
Abstract
Qualitative researchers are increasingly reanalyzing and synthesizing data sets from different studies, and this method has now been used across trials to inform trial methodology and delivery. Despite this work, however, limited guidance exists about how this method should be employed. This article details an example in which interview data collected during three primary care depression trials were brought together to explore trial participants’ study and treatment journeys. It details the process involved and the decisions made. It also presents findings from this synthesis to illustrate how this method can be used to inform the development of future trials and complex interventions, through raising questions about how researchers currently define and design treatment arms and indicating what factors may improve or hinder participants’ engagement with their allocated treatment.
Keywords
Introduction
Qualitative research is increasingly being conducted within or alongside randomized controlled trials (RCTs) of complex health interventions. Findings from these integrated or parallel studies are usually only interpreted and used in relation to the specific trial they are associated with, or are presented separately to detail patients’ and/or practitioners’ views of the treatment being evaluated. This limits their generalisability and does not fully utilize the material collected.
In recent years, there has been growing support for the secondary analysis and synthesis of qualitative data, and increasing effort and attention has been given to archiving qualitative material (Corti & Thompson, 2012). This method can entail researchers reanalyzing interview transcripts, field notes, and/or research diaries (Heaton, 2008) and aims to bring data sets together in a way that allows them to be “pooled,” to be compared, and to “talk” to each other (Irwin & Winterton, 2011a).
Within the health services research literature, there are now multiple examples of studies that have used this approach, including studies that have synthesized data across different trials (Donovan, Paramasivan, de Salis, & Toerien, 2014; Jepson et al., 2018), and across different trials and methods (Rooshenas et al., 2016), to improve trial methodology. Debates continue, however, about whether it is ethical to reanalyze data collected by others and for another purpose, and whether data can be effectively analyzed by someone not directly involved in its collection (Corti & Thompson, 2012). In addition, there is still uncertainty about how best to use this method.
Researchers have detailed how they have analyzed and synthesized data from different studies (e.g., Chew-Graham et al., 2012; Donovan et al., 2014; Heaton, 2015; Irwin & Winterton, 2011a; Kovandzic et al., 2011; May et al., 2004; Moran & Russo-Netzer, 2016; Rooshenas et al., 2016). They describe how they have selected data sets and sampled data within them, developed new conceptual frameworks and research questions to ensure the synthesis is exploratory rather than confirmatory, and brought data sets together by analyzing them thematically. However, this process is complex and, as the published examples show, there is no single or best approach. In addition, researchers’ descriptions of how they have synthesized data sets have been restricted to the methods sections of their publications. This has limited the extent to which they have detailed the methods used. Furthermore, very few published examples detail how this method has been used within RCTs, and those examples that do, focus on specific trial issues such as recruitment (Donovan et al., 2014) and conveying equipoise (Rooshenas et al., 2016). They do not detail how synthesizing data across different trials could inform trial designs more generally and the quality of the interventions they are evaluating.
This article describes a study in which data from three qualitative studies nested within RCTs were reanalyzed and synthesized. It describes the methods used and the decisions made. Findings from the analysis are presented to illustrate how synthesizing data across trials can provide insights that could inform the design of future trials and the development of complex interventions.
Method
Identifying the Opportunity to Conduct a Secondary Analysis and Synthesis
The three studies from which data were taken had all been nested within large, UK-based, multicentered, pragmatic primary care depression trials. Each trial had randomized individuals to one of two treatment arms (Table 1). In two of the trials (Trials 1 and 2), individuals were allocated either to an intervention plus usual care or to usual care only. Usual care was defined as the care the individual would normally receive from his or her General Practitioner (GP). In the third trial, women diagnosed with postnatal depression were randomized to initially receive either antidepressant medication or listening visits.
Details of the Trials and the Integrated Qualitative Studies.
