
Abstract
Items that capture group members’ outcomes from small group processes (e.g., satisfaction, cohesion) are often nonindependent. A primary assumption of most measurement models is that the data are independent; applying such models to group-outcome data measured at the individual level of analysis is thus likely to produce inaccurate estimates. A solution to the measurement of nonindependent data involves the use of multilevel modeling to estimate variances at item, individual, and group levels of analysis. Examples from several different statistics programs are provided, and Monte Carlo simulations are used to evaluate the effects of group size and number of items on reliability estimates.
Group processes are related to outcomes at different levels of analysis (Bonito & Hollingshead, 1997). Problems arise, however, when one measures a given individual-level outcome with multiple items because any group member’s true score is not independent from the group to which he or she belongs. Consider, for example, group satisfaction (Keyton, 1991). Individual satisfaction likely varies within and across groups, due in part to differences in the perceived quality of group interaction. Thus, satisfaction within groups is both heterogeneous (based on a set of individual differences) and homogeneous (related to the satisfaction of other members within the group). When data such as these are treated as independent, standard reliability estimates, for example, Cronbach’s (1951) alpha, may provide inaccurate estimates for the scale in question. Thus, one must use different, but by now familiar (at least to most group researchers), methods for assessing individual- and group-level influences on certain types of outcomes, but with a twist that we illustrate below.
We have three purposes in this article. The first is to provide details regarding the estimation of reliability from nonindependent data, focusing specifically on variables that are conceptualized as outcomes of group processes, but are measured at the individual level with multiple items. To illustrate our concerns and to demonstrate an alternative, we limit our discussion to unidimensional constructs, or subconstructs, for which this technique could be used for each dimension. Crucially, we concern ourselves with data collected from groups whose members have interacted with one another prior to measuring the outcome in question and for whom interaction is related to the outcome. 1 These techniques do not apply to, for example, examination of individuals’ satisfaction with groups in general (e.g., Anderson, Martin, & Riddle, 2001). Second, we provide examples of the data structures, syntax, and output for three popular statistical packages: SAS, SPSS, and R. Third, we provide data from Monte Carlo simulations that show the effects of group size, number of items, and interitem correlations on reliability estimates.
The logic underlying many of these issues has been published previously (e.g., Miller & Murdock, 2007; Raudenbush, Rowan, & Kang, 1991), mostly in education research. But group researchers are largely unaware of both the statistical problem and the means by which one generates appropriate estimates with current software packages. In addition, the phenomena of interest to group scholars generally differ from those in education research and can influence estimates of reliability and the inferences drawn from them (as Bonito & Kenny, 2010, have demonstrated in other, relevant areas of group research). The primary difference is the nature of interdependence. In education research, interdependence is often a result of common fate (see Kenny, Kashy, & Cook, 2006); students in a classroom do not generally work toward a common goal (because both the average class size and pedagogical objectives work against it). For groups of the sort that are featured in this journal, interdependence, both in terms of process and outcomes, is a common, often explicit, goal. It follows that interdependence among group members is a characteristic of groups that influences group outcomes as well as individual members’ evaluation of a group’s outcomes or the group processes by which those outcomes were achieved.
It is worth noting at the outset that there are other means to handle such data. For example, one might subtract group means from individual scores and then analyze those deviation scores using techniques that assume independence of observations (e.g., Dineen, Noe, Shaw, Duffy, & Wiethoff, 2007), or one might simply analyze group means for the variables of interest. But doing so is not without cost. When only group means are used as estimates, one is ignoring potentially important variation within groups. And the use of group mean–deviated scores subtracts and ignores the very thing that should be of interest to group researchers, namely, the effect of the group. By pursuing analyses at both the group and individual levels instead, one has a window into both individual functioning within groups and group influences on what individuals say, think, and do (see O’Connor, 2004). It is our hope that researchers and practitioners will employ these methods to gain a better understanding of behavioral phenomena that occur within various types of small groups.
Measurement Reliability
Classical measurement theory is based on the distinction between unobservable or latent constructs and their observable manifest indicators (DeVellis, 1991). Often, but not always, some sort of survey instrument with multiple items is used to assess the construct in question. Keyton (1999), for example, used such an instrument to measure satisfaction with group processes. In other cases, a set of related behaviors might indicate a given construct, such as when group members exhibit power or dominance via interruptions and turn-management (Ng, Brooke, & Dunne, 1995; Smith-Lovin & Brody, 1989). In either case, the items or behaviors are imperfect indicators of the actual magnitude or true score of the construct.
The correlation among multiple items or behaviors serves as a proxy for the relationship between the true score and a given item. The correlations among a set of items are assumed to be caused by the construct they purportedly measure; they function as estimates of association between the true score and the items used to measure it. Of course, the relationship between the true score and its indicators is imperfect and some variance among the items is common and is assumed to be caused by the construct and the remainder is unique to each item. The ratio of the sum of the item variances to the total variation provides the estimate of unique variance, and its complement (subtracting unique variation from one) provides the estimate of common variance. This leads to the familiar equation for Cronbach’s alpha:
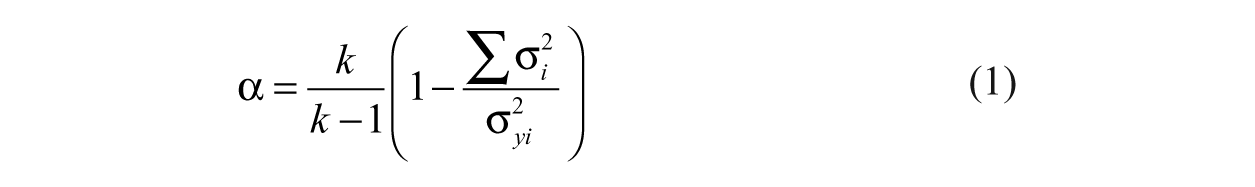
The term within parentheses is the common variance of the items, and the ratio of k items to one less than the number of items assures that the range for alpha is between 0 and 1.
