
Abstract
Music can convey emotions. Even in the performance of written rather than improvised music, the performer can modify the way they play particular elements of the music to convey specific emotions. Considerable research attention has been paid to the ways in which performers convey a small set of so-called basic emotions. In the current work, we investigated how musicians think they can convey a larger set of emotions in their performances by modifying musical elements and varying playing parameters. We presented 12 clarinetists trained in Western classical music with 55 pairs of expressive goals (EGs) derived from a list of 11 (e.g., to make the music sound happy, sad, or expressive), and asked them to provide similarity judgments for each pair representing how well they thought they would be able to distinguish between them when performing four excerpts of music, and how they would do it. The similarity judgments produced dissimilarity scores that were grouped using cluster analysis to form six independent, coherent clusters of EGs. Four clusters consisted of, or included, EGs representing four basic emotions: happy/humorous; sad; angry/mad/ugly; and fearful. The other two clusters consisted of the EGs expressive/overly expressive/beautiful and deadpan. We therefore suggest that this set of six clusters could be used in future research on emotional and musical expression in music. Participants reported that to achieve specific EGs, they would vary the way they played a wider range of musical elements than in previous studies, albeit including many of the same elements. Among the playing parameters they reported, reed-bite force was mentioned most often, with consistent associations between more force and ugly or angry, and between less force and fearful and expressive EGs.
Experienced musicians can communicate different emotions when they perform music. Such a form of communication is considered fundamental to performance, as it draws the listener’s attention to the aesthetic qualities of the sounds, and it also provides psychologists with opportunities for insight into human communication other than through vocal, facial, and postural modes. In this study, we aimed to find out if musicians think they can distinguish between a range of different emotions when performing music and how they would achieve the goal of expressing them by varying the way they play particular elements of the music.
Patrik Juslin (1997a, 1997b, 2000) conducted foundational research on musicians’ expressive intentions and how they achieve them in a series of studies published since 1996 (e.g., Gabrielsson & Juslin, 1996). He was particularly interested in how a performer could play the same excerpt from a piece of notated music in different ways to produce distinctly different expressive results. Musicians trained in the tradition of Western classical music—as in the present study—were recruited to play the same excerpt several times, each time modifying their performance to convey different emotions such as sadness or happiness (i.e., to achieve a specific expressive goal [EG]). Research participants from a similar cultural background were asked to listen to audio-recordings of the performances and decode the musician’s EG. If the participant’s decoding matched the musician’s EG it was considered that the musician had conveyed the emotion successfully and the elements of the music they had modified to achieve this EG were investigated to identify regularities, such as playing slowly to convey sadness rather than happiness.
Gabrielsson and Juslin (1996) gave careful consideration to the matter of expression. In their review of studies to date using similar methods, they observed that, when asked to play in such a way as to convey certain expressive goals such as deep, sophisticated, bright, beautiful, and dreamy (Senju & Ohgushi, 1987), the dissimilarity between pairs of performances was low to very low, suggesting that these expressive instructions did not have different meanings when applied musically. Gabrielsson and Juslin suggested that it is better to use a small set of specific emotions that are a priori distinct when investigating how musicians express different emotions in their performances. This set is referred to as the basic emotions, that is, those that are thought to be innate and universal, experienced by humans in all cultures (Ekman, 1992). Juslin (1997a) argued that the basic emotion categories represent the optimal compromise between two opposing goals of an emotion decoder [in this case the listener]: (i) the desire to have the most informative categorization possible, and (ii) the desire to have these categories be as discriminable as possible. (p. 79)
The EGs used in these early studies varied somewhat, but musicians were frequently asked to make the music sound happy, sad, fearful, angry, or tender, a set of terms deriving from the theoretical construct of the basic emotions that went on to be widely used in studies of emotional expression in music. Other nonbasic emotion terms such as expressive (e.g., Juslin, 1997b) were sometimes included, along with solemn and no expression (Gabrielsson & Juslin, 1996). Juslin and Laukka (2003) conducted a study using an extended set of 12 emotions in which content, curious, disgusted, jealous, with love, proud, shameful, and tender were added to the four basic emotions. This relatively systematic program of research led to the construction of a lexicon of musical elements that are associated most often with particular emotions (for a summary, see Gabrielsson & Lindström, 2010).
Although limiting EGs to those conveying the basic emotions has its strengths, as summarized above, it also has weaknesses, one of which is the assumption that every emotion that can be expressed by a musician can be confined to a rather narrow range of terms that do not necessarily represent distinctly different emotions. That is, the use of labels for the basic emotions to generate EGs has its theoretical origins in psychology rather than music, thus failing to ensure that the widest range of musically expressive possibilities can be considered.
Juslin’s use of such a small set of emotional words in his studies has been a major influence on researchers’ understanding of what it means to play music expressively. Some researchers now see it in terms of two broad phenotypes: performances that are musically expressive and performances that are emotionally expressive (Schubert & Fabian, 2014). It has been proposed that the term musical expression should refer to that which can be expressed, typically in a piece of Western classical music, according to some culturally agreed-upon standard, and the extent to which it can be expressed. The term emotional expression, by contrast, should refer to a performer’s expression of one or more of a set of emotions, independently or on request, as described by Juslin, without regard to musical expression as defined above.
