
Abstract
This study sought to examine the relative effectiveness of two forms of communication: verbal instructions and conducting gestures. High school choral students (N = 44) performed “Music Alone Shall Live” in a variety of ways (with and without word stress, and with varied articulations), while watching a video recording of a conductor and reading verbal instructions. Experienced choral teachers (N = 30) listened and rated the articulation and word stress of the students on a 7-point Likert-type scale. Results indicated that (a) experienced teachers perceived more staccato articulation and word stress when singers responded to verbal instructions (vs. conducting gestures) and (b) experienced teachers perceived more staccato and word stress in performances when verbal instructions and conducting gestures were congruent, compared with when these messages were incongruent.
Teachers of musical ensembles rely on multiple forms of communication when delivering instruction. Conducting gestures can be an efficient way to convey musical elements such as tempo, articulation, and dynamics in a nonverbal manner, especially in performing settings (concerts) when verbal methods are not available. However, conducting gestures might be misunderstood, or the students may not be watching, so there is a risk that these gestures might not yield the responses the teacher desires. Alternatively, teachers might choose to use verbal directives, which are more traditional and often used in other instructional settings. Ideally, the teacher transmits clear instructions using either method.
Researchers have examined teacher verbalizations/teacher talk in the classroom, with respect to categorization and time usage. Price (1985) classified teacher verbalization as pertaining to academic instruction, directions, social tasks, off-task, or some form of reinforcement/feedback. Blocher, Greenwood, and Shellahamer (1997) observed middle and senior high school band teachers and determined that they spent 30% of their time in verbal instruction/direction, and considerably less time in conceptual teaching (<3%). Caldwell (1980) noted that the verbal behavior of high school choral conductors was primarily devoted to music instruction (55%), followed by evaluation (24%), and illustration (21%). The ways in which teachers used their time distinguished novice from experienced teachers (Goolsby, 1996, 1999); experienced teachers spent considerably less time in teacher talk when compared with student teachers.
Teacher talk has been linked to off-task behavior (Brendell, 1996; Forsythe, 1977) and reduced student attentiveness (C. K. Madsen & Geringer, 1983; Napoles, 2007; Spradling, 1985). This may explain why some teachers choose to use conducting gestures as an alternative to talking. If students can remain on-task, there is a greater likelihood that the teacher will be able to accomplish his or her musical goals in that rehearsal. Conducting pedagogues have also urged teachers to reduce the amount of time they spend talking, since students will not be very engaged (Erwin, 1982; Green, 1996; Hicks, 1975; Kreichbaum & Dillon, 1976; Vermel, 1977). Willard (1986) offered that effective conducting was a good alternative to teacher talk, since it solved problems quicker. Bloomquist (1973) warned, “don’t attempt to accomplish with your mouth what your baton can do much better” (p. 79). Little empirical research has examined the validity of this pedagogical advice.
Conducting is most effective when the meanings of the gestures are clearly understood. Cofer (1998) taught conducting to seventh-grade students and found that this instruction allowed his participants to comprehend gestures and perform them better as a result. Kelly (1997) also taught conducting (to beginning bands in elementary schools) and discovered that individual rhythm skills were improved as a result of this instruction. To establish a shared gestural vocabulary, Mayne (1992) and Sousa (1988) identified several gestures that were considered “emblems,” which could be commonly recognized by musicians. These included various dynamics and articulations.
Several studies in conducting have indicated that participants perceived music differently depending on what visual information accompanied it (Napoles, 2011; Price & Chang, 2001, 2005), and that music conducted expressively was rated differently than the same music conducted nonexpressively (Morrison, Price, Geiger, & Cornacchio, 2009; Price & Morrison, 2011). Furthermore, presentation modes (audio vs. visual, or the combination thereof) affected participants’ aesthetic responses (Geringer, Cassidy, & Byo, 1996, 1997), ratings of vocal performance (Wapnick, Darrow, Kovacs, & Dalrymple, 1997) and marching bands (Johnson, 1991), and perceptions of expressive performance (Hamann, 2003; Lucas, Hamann, & Teachout, 1996; Lucas & Teachout, 1998; M. K. Madsen, 2009; Napoles, 2011). Thus, it is possible that presentation modes may also affect students’ responses to directions and that they may respond differently depending on how those directions are delivered. Skadsem’s (1997) research confirms this possibility. Her participants performed dynamic markings better when following verbal instructions, when compared with following written dynamic levels, singing with a pre-recorded choral ensemble (an aural stimulus), or a conductor’s gestures (a visual stimulus). She found that high school singers in particular seemed to be most influenced by verbal instruction and least by gestural changes of the conductor. In that study, she recommended further research with both conflicting and coinciding messages, perhaps incorporating other musical elements.
The purpose of this study was to examine whether there was a difference between verbal instructions and conducting gestures in eliciting desired articulations and syllabic/word stress from a chorus. A secondary purpose was to observe how experienced choral teachers perceived these performances when cues were consistent (verbal instructions and gestures congruent, sending the same message) and when they were inconsistent.
Method
Design and Procedure
This study was conducted in three phases (preparing the stimulus video, participant performance, and performance evaluation).
Phase 1
In the first phase, a graduate student in choral conducting from the state of Utah was video recorded conducting 12 bars of music in triple meter. This corresponded to the tune “Music Alone Shall Live,” a traditional German canon. The graduate conductor was asked to conduct in four ways: (a) using a strict 3 pattern, with no emphasis on any particular beat; (b) using a 3 pattern with a strong downbeat and a weaker second and third beat, delineated by added weight on the first beat; (c) using a 3 pattern where every beat was staccato, performed with minimal spatial movement and short wrist motion; and (d) using a 3 pattern considered legato, performed with a smooth connection between beats and little to no wrist movement. The conductor was video recorded (with TheFlip video camera positioned so that the torso, hands, and arms were in view but no head or face to provide visual cues) after several practice sessions with the researcher. There were 5 to 10 “takes” for each condition, and these were offered to independent observers for review.
Three experienced university conductors independently viewed each of the recorded excerpts and determined which best represented each of the conditions. Reliability (agreements divided by total observations) was 100%, as all three agreed there was a superior example for each condition. All three conductors also agreed that word stress and staccato/legato articulations were executed appropriately and could be interpreted accurately through the gesture.
After excerpts were selected, the researcher created a master video disc using iMovie. This recording included six excerpts total: (a) a screen with the printed text—“Please sing louder on beat 1, softer on beats 2 and 3” before the video of the conductor using a strict pattern (hereafter referred to as instructions only/inconsistent/word stress); (b) a screen with the printed instructions—“Please follow the conductor’s gesture” followed by the video of the conductor using a strong downbeat (hereafter referred to as gestures only-word stress); and (c) a screen with the printed instructions—“Please sing louder on beat 1, softer on beats 2 and 3” before the video of the conductor using a strong downbeat (hereafter referred to as both/consistent/word stress). Excerpts 4–6 followed the same pattern as above, except that the printed text for the “instructions only” excerpt was “Please sing this selection with a staccato articulation” and the gestures were either staccato (when consistent) or legato (when inconsistent). See Table 1 for a specific explanation of each excerpt. A random order was eschewed in favor of a purposeful order and its reverse, because of the possible learning effect that could conceivably occur. By the time the participants watched the final excerpt, they may well have understood that the study pertained to verbal instructions and conducting gestures as they performed staccato articulation and/or word stress. The two reverse orders ensured that such bias would be distributed in both directions. Table 1 illustrates the two orders incorporated. Both DVDs were 5 minutes and 45 seconds in duration, with 20-second transitions between excerpts.
Contents of Stimulus Video Excerpts.

Phase 2
Phase 2 of the study involved having high school choral musicians perform with the video. Participants were recruited from a summer choral camp in a large southeastern state, and included 44 females, in Grades 9 (n = 9), 10 (n = 16), 11 (n = 15), and 12 (n = 4), representing four states. They were randomly divided into two groups for the two different orders. The researcher went to their regular rehearsal room for the camp and taught them the pitches and rhythms for “Music Alone Shall Live,” a traditional German canon. Care was taken not to teach with any particular word stress (each note received equal weight). When the choir felt confident (when pitches and rhythms were secured), they were shown the video, projected onto a large screen in the front of the room.
The video began with printed instructions on the task—that they were to sing “Music Alone Shall Live” multiple times as a group, according to the printed instructions on the video, and continued to the excerpts as described above. Participants were given the opportunity to ask questions or refrain from participating. Each excerpt was preceded by the pitch A4, played on the piano in the room. Piano was determined to be the most effective procedure for giving starting pitches after several pilot studies (which also included a blown pitch pipe and a cued sung pitch directly inserted into the video). As participants watched the video and performed selections accordingly, they were being audio recorded by a Zoom H2 recorder (with a 16-bit resolution at a sampling rate of 44.1 kHz) positioned at the front of the room. These recordings were then transferred to an audio compact disc for evaluation using Audacity software. After the video task was complete, all participants were debriefed as to the purpose of the study, and discussion ensued.
Phase 3
The third phase of the study was the performance evaluation. Experienced secondary choral teachers (n = 30, 13 females and 17 males, with a mean 4.58 years of teaching experience) representing 11 states were asked to evaluate the participants’ performances, using a researcher-designed form. This form asked them to rate four elements per excerpt (ensemble diction, word stress, staccato articulation, and balance; see the appendix). Although word stress and staccato articulation were the primary areas of interest for this investigation, the form also included ensemble diction and blend, so that the adjudication would be considered more typical of a festival performance, and to partially disguise the purpose of the study. Participants were asked to rate these four elements using a 7-point Likert-type scale with the anchors “not displayed” on one side and “displayed to a large extent” on the other. The audio recording included 12 excerpts (six excerpts in two orders) and one minute of silence between each, to allow for completion of questions.
Results
Data from the 30 experienced teachers’ responses included four evaluations per excerpt, since ensemble diction, word stress, balance, and staccato articulation were evaluated for each excerpt. Only one of these four questions was relevant (i.e., each excerpt focused on only one musical element, word stress or staccato articulation). Thus, one data point per question was examined, for a total of 12 data points per participant/experienced teacher. These 12 points included four responses to verbal instructions, four responses to conducting gestures, and four responses to both. Means and standard deviations for all excerpts are presented in Table 2.
Means and Standard Deviations of Evaluations for Each Excerpt.
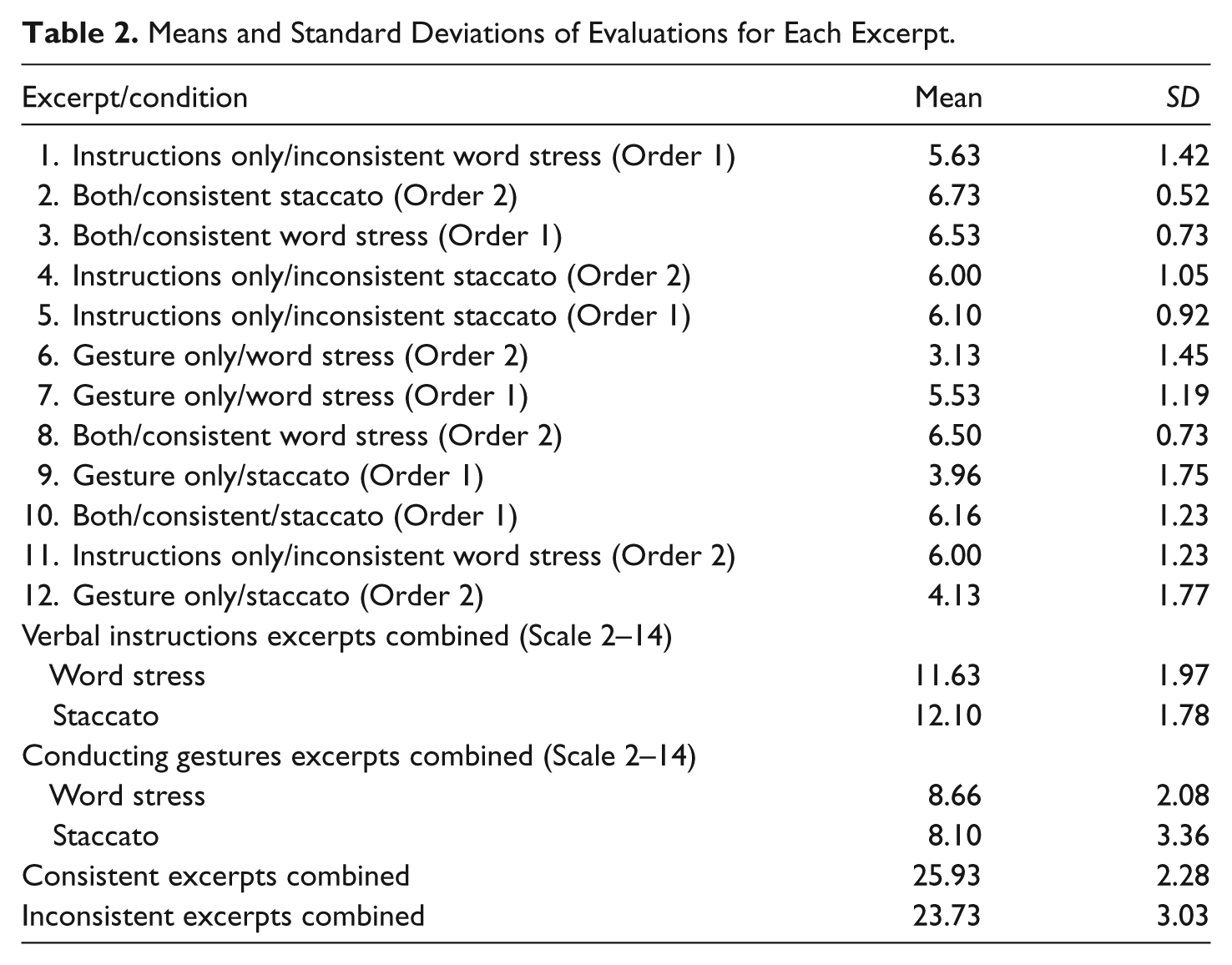
To answer the first research question, whether high school singers responded better to verbal instructions or conducting gestures, four separate categories were created as follows: verbal instructions–word stress, verbal instructions–staccato, conducting gestures–word stress, conducting gestures–staccato. Individual data points were combined (added) to compare means among these four categories, using the rating scale 2–14, since there were two per category. These means were then analyzed using a repeated-measures analysis of variance and were found to be significantly different, F(3, 87) = 30.59, p < .001, partial η2 = .51. Follow-up analyses, using the Bonferroni adjustment for multiple comparisons, revealed that means for verbal instructions (M = 11.63, SD = 1.97 for word stress and M = 12.10, SD = 1.78 for staccato) were not significantly different from each other, but were significantly different from means for conducting gestures (M = 8.66, SD = 2.08 for word stress and M = 8.10, SD = 3.36 for staccato), p < .001. There was no significant difference between musical elements for conducting gestures.
To answer the second research question, how experienced teachers perceived performances when conducting cues were consistent with verbal instructions and when they were inconsistent, the four “consistent” responses were combined for a total “consistent score” and compared with the “inconsistent score.” Results of a t-test indicate that these means (M = 25.93, SD = 2.28 for consistent, M = 23.73, SD = 3.03 for inconsistent) were significantly different, t(58) = 3.17, p < .01.
Discussion
The purpose of this study was to examine the relative effectiveness of two methods of communication, verbal instructions and conducting gestures, by having experienced teachers rate performances of high school choral students singing in various ways. Consistently, participants perceived more word stress and staccato in performances where singers were following verbal instructions. Furthermore, performances in response to consistent cues (when the conducting gesture and the verbal instruction conveyed the same message) seemed to be perceived as more evident (more of the musical element was displayed) than performances in response to inconsistent cues.
High school students seemed to have an easier time performing word stress and staccato articulation when they were asked to do so directly, as opposed to when they were asked to follow a conducting gesture. These findings are similar to those of Skadsem (1997). Although her participants were responding to dynamic changes, it appears that other musical elements (in this case, word stress and staccato articulation) were perceived in much the same way. However, a unique aspect of this study was having conductors send congruent messages, then send mixed messages, in an attempt to determine to which message (the verbal or the gestural) students would respond best. Not surprisingly, of all 12 excerpts, the highest rated performances were the four labeled “both/consistent,” since singers had both a verbal instruction and a corresponding gesture that matched. This is important pedagogically in that more information—two modes—is more effective than one in eliciting desired responses, but only when the messages are the same.
In observing the results of ratings given to performances under the “inconsistent” condition, it is interesting to note that these four scores (6, 6, 6.1, and 5.63) were still higher than the scores for the “gesture only” condition (3.13, 3.96, 4.13, and 5.53). It seems that these students responded better when given the verbal instruction to do something—even when the gesture was showing the opposite—than when given the instruction just to follow the conductor’s gestures. One might conjecture that perhaps the students did not understand the meaning of the gesture and therefore could not execute more of the requested word stress or staccato articulation in the absence of explicit instructions. Alternatively, students may have exaggerated their responses when told what to do, in an attempt to “get the right answer” and tempered them when they saw only the gesture. On a 7-point Likert-type scale, only one score (3.13) was on the lower half of the scale, indicating that participants still perceived some word stress and staccato under almost all of the conditions. No attempt was made to measure effectiveness of the performance, so it is inappropriate to equate “displayed often” with “good” or “bad.” Perhaps a future study might examine at which point in the scale execution of these musical elements is considered excessive and thereby ineffective.
In the debriefing session with the high school students, an insightful comment was made concerning the difference between printed verbal instructions and spoken verbal instructions. This student seemed to believe that there was a sharp difference in having to look at a screen and follow the printed instructions, which was not often the case in natural settings, where teachers often give directions in a spoken form. She claimed it was easier to ignore the teacher talk when spoken, but she found herself paying more attention to the screen when the instructions were printed. Of course, many research studies are conducted in unfamiliar contexts, and there is always the possibility of a testing effect. It is difficult to tell if this printed/spoken teacher talk issue is a design flaw of this particular study or a statement about high school students’ focus of attention. It is likely that students will do better on any task when they are focused than when they are not. Again, given the general trend toward high means overall in this study, students were following directions well, perhaps because they were attending to the screen, the directions, and the task. Another possibility is that these students were highly motivated and interested in singing, as evidenced by their participation in a summer choral camp.
Having students respond to a videotape of a conductor may have been a limitation of this study. In an attempt to establish a control measure and have the conductor do the same thing consistently, some students may have had difficulty following a conductor that was not “live.” In particular, students tended to want to speed up during staccato excerpts, and having to keep time with the conductor was challenging for them. It is also possible that these high school students have different understandings of conducting gestures, based on their background and experiences with their own teachers, despite Mayne’s (1992) and Sousa’s (1988) documentation of a shared gestural vocabulary understood by musicians. Without knowing the background of these singers, it was difficult to ascertain whether the participants understood these particular gestures and to what they were responding specifically. Additionally, this convenience sample may have been unique, so generalizations to other groups of singers may not be appropriate. Future studies may continue investigating ensemble students’ responses to verbal and gestural directions in a more natural setting and with their own teachers, even if some experimental control is sacrificed as a result.
Implications for Teacher Education
Results from this study have important implications for teacher educators. Music education curricula include coursework in conducting, instrumental and choral methods, and rehearsal techniques. In these courses, teacher educators work to improve the communication skills of preservice teachers so they can be effective when delivering instruction. Although pedagogical advice abounds, there is relatively little empirical research concerning effective modes of communication in these settings. Preservice teachers learn both nonverbal and verbal forms of communication, but it is not always clear whether there is a method that transmits information most effectively. Given the results of this research, perhaps more time needs to be spent working to increase the clarity of verbal instructions, since students appear to respond to these best. Alternatively, attempts must be made to make the conducting gesture—which can often be unique to the individual and less “universal” than verbal instruction—more clearly understood.
Although results of this study suggest that verbal instructions are more effective than conducting gestures, there are times when verbal instructions are not possible, as in a performance. Musicians have used conducting gestures as the primary form of nonverbal communication for many years, and it is important that this mode continue to be improved. It is incumbent on researchers to continue testing pedagogical advice empirically so that preservice teachers can employ effective strategies in the teaching and rehearsal setting.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.