The preceding is based on a set of assumptions related to the independence of the items, namely, that item error terms (a) vary randomly, (b) are not correlated with one another, and (c) do not correlate with the true score of the construct in question. For constructs such as the outcomes of group processes, however, such assumptions may not be tenable because manifest indicators covary among group members. It is assumed that such covariation is not coincidental because the outcomes in question share a common antecedent—the coordinated behaviors and verbal contributions to discussion. In short, one’s true score on a given construct depends, in part, on those of his or her colleagues, as evidenced by the intraclass correlations on the manifest indicators.
Generalizability theory (Cronbach, Gleser, Nanda, & Rajaratnam, 1972; Marcoulides, 1996, 2000) provides a window into the problem. Equivalence of measurement is the notion that assessment is relatively consistent across a variety of potentially relevant situations. Equivalence is assumed, for example, if a set of items provides similar assessments across paper and web-based administrations of a survey instrument. However, if mode of administration caused scores to vary, then measurement does not generalize to the universe of all possible types of administrations. The same principle applies to nonindependent data from groups; if a group member’s true score depends, in part, on the group to which a member belongs, then measurement cannot be said to be equivalent across groups.
In fact, several authors have evaluated procedures for estimating the reliability of nonindependent data in other types of designs and have shown how adjustments might be made. For example, Bonito and Kenny (2010) showed how reliability estimates for the social relations model are affected by dyadic- and group-level factors. In addition, Bost (1995) and DeShon, Ployhart, and Sacco (1998) have demonstrated that repeated-measures designs with correlated errors severely bias generalizability estimates when independence is assumed. Because reliability estimates from nonindependent data are informative about both the individual- and group-level processes associated with a construct, it is important to employ appropriate means of calculating such estimates. In the case of single-construct measures from group data, the item-based variance remains the estimate of unique variance, but the covariances represent commonality both within persons and within groups.
In what follows, we describe how to assess reliability for constructs that are assumed to be the outcome of group processes. Our aim is to alert researchers to the problems associated with measurement of nonindependent data, and to provide steps, using several popular software packages, for doing so.
Multilevel Reliability for a Single Construct
The estimation of reliability in the unidimensional case is surprisingly straightforward and is based on concepts familiar to group researchers who have used multilevel techniques. The first step is to compute a version of the so-called unconditional model and then use those estimates to compute reliability estimates at the individual and group levels.
The Unconditional Multilevel Model
Most group and relationship researchers are familiar with the two-level multilevel model (MLM), where individual responses are the first level, and the second level, the group, is the nesting variable. The unconditional model, which does not contain any predictors, is generally the first step in such modeling because it simultaneously identifies variation at the group and individual levels of analysis (Singer, 1998). The model with predictors is called the conditional model. Because computation of reliability estimates for the single-construct case requires only the unconditional model, we will not address the conditional model here. The variance components from the unconditional model are used to estimate the intraclass correlation for the outcome variable, expressed as a percentage. Thus, if 30% of the variation occurs at the group level, then 70% is at the individual level (reported as the residual in most statistical programs). Significance tests are also provided to evaluate whether, for example, group-level variance is significantly different from zero. One then generally adds theoretically relevant predictors at the individual and/or group levels of analysis to explain variation in the outcome variable.
Some statistical notation is warranted. Following Hox (2002), the unconditional model is

where

Here, Yij is the score on the outcome measure (for continuous variables) for person i in group j, β0j is the intercept for group j, γ00 is the grand mean (or the average of all j intercepts), µ0j is the group effect (or the difference between group j’s intercept and the grand mean, γ00), and e
ij
is the error term for person i in group j (which is randomly distributed). As Singer (1998) noted, the unconditional model is simply a one-way random effects ANOVA (analysis of variance) with group as the predictor. The model has two random components, µ0j and e
ij
.The remaining terms are fixed. The MLM decomposes the random components into two variances:

If there is no significant group-level variance, then a researcher could use more common statistical techniques (see O’Connor, 2004, for more on this point). 2
MLM Reliability Estimates Based on the Unconditional Model
Multilevel software allows for one dependent variable, but to estimate reliability in the multilevel case we must manipulate the software into working with multiple outcome variables, with group and individual as the predictors. In effect, we need to create a three-level unconditional model, with items nested within individuals who are nested within groups. In this case, all that is needed to estimate the measurement model is one vector containing all the scores from all of the items in the scale, a second vector indicating the participant to whom a given score belongs, and a third vector that identifies the group to which a given participant belongs.
