
Abstract
We study the effect of revenue decentralization (RD) and expenditure decentralization (ED) on sub-national growth in India from 1981–1982 to 2015–2016 for 14 large (non-special-category) states. Our study provides evidence that both RD and ED play a defining role in India’s sub-national growth in this three-and-a-half-decade period. We use a panel data model with fixed effects (FE) and Driscoll and Kraay standard errors that control for heteroscedasticity, autocorrelation and cross-sectional dependence. To test for causality between growth and decentralization, we use the Granger non-causality test. The regression analysis is supplemented with the distribution dynamics approach. We find that: (a) While decentralization Granger-caused economic growth, the reverse causality effect of growth on decentralization was not significant; (b) Economic growth increased significantly after liberalization; (c) Decentralization, capital expenditure and social expenditure had significant positive impacts on economic growth; and (d) States that had high levels of decentralization also had high levels of per capita income, while states that had low decentralization also exhibited low per capita income.
Keywords
Introduction
Growth economics has identified several factors, such as technology (Arrow, 1962; Romer, 1990; Solow, 1956), innovation (Grossman & Helpman, 1991), human capital (Barro, 1991; Becker, 1993), capital deepening (Kuznets, 1973), regional policies (Krugman, 1991), social and political institutions (Asher & Novosad, 2017; Deshpande, 2011; North, 1987), inequality (Alesina & Perotti, 1996; Deaton & Drèze, 2002) and public policy (Easterly, 2019), which impact income dynamics.
A different strand of literature explaining regional growth has pointed out that in a federal structure, it is possible to influence sub-national growth by reallocating expenditure and revenue responsibilities between different tiers of government (Davoodi & Zou, 1998). It has been argued in the same vein that greater democratization and devolution of powers could positively impact both the efficiency and effectiveness of economic policies (Feruglio, 2007). Therefore, an identical set of policies in a country may differ in effectiveness across different states due to the variations in institutional and organizational factors across states (Sala-i-Martin, 1996). Allocation of fiscal functions among different government tiers, depending on their comparative advantage, leads to better governance and economic efficiency (Oommen, 2006). The reason this may occur is that fiscal decentralization could improve the delivery of public services, as well as revenue collection (Kalirajan & Otsuka, 2012). Therefore, a better understanding of the extent and process of decentralization in a country may be vital to enhancing regional growth.
Decentralization is defined as the devolution of revenue, expenditure and decision-making authority to democratically elected lower-level governments, mostly independent of the central government (World Bank, 2000). Theoretically, three necessary conditions are required for decentralized provision of public goods and services to be Pareto-superior: heterogeneity, externalities and economies of scale. Welfare is maximized in a decentralized set-up when regions are heterogeneous in their preferences for public goods and services. Decentralization is considered beneficial when regions do not show evidence of interregional spillovers of the benefits of their expenditure to other regions and when there is no cost saving through uniform, centralized provision of public goods and services (Oates, 1972).
Fiscal decentralization enhances efficiency in usage of local resources for several reasons, as local governments are directly associated with the beneficiaries of these policies (Ebel & Yilmaz, 2002; RBI, 2006). Sub-national governments may be subject to greater scrutiny by the public, since they are closer to them in a decentralized set-up. Public scrutiny forces authorities to appoint competent staff and to undertake efficient expenditure. Decentralization can reduce moral-hazard and agency problems and reduce the number of bureaucracy layers (Boadway & Shah, 2007).
With fiscal decentralization, regional governments can provide public services based on the preferences of their respective constituencies in contrast to the central government (Weingast, 2014). Besides, these regional and local governments face competition from their counterparts, leading to the efficient provision of public services (Oates, 1999). These policies could impact not only growth but also inequality (Clements et al., 2015).
There are some potential risks associated with decentralization as well. Some economists have associated decentralization with slower growth, leading to macroeconomic instability (Prud’homme, 1995). Fiscal decentralization, if not done correctly, can widen regional inequalities, can have an adverse effect on the fiscal balances and can lead to coordination failures among sub-national governments and the centre (Hindricks et al., 2008; Rodden et al., 2003; World Bank, 2002). In order to realize the benefits of fiscal decentralization, it is essential that sub-national governments be able to undertake autonomous expenditure decisions and be accountable for them. Similarly, governments should have adequate revenue to undertake their spending responsibilities either through sufficient taxation autonomy or steady unconditional transfers (Hankla, 2008).
The jury is out on the impact of decentralization on economic growth. While some studies show that decentralization had a positive impact on economic growth (Akai & Sakata, 2002; Justin & Zhiqiang, 2000; Qiao et al., 2008), others have found that fiscal decentralization had a negative impact on economic growth (Davoodi & Zou, 1998; Jin, 2009; Zhang & Zou, 1998). The impact of fiscal decentralization differs from country to country and over time and would depend on the institutional economic structure of the economy.
The Indian Context
The Indian Constitution is federal in its set-up. However, from the 1950s till the 1980s, the fiscal power was mainly concentrated with the central government. It was only in 1991 that the states were given greater powers to follow their economic and social policies (Bagchi, 2003). In 1992, constitutional recognition was given to the third-tier level of government in India. Our study is restricted to the analysis of decentralization at the sub-national (state) level due to the unavailability of data at the local (third-tier) level for the time period of our study. While India has undertaken expenditure decentralization (ED) to the sub-national governments, it has still not achieved much in terms of tax devolution (Panda et al., 2019).
Multiple types of explanations have been used to understand India’s sub-national growth trajectory (Ahluwalia, 2000; Lolayekar & Mukhopadhyay, 2020; Raju, 2012; Sachs et al., 2002). However, data limitations have restricted the covariates that similar international studies have employed (Maiti & Marjit, 2015; Nayyar, 2008). For example, disaggregated data on investments and savings, interstate trade data, research and development expenditure are not available at the state level. While literacy rates could serve as a proxy to human capital, they are available only with decadal periodicity after the population census (Census, 2011).
There has been a varying degree of decentralization across regions in India. Concerning delivery of public services and mobilization of resources, both physical and human, some states have been more successful than others (Rao, 2008). With decentralization, it has been argued, the local elites have been in a position to have greater control over a larger share of public resources than the poor, which has implications for inequality (Drèze & Sen, 1995). Others have found that decentralization has fostered development equitably across states through health and education expenditures (Kalirajan & Otsuka, 2012). Therefore, apart from growth, decentralization also has a distributional impact.
