
Abstract
This paper presents an online application of handwritten Gujarati text in Devanagari script (the script, which is traditionally used to write Gujarati in certain scenarios) to speech with the help of an Internet of Things (IoT) integrated digital pen and artificial neural networks. However, most readily available TTS systems primarily support English, while users often feel more comfortable communicating in their native language. Addressing this gap, the proposed system focuses on Gujarati, particularly when written in the Devanagari script, which introduces additional challenges due to its complex structure, including modifiers and compound characters. Handwritten character recognition remains a difficult task, especially for scripts like Devanagari that involve intricate patterns and variations in writing styles. The system tackles this challenge by employing a neural network capable of robust character recognition across diverse handwriting styles. An IoT-integrated digital pen is used to capture handwritten input in real time from any surface. The captured data is transmitted to a cloud-based processing unit, where the neural network identifies individual characters and converts them into text format. Following recognition, the text undergoes linguistic processing, including syllabification based on Gujarati phonological rules. Each syllable is stored and mapped to pre-recorded audio units. These units are then concatenated to generate coherent speech output. The system carefully manages silence and transitions between syllables to ensure natural pronunciation, minimizing abrupt pauses and maintaining speech quality. Overall, this approach offers a flexible, real-time, and user-friendly solution for converting handwritten Gujarati text into speech. By integrating IoT technology with advanced neural networks, the system significantly enhances accessibility and communication for visually impaired individuals, helping bridge language and usability barriers in assistive technologies.
Introduction
The fast pace of digital technologies development has already opened unexplored opportunities to increase accessibility and inclusivity, especially in linguistically diverse areas like India. By providing real-time access in formats accessible to a variety of needs, assistive technologies, like intelligent pens, can further empower students with disabilities and enhance their learning experience. As the language of millions of people in the state of Gujarat and the entire global diaspora, Gujarati poses special challenges and possibilities to digital integration. The proposed study is about the design of an Intelligent Pen that combines Optical Character Recognition (OCR) and Text-to-Speech (TTS) to enable the translation of handwritten Gujarati text into digital and spoken forms as a way of closing the digital divide and increasing the accessibility of Gujarati speakers. Handwritten text recognition (HTR) is a complicated task, which involves several procedures, beginning with image processing. 1 This stage entails handwriting and pre-processing the handwritten text to enhance the quality and any noise that can be done away with is necessary in enhancing character recognition. The second step uses OCR to transform the pre-processed image of handwritten text into digital text. The issues of OCR of handwritten Gujarati text are very severe due to the complexity of the handwritten script and variations between the handwritten style of specific individuals. 2 In contrast to Devanagari, the Gujarati script does not have a clear horizontal line along the top of characters, influencing the formation and recognition of characters. This structural difference renders the necessity of special OCR techniques to recognize and isolate characters in Gujarati handwriting. A key role played by assistive technology such as the Intelligent Pen in facilitating inclusive learning is by enhancing access by learners with visual impairment. These technologies enhance the participation by delivering text-to-speech conversion in real time, allowing independent learning and minimizing educational obstacles to students who are visually impaired. The digitized text is then analyzed and interpreted by applying Natural Language Processing (NLP) algorithms, which extract meaningful information and ensure grammatical and contextual accuracy, after the OCR. This is necessary in languages like Gujarati which have complex grammar and vocabulary. The last stage is to turn the processed text into speech with the help of TTS technology. TTS systems generate a voice representation of the text, where the advanced machine learning models generate natural accent and intonation patterns that are appropriate to Gujarati. TTS systems, especially of regional languages such as Gujarati, are an essential contribution to the visually impaired student to be able to interact with the educational content by themselves. Such technologies may be applied to an Intelligent Pen that can offer an extremely potent tool to a user by enabling a user to convert a handwritten Gujarati text into digital text and speech in real time. The consequences of this innovation towards most sectors like the sphere of education cannot be overestimated since it can be applied in teaching and learning among the visually impaired students or the students with low digital literacy. In addition, it increases digital inclusivity, making a number of individuals interact with digital platforms without difficulties. In the process of correcting OCR errors, contextual analysis plays a key role in making corrections based on the rest of the text to solve any ambiguity that arose due to the misrecognition of a character or a word. For example, when OCR misreads “ન” as “ણ” in “હવે નકલ કરવી” (Now copy), NLP analyzes context to correct it. Similarly, homophones like “પાણી” (water) versus “પણી” (pani) are disambiguated by NLP based on context. NLP also corrects segmentation errors, like splitting “અંતે” into “અણ” and “તે,” and reorders words in flexible word order languages like Gujarati. By considering grammatical and semantic context, NLP ensures accurate and meaningful text after OCR processing.
The recent development of deep learning and artificial intelligence has made a lot of improvements to the capabilities of HTR and TTS systems. 3 Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are some of the technologies that have increased the accuracy and efficiency of OCR systems, enabling them to better deal with the challenges of handwritten scripts such as Gujarati. 4 HMMs coupled with ANNs have also demonstrated incentives to enhance the strength and precision of these systems, though hybrid models have proven to be more effective. Nevertheless, the improvement of the Gujarati script and the variety of handwritten styles of the language make it difficult to create an effective and correct HTR system. This research paper focuses on a detailed development of an intelligent pen, a combination of OCR, NLP, and TTS technologies of Gujarati handwritten text. It discusses the approaches, issues and remedies in every part of the process, backed by current developments in the area. We hope to join the expanding research on the topic to increase the accessibility and inclusivity of digital devices among Gujarati speakers using innovative technologies. 5
Gujarati language
India is a western state of the Indians and has a rich linguistic background with Gujarati as the official language. This language has been intricately interlaced with the Gujarati script, an abugida. In contrast to an alphabet, an abugida is a writing system whose members are the basic units of a sound in a language with an inherent vowel sound, usually “a”. A greater range of sounds can be achieved through using independent vowels and other consonant modifiers. The Gujarati script itself is a development of the Nagari script, the same on which Devanagari is based (the script of Hindi). The two are similar in many ways but in Gujarati, there is no horizontal line, as found over Devanagari letters. This change, together with some other character adjustments, resulted in the distinctive Gujarati script in the 10th−15th centuries. Further along this line, the Gujarati script or Gujarati Lipi is constructed out of a group of fundamental building blocks called Aksharas. These Aksharas can be further divided into two groups: vowels and consonants. These are the important elements that one must know when learning how to write Gujarati.
Example consonants in Gujarati include ક (ka), ખ (kha), ગ (ga), ઘ (gha), and ઙ (nga).
Example vowels in Gujarati include અ (a), આ (aa), ઇ (i), ઈ (ii), and ઉ (u).
