
Abstract
During the present decade a large body of research has employed confirmatory factor analysis (CFA) to evaluate the factor structure of the Strengths and Difficulties Questionnaire (SDQ) across multiple languages and cultures. However, because CFA can produce strongly biased estimations when the population cross-loadings differ meaningfully from zero, it may not be the most appropriate framework to model the SDQ responses. With this in mind, the current study sought to assess the factorial structure of the SDQ using the more flexible exploratory structural equation modeling approach. Using a large-scale Spanish sample composed of 67,253 youths aged between 10 and 18 years (M = 14.16, SD = 1.07), the results showed that CFA provided a severely biased and overly optimistic assessment of the underlying structure of the SDQ. In contrast, exploratory structural equation modeling revealed a generally weak factorial structure, including questionable indicators with large cross-loadings, multiple error correlations, and significant wording variance. A subsequent Monte Carlo study showed that sample sizes greater than 4,000 would be needed to adequately recover the SDQ loading structure. The findings from this study prevent recommending the SDQ as a screening tool and suggest caution when interpreting previous results in the literature based on CFA modeling.
Mental health problems constitute a large proportion of the disease burden in young people, with 10% to 20% of children and adolescents worldwide suffering from a disabling mental illness (Belfer, 2008; Kieling et al., 2011; Patel, Flisher, Hetrick, & McGorry, 2007; Polanczyk, Salum, Sugaya, Caye, & Rohde, 2015). Poor mental health is strongly associated with health and development problems in youths, including lower educational achievements, substance abuse, violence, poor reproductive and sexual health, and suicide, which is the third leading cause of death among adolescents (Belfer, 2008; Cook et al., 2017; Patel et al., 2007). In general, it appears that girls have more internalizing problems (e.g., anxiety, depression, somatic complaints), while boys exhibit greater externalizing problems (e.g., rule-breaking behavior, aggressive behavior), and that older adolescents tend to report more problems than younger adolescents (Rescorla et al., 2007).
Because up to 50% of all adult mental disorders have their onset in childhood and adolescence, it is vital to understand their magnitude, risk factors, and progression in youth, in order to more effectively transition to a paradigm of prevention and early intervention (Belfer, 2008, Kieling et al., 2011; Merikangas, Nakamura, & Kessler, 2009; Merikangas et al., 2010). For this reason, it is important to develop reliable and valid screening tools that can facilitate early detection and prevention of mental health problems in childhood (Lundh, Wångby-Lundh, & Bjärehed, 2008; Polanczyk et al., 2015). Some of the most commonly used mental health screening instruments available for children and adolescents include the Child Behavior Checklist (Achenbach, 1991), the Behavioral Assessment System for Children (Reynolds & Kamphaus, 1992), and the Strengths and Difficulties Questionnaire (SDQ; Goodman, 1997), all of which provide a multi-informant approach to measuring childhood behavioral and emotional functioning.
The SDQ, which is the focus of this study, is a one-page questionnaire that assesses the psychological adjustment of children and adolescents across 25 attributes, some positive and others negative, with the possibility of being completed by parents, teachers, and youths themselves (Goodman, 2001). The instrument is composed of five scales that purportedly measure Hyperactivity/Inattention (HI), Emotional Symptoms (ES), Conduct Problems (CP), Peer Problems (PP), and Prosocial Behavior (PB; Goodman, 1997). It has been recommended and adopted as a routine screening and outcome measure in many countries, and is currently translated into over 60 languages (Caci, Morin, & Tran, 2015; Goodman, 2001; Stone, Otten, Engels, Vermulst, & Janssens, 2010; Warnick, Bracken, & Kasl, 2008). Additionally, the SDQ has proven to be especially popular among clinicians for several reasons, including its short administration time of around 5 minutes—its “small” length compared with similar instruments has been dubbed as “beautiful” (Goodman & Scott, 1999)—its cost-free nature, and because it covers key aspects of common childhood and adolescence psychopathology (Mathai, Anderson, & Bourne, 2004; Niclasen, Skovgaard, Andersen, Sømhovd, & Obel, 2013). Furthermore, the strengths and difficulties approach of the SDQ makes it more acceptable for parents, particularly to those in the general population (Niclasen et al., 2013).
Controversy Regarding the Factor Structure of the Strengths and Difficulties Questionnaire
Despite its widespread use and apparent screening sensitivity, the factor structure of the SDQ has been a subject of controversy in the literature. Goodman (1997) originally developed the five-scale instrument based on the factor analytic findings of the Rutter questionnaires (Elander & Rutter, 1996). Although Goodman did not subject the SDQ to factor analysis in his initial study, the theorized five-factor structure of the SDQ was reproduced in early studies via principal component analysis (e.g., Goodman, 2001; Smedje, Broman, Hetta, & von Knorring, 1999). However, in the years that have followed numerous studies have emerged questioning the suitability of this latent structure, citing either a poor fit to the data (e.g., Mellor & Stokes, 2007; Patalay, Hayes, Deighton, & Wolpert, 2016), nonemergence of the theoretical factors (e.g., Kim, Ahn, & Min, 2015; Mansbach-Kleinfeld, Apter, Farbstein, Levine, & Ponizovsky, 2010), or very low internal consistencies for some of the scales (e.g., Capron, Thérond, & Duyme, 2007; Du, Kou, & Coghill, 2008). Furthermore, various studies have provided support for alternative models of three factors (PB, Internalization [ES + PP items], and Externalization [HI + CP items]; Essau et al., 2012; Gómez-Beneyto et al., 2013; Ruchkin, Jones, Vermeiren, & Schwab-Stone, 2008), four factors (either as PB, HI, CP, and Internalization, or PB, ES, PP, and Externalization; Liu et al., 2013; van de Looij-Jansen, Goedhart, de Wilde, & Treffers, 2011), and models with a positive wording factor (Hoofs, Jansen, Mohren, Jansen, & Kant, 2015; McCrory & Layte, 2012; Palmieri & Smith, 2007; Van Roy, Veenstra, & Clench-Aas, 2008).
The determination of an optimal factor structure for the SDQ is especially complex due to its multicultural, multilingual, and multi-informant nature. For example, in their meta-analysis of 48 studies, Stone et al. (2010) found that the reliability of the SDQ scales was substantially higher for teachers than for parents, which may be due to the items being more one dimensional for teachers as a result of halo effects (Niclasen et al., 2013; Stone et al., 2010). Likewise, Stevanovic et al. (2015) noted that the factor structure of the self-report SDQ has been particularly difficult to replicate across different ethnic/cultural groups. Yet another issue is the reverse-coded items included in the SDQ, which tend to have a negative effect in the goodness of fit of the factor models and oftentimes produces large cross-loadings that cannot be explained by theory (Percy, McCrystal, & Higgins, 2008; van de Looij-Jansen et al., 2011).
An important issue that has perhaps not received enough attention is the appropriateness of using confirmatory factor analysis (CFA) to assess the factor structure underlying the SDQ responses. In their literature review, Caci et al. (2015) identified 53 published studies that evaluated the internal structure of the SDQ scores. Of these, 62.3% used CFA (41.5% alone and 20.8% in combination with exploratory factor analysis [EFA] or principal component analysis). Since 2010, the use of CFA has become even more prevalent, with 17 of the 21 (80.9%) published studies identified in Caci et al. (2015) using CFA to make a final determination on the factor structure underlying its scores. However, researchers have called into question the suitability of CFA to model the responses to psychological scales, which are generally composed of items that are not pure or infallible indicators of a single factor (Asparouhov & Muthén, 2009; Guay, Morin, Litalien, Valois, & Vallerand, 2014; Marsh, Morin, Parker, & Kaur, 2014). In this regard, it has been shown that fixing all or the majority of the items’ cross-loadings to zero, as it is done in CFA, can produce biased estimations of the specified parameters, including substantially inflated factor correlations and distorted structural paths, if these cross-loadings are meaningfully different from zero in the population (Asparouhov & Muthén, 2009; Hsu, Skidmore, Li, & Thompson, 2014; Schmitt & Sass, 2011).