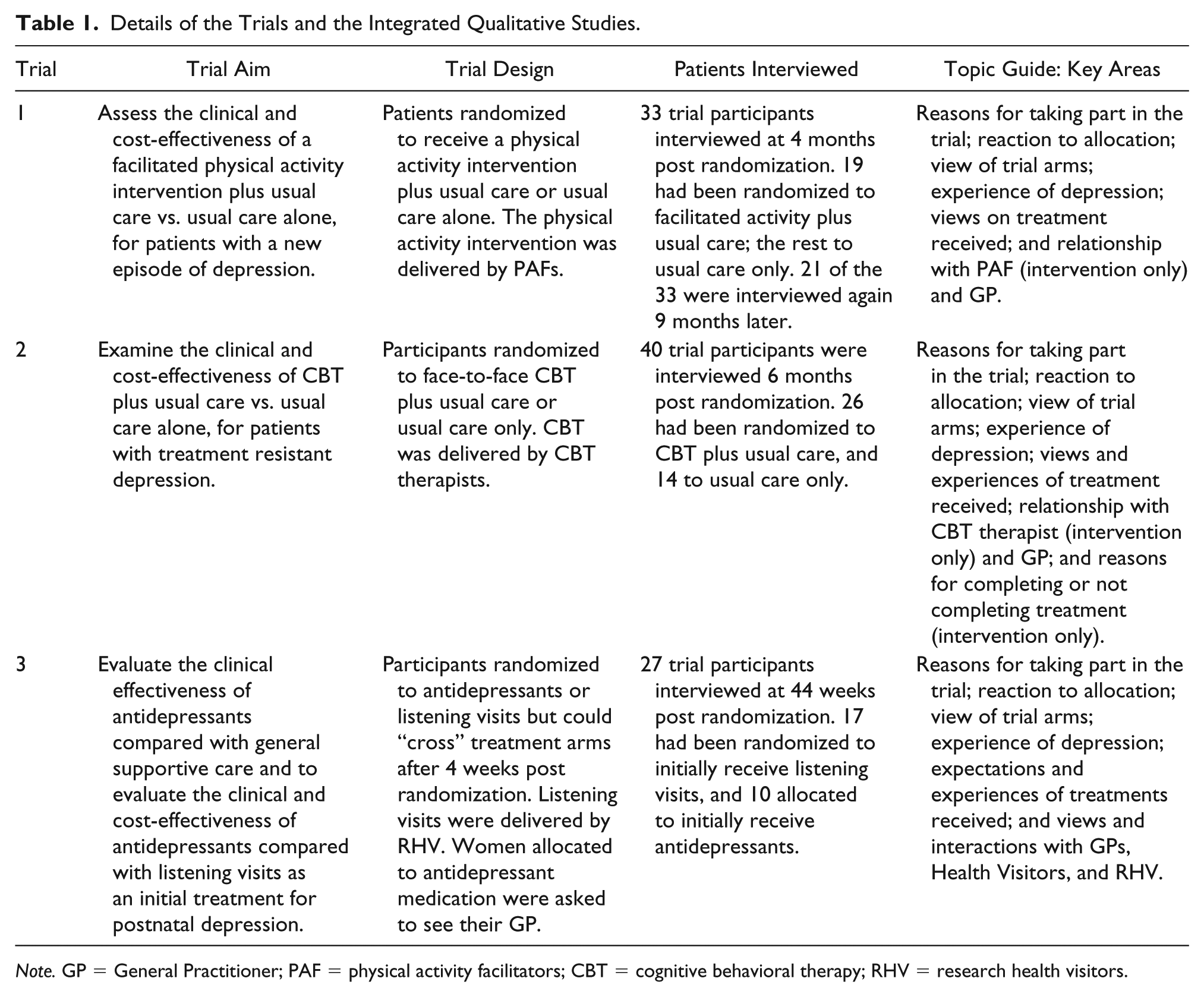
Note. GP = General Practitioner; PAF = physical activity facilitators; CBT = cognitive behavioral therapy; RHV = research health visitors.
Each qualitative study had entailed conducting in-depth interviews with trial participants to explore their experiences of the trial and treatments received. The interviews were conducted between 2006 and 2011. The studies received ethical approval from either the West Midlands Multi-Centre Research Ethics Committee (05/MRE07/42, 07/H1208/60) or the Multi-Centre Research Ethics Committee Scotland A (06/MRE00/54).
