
Abstract
This article employs data from 155 companies from 27 different industries listed on the Tehran Stock Exchange (TSE) for the period from 2000 to 2009 to examine the direction of causality between cash flow and earnings after taking consideration of stationarity and co-integration. The results indicate that there is a bidirectional causal relationship between cash flow and earnings at the level of all individual companies, so that cash flow variables caused earning variables and vice versa. However, at the level of industrial sectors, causality exists only between earning before interest and taxation (EBIT) and cash flow from operating activities (CFOA).
Introduction
Both earnings and cash flow are important to companies and shareholders. According to the Trueblood Committee, the objective of income statements and statements of financial activities (cash flow) is to provide useful information for predicting, comparing and evaluating enterprises’ earning power (Wolk, Dodd, & Tearney, 2004). Earnings are the net benefits of a corporation’s operation (Blanc & Setzer, 2015; Eccles, Herz, Keegan, & Philips, 2001). According to the different purposes of accounting activities, several more specific earnings are used, such as earnings before interest and taxation (EBIT) and earnings before interest, taxes, depreciation and amortisation (EBITDA). Cash flow can be defined as the movement of money into or out of the companies, businesses or projects. 1
Different interested parties, such as shareholders, investors or analysts, focus on different aspects of earnings and cash flow. If there is a one-way relationship between cash flow and earnings, it is worthwhile to find out which one is a driver of the other. However, few studies have used econometric models to look into the causality between earnings and cash flow, taking into consideration stationarity and co-integration.
The objective of this study is to explore the causal relationship between cash flows and earnings using the Iranian data, which has not been studied in this context earlier (refer to also Chowdhury, Uddin, & Anderson, 2018, and Tang & Yao, 2018, for discussions on the emerging markets). To ensure that the results are reliable, we test the stationarity and co-integration in the first step. To contribute to the literature, this article uses panel data to control for individual heterogeneity (Baltagi, 2005). This is the first study on such a topic in the Iranian market, which is the largest market in the Middle East in terms of the number of stakeholders, variation of industry and profitability.
The next section provides a review of previous research on cash flow and earnings. The third section describes the models and methodology. The fourth section explains the variables and data collection. The fifth section focuses on the empirical analysis, and the results, discussion and conclusion are presented in the sixth section.
Literature Review
So far, previous studies on determining the relationship between cash flow and earnings have not been conclusive. On the one hand, some studies have concluded that ‘earnings’ occupy a central position in accounting in predicting future cash flow for firms. FASB (1978) suggested that earnings provide a better indication than cash flow. However, FASB’s statement did not have empirical support. Greenberg, Johnson and Ramesh (1986) stated that earnings have a greater power of prediction than cash flow. Lorek and Willinger (1996) applied a multivariate, time-series prediction model, and their conclusions were consistent with the viewpoint of FASB that earnings and accrual accounting data can enhance cash flow prediction. Dechow, Kothari and Watts (1998) investigated the ability of current cash flow and earnings to estimate future operating cash flow. They concluded that earnings are a superior predictor than current cash flow and also pointed out that the difference varies with the operating cash cycle. Barth, Cram and Nelson (2001) disaggregated earnings into cash flow and six major accrual parts and found that disaggregated earnings do a better job in predicting future cash flow than current cash flow. Kim and Kross (2005) found that the significance of the relationship between current earnings and future operating cash flow has increased over time. Their conclusion was applicable to different-sized companies with or without paying out dividends.
On the other hand, some researchers have a different view. Bowen, Burgstahler and Daley (1986) used US data and found that net income plus depreciation and amortisation and working capital from operations is the best predictor of cash flow from operation among other four variables. The evidence in the UK (Arnold, Clubb, Mason, & Wearing, 1991) did not support that earnings is a superior predictor than cash flow. Using a large sample, Burgstahler, Jiambalvo and Pyo (1998) concluded that cash flow is a better predictor than aggregated earnings. Krishnan and Largay (2000) found that the direct method of calculating cash flow has a great predictive ability. They concluded that cash flow is superior to earnings in forecasting future cash flow. Seng (2006) examined the predictive ability of earnings and different types of cash flow. The results showed that reported cash flow measures (i.e., CFFO, CFFIA and CFFFA) are better predictors than earnings.
Furthermore, some studies have shown mixed results on the predictive ability of cash flow and earnings. Finger (1994) concluded that earnings or earnings with cash flow are greater predictors of cash flow for most companies. However, cash flow is a better predictor than earnings in the short term. Basu, Lee-Seok and Ching-Lih (1998) found that earnings calculated based on different accounting routines, when used for estimation, have different levels of significance in the prediction of cash flow. Nikkinen and Sahlstrom (2004) stated that the mixed results may be the result of neither cash flow nor aggregated earnings being a good predictor.
