
Abstract
Background
Recognizing sign language has emerged as a crucial method for closing communication barriers between the general public and hearing and speech-impaired individuals.
Purpose
In order to facilitate instantaneous recognition in mobile apps, this article presents an extensive collection of sign language in English.
Research Design
In contrast to earlier datasets, our collection includes a large number of signers, a wide range of hand gestures, and a diversity of environmental variables, guaranteeing reliable performance in a range of real-world situations.
Data Analysis
Our method improves real-time language of signs recognition and transforms gestures to speech with low latency by utilizing portable optimization approaches. High-resolution data, a specific English dataset, and dataset variety all work together to greatly enhance model generalization by eliminating errors imposed on by changes in user demographics, illumination, and hand placement as well as phrase interpretation using Natural Language Processing model.
Conclusions
By creating more accessible and inclusive mobile applications, our research opens the door for smooth sign-to-speech translation across linguistic and cultural borders.
Introduction
People with hearing difficulties can communicate with others in everyday life by using sign language, which is an essential communication tool. The absence of effective means of communication between non-signers and sign language users is still a major obstacle, nevertheless. Real-time conversion into spoken language is now feasible because of recent advances in computer vision and machine learning, which have automated the identification of sign language. In spite of the advancements in this field, a large number of sign language recognition databases now in use are lacking for the distinctive characteristics of various sign languages, especially geographical variances within languages and variations in gestures. In this work, a foundational dataset of English sign language that is tailored for immediate recognition within mobile applications is developed so as to address this issue.
By supplementing the English dataset, this one makes sure each of the languages are adequately represented for usage across the world. To improve the robustness of identification models, the dataset is constructed with a variety of hand gestures, various signers, and a range of ambient situations. The suggested system can reliably identify signs in real time by fusing advanced machine learning methods with high-resolution images and videos, thereby enabling smooth sign-to-speech interpretation. By making mobile applications accessible and useful for real-world applications, this research seeks to increase accessibility for users of English sign language.
Related work
Systems for recognizing sign language (SLR) have become essential assistive technology, facilitating smooth communication between hearing and deaf/hard-of-hearing people. In Ref. 1, input is provided as a sign language video, which is then framed and segmented. The Haar Cascade algorithm is utilized for sign detection, the CamShift approach is used for tracking, and P2DHMM is used for hand tracking. Following sign recognition, the POS tagging module receives the continuous words associated with the appropriate sign. The problem of hand overlap, which might compromise the precision of sign recognition, is not addressed by the system. Participants in the study are hearing-impaired students from Shankar Nagar Nagpur school. The system received 60 films as input, and 33 model feature expression samples were built into a database. The study aims to create NLP algorithms that can handle lengthy phrases; however, it ignores the vast database that will cover the most terms. Ref. 2 framework combines The Canny edges detection, region growth, SURF descriptors, clustering with K-means, and SVM classification to identify 16 classes of the American Sign Language alphabet with a mean accuracy of 97.13%. According to the study, a smartphone platform’s processing capability may be a limiting factor in its utilization. According to the study, 3 the MobileNet method could find value in additional fields including object identification and picture categorization. The work had real-world implications for creating an algorithm that can efficiently categorize various sign languages. Although it did not involve NLP, the research also demonstrated the model’s potential for usage in practical settings. The report makes a number of recommendations for future research, such as investigating other deep learning techniques and using bigger datasets. Available estimates of human landmarks and hand tracking were made achievable by the usage of MediaPipe, in the paper, 4 which also introduces the King Saud University Saudi-SSL (KSU-SSL) database, a Saudi Sign Language database, and employs a 3DGCN architecture for sign language recognition. The study 5 seeks to address the difficulties in recognizing sign language, such as the deficiency of posture annotation and the requirement for efficient pre-training and fine-tuning techniques. The study has some drawbacks, such as the requirement for a significant quantity of labeled data and its dependence on pre-trained posture detectors. The study also points out that the posture detection quality may have an impact on the method’s performance. The work may have restrictions if the suggested approach is applied to other fields, such as computer vision or natural language processing. According to the findings of the study, 6 existing video synthesis techniques lack the accuracy necessary for a fine-grained comprehension of the entire sign