The idea of synthesizing these data sets arose because it was evident that there were common themes across them. In addition, bringing these data sets together would provide a total of 121 interview transcripts and data from three different patient groups (i.e., patients with a new episode of depression, patients with treatment resistant depression, and women with postnatal depression), on five different treatments (antidepressant medication, cognitive behavioral therapy [CBT], facilitated physical activity, listening visits, and usual care). It would also provide data on patients’ views of the four different practitioners (i.e., GPs, research health visitors [RHVs], CBT therapists, and physical activity facilitators [PAFs]) who had delivered treatment to trial participants. Thus, synthesizing these data would allow us to compare patients’ views of different treatments and practitioners, and to explore whether these views varied depending upon whether the patient was newly diagnosed with depression or not. Furthermore, participants in each study had been asked about their reasons for taking part in the trial, their reaction to their treatment allocation, their experiences of depression, and their views and experiences of treatment(s) received. This meant there were areas of commonality across the studies that would allow comparisons to be made.
The decision to synthesize these data sets was also made because the first author had been the principal investigator for all three studies. Thus, she had access to the data and to copies of the consent forms used in the original studies that showed participants had consented to their data being available for future use by researchers at the university. She also had access to documents that would help contextualize participants’ comments and aid data analysis, for example, study protocols and participants’ demographic details. The data and these study documents were shared with other members of the research team.
Securing Funding and Defining the Study’s Aim
In the grant application, the study’s aim was stated as to synthesize qualitative data sets to bring together primary care patients’ views and experiences of treatments for depression. Study objectives were also listed and included assessing patients’ views and experiences of different treatments and investigating what patients valued when receiving care for their depression. The study objectives were based on our expectations of the data. They were not based on detailed knowledge of each data set. Whether we had the data needed to address all our study objectives would only be established once analysis had started.
Organizing the Data
To give the sense of working with one large data set, transcripts from all three studies were placed in one electronic folder and relabeled according to their host trial, the trial arm to which the interviewee had been allocated, and with the interviewee’s unique identification (ID) number that had been used in the original study, for example, Trial 1 usual care participant 12. Thus, all the data were placed in one location, creating a single data set, and labeled in a way that enabled us to easily sample transcripts from different studies and trial arms.
Data Analysis and Synthesis
Initially, we sampled and independently read six transcripts to gain a clearer sense of the data and to consider how it should be analyzed. These transcripts were purposefully sampled to achieve maximum diversity between interviewees regarding their trial, treatment allocation, age and gender. Having read these transcripts, we agreed that the data should be analyzed thematically as we had identified key themes across the data sets, and this approach would allow comparisons to be made between them. We also agreed the data should be coded according to codes that could be applied to any transcript. For example, codes included “view of the intervention” and “perception of practitioner” rather than “view of CBT” and “perception of CBT therapist.” This was because we wanted the synthesis to start at the level of the data. We did not want to analyze data from each study and then triangulate the resulting findings. Having one coding frame also encouraged us to look at the data at the level needed to bring the three data sets together, for example, to focus on the interactions occurring between participants and the practitioner providing their care, irrespective of who that practitioner was. It also helped in blurring the boundaries between the different data sets as we could sample any transcript and code it according to its content, regardless of which particular study the transcript had been drawn.
Having independently coded these six transcripts, we met to discuss our coding and to draft an initial coding frame. This coding frame was then applied to the same six transcripts, and we met again to compare our coding and to discuss any discrepancies. This discussion led to new codes being added and existing codes being deleted or defined more clearly.
We found it reassuring when we identified similar themes, despite varying in our knowledge of the original studies. We also found it helpful when our views or interpretation of the data differed, as this resulted in careful discussion of the data and the context in which it had been gathered. It took a month to establish what the codes should be, and four versions of the coding frame were drafted before a final version was agreed.
Once the coding frame had been finalized, further transcripts were purposefully sampled on the basis described above, imported into NVivo (version 10, QSR International) and electronically coded. While coding the data, transcripts from different studies were selected to code, one after the other, to maintain the aim of mixing the data sets and gaining a sense of what the data set, as a whole, provided.
During the analysis, data coded under specific codes were retrieved, read and discussed. Codes were selected according to which study objective was being considering during that particular stage of the study. This allowed us to determine when data saturation had been reached, and to consider whether the data could be used to address additional or alternative research questions.
It was during these discussions, we agreed that it had become apparent there were differences between the experiences of participants randomized to usual care and intervention arms. Some of these differences were due to the design of the trial and potentially could affect treatment outcomes and therefore were of interest. Thus, at this stage of the study, we established a new study objective to assess whether there are important differences between the experiences of individuals in different trial arms that researchers may want to consider when designing future trials and evaluating complex interventions. New codes were developed to accommodate this objective (e.g., reaction to allocation, view of trial arms, accessing care), and transcripts that had been already coded were reread and coded further where necessary.
