
Abstract
Introduction
ADHD affects about 4% of children and adults worldwide (Fayyad et al., 2007; Polanczyk & Rohde, 2007). It is diagnosed on the basis of psychological and behavioral criteria, as specified in the Diagnostic and Statistical Manual of Mental Disorders (DSM) and the International Classification of Diseases (ICD) and implemented in several rating scales (Snyder, Hall, Cornwell, & Quintana, 2006; Taylor, Deb, & Unwin, 2011). At present, there are no validated, reliable biomarkers for ADHD (Thome et al., 2012).
The fact that ADHD is still a controversial diagnosis in parts of the public and the medical establishment has made the search for such markers more pressing, as it may provide uncontentious evidence for a physical basis of the disorder. The field of electroencephalography (EEG) and event-related potentials (ERPs) seem particularly promising, as brain wave abnormalities have been widely observed in children with ADHD (Barry, Clarke, & Johnstone, 2003; Barry, Johnstone, & Clarke, 2003) and can be measured cheaply, noninvasively, and on-site.
This study reviews the literature on ERP-based markers for ADHD with the specific aim of assessing their usefulness as diagnostic tests.
Method
We searched MEDLINE, EMBASE, Web of Science Core Collection, BIOSIS, and Current Contents Connect (CCC) using the OVID SP web interface and the following search string:
(adhs or adhd or “attention deficit hyperactivity disorder” or “attention deficit with hyperactivity disorder”) AND (“evoked potential” or “evoked potentials” or “erp” or “event-related potential” or “event-related potentials” or p300 or p3 or p3a or p3b or “contingent negative variation” or “error-related negativity” or “early left anterior negativity” or “late positive component” or p600 or “syntactic positive shift” or “early posterior negativity” or “early directing-attention negativity” or “anterior directing-attention negativity” or “mismatch negativity” or “bereitschaftspotential” or “readiness potential”) AND (specificity or “receiver operating characteristic” or roc or classif* or discriminat*).
The abstracts of the search results were scanned for studies meeting, or appearing to meet, the following inclusion criteria:
Participants diagnosed with ADHD using DSM or ICD criteria;
Healthy control group;
ERP-based measure(s) used as index test to discriminate ADHD from controls; studies using the index test to discriminate between more than two groups (e.g., dyslexia, ADHD, and controls) were excluded;
Sensitivity and specificity of the index test and corresponding number of participants must be reported or derivable from the report.
The full texts of eligible abstracts were obtained. Studies not meeting the criteria were then excluded. In addition, the reference lists of all full texts were checked for additional studies meeting the requirements. This process was conducted independently by the two study authors. Disagreements were resolved by consensus.
The first author (A.G.) assessed the methodological quality of the studies using criteria from the second version of the Quality Assessment of Diagnostic Accuracy Studies (QUADAS-2) tool (Whiting, 2011). Seven items were rated, with the three possible response options “yes,” “no,” and “unclear.” Strict application criteria for these options were defined. All items were phrased in a way that a positive answer (“yes”) always signaled the absence of bias. Because for the present set of studies, not all types of bias are equally serious, we added an importance weighting to the QUADAS-2 items (see next section). Table 1 lists quality items, item weightings, response options, and application criteria.
Items Used to Assess Study Quality.