Although the econometrics model for causality is frequently used in economic studies (e.g., Aktaş & Yilmaz, 2008; Aqeel & Sabihuddin Butt, 2001; Athanasenas, 2010; Aydemir & Demirhan, 2009; Bowden & Payne, 2009; Calderón & Liu, 2002; Chimobi, 2009; Chiou-Wei, Chen, & Zhu, 2008; Chontanawat, Hunt, & Pierse, 2008; Chowdhury et al., 2018; Gross, 2012; Hurlin & Venet, 2008; Levine, Loaysa, & Beck, 2000; Magnus & Oteng-Abayie, 2008; Payne, 2010), only a few studies in accounting have examined the causality between cash flow and earnings. The empirical work by Bezuidenhout, Mlambo and Hamman (BMH) (2008, 2009) is an exception. Their study has investigated causal relationship between cash flow and earnings of stocks listed on the Johannesburg Stock Exchange using 70 companies from 16 different sectors from 1981 to 2000. They included four types of earnings (EBIT, earning before taxation (EBT), profit after taxation (PAT) and net earnings (EARN)) and compared them to three types of cash flow (cash generated from operations after adjustment for non-cash items (denoted by SUB1), cash generated from operations adjusted for investment income received and working capital (denoted by SUB2) and cash flow from operating activities after adjustments for interest and taxation paid (denoted by SUB3). In their studies, the variables were first tested for stationarity and/or co-integration. Regarding the causal relationship between earnings and cash flow, the authors found that in most cases, cash flow is found to cause earnings when the models are estimated in levels. However, when estimated in first differences, the causal relationship tended to be reversed as earnings cause cash flows. The authors claimed that the results in their study are likely to be affected by data limitations, since the tests used in their study are sensitive to sample sizes. They recommended a follow-up study, whereby panel data should be used.
Models and Methodology
Panel Data Regressions
In order to forecast by regression analysis, panel data need to be tested for stationarity and co-integration. Panel data is a pooling of time-series (t) and cross-section (i) data. According to Baltagi (2005), a panel data regression differs from a regular time-series or cross-section regression because it has a double subscript on its variables, that is,
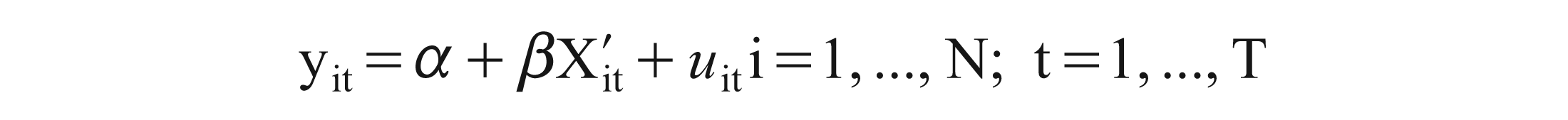
With i denoting firms and t denoting time, the i subscript therefore denotes the cross-section dimension, whereas t denotes the time-series dimension. α is a scalar, β is K × 1 and Xit is the itth observation on K explanatory variables. Most of the panel data applications utilise a one-way error component model for the disturbances, with
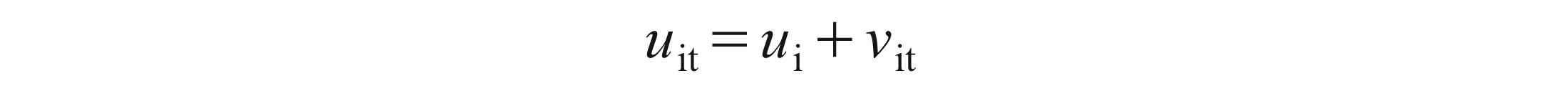
Where μi denotes the unobservable individual-specific effect and νit denotes the remainder disturbance.
In order to determine causality using an econometric model, the data must be investigated for stationarity and then co-integration.
Stationarity
Most of the econometric models used for forecasting require the underlying time series to be stationary (Gujarati, 2003; Harris & Sollis, 2003), as non-stationary data can lead to spurious results.
The regression Equation 1 can be used to illustrate the concept of ‘stationary’. Based on this definition, panel data are called stationary if μ, σ, cov and ρ remain the same and are constant over time. These conditions guarantee that the behaviour of panel data will identical. In other words, yit will be stationary if the coefficient of correlation (ρ) is smaller than 1, (0<;ρ<1), and if ρ = 1 means that the equation has a unit root, and in this case, the stationarity provision is abrogated and it is non-stationary.
The unit root test is considered as a more powerful method to test for stationarity (Bezuidenhout et al., 2008; Dickey & Fuller, 1979) and of great assistance in selecting a correct forecasting model (Diebold & Kilian, 1999). According to Baltagi (2005) and Im, Pesaran and Shin (2003), the Im, Pesaran and Shin (IPS) unit root test allows for a heterogeneous coefficient of yit−1 and proposes an alternative testing procedure based on averaging individual unit root test statistics. IPS suggests an average of the ADF tests when uit is serially correlated with different serial correlation properties across cross-sectional units. Im et al. (2003), in particular, proposed a test based on the average of (augmented) Dickey–Fuller (Dickey & Fuller, 1979) statistics computed for each group in the panel, which they referred to as the t-bar test.