The concept of musical expression, more nebulous than that of emotional expression, has been extended in recent work by Schubert (2022). Listeners’ responses to musical expression are not the same as their responses to the expression of emotions such as sadness, happiness, fear, and anger (Schubert et al., 2016). While they include enjoyment and pleasure, they also reflect listeners’ emotional states in response to the emotional intentions (i.e., musical expression) conveyed by the performer, such as feelings of awe, and sense of being moved by the music. In the present study, EGs are defined as encompassing the communication of musical as well as emotional expression.
Our aims were to investigate (a) the relationship between EGs and the musical elements that can be modified to achieve them, which has already been explored by researchers, and (b) the relationship between EGs and the variation of playing parameters used to achieve them, which to the best of our knowledge has not yet been explored. We therefore asked two broad research questions, each with subsidiary questions:
Would a small sample of clarinetists think they could distinguish between pairs of EGs when playing the same three musical excerpts and a fourth, self-selected excerpt? (a) If they were given a set of EGs larger than those used in previous research, encompassing musical as well as emotional expression, would they think they could distinguish between pairs, and if so to what extent, and are there some EGs that are sufficiently similar that they may be grouped together? (b) Would the participants think they could distinguish between pairs of EGs in the same way in each of the four excerpts?
How would they distinguish between pairs of EGs when playing the four musical excerpts? (a) Which musical elements would they modify? (b) Which playing parameters would they vary?
Our methodological approach was to administer a survey in which participants would be invited to carry out a paired-comparison task rather than rating each EG independently. The paired-comparison method derives from research in psychophysics, since it tends to produce greater discriminability than tasks in which constructs of interest are not compared with related constructs by the participant (Thurstone, 1987). Such tasks are easy to implement using computer technology (e.g., Tarricone & Newhouse, 2016), and there is evidence to suggest that the method offers high levels of contextualization (Patel et al., 2010), detail, and granularity (Stadthagen-Gonzalez et al., 2018).
One disadvantage of the paired-comparison method is, however, that a fully factorial design necessitates a lengthy procedure, as the number of comparisons is approximately proportional to the square of the number of EGs. We did not wish to fatigue our participants who, in any case, would be asked to carry out the task in no more than 3 hr, the length of a typical rehearsal. This meant that although we had intended to use a range of EGs, including some not usually found in the literature, we would need to restrict them to a manageable number. We therefore created a list of 11 EGs including the basic emotions happy, sad, angry, and fearful; two frequently investigated terms related to musical expression (expressive, overly expressive); and a combination of terms denoting the absence of musical expression (deadpan/lackluster/mechanical). The list also included the term beautiful because, arguably, it too is related to musical expression, explaining why it has rarely been used in empirical research on expressive intentions in music, and its antonym ugly (Sauchelli, 2014); this enabled us to explore both ends of the musically expressive spectrum. Finally, the list included the term humorous and the combination of terms mad/crazy.
We decided to limit our sample of participants to clarinetists to reduce the number of unknown variables and because the instrument itself is well understood (Almeida et al., 2013, 2017; Bak & Dolmer, 1987; Chen et al., 2009; Dalmont et al., 2005; Dickens et al., 2007; Kergomard et al., 2000; Li et al., 2016a, 2016b; Lulich et al., 2017). Simple physical models can be used to explain the way it works and several teams of researchers (e.g., Dalmont & Frappe, 2007; Guillemain, 2007; Li et al., 2016b; Pàmies-Vilà et al., 2018, 2020) have measured the parameters modified by performers when playing the clarinet, such as blowing pressure and bite force (playing parameters). The instrument has been automated (Almeida et al., 2013), so a better understanding of how clarinetists achieve EGs when performing could have important implications for improving automated performance (Juslin et al., 2001; Schubert et al., 2017). Finally, the present study adds to previous research on musicians’ EGs by involving clarinetists rather than pianists and string players.
Method
Design
An online survey 1 was constructed, including paired-comparison tasks to find out (1) if participants thought they could distinguish between pairs of EGs derived from the set of 11 listed above and (2) which musical elements they would modify and which playing parameters they would vary, to distinguish between pairs of EGs in performances of each of the same three musical excerpts and one self-selected excerpt (see Stimuli, below). Participants were invited to take part in the research via an email including a link to the online survey, which they completed in their own homes during a COVID-19 lockdown. They were encouraged to play their own instruments while responding to the survey, but no recordings were made of their performances. The survey was designed to take no more than 3 hr. It did not have to be completed in a single session, so participants could take breaks. The project was approved by UNSW’s human ethics committee (approval number HC200684).
Participants
Six men and six women aged 18–73, living in Australia and trained in Western classical music, completed the survey. They were all clarinetists: six professionals and six highly experienced nonprofessionals. They all had played the clarinet for at least 8 years and could therefore be classified as musically skilled, or having a musical identity (Zhang & Schubert, 2019). They were paid for their participation at rates recommended by the Musicians Union of Australia (https://musiciansunion.com.au).
Stimuli
The stimuli consisted of three musical excerpts selected by the researchers and one selected by the participant. The excerpts selected by the researchers were well known and diatonic, of which two have often been used in research on EGs. These were eight bars each taken from Happy Birthday and the American spiritual Nobody Knows. The third consisted of nine bars taken from the second movement of Beethoven’s 7th Symphony (Allegretto), a melody consisting mainly of repeated pitches to a simple rhythm, here using first the second and then the first clarinet part. The survey included the excerpts in standard music notation, each one followed by the paired-comparison questions shown below. When the participants had completed the three sets of paired comparisons, they were asked to nominate a fourth stimulus in the form of a suitable excerpt of their own choice and complete a final set of paired comparisons. We refer to the four excerpts, three researcher- and one participant-selected, as the four conditions.
