
Abstract
Subspace clustering (SC) approximates high-dimensional data as a combination of low-dimensional subspaces, which is suitable for high-dimensional data analysis across various domains including image segmentation and face recognition. Existing SC methods typically obtain the global structure representation solely through the self-representation of the samples, thereby neglecting the intrinsic local connections among the samples. Moreover, due to their inherent framework design, obtaining additional a priori information in unsupervised scenarios presents a significant challenge. To address these limitations, this paper proposes a new method, named Sample-Dependent Subspace Clustering with Elastic Structure Consistency Constraints (SDSC). Firstly, we introduce a new Elastic Structure Consistency Constraints (ESCC) strategy to measure global and local structures elastically. Benefiting from this strategy, SDSC can flexibly explore the structural information within the samples to obtain a comprehensive data representation. By employing the joint regularization term, SDSC can learn effective cluster assignment information directly from the constrained structured data representation, and the cluster assignment information and representation coefficient matrix are smoothly integrated into a unified framework and learn in a mutually reinforcing manner. This learning approach contributes to comprehensive and high-quality clustering results, enhancing the robustness and utility of SDSC. Extensive experiments on several real-world benchmarks and synthetic datasets demonstrate the feasibility and effectiveness of SDSC.
Keywords
Introduction
As a critical aspect of machine learning and artificial intelligence, clustering, particularly subspace clustering, is vital for exploring topological pairwise relationships in high-dimensional data.1,2 Subspace clustering (SC) believes high-dimensional data as consisting of concatenated sets of low-dimensional subspaces3,4 and its main purpose is to determine the subspace corresponding to the cluster of associated data points. Over the past decades, SC has been extensively studied and applied in various fields, including image clustering, motion segmentation, and face recognition. In general, the SC problem can be described as follows: Assume that the given data
Currently, existing SC methods can generally be categorized into four types: iterative methods,
5
statistical methods,
6
spectral clustering-based methods,
7
and algebraic methods.
8
Among these four types, spectral clustering-based methods have demonstrated superior performance in various applications due to their theoretical guarantees.9,10 The framework of the spectral clustering-based SC method is divided into two parts. In the first step, a reconstruction coefficient matrix
From the framework of spectral clustering-based SC methods, it is evident that their performance is highly dependent on the quality of the reconstructed coefficient matrix. Consequently, these methods suffer from the following issues. To ensure that different subspaces are independent of each other, most
To address the above issues, we first introduce a new strategy called Elastic Structure Consistency Constraints (ESCC). ESCC can flexibly explore the intrinsic structure of samples and accurately express the structural relationships between samples. Further, we propose a new clustering method called Sample-Dependent Subspace Clustering with Elastic Structure Consistency Constraints (SDSC). Instead of providing label information in advance, SDSC relies on samples to automatically learn reliable cluster assignment information. Meanwhile, SDSC introduces a joint regularization term to simultaneously learn the cluster information matrix and the representation coefficient matrix from the constrained structured data representation. This improvement mechanism allows SDSC to better adapt to various application scenarios.
The main contributions of the proposed method are as follows:
We propose a novel ESCC strategy that simultaneously captures both global and local structures while fully leveraging the complementarity of composite structures. Moreover, ESCC elastically captures the intrinsic structure of samples and accurately characterizes the affinity between samples. We develop a subspace clustering model with ESCC strategy, which directly learns clustering assignment information from the samples themselves. By introducing a joint regularization term, the constrained structured data representation effectively guides the model in performing subspace clustering. This process optimizes the clustering information matrix and representation coefficient matrix in a mutually reinforcing manner, leading to improved clustering performance. An effective iterative solution method is provided. Meanwhile, we perform several experiments on multiple real and synthetic datasets and analyze the results to illustrate the effectiveness of the SDSC method.
The rest of the paper is structured as follows: Section 2 provides a brief overview of existing subspace clustering methods. In Section 3, we introduce the proposed SDSC method. Then, we present the solution of SDSC and analyze the computational complexity. In Section 4, we conduct comparative experiments on seven benchmark datasets and six synthetic datasets. Finally, Section 5 presents the conclusions and future works.
Related works
Subspace clustering is a significant research area in machine learning. It posits that the complete feature space can be divided into multiple low-dimensional subspaces to explore meaningful patterns and relationships among data points. By focusing on these related subspaces, SC can effectively reveal the structural distribution of the data, even when it is complex and masked by noise. SSC and LRR are two of the most representative subspace clustering methods. Both regard the data itself as a dictionary of independent and disjoint subspaces.
27
This self-expressive approach assumes that if several data samples are in the same subspace, they are linearly correlated with each other. The specific problem can be described as follows:


Related subspace clustering methods for different

* I is the identity matrix.
However, these methods typically focus on a single representation of the data, either global or local. In reality, data usually exhibits a complex structure and is accompanied by various noise factors. 33 A single representation not only loses effective feature information but also makes these methods highly dependent on the data, potentially leading to overfitting 34 or out-of-sample problems 35 in practical applications. Additionally, supervised information significantly improves clustering accuracy. However, since clustering results are sensitive to the quality of a priori supervised information, inaccurate supervised information often negatively affects clustering results. Furthermore, the challenge of obtaining feasible and effective supervised information from unsupervised datasets remains open to debate. In summary, we propose a new subspace clustering method, named Sample-Dependent Subspace Clustering with Elastic Structure Perception (SDSC). SDSC considers the global geometric distribution and local neighborhood relationships of the data and can utilize the structural information to deeply uncover the complex associations among the data. Additionally, inspired by the spectral graph theory, useful cluster assignment information can be obtained directly from the samples, improving the accuracy of assigning the correct clusters and corresponding subspaces. The joint regular terms enable SDSC to optimize both data representation and labeling information, which in turn reinforce each other and ultimately achieve high-quality clustering performance. The following section describes the specific steps and implementation details of our proposed method in detail.
Elastic structure consistency constraints
Subspace clustering methods are used to identify highly correlated samples within the same space, under the assumption that data samples are self-expressive. Essentially, any data sample in a clean dataset can be linearly reconstructed by the linear combination of the other data samples, provided that there is no error or that the error is negligible. Consequently, 
It is widely acknowledged that manifold learning37,38 plays a pivotal role in revealing the local nearest neighbor structure among samples. By capturing the nonlinear relationships within the samples and maintaining the local geometric structure, manifold learning can more accurately reflect their intrinsic properties. Normally, the concept of the nearest neighbor is employed in manifold learning to emphasize the local relationships of the samples, as illustrated below.
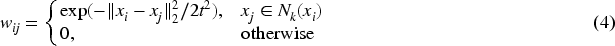

To obtain a good local nearest-neighbor representation, we provide the following definition:
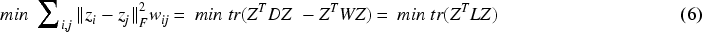
Although local neighborhood relationships play an important role in determining whether two samples share similar features and assigning them to a subspace, relying on local structure alone is not a reliable approach. This is because data representations based on local relationships are sensitive to outliers and noise, and a single representation does not capture the full range of data associations. By considering both local and global structures, it is possible to obtain a comprehensive understanding of the data, enhancing both intra-class similarity and inter-class separability. For a more comprehensive global linear description, we give the following derivation:
For the reconstruction coefficient matrix 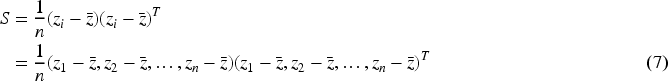
To simplify, we further deduce that
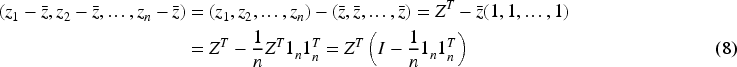
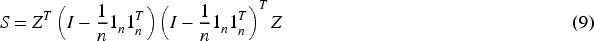
The center matrix M is idempotent and symmetric.
Firstly, we prove that the matrix M is symmetric, i.e.,
Since I and 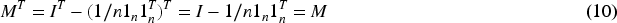
Therefore, the matrix M is symmetric.
Secondly, we prove that the matrix M is idempotent, i.e.,
For 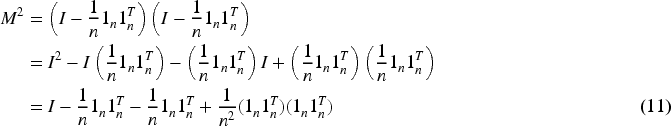
Notice that
Thus,
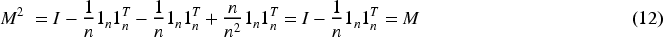
Therefore, the matrix M is idempotent.
According to Theorem 1, (9) can be expressed as

Redefining 
To maintain the elasticity between global and local structures and to explore the intrinsic associations of the samples deeply and flexibly, a trade-off parameter is used to unite (6) and (14):
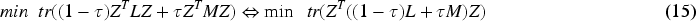
Integrating (15) into the subspace clustering framework, we can obtain
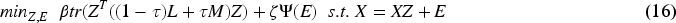
Existing studies40,41 have shown that even small amounts of supervised information can significantly improve the performance of clustering methods. While subspace clustering methods are often used in unsupervised scenarios, the challenge lies in how to obtain trustworthy labeling information in such contexts. Moreover, clustering performance is sensitive to the quality of supervised information; accurate supervised information guides the data to the correct subspace, while poor quality information leads to the wrong subspace. Because of this, we propose a new function that learns clustering information directly from samples. Furthermore, this function smoothly integrates the affinity matrix of the samples to enhance the confidence in H, as follows:
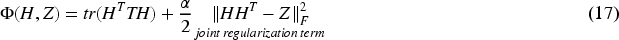
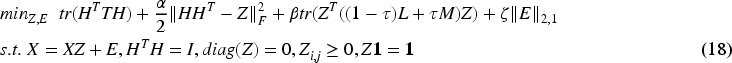
In this section, we use the Alternating Direction Method of Multipliers (ADMM) to find the solution to the objective function. We introduce a variable G and let 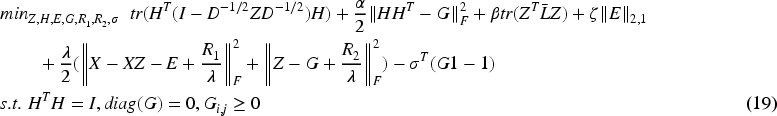
1. Updated H and other fixed
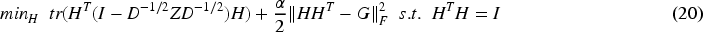
Further expansion for 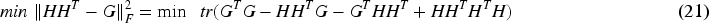
Due to 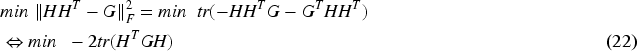
Substituting (22) into (20), we can get
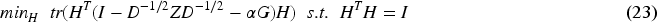
For (23), the eigenvectors corresponding to the k eigenvalues of the matrix
2. Updated G and other fixed
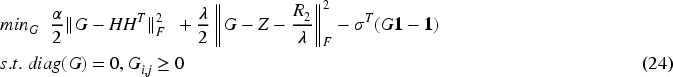
Let 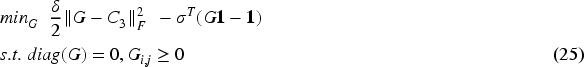
As reported in,
27
we can find the optimal solution of G as follows:

According to constraints 
3. Updated Z and other fixed
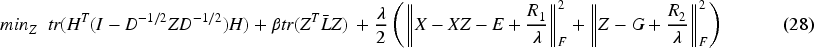
For simplicity, let 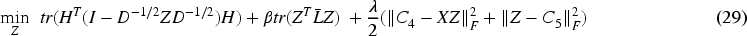
Taking the partial derivative of (29) and setting it to zero results in
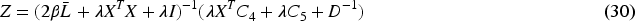
4. Updated E and other fixed

Similarly, we let 

Define 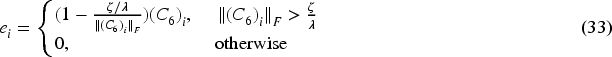
5. Updated other variables

In this section, the complexity of the proposed method is analyzed. Assume that the dimension of samples is d and the number of samples is n. According to Algorithm 1, the main complexity of the SDSC method in this paper comes from solving the four variables H, G, Z, and E, which are
Convergence analysis
Obviously, the augmented Lagrangian of the objective function represents a non-convex optimization problem, which does not guarantee strict global convergence. However, SDSC can converge to a stationary point where all Karush-Kuhn-Tucker (KKT) conditions are satisfied, albeit with relatively weak local convergence. For a detailed proof of model convergence, refer to Appendix I.
