
Abstract
With online news aggregators outperforming most traditional media sites, some news executives have accused Google News of stealing their content, even as they rely on Google for exposure. Through a content analysis, this study examines how leading traditional news providers and trade publications, during the 2007-2010 financial shock for U.S. newspapers, covered the newspaper industry’s delicate relationship with Google. Results indicate that such coverage de-emphasized the non-advertising nature of Google News, ignored readers’ views, and used emotion-laden language (e.g., sensational accusations against Google of “stealing” newspaper content or being a “parasite”). Although Google was often portrayed as the enemy, most coverage suggested that newspapers should work with Google, pointing to the challenge of assessing Google’s role in an unfolding era of news aggregation.
Keywords
News aggregation—the machine- or human-driven repurposing, repackaging, and redistributing of news content—has become a flashpoint of controversy in contemporary digital journalism. Many in the professional field and in public policy circles have come to see aggregation as a looming threat to the legacy model of original reporting through which news organizations inform society; the matter has been presented as a dichotomy between shoe-leather journalism by professionals and the supposed rip-off of aggregation sites (Anderson, 2013a, 2013b; Boyer, 2013; Coddington, 2015). Ultimately, aggregation strikes at the very heart of the economic arrangement for news: Who will underwrite the original creation of news reports? To the extent that aggregators recycle news produced by others, is this phenomenon helping or harming journalism (Bakker, 2012; Krakovsky, 2013)?
Newspapers and news wire services, as the leading suppliers of content for online aggregators, have been particularly troubled by such questions. Deepening their concern has been the success that aggregation sites have had in attracting news audiences online. In the United States, for example, portal news sites such as Yahoo News, Google News, and MSN, each of which aggregates news content from other sites, are the leading sources for online news, far surpassing the leading newspaper sites of the New York Times, the Wall Street Journal, and the Washington Post (Pew Research Center for the People & the Press, 2012; Sasseen, Olmstead, & Mitchell, 2013). Overall, U.S. newspaper sites have struggled—both in audience reach (Chyi & Lewis, 2009) and advertising share (Edmonds, Guskin, Mitchell, & Jurkowitz, 2013)—to match the power of portal sites that aggregate content.
This perceived imbalance has led many newspaper executives to accuse aggregators, especially Google, of “stealing” their content and unfairly profiting on their labor. This angst over aggregators hit a fever pitch in 2007 to 2010, as newspapers struggled mightily during the recession and newspaper executives sought to assign blame for their woes. Google, they said, was a “parasite” (quoted in Schulze, 2009, para. 1), a “content kleptomaniac” (quoted in Dawber, 2009, para. 1), and a “digital vampire” sucking “newspaper blood” (quoted in Szalai, 2009, paras. 2-3). “The aggregators and plagiarists,” said News Corporation owner Rupert Murdoch, “will soon have to pay a price for the co-opting of our content” (quoted in “Websites ‘Need to Pay for News,’” 2009, para. 5). Journalists, too, adopted this line of reasoning; The Atlantic, in a feature article headlined “How to save the news,” opened with a bit of hyperbole: “Everyone knows that Google is killing the news business” (Fallows, 2010, para. 1). Meanwhile, at a key public policy forum for debating the future of journalism, “news executives’ animus towards a variety of technological and digital information processes [came] through clearly in these hearings,” Anderson (2013b, p. 1013) finds in his analysis of the 2010 Federal Communications Commission (FCC) workshop. “The enemy is named, and the enemy is aggregation” (p. 1013). It was in this climate that Bill Keller (2011), then executive editor of the New York Times, likened news aggregation to Somali piracy, accusing aggregators of “harvesting revenue that might otherwise be directed to the originators of the material” (para. 8). Although U.S. publishers have backed off in recent years, the anti-aggregator fervor has spread to other countries: In Brazil, more than 150 newspapers stopped allowing Google News to index their content, and in the United Kingdom, Germany, France, and Spain, legislators considered forcing Google to pay for featuring headlines and the first few lines of an article—activities normally considered “fair use” (Carr, 2012; “Google Settles French Newspaper,” 2013; Levine, 2013; Pinedo, 2014; Ponsford, 2012).
Amid the tension between the declining yet still influential news industry and one of the world’s major online news aggregators, it is important to examine how major traditional news providers and trade publications cover the newspaper industry’s relationship with Google News because how traditional news organizations think about Google News may have meaningful consequences for editorial and business strategies. Therefore, this study, through a content analysis, examines such coverage during the critical 2007-2010 period. Drawing on literature regarding self-coverage, facticity, news sourcing, and the sociology of professions to articulate a framework for analyzing this coverage, our goal is to reveal how leading traditional news providers and trade publications portrayed a key player from the aggregator camp, as the interaction between the two will contribute to shaping the future of news.
In the sections that follow, research questions and hypotheses are introduced in light of literature regarding news aggregation and Google’s particular role in it; the nature of self-coverage by news providers and the role of facticity and contextual information therein; patterns of news sourcing and their place in self-coverage; and, finally, theoretical contributions from the sociology of professions that highlight the tension between shoe-leather journalism and online aggregation. Thereafter, we present the method and findings, and discuss the implications of the study’s results in connection with developments in Google News and aggregation since 2010.
Literature Review
Google as a News Aggregator
Generally, news aggregation involves some combination of algorithms and editors collating disparate information produced on a variety of news sites and reorganizing it for re-presentation on a single site. Such repurposing sites can be entirely automated (as in the case of Google News), mostly human-edited (e.g., The Huffington Post), or some combination of computers and humans (e.g., Techmeme). More particularly, however, the term aggregation, as Bakker (2012) notes, is primarily understood as a bundle of “strategies whereby (automated) Web searches result in relevant articles on specific subjects” (p. 631). The emphasis is on aggregation through automation. 1
Google News, which has no human editors, is the global leader in automated aggregation, even while national, local, and topic-specific aggregators exist (Bakker, 2012). Since it was launched in 2002, Google News has remained relatively constant in its approach: Using the same kind of PageRank algorithms that determine salience in Google search results, Google News filters, sorts, and evaluates the content on more than 25,000 news sites (Cohen, 2009) to present a series of headlines and snippets (i.e., an article excerpt or summary), along with hyperlinks back to the original content. The news is arrayed by subject (World, U.S., Business, Technology, Sports, etc.), and categorized by relative importance. Newsworthiness, and thus news placement, is determined by an algorithm that assesses a variety of factors, such as the authority of the source and keywords in the news content, as well as users’ previous searches and clicks, and users’ geographic location (e.g., Californians see state-specific news prominently featured; Machlis, 2009). Google says it focuses on “freshness, location, relevance and diversity,” and “how often and on what sites a story appears online” (Google News, 2015, para. 3). Besides the U.S. portal, there are dozens of region-, country-, and language-specific versions of Google News, such as the German edition analyzed by Schroeder and Kralemann (2005).