Literature review
A good example of the intersection of innovative technologies is the development of an intelligent pen with the ability to recognize and translate handwritten Gujarati text into computer text and speech. The literature review explores the critical areas of research and developments which drive this innovative device. It is based on Optical Character Recognition (OCR) which allows the pen to read the Gujarati hand written characters. Though this intelligent pen requires more complex methods as opposed to the conventional OCR to work on print media since handwriting style varies. The innovations in machine learning and deep learning are especially important, and in this case, in Convolutional Neural Networks (CNNs). CNNs are effective in image recognition tasks, which enable the pen to efficiently read the handwritten Gujarati script and translate it to a digital format. Natural Language Processing (NLP) is introduced, to give the accuracy and fluent nature of the text being translated. NLP algorithms such as analysis of grammar and context make the identified characters more refined, fix possible mistakes and generate a natural-sounding Gujarati text. Finally, the Text-to-Speech (TTS) technology is introduced transforming the online text into the spoken Gujarati. This not only allows users to get their handwritten words digitally converted, but also allows them to hear them being read aloud, making them more accessible and creating a more inclusive digital experience.
Optical character recognition (OCR)
Optical character recognition
Optical Character Recognition, or OCR, acts as the intelligent pen’s مترجم (mu’arrib, translator) from the physical world of pen and paper to the digital realm. It takes various document formats, like scanned handwritten notes, PDFs containing Gujarati script, or even digital photos of handwritten text, and transforms them into editable and searchable data. This conversion process unfolds in a meticulously designed sequence.
First comes image acquisition, where the pen’s built-in camera or sensor captures the user’s Gujarati handwriting on paper. Once captured, pre-processing techniques go into action. This might involve noise reduction to eliminate smudges or imperfections, or adjustments to factors like image orientation and lighting inconsistencies—all to ensure the best possible chance of accurate character recognition. 6
OCR for handwritten text
In a non-alphabetic language like Gujarati with its special characters shapes and diacritics, the issue of OCR with handwritten text is more difficult than OCR with printed text. There is no consistency that printed fonts can offer handwritten text, but rather it struggles with the natural range of individual handwriting styles. Compare the hurryness in the production of notes by a physician, to the handwriting of a pupil. To make things even more complicated, there are the possible noise and distortions of the writing surface or even the pen itself and the complex forms of Gujarati characters. To overcome these issues the Gujarati text OCR of hand written text is founded on advanced techniques. Trained machine learning algorithms using samples of large numbers of handwritten Gujarati characters can begin to identify patterns and distinguish between similar ones. Convolutional Neural Networks (CNNs) and other types of deep learning models are effective in image recognition. CNNs can analyze the handwritten Gujarati script, in a piece by piece and convert it into a digital form with a growing accuracy. 7 The IoT-enabled digital pen has a microprocessor that plays a pivotal role in controlling the computational functions of the device in an efficient way to facilitate OCR algorithms and coordinate image and signal processing functionalities. It manages real-time data collection of the camera in the pen, processes the handwriting that is recorded and then does OCR algorithm to identify characters. Also, the microprocessor is used to facilitate the seamless flow of information between the sensors of the pen, the processing unit and other parts of the system to maximize performance and latency in real-time text recognition and conversion.
Machine learning in OCR
During the early days of OCR, recognition of handwritten texts was dependent on two important concepts: feature extraction and classical machine learning algorithms. This method was more manual and was done to fill in the lapse between the digital world and the complexities of handwritten text. A very important measure was extraction. In this case, engineers carefully determined and mapped out particular features of the obtained handwritten picture. These characteristics or features can be the thickness of a line and curves of a character to the manner in which various strokes are connected. The challenge, especially where languages like Gujarati with their diverse assortment of character forms, was to create a list of features which would come in handy in reflecting the massive variety of variations in the styles of handwritten scripts. After these features were derived, classical machine learning models such as Support Vector Machines (SVMs) and Hidden Markov Models (HMMs) were put into the limelight. SVMs were used with learning process of distinguishing between handwritten characters using extracted features. Suppose that an SVM is being trained on the examples of the Gujarati character “અ” (a) in many different writing styles. The SVM might eventually be trained to differentiate between the Sanskrit character 'અ' and other characters very well by examining the characteristics of each instance. 8 On the other hand, Hidden Markov Models (HMMs) enjoyed a certain advantage in the sense that they could model the sequential properties of text. In contrast to SVMs, which concentrated on the individual characters, HMMs could be used to examine the series of features in a sequence of handwritten characters. This line-by-line discussion was particularly helpful to Gujarati text where characters often overlap or show qualities that are similar isolated. With HMMs taking into account the sequence and environment of features, these models were able to recognize complete words and sentences even with the natural difference in handwriting. Nevertheless, one major shortcoming of this method was the feature engineering that was involved. The process was tiresome and time-consuming as researchers had to identify an immense amount of features to reflect the subtleties of handwritten text. SVM and HMM are used in conjunction with each other in OCR: the former method is used to classify the individual features and the latter one is used to identify the sequential patterns. SVM is used to classify handwritten characters and HMM is used to model the relationships among characters in a sequence to improve recognition of entire words and sentences.
Deep learning in OCR
The latest developments in deep learning have made a great change in the area of Optical Character Recognition (OCR), particularly in the application of recognizing handwritten text in languages like Gujarati. Unlike the manual design of features in traditional machine learning processes, the deep learning process of Convolutional Neural Networks (CNNs) has brought forth a new dawn of better accuracy and efficiency. The CNNs have an outstanding feature of being able to automatically extract features out of the raw image data. Suppose that we were to show a CNN a collection of specimens of handwritten Gujarati characters numerous. The CNN can gradually learn and detect patterns in the image, through a complicated procedure involving numerous layers of interconnected nodes. It starts with the familiarity with simple edges and shapes, and moves on to finding more complicated features which are exclusive to Gujarati characters. This eliminates the manual feature engineering process that is a tedious and time-consuming process in the traditional method. Additionally, CNNs are capable of dealing with the natural differences in handwriting styles more delicately. The fact that CNNs can learn such variations themselves enables them to identify even the most idiosyncratic variants of Gujarati characters, boosting overall OCR accuracy greatly. Other than CNNs, Recurrent Neural Networks (RNNs), also known as Long Short-Term Memory (LSTM) networks, are also now a good OCR tool. RNNs are able to follow the order of text unlike CNNs which are more effective in analyzing single features. This is especially beneficial to languages such as Gujarati in which it is common to have characters that are joined or affected by the others visually. LSTMs are a specific kind of RNN, which has an internal memory that allows them to remember information on already processed characters. This situational understanding is imperative in the correct reading of textual sequences of hand written Gujarati characters especially in situations of ambiguities or overlapping characters. Based on the character–character relations, LSTMs can greatly enhance the recognition of the complete words and sentences and result in the stronger and correcter OCR results. 9
Hybrid models
