
Abstract
This study examines user support issues concerning open-source software in computational sciences. The literature suggests that there are three main problem areas: transparency, learnability, and usability. Looking at questions asked in user communities for chemistry software projects, the author found that for software supported by feature-based documentation, problems of transparency and learnability are prominent, leading users to have difficulty reconciling disciplinary practices and values with software operations. For software supported by task-based documentation, usability problems were more prominent. The author considers the implications of this study for user support and the role that technical communication could play in developing and supporting open-source projects.
Keywords
Shifts toward open-source software development have created both new user bases and new learning needs to which technical communicators must respond—but in ways that differ from traditional documentation practices. Big commercial software developers are still working to meet the needs of sizable user groups, whose tasks and contexts they understand, and for decades, technical communicators have been refining their techniques for understanding and addressing these audiences. Open-source software developers (whether companies or individuals) have steadily been gaining footholds in serving the needs of these large user groups as well as smaller, niche groups. The contributions of technical communicators to such open-source projects (especially those created by individuals) have been less consistent although just as important. Stallman (2010) described the importance of having good technical documentation to support these projects: The biggest deficiency in our free operating systems is not in the software—it is the lack of good free manuals that we can include in our systems. Documentation is an essential part of any software package; when an important free software package does not come with a good free manual, that is a major gap. We have many such gaps today. (para. 119)
One reason for the lack of documentation might simply be that the open-source community focuses more on software development than user support.
The problem of missing or poor documentation is especially problematic in the growing market of Open Source Science Software (OSSS), in which technical communication has been slow to make inroads (Kelly, 2009). While some open-source developers do hire technical communicators to help with software development and documentation, many projects, started as small-scale ventures and pet projects, make do without: “Many scientist-created programs are ad hoc efforts never intended for distribution or release, but all can be equally critical to research outcomes” (Morin et al., 2012, p. 159). Not having been intended for distribution or release, those software tools sometimes lack adequate user support, which can lead to divergence in how the tools are used and understood.
Open-source software development, then, clearly presents a market opportunity for technical communication, but it also presents a challenge that must be acknowledged and addressed in order to assist technical communicators in articulating the full scope of their value to open-source developers. In the following study, I describe this challenge and sketch out ways to address it. Specifically, my aim is twofold. First, I examine the communication and learning challenges uniquely presented by open-source technologies, using OSSS as an example. Because of the frequently specialized use and idiosyncratic development of open-source software, some development projects encounter challenges related to the transparency and usability of the software’s interfaces. These issues are related and create a set of circumstances in which software users are not always certain either how to use the software or how their disciplinary knowledge is represented in the software.
Second, I assess how far the commonplace technical communication practice of writing documentation, with an emphasis on user tasks, addresses the problems of transparency and usability. To do so, I conducted a content analysis of OSSS user forums in order to see what kinds of questions users ask when they have access to task-based documentation and when they do not have such access. Based on the results of this content analysis, I argue for a broader set of issues for technical communicators to address through documentation as well as a broader set of skills that they can bring to OSSS projects.
The outcome of this study, then, is not only an argument about how technical communicators can frame the value of their contributions but also concrete suggestions for how technical communicators can participate meaningfully in the processes of developing open-source software and user support for that software. There are qualities of the open-source user experience that documentation does not easily address, a level of situatedness and complexity that has long problematized technical documentation, for example (see Mirel, 1998; Mirel & Allmendinger, 2004). These issues may be helpfully addressed by other members of the user community, in the context of user forums, and technical communicators can find another outlet for their professional contributions through a partnership with these communities of users and developers.
The Challenges of OSSS
Granting the benefits of OSSS, gatekeepers of scientific research (e.g., publishers and funding agencies) as well as software developers themselves note that the transparency and usability of OSSS are hurdles that hinder people’s wider acceptance of science supported by that software, and each issue points to a particular kind of user need, but the very same issues trouble open-source projects in other areas as well (see Andreasen, Nielsen, Shrøder, & Stage, 2015).
Transparency Issues
Concerns about OSSS often focus on its transparency, whether that of the data being used or of how the software processes data and supports analyses. How does the software support the research objectives that the scientific community values? To address such concerns, publishers are beginning to require a level of transparency about OSSS. Some journals (e.g., Science) require authors to include code in their articles in order to aid readers in recalculating data and checking its veracity. But not all journals require this kind of information. Some require only natural-language explanations of the software, which, because of the imprecision of natural-language descriptions, can introduce ambiguity into the presentation so that readers attempting to verify analyses might misinterpret the explanations and compound reproduction errors (Ince, Hatton, & Graham-Cumming, 2012, p. 486). These concerns are not universally felt. Some editors trust that their contributors will use OSSS diligently and judiciously and that when different researchers use the same OSSS, the underlying code and functionality are consistent.
It is not always the functioning of the OSSS that raises transparency issues. While stock computer configurations are fairly consistent, there are differences in function that occur from the configuration of those systems. These functional and configuration differences could alter the operation of either OSSS or commercial software. A certain amount of “execution ambiguity” (Ince et al., 2012, pp. 486–487) is bound to creep in, given how individual systems handle numerical rounding and other processes (see also Morin et al., 2012, p. 159).
Another problem is that users do not always provide relevant details about the software that they used, such as version numbers, modifications, crediting information, and information verifying the software’s accuracy (Howison & Bullard, 2015). While there are many mentions of OSSS in journals with high impact factors (p. 7), those citations are sometimes problematic because the authors did not supply enough information about what software version they used (p. 12); versions can change rapidly, considering the continual development of OSSS packages. Also, few citations include the sources of software—namely, who deserves credit for its distribution and development (p. 13). And authors do not always provide enough information to support the reproducibility of the results they obtained using the software, sometimes supplying only sketches or neglecting to mention such details at all (p. 13).
While reportage problems contribute to OSSS’s lack of transparency, a more significant issue—the reason that reporting is so important—is the variation between instances of the same software package. Krylov et al. (2015) noted that there is enough variation across versions of OSSS that colleagues using the software might not have versions that run exactly the same. The authors noted that although the term “open source” is ubiquitous…its meaning is ambiguous. Some codes are “free” but are not open, whereas others make the source code available, albeit without binary executables, so that responsibility for compilation and installation is left to the user. (p. 2752)
The installation differences will vary according to the hardware configurations in each lab, accounting for discrepancies between inputs and outputs across users without offering any specific insight about those discrepancies. Beyond these differences, the openness of the code is positive in that it allows people to innovate the functionality of the software but negative in that it contributes to version citation problems and a nagging concern about exactly how disciplinary values and practices are supported.
