
Abstract
In methodological and practical debates about replications in science, it is (often implicitly) assumed that replications will affect public trust in science. In this preregistered experiment (N = 484), we varied (a) whether a replication attempt was successful or not and (b) whether the replication was authored by the same, or another lab. Results showed that ratings of study credibility (e.g. evidence strength, ηP2 = .15) and researcher trustworthiness (e.g. expertise, ηP2 = .15) were rated higher upon learning of replication success, and lower in case of replication failure. The replication’s author did not make a meaningful difference. Prior beliefs acted as covariate for ratings of credibility, but not trustworthiness, while epistemic beliefs regarding the certainty of knowledge were a covariate to both. Hence, laypeople seem to notice that successfully replicated results entail higher epistemic significance, while possibly not taking into account that replications should be conducted by other labs.
Keywords
For the scientific community, replicating empirical research findings increases the reliability of the results and the confidence in the truth value of the contingent claim (Lakatos and Musgrave, 1970; Nosek et al., 2012; Popper, 1959; Simons, 2014). In consequence, in order to make wider conclusions about the veracity of scientific claims, it is imperative that scientists publish not only studies that replicate the original results but also those that fail to replicate (Ferguson and Heene, 2012). In a recent huge collaborative effort, researchers attempted to replicate 100 psychological, experimental and correlational studies, many of them well-known effects: Results showed that about 61% of studies could not be replicated by other, independent labs and most of the results that were replicated had lower effect sizes (Open Science Collaboration, 2015). Similar analyses in other disciplines (medicine, economics) have also found low replicability of study results (Begley and Ellis, 2012; Camerer et al., 2016; Chang and Li, 2015; Errington et al., 2014; Prinz et al., 2011). The results of such publications likely affect the overall trust in the scientific claims that original studies allege, not only within the specific scientific communities but also in the view of the general public.
In fact, the Open Science Collaboration publication received extensive attention, leading various media outlets to portray a replication crisis and suggest a trust crisis in psychology. 1 Of course, a single replication study neither entirely validates (if successful) nor absolutely dismisses (if failed) the effect of the original study, nor should it affect the responsible researcher’s trustworthiness (Ebersole et al., 2016). However, researchers anticipate failed replications to have negative reputational consequences (Fetterman and Sassenberg, 2015). So, in the long run, if researchers do not achieve successful replications, doubts are bound to emerge about the reliability of the original results and the researcher’s reputation.
The understanding of the recent replication crisis as a trust crisis points to potential broader effects of failed replications on the public’s trust in scientists, and on the public’s belief about the credibility of scientific findings. The general public is mainly interested in scientific findings with regard to real-world problems, for example health issues (National Science Board, 2016; Wissenschaft im Dialog/Kantar Emnid, 2017); thus, what actually matters is the “truth” of these findings. Thinking about a researcher’s trustworthiness is a “secondhand” strategy for making such “truth” judgments, complementing a “firsthand” judgment about the credibility of the scientist’s knowledge claims (Bromme and Goldman, 2014). In the 2018 German Science Barometer (Wissenschaft im Dialog/Kantar Emnid, 2018), in which a representative German public is surveyed about their attitude toward science, only 17% of respondents answered that failed replications indicate that results from this area of research are unreliable. However, possible effects of (failed) replications on the perceived persuasiveness of scientific findings as well as on the public’s trust in scientists are of high importance in the context of recent debates about “fake news” and “fake science”. Science denialists use real as well as alleged instigations for doubts about the validity of single scientific findings for generalized attacks on the epistemic power of science (Kalichman, 2014; Levy, 2019).
In a large-sample survey study in the United States, Ebersole et al. (2016) investigated the effect of replications on the perceived “truth” of study results (perceived “Likelihood that the critical research result might be true”), and on public trust in the researcher whose results had been subject to a replication (perceived ability and ethicality). When another researcher had attempted to replicate results of the original study, but failed, participants rated the truth of the original finding lower as well as the ability and even ethicality of the original researcher. If the original researcher, however, then accepted the failed replication, or published a failed self-replication herself, her ability and ethicality were perceived to be higher than when participants only knew of the original study. Yet, the merit of providing a representative sample (with respect to US citizens) in this study inevitably comes along with the abstractness of survey questions. Ebersole et al. (2016) used a within-subject design, hence having participants compare different kinds of situations regarding failed replications. Their participants were asked about situations that did not refer to a specific topic or context of science communication. Thus, participants had no reason to be vigilant about the epistemic quality of the results provided by researchers who responded in such different ways to the failures of their replications.
To overcome this possible limitation, the present experimental studies investigate the effects of successful and failed replications on the trustworthiness of researchers and the assumed “truth” of study results in a between-design and in the context of reading a (fictitious) news report about a concrete health-related topic. These features are meant to model the real-world scenario of a citizen looking up health-related scientific evidence on the Internet in order to answer a question of personal interest. In our experiment, participants were introduced to either a successful or a failed replication. Beyond this, participants read that this replication study was either conducted by the original researcher (from here on, called self-replication) or by another researcher (from here on, called other-replication). Thus, the independent variables (IVs) to be investigated were the type of replication (self vs other) and the replication outcome (success vs failure). The dependent variables (DVs) “credibility and evidence strength” of the study’s results, as well as “trustworthiness” of the original researcher were measured on three dimensions. In the following, we elaborate our rationale for choosing these IVs and DVs.
