
Abstract
Narrowly defined personality facet scores are commonly reported and used for making decisions in clinical and organizational settings. Although these facets are typically related, scoring is usually carried out for a single facet at a time. This method can be ineffective and time consuming when personality tests contain many highly correlated facets. This article investigates the possibility of increasing the precision of the NEO PI-R facet scores by scoring items with multidimensional item response theory and by efficiently administering and scoring items with multidimensional computer adaptive testing (MCAT). The increase in the precision of personality facet scores is obtained from exploiting the correlations between the facets. Results indicate that the NEO PI-R could be substantially shorter without attenuating precision when the MCAT methodology is used. Furthermore, the study shows that the MCAT methodology is particularly appropriate for constructs that have many highly correlated facets.
Keywords
Introduction
In personality research, there is debate regarding the use of fine-grained versus broad personality variables, known as the bandwidth-fidelity controversy (e.g., Dudley, Orvis, Lebiecki, & Cortina, 2006; Ones & Viswesvaran, 1996; Paunonen & Ashton, 2001). Results of several studies have concluded that narrow personality traits can substantially increase the quality of prediction achieved by broad personality factors (e.g., Ashton, 1998; Dudley et al. 2006; Paunonen & Ashton, 2001; Paunonen, Rothstein, & Jackson, 1999; Stewart, 1999). These findings suggest that the use of multiple facets of personality provides important advantages over the use of multidimensional aggregates of these facets. These advantages pertain not only to the empirical accuracy in predicting outcomes but also to the psychological meaningfulness in explaining behavior (Paunonen et al., 1999). A more detailed picture of personality obtained through the facet scores also provides the test respondent with a richer source of information in the feedback process.
In contrast, Ones and Viswesvaran (1996) advocate the use of broader personality traits instead of narrow facets. They point out that the reliabilities of the narrow personality facets are typically lower than the broad measures, which decreases their predictive validity. They suggest that for specific personality trait measures to reach adequate reliability, scales would have to be lengthened by three to six times. This seems unrealistic in most test settings because assessment time is a precious commodity, which means that there is often a limit to the amount of time respondents are expected to spend on a test.
When personality tests contain many facets, it is time consuming and inefficient to accurately assess each one individually. Consequently, most personality tests are either long, or are designed to assess broad general constructs, thereby ignoring the individual facet scores that make up these general constructs. An example is the widely used NEO-PI, which has two versions: the NEO PI-R and the NEO FFI (Costa & McCrea, 1992). The NEO PI-R consists of 240 items. With this version score reports are available for the 30 facets within the Big Five model of personality. The NEO FFI consists of 60 items; however, scores are only reported for the five general factors.
The ideal personality test would be an instrument that reports reliable facet scores with few items, thereby limiting assessment time. Currently, most personality test scoring procedures ignore the fact that the facets included in a test are highly correlated. In addition, items are administered without consideration for the information that has been collected from previous items. More efficiency could be achieved if the known correlations between the facets on a personality test and the previous item responses could be used during a test. If information has been collected that suggests that a given person is dutiful, organized, and achievement striving, then it is likely that the person also has a high level of self-discipline. Therefore, an appropriate item may be one that provides high information in the high score range on this facet. If the respondent answers as expected, then more confidence can be placed in the hypothesis that the respondent is self-disciplined. Thus, the information reflected in correlations among related facets can be used to derive efficient scoring procedures.
Multidimensional item response theory (MIRT) models (e.g., Reckase, 2009), which use information about the correlations between facets to efficiently score test results, provide a framework for administering items adaptively based on the characteristics of the items and information about the test respondent from previous items. This is known as multidimensional computer adaptive testing (MCAT; e.g., Segall, 1996) and is similar to the general idea of computer adaptive testing (CAT; e.g., van der Linden & Glas, 2010) but within a multidimensional framework. MCAT has been found to increase the precision of trait scores compared with CAT and more traditional scoring methods for tests used in ability testing (Segall, 1996, 2000, 2010; Wang & Chen, 2004), certification testing (Luecht, 1996), and medical testing (Gardner, Kelleher, & Pajer, 2002; Heley, Pengsheng, Ludlow, & Fragala-Pinkham, 2006; Petersen et al., 2006). MIRT and MCAT are methodological developments that provide an intriguing opportunity for the field of personality testing where there is a need to assess a large number of correlated personality facets with a high level of precision.
The objective of this article is to investigate the possibility of increasing the precision of the NEO PI-R facet scores by efficiently administering and scoring items with the MIRT methodology. Furthermore, we will investigate if it is possible to make the NEO PI-R shorter without attenuating reliability with MCAT. The remainder of the article is organized as follows: First, we will outline the research questions posed in this study. Second, we will describe how item response theory (IRT) can be used to estimate personality facet scores. Next, we will provide a background to the method we use to estimate scores using MIRT and MCAT. Then, we will investigate the precision of the method by simulation studies based on real data from the NEO PI-R. Finally, we will discuss the practical implications of the results for personality testing.