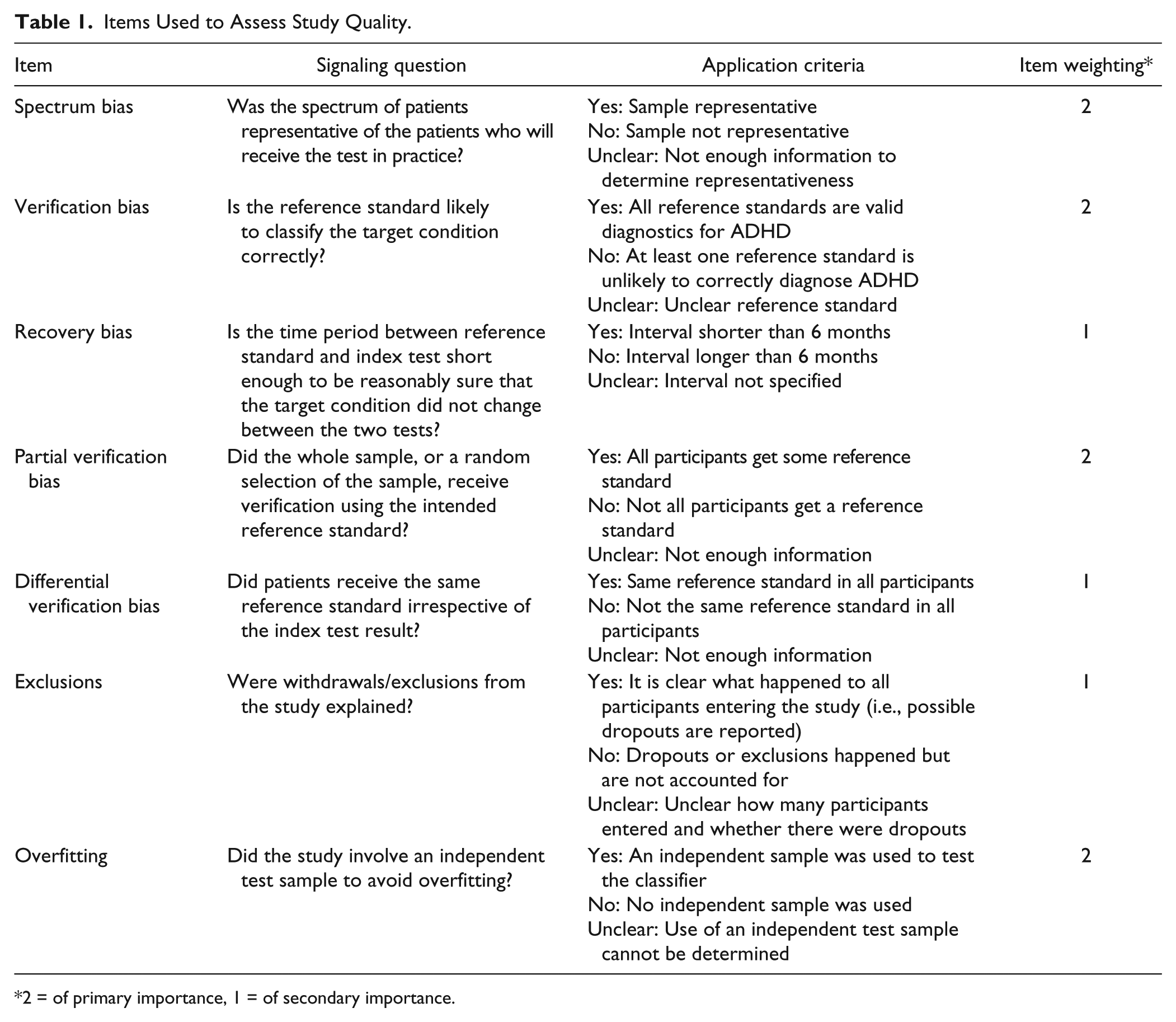
2 = of primary importance, 1 = of secondary importance.
Item Weightings
Spectrum bias, verification bias, partial verification bias, and overfitting were rated the most important. Spectrum bias means that a test might not be applicable to a particular sample. Verification bias means the test may not apply well to the target disorder. Partial verification means that the disorder has not been assessed in all participants, making a test unreliable. Overfitting means the test’s performance may be much worse than implied by the nominal estimates of classification accuracy. These four kinds of bias, alone or in combination, may more or less invalidate a test.
Recovery bias, differential verification bias, and exclusions of participants after recruitment were rated as of secondary importance. Recovery bias is less important because ADHD is a chronic condition whose nature will change only slowly, if at all. This means even intervals of several months between reference and index test may not bias index test accuracy. Differential verification, in the present set of studies, only applied to controls not receiving the same reference standards as ADHD patients. Assuming that confirming the absence of ADHD symptoms in controls should not be too error-prone even if done with less rigorous instruments as those used to evaluate ADHD patients, the effect of this bias should be relatively small. Exclusions of recruited patients after the fact may render samples less representative of the target population, but given that spectrum bias already looms large, the added effect of exclusions should be small and could even go in the direction of making the stayers more representative.
Results
The search yielded a total of 311 papers, whose abstracts were scanned by the authors. Forty-nine papers were selected for inspection of full texts, of which seven met all inclusion criteria and were selected for final review. These represented 284 ADHD patients and 219 controls. Figure 1 shows the details of the search strategy.

