
Abstract
Climate change is a significant concern to all of us. It is now becoming a hot topic of discussion among people around the world with social media being a ubiquitous platform for debate. As in other countries, the Government of India has started various initiatives to minimize the causes of climate change. But the success of all such initiatives depends on people’s participation and understanding. Therefore, this study’s aims are two-fold: (a) to capture the perception of Indian people towards different topics of climate change; (b) to mine the sentiment of Indian people using ‘deep learning’ algorithms. Data from various social media platforms have been used for this research. The study showed that people in India have demonstrated concern about topics related to climate change. The study also found that the convolutional neural network (CNN) was the most effective algorithm for sentiment classification. The results can help different stakeholders, including the Government of India, prioritize various actions to mitigate climate change’s causes and effects based on citizens’ sentiment.
Introduction
Global warming is the primary cause of climate change in the world. Global warming is defined as the average increase in earth temperature, which is significant enough to cause changes in climate. Climate change, global warming and the greenhouse effect are nowadays synonyms in the research domain. The major contributors to climate change are the excessive presence of CO2 and other pollutant gases. Over the past decades, there has been a significant increase in the earth’s average temperatures. Ocean water levels have been rising because of the melting glacial polar caps. According to the Intergovernmental Panel on Climate Change Assessment Report (Seggel & De Young, 2016), global climate change will have severe and irreversible impacts on sea-level rise, crop production, and ocean acidification.
Climate change will continue to be a hot topic of discussion among various stakeholders in the twenty-first century. The Paris Agreement (PA) is one such outcome of such discussion (Horowitz, 2016). The objective of PA was to deal with mitigation, adaption and finance to control greenhouse gas emissions. PA was signed in 2016, and as of November 2019, 188 countries have agreed on the proposed theme of PA. India is one of the signatories to the Paris agreement. The effect of climate change has led to climate disasters in many parts of the country and the Indian government is taking various steps to reduce the carbon footprint in India. Some significant actions are Swachh Bharat, a ban on single-use plastics, promoting electric vehicles, etc. But the people’s perception, understanding and sentiment are crucial for the success of these schemes.
Social media has become one of the primary tools to analyse people’s sentiment toward global climate change. Various studies have focused on classifying sentiment associated with this topic and tracked sentiment subtleties over time (An et al., 2014). Sentiment analysis in global climate change is primarily used to determine the different opinions on global climate change (Koto & Adriani, 2015). Nowadays, many heuristic-based algorithms are becoming popular for sentiment and opinion mining. One of these emerging technologies is deep learning (Ain et al., 2017; Jena, 2020). Deep learning-based techniques have been successfully used to predict sentiment in different domains and would provide great insight into the nature of discourse regarding climate change topics in India. Hence this research attempts to classify and predict the sentiments of Indian people on different issues of climate change. This study was aimed to answer the following research questions:
Do users express different opinions toward climate change topics on social media? How do the user demographics (e.g., gender, age) influence people’s opinions towards climate change? Can a robust model be built to predict Indian peoples’ sentiment towards different climate change topics?
The article is organized as follows: The literature review is presented in the second section. The third section discusses the detailed methodology used in this study. The results and analysis are presented in the fourth section. The fifth section is devoted to the discussion and implication of the results. The sixth section provides a conclusion and limitations of the study.
Literature Review
Climate change is a global issue, and all stakeholders are trying to address the topic. The present study has looked at the climate change-related sentiment mining perspective in India. The Indian government has taken different steps to alleviate the future impacts of climate change. However, the success of these steps largely depends on public opinion towards the issue. There are various frameworks available to access public views. Most of them are traditional polling methods and statistical methods. The conventional polling-based approach uses survey methods to measure public opinion but these methods are time-consuming and sometimes unfeasible.
Nevertheless, social media and micro-blogging sites have become popular discussion forums for different social and political issues worldwide in recent years. Micro-blogging site usage has increased vastly during the last decade (Perrin, 2015). Twitter, Facebook, Instagram, YouTube are the most popular social media and micro-blogging sites for public opinion. Hence, researchers are using data from these sites for their studies. Similarly, social media can provide abundant data for discriminating public sentiment on climate change topics.
The primary objective of sentiment analysis (SA) is to detect and identify sentiments and then classify them as positive, neutral or negative (Chen et al., 2015; Sharef et al., 2016). There are many techniques available for sentiment mining. These can be broadly classified into lexicon-based and machine learning-based techniques. Lexicon-based approaches begin with a small set of ‘seed’ words to generate a large lexicon using bootstrapping. Whitelaw et al. (2005) have identified significant drawbacks in lexicon-based methods. Their analysis depends mainly on a sentiment lexicon dictionary.
On the other hand, machine learning (ML) based approaches are fully automatic. ML techniques treat the documents/texts either as a string or group of words. Deep learning techniques are one of the most effective techniques among these ML approaches. Deep learning concepts are not new. They have been in existence since the 1940s. Deep learning has been renamed many times by various researchers based on different research perspectives. From the 1940s to 1960s, deep learning was known as ‘cybernetics’. It was again familiar with ‘connectionism’ from the 1980s to 1990s. In 2006, computer scientist Hinton coined the term ‘deep learning’ (Goodfellow et al., 2016). Its techniques are primarily based on the premise of a multi-level hierarchical learning pattern. The hierarchical feature learning process helps to extract non-linear features. Deep learning techniques perform better than the traditional data mining models (e.g., decision trees, logistic regression, random forest and support vector machines and so on). In the recent past, deep learning techniques have been used extensively in text mining and sentiment mining (Jena, 2020; Raj & Kumar, 2017). Deep learning algorithms have the capabilities to leverage the unlabelled text collected from social media. There are various techniques available to assess and quantify public opinion towards climate change-related topics. Using social media data, Van der Linden (2017) discussed the various parameters that influence risk perception and overall opinion on climate change. Cody et al. (2015) applied sentiment analysis to the climate change-related tweets’ dataset. They observed how the sentiment on climate-related issues has changed over time. Kirilenko and Stepchenkova (2014) conducted a geospatial and temporal study using tweet data to analyse peoples’ sentiment regarding different regions and time zones. Finally, to the best of my knowledge, there are no studies in the relevant literature that have applied deep learning sentiment analysis using climate change-related social media data in India. Therefore, this study will enlighten the sentiment of Indian citizens towards climate change topics using deep learning algorithms.