Research Questions
There are four main research questions in this study:
Research Question 1: Is the precision of the trait estimates for facet scores in the NEO PI-R improved when using MIRT compared with unidimensional IRT scoring methods?
Research Question 2: Is it possible to make the NEO PI-R shorter without attenuating precision when using the MCAT method?
Research Question 3: What is the loss of accuracy with even shorter test lengths when the CAT and MCAT methods are used?
Research Question 4: How similar are the results of a linear test scored with either IRT or MIRT, and a test administered and scored using CAT or MCAT methodology in a real testing situation?
Item Response Theory
IRT has become the dominant psychometric framework for the construction, analysis, and administration of large-scale aptitude, achievement, and ability tests (Embretson & Reise, 2000). Advances in IRT research have been applied to improving the interpretability and validity of widely used personality tests (e.g., Egberink, Meijer, & Veldkamp, 2010; Reise & Henson, 2000; Waller, Thompson, & Wenk, 2000). In IRT, the responses to items are modeled as a function of one or more person ability parameters and item parameters. The item parameters are item difficulty parameters and item discrimination parameters. The difficulty parameters define the overall salience of the response categories, and the discrimination parameters define the strength of the association of the item responses with the latent person parameters. The latent person parameters locate the person on a latent scale where high values are related to high item scores. The fundamental concept of IRT is that individuals and items are characterized on the same metric in terms of their location on the latent scale. IRT models can be applied to both dichotomous (two answer categories, e.g., true/false) and polytomous data (more than two answer categories, e.g., 5-point Likert-type scale). There are different types of IRT models, and more detailed information can be found in Embretson and Reise (2000) and Hambleton, Swaminathan, and Rogers (1991). In this article, we use the generalized partial credit model (GPCM; Muraki, 1992). In the GPCM, items are conceptualized as a series of ordered thresholds where examinees receive partial credit for successfully passing each threshold.
Multidimensional Item Response Theory and MCAT
Up to now most of the research that has applied IRT to personality data has used unidimensional IRT models. Unidimensional IRT models typically rely on the assessment of a score on a single unidimensional domain at a time. This does not take into account the multidimensional nature of the complex constructs that are assessed in most personality tests. Furthermore, when the facets measured by a test are correlated, responses to items measuring one facet can provide information about the examinee’s standing on other facets in the test (van der Linden & Hambleton, 1997). That is, knowledge of the magnitude of the correlation between the facets in the population of interest, in addition to the individuals’ performance levels, can add a unique source of information that can provide more precise trait-level estimates.
MIRT models account for the multidimensional nature of the complex constructs based on the premise that a respondent possesses a vector of latent person characteristics that describe the person’s level of personality on the different traits. In most personality tests, items are designed to measure a single facet. Therefore, we investigate a model where each item only contributes information directly to the facet that it is intended to measure and only contributes indirectly to the other facets through the correlations of the facets. In this case, the item has only one nonzero discrimination parameter associated with the dimension on which the item response depends. This is known as a between-items MIRT model or a simple-structure MIRT model. An alternative model is a within-items MIRT model or a complex-structure MIRT model in which each item measures several facets. Therefore, each item has nonzero discrimination parameters for each dimension on which the item response depends.
Many MIRT models exist (for an overview, see Reckase, 2009). In this article, we have chosen to use the multidimensional extension of the GPCM. In practice, results obtained using the GPCM can hardly be distinguished from results obtained using alternative models such as the graded response model and the sequential model (see Verhelst, Glas, & de Vries, 1997). The multidimensional GPCM is a straightforward generalization of the unidimensional GPCM. The multidimensional GPCM extends to cases where examinees can be characterized by their standing on multiple traits, which have a multivariate normal distribution.
The fundamental goal of MCAT is to locate the respondent’s position in a multidimensional latent space with a high level of precision (or low level of error). This can be done by administering items adaptively by selecting the next item that is expected to contribute most to the precision of the trait estimates. Three criteria are required to administer items adaptively with MIRT: a selection criterion that defines which item should be selected and presented in the next step, a stopping criterion that defines when the test should stop, and a method for estimating scores on the latent traits.
Segall (1996, 2000, 2010) developed a Bayesian method for selecting dichotomously scored items adaptively in an MCAT. This method was generalized to polytomously scored items by Wang and Chen (2004). The method estimates the running trait estimates on the facets based on the items that have been administered up to that point using the multidimensional IRT model. This information is used to choose the item that is expected to contribute most to the precision of the trait estimates, based on each item’s multidimensional information function (i.e., based on the predicted determinant of the information matrix). This model fits a so-called empirical Bayesian framework where the multivariate normal latent trait distribution is a prior. That is, this distribution models the correlations between the traits and these correlations are estimated along with the item parameters in the calibration phase and are treated as known in the MCAT phase. The unidimensional model is a special case of multidimensional model, in the sense that the covariance between the traits is ignored, that is, the covariances are set equal to zero. Therefore, in this case, the selection criterion corresponds to selecting the item that is expected to contribute most to the precision of the trait estimate in a unidimensional CAT.
