
Abstract
The authors added task-relevant sounds to a computer-mediated instructor in-the-loop virtual training for firefighter commanders in an attempt to raise the engagement and arousal of the users. Computer-mediated training for crew commanders should provide a sensory experience that is sufficiently intense to make the training viable and effective. In practice, sound is an important source of information for firefighters. During an evaluation of a soundless computer-mediated and instructor in-the-loop virtual training, both trainees and instructors frequently remarked that the lack of sound made the simulation less convincing and engaging. Research on entertainment games has shown that users may experience higher levels of presence, engagement, and arousal when sound is included in the simulations. The authors therefore hypothesized that the addition of task-relevant (informative) sounds to a virtual training would raise the engagement and arousal of the users, and the overall convincingness of the simulation. In this study, they included verisimilar and task-relevant sounds in an instructor in-the-loop computer-mediated firefighter training and assessed how these sounds affect user experience. In contrast to the common belief of trainees and instructors, the authors find that merely adding task-relevant sounds does not necessarily increase the engagement and arousal of the users. The authors conclude that the physical presence of (and verbal communication with) the instructor probably distracted from the simulation, and an integral sound design involving mediated communication with a remotely present instructor may be required to resolve this problem.
Keywords
The design of virtual environments (VEs) has traditionally focused on the quality of the visual representation. Auditory information is frequently lacking, incomplete, or merely added in afterthought as simple soundtracks. Users typically experience the absence of sounds as a deficiency in the simulation (Rohrmann & Bishop, 2002; Rohrmann, Palmer, & Bishop, 2000). During an evaluation of a soundless virtual training for firefighter commanders, we noticed that trainees and instructors frequently remarked that the lack of sound made the simulation less convincing and engaging (Houtkamp & Bos, 2007). It is known that emotionally compelling VEs provide more effective training (Gratch & Marsella, 2003; Wilfred et al., 2004), and result in a high degree of initial learning and subsequent retention of the lessons learned (Ulate, 2002). However, VEs used for serious gaming and training need not be fully realistic, but should provide a sensory experience that is sufficiently convincing for the task at hand to make the training viable and effective. Even the inclusion of a limited set of sounds can significantly contribute to this purpose (Dodiya & Alexandrov, 2007; Turner, McGregor, Turner, & Carroll, 2003). It is, for instance, known that music (Ekman, 2008; Hébert, Béland, Dionne-Fournelle, Crête, & Lupien, 2005; Tafalla, 2007) and hyperreal (i.e., exaggerated, louder than normal, or Foley) sounds that signal discrete events (Krebs, 2002; Tafalla, 2007) can effectively heighten tension and induce arousal during entertainment video game playing. It seems likely that veridical sounds may also increase the engagement and arousal of users of a serious game provided that the sounds are relevant for the task. In this study, we performed two empirical pilot field studies, to assess if the inclusion of veridical and task-relevant sounds can enhance the engagement and arousal of firefighters in a computer-mediated virtual training. The term engagement is used in this study in its broadest sense, encompassing involvement and spatial presence.
Sound in Virtual Training
The film industry (Chion, 1994) and, in its wake, game industry (Collins, 2008) devote many of their resources to develop soundtracks that evoke emotional responses and allow the viewer or player to be engaged, or immersed in the represented world. In contrast, the developers of serious games still focus on the visual environment (Doornbusch, 2002). A reason may be that the development of a dedicated soundtrack for a virtual training requires a considerable budget and expert knowledge, while the benefits for the users (e.g., in transfer of training) are not immediately evident.
It is known that humans learn more efficiently if they have an emotional involvement with the training scenario (McGaugh, Ferry, Vazdarjanova, & Roozendaal, 2000; Tulving & Craik, 2000; Ulate, 2002). This can be achieved through a simulation that “feels real” and may therefore trigger memories of similar situations and related emotions. The creation of soundtracks that effectively make virtual training scenarios more similar to the experience users would have when exposed to the corresponding situation in reality (and thus make them more convincing, engaging, and memorable) may therefore contribute to the effectiveness of the training.
Sounds can improve the ecological validity and effectiveness of virtual training scenarios by increasing the naturalness of the experience, by providing task-relevant information, and by affecting the users emotionally. First, users expect that the visual events they perceive in the computer-mediated environment are accompanied by sounds, just like they are in reality. The absence of sounds is therefore experienced as unnatural (i.e., it is a distracting factor) and thus degrades the perceived quality of the simulation. Moreover, since users are increasingly accustomed to computer games with high-quality soundtracks, they probably expect an equivalent experience in a virtual training. Any discrepancy between their expectation and the training experience actually provided may seriously degrade its perceived quality (Pettey, Campanella Bracken, Rubenking, Bunche, & Gress, 2010). Second, sounds in a virtual training can convey information on significant events on which the trainee should act. In addition, sounds can engage and immerse the trainee, which is thought to increase the effectiveness of the training (Rozendaal, Keyson, de Ridder, & Craig, 2009). Finally, sounds can be deployed to affect the emotional response of viewers (Bradley & Lang, 2000). Hence, scenarios can be designed to train professionals to perform in conditions in which they will experience negative emotions, stress, and arousal. This is called “affectively intense learning” (Wilfred et al., 2004) or “stress exposure training” (Tichon, 2007) and prepares trainees to perform effectively in stressful environments (C. S. Morris, Hancock, & Shirkey, 2004).
Two important aspects of the affective response that determine the effectiveness of a computer-mediated training are arousal and engagement. Sounds that present relevant information in the training make the scenario more convincing. A convincing scenario is thought to trigger memories of similar situations and related emotions, and awareness of the importance of performing well. In scenarios representing dangerous situations, this is expected to lead to higher arousal. By attracting attention, sounds also enhance the experience of presence and the engagement of the trainee. Engagement is a widely used concept in studies of game experience and interaction design, and various definitions currently exist (Bianchi-Berthouze, Kim, & Darshak, 2007; Garris, Ahlers, & Driskell, 2002; Jennett et al., 2008; Mallon & Webb, 2000; Rozendaal et al., 2009). Here, it is defined as a state of being involved in the training, without effort, and without extrinsic motivation.