Experiment
In this section, we conduct experiments on seven real-world datasets and six synthetic datasets to evaluate the performance of the proposed SDSC. The following section presents a detailed description of the methodology used.
Datasets
These seven real datasets include six well-known facial datasets (GT, ORL, YALE, UMIST, Terravic thermal, Coil20) and the Semeion handwritten digit recognition dataset. Details of these datasets are as follows:
The GT dataset contains images of 50 individuals, captured under varying conditions such as time of day, lighting, and facial expressions. Each individual has 15 color images in JPEG format. The ORL dataset includes 10 different greyscale images of each of 40 individuals, taken at different times and with varying facial details. The YALE dataset comprises 165 greyscale images in GIF format from 15 individuals, with 11 images per subject. The UMIST dataset consists of 564 images of 20 individuals, encompassing a wide range of poses from side to front. The Terravic thermal image dataset comprises thermal facial images of 20 individuals, captured from various angles. The Coil20 dataset captures images at 5-degree intervals, totaling 1440 images of 20 objects, with 72 images per object. The Semeion handwritten digit dataset consists of 1593 examples of digits written by approximately 80 individuals. Each digit is stretched into a 16*16 rectangular box with 256 grayscale values.
The details of the six synthetic datasets are provided in Table 2. The symbols N, D, and C represent the number of samples, the dimensionality of the dataset, and the number of categories in the dataset, respectively. For simplicity, the symbol “Mark” denotes the dataset name abbreviation.
Parameters to the Synthetic dataset.

Parameters to the Synthetic dataset.
The comparison methods used in the experiment are listed below:
Spectral Clustering (SC)
42
: This widely used method clusters data by constructing a graph based on the similarity between data points and using the spectrum of the graph (eigenvalues and eigenvectors) to group the data points. Low-Rank Representation (LRR)
14
: Obtains a low-rank approximation matrix using the self-representation of the data for classification purposes. Kernel Diagonal Block Representation (KBDR)
43
: Directly tracks a representation matrix with a block-diagonal structure in kernel Hilbert space, where the number of diagonal blocks corresponds to the subspace of the data. Structure-Aware Subspace Clustering (SASC)
23
: Captures the intrinsic structure of the data, including both global and local structures, with lower computational cost and model complexity than self-expressive subspace methods. Adaptive-order proximity Learning for Graph-based Clustering (AOPL)
44
: A graph-based clustering method that introduces higher-order proximity into structured proximity matrix learning to derive consistent structured proximity matrices from multi-order proximity. Structure-Preserving Projection Learning via Low-Rank Embedding (SPPLLRE)
45
: Aims to find low-rank projective representations with high energy. The model's ability to preserve local manifolds is enhanced by introducing graph smoothing of the representation matrix. Global and Local Structure Preserving Non-Negative Subspace Clustering (NSC)
22
: A NSC method that preserves global and local structures by kernelizing the space to improve its ability to handle non-linear data structures.
Clustering metric
The clustering performance of all methods in the experiment was evaluated using two commonly used metrics: accuracy (ACC) and normalized mutual information (NMI). ACC represents the proportion of correctly classified samples out of all samples, while NMI measures the consistency of the cluster labels with the true class labels. For both metrics, higher values indicate better clustering performance. All clustering results in the experiment are reported as percentages.
Parameter setting and robustness analysis
Based on the trends observed in Figures 1 and 2, the following conclusions can be drawn:(1) SDSC is extremely robust to the parameter ζ, with different values having an almost negligible effect on its final clustering performance; (2) The choice of parameters α and β affects the final performance of SDSC. The figure shows that, when other parameters are fixed, the clustering performance of SDSC fluctuates with different values of these parameters. Notably, for the ORL dataset, the clustering performance of SDSC improves significantly as the interval of
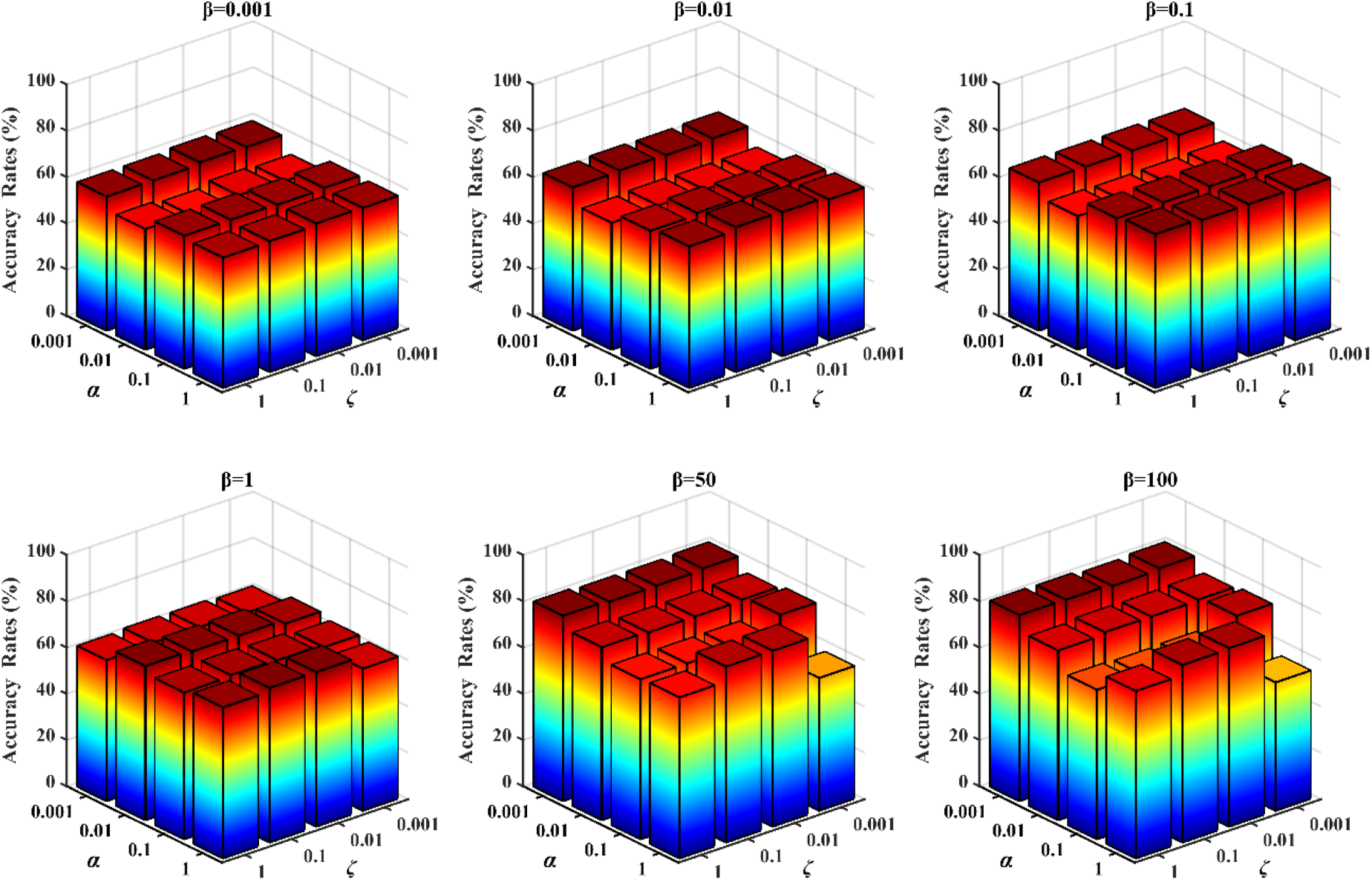
Different α and ζ corresponding to ACC on the Coil20 dataset when β is fixed.
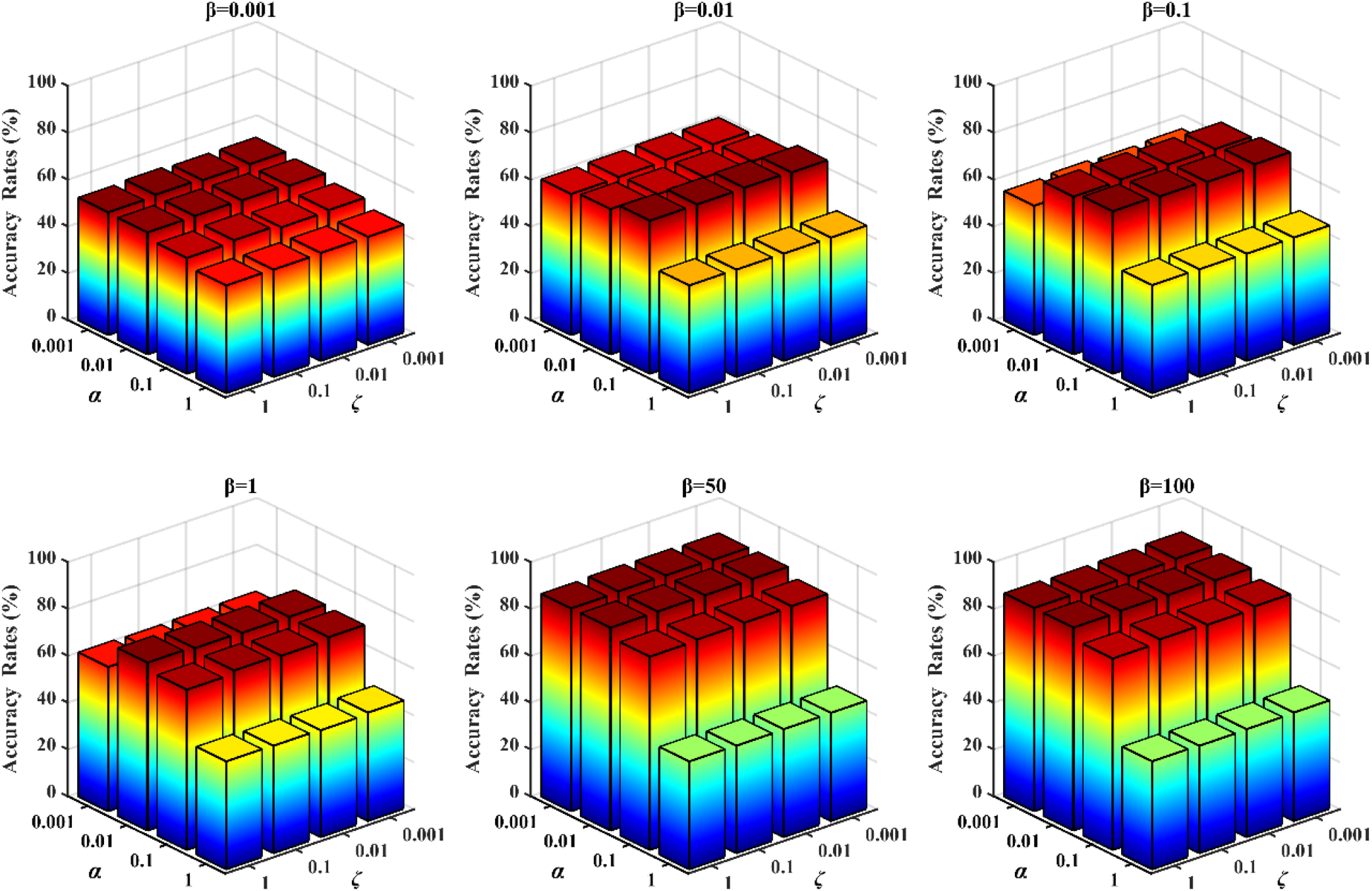
Different α and ζ corresponding to ACC on the ORL dataset when β is fixed.
