
Abstract
Wi-Fi sensing exploits radio-frequency signals emitted by Wi-Fi devices to analyze environments, enabling tasks such as people tracking, intruder detection, and gesture recognition. Its growing diffusion is driven by the IEEE 802.11bf standard, which facilitates environmental monitoring, and the increasing demand for tools capable of penetrating obstacles while preserving privacy. However, the performance of Wi-Fi-based sensing solutions is influenced by the environment in which signals are acquired. This is critical when extracting spatial and temporal information from the surrounding scene, as such data reflect both environmental structure and interference sources. A main challenge is achieving generalization across domains, that is, ensuring consistent performance under varying conditions, such as different rooms or buildings, without significant accuracy loss. This paper presents a deep model for domain adaptation of Wi-Fi signals by simulating a digital shielding mechanism. The model is based on a Relativistic average Generative Adversarial Network (RaGAN), which mimics physical shielding to suppress domain-specific features while preserving signal integrity. Both the generator and discriminator use Bidirectional Long Short-Term Memory (Bi-LSTM) architectures, enabling modeling of waveform and time-dimension signal characteristics. To support training, an acrylic box lined with electromagnetic shielding fabric, replicating a Faraday cage, was constructed. Spectra from same-sized objects made of different materials were acquired both inside (domain-free) and outside (domain-dependent) the box. A multi-class Support Vector Machine (SVM), trained on shielded spectra and tested on RaGAN-denoised data, achieved 96 percent accuracy. The SVM also distinguished materials, suggesting a promising approach for security systems aimed at identifying the nature and composition of potentially dangerous objects.
Introduction
In the current literature, the term sensing refers to the process of detecting and measuring physical properties, events, and changes, as well as the behavior of people and objects, in indoor and outdoor environments using various types of sensors.1–3 These sensors convert physical stimuli, such as light, sound, temperature, motion, or visual acquisitions like depth maps or RGB video streams, into data that can be observed and analyzed to derive a wide range of meaningful information for real-time informed decision-making. In recent years, these sensing technologies have become increasingly widespread and are playing a key role in an ever-growing number of application domains. Among the various sensing technologies, one widely known for its versatile applications across different fields is visual sensing, better known in the literature as scene understanding. The systems implemented with this technology generally consist of a distributed network of RGB cameras (occasionally other types of cameras) placed in various environments; these cameras acquire video streams that feed into computer vision models to achieve a multitude of purposes, such as person re-identification,4–7 object tracking,8–12 human action recognition,13–16 foreground modeling and analysis,17–21 and much more. Despite the remarkable achievements of computer vision techniques and models, many visual sensing applications still face significant challenges, such as illumination changes,22,23 background clutter,24,25 occlusions,26,27 and perspective distortions.28,29 Many of these challenges are cross-cutting across various fields. While current RGB devices remain the most suitable for spatial resolution, image quality, data richness, and noise management, they are inherently prone to the reported limitations. Consequently, recent efforts have been intensified to develop technologies capable of replacing or complementing current visual technologies, aiming to overcome, at least in part, these issues in visual tasks.
Wi-Fi sensing is an evolving technology that has already proven to be highly effective in a wide range of applications over the past two decades,30–33 from smart home automation and security to healthcare monitoring and human-computer interaction. In recent years, Wi-Fi devices have been used not only for current monitoring activities but also as a type of “vision” system capable of capturing and shaping significant information to accomplish computer vision tasks through deep analysis of propagated signal spectra. For example, in Avola et al., 34 the authors use Wi-Fi signal information that has passed through various subjects to develop a person re-identification system capable of providing more robust and reliable biometric signatures than visual ones, which are dependent on factors like changes in lighting or clothing. Meanwhile, Wang et al. 35 utilize Wi-Fi signals to reconstruct the skeletons of individuals, on which classical methods can then be applied to determine human body poses and movements. While there is potential to lose valuable information, such as the texture and colors that define the surface of objects, Wi-Fi sensing offers extraordinary capabilities, including analyzing the interior of solid objects, overcoming obstacles to mitigate occlusion issues, and providing stricter privacy constraints. The promising future of Wi-Fi applications in various domains is further supported by the recent establishment of the IEEE 802.11bf standard, 36 which formalizes and standardizes Wi-Fi sensing capabilities within the existing IEEE 802.11 Wi-Fi framework. It is now evident, especially in light of the next generation of applications under development, that regardless of the specific application being addressed, signal integrity remains a critical factor for the reliability and performance of Wi-Fi sensing applications. This is especially crucial for preserving signal fidelity and extracting rich semantic information required for accurate and complex manipulations.
At the core of Wi-Fi sensing lies the analysis of Channel State Information (CSI),37,38 which provides a comprehensive representation of how a Wi-Fi signal propagates from the transmitter to the receiver through an environment. CSI captures a range of critical data, including amplitude, phase, delay spread, Doppler Frequency Shift (DFS), and multipath effects. These characteristics are essential for in-depth signal analysis and the implementation of advanced Wi-Fi sensing applications. However, environmental variations present a fundamental limitation to the robustness of Wi-Fi sensing systems, as they can induce significant fluctuations in CSI characteristics. As highlighted in the study by Chen et al., 39 CSI is inherently sensitive to surrounding environmental factors, including room layout, furniture placement, and static reflectors. Even minor modifications, such as repositioning objects or the presence of transient obstacles, can alter the multipath propagation of Wi-Fi signals, causing domain shifts that negatively impact sensing accuracy. These variations impact key CSI metrics, such as amplitude, phase, and DFS, leading to inconsistencies in signal representation. In such conditions, models designed to perform specific sensing tasks often fail to generalize effectively when deployed elsewhere. This is particularly problematic for pre-trained models, which tend to experience a noticeable drop in performance when applied across domains characterized by different signal propagation conditions. As a result, Wi-Fi sensing systems frequently require continuous recalibration, retraining, or robust domain adaptation strategies to remain reliable in dynamic or previously unseen environments.
Considering the points discussed so far, this paper introduces an innovative deep model specifically designed to emulate the physical effects of a Faraday cage with the aim of filtering signals and removing any domain-dependent components together with possible noises and interferences that could be present in the environment. In other words, the proposed architecture purifies signals as if they had been acquired in a completely neutral and interference-free environment. To achieve this, a model based on the Relativistic average Generative Adversarial Network (RaGAN) was designed, which digitally mimics the protective characteristics of a Faraday cage, thus preserving the integrity and informative content of the Wi-Fi signal. In this proposed version of RaGAN, the generator and discriminator are implemented using Bidirectional Long Short-Term Memory (Bi-LSTM) networks. This configuration allows the model to effectively manage and interpret the sequential data present in Wi-Fi signals. The Bi-LSTM networks process the signal in two stages: first, by analyzing the sequence in the forward direction, thus capturing the dependencies as the signal evolves over time; then, by processing the sequence in the backward direction, thus ensuring that the model also considers future dependencies and provides a more comprehensive understanding of the temporal relationships within the waveform and time-series data of the Wi-Fi signals. To generate the data needed to train the RaGAN model, an acrylic box was constructed and lined with electromagnetic field shielding fabric designed to replicate the effects of a Faraday cage. Using this box, we collected an ad-hoc dataset in which various objects of the same shape and size but composed of different materials were acquired both inside the box, i.e., neutral environment, and outside the box, i.e., with real-world interference and domain-dependent. These acquisitions were then used to teach the RaGAN model to recognize the spectral representation with and without environment-dependent data, thus enabling the network to learn how to transform the spectrum of an object affected by the environment and possible interferences back to that of the same environment-free object. To evaluate the effectiveness of the obtained results, a multi-class Support Vector Machine (SVM) was subsequently employed. The multi-class SVM was trained using the spectra acquired inside the shielded box and tested with the spectra denoised by the RaGAN, achieving an accuracy of 96%. As an additional outcome of the research presented in this paper, which focuses on Wi-Fi signal cross-domain adaptation, the application of a multi-class classifier to verify the performance of the RaGAN also revealed the ability to classify the specific nature of the signal, successfully distinguishing whether a spectrum originated from an object composed of one material (e.g., aluminum) or another material (e.g., copper). In conclusion, the main contributions of the proposed work can be summarized as follows:
To the best of our knowledge, this is the first work in the literature to propose a RaGAN-based architecture specifically designed to emulate the physical shielding effect of a Faraday cage, with the goal of effectively suppressing environment-specific information from Wi-Fi signals. The experimental results confirm the effectiveness of the proposed approach. Given that the proposed method is designed to transform a signal affected by any type of interference and domain-specific data into its ideal form, as if it were acquired in an interference-free environment, this model does not rely on knowing or adapting to the specific nature of the interference or environment. It thus represents an initial step toward effective cross-domain adaptation of Wi-Fi sensing systems. A one-of-a-kind dataset has been created, consisting of objects made from different materials but with identical dimensions and shapes, acquired both in the presence and absence of environment data. This dataset can serve as a valuable starting point for various studies in the application fields of cross-domain adaptation and material analysis. The research proposed in this paper has shown that it is possible to distinguish between different materials based on their Wi-Fi signal features. This discovery opens up new possibilities in the emerging field of Wi-Fi-based material sensing, with significant implications, for example, in security-related studies such as detecting concealed objects or identifying hazardous materials.