3
Item is the lowest level—the error or residual variance
With the output from a three-level unconditional MLM, one may compute individual- and group-level reliability estimates (see Raudenbush et al., 1991). For the individual-level reliability estimate, the formula is
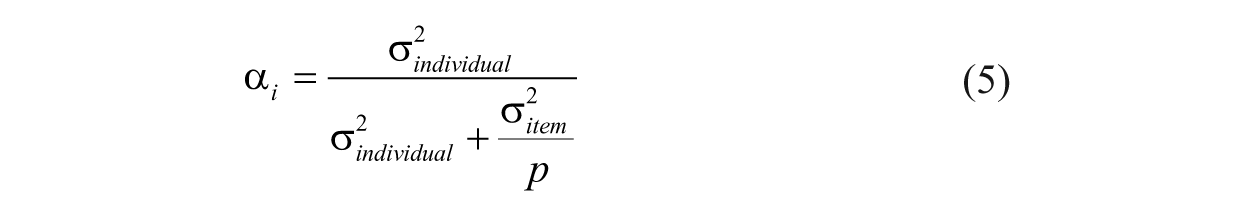
where p is the number of items in the scale. Group-level reliability is estimated with the following formula:
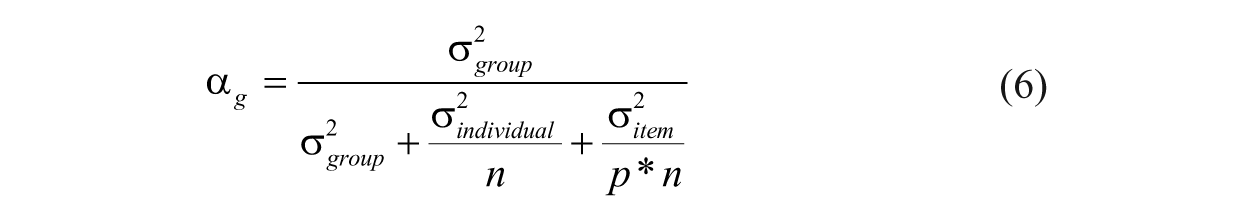
where n is group size. (In cases where a study includes groups of different sizes, the average group size may be used.) One might define group-level reliability as the homogeneity of means within a cluster or group, but as heterogeneity across groups or clusters. Just as knowing an individual’s mean for the set of items in question allows one to predict his or her score on any given item, knowing the group mean allows for the prediction of an individual’s mean score (as well as his or her item scores) within the group. The group or cluster has some influence on an individual’s response to the item set in question.
Illustration
Data
For illustration, we use data from a study by Park (2008), who examined the effect of socially shared cognition on satisfaction in small groups. Park studied 32 three-person and 35 four-person groups. These groups were composed of different male-to-female ratios. Each group was tasked with assembling an AM radio from a kit; discussion occurred during that task. Participants were asked to respond to the satisfaction items after discussion. The shared cognition manipulation involved giving all members in some groups the same instructions for communicating with other members, whereas members of other groups were given mixed instructions (in a given group, two members were given one set of instructions, and the other members of the group were given a different set).
Park (2008) measured satisfaction using a reduced version of Keyton’s (1991) satisfaction instrument. The original inventory contained 50 items, each of which was categorized as a global satisfier, global dissatisfier, situational satisfier, or situational dissatisfier. Keyton argued that satisfaction is a global construct if discussion progresses as anticipated but becomes more situational when groups fail to deliver what was expected. Park used only the 24 items that measured global satisfiers and of those kept 15, dropping items that related to politeness and efficiency, as well as those that seemed irrelevant to zero-history groups (e.g., “Everyone attends each group meeting”). Confirmatory factor analysis on the remaining 15 items revealed a unidimensional scale, with α = .93. Given the likely nonindependent nature of the data, however, the estimate does not account for group influences on satisfaction. In what follows, we describe how to obtain estimates that account for the nonindependent nature of these data.
Data Structure
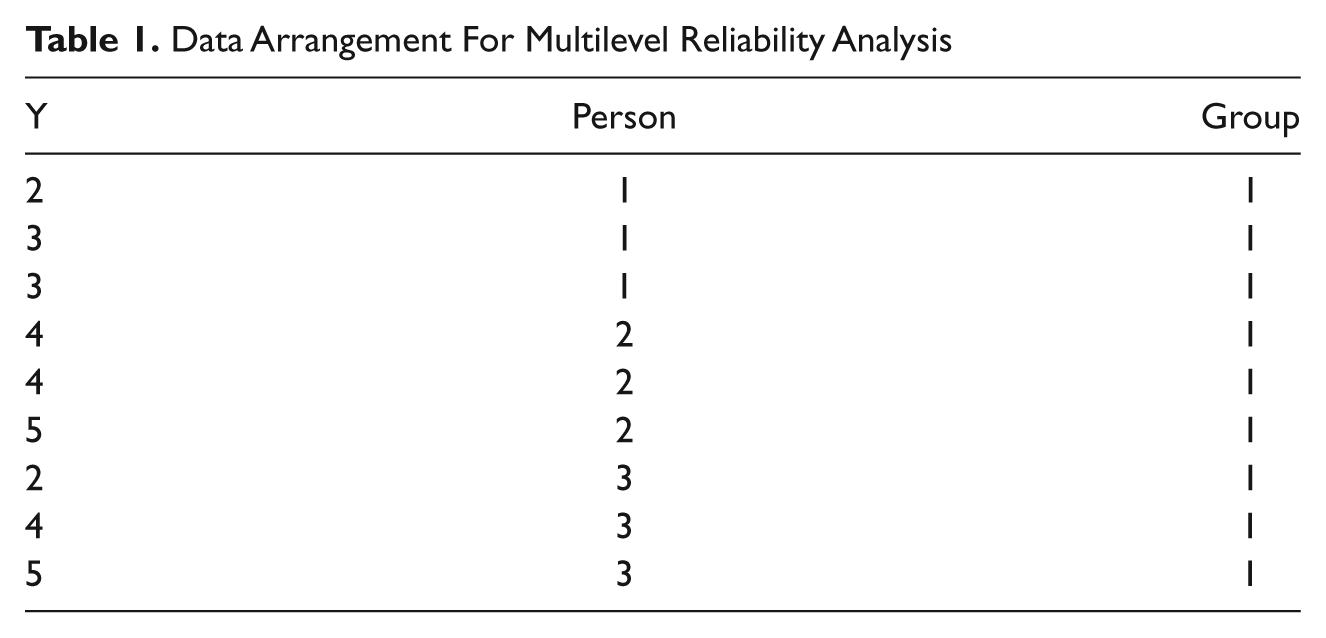
As noted, the basic structure for estimating the reliability of a single construct using the unconditional model is to have a column containing scores for all the items, a column indicating the person who provided the scores, and a column indicating the group to which that person belongs. Space concerns prevent showing the data for all of Park’s 15 items. Instead, as depicted in Table 1, we illustrate how the data were organized using the three-variable case with three-person groups. This can easily be extended to Park’s data by including all 15 scores on the satisfaction items for each participant. The score on the first variable for Person 1 in Group 1 is in the first three columns of the first row, the score for the second variable for that person is in the second row, and so on. Note that each person must have a unique identification number (e.g., the first person in Group 2 would have an ID of 4, and so on). 4
Data Arrangement For Multilevel Reliability Analysis
Syntax
SAS
PROC MIXED is SAS’s implementation of multilevel modeling and is arguably the most versatile, and most complex, of the three statistical programs discussed here. The syntax for estimating the unconditional model as described above is as follows:
PROC MIXED METHOD=ML COVTEST NOBOUND DATA= DATAFILE;
CLASS GROUP PERSON;
MODEL Y = /SOLUTION DDFM=SATTERTH;
RANDOM INTERCEPT / SUB= PERSON(GROUP) TYPE=UN;
RANDOM INTERCEPT / SUB= GROUP TYPE=UN;
RUN;
