data questions are time consuming because there is no single portal for access, and the librarian may have to search many resources in order to determine where or if the data exists (Bauder, 2014; Geraci et al., 2012; Kellam and Peter, 2011). Because of this challenge, it is important for administrators to understand the complex nature of data questions, and data librarians themselves should find ways to educate their colleagues, whether on an individual basis when working one-on-one with a subject librarian, or on a wider scale through publications, conference presentations, or other means. As part of this conversation and education, it is also important to emphasize that one of our most significant survey findings in our prior work was that data questions are time-consuming regardless of the librarian’s number of years of experience (McBurney and Kubas, 2019).
Related to the perceived lack of support from administrators is the difficulty around acquiring necessary databases and resources. One respondent noted that they had no input on which databases their library licensed, making it particularly difficult for them to answer data questions easily. Not surprisingly, many respondents called cost a major barrier, noting that many resources, especially specialized resources in a particular topic area, are frequently far too costly for academic libraries to afford, especially if that resource will have few users. One respondent noted, “Much business data is in market research reports that we cannot afford or would not purchase, [and] people find these reports online and then wonder why we can’t buy them.” As identified in our survey, 75% of librarians reported that they answer business data questions, and business was the second-most frequent topic area after demographics (Figure 3), suggesting that this limitation is widely felt. Respondents explained they simply did not have the resources to purchase access to many resources and datasets that were requested by their patrons.

Topic areas where librarians receive questions.
To deal with these major issues around costs and decision-making, we recommend that data librarians, collection development staff, and administrators work together to come up with a feedback process or policy around getting input on collection development decisions. An important part of this process will be educating everyone involved on how secondary data reference is different from regular reference. Building on the existing literature, the comments from this survey reveal that data acquisitions are particularly complex and of great concern to those doing the data reference work. Because most databases and resources are interdisciplinary, certain funding models will not take into account the high costs of each resource which are then out of reach to one individual subject liaison who only has a small, subject-specific budget available. The interdisciplinary aspect also puts into question who gets the final say in an acquisitions decision, especially if higher-ups are unaware of reasons why libraries might have to pay more for repackaged data or other issues (Kellam and Peter, 2011). Data librarians have working knowledge of how users actually use the data and specific insights into their needs, such as what file types they can and want to access, as well as a basic understanding of the research methodologies they often use. Therefore, we recommend that administrators and collection development staff solicit feedback from data librarians and collectively reexamine how funds are distributed for cross-disciplinary resources in order to make better collection development decisions.
Another institutional-level concern that arose in the survey responses was that many colleges and universities have no support or service around data cleaning, analysis, methodology, and so on, after the data are found. This gap in support puts the burden on librarians to try to help users with tasks they themselves lack training to do, or to be unable to direct users to an appropriate service on campus. One survey respondent said that there was a “lack of statistical support at my university—no where [sic] to refer users with questions about what to do with the data.” Administrators and data librarians need to work together to determine what level of support the library can provide, and that decision should in part be based on what the institution as a whole provides. If the campus lacks support around statistical packages or data analysis, the library may need to commit to at least a low-level of support for this type of work, or at the very least have a clear policy for librarians to follow when working with students. As noted by Kellam and Peter (2011) and Geraci et al. (2012), there are a variety of levels of support that the library could choose to make, and once the decision is in place, the library then needs to commit an adequate level of resources and support for offering those services. Overall, the library should have a clear policy about how far data librarians can take users along the research path and at what point they have to send users elsewhere. If there is nowhere else on campus to send them, then the library administration should advocate for this need at the campus level and encourage discussion with other units on campus about how to address this gap. This could result in another unit taking on the role or the library advocating for additional funding to support expanded library services.
Administrators thus need to do a full and honest assessment of the costs involved in providing data service. As noted above, the databases and resources needed to access and use secondary data as well as the cost of time and resources for training librarians tasked with providing this support should be part of the library administration’s assessment when determining the level of support to which the library can commit. Another key resource that needs to be considered is adequate level of software support available on library computers to match the level of data support the library intends to offer. Each piece of proprietary software will have a licensing cost that the library will have to weigh in the larger financial cost of providing data services. For data librarians to do their job well, committed support in infrastructure for students as well as for the librarians themselves is essential. Librarians will need access to the software for which they are expected to provide assistance and need library administration support and time for training. This was evident in the survey responses as well: one respondent described how it is important to “dedicate time and resources, train the trainers.” With the amount of time needed for training and the emphasis in the literature on continued need for training, administrative buy-in is key to maintaining a thriving and successful data service point.