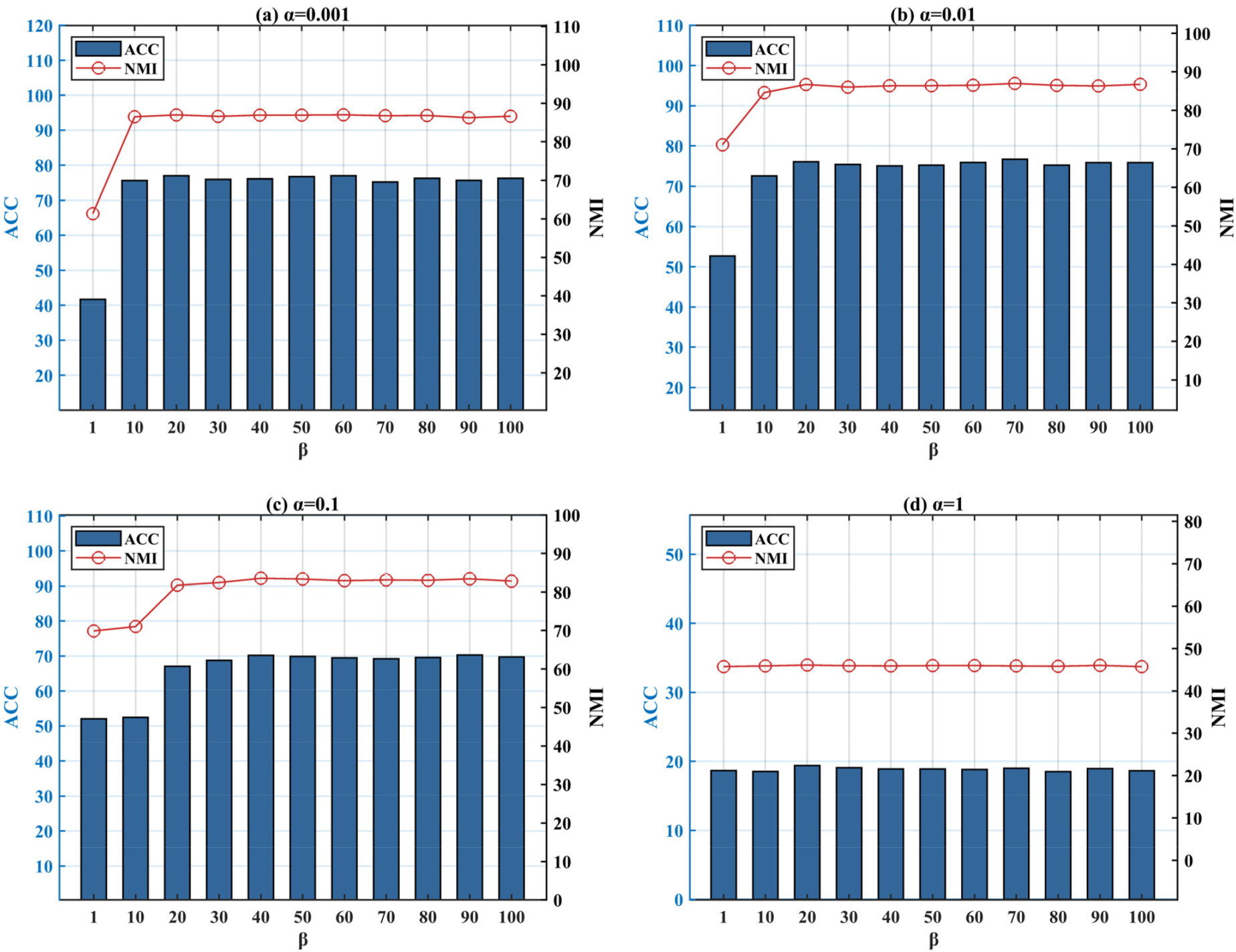
Two clustering scores were obtained on the ORL dataset with fixed ζ.
The combination of Figures 2 and 3 demonstrates that SDSC is highly sensitive to the parameter α. This sensitivity is primarily due to its role in controlling the joint optimization term of the labels and the representation matrix. The latter directly determines the ability to obtain high-quality label information from the multivariate data structure representation. Furthermore, the results indicate that our method can directly obtain useful label information from the sample data and positively influence the clustering results. This evidence supports the feasibility and effectiveness of our proposed method.
The initialization choices of Z and H are crucial for SDSC's performance. Z represents the self-expressive nature of the samples, whereas H denotes the labeling of the samples to the clusters. The closer the initial setting is to the true value, the more beneficial it is for SDSC. A common initialization setting for Z is to use KNN as the original input. However, the performance of KNN is heavily dependent on the choice of the k-nearest neighbor parameter. This pre-set setting is very unfriendly to unknown data. It should be noted that the coefficient of self-expression between any samples in the data must equal one. Consequently, the identity matrix is employed to initialize Z. For H, using H derived from K-means as an initial approximation appears to be a viable approach. Nevertheless, a similar issue persists with KNN, in that the results are inherently unpredictable and may not consistently yield a high-quality H. In light of this, we employ the maximum minimum distance to select k objects from the original sample. Subsequently, the clustering scores obtained with different initialization strategies on the GT and Terravic datasets are presented in Figure 4. In the experiment, the value of k is set to 5 for K-nearest neighbor (KNN), and the value of k in K-means is set to the number of categories present in the dataset. From Figure 4, it can be observed that the optimal experimental performance is achieved in terms of both ACC and NMI when SDSC is initialized using an identity matrix and the maximum minimum distance. This demonstrates that the initialization approach employed in SDSC for Z and H is both feasible and efficient.
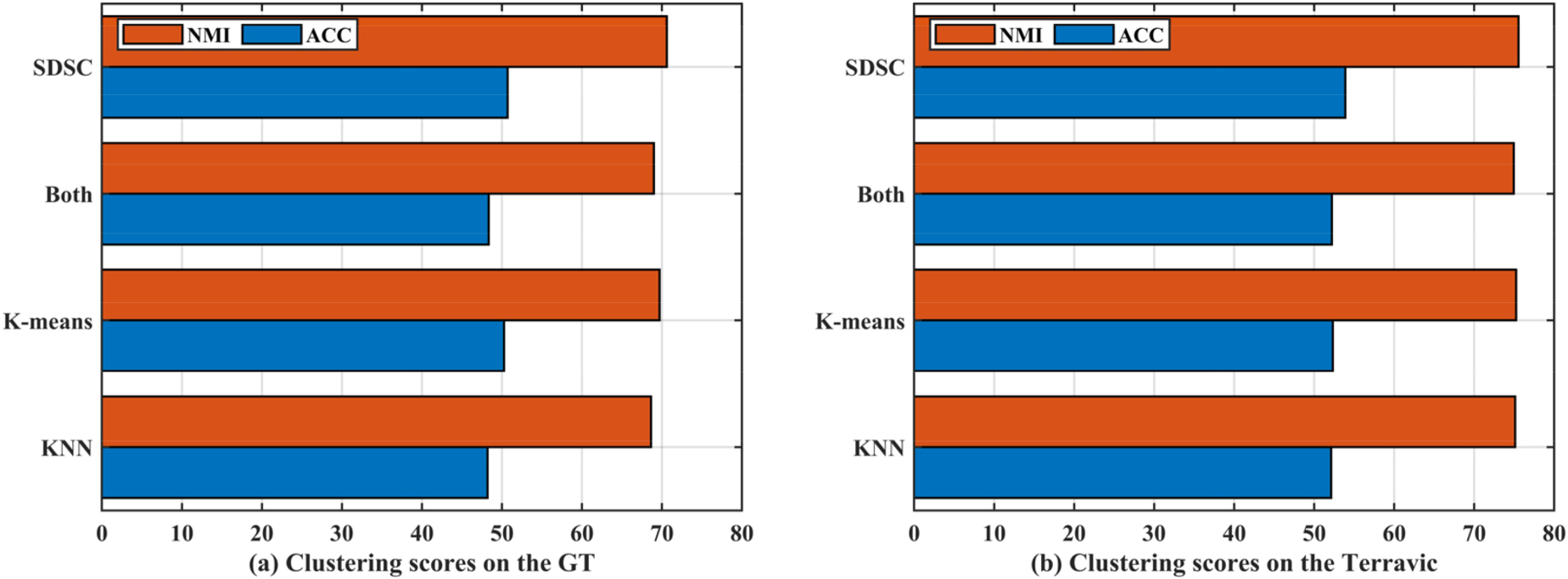
Clustering scores for different initialization methods for Z and H on two real datasets. (KNN means Z initialization via KNN, K-means means H initialization via K-means, both means both methods are used).