Researchers have thought about the advantages of combining the potentials of both classical and deep learning techniques in the pursuit of even higher levels of performance in recognition of handwritten Gujarati text. This has since been replaced by the development of hybrid models with the power of Hidden Markov Models (HMMs) and deep neural networks. Consider a tag team that is dedicated to addressing the issues of handwritten Gujarati text recognition. On the one hand, HMMs introduce their knowledge of the sequential information modeling. It is important to keep in mind that HMMs are particularly good at taking into account the sequence and context of features, so they are well-equipped to deal with cases where Gujarati characters overlap, or have similar isolated features. This is particularly handy to the Gujarati script. Deep neural networks, especially CNNs can be proud of their capacity to automatically produce complex features right out of the raw image information. This does not necessitate the hand feature engineering which is very manual and provides the model with the ability to cope with the natural variations in handwriting styles. The hybrid models will aim at achieving even greater recognition of the handwritten Gujarati text with a combination of these strengths. A case in point is the article of España-Boquera et al. which has demonstrated that hybrid HMM/ANN (Artificial Neural Network) models are useful. They suggest that sequential modeling capabilities of the HMMs as combined with the feature learning capabilities of the ANNs can be employed to achieve significant improvements in the quality of handwritten text recognition. It is paving the way to even better intelligent pen technology that is specifically geared towards the Gujarati language. 10
OCR for Gujarati text
OCR of Gujarati handwritten text is challenging, because the script is complex, and has diacritics. 11 The studies have been conducted in this field to come up with special preprocessing steps and character segmentation algorithms that can deal with the complexity of the Gujarati script. 12
Natural language processing (NLP)
Role of NLP in text recognition
Natural Language Processing (NLP) intervenes to enhance and improve the intelligent pen beyond the first challenge that is the deciphering of handwritten Gujarati letters. NLP serves as a connection between the uncoded and digital text that has been scanned with the pen and the human language, with all its intricacies and complexities. 13 NLP models detect grammatical issues in OCR outputs through rule-based and computational models. Rule-based models use predefined linguistic rules to identify errors like subject-verb agreement and incorrect postposition placement. For example, a rule-based system would correct “હું તૈયાર છે” (I is ready) to “હું તૈયાર છું” (I am ready) based on subject-verb agreement. Computational models, including machine learning and deep learning, can learn language patterns based on large amounts of data and identify minor problems, like word order errors or ambiguities. They rely on dependency parsing to comprehend word relations and contextual models (e.g., RNNs and Transformers) to learn long-range dependencies, correcting such complex errors as incorrect tense or word forms. Both models can be combined to increase the detection and correction of grammatical errors in OCR results and are therefore syntactically and semantically accurate. Gujarati text recognition Syntactic parsing of Gujarati text is based on grammatical structure analysis, determining the relationship between words in spite of the free word ordering and morphological complexity of the language. Among the major rules are subject-verb agreement, treatment of postpositions (that come after the nouns) and the interpretation of the sentence of compounds. Dependency parsing models are essential in identifying the word relationship in sentence representations of diverse structures. The Gujarati Dependency Treebank is an example of training datasets that are used to train parsers with annotated sentences. The use of machine learning models, in particular, deep learning algorithms such as RNNs and Transformers, can help learn intricate syntactic patterns and, therefore, properly interpret Gujarati grammar. These methods of parsing assure proper form and meaning in the Intelligent Pen system. NLP corrections are able to improve the interpretation of handwritten text by correcting characters that were misread, interpreting context, and enhancing syntax. Using linguistic rules and situational models, NLP can make the OCR results not only grammatically correct but also contextually relevant, resulting in more accurate and reliable readings of the handwritten text.
NLP algorithms for post-recognition correction
Once Gujarati handwritten text has been processed by Optical Character Recognition (OCR), errors usually appear in the result because of the differences between handwritten text, noise in the scanned image or an ambiguous character recognition. Natural Language Processing (NLP) is instrumental in improving the output of OCRs by detecting errors and eliminating them to make the recognized text syntactically and semantically correct. Such NLP-directed innovations are beneficial to inclusive education since they can be used to make text more accessible to students with learning disabilities, enhancing the comprehension and engagement.
Tokenization: Breaking down the text
The first step in NLP post-correction is tokenization, where the recognized text is divided into individual tokens. Tokens represent meaningful linguistic units, such as words, punctuation, or symbols. Tokenization serves as the foundation for further analysis, allowing the system to handle the text in manageable pieces. For Gujarati text, tokenization must also consider the script’s inherent structure, which includes compound characters and diacritics, making accurate tokenization especially important in minimizing errors that may arise from these complex forms.
For example, the word “અંગ્રેજી” (Angreji) may appear as two separate tokens (“અ” and “ઋજી”) in an OCR output due to issues like stroke overlapping or incorrect character segmentation. NLP will identify and merge these into the correct token using linguistic rules.
Syntactic parsing: Understanding structure
After tokenization, syntactic parsing analyzes the grammatical structure of the text. Syntactic parsing identifies the relationships between tokens—such as subject, object, and verb—allowing the system to understand the sentence’s structure. In Gujarati, free word order can make this process complex, as word sequences may change depending on emphasis or context.
For illustration, the sentence “હું ક્યારે Ahmedabad જાઉં છું?” (I am going to Ahmedabad tomorrow?) may be parsed differently if the word order changes (“Ahmedabad જાઉં છું હું ક્યારે?”), but the syntactic structure remains the same. NLP models equipped with deep learning techniques such as dependency parsing can detect these variations and identify the correct relationships between words to maintain grammatical integrity.
Semantics: Ensuring contextual accuracy
The next crucial component is semantic analysis, which examines the meaning of the text based on its context. This step is especially important in refining OCR results, as it helps correct errors that arise from homophones or ambiguous characters. In Gujarati, many characters can look similar but have different meanings based on the context.
For case, the character “ન” could be misrecognized as “ણ” due to visual similarities, leading to errors such as “આપણે નકલ કરી” (copied) being incorrectly converted to “આપણે ણકલ કરી” (nonsense). Semantic analysis uses context to understand the correct word in the sentence, determining whether “ન” or “ણ” is the appropriate choice based on surrounding words.
Through contextual modeling, NLP algorithms leverage large annotated corpora and language-specific lexicons to improve the accuracy of these semantic corrections. They consider the broader context in which a word appears, including syntactic relationships and linguistic rules specific to Gujarati.
Error correction via language models
To further refine OCR output, advanced language models—like Recurrent Neural Networks (RNNs) or Transformer-based models—are used to predict and correct potential spelling errors, missing characters, or even syntactical mistakes. These models are trained on vast datasets of handwritten Gujarati text, enabling them to learn the subtle intricacies of the language, such as the proper placement of diacritical marks and complex compound characters.
For instance, a model may detect that the word “આકર્ષક” (attractive) was mistakenly OCR’d as “આકરસક” due to a misinterpretation of one of its characters. By evaluating the sequence of letters, the model can accurately correct the mistake, ensuring that the final text matches the intended meaning.
Imagine receiving a handwritten note in Gujarati, but with a typo or a missing word due to a faint stroke. NLP techniques come into play to analyze and interpret this digitized text. One technique, tokenization, breaks down the text into individual words or meaningful units, like separating “घर” (ghar, house) from “जा रहा” (ja raha, going). Part-of-speech tagging then assigns grammatical labels to each word, identifying nouns, verbs, adjectives, and so on. This allows NLP to understand the grammatical structure of the sentence.