Compounding the uncertainty stemming from how OSSS systems are installed and operated from user machines is that these systems are often disruptive technologies anyway, leading users to fall back on their disciplinary expectations when making assumptions about how the software turns inputs into outputs: “When users face a new technology, they often experience ambiguity, invoke institutional norms” (Fraiha, 2009, p. 83), but a lack of transparency in the software can inhibit verification of these assumptions.
The result of introducing new technologies is learning needs that span multiple levels—individual, task, and organizational (see Nelson, Whitener, & Philcox, 1995). Any user support that attempts to address the disruption caused by new software requires a form of user support that also ought to cross those levels of user information needs (Nelson et al., 1995, p. 34). But it is not just the responsibility of documentation to support users across these domains of knowledge and practice: critically, “elements of a user’s social network, co-workers for example, can be important sources of help for overcoming the knowledge barriers that users have when facing a new system implementation” (Fraiha, 2009, p. 83). And in the instances in which we are working outside of specific organizations, the role of coworkers might well be replaced by colleagues in the field at large.
Also contributing to the transparency problem is that the user community depends on other users to pass along the knowledge required both to use the software and to reproduce the results and analyses supported by it. Undoubtedly, those who try to share this information have good intentions, but such a mechanism for sharing knowledge can be imprecise.
The result of these compounding problems is documentation that lags behind software development or insufficiently addresses user needs. Documentation, when it is considered, is often an afterthought to the software design process (Kelly, 2009). Further, some scientists and software developers are not particularly skilled at documentation (Segal, 2005). The difficulty with transparency, compounded by documentation problems, is one reason to consider relying on crowds as a potential source of documentation (see Pawlik, Segal, Sharp, & Petre, 2015) and a theme related to the analyses offered in this article. Of course proprietary software sometimes fares no better and suffers from transparency problems of its own, but at least it makes a concerted effort to support users with documentation.
Usability Issues
Like the developers of other open-source software, OSSS developers are among a group of people who use the software frequently and have skills in coding and developing software that not all users have. While developers will sometimes think about usability issues, a group of developers that Andreasen, Nielsen, Shrøder, and Stage (2015) studied relied on narrowly delimited and partial definitions of usability based on the International Organization for Standardization (ISO) ISO-9241 standard, which restricts concerns to effectiveness, efficiency, and satisfaction (p. 308). Andreasen et al. noted that little effort is expended in testing for usability adherence. Instead, usability is pushed down the line, relegated to the realm of bugs to be fixed by users who take up the software and adapt it to their needs (p. 311). This mind-set cannot be seen as negligence, however, because formal usability testing not only is impractical, given the scale on which OSSS is produced, but it is of limited value, especially if users adapt the software to their own needs. Also, because OSSS development is democratic (in principle), no owners or people are ultimately responsible for setting interface and operational requirements for all users (p. 309). Even when usability issues do rise to the surface, OSS developers or members of the developer community are not always particularly interested in addressing the issues: “From time to time we get some usability reports from professional people.…Once in a while they arrive and bless us with their wisdom” (p. 308). Although Andreasen et al. offered this as a positive response from OSS developers, it comes on the tail of more disparaging comments about those contributions, so the supposed gratitude in the response could be read as a little sarcastic.
In OSSS circles, the motivations that commonly guide development magnify usability problems. For example, the developers, who often have little in common with typical users, tend to be more focused on improving the functionality of the software than on improving its usability (Nichols & Twidale, 2003). Consequently, OSSS development tends to be directed inward toward more specialized audiences. The very process of OSSS development relies on distributed and decentralized development, which, Nichols and Twidale (2003) argued, complicates organized efforts at usability.
Although the distributive efforts of OSSS development might make it difficult to attend directly to usability, that same quality might also offer a solution (see Pawlik et al., 2015). The user base might benefit in that the effort of documentation could be distributed to members of the community who feel sufficiently compelled to produce documentation solutions. Stallman (2010) has argued the same: When people exercise their right to modify the software, and add or change its features, if they are conscientious they will change the manual, too—so they can provide accurate and usable documentation with the modified program. A nonfree manual, which does not allow programmers to be conscientious and finish the job, does not fill our community’s needs. (para. 122)
In some cases, the collaborative effort to produce documentation does produce something tangible, such as documentation wikis, and sometimes those documentation efforts are guided stylistically to produce support that will benefit users. When the community has taken responsibility for documentation, however, there are mixed results in the quality of documentation. Crowds of users do not spontaneously coordinate and might require some training and other assistance to do so (see Thominet, 2015).
The usability issues surrounding open-source software in general and in the sciences in particular come down to a couple of factors. First is the potentially idiosyncratic shape of OSSS. OSSS developers tend to be those who are not served by commercial software packages but have the development experience to devise their own solutions. We might expect these people to develop software in a way that accommodates their own work. If these developers are members of a disciplinary community whose members engage in similar work, the tasks supported by a software solution might be recognizable to those members, but the steps for completing those tasks might not. Second is the potential for user-customized versions of OSSS to diverge from the functionality of the original, making the OSSS more plastic over time as users customize the software to fit their circumstances of use. This factor also creates problems with reproducing research (Hey & Payne, 2015, p. 367). Local versions of the software could proliferate, leaving no standard version against which usability can be measured. All of these usability issues are exacerbated by poor user support. While it is not true of all OSSS packages, in many, the documentation and support for users are patchy and incomplete.
Documentation is instrumental in helping create shared knowledge about the software so that users are aware of what the software is capable of doing (i.e., supported tasks), how it is designed to handle those tasks (i.e., conceptual information), and how it affords execution of those tasks (i.e., operational knowledge). Without this information, OSSS users might well figure out how to accomplish their goals, but they would have little reassurance that other users would achieve the same ends by the same means, creating variations in practice that might erode confidence in the reliability of results from one person’s use of the software to another. The importance of user support is not lost on agencies that are interested in funding new computational tools in the sciences. The National Institutes of Health, for example, is interested in supporting research on new software tools and related infrastructures of support (PA-14-155, 2016).
Also, usability issues entail those of transparency. All of these issues are related, posing different kinds of learning needs that might be addressed in different places. A solution to the problem of using OSSS might not be as simple as developing proper documentation because tasks that are written for the software are unlikely to reflect the complexity of the social and disciplinary situations in which they are used (see Mirel & Allmendinger, 2004). These social and disciplinary dimensions of significance are likely reflected in user needs, communicated through questions or queries that they make about software. There are, undoubtedly, different ways to address these needs, all of which could benefit from the guidance of technical communicators.
The first step in investigating these usability needs is to determine what kinds of support issues arise and how existing documentation appears to mitigate those needs. Thus, I examine the following research questions: What kinds of support do OSSS users require and bring to a larger community of users? What mitigating effect does documentation appear to have? And are different OSSS support needs addressed with feature-based documentation or task-based documentation? What or who are good providers of support for users, and how can those providers be supported by technical communicators?