We examine these issues in our study that spans the last three and a half decade (from 1981–1982 to 2015–2016). During this period, the Indian economy saw significant institutional changes, with increased open market policies from the early 1990s (Kotwal et al., 2011) and the 73rd and 74th constitutional amendments devolving more powers to lower tiers of government (Rao, 2002). In India, an increase in capital expenditure simultaneous with a decrease in revenue expenditure (without affecting the fiscal deficit) was found to have a positive influence on the economic growth (RBI, 2016). The capital outlay of state governments was considered growth-inducing and had a more prolonged effect on the economy than revenue expenditure (Jain & Kumar, 2013). Social sector expenditures (including expenditures on education and health) are also significant for India’s growth and development (Mittal, 2016). These expenditures enhance economic growth by positively influencing the competitiveness, productivity and efficiency of labour and reducing absolute poverty. Further, sustainable economic growth requires social sustainability, and social expenditures could help achieve that (Kaur et al., 2013). Ganaie et al. (2018) found a positive impact of ED but a negative impact of revenue decentralization (RD) on economic growth.
We contribute to this literature by using a twofold strategy. First, we use a regression model to establish the impact of decentralization on growth. We use a panel fixed effects (FE) model with both ED and RD as covariates, along with social and capital expenditures (Devarajan et al. 1996). We also use the Dumitrescu and Hurlin (2012) Granger non-causality test to confirm causality between growth and decentralization. Second, we complement the regression-based approach with a distribution dynamics approach proposed by Quah (1997). This approach overcomes problems that could arise from the non-fulfilment of the normality assumption in regression-based approaches. More importantly, it can help better identify the presence of convergence clubs and polarization among states (Kar et al., 2011; Lolayekar & Mukhopadhyay, 2017).
We find that RD and ED had a positive impact on growth. Similarly, capital expenditure and social expenditure had a significant positive impact on economic growth, which was higher after liberalization. This has significant implications for public policy relating to the devolution of powers among different tiers of government in India. These findings also add to the growth and public finance literature.
The rest of the article is organized as follows. In the second section, we present the materials and methods. In the third section, we present the results, followed by the analysis in the fourth section. We conclude the article in the fifth section with a discussion of our findings and their policy implications.
Materials and Methods
The theoretical framework used to analyse the influence of fiscal decentralization on economic growth is the commonly used production–function approach (Davoodi & Zou, 1998).
As a first step, we define the quantitative measure of decentralization used in this study to measure the effects on income. Many cross-country studies in the past have measured fiscal decentralization as the ratio of sub-national government expenditure/revenue to total government expenditure/revenue (Ebel & Yilmaz, 2002). This measure may overestimate the extent of decentralization and can misrepresent the impact of fiscal decentralization on major economic indicators. The more recent trend is to construct measures of fiscal decentralization which reflect the sub-national governments’ autonomy in terms of both expenditure and revenue decisions (Akai & Sakata, 2002). Hence, it is necessary to subtract that expenditure from the sub-national-government share mandated by the central government or undertaken on behalf of the central government. Expenditure financed through conditional transfers whose use is predetermined by the centre is deducted from the sub-national expenditure. Again, in terms of revenue, it is necessary to distinguish between own revenue, shared taxes and transfers. In terms of the RD measure, only those resources over which the sub-national government has authority in terms of either the tax rate or the tax base are included.
We have constructed two measures of decentralization: expenditure and revenue. The ED variable measures the extent of autonomy a state enjoys in its expenditure vis-à-vis the centre. ED is measured by estimating the ratio of the ‘i-th’ state’s expenditure as a proportion of its total expenditure (centre plus state). This measure is adopted from Qiao et al. (2008) and modified suitably to measure the decentralization level of Indian states. We use per capita measures to control for heterogeneity in population across states. The state’s own expenditure does not include the central grants, and the formula used is as follows:
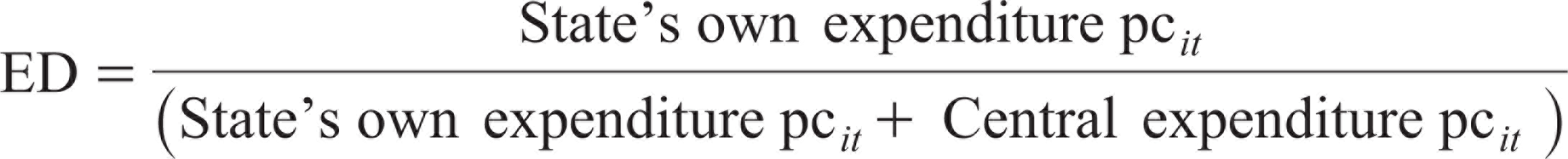
where
State’s own expenditure pc it = state’s aggregate expenditure minus central grants to the state in per capita terms;
Central expenditure pc it = central grants per capita, including grants under the central plan schemes, centrally sponsored schemes, state plan schemes and non-plan grants;
i = ith state; and
t = time period.
Although the state government undertakes state plan schemes, we excluded the grants to states under these schemes, as state governments do not have autonomy in their spending decisions. One of the reasons cited for terminating the Planning Commission in 2014 through which these grants to state plan schemes were provided was to increase the autonomy of states and promote cooperative federalism among states (Rao, 2016).
The RD variable measures the extent of autonomy a state enjoys in its revenues vis-à-vis the centre. This represents the ability of the ‘ith’ state to raise its own revenues through taxes. We measure this by estimating the ratio of the ‘ith’ state’s tax revenue as a proportion of its total revenue (centre plus state). Therefore, the state’s own tax revenue excludes the state’s share in central taxes, as the state has no control over the tax rate or base in terms of revenue collection. This measure is adopted from Oommen (2006) and modified suitably to measure decentralization at the sub-national level. The formula used is as follows:
RD = state’s own tax revenue per capita (pc) of state ‘i’ divided by the sum of aggregate central tax revenue per capita and state’s own tax revenue per capita.