Previous research has emphasized the extent to which Google News upends the traditional model of information gatekeeping. It does this not only by using algorithms to add a “second-order process” to human forms of gatekeeping (Hurley & Tewksbury, 2012, p. 133), but also by inverting the normal pattern of information retrieval from a single information source. Google itself plays up this distinction:
Traditionally, news readers first pick a publication and then look for headlines that interest them. We do things a little differently, with the goal of offering our readers more personalized options and a wider variety of perspectives from which to choose. . . . Click on the headline that interests you and you’ll go directly to the site which published that story. (Google News, 2015, para. 2)
In like manner, Carlson (2007) argues that news search engines challenge the “presentational authority of journalists” (p. 305, 1026), disaggregating the packaged news product into a series of disconnected stories; Google News, in turn, goes further in using automation to reassemble those news stories into a user-customizable package. Beyond the challenge to journalistic authority posed by Google News, other scholars have examined its quality and comprehensiveness as a news database (Galbraith, 2008; Weaver & Bimber, 2008)—finding key differences, for instance, in the kind of health news that Google News provides relative to that offered by a dedicated news source such as CNN (Hurley & Tewksbury, 2012). Thus, scholars have examined the structure and content of Google News; much less, however, has been said about the perception of Google News in the news industry—and why that matters for understanding the role of news aggregation in the digital media environment.
Self-Coverage
In examining journalistic norms, scholars have examined how journalists have covered their own company or profession (Carey, 1974; Turow, 1994). Key to the literature on self-coverage is Carey’s (1974) critique that “[t]he newspaper does not, perhaps it cannot, turn upon itself the factual scrutiny, the critical acumen, the descriptive language, that it regularly devotes to other institutions” (p. 235). In recent years, challenges for the news business have led to increased self-coverage of the news industry (Chyi, Lewis, & Zheng, 2012), especially by newspaper journalists (Roodhouse, Delli Carpini, Lee, & Venger, 2009). One study examining how three major newspapers covered newspapers’ financial troubles during the recent recession found that such coverage focused on short-term drama, lacked sufficient context, utilized death imagery, and shifted blame away from newspapers themselves. Overall, the content analysis documented newspapers’ overreaction to the so-called “newspaper crisis” (Chyi et al., 2012, p. 305). The consequence of publishers and journalists “running around arguing the sky is falling,” as Picard puts it, is that “they’re making the situation appear far worse than it is” and they have become “their own worst enemy” (quoted in Lieberman, 2009, para. 9). Therefore, analyzing news media’s self-coverage may provide insight into news organizations’ views on the market in which they operate.
The rise of online news aggregators in recent years has posed strong and unprecedented competition to traditional news organizations, but how the news industry, especially key players and opinion leaders within the industry, defines its relationship with aggregators has remained unclear. Therefore, this study seeks to empirically and systematically examine how major traditional news providers and trade publications covered the newspaper industry’s relationship with Google News.
Factual and Contextual Information
In their scrutiny of journalism, scholars have long taken an interest in the quality of news coverage, particularly its ability to base news reports on facts rather than emotions, opinions, or conjecture (Commission on Freedom of the Press, 1947; Kovach & Rosenstiel, 2007; Lasorsa & Lewis, 2010). Good journalism, in this sense, makes a good-faith attempt at portraying the world as it really is or as close to that as possible, given the inherent limitations and contested nature of facts and objectivity (Mindich, 1998; Schudson, 2001). As Carey (1974) noted, journalistic analysis should avoid “emotion-laden, highly charged drama” (p. 233), choosing words such that “affect is tightly controlled and information is maximized” (p. 237).
However, to report the relationship between Google and the newspaper industry as is can be intriguing because of the complexities involved in the Google–newspaper relationship:
The technical characteristics of Google News: A major source of the controversy surrounding Google News lies in its technical characteristics. For example, whether the display of hyperlinks and snippets on Google News constitutes “fair use” involves one key technical fact: The link displayed on the Google News site directs traffic to news sites that create and own the original content (and, thus, clicks on those links serve to increase those sites’ traffic and advertising revenue). A 2011 Pew study indicated that more than 69% of Google News visitors actually left for news sites such as nytimes.com (14.6%), cnn.com (14.4%), abcnews.go.com (14.0%), online.wsj.com (9.4%), foxnews.com (9.2%), reuters.com (8.9%), washingtonpost.com (8.7%), nydailynews.com (7.9%), and content.usatoday.com (7.5%); the rest (30.5%) headed to Google.com or another Google service (Pew Research Center for the People & the Press, 2011). Research also has identified a symbiotic relationship between the use of Google News and other media outlets (Lee & Chyi, 2015). However, news executives accuse Google of undermining the uniqueness of news sites “by aggregation of content which transfers the front page to the Google home page” and by socializing readers into accepting aggregation as the norm (Thomson, 2014, para. 5). Thus, the impact of Google News on the demand for traditional news sites is ambiguous at best.
The non-commercial nature of Google News: Although Google’s search engine service generates a tremendous amount of advertising revenue, which constituted 91% of the company’s total income in 2013 (Google, 2013), Google actually places no ads on its Google News pages. In other words, Google News is a free public service. It is thus difficult to argue that Google benefits directly from its news aggregation service—although, presumably, there are indirect benefits as Google learns more about its users via their news-reading habits, in order to deliver more relevant advertising on its other pages.