Using Exploratory Structural Equation Modeling to Assess the Factor Structure of the Strengths and Difficulties Questionnaire
Exploratory structural equation modeling (ESEM; Asparouhov & Muthén, 2009) is a modeling framework that can be seen as a generalization of EFA and CFA. Both EFA and ESEM specify unrestricted factor models (where variables are allowed to load on all the extracted factors) and produce the same measures of fit and factor loadings given the same estimators and rotation algorithms. Also, a priori theory can be tested for both EFA and ESEM for the factor loadings (Does the variable load significantly on its theorized factor?) using target rotation, and for the factor model (Does the specified model fit the data?), using the chi-square test of exact fit or fit indices (Asparouhov & Muthén, 2009). However, ESEM has much greater modeling flexibility because, unlike EFA, it can provide local measures of parameter fit, can accommodate correlated residuals, allows for measurement and structural invariance testing, can be incorporated into broader structural models, as well as models with method factors, covariates, and direct effects, among others (Asparouhov & Muthén, 2009; Marsh et al., 2014).
The ESEM framework can also be considered a generalization of CFAs in that the former specifies an unrestricted model where all cross-loadings are estimated, while the latter posits a restricted model where all or the majority of the cross-loadings are fixed to zero. Indeed, formal tests can be carried out to compare the two models—along with detailed examinations of parameter estimates—, for cases where the CFA is nested within the more general ESEM (Asparouhov & Muthén, 2009; Marsh et al., 2014). Furthermore, and notwithstanding the loss in parsimony, ESEM is able to accurately recover the factor structure of population models composed of independent clusters (where all cross-loadings are equal to zero; Morin, Arens, & Marsh, 2016). Additionally, depending on the nature of the research application, the available theory, and the data, ESEM can be used as an exploratory or a confirmatory tool (Marsh et al., 2014). Because it posits an unrestricted model, it is more amenable than CFA to exploratory data-driven studies where the available theory may be limited. However, it may also be used in a confirmatory manner similar to CFA, to test an expected factor structure on a new sample. This confirmatory application of ESEM is formalized by the use of target rotation, where the research analyst has much greater a priori control on the expected factor structure (Asparouhov & Muthén, 2009; Marsh et al., 2014).
The ESEM framework appears to be especially advantageous to assess the factorial structure of the SDQ scores. As noted previously, items from psychological scales such as the SDQ are expected to be fallible indicators of the constructs they are purported to measure, making it likely that they will have residual associations with other dimensions (Marsh et al., 2014). These residual associations can be accounted for by the unrestricted structures posited by the ESEM model. In addition, the SDQ is composed of several pairs of items that have very similar content (e.g., Item 2 “I am restless, I cannot stay still for long” and Item 10 “I am constantly fidgeting or squirming”), which have been found to produce stable correlated residuals (θ) across cultures (Bøe, Hysing, Skogen, & Breivik, 2016). ESEM, unlike traditional EFA, can be used to model these correlated residuals in the context of unrestricted factor analysis. Also, because the SDQ includes a combination of positively and negatively worded items, it is prone to generating wording method variance (Hoofs et al., 2015; McCrory & Layte, 2012; Van Roy et al., 2008), which can have a negative impact on the validity and reliability of its scores (Marsh, Scalas, & Nagengast, 2010; Weijters, Baumgartner, & Schillewaert, 2013; Woods, 2006). With ESEM, this wording method variance can be accounted for by the latent method factor strategy (Marsh et al., 2010).
The Present Study
The main objective of this study was to conduct a systematic assessment of the latent structure underlying the scores of the youth self-reported SDQ using ESEM. In this regard, we will show that a better understanding of its factor structure may be gained by taking advantage of the power and flexibility of the ESEM approach. Additionally, we will demonstrate how independent clusters CFA can distort the factorial structure of the SDQ scores in ways that can meaningfully affect decisions regarding their nature and usefulness. At the moment, we are only aware of one study (Chiorri, Hall, Casely-Hayford, & Malmberg, 2016) that has used ESEM to systematically evaluate the factor structure of the SDQ scores; however, the results provided by Chiorri et al. (2016) are difficult to interpret because their reported pattern matrices included numerous standardized item loadings greater than one (some as large as 1.88), which in most cases is a signal of model misspecification.
Another goal of the current study was to estimate the necessary sample size needed to accurately recover the structure of the SDQ scores. Because much larger sample sizes may be needed to recover unrestricted ESEM structures that are defined by only a small number of items per factor or that have items with moderate or low factor loadings (Schmitt, 2011), it is important to identify the type of samples that may be needed to conduct factorial studies of the SDQ. Indeed, it is possible that inconsistent findings in the literature may be partly due to some studies not having large enough samples to obtain accurate estimations. In order to achieve this goal, a Monte Carlo study was carried out to determine the congruence between the factor structure obtained with the full sample and those estimated at systematically varied sample sizes.
Method
Participants and Procedure
The initial sample was composed of 67,881 students attending secondary schools in the Valencian Community, Spain, during the 2003-2004, 2006-2007, and 2007-2008 academic years that provided information about gender and age. Following the recommendations of Hair, Black, Babin, and Anderson (2010), cases that had missing responses on more than 50% of the items of the SDQ were eliminated from the database; no further screening of the database was conducted after the deletion of these cases. Thus, the final sample was composed of 67,253 cases. Overall, 0.44% of the total number of responses was missing, with a minimum and maximum of 0.21% and 0.67% for individual items, respectively. Because the amount of missingness was very small (<2%), a single imputation of the missing data could be considered appropriate (Widaman, 2006). Thus, the missing values were imputed using the expectation-maximization algorithm with normally distributed errors, a superior technique for single imputation of missing data (Fox-Wasylyshyn & El-Masri, 2005). The gender distribution within the sample was almost equal, with 49.3% girls and 50.7% boys. The students, which were attending Grades 1st through 4th of Compulsory Secondary Education, had ages ranging between 10 and 18 years (M = 14.16, SD = 1.07) that were distributed as follows: 1 (0.0%) 10-year-old, 2 (0.0%) 11-year-olds, 103 (0.2%) 12-year-olds, 21,187 (31.5%) 13-year-olds, 24,398 (36.3%) 14-year-olds, 13,064 (19.4%) 15-year-olds, 6,722 (10.0%) 16-year-olds, 1,662 (2.5%) 17-year-olds, and 114 (0.2%) 18-year-olds.
In order to obtain the sample used for this study, regional health and education authorities from the Valencian Community, Spain, extended all secondary-level schools, including all public, charter, and private schools, an invitation to participate in a study of risk factors, early detection, and prevention of eating disorders (DICTA-CV Program). In total, 566 schools participated in the study, 312 from the Valencian province, 200 from Castellón, and 54 from Alicante. The sample was collected from the schools that accepted to participate in the study and only included those students for which passive informed consent had been obtained from their parents. After an initial assessment of the student’s age and gender, the teachers handed out the survey’s questionnaires, which were completed anonymously during school hours. The students did not receive any incentive to participate in this study. The current study was approved by the regional Department of Public Health (General Public Health Office of the Regional Valencian Government).
Measures
The Spanish self-report version of the SDQ (Goodman, 1997) developed by García et al. (2000) was used for the current study. The SDQ is composed of five subscales: Hyperactivity/Inattention (HI; sample item: “I am restless, I cannot stay still for long”), Conduct Problems (CP; sample item: “I get very angry and often lose my temper”), Emotional Symptoms (ES; sample item: “I am often unhappy, depressed or tearful”), Peer Problems (PP; sample item: “Other children or young people pick on me or bully me”), and Prosocial Behavior (PB; sample item: “I am helpful if someone is hurt, upset or feeling ill”). Each scale contains five items that are answered via a 3-point Likert-type scale (0 = not true; 1 = somewhat true; 2 = certainly true) producing scores that range from 0 to 10. Also, Goodman (1997) suggests that a total Difficulties score may be obtained by summing up the four problems subscales. Of the 25 items in the questionnaire, 10 are positively worded (5 on PB, 2 on HI, 1 on CP, and 2 on PP), while the remaining 15 are negatively worded. Additional information regarding the psychometric properties of the SDQ scores is provided in the introduction section.