Method
A sample of the top 50 OSSS downloads in most science areas reveals inconsistent attention to documentation. And the existing documentation is not written to a high standard of usability, often substituting system perspectives for task-based ones (see Barker, 2003). But despite the inadequate attention to support and documentation, OSSS users are not without assistance: Software forums and e-mail lists are important sources of user support (see Swarts, 2015) and documentation (see Pawlik et al., 2015). As such, these settings are important contexts in which to study the kinds of support issues that OSSS users face and are places in which user issues concerning transparency and usability are likely to arise.
Because OSSS community members are also members of the same or similar disciplinary communities, they hold certain paradigms and methods of knowledge creation in common and likely make similar assumptions about how OSSS packages adhere to disciplinary norms. Their discussion of OSSS, then, offers insight into the way that they draw software and disciplinary paradigms into alignment. As Kuhn (1996) pointed out, paradigms are not rigid constructs but instead have a degree of flexibility—they can be stretched to accommodate novelty (p. 23), and these disciplinary norms and paradigms can be invoked as ways of assimilating novel software tools (see Fraiha, 2009, p. 83). Online communities are places in which such stretching and accommodation takes place. It is a kind of enculturation of people and tools, a dramatization of the social interaction, that structures scientific thought (see Fleck, 1981, p. 47). As a result, it is a source of conversation in which some of the more thorny user support issues related to transparency and usability are likely to play out.
Such discussions among OSSS community members are likely to show how user support issues are taken up in the context of disciplinary values and software capabilities. From a technical communication standpoint, then, the value of analyzing these discussions lies in uncovering what kinds of support issues arise and what learning needs coincide with different styles of software documentation. Doing so helps us better understand the kind of learning problems posed by OSSS and the extent to which existing documentation helps address or forestall those issues.
Data Collection
To study user support issues in OSSS, I turned to the user communities associated with popular open-source projects in the field of chemistry. 1 To ensure a focus on commonly used OSSS, I consulted download statistics at SourceForge.com, filtering them to list the top downloads for chemistry. From that list, I took the top 25 OSSS packages that were supported with some kind of documentation and forum for user communication (e.g., a user forum or e-mail list). To ensure that the same stakes and expectations for transparency and usability were present for each software package, I cross-referenced each OSSS tool with Google Scholar to see if it was used in published scholarship. The result of this filtering left 17 OSSS packages that were referenced in publications.
I then sorted the OSSS packages into two contrasting groups based on the kind of documentation available to users. Some documentation sets were feature-based, organized in some arbitrary way (e.g., alphabetically) by features, lists of features, or capabilities of the software. Other sets were task-based, divided into user goals or tasks that were then arranged in some meaningful way (e.g., major task, subtask).
The differentiation between task-based and feature-based documentation is rooted in traditions of technical documentation, particularly from Carroll (1998), who advocated documentation focused on realistic tasks and contexts that motivate and inspire users to make cognitive leaps in the learning process (Barker, 2003; Carroll, 1998). Task-based documentation focuses on contexts of use and emphasizes generalizable principles rather than specific, stepwise procedural information, leading to better and more transferable knowledge about the software (see Eiriksdottir & Catrambone, 2011, p. 767). In contrast, product-based (Odescalchi, 1986), or feature-based (see Guzdial, 1999), documentation focuses less on the tasks and contexts in which the software might be used and more on what the software can do—its features. Research suggests that users find feature-based documentation more difficult and less satisfying to use and make more errors when using such documentation (Odescalchi, 1986, p. 17).
Given how it is developed and the stage in which user feedback and usability become a concern, OSSS lends itself to the development of feature-based documentation. Mehlenbacher (2003) noted that such documentation results when it “is produced much too late in the development cycle and, worse, [when it] is designed to describe only the features of the system or to compensate for shortcomings in the primary system” (p. 528). In all, 8 of the 17 OSSS packages were feature based, 7 were task based (see Table 1), and 2 had no locatable documentation and were thus excluded from the study.
Chemistry OSSS Selected for the Study.
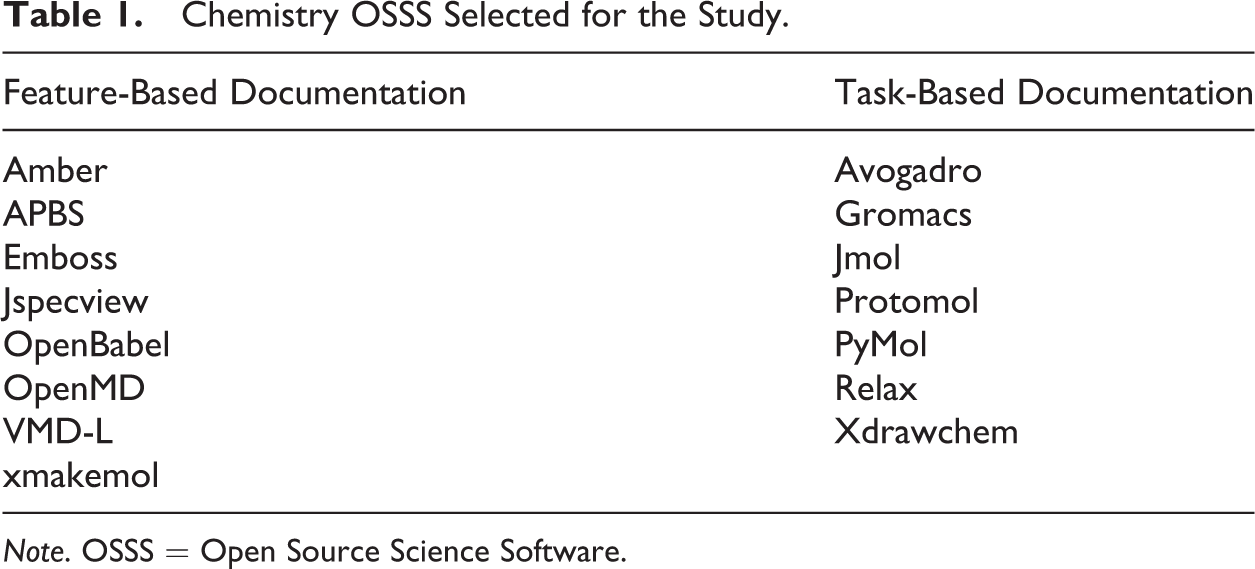
Note. OSSS = Open Source Science Software.