The panel unit root tests by Im et al. (2003) for the panel version of the augmented Dicky–Fuller (ADF) test are based on the following regression:
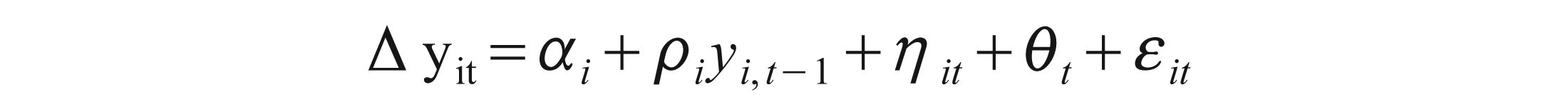
Where αi are individual constants, ηit are individual time trends and θt are the common time effects. The tests rely on the assumption that E[εitεjs] = 0 6 t, s and i → j which is required for calculating common time effects. Thus, if the different series are correlated, the last assumption is violated.
The null hypothesis is that each series in the panel contains a unit root, that is,
and the alternative hypothesis is that some (but not all) of the individual series have unit roots, that is,
Formally, it requires the fraction of the individual time series that are stationary to be nonzero, that is, lim N → 3 (N1/N) = δ, where 0 < δ ≤ 1. This condition is necessary for the consistency of the panel unit root test. The IPS t-bar statistic is defined as the average of the individual ADF statistics (refer also Baltagi, 2005, p. 242):

where tρi is the individual t-statistic for testing H0: ρi = 0 for all i. In cases where the lag order is always zero (pi = 0 for all i), IPS provide simulated critical values for
According to Bezuidenhout et al. (2008), differencing is often used to make the data stationary. Baltagi (2005) recommended that regression models involving non-stationary time series should be estimated in difference form.
Co-integration
Although many time series are non-stationary (having so-called random walk or stochastic trends), it is possible that in the long term, linear combinations of these variables have been stationary during the time (without random walk or stochastic trends). When variables are co-integrated, the regression results may not be spurious and the t- and F-tests are valid (Gujarati, 2003).
The methods for testing for co-integration in panel data have developed very rapidly (refer Pedroni, 1999, 2000, 2001, 2004). One of the most commonly used co-integration testing methods is the residual based panel co-integration test by Pedroni (2004) and Malinen (2011).
To ensure broad applicability of any panel co-integration test, it will be important to allow as much heterogeneity as possible among the individual members of the panel (Pedroni, 2004).
Pedroni (2000, 2004) proposed several tests for the null hypothesis of co-integration in a panel data model, which allows for considerable heterogeneity. Pedroni (2004) suggested two different test statistics for the models with heterogeneous co-integration vectors (Breitung & Pesaran, 2005). Let
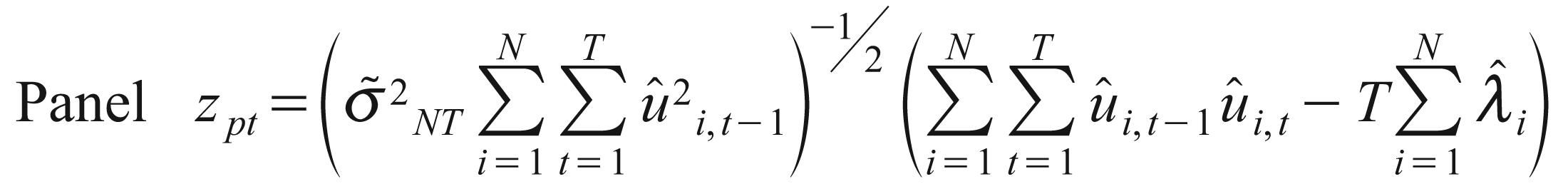

where
H0: The variables are not co-integrated.
H1: The variables are co-integrated.
If H0 can be rejected in favour of H1, then it can be concluded that the variables are co-integrated. Otherwise they are not.
Granger Causality
The Granger causality test is used in this study to determine whether causality exists between earnings and cash flows. Within a bivariate context, the Granger-type test states that if a variable x Granger causes variable y, the mean square error (MSE) of a forecast of y based on the past values of both variables is lower than that of a forecast that uses only past values of y (Magnus & Oteng-Abayie, 2008).
Based on definition: one variable is ‘Granger-causes’ (or ‘G-causes’) if a forecast of the second variable based only on its past values is made significantly more accurate by using past values of the first variable. More generally, since the future cannot predict the past, if variable x causes variable y, then changes in x should precede changes in y (Bezuidenhout et al., 2008). In other words, a relationship is causal if an intervention on A can be used to alter B. It can be expressed in this slogan: ‘no cause in, no cause out’ (Hoover, 2006).
According to the econometric model, tests for Granger causality require the variables to be stationary and co-integrated. At each time point, we observe two variables, xit and yit, which may have a reciprocal causal relationship.
