
Abstract
Advancing the science of gifted education requires that researchers and educators better understand when and why (and for whom) programs and services are effective. Assessing Fidelity of Implementation (FoI) is key to achieving this level of understanding and can be incorporated into formative or summative evaluations and formal or informal processes. FoI is especially critical when programs are being scaled up to new contexts. This article explores FoI in terms of defining the program and identifying important moderators of implementation.
“FIDELITY OF IMPLEMENTATION HELPS EVALUATORS AND RESEARCHERS GO BEYOND THE “BLACK BOX” OF INTERVENTIONS TO IDENTIFYING THE SPECIFIC MECHANISMS OR COMPONENTS OF THE PROGRAM THAT LEAD TO DESIRED OUTCOMES.”
Educators have long been frustrated when a new program implemented with great success in one school or district fails to have the promised outcomes when translated to another system or scaled up broadly. There are many possible explanations—Did the original program really understand what aspects were effective and how the program should be implemented? Did the new school system understand the program and implement it well? Is there something fundamentally different in the new system that caused the program not to work? In gifted education, some of these questions are further complicated by other considerations—Is this intervention appropriately adapted to benefit gifted students? Are the assessments sensitive to changes in knowledge for all students? In a mixed ability classroom, how can we determine the effectiveness for students with different instructional needs?
Each of these concerns relates to the idea of Fidelity of Implementation (FoI). FoI is the extent to which a program or intervention is enacted as originally intended and according to the design of program developers (Century, Rudnick, & Freeman, 2010; Mowbray, Holter, Teague, & Bybee, 2003; O’Donnell, 2008). It is also called treatment fidelity, treatment integrity, or degree of program implementation (Ruiz-Primo, 2006). FoI is achieved when a program’s key elements are implemented effectively and consistently as needed to have the desired outcomes. To evaluate FoI, the program must be carefully defined and variations explored with respect to the magnitutde of program effects (see Figure 1). Defining and measuring FoI helps evaluators and program leaders understand both why and when programs are effective and can help evaluators provide feedback to programs when outcomes are inconsistent.

Framework of FoI evaluation.
The goals of this article are to outline how a program’s fidelity can be defined in terms of its critical components and processes, how to assess the degree of implementation, and to suggest teacher beliefs and attitudes that may influence how (and how well) they implement a specific program. All of these strategies will help evaluators of gifted education programs conduct more thorough evaluations, better understand the program, and advance the science of gifted education through greater understanding of why and when programs are effective.
Illustrative Example From Professional Experience
Fidelity concepts are better demonstrated with an example, so we will start with an example from a project the first author worked with for several years as the external evaluator. Although this program was focused on general education students, teachers were expected to provide tiered activities appropriate to the needs of all students.
The NanoBio Science Partnership for Alabama Black Belt Region (Lakin & Wallace, 2015) provided curricular materials and professional development (PD) for teachers in Grades 6 to 8 science classrooms. The lesson plans were developed by university faculty to align with the 5Es approach to lesson planning for scientific inquiry (Bybee et al., 1989) and to emphasize cutting-edge nanotechnology concepts as they aligned with state standards. The primary activity of the program was to provide teacher training on the curricular units, which, when implemented in their classrooms, would enhance standards-aligned science learning and introduce scientific inquiry practices into the classroom (Bell, Smetana, & Binns, 2005; National Research Council, 2000). As there were gifted students being served in the regular classroom, lesson plans were also structured to include tiered activities, including small-group inquiry investigations. Teachers had substantial freedom to align the modules with their learning outcomes and student needs, but the focus on implementing lessons to achieve content and inquiry-based learning was a constant.
Planning to Evaluate FoI
The relatively complex process of defining and measuring FoI can be summarized in three deceptively concrete steps during planning (Mowbray et al., 2003): defining the program, identifying sources/indicators of evaluation information, and creating or selecting measures of those indicators. Figure 1 provides an outline of the key features and the role of moderators of FoI. We will detail each of these components in the sections that follow.
Defining the Program
The most complex step of assessing FoI is defining exactly what implementation should look like. Evaluators can begin by consulting experts on the program or formal program definitions. Formal evaluation of programs often include a logic model or theory of action for a program that breaks the program down into resources, activities, and the associated short-term and long-term program outcomes (Frechtling, 2002; McLaughlin & Jordan, 2004). The resources and activities from a logic model should provide a starting point for defining fidelity—Are the resources in place as expected based on the model? What are the intended activities? The simplified logic model for the NanoBio program is shown in Figure 2.