It has been observed that the addition of sound to a VE can significantly enhance the level of presence and engagement (Darken, Bernatovich, Lawson, & Peterson, 1999; Larsson, Västfjäll, & Kleiner, 2001a,b; Hendrix & Barfield, 1996; Larsson, Väljamäe, Västfjäll, & Kleiner, 2008; Lessiter & Freeman, 2001; Larsson, Västfjäll, Olsson, & Kleiner, 2007; Dekker & Champion, 2007; Dinh, Walker, Hodges, Song, & Kobayashi, 1999) and induce arousal in the user (Dekker & Champion, 2007; Krebs, 2002; Sanders & Scorgie, 2002). However, previous studies mainly focused on the effects of hyperreal (or Foley) sounds and music on tension and arousal during entertainment video game playing (Ekman, 2008; Hébert et al., 2005; Krebs, 2002). One study observed that the inclusion of both task-relevant and task-irrelevant audio information only improved the performance of the most experienced players, probably because these most effectively used the task-relevant information (Tan, Baxa, & Spackman, 2010). Here, we hypothesize that the inclusion of veridical sounds that provide information that is critical for a successful task performance in an instructor in-the-loop virtual training scenario will increase the convincingness of the simulation and the engagement and arousal of its users.
Experiment 1: Adding Realistic Sounds to a Computer-Mediated Training Environment
In this experiment, we added realistic and task-relevant sounds to an instructor in-the-loop computer-mediated procedural firefighter training, and we assessed the effects of these modifications on the experience of the users. This application allows procedural training on different virtual scenarios, with a range of emergency assistance tools. It has been used for several years by a large number of trainees, and is generally considered a valid and useful training tool. However, both trainees and instructors consistently claim that they miss the information provided by sounds, and the trainees believe that the absence of sounds degrades their engagement with the virtual world and the events therein (Houtkamp & Bos, 2007). Since the modifications that were applied in this study will only have practical value if they yield significant effects for a large fraction of the trainees, we only tested a small population in a pilot field test and in actual training conditions.
Method and Materials
Design
Two conditions were compared in a between-subjects design: (a) the original virtual firefighter training without sounds and (b) the same scenario, enhanced with sound events and ambient sounds.
Participants
The participants in the first experiment with the virtual training environment were 21 crew commanders (all males), aged between 27 and 55 years (M = 42.7 years, SD = 8.6). All participants had 8 to 32 years of firefighting experience (M = 17.8 years, SD = 7.1) and had been crew commanders for 0 to 22 years (M = 8.4 years, SD = 6.2). The participants had no previous experience with the virtual training exercise used in this study. Participants were randomly assigned to each of the two conditions: 11 to the sound condition and 10 to the no-sound condition.
Equipment and Setup
The experiment was performed in a dimly lit room at the Lieshout fire station (Lieshout, the Netherlands). The VE was generated using a desktop computer with a Pentium 4 processor and an ATI RADEON 2600 graphics card, and was displayed by means of a beamer on a projection screen subtending 1 m wide by 1.5 m high. The trainee was seated on a high chair that was placed at a distance of 2.5 m in front of the screen. The instructor, the operator, and the experimenter were all seated behind tables that were placed perpendicular to the screen, at a distance of 1.5 m from its right edge (Figure 1). This setup allowed them a clear view of the trainee and the screen, and is similar to the setup that is typically used in actual examinations. The trainees used a gamepad to move their avatar through the VE. A 5.1 Creative surround sound system, equipped with five speakers and a subwoofer, was used to present the audio signals. The sound level was such that the sounds of the simulation were clearly audible, while the instructor and trainee could still talk to each other. Galvanic skin response (GSR) was measured by attaching a self-made device, consisting of Velcro straps equipped with small metal plates, to a finger of the participant. The signal was read out and stored by a laptop computer at a rate of 28 Hz. Unfortunately, due to a system malfunction, the GSR data could not be analyzed.

Experimental setup
The VE
The computer-mediated scenario training environment was developed by VSTEP B.V. (www.vstep.nl) and Artesis B.V. in QUEST 3D version 3.6 (www.act-3d.com). This application provides procedural firefighter training on virtual scenarios in several environments, with or without an instructor in-the-loop. It includes a range of tools, equipment, and other emergency services that can be used by the trainee.
During the computer-mediated training, the trainees identify with a character that is initially located inside a fire engine (Figure 2a), and later in the vicinity of a house (Figure 2b) or inside a house (Figure 2c). At that stage in the training, the VE represents a typical modern Dutch suburb and contains all elements that are relevant for the scenario, such as water sources. The buildings and objects are geometrically accurate and textured. The representation of the environment is neutral and has not been designed to elicit arousal or tension. Although the characters featuring in the environment (such as firemen, police, and local residents or bystanders) are easily recognizable, their representation is rather schematic. The trainee has the option to toggle between a first-person view and a tethered view (Figure 3).

Screen shots from the computer-mediated firefighter training

(a) First person and (b) tethered point of view
Training Scenario
The training scenario selected for this study represents the response to a suburban house fire. A major task of trainees using the computer-mediated training is to optimize their situational awareness. They can achieve this by creating a mental model of the location of the fire, and the areas, objects, and victims in its immediate surroundings (i.e., on all six sides of the fire; the mental model is therefore known in practice as the “cube” model). In the real world, commanders use both the visual and auditory information they perceive directly, and information provided indirectly by crewmembers and other human sources to construct their mental model. In their own words, “crew members are the eyes and ears of the commander.” Commanders dynamically need to update and extend their mental model of the situation with incoming information and in response to events, for instance, to include or update the location of the crewmembers, their equipment, the position of potential victims, and the size or the spread of the fire to adjacent locations. In the virtual training, the trainee adopts the role of the fire commander. The instructor reacts verbally to requests from the trainee and impersonates all other characters that occur in the scenario (dispatch center, crewmembers, local residents, police, etc.). Using a separate command module, the operator responds to changes in the situation or requests from the trainee, by performing the appropriate actions in the VE, such as transporting and adding vehicles and avatars, and manipulating the fire. The operator controls the events and logs the main events and actions of the trainee.
At the start of the session, the trainee’s avatar is situated in a fully equipped fire engine at the fire station. When a dispatch call reports a fire in a house, the fire engine leaves the station on its way to the given address. During transit, the trainee’s task is to request all relevant information, to instruct the other members of the team, and to decide which actions need to be taken upon arrival. The operator lets the vehicle arrive at the location of the fire and places the trainee’s avatar outside the vehicle. From that moment on, the trainee is free to navigate in all directions using a gamepad.
The trainee then performs the required procedures, such as gathering information about possible victims, visually locating the fire from outside the house, saving victims, determining sources of danger in the immediate vicinity, inspecting the house, assessing the extent of the fire, and taking actions such as instructing the crew and ordering a second alarm. Before sending the crew inside, the trainee performs a quick outside inspection of the house. Adopting the role of the other crewmembers, the instructor provides the trainee with the required information about the layout of the house, the location of the fire, and any changes in the situation.