1. Self-replication vs other-replication
Replication studies are multifunctional: Beyond providing further evidence to verify the underlying hypothesis of the original study and extending it to further populations, replication studies are a means to control for sampling error, artifacts, and random noise (Ioannidis, 2005; Schmidt, 2009; Simons, 2014) as well as experimenter bias, and even fraud by researchers (Rosenthal and Rubin, 1978; Schmidt, 2009; Strickland and Mercier, 2014). For these reasons, it is a necessity that different research laboratories (repeatedly) address the same or similar research questions (Ioannidis, 2005). Replications by the same research lab (self-replications) do not possess the same theoretical significance as replications by unaffiliated labs (Simons, 2014). Nonetheless, self-replications can and should be performed for the purposes of a self-check in the case of unexpected or surprising results and to protect against Type I error (Hüffmeier et al., 2016; Simons, 2014). So far though, it is an open question as to whether or not laypeople 2 recognize the qualitative difference between self- and other replications in how they judge the credibility of study results and the trustworthiness of researchers.
2. Dimensions of trustworthiness
Interestingly, in a study by Fetterman and Sassenberg (2015), researchers ascribed less negative reputational outcomes to other researchers when those researchers admitted their wrongness (e.g. through social media) after a failed replication study had emerged. Indeed, not only fellow researchers, but laypeople also perceive researchers who admit that their own initial results might not be correct as more able and ethical (Ebersole et al., 2016). The findings of both studies show that different outcomes of wrongness admission might be expected for different dimensions of trustworthiness judgments: expertise, integrity, and benevolence. For example, readers might consider whether the source possesses the pertinent expertise, but they also might consider whether she follows the rules of proper scientific conduct (e.g. not withholding relevant information), acts for the benefit of others (e.g. patients) and is not driven by self-interest (Hendriks et al., 2015). For example, when scientists include in their reports certain flaws or uncertainties (Hendriks et al., 2016; Jensen, 2008), ratings of integrity and benevolence (but not expertise) might be positively affected. It is an open question whether publishing about a self-replication (especially a failed self-replication) would have a similar impact on laypeople’s ascriptions of integrity or benevolence.
3. Layers of credibility
Within science, it is widely understood that the results of a single study do not allow for strong inferences about the validity of a scientific claim—but that a successful replication by an independent research group would enhance the credibility and generalizability of a single (particularly the original) study’s effect (Asendorpf et al., 2012; Simons, 2014). Possibly, some of the conceptual distinctions between the epistemic status of data, hypotheses and further generalizations might also be present in public understanding of research. Therefore, we investigate the effects of (failed) replications on participants’ judgments about the credibility of study results on the following three layers: the credibility of the results of the study, the strength of collected evidence, and the credibility of the conclusion the researchers derive from their findings.
4. Prior beliefs about the topic and epistemic beliefs
Whether a claim is deemed credible is impacted by its accordance with a person’s prior beliefs (Fischer et al., 2005; Lewandowsky et al., 2012; Metzger and Flanagin, 2013). Whether a scientific claim confirms pre-existing prior beliefs might also impact judgments of source trustworthiness (Landrum et al., 2017); though, this association has not been consistently found in the domain of politics (Metzger et al., 2015; Westerwick et al., 2017). Hence, we will control for prior beliefs about the topic when we ask participants about their perceived credibility and evidence strength of study results, and the trustworthiness of its source.
Epistemic beliefs “offer a general schema about what has to be understood or acquired” (Mason and Bromme, 2010: 3) and may represent general beliefs about the nature of knowledge, but they also pertain only to specific disciplines (Buehl et al., 2002; Stahl and Bromme, 2007). Discipline-specific epistemic beliefs are assumed to be better predictors for problem solving in the specific discipline (Schraw, 2001) and might affect credibility ratings (Strømsø et al., 2011). It is possible that individuals’ evaluations of replications within science are influenced by such beliefs about the epistemic state of knowledge within a discipline (in our case, the assumed certainty or stability of medical knowledge).
In summary, two research questions are addressed in this article. First, it is yet an open question whether laypeople place more trust in results obtained by a scientific study, and in its author, if it has been replicated, and less trust if it is not. Second, we wanted to find out whether laypeople’s trust and credibility judgments were affected by who conducted the replication study: the author of the original study or another research group.
5. Hypotheses
All directional hypotheses are labeled Hx, research questions for which no directionality can be assumed are labeled RQx. All hypotheses state changes from ratings after reading an initial study to ratings after learning of the replication attempt. We expect that participants will have some knowledge about what successful and failed replication attempts mean on the one hand, and about the significance of self- versus other-replication on the other hand, and that they will rate the study’s credibility and evidence strength accordingly. Hence, we expect,
H1 A successful replication study (no matter who was its author) will enhance the credibility and evidence strength, and a failed replication will decrease it.
H2 Credibility ratings should increase even further for successful other-replication compared to successful self-replication, while a stronger decrease in ratings for failed other-than for failed self-replication is expected.
As noted earlier, several other studies (Hendriks et al., 2016; Jensen, 2008) suggest that a disclosure of uncertainty might increase ratings of integrity and benevolence, and this might also be true for a failed replication (Ebersole et al., 2016). Therefore, we expect for ratings of the trustworthiness of the researcher responsible for the original study:
H3 We expect that ratings of the expertise of the researcher will be increased after learning of a successful replication, and lower ratings are expected in case of an unsuccessful replication.