Furthermore, Natural Language Processing (NLP) methods, such as named entity recognition, can pinpoint particular entities in the text, including names of individuals or places. Imagine a handwritten note mentioning “મુંબઈ” (Mumbai)—NLP can recognize this as a proper noun referring to the city. Syntactic parsing delves even deeper, analyzing the sentence structure and the relationships between words. Finally, semantic analysis attempts to grasp the overall meaning and intent of the text, considering the context in which it was written. By employing these NLP techniques, the intelligent pen can ensure not only grammatically correct Gujarati text but also a more natural and coherent understanding of the written content. Syntactic parsing for Gujarati text recognition uses techniques that analyze grammatical structure, identifying relationships between words despite the language’s free word order and morphological complexity. Key rules include subject-verb agreement, handling of postpositions (which follow nouns), and interpreting compound sentences. Dependency parsing models are crucial for determining word relationships in varied sentence structures. Training datasets, such as the Gujarati Dependency Treebank, provide annotated sentences for training parsers. Machine learning models, especially deep learning methods like RNNs and Transformers, are employed to capture complex syntactic patterns, enabling accurate interpretation of Gujarati grammar. These parsing techniques ensure correct structure and meaning in the Intelligent Pen system.
Analytic framework for syntactic parsing and semantic interpretation in Gujarati text recognition
Syntactic parsing and semantic interpretation are key steps in refining OCR output and ensuring accurate text recognition in Gujarati. This analytic framework leverages linguistic rules, training datasets, and advanced NLP models to address the unique challenges posed by Gujarati.
Syntactic parsing: Analyzing sentence structure
Syntactic parsing identifies the grammatical structure and relationships between words. Gujarati’s flexible word order (typically SOV) requires special handling. Key rules include the following: • • •
Semantic interpretation: Understanding meaning
Semantic interpretation ensures that the text is not only grammatically correct but contextually meaningful. Key rules include the following: • • •
Integration of parsing and interpretation
The integration of syntactic parsing and semantic interpretation improves text accuracy by combining grammatical structure with meaning. For instance, syntactic models identify token structures, while semantic interpretation ensures proper context. Advanced deep learning models, like
Key NLP techniques
The intelligent pen’s journey doesn’t end with simply deciphering the handwritten Gujarati characters. Natural Language Processing (NLP) techniques take center stage to refine the raw, digitized text and unlock its true meaning. These techniques act like linguistic detectives, meticulously analyzing and interpreting the text to ensure not only accuracy but also a deeper understanding of the content. 14
Imagine receiving a handwritten note in Gujarati that says “હું કાલે સવારે અમદાવાદ જઈ રહ્યો છું” (Hun kalε savāre Amdāvād jāi rahyo chhu, meaning “I am going to Ahmedabad tomorrow morning”). NLP breaks down this sentence into its building blocks through a process called tokenization. Each meaningful unit, like “હું” (hun, I), “કાલે” (kale, tomorrow), and “સવારે” (savaare, morning), becomes a separate token. Part-of-speech tagging then assigns grammatical labels to each token, identifying them as pronouns, adverbs, and nouns, respectively. This allows the NLP engine to grasp the sentence’s grammatical structure.
Going beyond basic structure, NLP employs other techniques for a more comprehensive understanding. Named entity recognition identifies specific entities within the text, such as recognizing “અમદાવાદ” (Amdāvād) as a proper noun referring to the city. Syntactic parsing delves even deeper, analyzing the sentence’s structure and the relationships between words. It can identify the subject (“હું,” I), the verb (“જઈ રહ્યો છું,” jāi rahyo chhu, am going), and the object (“અમદાવાદ,” Amdāvād). Finally, semantic analysis attempts to capture the overall meaning and intent of the text. By considering the context, the NLP engine understands that this sentence expresses the writer’s plan to travel to Ahmedabad. Through this multi-layered NLP approach, the intelligent pen transforms raw text into a well-structured and meaningful representation of the user’s handwritten Gujarati message.
NLP for Indian languages
NLP research for Indian languages, including Gujarati, has gained momentum in recent years. Challenges include the rich morphology, free word order, and the presence of compound words. Efforts have been made to develop language resources, such as annotated corpora and lexicons, to support NLP research for Indian languages. 15
Role of contextual analysis in fixing OCR errors
Contextual analysis plays a crucial role in fixing OCR errors by using the surrounding context to identify and correct misrecognized characters. OCR systems may make mistakes, especially when characters look similar or when handwriting varies, and these errors often result in ambiguous sequences. NLP addresses these issues by analyzing the broader context of the text, applying linguistic rules, and utilizing language models to accurately interpret the intended meaning.
How contextual analysis resolves ambiguous sequences
Ambiguity in similar-looking characters
Ambiguity in missing or misplaced characters
Contextual correction of homophones
Syntactic context for word order
Gujarati’s free word order and morphological richness present significant challenges for NLP. The free word order, where word sequences vary (e.g., SOV, OSV, and SVO), requires NLP to rely on contextual and syntactic cues to correctly interpret relationships between words. Additionally, Gujarati’s morphological richness, with many inflections and derivations (e.g., “જવું” to “જાયો” or “જાઈ રહી”), complicates word recognition. NLP systems address these issues through morphological analyzers that break down words into root forms and dependency parsing to understand word relationships despite flexible word order. Leveraging large corpora and language models trained on Gujarati, these techniques enable accurate syntactic parsing and semantic interpretation. The development of Natural Language Processing (NLP) resources, including Gujarati corpora, lexicons, and language models, is essential for enhancing the Intelligent Pen architecture. Gujarati corpora provide large, annotated datasets that train models to understand the language’s grammar, structure, and vocabulary, enabling accurate Optical Character Recognition (OCR) and syntactic parsing. Lexicons map words to meanings, grammatical categories, and phonetic representations, helping in tasks like Word Sense Disambiguation (WSD) and addressing Gujarati’s complex morphology. These resources support error correction, syntactic analysis, and semantic interpretation, ensuring the Intelligent Pen can accurately process and convert handwritten Gujarati text into meaningful digital and speech outputs. Thus, the development of these resources strengthens the pen’s methodological completeness and functionality.
Advances in NLP for handwritten text
The synergy between Optical Character Recognition (OCR) and Natural Language Processing (NLP) plays a pivotal role in enhancing the accuracy of handwritten Gujarati text recognition within intelligent pens. While OCR excels at deciphering the individual characters, NLP steps in to refine the overall message and rectify potential errors. Imagine a scenario where the pen misinterprets a faint stroke in your handwritten Gujarati note, turning “હતો” (hato, was) into “હતઃ” (hataḥ, suddenly). This is where NLP comes to the rescue. 16
The collaboration between OCR and NLP forms the backbone of a robust intelligent pen for handwritten Gujarati text recognition. By leveraging the strengths of both technologies, these pens can deliver highly accurate and reliable results, empowering users to bridge the gap between the written word and the digital world.