The initial goal is to formulate a linear model that embodies a reciprocal relationship between x and y. Consider the following set of equations (Bezuidenhout et al., 2008):

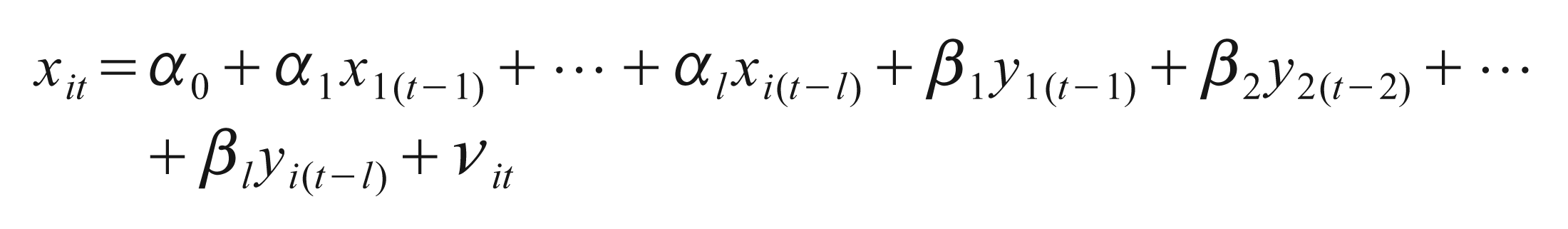
The reported F-statistics are the Wald statistics for the following null and alternative hypotheses:
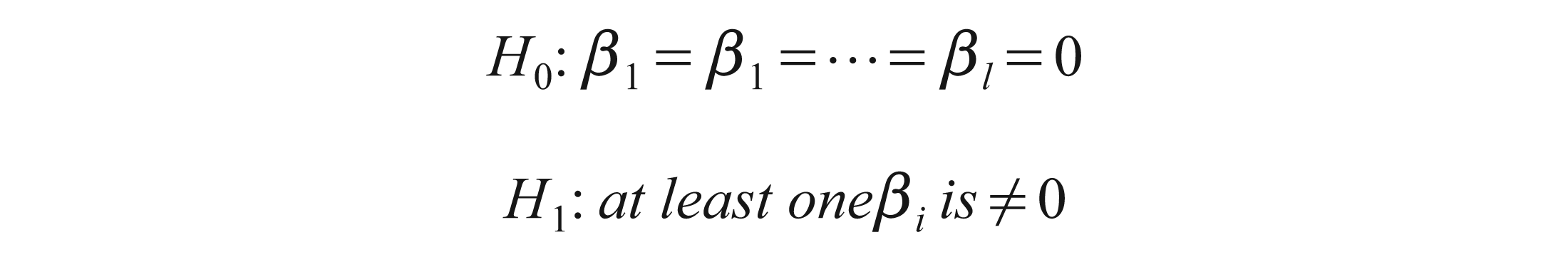
The null hypothesis is that x does not Granger cause y in the first regression and that y does not Granger cause x in the second regression against the alternative that one variable Granger causes the other.
The Tehran Stock Exchange (TSE) opened in February 1967, with only six companies listed during its first year of trading. Then Government bonds and certain state-backed certificates were traded in the market. The TSE has come a long way since then: today it has evolved into an exciting and growing marketplace where individual and institutional investors trade securities of over 420 companies. 2 The TSE is now the largest market in the Middle East in terms of the number of stakeholders, variation of industry and profitability.
From the year 2000, the Accounting Standards of Iran (ASI) were officially published and became compulsory for listed companies in Stock Exchanges in Iran. In addition, it is necessary to comply with International Financial Reporting Standards (IFRS), simultaneously. The initial sample includes all listed and delisted common corporations in the TSE.
The period of study is the years 2000 to 2009 (a nine-year period, as the statement of cash flow based on ASI is provided on the basis of five parts from year 2000 (refer Panel B in Table 1). The final sample is decided by applying the following two conditions: (a) corporations whose financial statements have been presented to the TSE for the period of the test and (b) because in pooled financial statements, negative items are neutralised by positive items, data have been selected for non-pooled statements. To meet these two conditions, 155 firms from 27 industries qualified for testing in the final sample.
Adjusted Income Statement and Statement of Cash Flow
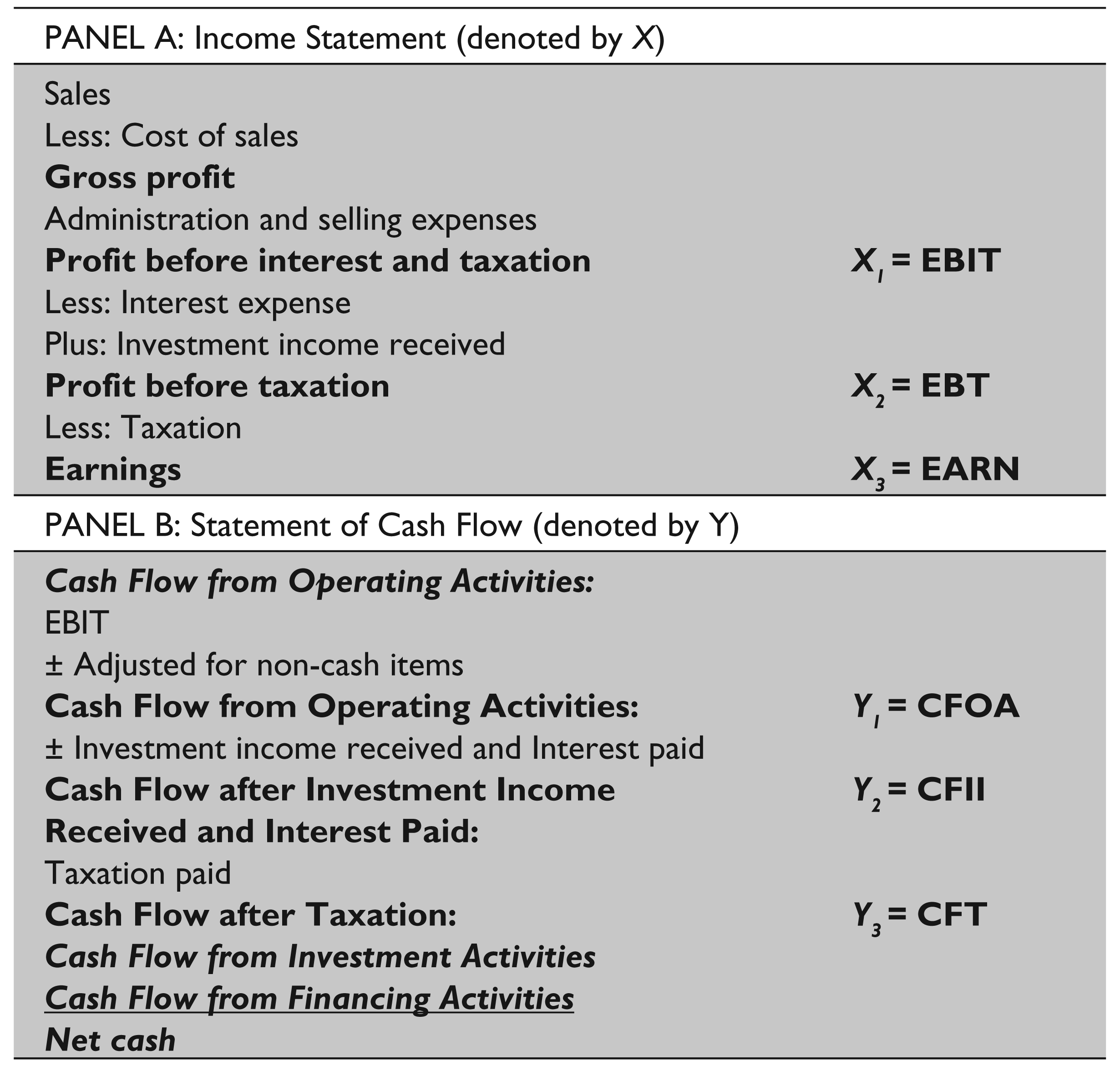
A sample of income and cash flow statements in compliance to ASI and IFRS can be seen in Table 1. While the statement of cash flow for IFRS has three parts, it has five parts based on ASI (refer panel B in Table 1).