H4 Higher ratings of integrity and benevolence are expected for self-replication (compared to other-replication), regardless of its failure or success.
RQ1 We investigated whether prior beliefs about the topic (malleability of cell phone radiation) and epistemic beliefs about the certainty and stability of medical knowledge would affect ratings of credibility and trustworthiness.
6. Documentation of this study and two prior studies
The experiment reported in this article was preregistered, osf.io/4xmc9. More detailed information on the data acquisition, statistical procedure, and results can be found in the Supplementary Materials to this article. The original materials, items, data, protocols of statistical analyses, and additional documentation of results can be found in the Open Science Framework (OSF) project pertaining to this study, osf.io/qjyrh.
Results of two prior studies also can be found in the OSF project. The experiment reported in this article is a direct replication of prior study 2 (leaving out some non-central items to make the questionnaire shorter), but with a larger, more diverse adult sample. In short, in the prior studies, we tested 75 (prior study 1) and 137 (prior study 2) college students. Results showed, that the success of a replication determined their ratings of credibility and evidence strength, but rather not the replication’s author. Prior beliefs were a significant covariate for all three ratings related to the study’s credibility. Besides expertise, trustworthiness ratings were mostly not affected by experimental variations.
7. Procedure and measures
Sample
Overall, N = 627 participants finished the online survey. Of those, n = 484 were included for analysis. Those participants were between 18 and 71 years of age; M = 32.48, SD = 10.90 (one value of 1 recoded as missing). Of participants, 51.9% were female, 47.7% were male, 2 participants chose not to disclose their gender. Regarding their formal education, 0.2% did not hold any educational degree, 26.9% did hold a secondary school qualification degree or had successfully concluded vocational training, 35.3% had a higher education entrance qualification, 37.6% held a university degree.
Most participants reported to read online science news rather infrequently (only 37.4% at least more than once a month, among them 3.5% who reported reading science news daily). Of participants, 51.9% reported to read online health information at least once a month, among them 2.9% daily.
Data acquisition
We recruited participants through a Swiss online recruiting service. Participants residing in Germany and over 18 years of age could fill out the questionnaire online in German language. Power analyses were conducted to determine the sample size. Further details on the procedure during data acquisition can be accessed in the Supplementary Materials.
Procedure
After initial ratings (time point T0), participants received an article from an online magazine about science (fictitious, but largely inspired from original materials). In this article, a study was described, having found that cell phone radiation was linked to tumor development in mice (higher percentage of tumor development in mice who had spent their life close to a radiation source compared to mice who had not). Subsequently (T1), participants rated the study’s credibility and evidence strength, and the trustworthiness of the responsible researcher. Next, they received the second newspaper article (from the same news source) about a replication of the study that had been described in the first article. Participants were randomly divided into four experimental groups (by the survey software): successful self-replication (n = 125), successful other-replication (n = 122), failed self-replication (n = 120), failed other-replication (n = 117). After reading both articles (T2), participants gave ratings on both DVs as well as prior beliefs a second time.
Measures
At T0, participants were asked to give information about demographics, which included age, gender, highest educational qualification, and, if applicable, their university major (maximum two subjects). Participants also answered how often they read (a) scientific and (b) medical information online before (scales from 1 = never to 5 = daily). Two scales of the inventory Epistemic Beliefs About Medicine (EBAM; Kienhues and Bromme, 2012) were used to measure medicine-specific epistemic beliefs (items are to be rated on a scale from 1 = don’t agree at all to 5 = agree very much). We only used the scales Certainty of Medical Knowledge (7 items; internal consistency for the present sample α = .72) and Stability of Medical Knowledge (5 items; α = .56). Epistemic beliefs were recoded, such that higher values express the belief that medical knowledge is less certain. There were no a priori differences between groups on the relevant EBAM scales (Certainty of Medical Knowledge: F(3, 480) = .36, p = .79; Stability of Medical Knowledge: F(3, 480) = .17, p = .92).
Also at T0, participants’ attitude toward the topic was assessed: Prior beliefs were measured with one item that inquired about participants’ stance regarding the harmfulness of cell phone radiation for humans (1 = not harmful to 5 = harmful); a second item assessed the confidence they had in their prior beliefs (1 = not confident to 5 = confident).
At T1, participants rated the epistemic trustworthiness of the researcher responsible for the study. For this, we employed the Muenster Epistemic Trustworthiness Inventory (METI; Hendriks et al., 2015), which is a 7-point semantic differential scale with 14 pairs of adjectives (e.g. competent–incompetent). In the present sample, internal consistencies were good for all three scales of this inventory: expertise (6 items; T1: α = .90, T2: α = .94), integrity (4 items; T1: α = .80, T2: α = .85) and benevolence (4 items; T1: α = .87, T2: α = .91). Regarding the study’s credibility and evidence strength, at T1, participants were asked to judge the credibility of the study’s results (results credibility: 1 = not at all credible to 7 = very credible), how much the researchers could prove the results (evidence strength: 1 = not at all proven to 7 = very proven), and the credibility of the researcher’s conclusion that cell phone radiation was linked with cancer (conclusion credibility: 1 = not at all credible to 7 = very credible).