Methodology
The complete framework is implemented in Python using deep learning techniques (Figure 1). Several application programming interfaces are used to supplement the functionality of the framework. The details of each step are discussed below:
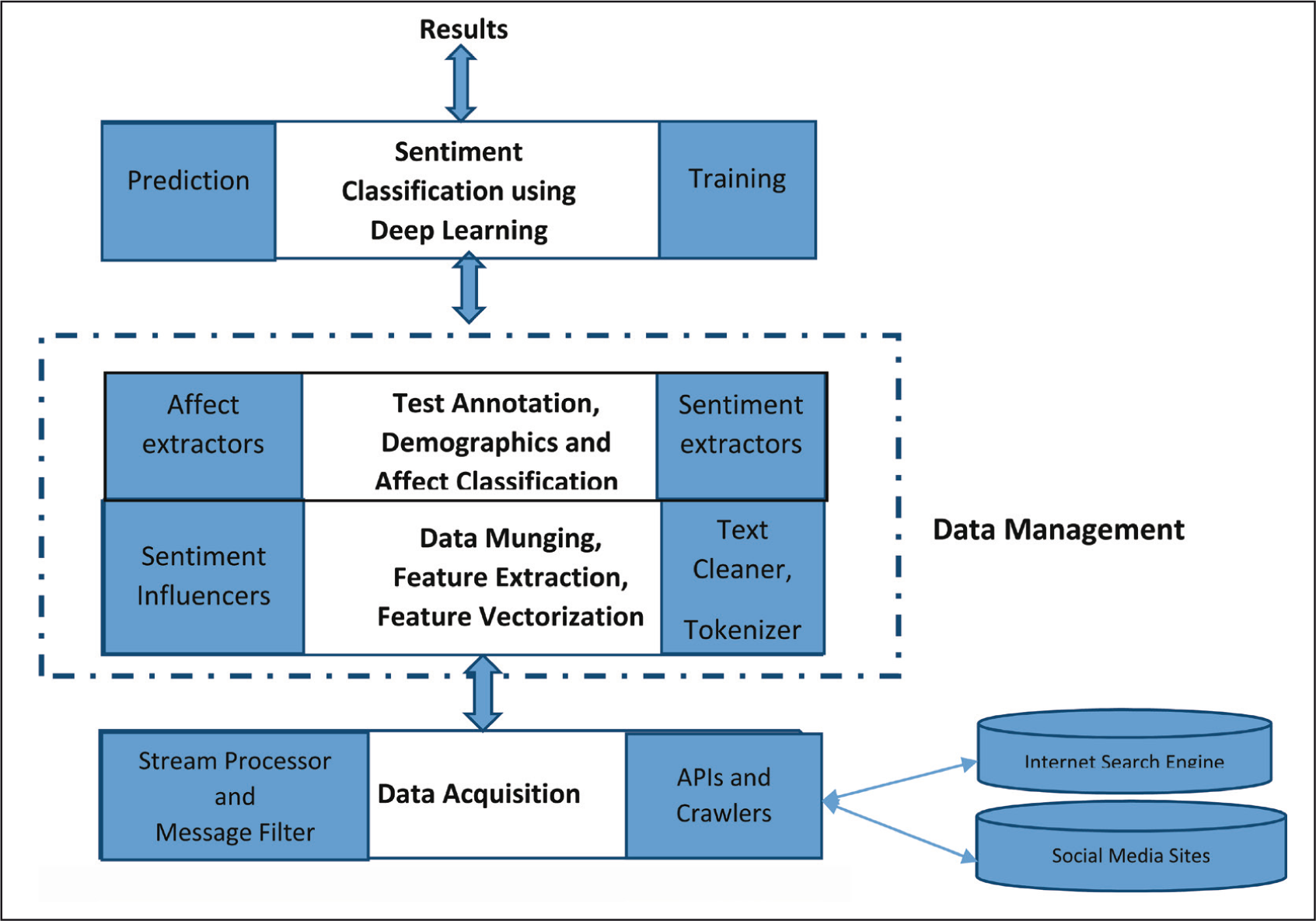
Data Acquisition
Nowadays, people are using social media platforms to express an opinion about everything necessary to them. The first step for sentiment analysis in the proposed model is to gather the data from various social media platforms (Twitter, Facebook, Internet portal, etc.) related to climate change. The majority of data was collected from Twitter for this study. Data was acquired for this research by filtering the texts that matched the terms and hashtags specified in Table 1. In addition to different keywords and hashtags, all data is in English and originated from India during 2015–2020.
Terms, Hashtags Accounts used to Retrieve Data from Social Media.

Scrapy Python package was used to collect climate-related posts from social media. In light of the fall-out of the Cambridge Analytica debacle, retrieving data from Twitter and Facebook was not easy for this research. However, data from Facebook and Twitter was collected with some limitations and proper permissions. The messages posted in the years 2015–2020 were collected for the study. More than 1.5 lakh posts were retrieved from social media. Each message includes a user ID, message ID, user country, user_text, gender and age (if available).
