
Abstract
Digital technology has made it easier for researchers to conduct and produce multimodal data. In terms of a social semiotic understanding, multimodal means that data are produced from different sign resources, such as field protocols combined with visual recordings or document analysis consisting of audiovisual material. The increase in multimodal data brings the challenge of developing analytical tools not only to collect data but also to examine them. In this article, I introduce a research approach for how to integrate multimodal data within the framework of grounded theory by extending the coding process with a social semiotic understanding of data as a combination of different sign modes. This approach makes it possible not only to analyze data based on different modes separately but also to analyze their combination, for example, the interweaving of text and image.
Introduction
Since its introduction, grounded theory has become one of the most widely used research programs in the social sciences for conducting qualitative studies. Not least because of its openness to every data format, grounded theory is used for a wide range of types of data. With the central premise that “all is data,” Glaser and Strauss based their research program in grounded theory as both a methodology and research program for qualitative research (Glaser & Strauss, 2008). My research also uses grounded theory as its basic research program, but in two studies in particular, it was challenged to adapt the coding model of Glaser and Strauss (2008) and Strauss and Corbin (1998) for very heterogeneous data. In one study, I examined online discourses that included videos, posts on social media platforms, and blogs with a huge amount of visual communication (see Author, 2016, 2018, 2020). Another study examined German–Polish border regions, and involved photo scripts in addition to text-based forms such as transcription of qualitative interviews and written field reports. In both studies, the aim was to reconstruct practices and knowledge that are related to more than just text-based data. While the study on online discourse dealt with the question of how memory practices and knowledge about the past constitute discourses on the internet, the focus of the second study was on how practices and knowledge about the German–Polish border are being transformed in the border regions. In both studies, I used a multiperspective research design to collect as comprehensive data as possible. The collection of these data was not a major challenge because of technologies like digital video cameras and specific software for storing audiovisual documents, such as screengrab and screen capturing software. In the analysis of these multimodal data, however, I discovered limitation in the coding approach of grounded theory, and I saw the need to integrate analytical tools to handle the combination of different sign systems.
When I characterize data as multimodal, I am referring to a social semiotic definition of multimodality as the interplay of different modes (Kress & van Leeuwen, 2010; van Leeuwen, 2006). These modes range from gestures to music, images, and language, among others, and are constituted of semiotic recourses. The recourses include both physiological resources, such as the human voice or the muscles for our facial expressions, and technical resources, such as a pen or computer hardware or software (van Leuwen, 2006, p. 32). The social semiotic concept of multimodality applies to all communicative situation, encompassing face-to-face interactions as well as mediated interactions among nonattendees, such as the communication between television and viewers. Every type of communication can therefore be characterized as multimodal, but because of the digitalization, we could recognize a “culmination” of multimodalization (Bucher, 2013, p. 64) because the use of digital technologies can enable the widespread use of semiotic forms. At a technical level, it is possible to translate all modes into a digital materiality, which simplifies technical production of visual communication in particular.
For researchers, on one hand, it has become easier both to produce and to collect multimodal data, but on the other hand, new methodological approaches are required to analyze these multimodal data beyond focusing only one mode. Following the perspective of social semiotics on multimodality, not only language but all semiotic resources are significant: “All are seen as equal, potentially, in their capacity to confer meaning to a complex semiotic entity . . .” (Kress, 2012, p. 122). It would therefore introduce an artificial discrimination to look only at either verbal or visual communication in a study combining different modes (Author, 2016). A concrete empirical procedure cannot be limited to a pure language analysis, nor would a sole analysis of (moving) images be sufficient. Instead, the interaction of the various sign systems must be focused on. In principle, the design level of visual communication must be examined in greater depth because in the case of images, the content level is only accessible via the level of design.
The methodological challenge in the analysis of multimodal data is that analytical tools that were primarily developed for text-based data cannot be directly transferred to visual data, and thus also not to multimodal data. Different modes are not always congruent in their structures, as is underlined by Kress and van Leeuwen: “The meaning which can be realized in language and in visual communication overlap in part, that is, some things can be expressed both visually and verbally; and in part they diverge—some things can be “said” only visually, others only verbally. But even when something can be “said” both visually and verbally the way in which it will be said is different.” (Kress & van Leeuwen, 2010, p. 2). They argue that it is not enough to apply qualitative research methods to multimodal data, and that a methodological understanding of the different modes must be combined with a multiperspectival understanding of the combination of these different modes. The challenge is then to adequately analyze the connections and interplay of various sign systems, as well as the different levels of modes. I argue that to be able not only to extend the analysis from language to other modes but also to include the interplay of sign systems in their multimodal linkage, it is fruitful to adapt qualitative methods through the lens of social semiotics. In both studies mentioned above, I used a coding system based on grounded theory, but with an extension of social semiotic categories to analyze the multimodal data. In the study of online discourse, I analyzed an internet-based debate about the former concentration camp guard John Demjanjuk. He was indicted in Germany in 2009 for his involvement in the murder of prisoners of the Sobibor extermination camp during the Holocaust. The media coverage of these processes addressed not only legal issues and aspects of the defendants and their crimes but also issues of historical circumstances as well as guilt and responsibility in a wider sense (Sommer, 2020). The coverage was not limited to mass media statements, but also included web-based forms of communication such as Facebook groups, forum discussions, YouTube videos with corresponding comments, blog entries, tweets, and so on. Online communication was mostly a combination of static voice image ensembles and video–audio formats. Online communication in general is highly multimodal, that is, it is constituted through the combination of various semiotic modalities, such as in a YouTube video by linking moving images with an audio track and a written caption and commentary.
