
Abstract
Consumer electronic devices with voice assistants are becoming increasingly popular in modern intelligent home. Nevertheless, directly uploading unprocessed speech data, which may contain sensitive attributes, to a cloud server poses a significant risk to user privacy. To address this privacy issue, this paper proposes a privacy-enhancing model to protect speech emotions based on generative adversarial networks (PSEGAN). The model aims to prevent the inference of emotional attributes while maintaining the accuracy and utility of speech features. PSEGAN benefits from three modules: (1) A pre-trained speaker matcher imposes generative constraints on the model during the training phase to ensure that the generated speech retains the essential information needed for speaker recognition. (2) Attribute adversarial networks can generate perturbed speech that transforms emotional attributes while preserving the utility of the speech. (3) Gated Recurrent Networks (GRN) can handle the long-short term dependencies of speech signals. PSEGAN model solves the problem of utility loss in traditional speech privacy preservation methods based on generative adversarial networks (GAN). Experimental results show that on the RAVDESS dataset, PSEGAN reduces emotion recognition accuracy by 80.7%, while speaker recognition accuracy only decreases by 1.1%. These findings demonstrate that PSEGAN effectively mitigates the leakage of emotional attributes while maintaining high utility.
Introduction
The rapid development of the intelligent consumer Internet of Things has popularized consumer electronic devices with voice assistants. The widespread use of voice technology in various fields greatly enhances our daily lives, especially in areas such as user authentication, system authorization, and recommendation services.1–8 For example, short video platforms and shopping platforms use voice data and advanced big data analytics to provide personalized recommendations, thereby increasing user engagement and retention.9–11 Consumer electronic devices with voice assistants represented by Amazon Echo and Google Home have surged recently and become an important auxiliary tool for supporting the intelligent life of modern people. Consumer electronic devices with voice assistants deployed in users’ homes collect speech data and upload them to cloud servers for storage and processing. These devices use speech recognition algorithms to analyze the data and generate corresponding speech feedback. A third party performs speech enhancement analysis of the speech data on the cloud server, which can yield valuable user information.12–14 Digital healthcare company CompanionMx can predict emotional states and mental disorders, such as depression and anxiety through subtle changes in a patient’s tone of speech. Speech analysis can serve as a model for evaluating the probability of customer default in the financial industry and for verifying the authenticity of a candidate’s experience in human resources.
Although speech technology brings convenience to our daily lives, it also raises serious privacy concerns due to the sensitive information contained in speech data, such as emotions, gender, and health conditions.15–17 When speech data containing sensitive information is stored on third-party cloud servers, it becomes vulnerable to theft by attackers. When emotional attributes are compromised, an attacker can use the compromised emotional data to conduct personalized psychological attacks or manipulation to influence an individual’s decisions and behavior. The Figure 1 illustrates the process of attribute inference attacks by a malicious entity on unprotected speech data in a speech system. In this scenario, the malicious entity extracts the user’s sensitive attributes through an attribute inference classifier, exposing the user to privacy risks. To protect user data, many countries have proposed data privacy protection policies and regulations, such as the General Data Protection Regulation (GDPR), 18 which emphasize data minimization principles. The development of attribute privacy-enhancing models is crucial for the security of consumer electronic devices with voice assistants. By protecting sensitive emotional attributes in speech data from malicious attacks while preserving other attributes, these models can maintain user trust and encourage the wider adoption of voice technology. Our research addresses these privacy concerns by proposing a novel model that effectively balances privacy protection with the utility of speech data. This model safeguards user privacy by protecting emotional attributes while retaining other valuable attributes, thereby enhancing the functionality and reliability of voice-assisted consumer devices. A straightforward method for protecting speech privacy is speech de-identification, which disrupts the association between biometric features and specific individuals.19–22 For example, noise is often added to obscure original speech and protect user privacy. However, this approach reduces the effectiveness of speech verification. However, these methods compromise the verification utility of the speech. Aloufi et al. 23 provided a privacy-preserving technology to sanitize speech input directly at edge devices, but their method always converts the original emotion to neutral, which will be detected by third parties. Pascual et al. 24 and Ericsson et al. 25 utilize adversarial learning theory to protect speech privacy, but existing GAN-based methods compromise the utility of generated speech. In summary, existing methods primarily have two limitations: (1) The speech utility of protected speech is significantly reduced while achieving privacy protection. (2) Inadequate privacy protection performance, deep neural networks can perform sensitive attribute inference on protected speech data and have high accuracy in attribute prediction, thus posing a risk of privacy leakage.
