
Abstract
This article presents an overview of recent psychometric developments in the area of multimethod measurement, in which we argue that different types of research designs require different types of models. In particular, two types of measurement models for method effects can be distinguished. First, models with a general factor, in which method effects are defined as deviations from a common trait, and second, models for contrasting methods, in which method effects are defined relative to another method but not to a general trait. We argue that the first type of models require a two-level research design (interchangeable methods) whereas the second type of models can be applied to a one-level research design (structurally different methods). Current directions in the uses of these approaches for longitudinal research and multiple-rater studies are described.
Keywords
It is one of the most widely accepted rules in psychology that researchers should use multiple methods in their empirical studies. According to Campbell and Fiske (1959), each measurement in psychology represents a trait-method unit (TMU). Interindividual differences in psychological test scores thus reflect at least two sources of influences: differences in persons’ trait (e.g., ability or personality) scores and differences due to the fact that individuals interact with a measurement device, causing individual differences in individual-specific method effects. If we measure, for example, anger through blood pressure, individual differences in blood pressure will represent not only individual differences in anger but also differences due to the fact that individuals with the same level of anger differ in the responsivity of their physiological system.
For many decades, method effects have been considered systematic “errors of measurement” that should be eliminated in order to obtain the “true” phenomena we are interested in. In this trait-oriented view, all methods measure the same trait with specific distortion and one has to get rid of method-specific influences. Method effects, however, are not errors produced by the measurement process. They are an integral part of psychological measurements that should be studied in detail (Cronbach, 1995). In order to be understood, method effects have to be measured empirically.
Measuring Trait and Method Effects: Traditional Multitrait-Multimethod Approaches
The analysis of trait and method effects was strongly influenced by Campbell and Fiske’s (1959) work on the multitrait-multimethod (MTMM) matrix. With the development of confirmatory factor analysis (CFA) in the late 1960s and early 1970s (e.g., Jöreskog, 1971), latent-variable modeling tools became available to MTMM researchers, allowing them to analyze MTMM data in more sophisticated and flexible ways. Early CFA-MTMM models developed in the 1970s focused on Campbell and Fiske’s (1959) original measurement design with just a single measured variable per TMU (e.g., Jöreskog, 1971; Kenny, 1976). A “classical” CFA-MTMM model, for example, is the correlated traits–correlated methods (CT-CM) model that was originally proposed by Jöreskog (1971; for an overview of other traditional models, see Dumenci, 2000; Marsh, 1989; Widaman, 1985; Wothke, 1995). The CT-CM model postulates a seemingly intuitive latent-variable structure for MTMM data: In a design with T traits and M methods, the model has T correlated trait factors and M correlated method factors (i.e., each measured variable in the MTMM matrix loads onto a trait factor that is shared by all variables that are supposed to measure the same trait and a common method factor that is shared by all variables that are assessed with the same method). Although the model allows correlations between all trait factors as well as between all method factors, correlations between trait and method factors are assumed to be zero.
The CT-CM model has intuitive appeal: Trait-factor loadings are supposed to be indicative of convergent validity, whereas method-factor loadings are supposed to indicate the degree of method specificity. Trait factors can be correlated, allowing researchers to assess the discriminant validity of different constructs. Method-factor correlations are supposed to indicate the degree of similarity (overlap) between different methods (e.g., parental reports vs. child self-reports).
Despite its intuitive appeal, empirical applications and simulations of the CT-CM model have shown that it is prone to nonconvergence, improper parameter estimates (e.g., negative-factor or error variances), and interpretation problems. Several simulation studies with correctly specified models have indicated that researchers have to expect nonconvergence for the CT-CM model in a large number of cases (Castro-Schilo, Widaman, & Grimm, 2013; Marsh, 1989). Even when convergence is achieved, the resulting estimates may be partly improper (e.g., negative variances) or difficult to interpret (Eid, 2000; Marsh, 1989). In addition, the CT-CM model in its original form uses only a single measured variable per TMU and therefore implies that method effects for the same method are unidimensional across different traits. Empirical applications of other CFA-MTMM models have shown that this assumption of unidimensionality is usually unrealistic—that method effects are trait-specific and that models with multidimensional trait-specific method effects are superior to models with unidimensional method effects (e.g., Eid, Lischetzke, Nussbeck, & Trierweiler, 2003). Despite these limitations, the CT-CM model continues to enjoy popularity among MTMM researchers.