The market share of Google News: Although often the target of criticism, Google News does not enjoy nearly as much market share as Yahoo News, the most visited news site since 2008. In 2008, Yahoo News was named by 28% of Web news users as their most frequented news site; only 11% said so about Google News (Pew Research Center for the People & the Press, 2008). In 2010, still 28% of online news users cited Yahoo News as their most visited news site, compared with 15% for Google News (Pew Research Center for the People & the Press, 2010). In 2012, Yahoo, mentioned by 26% of online news users as their most-used news site, remained the top news destination. Google, surpassing CNN to become No. 2 for the first time, was named by 17% of online news users (Pew Research Center for the People & the Press, 2012). Traffic wise, according to Nielsen’s metrics, Yahoo News had 58.9 million monthly unique visitors; Google News, by contrast, was frequented by 14.4 million users only (Sasseen et al., 2013). In sum, Google is by no means the dominant news aggregator in the U.S. market, yet news executives almost always focus on Google when criticizing the practice of news aggregation. In contrast, the relationship between Yahoo and newspapers has received little media attention. 2
Given the delicate relationship between Google and the news industry, this study seeks to examine what kind of factual information—that is, the technical characteristics, the non-commercial nature, and the market share of Google News—characterizes the coverage of the Google–newspaper relationship. In addition, journalists bear a responsibility in contextualizing what they report—that is, not only reporting facts truthfully but also reporting the truth about facts (Commission on Freedom of the Press, 1947), and serving as sense-makers and interpreters in the contemporary media environment (Singer, 2006). It is of interest whether traditional news media meet these expectations when covering their relationship with Google. Therefore, this study addresses this research question:
News Sourcing
The study of news sourcing is essential for assessing journalism’s role in constructing social reality (Carlson, 2009; Franklin, Lewis, & Williams, 2010; Gans, 1979). As key points of reference as authority figures (Tuchman, 1978), sources help shape what journalists come to see as credible, important, and true—thus providing information and a framework for interpreting it (Sigal, 1973). Therefore, when journalists rely on institutionalized sources in a routinized fashion, news coverage legitimizes the status quo (Bennett, 1990; Tuchman, 1978). Numerous studies have documented that sources tend to be elites holding power and privileged information (Hall, Critcher, Jefferson, Clarke, & Roberts, 1978), such as government officials (Bennett, Lawrence, & Livingston, 2006), experts (Albaek, 2011), and journalists themselves (Rafter, 2014). Different types of sources also have been found to influence public opinion in different ways (Son & Weaver, 2006).
Looking at media coverage of the news business, Picard (2009) has lamented that reporters too easily accept and rely on the views of news executives without critically evaluating the business dynamics of news. Such was found to be the case when newspapers covered their own financial troubles during the recent recession, with more than two thirds of the articles citing newspaper publishers and more than one third citing journalists (Chyi et al., 2012). Drawing on the literature and the sentiment among newspaper executives against Google, this study hypothesizes as follows:
Tension Between Shoe-Leather Journalism and Online Aggregation
Beyond the matters described above, what additional factors might explain, perhaps in a broader sense, the resistance that news personnel appear to have toward Google News as an interloper? Sociological research suggests that professions seek to establish and maintain jurisdiction over certain knowledge work that is practiced on society’s behalf (Abbott, 1988); these boundaries are forged, in part, through moral claims about normative roles—that is, in talk as much as in action (Carlson & Lewis, 2015; Gieryn, 1983). Applying these perspectives to study the professionalization of journalism, Lewis (2012) has argued that journalism has developed a “professional logic of control over content” (p. 26)—an overarching sense of purpose that is bound up in gatekeeping the production of information called news. Lewis contrasts this logic of control with the logic of “open participation” associated with digital culture, theorizing that journalism will struggle to resolve this tension insofar as it grounds its self-identity in a control paradigm. Beyond news production, this line of thinking also can be applied to news distribution, particularly to the jurisdictional turf wars that have developed around third-party aggregation and the threat that it poses to journalism’s control over the dissemination of news content. Anderson’s (2013b) analysis reveals that, at the level of rhetoric, the battle lines are clearly drawn: News executives tend to valorize shoe-leather journalism and demonize what they see as parasitic practices of aggregators. Yet, at the level of actual practice, Anderson finds the differences between “original reporting” and human-directed aggregation are not so distinct.
In the particular debate about search engines and their economic impact on original reporting, news executives have been insistent that aggregators reap the benefits of delivering news content to online audiences even while bearing none of the cost of the content creation. Thus, at the 2010 FCC workshop that Anderson (2013b) studied, they described Google as “a fragmentizing original content substitute, one which occupied an unfair position in the digital value chain. The name they gave to this process of fragmentation, excerption, and indexing was aggregation” (p. 1013). At the core was a concern about who gets paid for content—and news executives clearly felt they were being cheated.
Therefore, with some leaders in the news industry making moral claims by criticizing Google for “stealing” copyright, for being a “parasite,” or for “killing newspapers,” this study seeks to examine whether such overtones—the right versus wrong, good versus bad, or perpetrator versus victim analogy—characterized the coverage of the Google–newspaper relationship in general. Therefore, this study addresses this research question:
Eventually, if Google creates a problem for the news industry, what solutions exist? Newspapers may choose either to block Google (as the Brazilian papers did), to charge Google a fee (like what has been considered in Germany and France), or to continue working with it (by supplying content or collaborating on other initiatives). To examine which kind of solution was proposed in the news coverage, this study addresses this research question:
Overall, the controversial relationship between Google and newspapers can be interpreted as either competitive/hostile or complementary/friendly. Because the news industry has a stake in this controversy, it is of interest to examine whether major traditional news providers and trade publications took a certain stand. Therefore, this study addresses this research question:
Instead of assuming that all types of publications portrayed Google the same way, this study explores whether major traditional news providers and trade publications adopted unique perspectives when covering the Google–newspaper relationship, addressing this research question:
Finally, this study examines whether news articles and editorial/opinion pieces portrayed the relationship between the newspaper industry and Google News differently, addressing the following research question:
Method
This study sought to content-analyze the coverage of the Google–newspaper relationship by seven leading news publications, including three national newspapers (the Wall Street Journal, USA Today, the New York Times), one wire service (the Associated Press), and three trade publications (Editor & Publisher, the American Journalism Review, and Poynter.org).