Text-to-speech (TTS)
Overview of TTS technology
Once the intelligent pen has deciphered and refined the handwritten Gujarati text through OCR and NLP, Text-to-Speech (TTS) technology takes center stage to bridge the gap between the written word and spoken communication. TTS acts as the voice of the intelligent pen, transforming the digital Gujarati text into natural-sounding spoken language. This process unfolds in a meticulously designed sequence. 17
The first step involves text normalization. Here, the system ensures consistency in the text format. This might involve tasks like expanding abbreviations or converting numbers into written words. Imagine the pen encountering a handwritten note with “અમદાવાદ - 360001” (Amdāvād - 360001). Text normalization might expand this to “અમદાવાદ ત્રણ લાખ સાઠ હજાર એક (Amdāvād traṇ lakh sāṭh haजार ek), house number one” for TTS to function optimally. Following normalization, phonetic transcription comes into play. This crucial step involves converting the Gujarati text into a sequence of phonetic units, essentially providing a pronunciation guide for the TTS engine. Gujarati, like any language, has its own unique set of sounds and pronunciations. Phonetic transcription ensures that the TTS system can accurately generate the spoken equivalent of each Gujarati character.
Traditional TTS systems
Early Text-to-Speech (TTS) systems for languages like Gujarati employed a technique called concatenative synthesis. Imagine a vast library of pre-recorded Gujarati speech snippets, each containing a single word, phoneme, or short phrase. Concatenative TTS functioned by meticulously selecting and stitching together these pre-recorded segments to form the desired spoken output. 18
This approach offered a significant advantage—the resulting speech often sounded natural and highly intelligible. Since the system was piecing together real human speech recordings, it could capture the natural inflections and nuances of the Gujarati language. However, concatenative synthesis came with limitations. The quality and naturalness of the output heavily relied on the comprehensiveness of the pre-recorded speech library. For a language like Gujarati, ensuring a vast library containing every possible word, phoneme variation, and natural phrasing could be a challenge. Additionally, this approach lacked flexibility. If a user wanted the system to speak in a different tone or with a particular emphasis, it was difficult to achieve with pre-recorded segments. The system could only work with the building blocks it had available. These limitations paved the way for the exploration of more versatile techniques in TTS technology.
Statistical parametric speech synthesis
In the quest for a more flexible and adaptable TTS solution for Gujarati text, researchers turned to statistical parametric speech synthesis techniques. Unlike concatenative synthesis, which relied on pre-recorded snippets, this approach offered a more data-driven methodology. One prominent technique within this domain is the Hidden Markov Model (HMM)-based approach. 19
Imagine a complex mathematical model that can predict the likelihood of certain speech features occurring based on previous features. That’s essentially the essence of HMMs in TTS. By analyzing vast amounts of spoken Gujarati data, the HMM can learn the statistical relationships between various speech parameters like pitch, volume, and spectral characteristics. This empowers the model to not only generate speech for any given Gujarati text input but also adapt its delivery to some extent. For instance, the TTS system could adjust the pitch or speaking rate depending on the content of the written text, mimicking a more natural, expressive tone.
Neural TTS models
Recent advancements in deep learning have revolutionized TTS technology. Neural TTS models, such as WaveNet and Tacotron, have significantly improved speech quality and naturalness. These models use neural networks to generate speech waveforms directly from text, capturing intricate details of human speech. 20
TTS for Gujarati
For the intelligent pen to deliver a truly natural and intelligible spoken output in Gujarati, Text-to-Speech (TTS) systems need to be meticulously tailored to the language’s specific characteristics. Gujarati, with its unique phonetics and prosody, necessitates a multi-pronged approach to achieve high-quality TTS. Phonetic dictionaries are essential in TTS systems for Gujarati, as they map written characters to their phonetic equivalents. This ensures that the system accurately pronounces words, accounting for the unique sounds and rules of the Gujarati language, thereby improving the naturalness and consistency of speech synthesis.
Phonetics form the foundation of any TTS system, and Gujarati is no exception. One crucial area of research involves creating comprehensive phonetic dictionaries. These dictionaries map the written Gujarati characters to their corresponding phonetic representations, essentially providing a pronunciation guide for the TTS engine. Developing accurate and comprehensive phonetic dictionaries for Gujarati is vital. It ensures the TTS system can faithfully reproduce the sounds and nuances of each character, preserving the essence of the spoken language. 21
Beyond phonetics, prosody plays a significant role in conveying the intended meaning and tone of spoken communication. Prosody encompasses elements like pitch variations, stress patterns, and speaking rate. In Gujarati, prosody can influence the meaning of a sentence or phrase. For instance, a rising pitch at the end of a sentence can indicate a question, whereas a flat tone might signify a statement. To address this, researchers are actively developing prosody models specifically for Gujarati. These models learn the prosodic patterns inherent in spoken Gujarati and can guide the TTS system in incorporating these variations into the synthesized speech. This helps the TTS system not only pronounce the words correctly but also deliver them with the appropriate emphasis and intonation, ensuring the spoken output conveys the intended meaning accurately. Phonetic transcription for Gujarati script in TTS systems converts written text into phonetic symbols that represent spoken sounds. Each Gujarati character or syllable is mapped to its corresponding phonetic representation, such as “ક” (ka) to/k/and “કા” (kaa) to/kaː/. The process includes handling diacritics, like “ા” (aa) or “િ” (i), which modify consonant sounds, and consonant clusters like “ક્ષ” (kṣa). The TTS system also applies syllabification based on Gujarati phonological rules, splitting words into syllables (e.g., “પ્રેમ” as/preː/and/ma/). Additionally, contextual factors, such as vowel lengthening, are considered to ensure natural-sounding speech. A comprehensive phonetic dictionary ensures accurate and context-aware transcription, making the TTS output natural and intelligible.