The second study focused on transformation processes on the German–Polish border. Our empirical focus was on changes in the spatial knowledge and practice of the inhabitants of border regions (Kamil & Sommer, in press). Besides participating field observations, we also produced photo scripts (cf. Suchar, 1997) and “walking with videos” (Pink, 2007) in the context of walks with residents.
Multimodal Data Through the Lens of Social Semiotics
It has become common research practice in sociology and related research discipline to collect visual data using photographs in ethnographic fieldwork (e.g., Knoblauch & Schnettler, 2012; Pink, 2013; Suchar, 1997). In parallel, studies of discourse have also begun to analyze visual material, such as photographs and videos, in addition to text-based documents (Christmann, 2008; Traue et al., 2019). In both research traditions, grounded theory can be used as a basic research method to collect and analyze data (Clarke, 2003; Johnson, 2014; Timmermans & Tavory, 2012).
Owing to the increased importance of visual data in social science research, it is not surprising that some approaches have already adapted grounded theory. These adaptions, however, relate primarily to visual analysis rather than the analysis multimodal data, particularly when concerning the coding process of grounded theory. Suchar (1997) adapted grounded theory to examine and compare visual shooting scripts and qualitative interviews, focusing on similarities and differences between these two data types. In his description of the coding process, he gives some insights into his visual coding: “I gave each photograph several labels, allowing it to be used as an answer to different shooting script questions, or illustrating different characteristics of the subject” (Suchar, 1997, p. 38). What is not clear however, is how he actually reconstructs patterns in the visual analysis during the coding process. This lack of transparency is because Suchar does not reflect in a comprehensible way on the meaning production of visual signs on the specific characteristics of visual signs and their meaning making in communication processes, by skipping over the gestalt of the images. Furthermore, images are not merely supportive sign systems for language because meaning is constituted through the multimodal interplay of text and image. Even though Suchar’s approach is not suitable for a multimodal analysis, it hints at how a coding process could work. With the focus on representations in interviews and image, he considered an aspect of the interplay between different sign systems: “The photographs, I believe, allow for a preciseness of recall which give the resultant conceptualizations an enhanced richness of texture and detail” (Suchar, 1997, p. 42).
Another extension of grounded theory comes in Clarke’s (2005) model of a situational analysis. In addition, she further develops grounded theory to investigate discourses, especially visual discourses to include visual data through the process of memo writing (Clarke et al., 2015). She distinguishes between three types of memo: “locacting” the producer of the image, its audience, and social world; “the big picture,” which is a narrative description of the image; and “specification,” which deconstructs the image by interpreting it in different ways (Clarke, 2005, pp. 224–228). Based on that differentiation, she suggests producing situational maps of visual materials to draw and define connections with elements that are not part of the image, such as implicated actors and institutions. Clarke’s situational mapping goes in the direction of a multimodal analysis because the analytical focus does not rest on only one semiotic mode, but on both the visual material and its nonvisual context. However, it is missing a technical and transparent suggestion of how to describe the images, especially for the “locating” memo writing, and then, based on that, how to deconstruct images. This is due to the fact that there is no comprehensible way of analyzing how the images can be examined and interpreted, especially with regard to their gestalt. This also becomes clear in Clarke’s very vivid study on the visual culture of the U.S. healthscapes (Clarke, 2010). In the presentation of the results, images have a rather illustrative character for the analysis of the historical discourse, without being interpreted beyond a description. Visual communication in particular cannot be interpreted if one does not focus on the “how” of communication. The contents, which are constituted by visual practices, can be broken down primarily through visual representation. For the analysis, this means that in addition to the denotative level of an image, the connotative level of an image composition must also be part of the coding process.
Extending these attempts further, in my own analysis, I developed existing methods to examine both visual data in particular and the combination of different data types. My main argument is that an understanding of the social(semiotic) rules of visual communication and based on that of multimodal communication is necessary to analyze data beyond text-based data. In my opinion, this understanding can be adapted via the functions of the respective signs, as Halliday (1993) describes them for language and Kress and van Leeuwen (2001) then for images.
Both of my studies involved visual data. In my study of an online discourse about the former SS guard John Demjanjuk, an image of an SS identity card played a crucial role in the debate about whether he is guilty of having participated in the killing of at least 29,000 people as a guard in the Sobibor camp. Images of the supposed SS ID card and related visual representations were employed to identify the accused Demjanjuk as the agent responsible for committing the misdeed. The meaning of the image of the SS ID card is specified in more detail in the written text surrounding it. Possible objects, actors, and themes that are addressed in the text are in turn brought to view by the image.
In my study of German–Polish border regions, it was particularly important to understand the materiality and spatiality of the borders in different regions, and I therefore took a lot of photographs of bridges during my fieldwork. One example was a bridge connecting a Polish and German village with each other.
The first time I passed the bridge, I almost overlooked it. It looked like a ruin that has gradually fitted into the landscape and no longer appears to be in use. My first assumption was that it is one of the forgotten bridges between Germany and Poland that were destroyed during World War II. Only in an ethnographic interview with one of the inhabitants of the village on the German side did I find out that is still being used by the village’s inhabitants. In the analysis, I then pursued the goal of relating both the field notes of my ethnographic interviews and the photos with each other and interpreting them in an integrative way.