Data Management
Data management is a very crucial step for data analysis. There are many essential data management steps for sentiment analysis. All these steps are discussed below:
Target Missing Values Management/Handling: The first step in data management is ‘missing value management’. In this step, the redundant, unrelated text was removed. Further, feature engineering and proper transformation are required to clean the data.
Data Munging: Data munging is another essential step to remove more noise from the collected text for text analyses. It took about 80% of the time and effort of the data pre-processing task. The data munging task was subdivided into three significant steps (i.e., data cleaning, data normalization, and data pre-processing).
Data Cleaning
Data cleaning is a tedious step that needs a lot of care. Data from different social media platforms was collected for this study. So text cleaning and stringent cleaning steps were used to clean the text. At the text level, data cleaning includes removal of redundant irrelevant, and unintended text. This step was used to eliminate unnecessary, irrelevant and unwanted texts to obtain a clean data set at the next level. After text-level data cleaning, string-level data cleaning was applied to the data set. The main objective of this step was to remove social media handlers, hashtags, web-links, word shortening (w8, f9, gr8), long terms (Coooool), unusual acronyms (ASAP), neologism (webinar), etc. All of these steps were carried out by using regular expression techniques. Furthermore, punctuation, digits and data set-specific/less specific terms were also removed.
Data Normalization
Data normalization is a multi-step process to standardize the text. Case-normalization, spelling correction and contraction handling are the significant steps in data normalization. Multiple copies of semantically similar terms were removed in the case-normalization step. Contraction handling and spelling correction were essential as most of the data was collected from social media written in an improvised language. Therefore contraction handling and spelling correction was applied to the collected data.
Data Pre-processing
Data pre-processing steps have a minimum incremental impact on the overall accuracy of the classifier, but they help to improve execution time by reducing feature vector space. A three-step process was adopted for data pre-processing. The first step was word segmentation. In this step, the text was broken into a list of words, and is referred to as word segmentation or tokenization. Natural Language Toolkit (NLTK-3.2.5) was used to segment the text into tokens. Stemming/Lemmatization was the second step in data pre-processing. Stemming/Lemmatization maps different forms of verbs and nouns into a semantically related word. The main objective of stemming is to remove the trailing character(s) to reach the base form. Porter Stemmer algorithm was used for data stemming (Porter, 1980; Willett, 2006). Optionally, lemmatization can be applied to reduce the time complexity of the algorithm. Lemmatization was not used in this research. The third step of data cleaning includes removing language stop words. Stop words rarely contribute to sentiment significance. Therefore they were discarded from further analysis. NLTK-3.2.5 library was used for this purpose. Many researchers have noticed the impact of data pre-processing (i.e., removal of stop words) in the sentiment analysis (Da Silva et al., 2014; Loper & Bird, 2002).
Feature Engineering
Feature extraction and feature selection are the primary tasks of feature engineering. Feature extraction describes the input text at the different labels. The main objective of feature selection is to obtain the minimum feature set that may best describe the text. N-grams and TF-IDF features are used for text-level sentiment classification. All these features are being discussed below:
N-grams
The effectiveness of sentiment analysis algorithms depends on the probability distribution of a combination of words. N-gram is one of the features in language modelling, where documents are divided into a combination of n-words. In N-gram, ‘N’ refers to the number of words. So, there are different components of N-grams, that is, unigram, bigram, trigram, etc.
Unigram
Unigram divides the text document into single words. For example, the sentence ‘Global warming is causing a rise in temperatures’ can be divided into the following unigrams: ‘global’, ‘warming’, ‘causing’, ‘rise’ and ‘temperatures’. Stop words such as ‘is’, ‘in’, and’ ‘are’ are removed as they do not contribute to the sentiment analysis.
Bigram
When N = 2, it is called a bigram. For example, the sentence ‘Global warming is causing a rise in temperatures’ can be divided into the following bigrams: ‘global, warming’, ‘Change, is’, ‘is, causing’, ‘causing, rise’, ‘rise, in’ and ‘in, temperatures’.
Trigram
If the size of N is equal to three, it is called a trigram. For example, the sentence ‘Global warming is causing a rise in temperatures’ can be divided into the following trigrams: ‘global, warming, is’, ‘change, is, causing’, ‘is, causing, rise’, ‘causing, rise, in’ and ‘rise, in, temperatures’.
TF-IDF
TF-IDF stands for term frequency-inverse document frequency. TF-IDF is used to determine the weight of the words in the given document. Generally, high- and low-frequency N-grams are handled by TF-IDF implicitly. TF-IDF offers good results, where chances of word repetitions are frequent. TF and IDF are defined as follows:
TF(word) = Number of times a word is present in the document/ Number of total terms in the document IDF(word) = log
e
(Total number of documents/Number of times a word is present in it).
Feature Vectorization
Texts collected from social media are generally unstructured. But the unstructured data is not suitable as an input for the classifier. Therefore feature vectorization is helpful to convert the unstructured text features into a numeric feature matrix. Feature vectorization replaces each portion of the text with a massive number vector. Each dimension of that vector corresponds to a specific token in the data set. Finally, details about the vector representation used in this study are presented in Table 2.
Text Vector Representations and Parameters Used.