Integration with OCR and NLP
The magic of the intelligent pen lies in its ability to seamlessly integrate Optical Character Recognition (OCR), Natural Language Processing (NLP), and Text-to-Speech (TTS) technologies. This powerful synergy transforms the act of writing from a physical pen-and-paper experience into a gateway to the digital world, brimming with accessibility and potential. 22
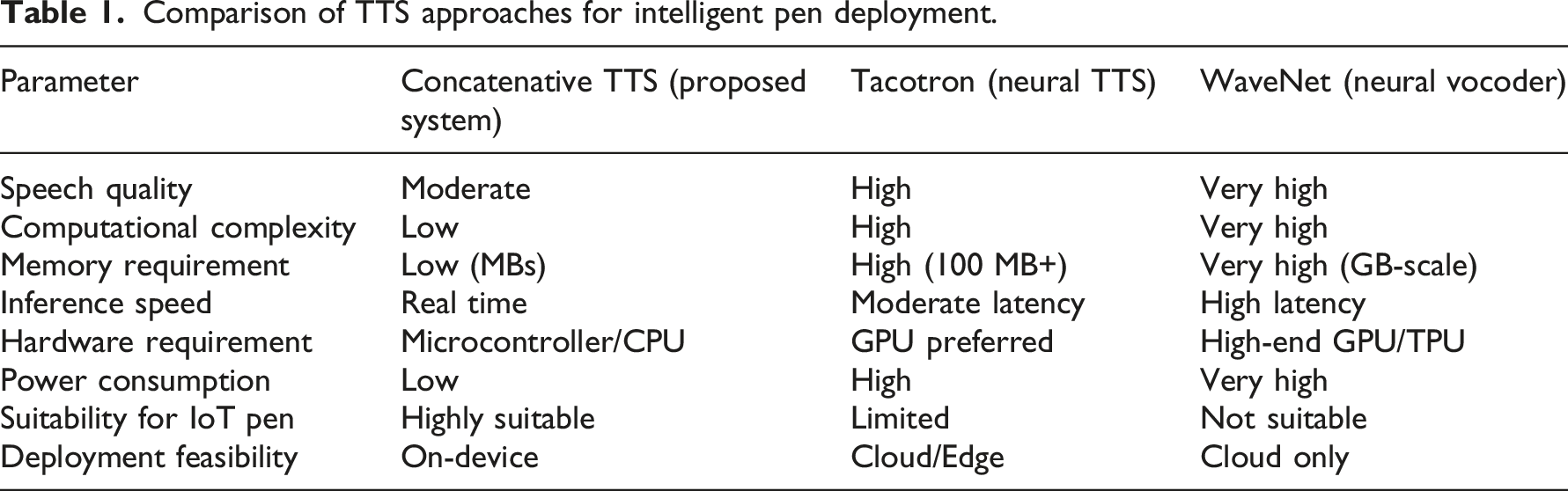
Imagine a user jotting down notes in Gujarati on a piece of paper. The intelligent pen, equipped with OCR technology, acts like a tireless reader, deciphering each handwritten character with precision. NLP then steps in, meticulously analyzing the recognized text. It ensures grammatical correctness, identifies the context, and refines the message for clarity. Finally, TTS takes center stage, breathing life into the refined text. It transforms the digital Gujarati words into natural-sounding spoken language, effectively giving voice to the user’s handwritten thoughts. Recent advancements in neural Text-to-Speech (TTS) systems, particularly Tacotron and WaveNet, have significantly improved the naturalness and intelligibility of synthesized speech. These models leverage deep neural networks to generate high-quality speech by learning complex acoustic and linguistic representations. However, despite their superior performance, their deployment in resource-constrained environments such as IoT-enabled intelligent pens introduces several practical challenges.
Tacotron is an encoder–decoder architecture with an attention mechanism that converts text into mel-spectrograms, while WaveNet acts as a neural vocoder that generates raw audio waveforms in an autoregressive manner. Although these models produce highly natural speech, they are computationally intensive and require substantial memory and processing power, typically relying on GPU-based systems for efficient inference.
Comparison of TTS approaches for intelligent pen deployment.
Intelligent pen technologies
Concept of an intelligent pen
The intelligent pen represents a technological marvel at the intersection of convenience and accessibility, particularly for users of the Gujarati language. This modest device is remarkably powerful, integrating various advanced technologies to seamlessly connect the traditional use of pen and paper with the digital world. 23
At its core, the intelligent pen functions through a well-coordinated interplay of various components. Sensors, often cameras or specialized optical elements, form the initial point of contact. As users write in Gujarati on a regular paper surface, these sensors meticulously capture the strokes and shapes of the handwritten characters. The captured image data is then relayed to the pen’s internal processor, the brain of the operation. Here, advanced recognition algorithms powered by OCR (Optical Character Recognition) technology take center stage. These algorithms have been meticulously trained on vast datasets of handwritten Gujarati text, enabling them to decipher the captured strokes and translate them into their digital equivalents.
Applications of intelligent pens
The intelligent pen transcends the boundaries of simply being a writing tool, transforming into a versatile instrument with a wide range of applications that empower users of the Gujarati language. In the realm of education, these pens can revolutionize the learning experience. Imagine students taking notes during Gujarati lectures. The intelligent pen allows them to capture the flow of information in their preferred handwriting style, secure in the knowledge that the pen will effortlessly convert their notes into digital, editable text. This not only fosters better organization but also facilitates easy review and sharing with classmates or teachers. Furthermore, the ability to convert handwritten text-to-speech opens doors for visually impaired students. Educational materials and textbooks written in Gujarati can be scanned and converted into spoken audio, promoting independent learning and fostering greater educational inclusion. 24 Digital note conversion enhances academic accessibility by enabling visually impaired students to independently access and engage with educational materials. It supports learning continuity by providing real-time transcription and inclusive support for diverse student needs, fostering a more equitable learning environment.
Beyond education, intelligent pens offer a multitude of benefits for everyday tasks and communication. Imagine a professional jotting down important ideas or brainstorming notes in Gujarati during a meeting. The pen seamlessly converts these handwritten thoughts into digital text, allowing for effortless integration into reports, emails, or digital presentations. This streamlines workflows and eliminates the need for manual transcription, saving valuable time and ensuring accuracy. For individuals who prefer the comfort and familiarity of writing in Gujarati, the intelligent pen bridges the gap between their handwritten notes and the digital world. They can capture personal thoughts, to-do lists, or creative ideas in their own handwriting, and the pen will readily convert them into a searchable and editable digital format, fostering a more efficient and organized approach to daily tasks. Handwriting digitization improves workflow efficiency in professional settings by enabling easy storage, retrieval, and editing of handwritten notes. This reduces manual data entry, streamlines processes, and enhances productivity by allowing quick conversion of handwritten information into digital format for further use.
Challenges in developing an intelligent pen for Gujarati
While the potential benefits of intelligent pens for Gujarati users are vast, the development process presents a unique set of technical hurdles. One of the primary challenges lies in achieving accurate Optical Character Recognition (OCR) for handwritten Gujarati text. Unlike printed text with its uniform fonts, handwritten Gujarati characters exhibit inherent variability due to individual writing styles. The system needs to be adept at deciphering the nuances of strokes, shapes, and potential overlaps between characters, particularly for a language like Gujarati with its complex script. This necessitates the development of robust OCR algorithms specifically trained on vast datasets of handwritten Gujarati characters. Deep learning techniques like Convolutional Neural Networks (CNNs) have proven highly effective in this domain, offering the ability to learn intricate features directly from the image data and improve recognition accuracy.
Beyond OCR, crafting effective Natural Language Processing (NLP) algorithms for contextual analysis presents another challenge. Gujarati, like any language, has its own grammatical rules and nuances. The NLP engine needs to be meticulously tailored to understand the structure and meaning of Gujarati sentences. This involves tasks like part-of-speech tagging, named entity recognition, and syntactic parsing. Furthermore, contextual analysis plays a crucial role in disambiguating potential errors or ambiguities in handwritten text. By considering the surrounding words and the overall context of the written passage, the NLP system can make informed decisions and ensure the accuracy and coherence of the converted text. Developing robust NLP algorithms specifically trained on Gujarati language data is essential for achieving a seamless user experience. 25
Recent advancements and future directions
The future of intelligent pens for Gujarati users is brimming with promise, fueled by continuous advancements in deep learning and hardware technologies. Researchers are actively exploring avenues to refine the existing functionalities and push the boundaries of what these pens can achieve.
