
Abstract
Research on maltreatment exposure often demonstrates mixed findings and a potential explanation for this may be the measurement of maltreatment. One approach for addressing measurement concerns, which also accounts for maltreatment’s multidimensional nature, is the use of a measurement or latent model. However, there is minimal evidence on the generalizability of this approach across populations of youth. This study examined measurement invariance of a one-factor maltreatment model across two samples of youth exposed to maltreatment using case file data from the SPARK and LONGSCAN datasets (N = 1286). Results showed that only partial metric invariance could be established for the one-factor model between SPARK and LONGSCAN subsamples, and neglect and emotional abuse indicators tended to show low factor loadings. Findings highlight the need to consider how potential differences in documentation and maltreatment rates influence model performance and the need for research on which maltreatment characteristics may best capture youths’ experiences.
Introduction
Maltreatment has been associated with a wide range of negative outcomes in both childhood and adulthood that span several areas of functioning, including areas of both physical and psychological wellbeing (e.g., Danese & Tan, 2014; Widom, 2014). Yet, despite robust and consistent links between maltreatment and subsequent poor functioning, some studies have also produced mixed or even conflicting findings. While there are several possible explanations for why contrasting results may emerge (e.g., differences in the methods used to measure a similar outcome variable), one possible explanation is the approach for examining the construct of maltreatment. The methods used to measure and analyze exposure to maltreatment in youth are often inconsistent between studies (Jackson et al., 2019). Further, the construct of maltreatment is multidimensional (Manly, 2005), making comprehensive description of the construct difficult to summarize in a parsimonious way. Over the last 20 years, there has been substantial progress in the development of methods that seek to better capture the complex experiences of youth who have experienced maltreatment (e.g., English et al., 2005; Gabrielli & Jackson, 2019). One such method with demonstrated promise is the use of a latent variable or measurement model approach. A key component of latent modeling involves the ability to replicate models across studies and samples. The current paper seeks to inform the science of maltreatment measurement by examining the generalizability of a latent modeling approach across two different samples of youth exposed to maltreatment.
Latent Variable Approaches to Maltreatment Measurement
Maltreatment is a complex variable that includes not just the recording of the event, but also recording facets of the experience like type, frequency, severity, and chronicity or duration of exposure (e.g., Manly, 2005). Thus, proper operationalization and examination of maltreatment in research requires the use of advanced statistical approaches that are able to account for the multifaceted nature of this construct. Over the years, a variety of statistical approaches have been applied to the study of maltreatment, including both person-centered and variable-centered methods (e.g., Gabrielli et al., 2017; Rivera et al., 2018). One such variable-centered approach is the use of a measurement model of maltreatment (or some more specific form of maltreatment exposure), where maltreatment is treated as a latent construct using structural equation modeling (SEM) and confirmatory factor analysis (CFA). In this approach, manifest or measured variables that represent characteristics of maltreatment exposure are used to create the latent maltreatment construct, which captures the shared or common variance among the various indicator variables used to create the model.
There are several proposed benefits for the use of a latent measurement model of maltreatment that address previous limitations in maltreatment measurement, such as limitations associated with measuring only a single dimension or trying to combine multiple but related measurements of maltreatment into a single analysis. By capturing multiple facets of maltreatment at once, it is thought that the subsequent “maltreatment score” or factor score in a measurement model will be a more accurate representation of maltreatment, compared to a single observed variable as factor scores are informed by multiple aspects of maltreatment. This approach is also appealing because maltreatment in most circumstances cannot be measured directly. The use of a latent modeling approach can account for the measurement error that may occur from gathering information across many different indicators or different sources of maltreatment (Kline, 2015). Further, the complexity of maltreatment may be captured through a variety of measures that each assess some aspect of these experiences. Specifically, a latent approach allows for the inclusion and representation of the heterogeneity of maltreatment exposure that youth experience. Because the model can utilize data on many characteristics simultaneously, such models can account for the common occurrence of polyvictimization across maltreatment types or differences in characteristics of exposure (e.g., frequency, severity) within and between certain types of maltreatment. This contrasts with other measurement methods, such as comparing group scores for youth based on a single type of maltreatment. Moreover, measurement models can account for the shared variance or commonalities that underlie each maltreatment type and its dimensions, such as parenting practices or poverty.
Over the last decade, several studies and projects have used measurement models of maltreatment in research. A series of models found to fit well with various samples of youth have varied with regard to the types of maltreatment exampled and number of latent factors. Several studies have utilized a one-factor model of maltreatment (Berber Çelik & Odacı, 2019; Gabrielli et al., 2017; McGuire et al., 2018). For example, a one-factor model was developed by Berber Çelik and Odacı (2019) using self-reported frequency of exposure for physical abuse, sexual abuse, and emotional abuse, while Gabrielli et al. (2017) and McGuire et al. (2018) used both self-report and case file report of frequency and severity ratings for the four main types of maltreatment (physical, sexual, and emotional abuse, and neglect). Briere et al. (2017) developed a two-factor model of maltreatment using frequency and polyvictimization estimates for non-sexual (i.e., physical and emotional abuse) and sexual abuse. As another example, Brumley et al. (2019) also found a well-fitting two-factor model based on binary indicators of the four main types of maltreatment, with the two factors appearing to be related to frequency of endorsement. Other studies have sought to examine bi-factor or higher order models, such as Lombera et al. (2021) who developed a bi-factor model using caregiver and child reported severity, frequency, age-of-onset, and duration of exposure for physical abuse, sexual abuse, and witnessing domestic violence. As these studies demonstrate, models have varied based on the type of indicators or characteristics of maltreatment utilized in model creation, with most models utilizing severity and frequency estimates of multiple types of maltreatment. Additionally, the source of data used to create models has differed. This includes some studies using case file (e.g., McGuire et al., 2018), self-report (e.g., Gabrielli et al., 2017), or a combination of case file and self-report data (e.g., Kobulsky et al., 2018).
