
Abstract
Users’ search performance indicates the effectiveness and success with which users’ information needs are met, which is calculated based on the relevance judgment by users themselves. This study proposed to explore the prediction of users’ search performance in the context of cross-device search. A user experiment was performed to collect users’ relevance judgments and search behaviors in cross-device search. Based on users’ relevance judgments, users’ search performance was evaluated by calculating the percentage of valid clicks, effective search time, nDCG@n, and satisfaction. A simple linear regression model was adopted to train the prediction model. The final results showed that a combination of users’ search performance in pre-switch sessions and their search behavior in post-switch sessions can attain the best prediction accuracy. Important features to predict users’ search performance in cross-device search shed light on improving search systems to aid users in completing the task efficiently.
Keywords
Introduction
Search behaviors have changed due to the diversity of search devices. Dearman and Pierce (2008) found that users had on average a laptop or desktop computer at work/school, a laptop or desktop computer at home, and three other digital devices (such as phones, digital cameras, and iPods) at other places. In everyday life, multi-device search is prevalent. For example, a person uses a mobile device to search for online shopping information while commuting and uses a desktop to search a document at the office. In this case, the search tasks are different. However, if the person performed the same search task using both mobile and desktop devices, this case could have been a cross-device search, which is the concern of this paper.
In a cross-device search, for example, a student searched images on a mobile phone before the class, and then after the class, the student resumed the search and downloaded some pictures on a desktop computer. The student might have found the pictures easily when resuming the search, or the student might have found it hard to access the pictures after changing the device. Users’ search performance may not remain constant in cross-device search, and this paper is curious whether there is a way to predict users’ search performance in post-switch sessions. By predicting users’ search performance, search systems can be improved to aid users in completing the task efficiently.
Search performance is a classic theme in information retrieval studies (Guo et al., 2013). There are two perspectives on studying search performance: system search performance and user search performance. The former indicates the quality of feedback based on an objective evaluation framework, taking TREC (Text Retrieval Conference) for example. It is evaluated using the ground truth of test collections that indicates how well the relevant documents are ranked. The latter involves an evaluation of how effectively and successfully the search fulfills users’ information needs. The relevance of search results is decided by users themselves, who know with certainty whether their instant information need has been satisfied. How well user-judged relevant documents are ranked can reflect the effectiveness of the users’ search. In other words, users’ search performance can be regarded as an aspect of users’ seeking behavior. Current studies on cross-device search behavior focus on feature description, behavior prediction, or comparison between different device-switching modes (Han et al., 2015; Montanez et al., 2014; Wang et al., 2013; Wu et al., 2018). However, users’ search performance is rarely considered in the context of cross-device search. This paper is interested in revealing cross-device search behavior from the dimension of users’ search performance. Therefore, this paper deals with two main research questions:
RQ1: How to predict users’ search performance in the post-switch session?
RQ2: What features of search behavior have a significant correlation with users’ search performance in the post-switch session?
Related work
Cross-device search
The study of cross-device search focuses on behavior analysis and behavior prediction. The data come mainly from search logs, including the search history, click streams, touch interactions, and eye movements. Statistical analysis and machine learning methods are frequently used in these studies.
Cross-device search behavior analyses have been performed from various aspects. Wang et al. (2013) studied the search time, geospatial characteristics, and search topics of cross-device search. They found that cross-device search activities frequently happened around 4 PM or 5 PM on a given day, one-third of cross-device searches involved a location shift, and the most popular topic is navigation. Montanez et al. (2014) studied the device-switching direction and found that a popular mode of device switching was mobile-to-desktop. Wu et al. (2018) studied the query reformulation of cross-device search in an open public access catalog and found that switching from PC to PC was most common and the cross-task pattern was the most frequent pattern of query reformulation. Wu et al. (2019) discussed characteristics of cross-device search tasks, further reflecting the information need of cross-device search users.
In addition, a number of studies have been performed on behavior prediction. Wang et al. (2013) predicted task resumption using features related to the search history, pre-switch sessions, pre-switch queries, the transition, and post-switch sessions. Kotov et al. (2011) predicted whether the user would return to the current task according to queries, features of the search session, and the search history. Montanez et al. (2014) proposed models to predict directions of device switch and the next device used for search. Han et al. (2017) identified different behavior patterns in cross-device search and predicted re-finding using a hidden Markov model. Enlightened by the task resumption in cross-session search, Wu et al. (2020) developed models of task preparation and resumption in cross-device search by the method of machine learning.
According to the existing study of cross-device search, there is little exploration being seen about users’ search performance. Wu and Cheng (2018) presented a preliminary work in this area. They used mobile touch interactions (MTIs) to predict the search performance, and found that the prediction model that combining times, duration and areas of MTIs performed best. Only considering MTIs is of limitation, since cross-device search consists of various specific search behaviors. Thus, this study predicted users’ search performance using more features including MTIs.
Search performance
In previous studies, search performance evaluation included both system-oriented and user-oriented approaches. System-oriented evaluation is based on the Cranfield methodology (Jiang and Allan, 2016). The metrics are not limited to the precision, recall (Ali and Gul, 2016), mean average precision, nDCG (Normalized Discounted Cumulative Gain) (Manning et al., 2008), p@n (precision@n), accuracy, and the number of relevant results (Kelly and Azzopardi, 2015). User-oriented evaluation involves motivations, cognitive processes, and emotional responses (O’Brien et al., 2016), for example, satisfaction (Han, 2018) and task difficulty (Jiang and Allan, 2016).