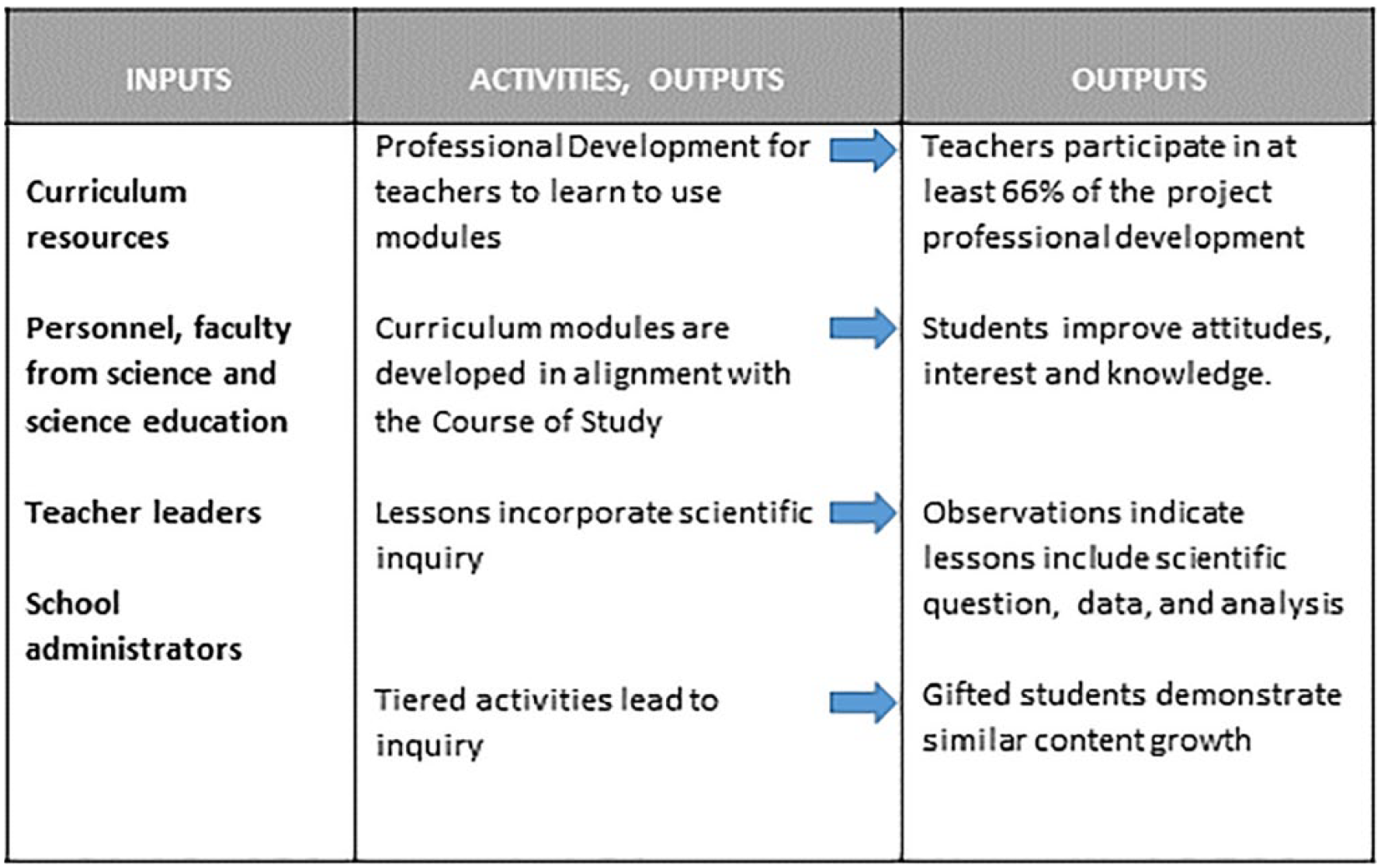
Simplified logic model.