Examining Maltreatment Latent Variable Approaches across Samples
Despite some progress in use of maltreatment measurement models, there remain several questions about the benefits of this approach. One concern is the generalizability of identified models to different samples of youth with experiences of maltreatment (e.g., McGuire & Jackson, 2018). It is unclear whether a model tested for one study can be applied to a new population of youth exposed to maltreatment, since multiple models to date have been utilized and no similar models have been observed across different samples. It may be the case that lack of knowledge about the generalizability of these models may be contributing to this approach’s lack of adoption more widely within the field of maltreatment research. Thus, determining the consistency or robustness of these models across samples has notable implications for guiding research in this field. For example, having an empirically informed model of maltreatment may provide clarity about how best to conceptualize maltreatment for research, assist in reproducibility of findings when research projects include the same structure or maltreatment measurement approach, and help determine whether mixed findings between studies may be a result of differences in maltreatment related factors as opposed to other sample characteristics.
Additional support for the need to examine model generalizability comes from evidence of within study model testing. Gabrielli et al. (2017) examined measurement invariance of a one-factor maltreatment measurement model based on age, gender, and foster care placement type in a sample of youth in foster care. Across all three comparison types, the authors only found support for metric invariance. This suggests that while the overall model may have fit the data well, other various aspects of the measurement model (e.g., model intercepts and means) were significantly different based on these characteristics of the youth within the study sample. These findings indicate that even with one sample certain aspects of a measurement model may differ between certain groups of youth. Further, these findings from Gabrielli et al. (2017) raise additional questions about how similar (or dissimilar) a measurement model may be between different samples of youth. For example, it is unclear whether a measurement model would even demonstrate a similar structure in two different samples of youth exposed to maltreatment. This may be because of the multitude of ways in which youth differ beyond just demographics because of sampling methods, as well as research methods. For example, there is a plethora of complex factors that contribute to exposure (and documentation) of maltreatment and other unique characteristics of project samples (e.g., child welfare involvement, region of the country) that may differ study to study (Coulton et al., 2007). Many of these factors could influence measurement model generalizability or possible invariance across samples. Further, many of these factors (e.g., community poverty or violence exposure, a county or state level agency’s procedures for handling maltreatment) go beyond what is possible to control or account for in a single study’s statistical analysis. With regard to the research procedures of this process, projects also often differ with regard to source of maltreatment data (e.g., self-report vs. case files), how data on maltreatment is measured (e.g., questionnaire vs. interview), or what coding system might be used to characterize exposure if case file data is utilized (e.g., English & the LONGSCAN Investigators, 1997; Jackson et al., 2019).
Current Study
The current study sought to address gaps in understanding regarding the utility of maltreatment measurement models through a direct comparison of maltreatment measurement models across multiple unique samples of youth with exposure to maltreatment. These comparisons were accomplished through multi-group confirmatory factor analysis (MGCFA) to examine measurement invariance of a maltreatment measurement model for commonly examined dimensions of maltreatment, the frequency and severity of four maltreatment types (physical, sexual, and emotional abuse, and neglect). The samples for the current study included the Longitudinal Studies of Child Abuse and Neglect (LONGSCAN; Runyan et al., 2014) and Studying Pathways to Adjustment and Resilience in Kids (SPARK; Jackson et al., 2012) projects. Given the multitude of factors that can vary between studies, these two samples provided a reasonable first step in examining stability of a maltreatment measurement model. Specifically, several similarities between the samples reduce some of the possible extraneous factors that may contribute to possible observed differences. Specifically, both studies: (a) were focused on youth with documented exposure to maltreatment or at-risk for maltreatment exposure, (b) examined and measured maltreatment exposure using a multidimensional approach, (c) utilized similar measurement procedures for measuring maltreatment using case file data, and (d) included a sample of youth in foster care. It was hypothesized that the one-factor maltreatment model would demonstrate scalar invariance across the datasets, such that the model structure, loadings, and intercepts would be equivalent between the two groups and suggest similarity in the interpretation of the level or score of the maltreatment factor.
Methods
Participants
LONGSCAN Sample
One sample was comprised of youth enrolled in the Longitudinal Studies of Child Abuse and Neglect (LONGSCAN; Runyan et al., 2014) project. The project consisted of data collection spread across five sites in the United States: Midwestern, Northwestern, Eastern, South, and Southwestern. Although there were many similarities between the sites (e.g., measures administered, data collection procedures, training), the recruitment at each data collection site varied depending on youths’ risk or actual exposure to maltreatment. There was a total of 1354 participants included in LONGSCAN. Of those participants in the full sample, 947 participants were used for the current study due to available case file information. Case file data was collected on youth until early adolescence (12–14 years); thus, only data from this time point and prior were used. Among the LONGSCAN sites, participants were separated into two primary groups for further comparisons during data analyses. This included a “Foster Care” subsample, which consisted of youth from the Southwest site since this site’s primary and unique focus was on youth in the county dependency system due to confirmed maltreatment. This allowed for an additional comparison beyond the full LONGSCAN sample between two samples of youth with involvement in the foster care system (i.e., SPARK vs. Foster care LONGSCAN subsample). The other group was an “At-risk Community” group, which consisted of youth from the other four sites who were all involved in some form of recruitment of youth at-risk for maltreatment or CPS involvement. Although, there is some potential for youth in the At-risk Community group to have been placed in foster care, it was anticipated that this would be a very minimal portion (e.g., English et al., 2015). See Runyan et al. (2014) for information on recruitment and procedures.