Going through each line, “proc mixed” invokes the MLM procedure, “method=ml” specifies maximum likelihood estimation 5 , “covtest” requests statistical tests for each of the variances and covariances estimated, and “nobound” allows the estimation of negative variances when the “random” statement is used. 6 The “class” statement identifies each of the nesting variables in the design; in this case, items or variables are nested within persons and persons are nested within groups. The “model” statement has the dependent or outcome variable to the left of the equal sign (independent variables go to the right of the equal sign, but the unconditional model does not use them). The “solution” switch tells SAS to print the fixed-effect estimates (which in this case is the intercept), and the DDFM = Satterth requests the Satterthwaite approximation for the degrees of freedom associated with the statistical test for the fixed effects (see Kenny et al., 2006). The first “random” statement (a) indicates the random variable in the design at the person level (intercept), (b) identifies the nesting at the person level (“person(group)”), 7 and (c) specifies the covariance structure, which is “unstructured.” This covariance structure estimates the variance of the intercept at the individual level. The second “random” statement is identical to the first, except that the nesting variable is the group.
SPSS
Unlike SAS, SPSS has a menu-based interface that allows the user to select a host of procedures with customized output. But SPSS also uses syntax, which, in the interest of space, we will provide here. If the reader would prefer to work with SPSS’s menu options, it should be a relatively simple matter to work from the syntax below to the menu choices available in the Mixed procedure (see Hayes, 2006, for a primer on using SPSS to analyze nested models).
SPSS syntax is similar to that for SAS:
MIXED Y /FIXED=| SSTYPE(3) /METHOD=ML /PRINT=SOLUTION TESTCOV /RANDOM=INTERCEPT | SUBJECT(SUBJECT) COVTYPE(UN) /RANDOM=INTERCEPT | SUBJECT(GROUP) COVTYPE(UN).
The first line invokes the “Mixed” procedure, which is SPSS’s implementation of multilevel modeling, and identifies the outcome variable, Y. (Some readers might notice that the “with” statement is missing from the first line, but this is correct, because normally one puts covariates to the right of the “with” statement. The unconditional model does not have covariates.) The “fixed” statement identifies the first level of the three-level unconditional model—there are no fixed predictors, so nothing goes to the right of the equal sign. The “print” statement requests that the parameter estimates and tests for the covariance parameters are included in the output. The remaining lines are comparable to the random statements in SAS. 8
R
Syntax for the R statistical package (available at http://www.r-project.org/) is much different from that in SAS and SPSS. The basics of R are beyond the scope of this article, and the reader is encouraged to invest the time needed to learn how to read, modify, and write data for that software, as well as to perform basic statistical tests. Two excellent references are Baayen (2008) and Faraway (2006). The syntax for R to estimate an unconditional model is as follows:
MODEL1<-LMER(Y ~ 1 + (1|PERSON) + (1|GROUP), DATAFILE, REML=FALSE) SUMMARY(MODEL1)
The statement begins with an arbitrary model name to the left of the “<-” symbol—here we use “model1,” but any useful name will do. It is important to note, however, that R uses this name when referencing estimates associated with the model that are stored in memory. The “lmer” statement is R’s MLM implementation and is extensively discussed by Baayen (2008) and Bliese (2009). 9 The model statement begins with the first open parenthesis, which is followed by the name for the column that contains the dependent variable (“Y,” in this case). The tilde (~) that follows is akin to the equal sign used by both SAS and SPSS, and the 1 immediately following the tilde includes the intercept in the model. (The default in R is to estimate the intercept. One may use “-1” to omit that estimate when needed.) The second open parenthesis contains the random effects at the individual level, which in this case is the variance associated with the intercept. The first closed parenthesis ends the individual-level specification. The next open parenthesis contains the group-level random effects and is identical to the statement for individuals (except, of course, the nesting variable). It ends with another closed parenthesis. The name of the data file (which for illustration is called “datafile” here), the estimation method “REML=FALSE” (which tells R to use maximum likelihood), and a closed parenthesis end the syntax. (It is important to note that R defaults to the unstructured covariance matrix and automatically computes the estimates of the random variances). Finally, the “summary” statement prints the results of the “lmer” procedure in the previous line.