Statistical Analyses
Analysis Sttif
In order to assess the factor structure of the SDQ scores the sample was randomly split into two, a derivation sample (n = 33,627) and a cross-validation sample (n = 33,626). In the first step, the derivation sample was used to assess a wide range of ESEM models of the SDQ, perform dimensionality analyses, and evaluate potential wording effects and correlated residuals. In the second step, the optimal model resulting from these analyses was then tested using the cross-validation sample, so as to evaluate the stability of the derived ESEM factor structure and to test corresponding CFA models. In order to choose between an ESEM and a CFA model, we followed the guidelines proposed by Marsh et al. (2014): if the fit and parameter estimates (e.g., factor correlations, factor loadings) of the ESEM and corresponding CFA model did not differ substantially, the CFA model was preferred on the basis of parsimony; if they were meaningfully different, then the better fitting ESEM model was preferred. In the third step, measurement invariance of the optimal factorial structure was examined across gender and age. In the fourth step, the internal consistency reliability of the SDQ sum scale scores was assessed. Finally, in the fifth step, a Monte Carlo study was conducted to determine the necessary sample size needed to accurately recover the factorial structure of the SDQ scores.
Dimensionality Assessment
Two of the most accurate dimensionality methods available for ordinal variables were used to provide aid in the decision of the number of factors to retain: parallel analysis (Garrido, Abad, & Ponsoda, 2013, 2016; Horn, 1965) and exploratory graph analysis (EGA; Golino & Epskamp, 2017). Parallel analysis compares the eigenvalues of the empirical data set with those obtained from generated variables that are uncorrelated in the population; factors are retained as long as their eigenvalues are larger than those from their random counterparts. As recommended in the literature, parallel analysis was interpreted in conjunction with the scree test (Hayton, Allen, & Scarpello, 2004). EGA, on the other hand, is a technique that is part of a new area called network psychometrics (see Epskamp, Maris, Waldorp, & Borsboom, 2016). In network psychometrics, undirected network models are used with psychological data in order to gain insight into the relationships between variables, their underlying structure, among others. With EGA, the number of latent factors is estimated by computing a Gaussian graphical model using regularized partial correlations (see Epskamp, Borsboom, & Fried, 2018). After the network model is estimated, the walktrap algorithm is used to identify which items belong to each dimension (Pons & Latapy, 2006).
Modeling Specifications
The SDQ items were factor-analyzed using the categorical variable estimator weighted least squares with mean- and variance-adjusted standard errors over polychoric correlations (Rhemtulla, Brosseau-Liard, & Savalei, 2012), and with geomin rotation for the ESEM structures. Item wording effects, which can be defined as a differential response style to positively and negatively worded items, were modeled using random intercept item factor analysis (RIIFA; Maydeu-Olivares & Coffman, 2006). With RIIFA, a separate wording method factor is modeled that is orthogonal to the substantive factors and in which all the items are specified to have the same unstandardized loading of 1 (assuming that the reversed items have not been recoded). Therefore, RIIFA uses only one degree of freedom (to estimate the variance of the method factor) and ensures that the method factor may only tap into wording variance by specifying an artifactual relationship between items of opposite wording polarity.
Fit Criteria
The global fit of the factor models was assessed with the root mean square error of approximation (RMSEA), the comparative fit index (CFI), and the Tucker–Lewis index (TLI). Values of RMSEA of less than .08 and .05 can be considered as indicative of reasonable and close fits to the data, respectively, while values of .90 and .95 may reflect acceptable and excellent fits to the data (Hu & Bentler, 1999; Marsh, Hau, & Wen, 2004). It is important to note, nevertheless, that these cutoff values should be considered as rough guidelines and not be interpreted as “golden rules” (Marsh et al., 2004). Local fit was evaluated using the standardized expected parameter change statistic (SEPC). The SEPC informs of the expected standardized value a fixed parameter would obtain if it were to be freely estimated, and absolute values above .20 have been suggested as potentially signaling large misspecifications (Saris, Satorra, & van der Veld, 2009; Whittaker, 2012). In the current study, SEPCs with significant modification indices were freed one at a time (starting from the largest) until the rotated structure became stable. The rotated structure was considered unstable if for at least one factor the coefficient of congruence (c.c.; Tucker, 1951) between the solution with the error correlation fixed to zero and the solution with the error correlation freed was less than .95 (Lorenzo-Seva, & ten Berge, 2006).
Measurement Invariance
Analyses of factorial invariance across gender and age were conducted according to three sequential levels of measurement invariance (Marsh et al., 2014): (a) configural invariance, (b) scalar (strong) invariance, and (c) residual (strict) invariance. Measurement invariance was supported if, in comparison with the configural model, the fit of the restricted models did not decrease by more than .01 in CFI or increase by more than .015 in RMSEA (Chen, 2007). The theta parameterization was used for the invariance analyses. After measurement invariance was established, effect sizes for the differences in latent means across groups were computed using Cohen’s d statistic. According to Cohen (1992), d values of 0.20, 0.50, and 0.80, can be considered as small, medium, and large effect sizes, respectively. Based on the literature of the SDQ, boys tend to score higher on CP and PP, while girls obtain higher scores on ES and PB (Bøe et al., 2016; He, Burstein, Schmitz, & Merikangas, 2013; Koskelainen, Sourander, & Vauras, 2001; Mellor, 2005; Van Roy, Grøholt, Heyerdahl, & Clench-Aas, 2006); the differences between boys and girls on HI have been inconsistent (Bøe et al., 2016; He et al., 2013; Koskelainen et al., 2001; Mellor, 2005). Regarding the SDQ scores across age, being younger has been associated with more CP and PP, while being older has been related to greater HI, PB, and ES (Koskelainen et al., 2001; van de Looij-Jansen et al., 2011; Van Roy et al., 2006; Yao et al., 2009).
Reliability Analysis
Internal consistency reliability for the summed scale scores was computed using the nonlinear structural equation modeling reliability coefficient (ρNL; Yang & Green, 2015), which is appropriate for ordinal indicators and can take into account correlated errors (Viladrich, Angulo-Brunet, & Doval, 2017; Yang & Green, 2015). In addition to ρNL, ordinal alpha (Zumbo, Gadermann, & Zeisser, 2007) was computed for comparative purposes, as this coefficient has been used in numerous SDQ studies (e.g., Björnsdotter, Enebrink, & Ghaderi, 2013; Bøe et al., 2016; Ortuño-Sierra et al., 2015; van de Looij-Jansen et al., 2011). It should be noted that ordinal reliability coefficients such as ordinal alpha or ordinal omega (Gadermann, Guhn, & Zumbo, 2012), do not measure the reliability of the observed scores but rather constitute estimates of the hypothetical reliability for latent scale scores based on the sum of the continuous variables that are thought to underlie the observed discrete scores (Chalmers, 2018; Yang & Green, 2015). In this regard, ordinal alpha and ordinal omega are of limited practical usefulness and should not be reported as measures of the reliability of a test’s scores (Chalmers, 2018; Viladrich et al., 2017). Moreover, the alpha coefficient provides upwardly biased estimates of reliability in the presence of correlated residuals (Viladrich et al., 2017).
Monte Carlo Study
Random samples with replacement between 200 and 10,000 observations, in increments of 200, were extracted from the total sample and the optimal ESEM model derived from Sttif 1 and 2 was estimated. Then, the c.c. was computed between all possible factor orderings of this estimated solution (factors with a negative c.c. were reverted) and the solution obtained with the total sample, and the alignment that produced the highest overall c.c. was retained. For each sample size evaluated, 1,000 random samples were extracted.