Among the three most widely circulated U.S. newspapers, the Wall Street Journal has a particular focus on business (Edmonds, Guskin, & Rosenstiel, 2011). USA Today appeals to a wide base of the consumer market. And, the New York Times was included because of its national prominence and role as an intermedia agenda-setter (Golan, 2007; Reese & Danielian, 1989). The Associated Press, a not-for-profit news cooperative owned by U.S. newspaper and broadcast members, is an influential news agency, supplying content to 1,700 U.S. newspapers and thousands of television and radio broadcast stations, in addition to international clients. Editor & Publisher, the American Journalism Review, and Poynter.org are three major trade publications, reflecting general perspectives of the news industry. Overall, these seven media outlets comprise some of the most influential publications in their respective category.
Relevance Sampling
This study sought to analyze all relevant articles published in the aforementioned publications from April 1, 2007, through April 1, 2010, during which time newspapers saw the worst damage in newspaper circulation and advertising revenue, and when several newspapers filed for bankruptcy or folded because of financial difficulties (Carlson, 2012; Chyi et al., 2012; Pérez-Peña, 2010). It was during this period that the tension between traditional news organizations and online news aggregators such as Google became an issue that newspaper publishers spoke about publicly.
As an attempt to identify all relevant articles on the current topic published by the seven media outlets, we took the “relevance sampling” approach (Krippendorff, 2004, p. 119). Full-text keyword searches through LexisNexis, Factiva, Communication & Mass Media Complete, and Poynter.org retrieved all articles containing “Google,” “newspaper,” and “(web)site” in the body text 3 published between April 1, 2007, and April 1, 2010. The keyword searches yielded 87 articles from the Wall Street Journal, none from USA Today, 284 from the New York Times, 296 from the Associated Press, 13 from the American Journalism Review, 11 from Editor & Publisher, and 17 from Poynter.org. Following the relevance sampling procedures, 4 the researchers screened all articles and excluded the vast majority that were irrelevant—that is, those that used the keywords but did not focus specifically on the role of Google as a news aggregator or the relationship between Google and the news industry. 5 The screening process generated a collection of 64 well-focused articles on the Google–newspaper relationship published by six major publications in three categories (newspapers, wire services, and trade publications) during the 3-year period.
Operational Definitions
Factual information refers to information revealing the technical characteristics, the non-commercial nature, and the market share of Google News discussed earlier. Coders were instructed to identify the following four types of factual information in each article: (a) Google News sends readers to the news site that produces the original content (and therefore, increases those news sites’ traffic and/or ad revenue), (b) functionality of Google News (e.g., automatically aggregates links to news sites, no human editor involved, algorithm determines rankings of stories, new features of Google News), (c) statistics/numbers/rankings about Google News’ traffic or readership, and (d) Google News pages contain no ads (and therefore, generate no advertising revenue).
Contextual information refers to information that is not directly related to Google News or its relationship with newspapers but may enhance readers’ understanding of the firm or the relationship in general. This study measured contextual information with two items: (a) references to other online aggregators (e.g., Yahoo, MSNBC, AOL News) and (b) legal issues about Google (e.g., copyright, privacy, anti-trust, patent, click fraud, lawsuits against Google).
The perceived impact of Google News on newspapers by the source was measured by the following: If any newspaper/Google source is quoted, how does that source evaluate the impact of Google (News) on the state of newspapers: (a) positive (e.g., Google helps newspapers monetize their content online by digitally indexing their archives), (b) negative (e.g., when publishers complain that online aggregators undermines newspapers’ efforts to develop an online business model), (c) neutral (neither positive nor negative, or both sides presented), and (d) no evaluation (no judgment about the impact of Google News was made).
Moral claims refer to viewpoints or criticisms containing the right versus wrong, good versus bad, or perpetrator versus victim overtones, measured by three items: (a) Newspapers deserve to be paid, or Google or readers should pay for news; (b) Google (News) is “stealing” content or traffic from media sites, Google (News) is a “parasite,” relying on media sites without creating content (or other strong negative word choice); and (c) newspapers are important for the health of democracy (e.g., as the watchdog, holding the officials accountable).
Plausible solutions to the problem facing the newspaper industry include the following: (a) Newspaper sites should work with Google or other online companies (e.g., provide content, share ad revenue, or develop new collaborative models), (b) newspaper sites should/can/may charge (news aggregators or users) for online content, and (c) newspaper sites should block Google News, Google Search, or other online news aggregators.
Finally, coders were instructed to determine whether the article portrays the overall relationship between Google and newspapers as competitive/hostile or complementary/friendly. An example of the former is an article featuring publishers’ attempt to protect their content by proposing new measures for more control over use by search engines. On the contrary, an article featuring Google’s newly developed service to improve the experience of reading newspapers and magazines online portrayed the relationship in a complementary way.
Coding
The unit of analysis was the article. Two trained coders, journalism students at a public U.S. university, performed the content analysis. To ensure inter-coder reliability, two rounds of pretests were conducted on 31% of all the articles randomly selected from the pool. Inter-coder reliability coefficients for all items, measured by percent agreement (i.e., the number of agreements divided by the total number of measures) were as follows: “Google News sends readers to newspaper sites” (65%), “How Google News works” (80%), “Google News traffic data” (80%), “No ads are placed on Google News pages” (80%), “ Other online aggregators” (90%), “Legal issues involving Google” (80%), “Source: newspaper publishers/journalists” (90%), “Source: Google” (80%), “Source: financial analysts/consultants” (90%), “Source: research reports” (90%), “Source: bloggers” (100%), “Source: scholars/media critics” (90%), “Source: readers” (100%), “Evaluation of Google by newspaper sources” (80%), “Evaluation of Google by Google sources” (80%), “Newspapers deserve to be paid” (80%), “Google is stealing content or traffic as a parasite” (80%), “Newspapers are important for democracy” (90%), “Newspaper sites should work with Google” (65%), “Newspaper sites should charge for online content” (90%), “Newspaper sites should block Google or other aggregators” (100%), and “Overall relationship” (80%).