My concern was to understand the nature of the support issues that users were facing with different OSSS packages. For this study, I limited my data collection to the questions users posed. Most often the unit of analysis that I included as a question was the first post in a thread, posted by a user seeking advice. Often this poster phrased the query as a question. I excluded those opening posts that were not presented as questions, either with punctuation or with syntactic choices (e.g., use of question words or conditional language). I also included any follow-up questions posed in the middle of a thread. I reasoned that any question posed by users would reveal enough about the nature of their inquiry to determine what kind of transparency or usability issues might be at stake.
After scraping the e-mail archives of each OSSS for 1 year’s worth of questions and ensuing discussions, I cleaned the data by removing junk characters and then searched for user questions. I pulled for analysis a comprehensive sample of user questions and preserved the remainder for analytic context.
Data Reduction
To understand both what the users were asking about and why they were asking it, I needed to develop codes for different question purposes and focuses. Following a constant comparative approach (see Glaser, 1965), I started with an inductive approach to data coding, looking at the purpose of each question. I used first-cycling coding approaches from Saldaña (2013) to identify three different purpose codes: inquire, explain, and describe.
To identify a preliminary list of question focuses, I coded genre-level features of procedures, including tasks, concepts, and operations (steps), which account for much of what user documentation addresses (see Farkas, 1999). Both the purpose and focus codes are explained in Table 2.
Codes for Purpose and Focus.

My codes for purpose and focus were verified by a second coder, who worked with a prepared set of 10% of the entire data set. The second coder first worked through a set of training questions, after which I adjusted the coding definitions to improve clarity and to add function words that accompanied the phenomenon of coding interest and that were reliable indicators (see Pennebaker, 2011). After I added function words to remove some level of coder judgment, the second coder and I were able to reach acceptable levels of coding agreement, corrected using Cohen’s κ: purpose at 0.73 and focus at 0.86.
Data Analysis
To examine problems with using OSSS, I considered the content of user questions to be focused on areas with which users were having difficulty. In science, we might expect scientific concepts and values to be the most stable and impervious to change. After that, the goals and tasks hold fast. The operations would show the greatest flexibility as scientists work toward more or less common goals, guided by the same values and concepts as they wrestle with their respective local conditions. Thus, I expected that if OSSS is transparent and usable, there should be few or no questions at the conceptual level (i.e., questions about how or if the OSSS aligned with field concepts). There might be more questions at the task level (i.e., questions about how to achieve tasks or goals), but those would be about how to accomplish tasks and goals that paradigmatic science suggests should be possible. But the largest number of questions should come at the operations level (i.e., how known tasks are carried out in the context of the software).
I also expected that the purpose codes would indicate how clearly OSSS represented disciplinary knowledge and practices. Increases in inquire and explain codes would represent a focus on the nature of the software. Questions coded as inquire ask whether some action is possible whereas those coded as explain ask why a function works as it does. Both codes would indicate that the OSSS is more of a virtual object (see Medway, 1996), something whose function is not fully determined or whose value is not yet established. Descriptions do not question the OSSS but rather treat it as more of a tool, seeking detailed steps for how to carry out its functions.
By examining these expectations within the contrastive framework of task-based versus feature-based documentation, then, I should see differences in the proportions of questions concerning software supported with feature-based documentation versus task-based documentation. Task-based documentation ought to define the goals and actions that are supported by the software and align them with a disciplinary context of practice and its associated principles and values. Feature-based documentation would be more challenged to do the same, potentially resulting in user questions that show more uncertainty about tasks and goals and how they intersect with accepted disciplinary values.
Results
In some ways, the data reveal what might be expected of any software package: Users have questions they cannot answer through the documentation or are unwilling to check against the documentation for an answer. But further analysis of these questions reveals patterns that point to disruptions in how users think about science and, more important, how they understand the software to be supporting scientific practices. Table 3 shows user questions by focus.
Differences in Question Focus Across OSSS Communities.
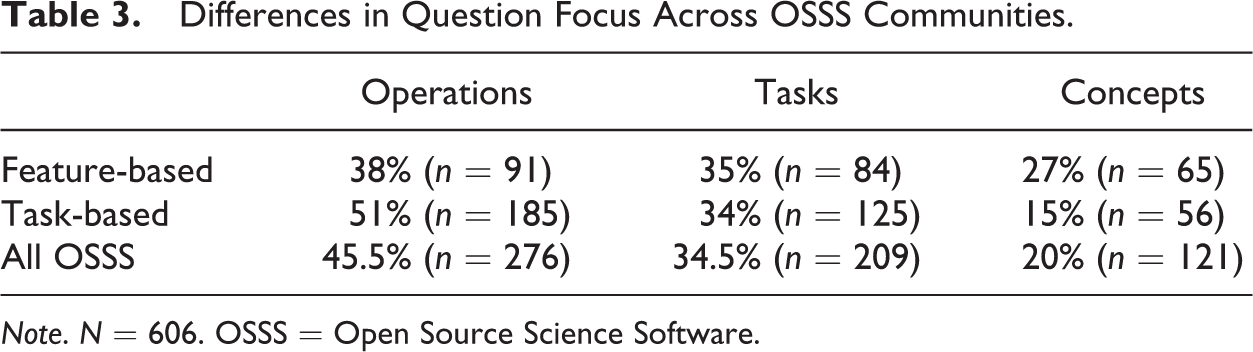
Note. N = 606. OSSS = Open Source Science Software.
Of the 606 questions I examined across all OSSS communities, most of them focused on operations (45.5%) and tasks (34.5%). Many of the users who participated in exchanges with fellow users had specific questions about the software conditions in which they could carry out known tasks. Or they had questions about chains or sequences of operations that would allow them to achieve a particular goal. Questions about operations were often about isolated steps (e.g., where to find menu options) whereas questions about tasks were about sequences of steps (e.g., how to model a molecule under certain conditions). Questions about concepts were less frequent (20%). Overall, this is a good finding and an expected one; it shows that the fields of computational chemistry supported by these OSSS tools are fairly stable.
Table 4 shows the breakdown of questions by purpose. My analysis showed that the most prominent purpose for these questions was seeking a description of operations or tasks (65.8%), followed by seeking explanations (22.6%) of the same. Although users seeking descriptions and those seeking explanations both wanted a list of the steps needed to complete a task, those seeking explanations also couched their requests in “why” questions, indicating that they needed not just concrete knowledge of how to accomplish some action with the software but additional insight as to the reasons behind the action.
Differences in Question Purpose Across OSSS Communities.