Analysis Software
Data handling and missing data imputation were computed using the IBM SPSS software version 20. All ESEM, CFA, and measurement invariance analyses were conducted using the Mplus program version 7.4. The ρNL and ordinal alpha coefficients were computed with the R function reliability contained semTools package (version 0.4-11; semTools Contributors, 2016). Parallel analysis was computed using the MATLAB code developed by Garrido et al. (2013), which is included in the online supplemental materials (all supplementary materials are available in online version of the article). Likewise, the specifications for parallel analysis were in accordance with the recommendations by Garrido et al. (2013) for ordinal variables, including the use of polychoric correlations, eigenvalues derived from the full correlation matrix, the mean criterion, random permutations of the empirical data sets, and the generation of 1,000 random replicates. EGA was computed using the R package EGA (version 1; Golino, 2017). The Monte Carlo study was carried out in the MATLAB programming environment version R2014a with code developed by the authors.
Results
Descriptive statistics for the SDQ scores, including item means, standard deviations, skewness, thresholds, and polychoric correlations are presented in Supplemental Table 1. Of note in these results was the extremely large correlation of .72 between Items 2 “restless” and 10 “fidgety,” which was substantially higher than the second largest correlation of .54 between Items 15 “distractible” and 25 “persistent.” Also, some items showed very high levels of skewness, including Item 11 “friend” (2.83), Item 22 “steals” (2.61), Item 12 “fights” (2.36), and Item 17 “kind” (−2.35).
Derivation Analyses
The first phase of the exploration of the factor structure underlying the SDQ scores involved dimensionality assessments with parallel analysis (aided by the scree test) and EGA (Figure 1). Using the scores of the full item set (25 variables), both parallel analysis and EGA suggested that five factors be retained (see Supplemental Table 2 for the parallel analysis eigenvalues). However, parallel analysis used in conjunction with the scree test suggested that six factors might be retained, as the sixth empirical eigenvalue (1.010) was only slightly below the sixth generated eigenvalue (1.036), and there was a noticeable elbow in the plot starting at the seventh eigenvalue. Subsequent ESEM analyses revealed that there was a large error correlation between Items 2 and 10, which had an extremely high sample polychoric correlation (.72). Likewise, in the EGA (Figure 1), it can be seen that these two items formed a separate dimension. In all, these results indicated that Items 2 and 10 were largely redundant, and thus were averaged to create a new composite variable. Both parallel analysis and EGA were computed again with the new composite variable and this time they suggested that four factors be retained. Again, parallel analysis used in conjunction with the scree test indicated that five factors might be retained, as the fifth empirical eigenvalue (1.036) was just barely below the fifth generated eigenvalue (1.040) and there was a notable elbow in the plot starting at the sixth eigenvalue. Taken together, the dimensionality assessments suggested that four or five factors might be retained after taking into account the large error correlation between Items 2 and 10.

Dimensionality assessment using parallel analysis and exploratory graph analysis.
The second phase of the exploration of the SDQ structure included a systematic evaluation of sequential ESEM models from one to six factors, with increasing numbers of correlated errors, and with the inclusion of a RIIFA wording method factor. A summary of the results from these analyses is presented in Table 1, which includes the model fit statistics, wording factor loadings, and error correlations.
Fit Statistics, Wording Factor Loadings, and Correlated Errors for the Estimated Factor Models.
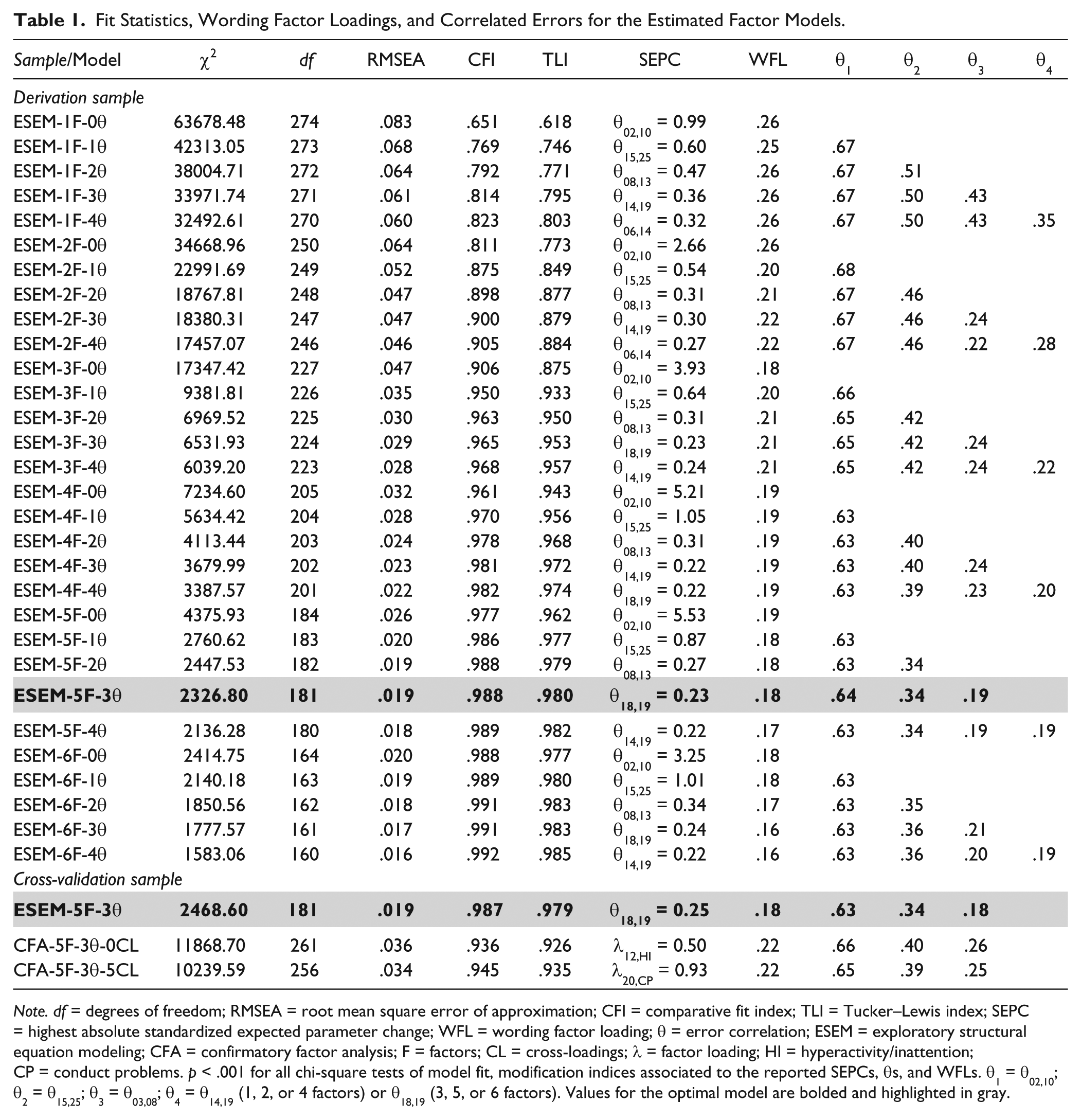
Note. df = degrees of freedom; RMSEA = root mean square error of approximation; CFI = comparative fit index; TLI = Tucker–Lewis index; SEPC = highest absolute standardized expected parameter change; WFL = wording factor loading; θ = error correlation; ESEM = exploratory structural equation modeling; CFA = confirmatory factor analysis; F = factors; CL = cross-loadings; λ = factor loading; HI = hyperactivity/inattention; CP = conduct problems. p < .001 for all chi-square tests of model fit, modification indices associated to the reported SEPCs, θs, and WFLs. θ1 = θ02,10; θ2 = θ15,25; θ3 = θ03,08; θ4 = θ14,19 (1, 2, or 4 factors) or θ18,19 (3, 5, or 6 factors). Values for the optimal model are bolded and highlighted in gray.