The activities can be further explored in terms of structural and process aspects (Mowbray et al., 2003; O’Donnell, 2008; Ruiz-Primo, 2006). Structure components are often the most obvious: What are the visible pieces of the program? In the NanoBio example, implementing the program included teachers participating in PD workshops and using lesson plans and activities in the classroom. Thus, the structural components of FoI were PD attendance and using lessons in the classroom. This is shown in Figure 2.
Process is about the quality of the components—How should an effective program be implemented? What are the qualities of successfully implementing the structural components? If a program was implemented well, what would its characteristics be? In the NanoBio program, the process components included implementing the lesson plans such that students engage in scientific inquiry and tiered activities provide appropraite challenge to all students. In other words, not only do teachers use the lesson plans, but they do so in a way that engages students in challenging inquiry through questioning and data analysis.
For gifted education, Azano et al. (2014) encouraged programs to specifically define how the program provides “differentiation.” They define differentiation as what makes the unit or program uniquely suited to gifted and talented students or what precisely distinguishes the intervention from the standard curriculum. Differentiation is part of defining the process of a program. For NanoBio, we expected lessons to include tiering so that students identified as needing gifted services would receive appropriate challenge. Therefore, we looked at the lesson plans and student outcomes via rubrics to determine if tiering occurred (structural) and was effective (process).
Identify Sources of Evidence for Each Component
To evaluate the program as defined in the first step, evaluators next need to identify sources of evidence that can be used to assess the quality of each component so that evaluators can assess structure and process FoI. Importantly, these sources should represent a range of stakeholders and consider all relevant sources of perspectives on the program. The variety of sources serves the goal of equity by including all voices in the evaluation of a program to be sure that all students’ needs are being addressed and met.
For each component, the evaluator should identify multiple sources of information that help to triangulate or deepen their understanding of how the program is implemented. In their review of the gifted education literature, Missett and Foster (2015) identified a variety of common measures of fidelity and assessed their appropriateness. Commonly used methods included observations of experimental and/or control group teachers (with or without an observation protocol), teacher self-report, interviews with experimental group teachers, and other assessments of the quality of implementation, including student measures or lesson plan analysis.
We have found that a table helps to plan multiple sources of information for each structure and process component of the program. In planning, evaluators can start with columns that reflect the main components of the program and rows that reflect various informants or sources of data (see Table 1 based on the NanoBio project). The evaluation team can then identify potential types of evidence that could be collected. If the evaluation is occurring during or after a program begins, evaluators may be constrained by the evidence already being collected, but this strategy can still be valuable. Not every cell needs to be filled, but a variety of sources for each component allows the evaluator to triangulate findings and support the validity of interpretations. Also, at least some evidence from each informant allows all stakeholders to have a voice in the evaluation. Both qualitative and quantitative as well as informal and formal data-gathering tactics should be used.
Mapping Components and Data Sources

Structural components of a program are often straightforward to measure—in this case, we used program records to track PD attendance and the student artifacts and teacher self-report to track curriculum module usage.
Evaluating the process components of a program can be more challenging, but especially important for educational interventions. In this example, we needed to understand whether inquiry was occurring during the lessons. Program-specific classroom observations could be used to assess this quality, and focus groups with teachers helped us delve into their understanding of inquiry and what inquiry looked like in their classroom during modules. This example assumes that gifted students are participating in many of the same activities as other students, and therefore, structural components are the same. However, tiered activities to support gifted students would need to be assessed separately. In this case, we chose rubrics to assess the content learning and inquiry process these students demonstrated. If an intervention required gifted students to work independently or in small groups, different measures of their program structure would be needed, such as hours on task when working independently or contact hours with the teacher specifically focused on their tasks.
Develop or Select Measures and Confirm They Meet Standards for Validity and Reliability
The final step of evaluating FoI can take up as much of an evaluator’s time as they let it—selecting measures and collecting validity and reliability evidence to support the choice and design of the measures. In this section, we will also review some particular challenges of assessing program implementation and outcomes for gifted students.
The first consideration for indicators that require data collection beyond program records is whether to use existing measures or develop project-specific ones. The advantage of existing measures is that they may already have validity or reliability evidence that you can review. They may also have a strong theoretical basis or experts who developed the measure, lending them more credibility. In the NanoBio project, we used existing measures of teacher and student attitudes toward science that were developed by experts and had substantial validity evidence (Karabenick & Maehr, 2007). We also selected relevant items from the publicly released items from the National Assessment of Educational Progress (NAEP), which is a valuable resource for creating student knowledge assessments.