Soundtrack
Next to visual information, auditory information evidently plays a major role in the construction of the trainee’s mental model of the situation. Since the original virtual training environment had no soundtrack, we designed, recorded, and validated a dedicated soundtrack consisting of verisimilar ambient and event-related sounds that are relevant for the task performance of firefighters engaging a suburban house fire. We added this soundtrack to the computer-mediated procedural firefighter training in an attempt to assess its effects on user experience. Our hypothesis was that the inclusion of task-relevant veridical sounds would increase the convincingness of the simulation, and the engagement and arousal of its users.
The design process of the soundtrack was as follows: We used a storyboard to identify important locations and events in the scenario. For each scene, a group of expert firefighters determined the type of required sounds (i.e., either ambient sounds, event-related sounds, or communication sounds). For each sound, we assessed the expected effect (i.e., whether the sound would induce a sense of location, provide information on an event, increase the convincingness of the scenario, and/or increase the perceived danger of the situation). Because the instructor performs a dialogue with the participant, there was no need to include communication sounds in the soundtrack. The sounds we used were either selected from existing databases or recorded at firefighting training centers. If necessary, the recorded sounds were separated from other background sounds, and noise was filtered out. Each individual sound was subjected to pretests, to evaluate whether the sound itself (without its visual counterpart) was evocative of the intended environment or event, whether it conferred the intended affective qualities, and whether it was considered appropriate for the visual environment or event that it represented. Because QUEST 3D does not include a physics engine, sound volume changes that should accompany actions like entering or leaving a house, or opening or closing doors, were hardcoded in the scenario. This workaround successfully simulated a physics sound engine. After implementing the soundtrack, its volume was corrected, and the overall simulation was assessed and fine-tuned with the help of expert users.
The resulting soundtrack consists of a continuous, low, background noise, which is appropriate for an urban environment. All relevant events are accompanied by sounds: the engine of the fire truck, pumps, fire, explosion, extinguishing of the fire (with water); sirens indicate the arrival of ambulances and police, and cries represent a victim in distress. In real emergencies, fire commanders wear helmets and continuously receive messages from other emergency responders, which affects the way they perceive the other sounds. We decided to adhere to the customary training situation in which helmets are not worn and communication with the instructor is not hindered by other (less relevant) information sources.
Measures
A questionnaire was used to assess the engagement and arousal of the trainees and the experienced convincingness of the training (see Table 1). The following measures were applied:
Self-reported scores on 9 points Valence and Arousal scales of the SAM (Self-Assessment Manikin; Bradley & Lang, 1994). The SAM is a nonverbal pictorial assessment technique that directly measures momentary feelings of pleasure, arousal, and dominance on a 9-point scale. It is widely used to measure emotional response (Detenber, Simons, & Reiss, 2000; J. D. Morris, 1995; J. D. Morris, Woo, Geason, & Kim, 2002; Poels & Dewitte, 2006). The Valence scale was applied to determine effects on the perceived pleasure of the experience.
Questions on engagement from the ITC-SOPI (The Independent Television Commission’s Sense of Presence Inventory; Lessiter, Freeman, Keogh, & Davidoff, 2001). The ITC-SOPI is developed to measure users’ experiences of media, without reference to objective system parameters. It consists of four factors: Engagement, Sense of Physical Space, Ecological Validity, and Negative Effects. Only the questions on Engagement were relevant and usable in the context of this experiment. We made a selection and slightly adapted some questions of the ITC-SOPI to the experimental situation (Items 7-9, 11, 18, and 40 in Table 1).
Questions about the perceived danger of the situation and the convincingness of the computer-mediated representation of the scenario, the events and victim in the scenario (Items 1-6 and 21-26 in Table 1).
To gather additional information on different aspects of the user experience related to Engagement and Convincingness, we included questions on Spatial Presence (the sense of being physically in the VE: Items 13-16 in Table 1), on Involvement (the attention devoted to the VE and the involvement experienced: Items 10, 12, and 17 in Table 1) from the Igroup Presence Questionnaire (Schubert, Friedmann, & Regenbrecht, 2006). Some questions were slightly adapted to the situation in this experiment.
In the sound condition, questions were included to measure the relative contribution of the sounds to the scenario and their perceived quality and appropriateness (Items 27-34 in Table 1).
Questions about the general impression of the training and its relevance for daily practice (Items 35-40 in Table 1). These questions were included to measure the perceived validity of the training.
Questions Related to the Engagement of the User, The Convincingness of the Simulation, and the Importance of the Sounds in the Simulation

Note: Items 41 to 43 were only administered in Experiment 2. Unless stated otherwise, the questions were answered on a 7-point scale (ranging from 1 = completely disagree to 7 = completely agree).
Filling in the questionnaire typically took about 5 minutes.
The experiments were performed during official firefighter training sessions. The training instructor scored the task performance of the trainees on a scorecard, which was based on the official score form of the Netherlands Institute for Safety (NIFV; www.nifv.nl) and had been adjusted to this virtual training scenario. For privacy reasons, this information was not available to the experimenters.
Procedure
First, the participants filled in a general questionnaire and scored the SAM Arousal and Valence scales. Then the participants performed the training scenario, which typically took about 10 to 12 minutes. Directly after they had finished the training, the second questionnaire was presented, including the SAM Arousal and Valence scales. Then the instructor finished his assessment of the trainee’s performance by filling in his scorecards. Finally, the instructor evaluated his assessment with the trainee. This evaluation was not part of this experiment.
Results
About half of the participants in the no-sound condition (6 out of 11) noticed that sounds were not provided in the scenario. In the sound condition, the trainees were fairly positive about the appropriateness of the sounds for the visual environment (M = 4.82, SD = 1.17 on a 7-point bipolar scale, n = 11), were not disturbed by the sounds (in the sense that the sounds were unrealistic or inappropriate and distracting from the simulation: M = 1.91, SD = 1.14 on a 7-point bipolar scale, n = 11), and agreed slightly that the sounds provided information about the seriousness of the situation (M = 4.55, SD = 1.21 on a 7-point bipolar scale, n = 11). When presented with two options, 90% of the participants considered the sounds good (vs. bad), 90% thought they were loud (vs. low), and all participants considered them helpful (vs. unhelpful) and realistic (vs. unrealistic). All participants had heard the sound of the fire, 82% had heard the sound of the explosion, and 55% had heard the sound of the pumps.
Table 2 shows the scores on the Arousal and Valence scales of the SAM, obtained directly before and after the training. For Arousal, a score of 3 to 4 means the participants expressed themselves to be rather calm (1 = very calm, 9 = very excited, and 5 represents the middle of the scale) before and after the training. A score of 7 for Valence means that the participant feels pleasant or happy (9 is the highest score on this scale). We performed a mixed two-way ANOVA, with the SAM scores as within-subjects factors. No significant main effects of condition, Arousal or Valence difference, and no interaction effect were seen. Thus, the training did not have a significant impact on the self-expressed emotional state of the trainee.