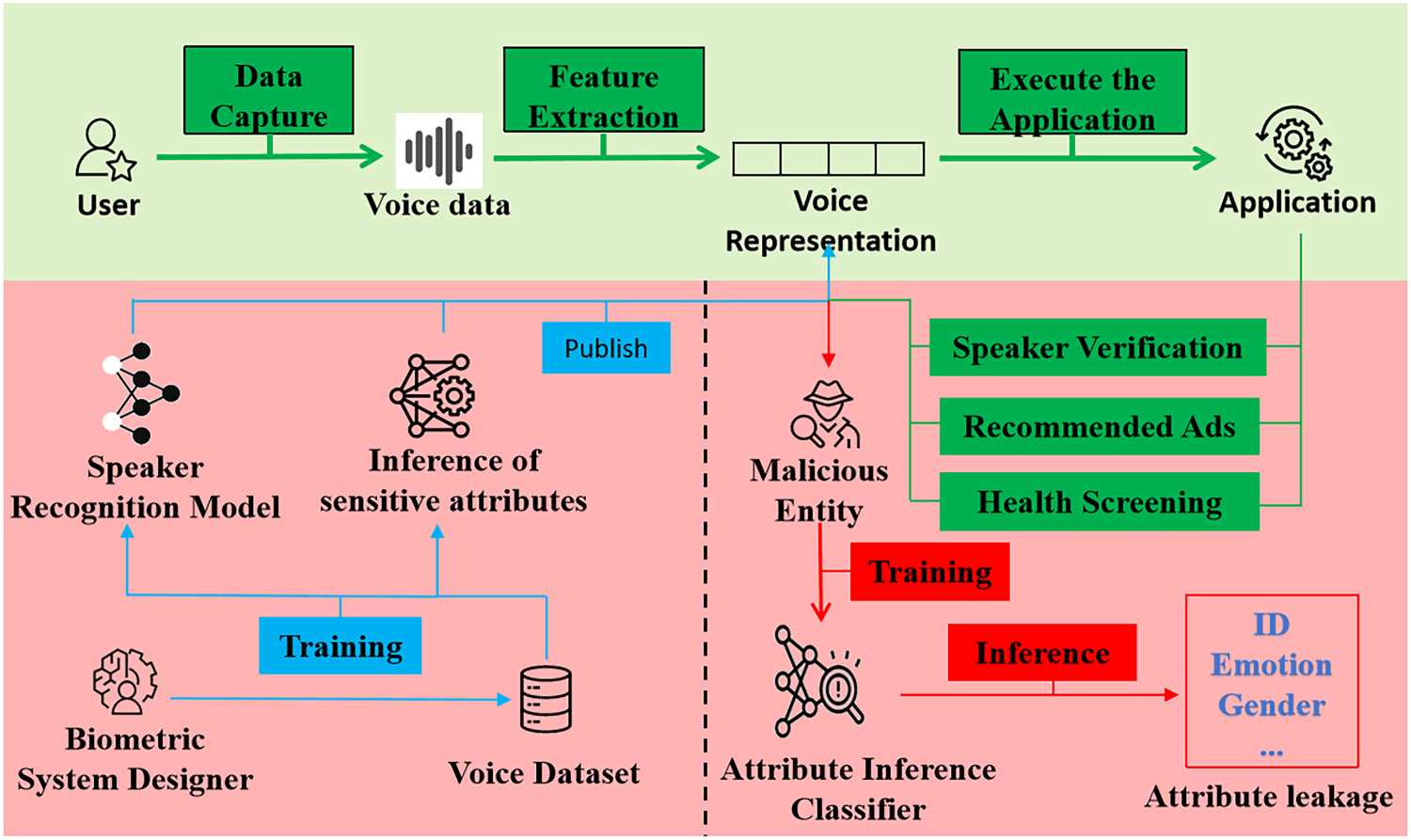
Example of inferred threat model for soft biometric attributes in speech recognition system.
To address the aforementioned limitations, we propose the PSEGAN model, which can accurately identify and transform the sensitive attribute of emotion in speech data. Differing from traditional methods of attribute deletion and binary attribute fusion, PSEGAN randomly transforms emotion attributes while preserving the utility of speech data. This model prevents the typical reduction in utility and authenticity caused by partial information loss after transformation. Additionally, by modifying the traditional GAN
26
architecture and introducing new modules. PSEGAN not only overcomes significant utility degradation post-privacy protection found in traditional speech privacy models but also enhances the quality of generated speech. The transformed speech retains the original content and speaker identification, achieving a trade-off between the utility of data sharing and personal privacy protection. After preprocessing the original speech input and extracting speech features, the network architecture of the model learns the features that need to be transformed and generates corresponding feature representations. The model is trained using a multi-task loss function, focused on both privacy preservation and utility retention. These features are then inversely transformed using a pre-trained MelGAN
27
model to generate desensitized speech. The PSEGAN model aims to learn biometric speech features via advanced GAN technology, transforming emotional attributes to maximize speech utility without disclosing sensitive information. The following are the major contributions of this work:
We proposed a generalized privacy-enhancing model for speech data stored in speech recognition systems that maintains the utility of speech while preserving the privacy of user emotional attributes. We mapped GRN
28
to learn the long-short term dependency associations present in the speech data, thus enabling the model to more accurately recognize the speaker’s intention, emotional state, and other relevant information. By constraining the generator with the output of a pre-trained speaker matcher, the speaker recognition accuracy of the generated speech is improved. The experimental results demonstrate that the method proposed in this paper outperforms other existing models in both privacy protection and speech utility, validating the effectiveness and superiority of PSEGAN model.
The remainder of this paper is organized as follows: Section 2 offers a brief overview of the related literature. Section 3 defines the privacy problem. Section 4 presents a detailed explanation of the proposed model. Section 5 showcases the experimental results and subsequent discussion. Finally, Section 6 summarizes the study and explores future research directions.