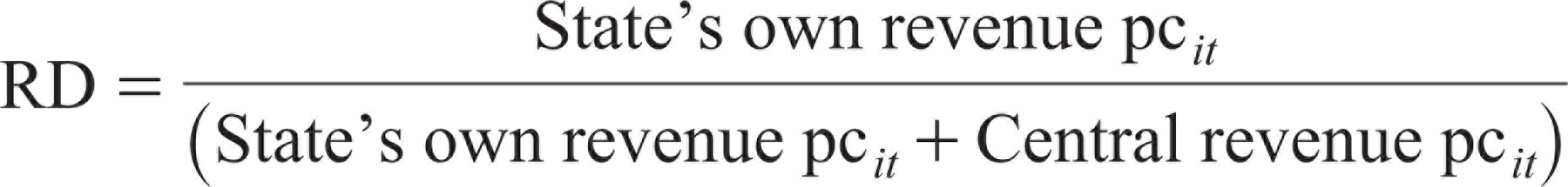
where
State’s own revenue pc it = states’ own tax revenue in per capita terms.
Central revenue pc it = contribution of the central funds to the ‘ith’ state.
Here, central revenue per capita is the state’s share in central taxes of the ‘ith’ state in per capita terms, i = ith state, and t = time period.
Regression-based Approach
We examine the impact of ED and RD on state-level growth using the commonly used regression method with a formal econometric model. We anticipate that growth is subject to many influences apart from fiscal decentralization, such as population, human capital, initial per capita GDP, the real investment share in GDP, total labour force, the degree of openness of economy/volume of trade, the inflation rate and policy reforms (Feltenstein & Iwata, 2005; Lin & Liu, 2000; Zhang & Zou, 1998). The tax rate has also been used as an explanatory variable (Davoodi & Zou, 1998; Zhang & Zou, 1998). Expenditures on health, economic development, administration and education (as a ratio of total state-government spending) have been used as control variables while determining the impact of decentralization on GDP growth (Zhang & Zou 2001). As a substitute for investment expenditure (for which data is not available at the sub-national level), we have used the government capital expenditure. In India, the crowding-out hypothesis and Ricardian-equivalence hypothesis have received mixed responses (Ghatak & Ghatak, 1996; Mitra, 2006; Pradhan et al., 1990), but there has been evidence of a positive correlation between private capital investment and public capital expenditure at the national level during certain phases (Bahal et al., 2018).
India undertook significant market reforms in the 1990s. The empirical growth literature often distinguishes economic policies between two periods: before 1990 and after 1990. We, therefore, wish to account for this structural change before and after the liberalization process. The conceptual model we propose predicts growth as an outcome of these factors (see Equation [3]).

The specific linear model used for estimation is stated in Equation (4):
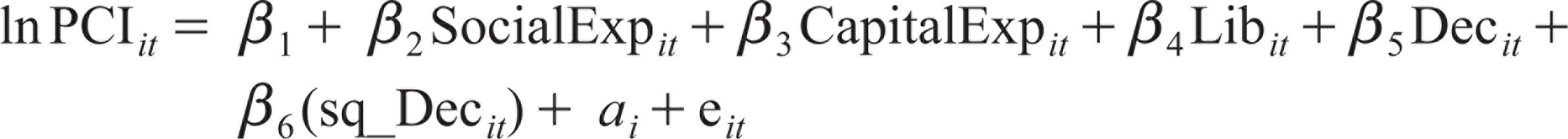
where
i is the ith state;
t is the time period;
lnPCI is the natural log of gross state domestic product (GSDP) per capita at current prices;
CapitalExp is the proportion of capital outlay to the aggregate expenditure of state i at current prices;
SocialExp is the proportion of social expenditure to the aggregate expenditure of state i at current prices;
Lib is a dummy variable separating the post-liberalization period from the pre-liberalization period. It takes the value ‘0’ for pre-liberalization years (up to 1990) and ‘1’ after that (1991 onwards);
Dec is a measure of decentralization (ED for expenditure and RD for revenue);
sq_Dec is the square of the measure of decentralization (ED for expenditure and RD for revenue);
α is an entity-specific intercept (used in the FE model); and
e is the stochastic error term.
Panel data models enable researchers to analyse economic processes while considering the heterogeneity of units and accounting for dynamic effects that are not included in cross-sectional data (Greene, 2010). One advantage also is that they are more informative and provide greater variability in terms of the data collected and are thus more efficient in the estimation of parameters. These models enable researchers to analyse complex behavioural models that are subject to less restrictive assumptions (Ullah & Giles, 1998).
A basic method applied to panel data is the pooled ordinary least squares (POLS) model, also known as the population-averaged model (see Equation [4], where αi = 0). POLS provide efficient estimates only when the classical model’s assumptions are satisfied, including zero conditional mean of error term, homoscedasticity, independence across units and strict exogeneity of independent variables. Such conditions are hard to fulfil, and if data is available, then researchers prefer panel data models, choosing between the random effects (RE) and FE models depending on the nature of the data. An RE model is resorted to when unobserved effects are not correlated with the explanatory variables. If this assumption is violated, the RE estimator will produce biased and inconsistent estimates (Greene, 2010). To solve this problem the within estimator or FE estimator is used. In this method, deviations from individual means are computed. Thus, even if a correlation between unobserved factors and some explanatory variables exists, the within estimator will produce unbiased and consistent estimates (Hausman & Taylor, 1981). Accordingly, in Equation (4), we would anticipate that βi = 0 and αi ≠ 0. We also use the Dumitrescu and Hurlin (2012) Granger non-causality test to analyse the two-way causality between growth and decentralization.
Testing for Causality
The popular test to analyse the causal relationship between time series variables was first proposed by Granger (1969). This was extended by Dumitrescu and Hurlin (2012) to analyse heterogenous, balanced panels and to test bidirectional causality. We tested whether decentralization causes growth (Equation [5]) and whether the causality runs from growth to decentralization (Equation [6]) using the following regression equations:

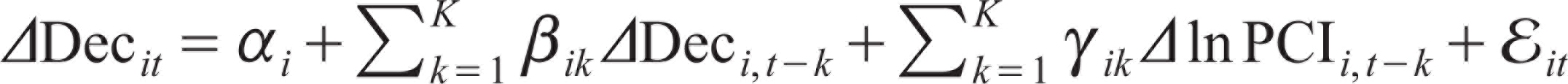
where:
Lag order k is assumed to be identical for all panels;
coefficients (β, γ) are allowed to differ across individuals but are assumed to be time-invariant; and
Δ stands for the first difference of the stationary variables.
A precondition to running the Granger causality test is that the variables be stationary. We used the Hadri Lagrange multiplier (LM) test to test for unit roots in our panel data. This test is suitable for data with a large T and a moderate N and balanced panel models, like the one we use for our study. While the variables were not stationary at level, they were found to be stationary when we used their first difference. For all the three variables (lnPCI, ED and RD), we could not reject the null hypothesis, meaning that all the panels were stationary at the first difference (Table 3).