For the experiments, we randomly select N images from each class for testing. This selection is performed ten times randomly, and the final clustering result is the average of these ten iterations. The experiment results and medians of our method and the comparison methods on seven real datasets are presented in Tables 3–9. For the synthetic datasets, the visualization results of all methods are shown in Figures 5–10. By analyzing the final experimental results, the following conclusions can be drawn:
Overall, SDSC achieves optimal clustering performance on nearly all real and synthetic datasets. In particular, SDSC outperforms other subspace methods that focus solely on a single data structure. This superiority stems from SDSC's ability to elastically explore both the global geometric distribution and local nearest-neighbor relationships, uncovering intrinsic structural information from multiple perspectives, thus enhancing clustering performance. Unlike previous methods, SDSC relies solely on unsupervised samples to find high-quality cluster assignment information. This self-reliance is a key reason for SDSC's outstanding performance across all datasets. Furthermore, SDSC demonstrates robustness, as evidenced by the analysis of its clustering scores and their medians presented in the tables. As evidenced by the experiment results presented in the table, LRR exhibits suboptimal performance relative to the other compared methods due to its employment of low-rank constraints to obtain a single global LRR. In contrast, SASC, SPPLLRE, and NSC further exploit the local structure while incorporating global information, significantly contributing to their superior clustering performance compared to LRR. Furthermore, both SPPLLRE and NSC address noise and redundancy to enhance the model's capability in handling nonlinear data. SPPLLRE utilizes dimensionality reduction projection, while NSC employs kernel mapping. Both techniques have distinct advantages and disadvantages in handling high-dimensional data. Kernel mapping addresses nonlinear problems by projecting the original data to a higher dimensional space. However, selecting the appropriate kernel function and parameters requires experience. Otherwise, the risk of overfitting or underfitting is significant. Dimensionality reduction reduces the original space to a lower-dimensional subspace, retaining sufficient valid information while potentially losing some data. This explains why the performance of SPPLRE and NSC is not consistently superior to one another. The visualization results of the synthetic dataset demonstrate that the SDSC method is clearly superior to other methods. The figure illustrates that the comparison methods are susceptible to being misled by nearest neighbor samples in different subspaces, leading to erroneous clustering outcomes. However, in the SYN-1, SYN-3, and SYN-5 datasets, SDSC exhibits a clear advantage and is not affected by this factor. This indicates that these comparison methods require improvement in terms of inter-class separability. Additionally, SPPLLRE performs significantly worse than the other methods in all synthetic datasets. This is because the dimension of the synthetic dataset is only two-dimensional, and reducing its dimension would result in a massive loss of useful information. Conversely, KBDR, SASC, and AOPL are considered graph-based clustering methods. Based on the clustering performance of the three methods, they all exhibit excellent performance on complex real-world datasets. However, in experiments on synthetic datasets, the performance of KBDR is considerably inferior to that of SASC and AOPL. This may be attributed to the curse of dimensionality, which occurs in the mapped high-dimensional space, rendering KBDR ineffective. In addition, the high-dimensional space leads to a sparse data distribution, which affects KBDR's ability to accurately assess the relationships between data points. For SASC, SPPLLRE, and NSC, which also focus on global and local information, SDSC further considers the elastic balance between global and local information to address different application scenarios. The experimental results in the table demonstrate that the ACC and NMI metrics of SDSC are generally higher than those of the three compared methods. The visualization results in Figures 5 to 10 show that although the comparison methods assign most sample points to the correct subspaces, there is still the problem of interaction between samples in neighboring subspaces. In contrast, SDSC successfully completes the clustering task. In both the simpler low-dimensional synthetic datasets and the more complex real-world image datasets, SDSC shows excellent clustering performance, proving its feasibility.

Clustering results of SDSC and comparison methods on SYN-1.
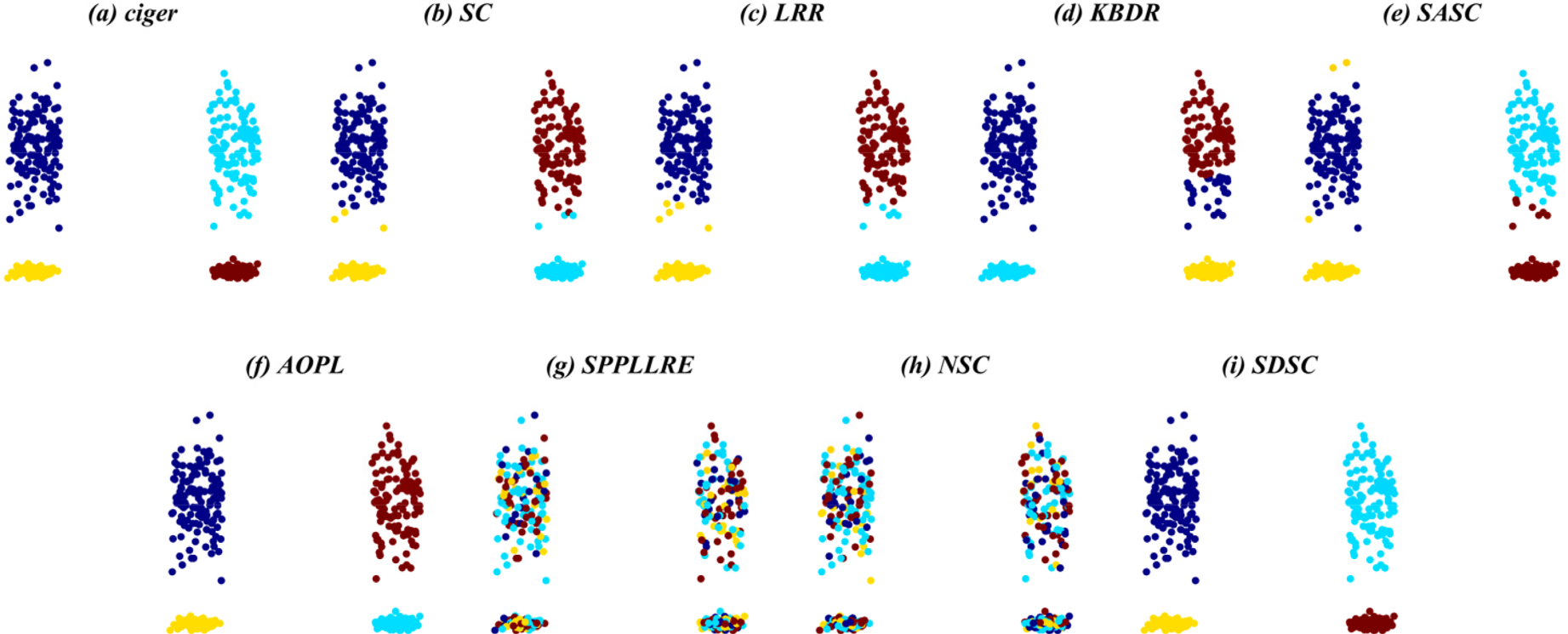
Clustering results of SDSC and comparison methods on SYN-2.
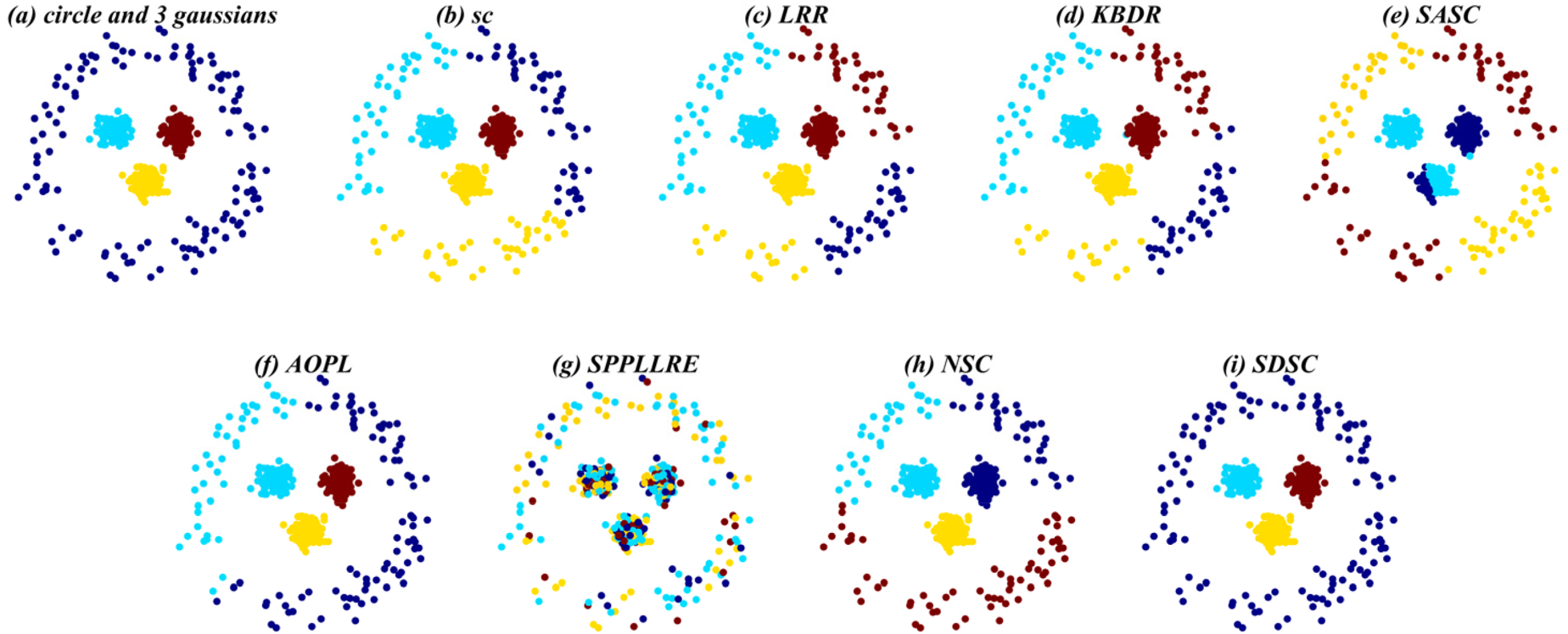
Clustering results of SDSC and comparison methods on SYN-3.
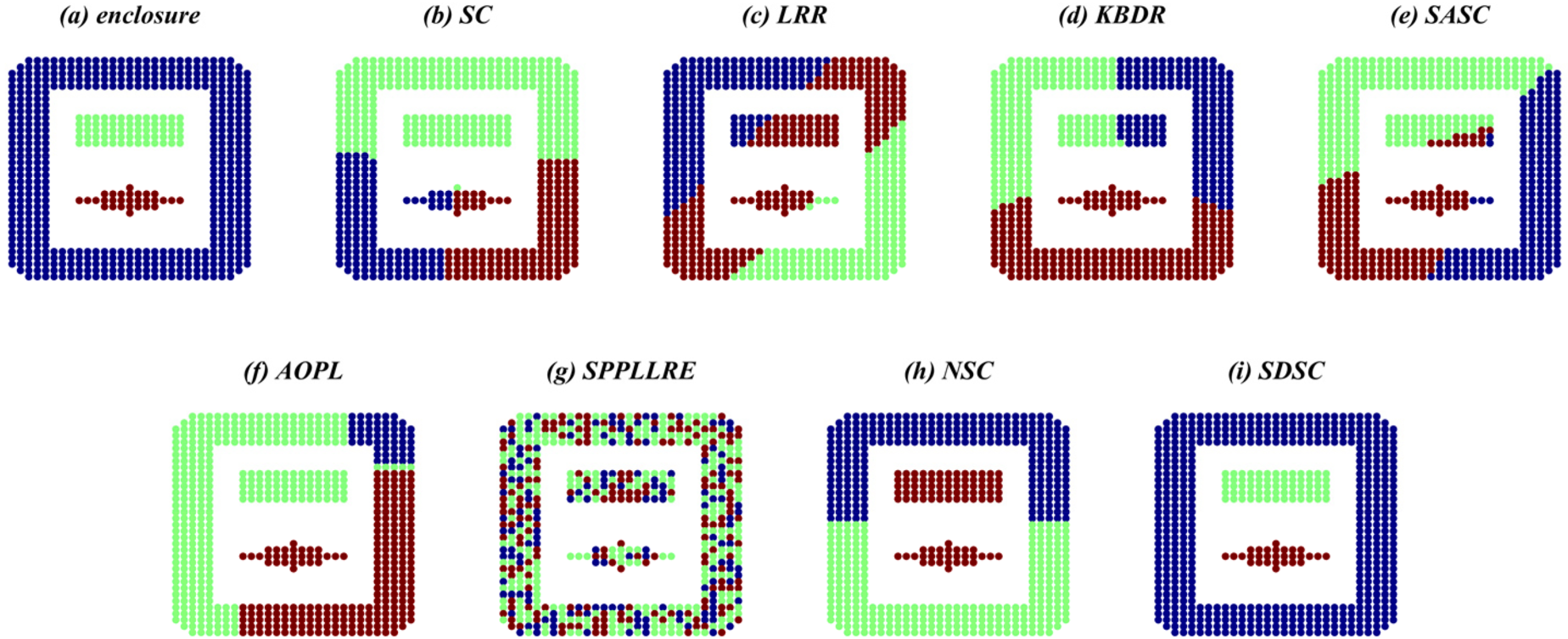
Clustering results of SDSC and comparison methods on SYN-4.