The two less reliable variables were “Google News sends readers to newspaper sites” (65%) and “Newspaper sites should work with Google” (65%). The former may be illustrated via the following examples: “But executives at some news organizations have called the ire at the search engines misguided, saying that much of their own Web traffic arrives through links on search pages” (New York Times, April 7, 2009); “It also said Google News drove a huge amount of traffic to newspaper Web sites, which the publishers monetize through advertising” (New York Times, April 8, 2009); “The Journal could simply block Google from indexing its stories, but that would cut traffic to its site significantly” (Associated Press, December 2, 2009). Examples of the latter include, “‘We need Google for the traffic,’ he said. ‘But Google is a giant, a monopolist, and you cannot afford not to play along’” (New York Times, January 19, 2010); “But even though this is not the world newspapers might have chosen, it is the one that they live in. Deprived of links—the oxygen of the Internet—many news providers would wither away” (New York Times, April 12, 2009).
Data Analysis
As suggested by Krippendorff (2004), relevance sampling is non-probabilistic, and the resulting units are not meant to be representative of a population of texts—they are the population of relevant texts. To address RQs 1 to 4, descriptive statistics (percentages) were reported. To answer
Results
Of the 64 articles, 22 were from the New York Times, 20 from the Associated Press, 11 from Poynter.org, seven from Editor & Publisher, three from the Wall Street Journal, and one from the American Journalism Review. The length of these news stories and editorials ranged from 114 words to 3,757, with an average of 864 words (SD = 696 words). About three of four (76.6%) were news articles, and the rest (23.4%) were editorial/opinion pieces.
Percent of Stories Supported by Factual and Contextual Information.
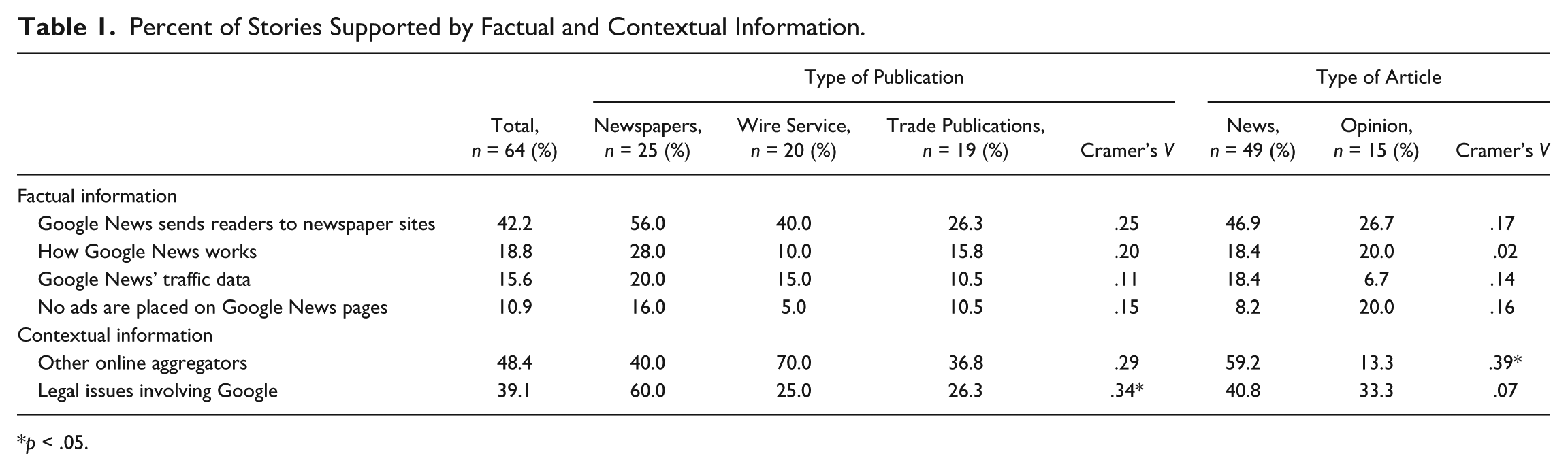
p < .05.
The most frequently cited fact is that Google News sends readers to newspaper sites and, therefore, increases their traffic and advertising revenue (42.2%). Only about one in five articles (18.8%) explained how Google News works (e.g., how it aggregates links to news sites, determines the ranking of search results, and, unlike most media news sites, involves no human content editors). Sixteen percent of the articles reported Google News’ metrics data. Only 10.9% of the articles mentioned that Google News does not generate advertising revenue because no ads are placed on their news pages.
Regarding contextual information presented in the coverage, almost half of the articles (48.4%) mentioned other online aggregators (Yahoo, MSNBC, AOL News, etc.). In addition, 39% mentioned Google’s legal issues in arenas such as copyright, privacy, anti-trust, patent, and click fraud. It is noted, however, that not all legal issues are relevant to Google News per se.
Sources Quoted in Articles.
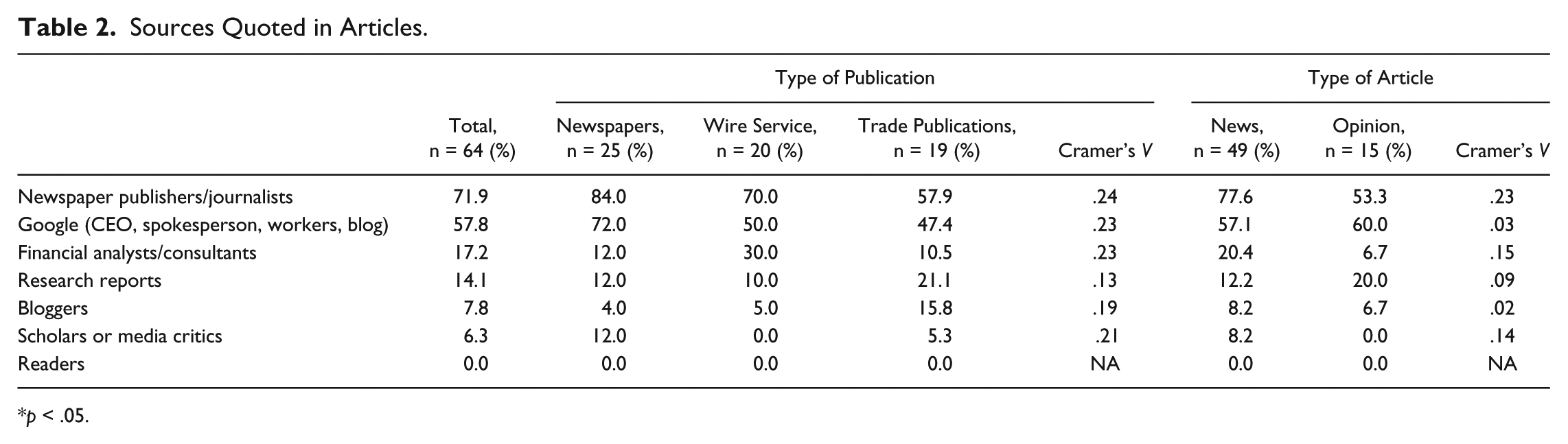
p < .05.