The survey
The platform used for the survey was Qualtrics (Provo, UT; www.qualtrics.com). After an introduction in which participants were asked to respond to auto biographical questions, the paired-comparison task was described as follows: Imagine that you are given a musical excerpt to be performed in order to convey a particular emotion. In the following sets of questions, you will be given a pair of emotions and asked to decide if the piece can be played to differentiate the two expressed emotions clearly. For each pair of emotions, you will be asked to If the two emotions would not produce the same musical result, please indicate briefly in the COMMENT BOX There will be three excerpts of music for which the emotion comparisons are to be made, plus a fourth one of your own choice, if you can think of a piece that could successfully be played to communicate a wide range of emotions.
The final set of paired comparisons was obtained by giving participants the following instructions: Please select an excerpt of a piece that YOU BELIEVE COULD EXPRESS THE WIDEST VARIETY OF DIFFERENT EMOTIONS IF THE WAY IT IS PERFORMED IS ALTERED BY THE PLAYER IN SEVERAL DIFFERENT WAYS (e.g., by altering the dynamics, tempo, articulation etc.). If you can do this, please indicate the details of the piece and the excerpt you would choose (e.g., the one or two phrases of the piece). Please write the details here:
The 11 EGs used in the study were sad, happy, fearful, angry, ugly, beautiful, expressive, deadpan/lackluster/mechanical (henceforth deadpan), and overly expressive, humorous, mad/crazy (henceforth mad). Every possible combination of two EGs—a total of 55 pairs—was presented, in a different random order for each participant, on the pages of the survey that followed. For each pair of EGs and for each condition, participants were asked “How differently could you convey the two emotions (1) and (2) shown on each row below,” where (1) and (2) represented paired emotions (e.g., happy and sad), and response options represented similarity judgments: very similar, somewhat different, or very different.
Participants were asked to describe how they would distinguish between pairs of EGs in each condition (Research Question [RQ] 2). We provided suggestions in the introduction to the task as to how musical elements could be modified (by playing, for example, loud, fast, articulated), and how playing parameters (such as the amount of reed in the mouth, blowing pressure, and lip force) could be varied, together with two- or three-letter codes to make reporting more concise (e.g., LO to indicate louder, MT to indicate more throat), as follows: If the two emotions could be distinguished from one another on the clarinet, provide a short explanation of what in performance with (2) would be changed with respect to (1), for example for musical elements:
Louder/softer (LO/SO)
Faster/slower (FA/SL)
More/less dynamic variation (MV/LV)
LEgato/StaCcato
RUbato/STeady tempo
INtense/FLat phrasing;
for playing parameters:
Harder Bite/Softer Bite
More Throat/Less Throat
More Reed/Less Reed in mouth
EMBouchure
(this list is a mere suggestion, please add your own list of parameters that you find relevant; add your own comments in full script if needed).
One of the playing parameters included here deserves particular comment: the amount of reed in the mouth. Some clarinet teachers advise that certain aspects of embouchure, including this one, should be held as constant as possible. Other teachers and professional performers recommend that the position of the lips on the reed may be changed in certain situations. The present study provided an opportunity to gather empirical evidence on this matter.
Where participants rated pairs of EGs somewhat or very different they tended to describe musical elements and playing parameters in terms of more or less opposing qualifiers (e.g., FAst vs SLow tempo). Where participants rated pairs of EGs very similar (i.e., the clarinet could not distinguish these two emotions for the piece), they were given three further response options: Please indicate if this is because the two emotions are just very similar [SE] or that they are different but the clarinet could not be used to communicate a distinction between the two [NO], or for this piece of music the two emotions could not be distinguished [DM].
In the end, participants were asked to provide open-ended comments on the survey.
Analyses
The survey responses were exported into a CSV table. Perhaps because the survey took so long to complete in full (typically 3 hr but more in some cases) only eight participants responded in the second (Nobody Knows) and third conditions (Beethoven Allegretto), and only seven in the fourth, participant-selected, condition. All responses obtained were analyzed using Python’s Machine Learning suite (scikit-learn) and statistics package (statsmodels).
We assigned 0 to very similar, 1 to somewhat different, and 2 to very different judgments and calculated mean dissimilarity scores across all four conditions for each pair of EGs (RQ1a). We applied a cluster algorithm analysis (AgglomerativeClustering from Scikit-Learn Package in Python, n.d.) to the mean dissimilarity scores to identify which EGs are clustered together, and which are distinct from each other (RQ1b). Finally, we listed the musical elements and playing parameters associated with each EG (RQs 2a and 2b) and interrogated pairs of EGs with low mean dissimilarity scores.
Results
RQ1a. Did participants think they could distinguish between pairs of EGs and if so to what extent?
The mean similarity judgments for pairs of EGs for all participants under all four conditions, obtained from 1344 responses, are obtained from mean dissimilarity scores and represent the extent to which participants thought they could distinguish between each pair of EGs. As shown in Figure 1, they judged expressive and overly expressive to be relatively similar, and beautiful as similar to expressive (dark blue). They judged happy to be similar to humorous and beautiful, but did not judge humorous and beautiful as being similar to each other. Likewise, they judged angry to be similar to ugly and mad, but did not judge ugly and mad as similar to each other.