Next, we undertook the Dumitrescu and Hurlin (2012) Granger non-causality test using the first difference of the lnPCI and decentralization variables. We used the Z-bar test for interpreting the results, as according to Hurlin and Dumitrescu (2012), it is suitable for our data with large time periods and few panels.
We ran two separate regressions for decentralization: model 1 for ED and model 2 for RD (see Table 2). In keeping with earlier contributions (Akai & Sakata, 2002; Hanif et al., 2020; Yushkov, 2015), we decided to run separate models with ED and RD, as the covariates had a significant correlation between them (the correlation coefficient value was 0.72). The correlation between the fiscal variables CapitalExp and SocialExp, on the other hand, was found to be low (correlation coefficient value was 0.11). We, therefore, did not anticipate the problem of multicollinearity arising if we kept both the fiscal variables in the regression estimation. Since our data took the form of a balanced panel, we could use either a POLS or a panel data model (FE or RE).
In the model with ED as a predictor (model 1), we used the Breusch–Pagan LM (BP-LM) test to choose between the RE and POLS models. The results (Prob. > chi-square = 0.000) suggested that the RE model would be preferred over the POLS. We next chose between the RE model and the FE model. Usually, we would have used the Hausman test to determine this. Since we used robust standard errors to avoid problems of heteroscedasticity, the preferred test then was the Sargan–Hansen test as a substitute for the Hausman test (Baum et al., 2014). The post-estimation test rejected the null hypothesis of RE, implying that the RE model would provide inconsistent estimates. The FE model was, therefore, the preferred option. In RD (model 2), the BP-LM test suggested that the POLS model was preferred to the RE model. Hence, we used the F-test to choose between the POLS and FE models. The results indicated that the FE model would be preferred over the POLS model (Prob. > F = 0.000). Therefore, in both the ED and RD models, the FE model was the preferred choice. Also, in both these models, the post-estimation tests indicated: (a) the presence of heteroscedasticity among the variables (modified Wald test in the FE model); (b) the presence of serial correlation—first-order autocorrelation (Wooldridge test); and (c) the presence of cross-sectional correlation between panels (BP-LM test for independence).
Three popular methods address the problem of heteroscedasticity, autocorrelation and cross-sectional dependence for long panel data (large T and small N) (Hoechle, 2007). The first method is the Parks-Kmenta method. This method is applied to panel data using a feasible generalized least square (FGLS)-based algorithm, but it produces unacceptably small standard errors. To overcome this problem, Beck and Katz (1995) proposed the estimation of POLS with panel-corrected standard errors. The third method produces the Driscoll and Kraay (DK) standard errors, which can be applied to POLS/weighted least squares (WLS) and FE (within) estimations. The DK standard errors are not only consistent in the presence of heteroscedasticity and auto-correlation but are also robust to general levels of cross-sectional correlation (Fofanah, 2020; Fuinhas et al., 2019; Hartwell, 2014; Simionescu et al., 2016).
Distribution Dynamics Approach
This approach encompasses both time series and cross-section properties of the data simultaneously. The density of distribution ϕt evolves as per Equation (7):

where M maps the transition between the income distributions for two consecutive periods, ‘t’ and ‘t - 1’. This is a first-order Markov process, as the density distribution ϕ for the period ‘t’ only depends on the density ϕ for the immediately preceding period ‘t - 1–. In our estimates below, we have assumed that the distribution ϕ has a finite number of states.
In estimating the dynamics of income distribution, there are three possibilities for an economy’s behaviour over a given period of time:
It may move ahead; It may stay where it was; or It may even fall behind.
The distribution dynamics information is encoded in a transition probability matrix (TPM). This is a square matrix that describes the probabilities of moving from one state to another in a dynamic system. Each row represents the probability of moving from the state represented by that row to the other states. All entries have a value between 0 and 1, which represents probability, and the sum of the entries’ values in a row adds up to 1. Here, the evolution of income is modelled as a Markov process governed by a transition probability. The current state (in a first-order Markov chain) only depends on the immediate previous state (Kemeny, 2003). The advantage of this methodology is that it formulates a law of motion for the entire distribution of incomes between the periods under analysis, allowing us to model the existence of convergence clubs in the data. In the case of transition probability matrix, it is assumed that an economy or region over a given time period (say, 1 year or 5 years) either remains in the same position or changes its relative position in the income distribution (Bandyopadhyay, 2012; Quah, 1996).
For the Markov transition matrices, we assume that the probability of variable st taking a particular value depends only on its previous value st-1 according to the first-order Markov chain:
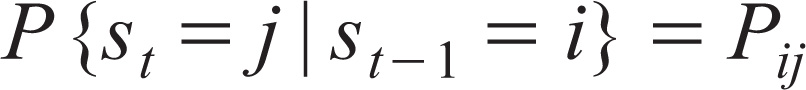
where Pij indicates the probability that state i will be followed by state j and the sum of values in each row will add up to 1:

The transition matrix constructed is as follows:
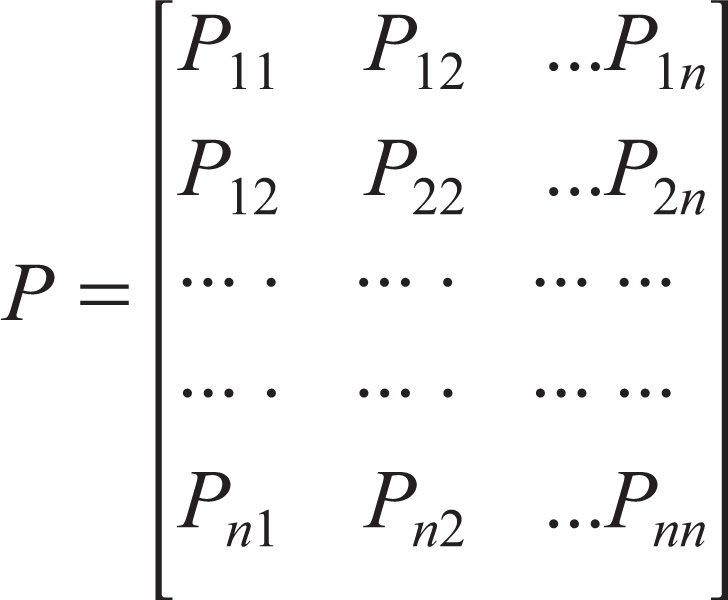
where row i and column j indicate the probability that state i will be followed by state j.