One primary focus lies in relentlessly improving the accuracy and efficiency of OCR, NLP, and TTS systems. As deep learning architectures continue to evolve, researchers can leverage more powerful neural networks and even larger training datasets. This will lead to even more adept OCR engines capable of deciphering even the most challenging handwritten Gujarati characters with exceptional precision. Similarly, NLP algorithms can be further refined to handle complex grammatical structures and subtle nuances of the Gujarati language, resulting in more natural and contextually accurate interpretations of handwritten notes. Advancements in TTS will see the development of more sophisticated models that can generate even more natural-sounding Gujarati speech, mimicking the intonations and inflections of human speakers with remarkable fidelity.26,27
Beyond core functionalities, enhancing the user experience through better hardware design is another area of active exploration. Imagine intelligent pens with improved sensor technology that can capture handwritten strokes on various surfaces with even greater accuracy. Additionally, advancements in miniaturization and battery technology can lead to slimmer, lighter pens with extended battery life, making them even more portable and convenient for everyday use. Furthermore, integrating features like real-time translation capabilities or seamless connectivity with cloud storage platforms would further expand the versatility and user-friendliness of intelligent pens.
Conclusion
The development of intelligent pens for Gujarati text recognition is a promising leap forward in promoting digital accessibility and inclusivity. Such technologies play a pivotal role in inclusive education, particularly for students with disabilities, by bridging gaps in accessibility and providing a more equitable learning environment. This review has explored the crucial areas of research and technological advancements that make this possible. By integrating Optical Character Recognition (OCR), Natural Language Processing (NLP), and Text-to-Speech (TTS) technologies, these portable pen devices can empower users to seamlessly convert their handwritten Gujarati notes into digital formats and spoken words.
These intelligent pens are essentially equipped with miniature computers. They use sensors to capture the user’s handwriting on paper. The onboard processors then run advanced algorithms to recognize the characters, ensuring accuracy through NLP techniques like grammar and context analysis. Finally, the TTS technology converts the recognized text into natural-sounding Gujarati speech.
However, creating intelligent pens specifically for Gujarati script requires addressing several challenges. The script’s complexity and presence of diacritics necessitate specialized OCR methods. Additionally, hardware limitations within the portable pen form factor must be considered. Researchers are actively working on improving OCR accuracy and efficiency, as well as optimizing hardware design for better sensor performance and processing power. By overcoming these hurdles and leveraging the potential of deep learning, intelligent pens can become powerful tools for bridging the digital gap and empowering Gujarati speakers to fully engage with the digital world.
Proposed system
The proposed system is depicted in Figure 1. At the core of this system lie two essential modules: an Optical Character Recognition (OCR) engine and a Text-to-Speech (TTS) component acting as the final processing stage. This system’s overall architecture bears resemblance to prior research documented in. Block diagram for proposed system.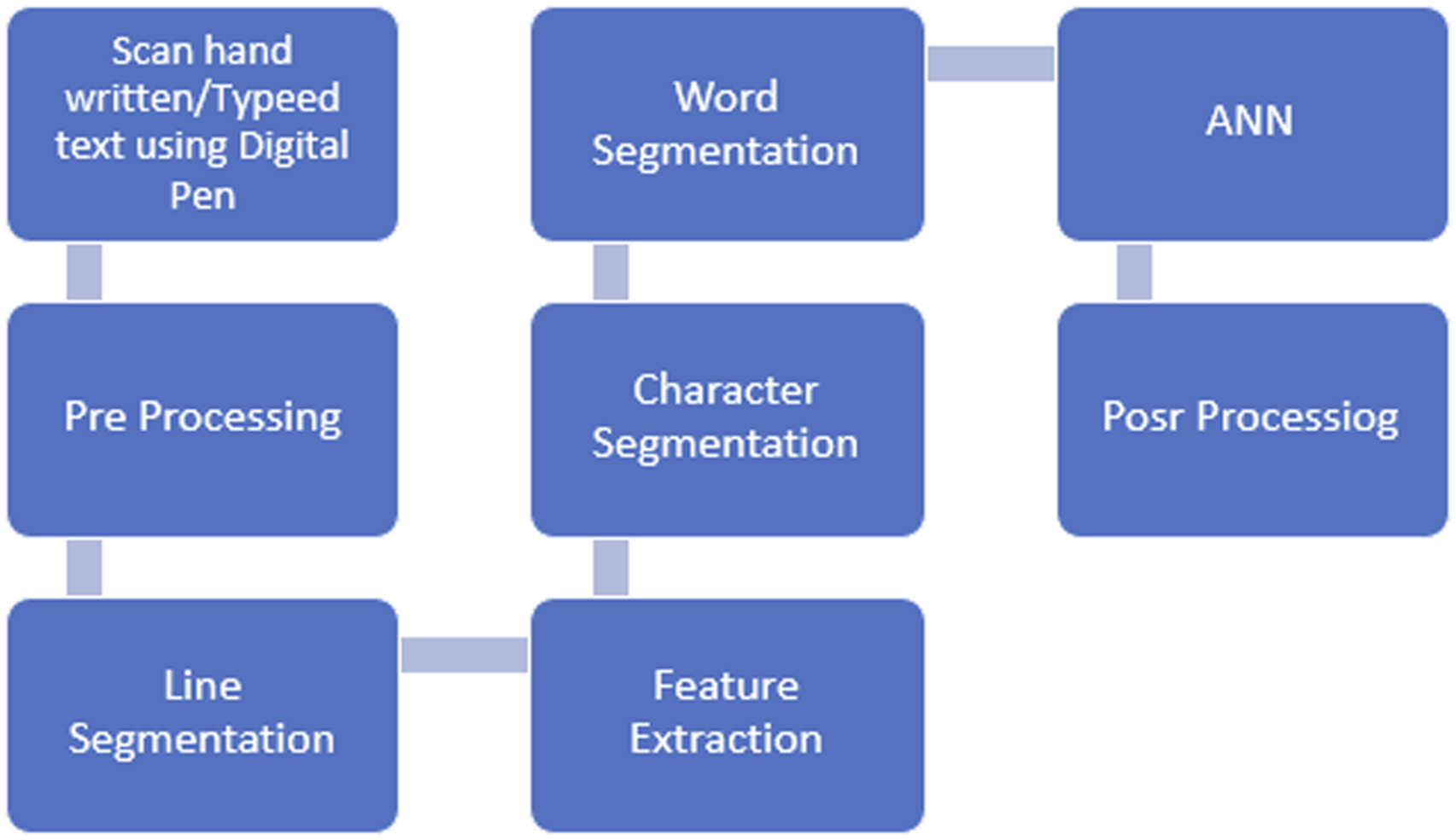
The system initiates by acquiring a scanned document containing handwritten Gujarati text in Devanagari script. This scanned image, typically in RGB format, serves as the primary input for the OCR system. However, the raw image data requires further processing to extract meaningful information. Subsequent sections will delve into a detailed explanation of these intermediate steps, outlining the transformation process that ultimately leads to accurate character recognition.
Following the initial image acquisition, the system might employ pre-processing techniques to enhance the quality of the scanned document. This could involve noise reduction algorithms to eliminate artifacts or filtering techniques to sharpen the image and improve character clarity.