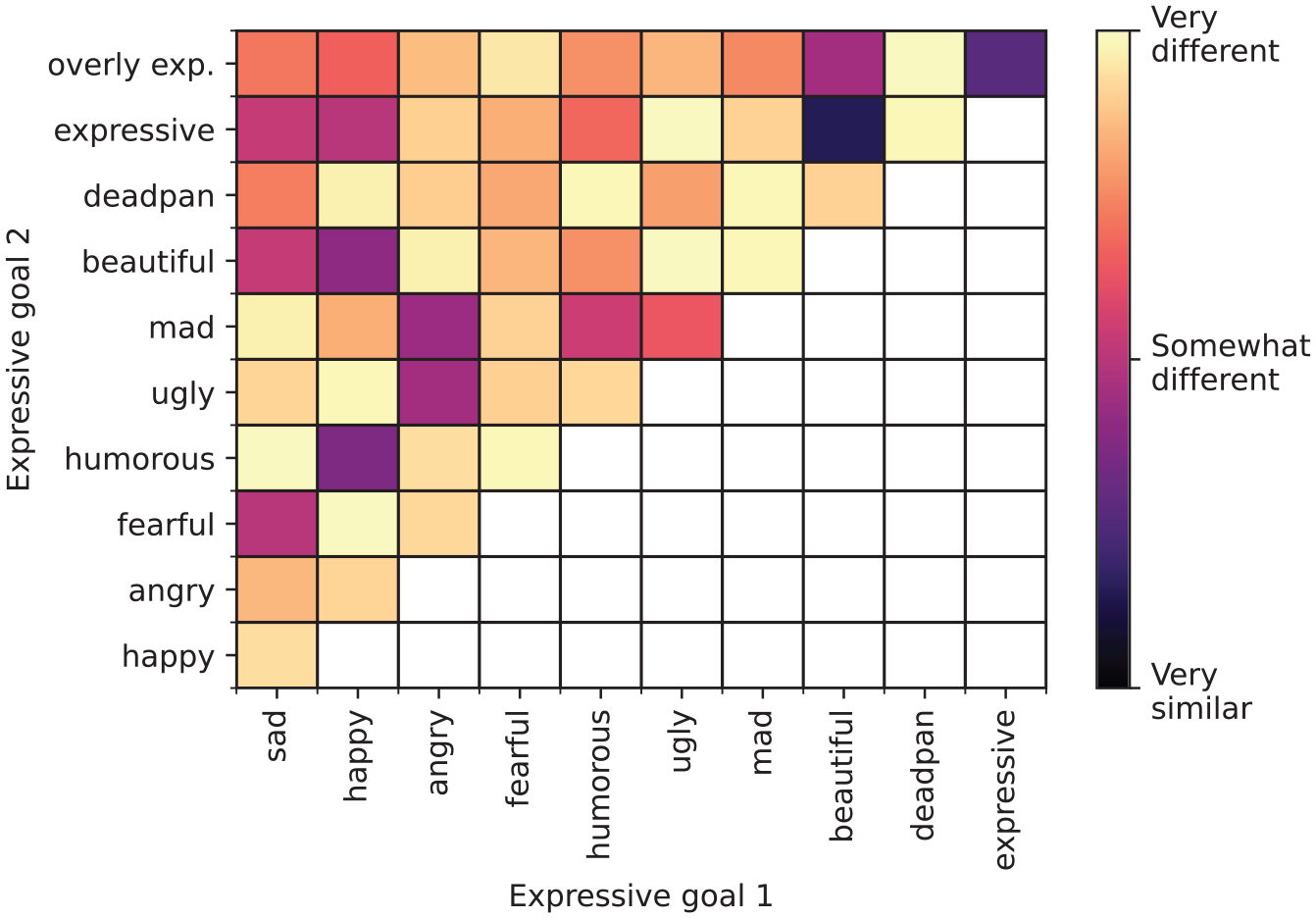
Mean similarity judgments for pairs of EGs across conditions.
RQ1b. Did participants think they could distinguish between pairs of EGs in the same way when playing each of the four excerpts?
Participants thought they could distinguish between pairs of EGs in much the same way under the different conditions, at least for eight of the 11 EGs. This is shown in Figure 2, which illustrates the results of the cluster analysis in the form of dendograms for each condition. Beautiful and expressive were tightly clustered under all four conditions, together with overly expressive. Happy and humorous were also clustered in all conditions, as were ugly, angry, and mad. Angry and mad were tightly clustered, except in the Beethoven condition, where they were more loosely clustered. While these eight EGs were clustered consistently under all four conditions, fearful, sad, and deadpan were clustered in only three of the four and will be considered in section “Discussion.”

Results of cluster analysis.
RQ2a. Which musical elements did participants say they would modify to distinguish between pairs of EGs when playing the four musical excerpts?
To distinguish between pairs of EGs in all conditions, participants said they would modify loudness, dynamic variation, tempo, timing variation, duration contrasts, and phrasing. They reported how they would modify each musical element using the codes for the opposing qualifiers we had suggested. The reports are shown in Figure 3 as orange (positive) and blue bars (negative), together with the number of times each element was mentioned (mentions) by all participants. The inset is an enlargement of the top left square for ease of reading. Thus participants consistently reported happy to be louder (LO) and faster (FA) than sad. If there were many positive qualifiers for a particular term (e.g., happy louder than sad) there would be few negative qualifiers for the same term (e.g., happy softer than sad), with the exception of the Rubato/Steady tempo pair for which there were few positive or negative qualifiers. Some musical elements received few mentions. Occasionally some participants chose contradictory qualifiers for pairs of EGs typically judged similar, such as fearful as compared to sad, humorous/mad, ugly/angry, and beautiful/expressive, suggesting that they did not agree on how musical elements should be modified to achieve these particular EGs.