In both examples, each sing modes in the data could not be understood without the combination of other sign modes, underlying the need for an innovative approach to analyze multimodal data in different research settings.
In contrast to the adaptions by Suchar and Clarke described above, Kress and van Leeuwen provide a language to describe images analytically. Their approach is based on Halliday’s (1993) functional grammar, which conceptualizes semiotic signs as realizations of three types of meaning functions: the so-called metafunctions. These where first worked out by Halliday on the basis of the sign system of language, and form the basic functions that language fulfills as an action. Halliday defines these three metafunctions as the modes of meaning that are presented in very use of language in every social context. A text is a product of all three; it is a polyphonic composition in which different semantic melodies are interwoven, to be realized as integrated lexicogrammatically structures. Each functional component contributes a band of structure to the whole. (Halliday, 1993, p. 112)
The first function is the ideational function (experience-based function), referring to the understanding that language always says something about cultural experiences. Speakers talk as members of a culture about experiences, perceptions, and the contents of consciousness. The interpersonal function describes the function of language through which speakers relate a position to the other person and thus negotiate a relationship. The textual function includes the structure and internal order of language. Kress and van Leeuwen applied Halliday’s functional grammar to other semiotic modalities, based on their assumption that all semiotic modalities fulfill the three metafunctions, including visual signs (Kress & van Leeuwen, 2010, pp. 15, 20). The ideational metafunction then encompasses representation, for example, the representation of contents and concepts. One could therefore focus on how concepts are presented in multimodal communication. The interpersonal metafunction refers to the relationship between the recipient and the content, and the textual metafunction focusses on compositions of the different elements of sign systems. Their approach offers the potential to complement the coding process of grounded theory. Especially, the metafunction can be used as concepts and categories to analyze multimodal data. The metafunctions can complement the analysis, so that in the coding process, visual signs are interpreted according to their design and that besides content concepts also social semiotic categories of design can be generated. Based on these definitions of metafunction, I formulated concrete questions for the analysis of multimodal data. Similar to the analytical strategy of grounded theory, these questions referred to the data material and coded the data.
The coding process in my analysis should enable me to reconstruct patterns of knowledge and practices about the phenomenon that go beyond the descriptive level. The central idea of coding in the research program of grounded theory is the constant comparison of sequences with each other, which should lead to the generation of theoretical concepts. During the coding process, sequences of data are separated and recombined to develop concepts based on that coding process (Strauss, 2003; Strauss & Corbin, 1998). As far as the procedure is concerned, I am guided by the three-step process described by Strauss and Corbin, in which open, axial, and selective coding build on each other and ideally should lead to theoretical saturation. I supplement all three phases with categories of analysis that I have derived from the metafunctions of social semiotics described above. At the beginning of their analysis, Strauss and Corbin (1998, p. 45) suggest asking general questions, such as who, when, where, what, how, how much, and why? Comparing these more general questions, with my own question based on the social semiotic understanding of meaning making, I focused only on both the level of content and the level of design. For visual communication in particular, it is necessary to analyze the level of gestalt to interpret the specific visual meaning making. Starting from the ideational metafunction, the following questions can be used for the coding process of visual data, and based on that also for multimodal data later in the analysis:
Actor: Who is represented?
Social role: What are the social roles for the actors based on their appearance?
Theme, event, object, situation: What is represented?
To reconstruct the interpersonal metafunctions for visual communication, the questions mainly circle around production practices, such as camera settings, perspective, and section. The following questions could be used for coding:
Camera setting/perspective: Which camera setting or perspective is chosen, and which (proximity) relationship can be described for the scenery?
With the focus on composition, the textual metafunction can be reconstructed, especially for visual signs with a focus on the following:
Movements: Which movements or dynamics can be determined by lines (vectors) in the picture?
Relationship between actors: How is the relationship between actors visualized through posture, proportions, and positioning?
Closeness or distance: How is the distribution of objects in the image organized, and how does this organization constitute closeness and distance of the elements to each other?
Dominance: What kind dominance, emphasis, and attention are constituted through the use of contrasts (light–dark, big–small, blurry–sharp, gloss–matt, monochrome–colored, foreground–middle ground–background)?
Affiliations and boundaries: What is the relationship between objects and context? (this includes questions about long shot, knee shot, close-up and extreme close-up, normal view, view from below and view from above, as well as the role of the observer as uninvolved, strongly addressed, eyewitness, or participant)
Image section: Which view on the image’s objects and contexts allows the image
The analysis does not entail answering all questions completely and comprehensively. Rather, these questions should provide guidance on how to deal with different elements of multimodal data, and building on this step, on how to analyze character combinations. Depending on the research question and research subject, a different level of emphasis can be placed on the different metafunctions.
Research Program: Multimodal Coding
The social semiotic understanding and the analytical focus on metafunctions form the starting point for my conceptualization of multimodal coding. The coding itself refers to grounded theory, and is based on an indicator–concept model, in which data are considered to be an indicator of concepts (Strauss, 2003, p. 25). During the process of analysis, one generates concepts by comparing the indicators over and over again, naming them with codes, and then grouping these codes into categories. Strübing (2008, p. 56) points to the problem of induction because to recognize what is “the case,” one refers to a preexisting extensive classification system that already takes effect before each naming and recognizing of a phenomenon. For unknown contents, the inductive strategy is therefore not always sufficient because there are no known rules and terms. My analysis in both studies also revealed the difficulty presented by my being barely familiar with the visual and audiovisual data material in particular. Therefore, I adapted the social semiotic approach by using its categories as “borrowed codes.”