Text Annotation
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a robust sentiment analysis model (Hutto & Gilbert, 2014). This model is used for text annotation for this research. First VADER examines the linguistic features of a document to obtain an initial sentiment score. Later the initial score is converted to the final score using different rules based on syntactic and grammatical conventions (−1: strongly negative and 1: strongly positive, etc.). The rules also handle the contrastive conjunctions (e.g., the word ‘but’) and negations (e.g., the word ‘not’).
In this research, to obtain a sentiment score for collected data, 500 texts were randomly selected. First, each text was manually classified as ‘negative sentiment’ or ‘positive sentiment’. Then, the VADER model was used to find a sentiment score of these 500 text sets. Generally, the classification strategy classifies a text as negative when the sentiment scores are less than zero, and positive when the score is more significant than zero. However, sometimes the output of the VADER technique may be biased toward assigning positive or negative sentiment. Therefore a threshold value other than zero was required for proper classification. Different threshold values affect the performance metric in terms of precision and recalls differently (Manning et al., 2014). After many iterations, the threshold value for this research was fixed at 0.45. That means any score less than 0.45 was classified as negative sentiment, and values equal to or greater than 0.45 were classified as positive. Neutral classes were not considered in this research. Finally, all the cleaned text was classified with two sentiment categories, that is, positive or negative.
Demographic and Affect Classification
Most of the text collected from different social media platforms didn’t have personal information like gender and age. For example, a Twitter profile does not require demographic information to operate; but a Facebook profile does have demographic information (Kosinski et al., 2014). Thus, to infer demographics for personal accounts in the text, the crowdsourcing model suggested by Volkova and Bachrach (2015) was used. Three thousand users’ demographic profiles, which were available in text data mainly from Facebook, were used to train the model with a high or moderate inter-annotator agreement. Finally, the remaining texts were annotated with two demographic attributes, that is, gender and age.
Sentiment Analysis Using Deep Learning
Deep learning is a handy technique for both unsupervised and supervised learning. Deep learning consists of many popular and effective models to solve different domains (Dashtipour et al., 2021; Omerustaoglu et al., 2020). The recurrent neural network (RNN) and convolutional neural network (CNN) are the most prominently used deep learning techniques. Various studies have used these deep learning models for sentiment classification (Dashtipour et al., 2021; Omerustaoglu et al., 2020; Terra Vieira et al., 2021).
All deep learning models work based on representation learning/feature learning. Deep learning models learn using multi-level representation using hidden layers (LeCun et al., 2015). The deep learning algorithms follow a non-linear transformation between the subsequent layers. This property enhances the expressive power of deep learning algorithms (Duda et al., 2006). Furthermore, the representation scheme of deep learning algorithms is not designed manually but learned via training data (LeCun et al., 1998). Hence deep learning models are very flexible in solving many problems.
On the other hand, it is not easy to find a suitable deep learning model for solving the problem. The best model for any problem can only be decided by conducting a comparative study using different techniques. CNN and RNN models were used for sentiment analysis due to structure and learning mechanism differences. The details of these algorithms are discussed below:
Convolutional Neural Network
A CNN is a particular case of the feedforward neural network model. CNN consists of convolution, pooling and fully connected layers. Unlike traditional artificial neural networks, where each neuron connects to all neurons of the next level, a CNN uses local connectivity between neurons to reduce the total number of parameters significantly. CNN is highly suitable for text processing. Fukushima first proposed this network structure in 1988 (Fukushima et al., 1983). The CNN architecture consists of three layers: convolution, max-pooling and classification. The even-numbered layers are for convolutions, and the odd-numbered layers are for max-pooling operations. Each node of the convolution layer extracts the features from the input layer by convolution operations. The output nodes of the convolution and max-pooling layers are grouped into feature mapping layers. Higher-level features are derived from features propagated from lower-level layers to higher-level layers. The output of the feature extraction layer is fed to the classification layer. The classification layer used a Feedforward Neural Network for better performance (Fukushima et al., 1983; Shin et al., 2016). The CNN has shown its capabilities for the classification task using fewer parameters than fully connected networks, with the same number of hidden layers (Alom et al., 2019; Fukushima et al., 1983). Many researchers have developed many classification models using CNN architectures. Some of them are as follows: AlexNet (LeCun et al., 1998), VGGNet (Simonyan & Zisserman, 2014), GoogleNet (Szegedy et al., 2015).
Recurrent Neural Network
One of the significant drawbacks of CNN is that it cannot understand each word or sentence based on the understanding of previous words or sentences. On the other hand, RNN is a state-of-the-art algorithm suitable for sequential data and uses the self-learning principle to learn from previously obtained knowledge. RNN remembers every input due to its internal memory structure. RNN can add the immediate past to the present. But vanishing gradients is a severe problem in RNN. The gradients carry information used in the learning process in RNN. But due to minimal gradients, the updated parameters for the next step become insignificant. This makes the learning of long data sequences difficult. Some methods can, however, address the RNN’s vanishing gradient problem. In this study, the vanishing gradient problem was overcome by: (a) training the model with non-linear hierarchical features; (b) establishing relationships beyond the immediate neighbourhood using long- and short-term memory (LSTM) data (Bengio et al., 2013; Sohangir et al., 2018); (c) using the rectified linear unit instead of sigmoid activation functions (Cho et al., 2014).
Performance Measure
Balanced accuracy and area under the receiver operating characteristic curve (AUC) were adopted as the performance metrics (Brodersen et al., 2010).

Results and Analysis
The average number of words in the input vector was 29. The minimum and the maximum number of words in the input vector were 8 and 46, respectively. The template of input was in < text >, < sentiment polarity >, < gender >, < age > format. For example, ‘the public is not aware of climate change and ….’, ‘−1’, ‘M’, ‘45’. The hyperparameters used in the model are shown in Table 3.