Recent developments in psychometric theory have shown how many of the problems of this traditional model can be circumvented. In particular, they have shown that it is important to consider the research design of an MTMM study because different research designs require different models. These models are constructions that serve specific purposes that are linked to a specific research design. Modern CFA-MTMM approaches differ from traditional models in the following key ways:
They rely on psychometric theory rather than intuition in defining latent trait and method factors.
They consider multiple (rather than single) measured variables (indicators) per TMU because multiple indicators are needed to model method effects that are not unidimensional across traits but trait-specific.
They distinguish between interchangeable and structurally different methods.
They define trait and method latent variables explicitly, based on a well-defined random experiment (i.e., they are design-oriented).
Because of space limitations, we will not discuss these key issues in detail (for an in-depth treatment of these issues, see, for example, Koch, Eid, & Lochner, in press). Instead, we give an overview of the basic ideas of modern MTMM models and recent developments based on the basic principles described above. For simplicity, we explain these basic ideas based on single-trait models and consider only the distinction between interchangeable and structurally different methods (Kenny, 1995).
The Distinction Between Interchangeable and Structurally Different Methods
Interchangeable methods are methods that can be selected from a set of methods sharing the same characteristics. The use of multiple randomly selected raters may be considered an example of interchangeable methods, with each rater representing a different “method” (Kenny, 1995). If, for example, different students attending the same lecture by a professor are asked to evaluate the lecture, they can be considered interchangeable. Although students may have different views on the quality of the lecture, they have the same access to the lecture and to the behavior of the professor. They can be considered a random sample from the population of student raters (Eid et al., 2008). In the case of interchangeable methods, there is a two-level sampling process. First, the target individuals whose traits are of interest are sampled (teachers, in our example). Second, for each teacher, the interchangeable methods (raters) are sampled.
The situation is quite different when parents, teachers, and peers are asked to assess the personality of adolescents. Parents, teachers, and peers can be considered structurally different methods because they do not belong to the same set of raters and differ in many regards. Another example of a measurement design with structurally different methods would be if spider phobia were measured by self-reports, observer reports, and electrodermal activity. In the case of structurally different methods, there is only a single-level sampling process. The target individuals are sampled, but not the methods. The methods are fixed by the researcher. With the exception of multi-rater studies, interchangeable methods are rather uncommon in psychology; structurally different methods are the more common case. Eid et al. (2008) showed that both types of methods (stemming from different research designs) require different types of psychometric models to analyze method-specific effects properly.
Measuring Method Effects: Design-Oriented Approaches
Two general types of design-oriented multimethod models can be considered (Eid et al., 2008; Koch et al., in press; Nussbeck, Eid, Geiser, Courvoisier, & Lischetzke, 2009): first, models in which method effects are defined as deviations of the measurement scores from a common cause, the latent trait (g-factor models), and second, models in which methods are contrasted (without assuming that there is a common trait).
g-factor models
In Figure 1a, a g-factor model is presented. To separate unsystematic measurement error from systematic method-specific influences that are trait-specific, at least two indicators of each method have to be applied—such as, for example, two halves of an anger questionnaire. In this model, there is a common factor (latent trait variable) that has an influence on all observed variables. Additionally, a method-specific factor is assumed for each method. It is assumed that the method-specific factors are mutually uncorrelated as well as uncorrelated with the g factor.