In my research program of multimodal coding, I follow Strauss and Corbin’s three steps of analysis: open, axial, and selective sampling and coding (Strauss & Corbin, 1998, p. 61; see also Strauss, 2003, p. 28). In the following, I illustrate the combination of the coding process of grounded theory with the social semiotic approach, using concrete coding examples. I draw on the two studies mentioned above, concerning the media discourse debating trials against a former concentration camp guard in online media and the examination of border regions at the German–Polish border and their transformation. Even though the data material of these two studies differs with respect to the form of multimodality, both the discursive documents in the first study and my field protocols enriched with photographs in the second study could be analyzed by the extended coding program.
The Multimodal Open Coding
In the first phase of coding, the aim is to collect and code as much relevant data as possible. The preliminary goal in this phase is to generate concepts from the data (Strauss & Corbin, 1998, p. 45). For my research projects, it was essential that the codes could be contextualized not only linguistically but also visually. The following example of an open coding is from the online discourse analysis of the debate about the former concentration camp guard, John Demjanjuk. In the discourse about this defendant, questions about guilt and memory were negotiated. In terms of the Demjanjuk discourse, basing the coding on provisional, first key concepts and associated phrases and images allowed us to order the various historical incidents, people, evidence, and strands of argumentation that constituted the different stages of Demjanjuk’s prosecution (see Author, 2016). The severity of Demjanjuk’s crime was addressed through comparisons with other criminal acts. For example, in one quotation (see Figure 1), his crimes, the participation in the murder of 29,000 people in the Sobibor extermination camp during World War II were compared with the U.S.-American criminal and cult leader, Charles Manson. The coding excerpt makes it clear that the comparison with other criminals takes place not only at the linguistic level but also at the visual level.
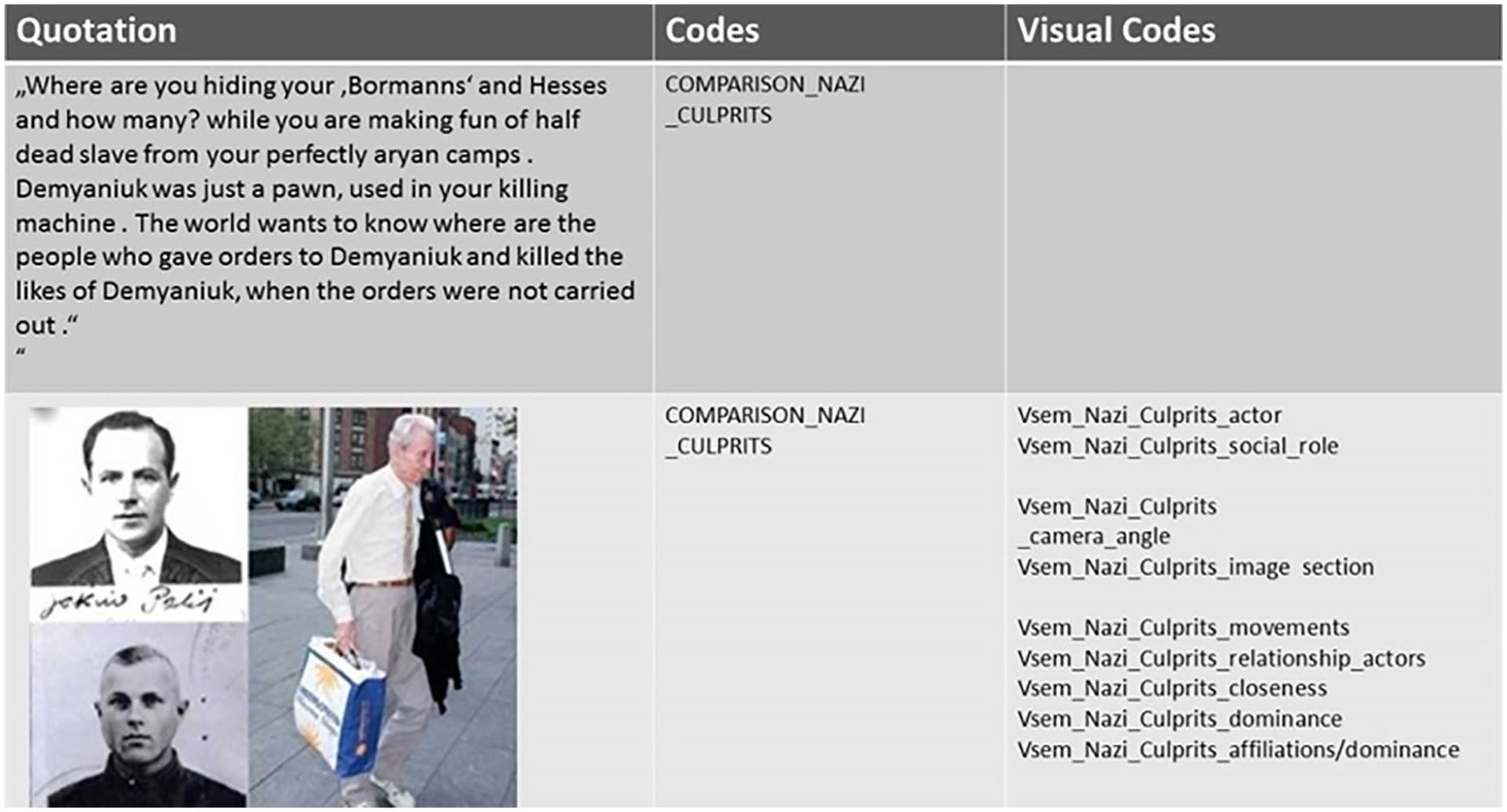
Coding sequences of the data in the open phase.