Search strategy and results.
Five out of seven studies were published after 2000, and all used DSM-III/DSM-III-R/DSM-IV (American Psychiatric Association, 1980, 1987, 1994) criteria as the reference standard. Patient groups consisted of children in three studies, children and adolescents in two studies, and adults in two studies. ADHD and control participants were well matched for age and sex, but overall, there was a 2.5:1 preponderance of male participants. All studies had participants do a task while recording ERPs. Importantly, however, all studies differed in their index tests, that is, the experimental tests used to classify participants into the ADHD or control group. All studies used some kind of machine learning algorithm, most of them based on peak amplitudes and latencies of various ERP components. The details of these methods, however, differed, and sometimes considerably. A meta-analysis of the results was therefore not conducted. For the same reason, we did not assess study heterogeneity. An overview of the studies, including year of publication, country, patient and control groups, task condition used for classification, classification method (index test), and reference standard is shown in Table 2.
Characteristics of Included Studies.
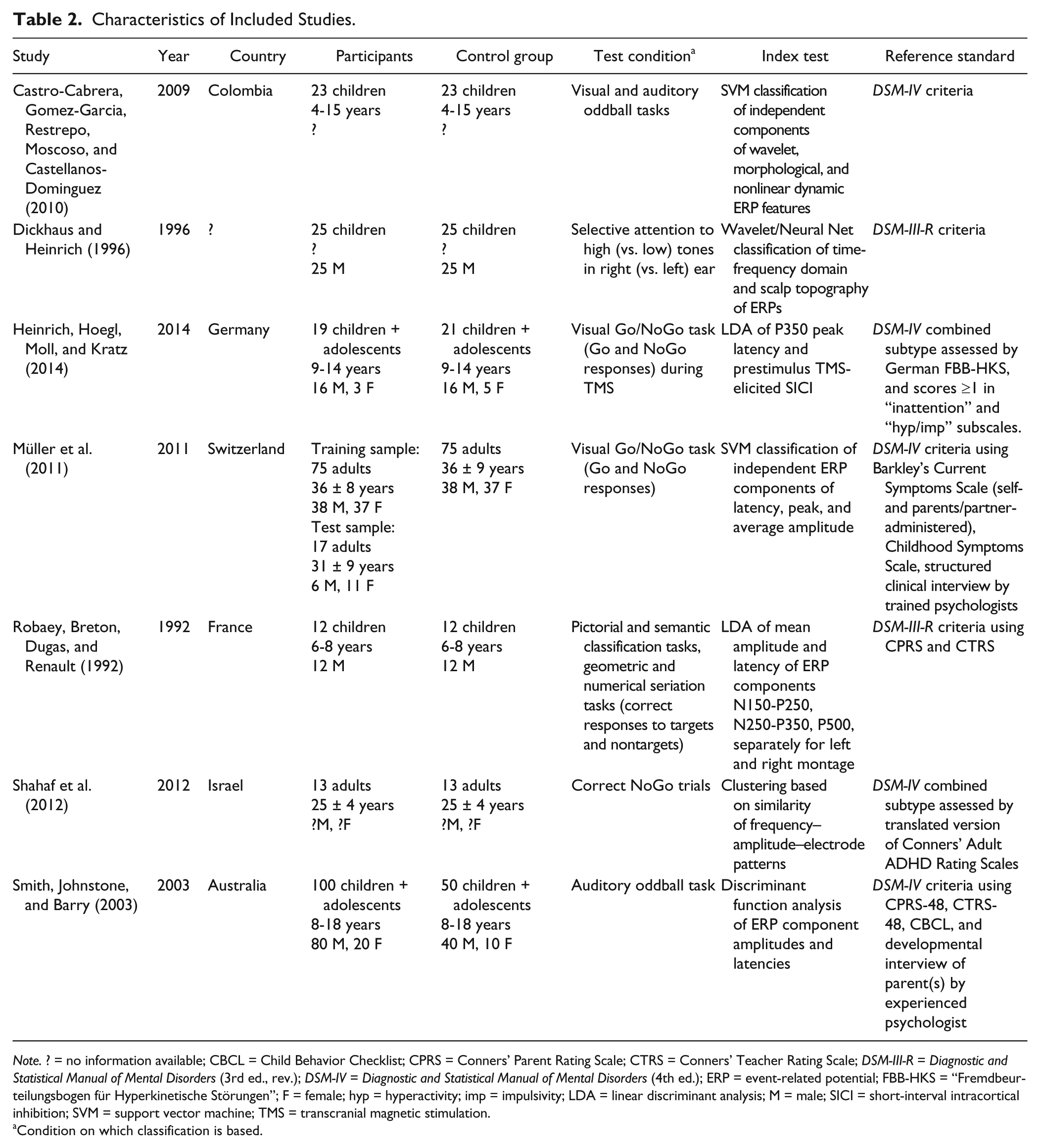
Note. ? = no information available; CBCL = Child Behavior Checklist; CPRS = Conners’ Parent Rating Scale; CTRS = Conners’ Teacher Rating Scale; DSM-III-R = Diagnostic and Statistical Manual of Mental Disorders (3rd ed., rev.); DSM-IV = Diagnostic and Statistical Manual of Mental Disorders (4th ed.); ERP = event-related potential; FBB-HKS = “Fremdbeurteilungsbogen für Hyperkinetische Störungen”; F = female; hyp = hyperactivity; imp = impulsivity; LDA = linear discriminant analysis; M = male; SICI = short-interval intracortical inhibition; SVM = support vector machine; TMS = transcranial magnetic stimulation.
Condition on which classification is based.
Quality Assessment (QUADAS-2)
Overall, the quality of the studies was acceptable (Figure 2). The biggest problems, faced by the majority of studies, were spectrum bias and overfitting. Spectrum bias means that the study sample is not representative of the target population, which in this case was defined as any person who might show up in primary care because of suspected or diagnosed ADHD. Most studies more or less severely restricted the range of eligible participants. Age range was limited in all studies, gender was restricted to boys in two studies, medication to methylphenidate in four studies, a drug washout period was implemented in three studies, comorbid disorders were excluded or limited in four studies, and the presentation of ADHD was limited to the combined subtype in two studies. One study included only right-handers. Recruitment populations were also circumscribed: Patients often came from outpatient clinics, whereas controls were frequently recruited from local schools. As a collective, these studies sample a more varied population than any single study by itself, but they still fall short of being fully representative of the target population.

Quality ratings of included studies.