The remainder of this paper is organized as follows. Related Work provides a comprehensive overview of prior studies addressing signal denoising across different areas. Proposed Method describes the architecture, detailing the Bi-LSTM-based generator and discriminator. Experimental Setup and Results introduces the collected dataset and discusses the results obtained, both in terms of the cross-domain generalization capability of the proposed method and the ability of the classifier to distinguish between different materials. Finally, Conclusion concludes the paper and outlines our ongoing research directions in Wi-Fi sensing.
Related work
Signal noise has consistently been a significant challenge in telecommunication systems due to the unpredictable nature of various noise types and their sources. Different signals and communication channels encounter distinct forms of noise, each requiring specific techniques to mitigate these disturbances. Furthermore, the term noise can refer to very different types of signal interference depending on the specific task the system is designed to perform, ranging from signal and hardware-related disturbances to environment-specific factors. In the context of Wi-Fi sensing, noise generally refers to all kinds of information gathered by the CSI that is not relevant to the specific task. Denoising techniques are typically divided into time-domain and frequency-domain approaches. The time-domain methods focus on mitigating signal noise by analyzing temporal patterns. A representative approach is median filtering, as reported by Wang et al. 40 on fall detection, where a weighted moving average filter was employed to reduce noise caused by environmental factors such as temperature and room conditions. Another commonly used method is Principal Component Analysis (PCA), as described by Wang et al. 41 on human activity recognition, where the first principal component, representing the highest noise variance, is discarded, while the subsequent five components are retained. The frequency-domain methods, instead, focus on reducing noise by applying filters to isolate useful signal components while attenuating unwanted noise. Common examples of these methods are represented by the work of Ali et al. 42 on keystroke recognition, where a low-pass filter is used, and the work of Liu et al. 43 on tracking vital signs during sleep, where a band-pass filter is employed. However, time-domain denoising approaches can distort the signal, thus potentially leading to the loss of high-frequency components or the removal of significant useful information. In contrast, frequency-domain denoising techniques struggle to effectively eliminate noise within the passband.
Moving into the time-frequency domain to leverage the benefits discussed above, the Discrete Wavelet Transform (DWT) has proven effective in denoising transient waveforms, such as ElectroCardioGrams (ECG) and Transient ElectroMagnetic (TEM) signals, as described in Guo et al. 44 and Wei et al., 45 respectively. Although CSI signals differ in nature, they share key characteristics like non-stationarity, which DWT effectively addresses. Its noise reduction capabilities are demonstrated in the work of Fang et al., 46 where the authors apply the Multilevel Discrete Wavelet Transform (MDWT) to denoise and extract signal features. Recent studies have also introduced Synchrosqueezed Wavelet Transform (SWT)47–49 as a powerful time-frequency analysis and denoising tool. The time-frequency approach enables DWT and SWT to capture transient signal details that single-domain methods might miss, thus making it especially suited for analyzing dynamic and non-stationary waveforms.
While the techniques discussed above help reduce fluctuations and interferences caused by the environment, they still fail to eliminate domain-dependent information embedded in the CSI. To address this limitation, several cross-domain adaptation strategies have been proposed to improve the generalization capabilities of Wi-Fi sensing models. Much of the existing work in Wi-Fi sensing focuses on tasks involving moving subjects, such as activity recognition, user identification, motion detection, human tracking, and fall detection. Consequently, many studies aim to remove the static component of the CSI and retain only the dynamic part, which reflects changes due to motion. Several methods have been developed to achieve this, including the Local Extreme Value Detection (LEVD) algorithm,50–52 conjugate multiplication of CSI measurements between antennas, 53 recursive filtering,54,55 and, to some extent, frequency-based filters, since motion-induced variations typically reside in the low-frequency range. 56 However, while these techniques are effective in motion-related scenarios, they are not suitable for applications where the dynamic component is irrelevant, such as material identification. In such cases, a different approach is required to preserve static, domain-relevant information and suppress domain-specific noise.
In the past decade, Deep Learning (DL) methods have been applied with increasing frequency across various fields, including the area addressed in this paper.57,58 Convolutional Neural Networks (CNNs) were the first DL approaches widely adopted for denoising, particularly in the image domain. Actually, many works have approached signal denoising as an image-denoising problem. For instance, Chen et al. 59 transformed a 1-D TEM signal into a 2D image, which was then processed by CNNs for noise reduction. Similarly, Zhu et al. 60 applied the Short-Time Fourier Transform (STFT) to convert seismic signals from the time domain to the time-frequency domain, thus creating an image input for a denoising U-Net. Likewise, Almazrouei et al. 61 computed the STFT of MATLAB-simulated IEEE 802.11a/n signals and fed these into a Convolutional Denoising AutoEncoder (CDAE) for effective noise reduction. Note that precise separation of noise from clear signal is not always possible and obtaining such a dataset is part of the challenge in denoising frameworks. A solution to address this issue was proposed by Wang et al., 62 which utilized a GAN with Wasserstein distance and Gradient Penalty (WGAN-GP) to learn the noise characteristics present in noisy TEM signals, generating noise signals to build an effective dataset for denoising models. In contrast, Yang et al. 63 introduced an alternative approach using a Conditional GAN (CGAN) to separate crucial signal information from noise. While these works have demonstrated promising results, several limitations remain to be explored and addressed. A key challenge lies in the extended training time and slow convergence speed of current noise reduction methods based on GANs. Another limitation is ensuring the denoising method is sufficiently generalized to handle various noise types. In addition, generative model cannot remove completely the domain-specific information contained in CSI if not supported with an ad-hoc and clean dataset to learn with. Finally, maintaining the informative content within the signal after noise removal remains an essential aspect to address. Inspired by works such as that of Jolicoeur-Martineau, 64 which proposed the relativistic discriminator to enhance limitations in standard GANs and that of Peng et al., 65 which examined the performance of a RaGAN for noise reduction in communication signals; the work proposed in this paper introduces a new paradigm for cross-domain adaptation and noise reduction based on the concept of digital shielding. This approach leverages the fast convergence of RaGAN while enabling an abstraction level in signal denoising that remains independent of the specific environment. The proposed method achieves a high degree of accuracy in cleaning, preserving carrier information and ensuring the informative content even in fine-grained classification case studies, such as distinguishing materials of different objects.