At T2, participants again gave ratings for epistemic trustworthiness, credibility and evidence strength, and their prior beliefs.
8. Results
Statistical analyses
We conducted analyses of covariance (ANCOVAs), which allow for examining main and interaction effects of our experimental variations (independent variables: replication success/replication author) on the dependent variables. Since we examine the effect of the independent variables upon learning of the replication study (i.e. as a change from ratings at T0/T1 to T2), we also include a repeated measures factor (time). For example, when an interaction effect of time and replication success is observed, this means that the change in ratings about successful replications was different (e.g. increased from T1 to T2) than the change in ratings about unsuccessful replication (e.g. decreased from T1 to T2). In the example, a change in ratings occurs as a result of different outcomes in success of the replication attempt, but not of the author of the replication (which would be indicated by a three-way interaction of time, replication success and replication author). Furthermore, ANCOVA allows including covariates, that is, a significant main effect shows the overall influence of our covariates (prior beliefs about the topic and epistemic beliefs about medicine on the two scales certainty and stability) on participant ratings. An interaction effect of time and a covariate would indicate an influence of the covariate on the change in participants’ ratings of the dependent variable from T0/T1 to T2.
Documentation of statistical procedure
For more detailed description of the statistical procedures see the Supplementary Materials, and for a full report of results from ANCOVAs, please consult Supplementary Materials, S1. We also conducted analyses of variance (ANOVAs using the same design without covariates), which allowed us to compute the effect size generalized eta squared (Lakens, 2013), which is comparable across research designs (a limitation of partial eta squared; Olejnik and Algina, 2003). These results can be found in Supplementary Materials, S2. In the Supplementary Materials, we also provide information on testing assumptions for executing ANOVA/ANCOVA. The data, and scripts for analyses, and visualization of the direction of covariates can be accessed at osf.io/qjyrh.
For means (and standard deviations) of all DVs reported, see Table 1. Here, for easier understanding of how participants’ ratings have changed from T0/T1 to T2, we also report the percentage of participants who had a lower, the same, or a higher rating at T2, compared to T0/T1 (Hanel and Mehler, 2019).
Means (and standard deviations), as well as percentages of how many participants chose a lower, the same, or a higher scale option at T2, compared to T1(or T0), for dependent variables.
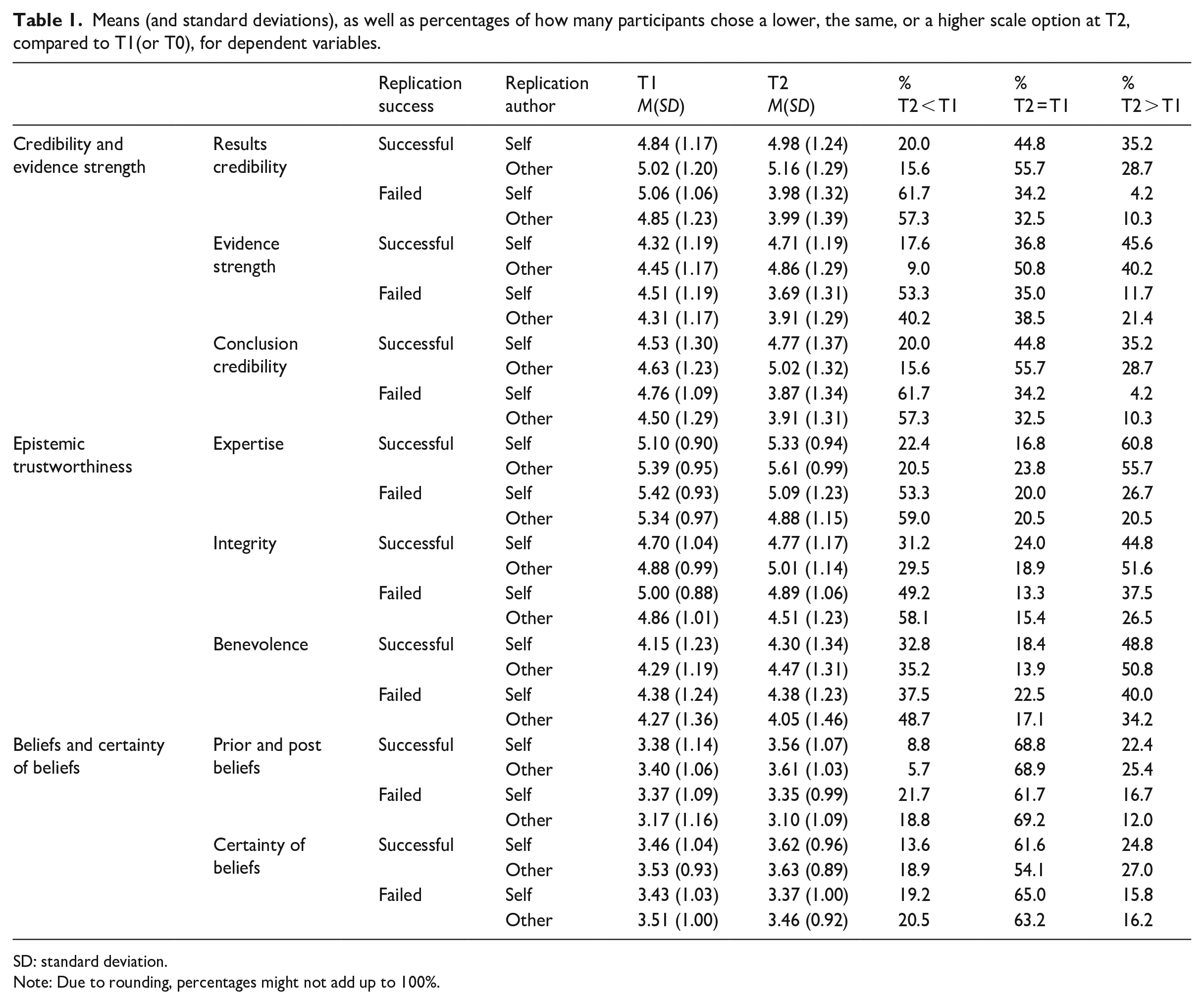
SD: standard deviation.