The decision to evaluate models with multiple error correlations was due to the high SEPC values (e.g., for θ02,10 the SEPCs ranged between 0.99 and 5.53) in the models without these error correlations (see Table 1) and because the factor structure changed meaningfully when these error correlations were estimated (see Supplemental Table 3). Specifically, for the four-factor model, two error correlations (θ02,10 and θ15,25) produced a notable change in the rotated structure when they were estimated (e.g., when adding θ02,10 the c.c. with the model that had zero correlated errors were .704, .998, .941, and .946, for factors one to four, respectively; when further adding θ15,25 the c.c. with the model that had only one correlated error were .897, .926, .922, and .468, for factors one to four, respectively), and for the five- and six-factor models, three error correlations had a discernable impact in the rotated structure when they were estimated (θ02,10, θ15,25, and θ08,13). In addition, an inspection of these item pairs revealed a substantial overlap in content (which appears to be even greater in the Spanish-translated version), in particular for Items 2 and 10 and Items 15 and 25 (see Supplemental Tables 10 and 11), which could help explain these large error correlations. Regarding the wording method factor loadings, they were significant and of notable magnitude (.16 to .26) for all ESEM models evaluated with the derivation sample. The rotated solutions for the ESEM models with one to six factors and zero to four correlated errors appear in Supplemental Tables 4 to 8.
The results shown in Table 1 reveal that the ESEM models with three or more factors and three correlated errors (θ02,10, θ15,25, and θ08,13) had a good fit to the data according to the conventional cutoff values (CFI, TLI ⩾ .95; RMSEA < .05). The rotated solutions for these ESEM models are shown in Table 2. As can be seen in Table 2, only one variable had a salient loading (⩾.30) in the last factor of the six-factor solution, suggesting that possibly too many factors had been extracted, which would be in line with the parallel analysis and EGA dimensionality results. In the case of the three-factor solution, the items from the PP factor had very similar salient loadings in both the second and third factors, while the PB items loaded saliently in the first and third factors; these type of solutions usually signal that too few factors have been extracted, which again would be in line with parallel analysis and EGA which suggested that at least four factors be retained.
Factor Solutions for Three-, Four-, Five-, and Six-Factor ESEM Models With the Derivation Sample.

Note. ESEM = exploratory structural equation modeling; F = factor; θ = correlated error; D = theoretical dimension; HI = Hyperactivity/Inattention; CP = Conduct Problems; ES = Emotional Symptoms; PP = Peer Problems; PB = Prosocial Behavior. Factor loadings ≥.30 in absolute value are bolded and highlighted in gray. p < .05 for all factor loadings and factor correlations, except those underlined. All models include the three correlated errors θ02,10, θ15,25, and θ08,13, and a wording method factor (estimates shown in Table 1).
Positive polarity item. bReversed item recoded.
Between the four- and five-factor solutions, the one with five factors appears to be the most interpretable. In the five-factor model 22 of the 25 items had their highest loading in their theoretical factor (all except Items 7, 10, and 11), providing support for this solution. Nevertheless, it should be noted that this solution was not robust, as there were many items with weak primary loadings (<.40) and multiple salient cross-loadings. In the case of the four-factor model, the HI and CP items created an “Externalization” factor, but the items from PP and PB presented a complex structure; the last factor was composed of only two PB items, while four PB items loaded saliently in the PP factor. Also, the PP items showed some high cross-loadings in the ES factor. Thus, it appears that the five-factor model is somewhat superior to the four-factor model in terms of interpretability, a result supported by the dimensionality assessment of parallel analysis when used in conjunction with the scree test. Nevertheless, it should be noted that the decision between the four- and five-factor solutions is not a very clear one, as evidenced by the small difference in fit between the two models (.023 vs. .019 for RMSEA; .981 vs. 988 for CFI; and .972 vs. .980 for TLI) and the weak fifth eigenvalue in the parallel analysis dimensionality assessment.
Cross-Validation Analyses
The optimal five-factor ESEM structure with a wording RIIFA factor and three correlated errors (θ02,10, θ15,25, and θ08,13) from the derivation analyses (ESEM-5F-3θ) was tested with the cross-validation sample. In addition, two CFA models with a wording RIIFA factor and three correlated errors were evaluated: the theoretical five-factor model (CFA-5F-3θ-0CL) and a CFA model that included the five nontheoretical salient loadings (CFA-5F-3θ-5CL) observed in the ESEM derivation analyses. A summary of the results from these models is shown in Table 1 and the factor loadings and factor correlations are presented in Table 3.
Factor Solutions for the Five-Factor ESEM and CFA Models With the Cross-Validation Sample.
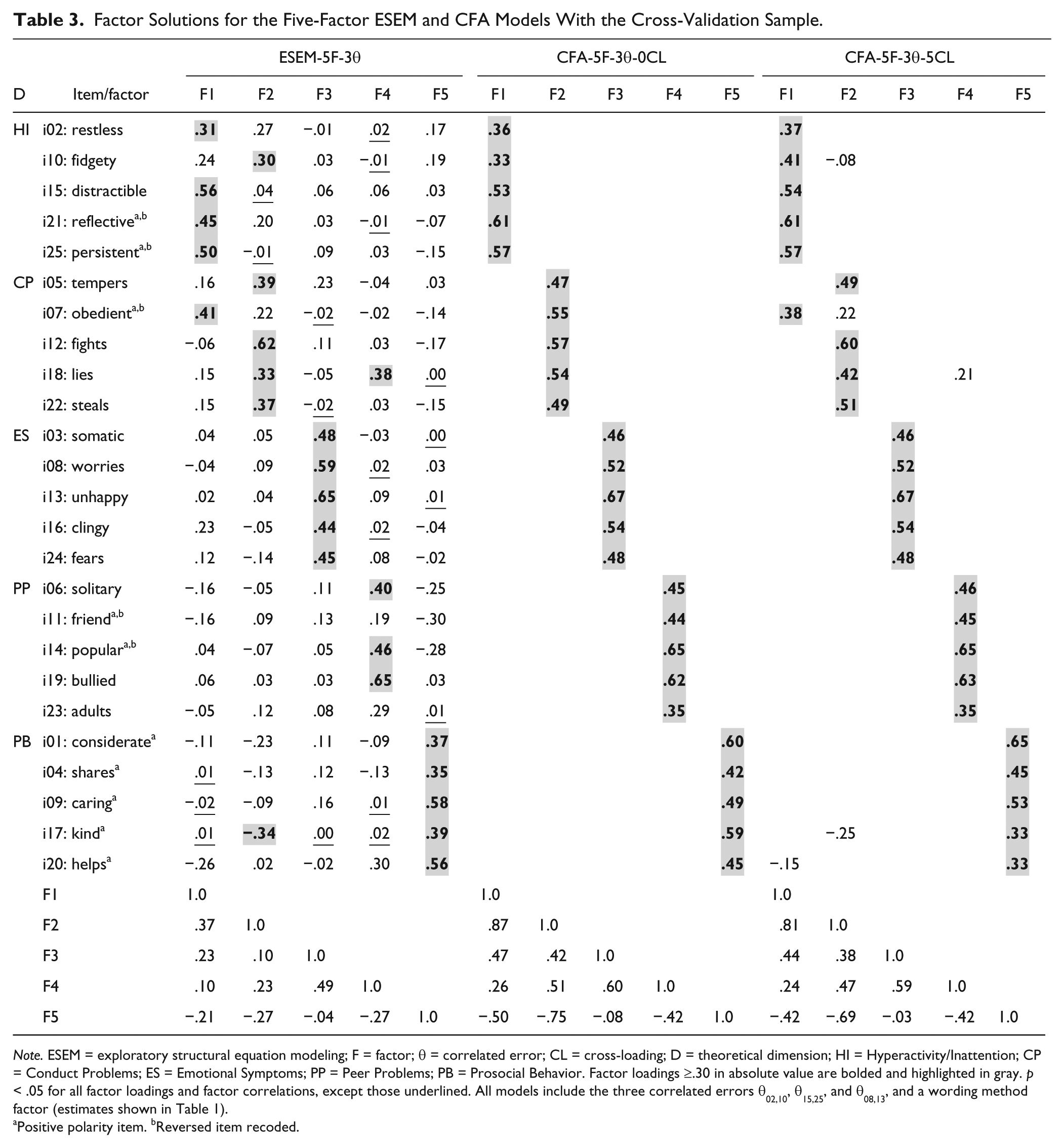
Note. ESEM = exploratory structural equation modeling; F = factor; θ = correlated error; CL = cross-loading; D = theoretical dimension; HI = Hyperactivity/Inattention; CP = Conduct Problems; ES = Emotional Symptoms; PP = Peer Problems; PB = Prosocial Behavior. Factor loadings ≥.30 in absolute value are bolded and highlighted in gray. p < .05 for all factor loadings and factor correlations, except those underlined. All models include the three correlated errors θ02,10, θ15,25, and θ08,13, and a wording method factor (estimates shown in Table 1).