Deep Learning Hyperparameter.
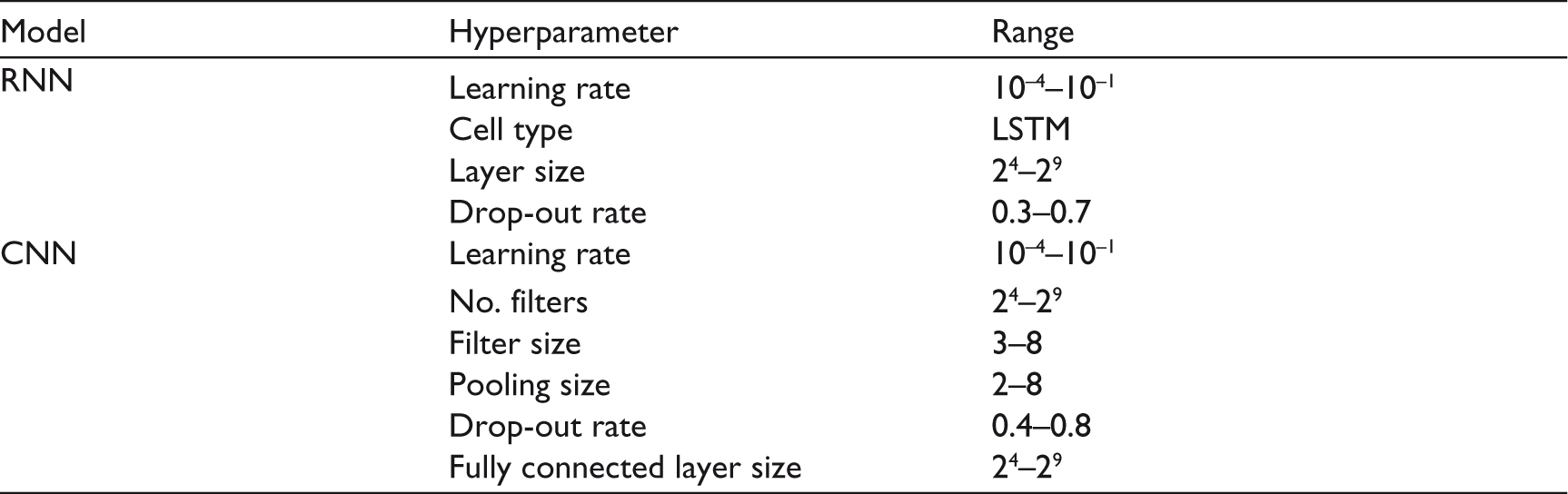
The AUC and balanced accuracy were used as the performance metric for the above models. The model was evaluated using 10-fold cross-validation. The system specification for the experiment was as follows: Intel Core i8 CPU @ 3.90GHz, Ubuntu 14.04.5 LTS and 16GB RAM.
Users’ Demographics and Perceptions towards Climate Topics
After cleaning the collected text, the frequency of prominent climate change topics discussed in the social media were estimated and shown in Figure 2. From the results, it was clear that global warming (22%) was the most discussed topic in social media, followed by air pollution (17%), weather (13%), water (12%) and climate denial (9%). That means the majority was concerned about global warming as an essential topic in climate change.

Figure 3 shows the variations in the number of discussions about different climate change topics concerning people demographics. It was observed that older people (age > 30) were more concerned about the weather, and younger (age < 30) people were more worried about air pollution.

Global warming was the most debated topic among males, whereas water issues were prominently discussed among females. Global warming, air pollution and weather were among the top listed cases across the demographics. Climate denial was the least discussed topic in social media.
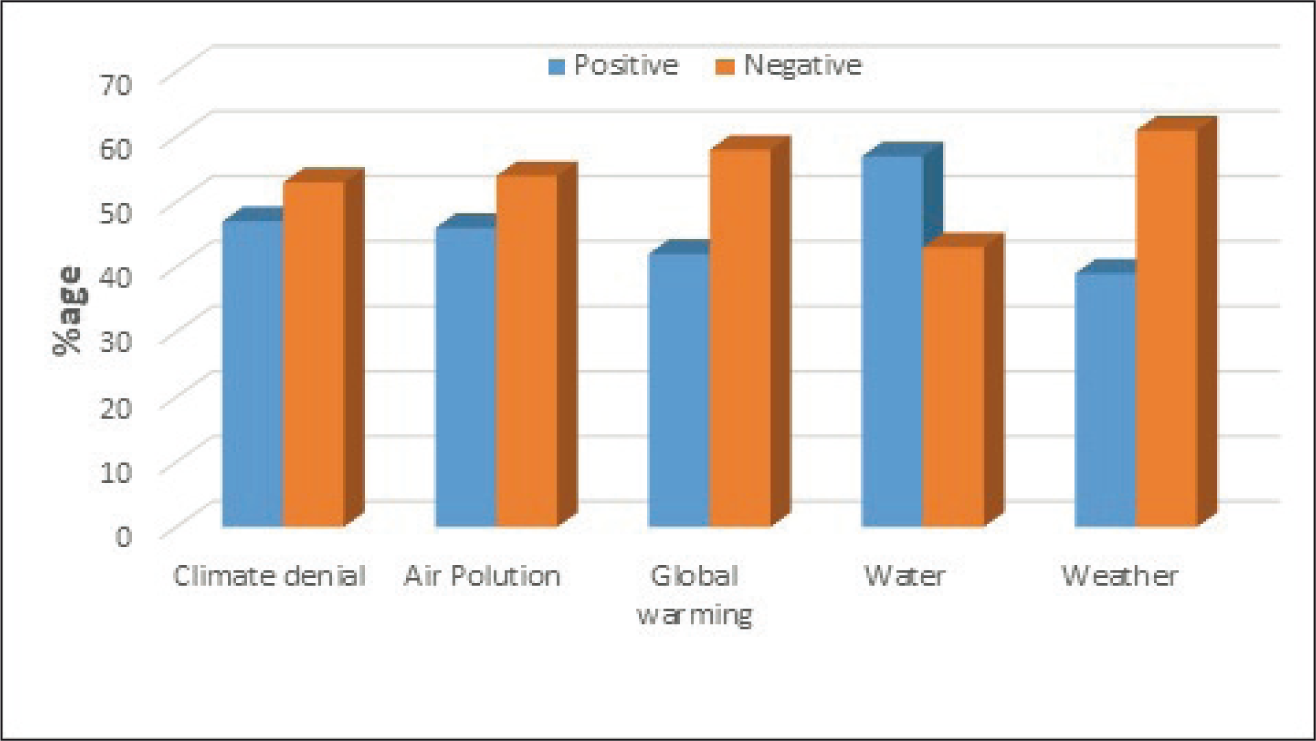