Mean (and SD) of the Scores on the Arousal and Valence Scales of the SAM, Obtained Before and Directly After the Training, in the Sound (n = 11) and No-Sound (n = 10) Conditions
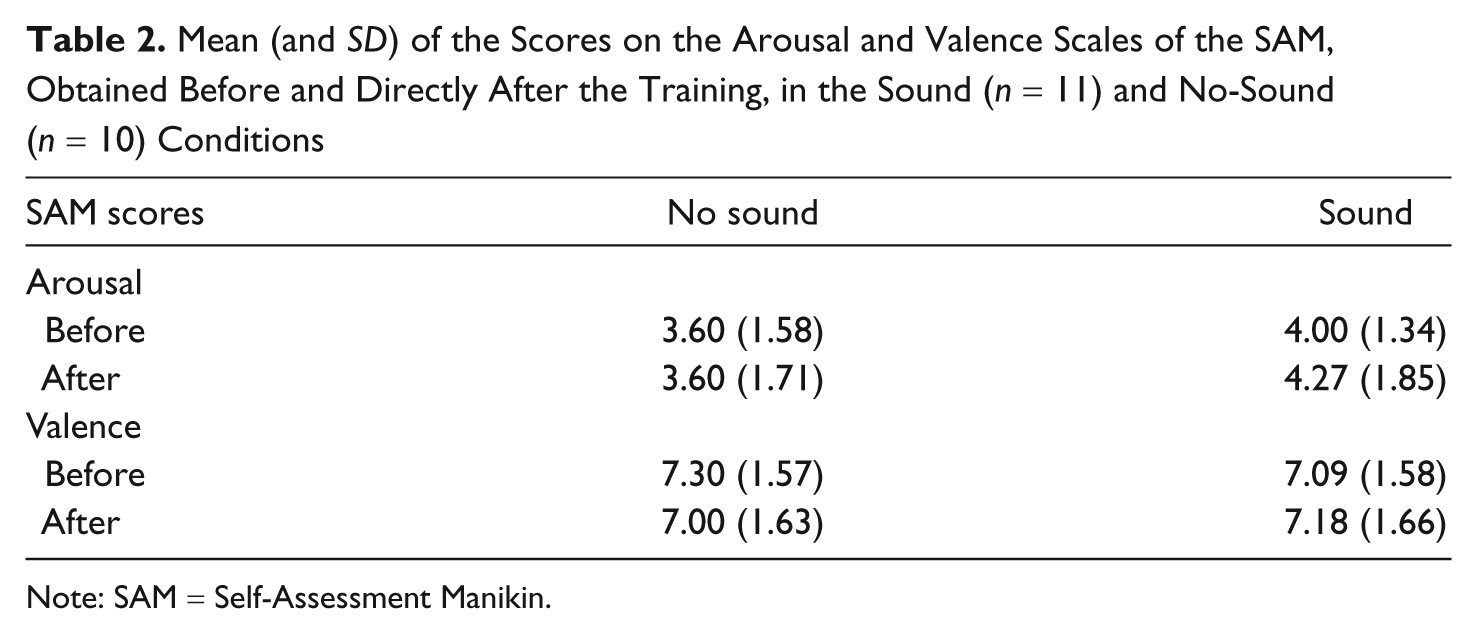
Note: SAM = Self-Assessment Manikin.
The construct “Engagement” was measured (on a 7-point bipolar scale) using six questions (Items 7-9, 11, 18, and 40 in Table 1). Cronbach’s alpha for this construct was .80. There was no significant difference (p = .97) in the mean Engagement scores between the sound (M = 5.35, SD = 0.79, n = 10) and the no-sound (M = 5.33, SD = 1.20, n = 11) conditions.
The degree of Involvement was assessed (on a 7-point bipolar scale) by three questions based on the Igroup Presence questionnaire (Items 10, 12, and 17 in Table 1; Schubert et al., 2006). Cronbach’s alpha remained below .6 for this construct (possible reasons are discussed in the “Conclusion” of this section). There was no significant difference (p = .88) in the mean Involvement scores between the sound (M = 5.03, SD = 0.91, n = 11) and the no-sound (M = 4.9, SD = 1.02, n = 10) conditions.
Spatial Presence was measured (on a 7-point bipolar scale) with four questions adapted from the Igroup Presence Questionnaire (Items 13-16 in Table 1). Cronbach’s alpha for this construct was .74. There was no significant difference (p = .53) in the mean Presence scores between the sound (M = 5.18, SD = 0.73, n = 11) and the no-sound (M = 5.45, SD = 1.16, n = 10) conditions.
The Perceived Danger for the victim and the overall seriousness of the situation were assessed (on a 7-point bipolar scale) through four questions (Items 1-5 in Table 1). The total of the scores did not show a significant difference between the sound and no-sound conditions (no sound M = 4.65, SD = 1.19, n = 10; sound M = 4.84, SD = 0.54, n = 10). The danger was thus perceived as existent, but not high, in both conditions.
Convincingness was measured using five questions on the representation of the victim, the environment, and the events in the scenario (Items 21-23, 25, and 26 in Table 1). The answers were scored on scales from 1 (not convincing at all) to 7 (extremely convincing). Cronbach’s alpha for this construct was .70. The mean scores for the convincingness of the elements in the scenario were higher in the condition without sounds (M = 5.47, SD = 1.0, n = 10) than in the condition with sounds (M = 4.73, SD = 0.62, n = 11) and were almost significant (p = .051, two-tailed).
The performance of the trainees during the training was assessed by the instructor, using standard scorecards. There was no significant difference between the mean performance of trainees in the no-sound and the sound conditions.
Conclusion
Contrary to our hypothesis, we found no significant effect of sound on the arousal and engagement of the trainees. In a separate evaluation session, expert firefighters judged the added sounds appropriate for the simulated events and of good quality. However, in actual training sessions, trainees judged the convincingness of the virtual scenario with the added sound effects almost significantly lower. Two causes seem probable for this effect. First, from our own observations and from comments by the trainees and the instructor, we inferred that the communication between the trainee and the instructor partly masked the sounds. Second, by coincidence, trainees in the sound condition had significantly more experience with 3D VEs and games than trainees in the no-sound condition (on a scale from 0 to 3, respectively, M = 1.45, SD = 0.82, n = 11, and M = 0.36, SD = 0.67, n = 10; p = .003). Using a univariate analysis with 3D VE experience as covariate, to correct for this experience, we found no significant difference in convincingness between both conditions, F(1, 19) = 1.42, p = .25. Experienced gamers are probably accustomed to high-quality soundtracks, which may have affected the present results. We therefore decided to repeat the experiment at a different location, with an enhanced soundtrack and with participants carefully balanced with respect to game experience.