When a program serves a gifted and talented population, outcomes such as knowledge and skills may not be as straightforward to define and measure as it might be for a standards-aligned project like the NanoBio project. Additional instructional challenge can sometimes be offered through self-selected projects or greater independence on content. In these cases, a knowledge test may not be appropriate or different types of knowledge assessments may be needed. If each student is delving into a different area of expertise, a rubric focused on quality of products rather than content might be more appropriate for assessing learning outcomes.
When knowledge tests are appropriate, another challenge arises as most assessments are validated on the general population and may not consider gifted students specifically. Testing students who perform much higher than the students for whom the test was intended will lead to a few problems.
One problem is greater than expected measurement error. Efficiency dictates that most of the items on typical assessments are designed to differentiate between the knowledge levels of average students, which results in the typical student being challenged with multiple items around their level of performance (i.e., less measurement error). However, gifted students may only have one or two items that are challenging enough to distinguish their level of performance from other students, introducing more measurement error (Frisbie, 1988; Lohman & Korb, 2006).
A second problem for testing gifted students is the ceiling effect. This often occurs when gifted students are already achieving above grade level, and thus hit the ceiling (maximum score) of the assessment, which prohibits the gifted students from demonstrating their true achievement level on the test. This is a serious problem for evaluation! If students score highly on the pre-test, there is no room to show growth from the intervention. Or if all students’ achievement scores hit the maximum on the post-test, it is impossible to look for effects of FoI variability on student outcomes. Therefore, ceiling effects are especially important to consider for gifted students, and it would be prudent for an evaluation process to include pre-testing the assessments to be sure that they are specific and sensitive enough to the program so that students do not come in with high scores at pre-test and fail to detect growth for all students.
Finally, a third problem is regression to the mean. Even when there is sufficient ceiling on a test, there is some amount of measurement error present in the scores, and this error is much larger for very high and very low scores, compared with average ones (Rambo-Hernandez & Warne, 2015; Traub & Rowley, 1991). This greater error will result in a pattern where students who had very high scores will tend to have lower scores when re-testing (with or without true learning gains). Likewise, students with very low scores will tend to increase their scores at re-testing, even without any learning gains.
Every one of these issues can be addressed by administering a test that puts the typical gifted student closer to the intended average student that the test was designed for. A relatively easy solution is to use tests developed for older students. For example, a program might use NAEP items developed for higher grades. However, the evaluators must be sure that the items are aligned to the same learning outcomes. Sometimes it may be necessary to develop a new test specifically designed to provide appropriate and aligned challenge for gifted students.
Developing new measures
The downside to using existing measures is that they may not align with the program’s goals or may have the measurement problems just discussed. Evaluators will not gain any insight into why or when the program is successful if the fidelity measures do not align with the program or show no variability among students. For example, in the NanoBio evaluation, if we used an observation tool that reflected a different model of scientific inquiry, our program’s results might show that our teachers never accomplished this style of teaching. The program emphasized guided inquiry as defined earlier. So, a program-specific observation rubric was designed to document that lessons (a) had a clear scientific question, (b) involved at least some data analysis, and (c) involved students in interpreting data and making sense of their inquiries. The result was certainly a more basic rubric than experts would have developed, but it provided a program-specific measure on which to provide feedback and measure FoI.
For our knowledge outcomes, if we used a measure of basic proficiency in inquiry, we may have had a ceiling effect when we pre-tested student knowledge. Instead, we designed the test to have fairly low scores at pre-test but have room to increase, based on module-specific lessons. We also added several very challenging questions about research design that only students with complete understandings of inquiry would answer correctly (these items came from Grade 8 NAEP items while others came from Grades 4 and 6). This allowed us to have an assessment that was tailored to our population, without too many or too few challenging questions.
If an evaluator is developing their own survey instruments or measures of knowledge, they will need to gather at least some validity evidence (Boller & Kisker, 2014; Fink, 2016) and use expert guidance while writing items (Grudens-Schuck, Allen, & Larson, 2004; Harlacher, 2016; Yohalem, Wilson-Ahlstrom, Fischer, & Shinn, 2009). When using existing measures, the evaluator needs to determine that appropriate evidence exists to support their intended use of the measure.