Note: Due to rounding, percentages might not add up to 100%.
Credibility and evidence strength
Ratings of the results’ credibility were affected by learning of the replication, contingent upon whether the replication had been described as successful or failed (interaction effect of time and replication success, ηP2 = .20). This confirms H1: while ratings were about the same or a little higher contingent to successful replication, they dropped after learning of a failed replication (in both cases no matter who was the author—no effect for replication author, or the interaction of this variable with time, as such, H2 could not be supported). Figure 1 illustrates the means of the credibility of study results at T1 and T2 for all experimental groups. Prior beliefs (ηP2 = .13) and epistemic beliefs about the certainty of medical knowledge (ηP2 = .04) were significant as main covariation effects. Regarding RQ1, results show that the more participants assumed cell phone radiation to be harmful, they also believed the study findings (that the study found an increase in cancer in mice when subjected to cell phone radiation) to be credible. The more uncertain participants assumed the domain of medicine to be, the less credible they rated the result.

Line graphs showing the change of mean ratings of credibility and evidence strength per experimental group from T1 ( after reading the first text, but before learning of the replication attempt) to T2 (after reading the two texts, that is, after learning of the replication).
Participants’ judgments regarding evidence strength increased when learning about the successful replication and decreased when learning the replication had failed (interaction time and replication success, ηP2 = .15). Again, this supports H1, while H2 is not supported by the results. Regarding RQ1, again, prior beliefs (ηP2 = .11) and epistemic beliefs about the certainty of medical knowledge (ηP2 = .07) did reach significance as main covariation effects, implicating that higher prior beliefs of harmfulness indicated higher evidence strength ratings, and a higher epistemic belief that medical knowledge is uncertain was associated with lower ratings of evidence strength (the marginally significant interaction with time suggesting that this was even more pronounced at T2, ηP2 = .01).
Participants judged the conclusion to be more credible after learning about the study’s successful replication, and less credible after learning about the failure to replicate (interaction effect time and replication success, ηP2 = .20), which confirms H1. A marginally significant interaction effect of time and replication author indicated that the mean ratings after learning of a self- versus other-replication showed different patterns (ηP2 = .01; see Figure 1 for means), however, since no three-way interaction effect of replication author with time and replication success was observed, and the effect size is quite small, this does not support H2. Again, prior beliefs (ηP2 = .24) and epistemic beliefs regarding the certainty of medical knowledge (ηP2 = .06) were significant as a main covariation effect, but not as an interaction effect, both in the same direction as reported before.
Hypothesis H1 was therefore confirmed by the experiment’s results: Participants’ ratings of the results’ credibility, evidence strength, and conclusion credibility were higher after learning of a successful replication, and lower after an unsuccessful replication. H2 was not supported; who was the author of a replication attempt did not change the increase/decrease in credibility and evidence strength ratings about successful/unsuccessful replications. Regarding RQ1, we can conclude that both participants’ prior beliefs and epistemic beliefs regarding the certainty of medical knowledge have an influence on their credibility and evidence strength ratings, however, epistemic beliefs about the stability of medical knowledge did not have a significant influence on all three DVs concerning credibility and evidence strength.
Scientist’s epistemic trustworthiness
For expertise, an interaction effect of time and replication success was observed (ηP2 = .15), showing that learning of a successful replication of the study raised ratings of the author’s expertise, while learning of a failed replication lowered them (see Figure 2 for means). This supports H3. Unexpectedly, a significant interaction effect of replication success and replication author was observed (ηP2 = .01). The EBAM certainty scale did reach significance as a covariate (ηP2 = .06; indicating that the more participants believed that medical knowledge was uncertain, the lower were their ratings of expertise), prior beliefs did not.

Line graphs showing the change of mean ratings of the epistemic trustworthiness ascribed to the primary scientist. Graphs show the change per experimental group from T1 ( after reading the first text, but before learning of the replication attempt in text 2) to T2 (after reading the two texts, that is, after learning of the replication).
Regarding ratings of integrity, a small three-way interaction effect of time, replication success, and replication author (ηP2 = .01; and significant two-way interaction of replication success and replication author, ηP2 = .01, as well as a significant interaction effect of time and replication success, ηP2 = .05) was observed, indicating that ratings of integrity were changed in accordance with a replication attempt being successful or not, and it being a self-replication, or an other-replication. In case of an other-replication, the change in ratings (higher if successful, lower if failed) was more pronounced, compared to the self-replication conditions. This is contrary to our expectations stated in H4. Certainty-related epistemic beliefs again reached significance as a covariate (ηP2 = .06), but not in interaction with time, indicating that the belief that medical knowledge was uncertain was again associated with lower ratings of integrity. Prior beliefs did not reach significance as covariation, but as a marginally significant interaction effect (ηP2 = .01).