Although there are many options available for stopping criteria, most operational adaptive tests use a fixed number of items as a stopping rule. There are also many options available for estimating the latent scores in adaptive testing. Previous research in the field of MCAT has favored the maximum a posteriori (Segall, 1996, 2000, 2010) method. The maximum a posteriori estimate is the mode of the posterior distribution of latent trait, which is a product of the prior distribution and the likelihood function.
Recent research has successfully investigated the use of MIRT for modeling the relationships of examinees to a set of test items that measure multiple constructs (e.g., de la Torre, 2008; Finch, 2010; Yao & Boughton, 2007). In the framework of dichotomous items, MCAT has been found to increase the precision of trait scores compared with CAT and more traditional scoring methods for tests used in ability and achievement testing (e.g., Luecht, 1996; Segall, 1996, 2000, 2010). Wang and Chen (2004) adapted CAT to multidimensional scoring of polytomous (e.g., Likert-type scale) items. The present study examines the benefits of MCAT for a highly dimensional real polytomous test. Furthermore, this study investigates the benefits of MIRT and MCAT for a personality test that uses Likert-type scale items.
Method
Instruments
The Danish version of the NEO PI-R (Costa & McCrae, 1992) is a computer-based Big Five personality questionnaire. It consists of 240 items, distributed over five constructs (Neuroticism, Extraversion, Openness, Agreeableness, and Conscientiousness). Each construct consists of 48 items, equally distributed over six facets: Neuroticism (N1 Anxiety, N2 Hostility, N3 Depression, N4 Self-Consciousness, N5 Impulsiveness, N6 Vulnerability to Stress), Extraversion (E1 Warmth, E2 Gregariousness, E3 Assertiveness, E4 Activity, E5 Excitement Seeking, E6 Positive Emotion), Openness (O1 Fantasy, O2 Aesthetics, O3 Feelings, O4 Actions, O5 Ideas, O6 Values), Agreeableness (A1 Trust, A2 Straightforwardness, A3 Altruism, A4 Compliance, A5 Modesty, A6 Tender mindedness), Conscientiousness (C1 Competence, C2 Order, C3 Dutifulness, C4 Achievement Striving, C5 Self-Discipline, C6 Deliberation). The items are scored on a 5-point Likert-type scale. The construct validity of the Danish version of the NEO PI-R has been established with exploratory factor analyses and by comparing the test with other commonly used personality instruments (Skovdahl Hansen & Mortensen, 2003).
Sample
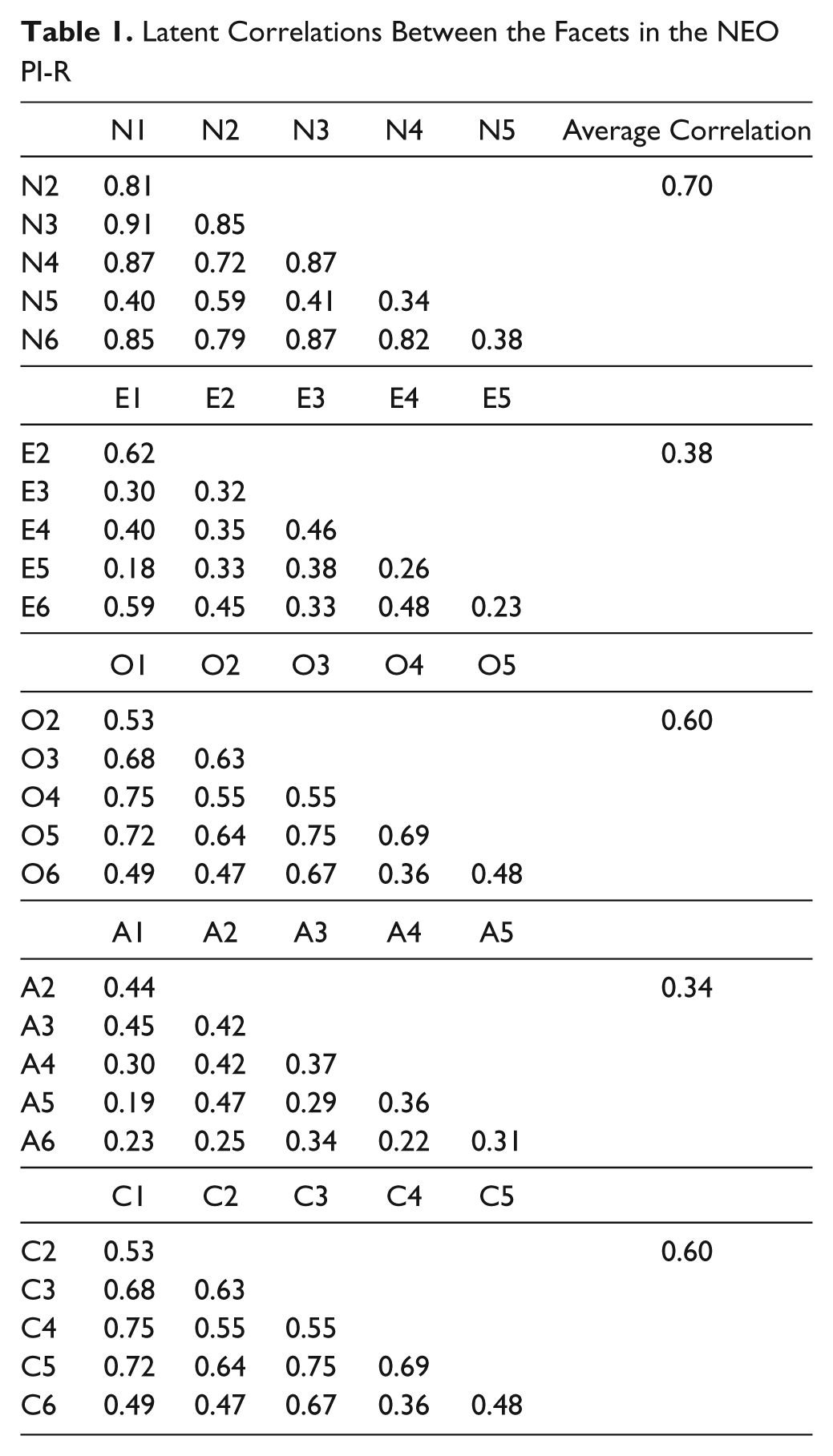
The NEO PI-R data set consisted of 600 respondents (300 males and 300 females) included in the Danish norm sample. Data were collected in the context of a large Danish twin study. The sample consisted of 1,213 twins aged 18 to 67 years. One twin was selected randomly from each pair to make up the norm sample. The latent correlations between the facets (see Table 1) and the item parameters were computed with the free MIRT software package (Glas, 2010). These values were used in all simulations presented below.