Intermediate speech representations
When modeling speech data, due to the complex interaction between the high temporal resolution of the original waveforms and their long-term and short-term dependencies, most studies typically used spectrograms to shift features toward low-dimensional domains. Two prevalent intermediate linguistic representations were aligned linguistic features 29 and Mel-Spectrograms. On the one hand, using aligned language features required a complex model architecture. On the other hand, it is not flexible enough to deal with the diversity and irregularity of natural language, which might have resulted in the inability to capture all subtle differences in spoken language. The Mel-Spectrogram utilizes the Mel Scale, a nonlinear frequency scale perceived linearly by humans, to reflect the design of the human ear. It accentuated low-frequency differences, which were information-rich, whereas high-frequency informational differences were given less domain weight. Kumar 27 addressed the challenge of non-invertible spectrograms by introducing MelGAN, a fully convolutional model crafted to convert Mel-Spectrograms back into original waveforms.
Speech morphing technology
Speech morphing technology had broad applications in the speech field. It was used in the entertainment industry for character dubbing and speech editing and could protect sensitive information by adjusting acoustic properties like pitch and volume. 30 While it is effective in protecting privacy, it can affect the naturalness, clarity of speech communication, alter intonation, and reduce the expressiveness and diversity of the speaker’s speech.
Speech anonymization techniques
The Google team 31 introduced the d-vector method, which marked a significant advancement in speech biometric technology through deep representation learning. By using speaker identities as labels for speech frames during training, the d-vector method improved the efficiency of speech biometric recognition. However, its reliance on speaker identity labels may result in poor performance with unknown speakers.Building on this approach, Snyder et al. 32 developed the x-vector model, which enhances model performance by merging frame-level features into higher-level segmental features through a pooling layer. Despite these improvements in feature extraction, the x-vector method still carries risks of identity leakage in high-dimensional feature spaces and can reduce the clarity and naturalness of converted speech. Srivastava et al. 33 extended the x-vector approach to speaker anonymization by converting speech to that of a random pseudo-speaker. The effectiveness of this anonymization depends on factors such as the distance metric between speakers, the selected region of speaker space, gender, and allocation strategy. Perero et al. 34 proposed a speech anonymization method using autoencoders (AE) and adversarial training. This method involves extracting x-vectors from discourse, converting them to new x-vectors through AE, suppressing speaker, gender, and stress information via adversarial training, and generating anonymous speech using a Neural Speech Synthesizer (NSS) with the anonymous x-vectors, fundamental frequency, and phoneme information. Nevertheless, this approach may compromise the naturalness and intelligibility of speech during the conversion process. Yao et al. 35 proposed a system comprising four main components: a feature extractor, an acoustic model, an anonymization model, and a neural vocoder. This setup effectively generates anonymous speaker vectors that do not correspond to any real speaker.
The vector quantized variational autoencoder (VQ-VAE)
The Vector Quantized Variational Autoencoder (VQ-VAE) effectively conceals speaker identity by quantizing linguistic content into a discrete latent space using learned codebooks and reconstructing speech waveforms during decoding through a combination of encoded attributes. Stoidis et al. 36 utilized VQ-VAE to separate biometric information, such as gender and identity, from speech content, thereby enhancing privacy while preserving utility. However, this method faces challenges, including reduced performance with complex speech features and bottlenecks when processing high-dimensional biometric data.
Adversarial representation learning for privacy
Adversarial learning plays a crucial role in privacy protection strategies by using adversarial methond to balance identity utility and soft biometric privacy. For example, GenGAN, 37 PCMelGAN, 25 and Double Anon 38 undergo adversarial training within the GAN model, aiming to minimize utility distortion in generated speech and maximize privacy protection for sensitive data. Training models to learn ambiguous sensitive attributes effectively reduces the risk of privacy inference. GenGAN is a model that synthesizes speech using generative adversarial networks. Synthetic speech that resembles real speech but contains ambiguous identity information can be generated through adversarial training within the GAN model. This method aims to reduce the recognizability of the speaker’s identity while maintaining the content and intelligibility of the speech, thus protecting the speaker’s privacy. PCMelGAN is a generative adversarial network method focused on reconstructing Mel-spectrograms. Through adversarial training, it can generate high-quality speech synthesis and learn speech features with ambiguous gender and identity information, thereby enhancing the effectiveness of speech privacy protection. PCMelGAN ensures the naturalness and intelligibility of speech by accurately reconstructing Mel-spectrograms while concealing sensitive personal features. Double Anon is a speaker anonymization system based on CycleGAN for protecting speech data privacy. This method modifies the gender and accent information of the speaker in the original speech signal, generating a more naturally sounding anonymized speech and achieving de-identification of the speaker.
In light of the shortcomings of the above approaches, we address the emotional privacy-preserving of speech by using GRN to learn the long and short-term associations in speech data, enabling more accurate categorization of speech attributes for sentiment transformation. Additionally, we use a speaker matcher with consistency loss to retain the valid information in speech, thus improving utility.
Problem formulation
Given a speech sample
Attribute privacy preservation
We define emotion as the sensitive attribute that needs to be protected. After the speech passes through the transformation by

Under the premise of achieving attribute privacy protection, the biometric utility of the transformed speech must be considered. In our work, our goal is to preserve the availability of attributes other than emotional information, that is, the accuracy of inference, to realize the utility of the speech. This means that for a given speech

Furthermore, both the original and transformed speech should maintain auditory realistic, which benefits that: (1) These speech samples remain suitable for existing computational speech system tasks; (2) There is auditory consistency between the original and transformed speech.