language phrase, but they do permit a certain level of understanding, such as how to identify the video category. It is used with the How2Sign dataset, which consists of a number of videos in sign language. The dataset’s restriction to American Sign Language as well as potential lack of generalizability to other sign languages are among the study’s shortcomings. The study also points out that gathering and annotating sign language data can be a costly and time-consuming process. There are real-world uses for the study 7 in language instruction and education, especially when it comes to learning sign language. According to the study, augmented reality-enabled mobile applications may be utilized to foster social understanding and awareness while offering inclusive and accessible learning opportunities for those with hearing impairments. Due to the small sample amount of thirty users and particular setting, the research could not be entirely typical of the general population. The suggested model has an extensive computational complexity, according to the study. 8 The quantity of the dataset is one of the study’s shortcomings. The intricacy of the model is another drawback of the study. Among the study’s shortcomings is the requirement for additional data to enhance the model’s functionality. It is necessary to solve the transformer constraints and computational complexity of the model. Using a trained convolutional neural network (CNN), the study 9 suggests a Rotation, Translation, along with Scale-invariant sign word-recognition system. However, the study notes that because of the CNN model’s computational complexity, the suggested system might not be appropriate for real-time applications. The study’s shortcomings include its inability to handle RTS variable pictures and complicated backdrops, which impair system performance. The efficiency provided by the MediaPipe framework in hand gesture detection is shown in the paper. 10 Without the use of wearable sensors, the system can instantly identify motions in sign language. The constraints of the suggested system are not thoroughly covered in the paper. The need for good-quality sign language datasets along with the possible complexity of the suggested model are two of the study’s shortcomings. In order to maximize feature representation, the study 11 suggests an Adaptive Transformer architecture that combines three innovative modules: Adapted Masking, Local Clipping Self-Attention, with Adaptive Fusion. Future research will examine how well ADTR generalizes across other sign languages, improves spatial learning for representation, and adapts to new sign language datasets and languages. By creating automatic systems for translating among spoken and signed languages, the work in Ref. 12 aims to enhance communication between the Deaf and hearing populations using noninvasive technology. The goal of the project is to solve the difficulties in using avatars to show and convey signed language. However, future research in this field will focus on creating increasingly complex avatar technology and more sophisticated methods for conveying signed language. The proposed system offers Sign Language Recognition for a single sign to a whole phrase as well as offers interesting different learning methodologies through a catchy mobile application.
Methodology
The proposed mobile application includes an efficient text-to-sign and sign-to-text using sign language for an e-learning purpose that has been upgraded with fascinating augmented reality visuals for sign language that also offers real-time practice choices. Figure 1 shows the general data flow of the application. Application data flow diagram.
Public datasets frequently don’t cover specialist topics or use cases, have quality problems like missing numbers or imbalances, and lack domain-specific data. Building a customized dataset gives users greater flexibility over the quality of the data, ensuring that it satisfies specific requirements and enhances the precision and dependability of your model.
Dataset
The system is developed using a methodical, systematic process to guarantee accuracy and efficiency. To start, a complete dataset is created by collecting and annotating sign language motions. To make model training easier, each move is labeled and classified. Using the data with annotations, machine learning models are then trained to effectively detect and categorize sign language motions.
Approach 1
Using MediaPipe
13
as the selection of features tool by which saves and captures hand landmarks for every sign as in Figure 2, then traditional machine learning algorithm can be trained and tested for validation purpose, the following steps in Figure 3 describe how to create a personalized, high-resolution datasets. MediaPipe hand landmark. Custom numbers dataset samples.

The following steps are for building a customized sign language dataset using approach 1: • Begin collecting data. • Verify the availability of the data directory. • If false, then Create a dataset directory. • If true, then continue iterating over every sign class. • Examine the class’s current images. • Proceed to the following class if the dataset size is achieved. • Encourage the user to begin recording • Take images and store them for each class. • Image processing using MediaPipe • Find landmarks and detect hands. • Store and normalize landmark data. • Repeat the above steps for every class. • End Data Gathering
The dataset consists of two parts: the first includes five ML models for gestures such as “Hello,” “I Love You,” “Yes,” “No,” “Like,” “DisLike,” and “GoodBye,” with 420 files organized into 7 folders, each containing 60 samples, totaling 17.8 MB.