Latent Correlations Between the Facets in the NEO PI-R
Analysis
The research questions outlined above were investigated by means of a Monte Carlo and a real data simulation study. The Monte Carlo simulation can provide information about the accuracy of the different scoring methods for a situation where the true trait scores are known. The real data simulation was used because the model will not fit perfectly in a real testing situation. Therefore, the consequences of using CAT and MCAT methods were investigated in a simulation study where the actual responses from the Danish norm sample were used.
Four different scoring methods were compared: unidimensional IRT scoring of a linearly administered test of all 240 items (Lin-IRT); multidimensional IRT scoring of a linearly administered test of all 240 items (Lin-MIRT); unidimensional computer adaptive administration and scoring of 180, 120, 90, and 60 items (CAT); and multidimensional computer adaptive administration and scoring of 180, 120, 90, and 60 items (MCAT).
Lin-IRT and CAT methods were carried out independently for one facet at a time. All six facets within each of the Big Five constructs were assessed simultaneously using the Lin-MIRT and MCAT methods. There were no constraints added to limit the item selection for the MCAT method. That is, the best item was selected regardless of its facet. An alternative approach is returned to in the Discussion section. The test was stopped when a fixed number of items had been administered.
Results
Study 1: Recovery of True Trait Scores
Research Questions 1, 2, and 3 pertaining to the precision of the test scores were investigated in the Monte Carlo simulation study. In this study, 6,000 simulated respondents’ true trait scores were randomly drawn from a normal distribution based on the scores from the NEO PI-R Danish norm sample. The root mean squared error (RMSE) was used to quantify the precision of the scoring methods. The RMSE is defined as the square root of the mean squared error. This error is the difference between the trait estimate and its true trait value. The RMSE incorporates both the variance of the estimator and its bias.
Figure 1 presents the RMSE between the true trait scores and estimated trait scores obtained using each testing method. To ensure that Figure 1 is interpretable, only the results for the full-length test (240 items) scored using Lin-IRT and Lin-MIRT, as well as the CAT with 120 items, and the MCAT with 90 and 120 items are presented. The RMSE is presented on the vertical axis. The first five panels present the six facets within each Big Five construct on the horizontal axis. The final panel presents the results averaged over facets for the Big Five constructs.