As shown in Figure 1, the image of comparative war criminals could also be assigned to a collage of images that juxtaposes three men. Labeling this image with the code, however, required putting on my social semiotic glasses to first describe and understand the elements of the image to analyze its meaning. The questions mentioned above, which I adapted from the metafunctions of social semiotics, helped me to generate visual codes.
Ideational metafunction
(who is presented?): This picture collage presents three men: two black and white portrait photographs (left in the picture) and with the whole body picture of an older man (right in the picture).
Both portrait photographs seem to be excerpts from a document, as indicated by the signature below the upper picture as well as the stamp marks on the lower photo. The right photo, however, looks like a snapshot. Through my analysis so far, I knew that the lower passport photo of this image section represents Demjanjuk. It is the passport photo of his SS ID card (see Figure 2), and I assumed that the upper photo also represents a Nazi war criminal in his active time.

Screenshot of an SS ID card and article.
Interpersonal metafunction
Vsem_image section: Through the section of the image and the coloring, two different time levels are represented, the past being represented in the two images on the left side and the present being represented on the right side.
Textual metafunction
Vsem_relationship between actors/vem_dominance: The relationship between the men is marked through the section of the images and their color. The right half of the picture is a color photograph and the left half is in black and white, which creates both a kind of closeness between the two portrait photographs but also gives a distance to the color photograph. Vsem_affilication/boundaries: The full body photo on the right may show the same but aged man in the present. The leg pose with the slightly bent left knee of the depicted man indicates that he is currently walking.
Demjanjuk is visually presented in the discourse again and again through contrasting a younger and older man. Unlike the old man in this picture, however, Demjanjuk is not “walking,” or cannot move freely. The older man on the right side of the picture goes out of the picture, so unlike Demjanjuk, he appears as having “got away with it.” To generate the code COMPARISON_NAZI_CULPRITS, I referred to the visual coding of the image. The illustrated coding example is part of a study in which I examined multimodal communication with a focus on a specific research question:
However, if I were to pursue a different focus and therefore collect other data, then I must adapt the coding accordingly.
For the coding of ethnographic fieldwork, it is also important to analyze the visual data produced during participant observations. Not all semiotic codes will be useful, as this will depend on the research question, but the codes that I have borrowed here provide an analytical tool box for the nontext-based data. Codes themselves then denote various concepts. Their names are preliminary (Strauss, 2003, p. 28). The naming can be done both by so-called in vivo codes, that is, word expressions that appear in the data material, and by “borrowed” codes from the previous knowledge of the researcher.
For example, in my ethnographic study on border regions, one research question was how potential processes of debordering and rebordering materialize in space. In addition to my field notes, I also collected visual data through shooting scripts (see Figure 3). The data analysis for this study was, as I mentioned before, based on the coding process of grounded theory, and, as with my field notes, I also “read” the pictures I had produced for the shooting scripts as if they had been created by a stranger (Emerson et al., 1995, p. 145). During the analysis, I looked with distant eyes on my material, and to do the coding with the aim of comparison.

Image of a photo script, produced during field explorations in the German–Polish border.
In the phase of multimodal open coding, I dissected the data fragments into their monomodal elements. This “breaking up” of data is typical of the grounded theory coding process. The specific method I have adapted is to use open coding to divide the visual clippings at the design level in a social semiotic way. In Figure 4, this coding process can be seen for the comparison of war criminals based on the data of the first study about the Demjanjuk discourse.

Open coding of multimodal data.
The division is based on linguistic and visual sections which are coded sociosemiotically, such that the meaning of pictures can be grasped as broadly as possible. The analytical separation in the coding of the different sign levels should make it possible to determine exemplary statements for the respective sign resources. In the coding of the visual material, as in the comparison between Nazi culprits in this example, this code can only be derived from the social-semiotic coding. This means that it is only through this coding that I am able to grasp the form of the images and thereby interpret what they say. In this case, for example, specific statements are made by the actors and the respective camera crew with regard to the role of Demjanjuk as a perpetrator in comparison with other criminals.
The Multimodal Axial Coding
This analytical phase forms the basis for reconstructing the various drawing levels in a multimodal interaction in the next step of coding. Whereas in the first phase of the analysis the data are mainly classified, the focus of the second phase is on a deeper interpretation of the data (Strauss & Corbin, 1998, p. 76). For this purpose, the relationships between the different categories that were developed in the first phase are determined. Following Glaser’s and Strauss’s assertion that grounded theory is suitable for every type of data, the extension of this research program is also usable for the analysis of every kind of multimodal data, where the research focus is not limited to one single semiotic resource. During the process of axial coding, I developed the concepts and categories that had previously been treated in a monomodal way through considering their multimodal relationships with each other. My focus in the axial coding was therefore on the audiovisual aspects of the interactions between the written and visual components. In the axial analysis, the data are recomposed by drawing connections between the categories and subcategories using an axial coding paradigm. For all components of the coding paradigm mentioned so far, it is crucial to determine how the different levels of semiotic modes correspond meaningfully with each other. As illustrated in Figure 5, I adapt the axial coding paradigm of Strauss and Corbin (1998, p. 75) in this phase of coding.