It is not possible to review assessment validity and reliability methods here, but a few examples of relevant validity evidence are provided in Table 2. For example, if a program is seeking to differentiate the quality of teaching in an experimental and control group using an observation rubric, then the observation ratings must be consistent enough to make that comparison across groups (Table 2 suggests seeking interrater reliability estimates). If a survey of student motivation is needed, then validity evidence should show that it aligns with current motivational theory (expert review) and shows variability between students (item difficulty and discrimination). When examining the reliability and validity information, pay attention to the samples used in the studies. Simply because a survey worked well in one sample does not necessarily mean the same results should be expected with gifted populations. A good rule of thumb is to evaluate the reliability and validity of all measures used with any new sample and not just trust the scales will work well based on previous studies. Textbooks on classroom assessment can provide a helpful introduction to these methods (Brookhart & Nitko, 2018), but the ultimate technical guide is the Standards for Educational and Psychological Testing (American Educational Research Association, American Psychological Association, & National Council on Measurement in Education, 2014).
A Few Examples of Validity Questions and Associated Evidence
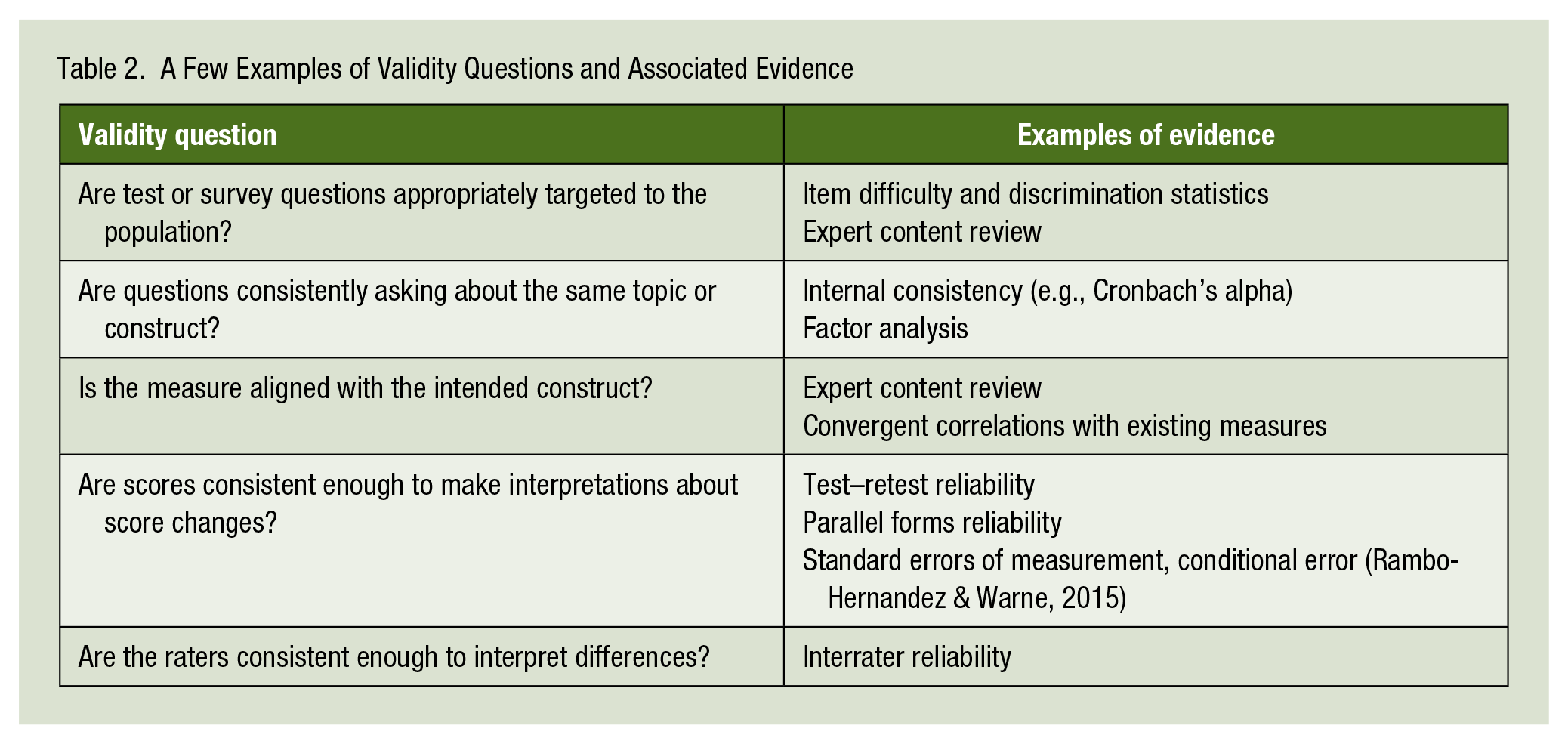
At a bare minimum, creating new measures should entail at least a small pilot test or expert review where members of the tested population (students or teachers) or experts in the field review the items. The goal is to confirm that the questions are (a) comprehensible and error-free and (b) aligned with the theory of the construct or concept you are trying to measure. For example, if an evaluator needed to measure content knowledge for students in a program, they might have a pilot study group of 10 students take the pre-test to make sure there are no confusions and that students do not already know the material before the lesson or program begins. If more intensive preparation is possible, the evaluator could also use a group of 20 or more participants to calculate item difficulty and internal consistency statistics for the test to provide that level of confidence in measures. If factor analysis is possible, which often requires a sample of over 100, it is also generally a good idea to test twice as many items as the evaluator thinks will be needed on the final test—that way the items that function the best can be retained and the others can be dropped before using the test in the evaluation.
Collecting validity and reliability evidence for fidelity measures should be aligned to the stakes associated with the evaluation project. A nation-wide, randomized control trial such as the one described in Callahan, Moon, Oh, Azano, and Hailey (2015) necessitated extensive survey and measurement development with validity studies conducted in advance of the evaluation study. A local evaluation of a program intended to communicate the impacts with donors or administration might not require nearly as much preparation or rigor.