Following Bezuidenhout et al. (2008), three variables from income statements (EBIT, EBT and EARN) and three variables from statements of cash flow (CFOA, cash flow after investment income received and interest paid (CFII) and cash flow after taxation (CFT)) (Panel A and B, respectively) are selected for the test, as shown in Table 1.
Data Analysis
Results for data analysis are presented in the following three sections, including test results for stationarity, co-integration and causality, respectively.
Results for Stationarity
To test for causal relationships, the variables need to test for stationarity first. The Im, Pesaran and Shin unit root test results for stationarity is shown in Table 2. The results show that EBIT, denoted by X1, EBT denoted by X2, and EARN, denoted by X3, are non-stationary.
In the statement of cash flow (denoted by Y), with the exception of CFOA denoted by Y1, the other two variables—CFII denoted by Y2 and CFT denoted by Y3—are stationary.
Unit Root Test for Stationary: IM, Pesaran and Shin Model

Because the variables X1, X2, X3 and Y1 have unit roots (are non-stationary), we must test for the existence of long-term relationships among the variables by using a co-integration test.
Results for Co-integration
The results for testing co-integration are presented in Table 3. Pedroni’s co-integration test with intercept shows the existence of long-term relationships among the six models. Because of the existence of long-term relationships, it is not necessary to use differencing (refer Baltagi, 2005; Gujarati, 2003; Hendry & Juselius, 2001; 2001; Yini, 2009). It means that panel data are co-integrated (i.e., they have no random walk or stochastic trends).
The null hypothesis, in this test, is a lack of long-term relationships between variables. As presented in Table 3, the p-value is zero, which means that the null hypothesis is rejected. In other words, long-term relationships exist among variables of the model. This makes it possible to investigate for causality among variables.
Results for Causality
The results of the Granger causality test for all individual companies are given in Table 4. All nine pairs were tested for causality, using the AR models as represented by Equations 6 and 7 in the third section. In all of these nine pairs of variables, cash flow variables were found to cause earnings variables and this relationship was two-way (earning ↔ cash flow). In other words, the results for causality indicate that all nine pairs of variables (for the companies) were causally related and that the causality was bidirectional (two-way).