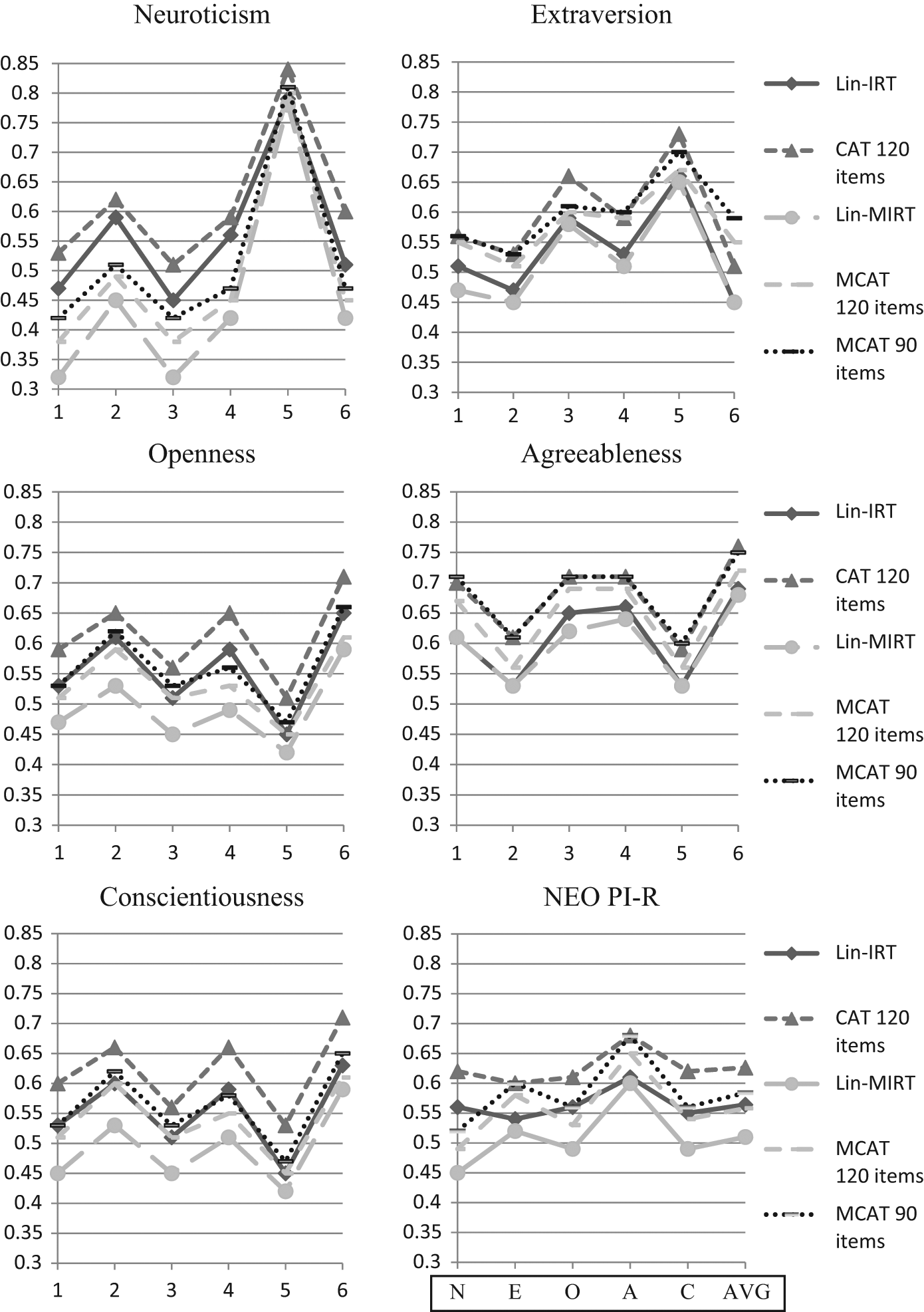
RMSE between the true trait scores and the estimated trait scores for the facets in the NEO PI-R
Clear results were found regarding Research Question 1, pertaining to the precision of the trait estimates for facet scores when using MIRT compared with unidimensional IRT scoring methods. The results indicate that the Lin-MIRT scoring method consistently decreased the error of the facet scores compared with the Lin-IRT method (see Figure 1). This decrease in RMSE averaged over facets was 0.11 for Neuroticism, 0.07 for Openness, 0.06 for Conscientiousness, 0.02 for Extraversion, and 0.01 for Agreeableness. This means that the individual facet scores are more accurate when the correlation matrix between the facets is used to score the NEO PI-R. The difference in the improved accuracy was a consequence of the magnitude of the latent correlations between the facets in the different Big Five constructs. The average latent correlations between the facets in the Neuroticism, Openness, and Conscientiousness constructs were 0.70, 0.60, and 0.60, respectively (see Table 1). In contrast, the average latent correlations for the Extraversion and Agreeableness constructs were 0.38 and 0.34, respectively.
Research Question 2, pertaining to the possibility of making the NEO PI-R shorter without attenuating precision when using the MCAT method, was investigated by calculating the accuracy of the facet scores with different test lengths using the CAT and MCAT methods. Averaging across all facets, the final panel of Figure 1 illustrates that the NEO PI-R could be reduced to 90 items with the MCAT method, while only slightly decreasing the general accuracy of the test compared with the Lin-IRT scoring method. The MCAT method with 120 items resulted in a slight increase in the general accuracy compared with the full NEO PI-R with the Lin-IRT scoring method. The MCAT method also produced facet scores that were comparable in terms of accuracy with the CAT method with half as many items per facet. Again, the improvement in accuracy for the MCAT method depended on the average latent correlation between facets within each construct. The MCAT method resulted in facet scores that were on average at least as accurate as the Lin-IRT scores with the 60-item test for Neuroticism, the 90-item test for Openness, the 120-item test for Conscientiousness, the 150-item test for Extraversion, and the 210-item test for the Agreeableness construct.