Proposed method
This section presents the three key aspects of the proposed method. In the first, an explanation of the simple yet effective concept behind the proposed approach, i.e., digital shielding, is given. In the second, the implementation of the RaGAN-based architecture designed to emulate the physical effect of a Faraday cage is presented. In the last, details of the simple multi-class SVM classifier, used both to measure the performance of the RaGAN-based architecture and to validate material differentiation as further evidence of the implemented domain-independent mechanism, are shown.
Digital shielding in Wi-Fi signals
As is well known, Wi-Fi sensing covers various tasks beyond traditional communication, such as fall detection or gesture recognition. These tasks, conducted in real-world environments, are inherently susceptible to diverse settings and contexts in which they are carried out. Indeed, Wi-Fi signals are subject to influence from numerous factors, such as electromagnetic interference, environmental morphology, and other contextual variables. The concept behind digital shielding is as follows: if a deep model can be trained to understand the behavior of a Wi-Fi signal during the execution of a specific task in an ideal, noise-free environment, then when that same signal is used in a real-world, noisy environment-dependent setting, the model should be able to clean the signal and restore it to a state similar to its ideal condition, allowing cross-domain adaptation and better generalization. A significant advantage of this approach is that the cleaning process becomes largely independent of the specific environment, as the model consistently aims to extract the fingerprint of the target signal regardless of the environment through which the signal propagates.
Bi-LSTM-based RaGAN
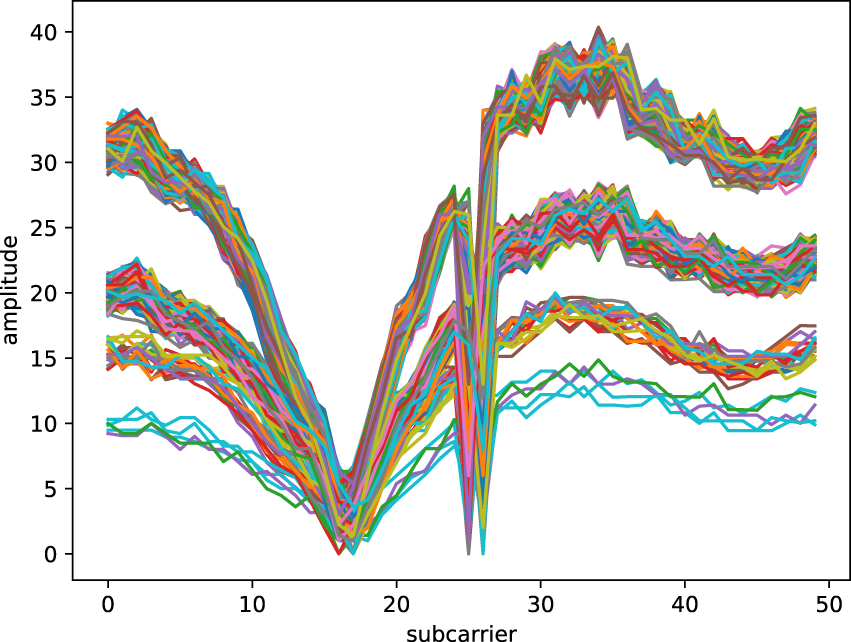
In Figure 1, the proposed model architecture for digital shielding is shown. The model consists of a RaGAN, where both the generator and the discriminator are implemented using Bi-LSTM networks. This design enables the model to interpret the sequential patterns present in Wi-Fi signals. By utilizing Bi-LSTM networks, the architecture processes the signal in both the forward direction, capturing dependencies as the signal evolves over time, and the backward direction, incorporating future relationships. This bidirectional processing allows for a more comprehensive understanding of the temporal dynamics embedded within the waveform and time-series data. In order to train the network to act as a digital Faraday cage, capable of restoring real-world signals as closely as possible to their ideal representations, a specific training strategy is employed. In particular, the discriminator is trained with shielded samples, i.e., signals acquired inside an acrylic box lined with electromagnetic shielding fabric, while the generator is trained with unshielded samples, i.e., signals acquired in real-world conditions. Regarding the features extracted from the CSI, only the amplitude is used, as it encapsulates both the waveform structure and temporal characteristics of the Wi-Fi signals. As an example, Figure 2 illustrates the amplitude computation for two acquisitions of a copper cube, performed in an unshielded (top) and shielded (bottom) environment, respectively.
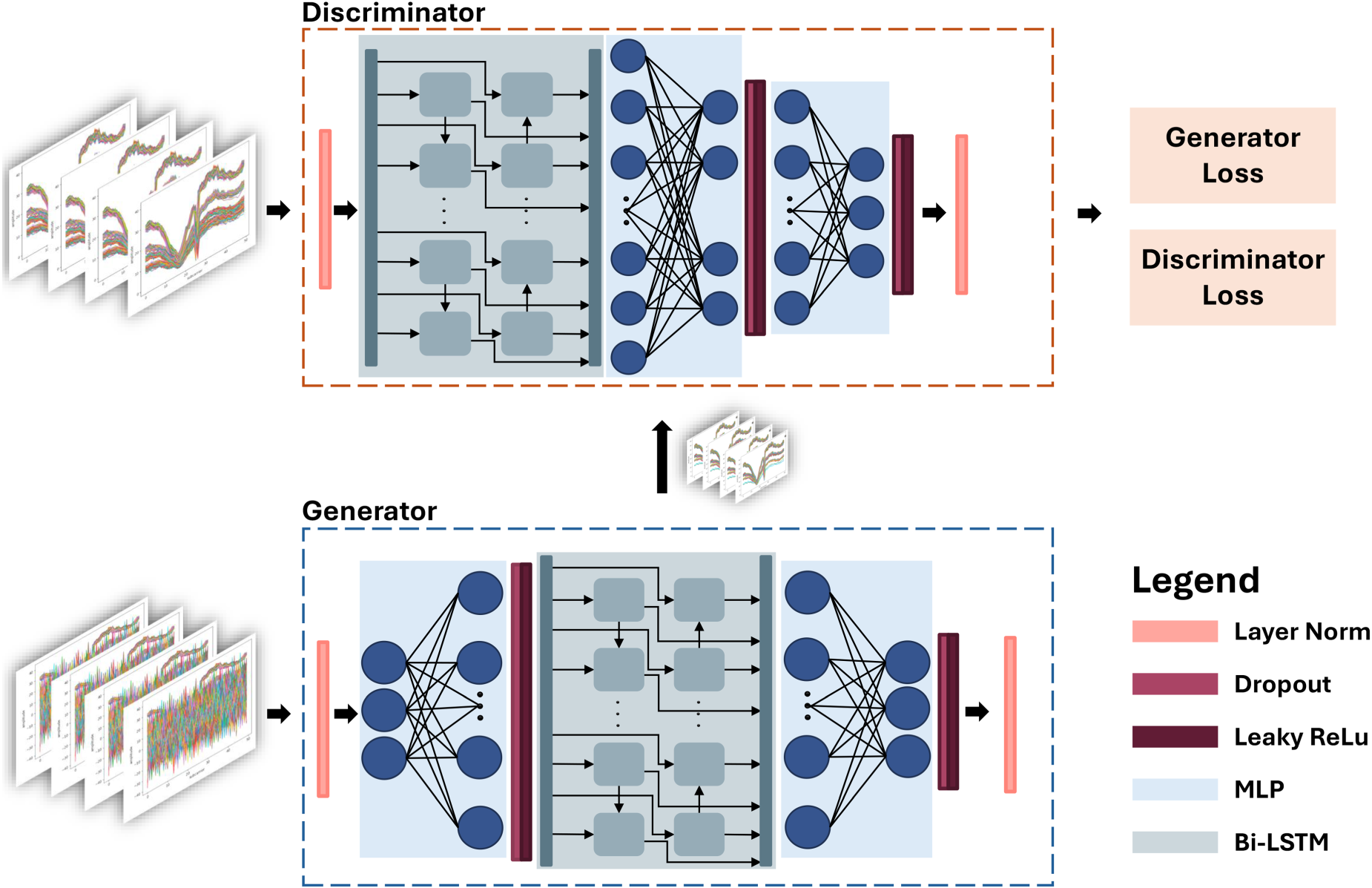
Proposed model architecture for digital shielding. The generator and discriminator are implemented using Bi-LSTM networks to process the sequential data in Wi-Fi signals. In the first stage, the model analyzes the sequence in the forward direction to capture dependencies as the signal progresses over time; in the second, it analyzes the sequence in the backward direction to account for future dependencies. This dual approach enhances comprehension of the temporal relationships within the waveform and time-series data of Wi-Fi signals.