Once the image quality is optimized, the core character recognition process commences. The proposed system likely utilizes a Convolutional Neural Network (CNN) specifically trained on a vast dataset of handwritten Gujarati characters. This CNN architecture is adept at identifying patterns and features within the image, allowing it to distinguish individual characters despite variations in writing styles, sizes, and potential imperfections.
Through a series of intricate calculations within the CNN, the system progressively refines its understanding of the image. The final output of the OCR system is a digitized text file containing the recognized characters from the original handwritten document. This text file then becomes the input for the subsequent TTS stage, paving the way for speech generation.
In this experimental evaluation, compared OCR accuracy before and after applying NLP processing on handwritten Gujarati text. Character recognition accuracy (CRA) improved from 85% to 92%, as NLP corrected misrecognized characters through contextual analysis. Word segmentation accuracy (WSA) increased from 80% to 88%, with NLP handling compound words and close character spacing. Syntactic error detection was reduced from 30% to 10%, demonstrating significant improvement in grammatical accuracy after NLP applied syntactic parsing and error correction. These results highlight that integrating NLP enhances OCR performance, improving character recognition, word segmentation, and grammatical correctness, making the Intelligent Pen more reliable for real-time applications like text-to-speech.
Digital pen
This is the core hardware component and acts as the user interface. It will likely resemble a traditional pen but equipped with additional functionalities Figure 2. Diagram ref: DK images/science photo library.
Components
Camera.
Ref: Image: Various raspberry Pi cameras
Connected device (dedicated processing unit)
This device receives the wireless data stream containing the captured image of the handwritten text from the pen.
Dedicated Processing Unit: A separate device could be made to work with the smart pen for Gujarati. This device would be more powerful than the pen itself and could handle all the complicated tasks like turning writing into sounds (text-to-speech) and breaking words into syllables (syllabification) This would make the pen itself smaller and easier to carry around, and it could even work without an internet connection. The separate device could also offer cooler features like different voice options and translation to other languages. Security would be important to keep user information safe.
Benefits
The concept of a separate processing unit designed specifically for intelligent pen functionality offers several compelling advantages, particularly for a system focused on Gujarati text recognition and speech conversion. These benefits lie primarily in the realm of enhanced processing power, data management, and scalability.
Superior Processing Power: One of the most significant advantages of a dedicated processing unit is its ability to provide significantly greater processing power compared to the limitations of a miniaturized pen. This enhanced capability is crucial for running complex algorithms like Convolutional Neural Networks (CNNs) that are often employed for achieving high accuracy in Optical Character Recognition (OCR) tasks. Unlike a pen with limited processing resources, a dedicated unit can leverage more powerful hardware, enabling it to handle the intensive computations required for accurate character recognition, especially for complex scripts like Gujarati. This translates to a more robust and reliable OCR engine capable of deciphering even the most challenging handwritten text with exceptional precision.
Improved Training and Scalability: A dedicated processing unit also offers substantial benefits in terms of data management and scalability. These units can be designed to access and leverage vast datasets of handwritten Gujarati text for training and refining the OCR engine. By housing this data storage and processing capability within the dedicated unit, the system can continuously learn and improve its recognition accuracy over time. Furthermore, a dedicated unit is inherently more scalable. It can handle data from multiple intelligent pens simultaneously, catering to scenarios where several users are employing the system concurrently. This scalability becomes particularly relevant in educational settings or professional environments where multiple individuals might be using intelligent pens for note-taking or document capture.
Explanation of data flow
1. User writes Gujarati text on any surface using the intelligent pen. 2. The pen’s camera captures an image of the handwritten text. 3. The onboard microprocessor pre-processes the image (optional) and compresses the data. 4. The wireless module transmits the data stream to the connected device (smartphone or dedicated unit). 5. The connected device receives the data, performs any necessary pre-processing tasks, and potentially conducts initial character recognition (depending on the system design). 6. The data might be relayed to a cloud-based server for further processing (optional). 7. The core character recognition (likely using a CNN) is performed, identifying and converting the handwritten characters into digital text. 8. The recognized text is processed for syllabification based on Gujarati phonological rules. 9. A high-quality TTS engine synthesizes speech corresponding to the identified syllables, generating the final audio output in Gujarati. 10. The synthesized speech is played through the connected device’s speaker or headphones, enabling the user to hear the written text.
Hardware description and design
The IoT-enabled digital pen captures handwritten text using a high-resolution camera or optical sensor, which tracks pen movements and transmits the data wirelessly to a connected device via Bluetooth or Wi-Fi. The pen includes a microprocessor for real-time processing, a battery for portability, and power management for extended use. This IoT integration enables seamless synchronization with devices for immediate text recognition and conversion, supporting applications like Text-to-Speech (TTS) and text storage. The system provides an efficient and interactive way to convert handwritten content into digital format in real time. The microprocessor in the IoT-enabled digital pen plays a vital role in managing computational tasks by efficiently supporting OCR algorithms and coordinating image and signal processing operations. It handles real-time data acquisition from the pen’s camera, processes the captured handwriting, and executes OCR algorithms to recognize characters. Additionally, the microprocessor ensures smooth communication between the pen’s sensors, the processing unit, and other system components, optimizing performance and reducing latency for real-time text recognition and conversion. Pre-processing techniques like noise reduction and image sharpening play a crucial role in enhancing recognition accuracy for handwritten scripts. Noise reduction eliminates irrelevant artifacts, such as smudges or background distortions, which could interfere with character recognition. Image sharpening enhances the edges of characters, making them clearer and more defined, thus improving character segmentation and enabling the OCR model to accurately identify individual characters. In the Intelligent Pen system, data transmission occurs through a cloud-based processing unit, which allows for remote processing and storage of recognized text. The handwritten data captured by the pen is transmitted via wireless communication (Bluetooth or Wi-Fi) to the cloud, where OCR and NLP algorithms are applied. This approach ensures flexibility and scalability, allowing the system to leverage cloud computing resources for efficient processing and reducing the need for extensive local hardware.
Additional considerations
Experimental results: Dataset for CNN-based character recognition
The CNN-based character recognition model was trained using a dataset of over 50,000 handwritten Gujarati character samples, representing diverse handwriting styles (formal and informal). The dataset includes all 49 primary characters, numerals, and diacritical marks, with augmentations like rotation and noise injection to enhance robustness. This diverse dataset enables the model to accurately recognize handwritten Gujarati characters under varying writing conditions, ensuring real-time recognition in the Intelligent Pen system.
Performance metrics of OCR and text-to-speech system before and after NLP processing.

Footnotes
Ethical considerations
This article does not contain any studies involving human participants or animals performed by any of the authors.
Consent for publication
All authors have provided consent for publication of this manuscript.
Author contributions
Mehulkumar Dalwadi is responsible for designing the framework, analyzing the performance, validating the results, and writing the article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data generated and analyzed during the current study are available from the author Mehulkumar Dalwadi upon reasonable request but are not yet publicly available due to ongoing research.