The results in Figure 1 also show that the accuracy of the test decreases as the number of items that are administered is reduced. Therefore, the results related to Research Question 3 indicate that the full-scale scores could not be completely recovered with the MCAT and CAT methods. The increase in the RMSE between the true and estimated scores was an average of 0.05 for the 120-item MCAT and 0.07 for the 90-item MCAT compared with the Lin-MIRT method. Similarly, the increase in RMSE was 0.01 for the 180-item MCAT and 0.12 for the 60-item MCAT method (not shown in Figure 1). The increase in error was larger for the CAT where the RMSE between the true and estimated scores increased by an average of 0.03 for the 180-item CAT, 0.07 for the 120-item CAT, 0.11 for the 90-item CAT, and 0.18 for the 60-item CAT compared with the full Lin-IRT version of the NEO PI-R.
Study 2: The Consequences of Using the Different Scoring Methods With Real Test Responses
The second simulation study used the existing item response data collected from real examinees in the Danish NEO PI-R norm sample to investigate what the result would be if the NEO PI-R had been administered and scored by using each of the four testing methods described above in a real testing situation (Research Question 4). The item exposure rates were calculated for the MCAT and CAT methods to assess the efficiency with which the NEO PI-R item pool was used. Finally, the study was used to examine if the conclusions from the first study remained accurate when real data rather than simulated data were used.
In general, the results showed that there was a high level of consistency across the different NEO PI-R factors. Therefore, Table 2 presents the correlations between the scoring methods averaged across all the Big Five constructs in the NEO PI-R.
Correlations Between Scoring Methods Averaged Across All Big Five Factors a

Note. CAT = computer adaptive testing; MCAT = multidimensional computer adaptive testing; Lin-MIRT = linear multidimensional item response theory; MIRT = multidimensional item response theory.
The average correlations between true trait scores and estimated trait scores from the first simulation study are presented in the diagonal.
The patterns of correlations are not unexpected. The Lin-IRT and Lin-MIRT methods had an average correlation of 0.95. In addition, tests of similar length correlated highly. For instance, the CAT and MCAT methods with four items had an average correlation of 0.90. Finally, test methods that used the same scoring methodology correlated highly (e.g., Lin-IRT or Lin-MIRT). The average correlations between the full NEO PI-R test using the Lin-IRT scoring method and shorter versions of the test using the CAT method were the following: 0.98 for the 180-item CAT, 0.94 for the 120-item CAT, 0.89 for the 90-item test, and 0.81 for the 60-item test. Similarly, the average correlations between the full NEO PI-R test using the Lin-MIRT scoring method and the shorter versions of the test using the MCAT method were the following: 0.98 for the 180-item test, 0.94 for the 120-item test, 0.92 for the 90-item test, and 0.87 for the 60-item test.
The pattern of correlations obtained in this study supports the findings obtained in the first study. That is, the testing methods that were identified as being the most accurate in the first study also had the highest correlations in the second study. Therefore, the results of the second study indicate that the conclusions based on the simulated data seem to hold when real data from actual NEO PI-R respondents are used.
The item exposure rates were also compared for the MCAT and CAT methods. This was done by calculating the proportion of respondents who were exposed to each item. Figure 2 groups the items based on the percentage of exposures for the MCAT and CAT with 120 items. Similar results were obtained with other test lengths. Although the figure illustrates that both methods resulted in a nonuniform use of items, the MCAT method had a slightly more effective use of the item pool compared with the CAT method. That is, 58 items in the MCAT compared with 87 items in the CAT were not used at all. Similarly, 90 items were administered to more than 90% of all test respondents in the MCAT, although this number was 100 in the CAT.
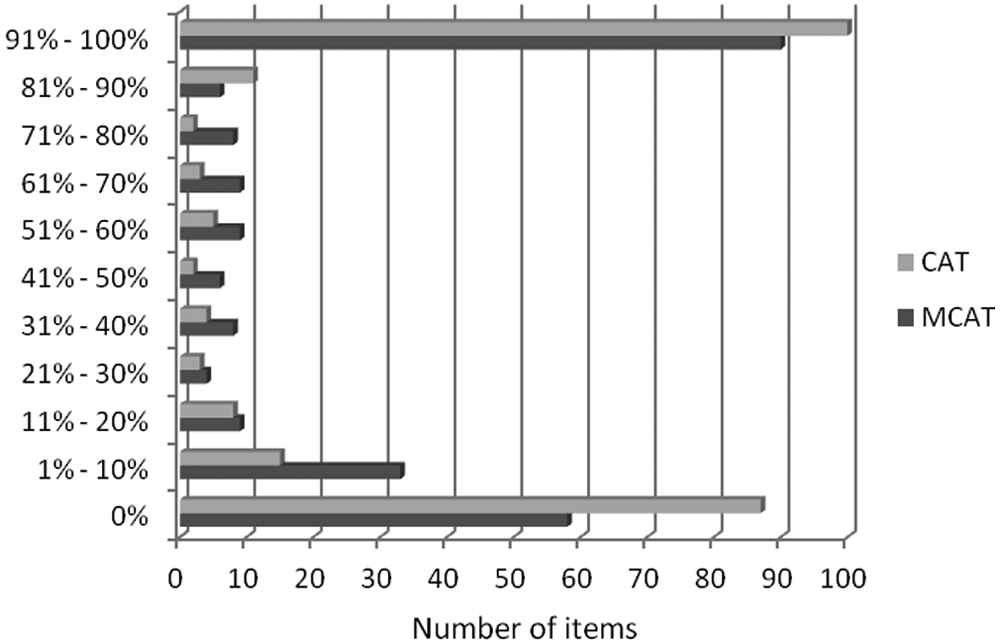
Item exposure rates for the MCAT and CAT tests with 120 items
The finding that the MCAT method resulted in a more uniform use of the item pool can be explained by the fact that more information is available for item selection in the MCAT method. This is the case because the scores from the other facets are taken into account when selecting the best item. Therefore, the item selection algorithm is more likely to select different items based on the different information that is available for each test respondent. In contrast, the unidimensional CAT starts by selecting the best item in each facet for all test respondents because there is no information available to differentiate the respondents. Even after the first item has been administered and there is information available to differentiate the test respondents, the CAT method tended to administer a similar set of items. This finding is consistent with the results obtained by Reise and Henson (2000) and occurs because the NEO PI-R consists of polytomous items that have an information function that is spread out rather evenly over the latent trait range. Since some items have considerably higher discrimination parameters because they are highly related to the latent trait, these items are consistently selected over items that have a low discrimination parameter because they appear to be only weakly related to the latent trait.