How Newspaper Versus Google Sources Evaluated the Impact of Google News.
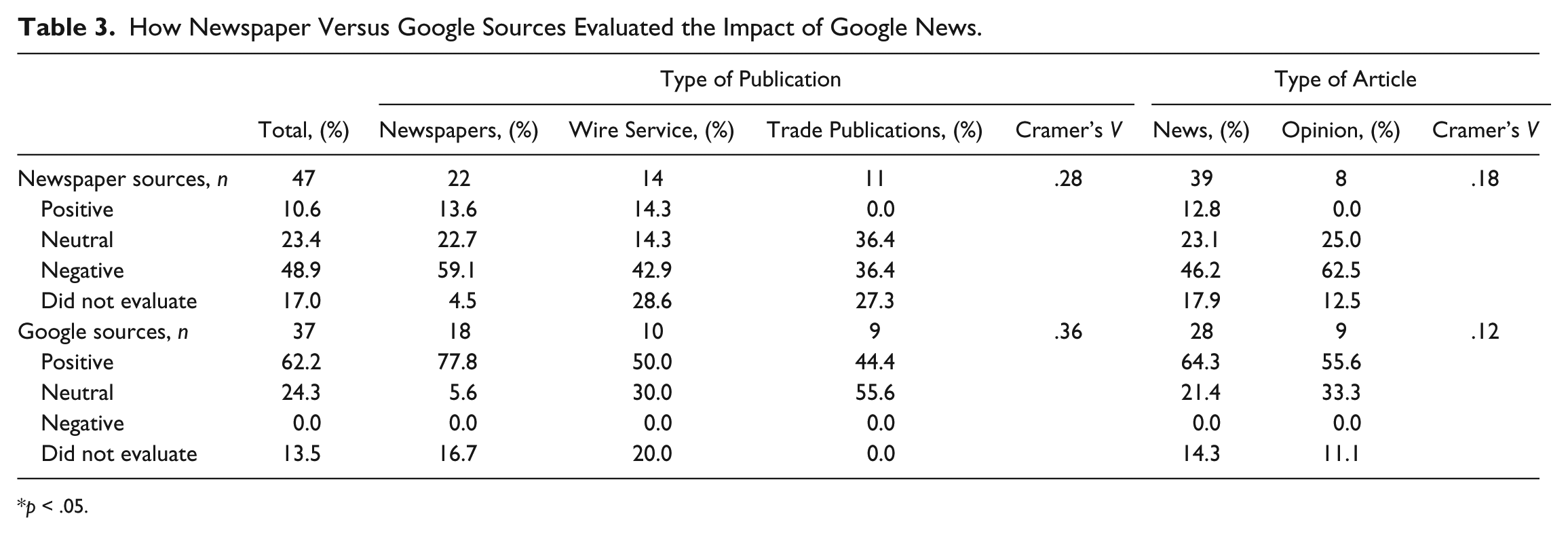
p < .05.
Percent of Stories Making Moral Claims and Proposing Solutions.
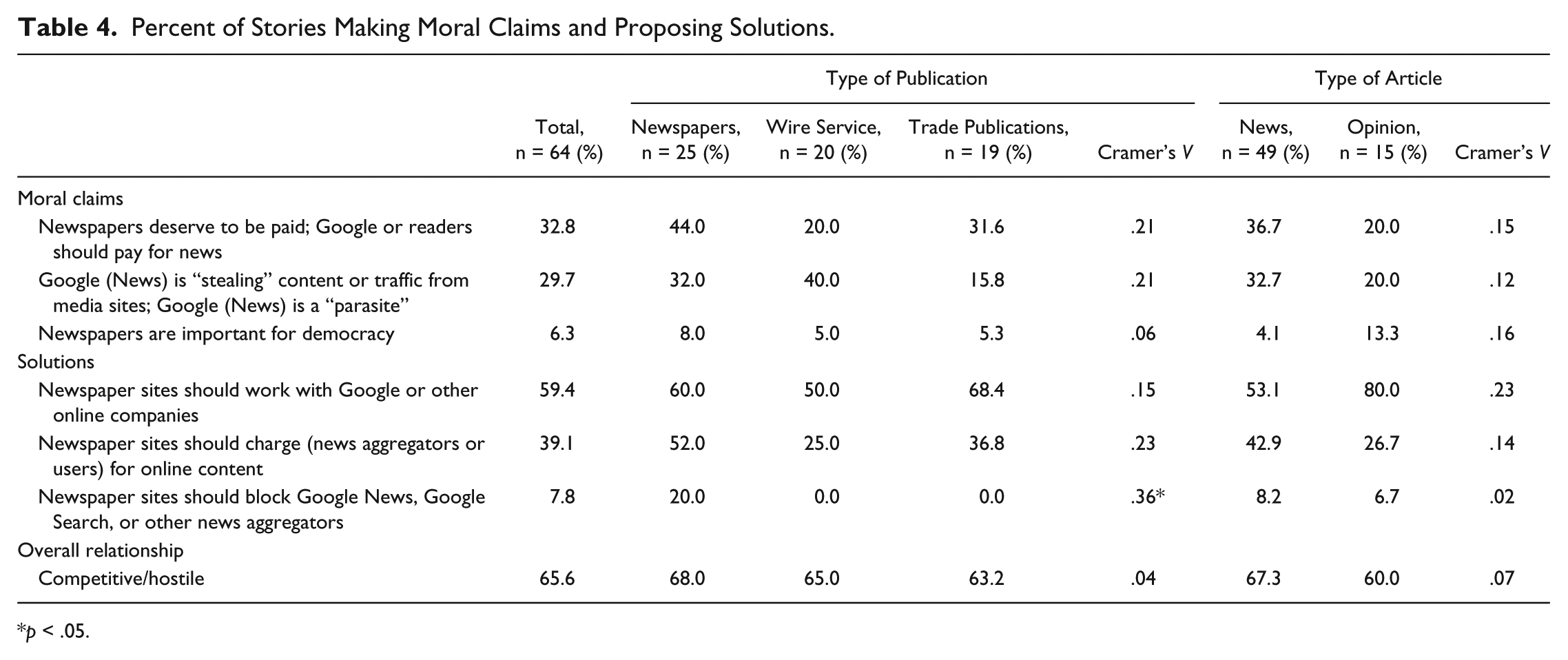
p < .05.