To reach data saturation in relation to this specific objective, a total of 44 transcripts were coded and analyzed. Using an approach based on framework analysis (Ritchie & Spencer, 1994), data from these transcripts were retrieved and summarized in tables to enable comparisons to be made within and across the data sets. The tables’ rows represented each participant and columns the codes developed. Within these tables, data from participants in the same study were placed in rows next to each other because each trial’s design might have influenced participants’ accounts. This did not mean that we analyzed data from one study before moving onto another but rather viewed the trial as a factor to consider when reflecting on a participant’s account, alongside other factors such as the participant’s treatment allocation, age and gender. When analyzing the data for this objective, participants who had been randomized to receive care from their GP, either having been allocated to usual care (Trials 1 and 2) or having been randomized to initially receive an antidepressant (Trial 3), were viewed as being in the usual care arm of their trial.
Results and Discussion
Results of the analysis have been detailed elsewhere (Turner, Percival, Kessler, & Donovan, 2017). In summary, they showed that randomization to an intervention arm had led to changes and increases in care, with patients embarking upon a clear, predefined treatment pathway and actively working with a practitioner, whereas allocation to usual care had led to little or no changes in treatment, and treatment usually being limited to being prescribed an antidepressant. “Intervention participants” had been pleased with their treatment allocation, contacted shortly after randomization by the therapist responsible for their care to arrange the first appointment, and were able to secure further appointments. In contrast, most usual care participants were disappointed by their treatment allocation (viewing usual care as inferior to the intervention), reluctant to consult their GP about their mental health, and sometimes described difficulties when trying to secure an appointment.
There were also differences between trial arms regarding continuity of care, in that the intervention participants consulted the same practitioner during the trial, whereas most usual care participants did not. Such continuity was described by participants as important and increasing their engagement with their treatment.
These differences were evident across all three data sets, increasing the confidence with which conclusions could be drawn. All were differences that could affect treatment outcomes and therefore trial results. Thus, findings highlighted that researchers need to focus on participants’ treatment and trial experiences when explaining trial outcomes, and not just treatment received, which is what researchers tend to do (e.g., Breitenstein et al., 2017; Richards et al., 2016). They also raised questions about whether researchers should give more attention to defining and characterizing usual care within clinical trials to address the “resentful demoralization” that usual care participants may experience (Torgerson & Torgerson, 2008), and which was evident here. This could also help ensure the treatment comparison made is not active intervention versus limited or no care, if this was not the intention. This possibility could also be addressed if researchers introduced trial processes to minimize some of the differences found, for example, mechanisms to ensure all trial participants are supported in securing treatment appointments. Finally, our synthesis indicated what primary care patients value when seeking help for depression (e.g., continuity of care) and what researchers may need to consider when engaging this patient population in a trial, for example, a reluctance to consult their GP about mental health issues. Thus, they also shed light on how researchers could improve the design of future interventions and trial participants’ engagement with them.
Strengths and Limitations
The success of our analysis related to the rich data we had, as well as to the common areas of inquiry across all three studies. Prior knowledge of the data sets had guided our selection of them, and as each data set was based on interviews, we were only dealing with one type of data, for which we could adopt one analytical approach, that is, thematic analysis.
There was a good fit between our study objective and the data we had. This fit was because we were willing to let our data drive what we focused on. The aim provided within our application for funding was intentionally broad to allow such flexibility.
The intention to synthesize the data was there from the start, with the placing of all transcripts into one folder, the relabeling of each according to the same format, the creation of one coding frame that could be applied to any transcript, and the decision to select transcripts from different studies throughout the coding process. Having research questions that drew on the data set as a whole, and in some cases, required comparisons to be made between the data sets, encouraged and enabled us to bring the data together in a way that allowed each data set to contribute without dominating.