Output
SAS
Relevant SAS output (excluding, for example, iteration history) is in Table 2. The intercept (the grand mean) is 5.27 on a scale of 7—see the “Fixed Effect Estimates” portion of the table. The column labeled “Cov Parm” provides two important pieces of information. The first is the abbreviation for the covariance structure used in the analysis (“UN” for “unstructured”), and the second is the matrix position for the variables in the analysis. Thus, “UN(1, 1)” is the first-row and first-column position for the first variable (the intercept) in the variance–covariance matrix. Because there is only one variable, the matrix consists of just one value, and because the row and column markers are the same, the estimate is a variance. In more complicated designs, one may have several random variances and covariances. The column “Subject” identifies the level of analysis, which in this case indicates that we have two intercept variances, one at the individual and the other at the group level of analysis. The “Estimate” column provides the value for the variance or covariance in question, and the remaining columns provide information regarding the statistical test for the null hypothesis that a parameter is zero in the population.
SAS Output for Park’s (2008) 15-Item Satisfaction Scale

SPSS
Output from the SPSS mixed procedure is reported in Table 3. Note that the output format differs from that used in SAS, but the estimates are virtually identical. In this case, the residual appears first in the table, the variance estimate for the individual-level analysis is next, and the group-level variance is last.
SPSS Output for Park’s (2008) 15-Item Satisfaction Scale
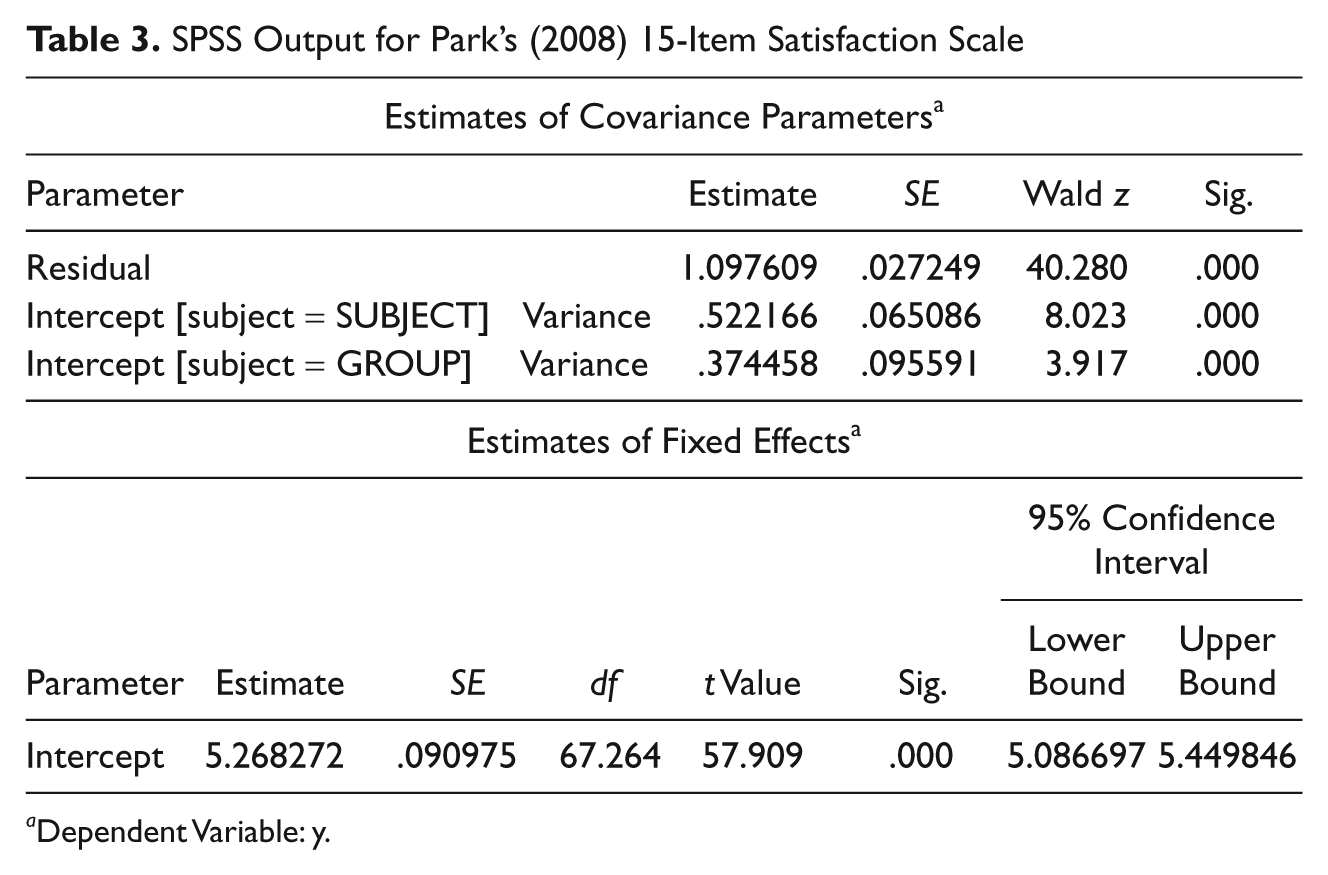
Dependent Variable: y.