Positive polarity item. bReversed item recoded.
As can be seen in Table 1, even though the fit of the two CFA models approximated the standard cutoff values, it was noticeably worse than the fit of the corresponding ESEM model (.036/.034 vs. .019 for RMSEA; .936/.945 vs. .987 for CFI; and .926/.935 vs. .979 for TLI). Indeed, the majority of the cross-loadings that were fixed to zero in the CFAs were significantly different from zero in the ESEM, and many had nontrivial absolute values (>.10). Additionally, when looking at the SEPCs reported in Table 1, the CFA models obtained SEPCs (.50 and .93, both for cross-loadings) that were markedly higher than the largest SEPC for the ESEM model (.25); this indicates that the CFA models displayed notable levels of local misfit that would make their acceptance questionable.
The bias introduced by fixing the cross-loadings to zero in the CFAs was evident in the estimated factor loadings and factor correlations of these models (Table 3). For example, whereas the correlation between the HI and CP factors was .37 in the ESEM, it was .87 and .81 in the CFAs. Likewise, the factor correlation between CP and PB was −.27 in the ESEM but −.75 and −.69 in the CFAs. Moreover, some of the most questionable items in the ESEM solution appeared as strong items in the CFAs, a biased result due to their unmodeled cross-loadings. For example, even though Item 7 had a .22 loading in its theoretical ESEM factor, it obtained a .55 loading in the corresponding CFA without cross-loadings. A similar result can be seen for Items 11, 18, 17, and so on. These biases were somewhat mitigated when some cross-loadings were included in the CFA-5F-3θ-5CL model, but the solution still produced a biased perspective of the quality of the SDQ items and extremely large factor correlations. Taken together, these results strongly suggest that ESEM is a more appropriate framework to model the SDQ responses than CFA. In terms of the cross-validation of the ESEM structure, all the factors obtained coefficients of congruence above .99 when the solutions from the derivation and cross-validation samples were compared, and the estimated error correlations and wording factor loadings were practically identical (see Table 1), providing strong support for the stability of this solution.
Measurement Invariance Analyses
After determining the optimal factorial structure for the total child and adolescent sample of the SDQ, the measurement invariance of this structure was evaluated across gender and age (see Table 4). In terms of age, the sample was divided between early adolescents (10-14 years) and late adolescents (15-18 years; Gore et al., 2011). As the results from Table 4 indicate, the five-factor ESEM model with a wording RIIFA factor and three correlated errors produced practically the same fit for the gender (girls/boys) and age (10-14/15-18 years) groups. Additionally, there was support for both scalar (strong) and residual (strict) levels of measurement invariance for gender and age, as the decrease in CFI in comparison with the configural model was less than .01, and the increase in RMSEA was less than .015 (in fact, the RMSEA improved [was lower] for the residual model across age groups in comparison with the configural model). In all, these results suggest that the SDQ scores had the same underlying structure and measurement properties for girls and boys, and early and late adolescents.
Measurement Invariance Analyses Across Gender and Age.

Note. df = degrees of freedom; CFI = comparative fit index; TLI = Tucker–Lewis index; RMSEA = root mean square error of approximation; MI = measurement invariance; FL = factor loadings; Th = thresholds; Uniq = uniquenesses. The parameters constrained to be equal across groups are shown in the parentheses next to the invariance models. The chi-square difference tests between nested models was conducted using Mplus’ DIFFTEST option. p < .001 for all chi-square tests.
In order to achieve model identification for the latent mean comparisons, the means and standard deviations of the SDQ factors were fixed to 0 and 1, respectively, for the girl and early adolescent groups. When comparing the latent means across gender, boys had higher means in HI (M = 0.066, p = .021, d = 0.065) and CP (M = 0.336, p < .001, d = 0.341), lower means in ES (M = −1.292, p < .001, d = 1.256) and PP (M = −0.691, p < .001, d = 0.677), and there were no differences in PB (M = 0.413, p = .329, d = 0.413). Of note in these results were the large and medium effects obtained for the ES and PP factors, where girls reported substantially more problems than boys. In terms of age, late adolescents had higher means in HI (M = 0.072, p = .013, d = 0.073), ES (M = 0.112, p < .001, d = 0.100), PP (M = 0.372, p < .001, d = 0.402), and PB (M = 0.872, p < .001, d = 0.807), but a lower latent mean in CP (M = −0.121, p < .001, d = 0.112). In this case, the difference in PB was the greatest one, achieving a large effect size (all the other differences could be categorized as “small”).
Internal Consistency Reliability Analyses
Because numerous studies of the SDQ have used the ordinal alpha coefficient to assess the reliability of its scale scores, we computed this coefficient for comparative purposes even though it would not be appropriate to interpret its values as estimates of observed reliability (see the Method section). Using the theoretical scales, ordinal alpha provided estimates of .69, .67, .73, .62, and .69 for the HI, CP, ES, PP, and PB scales, respectively. In contrast, and taking into account the three correlated errors included in the optimal ESEM Model (θ02,10, θ15,25, and θ08,13), the ρNL coefficient provided reliability estimates of .45, .53, .62, .50, and .57 for these same scales. As can be seen, the estimates of internal consistency reliability provided by ρNL are much lower than those of ordinal alpha, and the decisions regarding the reliability of the SDQ scale scores would differ if the latter were to be used. As it stands, ρNL shows that none of the SDQ scale scores approximate the minimum levels of reliability recommended for diagnostic or screening purposes (⩾.70).
Monte Carlo Study
The final assessment of the factorial structure of the SDQ scores involved the determination of the sample size needed to obtain an accurate recovery of the optimal ESEM structure obtained from the previous derivation and cross-validation analyses. The box plots in Figure 2 depict the coefficients of congruence between the ESEM solutions at sample sizes ranging between 200 and 10,000 and the estimated structure with the total sample. These results show that very large sample sizes of approximately 4,200 observations would be required to achieve a mean c.c. of .950. Moreover, even for samples this large, more than 25% of the estimated solutions still obtained coefficients of congruence lower than .950. Indeed, to have at least 90% of the solutions achieve a c.c. of .950 or greater, sample sizes of 7,000 or more observations would be needed. Additional results presented in Supplemental Table 9 and Supplemental Figures 1 to 5 show that some SDQ factors are more robust than others. For example, the CP and ES factors achieved a mean c.c. of .950 with sample sizes of 3,000 or greater, whereas the PB factor needed samples of at least 7,400 observations to achieve this same level of factor congruence. Taken together, these results indicate that typical sample sizes used in factor analytic studies (≤1,000) would not be nearly enough to obtain an accurate recovery of the population structure of the SDQ scores.