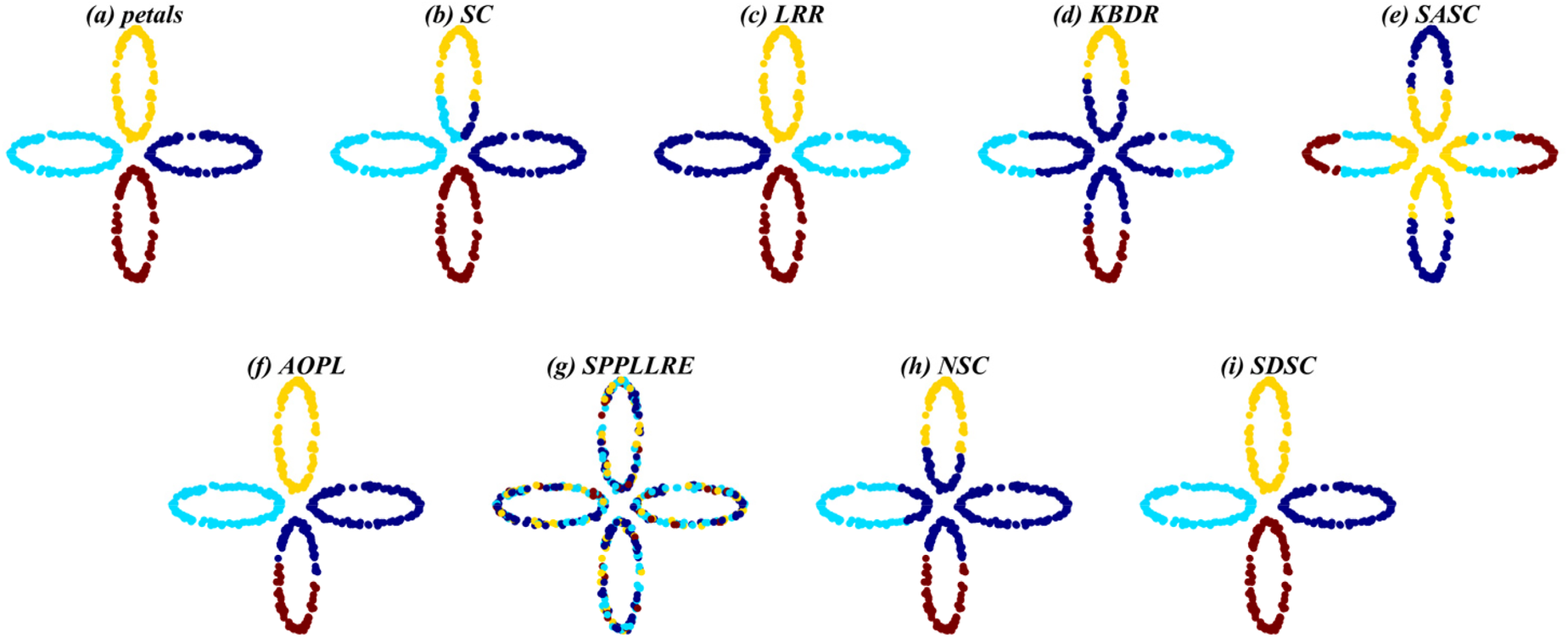
Clustering results of SDSC and comparison methods on SYN-5.
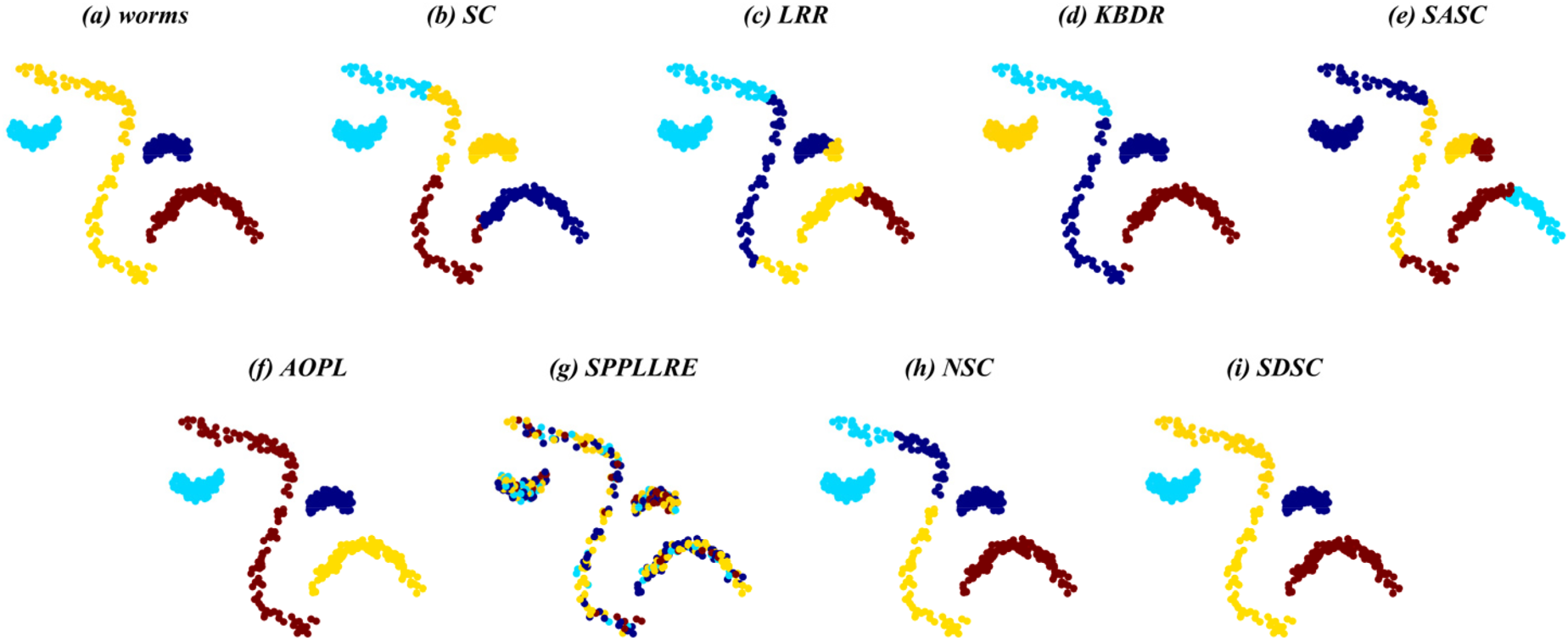
Clustering results of SDSC and comparison methods on SYN-6.
Clustering scores on the GT dataset.
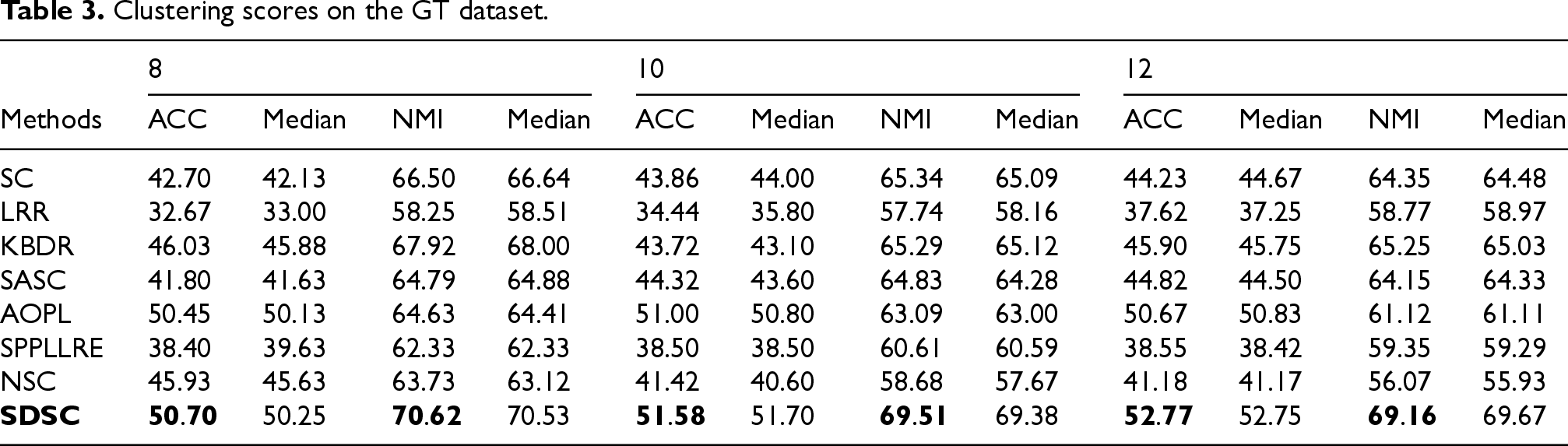
Clustering scores on the Coil20 dataset.