Experiment 2: Enhanced Sounds in a Computer-Mediated Training Environment
From the results of the first experiment, we concluded that some sound events probably required more emphasis to be noticed in the context of a computer-mediated instructor in-the-loop simulation. Since it is known in film industry that important sounds need to be “hyper real” (i.e., they should be played louder than normal) to stand off against other sounds and background noise (Hawkins, 2005), we adjusted the sound volume of two important (informative) sound events in the computer-mediated training scenario from Experiment 2. These were the sounds of the explosion and the screaming victim, and they were increased by 400% and 200%, respectively, compared with their volume in Experiment 1. The volume of the other sounds was kept the same, to prevent an overall increase in background sound level during the training, which would have interfered with the communication between the instructor and the trainee. We administered three extra questions (Items 41-43 in Table 1) to test if participants indeed perceived the sounds and if they also used them for their task performance.
Method and Conditions
This experiment was performed in a dimly lit room at the Alblasserdam fire station (Alblasserdam, the Netherlands). The acoustics at this location were better than at the location of Experiment 1. As a result, the overall audibility of the soundtrack was better than in Experiment 1.
In this experiment, we included additional questions (Items 41-43 in Table 1) to assess the importance of sound as a source of information, relative to other information sources that are available to the trainees (dispatch center, crewmember, the VE, etc.).
The other methods and materials, and the experimental design, were the same as in Experiment 1 (Figure 4).

Experimental setup.
Participants
The participants in the second experiment were 18 crew commanders (all males), aged between 29 and 51 years (M = 42.9 years, SD = 6.1). They had 0 to 22 years of firefighting experience (M = 21.2 years, SD = 7.8) and had been crew commanders for 0 to 22 years (M = 6.3 years, SD = 3.3). The participants had no previous experience with the virtual training exercise used in this study. Because we suspected an effect of gaming experience on the results in Experiment 1, we divided participants with little and extensive experience with gaming and 3D environments equally over the sound and no-sound conditions, resulting in 9 participants in both conditions.
Results
Again, only half of the participants in the condition without sound noticed that sounds were not provided in the scenario (four out of nine trainees). In the sound condition, the trainees were positive on the appropriateness of the sounds for the visual environment (M = 5.78, SD = 1.09). However, they were also somewhat disturbed by the sounds (M = 2.78, SD = 1.64). The sounds provided the trainee with information on the seriousness of the situation (M = 5.33, SD = 1.12, all on a 7-point bipolar scale). When presented with two options, all trainees (n = 8, one missing value) considered the sounds to be good (vs. bad), loud (vs. low) and realistic (vs. unrealistic), and all (n = 9) considered them to be helpful (vs. unhelpful). All had noticed the sound of the fire, the sound of the explosion, and 66.7% had heard the sound of the pumps.
Table 3 presents an overview of the results on the relative contribution of sound to different aspects of the user experience. It appears that sound contributes significantly to situational awareness and the assessment of danger, but not to any of the other aspects of user experience investigated in this study. These results will now be discussed in more detail.
Relative Contribution of Sound to Different Aspects of the User Experience.
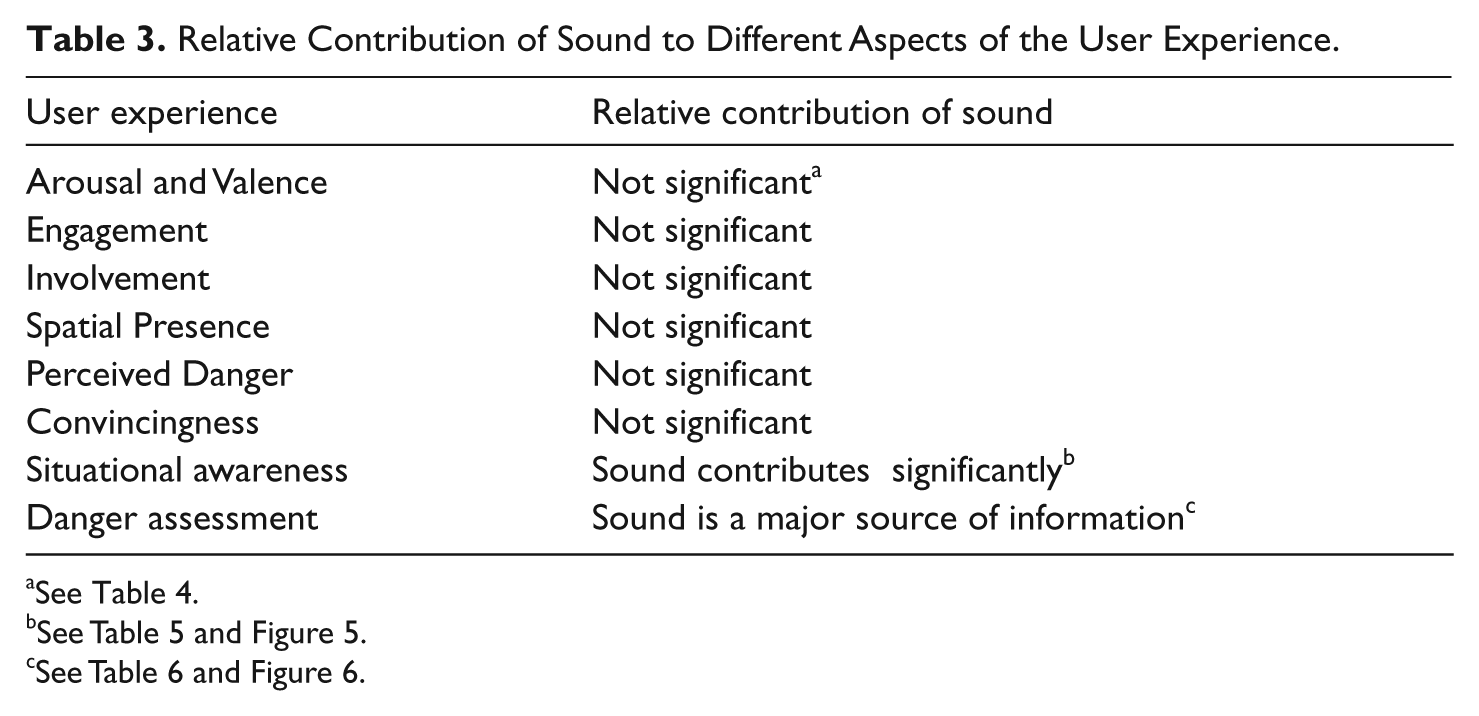
See Table 4.