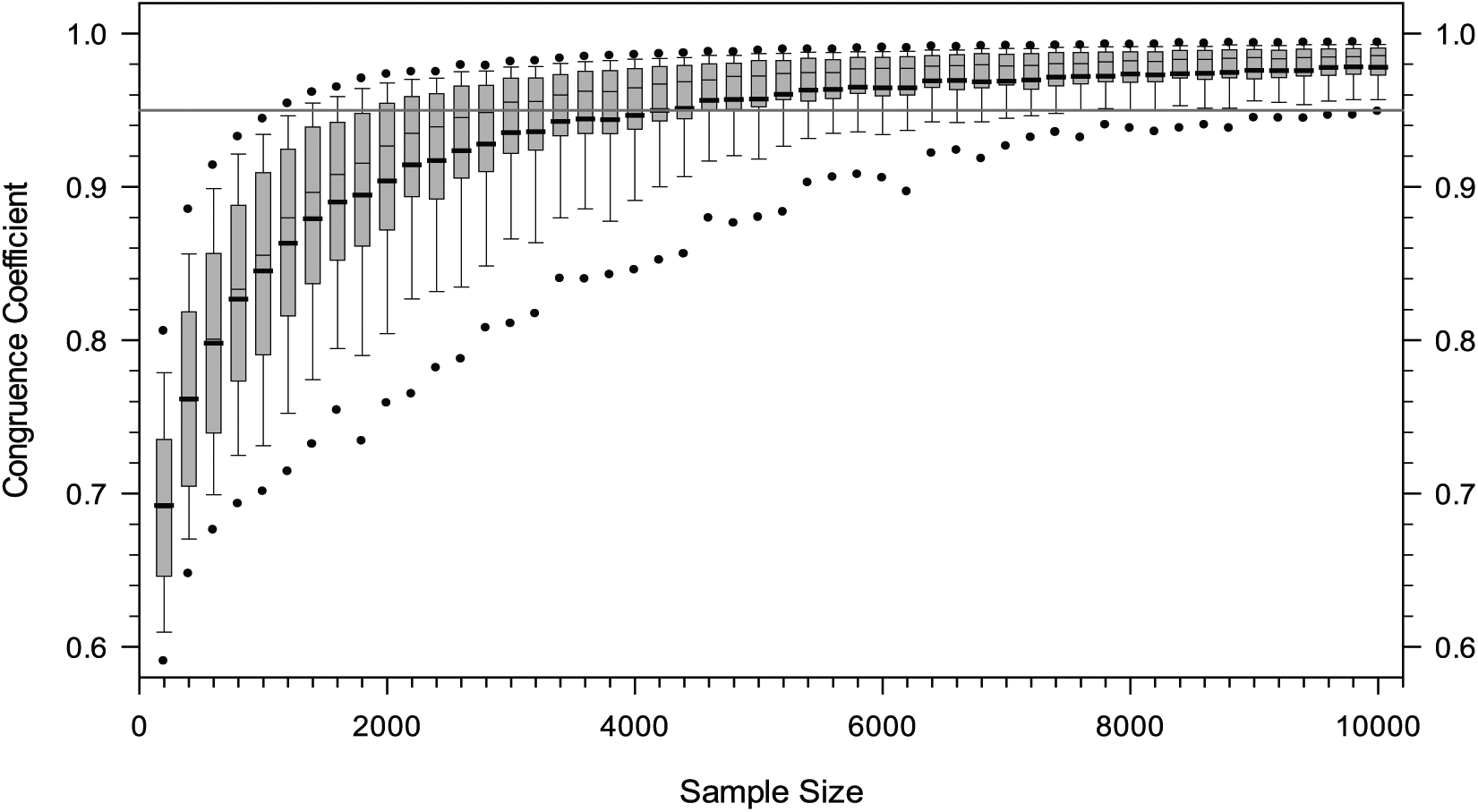
Box plots representing the factor loading congruence between the optimal five-factor ESEM solution with the total sample (N = 67,253) and the solutions obtained with the extracted random samples.
Discussion
The assessment of factorial validity is an integral component to the determination of how well instruments are able to measure underlying theoretical constructs, often dictating their potential usefulness for quantitative research, clinical diagnosis or screening, and theory development. Although the literature addressing the psychometric properties of the SDQ scores is substantial (Bøe et al., 2016; Stone et al., 2010), its interpretability may not be straightforward. This is because the techniques that have been used to factor analyze the SDQ, primarily CFA (but also EFA), appear to be unequipped to model the complex psychological mechanisms that account for the variability of its scores, possibly leading to biased results and suboptimal decisions. As a result, we sought to gain a greater understanding of the factorial validity of the SDQ scores by using the more flexible ESEM framework to conduct a systematic assessment of the latent structure underlying the scores from a large-scale Spanish adolescent sample. The main findings from this study are summarized next.
Main Findings
The results from the derivation and cross-validation ESEM analyses showed some support for the five-factor theoretical structure proposed by Goodman (1997), with the five-factor model providing an interpretable solution that had a good fit to the SDQ responses and that was invariant across gender and age. However, it also shed light into several problematic issues such as the presence of a number of questionable indicators, multiple residual correlations, wording effects, and a generally weak and unstable factorial structure. Complementary dimensionality assessments using parallel analysis and EGA also provided partial support for a five-factor SDQ structure, suggesting either a five-factor solution with a very weak fifth factor or a four-factor structure.
Overall, 7 of the 25 SDQ items (28%) were identified as questionable indicators of their theoretical constructs through the ESEM analyses. Four of these items had cross-loadings that were higher in absolute magnitude than their theoretical loading: Items 7 (“obedient,” CP), 10 (“fidgety,” HI), 11 (“friend,” PP), and 18 (“lies,” CP). Also, Items 11 and 23 (“adults,” PP) did not achieve a salient loading (⩾.30) on their theoretical factor, and Items 2 (“restless,” HI) and 17 (“kind,” PB) had main loadings that were less than .05 above their highest cross-loading. In addition to these questionable indicators, three error correlations were identified through the ESEM analyses that were of notable magnitude (⩾.20; Whittaker, 2012) and/or that had a discernible impact on the rotated structure when the parameter was freed. The two largest of these error correlations included item pairs from the HI dimension: Items 2 “restless” and 10 “fidgety,” and Items 15 “distractible” and 25 “persistent.” Error correlations between these item pairs have been reported in a great number of SDQ studies across many cultures and languages (e.g., Bøe et al., 2016; Niclasen et al., 2013; Ortuño-Sierra et al., 2015; Percy et al., 2008; Tobia, Gabriele, & Marzocchi, 2013; van de Looij-Jansen et al., 2011; Van Roy et al., 2008).
Although similar wording might help explain the positive error correlations between Items 2 and 10 (which refer to hyperactivity) and Items 15 and 25 (which refer to attention deficit), they could also signal problems in the theoretical conception of the HI scale. The contemporary literature regards hyperactivity and attention deficit as two related but separate constructs (Kuntsi et al., 2014; Willcutt et al., 2012). In this line, current diagnostic measures of attention deficit/hyperactivity disorder (ADHD), such as the one in the Diagnostic and Statistical Manual of Mental Disorders–Fifth edition (American Psychiatric Association, 2013) include separate conceptualizations for these traits. On one hand, attention deficit reflects the inability to focus the attention span for a sustained period of time, while on the other hand, hyperactivity–impulsivity relates to an excessive activity level combined with a lack of self-control (Garner, Marceaux, Mrug, Patterson, & Hodgens, 2010). Also, although in the past decade several studies have proposed the suitability of a general factor of ADHD (e.g., Martel, von Eye, & Nigg, 2010) a closer inspection suggests that the disorder is better represented as a multidimensional construct, rather than a single continuum (Arias, Ponce, & Núñez, 2018). Thus, the HI scale of the SDQ is bound to be problematic because it conceptualizes these two traits as being unidimensional, and by only including a few items of each (2 for hyperactivity-impulsivity and 3 for attemtion deficit), it may prevent their proper emergence as separate factors.
Regarding the robustness of the optimal five-factor ESEM structure derived and cross-validated in the current study, a subsequent Monte Carlo simulation revealed that very large samples of more than 4,000 observations would be needed to accurately recover the factor structure of the SDQ scores. In terms of the specific factors, PB was the least robust as it needed sample sizes greater than 7,000 to achieve a sufficient mean level of congruence with the structure estimated using the total sample. It is noteworthy that the optimal five-factor ESEM model included a wording method factor where the SDQ items obtained significant and nontrivial factor loadings, a result that is congruent with previous findings in the literature (e.g., Hoofs et al., 2015; McCrory & Layte, 2012; Van Roy et al., 2008). Thus, it appears that what remains of the PB factor (which contains only positive items) after extracting the wording variance from the data is not very well defined. These novel findings underscore the lack of robustness of the factorial structure underlying the SDQ self-reports.