Ratings of benevolence also were subject to a significant interaction of time and replication success (ηP2 = .03). Again, a significant covariation was observed of certainty-related epistemic beliefs (ηP2 = .06), in the same direction as before, but not topic-specific prior beliefs.
Regarding hypothesis H3, we can conclude that the success or failure of a replication attempt did not only influence ascriptions of expertise to the author of the replicated study (as expected), this was also true for ascriptions of integrity and benevolence. Hypothesis H4 was not supported by the results: Contrary to our expectations (but with a small effect size), ascriptions of integrity (but not benevolence) showed a larger increase after learning of a successful other-replication, and a larger decrease after learning of an unsuccessful other-replication (compared to the respective self-replication conditions). Regarding RQ1, we can conclude that participants’ epistemic beliefs regarding the certainty of medical knowledge had an influence on author trustworthiness ratings of participants on all three scales (expertise, integrity, and benevolence), while prior beliefs, and epistemic beliefs regarding the stability of medical knowledge did not.
Beliefs and certainty of beliefs
Exploratively, we also computed an ANOVA for detecting whether the prior belief (and its certainty) that cell phone radiation was harmful was changed after reading both articles. Ratings for this variable were slightly higher after learning of the two studies, but only when the replication attempt had described being successful (significant interaction of time and replication success, ηP2 = .02). Replication author did not achieve significance as an interaction or main effect. The certainty of this belief was also contingent upon replication success (significant interaction of time and replication success, ηP2 = .01). For means, see Figure 3.
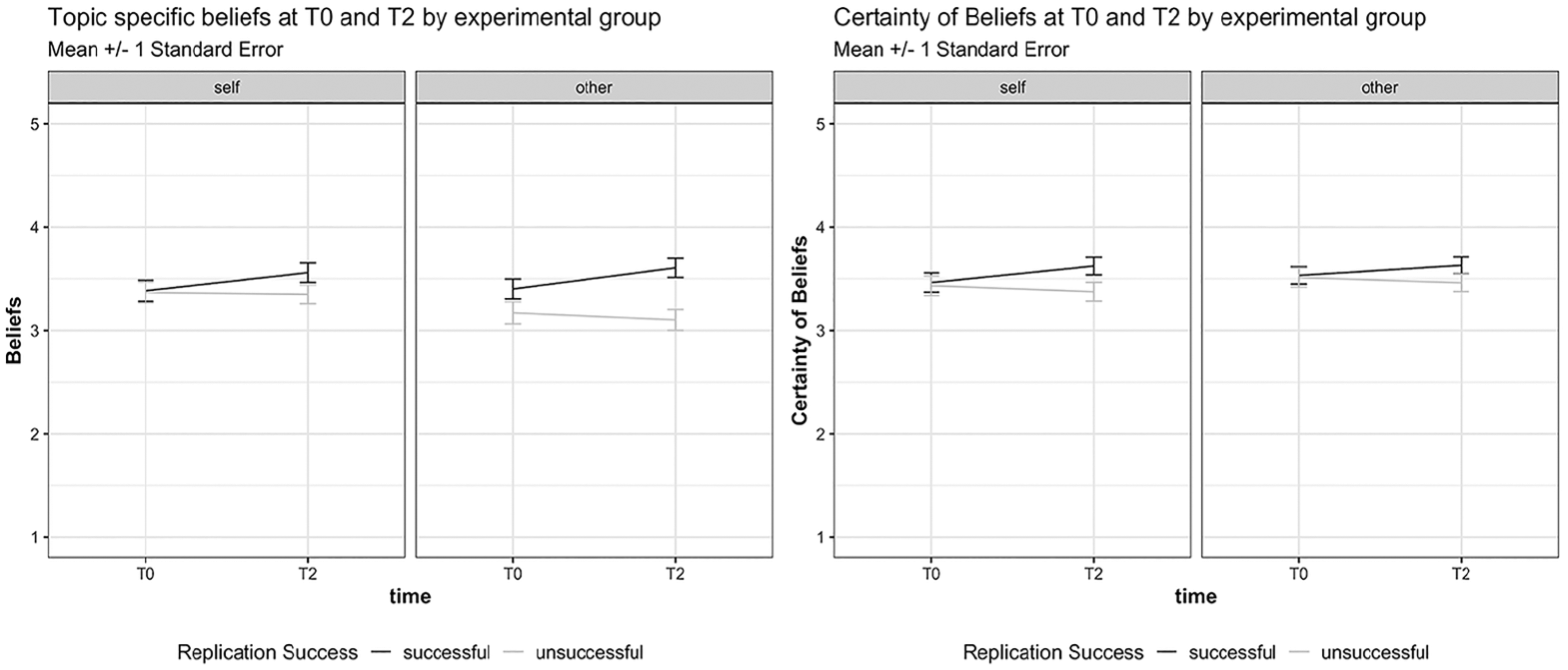
Line graphs showing the change of mean ratings of the two dependent variables pertaining to Beliefs and Certainty of Beliefs per experimental group from T1 ( after reading the first text, but before learning of the replication attempt in text 2) to T2 (after reading the two texts, that is, after learning of the replication).