Luckily for the NanoBio project, the evaluation team involved several other experts and was able to support a number of graduate students who collaborated to collect validity and reliability evidence to support (and improve) the evaluation measures over the course of the grant (Askia, Hill, & Lakin, 2018; Cooper, 2015). This is usually not the case for program evaluators who are based in schools, conducting informal evaluations, or those who are evaluating programs they are also leading. In such cases, it can be more practical to use existing measures wherever possible and consult evaluation or program experts when new measures are needed.
Moderators of Implementation and Fidelity 1
In the classroom, teachers play a critical role in whether curricular programs have significant impacts because they determine whether and how much the program elements occur in the classroom (Allinder, 1996). For more formal evaluations or when a program is ready for scale-up or dissemination, evaluators may want to consider not only measuring FoI but also some key moderators of implementation (Durlak & DuPre, 2008; Lakin & Shannon, 2015; Missett & Foster, 2015). Reimers, Wacker, and Koeppl (1987) provided a helpful model for explaining why high-fidelity treatment implementation does not always occur, using factors that are external, but related, to FoI. Most relevant to educational interventions are the concepts of treatment acceptability, perceived effectiveness, and understanding, which Reimers et al. argued would influence implementation and, therefore, affect the impact of the program (i.e., a moderating variable). Each of these features is especially important to understand and measure when a treatment or program involves the regular classroom teacher in supporting gifted education.
Treatment acceptability is based on the perceived appropriateness, fairness, reasonableness, and intrusiveness of a treatment to address a particular problem (Reimers et al., 1987). Acceptability suggests the following questions by program implementers—Is there a problem or need? Will the program address the need? Is it worth the time and resources it requires?
Teachers have many demands on their time. Therefore, they may not fully implement a program that they do not perceive as addressing an important need or that they see as too weak or too intrusive, given their other priorities and student needs (O’Donnell, 2008). Teachers must also perceive that the program is fair to all students to implement. For example, if teachers feel that gifted students are “already doing well,” they may not exert the effort to make a program effective for those students if they perceive it as taking time and attention from other students who need their focus (Hertberg-Davis, 2009). For school interventions, administration and community support and perceptions are also determinants of acceptability (Broughton & Hester, 1993). Teachers may resist a program they feel is not valued or acceptable to these stakeholders.