To address
Regarding
In addition, two items approach significance: mentioning other online aggregators (Cramer’s V = .29, p = .065; Table 1) and how Google sources evaluated the impact of Google News (Cramer’s V = .36, p = .052; Table 3). Specifically, 70% of Associated Press stories mentioned other online aggregators, whereas 40% of newspaper stories and 36.8% of trade publication articles did so. The vast majority of New York Times and Wall Street Journal stories (77.8%) quoted Google sources who evaluated the impact of Google News positively, whereas 50% of Associated Press stories and 44.4% of trade publication articles did so.
Regarding
Two items approach significance: quoting newspaper publishers and journalists (Cramer’s V = .23, p = .068; Table 2) and suggesting “newspaper sites should work with Google” (Cramer’s V = .23, p = .063; Table 4). Specifically, news articles were more likely to quote newspaper sources, compared with editorial/opinion pieces (77.6% vs. 53.3%). In terms of solution, 53.1% of news articles suggested that newspapers work with Google, whereas 80% of editorial/opinion pieces did so.
Discussion
This study may be the first to examine the coverage of the Google–newspaper relationship, particularly as it pertains to the critical period of 2007 to 2010 that was marked by widespread difficulty for U.S. newspapers and heightened controversy over news aggregation. At the intersection of old and new media, our content analysis uncovered the following findings worthy of discussion.
First, among two key facts most pertinent to the debate on whether Google News steals content from news sites—(a) Google News actually directs readers to the news sites that own the content and (b) no ads are placed on Google’s news pages—the former appeared in 42.2% of the articles, whereas only 10.9% of the articles included the latter. In other words, the coverage of the Google–newspaper relationship made salient one major technical characteristic of Google News that benefits newspaper sites but largely de-emphasized the non-commercial nature of Google News. In addition, whereas nearly half of the articles mentioned other online news aggregators, relatively few presented any market data to reflect Google News’ not-so-dominant market share. These mixed findings call into question how journalists select particular themes while neglecting others when covering a complicated issue such as the Google–newspaper relationship.
Regarding source selection, this study documented a heavy reliance on newspaper publishers and journalists as sources cited in the articles, which is consistent with previous research (Chyi et al., 2012). Yet, Google’s voice was also well represented in the coverage. It seems that the professional norms of balanced coverage were shaping the content examined here. Perhaps because of its status as a leading Internet company, Google was not marginalized or ignored in the conversation regarding its relationship with newspaper industry. Interestingly, although newspaper sources expressed largely negative but relatively diverse views about the impact of Google News on their industry, none of the Google sources acknowledged any downsides their aggregation service might pose for the news industry. In fact, Google very often emphasized that it is actually helping the news industry, as evidenced in the following remark: “We believe search engines are of real benefit to newspapers, driving valuable traffic to their Web sites and connecting them with new readers around the world” (Liedtke, 2009, para. 13) Google’s former CEO, Eric Schmidt, in his 2009 article published by the Wall Street Journal, “How Google Can Help Newspapers,” also indicated that Google is serious about developing technology to engage news audiences and was testing, with more than three dozen partners from the news industry, Google Fast Flip. “Our news partners will receive the majority of the revenue generated by the display ads shown beside stories” (Schmidt, 2009, p. 14). As we know today, that service did not deliver on its promises. 6 Overall, Google’s corporate voice has been consistently friendly, even while the actual impact of Google News on the news industry has been rather mixed.
What is completely missing from the coverage is the input of news users. No articles presented readers’ views; only 14% cited market reports, some of which might reflect user response or market demand for news in the aggregate.
One major moral claim made in the coverage is that “newspapers deserve to be paid” (by Google or readers), with about one third of the articles presenting such a view. This is not surprising because it mirrors the news industry’s intense discussion of digital paywalls as a possible solution to its financial woes. In addition, about three in 10 articles included sensational accusations against Google of “stealing” newspaper content or being a “parasite”—serving as another example of “emotion-laden, highly charged drama” (Carey, 1974, p. 233) that traditionally has characterized the way journalists cover themselves.
Overall, Google was portrayed as a foe of the news industry, with two thirds of the articles portraying the Google–newspaper relationship as competitive or hostile. As this passage from Poynter.org suggests, “I wouldn’t try to make the case that Google is single-handedly killing the newspaper business, but it does wield one of the longest daggers” (Edmonds, 2009, para. 8). But when it came to the solution, most of the articles (59.4%) suggested that newspaper sites should work with Google or other aggregators. For instance, it was suggested that newspapers could take advantage of the traffic directed from aggregators to create multiple revenue streams and that Google could help publishers control the number of news articles a user could access through search engines or enable newspapers to block portions of their sites from indexing more easily. In addition, it was proposed that Google could support news organizations with more credible brands by highlighting their content in search results. In other words, although most of the articles portrayed Google as a competitor of the newspaper industry, in the main they also stressed the importance of working closely with the apparent “enemy” or “parasite.”