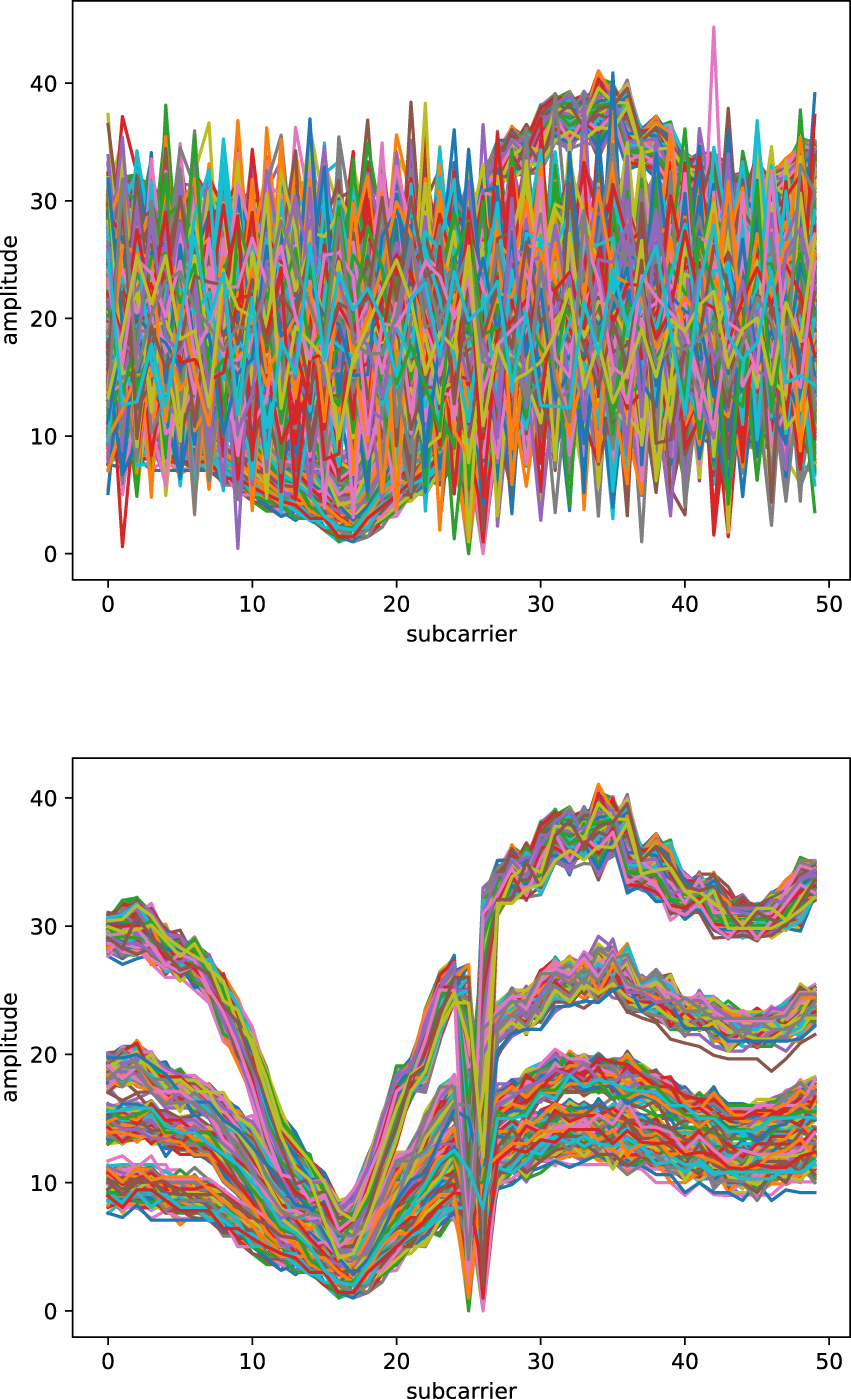
Amplitudes extracted from the CSI: the top plot shows the acquisition of the copper cube in a real-world environment, while the bottom plot represents the acquisition inside the acrylic box lined with electromagnetic shielding fabric (i.e., Faraday cage).
details regarding the construction of the shielded box for noiseless acquisitions, the transmission and reception devices employed, and the dataset created will be provided in the experimental section. In this subsection, however, the primary focus will be on the estimation of the CSI and the subsequent extraction of the amplitude, which will serve as a fundamental feature in the proposed method to be presented in this paper.
Modern wireless communication systems rely on advanced techniques to characterize and adapt to the complex nature of propagation environments. When a Wi-Fi signal spreads through an environment, it undergoes modifications influenced by the structures it encounters, such as walls, persons, and objects. These interactions alter the signal features, including amplitude, phase, and propagation path, shaping it according to the specific properties of the crossed elements. Among the advanced techniques designed to manage these effects, Orthogonal Frequency Division Multiplexing (OFDM)
66
has become a key modulation scheme in wireless communications. OFDM divides the available bandwidth into multiple subcarriers, each carrying a portion of the transmitted signal. This division enables efficient utilization of the frequency spectrum and provides significant mitigation against multipath fading, a phenomenon caused by the interactions between the signal and the environment. A key outcome of the OFDM structure is the ability to analyze the behavior of the channel at the level of individual subcarriers. This is achieved through the Channel Frequency Response (CFR),
67
which represents the frequency-dependent characteristics of the channel. The CFR captures how the channel modifies the transmitted signal at each subcarrier, encapsulating changes in signal strength, attenuation, and other frequency-selective effects introduced during propagation. To further quantify these modifications and generalize the analysis across multiple packets, the concept of CSI is introduced. The latter extends the CFR representation by encompassing multiple subcarriers and multiple time instances, providing a comprehensive picture of the behavior of the channel. Formally, in the frequency domain, the relationship between the transmitted and received signals can be expressed as:



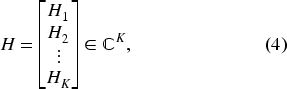
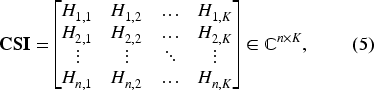
By analyzing the base case of SISO, the method concentrates on the core signal cleaning mechanism, thus allowing for a precise evaluation of the proposed digital shielding method. To achieve this, the amplitude component of the CSI is utilized as the primary feature for signal analysis and transformation. Representing the signal strength for each subcarrier, the amplitude encapsulates critical channel properties, including attenuation, multipath reflections, and scattering, which are directly influenced by the environmental interactions of the Wi-Fi signal during propagation. This makes the amplitude a robust abstraction for the channel state, providing a comprehensive and reliable way to represent how the channel behaves. Unlike the phase, which requires precise alignment, the amplitude offers a stable and computationally efficient feature for modeling the channel, preserving the essential characteristics needed for effective signal restoration. Furthermore, by focusing on the amplitude, the proposed method ensures that the restored signal closely approximates its interference-free state, effectively addressing broader signal properties such as phase and spectral coherence. Formally, the amplitude
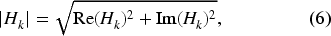
the initial idea behind the proposed digital shielding method took inspiration from GANs, which are applied to signal denoising in a wide range of application domains, such as ElectroEncephaloGraphy (EEG), 69 Magnetic Resonance Imaging (MRI), 70 Sound Recognition (SR), 71 and many others. These operational scenarios highlight the versatility of GANs in addressing noise-related challenges across different areas. However, traditional GANs are known to suffer from diverse issues,72–74 including instability during training, generally caused by the balance required between the generator and discriminator, slow convergence due to the iterative nature of adversarial optimization, and challenges in processing signals with complex dynamic patterns that demand a deep understanding of temporal dependencies. To overcome these limitations, this work proposes the adoption of a RaGAN, a variant specifically designed to address the shortcomings of conventional GANs. In general, the RaGAN modifies the objective of the discriminator to ensure a more stable training process, thus improving both convergence speed and performance. In particular, RaGAN introduces a relativistic average discriminator, which considers the real and generated samples as relative to each other rather than absolute entities. This approach aims to provide a more balanced and robust training process by incorporating the notion of relativistic comparison.