The Markov chains model the evolution of relative income distribution. We thus identify the position of the economy in the starting period. This is done by dividing the income distribution into ‘income states’ over a range of income levels. We then observe how many of the economies that are in an income state, say between 0.75 and 1 in the initial period, remain in that same state (persistence) or shift elsewhere in the next period (mobility). The TPM measures the probability of the income level in a country or region rising, falling or remaining unchanged between two periods (Magrini, 2007).
Data
We use data for 14 large general-category (also called non-special-category) states of India. The special- and general-category states differ significantly in terms of their own revenue generation, cost disabilities and central financial assistance and hence cannot be compared in terms of fiscal decentralization (FC, 2009; Rao, 2017). Hence, the special-category states have been left out of this study. We have also not included the states like Goa and Delhi in the analysis, because these are outliers in per capita income terms and have a comparatively small population. The period for the study is 1981–1982 to 2015–2016, which is the largest time span for which data is currently available for all variables under consideration.
We combine data from multiple sources. GSDP per capita data is taken from MOSPI (various years). GSDP data from 1980–1981 to 1992–1993 is based on the 1981 series, data from 1993–1994 to 1998–1999 is based on the 1993–1994 series, data from 1999–2000 to 2003–2004 is based on the 1999–2000 series, data from 2004–2005 to 2010–2011 is based on the 2004–2005 series, and finally data from 2011–2012 to 2015–2016 is based on the 2011–2012 series. Data on all types of state expenditures, state revenues and central transfers to states are taken from the (EPWRF various years). All the data used in our study are at current prices.
The state-level year-wise population estimates are obtained by interpolating decadal census estimates to obtain the states’ annual population from 1981–1982 to 2015–2016 (PC, 2014). The newly formed states (Jharkhand, Uttarakhand, Chhattisgarh and Telangana) have been merged with their respective original states (Bihar, Uttar Pradesh, Madhya Pradesh and Andhra Pradesh) for analytical comparability.
Results
We first present the summary statistics of the variables used in the regression analysis (Table 1). The 35-year period with 14 states generates 490 observations. LnPCI has a mean of 9.58 (overall) and has a standard deviation of 1.26 (overall). While ED has a mean of 0.9, RD has a mean of 0.69, confirming that India is much more decentralized in expenditure than in revenue. However, RD has a higher variation as compared to ED. The capital expenditure ratio has a mean of 0.11, and the social expenditure ratio has a mean of 0.31.
Summary Statistics of Variables of 14 States (from 1981–1982 to 2015–2016)

We present the regression results (including those of the Granger causality regression), followed by the analysis of the distribution dynamics approach.
The results of the regression Equation (4) are presented in Table 2. ED and RD both were found to have a significant and positive influence on lnPCI, confirming that a reallocation of expenditure shares and revenue collection responsibilities to the states will enhance growth. Moreover, this could be achieved without altering the aggregate government spending/revenue. A unit increase in RD will lead to a 4.81% increase in lnPCI. ED, on the other hand, was found to have a non-linear relationship with lnPCI, and therefore the extent of the impact of ED would depend on the value of ED at which change is being contemplated.
Fixed Effects Regression Using Driscoll–Kraay Standard Errors, with Dependent Variable LnPCI

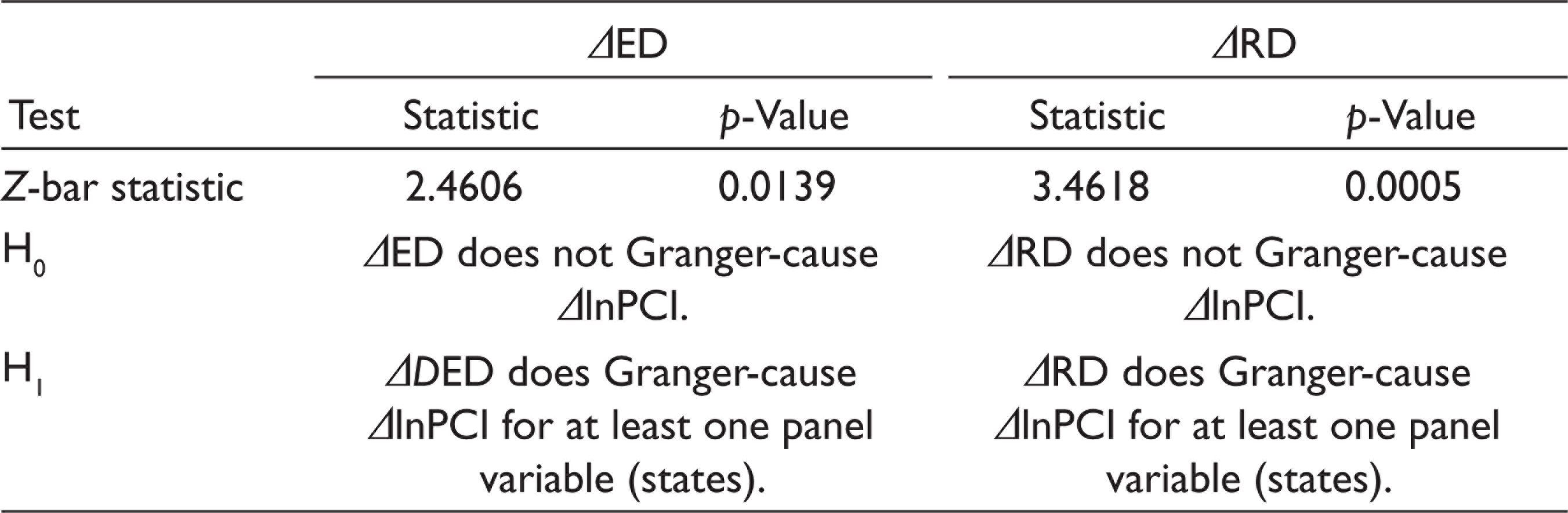
Social expenditure, as expected, was found to have a significant and positive influence on lnPCI in both regressions, confirming its importance for economic growth. Similarly, capital expenditure was also found to have a significant and positive influence on lnPCI. The liberalization variable was highly significant and positive, confirming the higher income growth in the post-liberalization phase in both the models. The R-squared (within) was around 0.69 for both the regression models and demonstrated the significance of estimates in the joint test of the hypothesis. Next, we discuss the results of the Dumitrescu and Hurlin (2012) Granger non-causality test. We find that in the case of ED and RD, we can reject the null hypothesis which states that ED/RD does not Granger-cause lnPCI and accept the alternative hypothesis that ED/RD does Granger-cause lnPCI for at least one of the states (Table 4 ).