Discussion
This article investigated the possibility of increasing the accuracy of personality facet scores in the NEO PI-R by scoring items based on the correlations between the facets in the test with MIRT. Furthermore, the article examined the possibility of making the NEO PI-R shorter without attenuating precision by selecting items adaptively based on the previous responses on the test and the correlation between the facets in the test, with MCAT. These issues were investigated by setting up a Monte Carlo and a real data simulation study based on data from 600 test respondents who had completed the Danish computer-based version of the NEO PI-R.
The results revealed that the MIRT and MCAT methods provide a promising alternative for administering and scoring personality tests, specifically when these include many highly correlated facets. The linear MIRT (Lin-MIRT) scoring method resulted in improved accuracy for all the facets within the NEO PI-R compared with the unidimensional item response theory (Lin-IRT) scoring method. The results were particularly evident for the three NEO PI-R constructs that had the highest correlations between the facets: Neuroticism, Openness, and Conscientiousness. The results of the study also revealed that the NEO PI-R could be reduced to 120 items (by 50%) while slightly improving the general accuracy of the test, and further to 90 items (by 63%) with a slight loss in precision compared with the Lin-IRT method. The MCAT method also produced facet scores that were comparable in terms of accuracy to the CAT method with half as many items per facet. In addition, the real data simulation indicated that there was a relatively high correlation between the Lin-MIRT and MCAT methods and the other testing methods described in this study. For example, the Lin-MIRT testing method had an average correlation of 0.95 with the Lin-IRT method. Also, the MCAT method with 120 items correlated by 0.94 with the full test scored using Lin-MIRT and by 0.89 with the full test scored using Lin-IRT. The MCAT method also resulted in a slightly better use of the item pool compared with the CAT method.
When making a decision about the appropriate length of a personality test, there is a trade-off between test accuracy and testing time. The benefits of saving time with a shorter test are difficult to quantify, because they vary greatly based on the test setting. Nevertheless, shorter tests can have several advantages for the test respondent and the organization or person administering the test. From the test respondent’s perspective long tests require a high level of cognitive demand. It may be difficult to maintain a high level of motivation throughout the test, which can result in careless mistakes. This may be particularly true for specific groups of respondents with clinical conditions. From the test organizations perspective, additional testing time is often equivalent to increased costs. This could include the cost of administering the test, including the salary of test supervisors and the cost of maintaining an available testing location. Furthermore, test respondents are often assessed on other measures in additional to a personality test that can increase the cognitive demand of the assessment process. In some settings, there is a limit to the amount of time that is available for testing, so a long personality test would mean that other important constructs are not assessed.
Before discussing the future perspectives of the MIRT and MCAT methods for personality testing, we will reflect on several practical and methodological issues and limitations involved in the current research. A consideration when deciding to score tests with MIRT is the potential impact on test structure. Is it possible that using information from all facets within a domain to inform the score on one facet will reduce the variability among the facets, which could narrow them to the domain and potentially limit criterion validity? This concern about MIRT might apply more strongly to MCAT in particular because in adaptive testing information is permitted to be lost in exchange for time. The issue is a greater concern for complex-structure MIRT models, because each item has several discrimination parameters. Consequently, an item that measures several facets simultaneously may be selected at the expense of an interstitial item that measures the facet of interest. The simple-structure MIRT model described in this article does not favor general items over interstitial items because only one discrimination parameter representing the strength of the item’s relationship with the latent facet is considered. Selecting items adaptively using CAT and MCAT does, however, mean that specific information from the items that are not administered is permitted to be lost in exchange for time. Therefore, future research needs to assess the impact on criterion validity when administering and scoring personality facet scores with MCAT as well as CAT methods.