The sentiment towards climate change topics was observed and is presented in Figure 4. Most people expressed negative sentiments towards climate denial, global warming and change in weather. It is evident that the change in weather due to climate denial and global warming has severely affected India during the last decade. The Government of India is now taking steps to reduce the effect of global warming-related issues. The government is promoting renewable energy use and electric vehicles to curtail pollution. This was visible from the results that revealed a more positive sentiment towards air pollution and water-related topics. This can be understood as a positive acknowledgment towards the government’s policies to reduce the global warming effects.
Sentiment Prediction Model
This section discusses the performances of the proposed sentiment prediction model using deep learning techniques (i.e., CNN and RNN). First, the RNN model was used for classification and prediction. The LSTM model was preferred over the basic RNN model to minimize the vanishing gradient problem (Graves, 2012). Theano Library (Python) was used for LSTM. The average pooling method was used for the pooling. The hidden layer size for the experiment was fixed at 100. Table 4 shows the experimental results for RNN.
RNN Performance Metric.
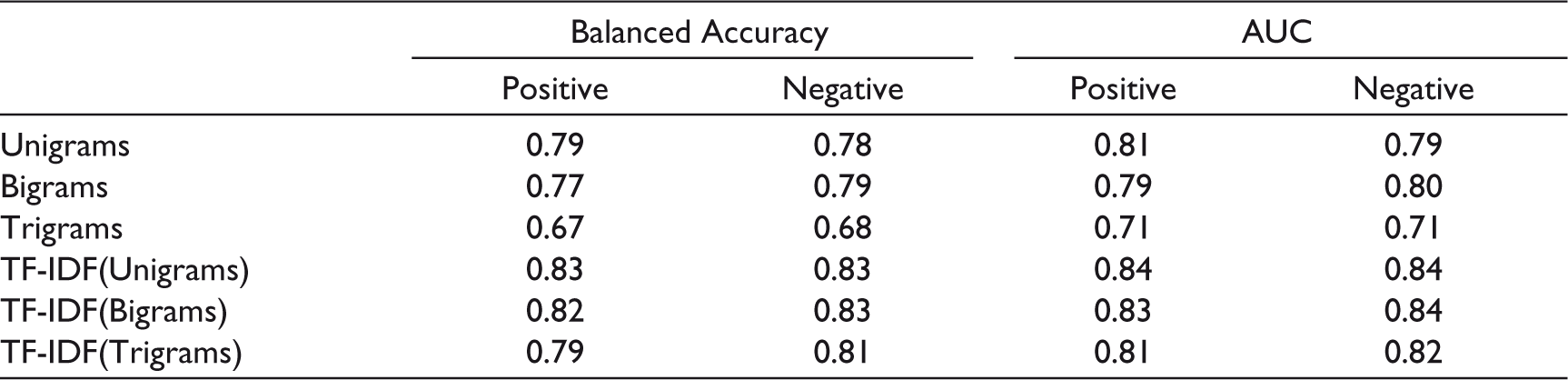
In RNN, TF-IDF (unigrams) performed better than other input text compositions concerning balanced accuracy. But for AUC, both TF-IDF (unigrams) and TF-IDF (bigrams) performed equally. Further, the CNN algorithm was adopted to improve the performance of the sentiment classifier (RNN). TensorFlow Python Package was used for CNN. A pre-trained GloVe model was used for word embedding. This experiment’s filter sizes were 3, 5, 7 and 100 feature maps for each filter used. The softmax classifier was used for classification.