Effectiveness is the perception that the treatment will impact the problem or outcomes of interest. Beyond acceptability, teachers must believe that this program is the right intervention to address a need. For gifted students, myths and misunderstandings could lead to perceptions that a program may not be effective (Lassig, 2009). For example, if an educator believes a gifted student is “always gifted” in every domain, they may not feel that a program designed to provide scaffolding for twice-exceptional students is appropriate for a student identified as gifted (e.g., Assouline, Nicpon, & Huber, 2006). Because educational programs often rely heavily on teachers to make the program happen as intended, their self-efficacy for implementing the program and their confidence in the program leaders are critical.
Finally, program understanding refers to the program implementer’s comprehension of general and specific components of the program. Teachers or other program implementers must understand the program and its components sufficiently to implement the program as intended (Lassig, 2009; Tanol, 2010). For example, if a new mathematics curriculum requires students to engage in investigations, teachers used to traditional math instruction will require many new skills to implement this strategy effectively, including pedagogical and content knowledge as well as new classroom management skills. If a school is implementing differentiation strategies in the regular classroom, gifted education coordinators need to make sure that regular classroom teachers understand the particular needs of the gifted students in their classroom and differentiate their classrooms appropriately for all. Neumeister, Adams, Pierce, Cassady, and Dixon (2007) demonstrated that teachers with a shallow understanding of giftedness failed to refer gifted minority students, thus failing to understand the program and its purposes. An obvious limitation to program understanding is the availability and effectiveness of PD. An entire literature exists on effective PD and should be consulted when designing a new program and training (e.g., Guskey, 2002).
In the NanoBio program, acceptability and perceived effectiveness were critical to the early success of this program. Teachers needed to recognize that this program would provide more engaging and effective science curriculum than the other programs available to them before they would invest the time to learn about the new modules. The program also had to forge connections to administration so that they would support their teachers and the nascent professional learning communities forming in their school. Once teachers began to implement the program, we focused on their understanding. We found that teachers held limiting ideas about scientific inquiry that needed to be addressed by the program through additional PD. In providing tiered instruction, we faced the challenge that many low-performing schools have of teachers reporting they have “no gifted students” at their school. To address this, part of our PD focused on identifying students who learn quickly (regardless of identification status) and building in practical modifications for additional challenge. We also worked with curriculum developers to integrate these features into their work.
Evaluators also need to consider various demographic and school-level features that may influence (moderate) the effectiveness of programs or affect implementation. Like teacher attitudes, student characteristics, school features, and other contextual variables can be moderators of program effectiveness (Harn, Parisi, & Stoolmiller, 2013). Understanding why programs lead to desired outcomes, therefore, also requires evaluators to understand when and where programs are most effective. Student and school characteristics can be collected as part of the evaluation and used in quantitative and qualitative analyses to understand the contexts in which programs are most effective. Appropriate adaptations to particular student needs can also be specified as part of the process components of the program.
Dosage: A Moderator of Program Effects
Another way to explore why and when a program has greater or weaker impacts is to measure program “dosage” (termed “exposure” in Azano et al., 2014). Measuring exposure to the program allows evaluators to correlate the magnitude of program effects to the amount of programming students receive. Dosage issues seem especially relevant to gifted education where students may only receive appropriate instruction when they are in a pull-out program or work with specific programs or specialists. It is also important to consider when regular classroom teachers vary in their ability or willingness to implement appropriate gifted education practices. In such cases, dosage is a critical consideration to determine if the program is effective or if it was not implemented enough to have intended effects.
For example, imagine a district where students who are identified for gifted services are expected to receive a specific curriculum implemented by a gifted specialist. In some schools, there is a gifted specialist working full-time and providing 3 hours of the program each week to all students in a given grade level. In that same district, there are three schools served by just one gifted specialist who has to travel between schools. Those students may only receive the program half the time of other students. Optimistically, we might hypothesize that those students who receive half the services might show half the academic gains of other students. If we carefully track the exposure or dosage and carefully measure achievement gains of students (being sure to avoid a ceiling effect!), we will be able to use regression statistics (using pre-test scores as a control variable and dosage as a predictor variable) to determine program impacts based on dosage. For more advanced programs, dosage may be specified if it is known how much of the program is needed to achieve desired outcomes.
Formative and Summative Purposes of Fidelity
Evaluators can benefit from exploring FoI whether an evaluation’s goal is formative or summative (or both). For example, if a program is collecting summative outcomes to document the impacts of a program, FoI can help identify when and why variations in effects occur. These variations may also be explored among subgroups of students, such as documenting effects for gifted versus regular classrooms.