At first glance, such contradictory themes seem perplexing—perhaps because the Google–newspaper relationship itself is so complicated. Or, perhaps these patterns speak to the conflicted nature of news aggregation and media business strategy more broadly. In that light, these findings usefully illustrate the apparent confusion with which news organizations confronted the aggregation challenge—a confusion that led to their failures in developing more purposeful and productive strategies for effectively managing aggregation as an emerging paradigm of news distribution. What might this portend for the future? The media environment is increasingly populated by a growing variety of “low-pay, no-pay and ‘automated’ journalism,” and yet news professionals, while initially denouncing the supposed lack of quality and originality in such models, may come to see the social value in distributing news to larger audiences (Bakker, 2012, p. 635). Moreover, even as some professionals and public policy experts charge that Google and other aggregators are undermining old-fashioned reporting, an emerging cadre of digital journalists is developing new modes of journalistic norms, routines, and expertise around aggregation—in effect, reclassifying news aggregation as an art form that is about “keeping an ear to the internet” (Anderson, 2013b, p. 1021). In any case, news aggregation—both of the automated and human variety—will continue developing, likely occupying an ever-larger share of the media environment. As it does, the debate about the relationship between Google and the news industry will not only continue, but may also serve as a backdrop against which underlying tensions regarding journalistic knowledge, expertise, and value-creation unfold (for additional discussion, see Coddington, 2014). To the extent that journalism’s professional logic of control gives way to an emerging “ethic of participation” (Lewis, 2012), one more open to enlarging the boundaries of journalism (Carlson & Lewis, 2015), perhaps the professional resistance to aggregation will fade. Moreover, as legacy newspapers discover financial opportunity in developing new digital aggregation products, organizational resistance to aggregation may fade as well (see Picard, 2011). In the meantime, as journalism struggles for jurisdiction in the media information environment, news organizations are torn between change and stasis—between the need for innovation and yet the need for institutional continuity and legitimacy (Lowrey, 2012; Ryfe, 2013).
Limitations and Future Research
We acknowledge this study’s weaknesses that should be addressed through further research. First, despite the inclusion of six major news publications in three categories, our sample does not represent the entire news industry. Particularly, no local newspapers were included in the analysis (although the Associated Press provides stories run by numerous local newspapers around the country). In addition, among all the newspaper sources quoted (N = 99), only 17% were local newspaper executives/journalists. Therefore, we do not intend to generalize the findings of this study to other publications or to other time frames. Instead, this study offers a close account of how six leading news publications portrayed Google at a critical time. Future studies may examine how local newspapers define their relationship with Google News because aggregation affects all traditional news providers, local or national.
Also worth mentioning are some issues associated with keyword search for article retrieval from a database such as LexisNexis, a common approach among content analysis studies. Different keyword combinations influence the articles retrieved—generic keywords yield a larger number of articles but lack precision, whereas specific keywords generate fewer but more relevant articles. Choosing the best keyword combination is often no easy task. When the topic under study involves specific keywords (e.g., “Columbine” school shootings or “Hurricane Katrina”), keyword search can effectively retrieve all relevant articles. In our case, we experimented with many keyword combinations, but “Google,” “newspaper,” and “(web)site” seemed to be the most effective in achieving thoroughness and relevance; however, these words appear frequently in all kinds of stories, so it took extra effort to exclude irrelevant articles from the final sample. Another factor beyond researchers’ control is how frequently the news media cover a specific topic. The Google–newspaper relationship, compared with other topics such as elections, is not as heavily covered, adding to the challenge of retrieving a large body of articles for analysis. As a result, despite the inclusion of six major publications and our good-faith efforts to include as many relevant articles as possible, the analysis includes no more than 64 articles.
This study content analyzes the news coverage of the Google–newspaper relationship, whereas a qualitative textual analysis might provide a richer understanding of Google’s role in contemporary journalism and how it was portrayed by the media. In addition, this study is limited in examining Google only and not other news aggregators; nonetheless, Google is unique because of its “prominence” as the world’s most-criticized online news aggregator. Future studies might examine the impact of Yahoo, which has contractual arrangements with many news organizations for content whereas Google does not.
In recent years, the Google–newspaper relationship has evolved. In 2010, Rupert Murdoch, who had waged a war of words with Google several times during the late 2000s, erected paywalls around the content on The Times and Sunday Times’ sites and blocked Google from indexing their stories altogether (Andrews, 2010). As a result, the papers disappeared completely from the public Internet (Kaletsky, 2012). In 2012, Murdoch reversed his policy and allowed Google and other search engines to index the first two sentences of each article, hoping to attract new subscribers (Andrews, 2012). Then, in 2014, Murdoch sent an open letter to the European Commission complaining about Google, contending that “[u]ndermining the basic business model of professional content creators will lead to a less informed, more vexatious level of dialogue in our society.” Google fired back by arguing, in part, that it sends “over 10 billion clicks a month to 60,000 publishers’ websites, and we share billions of dollars annually with advertising publishing partners” (Google Europe Blog, 2014).
On the policy front, some European countries have pushed for stricter copyright protection of news content (Carr, 2012; “Google Settles French Newspaper,” 2013; Levine, 2013; Pinedo, 2014; Ponsford, 2012). In 2013, Google agreed to spend 60 million euros to help French publishers develop their online business models and provide French media with greater advertising opportunity at reduced cost (“Google Settles French Newspaper,” 2013). In December 2014, Google dropped Google News in Spain in response to a law that would allow Spanish publishers to charge search engines for indexing and displaying their content (Chappell, 2014). As of March 2015, Spain’s Association of Newspaper Editors suggested that the drop in web traffic to Spanish newspapers has been about 12%. That is far less of an impact than what German newspapers experienced when, in response to a German law, Google stopped displaying snippets and thumbnails of their content (but still linked to headlines) in October 2014; at that time, some sites quickly lost 80% of their Google News traffic, prompting publishers to back down almost immediately (Slegg, 2015).
Some of these recent developments have illustrated the point that “the only thing worse than being aggregated by Google News [is] not being aggregated at all” (Carr, 2012, para. 3). Perhaps it is impossible to characterize the Google–newspaper relationship as either hostile or collaborative as it is essentially both hostile and collaborative, as similar industry relationships have been identified in media management research (e.g., Gade & Raviola, 2009; Liu & Chan-Olmsted, 2003). Future studies should continue monitoring how traditional news organizations compete and collaborate with their “frenemy,” Google, as the era of news aggregation unfolds.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) declared receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the School of Journalism at the University of Texas at Austin.