Query-related features were used to predict search performance, including query length, advanced query syntax, number of queries (Ageev et al., 2011), distribution of the amount of information in the query terms, query scope (He and Ounis, 2006), and users’ interactions with the query (e.g. search state, abandonment) (Ageev et al., 2011). Kim et al. (2013) predicted search performance by mining the categorical and lexical rules of query association. Okhovati et al. (2017) evaluated users’ search performance by the number of search terms, successful completion scores, and the number of errors made. In addition, features associated with time and search results were also used to predict search performance, such as dwell time, time of the first action, result ranks on search engine result page (SERP), and the number of visited results (Fox et al., 2005).
Task performance is a similar concept to search performance. Studies of task performance aim to understand how successful the search is. Two important measures of task performance are task completion time and task completion rate, for examples, the number of relevant pages and the number of tasks successfully resolved (Aula and Nordhausen, 2006). Turpin and Scholer (2006) used the time that was taken to find the first relevant document to measure task performance. Yuan and Liu (2013) used task completion time to evaluate task performance. Kim et al. (2017) used average search accuracy to evaluate performance and analyzed the reasons for differences in performance in mobile web search.
Existing studies mainly address system search performance, for example, CheshmehSohrabi and Sadati (2021) evaluated the search performance of four image search engines in terms of recall and precision. Unlike system search performance, users’ search performance is evaluated based on relevance judgment by users themselves. This study focused on users’ search performance which is rarely witnessed.
Research design
User experiment
To answer the research questions, a cross-device search experiment was conducted in laboratory settings to collect users’ cross-device search behaviors. The directions of device transition were desktop-to-mobile and mobile-to-desktop. A laptop was provided for the desktop search. Moreover, participants were expected to use their own smart phones for the mobile search and did not bother getting used to an unfamiliar operating system.
Search system
The search system used for desktop and mobile search was a custom-developed search system called the Cross-device Access and Fusion Engine (CAFÉ). 1 Referring to the cross-device search system developed by Han et al. (2015), the context-sensitive retrieval model was adopted in CAFÉ. The results of CAFÉ are based on Bing. Each of participants were given an account to log in before starting to search. CAFÉ can present two ways of result ranking: recommended search results and search results from Bing. In the first option, results are shown after re-ranking the search results from Bing based on users’ MTIs and viewing time. In the second option, the original SERP of Bing is presented. We used the re-ranking style in the experiment. Examples of the SERP (the re-ranking style) for desktop and mobile are shown in Figure 1. Different areas of SERP are labeled, including the top bar, results x, result title, result snippet, result URL, date, recording information, and page number. The recording information consists of previous search time, search device, and search query. Data on the search behaviors that CAFÉ records are listed in Table 1.
Recorded data of CAFÉ.

SERPs of CAFÉ. SERP of desktop is on the left and SERP of mobile is on the right.
Cross-device search tasks
There were four informational search tasks for this experiment. When recruiting participants, we surveyed their background of cross-device search experience, including the search frequency and search topics. The top four frequently cross-device searched categories in everyday life were used to design the search tasks, of which were Movie, Drama, Music, and Language. The tasks were all multi-faceted, in case that participants complete the search in one session. A pilot search was carried out for the four tasks to make sure that each task could not be fulfilled by a few queries in a single session. Participants were provided with printed tasks. There were instructions in the bracket to clear the information needed. Participants were asked to submit a report consisting of useful information for each task. Four search tasks were as follow:
Experiment procedure
We had 34 university students as participants searching across desktop and mobile devices. The demographics are shown in Table 2. Before the experiment, the experimental process and requirements were introduced to participants. Participants then tried out the CAFÉ system.
Demographics of the 34 participants.
In the experiment, participants needed to complete each of four tasks through two sessions, using desktop and mobile devices. The orders of search devices were fixed, which was desktop-to-mobile for the first and the third task and mobile-to-desktop for the second and the fourth task (see Figure 2). Meanwhile, the orders of the four topics were rotated by Latin Squares. We allowed participants to search 20 minutes for every session and rest for 20 minutes in the middle of the whole search, namely after searching four sessions. This design resulted in an interval between the two sessions of a task, because it takes time to switch the search onto a different device in a real situation. In total, it took the participant 3 hours to complete the experiment.

Search procedure.
Meanwhile, during each session, participants needed to judge the relevance of every result they clicked. This kind of relevance judgment depends on context and reflects the dynamic information needs of users, which was called Ephemeral State of Relevance in the study (Jiang et al., 2017). For each clicked result, participants needed to judge it as irrelevant, generally relevant, or highly relevant and record the corresponding query and device. If participants did not click any result or the rank of the clicked results exceeded 20, they did not need to perform an evaluation. Clicking results ranking over 20 means the page number of SERP exceeds 2. It is rarely for the participants to examined SRRP exceeded 2 pages. Therefore, excluding clicked results exceeded 20 can avoid the effect of extreme samples on result analysis.
Participants were required to evaluate their level of satisfaction with the current search every time they finished a session (five-level Likert scale). At the end of searching the four tasks, participants had a short interview about how the experience of pre-switch search had an impact on the searches in the post-switch session.