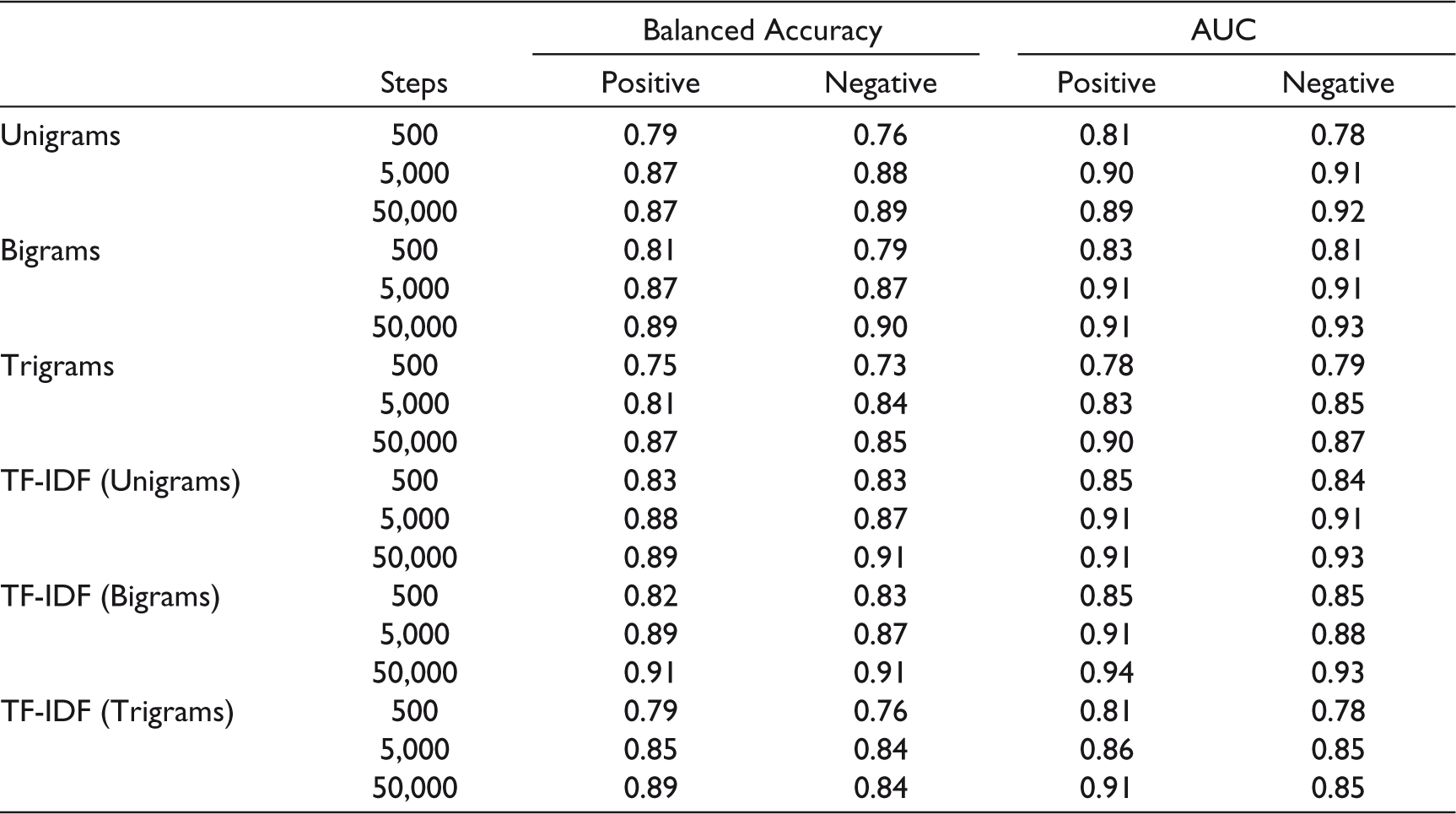
The results of the CNN model are presented in Table 5. The results concluded that CNN outperformed RNN models in both the performance criteria after 50,000 steps. The accuracy of CNN is around 87–91%, which is considerably higher than the RNN models (Table 4). On the other hand, the AUC of CNN was comparable to RNN, ranging between 0.78% and 0.93%. The results also showed that both the accuracy and AUC of the prediction increase gradually with size and iteration. The results also confirmed that TF-IDF (bigrams) performed relatively better than others.
CNN Performance Metric.
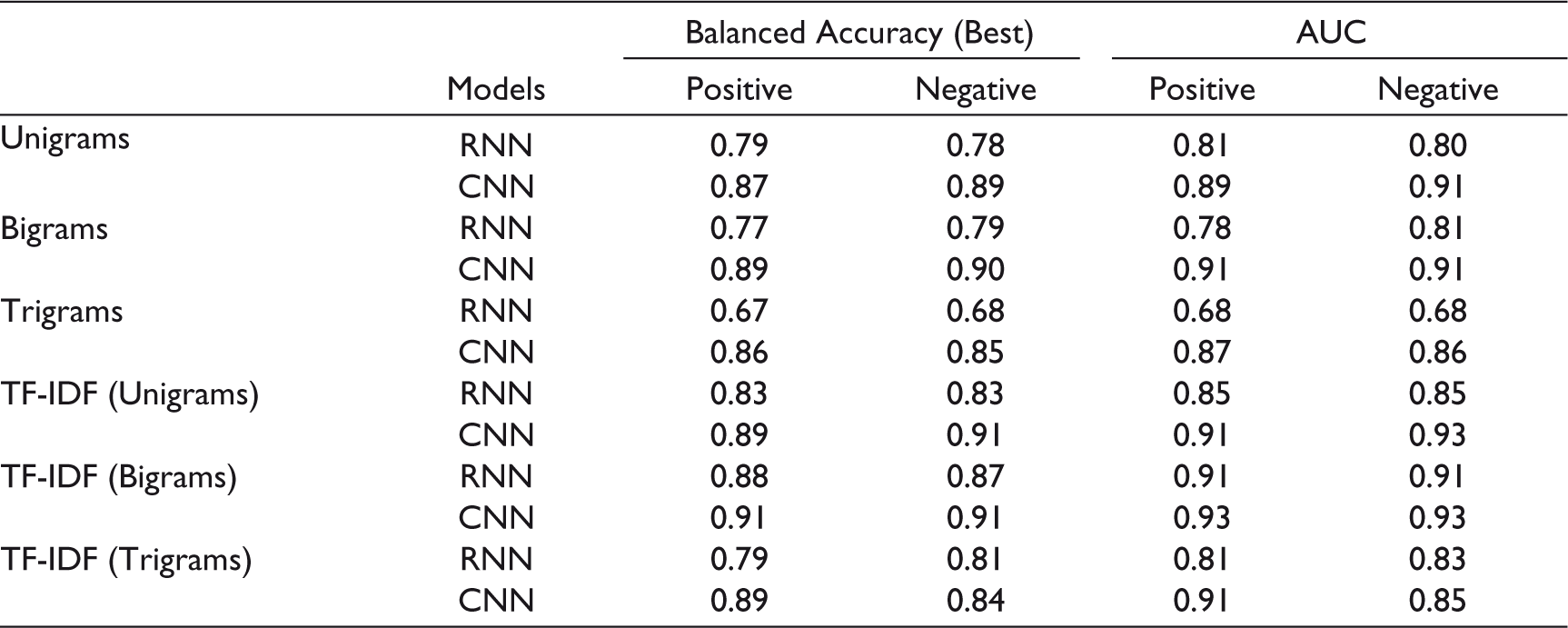
Comparative results of RNN and CNN are shown in Table 6. The above results conclude that CNN is a valuable model for climate topic sentiment prediction. Results shown in Table 6 established the performance of deep learning techniques in different climate change topics. For the climate denial topic, all algorithms performed equally. But for other issues, the CNN based model performed better than the other two models.