In Figure 3, details of the implemented generator and discriminator in the proposed RaGAN-based architecture are presented. As well known, traditional GANs designed for signal denoising consist of two primary components, i.e., a generator and a discriminator. These networks collaborate within an adversarial process to improve the quality of noisy input signals. Specifically, the generator is trained to consider every environment information contained in the CSI amplitude data as noise and transform signals acquired from real-world environments into their denoised counterparts by learning the mapping between noisy and clean signal domains. Through adversarial training, the generator iteratively enhances its capability to produce outputs that closely approximate reference clean signals, which represent the ground truth of the environment-free spectrum. The discriminator is tasked with distinguishing between real clean signals and those generated by the generator. By evaluating the quality of the generated outputs and providing constructive feedback, the discriminator plays a crucial role in enabling the generator to progressively refine its ability to create realistic and accurate denoised signals. Once the training process is complete, the generator operates independently to process new noisy signals, reconstructing their clean spectra with high fidelity. This separation allows the trained generator to function as a standalone model for effective signal denoising, capable of extracting and restoring spectral information from noisy inputs.
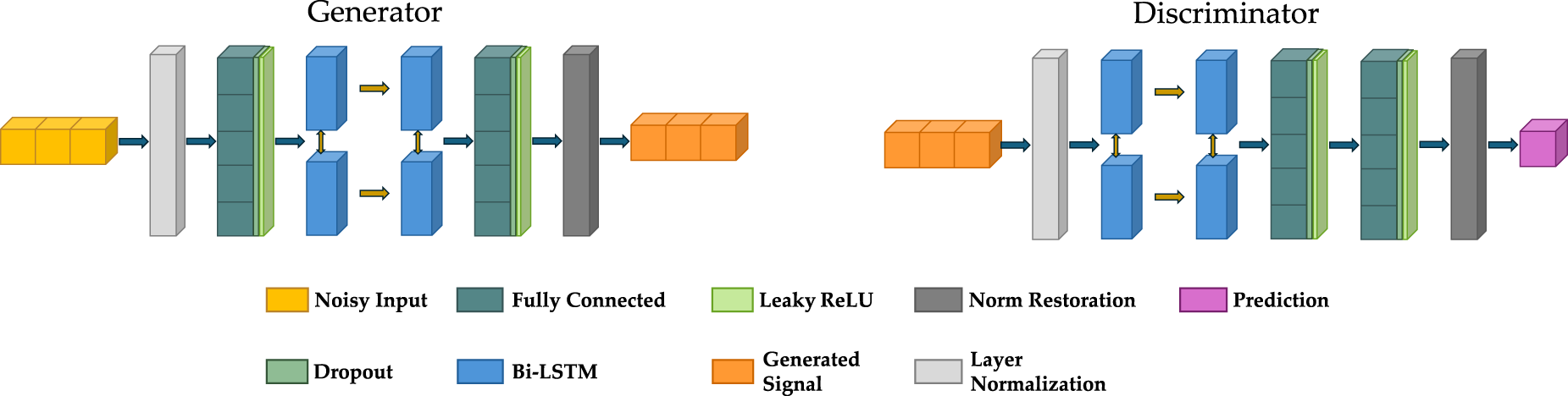
Details of the proposed architecture. The first part (left) shows the generator, whose main components are an initial fully connected layer, a Bi-LSTM layer, and a final fully connected layer. The second part (right) shows the discriminator, whose main components are a Bi-LSTM layer and two sequential fully connected layers.
From an overall perspective, the proposed RaGAN-based architecture follows the same logical pipeline as the previously described GAN-based architecture for signal denoising but differs from both conventional GANs and standard RaGANs in several fundamental aspects. To begin with, differently from conventional GANs, the introduction of a relativistic average discriminator allows the proposed RaGAN-based architecture to overcome the limitations outlined earlier. By evaluating the relative likelihood that real samples appear more authentic compared to generated ones, instead of relying on absolute classifications, the relativistic approach reduces instability during training. This comparative mechanism minimizes sensitivity to imbalances between the generator and discriminator, thus fostering a more stable optimization process. Additionally, the relativistic discriminator enhances convergence by providing richer informative gradients during adversarial training. Lastly, this comparative approach enables the model to better handle complex dynamic patterns by concentrating on the relative distinctions between noisy and clean signals, thus enhancing the ability of the generator to adapt to complex temporal and spectral variations in the input data. In addition, unlike standard RaGANs, the proposed architecture integrates Bi-LSTM networks as the core computational units for both the generator and discriminator. This modification introduces significant advantages as Bi-LSTMs are specifically designed to capture both forward and backward temporal dependencies in sequential data, thus making them well-suited for analyzing the waveform and time-dimension characteristics of noisy signals. By processing the signal bidirectionally, Bi-LSTMs enable the architecture to extract contextual information from both past and future signal states, providing a comprehensive understanding of the input.
Following the architecture presented in Figure 3 (left), the generator is designed to transform noisy amplitudes extracted from CSI into clean, interference-free counterparts. The input to the generator is represented by a matrix
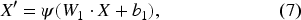


Following the architecture presented in Figure 3 (right), the discriminator is designed to evaluate the authenticity of the amplitudes generated by the generator. Its role is to differentiate between clean amplitudes from the ground truth and those synthesized by the generator. This is achieved through a Bi-LSTM network complemented by two sequential fully connected layers. The discriminator takes as input the same matrix

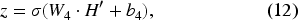
It is important to emphasize that the functionality of the Bi-LSTM differs between the generator and the discriminator. In the generator, Bi-LSTM is employed to capture temporal correlations within noisy inputs, thus enabling the network to reconstruct clean amplitudes that closely approximate their interference-free counterparts. This process involves learning a mapping that adapts to variations introduced by environmental noise, thereby ensuring effective denoising. Conversely, in the discriminator, Bi-LSTM is utilized to differentiate temporal patterns between real (i.e., clean) and generated (i.e., denoised) signals. This is achieved by analyzing the sequential structure of the input, where bidirectional processing enhances the ability of the network to detect inconsistencies in the generated samples.
A final innovation introduced in the proposed model concerns the loss functions. Specifically, while the discriminator employs the relativistic average loss, a standard choice for RaGAN-based architectures, the loss function of the generator has been customized. Inspired by the work of Ledig et al.,
75
the proposed model incorporates an overall loss function for the generator that combines content loss and contrastive loss. Considering both aspects, the generator is guided by both content information and confrontation between signal patterns. Formally, the customized loss function is expressed as follows:

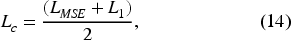
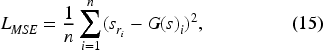
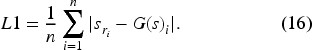
Through iterative adversarial training, the RaGAN enhances the ability of the generator to produce amplitudes that closely resemble their ground truth environment-free representations. Following training, the generator is deployed as a digital shielding mechanism, actively denoising real-world signal amplitudes on-the-fly, restoring them to their domain-free forms. To evaluate the effectiveness of the proposed method, a practical and challenging task was selected, i.e., material classification. This task involves distinguishing between four representative materials, i.e., acrylic, aluminum, copper, and pine, by analyzing the unique modifications induced in Wi-Fi signals as they propagate through the materials of varying compositions. Note that the four materials can be considered highly representative of the objects and items commonly present in real-world environments.