Data collection and analysis methods
The data used in this study mainly came from (i) logs of CAFÉ, (ii) relevance judgments, (iii) self-evaluations of satisfaction, and (iv) interviews. Sessions with missing records were eliminated. The dataset of this paper involves 134 search sessions, 482 queries and 883 records of relevance judgments.
This paper makes reference to task performance evaluations in previous studies, which evaluated performance from the aspects of time and completion rate. For metrics, due to the lack of metrics specifically measuring user search performance, multiple classic metrics for evaluating system search performance were adopted in this study, including percentage of valid clicks, effective search time, nDCG@n, and satisfaction. However, these metrics were used differently comparing to system search performance evaluation. Note that the result relevance evaluation method in this study is context-dependent. Because the results of CAFÉ were obtained from Bing, the relevance of results could not be controlled. The calculation of user search performance was based only on the user-evaluated relevance of clicked results, which reflected how well participants obtained the information that they wanted in the current period. For example, a participant issues a query A and gets 10 results in SERP. There were probably five relevant results, but the participant clicked only two results and judged these two results as relevant.
The reason for using multiple metrics was that different metrics can reveal users’ search performance from different perspectives. The effective time examines it from the view of time duration. The percentage of valid clicks sees it from the view of clicking behavior. nDCG@n takes the view of relevance, and satisfaction provides a cognitive view. Moreover, these metrics are based on different levels of relevance. The effective search and valid clicks were defined by a binary relevance, with values of irrelevant and relevant. Evaluations of generally relevant and highly relevant in the relevance judgment were seen as relevant. nDCG@n was based on a 3-level relevance judgment, with values of irrelevant, generally relevant, and highly relevant. Satisfaction was based on a five-level Likert scale. The user search performance discussed in this paper is session-level performance, or in other words, these metrics were calculated at the end of each search session. Calculations of these metrics are explained as follow.
Percentage of valid clicks
The number of relevant pages was used to evaluate task performance (Aula and Nordhausen, 2006). Similar to relevant pages, valid clicks in this paper indicate clicking a relevant result, although the relevance is judged by the users. The percentage of valid clicks is calculated by the number of valid clicks out of the total clicks in a session.
Effective search time
Task completion time, namely search time, is frequently used to evaluate task performance. This study fixed the time of a session as 20 minutes, and therefore the effective search time was used instead. The effective search time is defined as the search time of an effective query, which indicates a query that returns relevant results. The effective search time is calculated as the sum of search time spent on all effective queries in a session.
NDCG@n
nDCG@n is frequently used in system search performance evaluation and reveals the efficiency of the search system in returning relevant documents. We borrowed this metric to calculate relevance judged by users themselves. Correspondingly, nDCG@n is calculated according to relevance judged by the users themselves, indicating the efficiency of users in finding information that meets their information needs. The scores of irrelevant, generally relevant, and highly relevant were assigned for 1, 3, and 7 in sequence. The average of nDCG@n among sessions was calculated from the top 20 results.
Satisfaction
After finishing each session, participants were required to score their level of satisfaction (five-level Likert scale). We calculated the average satisfaction for pre-switch sessions and post-switch sessions according to the scores.
Feature selection
This section introduces the selection of a set of 70 features used for training prediction models. The features were grouped according to (i) device-switching mode, (ii) users’ search performance in the pre-switch session, (iii) search behavior in the pre-switch session, and (iv) search behavior with regard to the target query in the post-switch session.
Device-switching mode
The impact of different device-switching modes on the users’ search performance is explored. Figure 3 presents the evaluation of users’ search performance over a session of 20 minutes in terms of the percentage of valid clicks (a), effective search time (b), and nDCG@n (c), taking the device-switching mode into consideration. For the percentage of valid clicks (see Figure 3a), a notable gap between pre-switch sessions and post-switch sessions is apparent in desktop-to-mobile search, which indicates a potential impact of device-switching mode on users’ search performance. Each square in Figure 3b shows the proportion of effective search in every minute of a session, which is calculated as effective queries out of total queries. In different device-switching modes, the effective search distribution is markedly different. Note that the proportion of effective search in post-switch sessions in desktop-to-mobile search was less than that in mobile-to-desktop search. Seen in Figure 3c, the gap of nDCG@n between pre-switch and post-switch sessions is very small. The trend of nDCG@n in desktop-to-mobile search and mobile-to-desktop search seems similar. In other words, the device-switching mode has little impact on users’ search performance as measured by nDCG@n. As for the satisfaction, the level of satisfaction in post-switch sessions was higher than that of pre-switch sessions for desktop-to-mobile search (AVE = 3.71, SD = 0.676 > AVE = 2.97, SD = 0.627) and mobile-to-desktop search (AVE = 3.68, SD = 0.976 > AVE = 3.21, SD = 0.914). Note that the level of satisfaction differs between different device-switching modes.

Users’ search performance in terms of the percentage of valid clicks (a), effective search time (b), and nDCG@n (c).
To further test the significance of the impact of device-switching modes on the users’ search performance, a statistical analysis was carried out. Assuming that users’ search performance in the pre-switch and post-switch sessions were related samples, the Wilcoxon signed-rank test was conducted. Table 3 presents the results. Significant differences are observed in the measurements by effective search time and satisfaction. It can be concluded that the device-switching mode can have an impact on users’ search performance. Therefore, the device switching modes were selected as features to predict users’ search performance (Table 4).