The proposed model
Overview
For the original speech, our goal is to adaptively generate privacy-enhanced speech through a deep learning model. This speech will differ in emotional attributes from the original speech but will retain identity information, all while maintaining the speech’s intelligibility and usability. Figure 2 shows the process of converting original speech into privacy-enhanced speech using the PSEGAN model. Initially, the MFCC extraction module processes the original voice through several steps: pre-emphasis, framing, windowing, Fast Fourier Transform (FFT), Mel filtering, logarithmic transformation, and Discrete Cosine Transform (DCT). These steps extract the necessary speech features. These features are then input into the generator, which transforms them into desensitized features. Subsequently, the transformed features are processed by the pre-trained MelGAN module to generate the final desensitized speech. This resulting speech is privacy-enhanced, ensuring that user privacy is safeguarded while preserving the speech’s utility.
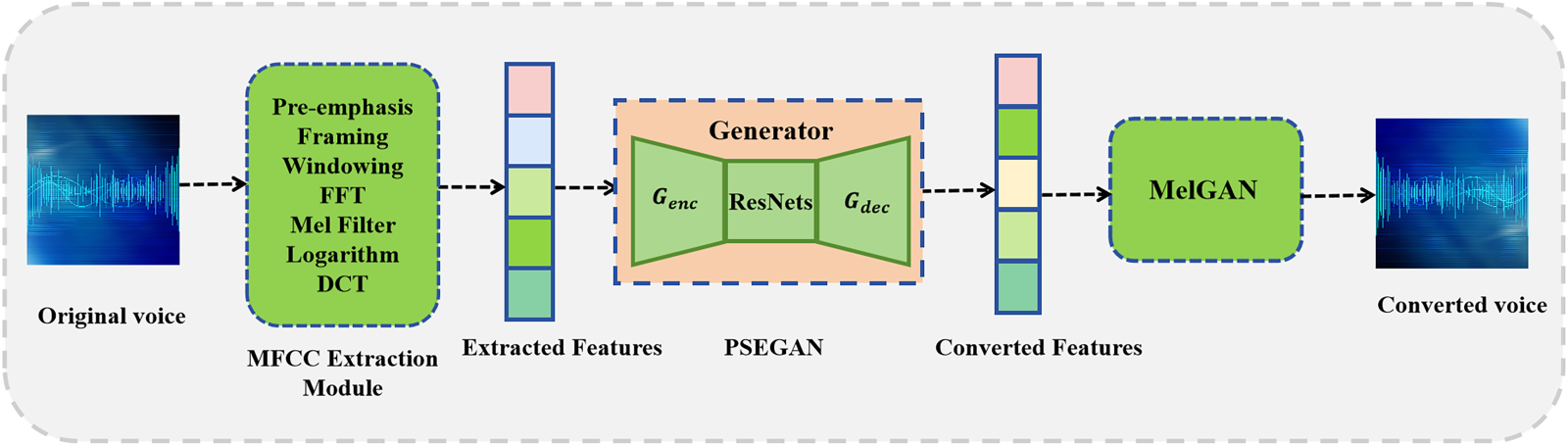
A block diagram of a model for speech privacy protection is presented. This model involves converting original speech data into feature representations through feature extraction. These representations are then fed into an adversarial generative network to generate transformed features. Subsequently, these transformed features are converted into privacy-protected speech using a pre-trained MelGAN model. The bottleneck layer incorporates a modified multi-layer gated residual network.
Privacy-Conditional Generative Adversarial Network (PCGAN)
26
architecture integrates the generator within the filtering model of the Generative Adversarial Privacy (GAP)
39
model, enhancing the protection of sensitive attributes while maintaining the practical utility of the data. The network architecture proposed in this paper is based on PCGAN and has been modified according to privacy and utility objectives. The task of the generator
In this adversarial question, the discriminator
Specifically, we operate on the input waveforms, which are converted into 80-band Mel-Spectrograms. In Figure 3, we present the architecture of the entire model and the composition of the related loss functions. We use a generator
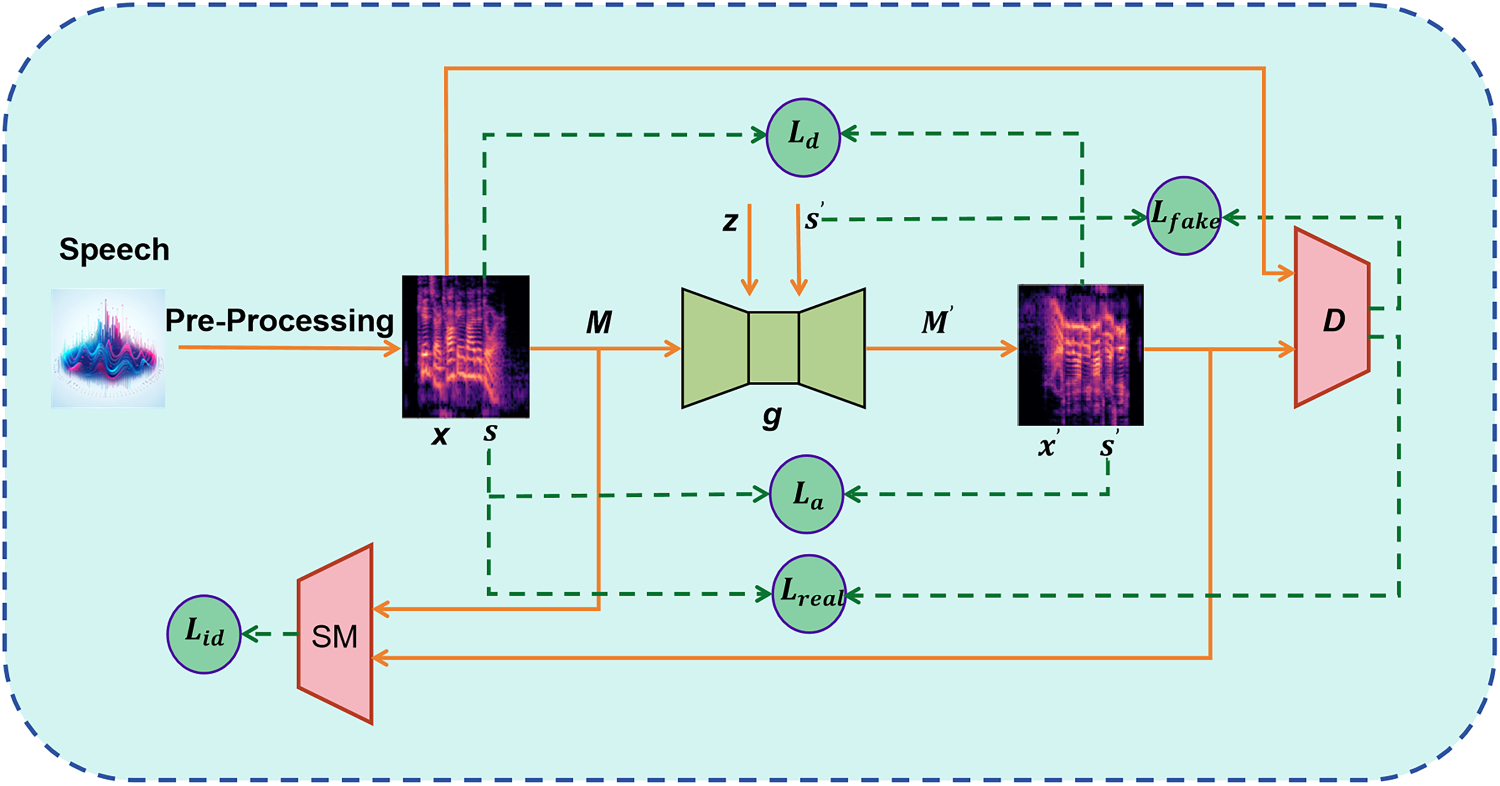
Schematic of the PSEGAN architecture, this paper aims to generate perturbations to obfuscate the sentiment attribute classifiers while preserving the usability of the speech data. (A) Different components of PSEGAN: generator, discriminator (emotion classification), and speaker matcher. (B) Transforming the input original speech label into a target label and processing it through the speaker matcher. The time-domain signal waveform is first converted into a Mel-Spectrogram