Overfitting refers to the situation when a statistical model (here: a diagnostic test) fits the data very well, and therefore predicts class membership very well, but completely fails to generalize to new data. This happens when a method does not only model the regularities in the sample that it shares with other samples from the same population but also the idiosyncrasies of the sample that are unique to it and therefore not generalizable. In other words, it occurs when a model does not just fit the “signal” (a systematic pattern in the population) but also the noise (chance deviations in a single sample). Overfitting is a problem that has become particularly prominent with the advent of machine learning algorithms that allow searching large numbers of variables for combinations that optimally predict class membership (James, Witten, Hastie, & Tibshirani, 2013). The availability of great numbers of predictors will virtually guarantee a solution that fits the data at hand well, but usually such models do not generalize. This also means that the test accuracy parameters from such models will be exaggerated.
Our criteria for the absence of overfitting bias are strict, but, we believe, appropriate. Only when a diagnostic test procedure has not only been evaluated in the study sample but also in an independent sample that is not part of the same population as the original sample, do we consider that the best has been done to avoid overfitting. While four of seven studies used cross-validation to estimate classification error, only Müller et al. (2011) went on to test their classifier in an independent sample, a group of 17 participants recruited and tested in a different country. However, this group was very small and raises another problem, that is, whether it has sufficient power to adequately test the classifier.
The only other bias found more than once was differential verification, where ADHD patients and controls do not receive the same reference standard. This could be an issue when the different reference tests lead to conflicting results and, hence, misclassification of some participants. The resulting overlap in class membership would decrease the discriminatory power of the diagnostic test. We have not rated this item as very important, however, as the studies use adequate reference tests for ADHD participants and we assume that correctly identifying participants without ADHD will generally be achievable even if a method other than the reference standard is used.
However, a general problem, not just with this item, was poor reporting. One fourth of reportable items (12 out of 49) could not be assessed because of insufficient information in the text. Fortunately, the most underreported items also tend to be the least important ones: Apart from differential verification, recovery bias was the item with the most missing ratings (only one study provided enough information). We weighted this item down because with a chronic condition like ADHD, significant changes in its presentation are expected to happen very slowly, if at all, so even delays of several months between reference and index test should not introduce too much bias.