R
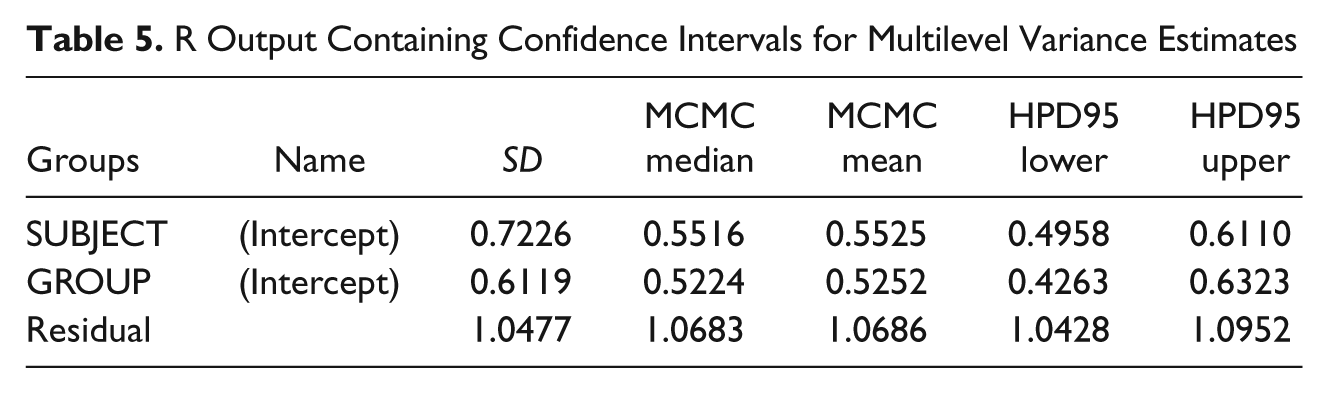
Output from R is presented in Table 4. Notice that the “summary” command (with the model name in parenthesis) was used to display model estimates that were computed by the lme4 procedure. The estimates are comparable to those produced by SAS and SPSS. An interesting issue regarding R multilevel output is the absence of significance tests. This is by design, because the R community treats such tests as flawed for these estimates and prefers Monte Carlo simulations to estimate confidence intervals (Baayen, Davidson, & Bates, 2008). Following Bayeen et al., the parameter estimates and confidence intervals for Park’s data are presented in Table 5. 10 The two rightmost columns contain the lower and upper bounds, respectively, for the confidence interval. Because variances are positive, and are never zero, the confidence interval will never contain zero. Estimates whose lower bounds approach zero should be treated with caution.
R Output for Park’s (2008) 15-Item Satisfaction Scale Random effects

R Output Containing Confidence Intervals for Multilevel Variance Estimates
Computing the Multilevel Reliability Estimates
Output from any of the three software packages may be used to calculate reliability for Park’s data using formulas 5 and 6. 11 Because group size is variable, the average of group size, approximately 3.5, was used. The number of items was 15. Individual-level reliability was estimated as .88, whereas group-level reliability was .69. These data still exhibit acceptable, by conventional standards, 12 reliability at the individual level, but the estimate is somewhat smaller than the estimate (.93) computed when the data were assumed to be independent. The group-level reliability of .69 indicates that the average of the scores within a group cluster around the group mean and that group means differ from one another. Thus, the group mean for a variable can be a relatively accurate predictor of the mean scores within the group on that variable. This is analogous to the information provided by acceptable individual-level reliability; that is, an individual’s score on a given item can be predicted from that individual’s mean score with relative accuracy. Thus, knowing the group to which a person belongs helps to estimate that person’s true score, at least in this case.
Simulation Studies
In this section, we provide the results of Monte Carlo simulations for the estimation of multilevel reliability. Individual- and group-level reliability (as shown in Formulas 5 and 6) differ slightly in terms of the components used in their estimation. Reliability at the individual level increases with the number of items and the correlation among items, whereas group size, the number of items, the correlation among items, and the homogeneity of scores of individuals within groups (i.e., intraclass correlation) influence group-level reliability (see Raudenbush et al., 1991, for computational details). Not evident in the formulas, but an inherent feature of MLM designs, is the separation of the variances at the three levels of analysis. Thus, the individual-level reliability estimate does not contain variance due to groups, which is preferred, and the group-level estimate accounts for individual variance in the numerator as part of the overall variance (controlling for group size). It is not clear, however, how the three levels of variance (item, individual, and group) interact to affect estimates. Thus, the general thrust of our simulations is to investigate the effects of group size, average item correlation, and number of scale items on the distribution of estimates that reach or exceed the conventionally accepted threshold of .70 for individual-level, nonindependent assessments of reliability.
Our simulations were based on our analysis of Park’s (2008) data. We used a grand mean of 5 (which is close to what Park observed) and set the group deviations from the grand mean to be randomly and normally distributed with variance = 1.00. Our approach was to generate a true score for each individual based on these estimates and then use that true score as the basis for each person’s item score (DeVellis, 1991). 13 This kept the item means and variances roughly similar but allowed the scores to vary within individuals (nested within groups). The average of the item correlations for Park’s data was approximately .50, but we varied the correlations using a range (.30-.80) that we reasoned was typical of self-report data—smaller correlations are typically not significant and larger ones are fairly rare. We used 1,000 simulations per run. Finally, we examined group sizes of 2, 4, and 6. 14
Table 6 contains the output from the simulations. Our primary concern is the difference between raw (unadjusted) and individual-level (adjusted according to Formula 5) reliability estimates, but we also report group-level reliability estimates because they provide an estimate of the extent to which the group figures into the individual-level estimates. The results show that raw alpha is relatively larger than adjusted individual alpha, and the difference persists across group size and number of items for low interitem correlations. The differences decrease, however, as the interitem correlations increase. For a five-item scale, interitem reliability must be relatively high, above .70, in order for individual-level reliability to reach conventionally adequate levels. Using 10 items, however, requires an interitem correlation of only .50 for adequate reliability. In general, for estimates of individual-level reliability, group size does not matter nearly as much as does the number of correlated items.