The input to the generator


For multi-class emotion encoding, we uniformly and randomly select emotion categories from a range of 0 to 7, representing eight distinct emotional labels:

The noise vector

GRN 28 is designed based on residual blocks, incorporating time-dilated convolutions and Gated Linear Units (GLUs) into traditional bottleneck residual blocks, effectively enhancing the network’s capacity to handle complex time-series data. In the field of speech enhancement, GRN utilizes its extensive receptive field to deeply model the Time-Frequency (TF) representation of the input, allowing the network to not only capture transient features in speech data but also learn long-short term dependencies, thus more accurately recognizing and preserving speaker and other attribute features. Furthermore, the structure of GRN is particularly suited to processing dynamic variations in speech, as time-dilated convolutions cover a wider temporal span without increasing the computational burden. This is crucial for capturing fluctuations in intonation, rhythm, and emotions in speech, which are highly variable over time and essential for understanding linguistic content and speaker intentions. In this paper, by integrating multiple layers of GRN into the bottleneck layer of the generator, we significantly enhance the model’s learning and expressive capacity for speech features. This not only improves the quality of speech reproduction but also optimizes the model’s understanding of long-short term features in speech, making the generated speech more natural and realistic, and achieving better results in learning emotional features, thereby enhancing the model’s broad applicability and performance.
The generator total loss

In the following, we describe the detail of each loss.

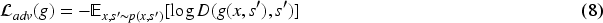
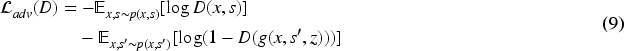
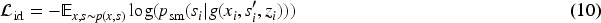

Dataset
In our experiments, we utilized the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) 44 and the Berlin Database of Emotional Speech (EmoDB) 45 for our study. RAVDESS contains speech recordings of 24 actors (12 male, 12 female) expressing 8 different emotions (calm, happy, sad, angry, fearful, surprised, disgusted, and neutral) with two intensity levels (normal and strong) for each emotion. The total duration of the recordings is approximately 15 hours. EMO-DB contains speech recordings of 10 actors (5 male, 5 female) expressing 7 different emotions (pleased, sad, angry, fearful, disgusted, surprised, and neutral), with multiple samples for each emotion. The total duration of the recordings is approximately 2.5 hours.