Results of Pedroni Co-integration Test
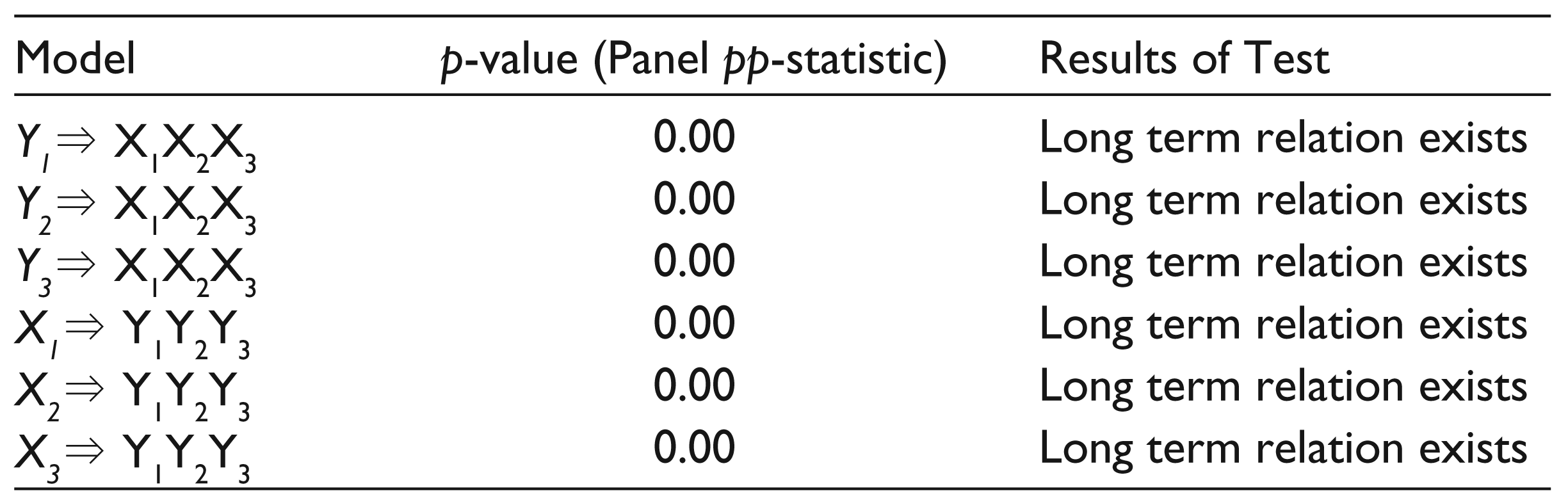
Results for Granger Causality Test from Level of All Companies
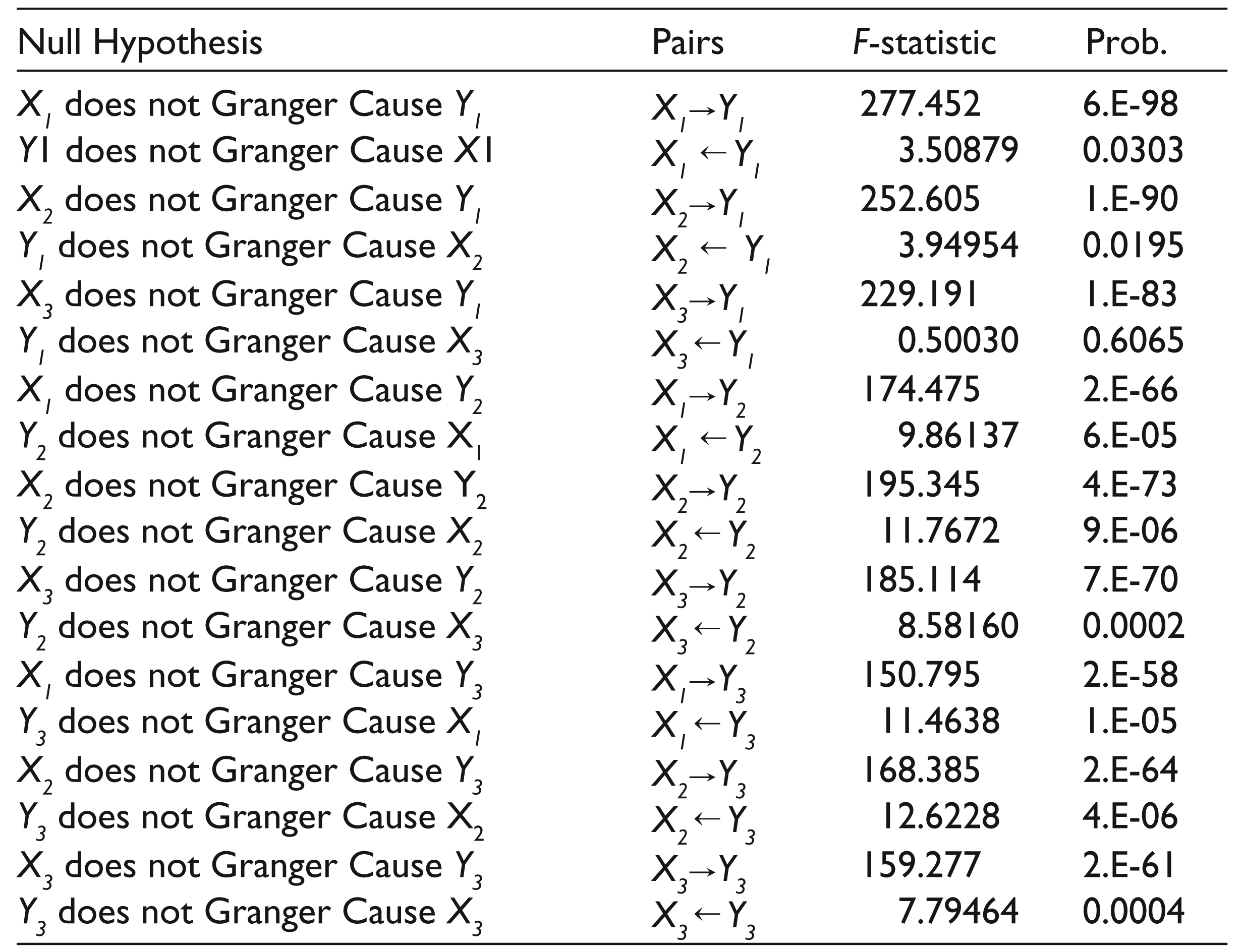
Because causality exists between cash flow and earnings, we can estimate the following equations:
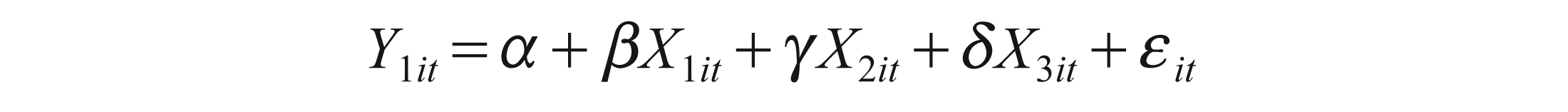
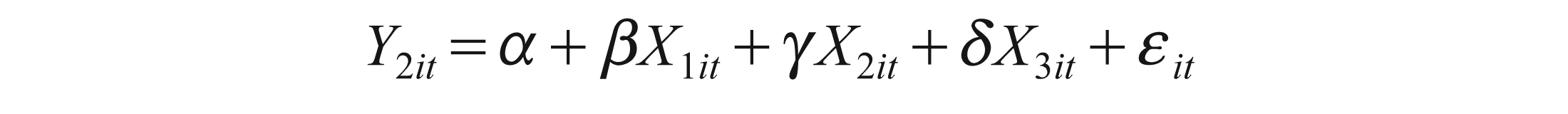
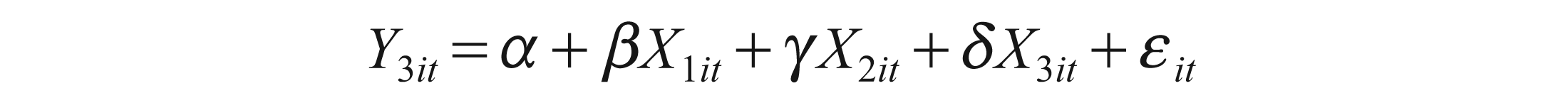