Although many of the comments about institutional support were negative and reflected the concerns that many data librarians feel about a lack of administrative support, one respondent expressed excitement to support colleagues in learning how to answer data questions. Administrators who notice and take advantage of staff members’ enthusiasm to share knowledge with colleagues will likely see an improvement in the library’s data services as well.
Personal limitations
In the free-response answers, respondents also described personal limitations to their success in answering data reference questions. While the discussion that follows notes that data librarians have more control over these personal limitations when compared to technological or institutional limitations, we also recognize that many of these personal limitations are reliant on investment from the librarian’s institution in both time and funding for training and skill development and not solely in the hands of the data librarian.
In addition to the time spent answering data questions, as discussed above in the institutional limitations section, librarians noted in their survey responses that they also need to take time to learn data reference skills and stay up-to-date in the field. One respondent said, “I just don’t have enough time to keep up professionally.” Just as colleagues and administrators underestimate the amount of time it takes to answer data reference questions, they also can underestimate the ongoing amount of time and energy it will take for a data librarian to continue their own learning. These results illustrate trends from the literature, where authors note that while some LIS programs are offering data librarianship courses, most people are not formally trained in data reference work specifically, which means that individuals have to keep current on their own (Geraci et al., 2012; Kellam and Peter, 2011; McCaffrey and Giesbrecht, 2016; Swygart-Hobaugh, 2017). To fill this gap, a number of authors have described their own methods for maintaining skills, including team-teaching and division cross-training (Hoffman, 2015; Kellam and Peter, 2011). Data librarians, whether accidental or assigned, should look for ways to implement these kinds of peer-to-peer assistance models in order to maintain their own skills as well as to raise awareness among their peers and administrators for the need for continuous learning in this growing area of librarianship.
One specific area of learning that some survey respondents highlighted as a limiting factor was their own lack of training in statistics or research methodologies. Beyond navigating new data sources and assisting in data discovery, there is a question around how far the library’s data services can and should go into methodology or analysis support. Geraci et al. (2012) offer a clear set of choices that a library must consider when selecting its level of support, and whether or not it must draw the line at discovery or if it can further support researchers into the analysis phase. Learning statistical software and analysis methods is an entirely different skill set, and in order to offer that level of support, not only would the library as a whole have to dedicate support, but individual librarians who take on this work would have to dedicate themselves to learning new skills and maintaining them over time. Since librarians, even in academia, often are not conducting data research projects that require this in-depth knowledge of analysis methods, this type of skill is not something that can be easily learned on the job without deliberately seeking out a reason to do so. One solution might be to pursue a project that would help the library or the librarian’s personal research that also will require them to learn a new kind of software or method of analysis. Because it is significantly more work for an individual to be trained enough to be able to support software and analysis, this hands-on experience would be essential to the success of the model. In addition, to echo the literature around how the process for finding data is different for every question, the process for analyzing the data will also be somewhat different for every question, so it will take time and experience to gain these types of skills.
When asked how they stay current on developing their personal knowledge of data sources, all of the suggested options (webinars, blogs or websites, scholarly publications, and conferences) were checked by a majority of respondents. Respondents could also write in their own additional methods, and the vast majority of these write-in comments stated that being on listservs and talking with colleagues were among their top strategies for staying current in the area of data reference. These results reflect the methods noted in the literature, which focused on attending conferences, keeping up with trends in the literature, and working with colleagues in a variety of ways.
We also asked respondents about their years of experience and self-reported level of success in answering data reference questions. A wide range of years of experience were represented, with 27% of respondents reporting at least 25 years of experience. The second-largest groups, at 19% each, were academic librarians who had 5–9 or 10–14 years of experience (Figure 4).

Length of time working in libraries.
We asked participants how successful they felt they were when looking for data, and a vast majority of respondents (80%, n = 188) indicated that they usually are successful in finding the data. When comparing respondents’ answers of how successful they reported they were at finding the data requested to their number of years of experience, we found that there was no statistically significant relationship, meaning that years of experience did not affect self-reported success (F = 0.462, df = 5, p = 0.804).
While this seems counterintuitive and particularly out of sync with our personal experience, as well as the conventional wisdom in the literature that data librarians need time and experience to gain the correct skills (Geraci et al., 2012; Kellam and Peter, 2011; Rice and Southall, 2016), we considered a number of reasons why this might be, mainly relating to the fact that these survey results are self-reported. We also took into account the related findings that we learned in our other related works: (1) that frustrations around answering data reference questions will always exist regardless of a librarian’s years of experience (Kubas and McBurney, 2019), and (2) that data questions do not become less time-consuming even as academic librarians gain experience and years in the field (McBurney and Kubas, 2019).