In this paper, we selected 1200 samples from the RAVDESS dataset as the training set and 120 samples as the test set. We uniformly selected these samples to ensure that the training and test sets include performances by different actors and expressions of various emotions. All recordings are labeled with the actor’s name, emotion, gender, and other information. In our experiments, these speech files were processed to reduce their sampling rate to 16 kHz, different from the original sampling rate of 48 kHz. To maintain the consistency of the speech segment length, we used zero-padding to make the length of each recording equal to 16.7 seconds multiplied by the sampling rate (i.e., 16.7 * 16000). Similarly, for the EMO-DB dataset, we selected 100 samples as the training set and 400 samples as the test set for experimentation and testing of the model.
Implementation and training details
This study adopts an end-to-end training strategy. All our experiments were conducted on an NVIDIA RTX A4000 GPU with 16GB of memory. Our model employs the Adam optimizer for parameter updates, with the learning rate set to 0.0001 for the generator and 0.0002 for the discriminator, while the betas parameters are set to (0.5, 0.9). For spectrogram preprocessing, the sampling rate was fixed at 16000 Hz, the frame length was 1024, 80 Mel frequency channels, as well as 32 MEL filters were used, and the window size and length of the STFT were set to 1024 to accurately capture audio features. In our model, we preprocess the speech signal by normalizing the entire spectrogram to the [0, 1] range. This normalization process helps maintain the overall features of the Mel-spectrogram while standardizing the input data. As a result, the model’s performance and accuracy in emotion recognition tasks are significantly improved. Subsequently, the spectrogram is transformed into a logarithmic Mel-spectrogram for use in the model.
Evaluation
We compared our proposed PSEGAN with two leading models, GenGAN and PCMelGAN, both designed for voice privacy protection. GenGAN generates gender-ambiguous voices to safeguard gender privacy, while PCMelGAN employs filtering and generation modules to replace sensitive information. For a fair comparison, we optimized GenGAN and PCMelGAN using the same voice datasets, RAVDESS and EmoDB, to achieve their best performance. GenGAN was chosen for comparison due to its focus on protecting predefined attributes, specifically emotion in this study. To ensure fairness, we configured GenGAN to produce voices with ambiguous emotional traits. Its generator uses a U-Net architecture and adversarial loss to balance signal distortion with privacy protection. We evaluated the effectiveness of GenGAN by assessing the privacy and utility of the emotion-ambiguous voices it generated. PCMelGAN excels in creating privacy-enhanced voices aimed at protecting various attributes. In our experiments, the sensitive attribute for PCMelGAN was set to emotion. This setup allowed us to investigate if spectrum-based privacy models might leak soft biometric information during voice verification processes.
Table 1 presents the performance of three models under the same testing conditions, all based on a pre-trained classification model. We conducted tests on both the RAVDESS and EmoDB datasets. In these datasets, the pre-trained classification model achieved speaker recognition accuracies of 97.6% and 95.6%, respectively, along with an emotion recognition accuracy of 94.9% from the original speech data. The models need to consider not only privacy protection performance but also utility, achieving a balance between the two. Specifically, we used a low success rate of emotion recognition as an indicator of privacy performance and used speaker recognition, gender recognition, and content recognition as metrics to evaluate utility performance, maintaining the usability of speech while ensuring privacy protection. In the RAVDESS dataset, PSEGAN desensitized unprotected speech without significantly reducing the utility of speaker recognition, lowering the emotion recognition rate of desensitized speech to 14.2%, close to the ideal 12.5%, which meets the requirement of equal probability selection for eight emotions. In the EmoDB dataset, although there was a noticeable decline in the accuracies of content and gender recognition, the model still performed well in terms of privacy protection and speaker recognition. Compared to other models, although PCMelGAN performs better in preserving other attributes of speech, it shows poorer performance in protecting emotions. The reason for the change in model performance is that the EmoDB dataset has fewer samples compared to RAVDESS, leading to the model not fully learning the data features. In summary, PSEGAN strikes a balance between privacy protection and utility compared to the other two schemes.
Comparing the recognition accuracy of different models.
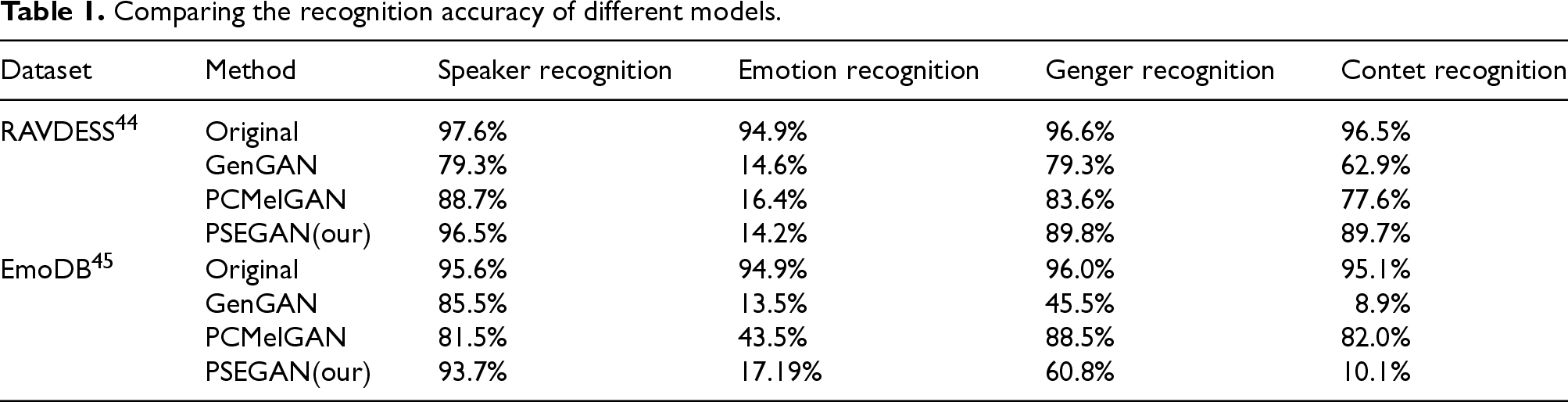
Comparing the recognition accuracy of different models.