Performance Comparison Metric.
Last, the deep learning algorithm was applied to classify the sentiment towards different climate topics. Table 7 illustrates the results. CNN outperformed RNN in all the issues except climate denial, where both RNN and CNN were comparable. The different input representations and climate topic classification TF-IDF with the bag-of-words approach showed a clear difference in performance irrespective of other models. Overall, CNN outperformed all deep learning algorithms in all performance metrics.
Sentiment of Climate Change Topics.

Discussion
This empirical research adopted a conceptual framework to measure and predict the sentiment of Indian citizens towards climate change topics. The proposed conceptual framework used deep learning techniques (RNN and CNN) to predict people’s opinions on related topics in India due to their superior performance in different applications. Further, the deep learning models are selected from traditional data mining approaches due to their shallow learning process. The study results show that CNN is the best model for classifying the different climate change topics into other sentiment scores (i.e., positive and negative). CNN performs effectively on N-grams features. These results align with many studies tested in a different domain (Banerjee et al., 2019; Jena, 2020).
On the other hand, Menger et al. (2018) found the performance of RNN was better than CNN. Therefore one cannot draw any conclusion regarding the interpretation of these techniques; it largely depends on the application domain and types of input patterns. But in this study, CNN was found effective due to its internal structure, where each computation unit responds to a small neighbourhood of input data. Therefore, the accuracy of the CNN algorithm was significantly better than RNN. The proposed model can be helpful to different stakeholders for predicting the sentiment of Indian people about climate change topics and implementing policies and initiatives to curtail climate change-related issues accordingly. However, the AUC scores were the lowest when the data related to climate denial with binary input schemes for the input text were used. But AUC scores did not cause a drastic decrease in performance for both the RNN and CNN models. Further, the deep learning models (RNN and CNN) performed best when the bag-of-words was combined with the TF-IDF document (AUC = 0.93).
In this study, selecting a classifier, data representation and choice of learning algorithms were crucial to yield better performance. The results showed that climate topics could be classified accurately using the deep learning algorithms. There are two significant contributions of this study. First, the proposed model evaluated and compared different data representations and deep learning algorithms on climate change topics. Second, the proposed model can build portable climate topic sentiment measuring classifiers without an expert’s involvement. During the analysis, it was observed that some features are hard to classify correctly. For example, the proposed framework performed poorly on detecting sentiments/opinions related to climate change denial. It is probably because the word ‘denial’ was heavily overloaded but rarely used in the collected data. Further, in some instances, it was used synonymously with ‘rejection’. Hence, programmatically, it was dicult to classify all such phrases present in the text.
Further, most errors induced in the prediction are due to the ambiguity and context-dependency of the words and complex structure of the used language (i.e., English). Again, some ambiguous texts were complicated to classify correctly even by human experts. For example, a parameter that sounds favourable to context, such as ‘Air pollution should be moderate by 2025’, is problematic for other people to agree with positively (e.g., ‘Air pollution should be less than 125 PM2.5 by 2025’). So it is algorithmically challenging to classify text correctly.
Conclusions and Limitations
The study used a deep learning-based framework to understand peoples’ sentiments towards climate change topics in India. The sentiment mining using the deep learning framework was preferred over field trials and survey-based methods due to the following reasons: (a) field trials or target surveys for generating perceptions of climate change are costly and time-consuming; (b) the easy availability of social media data for machine learning algorithms. The research results showed that the CNN model classified the climate change topics more accurately than the RNN model. Therefore the model based on CNN can help stakeholders assess the people’s sentiments from time to time correctly. It will also help governments and NGOs to take appropriate actions to deal with climate change issues.
There are several avenues for improvement, such as: (a) generally sentiments change over time, therefore periodically analysing them (e.g., weekly/monthly) can help to capture the people’s sentiments more effectively and correctly; (b) spam or malicious text detection is essential for any sentiment classifier. But this research was not focused on spam detection. Therefore, future studies should effectively treat spam and malicious texts to enhance the classifier’s performance; (c) this study used fundamental feature selection steps. For example, if more than one feature is found in the sentence, the classifier preferred the first noun matching. Hence more sensitive techniques can be helpful to increase the model performance in future research.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.