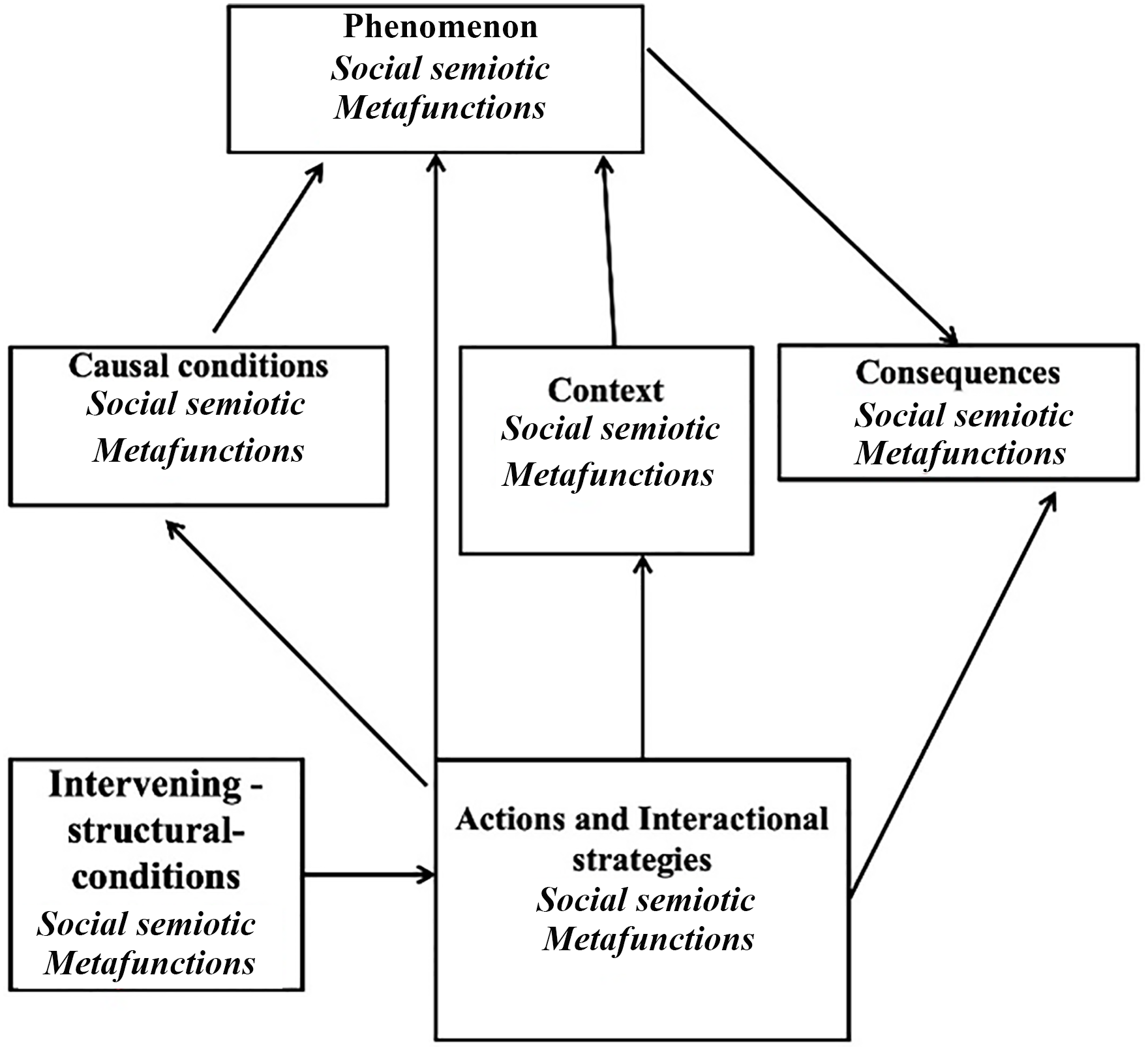
Axial coding of multimodal data.
This coding paradigm enables us to determine the relationships between codes and categories by relating them as phenomena, consequences, contexts, causal conditions, intervening conditions, and action and interactional strategies. In my analysis, this coding paradigm primarily served to condense the generated codes, which I had formed separately for the respective signs in the first step, into multimodal categories. To break down and examine the multimodal correspondences, for example, between text and image, I extended the axial coding of grounded theory by the social-semiotic metafunctions. Using the “borrowed codes” of social semiotic, I interpreted the “how” (how something is expressed/represented) for the combination of image and language. Through this multimodal axial coding and its focus on the multimodal elements of the data, patterns can be reconstructed. These patterns can allow us to understand how the various semiotic modalities in the multimodal interaction realize the ideational, interpersonal, and textual metafunctions. Through the social semiotic concepts, I was able to determine not only which knowledge was (re)formulated by different actors in the debate but also how this knowledge was constituted through practices. In the case study about the Demjanjuk discourse, for example, one multimodal category in the discourse was “disproportionality,” which could be identified referring to the axial coding paradigm as a phenomenon (see Figure 6).