SPARK Sample
The Studying Pathways to Adjustment and Resilience in Kids (SPARK) Project was a federally funded longitudinal research project investigating factors associated with resiliency among youth in foster care (Jackson et al., 2012). All participants were recruited from a metropolitan county in the Midwest. To be eligible for the study, youth needed to have: (a) been living in their current foster care placement for at least 30 days prior to beginning data collection, (b) English as their primary language, and (c) no prior diagnosis of an intellectual or developmental disability (e.g., autism spectrum disorder). Data for the current study included only information obtained on demographics variables from the first time point of the SPARK Project, in addition to the data extracted from youths’ case files. There were a total of 496 eligible participants who had case files and data on demographics variables in the SPARK sample. However, because of the lack of case file data past the age 12 data collection time point for LONGSCAN (which could also include youth up to age 14), SPARK participants older than 14 were excluded from the current study to aid in comparison with the LONGSCAN sample, resulting in a final SPARK sample size of 339. For more information on the recruitment and data collection procedures utilized for SPARK, please see Jackson et al. (2012).
Measures
Demographics
In both SPARK and LONGSCAN, a demographics form was administered to participants’ caregivers at baseline data collection (i.e., ages 4 or 6, or pre-age 4 for LONGSCAN, time point #1 for SPARK). Information from both studies was extracted on youths’ date of birth, race, ethnicity, and gender. For the LONGSCAN dataset, youths’ age at the age 12 (i.e., early adolescence [11–14]) timepoint was utilized, which was based on birthdate.
Maltreatment Exposure
For both the SPARK and LONGSCAN datasets, youths’ history of exposure to maltreatment was extracted from case file reports using the Modified Maltreatment Classification System (MMCS; English & the LONGSCAN Investigators, 1997). The MMCS is used in research to extract detailed information on maltreatment reports using the narratives included in youths’ Child Protective Services (CPS) files. For each study, trained coders (who met an internal standard of reliability) reviewed and extracted information on lifetime exposure from events involving only the youth. In line with previous studies and empirical evidence demonstrating the importance of including both substantiated and unsubstantiated reports (e.g., Fluke, 2009), all events for the youth were included in data analysis. For more information on the coding of the case files as part of the SPARK Project, please see Huffhines et al. (2016). For more information on coding in LONGSCAN, please see Runyan et al. (2014). Of note, LONGSCAN personnel who were involved in case files coding were consulted to support development of the coding process used in SPARK.
For the current study, information on the type, frequency, and severity of physical abuse, sexual abuse, emotional abuse, and neglect was included in the data analyses. These types were determined by matching the description of an event in a narrative with the definition of each type identified by the MMCS coding system. Similarly, severity for each type of maltreatment was coded on a five-point Likert scale, from 1 (representing least severe experiences) to 5 (representing the most severe types of experiences), based on information in the case file matched with the descriptive codes of the MMCS. Severity codes for each type of maltreatment were determined a priori by the measure developers and corresponded with the actual or potential physical and psychological harm for an event (English & the LONGSCAN Investigators, 1997). A weighted mean severity score was then calculated across endorsed events for each participant by adding together the severity level for each event and then dividing by the total number of endorsed events. For frequency of each maltreatment type, the number of reports for each type were summed together.
Procedures
Approvals of all study procedures for the SPARK and LONGSCAN studies were obtained from the respective institutions’ Institutional Review Board. Where required, further approval was also obtained from local state agencies and organizations for participation and access to necessary records for youth involved in the child welfare (e.g., Jackson et al., 2012).
LONGSCAN Procedures
Across the LONGSCAN sites, standardized protocols were utilized to ensure measures, training, data management, and data collection procedures were similar. For the current study, information on youths’ demographics was obtained during baseline assessments at least prior to the youth being age 6. This information was collected during face-to-face interviews with each youth’s primary caregiver. Information on maltreatment exposure was obtained through periodic review (approximately every 2 years) of case file data for those youth involved in LONGSCAN until the youth were around age 12.
SPARK Procedures
At the first of three data collection sessions, participants (including both the youth and their primary caregiver) were invited to a community location for an approximate three-hour data collection session. Data on youths’ demographics used in the current study were obtained from the primary caregiver using an audio-computer assisted self-interview (ACASI) program on a laptop computer. Youths’ case files were provided to the project by the Division of Social Services (DSS).