Hadri Lagrange Multiplier Test for Unit Root in Panel Data

LR variance: Bartlett kernel, 5 lags.
Cross-sectional means removed.
Asymptotics: N, T infinity sequentially.
Dumitrescu and Hurlin (2012) Granger Non-causality Test (decentralization ΔlnPCI)
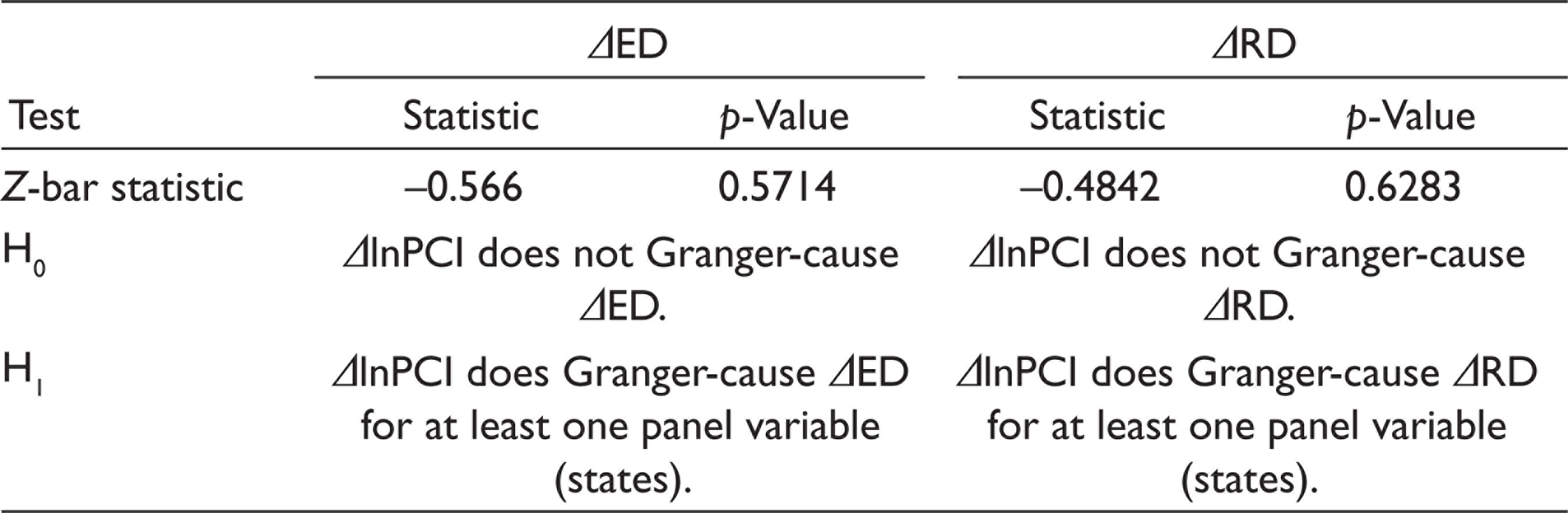
We also examined the bidirectional causality between lnPCI and decentralization. We found that while lnPCI does not Granger-cause decentralization, RD and ED do (Table 5).
Dumitrescu and Hurlin (2012) Granger Non-causality Test (ΔlnPCI decentralization)
Analysis
We now examine how decentralization has affected the distribution of growth in incomes across states (see Table 6)—how many states remain in the same state and how many move elsewhere during this period. If they have moved above the diagonal, then the relative performance has been good, and if they have moved below the diagonal, the relative performance has been lacking. This allows us to create a distribution of states based on their performance during the two periods.
Relative Per Capita Income Transition Dynamics, 1981–2015
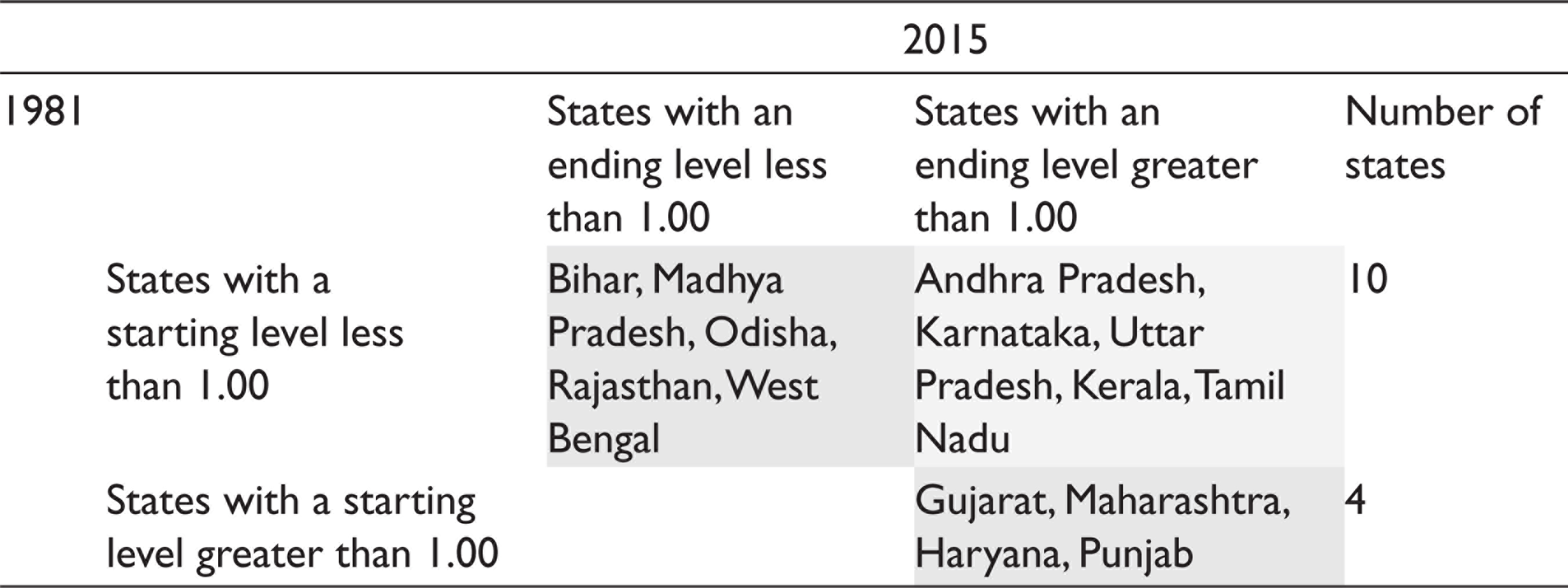
We use a 2 × 2 matrix to examine the mobility of states in PCI from 1981–1982 to 2015–2016. Five states (Andhra Pradesh, Karnataka, Uttar Pradesh, Kerala and Tamil Nadu) started with a PCI less than the national average but by 2015–2016 had moved above the national average (above the diagonal). Five states (Bihar, Madhya Pradesh, including Chhattisgarh, Odisha, Rajasthan and West Bengal) began with a PCI below the national average and ended in 2015–2016 below the national average. Four states (Gujarat, Maharashtra, Haryana and Punjab) began and ended with a PCI higher than the national average.