With formative evaluation goals, evaluators may find measuring process and structural aspects of fidelity especially valuable. For example, in the NanoBio program, by gathering information about teacher beliefs and attitudes regarding the program curriculum, we were able to determine that teachers needed more PD around the module content. They did not feel comfortable with the disciplinary content and felt that some modules aligned with the standards better than others. If we had only considered module use or evaluations of the overall program effects, we might not have been able to identify the specific needs of the teachers at this early stage and communicate that need to the program.
Fidelity Versus Necessary Flexibility
Can variations in fidelity be a good thing? When taken to its logical extreme, one might assume that a focus on FoI means that all teachers should be implementing the program identically at all times. Or it might suggest that any one program will meet all students’ needs. Clearly, the field of gifted education has proven that a one-size-fits-all approach to education is patently erroneous and ineffective. Furthermore, program flexibility is necessary to support the practices of culturally responsive teaching and differentiation approaches. Both strategies task teachers with adapting what they are teaching and how they are teaching it to the particular needs and abilities of their students. From this perspective, it is unreasonable and inappropriate to expect that every program will be implemented identically in every classroom (O’Donnell, 2008).
As a result of these influences, effective programs must be built to allow for the flexibility needed in the classroom and to allow teachers to exercise professional judgment. In turn, high-quality implementation of that program should reflect appropriate flexibility to the context, to the students, and to the content being taught (Harn et al., 2013).
One implication of this need for flexibility is that the structural and process components defined for the program must take into consideration acceptable variation or flexibility (O’Donnell, 2008). If the program developers are not sure how much flexibility is appropriate, another important product of an evaluation might be to document what types of variations or degree of flexibility yield similar program outcomes.
Some evaluators discussing fidelity will give a target compliance rate (e.g., 90% treatment is high-fidelity implementation). However, this is a concept from the clinical view of fidelity that does not readily translate to many educational evaluations of fidelity (Harn et al., 2013). Some programs may be able to set targets for implementation, particularly for structural components of the program. However, a more nuanced interpretation of “compliance” is needed in education, particularly for process components of programs. For our NanoBio project, teachers received a recommendation on how many modules to use during a school year, so we could quantify teachers in terms of whether they had met the target number or not. However, when assessing their inquiry implementation, we focused more on the formative, qualitative feedback we could provide rather than focusing on whether or not they had implemented inquiry a certain number of times.
Advancing the Science of Gifted Education
Beyond its importance to the practical needs of program evaluation, FoI is also a key to furthering the science of gifted education (Missett & Foster, 2015). Using the concepts in this article, and measuring fidelity in their work, evaluators can better understand when and why a program works. As Mowbray et al. (2003) put it, FoI helps evaluators and researchers go beyond the “black box” (p. 315) of interventions to identifying the specific mechanisms or components of the program that lead to desired outcomes. This in turn wil inform our knowledge of learning and student development.
Educators can also be more efficient when they understand the mechanisms of program effectiveness. A complex program may have extraneous complications and could be simplified or merged with other programs, retaining only the essential components. By understanding mechanisms, programs can specify the level of flexibility that is necessary for appropriate implementation. As gifted education increasingly seeks to enhance the quality of its research and confidence in its curricular theories, fidelity is a key element for program evaluation and evidence-based practice (Callahan et al., 2015; Coleman, Gallagher, & Job, 2012; Harn et al., 2013; Missett & Foster, 2015; O’Donnell, 2008).
Footnotes
Conflict of Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Bios
Joni M. Lakin (PhD, The University of Iowa) is an associate professor of educational research, methods, and analysis at Auburn University. She conducts educational measurement research related to test validity and fairness with a particular interest in the accessibility of tests for English learner students. She is co-author of the Cognitive Abilities Test (Form 8) alongside Dr. David Lohman. She also conducts research and evaluation in STEM education to promote STEM retention along the academic pipeline.
Karen Rambo-Hernandez (PhD, University of Connecticut) is an associate professor in the Department of Teaching, Learning, and Culture in STEM Education at Texas A&M University. Her research interests include novel applications of multilevel modeling and growth modeling, the assessment of educational interventions to improve STEM education, and access for all students—particularly high achieving and underrepresented students—to high quality education.