Data Analysis
All analyses were conducted in R (R Core Team, 2021). Data analysis for the current study was carried out in three parts. First, descriptive statistics were computed for each of the datasets. Further, possible differences along primary maltreatment (e.g., prevalence of physical abuse) and demographic (e.g., age, gender) variables were tested between the differing study samples (i.e., LONGSCAN vs. SPARK) using independent samples t-tests and examined for significance. In the second part of the analysis, confirmatory factor analysis (CFA) was used to establish baseline models for each dataset and sub-dataset. For the current study, a one-factor model was examined based on previous studies showing this model fits well with the SPARK sample using both case file and self-report data, as well as being a model that could incorporate the four primary types of maltreatment with multiple dimensions for each type (e.g., McGuire & Jackson, 2018). For these models, eight indicator variables were used to create the single latent maltreatment variable, which included the severity and frequency scores for the four primary types of maltreatment: physical abuse, sexual abuse, emotional abuse, and neglect (Figure 1).1 In each model across the datasets (i.e., total sample, SPARK, LONGSCAN, Foster Care LONGSCAN, At-risk Community LONGSCAN), the error covariances were estimated between the severity and frequency score for each maltreatment type, and the latent maltreatment variable(s) were fixed to 1.0. One-factor baseline maltreatment measurement model.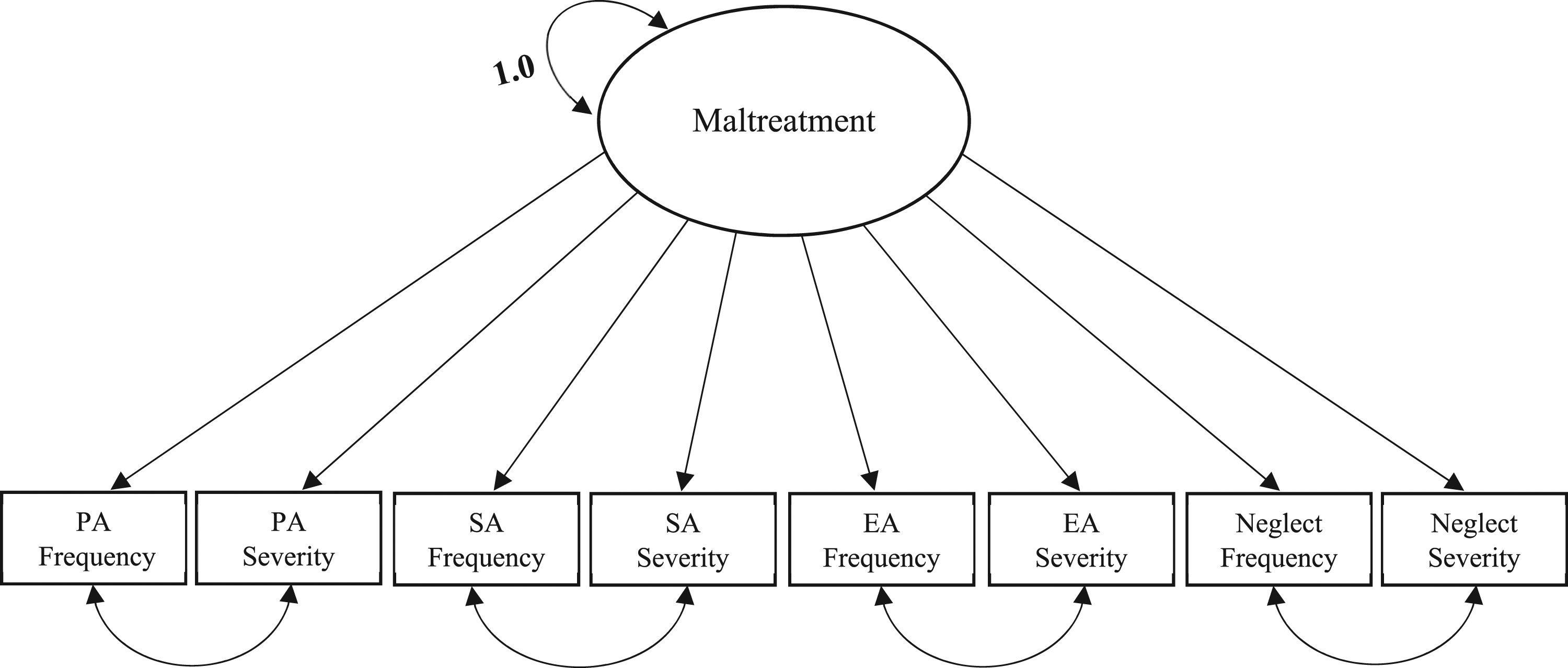
Each model with the various samples was constructed using structural equation modeling (SEM) using a maximum likelihood estimator with robust standard errors (MLR). Further, full information maximum likelihood (FIML) was utilized to account for missing data (total missing data = 2.1%). The use of these methods allowed for the calculation of unbiased parameter and standard error estimates, which can also account for multivariate non-normality in the distribution of the variables included in the models. To evaluate model fit as part of these confirmatory factor analyses, the following fit indices (with their respective cutoffs) were examined: the chi-squared test statistic, the root-mean-square residual error of approximation (RMSEA; <.05), standardized root mean square residual (SRMR; <.05), comparative fit index (CFI; <.95), and Tucker-Lewis Index (TLI; <.95; Hu & Bentler, 1999). Following creation of the baseline models, modification indices and standardized residuals were examined for possible model modifications that may improve model fit.
In the third part of the analysis, measurement invariance or the robustness of the model fit across the SPARK and LONSCAN samples was tested using multi-group CFAs for the well-fitting models from part two of the data analysis plan. In total, three MGCFAs were conducted, one for SPARK versus LONGSCAN, SPARK versus Foster Care LONGSCAN subsample, and SPARK versus At-Risk Community LONGSCAN subsample. As part of this process, models were created and tested in stepwise fashion with each level representing a model with a greater number of equivalence restraints on parameter estimation. The first level tested was configural invariance, involving evaluation of the maltreatment model structure. The next level, metric (weak) invariance, examined similarities of loadings. Next, for determining scalar or strong invariance, both the factor loadings and the intercepts were constrained between groups. Lastly, regarding strict invariance, the model for each group was compared with the addition of the residual error variances and covariances being constrained (Kline, 2015; Schmitt & Kuljanin, 2008). Failure to demonstrate measurement invariance or equivalence when comparing the more and less restrictive models was indicated by a significant chi-square difference test or a change greater than .01 in the CFI (Cheung & Rensvold, 2002; Contractor et al., 2019). If these criteria were not met, the process of testing measurement invariance was stopped. Partial invariance at each level was considered by examining model modification indices and multivariate tests.