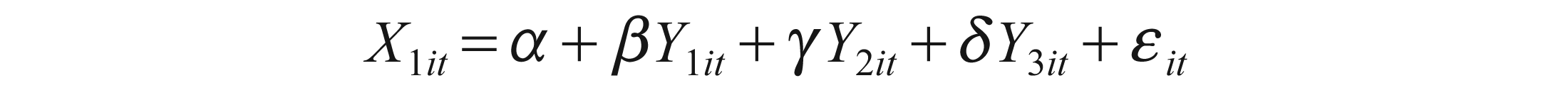
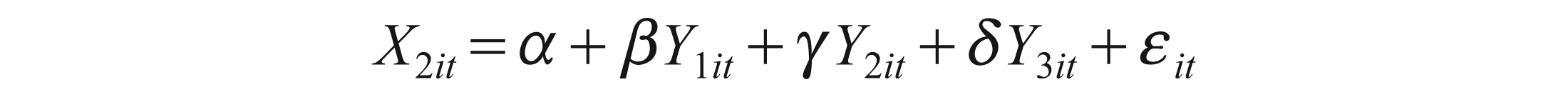
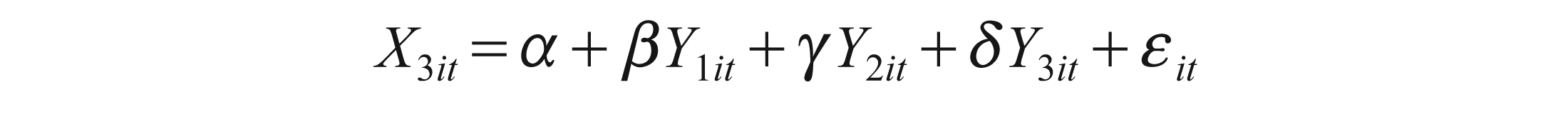
Where Y1, Y2, Y3 denote CFOA, CFII, CFT and X1, X2, X3 denote EBIT, EBT and EARN, respectively.
These equations can be used for forecasting, as we can estimate Y1 by X1, X2 and X3. Also, conversely, we can estimate X1 by Y1, Y2 and Y3. This applies to all variables in this test.