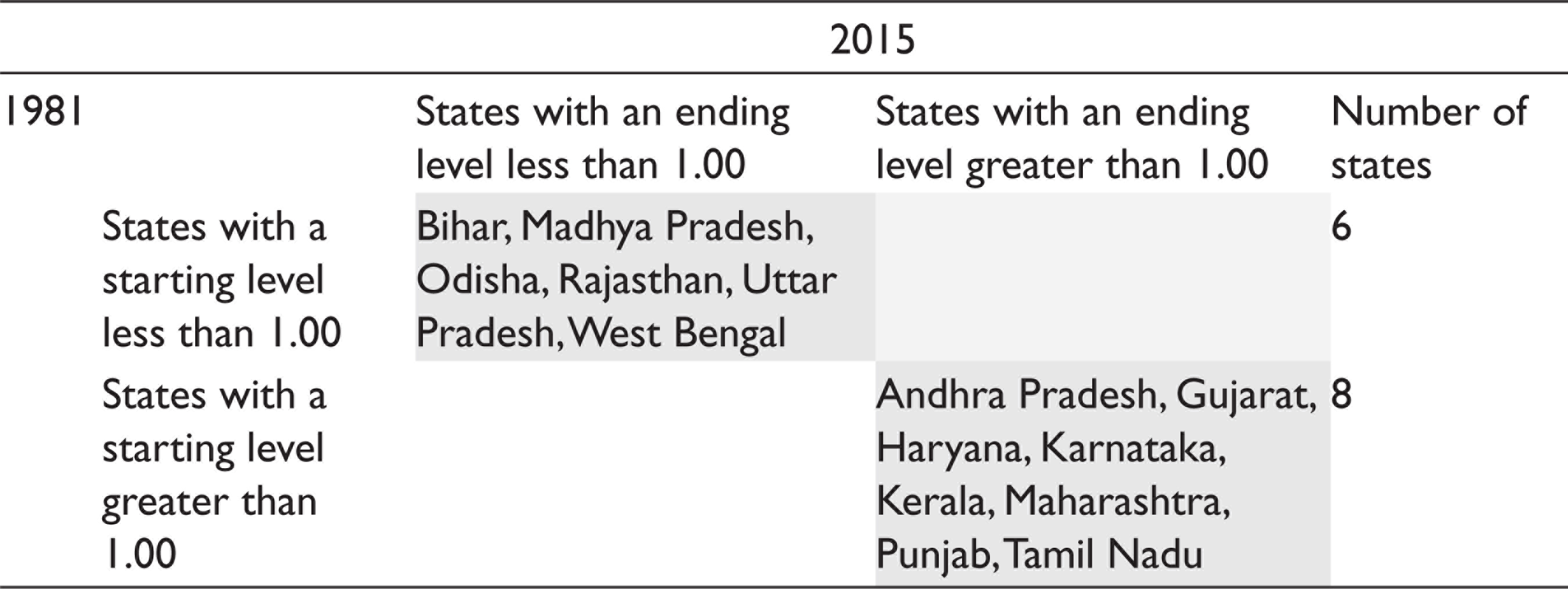
We now examine the degree of decentralization (expenditure and revenue). The transition matrices indicate heterogeneity in the degree of decentralization (see Table 7). Six states began the period with an RD lower than the average (Bihar, Madhya Pradesh, Odisha, Rajasthan, Uttar Pradesh and West Bengal), and eight states began with an RD higher than the average (Andhra Pradesh, Gujarat, Haryana, Karnataka, Kerala, Maharashtra, Punjab and Tamil Nadu). All these states maintained their relative positions, and there was no transition in RD during this period.