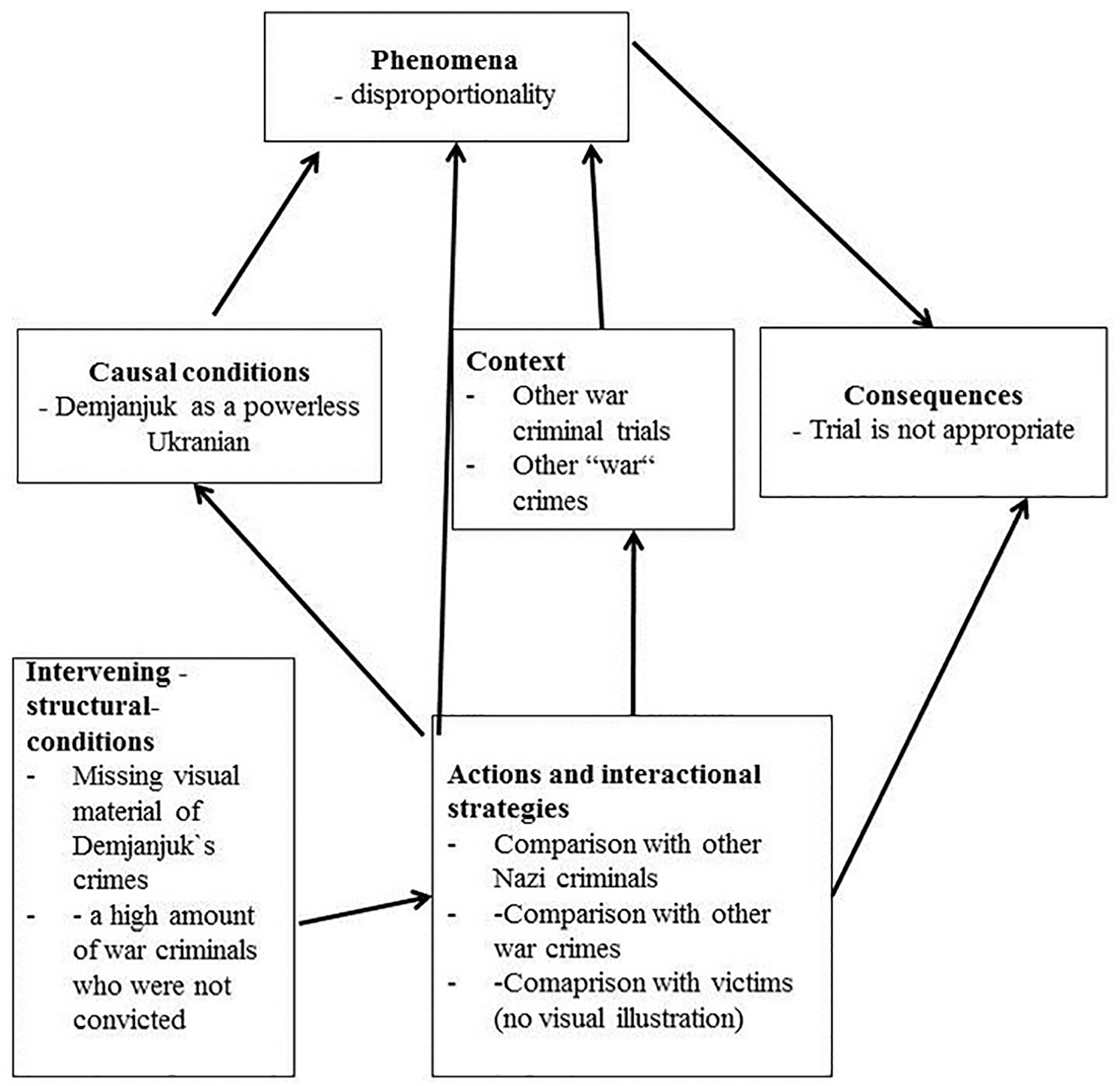
Example of axial coding of multimodal data.