Results
Descriptive Statistics for Study Samples.
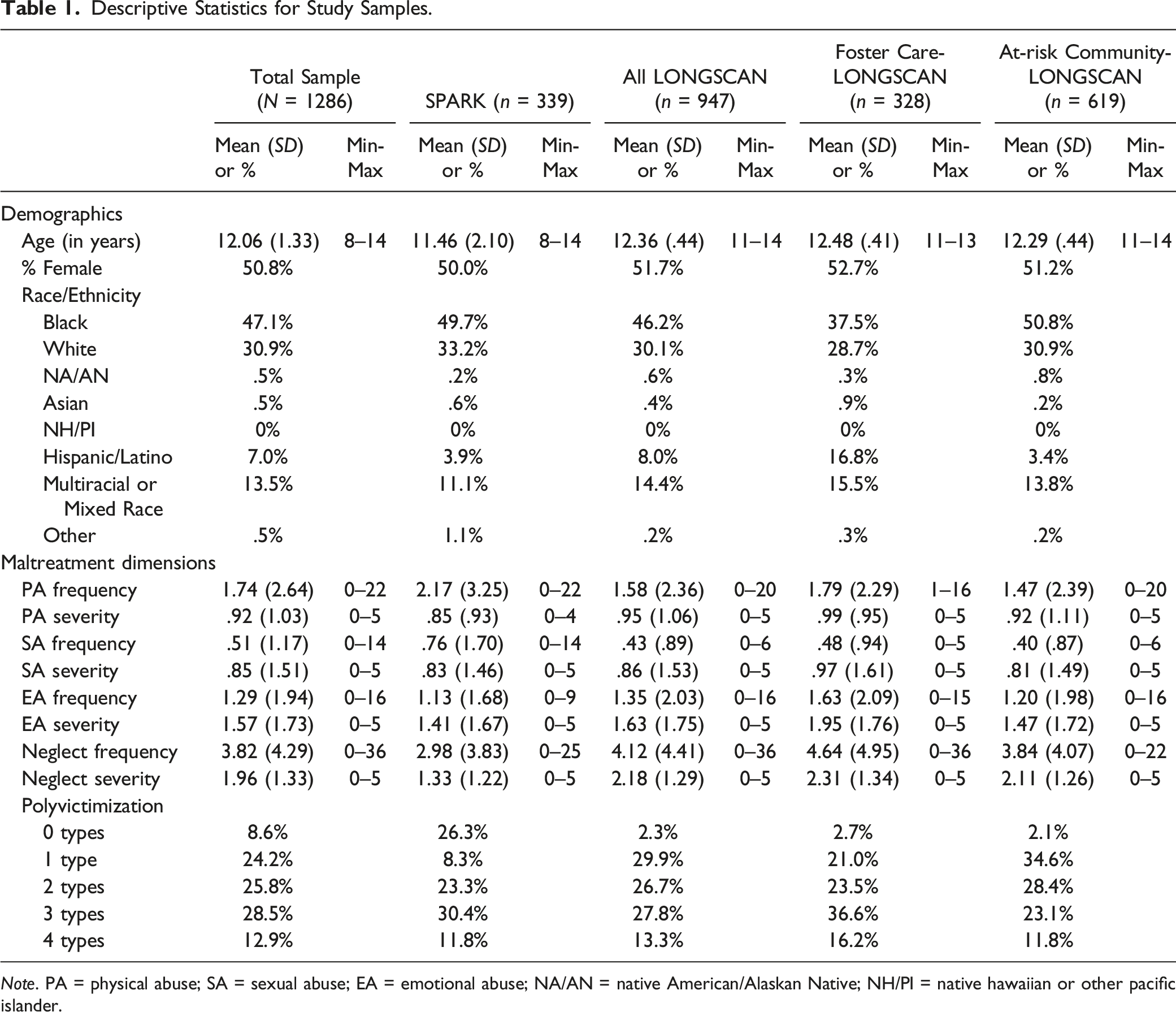
Note. PA = physical abuse; SA = sexual abuse; EA = emotional abuse; NA/AN = native American/Alaskan Native; NH/PI = native hawaiian or other pacific islander.
Correlations between the Study Variables for SPARK and LONGSCAN.

Notes. Correlations below the diagonal represent the SPARK sample values (n = 339), and correlations above the diagonal represent the LONGSCAN sample values (n = 947).
PA = physical abuse; SA = sexual abuse; EA = emotional abuse.
Gender (0 = female, 1 = male).
Initial Model Testing
Model Fit Statistics for One-Factor Model.

df = degrees of freedom.
* = p < .05.
aIncluded the addition of a covariance between physical abuse frequency and emotional abuse frequency.