Mean (and SD) Scores on the SAM Arousal and Valence Scales, Directly Before and After the Training (n = 9)

Note: SAM = Self-Assessment Manikin.
The scores on the Arousal and Valence scales of the SAM were obtained directly before and after the training. We performed a mixed two-way ANOVA, with the SAM scores as within-subjects factors. It showed no significant main effects of condition, or of the arousal or valence difference, nor an interaction effect.
As in Experiment 1, the reliability was satisfactory for Engagement and Spatial Presence, but low for Involvement.
There was no significant difference (p = .79) in the mean (n = 9) Engagement scores between the sound (M = 5.47, SD = 1.10) and the no-sound (M = 5.35, SD = 0.69) conditions.
There was also no significant difference (p = .56) in the mean (n = 9) Involvement scores between the sound (M = 5.33, SD = 1.15) and the no-sound (M = 5.04, SD = 0.94) conditions.
Finally, there was no significant difference (p = .56) in the mean (n = 9) Spatial Presence scores between the sound (M = 4.69, SD = 0.86) and the no-sound (M = 4.53, SD = 1.09) conditions.
The Perceived Danger for the victim and the overall seriousness of the situation were assessed through five questions. Cronbach’s alpha for this scale was .81. The total mean (n = 9) of the scores did not show a significant difference (no sound M = 5.04, SD = 0.65; sound M = 5.2, SD = 1.60). The danger was thus perceived as existent, but not very high, in both conditions. The Perceived Danger for the crew did not differ significantly between conditions (no sound n = 9, M = 3.56, SD = 1.67; sound n = 9, M = 4.11, SD = 2.26).
Again, the mean (n = 9) of the scores for the Convincingness of the elements in the scenario were higher in the condition without sounds (M = 6.18, SD = 0.76) than in the condition with sounds (M = 5.51, SD = 0.77). However, this time, the difference was not significant (p = .085, two-tailed). Cronbach’s alpha was satisfactory: α = .63.
The performance during the training was assessed by the instructor, using standard scorecards. Again, the mean (n = 9) performance scores in the condition without sound (M = 6.96, SD = 0.51) and the condition with sound (M = 7.11, SD = 0.69) were not significantly different (p = .62, two-tailed).