This category is used in the discourse by different actors to underline that the trial against Demjanjuk is inappropriate because of its disproportionality, which can be defined following the axial coding paradigm as the context in my coding process. This imbalance between Demjanjuk and other war trials is illustrated by comparison with other Nazi criminals much higher in the concentration camp hierarchy, who were either not convicted or acquitted, which can be characterized in the axial coding as a causal condition in this frame. Demjanjuk himself does not have enough power to avoid trial, so some statements about his case. Actors who see him in the role of the victim justify this, for example, with his lack of intelligence and with the fact that he was already a small light during the Second World War and is now used as a pawn sacrifice in court proceedings. Among other things, his nationality is cited as a reason for this. As a Ukrainian, he has less influence on German justice than potential German perpetrators. From a social semiotic perspective, these elements of the frame fulfilled the ideational metafunctions for the social role of Demjanjuk in comparison with others. Demjanjuk is being prosecuted, whereas the other perpetrators have escaped. Similarly, this category was also communicated in the online discourse through document photographs that point out various Nazi crimes, such as operations in the Warsaw Ghetto or mass shootings by German soldiers in Europe during World War II. These type of photographs about Demjanjuk’s crime was not available in the discourse, from his time as a guard in the camp Sobibor. This unavailability of such historical recordings is seen by actors referring to the category of disproportionality as proof that Demjanjuk was wrongly accused, according to their position in the debate I analyzed. In addition to the comparison with other perpetrators, Demjanjuk is also compared with the victims of the Holocaust in different online posts like on blogs or in Facebook groups, I coded in my study. The argument in the debate was that because he was also a prisoner of the Nazis, before he was recruited as a camp guard and should have been forced to work, he was not equal in status of Nazi perpetrators. In online discourse, the equation with victims of the Holocaust occurs primarily at the linguistic level. At the visual level, the victims are not addressed through historical photos in various contributions. It is striking that the references to victims of the Holocaust do not take place visually in the social media debate with images of prisoners of concentration camps. I assumed that based on the interpersonal metafunction, the intention was to create empathy for Demjanjuk and not for the victims. This omission highlighted to me that the social semiotic perspective led me to look at how something is expressed, that is, by means of which communicative practices the respective exemplary statements are constituted, for example, the practice of nonillustration of victims of the Holocaust in some of the analyzed contributions to the debates, which can be assigned, following the axial coding paradigm to action and interactional strategies. This nonillustration in this online discourse was also influenced by the intervening condition that there was limited historical visual material available for the Demjanjuk case of him during World War II which actors could use in their posts. The juxtaposition of Demjanjuk and victims was done visually through a selection of current trial images. These photographs were taken mainly during the trial of Demjanjuk in Munich, where he was accused and sentenced for his participation in the murder of 29,000 people in the Sobibor extermination camp. In the contributions, which describe Demjanjuk himself as a victim and therefore as innocent, a specific confrontation took place at a visual level between him as the accused and the survivors as joint plaintiffs in the Munich trial: The joint plaintiffs became particularly strong in some visual representations, for example, through a specific camera angle, for example, the viewers look from below at the person depicted. This view from below, also known as a “frog’s perspective,” gave the joint plaintiffs and contemporary witnesses a large, powerful impression (interpersonal metafunction). They were the central people in the respective photos; other people appear in the background or form the secondary figure. The contemporary witnesses and coclaimants themselves are visually staged as prosecutors, thus rather weakening their status as victims (textual metafunctions). In contrast to these depictions of the joint plaintiffs, Demjanjuk was presented visually; current photographs show him in a wheelchair or on a stretcher with his eyes closed, such that, in contrast to the survivors and relatives of Holocaust victims, he appears sick and weakened.
The Multimodal Selective Coding
In the third phase of my coding process, I again used the axial coding analysis tools described above, but to interpret the multimodal data at a more abstract level. The aim of the last phase is to reveal and formulate the central narrative, which provides an overview of the reconstructed patterns and communicative practices and their connections. This is the basis for the determination of the connection between the previously generated main categories and the determination of a core category. A core category is the central phenomenon around which all other categories are integrated (Strauss, 2003, pp. 24, 33, 69; Strauss & Corbin, 1998, p. 116 ff.). In my study on media discourse, the aim of this third phase was to reconstruct the communicative practices and actors involved. It should be noted, however, that axial coding does not entail classifying as many categories as possible into particular schemes. The function of the axial multimodal coding paradigm is rather to be an aid to interpretation to work out the multimodal categories, and in the final phase of my analysis, it provided a tool for deepening the interpretation through building up the axis of generated categories. For the reconstruction narrative structure, I added categories that I had reconstructed in the second phase. Through the description of their relationship, I was then able to describe the basic narrative of the debate about the social media coverage of the trial against John Demjanjuk. For example, an interpretive pattern can form the context or be a consequence for another pattern in the basic narrative (see Figure 7).

Example of selective coding.
To determine the basic narrative, I was then able to focus on a group of actors and their practices, who reformulated these frames through historical revisionist practices. They could be characterized as extreme right-wing actors; their statements could be classified as National Socialist, anti-Semitic, and/or racist, and they acted as spokesperson on right-wing extremist platforms and networks. Their communicative practices were performed not only in right-wing networks, however, but also in the comment section of YouTube videos, blogs, and online articles.
Conclusion
My research program was mainly developed in two different studies, and is applied to data from ethnographic studies and discourse analysis. The grounded theory (Glaser & Strauss, 2008, Strauss & Corbin, 1998) offered itself because of its circular procedure, which fruitfully combines the regularity and at the same time the openness of a qualitative research process. For Glaser and Strauss (2008, pp. 17 and 65f.), there is no limit to the nature of the data material itself. In their opinion, interview transcripts, observation protocols, written documents, and statistical surveys can be used as data and combined with each other in a case analysis. This was advantageous for my studies on online discourse and on German–Polish border regions, as I produced data of very different quality by means of a multiperspective analysis. The coding examples I have presented illustrate how social semiotics can be an important and fruitful addition for analyzing visual as well as multimodal data. It must also be emphasized that, despite the fact that the coding procedure is guided by rules, it should first and foremost be understood as an interpretative tool. The codes I have borrowed to generate metafunctions should serve as inspiration for getting an overview of the multimodal aspects of data beyond language- or visual-based analysis. For other empirical work that aims to investigate multimodal data and constructed theoretical concepts, this methodology provides a suitable starting point. However, it must also be noted that this method, like other qualitative methods, should generally always be adapted to the research topic and question. This extension of that research program can also be used for the analysis of every kind of multimodal data, where the research focus is not limited to one single semiotic resource.
Footnotes
Author’s Note
The author is confirming that the article is not currently being considered for publication by any other journal.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is financed by the Polish National Science Centre and the German Research Foundation as part of the Beethoven 2 project.