Overall fit was adequate, although not completely satisfactory, for the SPARK and LONGSCAN one-factor maltreatment measurement models (Table 3). Similar to the full sample model, the RMSEA was slightly above the recommended cutoff of .05 for both subsample models, in addition to the TLI being slightly below the recommended cutoff of .95. For the SPARK sample model, all factor loadings were significant (p < .05). Further, all factor loadings were greater than .30, with the exception of the factor loading for sexual abuse frequency (factor loading = .28). All estimated covariances were significant, with the exception of the covariance between emotional abuse frequency and severity (p = .36). For the LONGSCAN model, only the factor loading for neglect severity was non-significant (p = .46). All estimated covariances were significant. Several factor loadings were below .30, including: physical abuse severity (factor loading = .26), sexual abuse severity (factor loading = .22), and neglect severity (factor loading = .01). Similarity, in the At-Risk Community LONGSCAN subsamples, only the factor loading for neglect severity was non-significant (p = .47). Regarding covariances in the Foster Care LONGSCAN model, the covariance between emotional abuse frequency and severity, as well as neglect frequency and severity, were non-significant. Also, several factor loadings were below .30, including: physical abuse severity (factor loading = .18), sexual abuse frequency (factor loading = .24), sexual abuse severity (factor loading = .17), and neglect severity (factor loading = −.08). In the At-Risk Community LONGSCAN subsample, all covariances were significant (p < .05). Two factor loadings were below .30, including: sexual abuse severity (factor loading = .25) and neglect severity (factor loading = .05).
In examining the modification indices and standardized residuals for each model, a commonality across each model was the suggested estimation of the covariance between physical abuse frequency and emotional abuse frequency. This was also supported by the moderate to strong correlation between these factors in the overall sample (r = .55), which was the highest correlation among any of the non-similar maltreatment type dimensions. This covariance was added to the model, which significantly improved model fit across all samples (Table 3), as demonstrated by a significant chi-square difference (using the Satorra-Bentler correction given the use of MLR) between the old and new model for each sample (all ∆df = 1, all ∆χ2 > 6.41, all p’s < .05). Following the modification to the model, the concerns with low factor loadings (i.e., factor loadings <.30) were still present in each model.
Model Measurement Invariance
To examine measurement invariance, MGCFA was utilized to examine differences in the maltreatment measurement model between (a) SPARK versus LONGSCAN, (b) SPARK versus Foster care LONGSCAN subsample, and (c) SPARK versus At-Risk Community LONGSCAN subsample. For the invariance testing, the modified one factor model with the additional freed covariance between physical abuse frequency and emotional abuse frequency was utilized. Configural invariance was established with the one-factor maltreatment measurement model for the SPARK versus full LONGSCAN comparison, although concerns about the size of the factor loadings were still present. Metric or weak invariance was then tested by constraining the factor loadings for each of the indicators to be equivalent. Not surprisingly, given the observed issues with factor loadings from the second part of the analysis, this resulted in a poorer fitting model, as demonstrated by changes in the model chi-square and model fit indices, ∆χ2 (df) = 86.48 (7), p < .05, ∆CFI = .04, ∆TLI = .04, ∆RMSEA = .02, ∆SRMR = .03. Partial metric invariance was examined by allowing for the free estimation for certain factor loadings between samples based on examination of the model modification indices and multivariate score tests. Allowing the neglect and emotional abuse severity indicators to be freely resulted in similar fitting models between the SPARK and LONGSCAN sample, ∆χ2 (df) = 9.96 (5), p > .05, ∆CFI = .002, ∆TLI = .003, ∆RMSEA = .002, ∆SRMR = .01.
Next, measurement invariance was examined between the SPARK sample and the two LONGSCAN subsamples. Similar to the full LONGSCAN sample, the criteria for metric or weak invariance between the SPARK sample and Foster Care- LONGSCAN subsample was not met, ∆χ2 (df) = 73.09 (7), p < .05, ∆CFI = .04, ∆TLI = .06, ∆RMSEA = .03, ∆SRMR = .03. Following review of model modification indices and multivariate score tests, the neglect severity and emotional abuse frequency indictors were selected to be freely estimated between the samples. This resulted in a similar fitting model between the configural and weak invariance model, demonstrating partial weak invariance, ∆χ2 (df) = 8.81 (5), p > .05, ∆CFI = .003, ∆TLI = .000, ∆RMSEA = .000, ∆SRMR = .01. Next, the SPARK and At-Risk subsample was examined. As with the other model comparisons, metric or weak invariance was not established between the SPARK sample and At-Risk Community LONGSCAN subsample, ∆χ2 (df) = 62.48 (7), p < .05, ∆CFI = .03, ∆TLI = .04, ∆RMSEA = .02, ∆SRMR = .03. A similar fitting model and thus partial weak invariance was established by allowing the neglect severity and emotional abuse severity indictors to be freely estimated between the samples, ∆χ2 (df) = 5.73 (5), p > .05, ∆CFI = .000, ∆TLI = .004, ∆RMSEA = .003, ∆SRMR = .01.
Discussion
Progress has been made over the last several decades in the field of maltreatment research to improve on how maltreatment is measured and conceptualized in research (e.g., English et al., 2005; Gabrielli & Jackson, 2019). Yet, several gaps remain in the field’s understanding regarding the performance and generalizability of advanced statistical models for measuring maltreatment across populations, which is necessary for ensuring more accurate analyses of maltreatment exposure and its association with outcomes among youth. The current study sought to further examine the creation of a maltreatment measurement model using type, frequency, and severity characteristics of maltreatment, by testing the generalizability of a one-factor model across several different samples of youth with exposure to maltreatment.
The primary findings from this study raise concerns about the generalizability of a maltreatment measurement model combining across all four primary types of maltreatment exposure in different samples of youth with possible exposure to maltreatment. Specifically, for all three multi-group confirmatory factor analyses (MGCFAs), results revealed only partial metric invariance for the one-factor maltreatment measurement model when compared across the SPARK and LONGSCAN subsamples. Thus, although it was possible to establish acceptable fitting maltreatment measurement models with both samples, the inability to establish full metric invariance or higher indicates potential issues with comparable and appropriate factor loadings for each sample. Most often, factor loadings for the LONGSCAN models for the neglect and emotional abuse severity indicators were much lower compared to the SPARK sample, and these factors loadings for the LONGSCAN sample were also below an acceptable cutoff. Only after allowing some of the neglect and emotional abuse factor loadings to be freely estimated for each sample did the models demonstrate invariance at the metric level, suggesting that some but not all of a one-factor maltreatment measurement model are similar between two different samples.