Significance of the difference between pre-switching and post-switching sessions according to different device-switching modes.

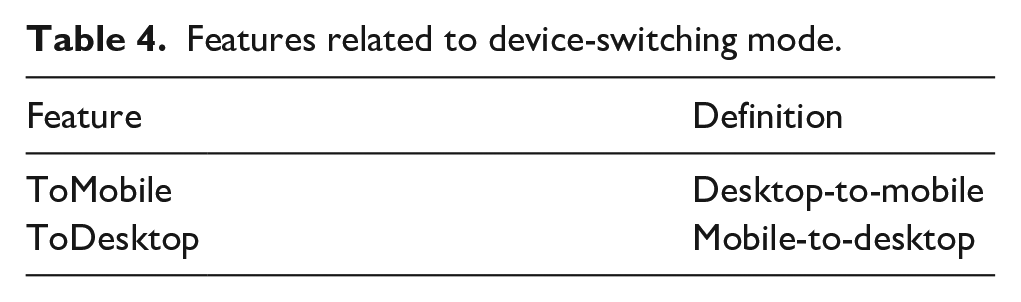
Features related to device-switching mode.
Users’ search performance in the pre-switch session
According to interview responses about the influence of the search experience in pre-switch session on the search in the post-switch session, 31 participants said they felt more familiar with the task and topics and became clearer about what information they needed in the post-switch sessions. For example, “Search on the first device (pre-switch session) helps me to accumulate knowledge.” “I understood search tasks better after pre-switch session search.” “Search on the first device made me more familiar with search results and contents.” Twenty participants claimed that the pre-switch session search had an impact on their relevance judgments of the post-switch session, and 14 participants expressed that their strategy of formulating queries in the post-switch session was affected by the pre-switch session search. For example, “I got a whole picture of search tasks by searching on the first device. Therefore, I could easily judge the relevance of results in second-device search (post-switch session).” “I was not satisfied with search results of first-device search. I changed query in second-device search.” These interview records encouraged the authors to extract features related to the pre-switch session. Table 5 presents four metrics of users’ search performance in the pre-switch session. Features of search behavior were extracted for the pre-switch session as well (see Table 6).
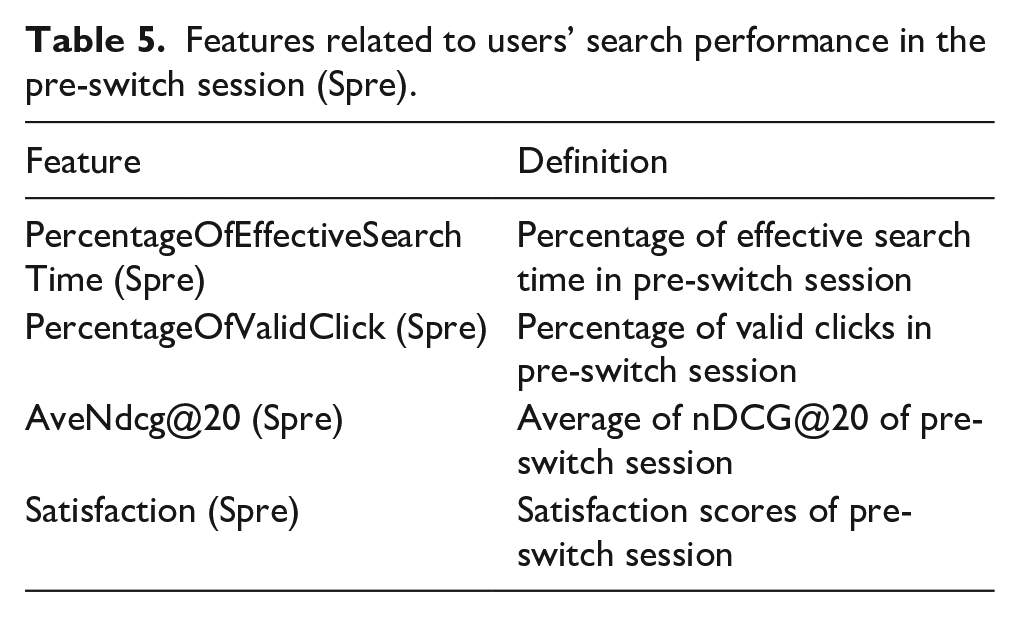
Features related to users’ search performance in the pre-switch session (Spre).
Features related to search behavior in the pre-switch session (Spre).
Search behavior of pre-switch session
Features of search behavior in Table 6 are selected with reference to previous studies. Features based on queries are frequently witnessed in search behavior prediction models. Ageev et al. (2011) used query word length to predict search success. In this study, the number and proportion of queries were used. Click behavior cannot be ignored in search behavior studies. Kelly and Azzopardi (2015) analyzed click distribution when studying users’ search behavior on SERP. Fox et al. (2005) tested the association between visited results as an implicit measure of users’ satisfaction during Web search. Hence, in this study, click depth and number of clicks were used to predict users’ search performance, which is an aspect of search behavior. In a mobile search context, users interact with the search system mainly by touching different areas. Guo et al. (2013) evaluated the utility of a set of touch interaction features as implicit relevance feedback. Han et al. (2015) used MTI to infer relevant content and further support cross-device search. In this study, the number, proportion, duration, direction and area of interactions were included in the set of features.