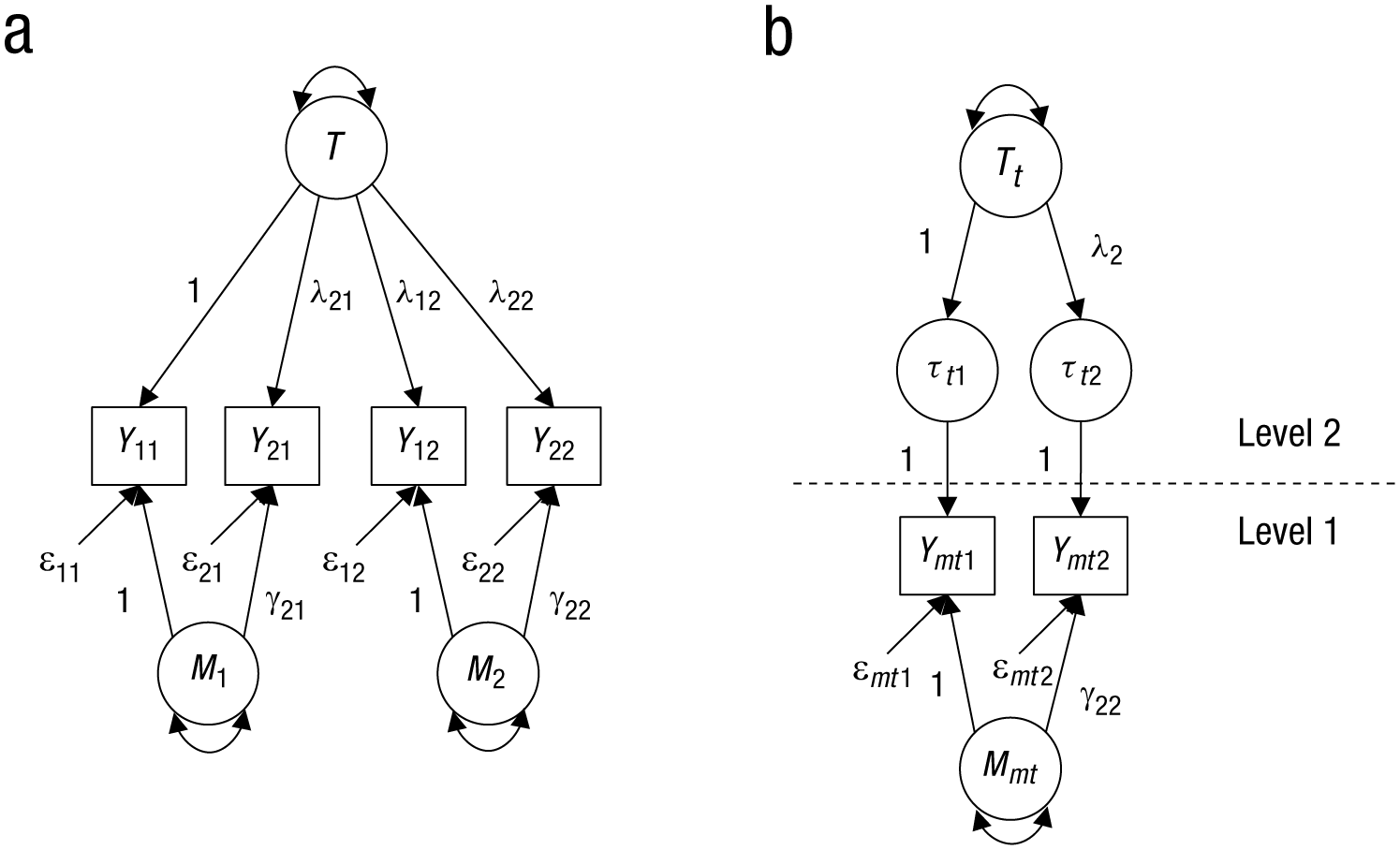
g-factor models for measuring one trait with interchangeable methods. Panel (a) depicts a classical confirmatory-factor-analysis (CFA) model, and panel (b) depicts a multilevel CFA model. Yim and Ymti represent observed variables; T and Tt represent common latent-trait variables; Mm and Mmt represent method factors; ε im and ε mti represent measurement-error variables; and λ and γ parameters represent loading parameters. For indices, t indicates randomly selected targets (Level 2 units); m indicates interchangeable methods (Level 1 units); and i indicates indicators. In cases where there are two indicators for a factor, both loadings have to be fixed to 1 to yield identified models if the factor is not related to another factor.