Having a researcher who had been involved in the previous studies, and researchers who had not, encouraged conversations to start at the level of the new pooled data set and encouraged us to reflect upon participants’ accounts and the context in which they had been given. Thus, our experiences support May et al.’s (2004) view that involving researchers in the analysis process who differ in terms of whether they were involved in the original studies, helps to ensure the re-analysis is critical rather than confirmatory of previous findings. In addition, the fact that researchers involved in the analysis contributed equally to this process supports Irwin and Winterton’s (2011b) comment that although the primary researcher may have unique insights into the data, this does not necessarily extend to privileged interpretation or explanation. It also supports their comment that when synthesizing data, it is the fit between the data and the research question, rather than proximity to the original context, that will enable analytic sufficiency and validity. We would argue though, if analysis is to be done solely by individuals not involved in its original collection, then those conducting the analysis should try and access documents such as the original study and trial protocols, as these were found helpful here in terms of helping to contextualize interviewee comments.
Some of the limitations of our study related to the original data. For example, all the data used were from interviews held with individuals participating in primary care mental health trials that included nonpharmacological interventions. We cannot comment, therefore, whether our findings apply to trials conducted in other clinical contexts and with different patient groups, and where the intervention and usual care arms are more similar in terms of what treatment would entail.
Another limitation was that some of the data were collected over 10 years ago and during this time period, Increasing Access to Psychological Therapy (IAPT) services have been established in the United Kingdom, and GPs are now able to refer patients with depression to these services for psychological treatments. However, we did not identify any clear differences between the data collected more than 10 years ago and more recently, suggesting our findings were robust.
Conclusions and Future Methodological Research
Synthesizing qualitative data sets across different trials can provide new insights that could inform future trial methodology and the design of complex interventions. The design of RCTs, where allocation is at the level of individuals, lends itself to this type of work, in that these trials have common areas, for example, recruitment, randomization, follow–ups, and treatment outcomes. Researchers have synthesized interview data and/or audio recordings of recruitment consultations from different trials to explore the experiences of practitioners and researchers recruiting participants to RCTs (Donovan et al., 2014), and to assess how recruiters convey the concepts of clinical equipoise (Rooshenas et al., 2016) and randomization (Jepson et al., 2018). Depending on the data available, future work could explore other areas, such as, potential participants’ reasons for declining to participate in a trial. It could also draw on data collected from trials involving different clinical contexts and patient populations to determine the extent to which current evidence can be applied across different contexts, populations and trial designs. Researchers may also want to explore whether other forms of data could be synthesized, such as patient diaries, researcher field notes, and/or audio recordings of clinical consultations in which the interventions being evaluated are delivered.
The extent to which there will be opportunities to undertake such work will depend on researchers’ willingness to archive their data. Researchers have expressed concerns that asking potential participants to consent to their data being available for future studies may deter them from taking part (Yardley, Watts, Pearson, & Richardson, 2014). Also, to protect participant confidentiality, researchers archiving data need to anonymize them. This takes time, can reduce the richness of the data set (Saunders, Kitzinger, & Kitzinger, 2015), and/or lead to incorrect inferences being made (UK Data Service, 2018a). Archiving data will also take time and therefore further add to the study’s research costs. However, there is increasing pressure on researchers to make their data available to others. Funders such as the Medical Research Council (MRC) and Economic and Social Research Council (ESRC) now ask individuals applying for funding whether they will be archiving their data, and some journals, for example, Trials and PLoS Medicine, now request authors to complete a statement about the availability of their data for reuse. It is also becoming easier to archive material. Data archives have now been established in the United Kingdom, Europe, Australia, and the United States (UK Data Service, 2018b). In addition, some universities now have their own data repositories. Furthermore, there are published guidelines for researchers on the ethical and legal issues surrounding informed consent and confidentiality with respect to re-using data (e.g., Oral History Society, 2002; UK Data Service, 2018c), and researchers have now developed lists to indicate what kinds of information should be archived alongside the research data to help future researchers orientate themselves to the context in which the data were originally collected (Irwin & Winterton, 2011b). Thus, in the future, there should be greater opportunities to synthesize data across trials to inform their development and delivery.
Footnotes
Availability of Data and Materials
The data sets analyzed during the current study are not publicly available as participants were not asked to consent to this at the time of data collection. However, they are available from the corresponding author on reasonable request.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the National Institute for Health Research School for Primary Care Research (study number 207). The views expressed in the article are those of the authors and not necessarily those of the NHS, the NIHR, or the Department of Health.