One of the advantages of a fixed test is that it can be designed optimally to ensure that the content of the construct is sufficiently covered. This is also possible with CAT and MCAT by establishing content constraints to ensure that the content of the adaptive test meets content specifications. Veldkamp and van der Linden (2002) suggest a method using linear programming that can successfully incorporate a large number of constraints to ensure that the adaptive test lives up to a large number of practical criteria. In the context of personality testing, this would require a thorough classification of the constraints that should be considered to maintain the content validity of the test. The addition of content constraints would result in a decrease in the accuracy of the CAT and MCAT methods because the optimal items are no longer selected. In the present study, the MCAT method was performed without any constraints. A replication of the first simulation study was conducted to assess the impact of a simple constraint on the MCAT item selection algorithm. The constraint consisted of administering the same number of items within each facet. The result of adding the additional constraint was an average increase in RMSE of 0.02 per facet. Therefore, the result suggests that the addition of constraints does increase the error of the MCAT method; however, the increase is not large enough to change the conclusions of the study. Further research could investigate the consequences of implementing more elaborate constraints.
An additional issue is the impact of the MIRT and MCAT models for test respondents that have a large variability in their facet scores within a particular construct. Preliminary results of a small number of replications (not described in this article) suggest that these respondent’s facet scores are shrunk toward their mean standing on the construct. Although this is only an issue for a limited number of respondents, future research should further investigate the consequences of the MIRT and MCAT scoring methods for respondents that have atypical profiles.
A further concern with the implementation of MIRT models is the added complexity of the model compared with the more parsimonious IRT model. The added complexity means that more assumptions are necessary, which can result in the possibility of model misspecification. A general discussion of model misspecification is beyond the scope of this article. However, examples of such assumptions are the nature of the multidimensional structure and the additional response function assumptions. In the present study, simple structure was assumed. Therefore, the only additional parameters that were estimated were the correlations between the facets. These correlations are similar to the correlations reported in the existing NEO PI-R literature; therefore, it is expected that the estimates are quite robust. The complexity of the model also means that a number of choices must be made regarding the methods to be used in conducting an MCAT. In the present study, a multivariate empirical normal prior was used, and the item selection algorithm used the predicted determinant of the information matrix. Other options such as Kullback–Leibler information (Mulder & van der Linden, 2010) are available. Future research could investigate different options for conducting an MCAT for personality testing.
Another possible limitation in this study is the generalizability of the results to other samples and other personality tests. The sample consisted of a representative Danish norm sample; however, this sample may not be representative of all samples that take the NEO PI-R. Furthermore, the sample was relatively small so the item parameters could be biased. In addition, it is not certain that the results would generalize beyond the NEO PI-R. To investigate this issue further, we conducted a small number of replications (not described in this study) with EASI (Makransky & Kirkeby, 2010) and found similar results. EASI is a personality typology test that is based on the Big Five model of personality. The benefits of MCAT would likely be greater than the results reported in this study with an item bank designed specifically for adaptive testing. In this study, we used the existing NEO PI-R items that were designed for a fixed test. Therefore, many items were designed to differentiate between “normal respondents.” The benefits of an adaptive test are maximized when the item bank is made up of items that differ in terms of where on the latent trait they provide the most information.
Possibly the greatest barrier to the widespread implementation of MIRT and MCAT is the lack of commercially available software to make these methods easily accessible to organizations that are convinced of their value. It is not until recently that commercial software has become available for administering a CAT (e.g., Weiss, 2008). The availability of accessible software has lead to countless CAT applications in a wide variety of fields. The requirements to apply MIRT and MCAT methods are similar to those of a CAT. Therefore, given the large amount of research interest and advantages of MIRT and MCAT, it is likely that commercial software will soon be available to implement these methods.
This brings us to the prerequisite that the MIRT and MCAT methods require computer administration. Although definitive usage data are lacking, it is becoming a standard to administer personality tests by computer. Handheld devices are beginning to be used in settings such as a doctor’s office where it has traditionally been difficult to administer tests and questionnaires by computer (Walter, 2010). Computers and the Internet will provide an even bigger role in personality assessment in the future (Riese & Hanson, 2000). In fact, the administration of tests by computer has many advantages, which are just beginning to be explored. One advantage that will likely increase the need for MIRT and MCAT is that a computer offers the option of administering different types of multimedia items. There are many existing tests that use complex interactive items such as video simulations. More realistic items increase the fidelity of the test, which could in turn increase the test respondent’s motivation level. The greatest challenges in developing multimedia items include the difficulty of establishing a valid scoring system and the higher cost associated with developing such items (Tuzinki, Shyamsunder, Sarmma, & Hawkes, 2011). Multimedia items challenge traditional psychometric models because it is difficult to ensure unidimensionality as the complexity of the items increases. This is the case because items often measure several important traits. In these cases, MIRT and MCAT provide viable options for administering and scoring such test items.
In conclusion, the results of this article imply that MIRT and MCAT are methodological developments that provide an intriguing opportunity for the field of personality testing, in particular for personality tests that contain many facets that are highly correlated. There can be practical and statistical advantages to incorporating the theoretical model directly into the test design. This opens up an attractive new step to more theoretically based testing that can enhance the validity of test score interpretations.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.