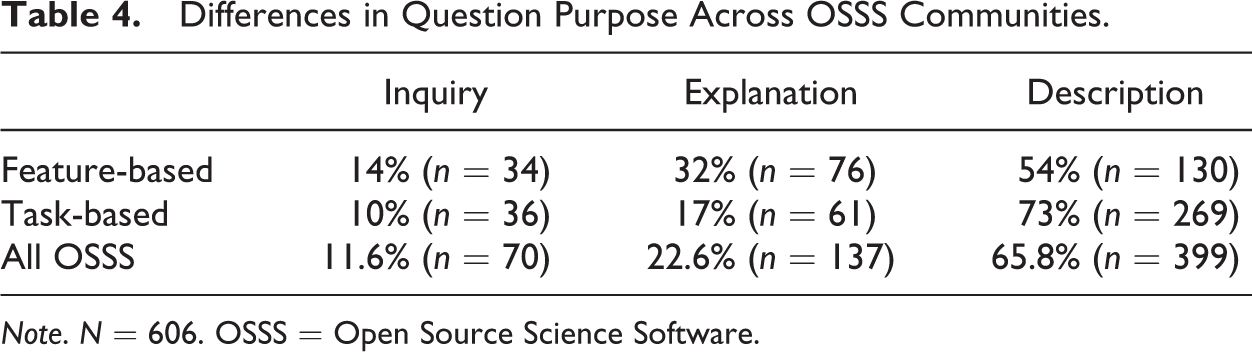
Note. N = 606. OSSS = Open Source Science Software.
When we separate the questions by feature-based documentation (n = 240 questions) versus task-based documentation (n = 366 questions), a different distributional pattern emerges, telling us more about the particular kind of problems that might appear with OSSS in different support environments. If OSSS tends not to invest much attention in documentation, then we have little reason to believe that the documentation would always follow a best practices, task-based approach. If there is documentation at all, it is more likely to be feature-based documentation because a feature-forward view of the software tends to predominate discussion of OSSS development (Stallman, 2010). It is interesting, then, that most of the questions about operations are from users of OSSS supported by task-based documentation, which suggests that technical communication adages about staying focused on tasks and users have some positive effects. The questions from users of OSSS supported by feature-based documentation, on the other hand, focus more on tasks and concepts than do those from users supported by task-based documentation (see Figure 1).
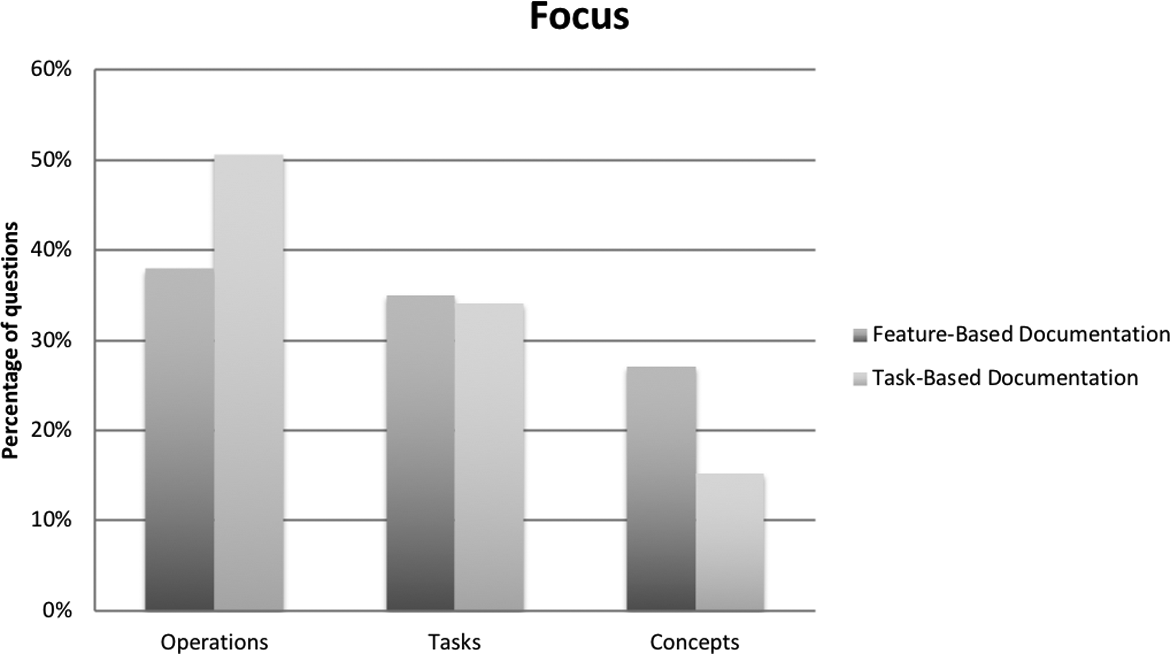
Distribution of questions across areas of focus.
A particularly important finding from this analysis is that questions about concepts account for a greater proportion of the overall questions in feature-based OSSS (27%) than in task-based OSSS (15%). This finding suggests that OSSS supported by feature-based documentation has a more opaque conceptual model.
Likewise, when we compare the OSSS questions on the dimension of purpose, we see a telling deviation between the two documentation types (see Figure 2). Both feature-based OSSS and task-based OSSS were characterized primarily by questions seeking descriptions (54% and 73%, respectively), but the proportion of questions seeking explanations was nearly twice as much for feature-based OSS (32%) than task-based OSSS (17%). This need for explanation points to a kind of user need that is significantly different from the need for mere description. Needing an explanation implies a disconnect between knowing how something should be done and knowing why it should be done that way.

Distribution of questions across areas of purpose.
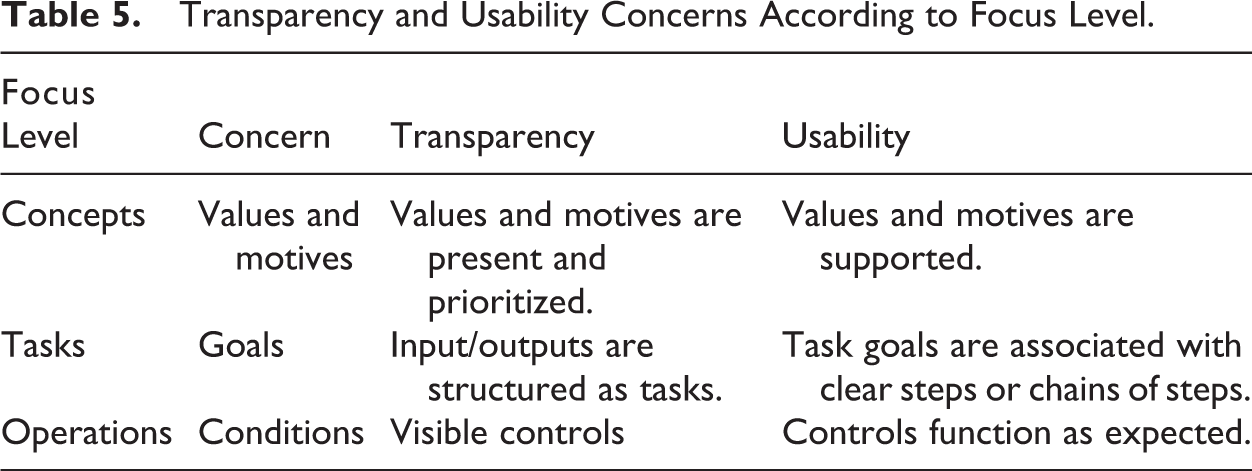
Thus, what these patterns lay out are the stakes associated with user support, in which problems with concepts and tasks might be more disruptive to the activity of science than are problems with operations. By looking more closely at the questions, we can determine where the disruptions might be. Looking back at the concerns of transparency and usability, we can predict particular disruptions (see Table 5). Problems with concepts might indicate that a field’s values and motives are not transparent or supported. Problems with tasks might indicate that basic software inputs and outputs are not visible or associated with clear steps to accomplish them.