Test Accuracy
Estimates of test accuracy are summarized in Table 3. Sensitivities achieved in discriminating between participants with ADHD and healthy controls ranged from 57% to 96%, while specificities fell between 63% and 92%. Four studies achieved pairs of sensitivity and specificity of ≥85% each. Müller et al. (2011), with a sample size of 150 and the best control of overfitting, reached a sensitivity and specificity of 91% each, and a correct classification of 94% in an independent test sample. If 10% of people being evaluated for ADHD using this test actually had the disorder, a positive test result would be correct in 50% of cases. If 25% had the disorder, a positive result would correctly identify the disorder in 75% of cases.
Diagnostic Accuracy of ERP-Based Tests for Discriminating ADHD From Control Participants.

Note. ERP = event-related potential; n = number; C = controls; TP = true positives; FN = false negatives; FP = false positives; TN = true negatives; Se = sensitivity; Sp = specificity.
Discussion
Research on the use of ERPs to diagnose ADHD is severely underdeveloped. Despite a long tradition of exploring ERP deviations in childhood disorders, we were able to find only seven studies that quantified the ability of such measures to discriminate between individuals with ADHD and healthy controls. These studies have their shortcomings, such as low sample sizes, nonrepresentativeness, and inflated estimates of test accuracy due to overfitting. But their most important problem occurs before these methodological details start to matter. It is the fact that there is no standardization with regard to the specifics of the tests used. The performance of the different classification methods used demonstrates that there is scope for valid and precise tests of ADHD, but this potential has not been used so far in collaborative efforts to develop a single test to the point of clinical applicability. What is needed therefore is concerted action among different research centers to develop test criteria that are not only diagnostically valid but can also be implemented for robust and simple use in clinical practice.
The lack of structure in diagnostic test research appears to reflect a similar disarray in the whole field of ERP studies in ADHD. Johnstone, Barry, and Clarke (2013) remarked that although there clearly exists a potential for improved understanding of the brain dysfunctions underlying ADHD, the field would benefit from a more rigorous approach to defining clinical groups and a stronger emphasis on replication studies. They noted in particular, in their literature review, that “no two studies use the same participant, task, and analysis parameters” (Johnstone et al., 2013, p. 655). These authors also recommended an increased focus on the diagnostic use of ERPs (Barry, Johnstone, & Clarke, 2003; Johnstone et al., 2013), but noted that not much progress had been made in the preceding decade.
We concur with this assessment. A successful ERP-based diagnosis requires a foundation of solid, reproducible research into the differences between the brains of ADHD patients and healthy individuals. If potential differences cannot be well established through systematic research programs, diagnostic markers of the disorder will not come to light or will not pass validation.
Particular attention will have to be given to the effects of age and gender, comorbidity, and the use of medication. These are some of the main determinants of the nature and size of alterations observed in ADHD, and combinations of different levels of these factors already produce a vast heterogeneity in potential study samples. To some extent, the search for diagnostic markers might therefore have to proceed on parallel tracks, with some researchers focusing on children, some on adolescents and/or adults, some on male, some on female participants, and so forth. It should not be assumed without further proof that one and the same diagnostic marker will be optimal for each subgroup. To assist in finding promising markers for different subgroups, a number of excellent literature reviews exist (e.g., Barry, Johnstone, & Clarke, 2003; Johnstone et al., 2013).
Recommendations
To advance ERP-based diagnosis of ADHD, the most pressing need is to establish collaborative networks that systematically explore test variants. Ideally, such tests should (a) be simple and easy to administer (e.g., use the signal from only one or a few electrodes), (b) be short, (c) produce results immediately, (d) be based on open source software, and (e) be implementable in a wide range of available EEG systems.
In the long run, (a) tests should be developed that tap into circumscribed biomarkers with known functions, so that (i) tests can contribute to an etiological understanding of the disorder, and (ii) test results are interpretable and communicable to patients, and (b) tests should be validated in a wide range of samples that map out as much as possible of the population of people who might show up in primary care with the need for a diagnostic evaluation of ADHD.
Footnotes
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: A.G. is part-time employed by A. Müller, the first author of one of the reviewed studies. Both A.G. and O.K. are in active collaboration with A. Müller.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.