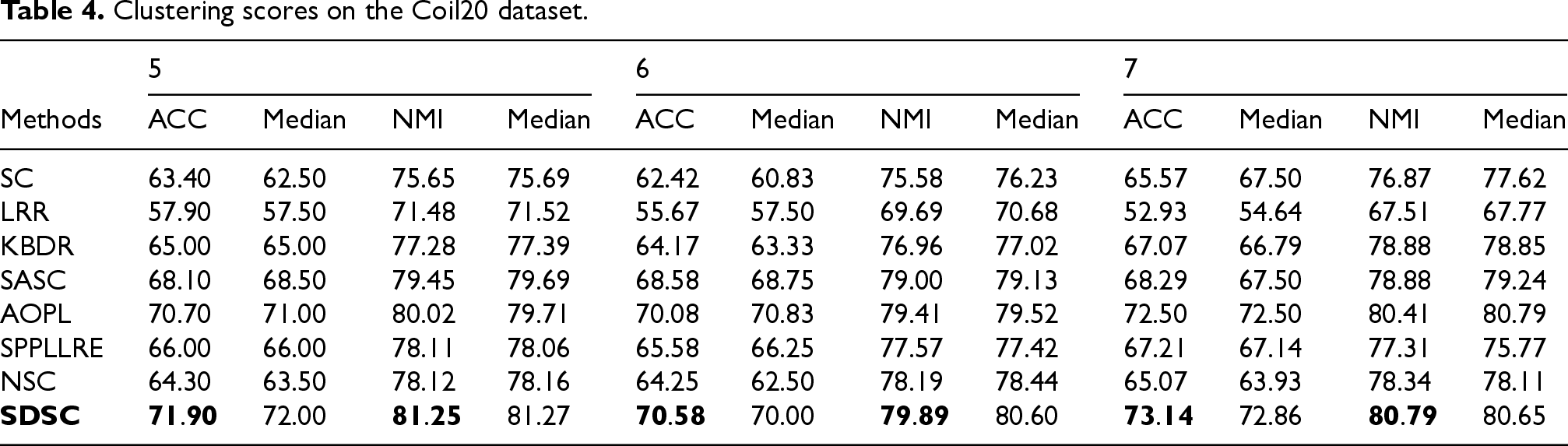
Clustering scores on the Terravic dataset.
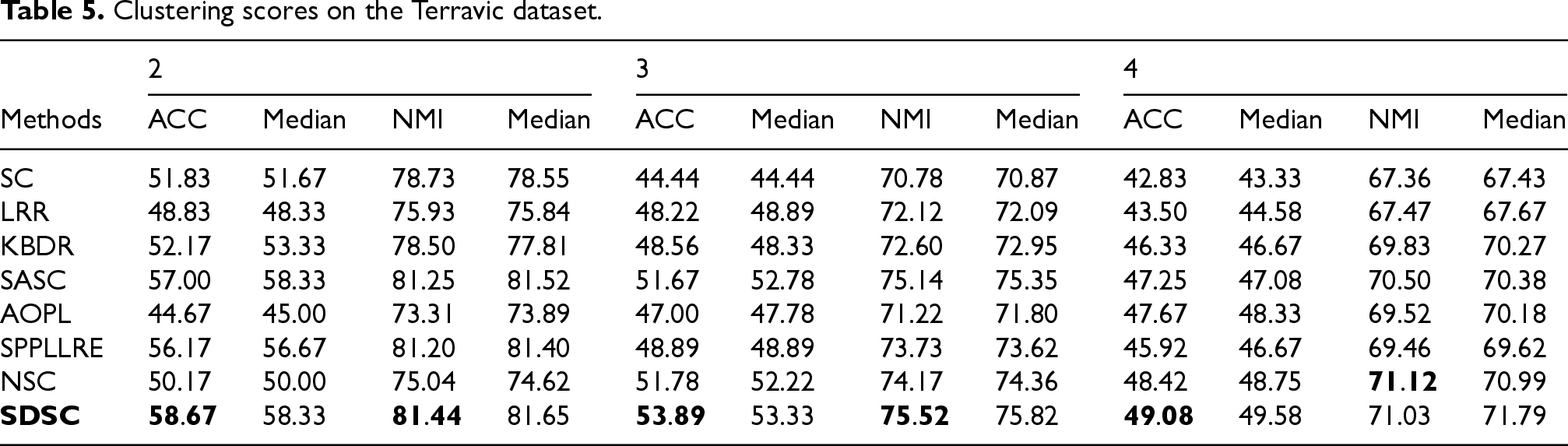
Clustering scores on the ORL dataset.
Clustering scores on the Semeion dataset.
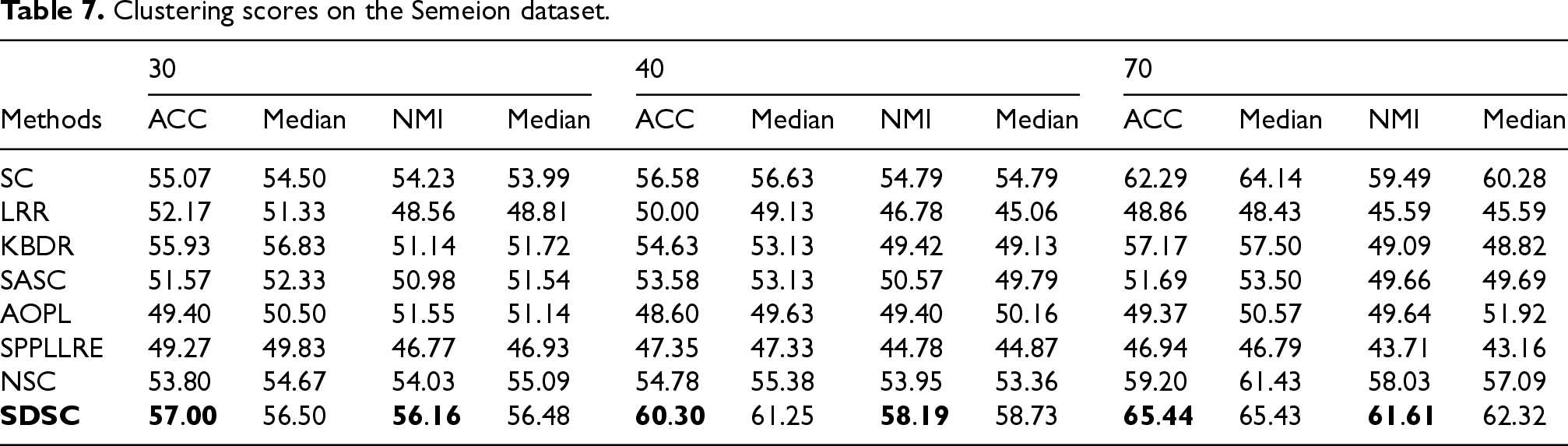
Clustering scores on the Umist dataset.
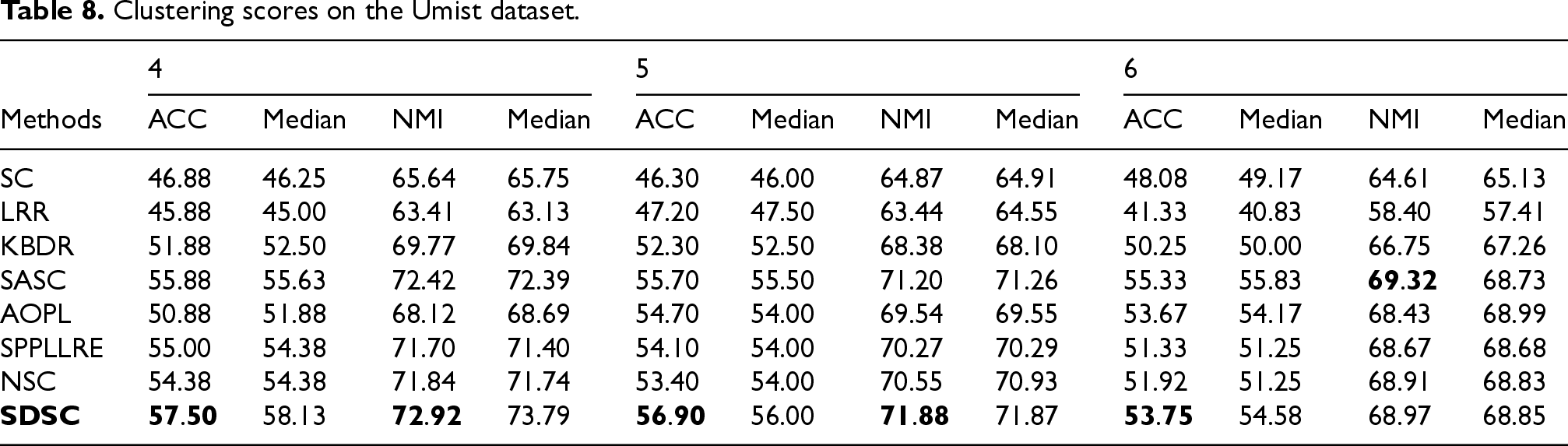
Clustering scores on the Yale dataset.