Trainees typically use the virtual environment shown on screen, the sounds, the crew, the dispatch center, or their previous knowledge and experience to construct their mental model or ‘cube’. We asked them to rate what fraction of each of these the information sources they had actually used in the experiment. The answers were given in percentages, totaling 100%. In both conditions, the trainees estimated that they derived less than half of the information from the VE and almost the same fraction from the crewmembers and dispatch center (i.e., the instructor; Figure 5 and Table 5). Knowledge and experience are also important information sources. The variation in the results also shows that the commanders use different strategies. Some trainees did not notice the absence of sound in the no-sound condition. As a result, even in the no-sound condition, sound is still estimated to contribute a minor fraction (1%) to the mental model.
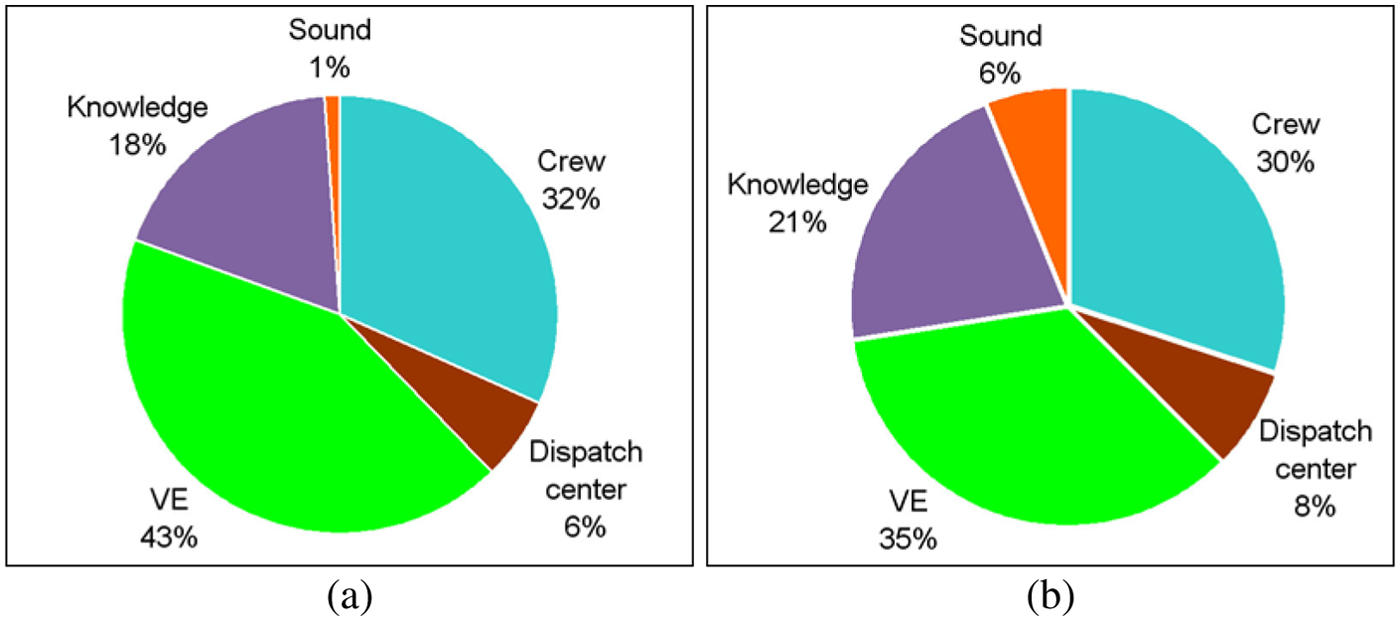
Information sources used by trainees to complete their mental model or “cube,” in the no-sound and sound conditions (n = 9)
Information Sources Used by Trainees to Complete Their Mental Model or “Cube,” in the No-Sound and Sound Conditions (n = 9)
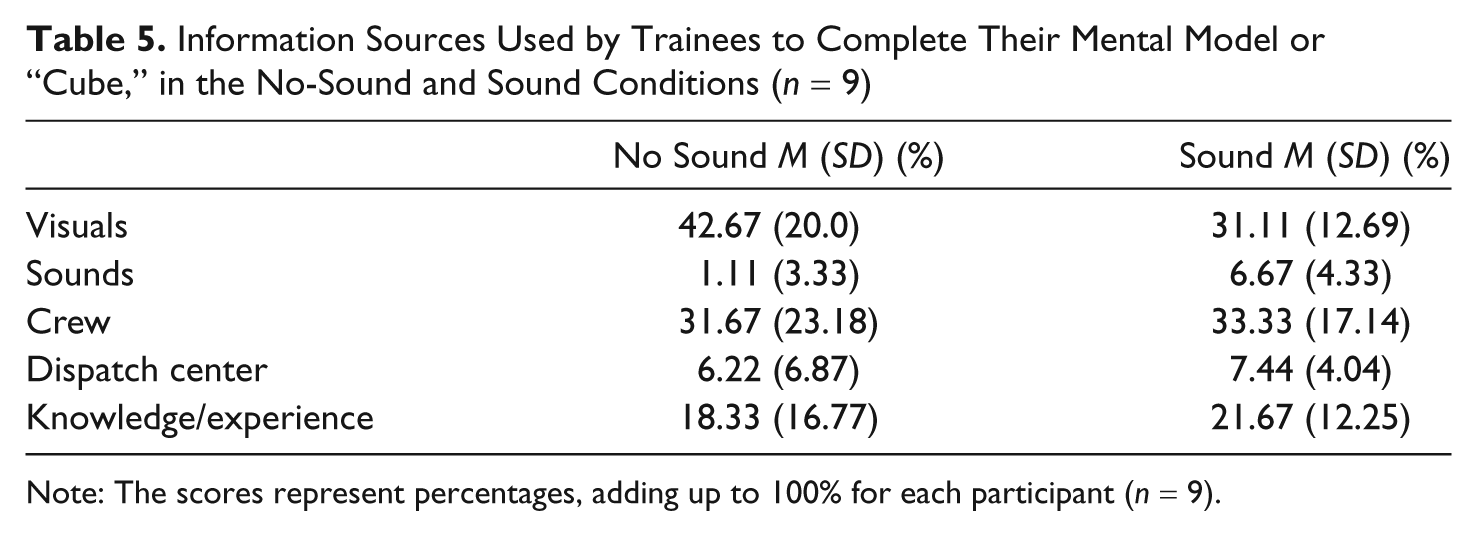
Note: The scores represent percentages, adding up to 100% for each participant (n = 9).
To assess dangerous episodes in the scenario, the trainees used the same sources, but now the sounds were said to be important. Again, the VE itself accounts for only a third of the information (Figure 6 and Table 6).
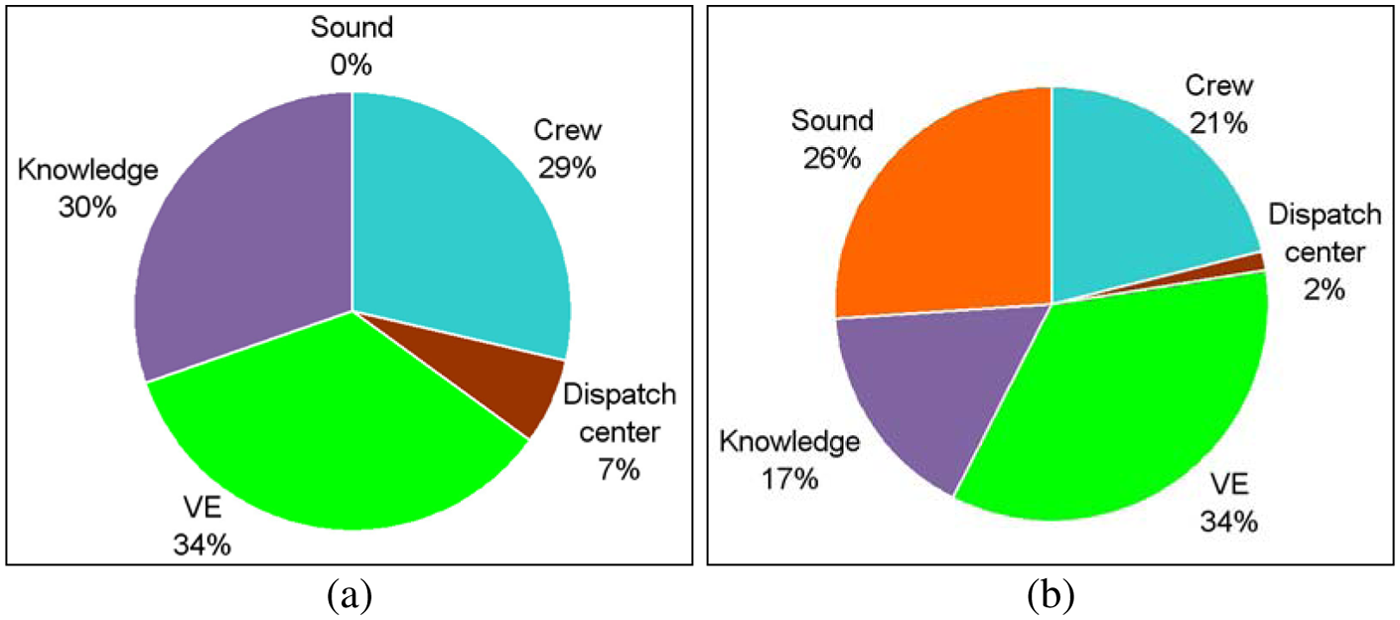
Information sources used by trainees to assess dangerous episodes in the scenario, in the no-sound (n = 8) and the sound (n = 9) conditions
Information Sources Used by Trainees to Assess Dangerous Episodes in the Scenario, in the No-Sound (n = 8) and the Sound (n = 9) Conditions

Note: The scores represent percentages, adding up to 100% for each participant.
The results show that sound was an important source of information, both for completing the mental model or “cube” (p = .008) and for assessing dangerous episodes (p = .018). A mixed ANOVA, with information sources as a within-subjects factor, shows a significant main effect for condition, F(1, 15) = 11.57, p = .004, and a significant interaction effect for condition and information source, F(1, 15) = 4.49, p = .05.
Conclusion
The results of Experiment 2 confirmed the findings of Experiment 1: A soundtrack with realistic ambient and event-related sounds did not increase the engagement and arousal of trainees in a computer-mediated instructor in-the-loop training scenario. In contrast to the realistic soundtrack used in Experiment 1, the enhanced soundtrack used in Experiment 2 did not degrade the convincingness of the computer-mediated environment. The present result agrees with an earlier study, which concluded that, in contrast to commonly used techniques in film industry, exaggerated (hyperreal) sounds do not enhance user engagement in virtual-reality simulations (Serafin & Serafin, 2004).