Results for Granger Causality Test from Level of Industry Sectors
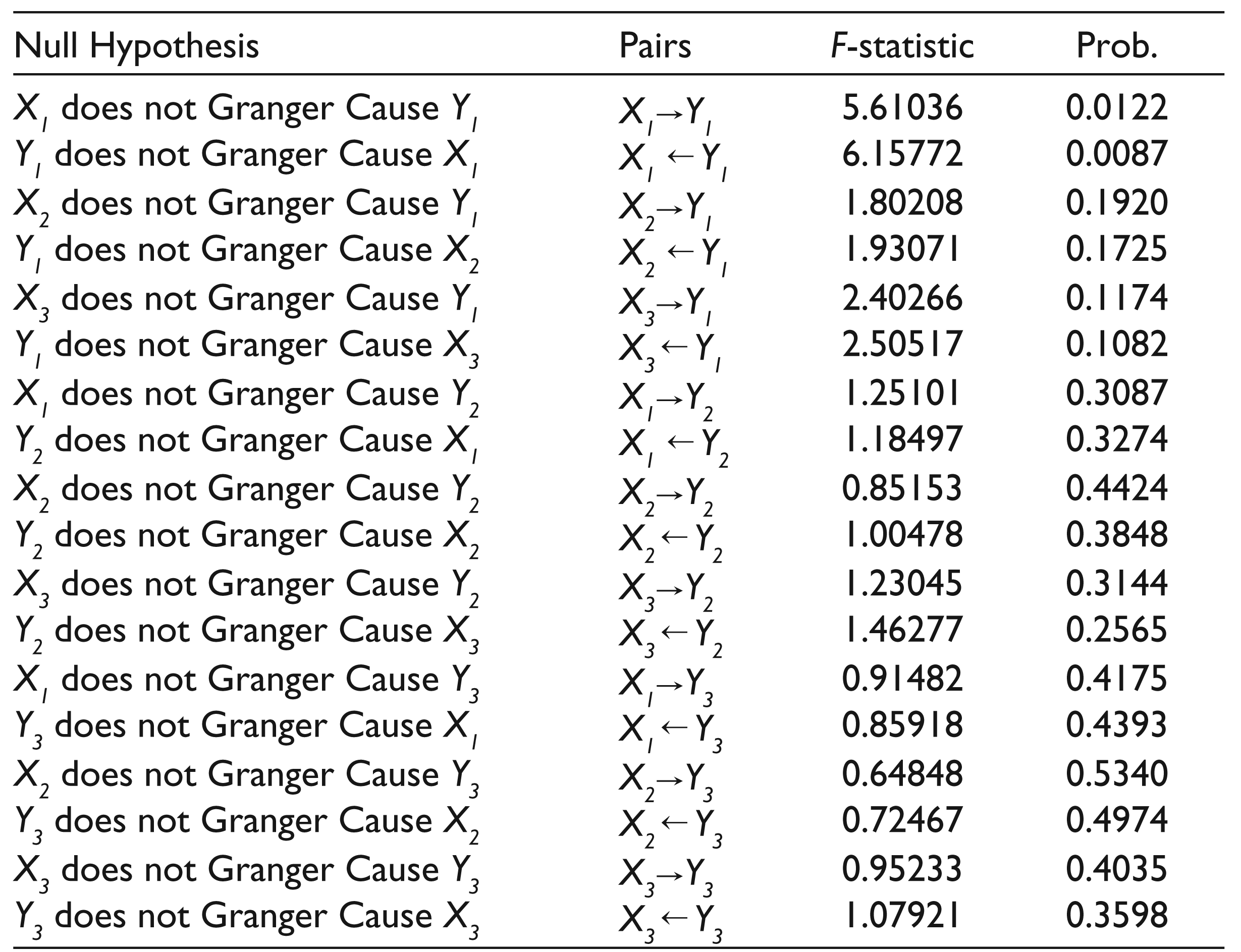
We also test causality for the level of industry sectors. Results from the Granger test are presented in Table 5 for 27 industry sectors. According to the results, causality was only found between variables X1 and Y1. In other words, EBIT, denoted by X1, was caused by CFOA, denoted by Y1, and vice versa. In other variables, causality was not found.
Discussion and Conclusions
To test for causality between earnings and cash flow, we have investigated stationarity and co-integration. The Im, Pesaran and Shin test is used to investigate stationarity. The Pedroni test is used to investigate co-integration or long-term relationships.
In determining causality for all individual companies, the results show that there are bidirectional relations in all six variables. In other words, all income statement variables have Granger cause (G-cause) on all statements of cash flow and vice versa. For example, EBIT (denoted by X1) is a Granger cause of CFOA (denoted by Y1) and vice versa. This means that EBIT can forecast CFOA and that CFOA can forecast EBIT. This bidirectional relationship exists between all pairs of variables X and Y (X↔Y).
As noted in literature review, Bezuidenhout et al. (2008) selected four variables from income statements and three variables from statements of cash flow, using time series analysis. In some conditions, they found bidirectional relations between earnings variables and cash flow variables.
In comparison, we use panel data to investigate causality between variables. Panel data give unbiased and compatible estimations in comparison to time-series data. As noted by Baltagi (2005), panel data give more informative data, more variability, less collinearity among the variables, more degrees of freedom, greater efficiency, and so on. Our panel data includes 155 companies, while the BMH study has 70. According to Bezuidenhout et al. (2008), because of sensitivity to sample sizes, large sample sizes are required if conclusive results are to be reached. As noted by BMH, the size of the sample has an effect on the result of research. We conclude that for individual companies, causality exists between variables of earnings and variables from cash flow, but at the industry level, this bidirectional relationship exists only between EBIT (EBIT = X1) and CFOA (CFOA = Y1).
In this study, panel data have more explanatory power and we find that it is better to include more companies. Therefore, we propose that researchers test causal relations in future by using panel data and by increasing the sample size.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.