Relative Revenue Decentralization Transition Dynamics, 1981–2015
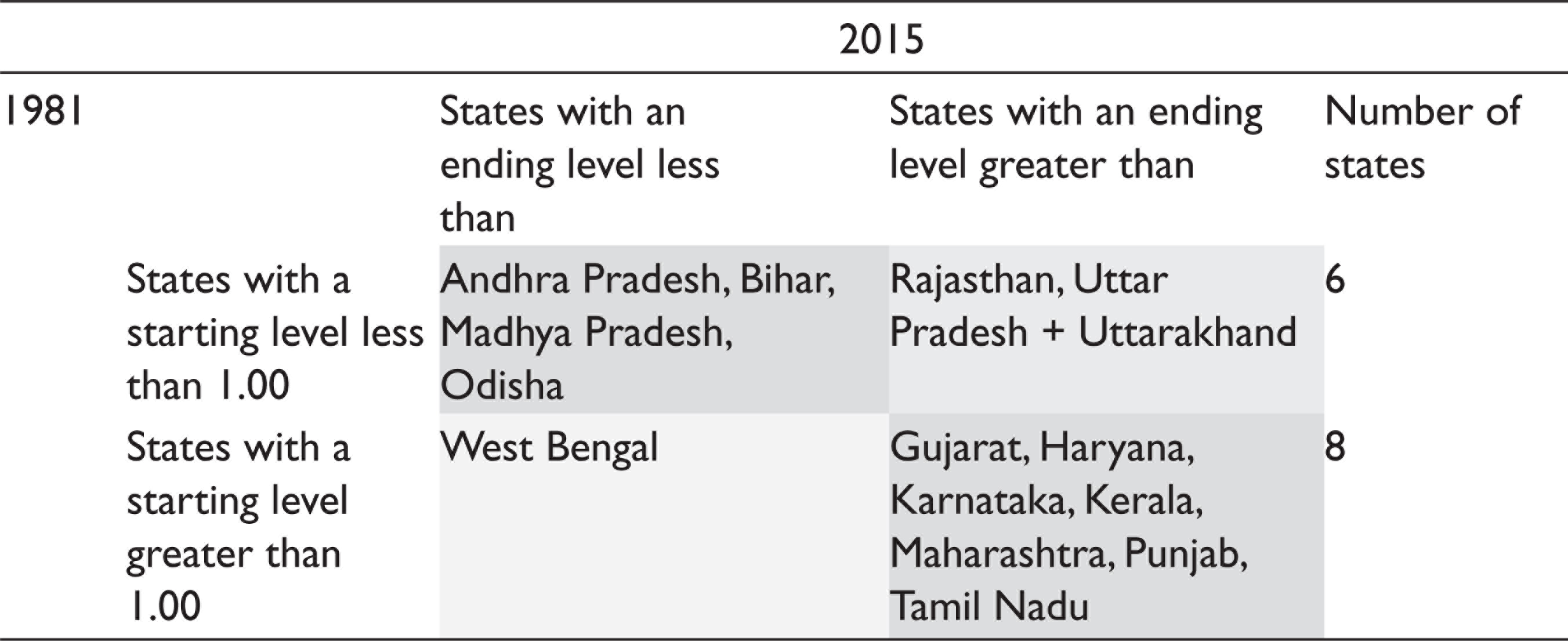
We find a higher transition among states in ED (see Table 8). Two states (Rajasthan and Uttar Pradesh) began with an ED lower than the national average and ended with an ED greater than the average. West Bengal was the only state that started with an ED greater than the average but ended with an ED lower than the average. Four states (Andhra Pradesh, Bihar, Madhya Pradesh and Odisha) began with an ED lower than the average and ended with an ED lower than the average. Seven states (Gujarat, Haryana, Karnataka, Kerala, Maharashtra, Punjab and Tamil Nadu) began with an ED greater than the average and ended with an ED greater than the average.
Relative Expenditure Decentralization Transition Dynamics, 1981–2015
Four states (Gujarat, Maharashtra, Haryana and Punjab) began with a high PCI and ended with a high PCI. These four states exhibited high RD and ED in both the beginning and the end. Kerala and Tamil Nadu also had high ED and RD like the above four states and transitioned from an initial low PCI to a high PCI. Andhra Pradesh, Rajasthan and Uttar Pradesh are exceptions in different ways. Andhra Pradesh had a high RD but had a low ED (beginning and end) and could transition from a low PCI to a high PCI. Uttar Pradesh, on the other hand, had a low RD (beginning and end) but transitioned from a low ED to a high ED and was able to transition from a low PCI to a high PCI. Rajasthan shared the same status as Uttar Pradesh but could not make PCI gains as Uttar Pradesh did. West Bengal became part of those states that began and ended with a low PCI. It had a low RD (beginning and end), and its ED reduced between the two periods. All the states (Bihar, Madhya Pradesh and Odisha) that had a low ED and RD (beginning and end) also had a low PCI (beginning and end).
We visualize the association between decentralization and PCI spatially by creating four categories—corresponding to the four cells of the 2 × 2 matrix. If the ED, RD and PCI of a state are all in the first cell (less than average), then the state takes a value of ‘1’. If the ED, RD and PCI are in the fourth cell (all above the average), then the state takes a value of ‘4’. If PCI is higher than the average but either RD or ED is less than the average, then the state takes a value of 3. Similarly, if either RD or ED is less than the average but PCI is also below the national average, the state takes a value of 2. In Figure 1, the dark-blue areas have the lowest decentralization level and growth, while the red areas have high decentralization and a high PCI. The orange areas have one aspect of high decentralization (either ED or RD) but a high PCI. The light-blue areas have a low PCI and one aspect of high decentralization (either ED or RD). As we can see, in 2015–2016, the red areas have spread along the west coast and the orange areas in the south-east. The western segment, which was deep blue, has changed to light blue, but eastern India has remained blue and, in one case, has receded.

Conclusion and Discussion
Our results show a positive impact of ED, as well as RD, on economic growth. Additionally, we find that: (a) ED has a non-linear relationship with economic growth; and (b) RD has a linear relationship with growth. This contrasts with some earlier studies that found a positive impact of ED but a negative impact of RD on economic growth (Ganaie et al., 2018). We also find that social sector expenditure and capital expenditure by the government have a positive impact on growth.
We used a twofold strategy to examine the research questions. A regression-based approach confirmed the direction of causality, as well as the significance of each of the covariates. We also used an alternative to the regression-based approach—the distributional dynamics approach—that did not capture causality but: (a) overcame the normality requirement for regression analysis; and (b) displayed the income distribution change using the Markov chain analysis.
Our results imply that by increasing the efficiency of resource allocation between the levels of government, it is possible to increase growth. Sub-national governments are better aware of the local needs and thus are in a better position to match local demand with the available resources. This can be achieved by increased devolution of expenditure and revenue raising responsibilities among the sub-national governments. Therefore, fiscal autonomy enhances growth. Besides this, the liberalization dummy variable, which was used to capture the structural change in the Indian economy, was found to have a significant and positive influence on growth.
Policy Implications
The findings of our study have important policy implications. The constitutional bodies of the central and state finance commissions, apart from their primary objective of fixing state shares, must also look at their role as being catalytic to economic growth. State governments that wish to expand their growth prospects should consider enhancing their decentralization efforts, infrastructure and social sector involvement. Our results also reiterate what is already well known in the growth literature: human capital enhances growth—thus, social expenditures have a positive influence on sub-national growth (Kalirajan & Otsuka, 2012).
In India, there has been wide diversity in the extent of decentralization, especially between third-tier governments. Many states have made very limited devolution of fiscal powers despite the constitutional provisions being available since the 73rd and 74th constitutional amendments in 1992. While our article has not looked at the third-tier level of government, we anticipate that further decentralization would not only strengthen local governance but may also enhance growth (Panagariya et al., 2014; Rao, 2008).
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.