9. General discussion
We investigated the degree to which (a) who replicated the study and (b) whether this replication was successful or unsuccessful, influenced laypeople’s ratings of the study’s credibility and evidence strength, and the trustworthiness of its responsible researcher. We expected that credibility ratings and ratings of the original author’s expertise would be higher when the replication had been successful and lower when this was not the case, and that this expected effect would be larger when another researcher had done the replication instead of the original author. Regarding integrity and benevolence ascriptions to the responsible author, we had predicted that a self-replication would positively affect those.
Results of our experimental study show that learning about the replication of a scientific study affected participants’ judgments of the study’s credibility and evidence strength. Ratings on the credibility of the original study’s results, the strength of evidence, and the credibility of the conclusion drawn from study increased, when the replication was successful, and they decreased in case of an unsuccessful replication (ANCOVA results in large ηP2, ANOVA results in small ηG2). Participants mostly did not give different ratings when replications were done by the same researchers or by other, unaffiliated labs. A marginally significant interaction of time, and replication author for credibility of the conclusion cannot be meaningfully interpreted due to its small effect size (ANCOVA ηP2 = .01; ANOVA ηG2 = .00). Participants’ prior beliefs about the topic affected ratings of credibility of results and evidence (ANCOVA results in medium sized to large ηP2), but not trustworthiness ratings. Interestingly, epistemic beliefs about the certainty of medical knowledge influence ratings both of credibility and evidence strength, as well as the responsible researcher’s trustworthiness (ANCOVA results in small to medium sized ηP2).
Our experiments can be understood as an empirical analysis of folk theories about replication, and our findings only partly concur with the scientific understanding of replications. In line with the scientific understanding of replications was the clear difference we found in the different ascriptions of credibility participants made for successful and failed replications. While we obviously expected participants to acknowledge a difference between failure and success, our participants did not differentiate their judgments about what exactly is put in question when the empirical results of an original study could not be replicated. From a scientific point of view, a single successful or failed replication would allow only for stronger evaluations about the validity of the empirical results, but not for the validity of the underlying claim. Furthermore, a single failed replication study does not provide answers to the question of why the original study could not be replicated. On the one hand, a failed replication could be attributed to weak execution of the original study (e.g. small sample size, inefficient tests), or even questionable research practices (e.g. altering hypotheses in the light of knowing the results). On the other hand, a failed replication could be the result different underlying “conceptual scope,” namely whether researchers put very narrow assumptions to the test in (direct) replication (such as, “can this specific effect be replicated using the exact same methods and materials”), or test broader assumptions about the scope and nature of an effect found previously (Feest, 2019). It is an interesting question whether evaluations about replications would be facilitated when participants learn about (a) a series of replicated or non-replicated studies (e.g. about a systematic review, a meta-analysis, or a large-scale replication attempt), instead of just one successful or failed replication study, and (b) about reasons why a failed replication might have occurred. For example, learning that only 39 out of a 100 studies have been replicated successfully, did result in participants assigning lower trust in the research domain (here, psychology), compared to an experimental condition in which they learned that 83 out of 100 studies had been successfully replicated (Wingen et al., 2019). Furthermore, loss in trust evoked by low replicability could be difficult to repair, as neither including information about open science practices nor mentioning that higher replicability could be achieved later on did result in higher trust ratings respectively (Wingen et al., 2019).
Regarding the trustworthiness of the researcher responsible for the original study, participants’ ratings were also higher, when a replication attempt of this study was successful, compared to when it was not (although very small effect sizes), no matter if it was a self-replication or other-replication. Again, this is not in alignment with the scientific understanding of replications because the probability of a negative outcome of an empirical study should not be attributed to its authors’ trustworthiness. To some extent, these results show that researchers worry that a failed replication of their own study would lead to negative reputational outcomes for them are justified (Fetterman and Sassenberg, 2015). However, this piece of folk theory about the relationship between a researcher running “successful” empirical studies and her trustworthiness mirrors questionable practices regarding research, publication, and selection within academia—which might account for the answers our non-expert participants gave.
Furthermore, the results of our study do not reflect participants making a difference between a replication by the same research team, and a replication done by another lab. While such independent replications hold far more significance from a scientific standpoint, participants did not seem to be aware of this. Moreover, following the result pattern of Ebersole et al. (2016) and our own findings (Hendriks et al., 2016), we expected the self-admission of failed replications to have a positive effect on integrity and benevolence judgments. However, our data could not support this hypothesis. For integrity as dependent variable there was a small, marginally significant interaction of time, replication success, and replication author, suggesting that integrity ratings were not affected as much by success or failure of a replication when the researcher replicated his own study, compared to when it was replicated by others. Our expectation was based on the stealing thunder effect that is disclosing information that could damage one’s reputation increases the ascription of integrity/benevolence, because it is unexpected in the sense that people regularly are less honest in order to avoid damages to their reputation (Eagly et al., 1978). In line with this, Ebersole et al. (2016) found that while more negative ratings for ability and ethicality were given (compared to just knowing about the single original study) when participants learned that the study’s results had not been replicated by another researcher, a self-replication led to higher ratings. Also, some information about the original researcher’s behavior led to more positive ratings of ability and ethics, for example when the researcher acknowledged that initial results might not have been correct, or when she launched a self-replication of her initial study, to determine why the two studies had different outcomes. An explanation for our different findings might be that, different from the study design in Ebersole et al. (2016), we used a between-subject design: Participants were not prompted to compare different ways of replicating a study (such as self- vs other- replication), but only one author and outcome of the replication. Hence, they might have assumed that replicating one’s own or another’s studies and publishing these results (failed or not) is a matter of course within science. Moreover, respondents might have been unaware of the different epistemic weight of self- and other-replications. Similar to results for identifying experimenter bias (Strickland and Mercier, 2014), our participants might have assumed that all replications are good scientific practice (checking up on results and detecting errors), while not grasping the inner-scientific norm that this should be done by unaffiliated labs. Underpinning this interpretation, in the German Science Barometer (Wissenschaft im Dialog/Kantar Emnid, 2018) 78% of respondents agreed that failed replications illustrate that making and correcting errors are a fundamental part of science.