To evaluate the performance of the proposed domain adaptation method, a multi-class SVM classifier was employed. This choice was motivated by two key considerations. On one hand, the SVM is generally considered as a robust and reliable classifier. On the other hand, it is known that its performance can degrade when dealing with particularly complex, non-linear, and noisy data. Given the nature of the Wi-Fi signal amplitudes, characterized by significant interference and a high degree of disorder, a poorly performing denoising method would have resulted in low classification accuracy. However, as demonstrated in the experimental section, the classification accuracy achieved in the material classification task remains remarkably high, despite the complexity of the input.
Experimental setup and results
This section shows the main stages involved in obtaining the experimental results. The first describes the construction of the shielded box and the process of acquiring the data used for training the RaGAN-based architecture and testing the multi-class SVM. The second details the training of the architecture and presents the accuracy achieved in the material classification case study, demonstrating the effectiveness of the domain adaptation method.
Shielded box and data collection
As shown in Figure 4, a shielded box was constructed to replicate the effects of a Faraday cage. The structure, made of acrylic due to its mechanical properties, has internal dimensions measuring
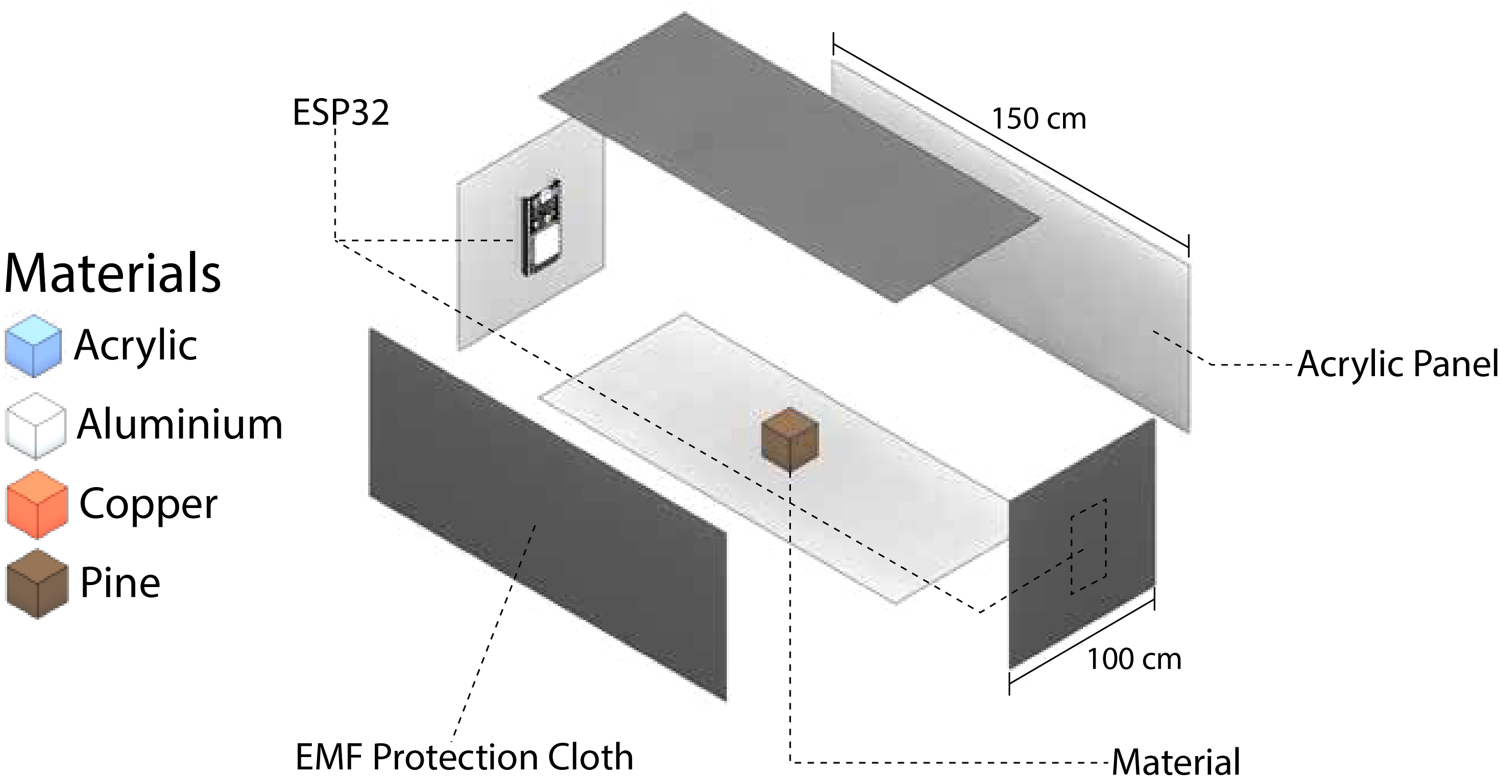
Acrylic box lined with electromagnetic shielding fabric, designed to replicate the effects of a Faraday cage. The box isolates objects, enabling the RaGAN to learn the impact of physical shielding. The legend shows four cubes made of different materials (acrylic, aluminum, copper, and pine), each with dimensions of
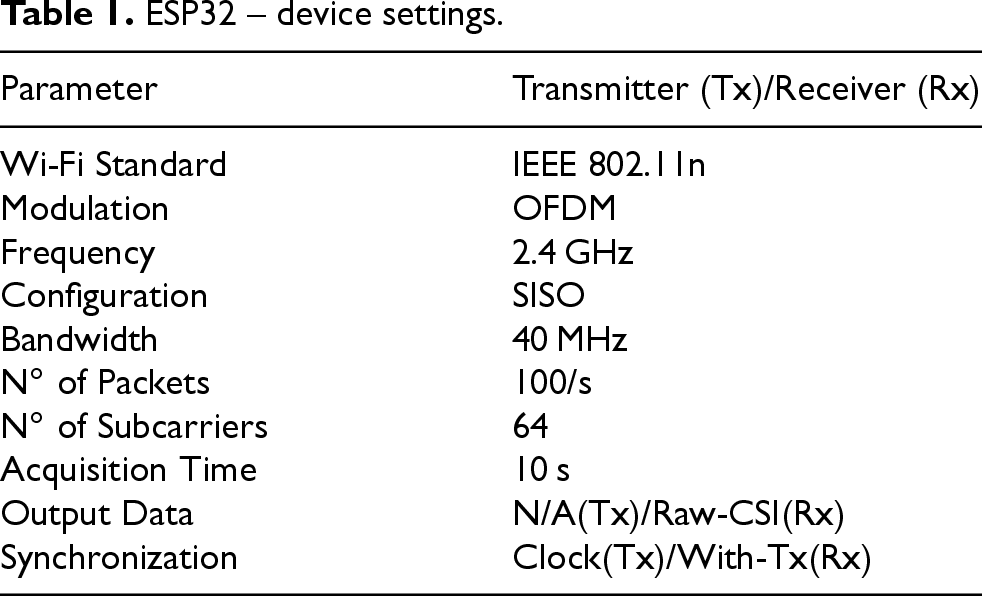
Regarding ESP32, it is a highly versatile device known for its dual-core processors and integrated Wi-Fi capabilities. Operating at 2.4 GHz and supporting the IEEE 802.11n standard, the ESP32 is configured in this work with a SISO setup involving one transmitting and one receiving antenna. This configuration simplifies the representation of CSI while preserving the essential characteristics of the signal. Leveraging the OFDM modulation scheme, a key feature of the IEEE 802.11n standard, the ESP32 divides the available bandwidth into multiple subcarriers, thus enhancing robustness against multipath fading and interference and ensuring data integrity during transmission. In the SISO configuration, the ESP32 achieves a theoretical maximum transmission speed of 150 Mbps with a 40 MHz channel width. This capability makes it well-suited for Wi-Fi signal denoising tasks, providing high spectral efficiency and enabling precise extraction of channel properties, including amplitude. In the experimental setup, one ESP32 device functions as a transmitter, sending Wi-Fi packets at a constant rate of 100 packets per second to create a stable signal source. The transmitted signal interacts with the object placed inside the shielded box, and the resulting signal is received by the second ESP32 device configured as a receiver. The receiver records the CSI, capturing variations in amplitude introduced by the material properties of the object during signal propagation. To ensure high-quality data collection, the ESP32 receiver is configured to extract CSI data from 64 subcarriers, thus providing a detailed frequency-domain analysis of the channel. Both ESP32 devices are synchronized during acquisition to maintain consistency in packet transmission and reception. This setup ensures accurate and reproducible measurements of Wi-Fi signals under both shielded and unshielded conditions. The modular design of the box and the adaptability of the ESP32 devices contribute to a controlled and flexible experimental environment, enabling the reliable acquisition of clean Wi-Fi signal data for various test scenarios. In Table 1, the main parameters selected for configuring the device settings are reported.