The final step in the assessment of the factor structure of the SDQ scores involved a comparison of the ESEM results with corresponding CFA structures. In terms of model fit, there was a noticeable decrease in fit when going from the ESEM to the CFAs; indeed, many of the cross-loadings that were fixed to zero in the CFAs were significant and of nontrivial magnitude in the ESEM. However, the fit of the CFA models approximated and even surpassed conventional cutoff values established for the fit indices, so that researchers without knowledge of the ESEM results would be inclined to accept these models as providing a good-enough fit. For example, very recently Ortuño-Sierra et al. (2015) and Bøe et al. (2016) accepted five-factor CFA models of the adolescent SDQ across samples from six European countries that achieved a level of fit that was very similar to those obtained in the current study. Even more disconcerting, in the theoretical five-factor CFA with independent clusters, some of the most questionable items from the ESEM solution (the ones with the highest cross-loadings), obtained particularly high loadings in the CFA. Again, by just looking at the loadings from the CFA a researcher might mistakenly conclude that these items were strong indicators of their factors. Additionally, the factor correlations from the CFAs were considerably higher than those from the ESEM (e.g., a .37 factor correlation in the ESEM became .87 in the corresponding CFA), to the point where the discriminant validity of the factors would be questioned. This result is congruent with the literature that has shown that CFAs can grossly overestimate the factor correlations when the population model meaningfully departs from the independent clusters model (Asparouhov & Muthén, 2009; Hsu et al., 2014; Marsh et al., 2009; Schmitt & Sass, 2011). In similar fashion, Bøe et al. (2016) reported CFA factor correlations as high as .80, which at least superficially would question the suitability of CFA for their data as well (Ortuño-Sierra et al., 2015, did not report the factor correlations obtained in their study).
Regarding the internal consistency reliability of the theoretical SDQ scale scores, the results from this study showed that none achieved the minimum recommended levels of reliability (⩾.70; Cicchetti, 1994). Moreover, only the ES’ scores produced a reliability estimate higher than .60. Although at first glance these results would appear to contradict recent findings of acceptable reliabilities for the adolescent SDQ (e.g., Bøe et al., 2016; Ortuño-Sierra et al., 2015), it is worth noting that these studies, along with others in the SDQ literature (e.g., Björnsdotter et al., 2013; van de Looij-Jansen et al., 2011) relied on ordinal estimators of reliability to reach these conclusions. Specifically, the ordinal alpha coefficient (Zumbo et al. 2007) used in these studies is a measure of hypothetical reliability, of the sum score obtained from the unobserved continuous variables that are thought to underlie the obtained discrete scores (Chalmers, 2018). As such, these reliabilities are of limited usefulness to researchers who may wish to use the SDQ scores for screening or even research purposes. Furthermore, the alpha coefficient assumes that the items do not have correlated residuals, an assumption that would be violated in the majority of studies of the SDQ. For example, whereas the observed sum scores of the HI scale achieved a reliability of .45 when taking into account its two correlated errors, the ordinal alpha coefficient produced a much higher reliability of .69.
Limitations
There are some limitations in this study that should be noted. Because this research relied on a sample from a specific region of Spain, generalizations to other cultures and languages require caution. Likewise, the current findings pertain to the adolescent self-reported SDQ, which may function differently from the parent or teacher versions, which were not evaluated here. Nevertheless, the results of this study that pertain to methodologies that have been commonly used in the SDQ literature (e.g., CFA, ordinal alpha reliability) were not too dissimilar from previous findings obtained from a diverse group of cultures and languages. Also, the very large sample size that was examined allowed for the implementation of a split-sample approach that helped ensure the stability of the findings derived from these analyses. It is also worth noting that the present study did not include external variables that could have aided the decision process that was followed to arrive at an optimal factor structure for the SDQ self-reported scores.
Practical Implications
The combined findings of the present study prevent the recommendation of the SDQ as a screening measure for the current adolescent population. First, the conceptualization of HI as a single trait is not supported by this data, previous factor analytic studies of the SDQ, or the vast literature on hyperactivity and attention deficit. Second, according to the ESEM analyses more than 25% of the SDQ items could be considered as questionable measures of their theoretical dimensions, leaving some factors with as few as three proper indicators. Third, the internal consistency reliability of the SDQ scale scores ranged from .45 to .62, which falls well below of recommended guidelines for psychological screening instruments (⩾.70; Cicchetti, 1994).
Regarding the last point, it is worth noting that the low internal consistencies of the SDQ scale scores reflect, at least partly, the inherent difficulties of trying to measure broad domains reliably with very few indicators and response options. Indeed, one of the reasons for the SDQ’s popularity has been its short length, a characteristic that has been labeled as “beautiful” in relation to competing instruments with longer formats (Goodman & Scott, 1999). However, previous psychometric studies of the SDQ have consistently found poor score reliabilities. For example, in their meta-analysis of 48 studies (N = 131,223), Stone et al. (2010) found that for the SDQ Parent version four scales (all except HI) had mean internal consistency reliabilities below .70 (including two below .60). Although subsequent studies have provided higher internal consistency estimates using the ordinal alpha (Björnsdotter et al., 2013; Bøe et al., 2016; Ortuño-Sierra et al., 2015; van de Looij-Jansen et al., 2011) or ordinal omega (Gómez-Beneyto et al., 2013; Stone et al., 2013) coefficients, these measures of hypothetical reliability should be avoided, as discussed previously. In all, the findings from this study and of previous meta-analytic research indicate that trying to obtain reliably enough trait estimates with the current SDQ “small” format might be unfeasible.
The results from this study also suggest caution when interpreting the factor analytic literature of the SDQ that has relied on CFA for construct validation. As the current findings show, when an independent cluster CFA model is imposed on data that has numerous nontrivial cross-loadings, the estimated parameters are likely to be biased, potentially to a severe degree, even in cases where the CFA model has met or approximated conventional global fit criteria. This phenomenon extends beyond the SDQ, and has been documented for diverse constructs such as personality, well-being, motivation, engagement, bullying/victimization, and students’ evaluations of university teaching, among others (Joshanloo, Jose, & Kielpikowski, 2017; Marsh et al., 2009; Marsh, Liem, Martin, Morin, & Nagengast, 2011; Marsh, Nagengast, & Morin, 2013; Marsh, Nagengast, Morin, Parada, et al., 2011). In light of this, we recommend that even in confirmatory applications researchers always estimate an ESEM model and compare its results with those obtained from the independent cluster CFA. If the fit and parameter estimates (e.g., factor correlations, main factor loadings) for the independent cluster CFA do not differ meaningfully from the corresponding ESEM, the CFA should be retained on the basis of parsimony (Marsh et al., 2014); otherwise, the ESEM model should be retained. Also, researchers can use ESEM solutions to identify large cross-loadings that could be freed in a CFA model, and then proceed to compare this modified CFA with its corresponding ESEM using the same criteria described previously. Finally, irrespective of whether an ESEM or a CFA is estimated, we encourage researchers to thoroughly inspect the local fit of their models and to at minimum report the largest SEPC for their retained models.
Supplemental Material
SDQ_supplemental_material – Supplemental material for Is Small Still Beautiful for the Strengths and Difficulties Questionnaire? Novel Findings Using Exploratory Structural Equation Modeling
Supplemental material, SDQ_supplemental_material for Is Small Still Beautiful for the Strengths and Difficulties Questionnaire? Novel Findings Using Exploratory Structural Equation Modeling by Luis Eduardo Garrido, Juan Ramón Barrada, José Armando Aguasvivas, Agustín Martínez-Molina, Víctor B. Arias, Hudson F. Golino, Eva Legaz, Gloria Ferrís and Luis Rojo-Moreno in Assessment
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.