Just as in many other studies (see references earlier), we found prior beliefs about the harmfulness of cell phone radiation, the topic in question, to have an effect on credibility of the study’s results and evidence strength judgments (medium sized effects), and on the credibility of the conclusion (large effect), but not ascriptions of trustworthiness to the researcher responsible for the original study. However, prior belief did not reach significance as an interaction effect with time. This means that the original acceptance of a study’s results might be contingent on general beliefs about the topic, but participants nonetheless adapted their ratings in the light of a successful or failed replication effect to some extent. Moreover, participants topic beliefs were affected by reading about the success or failure of the replication (reflected by higher/lower agreement with this item at T2), as was their certainty of this belief. This is interesting, as beliefs addressed the harmfulness of cell phone radiation for humans; therefore, this finding also reflects that false assumptions about the extent to which animal models can be used derive valid conclusions for effects on humans. These results illustrate the need to further research about the effect of the persuasiveness of single replication studies versus more large-scale replication attempts, and also on the understanding of animal models in medical research.
Furthermore, epistemic beliefs about the certainty of medical knowledge (e.g. “research in medicine has shown that there is one clear answer to most problems”) did influence ratings of credibility and evidence strength, as well as trustworthiness ratings (small to medium sized effects); lower ratings on all DVs were associated with higher ratings of the uncertainty of knowledge in the medical domain. Recognizing the uncertainty in scientific knowledge is understood as a more advanced epistemic belief. Hence, it seems as if more advanced scientific beliefs in a domain (with regard to the uncertainty of scientific knowledge and knowledge claims) lead to more critical assessments of the credibility and evidence strength of single studies in this domain, as well as of the responsible researchers’ trustworthiness. It could be a possibility that such advanced epistemic beliefs can be attributed to higher knowledge of the scientific process. Further research should investigate this and the role of epistemic belief in the understanding and evaluation of scientific research in general.
10. Conclusion and suggestions for further research
Of course, further research is needed to test our results and the interpretations derived. We assumed that failed replications would be seen as much more problematic if the scientific issue at stake is publicly contested. The topic of our study was the relationship between cell phone radiation and tumor development in mice. Effects of cell phone radiation are currently not a hot topic in public debates in Germany, and our participants also did not hold strong beliefs about it. If a successful or failed replication would have been discussed within a public controversy on a contested socio-scientific issue, this might have more strongly affected participants’ thoughts about the scientific claim as well as the reputation of the researchers involved.
We found in our study that laypeople judge the credibility and evidence strength of research results and the trustworthiness of researchers differently after learning about a successful or failed research study. This could be because participants recognized and evaluated the replication as a scientific practice used to ascertain the certainty of results. Alternatively, it might suggest that participants were just using simple heuristics (Kruglanski et al., 2005), such as “the more the better.” Therefore, future studies might investigate the depth of processing and also, how knowledge about the scientific process and the fundamental epistemic principles and values of science (Kind and Osborne, 2017) might contribute to laypeople’s understanding of a replication study.
Still, results from scientific studies are usually communicated by (science) journalists. Our results show how members of the general public perceive the credibility of replicated results, and they illustrate that addressing replication studies in journalistic articles is highly needed. First, even though splashy results from single studies might be more newsworthy and more appealing to authors and readers of science news outlets, we found that replicated results are considered to be more reliable than results from single studies. As such, this finding may represent an important motivator for science journalists to publish more results that have been replicated well. Second, replication studies are an example of a process that the scientific community has established to handle the uncertainty that comes with scientific methods as well as to deal with potential researcher fraud. Because such specifics of replication studies might not be generally known, reporting on large-scale replication efforts is important, as is reporting on single studies that have been repeatedly replicated well.
Supplemental Material
HenKienBrom_Replication_Supplementary_Materials_final – Supplemental material for Replication crisis = trust crisis? The effect of successful vs failed replications on laypeople’s trust in researchers and research
Supplemental material, HenKienBrom_Replication_Supplementary_Materials_final for Replication crisis = trust crisis? The effect of successful vs failed replications on laypeople’s trust in researchers and research by Friederike Hendriks, Dorothe Kienhues and Rainer Bromme in Public Understanding of Science
Footnotes
Acknowledgements
The authors would like to thank the editor and two anonymous reviewers for their remarks that were great help for improving the article. They also are thankful to Leonie Stratmann for pretesting some initial ideas regarding this research question, and Sandra Schaber and Gundolf Schneider for their help in data acquisition. They would like to thank everybody who took part in the experiments.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.