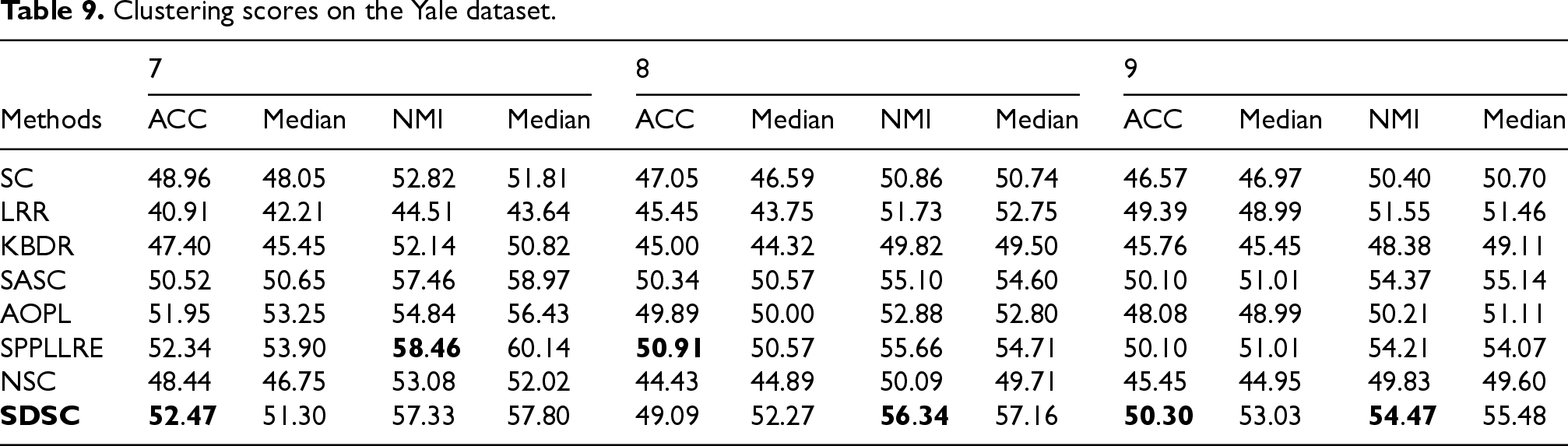
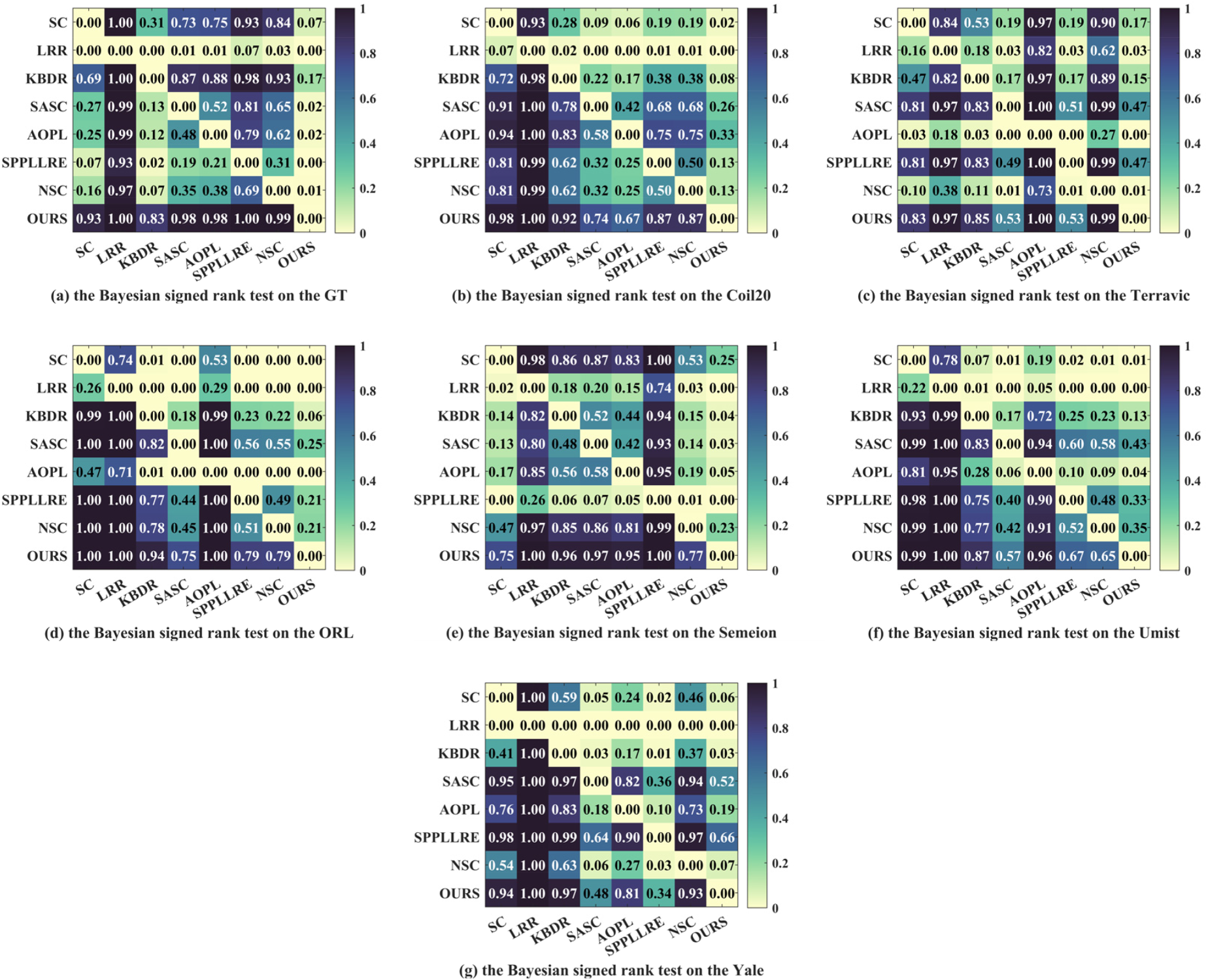
To further demonstrate the superiority of our method with respect to, 3 we performed the Bayesian signed rank test on ACC and NMI. The results are visualized as shown in Figures 11 and 12, where the values reflect the probability that the methods listed in the rows are superior to those listed in the columns. From the results in Figures 11 and 12, it is obvious that our method outperforms the other methods. Taking Figure 11 as an example, our method significantly outperforms the classical subspace method LRR, with probability improvement ranging from 96% to 100%. Compared to recent methods such as NSC and SPPLLRE, our method also shows superior performance, with probability improvements ranging from 54% to 100%. Combining all the subplots in Figures 11 and 12, the probability of other methods outperforming ours in the last column is close to zero. In particular, the last column represents the probability where other methods perform better than ours, with only a few methods, such as AOPL, which achieves 46% in Figure 11(a). Overall, these results strongly confirm the superiority of our method.
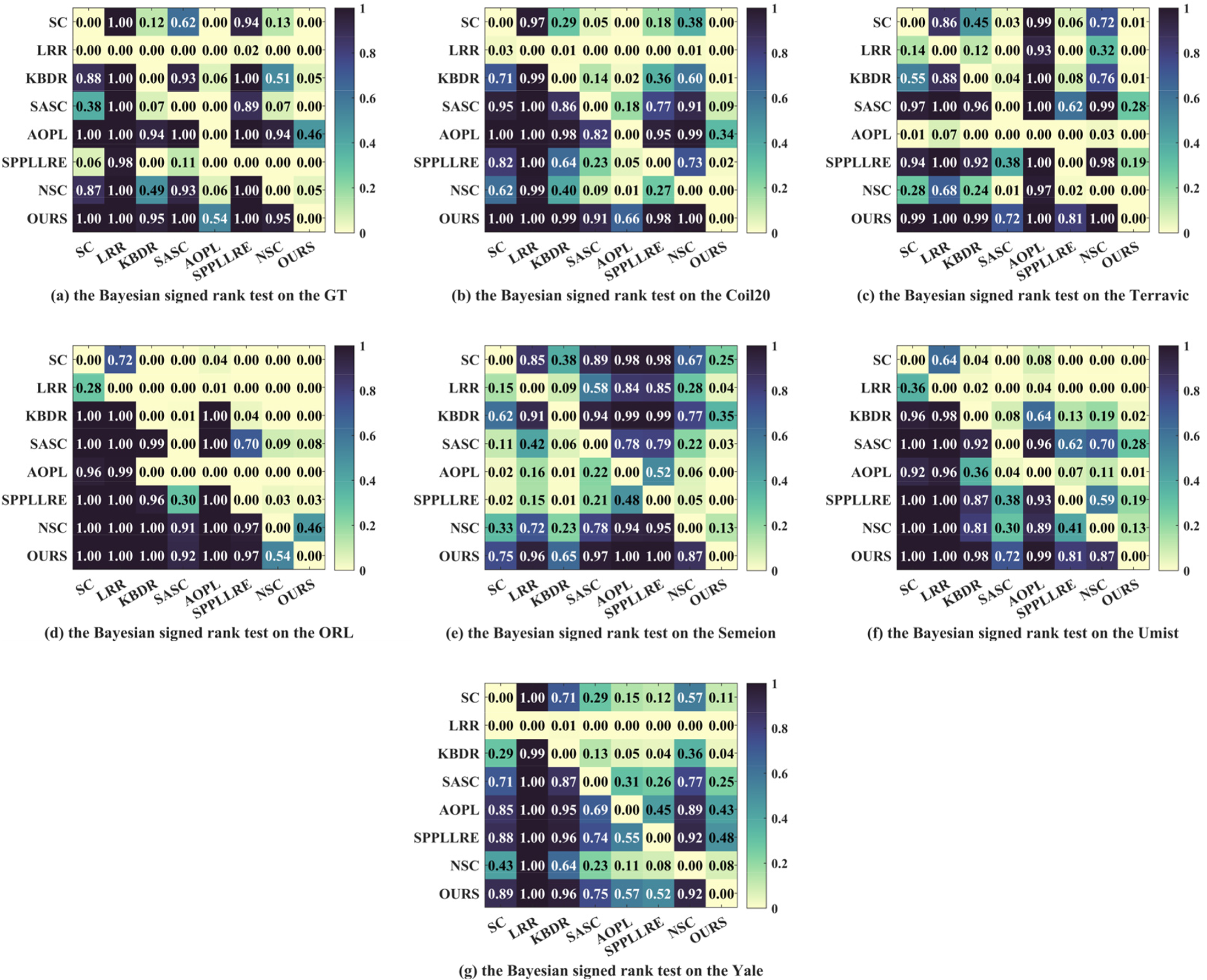
Visualization of the Bayesian signed rank test about ACC on seven image datasets.
Visualization of the Bayesian signed rank test about NMI on seven image datasets.
In this subsection, we conduct ablation experiments to evaluate the feasibility of the proposed method, employing the following setup:
The proposed method does not consider the ESCC strategy (SDSCe):
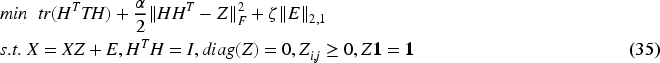
The proposed method does not consider the joint regularization term (SDSCj):
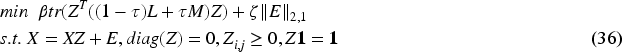
The proposed method does not consider the noise error (SDSCn):
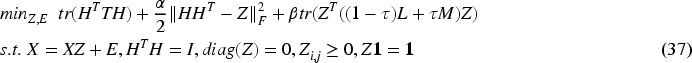
Figure 13 presents the clustering performance of three variants alongside our original method across seven image datasets. From Figure 13, it can be observed that each regularization term is crucial to our method. Regarding the noise term, the clustering performance of SDSCn decreases when noise errors are not considered, demonstrating the effectiveness of this term. In comparison, the importance of the joint regularization term is even greater. When this term is removed, SDSCj can no longer adaptively learn label information from samples to constrain clustering, leading to performance degradation. Furthermore, the impact of the ESCC strategy is far more significant than that of the above two regularization terms. As shown in Figure 11, when ESSC is removed, our method nearly fails to perform the clustering task. The clustering performance of SDSCj and SDSCn is lower than that of SDSC, but they still utilize the ESSC strategy to extract intrinsic structural information from the data. This mechanism ensures that the final self-expressive matrix Z retains strong structural representation capabilities. In contrast, SDSCe abandons this advantage, resulting in the worst clustering performance. These experimental results not only confirm the superiority of the SDSC method but also further validate the feasibility and importance of the ESSC strategy.