SAS Output From Simulations Based On Park’s (2008) Data
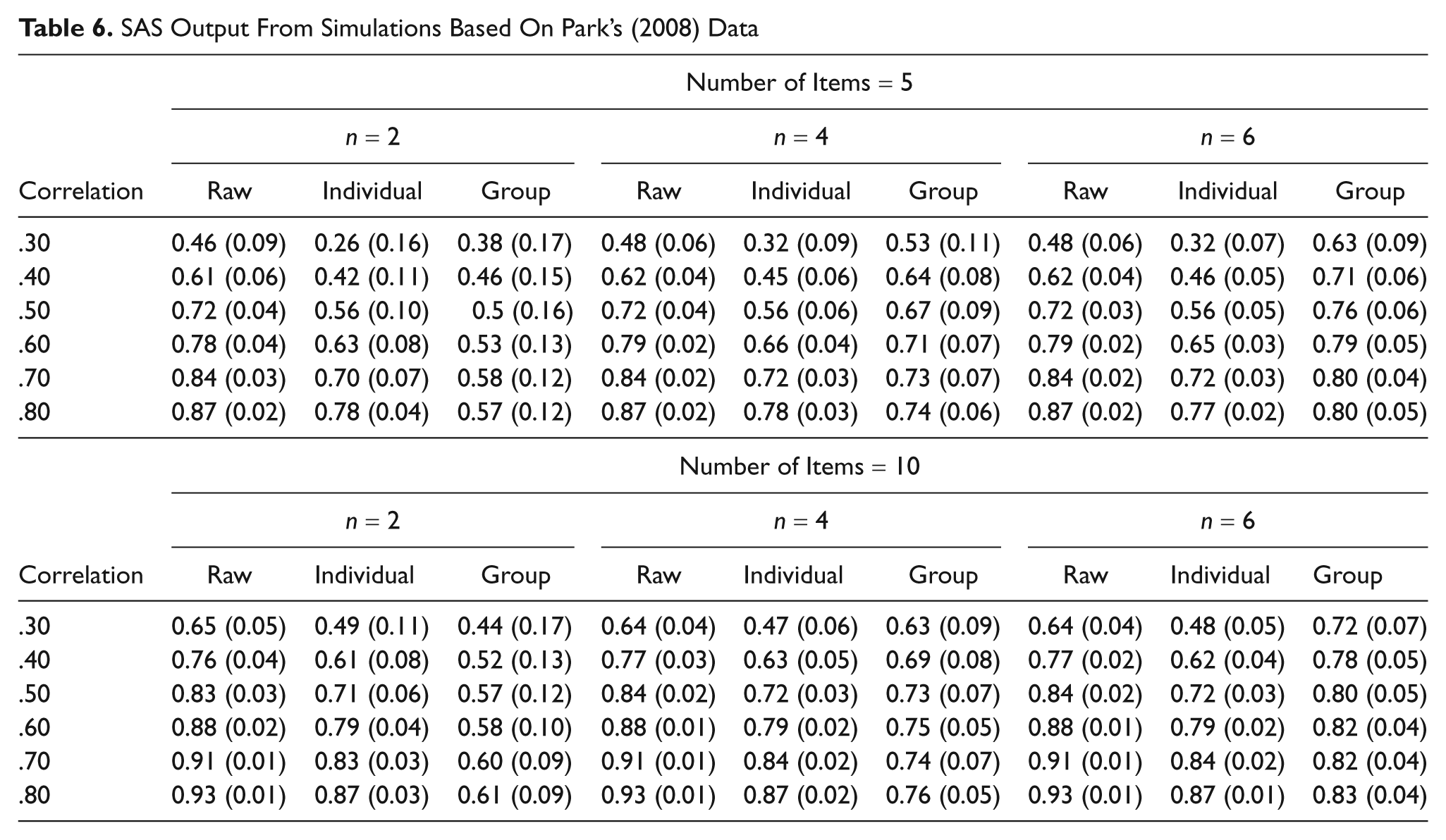
It is instructive to examine how varying group size and the item correlations affects group-level reliability because group-level reliability (a) figures prominently in the estimation of individual-level reliability, and (b) is of potential interest in its own right. The larger the group, the greater the group-level alpha. For six-person groups, a moderate to small correlation among items provides acceptable group-level reliability estimates in both 5- and 10-item scales. In contrast, for two-person groups, a large interitem correlation of .80 and 10 items is not sufficient to increase group-level alpha above .70. This trend follows other features of multilevel designs, for example, that power to detect significant differences rests on larger cluster sizes but not necessarily more clusters (e.g., Hox, 2002).
Discussion
Conceptual and Practical Issues
Scale reliability estimation using MLM relies on a three-level model, with scale items nested within individuals and individuals nested within groups. Implementation of MLM for reliability estimation allows researchers to answer questions about correlations among scale items at multiple levels of analysis. Our goal was to demonstrate the application of MLM to the computation of correlations and reliability estimates in multilevel data using three popular statistics packages and to report on the effects of number of groups, group size, average item correlation, and number of scale items on reliability estimates with nonindependent data. We provided an example of applying the MLM to the computation of individual- and group-level Cronbach’s reliability estimates and Monte Carlo simulation regarding the effects of group size, average item correlation, and number of scale items on reliability estimates at the group and individual levels.