As previously mentioned, each Wi-Fi packet transmitted under the IEEE 802.11n standard consists of 64 subcarriers. Of these, 52 are actively used for data transmission, while the remaining subcarriers, categorized as pilot and guard subcarriers, serve as reference signals. Pilot subcarriers assist with channel estimation and phase correction, ensuring synchronization and stability during transmission. Guard subcarriers, positioned at the edges of the frequency spectrum, help mitigate inter-channel interference and prevent spectral leakage. Together, these unused subcarriers contribute to the overall robustness and reliability of the communication channel.
ESP32 – device settings.
Now that the acquisition specifications, such as the number of packets and subcarriers, have been detailed, it is possible to quantify the network configuration to facilitate the reproducibility of the proposed method. Referring to Figure 3 (left), the generator consists of two fully connected layers and a Bi-LSTM layer, designed to effectively capture both the waveform and time-dimension characteristics of the noisy signal. The input and output dimensions of the generator are both set to
The dropout rate of
An ad-hoc dataset was collected to train the RaGAN-based architecture and evaluate its signal denoising capabilities using a multi-class SVM. Four objects with identical sizes of
Once the datasets
Grid search hyperparameter ranges.
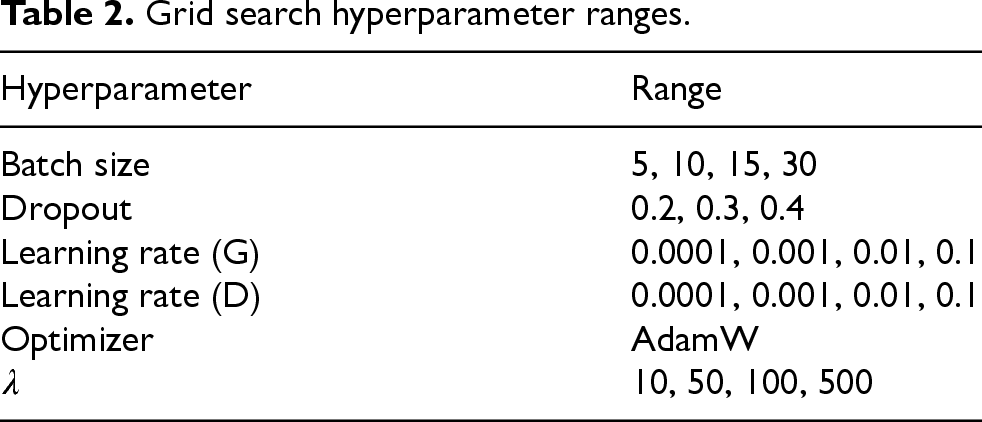
Grid search hyperparameter ranges.
Optimal hyperparameter set.

The main objective of applying the RaGAN model was to create a new dataset
Amplitudes extracted from the CSI: the plot shows the reconstructed spectrum of the copper cube derived from data acquired in a real-world environment.
To quantitatively evaluate the synthesized spectra generated by the RaGAN model, a multi-class SVM classifier was employed. The classification task aimed to distinguish between spectra corresponding to different materials, each one characterized by unique spectral features influenced by its physical and electromagnetic properties. The classifier was trained using both the shielded spectra, serving as the ground truth, and the unshielded spectra as input data. This evaluation approach simultaneously assesses the similarity between the generated spectra and the shielded spectra while also evaluating the capacity of the model to retain the distinct features that differentiate materials. The multi-class SVM was initially trained on the shielded spectra to learn material-specific features, e.g., attenuation patterns and frequency responses, that are unique to each material. Note that these features allow the classifier to differentiate between spectra corresponding to different materials. The trained classifier was subsequently tested on the spectra reconstructed by the RaGAN generator, achieving an impressive accuracy score of 96%. This result demonstrates that the proposed method effectively removes noise from the unshielded input while preserving the distinguishing characteristics that make each material identifiable. The confusion matrix, presented in Figure 6, further illustrates the classification performance, highlighting high accuracy in differentiating the reconstructed spectra. Most classifications align correctly along the main diagonal, thus confirming the ability of the RaGAN-generated spectra to effectively retain the distinctive features of the specific materials. In addition to the classification-based evaluation, a Mean Squared Error (MSE) 80 analysis was conducted to quantify the pointwise similarity between the signals reconstructed by the RaGAN model and the corresponding ground truth spectra acquired in the shielded environment. The reported MSE value of approximately 0.19 (normalized over a 0-to-1 scale), computed as an average across all ground truth and reconstructed signal pairs obtained during experimentation, was calculated after normalizing the signal amplitudes on a scale from zero to one. This normalization ensures a consistent evaluation metric across all samples and facilitates fair comparisons between different signals. While MSE offers a useful numerical indication of the overall reconstruction quality, it does not necessarily capture the preservation of discriminative spectral features that are essential for classification tasks. In Wi-Fi sensing scenarios, such as the material identification task proposed in this study, the primary objective is not only to reduce noise but also to preserve semantic information that enables class separability. In this regard, the classification accuracy achieved by the SVM, 96% on the reconstructed spectra, demonstrates that the denoised signals retain the critical features required to distinguish among different materials. Taken together, the MSE evaluation, classification accuracy, and visual inspection of the signal profiles provide a multi-faceted and robust assessment of the performance of the model. This integrated evaluation framework confirms the ability of the proposed method to effectively suppress environment-specific interference while preserving the information necessary for downstream classification.