Recent work in measurement theory has shown that such a model is reasonable only if the methods can be considered interchangeable (Eid, Geiser, Koch, & Heene, in press; Eid & Koch, 2014; Koch et al., in press)—for example, when there are two different interchangeable peer ratings (Method 1 and Method 2) of anger. In this case, the different ratings stem from the same distribution of peer ratings, and a trait value of a target can be defined as the expected value of this distribution of all possible peer ratings. In the case of structurally different methods, however, a trait value cannot be defined in this way because the ratings stem from different distributions. In the case of interchangeable methods, the model in Figure 1a is equivalent to a multilevel CFA model with targets on Level 2 and raters on Level 1 (see Fig. 1b; Carretero-Dios, Eid, & Ruch, 2011; Eid et al., 2008) if one puts some restrictions on the parameters in Model 1a (for further details, see Nussbeck et al., 2009). In cases in which methods cannot be considered interchangeable but differ structurally from one another, this model poses many theoretical and practical problems (Eid et al., in press; Eid & Koch, 2014; Geiser, Bishop, & Lockhart, 2015). For example, inadmissible solutions (e.g., negative variances of method factors) are quite often found. Moreover, the meaning of the g factor is less clear when the methods do no stem from the same population of methods.
Models for contrasting methods
The starting point of a multimethod model without a general trait factor is a model with correlated first-order factors (Fig. 2a). All factors are purportedly measures of the same construct, but the indicators of each factor belong to different methods. For example, the first factor represents the construct measured by the first method, and the second factor represents the construct measured by the second method. Consequently, trait and method effects are not separated in this model. However, it is possible to reformulate the model in such a way that method effects can be defined. This is achieved by choosing one method as a reference and contrasting all remaining methods against this reference method.
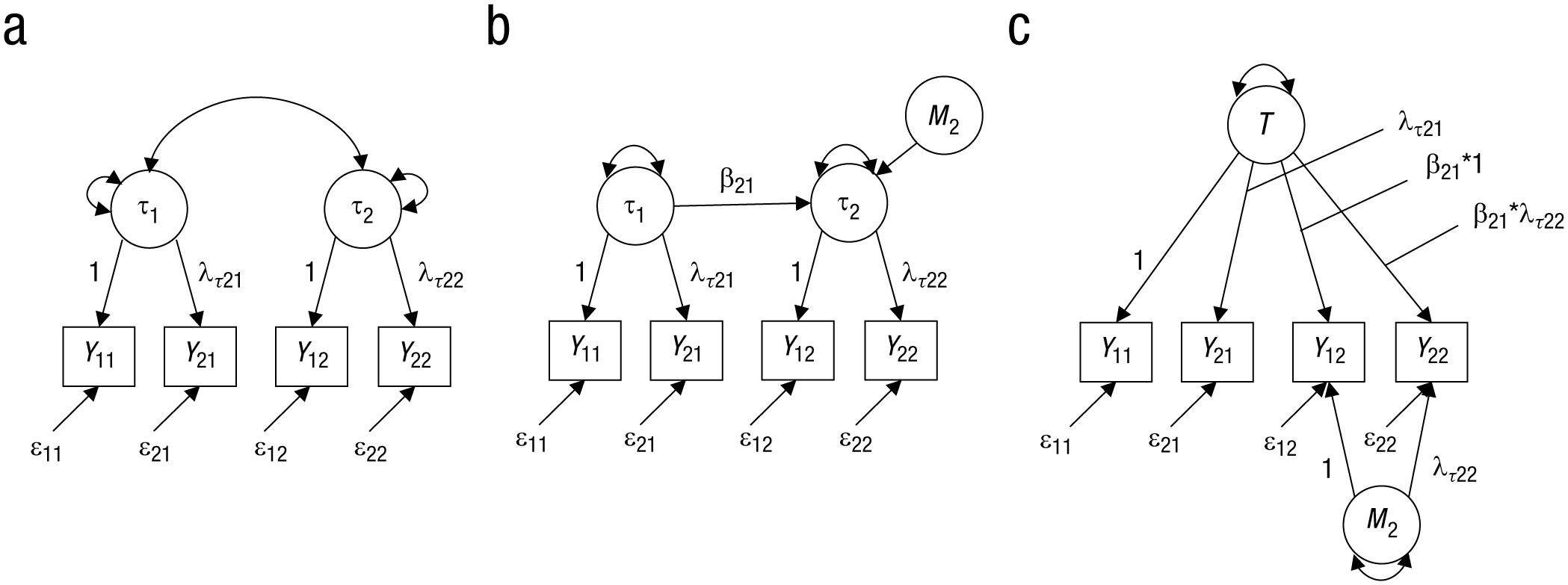
Multimethod models for measuring one trait with two structurally different methods. The first method is taken as reference method, which means that T = τ1. Panel (a) shows a correlated-factors model, panel (b) shows a latent regression model, and panel (c) shows a trait-method-minus-one, or T(M – 1), model. Yim represents observed variables; τ m represents first-order factors; M2 represents the method factor; T represents the trait factor; εim represents measurement-error variables; λ parameters represent loading parameters; and the β parameter represents the regression slope. For indices, τ indicates first-order factor loadings; i indicates indicators; and m indicates methods. In the case of two indicators of a method factor in the T(M – 1) model, both loadings have to be fixed to 1 to yield an identified model.