Search behavior regarding the target query in the post-switch session
The features in Table 7 refer to previous studies as well as to Table 6. The difference between them is that the features in Table 6 relate to the pre-switch session, whereas those in Table 7 relate to the target query in the post-switch session. The purpose of this paper is to predict users’ search performance in the post-switch session, and the prediction target is the search performance of issuing each query in the post-switch session, when the model is trained. Therefore, search behavior in the post-switch session should be taken into consideration, and the features relate to the target query.
Features related to search behavior regarding the target query in the post-switch session (Qpost).

Users’ search performance prediction
The work described in this section attempted to predict users’ search performance in post-switch sessions through different feature combinations. This section compares the model performance and finds the highest-performing combination of features. To test what combination of feature groups can achieve the best prediction performance, eight prediction models were developed (see Table 8). Model A was set as a baseline.
Prediction model.

Prediction result
Search performance prediction was treated as a regression problem, and a simple linear regression model referring to Han et al. (2015) was applied. IBM SPSS Modeler 18.0 was used to execute model training. The idea of users’ search performance is inspired by the system’s search performance which is based on the relevance of search results. The difference is the users’ search performance is based on the user’s own relevance judgments. The four metrics of search performance were proposed in this study, but the metric of satisfaction is independent of relevance judgments. Among the other three metrics, the percentage of valid clicks and the effective search time is based on the binary relevance judgment, while the nDCG@n is related to the multi-level relevance judgment. Moreover, nDCG@n is a popular metric of search performance evaluation. Therefore, the prediction selected nDCG@n as the metric of users’ search performance. Users’ search performance in the post-switch session was measured by nDCG@10 because 95.24% of the clicked results in the dataset ranked in the first 10. The value of nDCG@10 was calculated as the relevance of the query in the post-switch session, and there were 237 queries in total.
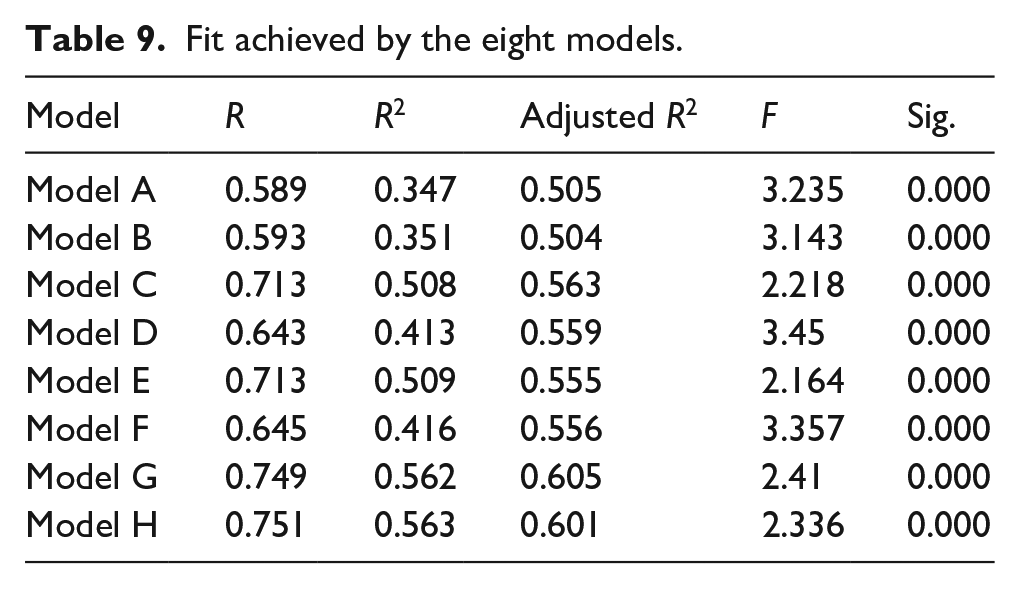
A set of 237 records was used for training (80% of records) and testing (20% of records) the prediction models. The training and testing sets were randomly sampled. Table 9 shows the fitting result of training the eight models. Model G achieved the best fit among all eight models, and Model H achieved a fit slightly weaker than Model G. This indicates that the device-switching mode has little effect on improving predictive performance. Furthermore, Users’ search performance in the pre-switch session and their search behavior altogether plays an important part in predicting users’ search performance in the post-switch session.
Fit achieved by the eight models.