Transparency and Usability Concerns According to Focus Level.
Discussion
Correlating the dimensions of purpose and focus, we can see the kinds of needs that predominated the questions. These needs point to obstacles that prevent users from adopting OSSS and connect with what has been written about the transparency and usability issues of OSSS, clarifying them in terms of specific help needs. By analyzing these needs, we can find variances in users’ understanding of OSSS, consider the potential negative impact on OSSS use in support of scientific research, and consequently determine the areas of greatest need for user support.
To determine how the dimensions of purpose and focus interacted, I analyzed the frequency data using a χ2 test of independence (see Geisler, 2003) to determine whether the dimensions were independent of one another (i.e., not influential) and whether these findings would hold true across the contrast. While this analysis does not have enough data points in order to make claims of statistical significance, the χ2 allows us to focus the descriptive analysis on the more salient interactions, two of which occurred more often than expected by chance: those between explanation and concept and between description and operations.
Explaining Concepts
The first interaction—between explanation and concepts (+62.03, Chi = 175.10)—was predominant in questions about OSSS supported by feature-based documentation. This interaction indicates that there is an unclear fit between what the OSSS does and why it does it. The users asked questions in two different ways. At times, they asked how concepts from the field were captured in the functions of the software. At other times, they asked how the concepts present in the OSSS (e.g., in the interface, in menus) connected with concepts from the field. While users sometimes had questions about how to accomplish tasks in the software, they also questioned how the software worked conceptually. By what concepts did the software operate? How did it organize and process inputted data? How did it create and render analytic objects that researchers could fit into their publications and grants? The explanations to these questions and the concepts involved were sometimes linked to underlying disciplinary values and analytic presumptions, so questioning how the software worked conceptually was often a way of asking whether the software operated according to disciplinary analytic norms. In this way, the lack of transparency was a disconnect between how users thought about their disciplinary content and how the software thought about or processed it.
Incompatibility Between Expected and Actual Outcomes
One set of questions, coded as explaining concepts, were those in which researchers attempted to use software to facilitate an analysis that they already knew how to complete and for which they had a sense of what the outcome should be. When the data were run through the software, however, the results were sometimes anomalous enough to make researchers doubt the functioning of the software or their own input, leading them to ask for explanations about the fit between disciplinary concepts and software concepts. In the following example, the researcher states the discrepancy, calling for an explanation of a calculation, the mathematical concept behind how the software works: I have been trying to compute the principal axes for two 4mer water clusters and have ran into what I think is a discrepancy in the calculations. The structure of both clusters is the same but they differ in their input coordinates and in the ordering of the TP3 water residues…by that I mean if you start with residue 1 and proceed clockwise the residue numbering goes 1342 (4mer-1 in red) versus 1234 (4mer-2 in blue)…. Using cpptraj (fully patched AmberTools14) I then compute the principal axes of each cluster. I expected that I obtain the same results. Instead if I view the resulting principal axes overlayed with the output cluster structures (as obtained from the dorotation keyword) I see that the axes are indeed identical but the clusters are offset.
2
The researcher followed up with an explanation of what he did, revealing his thinking on the problem, and he attempted to resolve it: I have also tried the “origin” keyword (both before and after the principal command) to help correct the structures’ offset but this doesn’t change the final coordinates within the mol2 file…. I would appreciate if someone could point out if I have made an error in my input or in my thinking. My only guess(!) is that perhaps something is going wrong with dorotation within the principal command.
What the researcher needed, then, was an explanation of the software concepts as compared to the concepts he held. He was calling for the software to be made more transparent if there was no essential conflict in conceptual workings.
The researcher described his issue as being related to data input and analysis, and he clearly had some expectation of what the answer should be. Being unable to get the analysis he was expecting led to a disruption that caused him to doubt everything from his inputs to his thinking to the underlying ways that the software made the calculations. The analytic objects, “principal axes for two 4mer water clusters,” were more plastic than he was expecting, and since he could not peer into the software to see how it was thinking about the analytic construct (i.e., a lack of transparency), he was prompted to question this issue.
Even when issues are addressed through the documentation, problems can persist: “I think there’s an error either in the documentation or in the implementation of the filter by pattern in obabel (v2.3.2).” That too is an example of a mismatch between expectations and outcomes that led the researcher to wonder whether there was a problem “in the documentation or in the implementation of the filter by pattern” function of the software. Some problem exists when researchers cannot generate results that match their expectations and there are no other factors (other than software or input error) to suggest a source for the error.
Similar questions arose when researchers attempted to complete analyses but had difficulty knowing which OSSS interface options mapped to the functions they needed. This is an example of a usability problem in which the concept of the software as a working system was challenged by unclear labeling or programming that made it difficult for users to connect what they wanted to do with how the OSSS wanted to do it. The result was a gulf between what the researchers expected and what the software provided: As a test run we are trying to compute diffusion constant of water. We have taken 64 water molecules. I am confused about the “center” and “image” command. Using the following command we are getting the value 2.918 and without using the two commands we are getting a different value (2.026).
Or the software concept that is visible as a command or menu option might have no clear connection to analytic processes that are familiar to the researcher: “I would like to request for help with regard to the “cbrange” setting in gnuplot. My questions are: 1.What does it really mean?” In both cases, the researchers point to the gulf between their expectations and what the software delivered. The relevant point in the first example is the difference between the “center” and the “image” commands. In software in which the functions and their connections to disciplinary knowledge are completely transparent, there would be no question about the difference between the two commands and why they led to different computational outputs. In these cases, however, there is a gulf in understanding that manifests as uncertainty about the conceptual shift between two software functions.
A lack of transparency can sometimes also be made more recalcitrant when the results of OSSS use are instantiated in published papers: I would like to know if there is any direct relation between h-twist and h-rise. Is there any significant difference between h-rise and L-rise. it feels that in some papers though rise of standard BDNA and ADNA were quoted with helical values but values got from theoretical calculations were L-rise.
Of course, this kind of problem is exactly what journal editors worry about: the replication of idiosyncratic analyses in published literature leading to incomparable results derived from analyses based on different analytic presuppositions.
Lack of Fit Between Accepted Disciplinary Knowledge and Software Operation
Another kind of transparency issue related to conceptual incompatibilities arose when users were unclear about how to apply what they knew about their field of study to the software. In some cases, there was a poor match between concepts of disciplinary knowledge and software operations. Sometimes users caught the differences: “The formula about Leonnard-Jones potential in [URL] is correct? Seems that the ‘4’ outside the parenthesis is missing.” Here is another instance regarding the same software: Was wondering how does APBS define the surface of the molecules? Looking for the answer I read some of M. Holst’s PhD work where he divides the simulation box into three regions: 1—the protein 2—a layer of solvent that does not have any mobile charges and 3—the solvent with ions. I was wondering if the same principles are implemented in APBS if so then how does APBS calculates width of the region 2.
In this instance, the attempt was not to point out a fault in the software but to align the operation of the software with a published account of the same phenomenon that the user was studying, thereby clarifying the relationship between field concepts and software concepts. Since the same terminology was used and “surface” can potentially mean two different things, it was important to differentiate the software’s model.
Even when researchers came to the software with knowledge of how the underlying analyses ought to be handled, their interactions with the software could, at times, create the smallest cracks of doubt in that knowledge: I can’t understand the way in which chiral winding is handled by OpenBabel. I wrote a small test script in Python (attached) to try to clarify the concept. The output is: ClC(I)Br -> WINDING [1->2] -> ClC(I)Br Cl[C@…](I)Br -> WINDING [1->2] -> Cl[C@@H](I)Br Cl[C@@H](I)Br -> WINDING [1->2] -> Cl[C@…](I)Br The winding is always perceived as 1 and this is wrong by definition (right?).
So in this case, the issue was a lack of fit between the accepted disciplinary knowledge and the apparent analytic assumptions of the software.
This kind of issue—the lack of fit between accepted models of analysis and analytic presumptions built into the software—can have a detrimental effect on enculturation. If one of the outcomes of people working with software is that they acquire a better understanding of their field by working through the framework of the software, then software built on faulty assumptions about discipline-specific analyses will certainly problematize learning.
Description of Operations
While the questions about the OSSS that are supported by feature-based documentation predominantly asked for explanations of concepts, those about the OSSS supported by task-based documentation predominantly asked for descriptions of operations. Users of the latter type of OSSS appeared to be more familiar with the kinds of tasks supported by the OSSS and less overtly concerned with the match between disciplinary paradigms and concepts and those programmed into the software. In this way, OSSS supported with task-based documentation seemed to exhibit fewer transparency issues although usability was still a concern. Another χ2 of independence showed that the Description: Operations pairing was much more likely to occur than by chance (+64.33, Chi = 33.2). Here again, there are not enough data points in this analysis to make claims of significance, but the result does allow us to focus the descriptive analysis on the more salient interactions.
Many experienced and novice users alike appeared to have a good idea of how the OSSS with task-based documentation aligned with their disciplinary values and common tasks. In this sense, the OSSS appeared to be less contested and plastic than did OSSS supported with feature-based documentation. Although users had suggestions for improving the OSSS, they had less apparent confusion about what the software did and why.
Steps for Known Tasks in Local Conditions
Among the most common issues that users had with the OSSS concerned attempts to carry out tasks that they knew or assumed to be supported within the software. Often users had figured out all but a step or two and needed assistance. Such issues point to usability problems—the supported functions are part of the software, but their location in the interface is not always easily determined. Many questions were of this routine variety: I am experiencing some troubles using the command select in order to select a chain. According to the web page Select Commands in Jmol and RasMol by Eric Martz and Bob Hanson I can select the whole atoms of a chain by typing ‘select *a’. That command does not seem to work neither in standalone 14.4 jmol or in first glance using jmol 14.4 (no java). When I select in the opposite order: select a* the it does not select all the atoms in the chain but a small number.
In that example, the user presumed that the particular type of selection was possible but could not easily locate the steps or controls for accomplishing it. In fact, the user references a Web page where tasks supported in this OSSS were documented. This example and others like it represent a minor usability issue in which users have difficulty understanding how the OSSS sets operational conditions for common tasks, that is, how they can manipulate the interface to accomplish what they are trying to achieve. Here is another example: I want to find the number of ions in a specific part (say left half) of the cell as a function of time. gmx density gives me a time average value across the box (cell) and I know that I can manually find the density for small time steps(0-11-2 ns…) and plot the values obtained for the left half of the cell as a function of time [emphasis added] but it would be much easier to do the same with a single command. Any suggestions?
As I have highlighted, this user also understands what is possible to do in the OSSS but experiences an interesting complication arising from the local circumstances in which she is attempting to complete this task: She wants to complete the tasks “with a single command,” and so her user support issue is not understanding how to do so. She knew there were ways to accomplish what she wanted and had (presumably) learned those already, but the situation required a simpler or different way. The uniqueness of such local circumstances were what made adaptable and customizable OSSS so valuable in the first place, yet the idiosyncrasies of those local circumstances were what created the issues that were too specific to be addressed in documentation, even in task-based documentation.
Troubleshooting and Local Expectations
A related issue in these questions concerns how to troubleshoot problems that arise when using OSSS in expected ways. In these cases, users appear to be familiar with how the software ought to be working and, in some instances, might have been able to get the software operating as expected; however, for whatever reason, the OSSS was no longer working as expected. The functions and steps they normally took to accomplish a goal were meeting with dead ends. The more savvy users would sometimes troubleshoot the problems across multiple machines or multiple installations of the software: Hi I’m having some trouble using CGO spheres. When I create one it is not visible in the viewer although there is an (apparently empty) object in the object pane. It is somewhat confusing because with some parameters the spheres ARE visible when ray tracing although they are still not visible when non ray traced. I have not had this problem in the past although I haven’t tried in a while (> 1 year). I am using pymol v1.7.4.0 which is up to date from the SVN repository (revision 4107). And I am on Ubuntu 14.04. I reproduced this problem on another computer running 1.7.x.
This user went on to give instructions for reproducing the issue. This usability problem is interesting in that it has not always been an issue and might not be an issue for others. As the user noted, he had not had this problem before, but what had changed since he last tried was that he was using a new version of the PyMol software and a new operating system. These local conditions created their own usability issues that might not be the same for all users. Troubleshooting usability problems, then, entailed understanding differences between versions of the software, especially in cases where the problems were intermittent. Documentation might help users accomplish general tasks, but what contributed to the usability problems here were the specific localized applications and the changes between versions. The user community is a particularly good place to address questions like this because the problems first need to be confirmed by others in order to narrow down the possible sources (Swarts, 2015). Without such confirmation, it cannot be ruled out that the source of the problem is not the user’s system set up or local files rather than the OSSS.
These are usability issues, but not typical ones since the way that they are addressed is not necessarily through making changes to the program interface so much as in helping users troubleshoot technologies that are incidentally connected to and interoperating with the OSSS. The context for considering usability problems expands with OSSS, and not all problems are easily redressed.
The OSSS supported with task-based documentation drew more questions about software operation within specialized circumstances. The OSSS supported by feature-based documentation does yield the same kinds of questions, but they get drowned out by broader problems concerning how the software fits in with disciplinary paradigms and expectations. Those issues of transparency appear to precede the usability issues that become more apparent to users with software that they understand and can more easily relate to their work.
Supporting Users of OSSS: Implications for Technical Communicators
One of the distinct advantages of OSSS is its plasticity and adaptability to the specialized needs of its users. The software has room to be adapted and to fill niches that commercial software cannot. At the same time, this plasticity of form is also a liability for user support and a hurdle for building trust around the results that OSSS produces, especially when the science that OSSS supports is turned into publications, funding, textbooks, public policy, and so on (see Fleck, 1981; Latour, 1987). Rather than seeing this problem as a reason not to support OSSS projects, we should instead see it as a call for greater attention to user support issues. The aim of my analysis has been to show what those user support issues are.
By creating two contrasting groups of OSSS—one supported by feature-based documentation and the other supported by task-based communication—I attempted to see if the common wisdom of technical communication, that task-based approaches to documentation are better at supporting users, is true. The results suggest that our disciplinary inclination toward task-based documentation is warranted. The users who had access to such documentation asked fewer questions about tasks and needed less explanation of how the software supported the tasks that they wanted to accomplish. But the results also reveal issues that neither kind of documentation addressed entirely, and an examination of those unmet needs suggests some clear implications for technical communicators, especially in the roles they could play in both developing and supporting OSSS and open-source projects in general.
One obvious way that technical communicators could address these problems is by working with software developers to provide the documentation that might be missing. A slightly more interesting version of the same solution would be to ask technical communication students to take on documentation projects, especially if the project allows them to work with users of the software on campus. Such a project would certainly help technical communication students understand the importance of working with users in a participatory manner (see Johnson, 1997). But beyond writing documentation, two other roles for technical communicators are equally important.
The first and perhaps most directly influential role for technical communicators would be to partner with software developers from early on in the software design process. In some commercial software development environments, processes such as Agile development integrate documentation with the software development from early on, and an early and continuous focus on documentation helps refine the functionality of the software as well as the usability and transparency of its interface design. In OSSS, technical communicators can certainly add the same kind of benefit. And by working with users and the software developer, they can help ensure that the software is designed to accommodate common tasks and that the documentation foregrounds those tasks without making faulty assumptions about users and tasks that get baked into the software from the early design phases. The partnership might also continue through the launch of the software, as members of the user community start to interact with it, touching on the second role of technical communicators as contributors to OSSS communities.
Only some of the problems outlined here can be addressed with static documentation, however, because it might be too generic in scope to address the complexities of situations that OSSS users face. As the traffic on OSSS lists seems to confirm, user communities are a much more accessible option for user support. But this form of user support poses its own set of problems. We do not know who is participating in user communities, and there is no accountability for producing support that meets user needs as well as those of the software developers. Communities of users regularly offer hacks and workarounds that do not necessarily pervert the function of the software but do lay down developmental forks in the road, making instances of the software that are less instead of more alike. When the help provided by user communities is individualized, because such individualization appears necessary, the problems of transparency and usability might be solved for individuals, but the problems persist at the community level, further fracturing the cohesiveness of that community’s knowledge of the software and contributing to problems with how scientific analyses are distributed.
As a continuation of the proposed partnership between technical communicators and software developers, the technical communicators could see the user community as a forum for user engagement and a space for participatory design. I have reported elsewhere (Swarts, 2015) that technical communicators could forge a new role in helping to manage help communities, not writing the documentation necessarily, but encouraging its development. One thing that technical communicators could supply to conversations in user communities is a structure for thinking through help problems, eliciting the most helpful kinds of information from users and refining the answers provided by the community. This kind of intervention helps individuals but might not provide assistance that helps the larger user community develop a cohesive understanding of the software as a disciplinary tool. On this point, technical communicators could serve another function in user communities—as analysts of help content.
Technical communicators could help online communities work as communities by finding trends in questions and solutions and from that trend analysis find points at which to intervene with targeted documentation. To support this work, technical communicators should develop skills in analyzing and mining text (see Geisler, 2003; Kaufer, Ishizaki, & Cai, 2016) in order to develop awareness of the discourse patterns that signal different kinds of questions and purposes for asking. Individual questions can easily get lost in the rush of conversation in an online forum, but as the research here demonstrates, users often relied on similar kinds of language to signal types of questions. Technical communicators who study these patterns can develop dictionaries, word lists, and other filters that flag posts or collections of posts for special attention and possibly for targeted documentation. In this way, the role that we might envision for technical communicators still stays close to documentation but also involves a kind of community management that pushes users toward better questions, better answers, and better recognition of community knowledge that needs to be preserved.
Technical communicators could also take feedback from the user community and understand it not only as areas for elaboration and clarification but also as potential areas for software development. Technical communicators could become better mediators between the users with whom they are interacting and the software developers who want to develop and refine a product to meet their needs.
This model of early and continuous technical communicator interaction helps to address what Stallman (2010) saw as the problem with documentation and usability in OSS, but if technical communicators could insert themselves into the software design process from the start and stay with it through subsequent development cycles, they could make incremental contributions to documentation that are always aimed at making the software usable and transparent about disciplinary values and practices.
Openings for such contributions are more difficult to find, however, especially since OSSS development might not happen in very visible places. The inroads that we might need to make could come, first, from working through our institutional offices of funded research to connect with people who are developing software. Another might come from aiming higher by lobbying groups that fund science research achieved with OSSS. Groups such as the National Institutes of Health and the National Science Foundation might be persuaded, with research such as that presented here, that problems of knowledge cohesion, transparency, and usability fall within the traditional skill set of technical communicators, and software development and implementation projects might be served by including technical communicators and technical communication scholars on those interdisciplinary development teams.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.