One example of such a reformulation is the trait-method-minus-one, or T(M – 1), model, in which the factor of the reference method is an independent variable in a latent regression model predicting the other factors (see Fig. 2b). The residuals of the factors of the nonreference methods are the method-specific variables representing that part of a trait measured by a specific method that cannot be predicted by the reference method. As Geiser, Eid, and Nussbeck (2008) have shown, this model is equivalent to the model presented in Figure 2c, if one puts specific restrictions on the loading parameters. The advantage of the model in Figure 2c is that method effects are represented by latent factors. Furthermore, its structure can be compared more easily to the structure of other multimethod models, such as the model presented in Figure 1a.
There are some important properties of this model. First, because the model in Figure 2c represents only a reformulation of the basic measurement model in Figure 2a, it shows the same fit to a given data set. Second, there is one fewer method factor than there are methods considered. This is a property of the model that cannot be wrong, because one method is taken as a reference method (Eid et al., 2003). Therefore, the meaning of a method factor in the T(M – 1) model is different from the meaning of a method factor in the g-factor model shown in Figure 1a. In the g-factor model, a method factor represents deviations from a general trait variable, whereas in the T(M – 1) model, method factors capture deviations of a specific method from a value expected based on this method’s regression on the reference method. Both types of method factors have a clear meaning. However, method factors in g-factor models require a two-level sampling process in order to be meaningful and easily interpretable. Referring to the example of anger measured by self-report and blood pressure and using the self-report as reference method, the scores of the method factor in Figure 2c indicate whether the blood pressure of an individual is higher than, equal to, or lower than would be expected on the basis of the self-report. The method factor indicates whether a person shows stronger, similar, or weaker physiological reactions compared to all other individuals reporting the same level of anger.
This type of model can also be applied in studies in which data from one method is obtained from only a subsample because it is too expensive (e.g., brain-imaging data), but data from another, less expensive method (e.g., questionnaires, tests) is available from the total sample (a two-method planned-missing-data design; Graham, 2012). Applying this model in the context of planned-missing-data designs even makes it possible to improve the estimation of the factor scores of the method that is available only for the subsample.
Besides the T(M – 1) approach, there are alternative ways to define method effects as contrasts, such as by taking the latent difference scores between two TMUs (Geiser, Eid, West, Lischetzke, & Nussbeck, 2012; Pohl, Steyer, & Kraus, 2008) or taking the difference between a latent TMU score and the mean across all TMU scores (Pohl & Steyer, 2010).
Current Directions
The basic idea of defining method factors in a design-oriented way has been extended to more complex MTMM structures. For example, multimethod longitudinal models have been developed for structurally different methods (e.g., Courvoisier, Nussbeck, Eid, Geiser, & Cole, 2008; Geiser, Eid, Nussbeck, Courvoisier, & Cole, 2010a, 2010b), for a combination of structurally different and interchangeable methods (Koch, Schultze, Eid, & Geiser, 2014), and for evaluation research (Crayen, Geiser, Scheithauer, & Eid, 2011). Moreover, models for different types of raters have been defined—for example, for designs in which structurally different raters are nested within contexts (e.g., school classes; Koch, Schultze, Burrus, Roberts, & Eid, 2015), in which interchangeable methods are not totally independent (Koch et al., 2016), and in which there are different sets of interchangeable raters, such as in 360-degree-feedback studies in organizational psychology (Mahlke et al., 2016).
Conclusions
A design-oriented approach to multimethod studies can help researchers avoid methodological problems such as estimation and interpretation problems due to inappropriate models. It guides researchers to choose multimethod models that fit their theoretical ideas and research design. It implies that there is not just one single appropriate and globally fitting model for multimethod research but many different models that are appropriate for different purposes.
Footnotes
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.