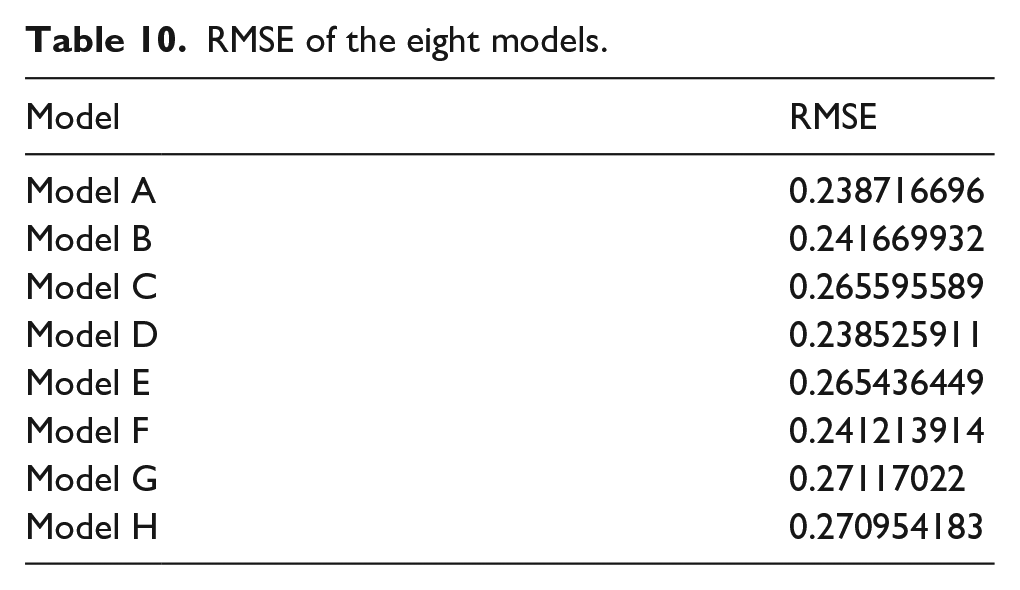
Root mean square error (RMSE) (Zhan et al., 2016) was used to validate these eight models. RMSE can reflect the precision of models. The smaller the value, the better is the precision. The results are shown in Table 10. Model D was the best performer, followed by Model A. The result shows that the combination of users’ search performance in the pre-switch session and their search behavior with regard to the target query in the post-switch session can attain the best performance accuracy. The gap between Model D and Model A is small, which means that users’ search performance in the pre-switch session contributes slightly to predicting users’ search performance in the post-switch session.
RMSE of the eight models.
Important features
Standardized coefficients (β) indicate the relationship between the independent variable (IV) and the dependent variable (DV). In this paper, IV refers to the feature and DV refers to nDCG@10. The absolute value of β reflects the impact of IV on DV. The larger the absolute value of β, greater the impact will be (Jiang et al., 2017). Based on β, the top three important features of each model are listed in Table 11.
Top three important features of the eight models (* sig <0.05).
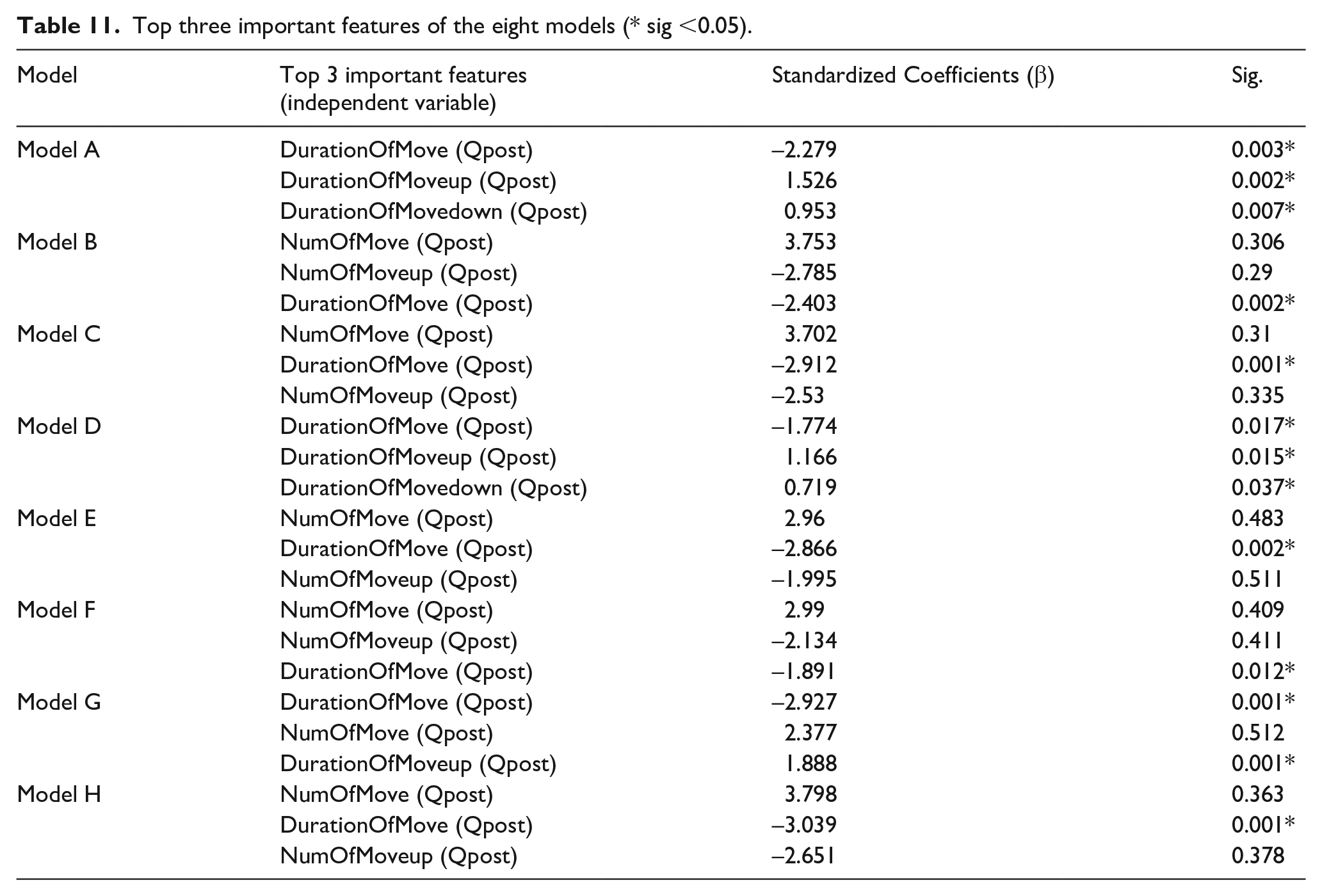
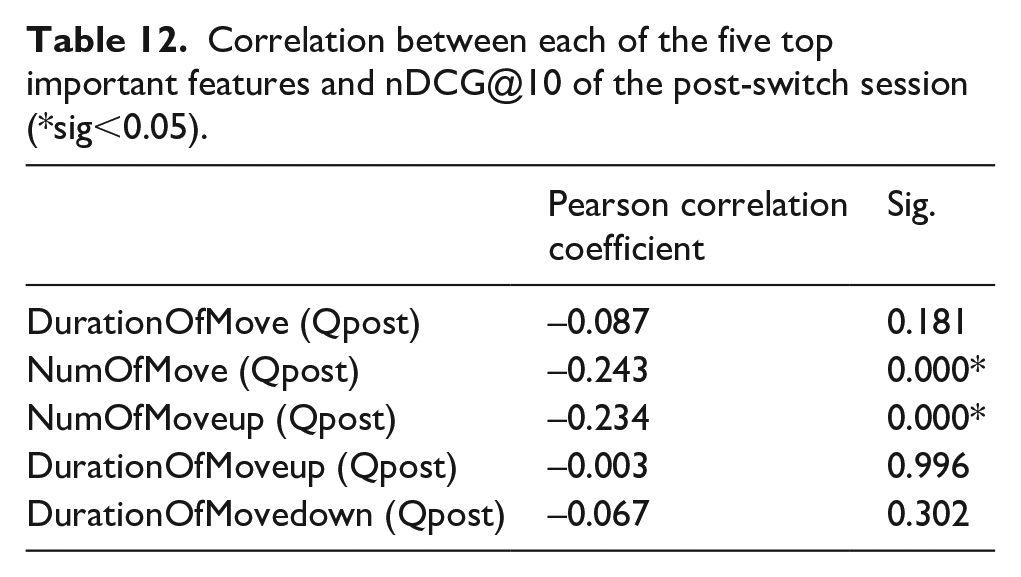
Five unique features are shown in Table 11: DurationOfMove (Qpost), NumOfMove (Qpost), NumOfMoveup (Qpost), DurationOfMoveup (Qpost), and DurationOfMovedown (Qpost), of which three features are shown a significant impact. Obviously, scrolling the screen is an important action to predict users’ search performance. Meanwhile, these five features are all about the post-switch session, which indicates that users’ touch interaction in the post-switch session is important to predict users’ search performance in that session.
Table 12 presents the bivariate correlation between each of these five important features and nDCG@10 of the post-switch session. nDCG@10 of the post-switch sessions has a negative correlation with the frequency of screen scrolling. The more frequently users scroll the screen, the more likely it is that users’ search performance is worse. The time spent on scrolling the screen has no significant correlation with nDCG@10, which means that how long users scroll the screen has little impact on users’ search performance.
Correlation between each of the five top important features and nDCG@10 of the post-switch session (*sig<0.05).
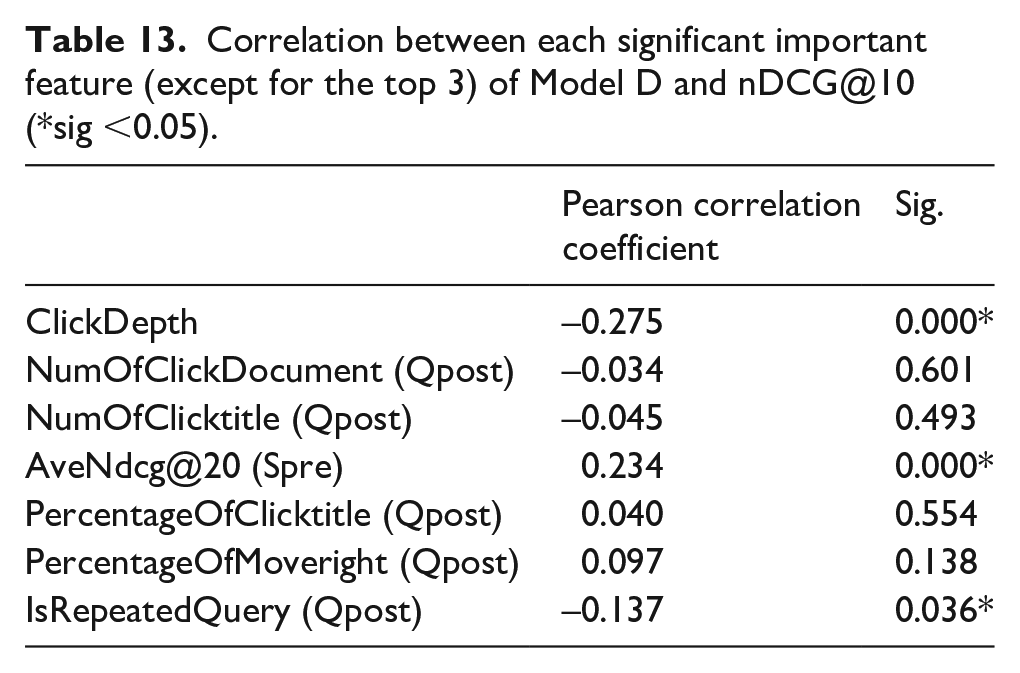
Top 10 important features in Model D were examined the correlation with nDCG@10, and the results of 7 features (top 10 exclude top 3) are shown in Table 13. Three features were found to have a significant correlation with nDCG@10: ClickDepth (Qpost), AveNdcg@20 (Spre), and IsRepeatedQuery (Qpost). Clearly, scrolling the screen and clicking on results are important actions for prediction. ClickDepth (Qpost) indicates the depth to which users view SERP, which is the outcome of two actions, scrolling the screen and clicking on results. IsRepeatedQuery (Qpost) calculates the maximum similarity between the target