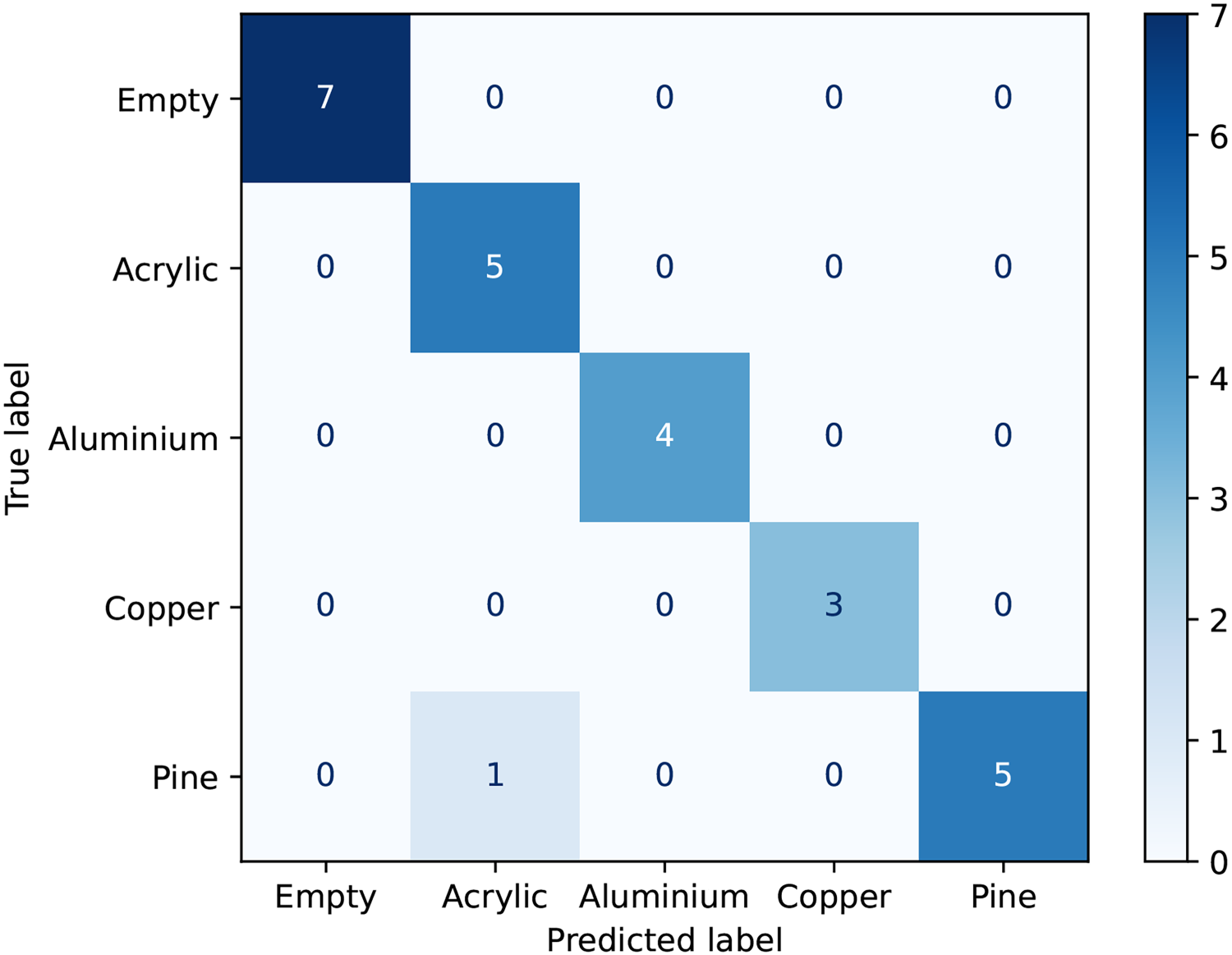
SVM classifier: confusion matrix.
The final architecture of our model was carefully selected through a thorough process of empirical testing, which involved exploring a range of different combinations of layers and generative techniques. We began by evaluating various configurations of Bi-LSTM layers, exploring different possibilities, including setups with and without linear layers for data processing. This systematic approach allowed us to gather valuable performance data, which is summarized in Table 4. Throughout our testing, we found that the generative Bi-LSTM models exhibited remarkably similar performance, whether they employed only LSTM layers or utilized a combination of a single LSTM layer along with linear layers. Given the significant increase in the number of parameters required when using only LSTM layers, we made the informed decision to adopt the lighter model. This model not only proved to be less complex but also demonstrated performance metrics that were comparable to those of the more parameter-heavy configurations. In addition to our analysis of the Bi-LSTM models, we also explored variations alongside the RaGAN method, examining the performance of the CGAN approach through a similar analytical framework. The results revealed that the Bi-LSTM_CGAN achieved levels of performance that were comparable to those of the Bi-LSTM_RaGAN. This finding demonstrated that linear layers can perform effectively, similarly to LSTM layers, while potentially simplifying the architecture. To provide a comprehensive understanding of our experimental framework, we also presented the baseline models utilized in our analysis. These included a Denoising Autoencoder (DAE) and a SVM, both of which were applied to the preprocessed noisy data collected during the testing phase. The DAE represents a straightforward implementation, consisting of four hidden layers in both the encoder and decoder components, allowing for effective denoising of the input data. On the other hand, the SVM used in our experiments was consistent with the one leveraged for classifying the generated signals produced by the GAN models. This SVM was based on a Gaussian radial basis function, with a specified parameter of
Ablation study.
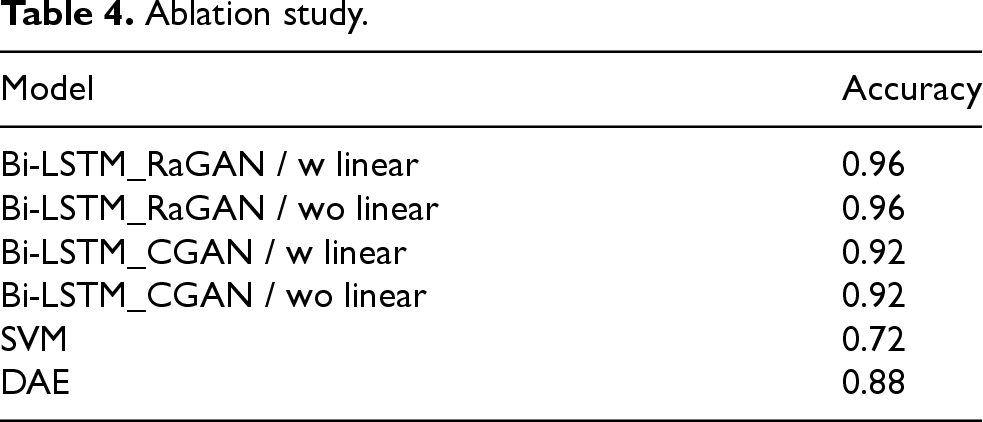
Ablation study.
To the best of our knowledge, this paper introduces, for the first time in the literature, a RaGAN-based architecture with customized Bi-LSTM-based generator and discriminator networks, specifically designed to denoise Wi-Fi signals by digitally replicating the effects of a Faraday cage. The effectiveness of this foundational study on cross-domain adaptation is demonstrated through a challenging material classification task. Wi-Fi signals of four objects made of distinct materials (i.e., acrylic, aluminum, copper, and pine) were acquired in real-world scenarios and subsequently purged of environment-specific information using the proposed architecture. A multi-class classifier, trained on interference-free counterparts acquired within the shielded box, was employed to classify the denoised signals, achieving an remarkable accuracy of 96%. This result underscores the ability of the domain adaptation and denoising mechanism to effectively restore signal fidelity. Furthermore, the evaluation highlights the added value of the proposed approach, as the high classification accuracy demonstrates its potential for advanced security applications. By reliably distinguishing materials based on the denoised spectra, the method provides an innovative solution for identifying the nature and composition of objects, including those that may be carried by individuals in sensitive or high-security environments. In future work, a more comprehensive dataset will be collected, including a broader variety of materials. The proposed model will also be evaluated in more complex real-world environments to assess its generalizability. Finally, while this study adopted a multi-class SVM to validate the effectiveness of the signal purification process, future efforts will explore advanced classification frameworks specifically tailored to material recognition tasks. These may include state-of-the-art deep learning models, such as Neural Dynamic Classification (NDC) algorithms, 81 Dynamic Ensemble Learning (DEL) techniques, 82 Finite Element Machines (FEM) for fast learning, 83 and self-supervised learning approaches.84,85
Footnotes
Acknowledgement
This work was supported by “EYE-FI.AI: going bEYond computEr vision paradigm using wi-FI signals in AI systems” project of the Italian Ministry of Universities and Research (MUR) within the PRIN 2022 Program (Grant Number: 2022AL45R2) (CUP: B53D23012950001) and MICS (Made in Italy – Circular and Sustainable) Extended Partnership and received funding from Next-Generation EU (Italian PNRR – M4 C2, Invest 1.3 – D.D. 1551.11-10-2022, PE00000004). CUP MICS B53C22004130001.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.