In light of the study’s findings, it is necessary to consider why these differences in model fit may have been observed. One of the strengths of the current study is that there were several similarities between the SPARK and LONGSCAN project samples and procedures that help to rule out (or at least minimize) some possible factors. For example, reasons for the findings being related to potential measurement procedures were partially alleviated as both projects used case file data from official CPS records and a similar and well validated coding system (i.e., the MMCS) for characterizing the dimensions of maltreatment. Moreover, study populations and methods within the current study resulted in a similar study composition of youth by age, gender, and ethnicity. One difference between the samples that could in part explain model performance was rates of maltreatment exposure and the relation between maltreatment dimensions. Overall, there were similar patterns of exposure between the SPARK and LONGSCAN samples. For example, the order from most to least frequent types of maltreatment and single type victimization was the same. However, the overall number of experiences was different between the two samples, such that there were significant differences in the frequency scores for each maltreatment type. Notably, for neglect and emotional abuse, both the severity and frequency scores were significantly greater for the full LONGSCAN sample, compared to the SPARK sample. Additionally, neglect severity for the LONGSCAN showed notable difference in the pattern of relations between the other maltreatment dimensions, as observed in its correlations with the other variables and its performance in the models. Compared to the other indicators for both the LONGSCAN and SPARK sample, neglect severity for LONGSCAN had a close to zero correlation with almost all other indicators of maltreatment (including its own frequency indicator) and was the only indicator to have a negative correlation with multiple indicators. Thus, model differences presented by indicators of neglect and emotional abuse within the LONGSCAN sample driven by differences in patterns of exposure may have contributed to measurement non-invariance during the MGCFA when compared with the SPARK sample.
One possible explanation for these differences, and in particular the differences in observed relations and rates of neglect and emotional abuse, could be related to documentation and site differences associated with youths’ case files. It is widely recognized that maltreatment reporting and recording practices vary state-to-state in the United States (for a review of states’ definitions of child maltreatment, please see the State Child Abuse and Neglect [SCAN] Policies Database; Weigensberg et al., 2021). Further, how and what information is documented considerably vary by state as well (e.g., Dubowitz et al., 2005; Witte, 2020). This in turn can influence the types, rates, and severity characteristics of maltreatment extracted from case files for research purposes when using a case file coding system. General difficulties with consistency in defining and reporting in case files among agencies are especially prevalent with regard to neglect and emotional abuse because of the heterogeneity and inconsistent guidelines for these forms of maltreatment (e.g., Child Welfare Information Gateway, 2018; Tonmyr et al., 2011). Given that there were five different sites in LONGSCAN, it may be likely that certain documentation practices present in the location of the SPARK sample influenced its model fit in a unique way for the one-factor model that does not translate to LONGSCAN samples. For example, in the state where children were recruited for SPARK, witnessing or experiencing domestic violence is not defined as a form of maltreatment, whereas other states may consider this a form of neglect as failure to protect (Child Welfare Information Gateway, 2018).
In considering potential documentation practice differences that may have influenced the models, it is possible that the SPARK sample location may have been more selective in reporting and documenting neglect only with another co-occurring maltreatment type (Dubowitz et al., 2005). This may explain why there were higher correlations between neglect characteristics and other forms of abuse in the SPARK sample compared to the LONGSCAN sample. Moreover, there was also a much higher proportion of youth who only experienced one type of maltreatment in the LONGSCAN sample compared to the SPARK sample. This was true across all maltreatment types for the LONGSCAN sample, and for neglect the rate of single type exposure was four-times greater for the LONGSCAN sample compared to the SPARK sample. This also includes a difference between the samples in no maltreatment exposure, with SPARK having a greater proportion compared to LONGSCAN of youth with no maltreatment exposure. Taken together, these differences in polyvictimization would likely have an influence on the models given the purpose of the measurement model is to help account for shared variance across types and indicators of abuse. As a result of these patterns, this likely produced a better fitting model with the SPARK sample because more of the maltreatment types were related to each other when maltreatment exposure occurred, compared to the LONGSCAN samples, thus producing a better fitting one-factor model.
The potential that differences in rates of exposure and possible documentation and recording practices between states impacts model performance is concerning for the field of maltreatment research and has implications for researchers wishing to utilize case file data to build measurement models. Significant concerns exist with regard to the measurement of maltreatment, given the diversity of methods used to measure and conceptualize maltreatment exposure in research (e.g., self-report vs. case file, interview vs. questionnaire; Jackson et al., 2019). Although the study only tested one previously established type of model, notable differences emerged, even when using parallel data sources and coding systems that are considered to be the gold standards in the field of maltreatment research for case file data (e.g.,English et al., 2005). Again, this is not to say that other study specific factors may explain the findings. Another potential explanation for these findings may be related to the populations recruited for each project. Whereas SPARK involved only youth in foster care, LONGSCAN included both community samples at-risk for maltreatment and youth in foster care. Factors associated with these differences in population and maltreatment reporting or exposure, such as socioeconomic status (e.g., Berger, 2004), may have contributed to model differences. However, this study still found a similar pattern of measurement invariance when looking at only youth in foster care between the SPARK and LONGSCAN subsample.