One possible cause for this surprising result is that there may be a sliding scale effect, where a more experienced librarian tackles harder and harder questions over time, so it feels like the same level of effort is involved, but the librarian is actually working at a higher level. It could also be the case that more experienced librarians are more aware of what is possible, and they know more accurately when to stop looking or when to cap their time and effort or pass the question off to a more experienced colleague. In addition, it could be related to the idea that “the more you know, the more you know you don’t know,” which can lead to imposter syndrome tendencies of doubting your own expertise. Overall, it seems likely that feeling successful as a data librarian is challenging because of all the reasons that we have discussed so far: there is no single discovery tool, there is difficulty around determining if data exists, and so forth. While a librarian’s years of experience matter in that they can gain awareness of resources and strategies over time, making them feel more comfortable with the role on a day-to-day basis, the work itself is still challenging as it changes over time and will not necessarily get easier just as one gains years of hands-on training. This may seem daunting, but it also drives home the fact that it is both acceptable and necessary to continue learning throughout your career, accept feelings of uncertainty, and advocate for yourself and your colleagues’ training and opportunities in order to support researchers in their work.
Conclusion
In this paper, we describe a theoretical framework of structural limitations in data reference support. As data reference services continue to grow and expand in academic libraries, how we as librarians ensure or inhibit the success of these programs becomes even more important.
The themes that emerged in this study illustrate that how well data librarians can do data reference work is based on a variety of factors, all with varying degrees of influence, from no control at all to a higher level of control that still has constraints. Of the three themes found in our framework, technological limitations are the area where data librarians have the least amount of influence on change and improvement as those entities that create the technology and make data resources available are largely able to make their own decisions. They may take input from users or subscribers, but ultimately data librarians have to work with what is available to them and work through the clunky interfaces and data access issues to offer the best service they can. Institutional limitations pose some uncontrollable barriers, but there is more room to advocate and directly demonstrate needs to library administration. Finally, data librarians have the most sway over their own personal limitations and barriers to offering data support to patrons, such as seeking out training and boosting their own skill set. While these usually require some level of flexibility and support from their institution, library administration presumably would be motivated to ensure success of their programs and initiatives. These findings, while specifically looking at data reference, also relate back to wider discussions happening in research data management (RDM) and librarianship as a whole. Our work in all areas continues to change and adapt along with technology and the research needs of our patrons, and data reference is just one area where we need to advocate for resources and support.
While some limitations will always exist in the world of the data librarian, there are ways to push back against these limitations to mitigate their impact on data services. Where we invest our dollars in terms of data and statistical resources gives us some level of influence and often vendors will take and sometimes implement recommendations for improvements. Librarians can educate their colleagues and administration about the realities of data reference work including how time consuming and difficult this work can be as well as the uniqueness of collection development of data and statistical resources. We recommend that library administration and collection development staff work closely with data librarians to determine how budgeting and purchasing of data resources should function and to create a clear policy on the level of support around data services the library provides, keeping in mind the technology needed and day-to-day allocation of librarian time and resources.
The results discussed in this paper are limited by the reach and distribution of our survey via listservs and informal channels like social media. The majority of our respondents were from North America, which is likely due to our limited access to broader listservs. While we shared our survey on the international IASSIST listserv, most of our other listservs were focused in the United States and Midwest area specifically since we are located in the Midwest region of the United States and have more connections to networks and listservs in this area. This could lead to regional bias in our findings. Further research is needed to determine if these findings also hold true in other regions. There could also be library staff who answer secondary data questions but do not necessarily classify themselves as such or believe they do not answer enough questions to qualify to respond to the survey. Overall, we cannot know the full distribution of data librarians in the US or globally, and therefore cannot know the total response rate.
This paper has informed our own practice at our home institution, and we intend to continue growing and evaluating our own data reference services in light of these findings. Future research on academic data reference support building on this paper could dig deeper into how to systematically approach policy and guidance to create or expand a data reference service point, including how to handle collection management and access issues. Future research could also explore how this theoretical framework of structural limitations could be tested or applied in other areas of library support.
Supplemental Material
sj-pdf-1-lis-10.1177_0961000621995530 – Supplemental material for Limitations to success in academic data reference support
Supplemental material, sj-pdf-1-lis-10.1177_0961000621995530 for Limitations to success in academic data reference support by Jenny McBurney and Alicia Kubas in Journal of Librarianship and Information Science
Footnotes
Acknowledgements
The authors would like to thank Andrew Kubas for assistance with quantitative data analysis and Danya Leebaw and Cody Hennesy for their feedback on the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.