query in the post-switch session and the query in the pre-switch session, which reflects the importance of refinding to predict users’ search performance in the post-switch session. Except for AveNdcg@20 (Spre), the remaining nine features are all about search behavior for the target query in the post-switch session. ClickDepth (Qpost) has a negative correlation with users’ search performance, which means that viewing deep SERP can predict a poor search performance of the user. It is easy to understand that the underperformed user views more results to find the information in demand. IsRepeatedQuery (Qpost) also has a negative correlation with users’ search performance, which means that the greater the number of similar queries in the pre-switch and post-switch sessions, the more likely it is that users’ post-switch search performance is becoming worse. Moreover, AveNdcg@20 (Spre) has a positive correlation with nDCG@10 in the post-switch sessions, which means that the better users’ pre-switch search performance, the more likely it is that users’ post-switch search performance improves.
Correlation between each significant important feature (except for the top 3) of Model D and nDCG@10 (*sig <0.05).
Discussion
Features of predicting users’ search performance
According to the model testing results, Model D was the best performer, followed by Model A. It has been found that combining users’ search performance in the pre-switch session and their search behavior with regard to the target query in the post-switch session is better than any other combination for predicting users’ search performance in the post-switch session. The difference of model training results was small between Model G and Model H. It was also found that the device-switching mode contributes little to predicting users’ search performance in the post-switch session.
An analysis of the important features shows that MTI performs better in prediction than other features, especially scrolling. The importance of scrolling in search behavior has also been confirmed in previous studies. Fox et al. (2005) found that scroll counts have a significant impact on users’ feedback of search result evaluation. This study also found that the frequency of screen scrolling has a negative correlation with users’ search performance. Consistently with the findings of Guo et al. (2013), swipe frequency has a significant negative correlation with document relevance.
Analysis of Model D revealed that the frequency of screen scrolling and the depth of viewing SERP have a negative correlation with users’ search performance. This finding suggests that users interact with SERP frequently when they cannot obtain the information they want, which further leads to low search performance. Meanwhile, the time users spent on interacting with SERP has no significant correlation with users’ search performance. This explains that interaction time cannot represent the quality of users performing the search.
One interesting finding was that there is a negative correlation between IsRepeatedQuery (Qpost) and users’ search performance. This suggests that diversification in formulating queries can help users achieve better search performance. In cross-device search, users tend to find new information to develop a complete answer to the search task.