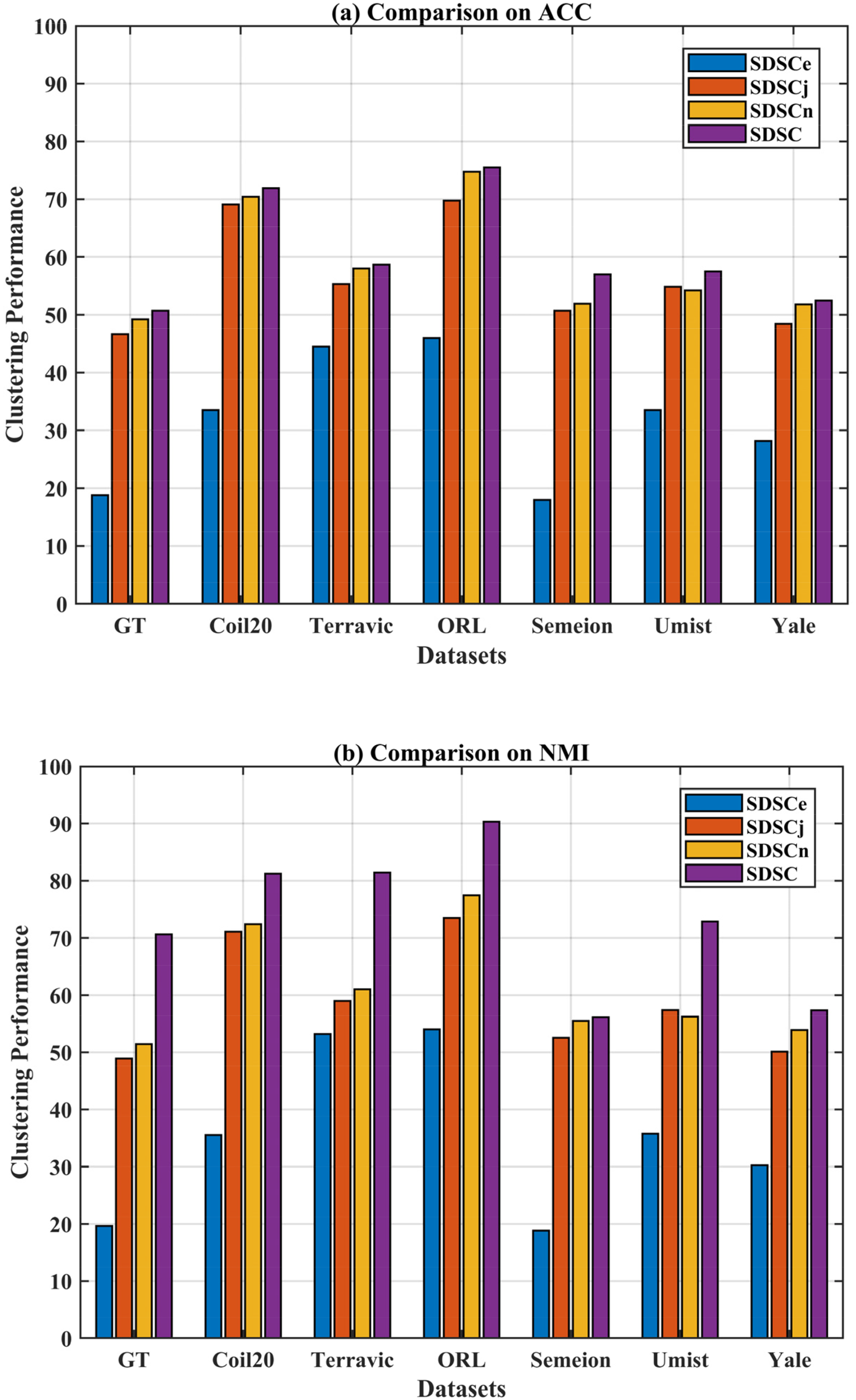
Ablation results analysis of the proposed method on seven datasets.
As described in,46,47 we show the relative error of the objective function as the number of iterations varies over all datasets. Figure 14 shows the convergence curves of SDSC relative to the number of iterations on the seven datasets. Due to the significant variation in some values, Figure 14 further illustrates the specific error to accurately reflect the actual number of convergence iterations. It can be observed from Figure 14 that SDSC tends to converge as the number of iterations increases. Usually, the convergence of SDSC occurs after 6 to 8 iterations which provides further evidence of convergence of SDSC.
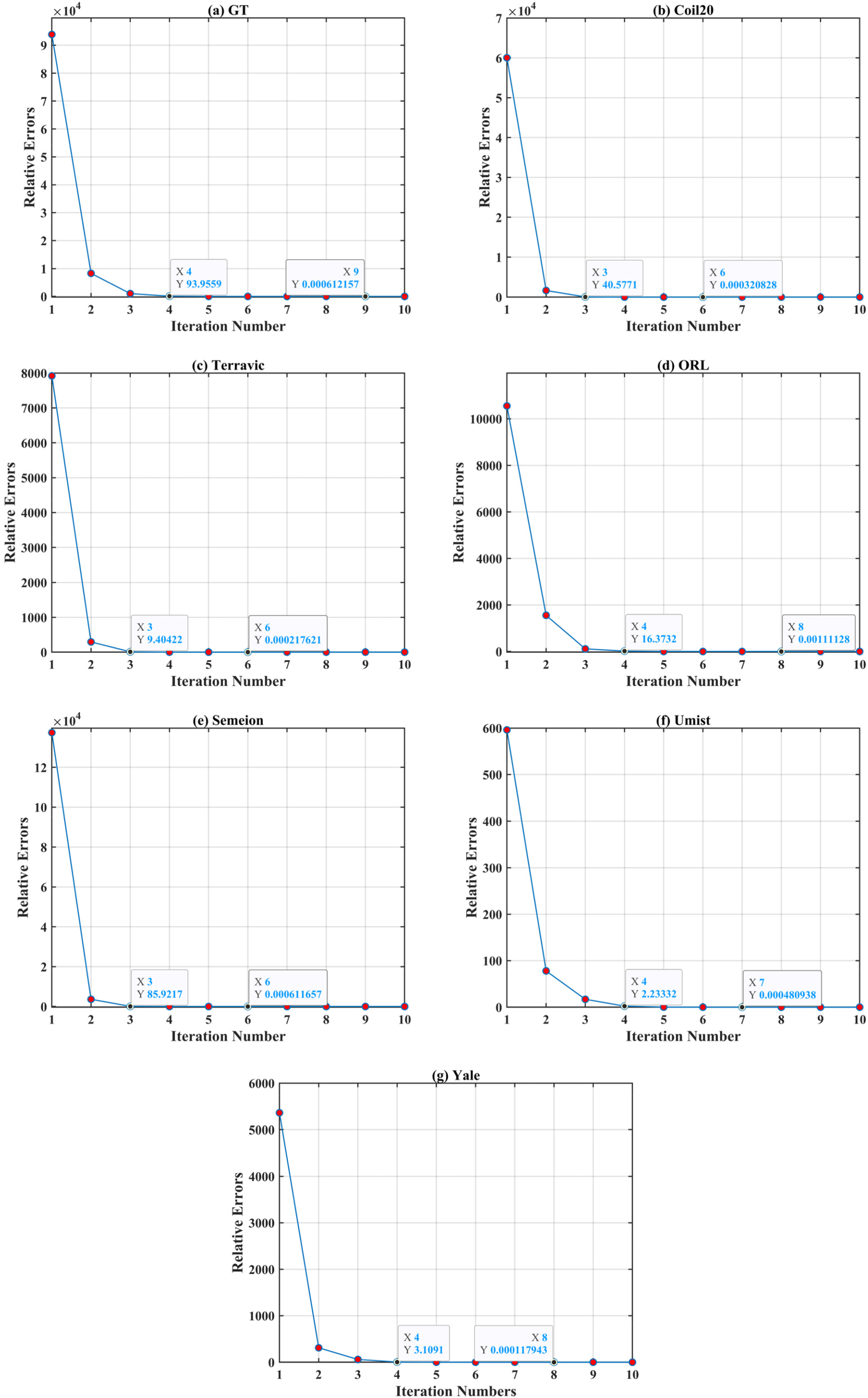
Convergence curves on the seven datasets.
In this section, we provide a comparative analysis of running times and clustering performance across seven datasets. To validate the effectiveness of our method, Table 10 presents the running times measured in seconds for various clustering algorithms. As indicated in Table 10, our method exhibits competitive running times on several datasets, outperforming approaches such as AOPL and SPLLLRE. While the runtime is slightly higher than that of faster methods like SC and LRR on specific datasets, our method achieves a commendable balance between efficiency and clustering accuracy, as demonstrated in Tables 3–8. Overall, our method not only delivers superior clustering performance but also maintains a relatively low computational cost, underscoring its accuracy and efficiency. These results indicate that our method holds significant promise for practical applications in clustering tasks.
Running times on of different methods the seven image datasets.
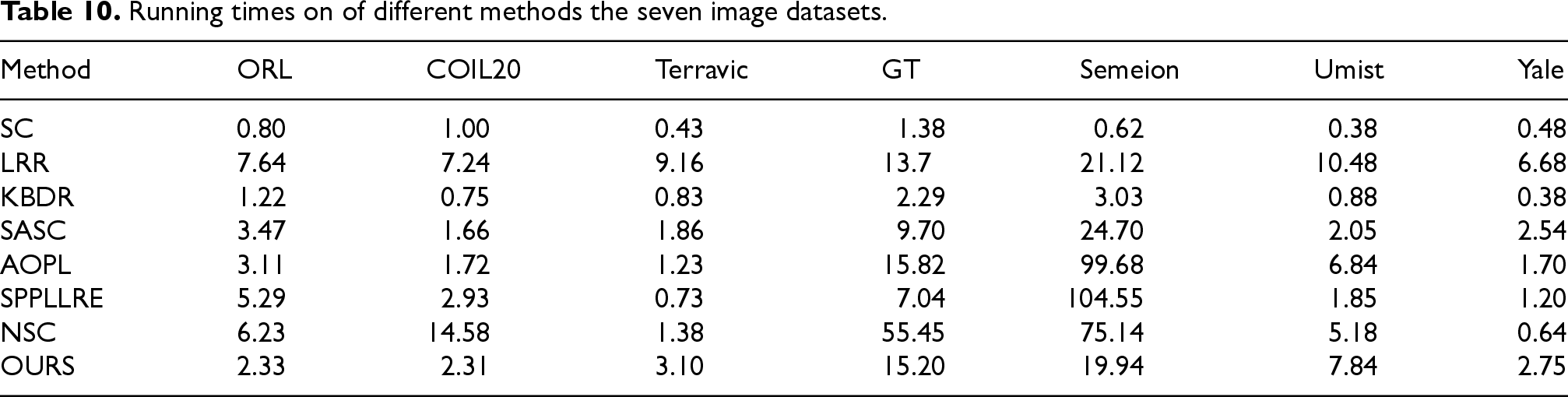
Running times on of different methods the seven image datasets.
This paper presents a new subspace clustering method, Sample-Dependent Subspace Clustering (SDSC). Benefitting from the Elastic Structure Consistency Constraints (ESCC) strategy, SDSC can uncover both global and local structural information by learning a high-quality and flexible affinity matrix. Furthermore, SDSC can extract clustering guidance information from samples during the learning process of the affinity matrix, which is iteratively optimized by mutual reinforcement with the affinity matrix to achieve optimal clustering performance. Finally, compared to other methods, SDSC has demonstrated superior experimental results on several well-known real and synthetic datasets, evidenced by higher clustering accuracy and enhanced robustness.
There are two improvements for future work. First, an adaptive method should be designed to automatically determine the local nearest neighbor structure of the data to further improve the robustness of the method. Second, the method should be extended to multi-view learning to handle data with different feature perspectives and improve the diversity and accuracy of clustering results.
Footnotes
Acknowledgment
This work is supported by the Hong Kong Innovation and Technology Commission (InnoHK Project CIMDA) and City University of Hong Kong (Projects 9610034 and 9610460).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Hong Kong Innovation and Technology Commission (InnoHK Project CIMDA) and City University of Hong Kong (Projects 9610034 and 9610460).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix I
Assuming SDSC reaches a stationary point, the KKT conditions
49
for (19) can be derived as follows:
Subsequently, we demonstrate the rationale for why SDSC can converge to a stationary point by the KKT conditions.
As described in (27),
From the above equation, the KKT condition (37) is satisfied.
To prove the KKT condition (39), the following equation can be given
Then, (44) can be further described as follows.
When
Thus, the KKT condition (38) is proved.
For proving the KKT condition (40), the following equation can be given
We define a simple function
According to (48), we have