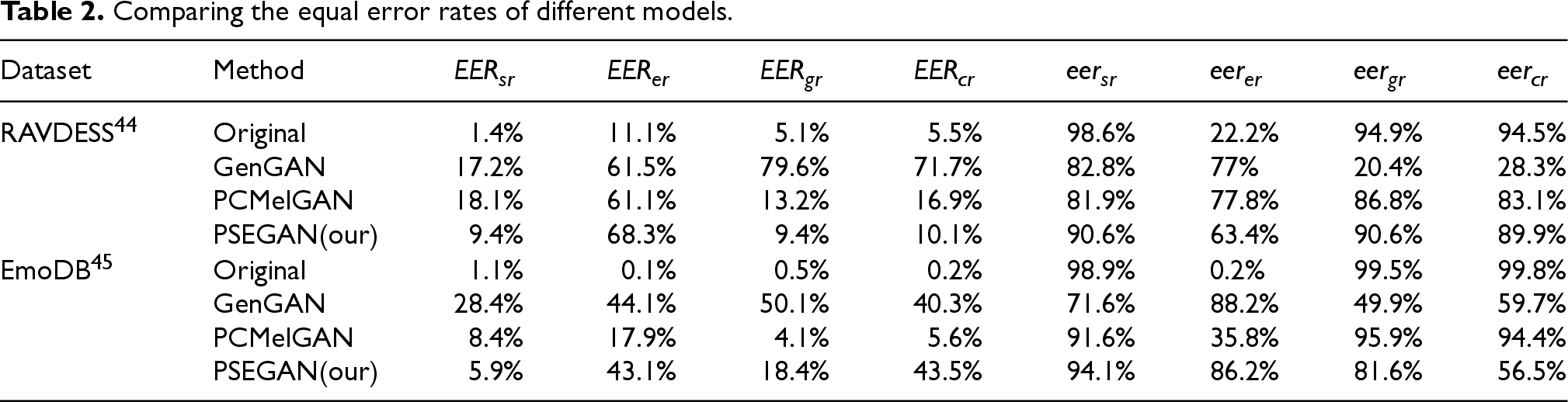
In Table 2, we evaluate the comprehensive performance of models in terms of privacy protection and utility maintenance by calculating the Equal Error Rate (EER) of the original speech and speech processed by different models. We select the EER of speaker recognition (
Comparing the equal error rates of different models.
Subfigures (a) and (c) in Figure 4 compare the waveforms of the original and transformed speech samples. These waveforms are largely similar, with the main differences arising from noise introduced during the training process. This similarity indicates that the waveforms maintain consistent characteristics in terms of content, demonstrating effective utility preservation. In contrast, the spectrograms in subfigures (b) and (d) show some frequency differences, but they also retain a certain degree of similarity. This suggests that only a small portion of the content has changed, specifically in terms of emotional characteristics, while most of the original content has been preserved.

The waveforms and spectrograms of the original and synthesized speech. Subfigures (a) and (b) illustrate the waveform and spectrogram of the original speech, respectively. Subfigures (c) and (d) showcase the waveform and spectrogram of the synthesized speech, respectively.
In Figure 5, we employ the t-SNE 46 dimensionality reduction technique to visualize the emotional attributes of the original speech data and the speech data transformed by PSEGAN on a two-dimensional plane. From the Figure 5 (a) (original speech), we can observe an apparent clustering effect among sample points with the same label attributes. This indicates that the emotional attribute features in the speech data are distinguishable. That emotional information can be analyzed through features. However, in the Figure 5 (b), sample points of all categories are clustered together, indicating that the emotional attribute features in the transformed data have been effectively concealed, preventing the inference of emotional information from features thereby achieving protection of the emotional attributes.

Data distribution of speech emotion representation based on t-SNE 46 dimensionality reduction Technique. Subfigures (a) presents the dimensionality reduction results of the emotional attributes of the original speech data, while subfigures (b) shows the dimensionality reduction results of the emotional attributes of the speech data after being transformed by PSEGAN. Each point in the figure represents a speech sample extracted from the dataset.