Users’ search performance based on user-evaluated relevance
Different methods of judging relevance may be suitable for the different evaluations of search performance. Context-independent relevance judgment is frequently used in system search performance evaluation, where external assessors judge the relevance of results based on topical relevance in advance. The number of relevant results is known, and the relevance of clicked results is fixed, which is independent of human will. Context-independent relevance judgment is objective, and it is hard to reveal the instant and real information need. In contrast, context-dependent relevance judgment is subjective; the relevance is judged by users themselves over the whole search process. Compared with topical relevance, the novelty has a much greater impact on context-dependent relevance judgment (Jiang et al., 2017). In this case, the context-dependent relevance judgment is better to fit evaluating the users’ search performance. In this study, users’ search performance was evaluated based on the context-dependent relevance judgment. It can be seen the users’ search performance experiences up and downs during the process of searching. Users judge relevance based on their needs, reflecting changes in their actual needs. Studying the users’ search performance has opened up the search service providers’ minds that the user’s floating needs during the search process should be satisfied, especially in a complex and lasting search activity like the cross-device search. Further and more exploration of users’ search performance should be attached importance, and the classic metric to measure the system’s search performance could be utilized and adapted by the context-dependent relevance judgment.
Conclusions
This paper predicts users’ search performance in the post-switch session, and analyzes the effective features for predicting users’ search performance. Combining users’ search performance in the pre-switch session and the search behavior with regard to the target query in the post-switch session can best predict users’ search performance in the post-switch session. This study also has limitations. The small scale of participants in the experiment limits the generality of the findings, but the results of this exploratory study can shed the light on further exploration of cross-device search. The absence of any recording of mobile search causes data inconsistency between desktop and mobile, and therefore data for many sessions had to be eliminated. Other metrics except for the nDCG@n were not used in the prediction task, thus it remains unknown whether similar results will be achieved. The device-switching mode considered only desktop-to-mobile and mobile-to-desktop search, not mobile App search. Future work will be worthwhile to study users’ search performance in the context of mobile App search.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Social Science Foundation of China [No. 19ZDA341].