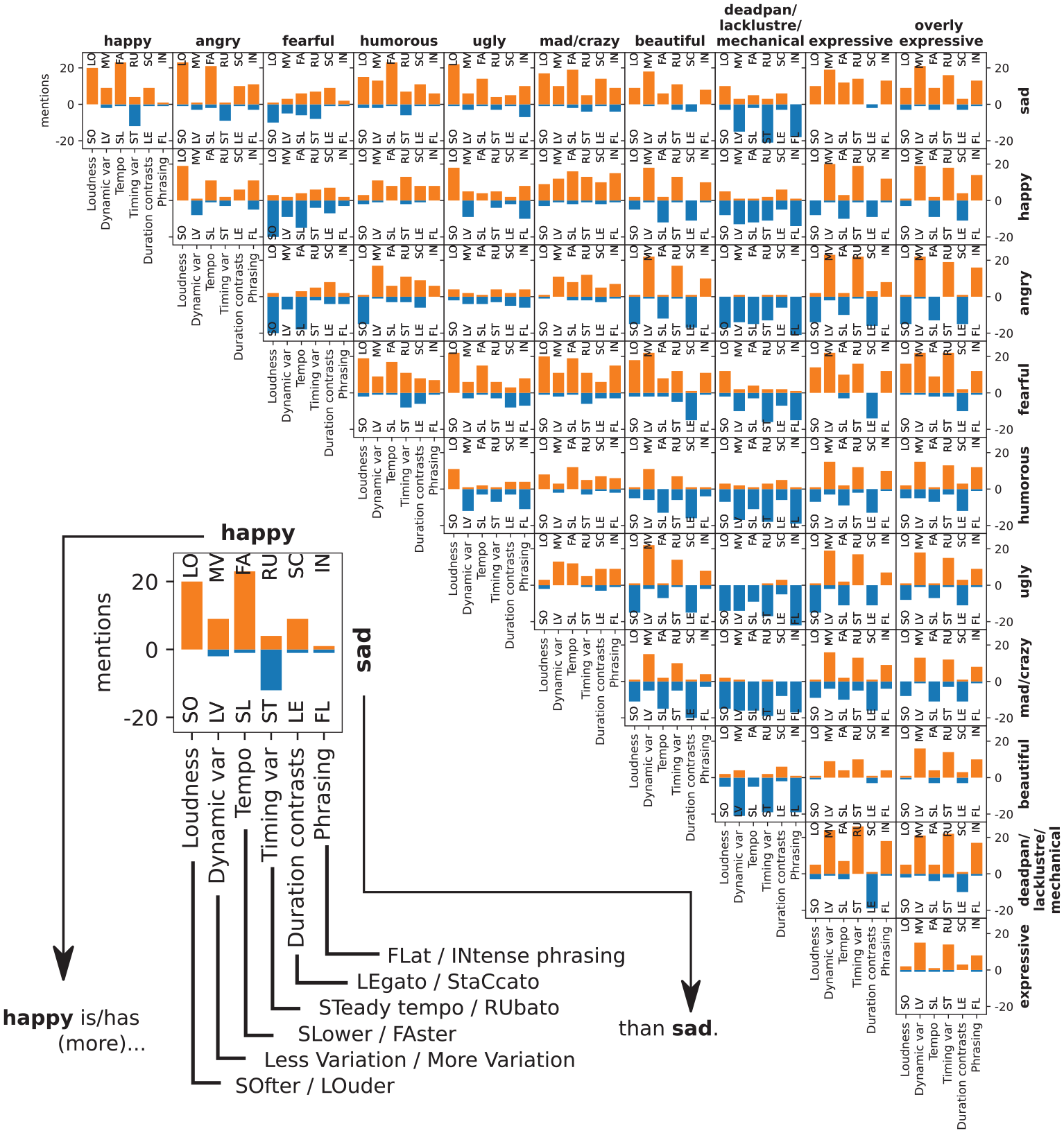
Proposed modifications of musical elements (x axis) to distinguish EG 2 (column headers) from EG 1 (row headers at right).
In 460 free-text responses, participants reported how they would modify each musical element in their own words rather than using the codes provided. The terms they used related most frequently to loudness (275), tempo (244), articulation (203), and phrasing (199), reflecting the elements already suggested to the participants. These responses were omitted from the analysis to reduce the chances of terms being used inconsistently, but also because it seemed that we had already captured the most commonly reported musical elements.
RQ2b. Which playing parameters did participants say they would modify to distinguish between pairs of EGs when playing the four musical excerpts?
Of the four playing parameters suggested (more/less throat, more/less reed in mouth, more/less bite force, and embouchure adjustment), participants mentioned bite force most often. They said they would increase it to achieve ugly and angry EGs, and reduce it to achieve fearful and expressive EGs, as shown in Figure 4.