Figure 6 presents the ROC curves for anonymized speech in terms of speaker and emotion recognition. Subfigure (a) shows that PSEGAN achieves the smallest area under the curve (AUC), indicating robust privacy protection. Conversely, Subfigure (b) reveals that PSEGAN’s AUC is the largest, effectively preserving speaker recognition capabilities. Collectively, these findings highlight PSEGAN’s outstanding performance across both metrics.
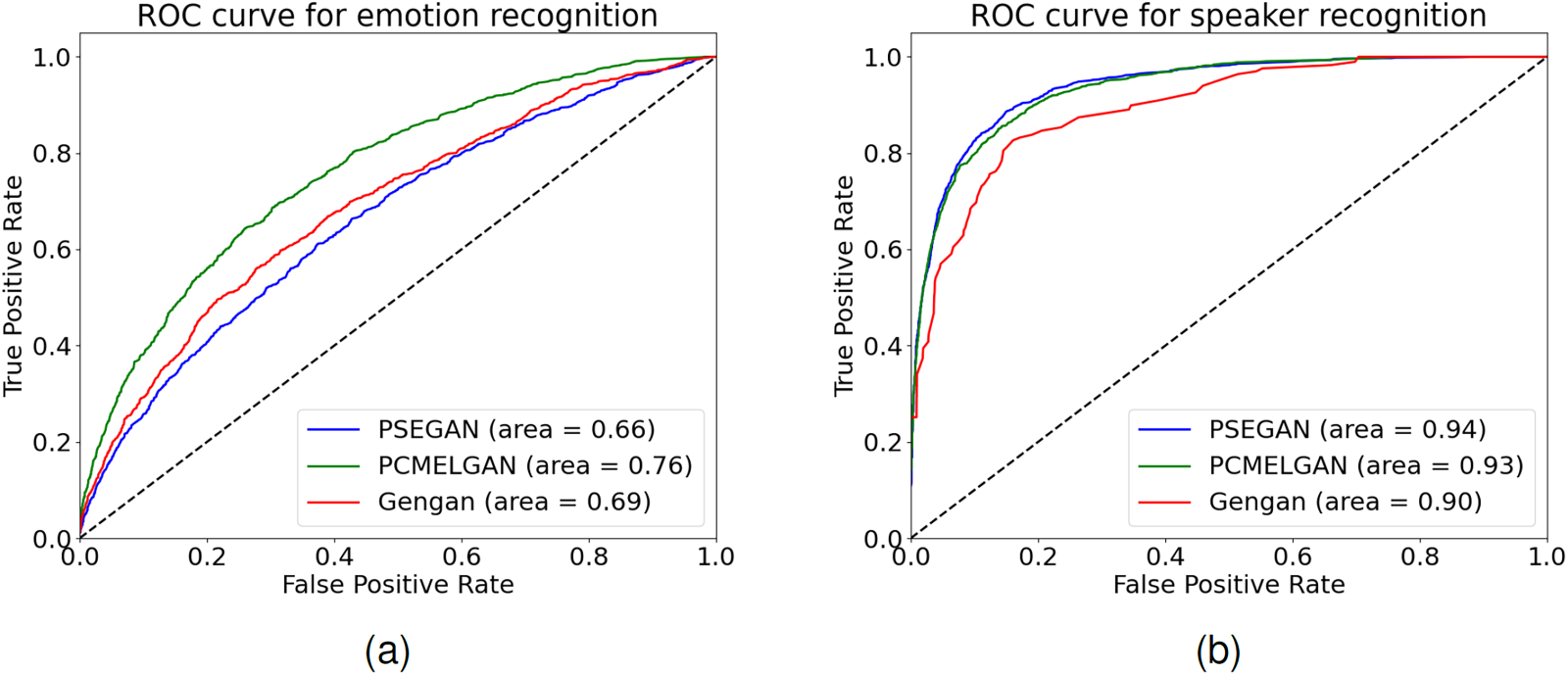
Demonstrates ROC curves for desensitized speech with respect to speaker recognition and emotion recognition.
In Table 3, we evaluate several ablations of our method in different settings to study the effect of each add-on component in the framework. Removing the SM component leads to a significant decrease in speaker recognition accuracy, highlighting the compromised preservation of speech utility. Additionally, eliminating the GRN module results in a marked increase in emotion recognition accuracy, indicating a substantial reduction in the effectiveness of emotion privacy protection.
Ablation experiment results.

In this paper, a privacy protection mechanism, abbreviated as PSEGAN, was designed to safeguard the emotional privacy of speech data in consumer electronic devices with voice assistants. By employing adversarial learning strategies, PSEGAN effectively removes sensitive information from original speech data and replaces it with realistic new information, significantly enhancing privacy protection. Experimental results demonstrate that PSEGAN strikes a favorable balance between maintaining speech utility and preserving privacy, underscoring the innovative nature of our model. However, this research still has some limitations. The model proposed in this paper focuses on single-attribute protection, which may limit its applicability in more complex scenarios. Furthermore, the reliance on specific datasets could impact the generalizability of our findings. Future research should aim to expand PSEGAN’s capabilities to protect multiple sensitive attributes simultaneously, enhancing its overall performance. Additionally, incorporating diverse and large-scale datasets will improve the model’s robustness. Optimizing computational efficiency will be crucial for the practical deployment of PSEGAN in consumer speech devices.
Footnotes
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant 62272103, 61872090 and the Natural Science Foundation of Fujian Province under Grant 2023J01531.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.