Limitations
In evaluating the study’s findings, it is necessary to account for study limitations. One limitation was the lack of ability to consider self-reported maltreatment exposure. Discrepancy in maltreatment prevalence is often observed between case file and self-reported measures, which may have been related to the study’s findings as case files tend to report more neglect, whereas self-report measures tend to show higher rates of physical, sexual, and emotional abuse (Cooley & Jackson, 2022). Another limitation of the current study was the assessment of participants’ race and ethnicity, as both projects asked participants to select from a short, pre-determined list of different races, which also contained ethnicity identifiers (i.e., combining labels for race [e.g., Black, White] and ethnicity [e.g., Hispanic or Latino]). In addition to small sample sizes for some identified races, this greatly limited what could be explored regarding potential racial and/or ethnic differences in model performance. These are important aspects to consider as it relates to maltreatment exposure given well-documented findings on how race and ethnicity, and in particular systematic injustices for children of color, influences maltreatment documentation in case files, such as a bias to report children of color to child protective services for suspected maltreatment (e.g., Cénat et al., 2021).
Future Directions
Despite the concerns raised about model generalizability, the findings from the current study do not suggest that latent model approaches for maltreatment exposure should be abandoned. Rather, these findings indicate that further research (particularly on accurate capture of neglect severity) is needed to improve these models for applicability across populations. In particular, the current study’s findings have several implications as it relates to how maltreatment is measured as part of a measurement model. One option may be to modify previously established indicators used for each type and characteristic of maltreatment exposure. For example, while the current study used mean severity across each maltreatment type, evidence from studies comparing different approaches for measuring severity suggest that highest or max severity rating per type may provide a better indicator than other measurement approaches (including mean severity; Litrownik et al., 2005). In cases where there are many events of one maltreatment type, using a mean value may dilute important, severe events within that type. This may explain why the severity variable for more frequently experienced maltreatment types (e.g., neglect, emotional abuse) did not contribute much variance explained for the latent construct.
Another option to consider in further research in this area may be to add and/or abandon currently used indicators. The current study model utilized type, frequency, and severity indicators based on previously validated models of maltreatment, which are some of the most widely used dimensions of maltreatment for these models. While these variables tend to be some of the most frequently studied characteristics (Jackson et al., 2019), these are not the only characteristics that are critical to understanding maltreatment. For example, one potential characteristic of maltreatment that could account for shared variance between and within maltreatment types is age of onset, as age related factors might help explain shared variance between maltreatment types and characteristics given developmental differences in rates of exposure (e.g., Hodgdon et al., 2018; Kaplow & Widom, 2007). There is also emerging evidence suggesting that perpetrator of maltreatment may be a necessary variable to consider in these types of models, considering that maltreatment is an interpersonal form of trauma by nature (D'Andrea et al., 2012). In the context of a measurement model approach, including perpetrator type may help capture a portion of shared variance between experiences, types, and other aspects of a youth’s maltreatment history given that it can often be the case that a similar form of perpetrator (e.g., caregiver) may be responsible for multiple incidents of maltreatment (e.g., Hurren et al., 2018; U.S. Department of Health and Human Services, 2020). This might also include expanding beyond dimensions of maltreatment to incorporate associated risk factors for maltreatment, such as family environment and caregiving behaviors or mental health concerns (e.g., substance use; Hurren et al., 2018). Taken together, although severity and frequency indicators have shown promise, it should not be the case that the field is beholden to continue using these indicators, especially if models continue to show poor performance.
Moreover, another area of future investigation in measurement models of maltreatment could consider higher order or bi-factor models. Such models may help capture additional shared variance between aspects of maltreatment experiences in a novel way. There is some initial evidence in support of such models (e.g., Lombera et al., 2021), in addition to related research suggesting that grouping certain forms of maltreatment together may better explain some of the similarities between types (e.g., threat vs. deprecation forms of maltreatment; McLaughlin et al., 2014). Such an approach may help address some of the concerns observed in modeling related to the deprecation forms of maltreatment (i.e., neglect and emotional abuse) that did not contribute much to the overall model in the current study. Additionally, efforts should be made to consider the overlap and relation between maltreatment and other more general forms of adversity exposure in such higher order or complex models, such as was partially addressed in the bi-factor model created by Lombera et al. (2021) with maltreatment and domestic violence. Maltreatment and other types of adversity exposure (e.g., witnessing domestic violence, community violence exposure) tend to co-occur and in some cases may be related to each other (e.g., Schouwenaars et al., 2016). Thus, including all forms of adversity may help provide a more accurate characterization of youths’ adversity history.
Conclusions
Although variable-centered measurement models of maltreatment exposure show great promise in providing an approach to more accurately capture maltreatment exposure history in youth, concerns exist about the generalizability of these models across different samples of youth with exposure to maltreatment. Results from the current study provide initial indication that at least one type of model, a one-factor maltreatment model with characteristics of type, severity, and frequency, may not translate well from population to population. Thus, continued research is needed on measurement model approaches for maltreatment that explore what characteristics and model structures may best capture the complex history of maltreatment exposure in youth.
Supplemental Material
Supplemental Material - Trying to Fit a Square Peg in a Round Hole? Testing the Robustness of Maltreatment Measurement Models for Youth
Supplemental Material for Trying to Fit a Square Peg in a Round Hole? Testing the Robustness of Maltreatment Measurement Models for Youth by Austen McGuire, Joy Gabrielli, and Yo Jackson in Child Maltreatment
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by funding from the National Institute of Mental Health, RO1 Grant MH079252-03.
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.