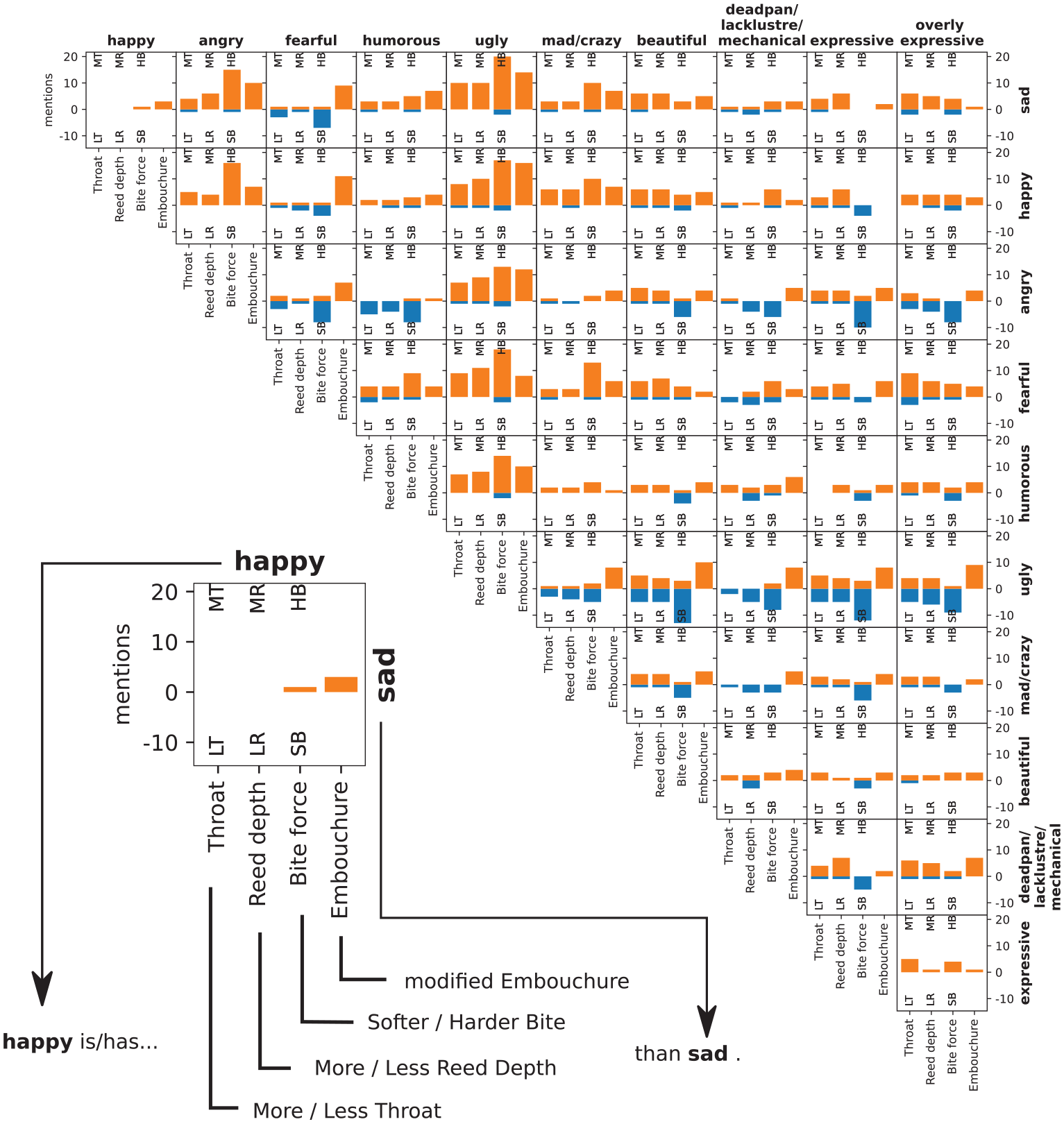
Modifications of playing parameters (x axis) to distinguish EG 2 (column headers) from EG 1 (row headers at right). Numbers of mentions are shown on the y axis.
Reasons for very similar responses
Participants rated 199 pairs of EGs very similar. In 92 cases (46%), they chose one or more of the three response options provided. Forty-two pairs were described as “just very similar emotions [SE]”: beautiful vs expressive (n = 8), angry vs mad (n = 6), happy vs beautiful (n = 5), and happy vs expressive (n = 5). Twenty-four pairs were described as “different but the clarinet could not be used to communicate a distinction between the two [NO]”: sad vs fearful (n = 3), sad vs expressive, sad vs beautiful, humorous vs mad, humorous vs expressive and beautiful vs overly expressive (all n = 2). Thirty-three participants chose the third option (“for this piece of music the two emotions could not be distinguished [DM]”) with reference to the Beethoven excerpt (n = 27), which had the least variation in pitch and rhythm compared to the other three excerpts.
Excerpts selected by participants
In response to the request to suggest a fourth excerpt that would be appropriate for achieving a wide range of expressive goals, participants suggested the following:
Brahms Clarinet Sonata No. 1 in F minor, 2nd movement, Andante un poco Adagio. bars 1–9
Brahms Clarinet Sonata No. 1 in F minor, 3rd movement, bars 1–8
Brahms Clarinet Sonata No. 2 in E flat—opening phrase
Dvorak Symphony No. 8. 4th movement—main theme as played by the solo clarinet
Jeanjean 25 Etudes No. 1 (Style Ancien)—first four bars.
One participant wrote, “I would choose a work that is harmonically ambiguous, rhythmically neutral and has minimal expressive direction. The piece in my repertoire that I think best meets this criteria is a particular technical study by Rudolph Jettel.”
Despite the small sample, it is interesting to note that three participants suggested different extracts from the clarinet sonatas by Brahms, which are his last chamber works. This suggests they might be used to advantage in future studies of EGs.
Discussion
The results of our survey relating to musical elements were largely congruent with the findings of previous studies, in particular the modification of loudness and tempo to achieve EGs. In RQ1a, we asked if participants, given a set of pairs of EGs larger than used in previous research, thought they would be able to distinguish between them. Our selection of 55 pairs of 11 EGs enabled us to address the question of whether basic emotions, commonly used in research on expressive performance in music, represent a sufficiently broad expressive goal space. Cluster analysis of participants’ similarity judgments for each pair, in each condition, revealed that most clusters of emotions featured basic emotions; for example, happy was clustered with humorous, and angry with mad and ugly (Figure 2). While the clustering together of the remaining two basic emotions fearful and sad might seem surprising, it can be inferred on the basis of the literature outlined in the Introduction, and upon closer inspection of the dendrograms in Figure 2 that they only appear to be clustered because they do not cluster with the other EGs. This justified our treating fearful and sad as distinct EGs. Participants who deemed pairs of EGs very similar and selected the response option “the two emotions are just very similar” could have low levels of music empathy (Kreutz et al., 2008).
The musical expression terms overly expressive, expressive, and beautiful clustered together but not with the basic emotion terms, supporting the argument that these form a distinct class of EG (musical expression, or positive affect valence; see Schubert et al., 2016). We decided to call this cluster expressive since it is the term used most frequently in the literature. The final EG in our proposed set of six is deadpan, which was generally easy to distinguish from the other EGs. The reorganized set of EGs retains only six emotions. The first two are labeled with terms representing musical expression, and the remaining four with terms representing one of the basic emotions:
expressive including beautiful and overly expressive
deadpan
happy including humorous
angry including mad and ugly
sad
fearful
This proposal incorporates and adds to the terms often used in studies of expressive performance. While it draws on the legacy of work by Juslin, who advocated the use of basic emotion terms, our research suggests that including musical expression terms can capture a wider range of expressive possibilities. Expressive and deadpan are particularly useful, but because these are not emotions, strictly speaking, and certainly not basic emotions, we suggest that expressive performance should be considered not in terms of conveying emotion but rather achieving EGs.
In RQ1b, we asked if participants thought they would be able to distinguish between pairs of EGs in each of the four conditions, that is, the three researcher-selected musical excerpts and the excerpt they had selected themselves. The criteria for our selection of excerpts from Happy Birthday and Nobody Knows were that they should be well known and contrasting, and that they had been used in previous studies of expressive performance. The rationale for our selection of the Beethoven Allegretto were its melodic and rhythmic simplicity, which we believed would provide a challenge for participants when carrying out the paired-comparison tasks. There was general agreement between participants that they would modify musical elements and vary playing parameters in similar ways in the three excerpts, suggesting that they have similar intrinsic expressive potential. This finding was supported by a similar agreement between participants for the excerpts they had selected themselves according to the criterion that they “could express the widest variety of emotions.” In short, it can be inferred that EGs cluster in similar ways and that clarinetists achieve EGs in similar ways, regardless of the work that is being performed.
It is also worth noting that three of the six participants who selected their own excerpts chose music for clarinet by Brahms. It may be that the most appropriate stimuli for research on EGs are not necessarily those used in previous studies and that, in future, investigators should carry out pilot research exploring suitable pieces. We have listed those that were suggested in the present study.
In RQ2a, we asked which musical elements participants would modify to distinguish between pairs of EGs under the four conditions. Participants generally reported that they would modify the same musical elements to achieve the same EGs. We were able to examine the generalizability of our findings by comparing them to those of previous research. For example, Juslin and Laukka (2003) carried out a review of literature reporting 73 experiments in which listeners decoded the communication of the five basic emotions in vocal expression and music performance, three of which (happiness, anger, sadness) featured as EGs in our study. Rather than using a paired-comparison task, Juslin and Laukka rated musical elements associated with each of the five basic emotions on 2- and 3-point scales. In the case of tempo, for example, they listed studies in which fast, medium, and slow tempi were found, respectively, to be associated with happiness. They did this for all musical elements associated with the five basic emotions. We tallied the number of studies they reviewed reporting how each element was modified for the three basic emotions featured in our study, as shown (for tempo only) in Table 1. In this way, we were able to compare our findings with theirs.
Number of Studies Reviewed by Juslin and Laukka (2003) Reporting Modifications of Tempo to Convey Emotions.
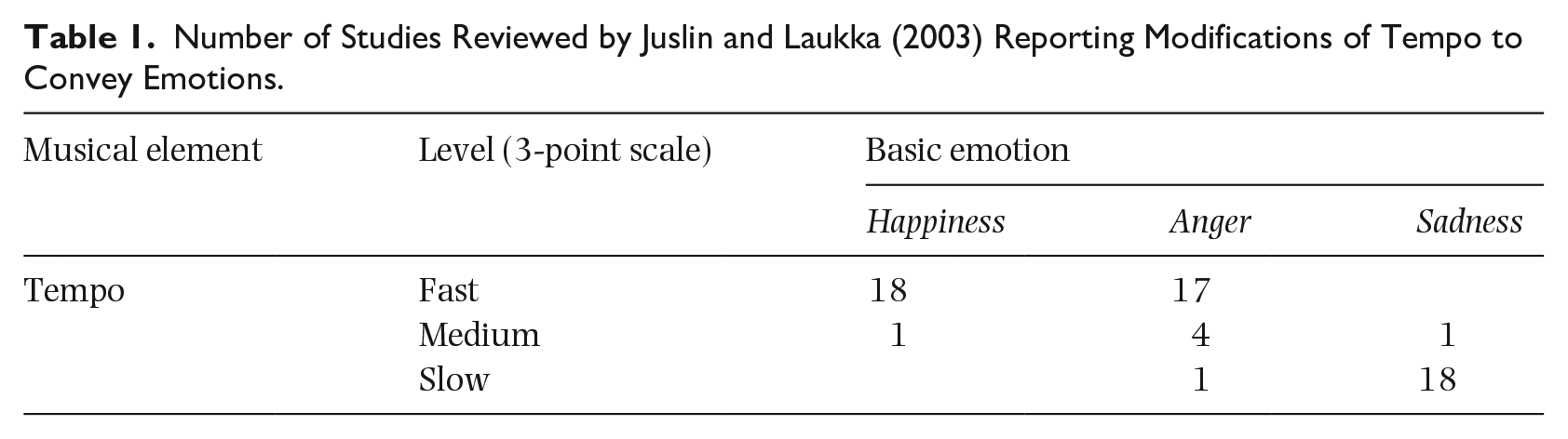
As shown in Table 1, happiness and anger were clearly associated with faster tempo than sadness. Our findings resemble those of Juslin and Laukka (2003) for tempo, insofar as our participants consistently said they would play happy faster than sad. Our findings also resembled theirs for conveying all three basic emotions via loudness, timing variation, and duration contrasts. Juslin and Laukka report similar numbers of studies in which anger was associated with either faster or slower tempo than happiness, however, the majority of our participants said they would play angry faster than happy. Generally, there was disagreement as to how anger and happiness should be conveyed, in Juslin and Laukka’s review; our participants were also more likely to disagree on how to modify all musical elements to distinguish between happy/angry than happy/sad and angry/sad. The differences between the findings reported in Juslin and Laukka’s review, and between their review and our study, may be attributable to differences between experimental paradigms, as pairwise discrimination tasks, as used in our study, and direct assessment of items, characterizing the majority of the studies reviewed by Juslin and Laukka, can produce different results for purely psychometric reasons (e.g., Patel et al., 2010).
Our findings also differed from those reported in the literature reviewed by Juslin and Laukka (2003) for loudness variability. This may or may not include the use of vibrato, depending on the question asked. Vibrato was considered an independent musical element in many of the studies reviewed by Juslin and Laukka (2003), but not ours.
A novel aspect of our study was to ask which playing parameters participants would vary to distinguish between pairs of EGs under the four conditions and how (RQ2b). Of the four parameters we suggested, participants mentioned reed-bite force most often saying they would increase it to achieve angry and mad EGs. At the level of physics, increased bite force reduces the gap between reed and mouthpiece, making it easier to achieve a harsh and bright tone with low blowing pressure (Almeida et al., 2013). Outside the context of clarinet playing, increased force might suggest teeth clenching, which could be associated with anger and madness (Averill, 1982) and even provide an ethological explanation whereby emotion signals are transmitted multimodally to make their communication more salient, cross-modally (Huron, 2015), for example, through facial expression (e.g., teeth clenching) as well as sound.
After bite force, the parameter participants mentioned most often was more/less reed in mouth. Applying bite force to the reed further away from the tip of the mouthpiece reduces the player’s control of the distance between the vibrating section of the reed and the mouthpiece, and the damping of its vibration. We were surprised that participants said they would vary this parameter such that they would use both more and less reed in the mouth to achieve both ugly and beautiful EGs. It may be that players combine the amount of reed in the mouth with other playing parameters, for example, a high blowing pressure with low damping, to produce a bright, harsh sound, whereas less reed in the mouth combined with a low blowing pressure would produce a simple (i.e., more sinusoidal) vibration. Similarly, using more throat was associated with both ugly and beautiful EGs.
Even though we investigated a larger set of emotions that is common in research on emotion in music performance, our study was still necessarily limited by the decision to compare all combinations of EGs and the length of time it took participants to complete the survey. It is thus possible that we omitted some important EGs. Similarly, we limited our study to one instrument and to Western classical music. It is possible that players of instruments with different technical capabilities and constraints would provide different responses to our survey.
Nevertheless, we believe that both performers and researchers could benefit from the findings of this study. It would be useful for clarinetists and their teachers to have a better understanding of the relationship between playing parameters and the communication of emotional and musical expression. For researchers, the six EGs we have identified, which participants thought they could achieve consistently across musical excerpts, could be used in future studies of expressive intentions in music performance; similarly, the paired-comparison approach and analysis could also prove useful in future experiments.
Conclusion
We asked if clarinetists thought they could distinguish between pairs of EGs in performance and, if so, which musical elements they would modify (e.g., dynamics and tempo), and which playing parameters they would vary (e.g., bite force and position of reed in the mouth). They carried out a pairwise-comparison task in which they were presented with 55 pairs of 11 EGs including terms representing basic emotions and musical expression and were asked to distinguish between them in the performance of four musical excerpts. Participants’ similarity judgments were converted into dissimilarity scores and subjected to cluster analysis producing six clusters. Four consisted of or included the basic emotions happy/humorous; sad; angry/mad/ugly; and fearful. The other two represented musical expression: expressive/overly expressive/beautiful and deadpan. These six EGs thus extend those representing the basic emotions used in previous research.
We also investigated the musical elements that could be varied to distinguish between each pair of EGs and how. Generally, our results supported the findings of the literature exploring the musical elements associated with the basic emotions reported by Juslin and Laukka (2003), even though these concerned music for instruments other than the clarinet. For this single-reed wind instrument, bite force was the playing parameter most participants said they would vary to achieve particular EGs, followed by the amount of reed in mouth.