In our example of reliability estimation using Park’s (2008) study of group satisfaction, Keyton’s (1991) global satisfier scale displayed internal consistency at the individual level but not at the group level. Furthermore, the individual-level reliability estimate was slightly inflated when nonindependence was ignored. As the results of our example suggest, accounting for the multilevel nature of group data when examining correlations and reliability is important to the appropriate conceptualization of both observed effects and the variables on which those effects are based. Failing to account for group membership confounds group- and individual-level effects, producing an estimate that might not be representative of either.
Although the statistical benefits of an appropriate analysis of the correlations and reliabilities in nonindependent data are clear, the conceptual implications of such analyses are less straightforward. For example, it is not clear what to do with scales that lack sufficient reliability at the individual level, but exceed conventional thresholds of reliability at the group level, or vice versa. Statistically, we know that poor reliability increases the standard error for statistical tests, so it makes sense to refine the instrument rather than go ahead with tests based on unreliable (and, by extension, not valid) scales.
Furthermore, it would be helpful to know which aspects of group process account for variation at the group level of analysis. Consider, for example, the case of participation in small groups (e.g., Bonito & Hollingshead, 1997). It is possible that groups with higher mean participation rates have higher (or lower) means on the outcome measure of interest (e.g., satisfaction), which obviously contributes to variation in that outcome measure at the group level. The principle is similar for the effect of the group on reliability estimates and is analogous to how generalizability theory (Cronbach et al., 1972; Marcoulides, 2000) evaluates the contributions of testing context to the variability of the items in question. In both cases, the goal is to identify and isolate sources of variance to better understand internal consistency.
The preceding is not limited to the unidimensional case. Although not discussed here, the techniques for assessing reliability for the unidimensional case can be extended (with difficulty) to constructs with multidimensional features. The basics for developing covariance matrices at multiple levels are found in Hox (2002) and Gonzalez and Griffin (2002). Also problematic is the fact that measurement models may fit the data at one level of analysis but not at others. Hollenbeck and associates (Hollenbeck, Ilgen, LePine, Colquitt, & Hedlund, 1998; Hollenbeck et al., 1995), for example, have argued for multilevel model of decision making, in which factors at the individual, dyadic, and group levels influence (or at least account for significant amounts of variance in) decision making. It is not yet clear how measurement issues should be addressed at multiple levels, but any theory or model of group processes that makes claims at multiple levels should consider how measurement may work at one level but not at others (see also Bonito & Kenny, 2010, on this point).
The Importance of Evaluating Outcomes Associated With Group Process
As some psychologists have noted, there is a research trend away from the direct observation of people working together (e.g., “people talking to one another”; Moreland, Fetterman, Flagg, & Swanenburg, 2010, p. 28) to the study of less social activities (e.g., self- or other-ratings), using social cognition as a research foundation. Thus, in psychology, process is anchored at the individual and internal level rather than at the group and observable level. The examination of individual- and group-level outcomes is similarly anchored in internal rather than in social and communication processes (see Hewes, 1996, 2009, for more on this point). Our analysis of Park’s satisfaction data shows, however, that even something that is putatively an internal, individual-level process is also imbued with group-level influences.
Throughout this article, we have acknowledged our preference for evaluating outcomes associated with group processes. More specifically, as communication scholars we argue that group processes (i.e., interactions among group members) are the primary influence on group outcomes. Moreover, we posit that what happens is communication among group members and that such communication will account for the interdependence of group members’ perceptions. A group’s outcomes are a direct result of all members’ interactions. Although reliability estimates of individual group members’ perceptions may be useful if individual rather than group outcomes are evaluated, the presence of group outcomes in a research design, especially when process variables are outcome measures, requires a different approach. Pavitt (1993) cleverly directed readers through different configurations of the role that communication can play in group decision making. He argued that “process is related to outcome variables independent of the impact of relevant input variables on that outcome” (p. 224) and that any change that occurs in a group (e.g., from pre- to post-discussion preferences) “implies that we must consider communication for an adequate explanation of the decision-making process” (p. 225). And as with many processes, communication can influence more than group decision making. For example, communication can also influence cognitive change at the individual level and relationship development among group members. As demonstrated in this article, however, that influence will vary for members within and across groups. We posit that only by estimating reliabilities at both individual and group level will group researchers better understand group process.
If group process (and hence, communication) does not matter, then why do communities and societies rely on groups to problem solve at work, create laws, adjudicate guilt or innocence, nurture children, entertain, socialize, or worship? Even in groups or teams that have more physical than cognitive tasks (e.g., soccer team vs. decision-making group), verbal and nonverbal communication as a process matters. If not, then how could team players signal to one another to change their strategy for making a goal while playing the game? Moreover, the influence of communication (or any process) among group members is not universal in causing within-group variation. Thus, we argue that group process, especially group members’ interactions, drives variation in group outcomes (e.g., satisfaction) and outputs (e.g., winning). Teams do not exist without members and the interactions among them. Thus, the inherent nesting of individuals in groups and teams requires that researchers account for group membership when assessing the reliability of outcome variables.
Conclusion
Although use of the MLM is not without complications and complexities remain regarding the interpretation of the resulting reliability estimates, the ability to examine those estimates at multiple levels of analysis allows for the use of theories and investigation of effects in which individual- and group-level processes are distinguished. This type of analysis can be applied not only to groups but also to dyads, families, organizations, and any other type of data in which some nesting variable serves to group individuals. We hope that the examples we have provided will allow team and group researchers interested in examining the influence of group process to more easily implement the MLM in relevant investigations.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.