The second part involves BiLSTM 14 and Bidirectional GRU 15 models using MediaPipe for numbers 0–10, with 2200 files in 11 folders, each containing 200 samples, and a total size of 120 MB. Hand landmarks tagged with signs are used to offline train the MediaPipe ML model. The model uses MediaPipe to identify hand landmarks during runtime, then extractions and normalized the landmark points for creating a feature vector (making sure that the model’s place within the frame has no impact on predictions). After predicting the matching gesture, the model uses a labels dictionary to translate its prediction into a word. Last but not least, the word is uttered and shown in real time. For a dataset of numbers 0–10 as in Figure 3, the BiLSTM and Bidirectional GRU models with MediaPipe come with 2200 files arranged in 11 folders, each of which has 200 samples. The dataset has a total size of 120 MB.
To capture the essential joint movement and spatial relationships of each motion, the datasets employ hand landmarks with the help of ten preprocessed and standardized signers. This scale-invariant format allows for the efficient training of deep recurrent architectures with a limited number of samples by telling the model to learn the basic structure of the signs while ignoring superfluous background or positional variation. Consistently collected and balanced by class, the data promotes steady convergence and reduces intra-class variability. This approach is inherently extensible since the same landmark recognition pipeline can be used to instantly gather data for more signs and users. Therefore, successful performance on this monitored dataset points to a strong, widely applicable foundation for an expanding sign collection in the future.
Approach 2
Using deep learning techniques, including Convolutional Neural Network and the related models, to extract features from images with and without MediaPipe features is an alternate strategy. The purpose of these models is to automatically extract complex information from the input images. To ensure that the dataset is adequately represented and that the model can effectively generalize to new data, its extracted features are subsequently verified through training and testing.
The depicted numbers range from 0 to 10. While, the dataset for the hybrid VGG16
16
with BiLSTM model, is used without MediaPipe, includes gestures for letters A-Z as in Figure 4 and a blank (no hand gesture). It consists of 8426 files organized into 27 folders, with each folder containing 301 samples, except for the blank gesture folder, which has 600 samples. The total size of this dataset is 90.5 MB. The generalization capacity of our dataset is enhanced by its acceptable signal-to-noise ratio, which is the result of well-organized data collection with the help of 10 signers that eliminates environmental volatility. This enables efficient acquisition of fundamental gesture patterns using a limited quantity of examples. Further enhancing generalization, the pre-trained weights of VGG16 provide transferred feature extraction for hand forms, while the BiLSTM layer depicts temporal relationships across frames. This hybrid approach combines spatial feature transfer and temporal pattern learning to enable the model to learn powerful recognition abilities. Therefore, its effectiveness on the manipulated dataset confirms that it can generalize even with the current sample size by showcasing basic understanding that can expand to larger vocabulary and real-world contexts. Custom letters dataset samples.
The steps below are involved in the preprocessing steps without MediaPipe to utilize the image for the Composite VGG16 along with BiLSTM processing, to build a customized sign language dataset using approach 2. • Start the Program • Establish Directories • Path: blank SignImage 224 × 224/A–Z • Set up the Webcam, select a frame, and draw the ROI (Region of Interest). Extract and Process the Rectangle on the Frame ROI: Make the conversion to grayscale • Set size 224 × 224. • Show Real-time Stream & ROI Processed • Verify the Key Press: A–Z → Save in the appropriate letter folder • Click ‘1' to save in the ‘blank’ directory. • Hit Esc → Leave • Close the window and release the webcam.