Sound appears to be more relevant for the assessment of danger, which is an affective task (involving the appraisal of the environment and the events therein), than for constructing the mental model, which is a procedural and cognitive task. This result agrees with the theory that emotional reactions to risks can diverge from cognitive evaluations of the same risks (Loewenstein, Weber, Hsee, & Welch, 2001; Slovic, Finucane, Peters, & MacGregor, 2004; Slovic & Peters, 2006). Sound may stimulate mental images and associations, which induce a feeling of risk (Slovic et al., 2004), and thereby determine the overall assessment of danger.
Some trainees estimated that sound contributed slightly (a fraction of 1%; see Table 5) to their mental model in the no-sound condition. Questions related to sound may, in principle, induce the formation of false memories in a no-sound condition. In an attempt to minimize this effect, we first explicitly asked the participants whether they recalled hearing some of the characteristic sounds in the simulation (Items 27-29 in Table 1). In addition, we deliberately kept the questionnaire short so that it could be completed in a minimal amount of time, and we presented it to the participants immediately after finishing their training, while their memories were still fresh.
Conclusion and Discussion
The addition of a realistic soundtrack with emphasized task-relevant sounds to a computer-mediated instructor in-the-loop firefighter training did not increase the arousal and engagement of the trainees. The original version of this soundtrack even degraded the convincingness of the computer-mediated environment (Experiment 1). It is unlikely that the quality of the sounds or their implementation were insufficient, since the soundtrack was carefully designed and evaluated with the help of expert firefighters, and the trainees judged the sounds as appropriate and adequate.
From our own observations of the training program for firefighters over a longer period of time, and from discussions with expert firefighters, we conclude that the sounds in this study probably did not have an effect on arousal or engagement because the trainees were not fully involved with the virtual world, which is a prerequisite for engagement. The sounds used in the experiments were probably not potent enough to overcome the distractions provided by the physical presence of the instructor and induce an emotional response in the trainees. Further studies in which instructor presence is an independent variable (e.g., by replacing the physical presence of the instructor by mediated communication) are required to investigate this issue.
In addition to visual and auditory information, commanders heavily rely on information provided by fellow crewmembers and other human sources to construct their mental model. The trainees probably focused on the information verbally provided by the instructor and therefore paid less attention to the events that were displayed and represented by the sounds. When the operator and the computer-mediated simulation provided contradictory information (which sometimes happened when the operator made a slight mistake in the scenario), the trainee always relied on the information provided by the crew (i.e., the instructor) and ignored the events that were displayed on the screen or indicated through the soundtrack. About half of the trainees in the soundless condition did not even notice the absence of sounds. They apparently completed their mental model of the events using other information sources. Support for this argument is supplied by the importance that trainees attributed to the crew and the dispatch center, and to their experience, as information sources for completing their mental model (Experiment 2). Further evidence is also provided by the involvement scores, which varied considerably between participants and between questions. This may have contributed to the low internal reliability of the involvement scale. In addition, the fact that some trainees experienced problems with navigation and the use of the controller may also have diminished their engagement with the virtual world (Lessiter et al., 2001).
We expected that task-relevant sounds would raise the convincingness of the computer-mediated training and thus increase the arousal of the trainees. However, the convincingness was judged lower in the condition with sound in Experiment 1. Although the sounds supported the scenario and served to aggravate the situation, the scenario itself did not involve any extreme risks or unforeseen complications. Participants could therefore rely on the standard procedures, which they had frequently trained before in role-playing games (although not in a VE setting). They did not perceive the scenario as complex or dangerous and were mostly in control of the situation. Also, firefighters are generally self-assured individuals who do not easily get nervous or show strong emotional response to danger. The combination of a typical scenario, an extensive training, and a high degree of self-confidence may have resulted in rather small emotional effects that may require measures that are more sensitive than the SAM.
Factors related to user characteristics and content of the training may also have contributed to the unexpected results on the assessment of the convincingness of the VE. First, as we noted before, sound effects in entertainment games and films often need to be exaggerated (made hyperreal) in order to be noticed or to be perceived as “real” or convincing. A similar effect may occur in computer-mediated trainings. This suggests that trainees experiencing a virtual scenario may expect similar “hyperreal” sounds or may not even be aware of sounds when they are not accentuated. However, in Experiment 2, we found that exaggerated (hyperreal) sounds do not enhance engagement and arousal. This effect has also been observed in the context of panoramic landscape visualizations (Serafin & Serafin, 2004). Second, in real incidents, communication over the radio, directed to the commander and to the other professionals involved, is an important part of the “soundscape.” In those conditions, several voices may be heard simultaneously and indistinctly, and the commander must filter out the information that is relevant for his task. In the training, the auditory environment is much simpler, since the instructor is the only one speaking, and offers the information clearly audible and sequentially. By splitting event-related sounds from communication sounds, the trainees may have focused only on the communication with the instructor.
We conclude that verisimilar and task-relevant sounds do not affect the arousal and engagement of users of a computer-mediated instructor in-the-loop training when other factors (e.g., the physical presence of and direct communication with an instructor, navigation problems, or operator errors) prevent them from focusing their full attention on the computer-mediated simulation. A previous study indicated that distraction may indeed prevent users from successfully using task-relevant audio information (Tan et al., 2010). Making the auditory effects hyperreal (exaggerated) does not help to overcome the distractions provided by the training context and fails to achieve “affectively intense training.” Also, enhanced sound effects and nonrealistic sounds cannot be deployed when accurate audio-visual representations of incidents are essential for the training scenario (Serafin & Serafin, 2004). A better option is probably to increase the realism of the simulation by integrating the communication with a remotely present instructor in the computer-mediated soundscape. In the development of virtual training scenarios, individual and explicit requirements should therefore be made for the learning goals and for the desired affective response of the trainees, to establish and augment relevant sounds (Hoorn, Konijn, & van der Veer, 2003) that address the different listening modes involved (Tuuri, Mustonen, & Pirhonen, 2007). Dependent on the relative importance of the affective response of the trainees, these requirements may lead to the identification of different types of training environments.
Footnotes
Acknowledgements
We thank Per Backlund, Igor Mayer, and Karolien Poels for their initially blind, and subsequently coaching, reviews of this article and for their numerous insightful comments and suggestions. Above all we thank David Crookall for his continuous encouragement and support.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: This research has been supported by the GATE project, funded by the Netherlands Organization for Scientific Research (NWO) and the Netherlands ICT Research and Innovation Authority (ICT Regie).
Bios
Contact:
Contact:
Contact: