
Abstract
The language argument is a classic argument for human distinctiveness that, for millenia, has been used to distinguish humans from non-human animals. Generative language models (GLMs) pose a challenge to traditional language-based models of human distinctiveness precisely because they can communicate and respond in a manner resembling humanity’s linguistic capabilities. This article asks: have GLMs acquired natural language? Employing Gadamer’s theory of language, I argue that they have not. While GLMs can reliably generate linguistic content that can be interpreted as “texts,” they lack the linguistically mediated reality that language provides. Missing from these models are four key features of a linguistic construction of reality: groundedness to the world, understanding, community, and tradition. I conclude with skepticism that GLMs can ever achieve natural language because they lack these characteristics in their linguistic development.
Artificial Intelligence and the Question of Human Distinctiveness
The language argument is a classic argument for human distinctiveness that, for millennia, has been used to distinguish humans from non-human animals. 1 Aristotle famously called human beings the animal with logos, which, although usually translated as “reason,” is more accurately understood as “language” (Gadamer 1977). 2 While dogs and dolphins can communicate by sending limited signals of information to each other, few would equate these limited capacities with the limitless subject-discussion characteristic of human language (Gregg 2022, 61). Humans have long fantasized about creating artificial life that communicates and responds to us in a way that is virtually indistinguishable from or even equivalent to human language. An advanced language-speaking artificial intelligence machine—like a shrewd H.A.L. 9000 capable of communicating verbally with human astronauts or Victor Frankenstein’s well-spoken Creature—have always been a projection of a possible future, usually created to warn current generations of the need to ask ethical questions amidst the rapid growth of technology, science, and culture (Botting 2021). Only very recently has the possibility of AI employing something like natural language become a reality. The explosion of interest in generative language models since early 2023 (e.g., OpenAI’s ChatGPT, Google’s Bard, or Microsoft’s Bing) is evidence of this. The generative language models are remarkable for being able to construct coherent, grammatically correct, and informative prose. The most advanced of these models, operating under the large language model (LLM) architecture—like OpenAI’s GPT-4—can be tasked with text summarization, chatbot behavior, live web searches, code generation, and essay generation. Some AI models have even become capable of generating content with greater fluency and precision than human authors. 3
The rapid advancement of generative language models has convinced many that language generation models have finally acquired the capacity for natural language. Generative models thus pose a challenge to traditional language-based models of human distinctiveness precisely because they can communicate and respond in a manner resembling humanity’s linguistic capabilities.
The question for this paper is this: to what extent, and in what ways, can the “language” of generative language models accomplish the tasks that natural language can? 4 In posing this question, I am not asking whether AI have become human by acquiring linguistic capabilities. Rather, I am assessing whether this classic feature of human distinctiveness vis-à-vis the functions of language is no longer unique to humans. Answering this question requires that we examine not only the linguistic content that these models produce but also what the models themselves are doing when generating linguistic content and “learning” to perform more complex tasks from past errors. Employing Gadamer’s theory of language, this paper assesses the linguistic capabilities of AI to determine whether recent generative language models have acquired natural language. 5 In this assessment, two categories are analyzed: (1) the linguistic content of the sentences that generative language models produce and (2) the actions that AI perform to generate language. It is argued that generative language models have not acquired an artificial equivalent to natural language because they lack the elements of groundedness to the world—and by extension, understanding—community, and tradition that are embedded in natural language acquisition and expression. While the content produced by generative language models can be understood as a “text” with linguistic content and a “world” that can merge with our own, the models that produce this content lack a linguistically mediated connection to the world and hence have not acquired the exact functions of natural language.
My argument proceeds as follows. I begin by reconstructing Gadamer’s theory of language. Next, I analyze the claims about the linguistic capacities of AI language models and assess whether they can generate linguistic content—“texts,” in Gadamerian terms. I then assess four categories that demonstrate why generative language models lack language according to Gadamer’s linguistic theory: disclosure to the world, understanding, linguistic tradition, and linguistic community. I conclude that generative language models are merely artificial language, and I reflect on whether these models could ever acquire the functions of natural language with further software advancements.
Gadamer’s Theory of Language
The history of political thought is ripe with thinkers who have discussed theories of language and artificial intelligence, respectively. Among philosophical approaches to linguistics are Rousseau, Herder, Humboldt, Derrida, Ricœur, and others. 6 Those interested in artificial intelligence nowadays are even greater in number (e.g., Kasirzadeh and Gabriel 2023; Monett and Lewis 2018; OpenAI et al. 2023; Paris, Swartout, and Mann 2013; Rakover 2023; Rodman 2023; Wu et al. 2023). Strictly speaking, Gadamer did not write about artificial intelligence. He did, however, write extensively about language. I turn to Gadamer for my analysis for the utility of his philosophical hermeneutics in current linguistic debates on AI technology. Gadamer’s theory of language offers insight into the deeper structure of human language through his phenomenological approach. Gadamer’s philosophical hermeneutics is more useful for an assessment of the linguistic structures of AI, for example, than the scientific methods employed by computer scientists and linguists because it investigates the experience of what language is and does, in addition to the observable effects of language. In so doing, Gadamer’s linguistics goes beyond the merely empirical assessment of an AI’s textual output, and instead points toward the fundamentally phenomenological question of what relation to the world enables the production of that output in the first place. 7 Hence, Gadamer’s approach will help assess both whether AI can generate texts with linguistic content, and whether AI and humans share the linguistic connection to reality that has long been referenced to distinguish humans from non-human animals.
Our first task is to understand Gadamer’s seemingly abstruse definition of language. For Gadamer, “Being that can be understood is language” (Gadamer 2003b, 474). This understanding of language approaches linguistics through the lens of phenomenology. His conception of language amounts to far more than words and syntax—what Darren Walhof has called “the toolbox model of language” (Walhof 2017, 18–19). 8 Gadamer understands language as the medium that makes possible the disclosure of the world to us. The disclosive character of language is possible only because what is said and written is always connected to and situated within much more that is unsaid or unwritten. The actual words used in a particular context always point beyond themselves, to the whole of a given language in which truth is sedimented. To interpret something spoken, then, requires that we look both at the words of a given text and the external direction that the words point us toward.
The central task of Gadamer’s hermeneutics is getting at the meaning of “texts”—which, not exclusive to written text from books, can include events and experiences. Such texts may include written expressions of language but could also include the non-spoken features of communication. For example, language contains a historical component, since there is a whole linguistic tradition that outlasts any interpreter’s individual consciousness. 9 There is also a communal element to language development from the fact that children learn to speak in a social context. Discerning the meaning of texts, for Gadamer, marks the disclosure of Being in and through texts to merge worlds between the reader and the text. In this way, Gadamer’s theory will help assess whether these models truly possess the deeper structures of language that make it more than a mere simulacrum of language.
The Claims of Generative Language Models
The most popular generative language models such as GPT-4, ChaptGPT, and Bard, operate with a LLM architecture. Large Language Models are designed with the capacity to generate language of equal or superior quality to what a human being can produce, but with greater speed and precision. OpenAI says that their most recent LLM project, GPT-4, “can accept a prompt of text and images, which—parallel to the text-only setting—lets the user specify any vision or language task. Specifically, it generates text outputs (natural language, code, etc.) given inputs consisting of interspersed text and images. Over a range of domains—including documents with text and photographs, diagrams, or screenshots—GPT-4 exhibits similar capabilities as it does on text-only inputs. Furthermore, it can be augmented with test-time techniques that were developed for text-only language models, including few-shot and chain-of-thought prompting” (Wei et al. 2022).
OpenAI has claimed that one feature of their generative language model is that it has natural language capabilities, which, while not equivalent to human language capabilities, can perform the same tasks as well as or better than humans can. The models themselves are also programmed to respond similarly when prompted about their linguistic capacities. To illustrate this, I asked ChatGPT (running GPT-3.5) whether it was programmed with natural language capabilities. To the question “Do LLMs have language?” ChatGPT responded thusly (see Figure 1)
10
: ChatGPT 3.5’s response to “Do LLMs have language?”.
I ran this question several times, and Figure 1 conveys a typical response. This first response notes that ChatGPT (and by extension, other comparable LLMs) does have “language” of a certain kind, but its linguistic capacities are not identical to natural human language due to its lack of true understanding, emotions, and consciousness. More recent versions of ChatGPT and GPT-4 specify that LLMs do not, in fact, understand language the way humans do (see Figures 2 and 3). ChatGPT-3.5’s Response to “Have large language models acquired natural language?”. GPT-4’s response to the question, “Have large language models acquired natural language.”
12
As Open AI has stated, GPT-4’s responses are more precise than GPT-3.5 and generate responses based on more specialized data than its predecessors.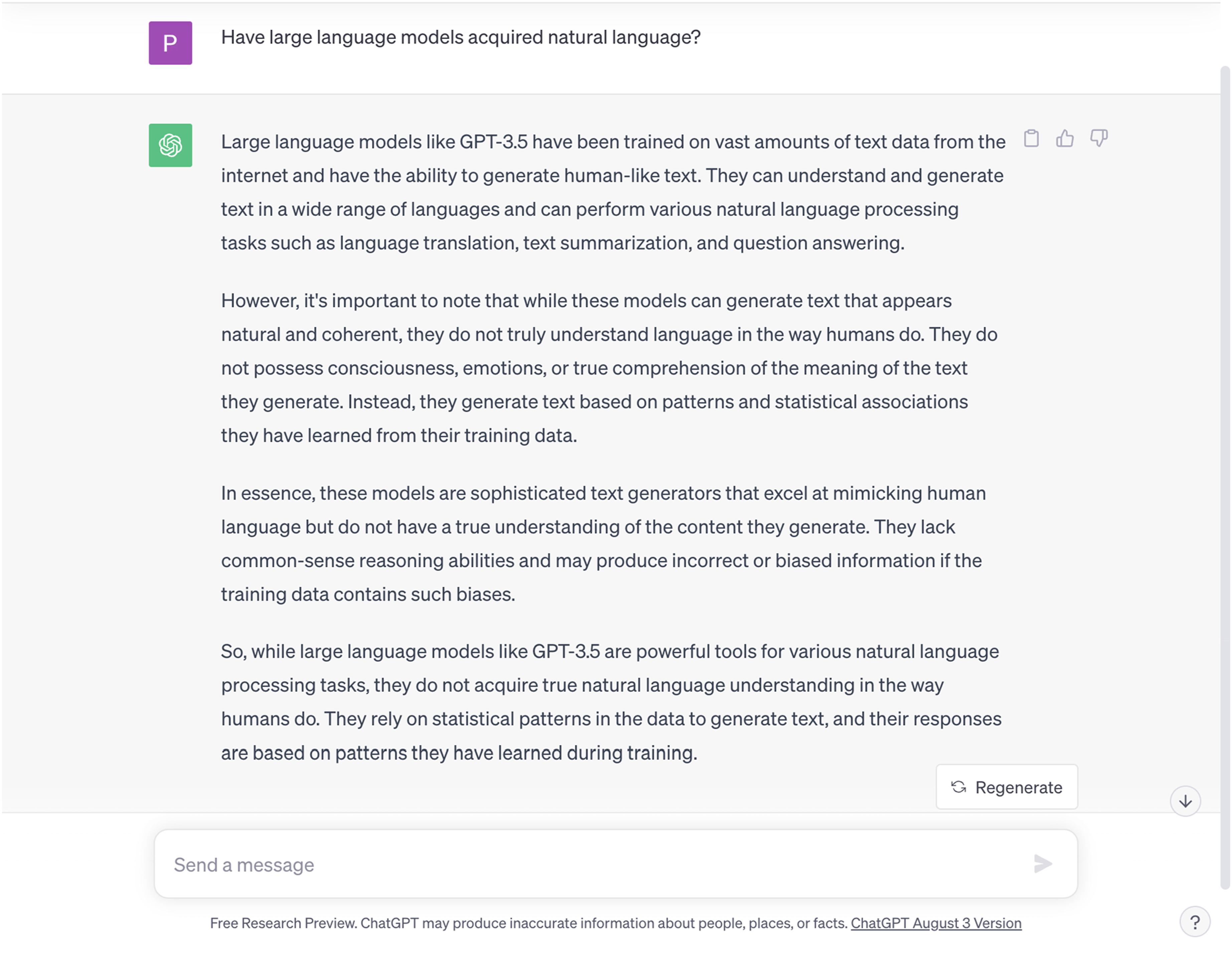
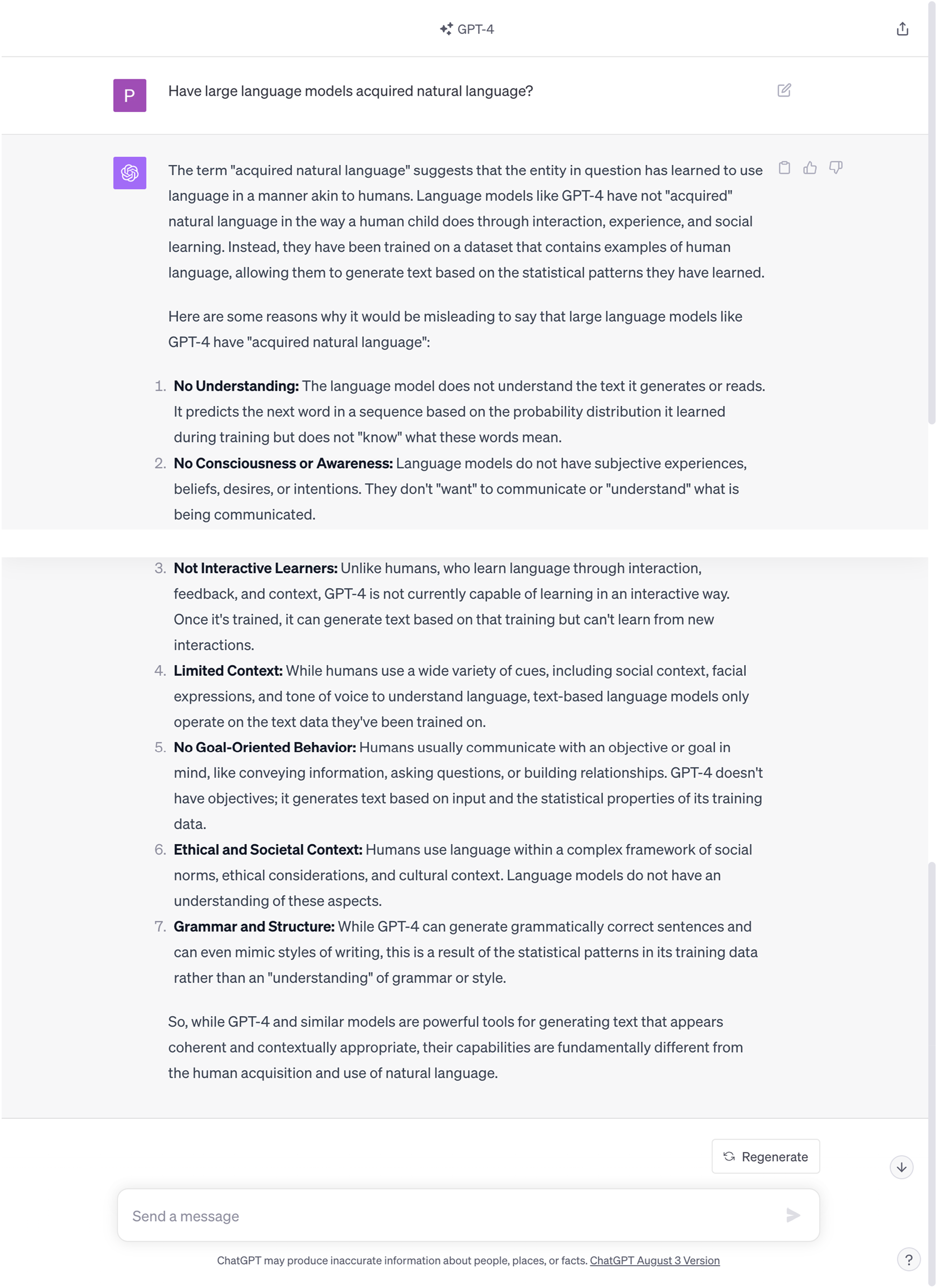
GPT-4 has more sophisticated features than any of its predecessors, including GPT-3.5 in ChatGPT. In their product description for GPT-4, OpenAI indicates that, “GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.” 11
OpenAI has noted that GPT-4, like previous GPT models, still “hallucinates” facts and warns against using GPT for generating text that requires acute precision. Next, I gave the same prompt to Google’s Bard (see Figure 4). Google’s Bard gives the least sophisticated response to my question, producing sentences that do not match the depth and nuance of GPT-4’s.
These models and their developers each indicate—accurately—that LLMs possess advanced linguistic capabilities but lack the full capacities of genuine language. Even with their impressive capabilities, these models have not acquired all the requisite features of natural language. Let us apply Gadamer’s theory of language to understand why these models lack the disclosive character of language. Recall that there are two main components to assessing their linguistic capacities: (1) assessing what these models produce and (2) how they produce it. Let us first assess whether AI can produce texts.
Can AI Produce Texts?
Is the content produced by generative language models a “text,” in the Gadamerian sense? This depends on what sort of things can be considered a text. For Gadamer, hermeneutical interpretation is based on dialogue between an “I” and a “thou,” though the identities of the “I” and “thou” are not restricted to humans. Gadamer’s dialogical model defines a text as a “thou” with whom we can enter conversation. Texts are not just carriers of meaning but are also embedded in tradition and are active participants in the hermeneutical process. In this sense, machine-generated responses could be considered “texts,” in Gadamer’s sense, if they can enter a dialogical relationship with the interpreter and, in so doing, participate in the unfolding of understanding. With this notion of a text in mind, the most advanced generative language models certainly produce content that qualifies as a text because it can become part of the dialogical conversation between text and interpreter. As Gadamerian hermeneutics does not seek to unveil authorial intent, the absence of a human creator does not remove from a human interpreter the capacity to view the text as a “thou.”
The content produced by ChatGPT, then, can be considered a text as much as the article you are currently reading. For instance, if I were to ask ChatGPT to “write a story about two boys named Francis and Lawrence and their search for the Holy Grail,” ChatGPT’s response would be something that I, as an interpreter, could view as a “thou.” The author’s experience of the model’s response, no matter that it was generated by a machine, would still fuse with my horizons to produce a new understanding. Why then, would ChatGPT or Bard lack language if they can produce texts as we can? The answer is simple: even though an LLM can manipulate words into coherent sentences from the perspective of a human reader, it nevertheless lacks a medium that discloses the world to it and is embedded within tradition and community. I will elaborate on AI’s lack of linguistic tradition and community in later sections. Let us now assess why AI lacks a genuine disclosure of the world.
AI and Worldliness
For Gadamer, language is the medium of “worldliness” 13 —that is, the disclosive character of the world. Language is not just a tool for communication but is the medium that brings the world into view for us. From the hermeneutic perspective, a person’s understanding of the world is always linguistically mediated, and conversation with an “other” always occurs within language. Through language, we can conceptualize, verbalize, discuss, and convey interpretations about the world to make it understandable for ourselves and others. In all our interactions with the world, we are already encompassed by the language that is our own (Gadamer 1977, 62). Language is thus a precondition to all experience of reality, being more primordial than even consciousness in terms of our capacity to interact with and understand the world. Without language, there is no understanding of the world and hence no potential for the fusion of horizons as the successful conclusion of dialogue. 14
A test for discerning the presence of language in generative language models is to assess whether the world is disclosed to them. For this to be the case for an AI, the world must be linguistically mediated as something that it can make understandable. With models like GPT-4 and ChatGPT operating under a static dataset with limited information, despite containing billions of entries, the question is whether they have a genuine connection to the world based on the linguistic content they assess.
Even though AI models and their respective manufacturers do not claim that their models have acquired the full features of human language, certain computer scientists defend current LLMs as having a connection to the world comparable to human beings. Bubeck et al., for example, argue that ChatGPT has a genuine connection with the world in its advanced tools that allow it to solve complex algorithms like mathematics, coding, medicine, law, psychology, and many more, all without prompting, and arguably better than a human could—in alignment with the mission of GPT technologies (Bubeck et al. 2023). Li et al. argue that LLMs have become capable of human-like representations of the world because the larger neural language models get, the more their representations are structurally similar to neural response measurements from brain imaging (Li et al. 2023). The trend from these arguments is that LLMs are capable of interacting with complexities that arise from data taken within the world and that their inner modeling has remarkable similarities to human brain structure. The problem with these arguments is that while they examine what tasks LLMs can accomplish and the inner structure that operates LLMs, they miss the key aspect of LLMs that it matters how they are coded to perform their actions and what they do to produce these results. What, then, is a model like ChatGPT doing when it generates language?
Stephen Wolfram has argued that while ChatGPT is remarkable for its capacity to generate text that looks like it was written by a human being, it is ultimately just a word-prediction software. Wolfram describes it thusly: The basic concept of ChatGPT is at some level rather simple. Start from a huge sample of human-created text from the web, books, etc. Then train a neural net to generate text that’s “like this”. And in particular, make it able to start from a “prompt” and then continue with text that’s “like what it’s been trained with” (Wolfram 2023).
According to Wolfram, ChatGPT is trained to study a data source containing billions of websites—whether accessing archived data sources or, more recently, searching websites or search engines—and predict the next word based on what word(s) had been used in answer to similar questions. As Wolfram observes, the code does not always choose the most frequently used word, since, as when humans form sentences, the best sounding sentence does not always employ the most predictable word but the least predictable word. Then the model selects the next word, then the next, and continues until its response is complete. The internal neural networks of ChatGPT consists “essentially of passing input derived from the text it’s generated so far ‘once through its elements’ (without any loops, etc.) for every new word (or part of a word) that it generates” (Ibid). Hence, what ChatGPT is programmed to do is not the same as the human experience of language because word prediction does not mediate the world via language for these models. In this sense, ChatGPT does not have language, per se. It is simply programmed to add one word at a time to continue the text in a “reasonable way.” 15
While Wolfram is correct that ChatGPT and its competitors are merely word prediction software rather than language-speaking models, he misses the greater significance of why this word prediction, with the convincing responses it produces, is not language. This is where Gadamerian hermeneutics can provide an answer. The human experience of language and the deeper structure of natural language is more than a process that analyzes statistical patterns of previously written-text and context clues to predict the next word in a prompted response. Rather, as Gadamer argues, language is the “communicative sedimentation of our experiential world that encompasses everything that we can exchange with one another” (Gadamer 2003a). Put differently, truth is sedimented language, and language is sedimented truth. As Darren Walhof observes, for Gadamer, truth resides not in the words or concepts themselves, but “in their relation to other words and concepts.” Logos is a kind of “relational ordering” among words, and “the truth of things resides in discourse ... and not in individual words, not even in a language’s entire stock of words.” What we say is always connected backwards and forwards to what we do not say—our unspoken past experiences of the world or thoughts about the world. As word prediction software, LLMs have no experience of the “truth of things,” in Gadamer’s sense, despite being trained to order words from a vast database of knowledge. As Gadamer notes, truth is made known to us in a relational ordering of words based on experiential knowledge of the world, not just in having access to words or in being capable of ordering words when prompted. In this sense, possessing the capacity for word prediction based on access to a database of written information does not give LLMs language.
There is an additional problem to consider: do LLMs, as word prediction software with access to immense data about the world, have a genuine connection to the world? If the reality of the world and our thoughts about the world are linguistically mediated, as Gadamer argues, then how can we distinguish between a process that builds a model of “natural sounding language” through word prediction and a process that models our linguistically meditated experience of the world? A linguistically mediated experience of the world has access to the world itself, not just to written descriptions of the world. For Gadamer, what is significant about human language is not the words themselves but the world to which the words always point beyond. Put differently, the disclosive character of language is only possible because what is said or written is always connected to what is unsaid or unwritten. The words used in any context always point beyond themselves, to the whole of a given language in which truth is sedimented. Large Language Models, it seems, are cut off from what is unsaid and unwritten in the world that gives language its disclosive possibilities. In this sense, a significant limitation in LLMs is that they have access to words, not the world through language.
The growing capacity for image analysis in LLMs does not bring them closer to having a genuine connection to the world. The capacity to experience the world through sensory representations is certainly part of a linguistically mediated reality, as humans can represent the physical world they experience by using language. To be sure, AI photo recognition technology has made impressive advancements. For instance, as of November 2023, GPT-4 can recognize an image of a lasagna and parse its ingredients (Gong et al. 2023). However, the first problem is that photo recognition technology is still in a nascent stage compared with their linguistic capacities. For instance, as a minor point, GPT-4, in its current state, is less capable of photo recognition the blurrier the photo is. Second, even if this sensory-replication technology is soon perfected, the addition of photo or auditory recognition would be insufficient for adding a structure that allows the information accessed to become sedimented truth. As Gadamer observes, truth is revealed through a relational ordering of words with reference to one’s experience of the world, not with words themselves. Similarly, access to images of the world is not the same as a relational ordering of words about the world expressed within those images. Photo recognition, then, is not so different from having access to a database of words in as much as both are insufficient for possessing language.
One limitation in AI that additionally inhibits them from the functions of natural language is their lack of a corporeal experience of reality (Pfiefer and Bongard 2006). The possession of a body is not an explicit part of Gadamer’s linguistic theory. However, the body and our senses are always part of human existence and shape our perceptions and interpretations during the hermeneutical process. Moreover, the body can communicate non-verbal messages through “body language,” and our senses allow us to identify non-spoken facts about the world that words alone may fail to communicate. Hence, our embodied existence is crucial to consider when discussing how the world is disclosed to us. Granted, any animal with a body is not necessarily an animal with logos. A cow has a body but is incapable of abstracting from reality to create understanding. Like animals, LLMs lack certain elements of communication that can only be conveyed through a body. For instance, a model cannot yet read the body language of its interlocutor, such as squirming in one’s seat from physical discomfort during a heated exchange. AI modeling of course is not limited to software. Robotics technology allows AI to make spatio-temporal decisions regarding their movement. Google’s RT-2 is an AI machine that, instead of predicting the best word to use next, uses AI programming to predict where its arm should move next. AI might, then, be designed with something resembling a body. But advancements have not yet reached the point of expressing body language themselves and still have not developed technology that can reliably interpret human body language.
As a study from Zimmerman et al. demonstrates, another blind spot for LLMs is that, due to their incorporeality, they are incapable of processing “supradiegetic linguistic information.” Diegetic information is information accessible from within the world, roughly the inside of the word/symbol, its function, the meaning, the semantic component, propositional, descriptive (imagine a word minus any letters or sounds). Supradiegetic information is the arbitrary part of the information that comes along with the word (for us) because of the way it is packaged, because it has a physical form (the clicky, hard sound and short appearance of the letter “c” in “cat,” or the sounds of the syllables), the exterior of the word/symbol. ChatGPT can, at least sometimes, make use of descriptive (diegetic) approximations of sensory experiences it has no direct access to, but it has no access to things depictively (supradiegetially) (Zimmerman et al. 2023). ChatGPT fails to comprehend supradiegetic information because it lacks the corporeal experience that gives humans the capacity to experience the object referenced by the word. While it may grasp that the letter “a” has a circular loop with a small tail, this information about the “a” is not reachable in ChatGPT’s “universe.” This problem in ChatGPT has not yet been solved in more advanced iterations like GPT-4 with its capacity for analyzing photos and text. The result of ChatGPT’s inability to reach supradiegetic information is that it is limited in what it can communicate. For instance, as Zimmerman indicates, ChatGPT is not a reliable translator of languages like Cuneiform, does not know its own limitations, and runs into trouble with producing palindromes and symmetry.
Once again, to the credit of LLMs, they are able to sift through billions of pages of text that describe the world. However, disclosure to the world implies a historicity and temporality in line with the progression of world events, as this disclosure is an ongoing and never-ending phenomenon. The lack of disclosure is the source of shortcomings in GPT technology. As Tamkin et al. have noted, “GPT-4 still suffers from various well-documented weaknesses of language models. These weaknesses include (but are not limited to) lack of current world knowledge, difficulty with symbolic operations (e.g., math), and inability to execute code” (Tamkin et al. 2021, 41). They found that when asked who the current President of the United States, GPT-4 incorrectly replied “Donald Trump,” while ChatGPT refused to answer this question and replied that it is incapable of assessing time-based questions past the year 2021. What these generative language models “understand” is not the world as we know it but something of a different size and with certain limitations that humans lack. Due to the immense size of information they can access, they might perform better than humans at certain tasks, but they have not yet matched our linguistic connection to the world. Indeed, without genuine understanding they cannot form a proper structure of reality. I will discuss this problem next.
AI and Understanding
The larger side of the problem of lack of groundedness to the world is that, by extension, AI models lack genuine understanding of the sentences they communicate. Indeed, a common human prejudice against AI is that it cannot understand concepts in the same way that humans can. 16 Many say that AI are far more limited in intelligence than recent developments would suggest (Arkoudas 2023). Some even question the possibility of artificial intelligence due to the purported undefinability of intelligence. (Wang 2008). OpenAI even admits that no model of GPT has human-like comprehension of the text it produces.
On the opposing side, we see teams of scholars who fiercely defend the capacity of AI models to understand. One scholar declares that “statistics do amount to understanding, in any falsifiable sense” (Agüera y Arcas 2022). Some scholars argue that human-like representations have arisen in LLMs because the larger neural language models become, the more their representations are structurally similar to neural response measurements from brain imaging (Li et al. 2023). Landgrebe and Smith argue that Transformer models (the most popular AI architecture, used by GPT-3, BERT, and others) says that understanding is seeing the relevance of words and phrases to actions and thoughts—that is, having awareness (Landgrebe and Smith 2021). Others have suggested that AI has contributed to a new type of understanding, “one that enables extraordinary, superhuman predictive ability, such as in the case of the AlphaZero and AlphaFold systems from DeepMind” (Mitchell and Krakauer 2023).
The definition of understanding has long been contested. Mitchell and Krakauer observe that human understanding “does not seem to be based on the kind of massive statistical models that today’s LLMs learn; instead, it is based on concepts—internal mental models of external categories, situations, and events and of one’s own internal state and ‘self’” (Ibid). Many scholars and test participants have defined understanding in many ways, including getting something “almost right,” recognizing causality, and other such ways that characterize understanding and language as tools that humans can summon at will. This definition, however, seems to arrive at a backwards conceptualization of language. In one of his interviews, Gadamer noted that “[o]ne should not imagine that interpretive concepts only enter into one’s understanding subsequently, as if one drew them out of a linguistic storeroom, so to speak, and applied them as needed to the ‘thing to be understood’” (Gadamer 2001, 37). Understanding “does not reach out and take hold of language” but is rather “carried out within language” (Ibid).
For Gadamer, understanding is an event where “Being comes to present” (Gadamer 1977). Understanding always occurs within conversation, which is situated within a historical and communal context. In the event of understanding, “something plays back and forth between the human being and that which he or she encounters in the world” and in so doing “a new horizon is disclosed that opens onto what was unknown to us” (Gadamer 2001, 49). Individuals always come to understand something by applying what Gadamer calls their “prejudices” and “fore-meanings”—previously made judgments which are shaped by their particular historical and cultural circumstances. The meaning of a text is always a matter of self-understanding where we engage in dialogue not only with the text but with our prejudices. Moreover, understanding is not an activity we engage in from time to time, but an ongoing activity that people are constantly participating in, in the same way with a conversational partner as with a text. The desire to understand governs our whole process of questioning. As Gadamer remarks, “[a]t the beginning of every effort to understand is a concern to understand something: confronted by a question one is to answer, one’s knowledge of what one is interpreting is thrown into uncertainty, and this causes one to search for an answer” (Ibid). To illustrate the lack of genuine understanding in AI, let us take each of these descriptors point by point.
First, an AI is incapable of experiencing the fusion of horizons. The “fusion of horizons,” in Gadamer’s hermeneutics, is the ideal end of a dialogue where mutual agreement is reached. 17 A horizon, for Gadamer, marks the limit of someone’s sight at a given moment, but one’s limit of sight can always be expanded with little effort (Gadamer 2003b, 302). Horizons can function as a limit for a limited period, but they are always gateways to something beyond. The questions at hand are whether LLMs have horizons and whether they can fuse horizons. In a certain sense, it is true that LLMs are capable of crafting text that presents a limited vision of the world which can qualify as a horizon. Moreover, the very basis of LLMs is that they improve their written responses by observing patterns in previously written information, which could be considered a sort of fusion of horizons. However, I reject that AI can, properly speaking, experience the fusion of horizons because they lack historicity and community (points which I elaborate upon in later sections). The fusion of horizons, in Gadamer’s vision, is not an event that takes place in abstraction from the world. It occurs within a dialogue between two ever-changing entities that have acquired their present horizons through their past experiences and interactions with other people. While an AI’s capacity to “learn” from an abundance of data and its own mistakes, its “horizons” are based on a static data source, and it does not expand its horizons in the same way as a human does within the dynamic influences of history and community, as a being with a past that is always oriented towards the future.
Second, at present, an AI cannot enter genuine conversation with a human being. ChatGPT exploded in popularity due to its Chatbot features that responded to repeated human inputs comparably to a conversation between two people. For Gadamer, the event of language where we develop understanding emerges through a dialectical relationship, typically between two people or when a person engages with a text. The most likely scenario to find ourselves open to the event of language and consequently to the power of language to bring something into presentation is a face-to-face conversation. In a conversation, we cannot plan or control the exchange of information; rather, a conversation is an organic process in which understanding occurs spontaneously. In this sense, it is more correct to say that we “fall into conversation,” and that a conversation leads us rather than us guiding it. In a conversation, we do not necessarily know the topic or what the topic will be; rather, it seems as though the topic emerges as the conversation guides itself. To quote Gadamer, a good conversation “bears its own truth within it” (Gadamer 2003b, 401). Of course, a conversation between humans is not limited to face-to-face interactions, as we can also communicate via exchanges of text. Even so, a conversation in a text message or email exchange emerges with a similar spontaneity about its destination that AI, even with their Chatbot functionalities, have not yet learned.
In particular, LLMs have not successfully replicated the experience of falling into conversations with us. 18 For instance, ChatGPT can certainly respond to our specific inputs, and we may even hop onto ChatGPT out of boredom and enter an input rabbit hole of repeatedly inputting questions and receiving responses. However, becoming distracted with input technology is not the same as falling into conversations with another person. 19 A conversation between humans is not simply a rote exchange of opinions and information; rather, it has an openness to being changed by the opinions exchanged and, in so doing, arriving at a mutual understanding that neither party possessed prior to the conversation. While an LLM like GPT-4 may simulate conversational behavior by providing contextualized responses, its responses, once again, are based on their coded and trained responses to human prompts, not on its “openness” to be changed from mutual agreement in our conversation. To the contrary, most frequently, humans are attempting to learn from GPT-4 rather than the inverse. In this sense, a human’s relationship with GPT-4 is closer to a court interrogation from a human to a machine than a genuine dialogue between conversational partners: we probe it with questions or requests, and it may ask questions only to clarify an ambiguity. While GPT-4 is trained to adapt its responses to user input, it is simply fixing its mistakes, not seeking to learn a truth from conversing with us. There also remains the minor but legitimate problem of input lag and needing to type our replies that inhibit a conversation with an AI from “leading us.”
Third, when engaging in the dialogical process, an AI cannot engage in self-understanding of its “prejudices” and “fore-meanings.” 20 Gadamer argues that individuals bring their preconceptions to the texts they interpret. For this reason, he advises interpreters to become conscious of the prejudices they carry. An AI may indeed generate a response according to the prejudice and fore-meanings of its programmers (e.g., an error response or a declaration of its search limitations) or the biases from its training data. However, it does not present those prejudices as its own, but as a remnant of its sources’ prejudices. To be sure, developers can take steps to mitigate these prejudices during training. But GPT-4 lacks its own interpretive prejudices, as its “opinions” and “biases” come from outside sources, not from its personal beliefs formed from lived experiences within a certain historical and cultural environment. I elaborate upon this latter point in the next section.
AI and Linguistic Community
One component of language that is often overlooked by computer scientists is that language always develops and is expressed within the context of community. 21 As described in the previous section, Gadamer assumes that tradition and community are part of the fore-structure (the backdrop) of understanding. Ingrained within the concept of community is what Gadamer calls “lingusitic community,” an underexplored idea within Gadamer studies. For Gadamer, “linguistic community” is not a particular kind of community, but rather is a term that emphasizes the shared understanding of values sedimented within a language according to a shared tradition and culture of like-minded people. Linguistic community also emphasizes the living character of language as something that is shaped and changed by shared culture, values, and history, rather than being a static phenomenon.
A deficiency in generative language models is that they do not actively participate in the constantly evolving character of human language grounded within a linguistic community. Now, one might argue that, to the contrary, their language does participate in a linguistic community because of how they develop their linguistic capabilities. Large Language Models are trained to develop responses in a feedback loop process based on “training data” that, comparably to a child’s social environment, creates a standard for comparing its responses to the linguistic norms of the world. However, while such an assessment recognizes that LLMs acquire their linguistic capabilities from human communities, it fails to understand that genuine linguistic development within a community is a dynamic, interactive experience, whereas LLMs like GPT-4 are trained on a static dataset. Even recent advancements that have given GPT-4 live web browsing capabilities still grant it access only to static data from the Cloud that needs continuous updating from human sources. Moreover, its responses are based on pre-existing patterns rather than dynamic dialogues. It does not contribute to real-time conversations or the evolution of shared linguistic traditions. Where human beings can interpret implied meanings, identify cultural references, or understand inside jokes, GPT-4 relies on assessing statistical correlations from training data, which may produce inaccurate responses or misinterpretations.
In this sense, an LLM does not develop its type of understanding in a manner comparable to, say, an infant. In an infant, “there is no identifiable beginning” (Gadamer 2000, 33). An infant develops its speech by living and participating in a linguistic community with established rites, customs, and morals—practices that carry implied assumptions about the structure of reality. In contrast, GPT-4 does not carry assumptions about the structure of reality derived from dynamic interactions in human community. All AI models have been programmed to operate according to certain measurable rules of propriety that restrict the content of user inputs—for example, identifying certain profanities as inappropriate and prohibited. Simply following inputs is not sufficient for gathering data from the world vis a vis community.
AI and Linguistic Tradition
Intertwined with linguistic community is the notion of linguistic tradition: the element of historicity that shapes the structure of linguistic experience. All people, for Gadamer, have a historically effected consciousness, in that all our understanding is shaped by our historical and cultural context. Not only is our understanding shaped by history and culture, but the objects interpreted are themselves constructions of the past. When communicating with or receiving information from an “other,” we are interpreting something handed down to us from the past—that is, tradition. Gadamer claims that “the essence of tradition [Überlieferung] is to exist in the medium of language” (Gadamer 2003b, 391). 22 When referring to tradition as the object of language, he means that language is the medium through which we make meaning explicit from what is handed down to us. Put differently, language hands down part of the past so that it can communicate with us and be understood. That which is handed down to us through language is the “linguistic tradition” in which we are situated (Gadamer 2003b, 391). Linguistic tradition shapes how we interpret the world and make sense of our experiences. Examples of such traditions include the oral transmission of myth or transcribing the past in writing, as in the case of literature and philosophy, but it can include anything handed down from the past.
The question remains: are LLMs situated within linguistic tradition? LLMs certainly have the capacity to hand down particular traditional practices or cultural knowledge with their limited functions of reordering pre-existing knowledge. However, this database remains unaffected by practices across time. An LLM could not immediately understand the arrival of new jargon among young people, for instance, without receiving updated inputs from human supervisors. Human language, in contrast, is constantly engaging with tradition. For instance, a person born in ancient Greece engaged with the Homeric traditions handed down to them in that period, and those traditions influenced their language. A Greek person in Plato’s time might swear by exclaiming “By Zeus the King!” For a later figure like Petrarch, the Christian tradition is the environmental backdrop that facilitated his formation as a great Italian Humanist. Yet it is worth noting that Petrarch, like any person from ancient Greece, was a historically singular individual whose full self was never fully present in any of his incarnations or inscriptions. In this way, tradition is the medium of our formation as historical beings. 23 An individual is constantly developing through constant interactions with tradition in their lifetime.
Another aspect of access to the linguistic tradition is the capacity to “experience” and “belong to” tradition. In Gadamer’s terminology, experiencing tradition refers to the capacity to enter hermeneutical dialogue with the past, while belonging to tradition refers to the passive experience of being embedded within a particular cultural and historical context (Warnke 2014). To be sure, AI models are trained with self-correction technology to identify and avoid past errors and misinterpretations in its later responses. We have evidence that AI models learn from past mistakes: for example, the famous IBM machine “Deep Blue” that learned to defeat the greatest human chess player. 24 But is this capacity for self-correction the same as making sense of one’s past? I would argue it is not. While it can have records of the past that affect its decisions in the present, it does not experience tradition because it does not seek to be changed by the tradition it interprets, as the tradition handed down to it is static, as mentioned. It also does not belong to tradition in the same way that a Latino can belong to Latino culture. GPT-4 could certainly be prompted to mimic cultural expressions or regional dialects, but in its model of self-learning, chain-of-thought prompting, fine-tuning, and reinforcement learning, it does not participate in the ongoing development of tradition or the meaning of tradition within particular cultural or historical contexts. For this reason, it fails to identify with core traditions and could never, properly speaking, identify as part of an existing cultural tradition.
Now, does an AI develop associated prejudices from their experiences, cultural background, and spoken language, as humans do? The answer is still no. Because AI lacks a framework of genuine understanding, as mentioned previously, it is not plausible that they could have prejudices and fore-meanings in the sense of having structures of understanding that change upon merging worlds with a text. ChatGPT could have a certain, albeit less complex kind of linguistic tradition in their capacity to survey billions of records, keep track of which records it has examined, and record what it has said previously. They can even adapt their responses based on user inputs. But this would hardly resemble the kind of tradition that AI could experience and that could transform its understanding.
The absence of linguistic tradition yields additional limitations on an AI’s linguistic development. For instance, we learn to speak in our own dialects based on the regional dialects of those with whom we converse most frequently. In learning to speak, we pass on not only content from the past—like regional traditions or certain ways of thinking—but also the mentalities and biases that someone from a certain subgroup would develop. ChatGPT could be programmed to output these elements of tradition, but it does not belong to tradition in the way that a child could be raised Catholic, Hindu, Cuban, or Indian would; nor does it develop the prejudices and fore-meanings associated with it.
Conclusion
Let us return to the framing question of this paper: does AI speak our language? I have attempted to answer this question by employing Gadamer’s theory of language. 25 If Gadamer’s philosophical hermeneutics has anything to teach us, we must conclude that, at present, natural language generation models fall short of genuine natural language generation.
The question remains: what kind of “language” do LLMs have? Current LLMs fall under a category that Gadamer calls “artificial language.” Artificial language includes tools that are manufactured by human beings for human use (Gadamer 2003b, 446). LLMs are created for human use and are adept at using words and sentences as tools. OpenAI and Google advertise their products according to their utility, listing such things as Icelandic language preservation, usage by Khan Academy, Morgan Stanley and DuoLingo as evidence of its utility as a potentially lucrative tool. 26 Even so, it is not as though humans communicate with GPT-4 in the same way that we communicate with each other through sign language. GPT-4 is a tool for generating text or images that a human can use to communicate. In its uncanny resemblance to human language, generative language models more closely resemble an image of reality in the Platonic sense, much like how a painting, for Plato, is an imitation of reality. 27 Hence, we should not accept Alan Turing’s famous “Imitation Game” argument that a mere imitation of language is sufficient for AI to have language (Turing 1950). Either AI has language, or it does not. A mere simulacrum of language is not language. An AI model today is missing that which may allow genuine language to disclose the world to it.
At present, there is no evidence that current advancements in generative language models could ever allow AI to develop language as its mediator of understanding. Such an advancement would require humans to deliberately construct a model whose structure of reality is mediated by language. For such an accomplishment, one would be at a loss at even where to begin. If such an accomplishment ever comes, the AI’s “inner life,” mediated by language, could be identified by making continued use of Gadamer’s philosophical hermeneutics. 28
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.