Phrase interpretation
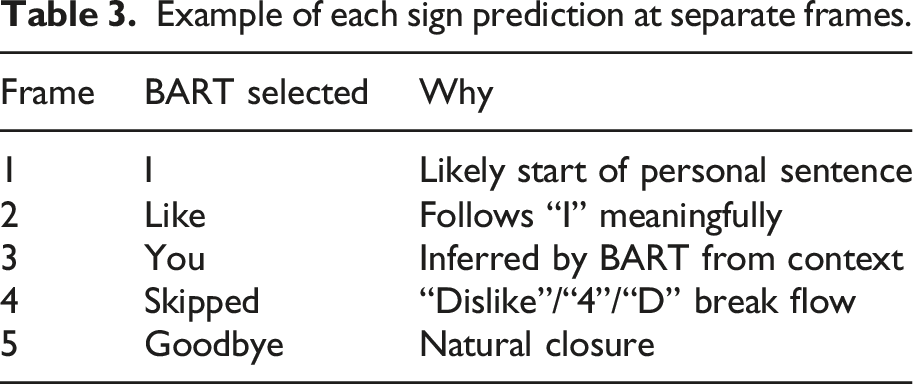
Utilizing three pre-trained models to recognize sign language in real time per frame, Keeping track of each model’s letter, number, along with word predictions for each sign, To improve final interpretation and resolve context, the entire video sequence is input to an NLP model at the final stage as shown in Figure 5. Using the BART
17
NLP model, which takes the sequence as input, interprets the context, and then chooses the best prediction for each sign based on the context rather than trying every possible combination because each sign has three predicted tokens that are based on the language and context, as shown in the comparable Table 1. On the other hand, a Pre-trained languages model scores using a brute force method which tries every potential phrase combination without producing text, then determines which sentence sounds the most probable or natural. BERT,
18
a pre-trained language model, is able to give a sentence a likelihood or log-probability. This “score” indicates the likelihood that a human linguist would use this statement in a natural setting. After scoring each combination, choose the one that comes with the highest probability, also known as the lowest loss. Phrase prediction flow diagram. Compare different models for phrase interpretation.

Mobile application
Front-end
This Flutter application facilitates seamless navigation, Firebase user authentication, and instantaneous sign language interaction through video input. After an animated SplashScreen, there is a WelcomeScreen with sign-in and sign-up choices. The app’s dynamic and flexible layout allows for safe registration of new members and provides quick accessibility to Home, Categories, Chatting, and Settings through a bottom tab bar. Three key interactive features are offered by the application’s frontend: real-time sign-to-text phrase detection using a language model, augmented reality for text-to-sign conversion in real-time, and e-learning modules to assist with individual signs. Along with an interactive quiz-style game that assesses the user’s ability to recognize signs by choosing the proper interpretation, the e-learning area offers users short, offline films that are organized by sign kinds, allowing them to study at their own entertainment.
Back-end
Firebase’s 19 real-time features, secure user authentication, and smooth integration make it an excellent choice for this Flutter-based signing application. The application manages user registration and login with ease using Firebase Authentication, while Cloud Firestore acts as a powerful NoSQL database to save and sync user data, such as phrase history or sign inputs. Key actions including adding, retrieving, modifying, and deleting records are supported by each user’s unique data collection, which is recognized by their UID. A dynamic, synchronized user experience and effective data management are guaranteed by this configuration.
E-learning phase
To assist users in learning the signs, the program offers E-learning for every sign category through brief offline videos. Additionally, it has a training quiz that tests users’ ability to choose the right response for the sign that is presented.
Augmented reality
The initial step in integrating Augmented Reality (AR) 20 with Flutter software is to use a Unity-Flutter plugin, including flutter_unity_widget, to connect Unity’s AR features with Flutter. Start by using Unity’s AR Foundation to produce interactive augmented reality material in order to construct the AR experience. Whenever the Unity project is completed, export it as a platform-specific release (such as an iOS or Android build) or as a Unity package.
Real-time practice phase
Real-time testing is made possible by the application, which lets users enter sign language gestures as whole phrases or by dataset classification (letters, digits, or words). The BART NLP model is then used to construct the final interpretation.
Results
Dataset
The results of applying the different ML approaches in Figure 6 on the gestures English expressions of approach 1. Prediction of English Sign Words as samples are shown in Figure 7. Accuracy of applying different ML. Prediction of English sign words.

Figure 8 shows the prediction accuracy samples of the alphabetic dataset by the hybrid VGG16 with BiLSTM model and overall train and validation accuracy and loss in Figure 9. Prediction of English sign letters. BiLSTM & VGG16 train and validation accuracy and loss.

The following involves the BiLSTM and Bidirectional GRU models using MediaPipe for numbers with dataset numbers ranging from 0 to 10 as shown in Figure 10 and the training and validation accuracy and loss are illustrated in Figure 11. Prediction of English sign numbers. BiLSTM & GRU & mediapipe train and validation accuracy and loss.

Phrase interpretation
Example of each sign prediction at separate frames.
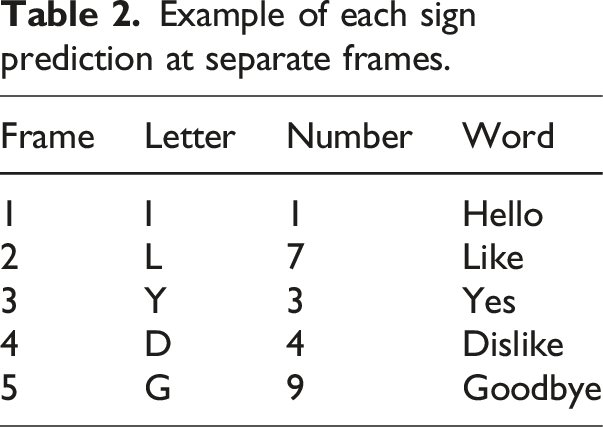
Example of each sign prediction at separate frames.
Using a test set of 100 signed phrases that included greetings, self-introductions, and basic assertions, we assessed our end-to-end system. The system’s BLEU score of 78.2 indicated that it could not only identify signals but also use the sequence to create cohesive English sentences. This result shows the fact that the NLP module (BART) generates fluent output and successfully corrects for small recognition failures.
Mobile application
Front-end
The user first register for creating his account for future sign in for the proposed mobile application.
Back-end
The sign-up phase sends to the firebase the user information to be saved.
E-learning phase
There are many offline learning sign language categories as shown in Figure 12, each can display an offline video for the sign for learning purposes as in Figure 13. After the user studies the signs he can tackle a quiz for testing his learning through online detection of the presented sign and an overall score is calculated with illustrations of his mistakes and customized advice for selective learning as shown in Figure 14. Offline sign language learning. Learning signs of days of the week. Learning signs quiz and correction feedback.


Augmented reality
Figure 15 shows the use of AR in learning sign language; when any of the pre-saved phrases is recognized using the mobile camera, the related pre-saved sign image is displayed automatically. Augmented reality E-learning converting text to sign.
Real-time practice phase
The user can use his real-time camera to predict each sign separately as shown in Figure 16. The system operates on modern smartphones, capturing 1080p video at 30 FPS to accurately track hand movements, where the sign recognition runs locally for minimal delay. Real-time sign language prediction.
Conclusion and future work
A thorough dataset of English sign language is presented in this paper, enabling real-time sign language detection for mobile apps. The research improves the overall efficiency of sign-to-speech translation systems. For real-time applications, the combination of deep learning algorithms with high-resolution data guarantees great accuracy and efficiency. Additionally, the use of this technology may greatly increase accessibility, particularly in educational facilities where listening-impaired people can benefit from enhanced learning resources.
Future research will concentrate on adding more sign languages to the dataset, integrating gesture detection for non-manual cues (such facial expressions), and enhancing the mobile app’s real-time processing capabilities. Multi-modal learning integration might be investigated further to enhance sign comprehension in various circumstances. Additionally, improving the system’s performance on low-end smartphones and tablets will be essential to expanding the technology’s accessibility across a range of geographical areas. Although creating a fully working application that benefits the Deaf population is the ultimate aim, the current study mainly focuses on assessing the system’s technological structure and algorithmic performance. Future study will include extensive user studies with Deaf individuals and thorough usability testing.
Footnotes
Acknowledgments
The author expresses their heartfelt gratitude to the individuals who generously contributed their time and effort to the experiments in this research. Special thanks go to Arwa Mohamed Ayman Mekawy, Retag Mamdouh Masoud, Yassmin Hassan Mosad and Rahik Osman Khalaf Osman from the Faculty of Computer Science and Artificial Intelligence at Pharos University in Alexandria, Egypt. Their invaluable participation and dedication were integral to the practical validation and success of this study.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data is contained within the article.